

Comparing Hierarchical Approaches to Enhance Supervised Emotive Text Classification


Abstract
1. Introduction
- The behaviour of a range of supervised models used for classifying emotions expressed in text distributed as part of a hierarchical scheme;
- Exploring how extended classification methods can be used to capture the characteristics of a hierarchical emotive scheme and increase the overall performance of popular supervised models.
2. Related Work
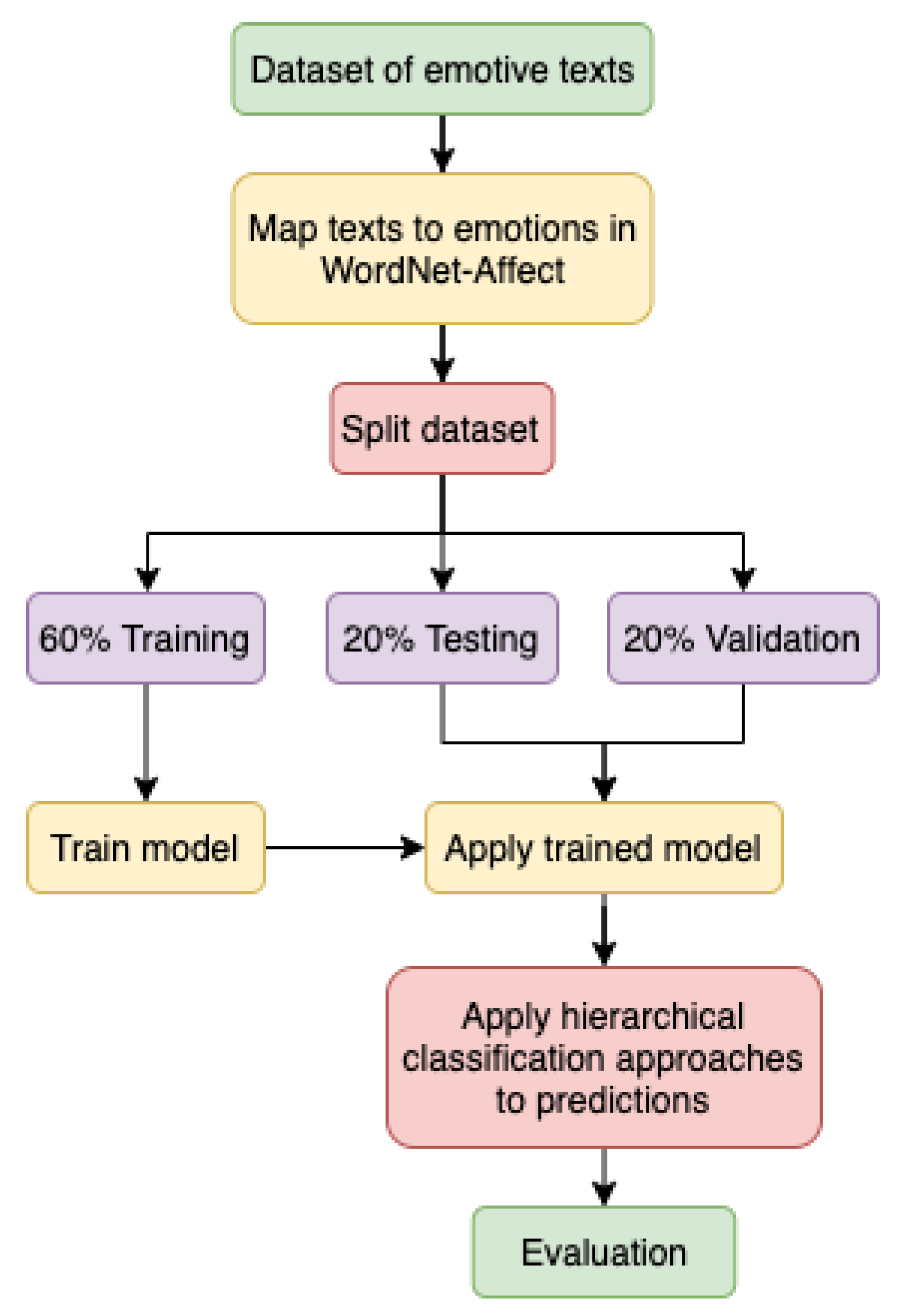
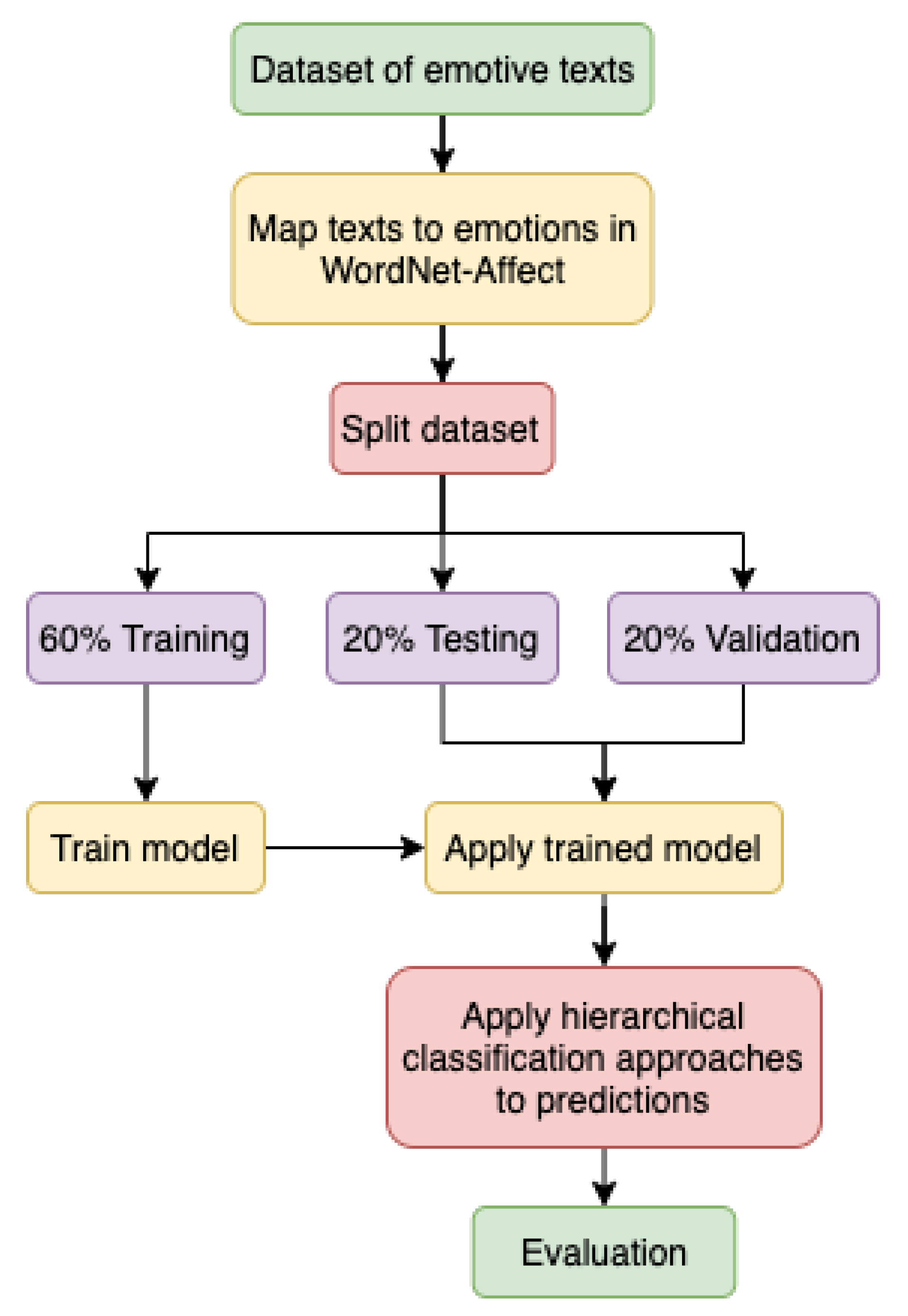
3. Data Annotation and Preparation
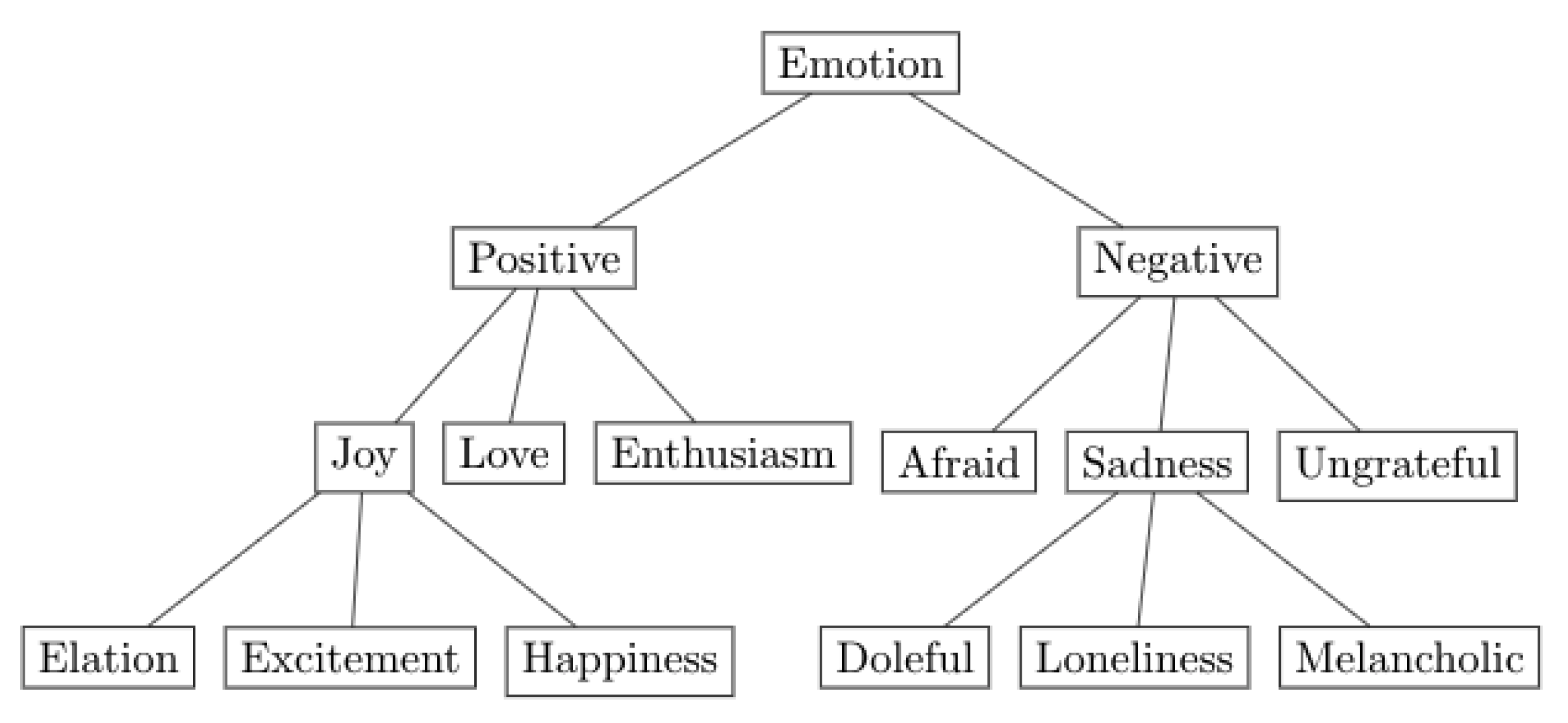
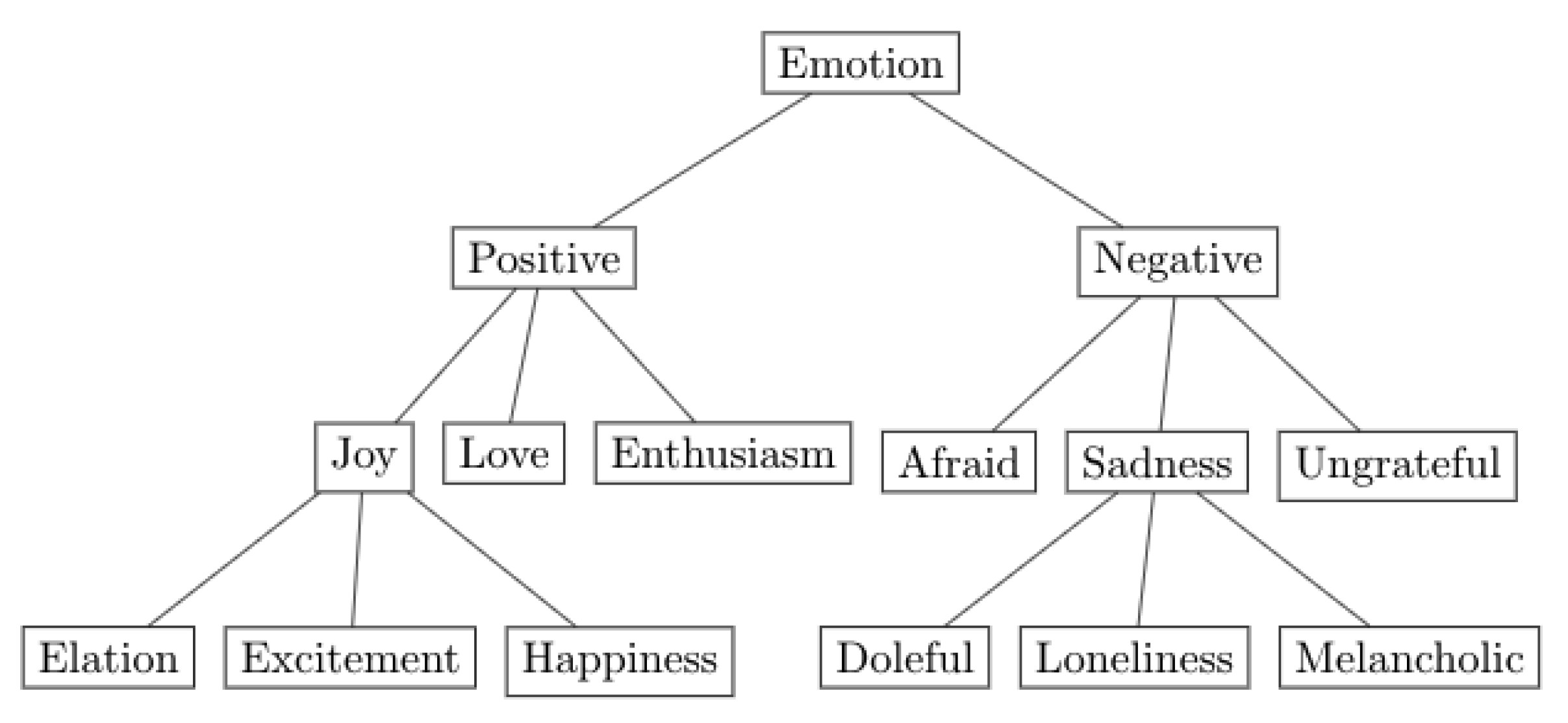
3.1. Hierarchical Classification Framework
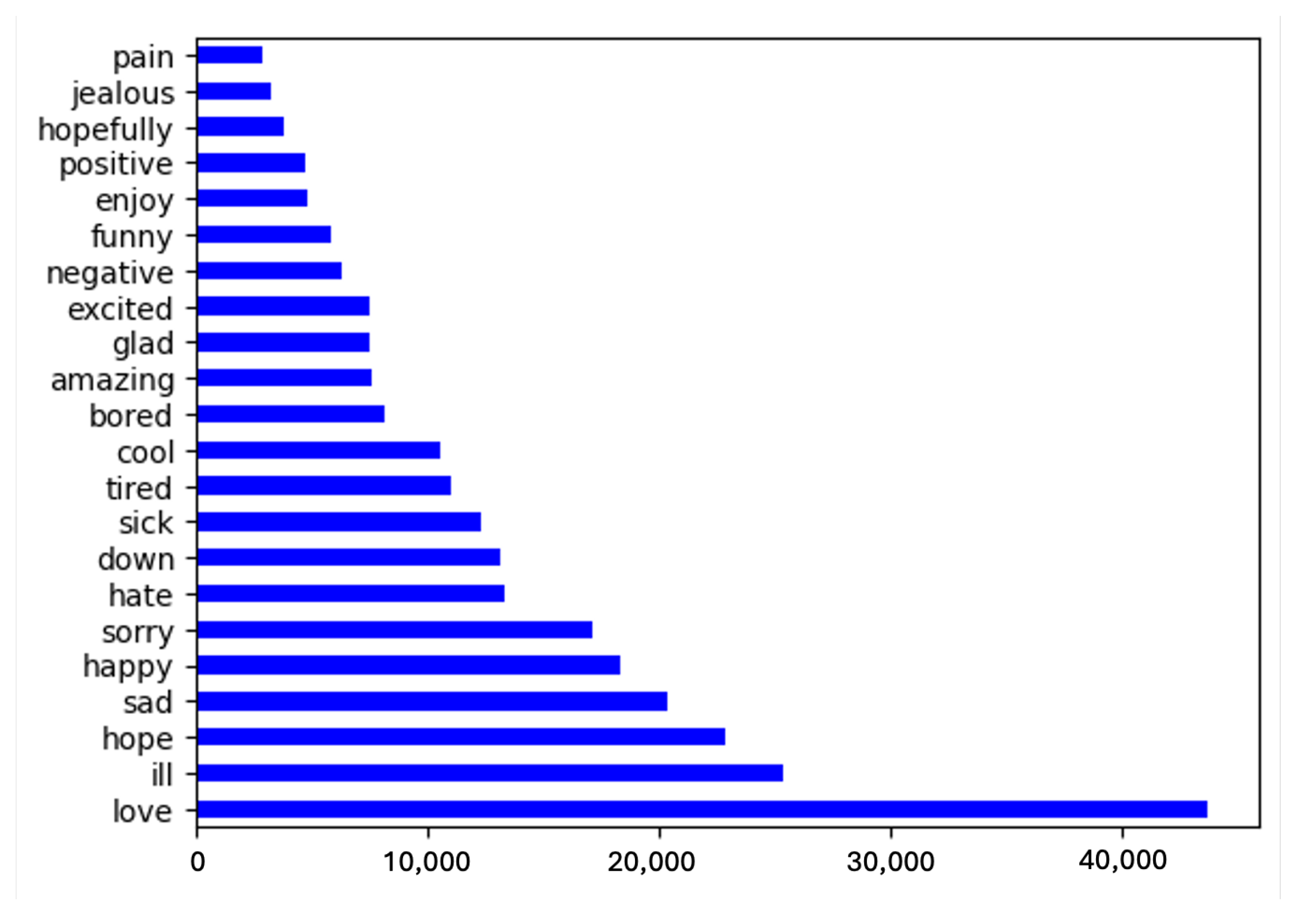
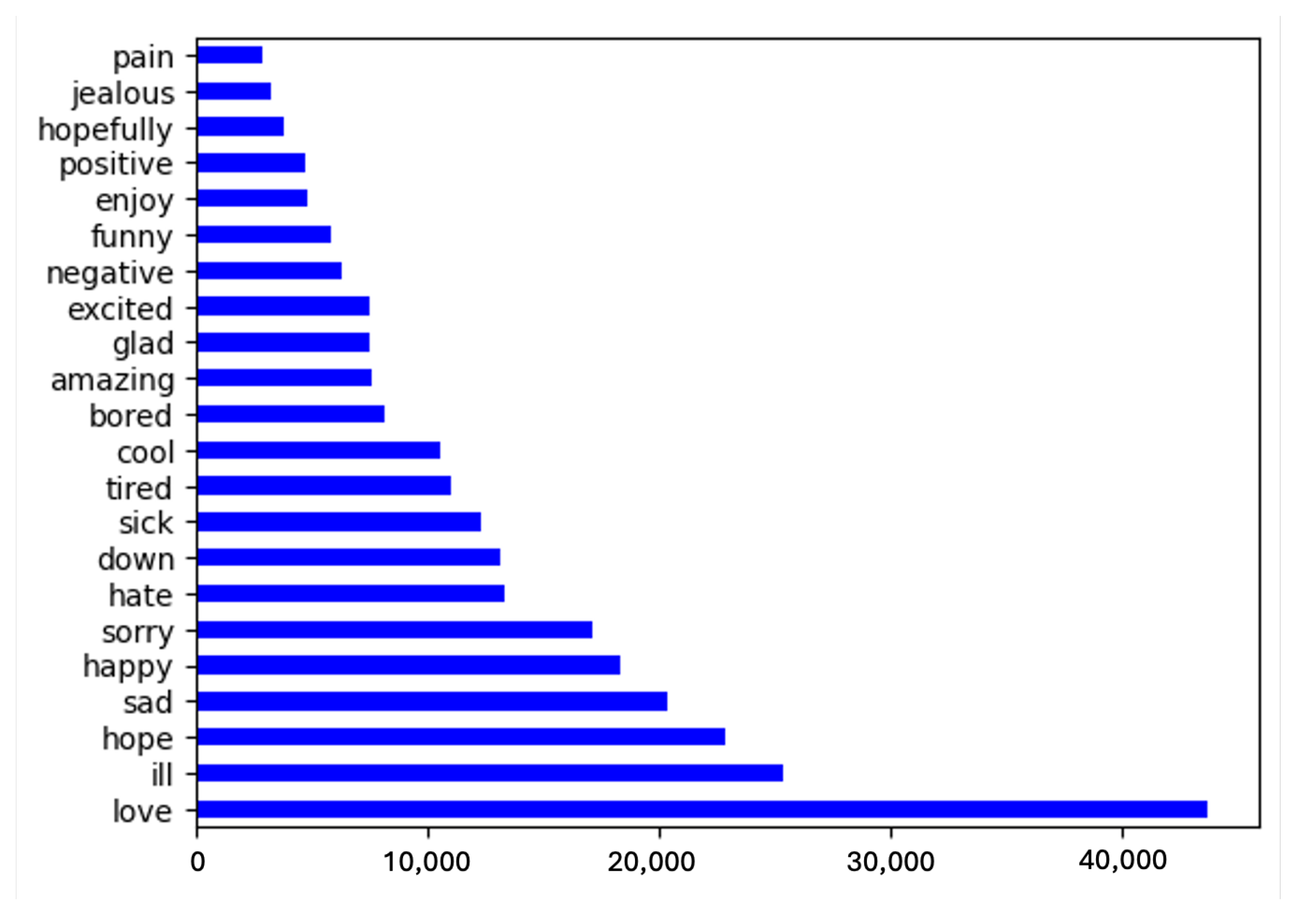
3.2. Text Corpus
3.3. Mapping Texts to Emotions
- If all emotions originate from the same root (i.e., Positive, Negative, Neutral, and Ambiguous), assign the emotion that is located the deepest in the hierarchy. The following is an example of a tweet that was allocated the emotion Bored as a consequence of being located on the fourth hierarchical level, as opposed to Hate, which is located on the third: “I hate this time, I am super bored but everyone is sleepin”.
- If all emotions originate from the same root but are located on the same hierarchical level, assign the root emotion. The following is an example of a tweet that was allocated the emotion Positive as a consequence of containing the emotions Love and Joy, which are both located on the second hierarchical level: “When spreading love and joy to others—also remember yourself!”.
- Omit the tweet if the emotions it contains do not originate from the same root. The following is an example of a tweet that was omitted from the study as a consequence of containing the emotions Love and Sad, which originate from the root emotions Positive and Negative, respectively: “Ohhh. I love it. Ps I’m sad we didn’t get to hang out”.
3.4. Vector Representation
- Converting text to lowercase.
- Removing mentioned usernames and URLs using regular expressions.
- Removing punctuation and digits using regular expressions.
- Removing stop words using Python’s natural language package, Natural Language Toolkit (NLTK) [48] (version 3.4.1).
- Tokenising text using the pre-built tokeniser as part of the NLTK package.
- Lemmatising tokens using the WordNet Lemmatiser as part of the NLTK package.
4. Hierarchical Classification Evaluation Metrics
- —the known input to the classifier.
- —the predicted output from the classifier.
- —tweets are correctly classified as the class of interest.
- —tweets are incorrectly classified as the class of interest.
- —tweets are incorrectly classified as not the class of interest.
- P—measures the number of retrieved tweets that are relevant.
- R—measures the number of all the relevant tweets that are successfully retrieved.
- F—the harmonic mean of P and R, and provides a single weighted metric to evaluate the overall classification performance.
4.1. Flat Hierarchical Classification
4.2. Relational-Based Classification
4.3. Distance-Based Classification
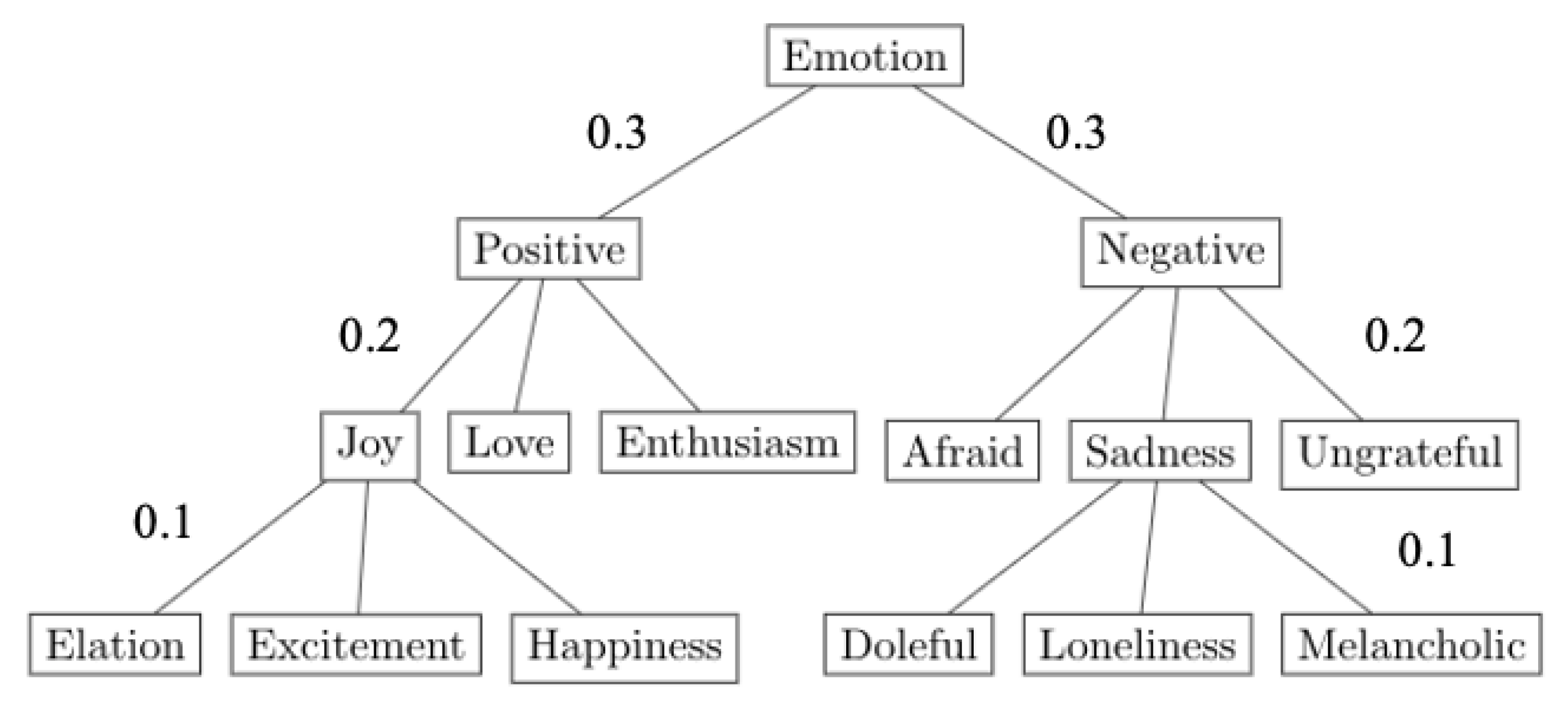
4.4. Depth-Based Classification
4.5. Semantic-Based Classification
5. Evaluating Hierarchical Classification Evaluation Metrics
5.1. Model Identification
5.2. Hierarchical Classification Experiments
6. Conclusions
7. Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Williams, L.; Bannister, C.; Arribas-Ayllon, M.; Preece, A.; Spasić, I. The role of idioms in sentiment analysis. Expert Syst. Appl. 2015, 42, 7375–7385. [Google Scholar] [CrossRef]
- Liu, B. Sentiment analysis and subjectivity. In Handbook of Natural Language Processing; Chapman and Hall: Boca Raton, FL, USA, 2010; Volume 2, pp. 627–666. [Google Scholar]
- Munezero, M.; Montero, C.S.; Sutinen, E.; Pajunen, J. Are they different? Affect, feeling, emotion, sentiment, and opinion detection in text. IEEE Trans. Affect. Comput. 2014, 5, 101–111. [Google Scholar] [CrossRef]
- Williams, L.; Arribas-Ayllon, M.; Artemiou, A.; Spasić, I. Comparing the utility of different classification schemes for emotive language analysis. J. Classif. 2019, 36, 619–648. [Google Scholar] [CrossRef]
- Ekman, P.; Keltner, D. Universal facial expressions of emotion. In Nonverbal Communication: Where Nature Meets Culture; Segerstrale, U., Molnar., P., Eds.; Routledge: Abingdon, UK, 1997; pp. 27–46. [Google Scholar]
- Alm, C.O.; Sproat, R. Emotional sequencing and development in fairy tales. In Proceedings of the International Conference on Affective Computing and Intelligent Interaction, Beijing, China, 22–24 October 2005; Springer: Cham, Switzerland, 2005; pp. 668–674. [Google Scholar]
- Aman, S.; Szpakowicz, S. Identifying expressions of emotion in text. In Proceedings of the International Conference on Text, Speech and Dialogue, Pilsen, Czech Republic, 3–7 September 2007; Springer: Cham, Switzerland, 2007; pp. 196–205. [Google Scholar]
- Strapparava, C.; Mihalcea, R. Learning to identify emotions in text. In Proceedings of the 2008 ACM Symposium on Applied Computing, Fortaleza, Brazil, 16–20 March 2008; pp. 1556–1560. [Google Scholar]
- Sun, A.; Lim, E.P. Hierarchical text classification and evaluation. In Proceedings of the 2001 IEEE International Conference on Data Mining, IEEE, San Jose, CA, USA, 29 November–2 December 2001; pp. 521–528. [Google Scholar]
- Holden, N.; Freitas, A.A. Hierarchical classification of G-protein-coupled receptors with a PSO/ACO algorithm. In Proceedings of the IEEE Swarm Intelligence Symposium (SIS’06), IEEE, Indianapolis, IN, USA, 12–14 May 2006; pp. 77–84. [Google Scholar]
- Eisner, R.; Poulin, B.; Szafron, D.; Lu, P.; Greiner, R. Improving protein function prediction using the hierarchical structure of the gene ontology. In Proceedings of the 2005 IEEE Symposium on Computational Intelligence in Bioinformatics and Computational Biology, IEEE, San Diego, CA, USA, 14–15 November 2005; pp. 1–10. [Google Scholar]
- Go, A.; Bhayani, R.; Huang, L. Twitter sentiment classification using distant supervision. CS224N Proj. Rep. Stanf. 2009, 1, 2009. [Google Scholar]
- Esmin, A.; De Oliveira, R.L., Jr.; Matwin, S. Hierarchical classification approach to emotion recognition in twitter. In Proceedings of the Machine Learning and Applications (ICMLA), 2012 11th International Conference on Machine Learning and Applications, IEEE, Washington, DC, USA, 12–15 December 2012; Volume 2, pp. 381–385. [Google Scholar]
- Ghazi, D.; Inkpen, D.; Szpakowicz, S. Hierarchical approach to emotion recognition and classification in texts. In Proceedings of the Canadian Conference on Artificial Intelligence, Ottawa, ON, Canada, 31 May–2 June 2010; Springer: Cham, Switzerland, 2010; pp. 40–50. [Google Scholar]
- Charoensuk, J.; Sornil, O. A Hierarchical Emotion Classification Technique for Thai Reviews. J. ICT Res. Appl. 2018, 12, 280–296. [Google Scholar] [CrossRef]
- Angiani, G.; Cagnoni, S.; Chuzhikova, N.; Fornacciari, P.; Mordonini, M.; Tomaiuolo, M. Flat and hierarchical classifiers for detecting emotion in tweets. In Proceedings of the Conference of the Italian Association for Artificial Intelligence, Genova, Italy, 29 November–1 December 2016; Springer: Cham, Switzerland, 2016; pp. 51–64. [Google Scholar]
- Keshtkar, F.; Inkpen, D. A hierarchical approach to mood classification in blogs. Nat. Lang. Eng. 2012, 18, 61. [Google Scholar] [CrossRef]
- Zhang, F.; Xu, H.; Wang, J.; Sun, X.; Deng, J. Grasp the implicit features: Hierarchical emotion classification based on topic model and SVM. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), IEEE, Vancouver, BC, Canada, 24–29 July 2016; pp. 3592–3599. [Google Scholar]
- Xu, H.; Yang, W.; Wang, J. Hierarchical emotion classification and emotion component analysis on Chinese micro-blog posts. Expert Syst. Appl. 2015, 42, 8745–8752. [Google Scholar] [CrossRef]
- Mishne, G. Experiments with mood classification in blog posts. In Proceedings of the ACM SIGIR 2005 Workshop on Stylistic Analysis of Text for Information Access, Salvador, Brazil, 15–19 August 2005; Volume 19, pp. 321–327. [Google Scholar]
- Laros, F.J.; Steenkamp, J.B.E. Emotions in consumer behavior: A hierarchical approach. J. Bus. Res. 2005, 58, 1437–1445. [Google Scholar] [CrossRef]
- Shaver, P.; Schwartz, J.; Kirson, D.; O’connor, C. Emotion knowledge: Further exploration of a prototype approach. J. Personal. Soc. Psychol. 1987, 52, 1061. [Google Scholar] [CrossRef] [PubMed]
- Storm, C.; Storm, T. A taxonomic study of the vocabulary of emotions. J. Personal. Soc. Psychol. 1987, 53, 805. [Google Scholar] [CrossRef]
- Miller, G.A. WordNet: A lexical database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Valitutti, A.; Strapparava, C.; Stock, O. Developing affective lexical resources. PsychNology J. 2004, 2, 61–83. [Google Scholar]
- Balahur, A.; Steinberger, R.; Kabadjov, M.; Zavarella, V.; van der Goot, E.; Halkia, M.; Pouliquen, B.; Belyaeva, J. Sentiment Analysis in the News. In Proceedings of the Seventh International Conference on Language Resources and Evaluation (LREC’10), Valletta, Malta, 17–23 May 2010; European Language Resources Association (ELRA): Paris, France, 2010. [Google Scholar]
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up? Sentiment classification using machine learning techniques. In Proceedings of the ACL-02 Conference on Empirical Methods in Natural Language Processing—Volume 10; Association for Computational Linguistics: Kerrville, TX, USA, 2002; pp. 79–86. [Google Scholar]
- Pang, B.; Lee, L. A sentimental education: Sentiment analysis using subjectivity summarization based on minimum cuts. In Proceedings of the 42nd annual meeting on Association for Computational Linguistics, Barcelona, Spain, 21–26 July 2004; Association for Computational Linguistics: Kerrville, TX, USA, 2004; p. 271. [Google Scholar]
- Whitelaw, C.; Garg, N.; Argamon, S. Using appraisal groups for sentiment analysis. In Proceedings of the 14th ACM International Conference on Information and Knowledge Management, ACM, Shanghai, China, 3–7 November 2005; pp. 625–631. [Google Scholar]
- Hu, M.; Liu, B. Mining and summarizing customer reviews. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ACM, Seattle, WA, USA, 22–25 August 2004; pp. 168–177. [Google Scholar]
- O’Hare, N.; Davy, M.; Bermingham, A.; Ferguson, P.; Sheridan, P.; Gurrin, C.; Smeaton, A.F. Topic-dependent sentiment analysis of financial blogs. In Proceedings of the 1st International CIKM Workshop on Topic-Sentiment Analysis for Mass Opinion, ACM, Hong Kong, China, 6 November 2009; pp. 9–16. [Google Scholar]
- Koppel, M.; Shtrimberg, I. Good news or bad news? let the market decide. In Computing Attitude and Affect in Text: Theory and Applications; Springer: Cham, Switzerland, 2006; pp. 297–301. [Google Scholar]
- Mullen, T.; Malouf, R. A Preliminary Investigation into Sentiment Analysis of Informal Political Discourse. In Proceedings of the AAAI Spring Symposium: Computational Approaches to Analyzing Weblogs, Stanford, CA, USA, 27–29 March 2006; pp. 159–162. [Google Scholar]
- Yu, H.; Hatzivassiloglou, V. Towards answering opinion questions: Separating facts from opinions and identifying the polarity of opinion sentences. In Proceedings of the 2003 Conference on Empirical Methods in Natural Language Processing, Sapporo, Japan, 11–12 July 2003; Association for Computational Linguistics: Kerrville, TX, USA, 2003; pp. 129–136. [Google Scholar]
- Wiebe, J.; Wilson, T.; Bruce, R.; Bell, M.; Martin, M. Learning subjective language. Comput. Linguist. 2004, 30, 277–308. [Google Scholar] [CrossRef]
- Alemi, F.; Torii, M.; Clementz, L.; Aron, D.C. Feasibility of real-time satisfaction surveys through automated analysis of patients’ unstructured comments and sentiments. Qual. Manag. Healthc. 2012, 21, 9–19. [Google Scholar] [CrossRef] [PubMed]
- Liu, D. The most frequently used spoken American English idioms: A corpus analysis and its implications. Tesol Q. 2003, 37, 671–700. [Google Scholar] [CrossRef]
- Pak, A.; Paroubek, P. Twitter as a corpus for sentiment analysis and opinion mining. In Proceedings of the LREc, Valletta, Malta, 17–23 May 2010; Volume 10, pp. 1320–1326. [Google Scholar]
- O’Connor, B.; Balasubramanyan, R.; Routledge, B.; Smith, N. From tweets to polls: Linking text sentiment to public opinion time series. In Proceedings of the International AAAI Conference on Web and Social Media, Washington, DC, USA, 23–26 May 2010; Volume 4. [Google Scholar]
- Tumasjan, A.; Sprenger, T.; Sandner, P.; Welpe, I. Predicting elections with twitter: What 140 characters reveal about political sentiment. In Proceedings of the International AAAI Conference on Web and Social Media, Washington, DC, USA, 23–26 May 2010; Volume 4. [Google Scholar]
- Agarwal, A.; Xie, B.; Vovsha, I.; Rambow, O.; Passonneau, R.J. Sentiment analysis of twitter data. In Proceedings of the Workshop on Language in Social Media (LSM 2011), Portland, OR, USA, 23 June 2011; pp. 30–38. [Google Scholar]
- Kouloumpis, E.; Wilson, T.; Moore, J. Twitter sentiment analysis: The good the bad and the omg! In Proceedings of the International AAAI Conference on Web and Social Media, Barcelona, Spain, 17–21 July 2011; Volume 5. [Google Scholar]
- Spasic, I.; Nenadic, G. Clinical text data in machine learning: Systematic review. JMIR Med. Inform. 2020, 8, e17984. [Google Scholar] [CrossRef] [PubMed]
- Harish, B.S.; Guru, D.S.; Manjunath, S. Representation and classification of text documents: A brief review. IJCA Spec. Issue RTIPPR (2) 2010, 110, 119. [Google Scholar]
- Gutiérrez, L.; Keith, B. A systematic literature review on word embeddings. In Proceedings of the International Conference on Software Process Improvement, Gothenburg, Sweden, 26–27 May 2018; Springer: Cham, Switzerland, 2018; pp. 132–141. [Google Scholar]
- Levy, O.; Goldberg, Y. Dependency-based word embeddings. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Baltimore, MD, USA, 23–24 June 2014; pp. 302–308. [Google Scholar]
- Genism. Available online: https://radimrehurek.com/gensim/intro.html (accessed on 3 March 2021).
- Bird, S. NLTK: The natural language toolkit. In Proceedings of the COLING/ACL 2006 Interactive Presentation Sessions, Sydney, NSW, Australia, 17–18 July 2006; pp. 69–72. [Google Scholar]
- Costa, E.; Lorena, A.; Carvalho, A.; Freitas, A. A review of performance evaluation measures for hierarchical classifiers. In Proceedings of the Evaluation Methods for Machine Learning II: Papers from the AAAI—2007 Workshop, Vancouver, BC, Canada, 22 July 2007; pp. 1–6. [Google Scholar]
- Cerri, R.; Pappa, G.L.; Carvalho, A.C.P.; Freitas, A.A. An extensive evaluation of decision tree-based hierarchical multilabel classification methods and performance measures. Comput. Intell. 2015, 31, 1–46. [Google Scholar] [CrossRef]
- Kiritchenko, S.; Matwin, S.; Famili, F. Hierarchical text categorization as a tool of associating genes with gene ontology codes. In Proceedings of the European Workshop on Data Mining and Text Mining in Bioinformatics, Pisa, Italy, 20–24 September 2004; pp. 30–34. [Google Scholar]
- Kiritchenko, S.; Matwin, S.; Famili, F. Functional annotation of genes using hierarchical text categorization. In Proceedings of the ACL Workshop on Linking Biological Literature, Ontologies and Databases: Mining Biological Semantics, Detroit, MI, USA, 24 June 2005. [Google Scholar]
- Kiritchenko, S.; Matwin, S.; Nock, R.; Famili, A.F. Learning and evaluation in the presence of class hierarchies: Application to text categorization. In Proceedings of the Conference of the Canadian Society for Computational Studies of Intelligence, Québec City, QC, Canada, 7–9 June 2006; Springer: Cham, Switzerland, 2006; pp. 395–406. [Google Scholar]
- Kosmopoulos, A.; Partalas, I.; Gaussier, E.; Paliouras, G.; Androutsopoulos, I. Evaluation measures for hierarchical classification: A unified view and novel approaches. Data Min. Knowl. Discov. 2015, 29, 820–865. [Google Scholar] [CrossRef]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA data mining software: An update. ACM SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Wolpert, D.H. The supervised learning no-free-lunch theorems. In Soft Computing and Industry; Springer: Cham, Switzerland, 2002; pp. 25–42. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Level | Examples of Emotions | No. of Emotions |
|---|---|---|
| 1 | Positive, Negative, Neutral, Ambiguous | 4 |
| 2 | Love, Surprise, Sad, Fear | 162 |
| 3 | Adore, Amusement, Distress, Embarrassed | 582 |
| 4 | Jolly, Peaceful, Annoyed, Confused | 527 |
| 5 | Pride, Fulfilment, Aggressive, Livid | 198 |
| 6 | Remorse, Contrite, Guilt, Woeful | 46 |
| 7 | Covet, Jealousy, Greedy, Green-eyed | 12 |
| Tweet | Emotion |
|---|---|
| I wish I had someone to talk to. I’m so upset. | Upset |
| I hate when I have to call and wake people up | Hate |
| Is strangely sad about Lilo and Samro breaking up. | Sad |
| Leanne is angry at me. | Angry |
| I’m glad ur doing well. | Glad |
| Love your tattoo! | Love |
| My cluster is back and I’m a happy man. | Happy |
| Is excited for the day. | Excited |
| Level | No. of Tweets | Percentage of Tweets |
|---|---|---|
| 1 | 11,213 | 2.8 |
| 2 | 84,149 | 21.3 |
| 3 | 200,711 | 50.9 |
| 4 | 46,432 | 11.8 |
| 5 | 47,321 | 12.0 |
| 6 | 1347 | 0.3 |
| 7 | 3385 | 0.9 |
| Classifier | P | R | F |
|---|---|---|---|
| Naïve Bayes | 27.79 | 42.11 | 28.97 |
| J48 Decision Tree | 33.48 | 17.35 | 20.67 |
| SVM | 26.34 | 11.35 | 13.57 |
| One R | 3.36 | 0.43 | 0.48 |
| Bayesian Network | 0.02 | 0.11 | 0.03 |
| ZeroR | 0.02 | 0.11 | 0.03 |
| Random Forest | N/A | N/A | N/A |
| Simple Logistic | N/A | N/A | N/A |
| Testing | Validation | |||||
|---|---|---|---|---|---|---|
| Method | P | R | F | P | R | F |
| Flat hierarchical | 8.30 | 9.74 | 7.33 | 8.46 | 9.83 | 7.53 |
| Relational-based | 52.22 | 50.85 | 51.19 | 52.92 | 51.19 | 51.60 |
| Distance-based | 46.42 | 41.78 | 34.82 | 38.63 | 71.86 | 38.75 |
| Depth-based | 77.45 | 77.49 | 74.79 | 77.70 | 77.19 | 74.78 |
| Semantic-based | 18.78 | 21.42 | 13.03 | 20.26 | 23.08 | 13.45 |
| Testing | Validation | |||||
|---|---|---|---|---|---|---|
| Method | P | R | F | P | R | F |
| Flat hierarchical | 1.98 | 1.72 | 1.69 | 1.86 | 1.69 | 1.63 |
| Relational-based | 36.38 | 37.09 | 36.41 | 36.09 | 36.73 | 36.05 |
| Distance-based | 48.38 | 87.08 | 58.06 | 26.88 | 58.65 | 33.52 |
| Depth-based | 64.69 | 86.28 | 71.99 | 65.46 | 86.26 | 72.67 |
| Semantic-based | 21.02 | 20.49 | 12.51 | 17.79 | 19.64 | 11.03 |
| Testing | Validation | |||||
|---|---|---|---|---|---|---|
| Method | P | R | F | P | R | F |
| Flat hierarchical | 17.88 | 9.18 | 10.73 | 17.35 | 9.22 | 10.70 |
| Relational-based | 72.07 | 71.36 | 71.63 | 72.47 | 71.84 | 72.05 |
| Distance-based | 76.75 | 37.50 | 38.25 | 38.68 | 27.21 | 59.05 |
| Depth-based | 61.23 | 94.97 | 73.03 | 61.38 | 94.89 | 73.15 |
| Semantic-based | 34.98 | 29.50 | 21.08 | 33.90 | 29.94 | 20.71 |
| Testing | Validation | Testing | Validation | |
|---|---|---|---|---|
| Classifier | No. of Tweets | Percentage of Tweets | ||
| Naive Bayes | 49,985 | 49,777 | 63.34 | 63.08 |
| J48 Decision Tree | 42,357 | 41,857 | 53.68 | 53.04 |
| SVM | 61,153 | 61,278 | 77.50 | 77.65 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Williams, L.; Anthi, E.; Burnap, P. Comparing Hierarchical Approaches to Enhance Supervised Emotive Text Classification. Big Data Cogn. Comput. 2024, 8, 38. https://doi.org/10.3390/bdcc8040038
Williams L, Anthi E, Burnap P. Comparing Hierarchical Approaches to Enhance Supervised Emotive Text Classification. Big Data and Cognitive Computing. 2024; 8(4):38. https://doi.org/10.3390/bdcc8040038
Chicago/Turabian StyleWilliams, Lowri, Eirini Anthi, and Pete Burnap. 2024. "Comparing Hierarchical Approaches to Enhance Supervised Emotive Text Classification" Big Data and Cognitive Computing 8, no. 4: 38. https://doi.org/10.3390/bdcc8040038
APA StyleWilliams, L., Anthi, E., & Burnap, P. (2024). Comparing Hierarchical Approaches to Enhance Supervised Emotive Text Classification. Big Data and Cognitive Computing, 8(4), 38. https://doi.org/10.3390/bdcc8040038