
Leveraging Large Language Models for Enhancing Literature-Based Discovery


Abstract
1. Introduction
2. Related Work
- A
- Swanson’s ABC Model Evolution: Developments and Impact on Literature-Based DiscoverySwanson’s ABC model has undergone significant evolution since its inception. The model’s fundamental principle of linking disparate literature through shared concepts has been expanded upon by integrating advanced computational techniques and semantic resources. This evolution has profoundly impacted the field of literature-based discovery, enabling researchers to uncover hidden relationships and generate novel hypotheses with greater efficiency and accuracy. These developments have made the LBD process more efficient and scalable and expanded its potential to contribute to various fields, from healthcare to environmental science. They represent the continuing evolution of Swanson’s vision in the age of digital information, big data, and artificial intelligence. Some critical areas of this evolution are as follows:Two-Node Search Tools: Two-node search tools like Arrowsmith [7] are designed to identify biologically meaningful links between any two sets of articles in PubMed, even when they share no articles or authors in common. This approach allows users to explore indirect linkages between disparate topics or disciplines.Semantic Predications and Graph-Based Methods: Recent advancements in LBD involve the integration of semantic predications and graph-based methods. Semantic web technologies and ontologies (structured frameworks to represent knowledge in a specific domain) have enhanced the ability to semantically link different pieces of information and automate the discovery of potential A-B-C links. Tools like SemPathFinder [8] utilize graph embeddings and link prediction techniques to facilitate literature-based discovery in specific domains, such as Alzheimer’s Disease. By predicting potential connections between biomedical concepts, LitLinker [9] utilizes a graph-based approach to visualize and explore the relationships, facilitating the discovery of novel insights through LBD. Incorporating multi-level context terms into the ABC model, Lee et al.’s method [10] outperforms traditional techniques by delivering higher precision in uncovering meaningful drug-disease interactions from extensive biomedical texts. Their approach leverages a novel context vector-based analysis to discern more relevant and substantial connections within biological literature.Automated Knowledge Base Construction: Another approach in LBD is the automated construction of knowledge bases [11] from biomedical literature. This involves extracting entities and relations to represent information in different domains, such as nutrition, mental health, and natural product-drug interactions.Knowledge-Augmented NLP: The development of memory-augmented transformer models [12] that encode external biomedical knowledge into NLP systems shows promise in enhancing performance on knowledge-intensive tasks, such as LBD. Manjal [13] efficiently sifts through scientific publications from the MEDLINE database, extracting crucial information to streamline the research process and facilitate the discovery of novel insights. The study by Baek et al. [14] enhances hypothesis generation in biomedical research by integrating multiple biological terms and semantic relatedness into the ABC model, leveraging contextual information for more informed hypothesis development. These models leverage pre-existing domain knowledge to improve the identification and generation of hypotheses from biomedical texts.Integration with Databases and Big Data: LBD methodologies now often integrate with various scientific databases and utilize big data analytics. This integration allows for a more comprehensive and detailed exploration of potential links across a broader range of scientific knowledge. Agarwal and Searls [15] illustrate pharmaceutical research’s significant economic impact and enhancement through data-driven literature mining.Open and Closed Discovery Approaches: Open discovery involves generating a hypothesis by starting with a disease or concept and searching for substances or mechanisms related to it. Closed discovery focuses on evaluating and elaborating an initial hypothesis by searching for common mechanisms that link a disease with a substance or concept. The study [16] highlights the significant advancements in employing neural networks for LBD tasks. It demonstrates that these methods outperform traditional LBD techniques, underscoring the effectiveness and potential of incorporating neural network algorithms in discovering hidden relationships within biomedical literature. Drug Repurposing for COVID-19 via Knowledge Graph Completion [17] showcases a novel LBD approach combining semantic triples extracted using SemRep with neural knowledge graph completion algorithms, demonstrating the feasibility of neural network-based LBD in generating actionable medical hypotheses.Cross-Disciplinary Collaborations: There’s an increasing emphasis on cross-disciplinary collaborations, bringing together experts from different fields (e.g., biology, computer science, statistics) to enhance the discovery process. The study on cross-disciplinary research [18] offers an overview of the methodologies and findings related to cross-disciplinary research, utilizing bibliometric analyses to explore the collaboration between authors from different disciplines and the impact of such efforts.
- B
- Limitations of Traditional LBD Methods and the Need for Advanced FrameworksSwanson’s ABC model has been instrumental in uncovering hidden relationships between disparate pieces of information in the biomedical literature. However, it faces several challenges, particularly in terms of scalability, reliance on structured data, and the need for manual curation. These limitations have prompted the development of more advanced methodologies that leverage the capabilities of LLMs to enhance the LBD process.As illustrated in Table 1, our proposed LLM-based framework addresses these limitations by enhancing scalability, automating hypothesis generation, and enabling the integration of multimodal data sources.
- C
- Recent advances in Literature-Based DiscoveryIn the field of literature-based discovery (LBD), building upon Dr. Swanson’s methodologies has focused on various innovative approaches and applications. The ongoing evolution of the LBD field is evident in its broadening applicability across different scientific domains, driven by advanced computational techniques such as LLMs. Recent studies have demonstrated the potential of LLMs to uncover novel insights from biomedical literature, significantly enhancing the efficiency and depth of discovery processes [22]. The use of ChatGPT in LBD, as explored in recent studies, further showcases the advancements in LLM-based methods for literature discovery, particularly in biomedical research [23]. Comprehensive surveys have documented the broader impact of LLMs on drug discovery and development, underlining their growing influence in the healthcare domain [24,25]. Notable recent works include:
- Gap Analysis in Literature: A study by Peng et al. analyzed the concept of “gaps” [26] in literature as topics that should occur together but are unexpectedly missing. Their findings indicated that gap-filling articles on human diseases were often more cited and published in high-impact journals, underscoring LBD’s value as a knowledge discovery tool.
- Metabolomics and LBD: Henry et al.’s [20] work combined classic LBD techniques with high throughput metabolomic analyses. This study revealed new metabolomic pathways, identifying lecithin cholesterol acyltransferase as a potential target for cardiac arrest treatment. This represents a unique application of LBD in the field of metabolomics.
- Domain Independence and Visual Capabilities in LBD: Research by Mejia and Kajikawa [19] demonstrated that LBD could produce meaningful results in domains lacking controlled vocabularies, such as social sciences. Their approach utilized semantic similarity modeling and high-quality data visualizations to aid discovery.
- CHEMMESHNET: Introduced by Škrlj et al., CHEMMESHNET [21] is an extensive literature-based network of protein interactions derived from chemical MeSH keywords in PubMed. This network facilitates LBD tasks, particularly in discovering novel protein-protein interactions.
- Contextualized LBD: A recent study [27] focused on generating novel scientific directions using a contextualized approach to LBD. This involved using generation models like T5 and GPT3.5 for hypothesis generation and exploring dual-encoder models for node prediction, thereby advancing the scope of LBD in generating scientific hypotheses.
- BERT SPO Language Model in LBD: Another study employed the BERT SPO [28] language model to annotate SPO triples from the CORD-19 dataset for their importance, exploring a new way to identify significant information for LBD. This approach helped categorize data for more effective discovery and evaluation.
These approaches are integral to LBD, allowing researchers to explore new hypotheses and validate existing ones in a structured manner. - D
- Generative AI Models in Literature-Based DiscoveryGenerative AI models are revolutionizing LBD by automating the synthesis and analysis of vast scientific literature. These models facilitate the identification of novel insights and connections that may not be immediately apparent to human researchers, thereby accelerating the pace of discovery in various fields.Table 2 details critical insights from various state-of-the-art methods that explore the applications and impacts of Large Language Models (LLMs) and Generative AI across multiple disciplines, including healthcare, education, chemical research, and oncology. It highlights the essential findings and each study’s contribution to LBD.
- E
- Current State of Large Language ModelsDespite their impressive capabilities, LLM’s are still under active development, with researchers tackling challenges such as factual accuracy and efficiency. Table 3 provides a snapshot of leading LLMs, highlighting their developers, release dates, training data size, and capabilities. Current LLMs vary significantly in size and training data, with models like PaLM boasting massive parameters, while others like ERNIE 3.0 prioritize efficiency with a smaller footprint. Despite these differences, most LLMs leverage techniques like fine-tuning and multi-tasking for increased adaptability and real-world application. Auto-regressive models, such as GPT-4 and LLaMA, build text step-by-step, predicting the next word based on the sequence before it. This approach offers a more controllable generation process but can be computationally expensive and prone to repetitive outputs. In contrast, non-autoregressive models, like PaLM, consider the entire context simultaneously to generate text. This can lead to more creative and diverse outputs but may also be less predictable and require additional post-processing for accuracy.
- F
- LLM FeaturesLLMs offer numerous features that significantly enhance their utility in scientific research. Fine-tuning these models on domain-specific datasets enhances their understanding of scientific terminology, enabling more accurate and relevant responses in specialized fields. For instance, data from fine-tuning psychological experiments has demonstrated that LLMs can accurately model human behavior, even outperforming traditional cognitive models in decision-making domains [48]. Explainability is another crucial feature, where LLMs are integrated with techniques to elucidate their reasoning processes, providing clear explanations and supporting evidence for their outputs. The user interface plays a pivotal role, allowing researchers to input concepts and explore connections suggested by the LLM with detailed explanations and evidence, enhancing the research process [49]. Iterative refinement capabilities enable users to provide feedback, refining the model’s accuracy and relevance over time [50]. Continuous learning ensures that LLMs remain up-to-date by integrating new scientific publications and user feedback, continually improving their discovery capabilities [51]. These features collectively make LLMs indispensable tools for advancing scientific research and knowledge synthesis.
- G
- Limitations and Risks of LLMWhile LLM provides exciting features, as depicted above, it is worth highlighting some inherent challenges related to applying LLM, particularly the issue of hallucination. LLMs can generate responses containing information not present in the input, termed “hallucination”. This issue is pervasive across various models and applications, from vision-language models to text-based tasks [52]. Artificial hallucinations can undermine the reliability of LLMs in critical applications, such as medical and financial domains, and create risk and harm to a victim since accurate information is paramount [53]. LLMs often reflect biases in their training data, leading to unfair or discriminatory outputs [54]. LLMs struggle with multimodal tasks, such as those involving text and images, due to their inadequate integration of diverse data types [51]. They can also misunderstand the context or intent behind user queries, resulting in inappropriate responses. Furthermore, LLMs lack transparency in their decision-making processes, complicating their use in fields that demand explainability [55]. Lastly, their inability to retain information over time hinders the development of personalized responses unless specifically programmed for such tasks [56].
3. LLM Grounded Literature Discovery Model
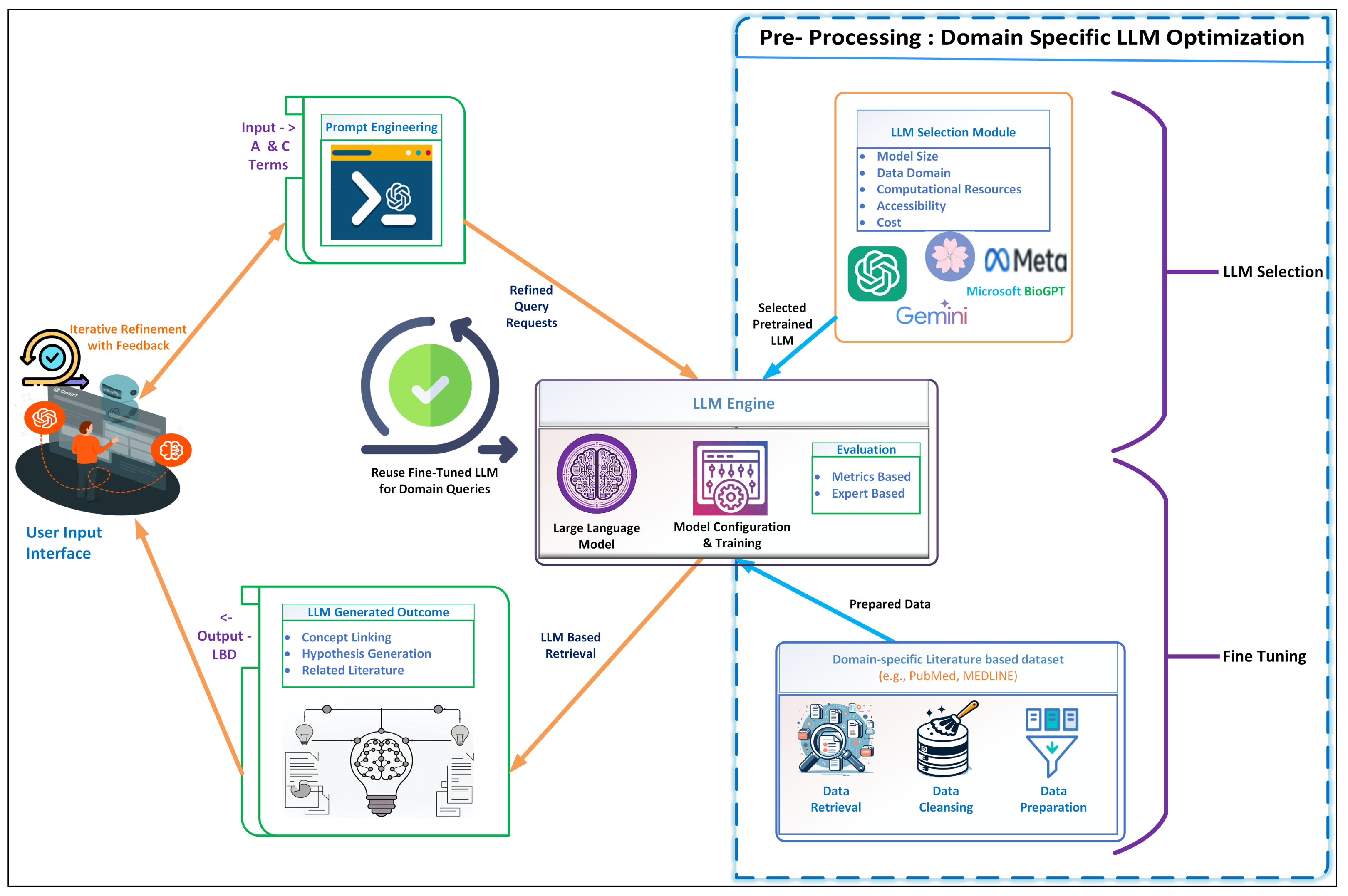
LLM-Based Architecture
4. Methodology
- A
- Algorithm for LLM Model SelectionWe developed Algorithm 1 to select an appropriate LLM based on the available GPU memory, ensuring optimal performance by matching the model to the hardware capabilities.The algorithm first checks the GPU memory and assigns the most suitable model, handling cases where there is insufficient memory by considering the use of quantized models or switching to cloud-based alternatives if necessary. Quantized models reduce the precision of the weights and activations (e.g., 32-bit to 8-bit) to decrease memory usage and improve inference speed, enabling deployment on hardware with limited resources [57]. If sufficient memory is available, the algorithm selects a complete model to leverage full precision and performance.When local resources are insufficient, the algorithm can switch to cloud-based LLMs, selecting from options such as OpenAI, BioGPT, or Gemini, based on criteria such as accessibility, cost, and model size. This comprehensive approach ensures that the selected LLM meets the specific needs of the task, whether through using local hardware, quantized models, or cloud-based resources, all while staying within the constraints of available resources.
- B
- Algorithm for Fine-TuningThe Fine-Tuning (Data Preparation) is detailed in Algorithm 2 and is designed to preprocess a domain-specific LBD dataset, such as abstracts or full PDFs retrieved from PubMed, to prepare the data for ingestion by a pre-trained LLM. The process begins with data retrieval, where relevant abstracts are fetched using the PubMed API based on specific query parameters. The abstracts are then filtered to include only those from reputable sources, such as Scopus-indexed journals, ensuring the quality and relevance of the dataset.Following data retrieval, the text is normalized and cleaned by removing HTML tags, converting it to lowercase and removing special characters and digits through regular expressions. This standardization ensures consistency across the dataset. In the next step, the text is tokenized and lemmatized. Tokenization involves breaking down the text into individual tokens (words or phrases), and lemmatization reduces words to their base or root form [58]. This step uses SpaCy [59] to tokenize the text, lemmatize tokens, and remove stopwords and non-alphabetic tokens, ensuring the text is in its most informative form for further processing.In the following step, text is encoded into sentence embeddings using SBERT (Sentence-BERT) [60], a variant of the BERT [46] model specifically designed to generate semantically meaningful embeddings for sentences. These embeddings capture the semantic content of the text in a multi-dimensional vector space, making them suitable for further processing and analysis by the LLM. Incorporating SBERT provides a substantial methodological improvement in the generation of sentence embeddings.Traditional BERT [46] architectures, while state-of-the-art in their performance on sentence-pair regression tasks are computationally intensive as they require pairwise sentence input, making them unsuitable for tasks like semantic similarity search across large datasets. SBERT modifies the pre-trained BERT [46] network to use Siamese [61] and triplet network structures, to derive semantically meaningful sentence embeddings that are efficient for comparison via cosine similarity [60].Finally, the cleaned abstracts and their corresponding embeddings are stored in a Data Frame, a data structure provided by the Pandas library for efficient data manipulation and analysis.Any rows with missing values are removed to ensure data completeness. The resulting cleaned and preprocessed data, now in the form of embeddings, is then outputted and ready for ingestion and utilization by the LLM for various downstream tasks, such as hypothesis generation. This comprehensive preprocessing pipeline ensures that the data fed into the LLM is high quality, relevant, and semantically rich.
- C
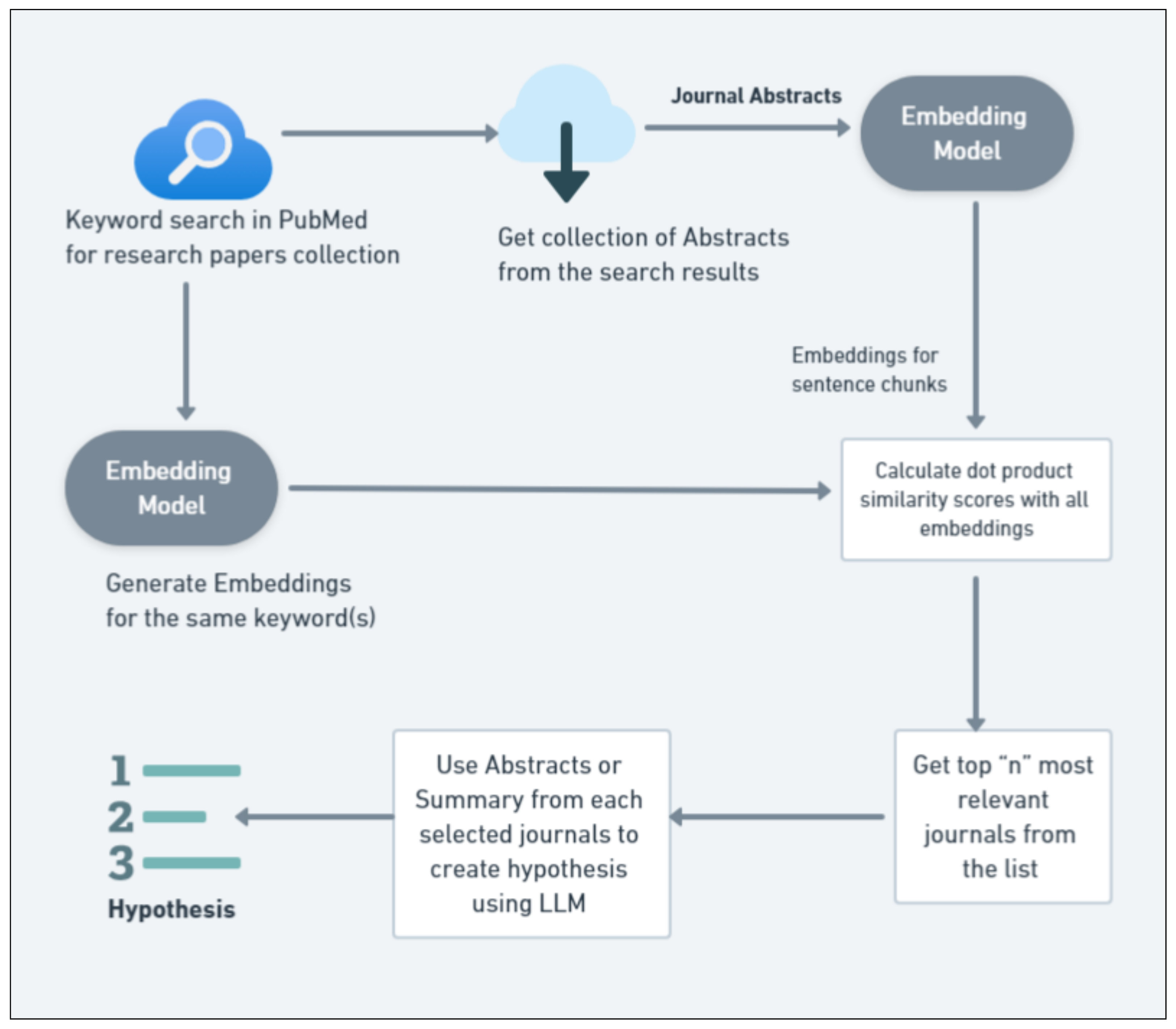
- Algorithm for Hypothesis GenerationThe hypothesis Generation is detailed in Algorithm 3 and inputs a pre-trained LLM and the cleaned, preprocessed data from the fine-tuning phase to generate meaningful hypotheses based on user inputs.The process begins by obtaining user input terms and generating initial hypotheses using LLMs, which are then encoded into sentence embeddings using SBERT. These embeddings are further refined by retrieving and analyzing full-text journal articles, ensuring that the hypotheses are well-supported by detailed and comprehensive sources. The cosine similarity between the embeddings of initial hypotheses and full-text documents helps in this refinement process.The algorithm computes a similarity threshold based on known related pairs from a validation set to validate the refined hypotheses. It then queries ClinicalTrials.gov [62] for related clinical trials and computes the cosine similarity between hypothesis and trial embeddings. Hypotheses with similarity scores exceeding the threshold are validated. The final step involves compiling references and presenting the validated hypotheses and their validation scores to the user. This user-centric approach ensures that the hypotheses are scientifically robust and practically relevant, allowing for iterative refinement based on user feedback.
| Algorithm 1: LLM Model Selection |
 |
| Algorithm 2: Fine-tuning (Data Preparation) for LLM |
 |
| Algorithm 3: Hypothesis Generation |
 |
5. Experimental Evaluation
5.1. Dataset
5.2. Experimentation Setup
5.3. Scenarios
5.3.1. Scenario 1: Validating the Efficacy of Embedding-Based Semantic Similarity Searches in LBD
5.3.2. Scenario 2: Analysis with Different Search Use Cases and Report the Results (Local LLM)
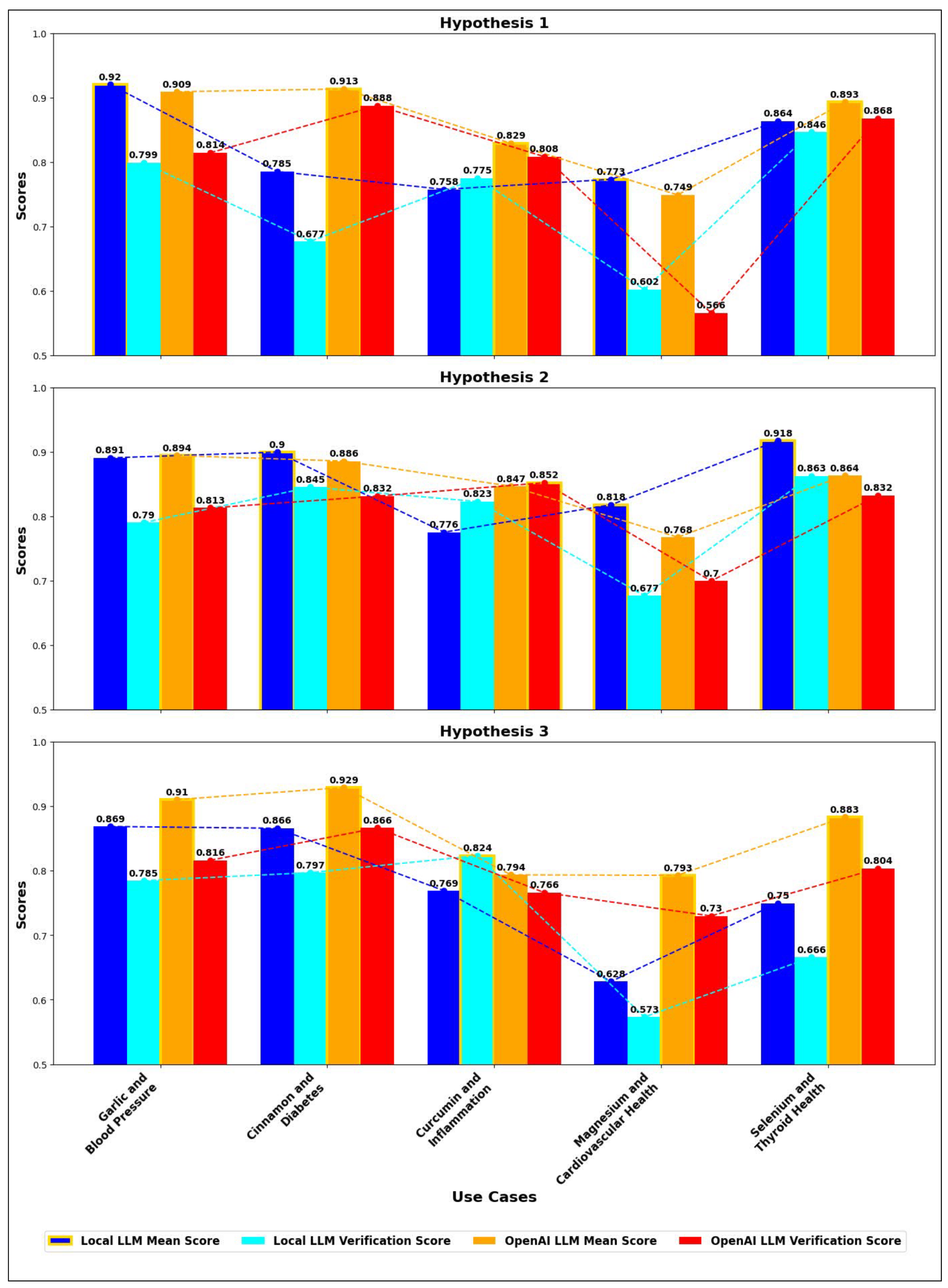
5.3.3. Scenario 3: Impact of Changing LLM Models on Performance Metrics (Local LLM Model vs. OpenAI Model)
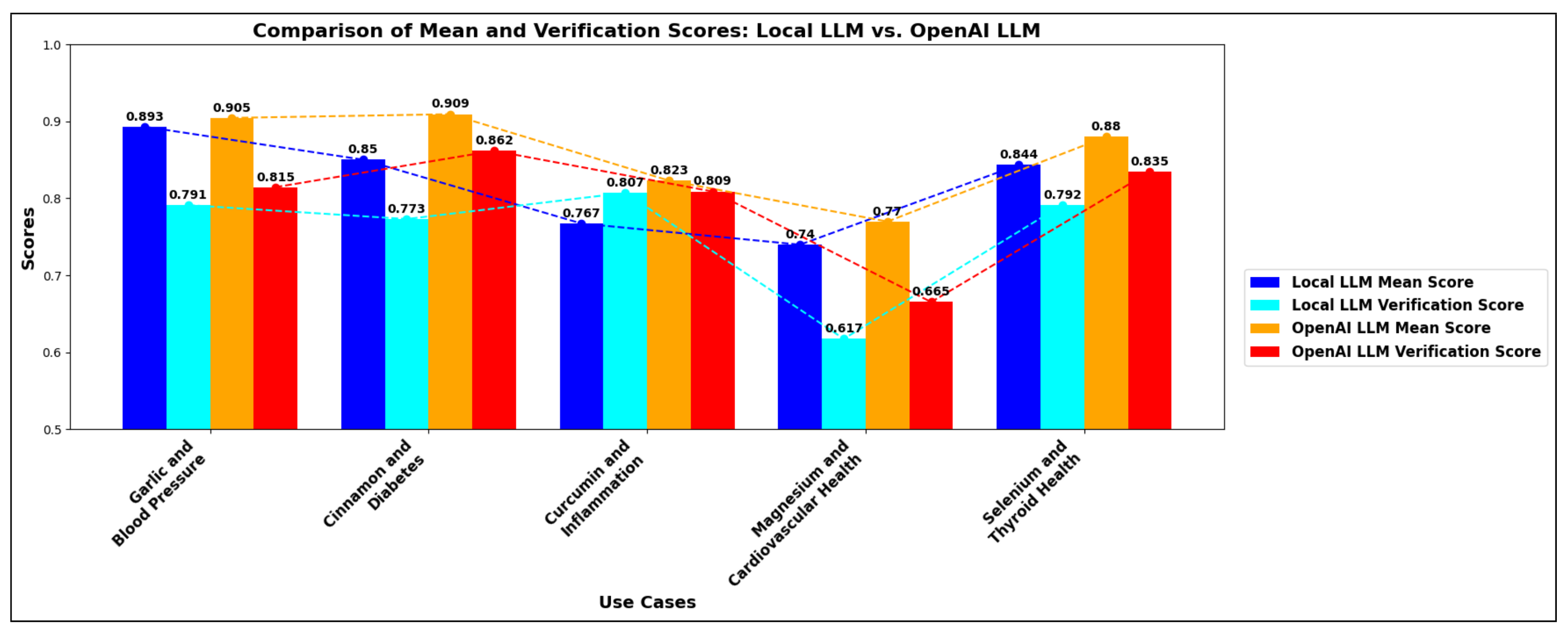
5.3.4. Scenario 4: Comprehensive Comparison of the Performance: Local LLM vs. OpenAI
5.3.5. Scenario 5: Comparative Analysis with Swanson’s ABC Model
5.4. Results, Discussion and Limitations
6. Conclusions and Future Work
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| API | Application Programming Interface |
| BERT | Bidirectional Encoder Representations from Transformers |
| CPU | Central Processing Unit |
| EMNLP | Empirical Methods in Natural Language Processing |
| GPU | Graphics Processing Unit |
| LBD | Literature-Based Discovery |
| LLM | Large Language Model |
| Mg | Magnesium |
| NCBI | National Center for Biotechnology Information |
| NLP | Natural Language Processing |
| PMID | PubMed Identifier |
| RTX | Ray Tracing Texel eXtreme |
| SBERT | Sentence-BERT |
| Se | Selenium |
References
- Swanson, D.R. Fish oil, Raynaud’s syndrome, and undiscovered public knowledge. Perspect. Biol. Med. 1986, 30, 7–18. [Google Scholar] [CrossRef] [PubMed]
- Weeber, M.; Klein, H.; De Jong-Van Den Berg, L.T.W.; Vos, R. Using concepts in literature-based discovery: Simulating Swanson’s Raynaud-fish oil and migraine-magnesium discoveries. J. Am. Soc. Inf. Sci. Technol. 2001, 52, 548–557. [Google Scholar] [CrossRef]
- Brown, T.B. Language models are few-shot learners. Advances in Neural Information Processing Systems. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Tophel, A.; Chen, L. Towards an AI Tutor for Undergraduate Geotechnical Engineering : A Comparative Study of Evaluating the Efficiency of Large Language Model Application Programming Interfaces. Res. Sq. 2024. [Google Scholar] [CrossRef]
- Chen, L.; Tophel, A.; Hettiyadura, U.; Kodikara, J. An Investigation into the Utility of Large Language Models in Geotechnical Education and Problem Solving. Geotechnics 2024, 4, 470–498. [Google Scholar] [CrossRef]
- Bünau, P.V. From the Depths of Literature: How Large Language Models Excavate Crucial Information to Scale Drug Discovery, 2023. Available online: https://idalab.de/insights/how-large-language-models-excavate-crucial-information-to-scale-drug-discovery (accessed on 13 March 2024).
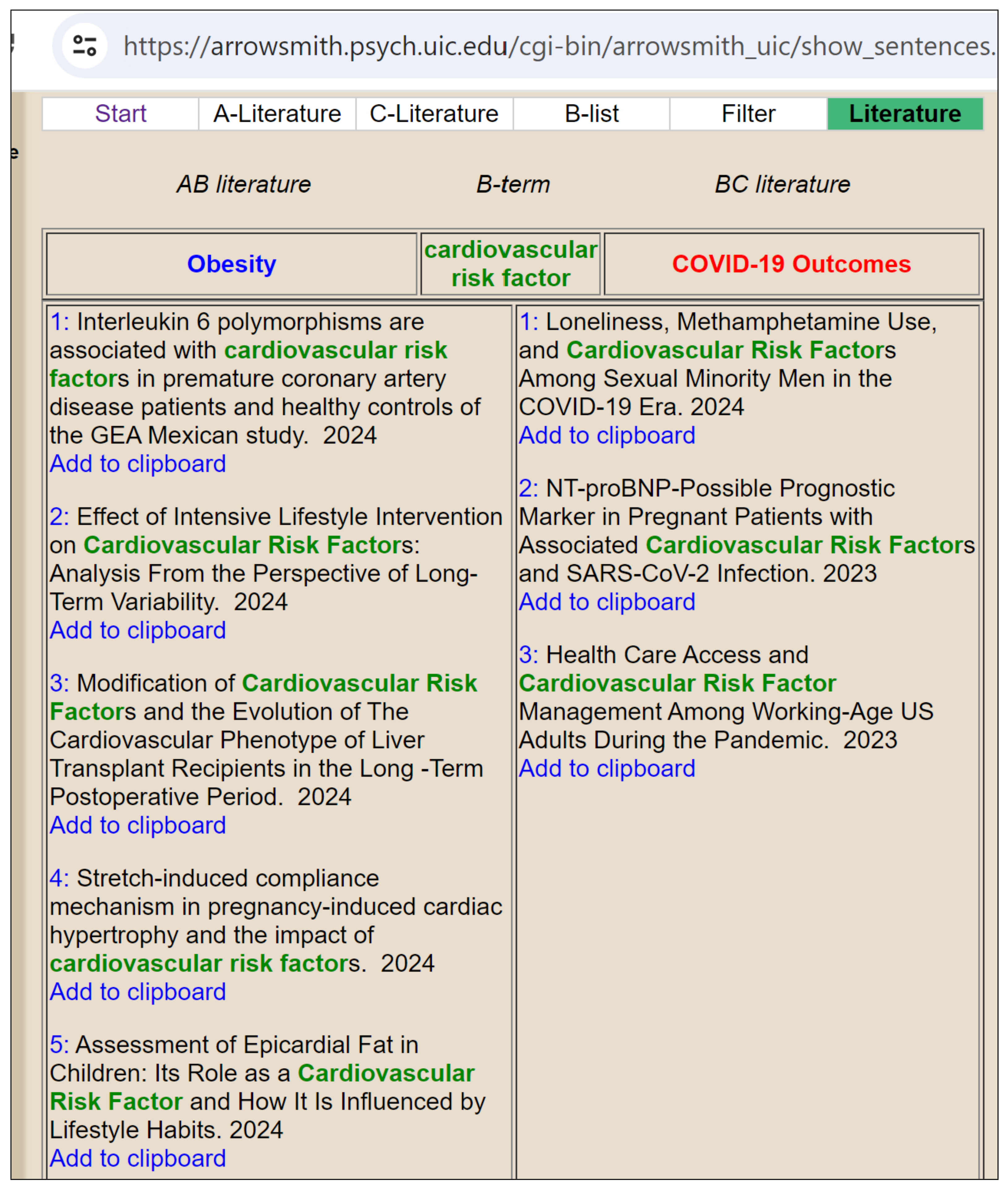
- Smalheiser, N.R.; Swanson, D.R. Using ARROWSMITH: A computer-assisted approach to formulating and assessing scientific hypotheses. Comput. Methods Programs Biomed. 1998, 57, 149–153. [Google Scholar] [CrossRef]
- Song, M.; Heo, G.; Ding, Y. SemPathFinder: Semantic path analysis for discovering publicly unknown knowledge. J. Inf. 2015, 9, 686–703. [Google Scholar] [CrossRef]
- Yetisgen-Yildiz, M. LitLinker: A system for searching potential discoveries in biomedical literature. In Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Seattle, WA, USA, 6–11 August 2006. [Google Scholar]
- Lee, S.; Choi, J.; Park, K.; Song, M.; Lee, D. Discovering context-specific relationships from biological literature by using multi-level context terms. BMC Med. Inform. Decis. Mak. 2012, 12, S1. [Google Scholar] [CrossRef]
- Alam, F.; Giglou, H.B.; Malik, K.M. Automated clinical knowledge graph generation framework for evidence based medicine. Expert Syst. Appl. 2023, 233, 120964. [Google Scholar] [CrossRef]
- Wu, Y.; Zhao, Y.; Hu, B.; Minervini, P.; Stenetorp, P.; Riedel, S. An Efficient Memory-Augmented Transformer for Knowledge-Intensive NLP Tasks. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP), Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 5184–5196. [Google Scholar] [CrossRef]
- Sehgal, A.K.; Srinivasan, P. Manjal: A text mining system for MEDLINE. In Proceedings of the 28th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Salvador, Brazil, 15–19 August 2005; p. 680. [Google Scholar] [CrossRef]
- Baek, S.H.; Lee, D.; Kim, M.; Lee, J.; Song, M. Enriching plausible new hypothesis generation in PubMed. PLoS ONE 2017, 12, e0180539. [Google Scholar] [CrossRef]
- Agarwal, P.; Searls, D.B. Literature mining in support of drug discovery. Briefings Bioinform. 2008, 9, 479–492. [Google Scholar] [CrossRef] [PubMed]
- Crichton, G.; Baker, S.; Guo, Y.; Korhonen, A. Neural networks for open and closed Literature-based Discovery. PLoS ONE 2020, 15, e0232891. [Google Scholar] [CrossRef] [PubMed]
- Zhang, R.; Hristovski, D.; Schutte, D.; Kastrin, A.; Fiszman, M.; Kilicoglu, H. Drug repurposing for COVID-19 via knowledge graph completion. J. Biomed. Inform. 2021, 115, 103696. [Google Scholar] [CrossRef] [PubMed]
- Bordons, I.; Morillo, F.; Gómez, I. Analysis of Cross-Disciplinary Research Through Bibliometric Tools; Springer: Dordrecht, The Netherlands, 2004. [Google Scholar]
- Mejia, C.; Kajikawa, Y. A network approach for mapping and classifying shared terminologies between disparate literatures in the social sciences. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Singapore, 11–14 May 2020; Volume 12237, pp. 30–40. [Google Scholar] [CrossRef]
- Henry, S.; Wijesinghe, D.S.; Myers, A.; McInnes, B.T. Using Literature Based Discovery to Gain Insights into the Metabolomic Processes of Cardiac Arrest. Front. Res. Metrics Anal. 2021, 6, 644728. [Google Scholar] [CrossRef] [PubMed]
- Škrlj, B.; Kokalj, E.; Lavrač, N. PubMed-Scale Chemical Concept Embeddings Reconstruct Physical Protein Interaction Networks. Front. Res. Metrics Anal. 2021, 6, 644614. [Google Scholar] [CrossRef]
- Sarrouti, M.; Ouatik El Alaoui, S. A passage retrieval method based on probabilistic information retrieval and UMLS concepts in biomedical question answering. J. Biomed. Inform. 2017, 68, 96–103. [Google Scholar] [CrossRef]
- Nedbaylo, A.; Hristovski, D. Implementing Literature-based Discovery (LBD) with ChatGPT. In Proceedings of the 2024 47th ICT and Electronics Convention, MIPRO 2024—Proceedings, Opatija, Croatia, 20–24 May 2024; pp. 120–125. [Google Scholar] [CrossRef]
- Gopalakrishnan, V.; Jha, K.; Jin, W.; Zhang, A. A survey on literature based discovery approaches in biomedical domain. J. Biomed. Inform. 2019, 93, 103141. [Google Scholar] [CrossRef]
- Mirzaei, S.; Gholami, M.H.; Hashemi, F.; Zabolian, A.; Farahani, M.V.; Hushmandi, K.; Zarrabi, A.; Goldman, A.; Ashrafizadeh, M.; Orive, G. Advances in understanding the role of P-gp in doxorubicin resistance: Molecular pathways, therapeutic strategies, and prospects. Drug Discov. Today 2022, 27, 436–455. [Google Scholar] [CrossRef]
- Peng, Y.; Bonifield, G.; Smalheiser, N.R. Gaps within the Biomedical Literature: Initial Characterization and Assessment of Strategies for Discovery. Front. Res. Metrics Anal. 2017, 2, 3. [Google Scholar] [CrossRef]
- Wang, Q.; Downey, D.; Ji, H.; Hope, T. SCIMON: Scientific Inspiration Machines Optimized for Novelty. arXiv 2023, arXiv:2305.14259. [Google Scholar]
- Preiss, J. Avoiding background knowledge: Literature based discovery from important information. BMC Bioinform. 2022, 23, 570. [Google Scholar] [CrossRef] [PubMed]
- Patil, D.D.; Dhotre, D.R.; Gawande, G.S.; Mate, D.S.; Shelke, M.V.; Bhoye, T.S. Transformative Trends in Generative AI: Harnessing Large Language Models for Natural Language Understanding and Generation. Int. J. Intell. Syst. Appl. Eng. 2024, 12, 309–319. [Google Scholar]
- Prather, J.; Denny, P.; Leinonen, J.; Becker, B.A.; Albluwi, I.; Craig, M.; Keuning, H.; Kiesler, N.; Kohn, T.; Luxton-Reilly, A.; et al. The Robots Are Here: Navigating the Generative AI Revolution in Computing Education. In Proceedings of the 2023 Working Group Reports on Innovation and Technology in Computer Science Education, Turku, Finland, 7–12 July 2023. [Google Scholar]
- Zheng, Z.; Zhang, O.; Nguyen, H.L.; Rampal, N.; Alawadhi, A.H.; Rong, Z.; Head-Gordon, T.; Borgs, C.; Chayes, J.T.; Yaghi, O.M. ChatGPT Research Group for Optimizing the Crystallinity of MOFs and COFs. ACS Cent. Sci. 2023, 9, 2161–2170. [Google Scholar] [CrossRef] [PubMed]
- Iannantuono, G.M.; Bracken-Clarke, D.; Floudas, C.S.; Roselli, M.; Gulley, J.L.; Karzai, F. Applications of large language models in cancer care: Current evidence and future perspectives. Front. Oncol. 2023, 13, 1268915. [Google Scholar] [CrossRef]
- Ghimire, P.; Kim, K.; Acharya, M. Opportunities and Challenges of Generative AI in Construction Industry: Focusing on Adoption of Text-Based Models. Buildings 2024, 14, 220. [Google Scholar] [CrossRef]
- Birhane, A.; Kasirzadeh, A.; Leslie, D.; Wachter, S. Science in the age of large language models. Nat. Rev. Phys. 2023, 5, 277–280. [Google Scholar] [CrossRef]
- Wysocka, M.; Wysocki, O.; Delmas, M.; Mutel, V.; Freitas, A. Large Language Models scientific knowledge and factuality: A systematic analysis in antibiotic discovery. arXiv 2023, arXiv:2305.17819. [Google Scholar]
- OpenAI. GPT-4. 2024. Available online: https://openai.com/research/gpt-4 (accessed on 5 March 2024).
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Taylor, R.; Kardas, M.; Cucurull, G.; Scialom, T.; Hartshorn, A.; Saravia, E.; Poulton, A.; Kerkez, V.; Stojnic, R. Galactica: A Large Language Model for Science. arXiv 2022, arXiv:2211.09085. [Google Scholar]
- Workshop, B.; Scao, T.L.; Fan, A.; Akiki, C.; Pavlick, E.; Ilić, S.; Hesslow, D.; Castagné, R.; Luccioni, A.S.; Yvon, F.; et al. BLOOM: A 176B-Parameter Open-Access Multilingual Language Model. arXiv 2022, arXiv:2211.05100. [Google Scholar]
- Luo, R.; Sun, L.; Xia, Y.; Qin, T.; Zhang, S.; Poon, H.; Liu, T.Y. BioGPT: Generative Pre-trained Transformer for Biomedical Text Generation and Mining. Briefings Bioinform. 2022, 23, bbac409. [Google Scholar] [CrossRef] [PubMed]
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S.; et al. PaLM: Scaling Language Modeling with Pathways. J. Mach. Learn. Res. 2023, 24, 1–113. [Google Scholar]
- Wang, S.; Sun, Y.; Xiang, Y.; Wu, Z.; Ding, S.; Gong, W.; Feng, S.; Shang, J.; Zhao, Y.; Pang, C.; et al. ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation. arXiv 2021, arXiv:2112.12731. [Google Scholar]
- Microsoft. Turing-NLG: A 17-Billion-Parameter Language Model by Microsoft. 2020. Available online: https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft/ (accessed on 5 March 2024).
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Narayanan, D.; Shoeybi, M.; Casper, J.; LeGresley, P.; Patwary, M.; Korthikanti, V.; Vainbrand, D.; Kashinkunti, P.; Bernauer, J.; Catanzaro, B.; et al. Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM. Assoc. Comput. Mach. 2021, 1, 1–15. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the NAACL HLT 2019—2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies; Minneapolis, MN, USA, 2–7 June 2019, Volume 1, pp. 4171–4186. Available online: http://xxx.lanl.gov/abs/1810.04805 (accessed on 21 July 2024).
- Google. Gemma: 2B. 2023. Available online: https://huggingface.co/google/gemma-2b-it (accessed on 13 July 2024).
- Binz, M.; Schulz, E. Turning large language models into cognitive models. arXiv 2023, arXiv:2306.03917. [Google Scholar] [CrossRef]
- Boyko, J.; Cohen, J.; Fox, N.; Veiga, M.H.; Li, J.I.; Liu, J.; Modenesi, B.; Rauch, A.H.; Reid, K.N.; Tribedi, S.; et al. An Interdisciplinary Outlook on Large Language Models for Scientific Research. arXiv 2023, arXiv:2311.04929. [Google Scholar] [CrossRef]
- Boiko, D.A.; Macknight, R.; Gomes, G. Emergent autonomous scientific research capabilities of large language models. arXiv 2023, arXiv:2304.05332. [Google Scholar]
- Zheng, Y.; Koh, H.Y.; Ju, J.; Nguyen, A.T.; May, L.T.; Webb, G.I.; Pan, S. Large Language Models for Scientific Synthesis , Inference and Explanation. arXiv 2023, arXiv:2310.07984. [Google Scholar] [CrossRef]
- Wang, J.; Zhou, Y.; Xu, G.; Shi, P.; Zhao, C.; Xu, H.; Ye, Q.; Yan, M.; Zhang, J.; Zhu, J.; et al. Evaluation and Analysis of Hallucination in Large Vision-Language Models. arXiv 2023, arXiv:2308.15126. [Google Scholar]
- Birkun, A.K.; Gautam, A. Large Language Model (LLM)-Powered Chatbots Fail to Generate Guideline-Consistent Content on Resuscitation and May Provide Potentially Harmful Advice. Prehospital Disaster Med. 2023, 38, 757–763. [Google Scholar] [CrossRef]
- McKenna, N.; Li, T.; Cheng, L.; Hosseini, M.J.; Johnson, M.; Steedman, M. Sources of Hallucination by Large Language Models on Inference Tasks. Findings of the Association for Computational Linguistics: EMNLP 2023. arXiv 2023, arXiv:2305.14552. [Google Scholar] [CrossRef]
- Questions, O.; Yu, W.; Ma, W.; Zhong, W.; Feng, Z.; Wang, H.; Chen, Q.; Peng, W.; Feng, X.; Qin, B.; et al. A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions. arXiv 2023, arXiv:2311.05232. [Google Scholar]
- Zhang, Y.; Li, Y.; Cui, L.; Cai, D.; Liu, L.; Fu, T.; Huang, X.; Zhao, E.; Zhang, Y.; Chen, Y.; et al. Siren’s Song in the AI Ocean: A Survey on Hallucination in Large Language Models. arXiv 2023, arXiv:2309.01219. [Google Scholar]
- Quantization. 2024. Available online: https://huggingface.co/docs/optimum/en/concept_guides/quantization (accessed on 16 May 2024).
- Tabassum, A.; Patil, R.R. A Survey on Text Pre-Processing & Feature Extraction Techniques in Natural Language Processing. Int. Res. J. Eng. Technol. 2020, 7, 4864–4867. [Google Scholar]
- spaCy. Industrial-Strength Natural Language Processing in Python. 2024. Available online: https://spacy.io/ (accessed on 20 March 2024).
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence embeddings using siamese BERT-networks. In Proceedings of the EMNLP-IJCNLP 2019—2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 3982–3992. [Google Scholar] [CrossRef]
- Roy, S.; Harandi, M.; Nock, R.; Hartley, R. Siamese networks: The tale of two manifolds. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3046–3055. [Google Scholar] [CrossRef]
- ClinicalTrials.gov. 2024. Available online: https://clinicaltrials.gov/ (accessed on 1 July 2024).
- PubMed—National Center for Biotechnology Information. Available online: https://pubmed.ncbi.nlm.nih.gov/ (accessed on 2 July 2024).
- Sayers, E.W.; Barrett, T.; Benson, D.A.; Bryant, S.H.; Canese, K.; Chetvernin, V.; Church, D.M.; DiCuccio, M.; Edgar, R.; Federhen, S.; et al. Database resources of the National Center for Biotechnology Information. Nucleic Acids Res. 2021, 49, D10–D17. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An imperative style high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Van Der Walt, S.; Colbert, S.C.; Varoquaux, G. The NumPy array: A structure for efficient numerical computation. Comput. Sci. Eng. 2011, 13, 22–30. [Google Scholar] [CrossRef]
- Cappi, R.; Casini, L.; Tosi, D.; Roccetti, M. Questioning the seasonality of SARS-COV-2: A Fourier spectral analysis. BMJ Open 2022, 12, e061602. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Limitation of Traditional Model | LLM-Based Framework Capabilities | References |
|---|---|---|
| Scalability Issues: Traditional LBD methods, including Swanson’s ABC model, struggle to efficiently scale with the growing volume of biomedical literature. This often results in missed opportunities to uncover hidden relationships due to the overwhelming amount of data. | Enhanced Scalability: The proposed LLM-based framework leverages the computational power and advanced natural language processing capabilities of LLMs to efficiently process and analyze vast datasets, enabling the discovery of subtle and complex relationships that would be missed by traditional methods. | [1,15] |
| Dependence on Structured Data: Swanson’s ABC model relies heavily on structured data and predefined keywords, limiting the scope of discovery to only those relationships explicitly defined by the chosen terms. | Semantic Understanding: The LLM-based framework enhances the discovery process by understanding and interpreting unstructured data, enabling it to identify relationships based on semantic content rather than just predefined keywords. This allows for the discovery of more nuanced and indirect connections. | [14,19] |
| Manual Curation Required: Traditional LBD methods often require significant manual curation and intervention, particularly when identifying intermediary concepts (B-terms) that link two unrelated domains. | Automated Hypothesis Generation: The LLM-based framework automates the process of identifying intermediary concepts and generating hypotheses, significantly reducing the need for manual intervention and improving the efficiency of the discovery process. | [10,20] |
| Limited to Textual Data: Swanson’s ABC model primarily operates on textual data, limiting its ability to integrate multimodal data sources (e.g., images, genomic data) that are increasingly important in biomedical research. | Multimodal Integration: The LLM-based framework has the potential to integrate and process multimodal data sources, enabling a more comprehensive analysis and the discovery of complex relationships across different types of data. | [14,21] |
| Static Model: The ABC model is relatively static and does not adapt well to new information or evolving research areas, leading to potential gaps in discovery. | Continuous Learning and Adaptation: LLMs can be fine-tuned continuously with new data, allowing the framework to adapt to emerging research areas and maintain relevance in the rapidly evolving biomedical field. | [14,19] |
| Article Title | Focus Area | Key Findings | Contribution to LBD |
|---|---|---|---|
| Transformative Trends in Generative AI: Harnessing Large Language Models for Natural Language Understanding and Generation [29] | Large Language Models in AI | Explores the evolution and impact of LLMs in language understanding and generation | Facilitates LBD in natural language understanding and generation, enabling the discovery of new knowledge through textual data analysis. |
| The Robots are Here: Navigating the Generative AI Revolution in Computing Education [30] | Impact of Generative AI on computing education | Highlights opportunities and challenges of LLMs in education | Supports LBD by exploring how LLMs can uncover novel pedagogical insights through educational content analysis. |
| ChatGPT; Research Group for Optimizing the Crystallinity of MOFs and COFs [31] | Chemistry research optimization | Demonstrates the use of ChatGPT and Bayesian optimization in chemical research | Illustrates LBD in chemical research using LLMs for optimizing experimental conditions and interpreting results. |
| Applications of large language models in cancer care [32] | LLMs in oncology | Evaluates ChatGPT’s role as virtual assistants in oncology, highlighting challenges | Shows the potential of LLMs in LBD for oncology by providing insights from medical literature and aiding in clinical decision-making. |
| Opportunities and Challenges of Generative AI in Construction Industry: Focusing on Adoption of Text-Based Models [33] | Generative AI in the Construction and Engineering domains | Discusses integration of text-based models in construction, highlighting efficiency and innovation opportunities, addressing adoption challenges | Demonstrates LBD’s potential in the construction industry by leveraging text-based generative models to uncover new insights and improve decision-making processes. |
| Science in the age of large language models [34] | Impact of LLMs on scientific practices | Discusses the impact of LLMs on scientific research and the need for responsible use | Highlights LLMs’ role in generating scientific text and answering questions while cautioning against limitations, such as hallucinations. |
| Large Language Models, Scientific Knowledge, and Factuality: A Systematic Analysis in Antibiotic Discovery [35] | LLMs in Antibiotic Discovery | Critical assessment of LLMs’ factual knowledge reproduction in biomedicine | Underlines the importance of enhancing LLMs’ accuracy and the need for domain-specific training to support LBD in scientific practice. |
| Model | Developer | Release Date | Training Size (Parameters) | Auto- Regressive | Fine-Tuning | Multi-Task Learning | Knowledge Integration |
|---|---|---|---|---|---|---|---|
| GPT-4 [36] | OpenAI | March 2023 | 175 billion | ✓ | ✓ | ✗ | ✗ |
| LLaMA [37] | Meta AI | February 2023 | 7–65 billion | ✓ | ✓ | ✗ | ✗ |
| Galactica [38] | Meta AI | November 2022 | 120 billion | ✓ | ✓ | ✗ | ✓ |
| BLOOM [39] | BigScience | July 2022 | 176 billion | ✓ | ✓ | ✗ | ✗ |
| BioGPT [40] | Microsoft Research | 2022 | Varies | ✓ | ✓ | ✗ | ✗ |
| PaLM [41] | Google Research | April 2022 | 540 billion | ✗ | ✓ | ✓ | ✗ |
| ERNIE 3.0 [42] | Baidu | June 2021 | 10 billion | ✗ | ✓ | ✓ | ✓ |
| Turing-NLG [43] | Microsoft | February 2020 | 17 billion | ✓ | ✓ | ✗ | ✗ |
| T5 [44] | Google AI | October 2019 | 11 billion | ✗ | ✓ | ✓ | ✗ |
| Megatron-LM [45] | NVIDIA | August 2019 | 8.3 billion | ✓ | ✓ | ✗ | ✗ |
| BERT [46] | Google AI | October 2018 | 110–340 million | ✗ | ✓ | ✗ | ✗ |
| Gemma-2B-It [47] | July 2024 | 2.51 billion | ✓ | ✓ | ✗ | ✗ |
| Hypothesis | Justification | PMIDs Used | Hypothesis Weightage on Journals (PMID: Score) | ClinicalTrials Rec ID | Validation Score |
|---|---|---|---|---|---|
| 1. Garlic consumption may be associated with a significant reduction in blood pressure in patients with hypertension, compared to placebo. | The meta-analysis provides evidence that garlic reduces blood pressure in hypertensive patients, with a significant mean difference in systolic and diastolic blood pressure in the garlic group compared to the placebo group. The heterogeneity was low in the meta-analysis, suggesting that the effect of garlic on blood pressure may be consistent across different patient subgroups. | 18554422 22895963 16335787 19017826 25557383 | 18554422: 0.9398 22895963: 0.9325 25557383: 0.8883 | NCT04915053 | 0.7989 |
| 2. Garlic consumption may be associated with a reduced risk of cardiovascular events and mortality in patients with hypertension. | The meta-analysis suggests that garlic consumption is associated with a significant reduction in systolic and diastolic blood pressure in hypertensive patients, suggesting that garlic may have a beneficial effect on cardiovascular health in this population. | 18554422 22895963 16335787 19017826 25557383 | 22895963: 0.9076 25557383: 0.8862 16335787: 0.8787 | NCT06264622 | 0.7903 |
| 3. Garlic consumption may be beneficial in lowering blood pressure in patients with hypertension due to its positive effects on blood pressure and chronic inflammation. | The presence of vitamin levels and TAS in the study suggests beneficial effects of garlic supplementation on blood pressure. | 18554422 22895963 16335787 19017826 25557383 | 16335787: 0.8779 22895963: 0.8721 18554422: 0.8561 | NCT04915053 | 0.7846 |
| Hypothesis | Justification | Supporting Studies (PMIDs) | Validation Scores |
|---|---|---|---|
| Cinnamon also possesses a high affinity for glucose transporters in the body, which may explain how it improves glucose uptake. | The study on prediabetes showed that cinnamon improved fasting blood glucose and glucose tolerance, suggesting that it may also have immunomodulatory effects. | 35807953 36206028 33123653 | 0.8026 0.7898 0.7638 |
| Cinnamon may have immunomodulatory effects that can beneficially influence diabetes progression in individuals with prediabetes or T2DM. | Cinnamon has been shown to modulate the immune system and reduce inflammation, which may play a role in the beneficial effects on blood glucose parameters. | 35807953 33123653 36206028 | 0.9219 0.8908 0.8864 |
| Cinnamon may have a direct effect on the production of insulin or its action, leading to improved glucose metabolism. | The evidence suggests that cinnamon may reduce inflammation in individuals with T2DM. | 35807953 36206028 33123653 | 0.8914 0.8653 0.8410 |
| Hypothesis | Justification | Supporting Studies (PMIDs) | Validation Scores |
|---|---|---|---|
| Curcumin may exert anti-inflammatory effects by regulating the production of inflammatory cytokines. This may be mediated through the modulation of immune cells and the production of anti-inflammatory molecules. | The study found that curcumin suppressed the degradation of IB, a protein that is essential for the activation of the NF-B pathway. Curcumin also reduced the expression of pro-inflammatory cytokines, such as IL-1 and TNF-. The study did not mention any changes in the production of inflammatory cytokines, so it is possible that curcumin may have modulated the production of inflammatory cytokines instead of directly inhibiting the NF-B pathway. | 31455356 25688638 33926561 | 0.8146 0.7374 0.7206 |
| Curcumin may exert therapeutic effects by modulating the release and bioavailability of curcumin in the body, leading to sustained protection of joint structures from inflammation. | EV-mediated delivery of curcumin from hBMSCs to OA-CH may improve its bioavailability and protect joint structures from inflammation. | 33926561 25688638 31455356 | 0.7833 0.7779 0.7654 |
| Curcumin may exert therapeutic effects through reducing inflammation by inhibiting the activation of the NF-B signaling pathway, thereby protecting joint structures from damage. | Curcumin’s anti-inflammatory properties and its ability to suppress the NF-B signaling pathway suggest that it may help prevent and treat joint inflammation in osteoarthritis. | 31455356 25688638 35010916 | 0.8057 0.7594 0.7419 |
| Hypothesis | Justification | Supporting Studies (PMIDs) | Validation Scores |
|---|---|---|---|
| Oral Mg supplementation can suppress the frequency of ventricular extrasystoles (VES) in children with a history of ventricular tachycardia. | The study found that oral Mg therapy was effective in suppressing VES in children with a history of VES without structural heart disease. Additionally, the absence of significant difference between the pre-treatment serum Mg levels and the decrease in the frequency of VES suggests that Mg therapy may have exerted its effect through a mechanism independent of serum Mg levels. | 38243650 32670733 33037777 | 0.9409 0.6980 0.6806 |
| Intravenous Mg administration can decrease the number of ventricular ectopic beats or convert ventricular tachyarrhythmia to sinus rhythm in dogs. | The results from the study on dogs with refractory ventricular fibrillation suggest that intravenous Mg administration can decrease the number of ventricular ectopic beats or convert ventricular tachyarrhythmia to sinus rhythm. | 33037777 34499802 38243650 | 0.9115 0.8236 0.7189 |
| IV Mg therapy is effective in reducing the QT interval in patients with end-stage kidney disease who develop prolonged QT after hemodialysis. | The study found that IV Mg significantly reduced the QT interval after hemodialysis in patients with end-stage kidney disease, suggesting that IV Mg may have cardioprotective effects in this population. | 32670733 38243650 33899191 | 0.8143 0.5389 0.5313 |
| Hypothesis | Justification | Supporting Studies (PMIDs) | Validation Scores |
|---|---|---|---|
| Selenium deficiency may contribute to the development of autoimmune thyroid diseases through the induction of inflammation and the production of thyroid autoantibodies, leading to the characteristic clinical presentations of the disease. | Studies suggest that selenium deficiency is associated with an increased risk of autoimmune thyroid diseases and that supplementation may alleviate disease activity. | 20810577 30844687 36622057 | 0.8784 0.8577 0.8544 |
| The clinical efficacy of selenium supplementation in autoimmune thyroid diseases is supported by the association between selenium deficiency and the presence of thyroid autoantibodies in clinical practice and the beneficial effects of selenium supplementation on biochemical markers of thyroid function and disease activity. | Studies suggest that selenium is a critical factor for the regulation of thyroid function and that its supplementation may mitigate the development and progression of autoimmune thyroid diseases. | 36622057 20810577 30844687 | 0.9273 0.9256 0.8995 |
| The optimal plasma Se concentration for preventing thyroid diseases is lower than previously thought and that supplementation with high doses and long-term treatment may be beneficial. | Evidence supporting the efficacy of Se in preventing thyroid diseases comes from clinical trials in autoimmune thyroid diseases, despite the limited number of high-quality randomized controlled trials. | 33970480 18686295 20810577 | 0.7717 0.7616 0.7161 |
| Use Case | Mean Score | Median Score | Standard Deviation | Minimum Score | Maximum Score |
|---|---|---|---|---|---|
| Garlic and Blood Pressure | 0.8932 | 0.8908 | 0.0214 | 0.8687 | 0.9202 |
| Cinnamon and Diabetes | 0.8503 | 0.8659 | 0.0586 | 0.7854 | 0.8997 |
| Curcumin and Inflammation | 0.7673 | 0.7690 | 0.0090 | 0.7575 | 0.7755 |
| Magnesium and Cardiovascular Health | 0.7398 | 0.7732 | 0.0970 | 0.6282 | 0.8180 |
| Selenium and Thyroid Health | 0.8436 | 0.8635 | 0.0689 | 0.7498 | 0.9175 |
| Hypothesis | Justification | PMID: Score | ClinicalTrials Rec ID | Validation Score |
|---|---|---|---|---|
| People who gained weight during the pandemic, regardless of their weight category, had a significantly higher risk of CVD associated with COVID-19 compared to those who maintained their weight before the pandemic. | Individuals who gained weight during the pandemic likely had an increased risk of obesity-related CVD, which is a known risk factor for COVID-19. The study included a large number of participants with a diverse range of body weights, which allowed for the identification of specific risk factors associated with obesity-related CVD. | 38167158: 0.8672 38553629: 0.7662 38699419: 0.7632 | NCT04802044 | 0.5866 |
| Obesity is a strong independent risk factor for the development of CVD associated with COVID-19, particularly in individuals with a higher body mass index. | Higher body mass index is associated with increased inflammation and insulin resistance, both of which are known risk factors for CVD. Additionally, obesity is associated with chronic diseases such as high blood pressure, diabetes, and dyslipidemia, which are also risk factors for CVD. | 38167158: 0.8632 37833678: 0.8097 38553629: 0.8092 | NCT04802044 | 0.6612 |
| Obesity is a well-known modifiable risk factor for cardiovascular disease and has been identified as a factor which leads to poorer COVID-19 related outcomes. | This hypothesis is supported by the fact that obesity was associated with more extended hospitalization and hypoxia in patients with COVID-19. Additionally, obesity is a risk factor for COVID-19 related death. | 38167158: 0.8778 38590764: 0.8658 37833678: 0.8389 | NCT04802044 | 0.6885 |
| The study suggests that the association between obesity and CVD associated with COVID-19 is stronger in older adults. | Older adults are more likely to be overweight or obese due to various factors, including decreased physical activity and poor nutrition. Additionally, older adults may be more vulnerable to the negative effects of obesity, such as increased inflammation and impaired immune function. | 37833678: 0.8344 38167158: 0.8042 38553629: 0.7970 | NCT04802044 | 0.7234 |
| Obesity is a significant contributor to the risk of CVD associated with COVID-19, regardless of weight status. | People who gained weight during the pandemic, regardless of their weight category, had a significantly higher risk of CVD associated with COVID-19 compared to those who maintained their weight before the pandemic. | 38167158: 0.8650 38699419: 0.8131 37833678: 0.8094 | NCT04802044 | 0.6421 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Taleb, I.; Navaz, A.N.; Serhani, M.A. Leveraging Large Language Models for Enhancing Literature-Based Discovery. Big Data Cogn. Comput. 2024, 8, 146. https://doi.org/10.3390/bdcc8110146
Taleb I, Navaz AN, Serhani MA. Leveraging Large Language Models for Enhancing Literature-Based Discovery. Big Data and Cognitive Computing. 2024; 8(11):146. https://doi.org/10.3390/bdcc8110146
Chicago/Turabian StyleTaleb, Ikbal, Alramzana Nujum Navaz, and Mohamed Adel Serhani. 2024. "Leveraging Large Language Models for Enhancing Literature-Based Discovery" Big Data and Cognitive Computing 8, no. 11: 146. https://doi.org/10.3390/bdcc8110146
APA StyleTaleb, I., Navaz, A. N., & Serhani, M. A. (2024). Leveraging Large Language Models for Enhancing Literature-Based Discovery. Big Data and Cognitive Computing, 8(11), 146. https://doi.org/10.3390/bdcc8110146