1. Introduction
Model-based deep learning has long been viewed as the go-to method for the detection of defects, process outliers and other faults by engineers who wish to use artificial intelligence within computer vision-based inspection, security or oversight tasks in manufacturing. The data-hungry nature of such deep learning models that have accompanied the proliferation of AI-enabled data acquisition systems means that the new information that is either captured or inferred in realtime by sensors, IoT devices, surveillance cameras and other high definition images must now be gathered and analysed in an ever smaller time window. Additionally, transfer learning and transformer networks are now providing researchers with the capacity to build pre-trained networks [
1], which, when coupled with a deep learning framework, enable the generation of diagnostic outputs that give highly accurate real-time answers to difficult inspection questions, even in those cases where only relatively small datasets are known to exist a priori. The requirement that data need to be independently and identically distributed
(i.i.d) across the training and test dataset has arisen with the advent of transfer learning and the availability of pre-trained models that can be ‘fine-tuned’ for a particular task at hand.
More recently, there has been an emerging trend within the literature that proposes the use of generative networks and synthetic datasets for inspection [
2]. Such procedures provide a repeatable method whereby a dataset can be augmented in real time with enough process-specific samples so that the model training step can be continuously updated. Numerous data augmentation processes have been proposed for the training phase that optimises the size of the data window required to facilitate accurate decision making in a resource-efficient manner [
3,
4,
5]. As an illustration, in [
6], the authors claim that models trained using generative adversarial network data and fine-tuned using (10% by volume) randomly selected data gathered in real time from actual MRI analysis exhibits higher performance in tumour segmentation trials.
Classically, deep learning models were trained based on an underlying assumption that all the possible exceptions to be detected were available within the dataset a priori. In such an
offline learning setup, sufficient numbers of static images would be collected, labelled and classified into fixed sets or categories [
7]. The generated datasets would be then further divided into training and test subsets, where the training data would be fed into the network for sufficiently many epochs and test evaluation performed so that a high level of confidence would exist that all possible faults could be reliably detected. Such an approach to defect detection has its roots in the AdaBoost algorithm [
8] and papers therein. Limiting factors in such an approach include that the classifier parameters are generally fixed and huge amounts of data are required, making the whole process cumbersome and resource intensive. Furthermore, the response of the model to new error (exception) data is not likely to be robust.
The pre-design phase that is invariably required for offline training is the most important differentiating factor between offline and
online or
dynamic approaches to detection or inspection. Online models are tuned using exception data from particular examples of interest rather than simply being restricted to a larger fixed set [
9]. Complete re-training of existing models is an expensive task. Although retraining can be achieved in stages using cloud infrastructure while the manufacturing process continues, the streaming nature of data becomes a constraint in retraining the existing network model when new products are added or new process defect information comes to light.
The way in which new classes/tasks are added to a deep learning model once it has been deployed in the field for a specific inspection task is a recurring engineering challenge for the deployment of AI in manufacturing.
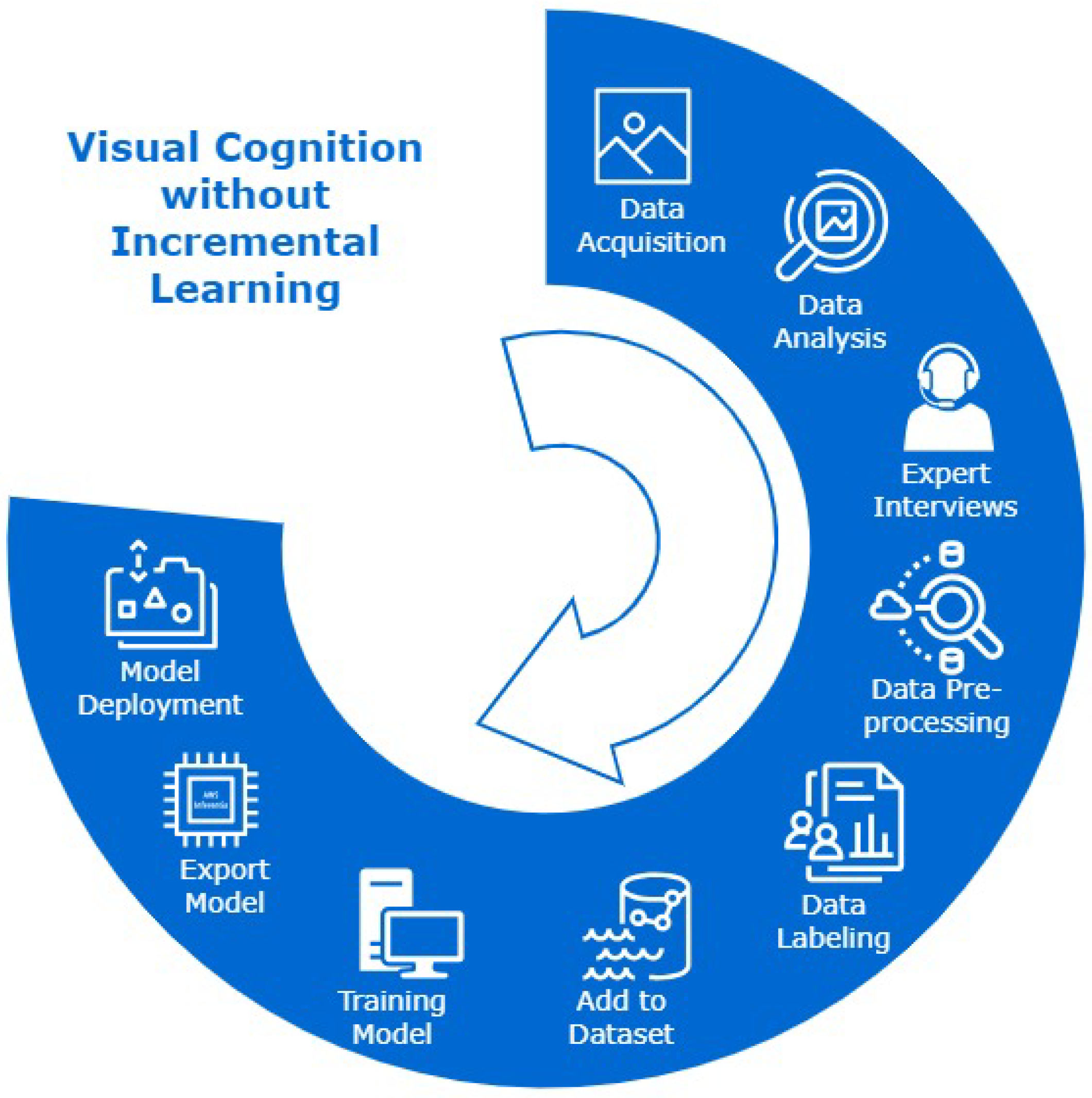
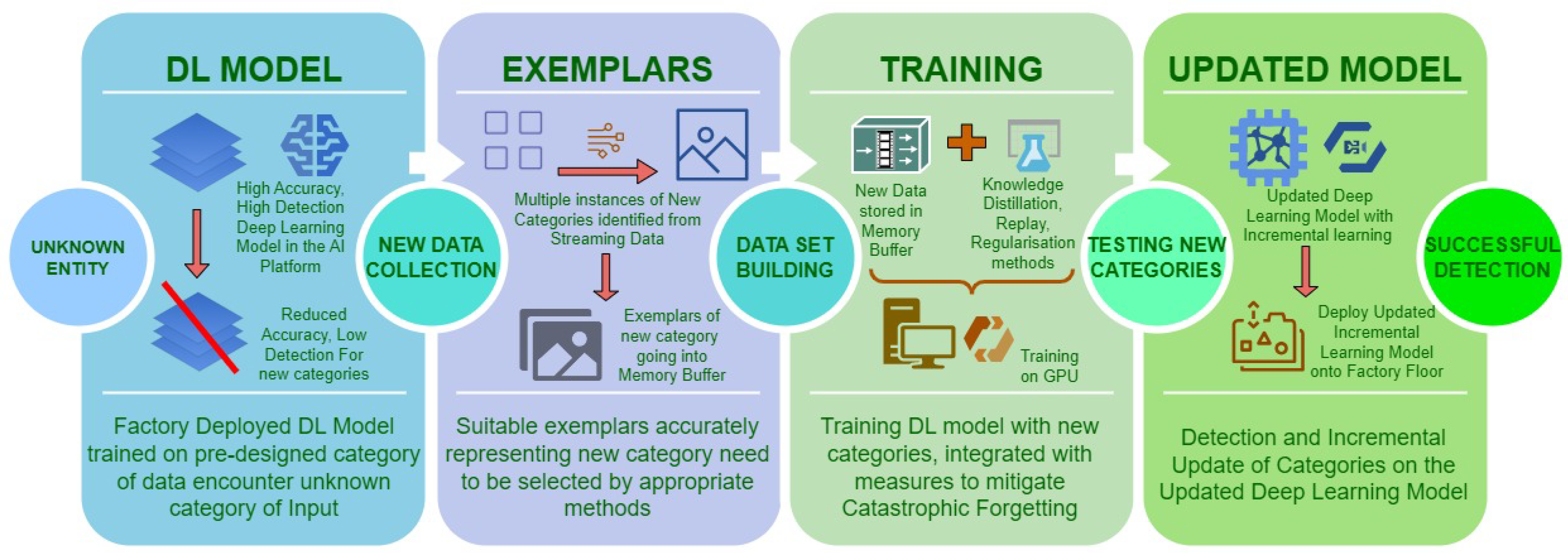
Figure 1 is an illustration of process cycle without incremental learning. In a practical real-world setting, decision loops based on continuous, temporal streams of data (of which only a narrow subset maybe potentially actionable) must be considered dynamically so that categorisation, exception handling and object identification are not pre-designed or classified a priori. In recent times, the concept of continual or dynamic learning is a recurring significant theme in the literature. Continual learning is the process of learning wherein a new category can be added or processed by the same neural network from a continuous stream of data while at the same time maintaining (or ideally improving) detection accuracy [
10]. This concept has been considered by multiple authors, where the overarching principle for process fault detection is one of continual, dynamic learning that has been denoted by authors as
lifelong or
on the fly.
A particular focus of this review is a consideration of model-based detection in case studies where a requirement for sustainability through life cycle extension is providing the impetus for the real-time detection, decision making, refurbishment, rework or re-manufacture within a process. The objective is to develop self-healing rather than pushing a ‘Bin’ or ‘End-of-Life’ decision within the process. Reliable defect detection is an important step in re-manufacturing, most importantly where inspection fails in (possibly recycled) products that need to be effectively classified so that an improved or refurbished product can be efficiently graded for market or for an appropriate downstream process task. The difference in re-manufacturing as opposed to manufacturing is that a dramatically larger set of variables can affect product sustainability. Moreover, if recycling is a consideration, then fault/defect decisions that are made can be radically different. Defects need to be detected and rework/repair work needs to be predicted, possibly using a deep learning model if appropriate, for every new part or device that is inspected. This requires continuous updates of deployed process models as newer inspection information is gathered. The recycling of devices help manufacturers reduce their carbon footprints in manufacturing [
11]. In this domain, there is an increased premium placed on dynamic, continual or incremental learning that reduces mislabelling, handles new exceptions reliably as they occur and is robust to a high degree of variation in products that are inspected in real time.
This review article is laid out as follows: First, a general summary of inspection algorithms that use incremental learning is presented in
Section 2,
Literature Study. This section discusses incremental learning in manufacturing deployments, and also the question of imbalance or bias in data handling that can occur due to dynamic streaming. Next, in
Section 3, a comprehensive analysis of the use of incremental learning in model-based machine learning frameworks that have been deployed for defect detection is presented. This section also discusses process complexities such as
catastrophic forgetting and ensuing mitigation strategies that have been reported. An analysis of the deployment of incremental learning in applications where processing takes place
at the edge or the use of edge devices is explicitly considered in
Section 4.
Section 5 considers process prediction and operator training challenges with a particular emphasis on the drift phenomenon problem that is a pressing concern in incremental learning deployments for process prediction applications. In
Section 6, the performance and applicability of different incremental learning algorithms are considered, with a particular emphasis on the size of the datasets that are necessary and the related efficiency of the processing that takes place. Finally,
Section 7 presents some conclusions and reflections on future research challenges in this space.
2. Literature Study
Against the backdrop of data engineering challenges that arise in cyber–physical systems and automated inspection systems within an Industry 4.0 setting, there is an increased requirement for intelligent agents and processes that can adapt and update dynamically in uncertain environments [
12]. A number of deep learning frameworks have been proposed in the incremental learning literature as detection and/or classification steps within a process that are trained on
i.i.d datasets, which use batch processing of well-labelled data. The challenge is one of adapting a model in real time so that it is capable of reliably incorporating new information while at the same time being stable in terms of process performance based on existing information.
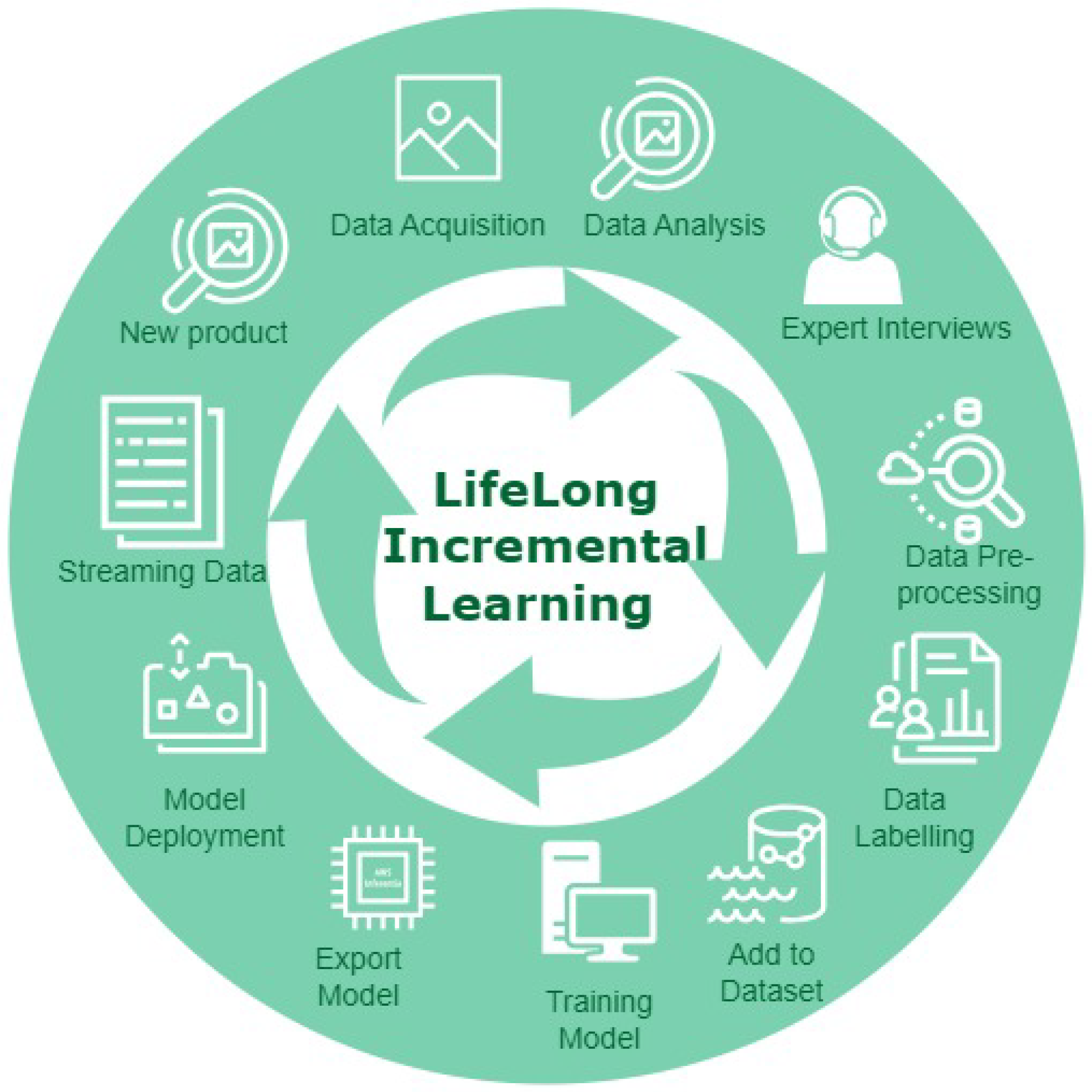
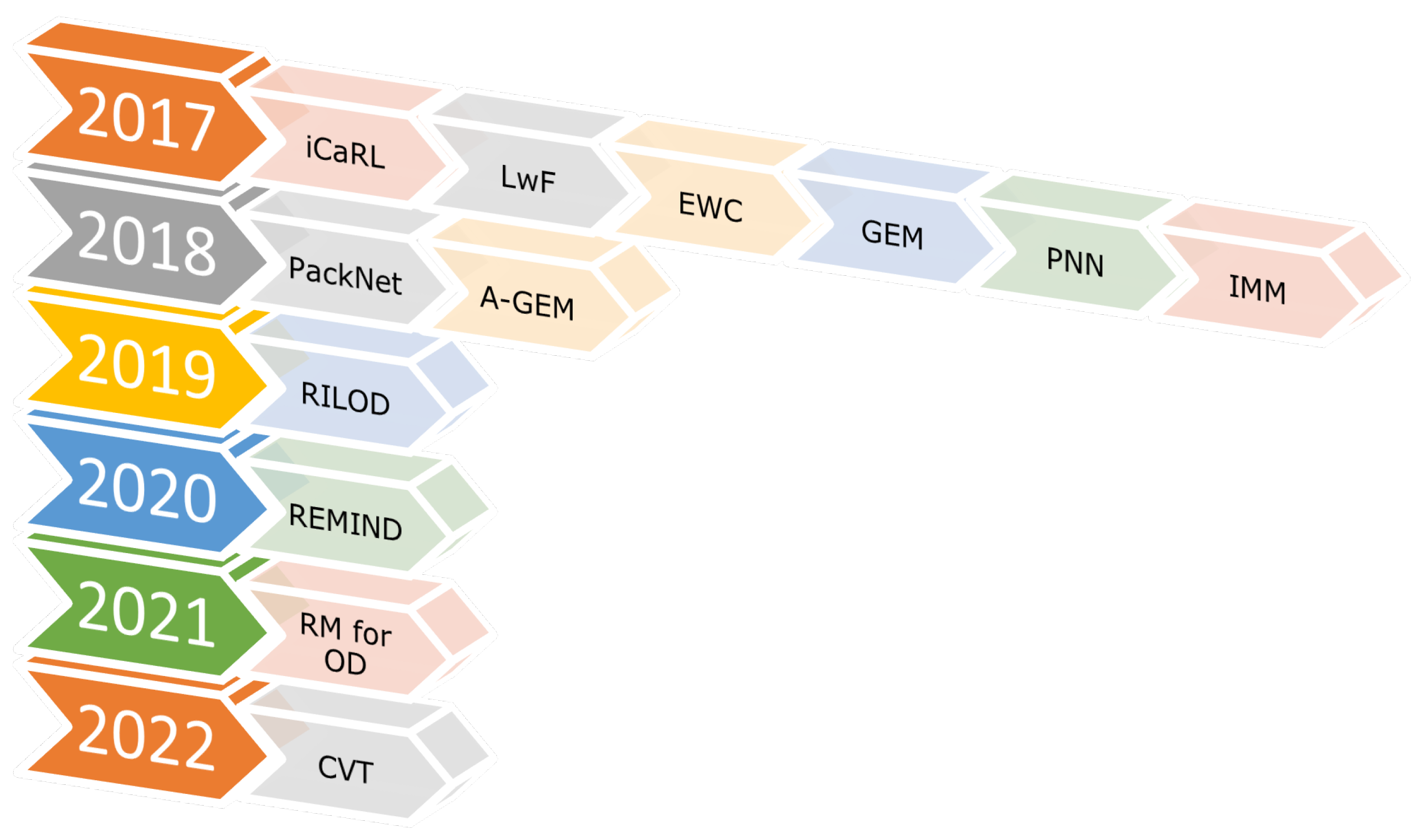
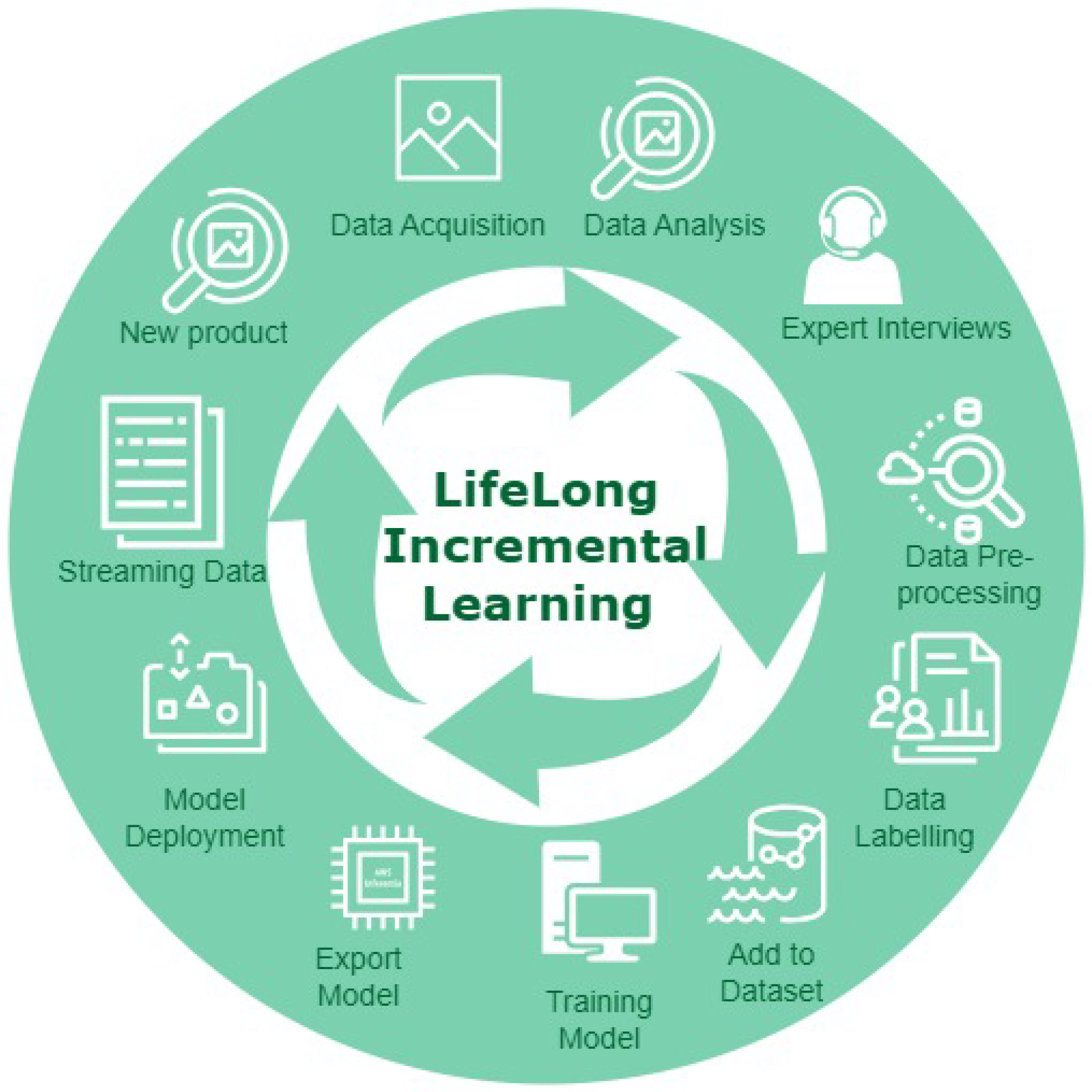
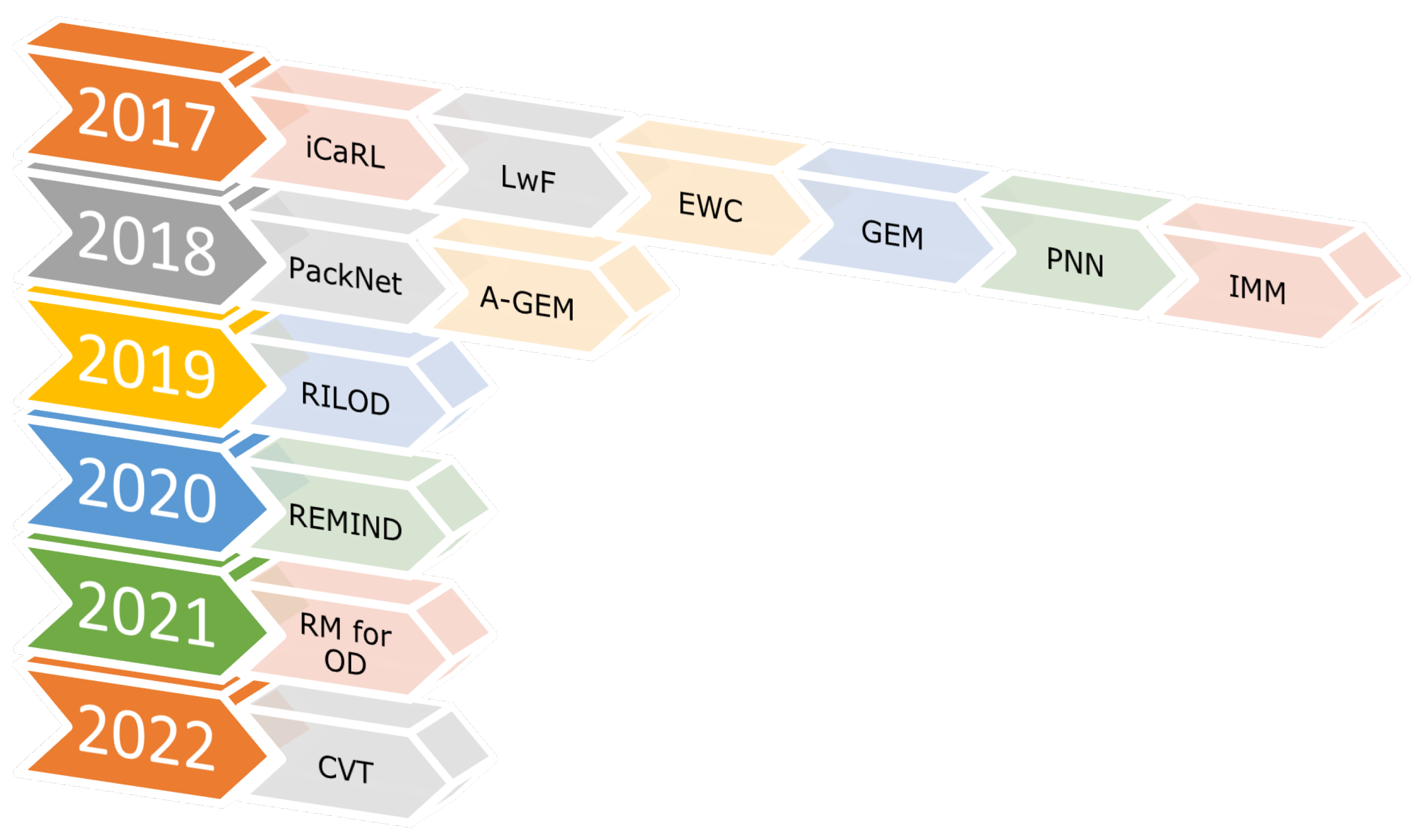
Table 1 provides a timeline for recent advances within incremental learning that have particular impact in relation to manufacturing. The concept of lifelong learning in the context of visual cognition engine development process cycle is illustrated in
Figure 2.
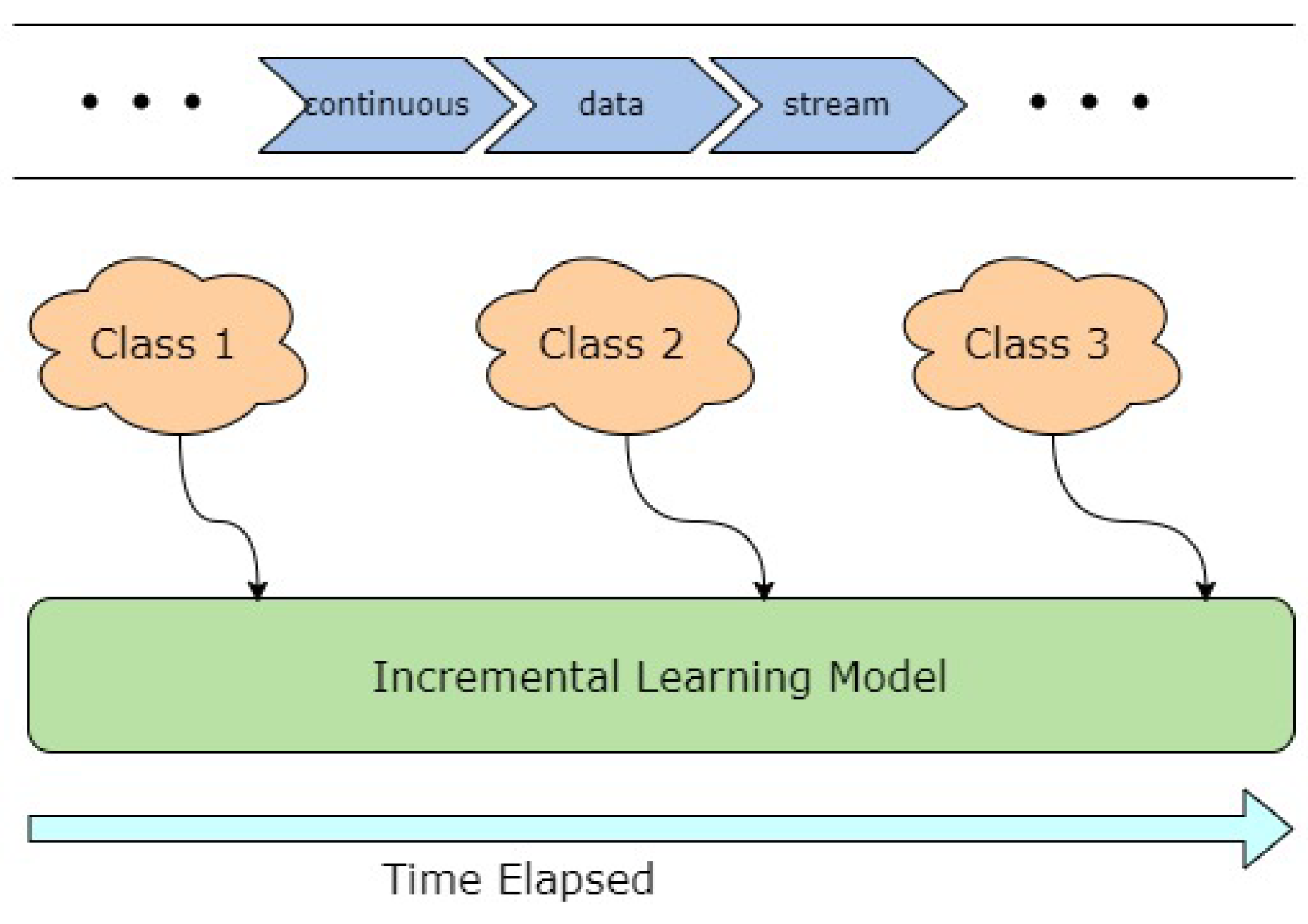
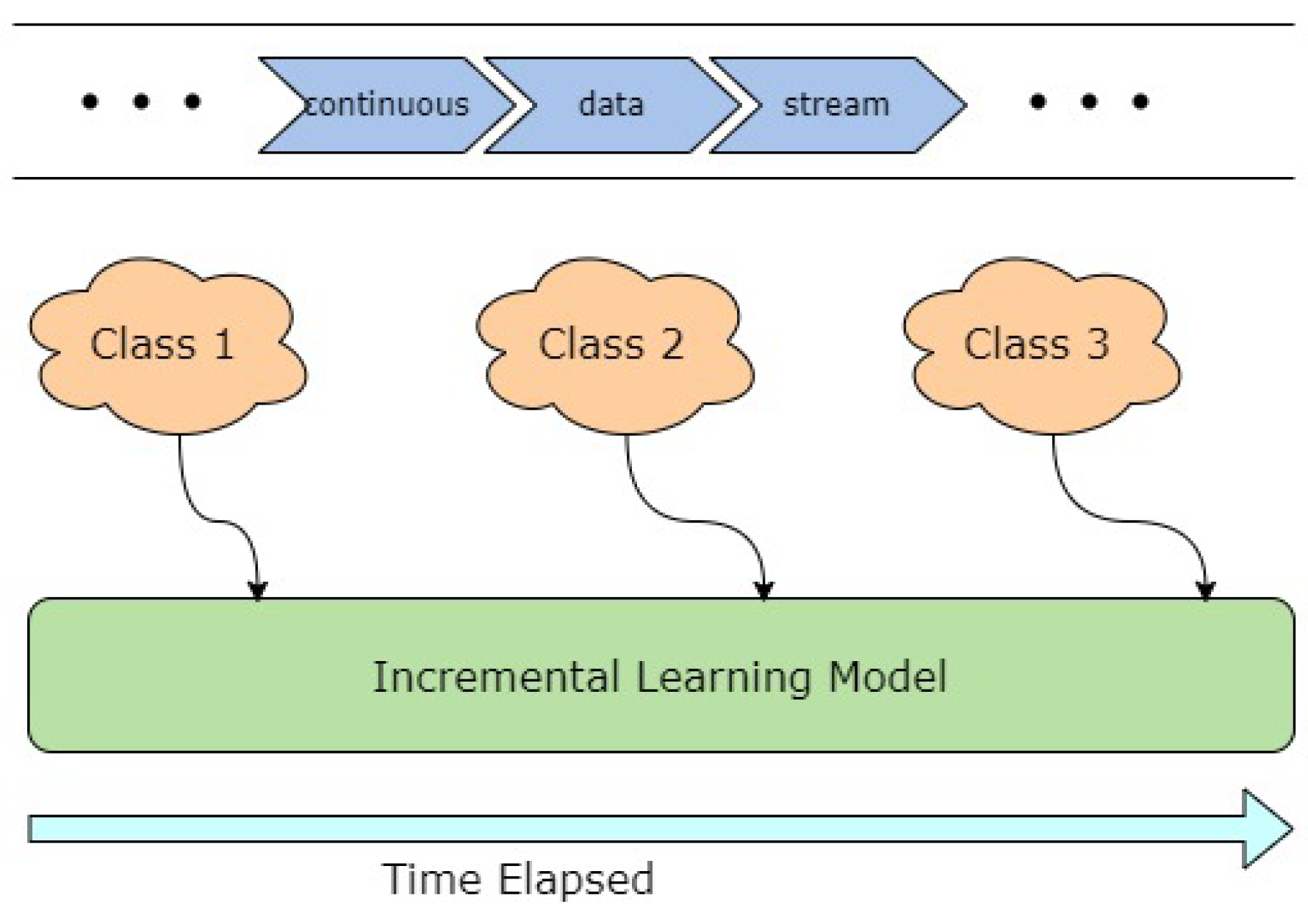
In this context, the authors have considered analogous, subtly different incremental learning variations such as lifelong supervised learning, continual learning, open-world learning and online continual learning so that an overarching picture of dynamic, incremental learning can be established. This concept of adding new classes to an existing model from streaming data is schematically represented in
Figure 3. The
continual process of intelligent adaptive learning from dynamic streams of data where new ’teachable moments’ arise non-deterministically is of special interest in manufacturing since any new exception data becoming available will need to be acted on and assigned, generally aperiodically. Such assignment is a challenge that resides at the core of all the aforementioned dynamic learning paradigms. In particular, the focus here is on case study examples where new exceptions and categories are learned in real time so that mitigation of the phenomenon that has been identified as ’catastrophic forgetting’ [
10,
13,
14,
15,
16,
17,
18] is considered.
Consider an ideal case, where for any Class
C, where
is the
instance of that class where learning takes place incrementally:
Thus, the process of adding information continues incrementally until no new information can be gathered. Catastrophic forgetting refers to the practical loss of information that might occur due to model update or retraining in the attempt of adding a new class to the existing model so that the size of the class window C is constrained. In a situation where information from only the n most recent instances of the class is stored reliably, then any information about the class that has been learned prior to this window might be lost. When a new class, is learned, the performance on drops drastically.
In the context of incremental learning in the manufacturing process, the addition of a new class into a detection system reduces the accuracy in performance for a previously learned class. In case of mobile phone defect detection, consider a detection model trained on surface scratches on the phone screen. In an event of a new class being presented to an already existing high performing model, the process of fine-tuning and updating the previously working model with the new class (cracks) is adopted. This update in the class window of the model-based detection system further leads to rapid reduction in accuracy of detection on phone screen scratches, the previously learned class. This is where the research for incremental learning is significant in a manufacturing use case. A deep learning model deployed in a factory setting will be presented with new defect formats or types, and the model needs to be equipped to incrementally learn the new classes and maintain the high detection rate on all the class categories learned.
Window sizing within continual learning and the necessary size of the training window for a specific task has been considered by many authors [
19] and references therein. Strong consensus has emerged that the problem of catastrophic forgetting needs mitigation measures [
20]. Lifelong learning has been proposed by Thrun et al. as early as 1995, where a robot agent is desired to optimise to a different control policy for learning a new function and new environment where functionality can be maximised over time [
13]. Classification attributes such as
knowledge bottlenecks where categories in offline learning need to be pre-designed,
engineering bottlenecks where sufficient data on each category need to be collected and
new data collection methodologies such as sensor systems, image acquisition systems and further concerns about complexity and maintaining precision of once-developed robotic systems have all been considered. More recently, authors have considered how decisions that are taken are orchestrated at the edge interface between a physical machine and cloud infrastructure that might be deployed to support the process.
Knowledge distillation and replay-based methods were a feature of early case study experiments in incremental learning. In knowledge distillation, learned parameter values, referred to as ’knowledge’ parameters, are transferred from one neural network model to a second neural network model by training the new model on a transfer set, despite (or indeed overcoming) any differences that may exist in model architecture [
21]. Maintaining process knowledge when engaging in model order reduction has been considered by many authors. Caruana et al. [
22] has referred to the concept of model compression and has introduced knowledge distillation, which is now a proven method for the transfer of learned parameter data among deep learning models. This transfer is made by using class probabilities produced by larger models as soft targets in the newer, smaller model, thereby achieving the generalisation ability in the smaller model otherwise harder to achieve through training [
23].
Model compression is a concept inherently different from model order reduction. Model compression refers to the process of effectively reducing the network size in memory leading to faster inference. This reduction in size is achieved by change in model quantisation, adjusting the floating point variables required for inference. Redundant connections in an otherwise over-parameterised model can be pruned to reduce model size, but the number of hidden layers will remain the same. Thus, model compression is different than the concept of model order reduction. In the context of incremental learning, model compression comes into context with the adaptation of knowledge distillation as a method to alleviate catastrophic forgetting.
Replay-based methods are integrated as an effort to alleviate catastrophic forgetting by replaying the previously learned knowledge [
24]. One of the essential requirements for replay methods is buffer memory to store new exemplars of new classes/tasks to be learned. The authors in [
25] trained a deep neural network with a cross-distilled loss function and approached incremental learning as a four-stage process. The first stage is preparation of training data with representative samples, the second stage is the training process for the selected model, the third stage is fine-tuning with a subset of the data and fourth and final stage is updating the representative memory with samples from a new class. This work is important in the current discussion of incremental learning for the concept of
representative memory, which performs two significant operations, selection of new samples and removal of unused samples. In a class incremental learning method, termed as IL2M (incremental learning with dual memory) [
26], a second memory is introduced to store the statistics of prediction of previously learned classes in an effort to reduce forgetting. Following on from
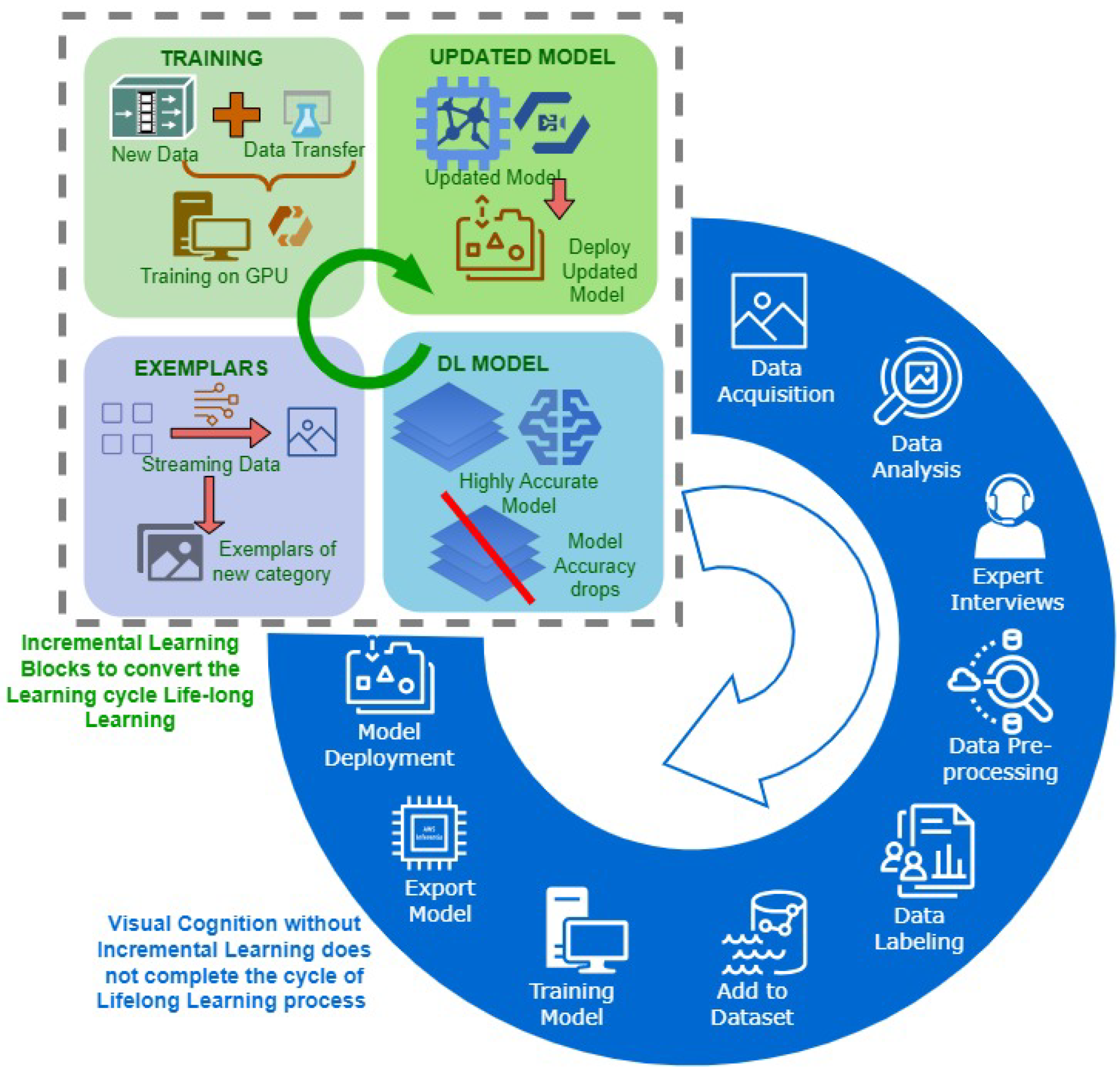
Figure 1,
Figure 4 illustrates that by the addition of incremental learning operations, process cycle without incremental learning can be converted into a lifelong learning process cycle.
An end-to-end trainable adaptive expansion network (E2-AEN) network to dynamically generate light-weight modules called adaptively expandable structures (AES) for new tasks, while maintaining accuracy for previously learned tasks has been proposed by Cao and collaborators [
27]. The proposed network also includes feature adaptors, which play the essential role of acquiring new concepts and avoid task interference effectively. The network structure is dynamically changeable by the adaptive gate-based pruning strategy that is used to reduce the redundant parameters. This method achieves good accuracy with Pascal VOC [
28] and COCO [
29] datasets, but the network accuracy has been shown to be dependent on representation by the backbone network and the large dataset used in pre-training this backbone framework.
Further, end-to-end architecture for class-incremental learning with knowledge distillation in [
30] used Faster-RCNN [
31] as the backbone and adapted it to incremental learning using domain expansion to include newly added classes of objects and knowledge distillation to maintain accuracy of previously learned classes. The highest accuracy achieved by this method is 72% on newly added classes, but on previously learned classes, the performance is still lower by more than 10% of the original, thereby indicating the challenge of catastrophic forgetting and hence being not feasible for real-time deployment. In [
32], incremental end-to-end learning is used for further data collection closer to the data collected by the human individual in an attempt to perform online learning in the autonomous driving domain. The method is reported to achieve 70% accuracy in previously unseen data, but the discussion did not include model architecture or any mitigation technique for loss of previously learned information.
To address the challenge of forgetting, authors in [
33] have proposed a unified framework for classification problems where new and old classes are treated uniformly and the average incremental learning accuracy increased by 6% and 13% on CIFAR-100 [
34] and ImageNet [
35], respectively. The work reduces the imbalance between old and new classes and proposes a method to preserve effectively previously learned information. The challenge of increasing the type and number of newly learned classes within model-based incremental learning is a significant and central challenge that has been identified by multiple authors. Data imbalance has been identified as an issue when a model is being trained to distinguish between different types and numbers of classes. The authors in [
36] addressed this issue using a
bias correction method, where a diagnosis parameter is used to measure how a classifier is biased towards new data. An optimisation is proposed to measure the bias parameters within a fully labelled and connected layer of the classification model. The method is shown to have achieved high accuracy when tested using the ImageNet [
35] and MS-Celeb-1M-10000 [
37] datasets, but issues have been shown to exist for examples where smaller class numbers are known to exist. The problem of dataset imbalance requires particular attention when wishing to apply incremental learning in inspection and is discussed in
Section 2.1.
2.1. Treating Imbalanced Data in Inspection
When it comes to carrying out inspection, a myriad of non-destructive evaluation (NDE) methods have been reported. These can include, inter alia, material inspection or defect detection using techniques such as ultrasonic inspection, or any computer vision techniques that do not cause damage to the component under inspection [
38]. Apart from the increased efficiency in defect detection, deep learning frameworks are not widely used in this domain, owing to the difficulty in augmenting trained models, which require significant retraining and redeployment. The authors in [
39] analyse the case of anomaly detection in video surveillance using spatio-temporal auto encoder networks to illustrate the difficulties in detection of previously unknown anomalous behaviors, even to human operators. The complexities in detecting and dynamic adaptations to new defect categories and further evolving behaviors are challenged by the limitations in incremental learning methodologies.
Several studies have found that, when considering traditional classifiers with pre-defined categories, machine learning algorithms showcase better performance in classification even with imbalanced data, significantly simplifying the process of data cleaning and balancing [
40]. Data imbalance in defect detection is a particular issue when the number of defective components is low as a proportion of an overall batch size. In an effort to mitigate the risks due to non-stationary imbalanced data streams, Chen et al. [
41] proposed a recursive ensemble approach (REA) where they estimate the similarities between the minority/defective class in previous and current batches. Traditional classifiers were built on the assumption of equal/fair distribution of instances of all different classes identified in the dataset [
40]. When this is not true within a sample set, the question of corrective action or model updates becomes more complex.
A variety of data sampling methods have been proposed to handle imbalanced datasets by balancing the sample distributions for the classes that are under consideration [
42]. Clearly, such a balancing approach is difficult to achieve successfully in real time, particularly when quite small batch size windows can exist. Under-sampling eliminates random samples of majority classes in an attempt to balance the class instances within the dataset. Drawbacks with this approach are known to be an increased risk of missing important instances or exceptions in the dataset. Random over sampling has been used as a method to increase the occurrences of random minority instances. The engineer can choose to control oversampling rates, particularly when increased or novel failure classes are identified at the output layer. The Synthetic Minority Oversampling Technique, SMOTE [
43], is a synthetic sampling data generation technique where the kth-nearest neighbour of every minority sample is calculated, followed by taking random samples according to the over-sampling rate set by the engineer. A new minority class can be generated by interpolating between the minority class instances and selected neighbours, particularly when new defects are identified at the output layer. In synthetic sample data cleaning, a Tomek-Link is proposed as an under-sampling method in Batista et al. [
44] where Tomek-Link is denoted as the distance between the two samples under consideration, using the methodology proposed in [
45]. The Tomek- Link method removes instances belonging to majority classes from the task window until all minimally distanced pairs of nearest neighbour points belong to the same class [
40]. In [
46], an AI-tuned application example that combines SMOTE and Tomek-Link generates better results on imbalanced datasets for an inspection process [
46].
Another way of dealing with imbalanced data is referred to in the literature as
cost sensitive learning, where each misclassification is assigned a cost within a classification matrix. By setting diagonal matrix elements to zero, the effect of a misclassification error can be computed [
47]. Boost algorithms have been proposed as another type of classification cost sensitivity method, where weights on misclassifications are increased and decreases on the weights for correctly classified examples are considered in each iteration. This has been shown to improve classification performance especially on rare inspection classes that are more often misclassified due to imbalance (or bias) in the data. Ada-Boost and Rare-Boost are further developments that add weights to misclassified samples, Rare-Boost weighs the proportion by which false positives are distinguished when measured against true-positive and true-negative samples.
To address the imbalance in text data for incremental learning, Jang et al. [
48] have proposed a training architecture, sequentially targeting where the entire training data corpus is divided into mutually exclusive partitions to balance data distribution and adapting it to predefined performance distribution targets. A target distribution in this context is a distributional parameter setting where the trained model is tuned to achieve the best learning outcome. In an imbalanced setting, where there is no pre-defined target distribution, all classes will be given equal importance. The need for a pre-defined target distribution for so-called
forced incremental learning has been observed to yield a model that gives better performance while incrementally learning individual tasks than with a learning process for multiple tasks that are taken together in static fashion [
48].
4. Incremental Learning for Edge Devices
In 2019, Li et al. studied incremental learning for object detection at the Edge [
101]. The increased use of deep learning models for object detection on Edge computing devices was accelerated by one-stage detectors such as YOLO [
102], SSD [
103] and RetinaNet [
104]. A deep learning model deployed at the Edge needs incremental learning to maintain the accuracy and robust performance in object detection in personalised applications. The algorithm termed as RILOD [
101] is a method for incremental learning where the one stage detection network is trained end-to-end using a comparatively smaller number of images of the new class within the time span of a few minutes. The RILOD algorithm uses knowledge distillation, which has been used by several researchers to avoid catastrophic forgetting. Three types of knowledge from old models were distilled to mimic the output of previously learned classes on tasks such as object classification, bounding box regression and feature extraction. A pipeline for real-time data collection for dataset construction and automatic labelling of these collected images based on category and bounding box annotations have also been developed.
In DeeSIL [
105], fixed representations for class are extracted from a deep model and then used to learn shallow classifiers incrementally, which makes it an incremental learning adaptation for transfer learning. Since feature extractors replace real images, memory constrain for new data is addressed, hence making it a possible candidate for Edge devices. Train++ [
106] is an incremental learning binary classifier for Edge devices, though it is based on training ML models on micro-controller units. In [
107], a task adaptive incremental learning,
TeAM for convolutional neural networks (CNN) is proposed as a method to transform large CNN models into optimised forms as to work in Edge devices and a global aggregation of collaborative models on local devices into a global model, thereby making incremental learning possible. Hussain et al. [
108] proposed learning with sharing (LwS) as a method for incremental learning in deep learning framework optimised for Edge devices, which involves cloning of the initial DNN framework except the output layer and freezing all those layers excluding fully connected (FC) layers. These cloned layers and FC layers combined with new output layers are used in the next stage of training, effectively transferring previously learned data. The authors report 75.5% accuracy with Mobile-NetV3 [
109] on the ImageNet dataset.
Rapid development of Edge Intelligence with optimisation of deep neural networks led to increased use of model-based detection in computer vision applications. Due to its huge reduction in size as well as reduction in computational costs, the model quantisation is the most widely used optimisation method among all the other types of optimisation and compression techniques for deep learning.
To analyse comparative performance of visual cognition-based deep learning models on a GPU-accelerated device versus a resource-constrained Edge device, Raspberry Pi, we conducted a case study [
110]. The emphasis of the study is to assess the detection time and accuracy of deep learning models optimised for Edge functionality. The SSD inception network trained on the INRIA [
111] dataset is the reference experiment for the model optimisation criteria. This is included as the first model in both
Table 2 and
Table 3. In 2014, Szegedy et al. and a team from Google proposed GoogLeNet (22 layers), which consists of inception modules. This later came to be widely known as Inception Net [
112]. The architecture of these networks were further modified in 2015, which led to versions Inception-v2 and Inception-v3 [
113]. MobileNets were lighter networks and were also designed by Google engineers for mobile vision applications [
114].
The detection models were trained on TensorFlow Object Detection API on a local GPU accelerated device running TensorFlow-GPU version 1.14, Python 3.6 and OpenCV 3.4 as the package for image analysis. The GPU used for training was GPU GeForce RTX 2080 Ti, after which TensorFlow-lite graph was exported as the frozen inference graph. This was then converted into flat-buffer format before integrating into Raspberry Pi 4, the resource constrained device used for detection experiments. The Raspberry Pi 4 runs Raspbian Buster-10 OS, with an integrated Raspberry Pi Camera Module V2 for real-time image capture in detection experiment. The Raspberry Pi camera is 8 megapixels, single channel, and has a maximum frame rate capture of 30 fps. The camera module connects to Raspberry Pi 4 via 15 cm ribbon cable which attaches the Pi Camera Serial Interface port (CSI) to the module slots on the Pi.
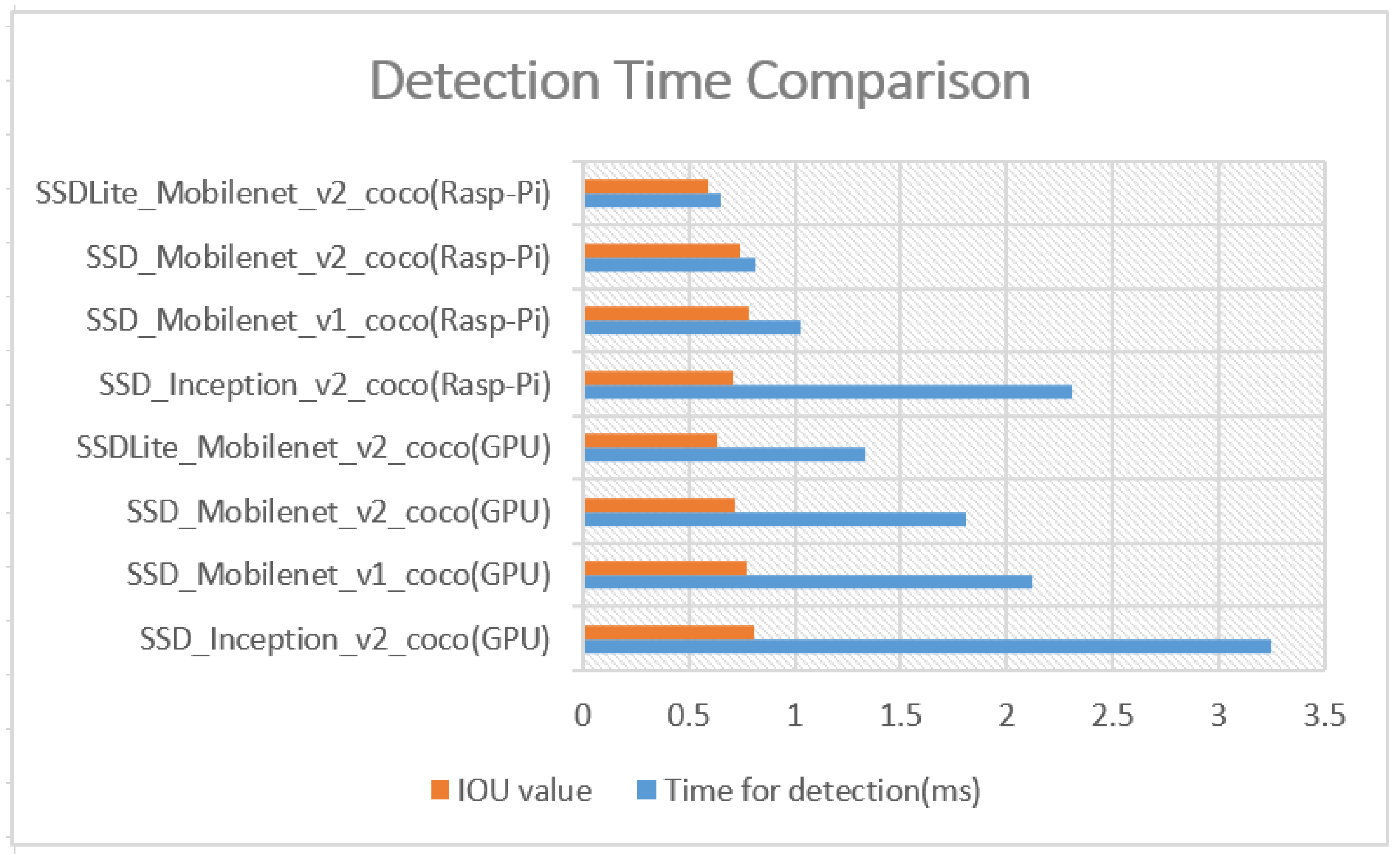
The inference time of TensorFlow Lite model were compared against that of larger models in the
Figure 8, and the results were promising. In industrial application where accuracy is a concern, a 10% reduction in accuracy could lead to higher number of erroneous products, causing huge loss in a mass production system. For an acceptable floor rate of above 70% accuracy within 3 ms detection time, the winning candidate models are the quantised versions of SSD-Inception-v2 and SSD-Mobilenet. SSD-Mobilenetv1, the framework designed for mobile and Edge devices, is the best performing with a detection rate of 78% and detection time of 1 ms in this detection experiment. The IOU values fall to the value of 59% with low precision of 0.66 for SSDLite-Mobilenet model, which makes it unsuitable for industrial application with the previously defined criteria. In a person identification operation, floor rate of detection above 70% is a sufficient and standard engineering performance requirement for cell-based manufacturing environment.
The comparative study was performed to establish that performances comparable to the GPU-accelerated device RTX 2080Ti could be achieved on a Raspberry Pi, a resource-constrained Edge computing device used in the experiment. The Raspberry Pi was chosen as the resource-constrained experimental device because of its versatility to be retrofitted into any manufacturing setting for dynamic decision making. The factory floor prototype setting in the research facility where the study was conducted further utilised Raspberry Pi in numerous edge processing applications. The developed system was a component of a larger detection system, one of which was an operator safety detection mechanism and hence not stand-alone. The detection algorithm when needing to be retrofitted into larger mechanism needed seamless communication with the counterparts and hence TensorFlow-based operations were preferred to PyTorch.
5. Process Prediction and Operator Training
Concept drift is another type of problem that occurs in continual learning [
15,
18], which needs mention for the completeness of challenges in continual learning. Concept drift, also known as model drift, is the change in the statistical properties of a target variable that occurs due to the change in streaming data with the addition of new products/defects [
115]. Data drift is found to be one of the factors leading to concept drift. Data drift is the change in distribution of input data instances, which result in variation of predictive results from the trained model. Concept drift can happen over time when the definition of an activity class previously learned might change in the future data streams when the newer models are trained from the streaming data. In the manufacturing setting, maintaining and improving machining efficiency is directly related to the quality of manufacturing end products [
116]. Yu et al. studied process prediction in the aspect of milling stability and the effect of damping caused by tool wear in the manufacturing setting. This is an application of incremental learning from the sequential stream of data available and heavily based on concept drift, one of the imminent challenges in incremental learning. The concept drift in this application is the stability domain change, which in turn makes change to the stability boundary. Taking into consideration the time frame in which the sequential data are available, the concept drift is identified as four types:
sudden drift: introduction of a new concept in a short time
gradual drift: introduction of new concept gradually over a period of time to replace the old one
incremental drift: the change of an old concept to a new concept, incrementally over a period of time
reoccurring drift: an old concept reoccurs after a certain period of time.
In [
117], Li et al. made the attempt to combine the incremental learning paradigm with incremental SVM to propose a double incremental learning algorithm for time series prediction. Incremental learning to update predictive models has been studied by the authors of [
118] in relation to COVID-19 data to predict variables to characterise the pandemic. This methodology also considers three important points in incremental learning, the complete dataset is not available at the time of creating the model, alleviate catastrophic forgetting and maintaining a balance for the stability–plasticity trade-off. It is also interesting to note that this incremental learning methodology is time series analysis-based as opposed to the deep learning-convolutional neural network-based ones that have been gaining popularity in recent years of research.
Research directly related to incremental learning using deep learning has been conducted by Pierre et al. in [
119], where they use correction-based incremental learning in the domain of autonomous vehicles. The algorithm has been tested in relation to truck platooning in simulation and laboratory. The back drop of this project is the inaccuracies that arise from limited/scarce training data near decision boundaries. Driving scenarios such as sudden emergency stop, swerving through multiple curves and drifting off the road are such scenarios under consideration, which can be considered as new instances of interest for the deep learning model. This can be considered as an anomaly in a normal driving situation and could be mapped to a new type of defect occurring in a manufactured component, and the model has to look out for further instances in the manufacturing process.
Correction-based incremental learning augments negative samples into the training set, which were previously classified as positive samples (false positives) to improve the decision boundary. This experiment is also research in incremental learning but without convolutional neural networks for object detection applications. Fully connected layers in neural network architecture are trained in stochastic gradient descent manner with fewer samples that strategically improve the decision boundary for the required task. In the study conducted by Ramos et al. [
120], incremental learning based on artificial neural networks are again used to predict industrial electricity consumption by a facility using real-time data and forecasting algorithms. Sequential training data are updated every midnight during the forecast process, where the forecast process is supported by periods split by 5 min intervals. Yu et al. [
121] worked with fault diagnosis in the industrial process using incremental learning, again using deep learning framework they termed as the broad convolutional neural network, BCNN. In this method, the abnormal samples collected are combined as a matrix from which non-linear structure and fault tendency are captured by performing convolution operation on the obtained data matrix. Weights of models are calculated from these extracted features to develop the BCNN framework. This methodology permits the feature extraction of any new faults arising in the manufacturing setting and effectively incremental learning on these new faults without retraining.
When considering the paradigm shift from Industry 4.0 to Industry 5.0 use case studies, the impact on people and organisation as well as the technological advances that are proposed must be considered. The main implementation challenges that have been reported in Industry 4.0 applications have been in relation to security, resilience, the ability to withstand disruptions and catastrophic events, operator training and efficient use of digital data from sensors. Industry 4.0 and 5.0 are both aimed at an important dimension of efficient use of energy and technology [
122]. Humans create and manage the production systems, hence humans are the main drivers of activities and creators of infrastructure, but the processes in the production will be automated, and any human operator will only be considered as the human-in-the-loop to assist the automated systems. This role of the operator will include selecting the samples from the sequential data acquired by the sensors and labelling or pre-processing for incremental learning techniques. Industry 5.0 prioritises human–machine interaction as opposed to the introduction of robots and automated systems into the manufacturing process in Industry 4.0 [
123].
6. Discussion and Analysis
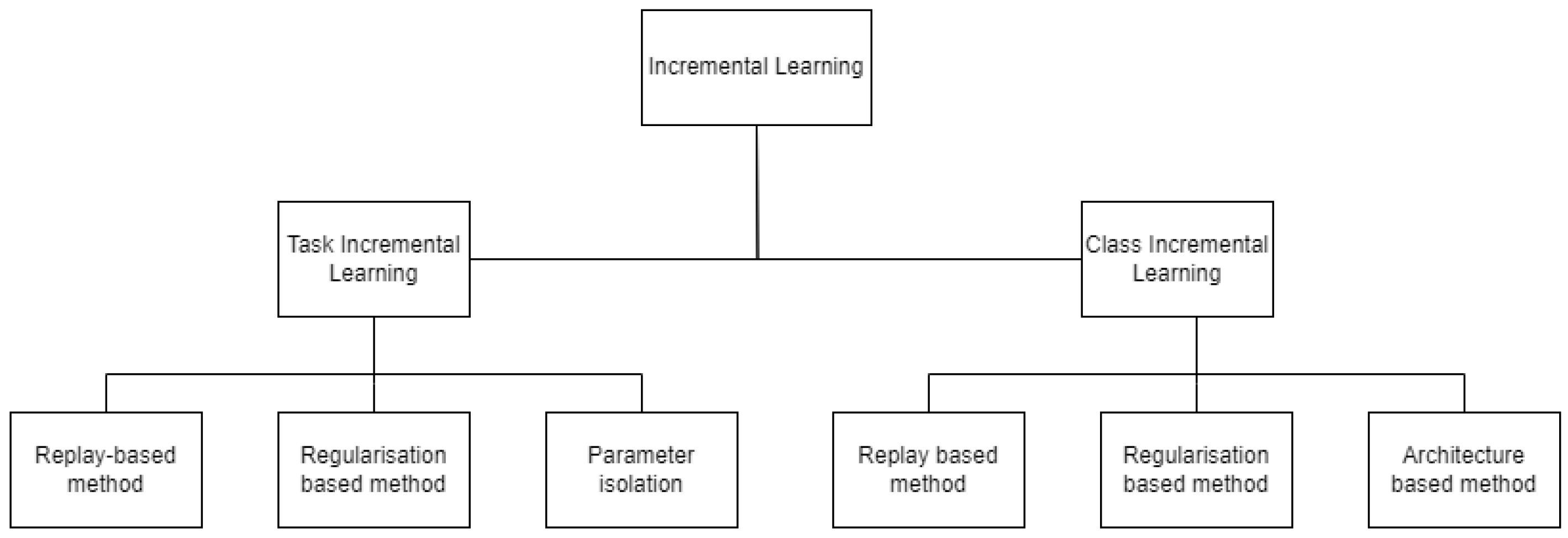
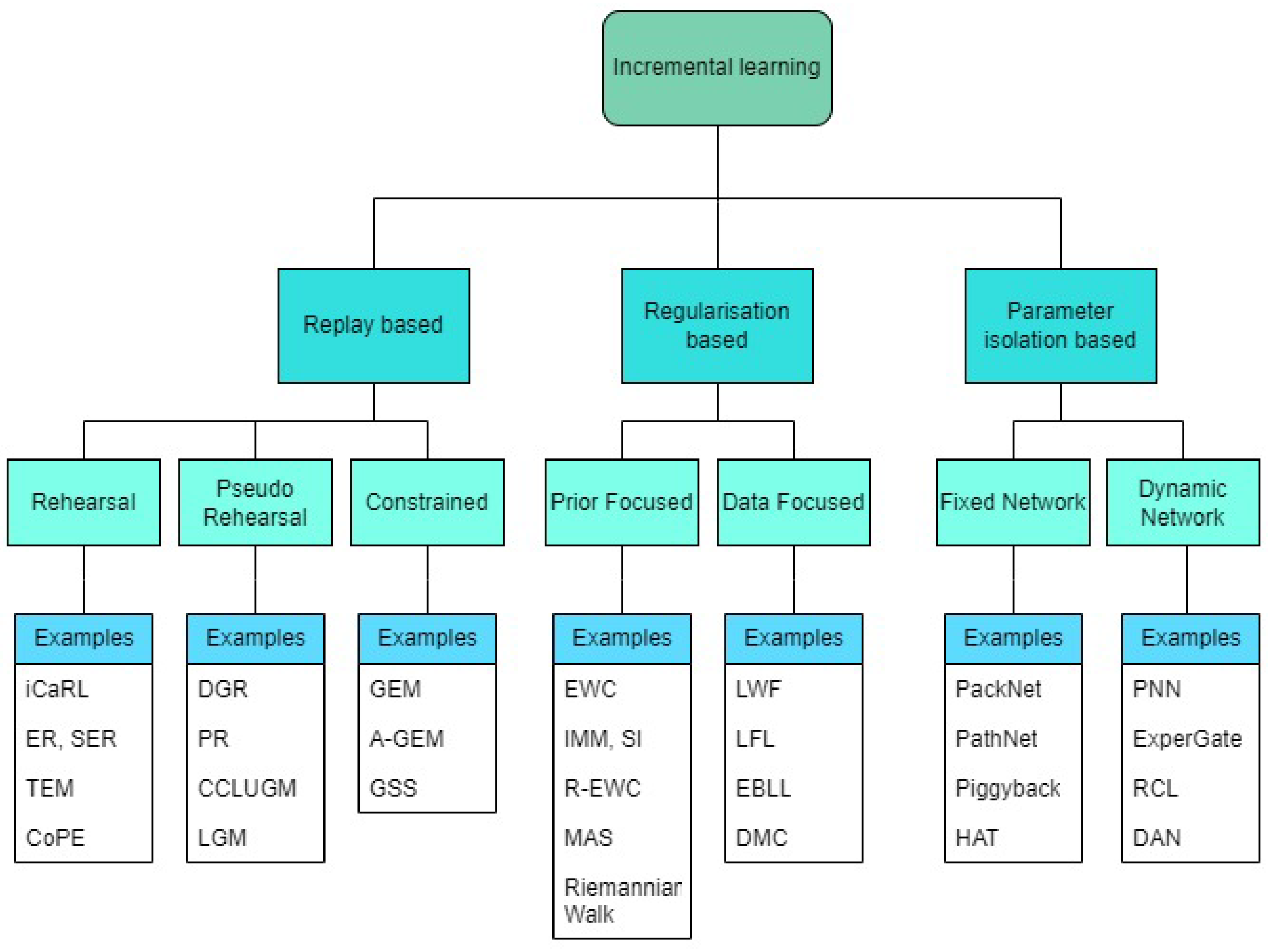
Incremental learning has been researched under two criteria, class incremental learning and task incremental learning. A timeline of state-of-the-art incremental learning algorithms is given in
Figure 9. In [
24], Mittal et al. studied class incremental learning in an attempt to alleviate catastrophic forgetting. They also used metrics such as ‘class-incremental learned models, Class-IL’ as referred by them to evaluate the performance. The metrics used are average incremental accuracy, forgetting rate and feature retention. The three important attributes of the class-IL system in their experiment are a memory buffer for storage of examples from old classes, forgetting constraint to mitigate catastrophic forgetting and, the most important element, learning of new classes while balancing old classes.
From the experiments conducted by the authors in [
70], catastrophic forgetting has an inverse relation to model scale. Pre-trained vision transformer (ViT) [
124] models and pre-trained ResNet both suffer less when the model size is large. Large models suffer less forgetting. The technique used in this analysis, termed as ‘forgetting frontier’, is a measure of the maximum performance on new data learned for a given stable model performance for old data. A comparison of accuracy loss against model parameter size is given in
Table 4.
However, Sarwar et al. observed incremental learning as computationally expensive [
125]. Their approach focused on using network sharing in the unique clone-and-branch technique, where the cloned layers provide a better starting point to the weights as opposed to randomly initialised ones and hence result in faster learning kernels and faster convergence. The evaluation was based on energy–accuracy trade off, taking into consideration the architecture of the deep convolutional neural networks and complexity of gradient computation and weight update stages.
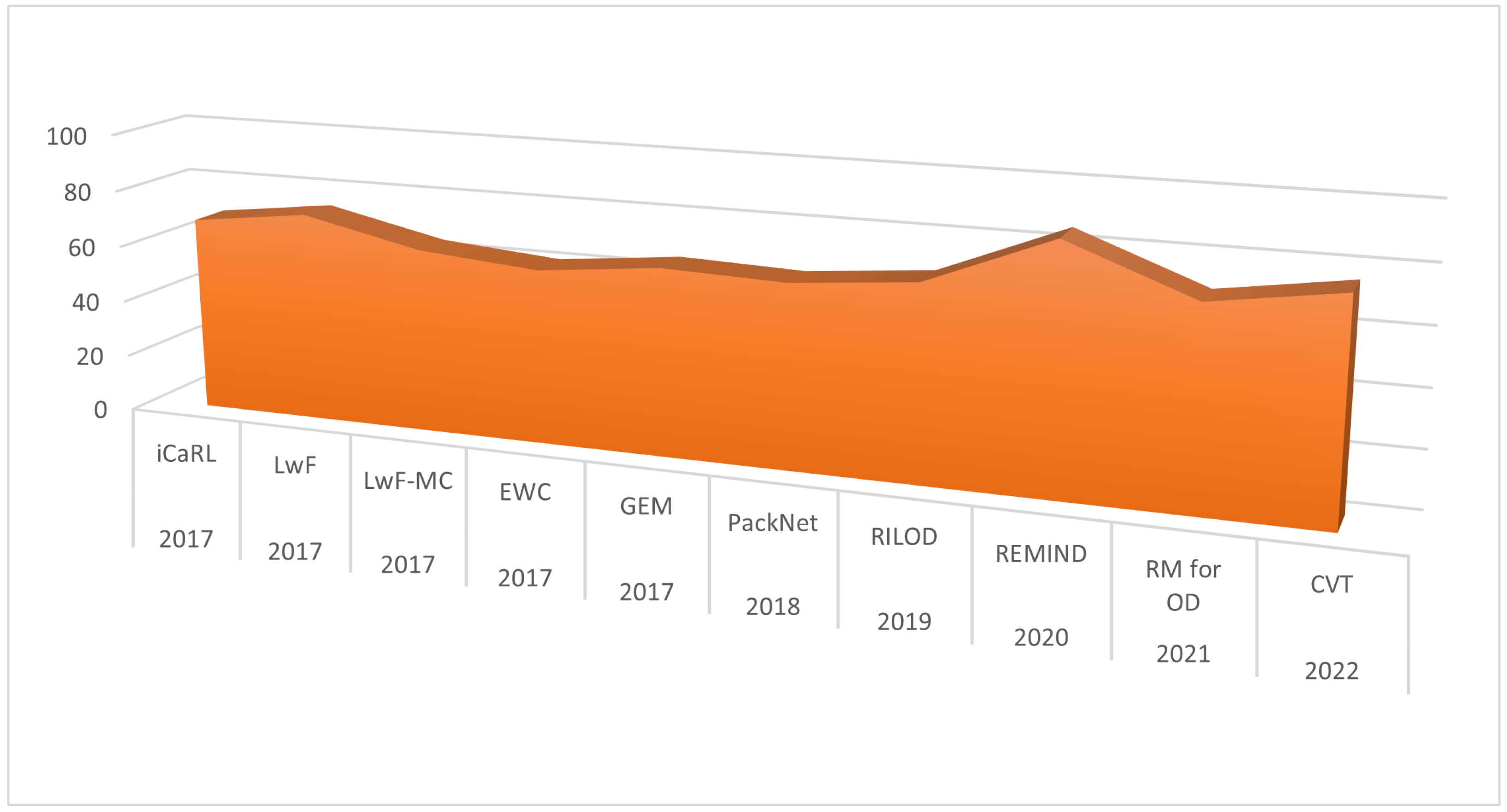
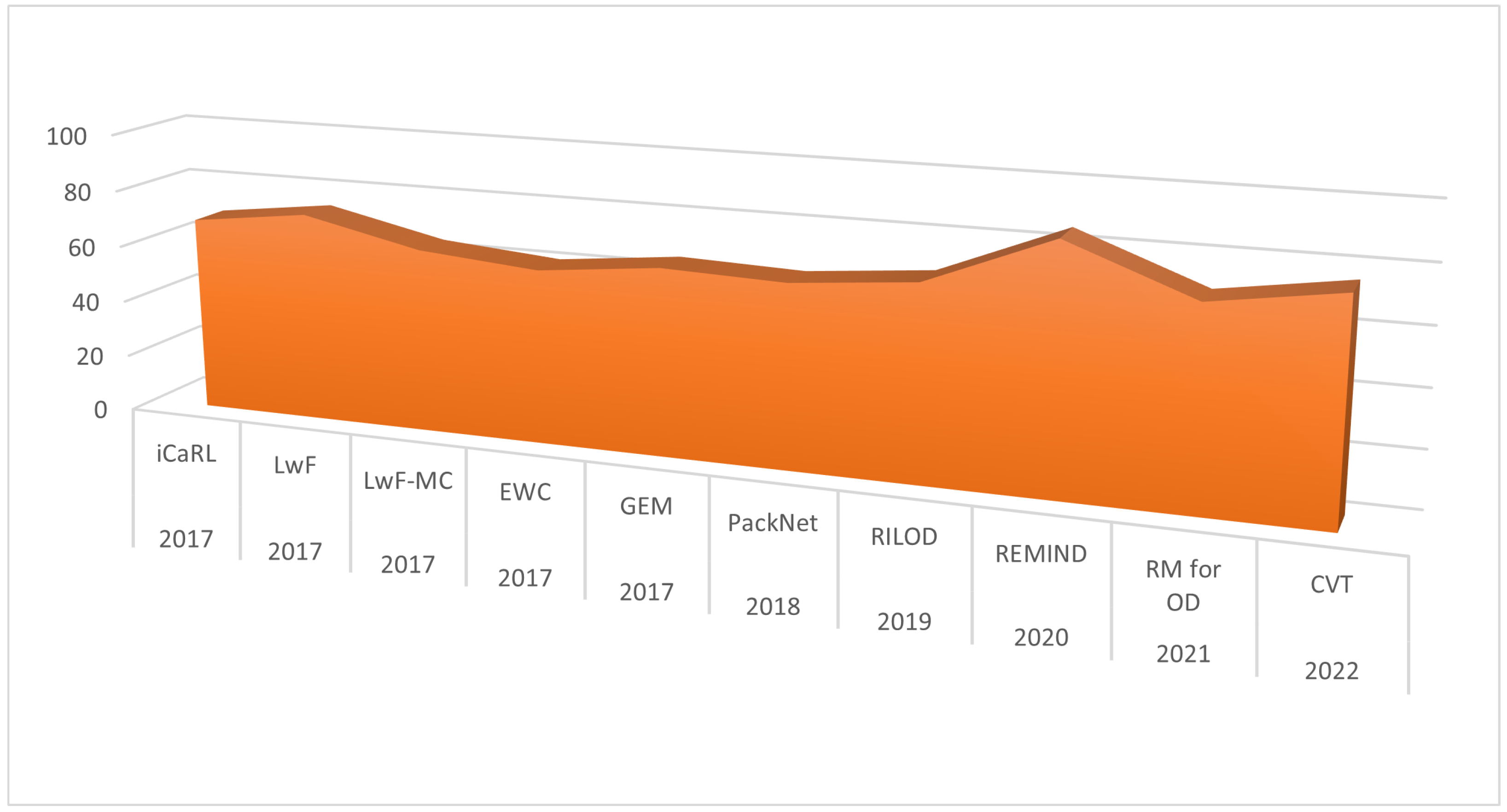
Regarding the state-of-the-art incremental learning algorithms, there was immense advancement in the research resulting in various benchmark algorithms in the year 2017. iCaRL [
73] achieved average accuracy of 68.6%, LWF [
64] and EWC [
63] with 61%, GEM [
61] with 65.4% and IMM [
83] and SI [
84] were a few of the most significant among them. Since the inception in 2017, iCaRL [
73] has become the bench mark against which numerous class incremental learning algorithms have been analysed. The difference of class-based and task-based is trivial when it comes to learning and weight update criteria from the deep learning perspective.
Figure 10 shows the performance analysis of important incremental learning algorithms developed in recent years. In the year 2017 alone, four more significant algorithms were proposed, with average accuracy in the range 64% to 73% among class incremental learning applications. A comparison in accuracy of recently developed incremental learning algorithms with regard to models used and dataset of evaluation is given in
Table 5.
Table 6 provides important details of benchmark datasets used for pre-training and fine-tuning detection models widely used in the incremental learning research.
Incremental learning has also been evaluated based on the loss of information for previously learned tasks. In the correction-based incremental learning approach, the percentage of autonomy and mean time to failure were used in analysis, where autonomy is the percentage of time the system operates without the need for correction or intervention from a human operator [
119]. The mean time to failure is the average time the system operates without failure between correction or intervention.
The discussion on incremental learning cannot be completed without accounting for the benchmark datasets used in pre-training complex, cumbersome deep learning architectures for faster convergence and better generalisation. The deep learning frameworks serve as the backbone for tasks such as detection, segmentation and classification [
131,
132,
133]. The most widely used method of pre-training as an initialisation method for computer vision tasks is the supervised pre-training [
133] using ImageNet with 1.2 M images [
35]. Further datasets used in pre-training deep learning architectures include COCO (Microsoft COCO: Common objects in context) [
29], PASCAL-VOC [
28], OpenImages [
128] and JFT [
129], which was an internal Google dataset with more than 300 M images that are labeled with 18,291 categories, later published in 2017 [
21].
While there is an ongoing debate whether pre-training is necessary for all types of tasks, incremental learning approaches in the literature are found to have used pre-trained models, which were later fine-tuned for specific detection or classification experiments. The datasets used in research studies included in this review article were generic datasets such as MNIST [
134], FashionMNIST [
135], SVHN [
136], CIFAR-10 [
137], CIFAR100 [
34], Tiny ImageNet [
138], which is a strict subset of the large ImageNet dataset, CORe50 [
130] and a few task-specific datasets available. MNIST is a hand-written digits dataset. Task agnostic incremental learning is yet in the infancy stage of experimentation, and the incremental learning accuracy on real-world datasets is very low, which implies that real-world experimentation of this technique is under process or not yet available for the research community. The classes/tasks being learned from streaming data can also lead to concept drift as discussed above when there is change in data distribution. Accounting for all those factors, despite all the different types of methods and models studied in the area of incremental learning, there is no clear winner model that can produce state-of-the-art comparable results in an online real-time deployment [
15].









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}