1. Introduction
Communication is one of the greatest needs of human beings since interaction with our fellow human beings allows us to develop, learn, and work to express ideas and feelings. As people age, they often face physical and cognitive challenges that hinder their ability to convey their needs, thoughts, and emotions. Among visual, speaking, or hearing limitations there are some physical problems, while on the mental level there is memory loss or senile dementia [
1]. Additionally, the inability to maintain adequate communication can lead to isolation and loss of social connections due to fear of rejection, ridicule, or lack of trust. It can increase the risk of severe depression and significantly affect their quality of life [
2].
Although communication problems are common in older adults, they are not exclusive to this population segment. Many children and adolescents suffer from disorders, such as autism spectrum disorders or cerebral palsy, which prevent them from having a fluid interaction with their social environment. It can impact their well-being and self-esteem or intensify bullying problems. For these reasons, it is essential to use alternative methods that facilitate communication while promoting an inclusive environment of patience and respect.
Augmentative and Alternative Communication (AAC) techniques and tools have been widely used to support integrating individuals with verbal or gestural communication limitations. These tools, systems, devices, or strategies help people communicate when they have different communication difficulties, including speech impediments [
3]. AAC are divided into two groups: (i) AAC that does not require physical aids such as facial expressions, sign language, and gestures and (ii) AAC that uses physical aids, especially with high-tech, such as speech voice devices, reproduction of recorded-synthesized phrases, through text-to-speech software [
4]. Additionally, there are two categories in AAC systems: systems that use text or typing, called text-based AAC, and those that are supported by symbols or images that represent those words (pictograms), called symbol-based AAC [
5].
The advancement of technology, especially Artificial Intelligence (AI), has allowed us to improve the efficiency of systems that use transfer learning algorithms to train speech-to-text models to improve communication. However, the success rate varies constantly due to constant changes in popular native speaker slang, creating ambiguity in terms used by older adults [
6].
Combining machine learning tools with AAC techniques offers excellent potential to facilitate and improve communication with older adults [
7]. Therefore, developing technologies that adapt to needs, abilities, and limitations is mandatory, which holds substantial advantages for the population. This enables older adults to maintain their autonomy, engage actively in conversations, and connect with their family, friends, and caregivers in daily activities. Also, it can help to combat the potential loneliness and isolation often associated with aging.
For this reason, this paper proposes a semantic analysis of the context in verbal expressions that older adults usually use and the corresponding meanings of the phrasing from different sources. Hence, we used Natural Language Processing (NLP) techniques and a pre-trained language model to understand the particularities and the connotations implicit in the verbal expressions of older adults, using semantic similarity and later matching those verbal expressions with a pictogram. Previously, it was essential to extract and preprocess the data to analyze and evaluate the textual semantic similarity of those expressions with algorithms such as cosine similarity.
The rest of this document is organized as follows.
Section 2 includes a summary of the studies related to the proposed research.
Section 3 describes the materials and methods used.
Section 4 details the results found. Finally,
Section 5 presents the conclusions and further research directions.
2. Related Work
In recent years, AAC has relied on technological tools to support communication. In this context, multiple studies have proposed the integration of databases of pictograms and their definitions to use NLP techniques in applications that allow the recognition or automatic generation of these symbols. Schwab et al. [
8] propose the integration of the Argonese Center of Argumentative and Alternative Communication (ARASAAC) pictogram database with the WordNet lexicon database as a prerequisite for generating tools that use NLP. The integration presented problems such as the identification of pictograms with a similarly tagged identification and different semantic meanings, i.e., mouse (animal) vs. mouse (computer device), the difficulty in interpreting the original meaning of the pictograms and the analysis of words that depend on the context, such as verbs. The resulting database is publicly available and can be used in languages other than English.
Another work involving NLP and pictograms is presented by Norré et al. [
9], through the Word Sense Disambiguation (WSD) task that automatically translates French dialogues between doctors and patients with intellectual disabilities into ARASAAC pictogram sequences. For this purpose, they evaluate different pre-trained language models and Word Embeddings models. The results demonstrate that the Word2Vec Skip-Gram implementation significantly improved the accuracy of the translations by obtaining an accuracy of 73%.
Beyond structuring databases that perform a correspondence between pictograms and their meaning, some studies have developed applications that have allowed tests to translate text or voice towards pictograms. Pictalky is a program aimed at children up to 14 years of age with language problems caused by intellectual disability or autism [
10]. The application captures spoken sentences and automatically generates a sequence of equivalent pictograms using a speech-to-text transformation system, a grammar correction module, a module that transforms text to pictograms (n-gram mapping), and a system for handling text that does not have a representation. The transformation was successful in the tests, and a robot was even developed to improve interaction with infants.
Cabello et al. [
11] structure a system that generates phrases with pictograms from a processed text representing the meaning of the information entered. The NEWS1709 database was used to train the model, and the ARASAAC database as a source of the pictograms. The information entered is subjected to text preprocessing techniques (lemmatization, filtering of irrelevant terms and spelling errors) to apply Word Embeddings and topic model methods, which allow the generation of sentences from which the most appropriate pictograms can be recovered, with an average accuracy of 74%. Similarly, Bautista et al. [
12] developed a tool called AraTraductor that allows translating Spanish text into pictograms, using NLP techniques to improve results. The application uses the ARASAAC database, and the entered text is parsed using the Maltparser system. An analysis of n-grams (sequence of the n-words in the modeling of NLP) and lemmas that represent a pictogram is performed to enhance the translation.
To improve the communication of children with cerebral palsy, the Accelerated CA
JU and Illustrated CA
JU systems were developed, which allow predicting the words of a sentence as a user enters them and converting a sentence, written in Portuguese, into a sequence of pictograms that represents it [
13]. The second system uses tools such as a Naive Bayes classifier and an entity name recognizer to create meaningful glyph sequences validated during testing.
Meanwhile, another tool that facilities the communication of people with cerebral palsy is presented by Pahisa-Solé and Herrera-Joancomartí [
14]. This companion system transforms the telegraphic language resulting from pictogram-based AAC systems into natural language so that people with cerebral palsy can learn new language skills and improve their quality of communication. This system demonstrated an average increase in the communication rate of 41.59% in tests performed on four participants in Spanish and Catalan.
Another application that assists communication with people with autism spectrum disorder is PictoEditor, which uses pictograms that are added to form phrases in Spanish, the same ones that can be heard or shared with other people [
15]. This application uses the ARASAAC database, and its strength lies in its implementation of pictogram prediction mechanisms based on their frequency of use or by label classification. Combining both techniques was enough to present the pictograms with the highest use probability.
3. Materials and Methods
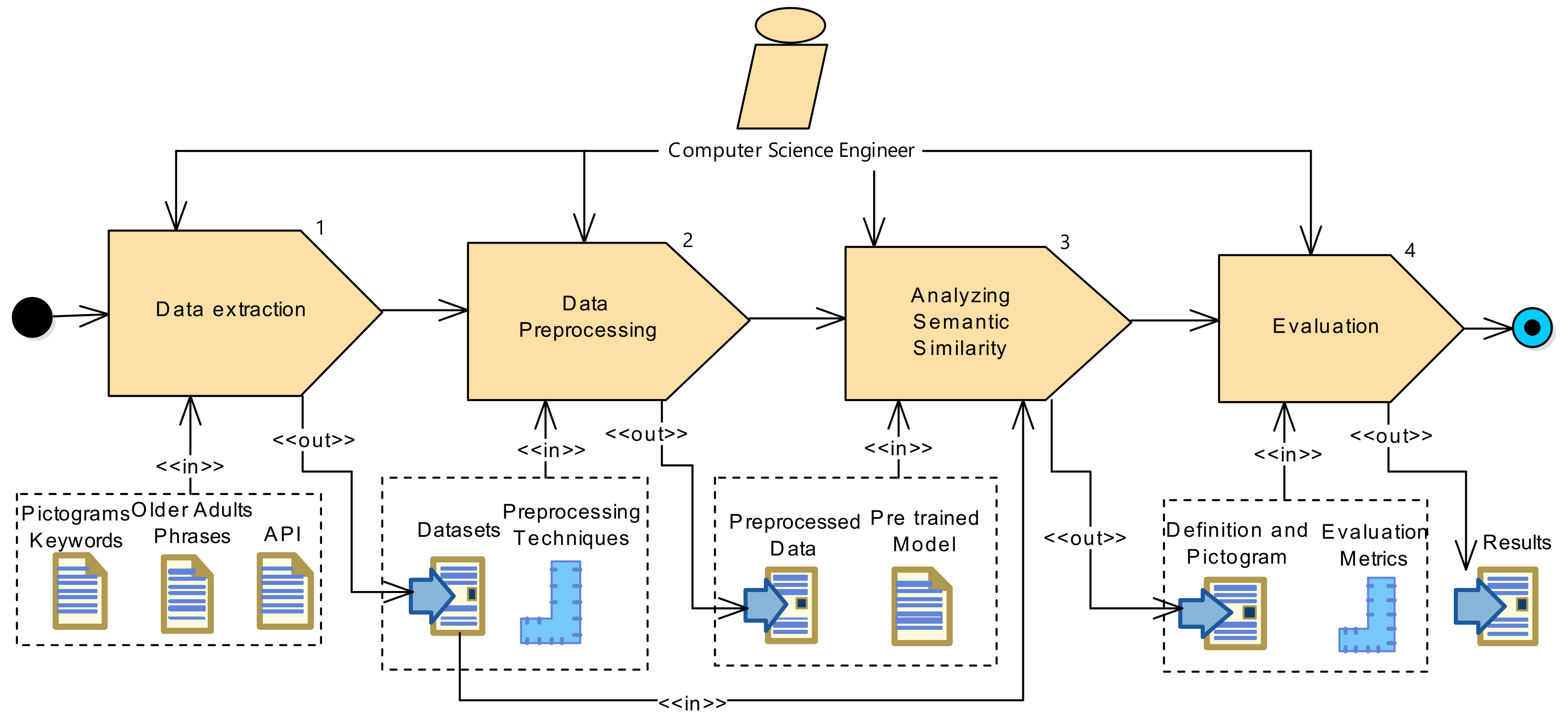
The methodology used in this article was divided into four steps: (i) data Extraction, (ii) Data Preprocessing, (iii) Analyzing Semantic Similarity, and (iv) Evaluation. Each step was represented with the Systems Process Engineering Metamodel 2.0 (SPEM), as shown in
Figure 1.
The initial process was focused on extracting the definitions required for the pictograms from three different sources such as ARASAAC, Royal Spanish Academy (RAE), and Wikipedia. Then, conventional preprocessing techniques were applied to the sentences of older adults in the data preprocessing step. The semantic similarity between the processed information and the stored definitions was analyzed in the following step using a pre-trained model. In the last step, the results obtained (definitions and corresponding pictograms) were evaluated with experts in this area.
3.1. Data Extraction
The pictograms on the ARASAAC web portal were used to acquire the necessary definitions. This website offers graphic resources to improve communication and cognitive accessibility for people facing challenges in these areas. This portal continually incorporates new pictograms, and its Application Programming Interface (API) for developers provides access to information related to each pictogram [
16].
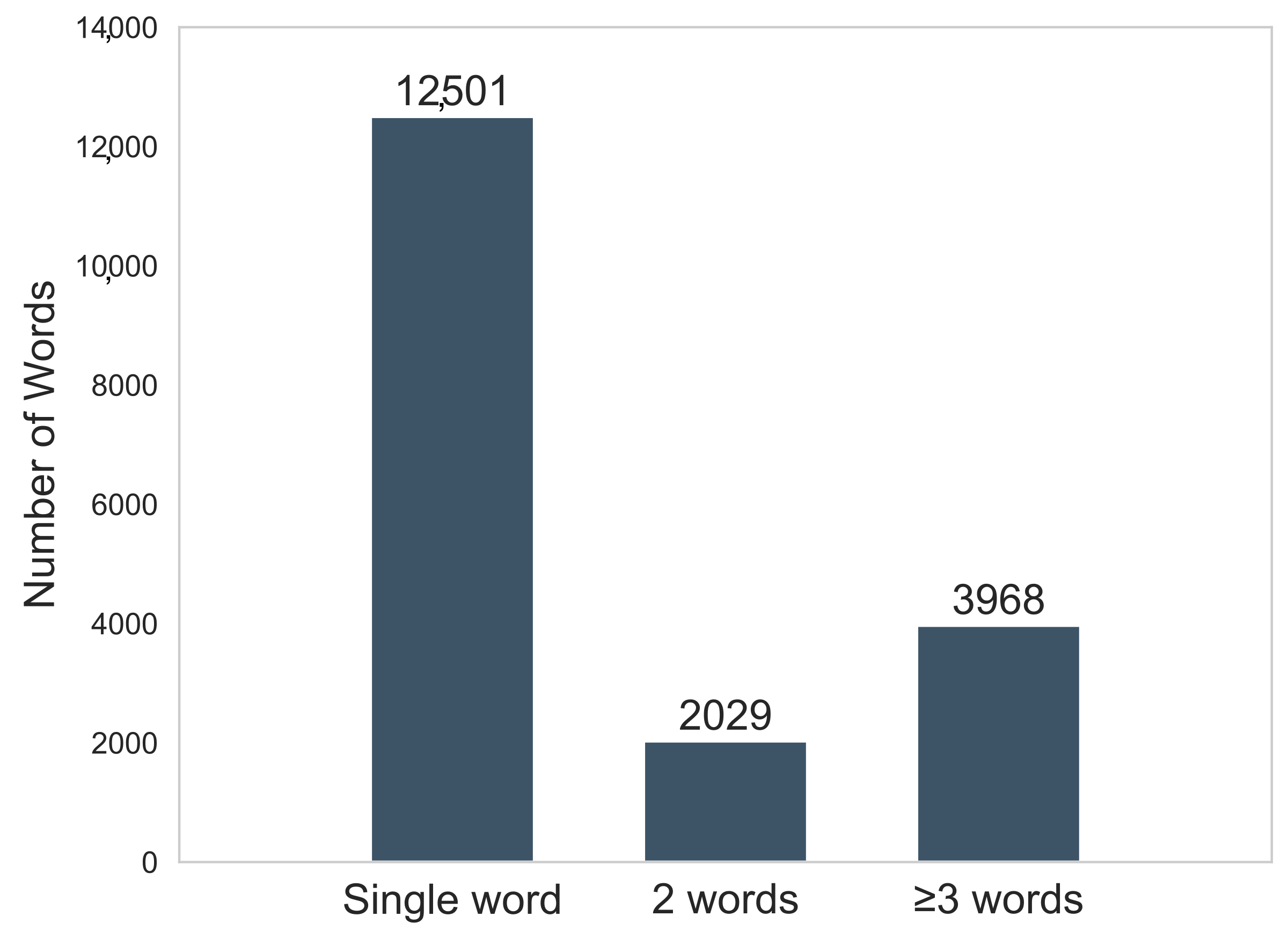
Accordingly, a set of 18,498 pictograms was downloaded from ARASAAC. Each pictogram contains one or more keywords, a representation graphic (pictogram), and its corresponding definition. It is worth mentioning that some pictograms lack a definition, and in some instances, several pictograms share one or more keywords, their only distinction being the image representing them.
Figure 2 details the distribution of the keywords per pictogram.
Due to these issues in some keywords associated with the pictograms, we downloaded the information from two additional sources: the RAE and the Wikipedia encyclopedia. Both online platforms provide an API for developers that makes it easy to consult definitions.
In the case of the RAE, its API limits the query to a single keyword at a time, while, in Wikipedia, it is possible to configure the number of retrieved definitions; in our case, a limit of three definitions per keyword was established. A total of 81,827 definitions were obtained from the three sources described above.
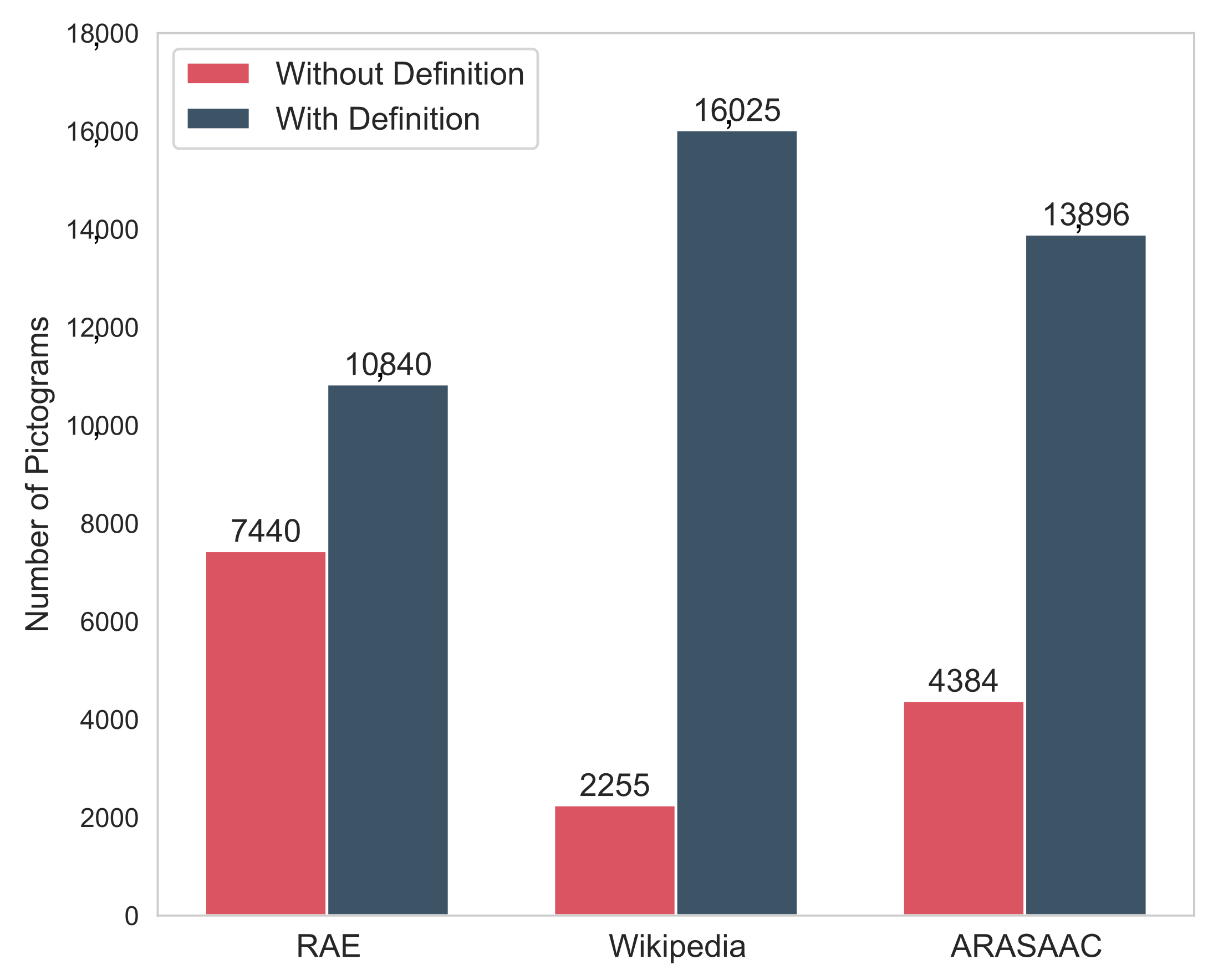
However, there were 218 pictograms for which no definition could be found in any of the sources, resulting in 18,280 pictograms with definitions.
Figure 3 is the distribution of the meanings of these pictograms.
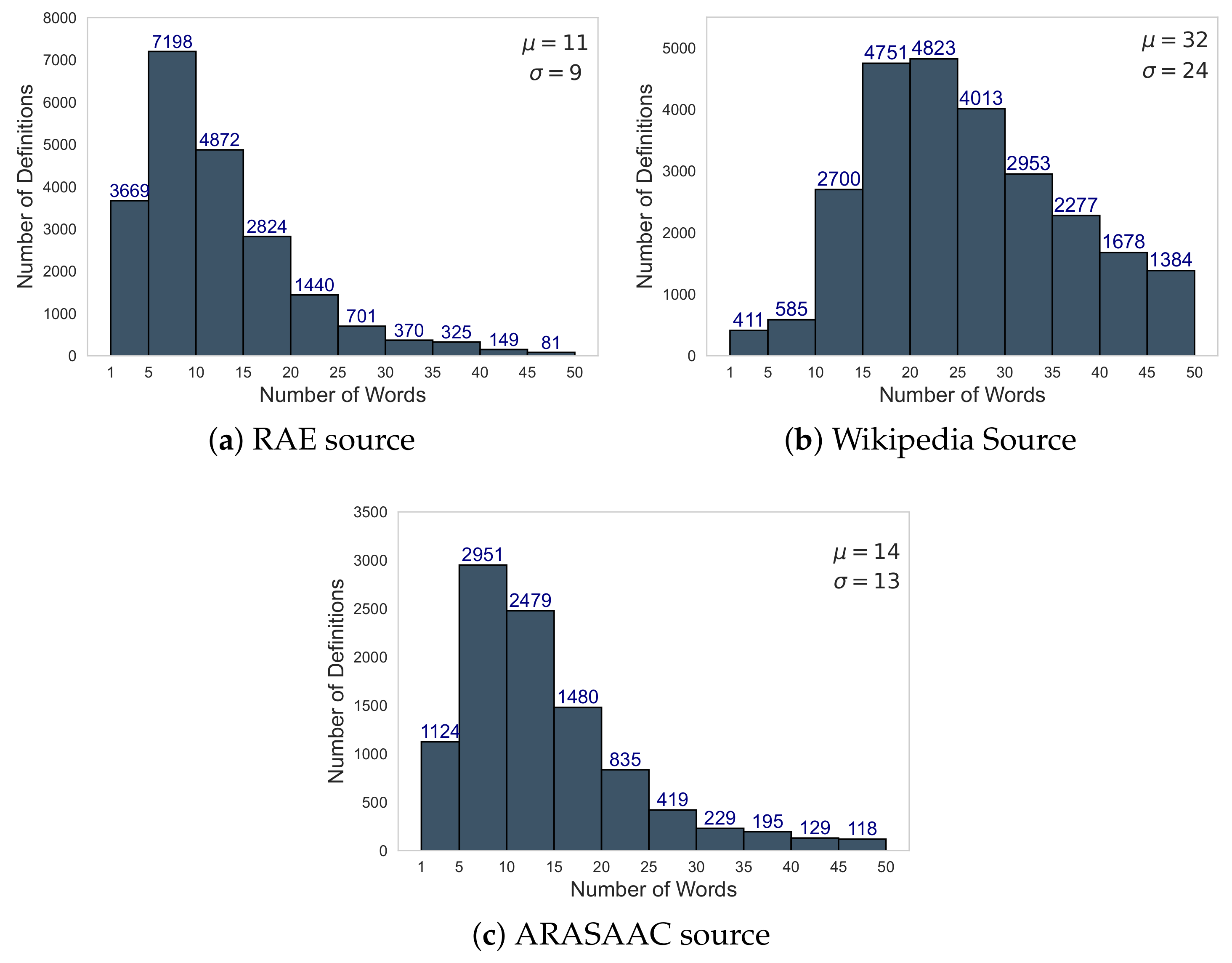
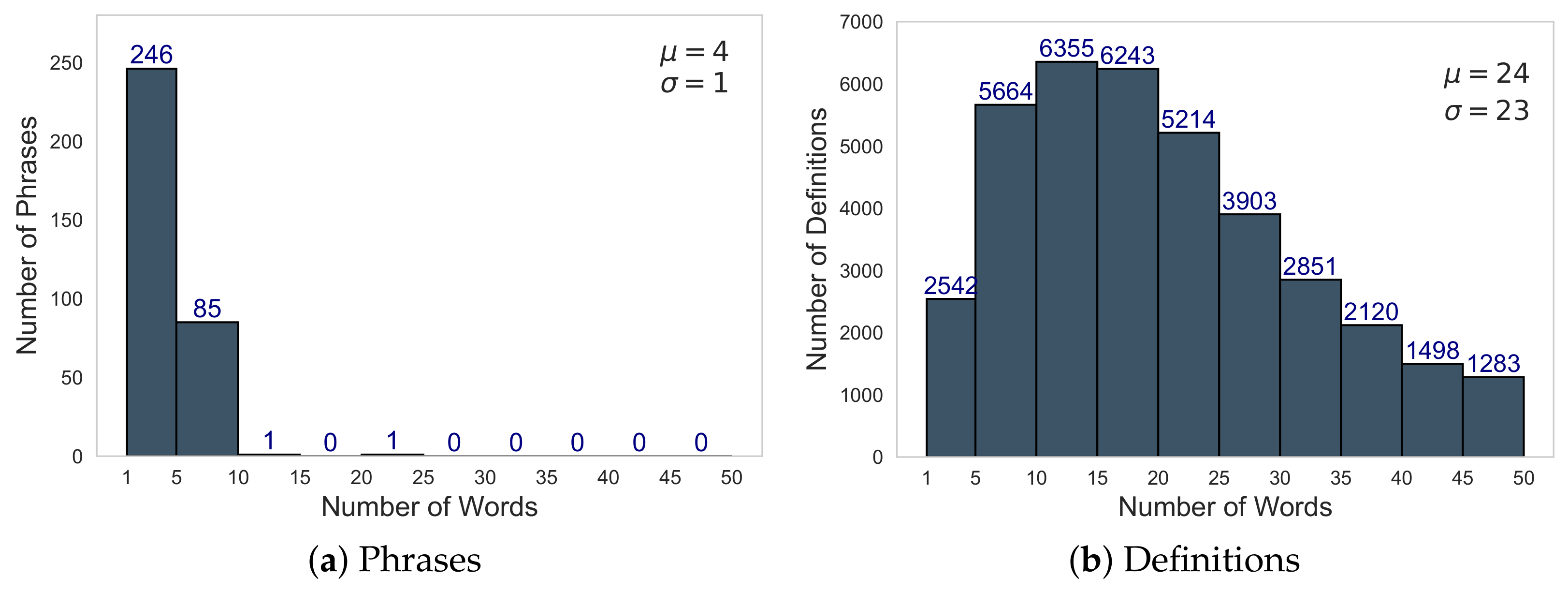
In total, 81,827 definitions were recovered from the sources. In
Figure 4 shows the distribution of words per definition from each of the sources. A range between 1 and 50 words was chosen because it represents most of the definitions in the three sources.
As we can observe in
Figure 4, most definitions obtained from the RAE and ARASAAC are between 1 and 20 words, with an average (
) of 11 and 14, respectively. However, most Wikipedia definitions are between 10 and 45 words, with an average number of words per definition (
) of 32. This indicated a greater consistency in Wikipedia definitions as compared with RAE and ARASAAC.
Therefore, a dataset was structured to store the pictograms and their definitions in a database. The structure is described in
Table 1. To collect phrases from older adults, the researchers were tasked with accumulating common phrases from older adults with affinity or family ties. This work was performed without previously designed questionnaires due to following a conversation model without a previous script.
Each researcher recorded the common phrases precisely as the older adults expressed them. In total, 333 phrases were collected and organized into a dataset with their characteristics. It is shown in
Table 2.
3.2. Data Preprocessing
In this step, preprocessing techniques were applied to the definitions and short sentences of older adults. Those techniques were essential elements of the research. With these short texts in Spanish, some standard techniques [
17] were selected and combined for the semantic similarity analysis. The Python programming language and the Gensim library were used; the techniques used are described in
Table 3.
Thus, duplicate records were eliminated from the set of older adults’ phrases and the definitions, along with words of one letter such as abbreviations, conjunctions (coordinating and subordinating), and prepositions. Many of these words relate terms and join words or sentences. Similarly, both datasets were standardized by converting them to lowercase letters and removing special characters, punctuation marks, and symbols (pipe, dash, asterisk, apostrophe) except diacritic marks [
18,
19].
3.3. Analyzing Semantic Similarity
In this step, a script was developed through a pre-trained model, the Python programming language, and the Pytorch framework to analyze the semantic similarity between the older adults’ phrases and the available definitions. The script presents the most representative pictogram with the value resulting from the semantic similarity.
With the processed data and available definitions, a pre-trained model was implemented and hosted in the Hugging Face model repository, a company specialized in developing projects related to NLP and machine learning [
20].
Additionally, the script required the Transformers libraries and a sentence-transformers model called
sentence_similarity_spanish_es based on the Bidirectional Encoder Representations from Transformers (BERT) model trained on an extensive Spanish corpus [
21]. This language was chosen because of its syntax and semantic complexity, characterized by various jargon elements, idioms, and words typical of each region. These libraries provide an interface that simplifies the use of pre-trained models available in the Hugging Face repository. The pre-trained model is responsible for executing the sentence similarity task. In this task, the pre-trained model converts the input texts (older adults’ sentences), the corpus (definitions), and the retrieved top
k matching entries as input parameters into vectors (embeddings). Those parameters capture semantic information and subsequently calculate the distance between these vectors, then return a list of dictionaries sorted by decreasing cosine similarity score.
A standard measure for this comparison is cosine similarity, which evaluates the similarity between two vectors (phrases) by calculating the cosine of the angle between them using Equation (
1),
where
represents the angle between two vectors, and
and
are the components of vectors
and
.
This measure is expressed between −1 and 1, with 1 being the most significant possible similarity [
22,
23]. Once the pre-trained model was loaded, comparisons were performed between all the phrases provided by the older adults and the definitions extracted from sources stored in the database. The definition with the highest cosine similarity was applied in each comparison as a selection criterion.
Finally, the corresponding pictogram image representing the older adults’ phrase was selected upon finding the most accurate definition.
3.4. Evaluation
For this phase of the project, it was necessary to evaluate the semantic similarity obtained from the older adults’ phrases and the definitions from the different sources. Therefore, it can generally be assessed directly with the data obtained from the cosine similarity calculation contrasted with the experts’ scores. The reliability of semantic similarity is determined by the approximation of the results between the cosine similarity score and that represented by human judgment [
24]. For this reason, we analyzed the precision of our study through the Pearson correlation coefficient since it demonstrates how strong the relationship is between the calculated cosine similarity scores and the scores the experts have given within a framework-specific reference. The Pearson correlation coefficient was calculated using Equation (
2),
where the values of
in the sample are the cosine similarity score,
is the mean of the values of the cosine similarity score,
y is the human judgment score, and
is the mean of the human score.
4. Results
For greater understanding, the results of this research were divided into three subsections. First, the results of applying preprocessing techniques to the set of older adults’ sentences and definitions; second, the results of the semantic analysis stage between the older adults’ phrases and the definitions; and finally, the results of the evaluation stage.
4.1. Application of Preprocessing Techniques
After applying the preprocessing techniques, the records in the definition and phrase sets were transformed to lowercase, and any special characters present were removed. Special characters included symbology and words related to other languages found in Wikipedia definitions and could alter the operation of the model.
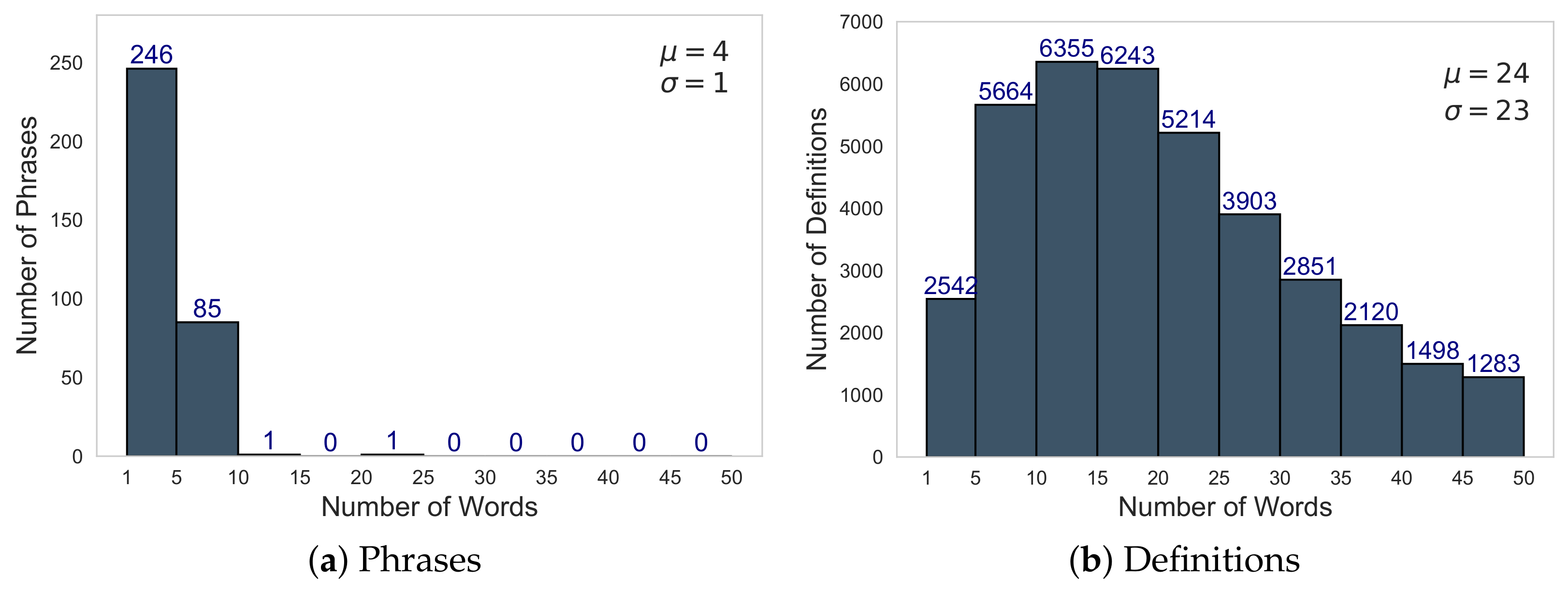
However, accents, being an essential part of the Spanish language, were preserved. Nevertheless, words containing fewer than two characters were eliminated from all definition records. Hence, some abbreviations that introduced the definitions and did not contribute to the context of the definition were eliminated. However, these words were retained in the sentences of older adults because most of them are of short length, as we can observe in
Figure 5a.
Finally, duplicate definitions were eliminated, resulting in a total of 41,324 definitions.
Figure 5b shows their distribution in 1 to 50 words, and the distribution after applying the preprocessing techniques. Regarding the older adults’ phrases, the record still needs to be eliminated after using these techniques, resulting in 333 phrases.
4.2. Semantic Similarity Analysis
The results obtained at this stage of our methodology are shown in
Table 4, where the six phrases with the highest degree of semantic similarity between the phrases obtained from the older adult and the different definitions of the selected pictograms are presented. Each older adults’ expression is related to a definition obtained by the pre-trained model used, and the corresponding pictogram is extrapolated according to the highest similarity semantic score obtained.
As we observe in
Table 4, the value obtained for using the pre-trained semantic similarity model in six random phrases ranges between 0.85 and 0.88. This demonstrates a considerable similarity between the definition obtained and the older adults’ expression.
This is evident from the recommended pictogram that has a strong relationship with the phrase mentioned by the older adult. It facilitates communication between the people in change of their care, such as geriatric nurses and older adults with communication problems.
4.3. Evaluation between Similarity Semantic and Human Score
After conducting the corresponding analysis of the semantic similarity performed with a pre-trained model, evaluating the reciprocal relationship between the older adults’ phrase and the definition with its corresponding pictogram is necessary.
To achieve this, the phrases and their definitions were presented to language experts/linguists for their evaluation since our corpus contains jargon and idioms used within the informal sphere and whose meaning cannot be deduced from the words that compose it. For this reason, an evaluation with human judgment is necessary to know if the pre-trained model manages to provide us with correct semantic similarity. Once both scores were obtained from the pre-trained model and the human judgment, the Pearson coefficient correlation was applied to measure the strength of the association between both scores received. Therefore, a moderate Pearson correlation of 0.57 was obtained, showing that the two scores tend to increase linearly together positively and have a moderate correlation.
In addition, it is necessary to know how the semantic similarity scores performed with both the pre-trained model and the experts’ evaluation are distributed, so we use a Laplace–Gauss distribution, as shown in
Figure 6.
The semantic similarity scores model has a symmetrical and platykurtic distribution because its kurtosis is −0.3832, giving us the impression that its data are dispersed. However, the experts’ scores show that it is a platykurtic distribution whose kurtosis is −1.1278, referring to the fact that its data are more dispersed than the semantic similarity scores of the model. The main reason for the difference between the two distributions is the regional idioms of the older adults’ sentences used to perform semantic similarity with a pre-trained model in formal Spanish.
Therefore, the experts’ score presents a slight right-skewed distribution, demonstrating that the older adults’ phrases and the definitions selected by the pre-trained model with more significant semantic similarity sometimes differ.
5. Conclusions
In this article, a semantic analysis was performed between the phrases of older adults and the definitions extracted from pictogram keywords. The pictograms, accompanied by their keywords, were extracted from the ARASAAC portal, and various researchers collected the phrases of older adults. A pre-trained model in Spanish, available in the Hugging Face repository, was used to obtain the cosine similarity between the phrases of older adults and the definitions to recommend the pictogram that leads to a better representation of the phrase.
This analysis aimed to determine if the relationship between the older adults’ phrase, the definition obtained by the model, and the recommended pictogram is consistent. Therefore, an evaluation system was structured based on correlation analysis. The results of the correlation analysis performed between the definitions score and the human score revealed a positive correlation. This suggests that pictograms, in conjunction with pre-trained Natural Language Processing models, can be a helpful tool for communication with older adults.
However, the presence of idioms, native words, and slang in some older adults’ phrases resulted in inconsistencies in the definitions and recommended pictograms, altering the value of the correlation performed. These types of expressions are common in people, especially older adults, and continue to be a challenge for pre-trained models available in Spanish. For this reason, as future work, fine-tuning can be performed with those phrases that contain words or expressions exclusively used in particular geographical areas to improve the efficiency in the semantic similarity between the phrases and their corresponding definitions. Furthermore, this study can be applied to practical situations that can serve as a basis for implementing a system that older adults can use and communicate better with family members or caregivers by implementing pre-trained models and pictograms.
Author Contributions
Conceptualization, M.O., A.P.-L., M.V.S. and P.C.; formal analysis, M.O., A.P.-L. and M.V.S.; investigation, P.S.G., G.D.R. and J.L.Z.-M.; methodology, M.O., P.S.G. and G.D.R.; project administration, M.O. and P.C.; resources, M.O.; supervision, M.O., J.L.Z.-M. and P.C.; validation, M.O. and J.L.Z.-M.; writing—original draft, P.S.G.; writing—review and editing, M.O., P.S.G., G.D.R., J.L.Z.-M., A.P.-L., M.V.S. and P.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Corporación Ecuatoriana para el Desarrollo de la Investigación y la Academia—CEDIA grant number I+D+I-XVII-2022-61.
Institutional Review Board Statement
Ethical review and approval were waived for this study due to it is a non-interventional study and the data obtained are common phrases used daily by anyone who did not engage in human medical research. All participants were guaranteed anonymity throughout the data use investigation.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
Data are contained within the article.
Acknowledgments
This work was financial supported by the Corporación Ecuatoriana para el Desarrollo de la Investigación y la Academia—CEDIA through its program, especially for the “Análisis y aplicación de formas de interacción humano-computador (HCI) en una herramienta tecnológica de Comunicación Aumentativa y Alternativa (CAA) basada en pictogramas, que ayude a las personas adultas mayores a comunicarse con su entorno” fund. Also, the entire staff in the Computer Science Research & Development Laboratory (LIDI) of Universidad del Azuay are thanked for their academic support.
Conflicts of Interest
The authors declare that this study received funding from “Corporación Ecuatoriana para el Desarrollo de la Investigación y la Academia—CEDIA”. The funder was not involved in the study design, collection, analysis, interpretation of data, the writing of this article, or the decision to submit it for publication.
Abbreviations
| AI | Artificial Intelligence |
| API | Application Programming Interface |
| SPEM | Systems Process Engineering Metamodel 2.0 |
| NLP | Natural Language Processing |
| RAE | Royal Spanish Academy |
| AAC | Augmentative and Alternative Communication |
| ARASAAC | Argonese Center of Argumentative and Alternative Communication |
| WSD | Word Sense Disambiguation |
| BERT | Bidirectional Encoder Representations from Transformers |
References
- Wong, C.G.; Rapport, L.J.; Billings, B.A.; Ramachandran, V.; Stach, B.A. Hearing loss and verbal memory assessment among older adults. Neuropsychology 2019, 33, 47. [Google Scholar] [CrossRef] [PubMed]
- Hall, E.D.; Meng, J.; Reynolds, R.M. Confidant network and interpersonal communication associations with depression in older adulthood. Health Commun. 2019, 35, 872–881. [Google Scholar] [CrossRef] [PubMed]
- Loncke, F. Augmentative and Alternative Communication: Models and Applications; Plural Publishing: San Diego, CA, USA, 2020. [Google Scholar]
- Syriopoulou-Delli, C.K.; Eleni, G. Effectiveness of different types of Augmentative and Alternative Communication (AAC) in improving communication skills and in enhancing the vocabulary of children with ASD: A review. Rev. J. Autism Dev. Disord. 2022, 9, 493–506. [Google Scholar] [CrossRef]
- Shane, H.; Costello, J.; Seale, J.; Fulcher-Rood, K.; Caves, K.; Buxton, J.; Rose, E.; McCarthy, R.; Higginbotham, J. AAC in the 21st century The outcome of technology: Advancements and amended societal attitudes. In Rehabilitation Engineering: Principles and Practice; CRC Press: Boca Raton, FL, USA, 2022; Volume 1. [Google Scholar] [CrossRef]
- Plaza, J.; Sánchez-Zhunio, C.; Acosta-Urigüen, M.I.; Orellana, M.; Cedillo, P.; Zambrano-Martinez, J.L. Speech recognition based on spanish accent acoustic model. Enfoque UTE 2022, 13, 45–57. [Google Scholar] [CrossRef]
- Sennott, S.C.; Akagi, L.; Lee, M.; Rhodes, A. AAC and artificial intelligence (AI). Top. Lang. Disord. 2019, 39, 389. [Google Scholar] [CrossRef] [PubMed]
- Schwab, D.; Trial, P.; Vaschalde, C.; Vial, L.; Esperança-Rodier, E.; Lecouteux, B. Providing semantic knowledge to a set of pictograms for people with disabilities: A set of links between WordNet and Arasaac: Arasaac-WN. In Proceedings of the LREC, Marseille, France, 11–16 May 2020. [Google Scholar]
- Norré, M.; Cardon, R.; Vandeghinste, V.; François, T. Word Sense Disambiguation for Automatic Translation of Medical Dialogues into Pictographs. In Proceedings of the 14th International Conference on Recent Advances in Natural Language Processing, Varna, Bulgaria, 4–6 September 2023; pp. 803–812. [Google Scholar]
- Park, C.; Jang, Y.; Lee, S.; Seo, J.; Yang, K.; Lim, H.S. PicTalky: Augmentative and Alternative Communication for Language Developmental Disabilities. In Proceedings of the 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing: System Demonstrations, Gyeongju, Republic of Korea, 20–23 November 2022; pp. 17–27. [Google Scholar] [CrossRef]
- Cabello, L.; Lleida, E.; Simón, J.; Miguel, A.; Ortega, A. Text-to-Pictogram Summarization for Augmentative and Alternative Communication. Proces. Leng. Nat. 2018, 61, 15–22. [Google Scholar] [CrossRef]
- Bautista, S.; Hervás, R.; Hernández-Gil, A.; Martínez-Díaz, C.; Pascua, S.; Gervás, P. Aratraductor: Text to pictogram translation using natural language processing techniques. In Proceedings of the XVIII International Conference on Human Computer Interaction, Cancun, Mexico, 25–27 September 2017; pp. 1–8. [Google Scholar] [CrossRef]
- Santos, F.A.O.; Júnior, C.A.E.; Teixeira Macedo, H.; Chella, M.T.; do Nascimento Givigi, R.C.; Barbosa, L. CA 2 JU: An Assistive Tool for Children with Cerebral Palsy. In MEDINFO 2015: eHealth-Enabled Health; IOS Press: Sao Paulo, Brazil, 2015; pp. 589–593. [Google Scholar] [CrossRef]
- Pahisa-Solé, J.; Herrera-Joancomartí, J. Testing an AAC system that transforms pictograms into natural language with persons with cerebral palsy. Assist. Technol. 2017, 31, 117–125. [Google Scholar] [CrossRef] [PubMed]
- Hervás, R.; Bautista, S.; Méndez, G.; Galván, P.; Gervás, P. Predictive composition of pictogram messages for users with autism. J. Ambient. Intell. Humaniz. Comput. 2020, 11, 5649–5664. [Google Scholar] [CrossRef]
- Rodrigo, J.; Corral, D. ARASAAC: Portal aragonés de la comunicación aumentativa y alternativa. Software, herramientas y materiales para la comunicación e inclusión. Inform. Educ. Teor. Prát. 2013, 16, 813–823. [Google Scholar] [CrossRef]
- Orellana, M.; Trujillo, A.; Cedillo, P. A comparative evaluation of preprocessing techniques for short texts in Spanish. In Proceedings of the Future of Information and Communication Conference, San Francisco, CA, USA, 5–6 March 2020; Springer: Cham, Switzerland, 2020; pp. 111–124. [Google Scholar] [CrossRef]
- Hussain, A.; Ali, G.; Akhtar, F.; Khand, Z.H.; Ali, A. Design and Analysis of News Category Predictor. Eng. Technol. Appl. Sci. Res. 2020, 10, 6380–6385. [Google Scholar] [CrossRef]
- Jauhiainen, T.; Lui, M.; Zampieri, M.; Baldwin, T.; Lindén, K. Automatic language identification in texts: A survey. J. Artif. Intell. Res. 2019, 65, 675–782. [Google Scholar] [CrossRef]
- Jain, S.M. Hugging face. In Introduction to Transformers for NLP: With the Hugging Face Library and Models to Solve Problems; Springer: Berkeley, CA, USA, 2022; pp. 51–67. [Google Scholar] [CrossRef]
- Cañete, J.; Chaperon, G.; Fuentes, R.; Ho, J.H.; Kang, H.; Pérez, J. Spanish Pre-Trained BERT Model and Evaluation Data. In Proceedings of the PML4DC at ICLR 2020, Ababa, Ethiopia, 26 April 2020. [Google Scholar] [CrossRef]
- Alqahtani, A.; Alhakami, H.; Alsubait, T.; Baz, A. A Survey of Text Matching Techniques. Eng. Technol. Appl. Sci. Res. 2021, 11, 6656–6661. [Google Scholar] [CrossRef]
- Erkan, G.; Radev, D.R. Lexrank: Graph-based lexical centrality as salience in text summarization. J. Artif. Intell. Res. 2004, 22, 457–479. [Google Scholar] [CrossRef]
- Tsatsaronis, G.; Varlamis, I.; Vazirgiannis, M. Text relatedness based on a word thesaurus. J. Artif. Intell. Res. 2010, 37, 1–39. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).



 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




