Author Contributions
Formal analysis, O.A. and K.M.F.; conceptualization, O.A. and K.M.F.; methodology, O.A., K.M.F. and A.A.E.; software, O.A.; validation, O.A.; investigation, O.A.; resources, O.A.; data curation, O.A. and K.M.F.; writing—original draft preparation, O.A.; writing—review and editing, K.M.F. and A.A.E.; visualization, O.A., K.M.F. and A.A.E.; supervision, K.M.F. and A.A.E.; project administration, K.M.F. and A.A.E. All authors have read and agreed to the published version of the manuscript.
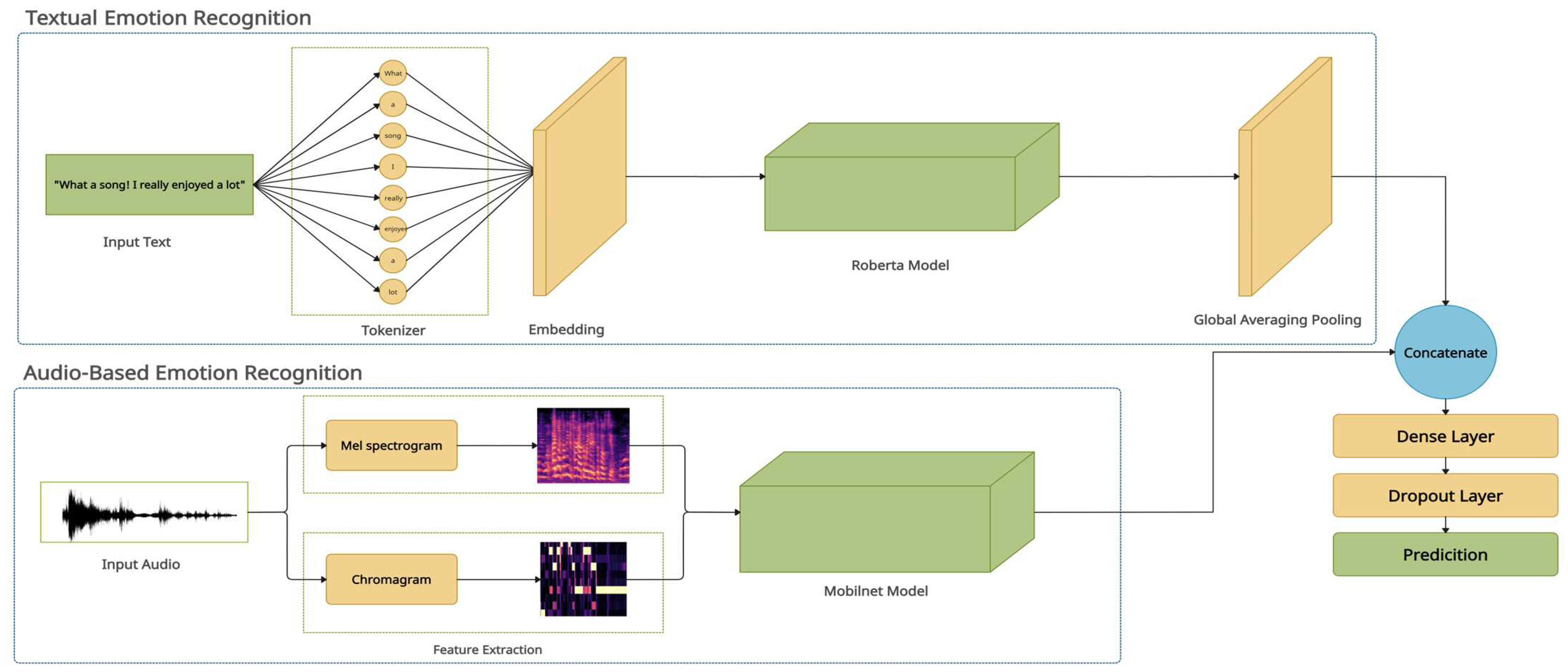
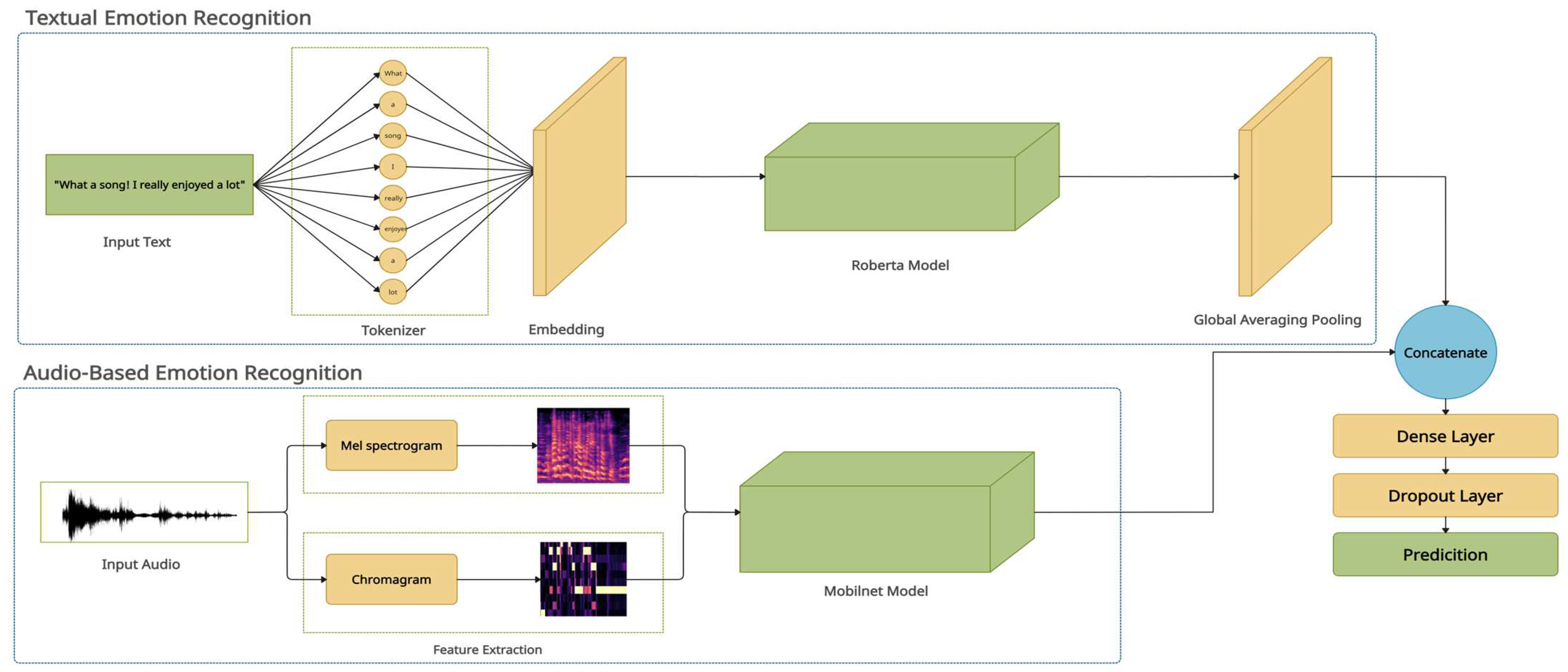
Figure 1.
The proposed MM-EMOR system.
Figure 1.
The proposed MM-EMOR system.
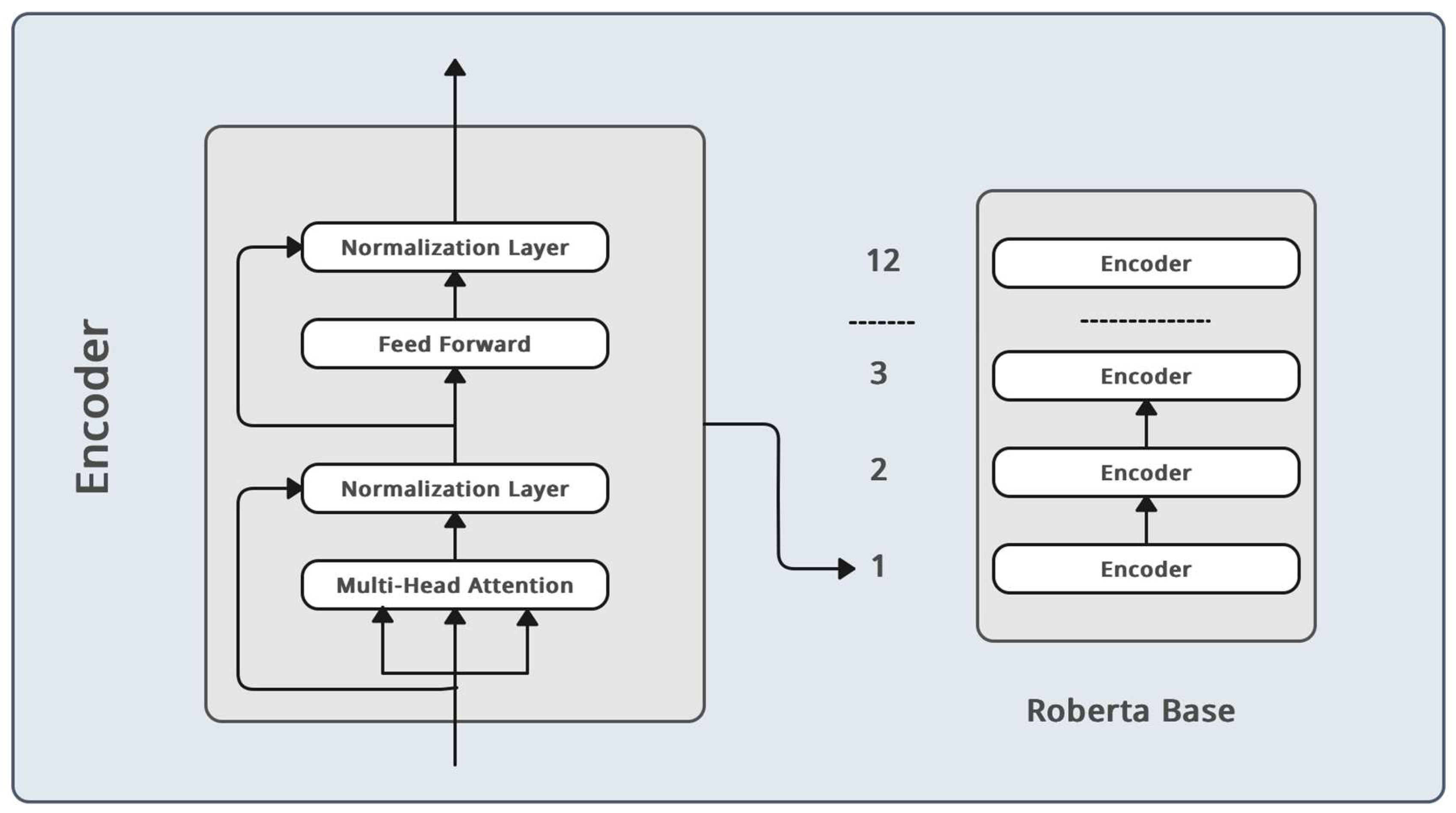
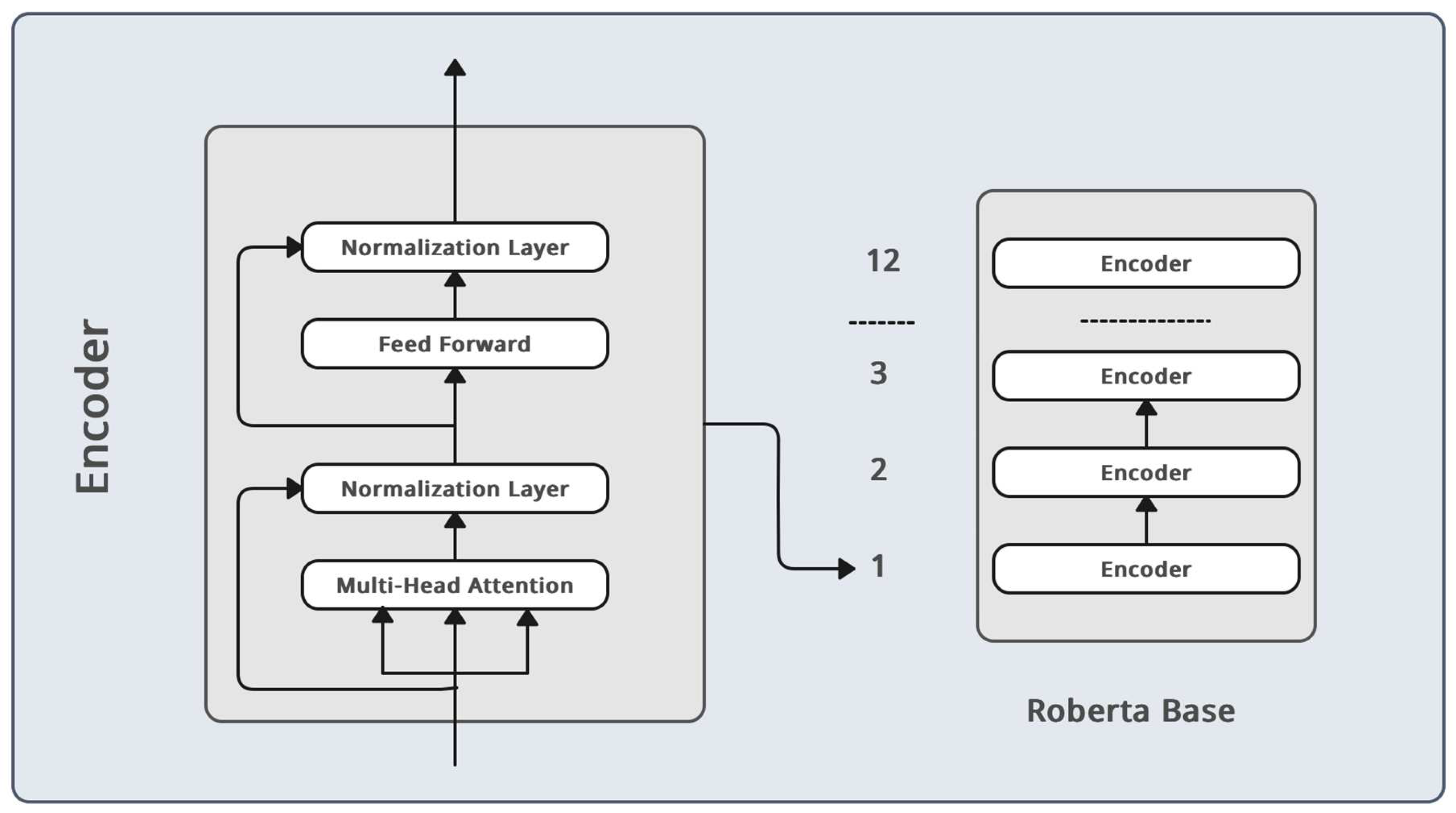
Figure 2.
Roberta model architecture.
Figure 2.
Roberta model architecture.
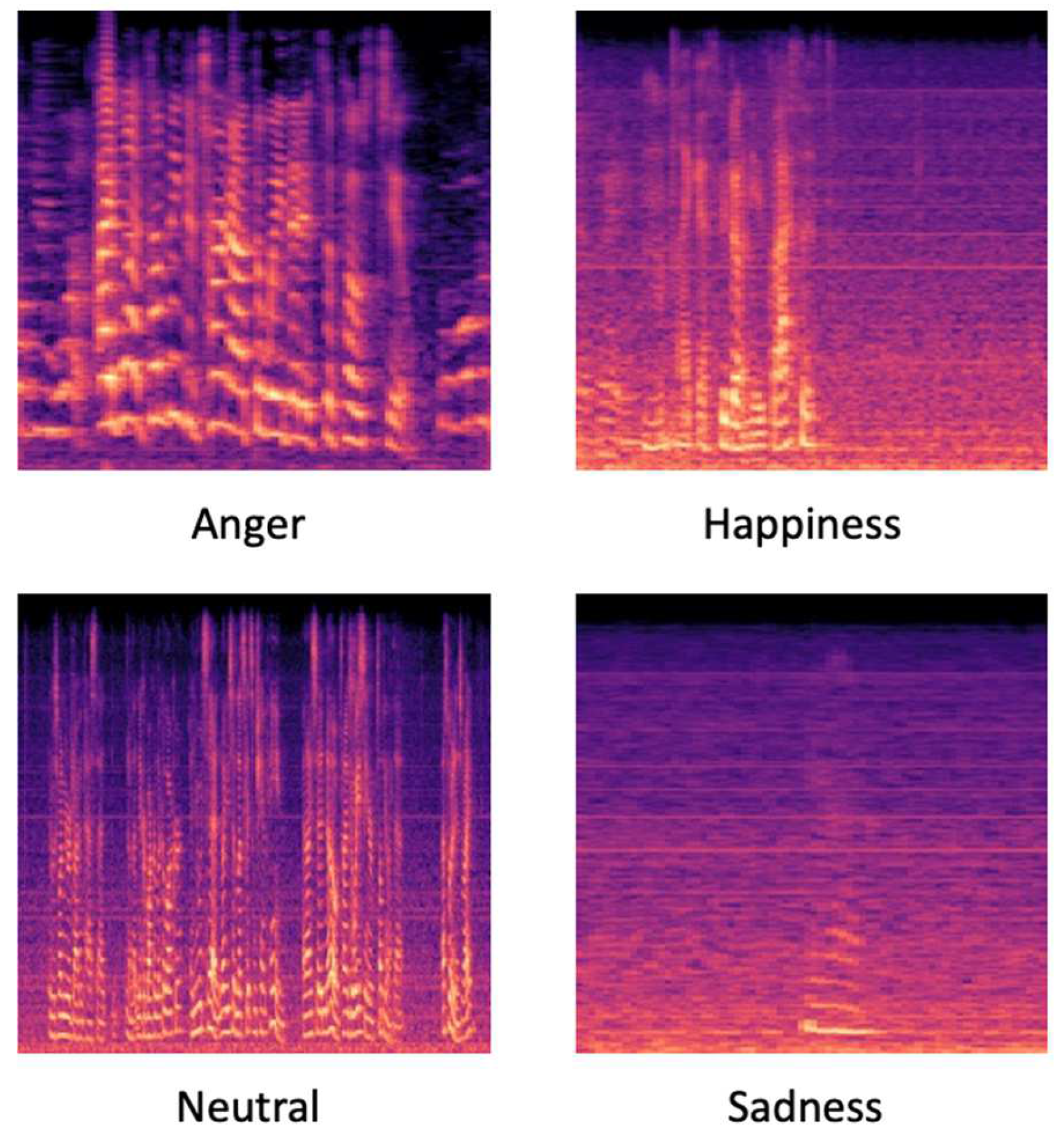
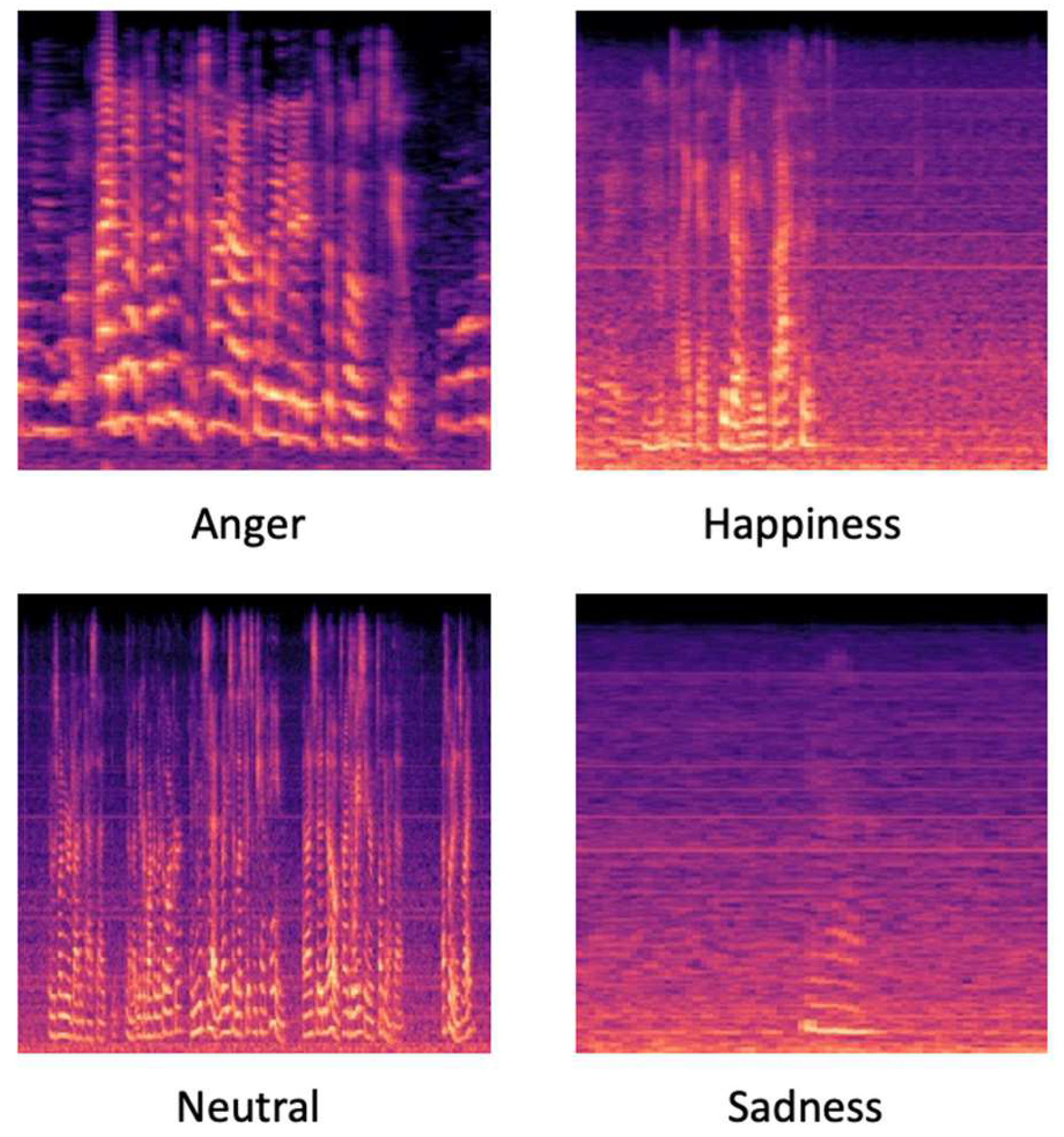
Figure 3.
Differences between classes Mel spectrogram.
Figure 3.
Differences between classes Mel spectrogram.
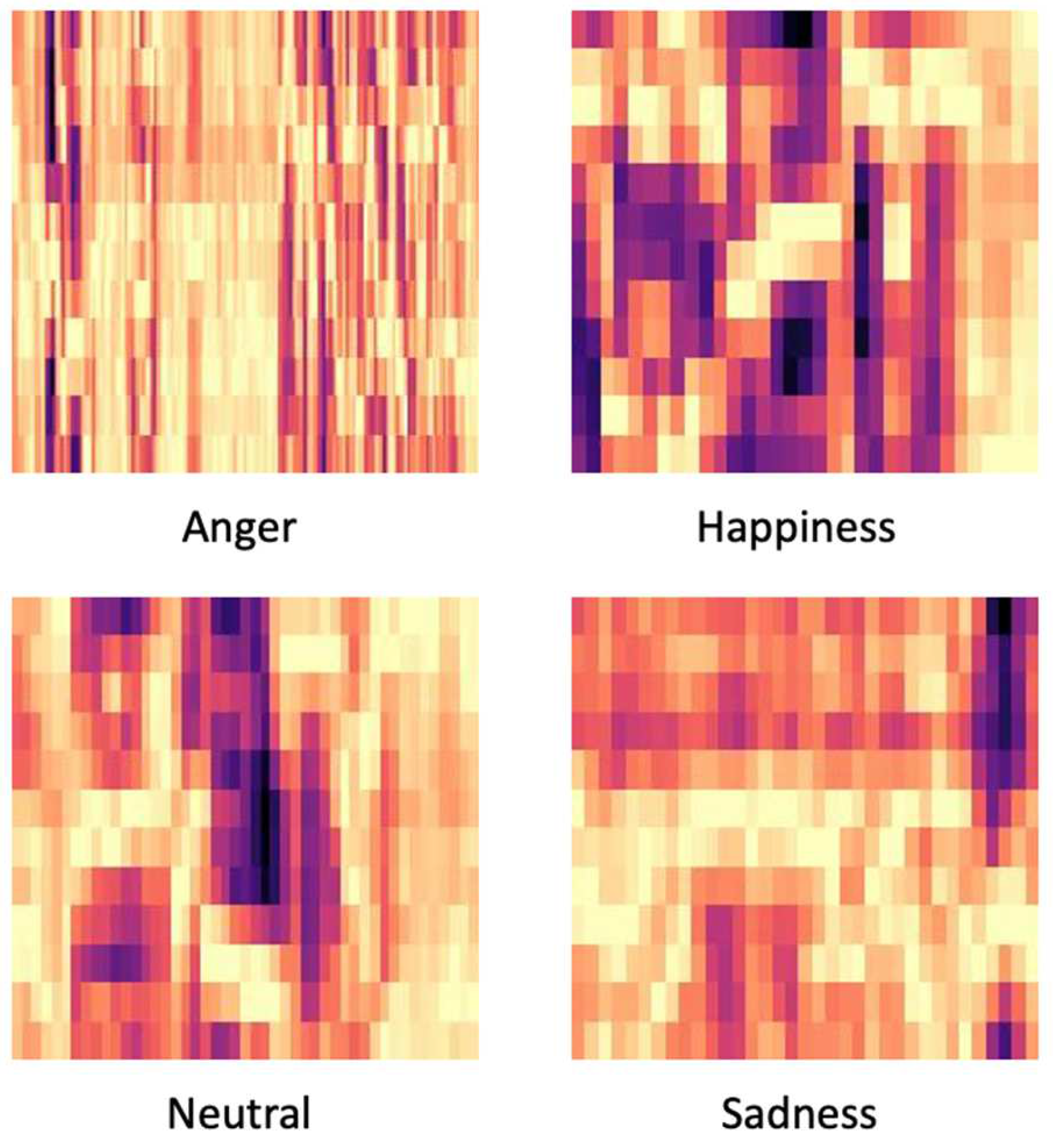
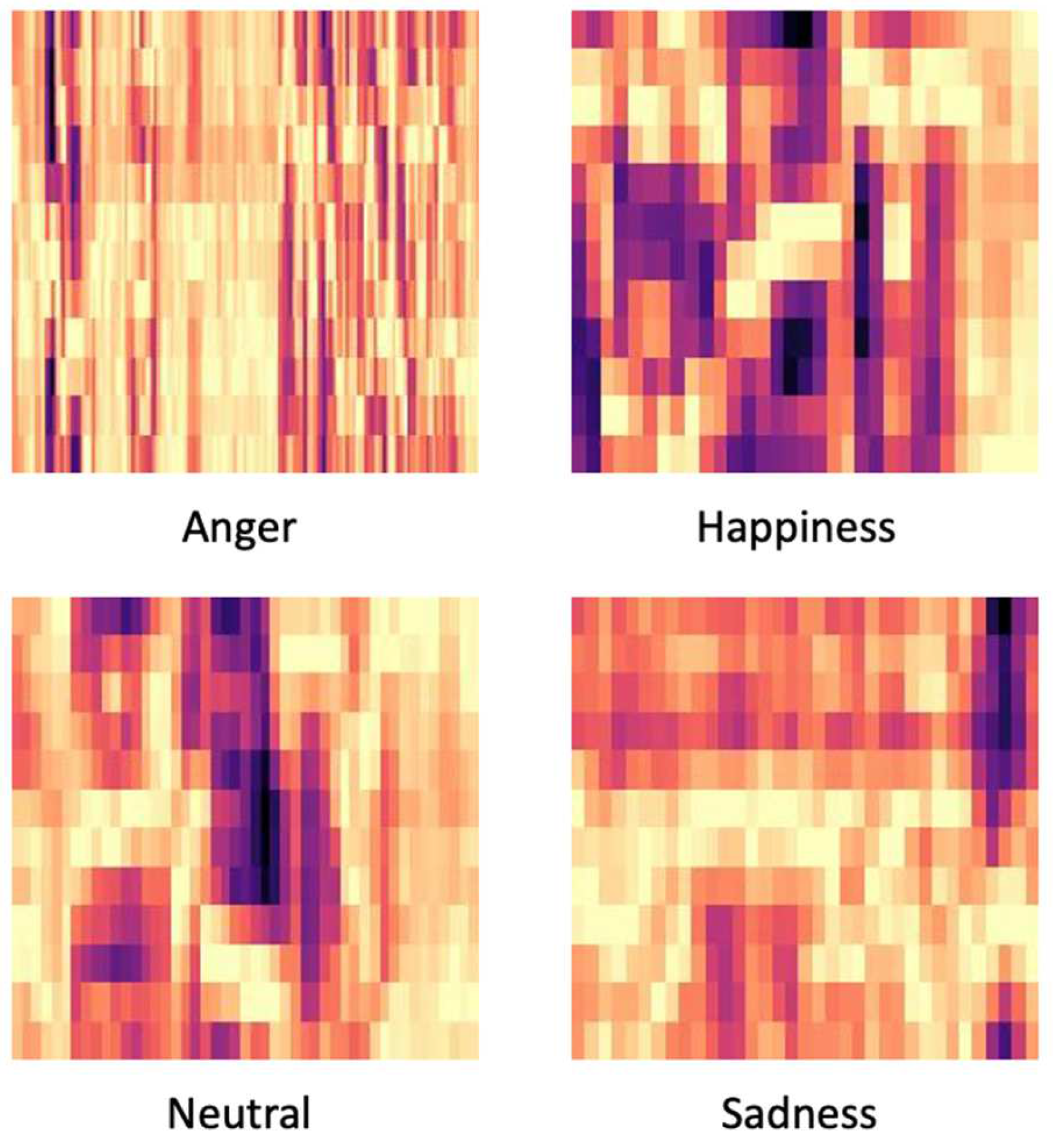
Figure 4.
Differences between classes chromagram.
Figure 4.
Differences between classes chromagram.
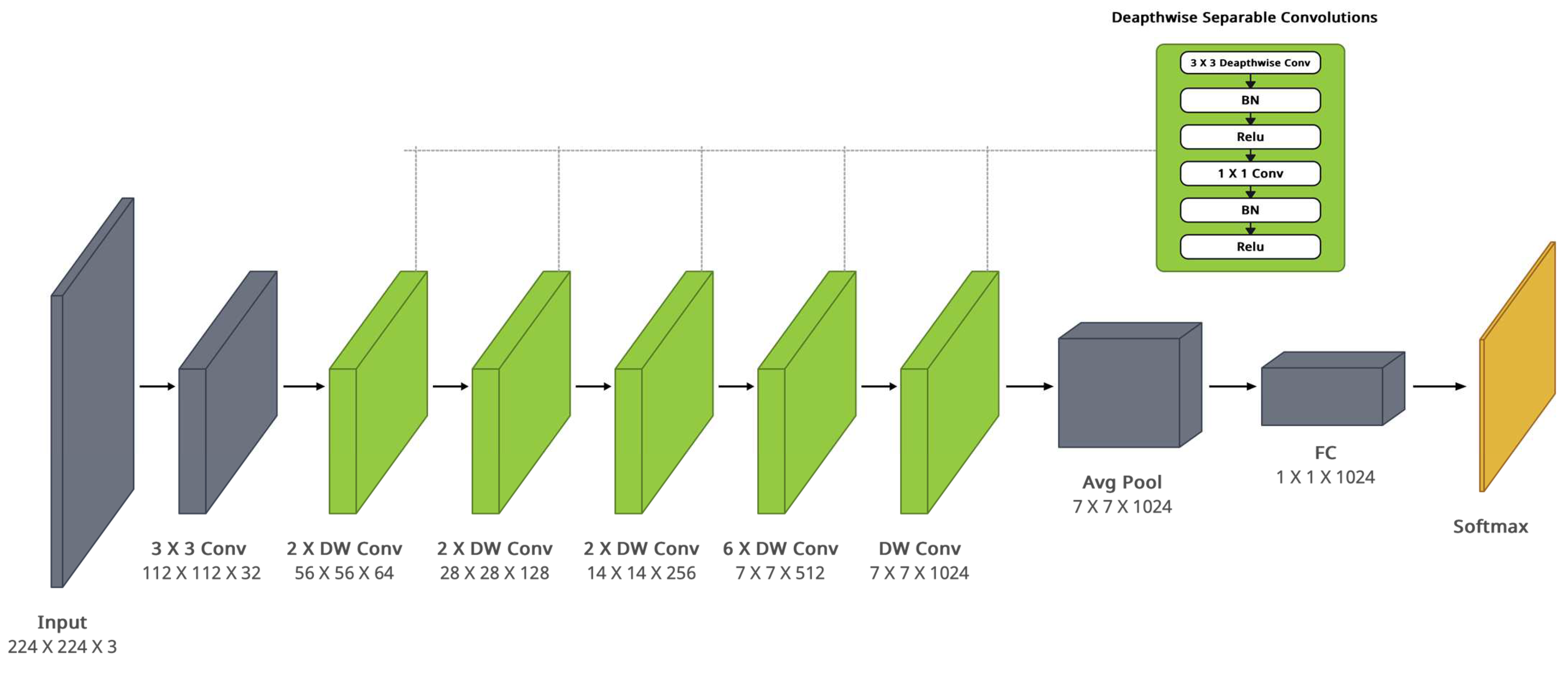
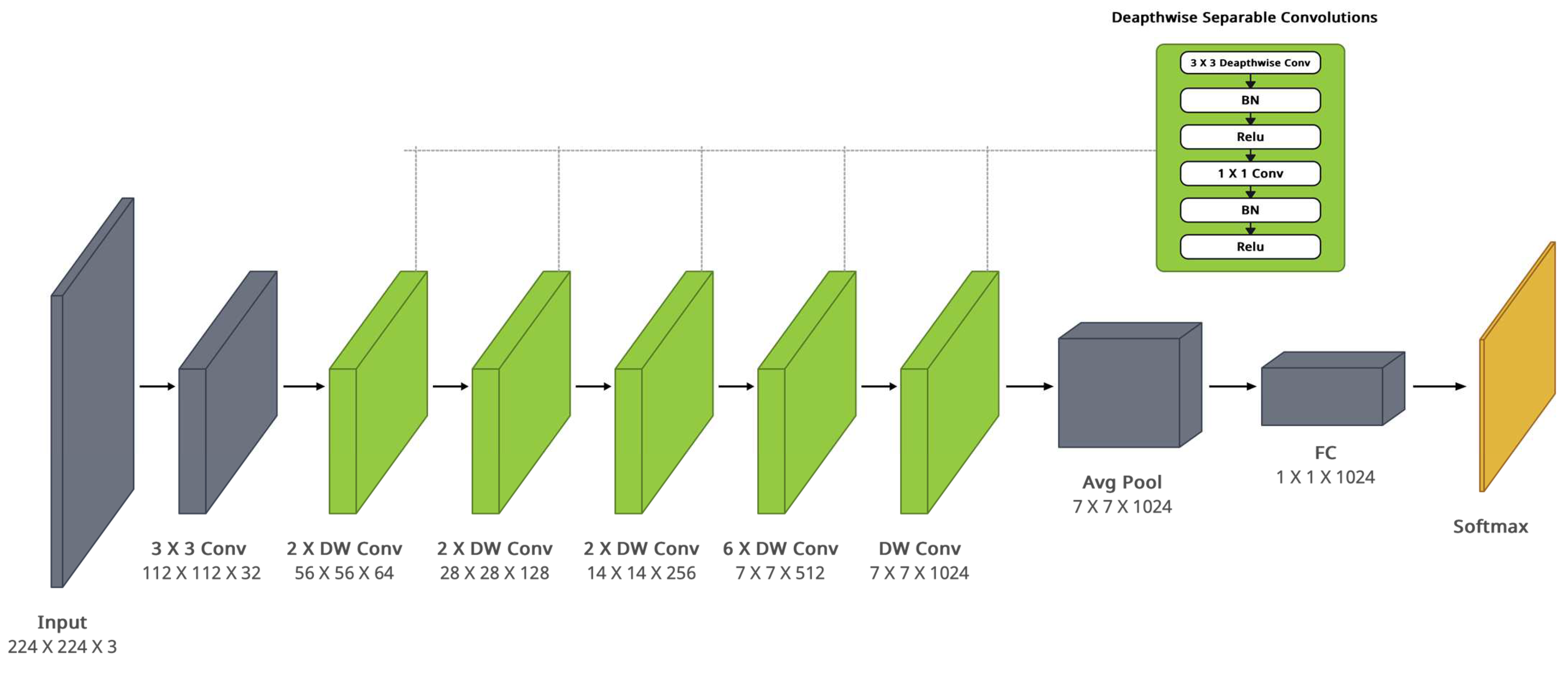
Figure 5.
MobileNet architecture.
Figure 5.
MobileNet architecture.
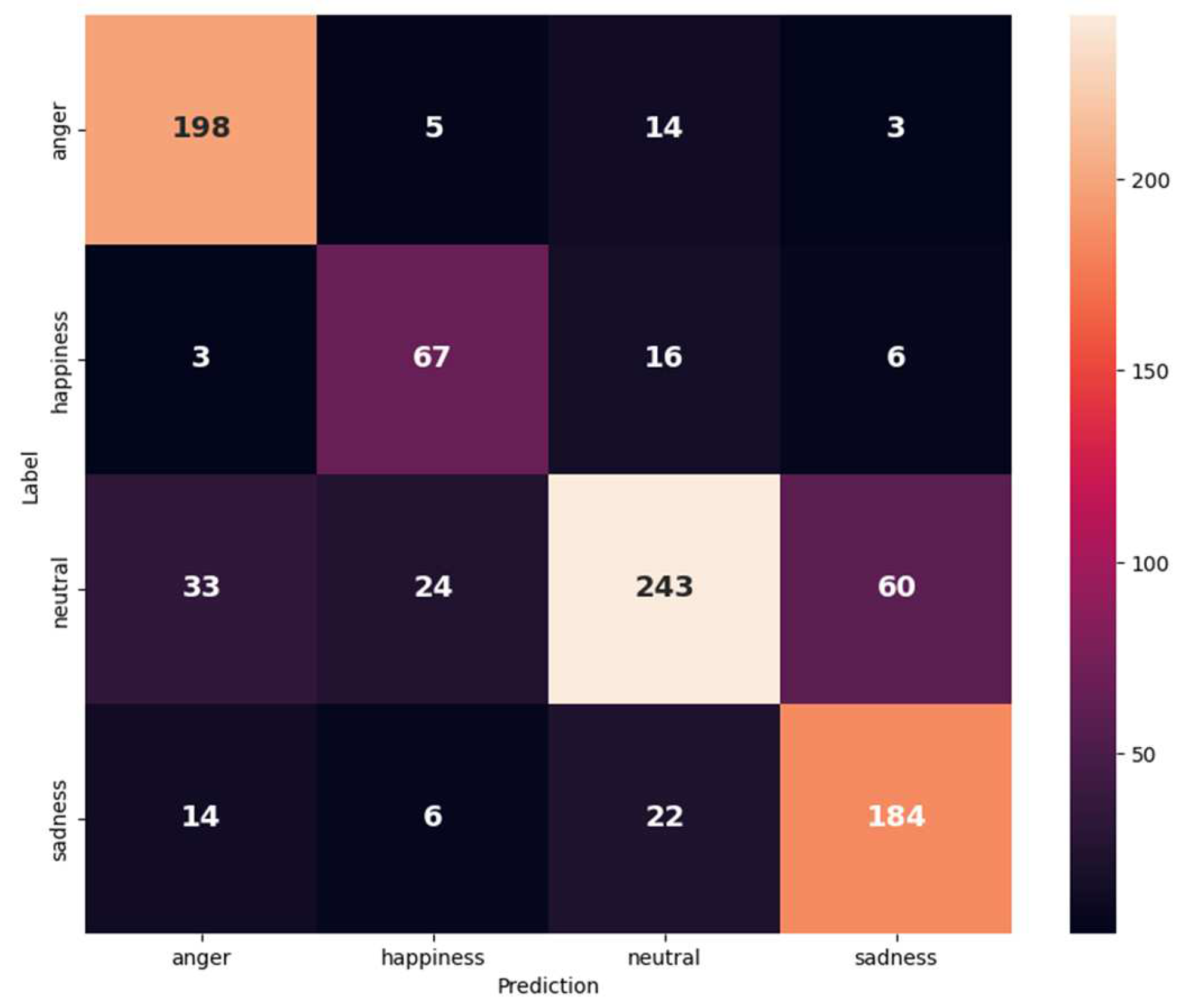
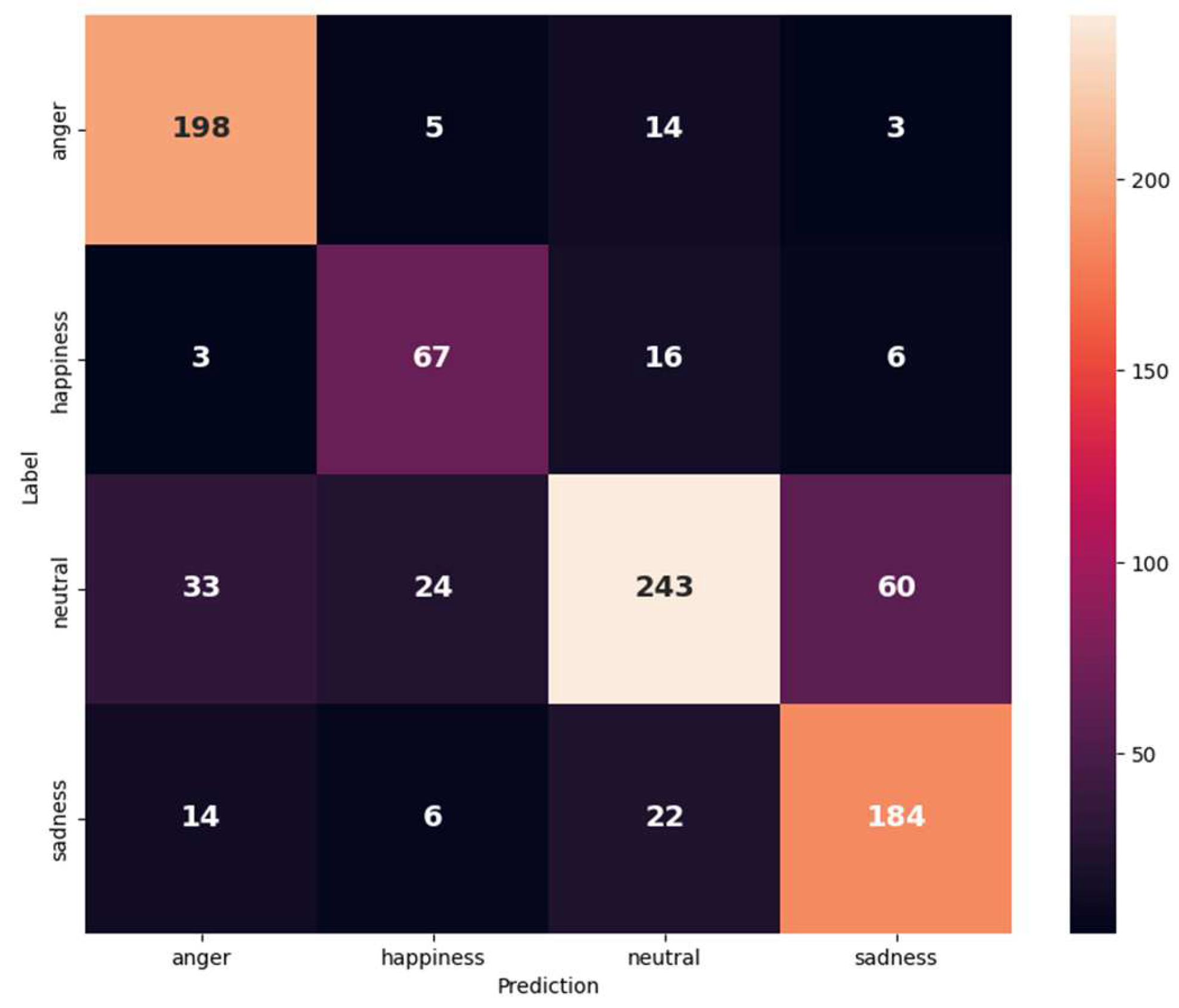
Figure 6.
Confusion matrix for IEMOCAP (anger, happiness, neutral, and sadness) on the text and audio modalities.
Figure 6.
Confusion matrix for IEMOCAP (anger, happiness, neutral, and sadness) on the text and audio modalities.
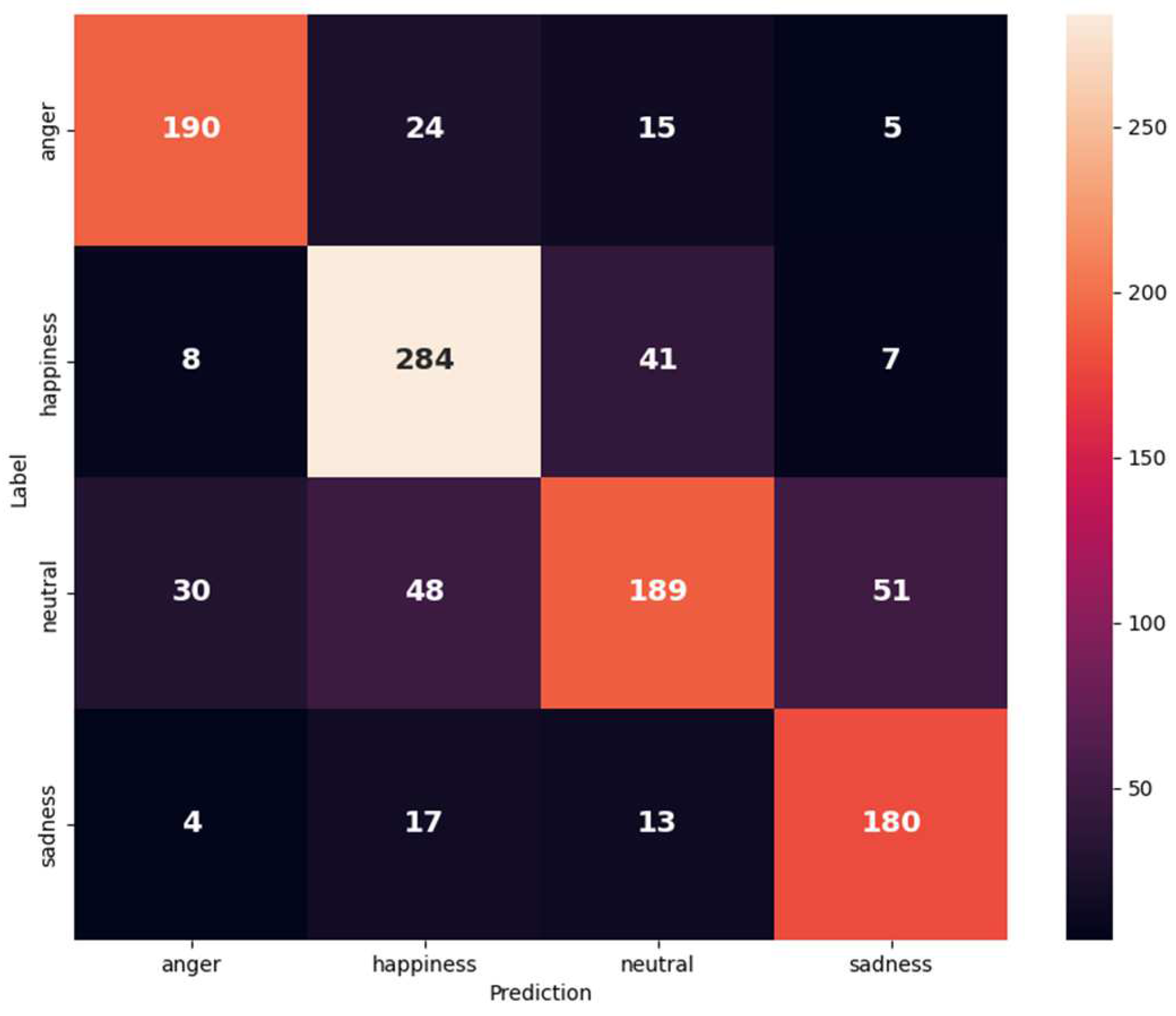
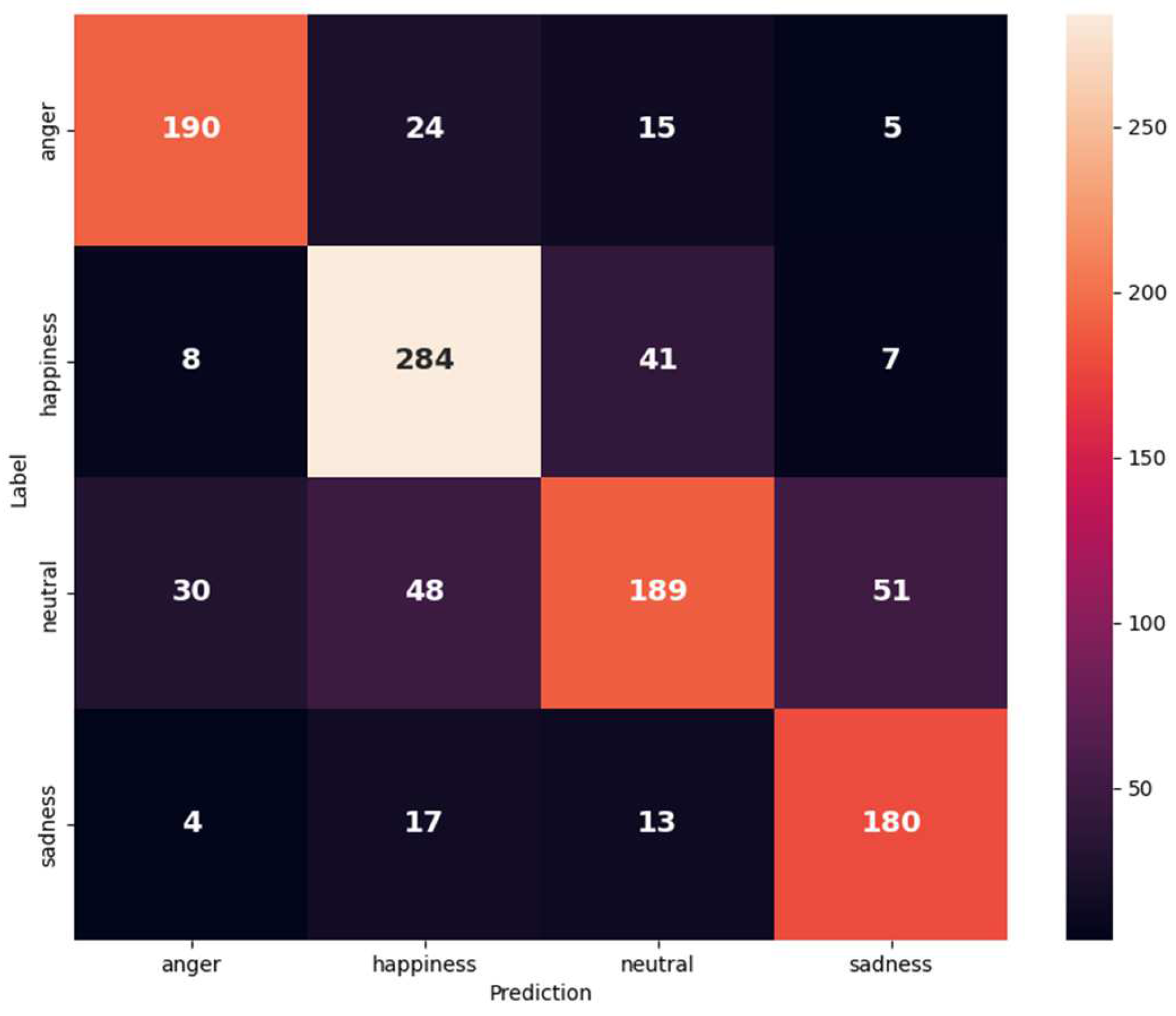
Figure 7.
Confusion matrix of IEMOCAP (anger, happiness merged with excitement, neutral, and sadness) on the text and audio modalities.
Figure 7.
Confusion matrix of IEMOCAP (anger, happiness merged with excitement, neutral, and sadness) on the text and audio modalities.
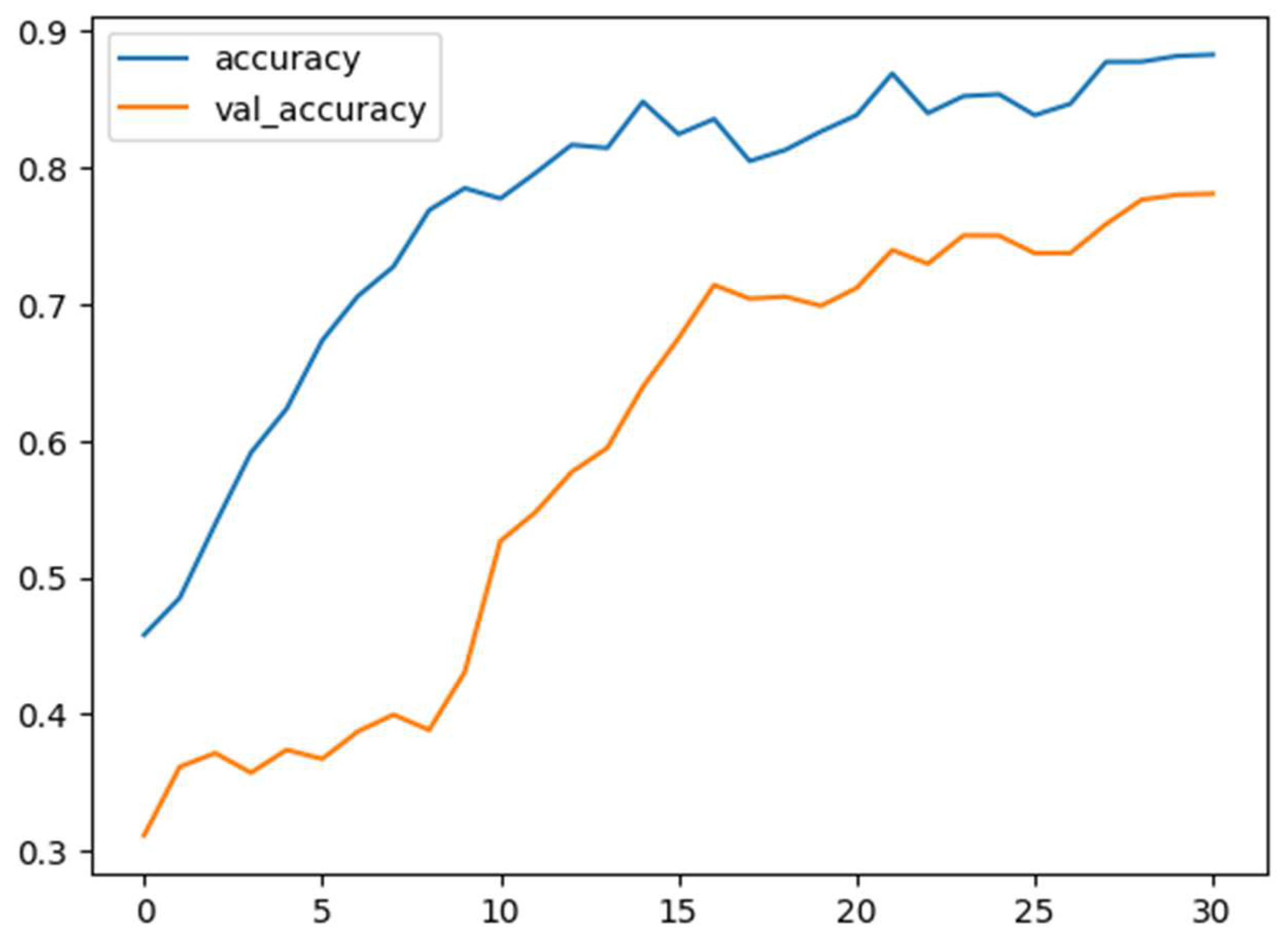
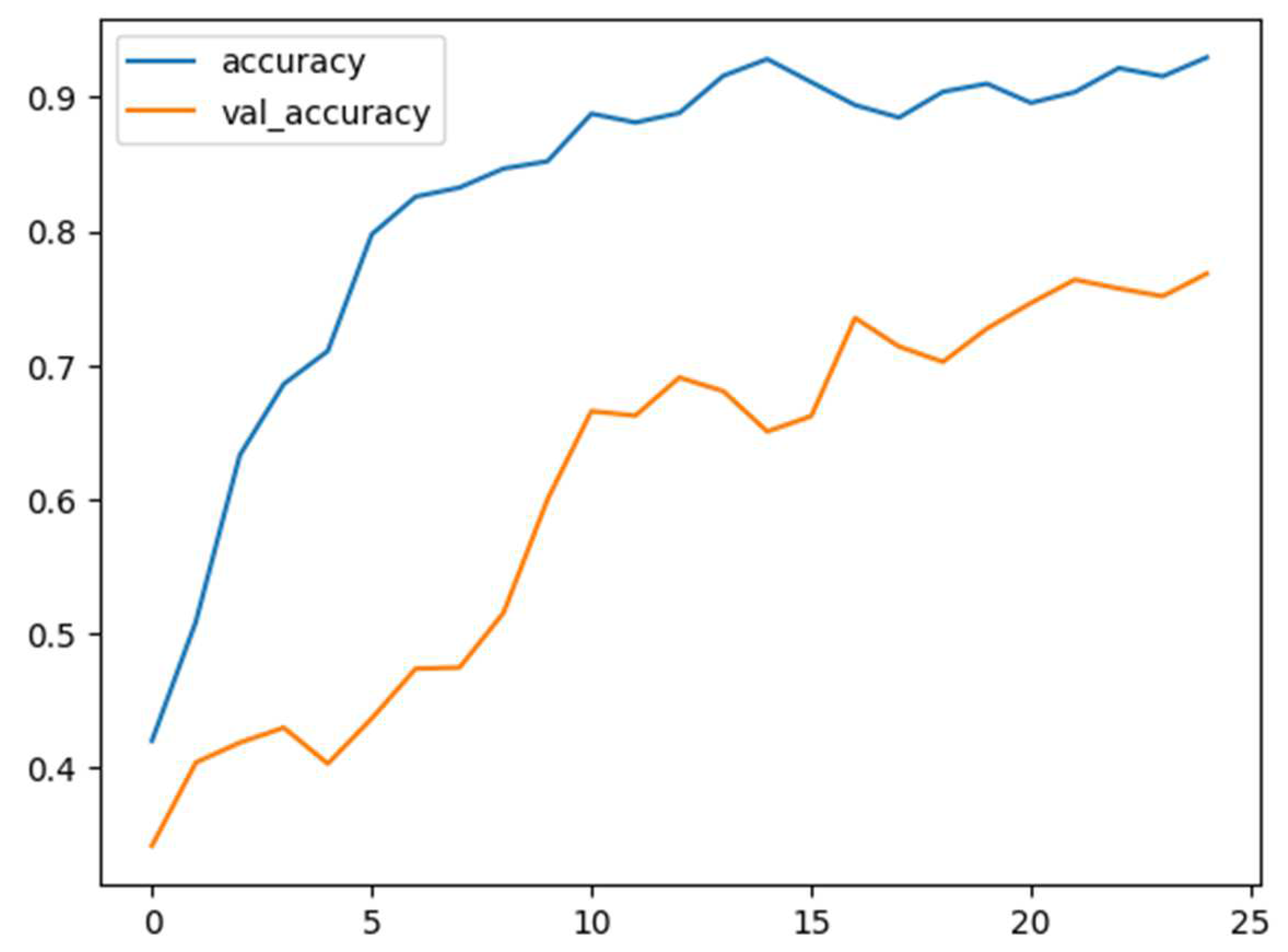
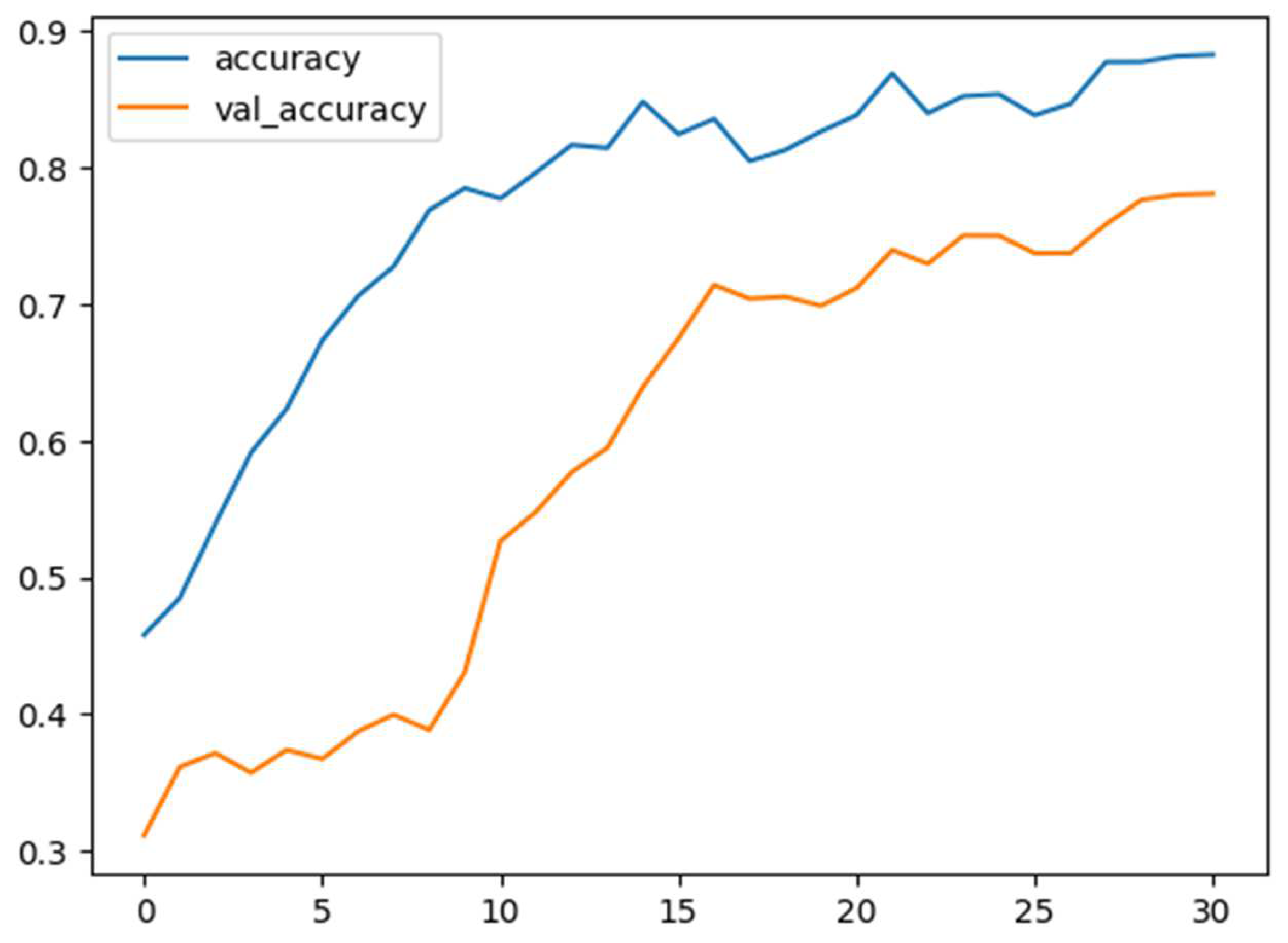
Figure 8.
Training and validation accuracy versus epochs in happiness, anger, sadness, and neutral classes of IEMOCAP.
Figure 8.
Training and validation accuracy versus epochs in happiness, anger, sadness, and neutral classes of IEMOCAP.
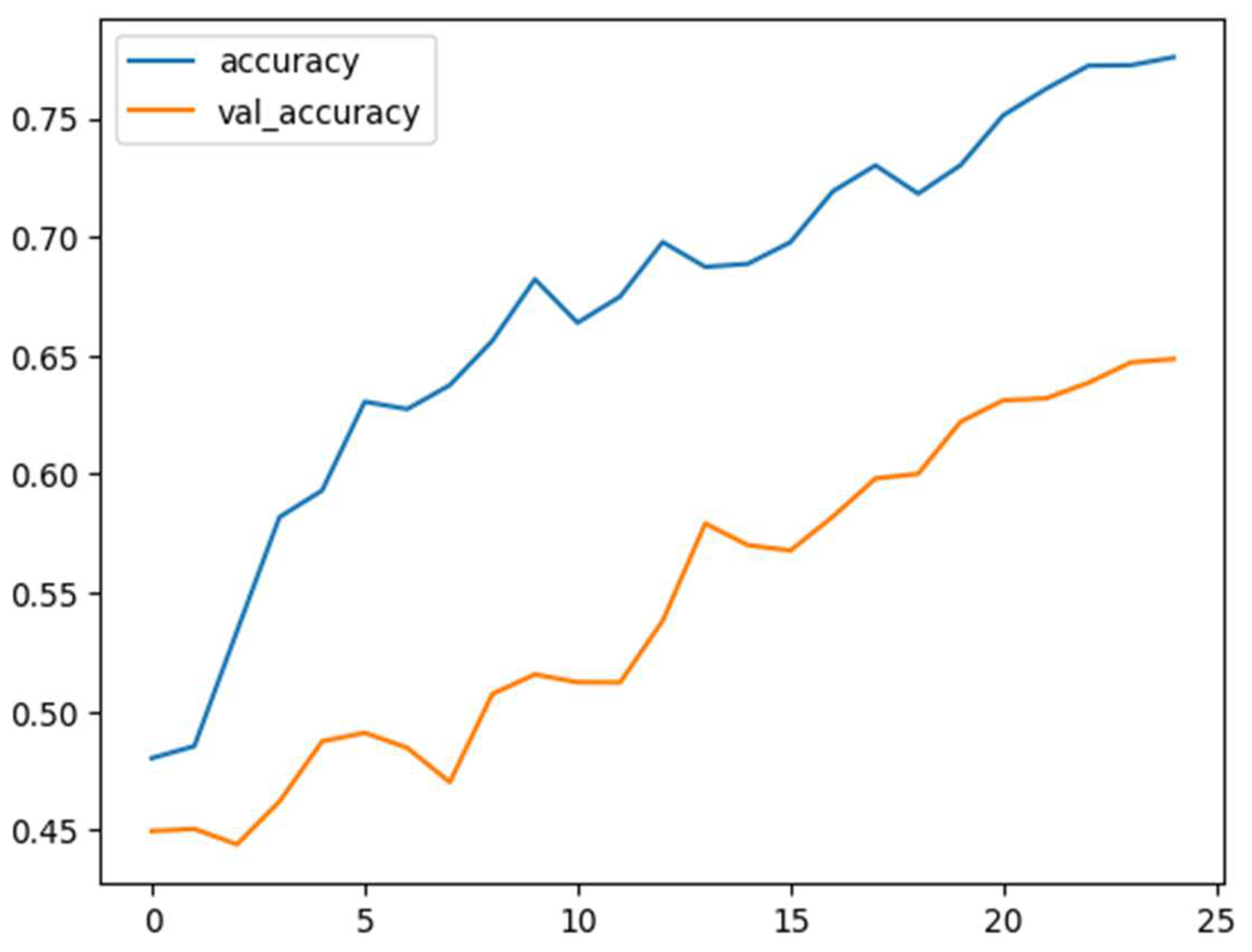
Figure 9.
Training and validation accuracy versus epochs in happiness merged with excitement, anger, sadness, and neutral classes of IEMOCAP.
Figure 9.
Training and validation accuracy versus epochs in happiness merged with excitement, anger, sadness, and neutral classes of IEMOCAP.
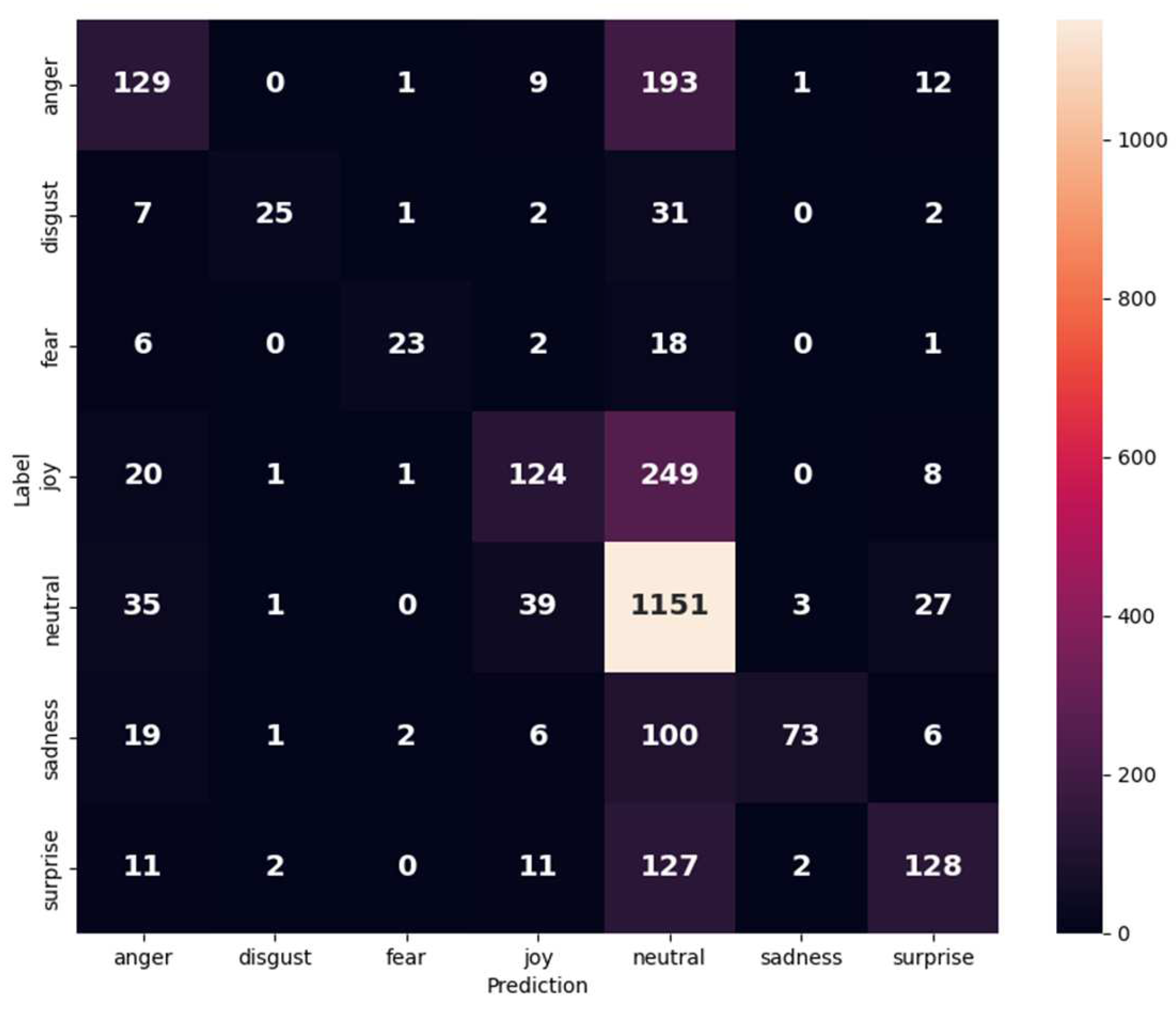
Figure 10.
Confusion matrix of the MELD dataset.
Figure 10.
Confusion matrix of the MELD dataset.
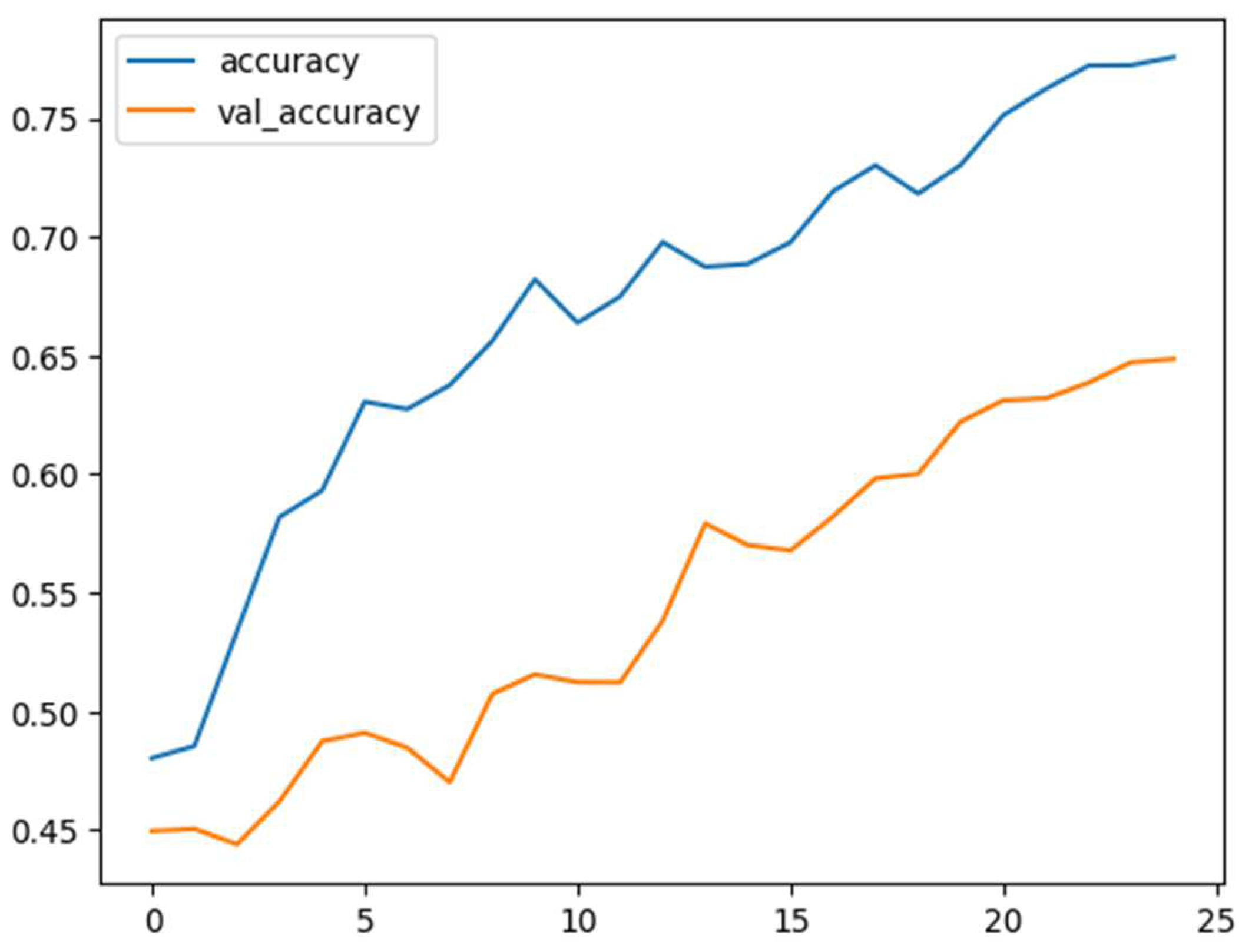
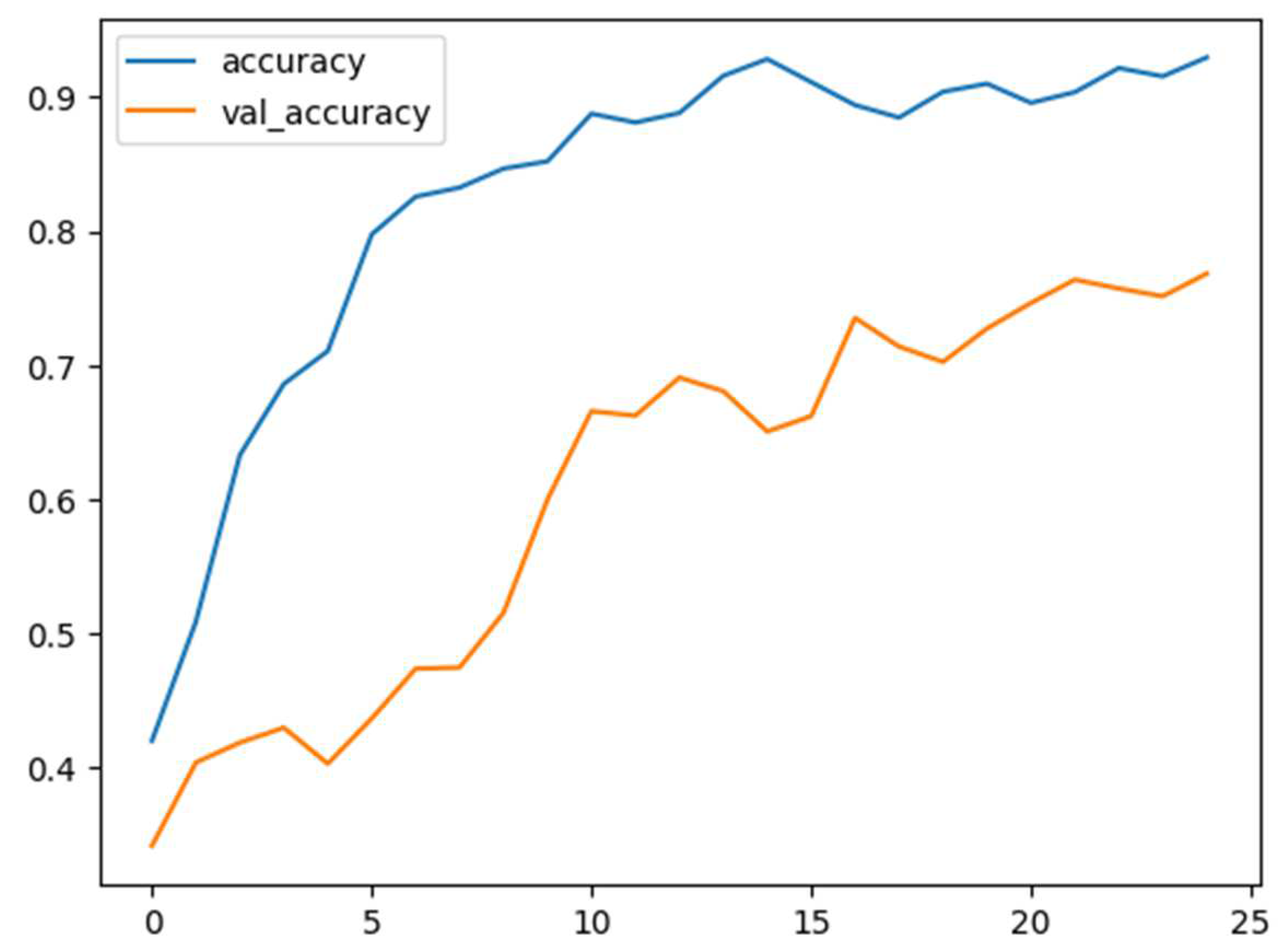
Figure 11.
Training and validation accuracy versus epochs in MELD.
Figure 11.
Training and validation accuracy versus epochs in MELD.
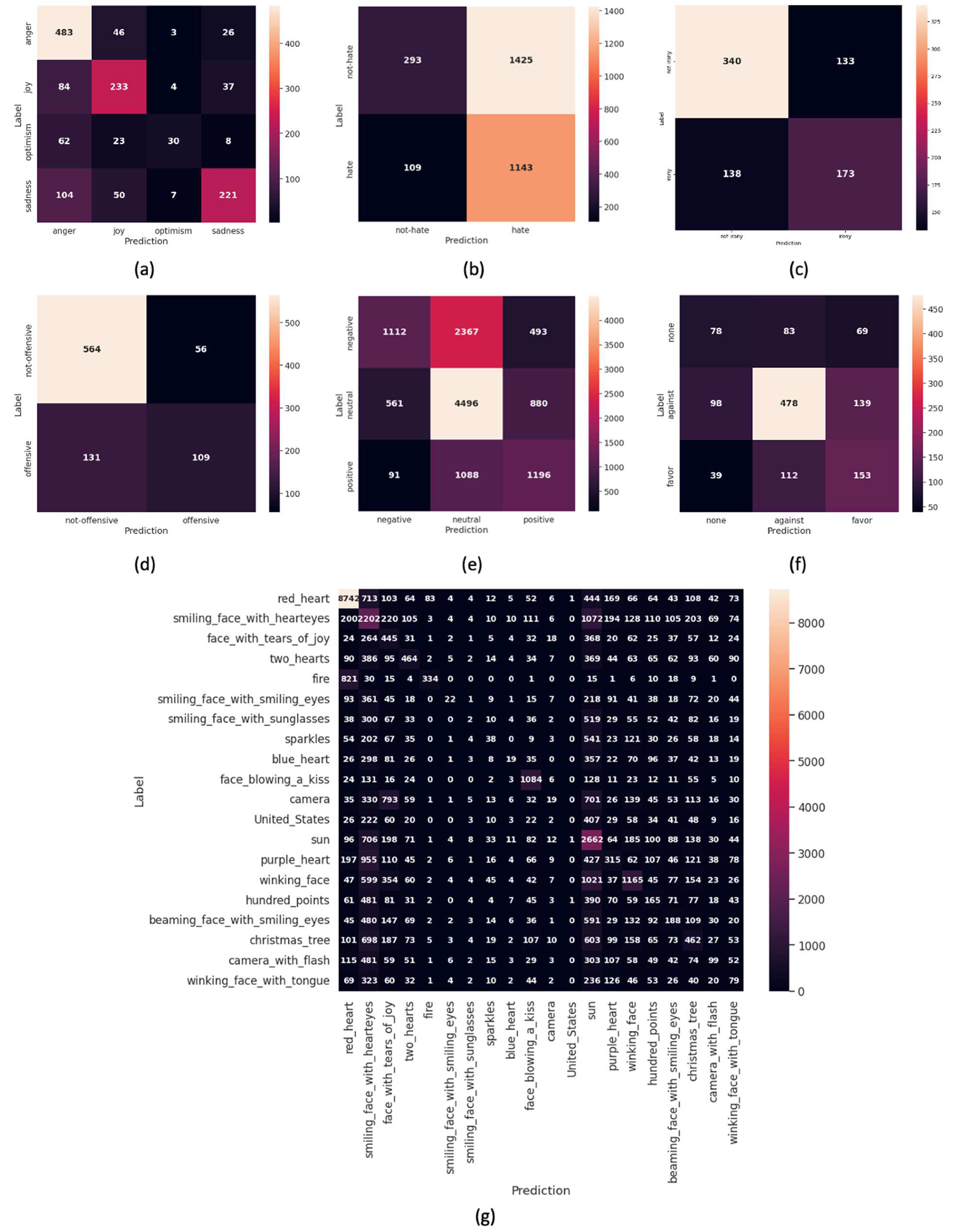
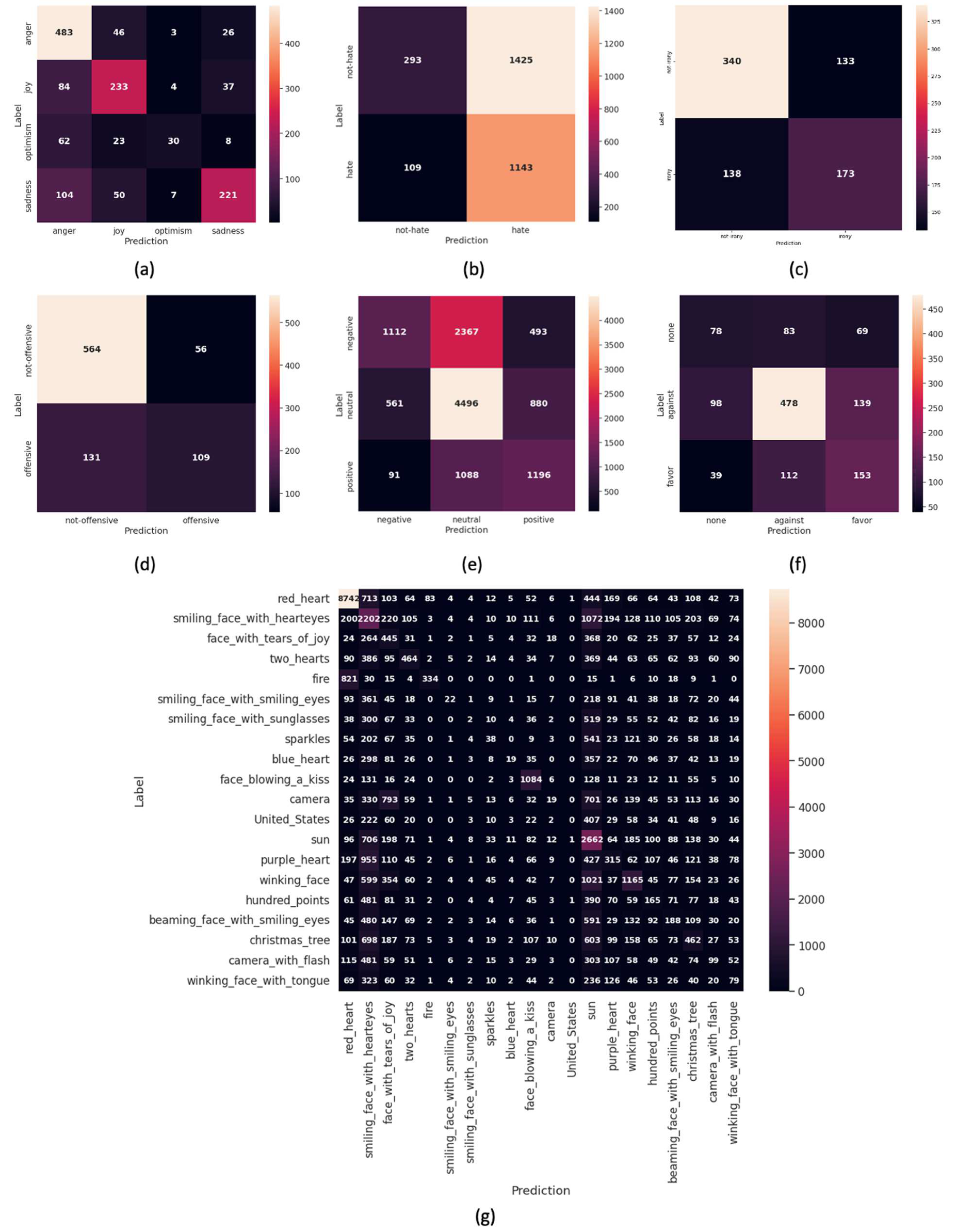
Figure 12.
Confusion matrix for (a) emotion, (b) hate, (c) irony, (d) offensive, (e) sentiment, (f) stance, and (g) emoji in the Tweeteval dataset.
Figure 12.
Confusion matrix for (a) emotion, (b) hate, (c) irony, (d) offensive, (e) sentiment, (f) stance, and (g) emoji in the Tweeteval dataset.
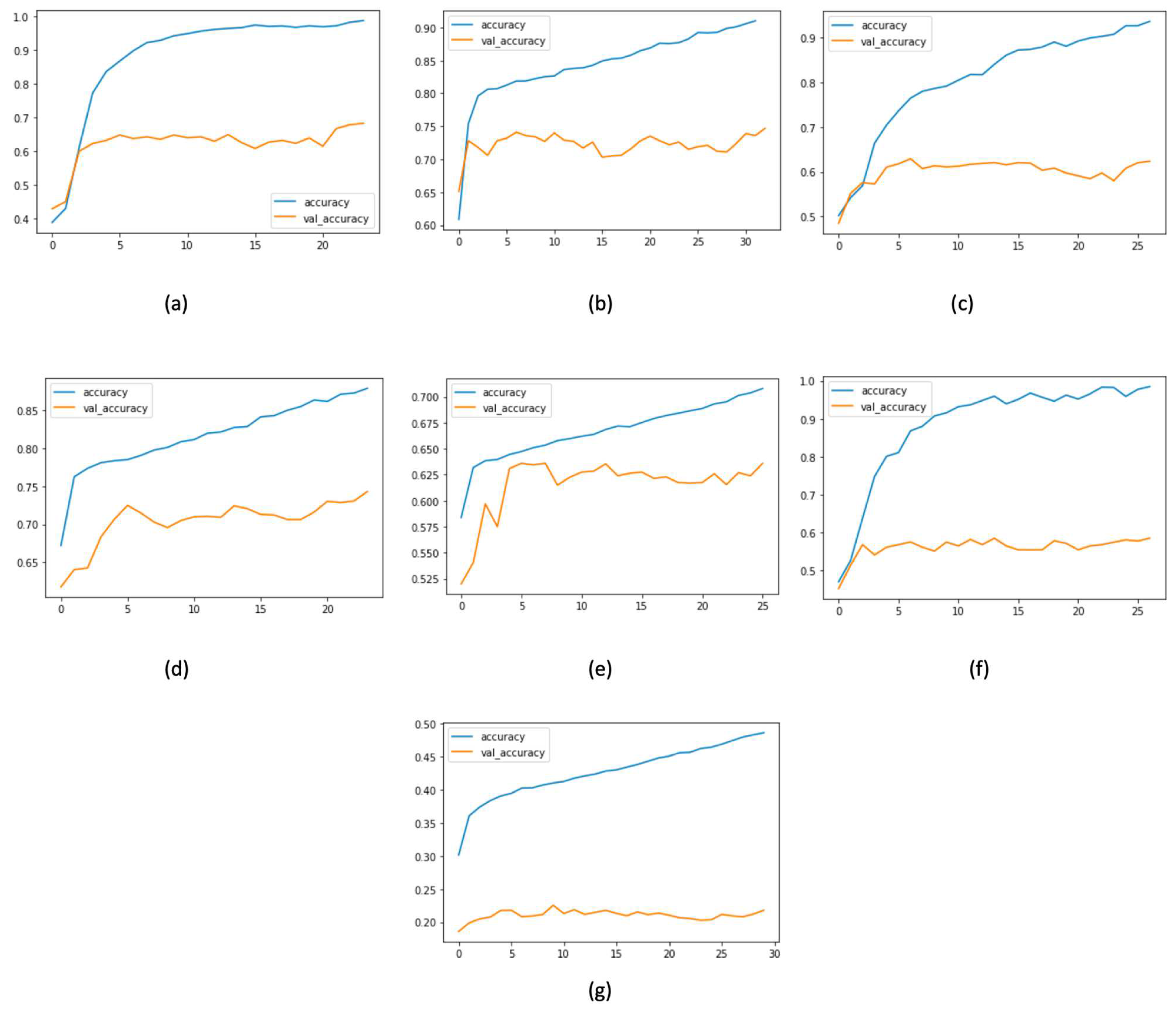
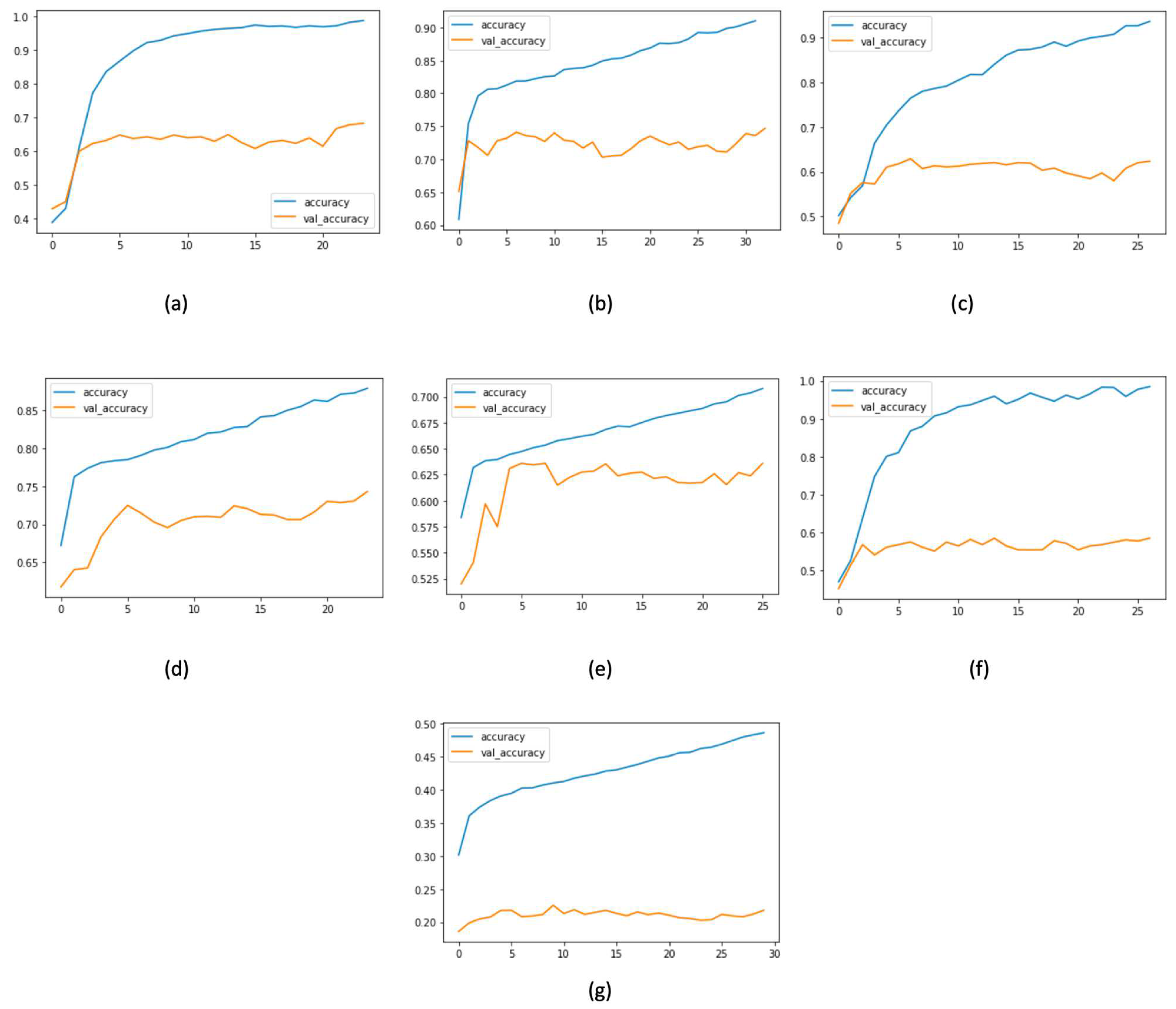
Figure 13.
Training and validation accuracy versus epochs in (a) emotion, (b) hate, (c) irony, (d) offensive, (e) sentiment, (f) stance, and (g) emoji tasks in the Tweeteval dataset.
Figure 13.
Training and validation accuracy versus epochs in (a) emotion, (b) hate, (c) irony, (d) offensive, (e) sentiment, (f) stance, and (g) emoji tasks in the Tweeteval dataset.
Table 1.
Tweeteval dataset stratification for the used classes.
Table 1.
Tweeteval dataset stratification for the used classes.
| Task | Number of Classes | Train | Val | Test |
|---|
| Emotion | 4 | 3257 | 374 | 1421 |
| Hate | 2 | 9000 | 1000 | 2970 |
| Irony | 2 | 2862 | 955 | 784 |
| Offensive | 2 | 11,916 | 1324 | 860 |
| Sentiment | 3 | 45,389 | 2000 | 11,906 |
| Stance | 3 | 2620 | 294 | 1249 |
| Emoji | 20 | 45,000 | 5000 | 50,000 |
Table 2.
IEMOCAP dataset stratification for the used classes.
Table 2.
IEMOCAP dataset stratification for the used classes.
| Classes | Happiness | Anger | Sadness | Neutral |
|---|
| Happiness, anger, sadness, and neutral | 595 | 1103 | 1084 | 1708 |
| Happiness + excitement, anger, sadness, and neutral | 1636 | 1103 | 1084 | 1708 |
Table 3.
MELD dataset stratification for the used classes.
Table 3.
MELD dataset stratification for the used classes.
| Classes | Surprise | Neutral | Fear | Joy | Sadness | Disgust | Anger |
|---|
| Train | 1205 | 4710 | 268 | 1743 | 683 | 271 | 1109 |
| Test | 281 | 1256 | 50 | 402 | 208 | 68 | 345 |
| Validation | 150 | 470 | 40 | 163 | 111 | 22 | 153 |
Table 4.
Classification report results for the IEMOCAP (anger, happiness, neutral, and sadness) on the text and audio modalities in the function of (precision, recall, and F1-score).
Table 4.
Classification report results for the IEMOCAP (anger, happiness, neutral, and sadness) on the text and audio modalities in the function of (precision, recall, and F1-score).
| Classes | Precision | Recall | F1-score |
|---|
| Anger | 0.90 | 0.80 | 0.85 |
| Happiness | 0.73 | 0.66 | 0.69 |
| Neutral | 0.68 | 0.82 | 0.74 |
| Sadness | 0.81 | 0.73 | 0.77 |
Table 5.
Classification report results for the IEMOCAP (anger, happiness merged with excitement, neutral, and sadness) on the text and audio modalities in the function of (precision, recall, and F1-score).
Table 5.
Classification report results for the IEMOCAP (anger, happiness merged with excitement, neutral, and sadness) on the text and audio modalities in the function of (precision, recall, and F1-score).
| Classes | Precision | Recall | F1-score |
|---|
| Anger | 0.81 | 0.82 | 0.82 |
| Happiness | 0.84 | 0.76 | 0.80 |
| Neutral | 0.59 | 0.73 | 0.66 |
| Sadness | 0.84 | 0.74 | 0.79 |
Table 6.
Accuracy results of the IEMOCAP dataset.
Table 6.
Accuracy results of the IEMOCAP dataset.
| Classes | UA | WA |
|---|
| Happiness, anger, sadness, and neutral | 0.7706 | 0.7792 |
| Happiness + excitement, anger, sadness, and neutral | 0.7622 | 0.7705 |
Table 7.
Classification report results for the MELD on the text and audio modalities in the function of precision, recall, and F1-score and accuracy of the model.
Table 7.
Classification report results for the MELD on the text and audio modalities in the function of precision, recall, and F1-score and accuracy of the model.
| Classes | Precision | Recall | F1-score | Accuracy |
|---|
| Anger | 0.37 | 0.57 | 0.45 | |
| Disgust | 0.37 | 0.83 | 0.51 | |
| Fear | 0.46 | 0.82 | 0.59 | |
| Joy | 0.31 | 0.64 | 0.42 | 0.6333 |
| Neutral | 0.92 | 0.62 | 0.74 | |
| Sadness | 0.35 | 0.92 | 0.51 | |
| Surprise | 0.46 | 0.70 | 0.55 | |
Table 8.
Classification report results for the Tweeteval on the text and audio modalities in the function of precision, recall, and F1-score and accuracy of the model.
Table 8.
Classification report results for the Tweeteval on the text and audio modalities in the function of precision, recall, and F1-score and accuracy of the model.
| Task | Average Precision | Average Recall | Average F1 Score | Accuracy |
|---|
| Emotion | 0.59 | 0.69 | 0.61 | 0.6806 |
| Hate | 0.54 | 0.59 | 0.44 | 0.4835 |
| Irony | 0.64 | 0.64 | 0.64 | 0.6543 |
| Offensive | 0.68 | 0.74 | 0.7 | 0.7826 |
| Sentiment | 0.51 | 0.56 | 0.51 | 0.5539 |
| Stance | 0.5 | 0.5 | 0.5 | 0.5677 |
| Emoji | 0.22 | 0.27 | 0.21 | 0.3701 |
Table 9.
Comparison of our proposed approach with state-of-the-art (anger, happiness, neutral, and sadness) classes on the IEMOCAP dataset.
Table 9.
Comparison of our proposed approach with state-of-the-art (anger, happiness, neutral, and sadness) classes on the IEMOCAP dataset.
| Methods | UA | WA |
|---|
| H.Xu et al. [12] | 0.709 | 0.725 |
| Guo et al. [10] | 0.725 | 0.719 |
| Zaidi et al. [20] | 0.756 | - |
| Ours (Chromagram) | 0.761 | 0.769 |
| Ours (Mel spectrogram) | 0.766 | 0.775 |
| Huddar et al. [14] | 0.766 | - |
| Wang et al. [37] | 0.77 | 0.765 |
| Ours | 0.771 | 0.779 |
Table 10.
Comparison of our proposed approach with state-of-the-art (anger, happiness merged with excitement, neutral, and sadness) classes on the IEMOCAP dataset.
Table 10.
Comparison of our proposed approach with state-of-the-art (anger, happiness merged with excitement, neutral, and sadness) classes on the IEMOCAP dataset.
| Methods | UA | WA |
|---|
| S. Sahoo et al. [38] | 0.687 | - |
| H. Feng et al. [39] | 0.697 | 0.686 |
| S. Tripathi et al. [13] | 0.697 | - |
| Ours (Chromagram) | 0.744 | 0.753 |
| Kumar et al. [17] | 0.750 | 0.717 |
| Ours (Mel spectrogram) | 0.759 | 0.767 |
| Setyono et al. [40] | 0.76 | 0.76 |
| Ours | 0.762 | 0.771 |
Table 11.
Comparison of our proposed approach with state-of-the-art MELD dataset.
Table 11.
Comparison of our proposed approach with state-of-the-art MELD dataset.
| Methods | Accuracy |
|---|
| Wang et al. [19] | 0.481 |
| Guo et al. [10] | 0.548 |
| Wang et al. [41] | 0.558 |
| Ours (Chromagram) | 0.588 |
| Ours (Mel spectrogram) | 0.592 |
| Lian et al. [42] | 0.62 |
| Ho et al. [43] | 0.632 |
| Ours | 0.633 |
Table 12.
Comparison of our proposed approach with state-of-the-art Tweeteval dataset.
Table 12.
Comparison of our proposed approach with state-of-the-art Tweeteval dataset.
| Methods | Emotion | Hate | Irony | Offensive | Sentiment | Stance | Emoji |
|---|
| Li et al. [1] | 0.6770 | 0.5950 | 0.6667 | 0.7371 | 0.6143 | 0.6756 | 0.1907 |
| Ours | 0.6806 | 0.4835 | 0.6543 | 0.7826 | 0.5539 | 0.5677 | 0.3701 |







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}