1. Introduction
As the digital world advances, there has been an increase in the number of day-to-day interactions over proliferating forms of communication, including newer, nuanced products such as Siri, Alexa, and Google Assistant, known as virtual personal assistants (VPA), and the internet of things (IoTs) applications [
1,
2]. The two key drivers of the digital revolution are Moore’s Law—the exponential increase in computing power and solid-state memory, and the substantial progress in enhancing communication bandwidth [
3]. This, in fact, has raised the expectations and demands of customers. As customers become more adept and demand higher quality products and services, it is becoming a challenge to keep evolving customer expectations satisfied. Technology has played a major role in the evolution of customer demands, since it has ushered in and fostered the ‘instant gratification’ culture. Customers are better informed, with easy access to information, and are able to gain access instantly from anywhere.
With the growing advancement and adoption of technology, new opportunities and challenges arise and sentiment analysis becomes an even more important subject. For businesses, it has become vital to understand their customers’ thoughts, feelings, and behaviors, in order to better model their strategy and align their offerings accurately with customer demands. Advances in machine learning (ML) have improved bimodal (employs more than one data modality) and multimodal (employs more than two data modalities) sentiment analysis substantially [
4,
5]. Detecting bimodal sentiment can be an essential aspect of many applications, mostly in contact centers (CCs), which are the first point of contact with organizations for most customers. Although very few studies have addressed the detection and analysis of bimodal sentiment in CC conversations, interest in this area is steadily gaining traction from vertical organizations and the NLP community at large, to analyze CC conversations that take place on different communication channels [
6,
7]. However, the data produced in CCs are in the form of unstructured data that cannot be fed into an algorithm directly. Compounded with the fact that NLP is nuanced and subjective, the problem becomes much more difficult to solve.
The two primary research areas in bimodal sentiment analysis are (1) how to represent data modalities and (2) how to fuse them together. The recommendation for the former is that a good representation of raw data should capture sentiment features that can be generalized over distinctive semantic content. For the latter purpose, it is recommended to have a fusion mechanism that effectively combines audio and text representations [
8]. To represent text and audio data modalities, various low-level features, often referred to as low-level descriptors (LLDs), have been employed previously, such as Word2Vec, GloVe, Mel-frequency cepstral coefficients (MFCC), log-frequency power coefficients (LFPC), energy, pitch, and log-Mel-spectrograms [
9,
10,
11,
12,
13]. These features have been mostly used as input to models such as long short term memory (LSTM), convolutional neural networks (CNNs), hidden Markov models (HMMs), recurrent neural networks (RNNs), and deep neural networks (DNNs). Most of the prior work used both low-level features and features extracted from deep learning (DL) models [
14,
15,
16,
17,
18,
19,
20,
21].
In contrast to previous work, this study shows the significance of pretrained model representations of two modalities (audio and text). We also evaluate the performance of the models following the fusion of text and audio embeddings. The main contribution is the use of the ensemble learning technique, where multiple classifiers are combined using various techniques to establish a well-trained single classifier. Ensemble techniques have demonstrated better performance in diverse classification tasks [
22]. This is attributed to their ability to combine the predictions of multiple models, thereby reducing the impact of individual model errors and biases [
23]. Ensemble techniques are also flexible in terms of training and updating classifiers, which allows them to adapt to changing data patterns and improve over time [
24]. Numerous studies have demonstrated the superiority of ensemble techniques over individual classifiers in various domains. For example, in a study on the classification of gene expression data, an ensemble of support vector machines (SVMs) outperformed individual SVMs and other popular classification methods, achieving higher accuracy and stability across different datasets [
25]. Another study, on land use/land cover classification, showed that a hybrid ensemble of decision trees and SVMs achieved higher accuracy than individual classifiers and other ensemble methods [
26].
Furthermore, ensemble techniques have been applied successfully in various real-world applications, such as intrusion detection in network security [
27], diagnosis of breast cancer [
28], and prediction of stock prices [
24]. In real-world applications, models often encounter multiple orientations and other language nuances that can be difficult for individual classifiers to capture accurately. One of the key advantages of ensemble techniques is their ability to handle noisy and ambiguous data, which helps in identifying complex patterns in large volumes of data. By combining the predictions of multiple classifiers, ensemble methods can reduce the impact of such noise and improve overall accuracy. Ensemble techniques also provide a flexible framework for incorporating new data and updating the model over time. As new data becomes available, ensemble methods can adapt and re-weight the base classifiers to better capture the changing sentiment trends and dynamics in the data [
29,
30]. This adaptability is particularly useful in sentiment analysis applications that involve analyzing social media streams, where the sentiment can change rapidly in response to events and trends. The aforementioned advantages demonstrate the flexibility and effectiveness of ensemble techniques in solving today’s complex classification problems of bimodal sentiment analysis.
The study seeks to achieve the following:
Compare multiple pretrained text model representations—BERT, ALBERT, and RoBERTa.
Compare multiple pretrained audio model representations—2D CNN and Wav2Vec 2.0.
Among the models that are tested, conduct an analysis of potential models to be incorporated in the bimodal approach and compare the performance of individual models, with a bimodal strategy.
To further improve the accuracy of their analysis, our proposed ensemble learning technique will be employed to combine multiple models and minimize the impact of individual model errors and biases.
The study aims to enhance our understanding of how emotions are expressed in conversations and improve the reliability of sentiment analysis methods in real-world applications. The study argues that the proposed approach can better handle noisy and ambiguous data, adapt to changing sentiment trends and dynamics, and improve overall accuracy, making it a valuable contribution to the field of sentiment analysis. The MELD dataset was chosen as the primary data source for this study, as it was considered to be a suitable alternative to real-world conversations due to its similarity in structure and content. The rest of this paper is organized as follows:
Section 2 presents an overview of related research;
Section 3 details our methodology;
Section 4 and
Section 5 outline the experimental setup and results, and draw up a comparison of the state-of-the-art methods used, including the ensemble learning method presented in this paper;
Section 6 presents the conclusions and outlines possible future work.
2. Related Work
In this section, we first introduce and briefly discuss the feature extraction approaches used in bimodal sentiment analysis. The theory underlying the models used in this research is then introduced and discussed. Finally, we highlight work closely related to the sentiment classification task associated with data from multiple modalities, specifically sentiment analysis in conversations, particularly the architecture and fusion approaches employed.
2.1. Feature Extraction Approaches
The majority of studies have used a mix of low-level and deep features for bimodal sentiment analysis. The algorithms employed in bimodal sentiment analysis usually involve both feature extraction and fusion methods, since the data vary fundamentally in terms of origin, sequence, and mechanism. This section provides an overview of the various feature extraction approaches used previously.
2.1.1. Low-Level Features
Acoustic features can be broadly classified into two categories: time-domain features and frequency-domain features. Time-domain features include the short-term energy of the signal, zero-crossing rate, maximum amplitude, minimum energy, and entropy of energy [
31]. These sets of features are computationally efficient and provide useful information for detecting certain types of acoustic events [
31,
32]. However, they have limited discriminative power and do not capture higher-level features [
33,
34]. Where there is limited data, frequency-domain features reveal deeper patterns in the audio signal, which can potentially help in identifying the emotion underlying the signal [
1,
35]. Frequency-domain features include spectrograms, MFCCs, spectral centroid, spectral roll-off, spectral entropy, and chroma coefficients. LFPC can be classified as both time- and frequency-domain features [
31]. Frequency-domain features capture fine-grained information about the frequency content of the speech signal, provide useful information for detecting certain types of acoustic events, and can capture phonetic and phonological information [
31,
32]. However, they are computationally expensive, sensitive to noise reverberation, and may require careful normalization and parameter tuning [
33,
34]. The selection of low-level features for speech analysis depends on the specific task and characteristics of the speech signal. Time-domain features may be useful in detecting speech in noisy environments, while frequency-domain features may be more informative for analyzing prosodic features of speech. Works that have used low-level features include [
1,
12,
35,
36,
37,
38].
For text-based features, traditional Word2Vec-based models such as continuous bag of words (CBOW), Skipgram, GloVe, and ELMo have been previously used [
10,
39,
40,
41]. Contrary to other studies, ref. [
42] proposed a network-based pattern analysis approach to extract more salient insights from Reddit textual data. More recently, transformer encoder-only models have become a popular choice, due to their ability to capture meaningful features for text classification tasks [
43].
2.1.2. Deep Features
The features extracted using pretrained DL models are referred to as deep features. Typically, these models are initially trained with one, or more than one, large annotated dataset. In previous research works, pretrained models have been used to extract speech and textual features for the task of sentiment analysis [
35,
43,
44,
45,
46]. Such works suggest that deep features can be a better choice in terms of accuracy when compared to low-level features. Similarly, BERT, GPT, and ELMo models have been used to extract deep features for various text classification tasks, including sentiment analysis, topic modeling, and named entity recognition. For instance, in [
47], pretrained BERT features were used for text classification in the medical domain, and in [
48], pretrained GPT-2 features were used for sentiment analysis. In [
49], pretrained WaveNet features were used for speech recognition in noisy environments, and in [
50], pretrained transformer features were used for sentiment analysis of spoken language. Deep features have demonstrated superior performance in numerous domains in comparison to other types of features. Their popularity for feature extraction is on the rise due to their capacity to learn significant representations more effectively [
51,
52,
53,
54,
55].
2.2. Summary of Models Used in Bimodal Sentiment Analysis
Following our extensive research, we shortlisted three models for this research. We fine-tuned the models, which involved feature extraction, training, and evaluation for each data modality.
2.2.1. RoBERTa
The robustly optimized BERT approach (RoBERTa) is a pretrained language model, an extension of the original BERT model, which has shown substantially better results according to the general language understanding evaluation (GLUE) benchmark for evaluating natural language understanding systems [
43,
56,
57]. The key difference between BERT and RoBERTa is in the training phase of the model. It does not rely on next-sentence prediction and masking is performed during the training time, as opposed to during the data preparation time for BERT. The ’RoBERTa-base’ version of the model is downloaded using the transformers library that loads the model from the open-source repository. The model version used has 110 M parameters and has been pretrained on a larger English language dataset of 160 GB. With its 24-layer encoder architecture, longer sequences can be used as input [
56]. However, the maximum number of tokens remains limited to 512 tokens, similar to the limit for BERT, which is then mapped to an embedding size of 1024 [
8].
2.2.2. Wav2Vec 2.0
Wav2Vec 2.0 is one of the current SOTA models pretrained in a self-supervised setting, similar to BERT’s masked language modeling [
58,
59]. The architecture is made up of two convolutional neural networks; encoder and context networks. The encoder network
takes input raw audio samples
and outputs low-frequency feature representations
, which encode about 30 ms of 16 kHz audio every 10 ms. The context network
converts these low-frequency representations into a higher-level contextual representation
for a receptive field
v [
60,
61]. The overall receptive field, after passing through both networks, is 210 ms for the base version and 810 ms for the large version. The main aim of this model, as reported in their first paper, is to improve automatic speech recognition (ASR) performance with fewer labeled training data and enable its use for low-resource languages. The model consists of 35 M parameters and was pretrained on 960 h of unannotated speech data from the LibriSpeech benchmark audiobooks data [
62]. The authors set the embedding size to 512 and the maximum audio waveform length to 9.5 s.
2.2.3. 2D CNN
Over the years, convolution neural networks (CNNs) have made substantial progress in image recognition tasks as they are good at automatically learning useful features from high-dimensional images [
63]. CNNs use shared kernels (weights) to exploit the 2D correlated image data structure. Max pooling is added to CNNs to introduce invariance; thus, only the relevant high-dimensional features are used in classification tasks [
64,
65]. This study explores the assumption that CNNs can work well with audio classification tasks due to the fact that when the log-Mel filter bank is applied to the fast Fourier transform (FFT) representation of raw audio, linearity is produced in the log-frequency axis, allowing a convolution operation to be performed along the frequency axis. Otherwise, different filters (or kernels) would have to be used for different frequency ranges. This property, along with CNN’s good representation power, allows the model to learn the underlying patterns effectively within short time frames, resulting in superior performance [
1,
21,
66]. To put it simply, the intuition here is to consider the audio segments as input images. The CNN layer will identify local contexts by applying
n convolutions over the input audio images along the time axis, and generate sequences of vectors. In our paper, we employed two 2D CNNs—one trained on MFCCs and the other on log-Mel-spectrogram matrices.
2.3. Sentiment Analysis Architecture and Fusion Approaches
Over the years, sentiment analysis research has shifted from analyzing full documents or paragraphs to a finer level of detail—identifying sentiment towards particular phrases or words, audio and visual cues [
7,
67,
68]. Correspondingly, sentiment analysis has gained much more research interest, mainly because of its potential application in dialogue systems to produce sentiment-aware and considerate dialogues [
67]. However, studies using real-life conversational data are scarce. While this area is attracting a plethora of research work focusing on algorithmic aspects, such studies are typically evaluating a selection of datasets and little effort is dedicated to the expansion of the research scope, where bimodal data is explored within the setting of conversational datasets [
6]. In this section, we briefly discuss the previous studies on the two different approaches to data modality sentiment analysis.
2.3.1. Bimodal
The bimodal approach utilizes two modal input representations to judge the sentiment of each utterance. Current bimodal-based approaches are scarce and the few of those who have focused on this have mainly preferred to use textual and acoustic modalities for sentiment analysis tasks.
In [
69], a method was used that statistically combined features with N-grams, sentiment words, and domain-specific words to predict user sentiments. Their work applied a combination of acoustic and linguistic rules through a multi-dimensional model on CC data using SVMs, MaxEnt entropy, and traditional Bayesian as classifiers. The main contribution of their work is the approach they took to incorporate the results from each of the classifiers while also adding language and acoustic rules to the model. The F1 score of their proposed method improved to 69.1%, against the baseline F1 score of 65.4%. In [
35], a novel transfer learning method is proposed to be used when there is training data with as few as 125 examples per emotion class. Their method is comparable to that in our study, as they combine pretrained embeddings for both text and audio. In their experiment, sub-words from BERT-base and wav2vec2-large-960h representations are aligned through an attention-based recurrent neural network. Their method reported better performance compared to previous SOTA and frequently cited works using feature representations such as LLDs and GloVe embeddings and pretrained ASR representations. Correspondingly, both audio and textual pretrained representations were fused through an attention mechanism over a bidirectional recurrent neural network—BiLSTM in [
21]. The audio features extracted were 34-dimensional feature vectors from each frame, including MFCC, and zero-crossing rate, among others, and GloVe embeddings were used as textual features. Several other works explored fusing bimodal information—linguistic and acoustic. In [
18,
46], an approach was adopted to combine utterance-level audio and textual embeddings before the softmax classification layer. In [
44], a different approach was followed, which used pretrained representation from an ASR model with semantic information.
Another study, which was distinct yet relatable to our work, explored the classification of psychiatric illnesses, initially through single data modality (audio and text) and then through hybridization of both modalities [
13]. Text features from the RoBERTa model and speech features including MFCC were used. In their hybrid model, a “late fusion” approach was highlighted with a fully connected neural network layer to map the outputs from both models. Their results indicated that their proposed hybrid text model outperformed the single data modality models.
Table 1 provides a summary of bimodal sentiment analysis studies.
2.3.2. Multimodal
Multimodal methods detect sentiments in conversations through analysis of more than two modal input representations. As the information contained in unimodal data can often be biased and interfered with by external noise factors, researchers on multimodal sentiment analysis tasks are receiving widespread attention for their unique approaches to combining different modalities [
70]. Although multimodal sentiment analysis is not the scope of this paper, key lessons have been drawn from the studies mentioned in this section.
A wide range of work has been conducted previously, and researchers have proposed models based on DNNs, RNNs, CNNs, and LSTMs over multiple data modalities [
71,
72,
73] with varying fusion techniques [
74,
75,
76,
77,
78,
79]. Recently, the effectiveness of novel DL architectures, such as transformers [
80] and graph convolution nets [
15], as fusion methods have been explored and highlighted as computationally efficient. In [
81], BERT-based self-supervised learning (SSL) features were used for text, while other modalities were represented with low-level features, and fusion mechanisms were based on RNN and self attention. In the work of [
8], pretrained SSL models were used as feature extractors, and a transformer-based fusion mechanism was employed. In contrast to our work, their proposed fusion mechanism represents audio, text, and video modalities. The authors emphasize that their proposed fusion mechanism is both efficient and more accurate than previous SOTA methods when dealing with high-dimensional SSL features, in terms of the size of embedding and large sequence length when working with three modalities. Another proposed fusion method is GraphMFT, where graph neural networks (GNNs) are leveraged to integrate and complement the information from multimodal data [
70]. The results indicate that this method achieved better performance than previous SOTA approaches. Other relevant multimodal approaches previously proposed include ConGCN [
82], MMGCN [
83], MFN [
84], ICON [
85], BC-LSTM [
79], CMN [
86], and DialogueRNN [
87].
Table 2 provides a summary of bimodal sentiment analysis studies.
4. Experiments
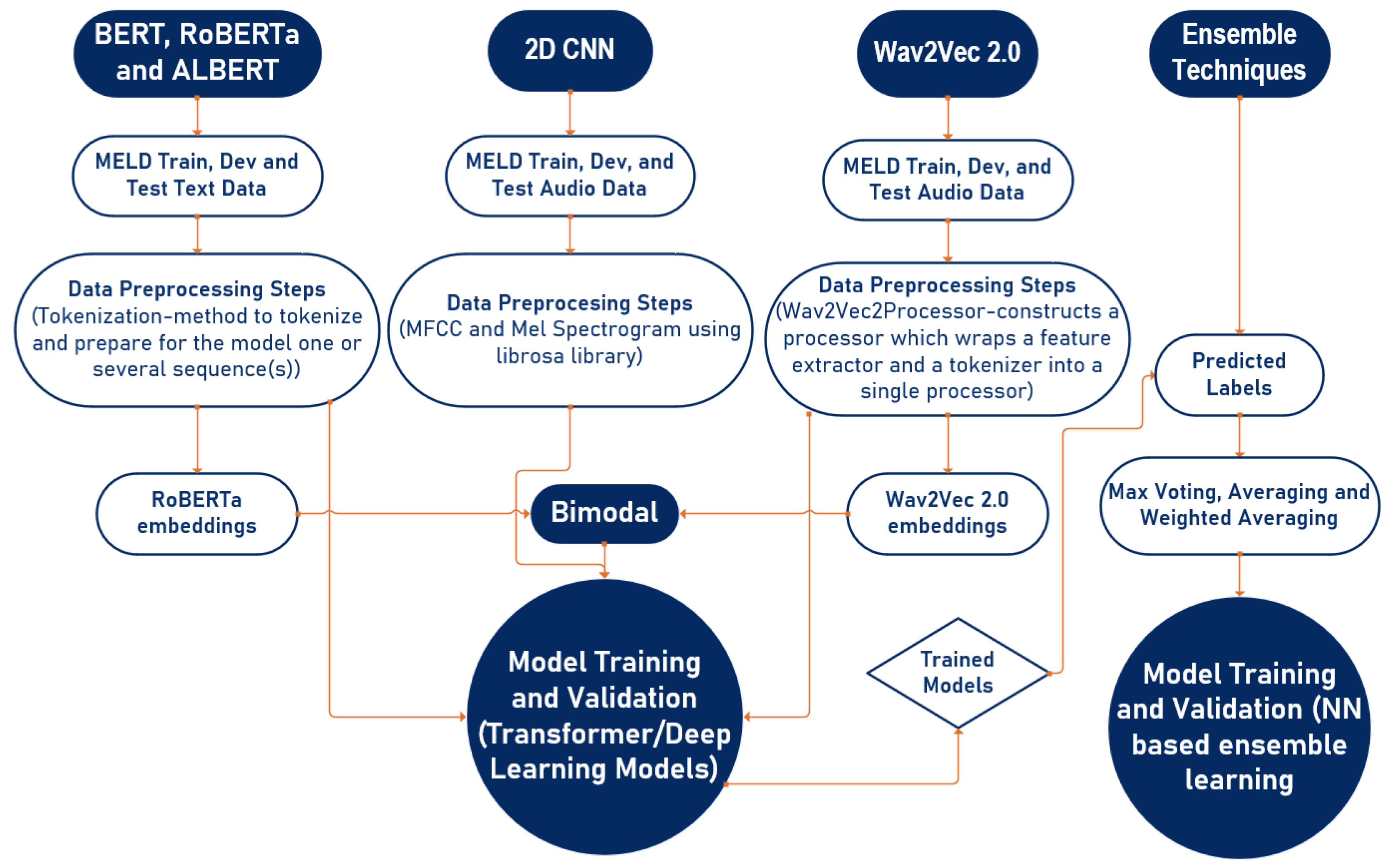
In this section, we describe several experiments conducted in this research, including all details related to their implementation. We classify them into; textual, acoustic, bimodal, and ensemble learning, as shown in
Figure 2.
4.1. Implementation Details
This section presents the details of the model’s implementation and the experimental setup. We implemented our model by following the official guidance on Hugging Face’s transformer library [
92]—a Python library providing detailed code explanations for building BERT-based models [
93]. A sequential data processing and modeling framework was built using mainly the PyTorch and Keras libraries. Other libraries that were used for extracting acoustic features and model training included TensorFlow, scikit-learn, and librosa. The training was conducted using a single NVIDIA Quadro T1000 GPU, and the operating system was Windows 10. For evaluation purposes, we calculated weighted accuracy, loss, precision, recall, and F1 score and generated a confusion matrix graph.
4.2. Textual
In this experiment, we extracted features from the MELD text data modality and used them as input into the model, as described in
Section 2.2.1. The features extracted are vectors represented in tensors: ‘input ids’ and ‘attention_mask’. The model also adds
, which is a marker for the ending of a sentence, and
to the start of each input, so the transformer model knows it is a classification problem. In addition to that, a special token called
is also added, which defines the maximum length of a sequence that the transformer can accept. All the sequences that are greater in length than max_length are truncated, while shorter sequences are padded with zeros. Another token is also added which encodes unknown tokens as
.
In the first experiment, we used the RoBERTa-base model with a basic configuration. The size of an extracted embedding was 768. In our second experiment, we used the concatenated outputs of the last four hidden layers. The size of an extracted embedding increased to 3072. In both experiments, the maximum training sequence length was set to 60, batch size to 16, the number of epochs to 10, and early stopping with the patience of 3 epochs. The training set contains utterances of less than 60 tokens. In addition, the loss was computed using a softmax layer with cross-entropy and one-fifth of the training steps were set as warm-up steps. While training, we used Adam optimization, with a learning rate of 0.00002.
4.3. Acoustic
The MFCC and Mel-spectrogram features for 2D CNN implementation on the MELD audio data modality were extracted using the librosa library—a python package commonly used for music and audio analysis. For computational reasons, the audio duration to be loaded was set to 41 s. The maximum audio length for MELD data is also 41 s. The number of MFCCs returned was set to 30 and the Mel-spectrogram was set to 60. The batch size was set to 16. The 20-epoch training of 2D CNNs started with four convolutional layers, max pooling with a dropout rate of 0.2, and activation function as “relu”. The final layer used activation softmax, loss was computed with cross-entropy, and the optimizer was set as Adam, with a learning rate of 0.001.
In the case of Wav2Vec 2.0, the feature encoder has a total receptive field of 400 samples, or 25 ms of audio at a sample rate of 16,000 Hz. We used a maximum sequence length of MELD audio data as input to the network. The variable audio lengths used as input were passed through a temporal CNN network as explained in
Section 2.2.2. The batch size was set to 16, the maximum number of epochs to 100, and early stopping with the patience of 30 epochs. The size of each dimensional vector was 768, the same as in RoBERTa, since both are transformer-based models. The extracted embeddings were then passed to six linear layers before passing to a softmax layer. The loss criterion was set as cross-entropy, one-fifth of the training steps were calculated as warm-up steps and the optimizer was Adam, with a learning rate of 0.00002.
4.4. Bimodal
In our bimodal experiment, we applied two settings immediately before modeling. In our first setting, RoBERTa’s pooler output embeddings were merged with Wav2Vec 2.0 embeddings. In our second setting, RoBERTa’s last four hidden layers’ outputs were concatenated, and the embeddings were merged with Wav2Vec 2.0 embeddings. This was achieved by first casting layers to a tuple and concatenating over the last dimension. Following that, the mean of the concatenated vector over the token dimension was taken as the final output. For modeling, we introduced a simple concatenation function at the start of the modeling architecture, where embeddings from text and audio modalities are joined and fed as a single input for model training. In both settings, the batch size was set to 16, the maximum number of epochs to 100, and early stopping with the patience of 30 epochs. The size of each dimensional vector was 768, but in the case of the RoBERTa’s last four hidden layers, the size was 3072. For the first setting, the concatenated dimension size was 1536, while for the second, it was 3840. The concatenated embeddings were then passed to five linear layers before passing to a softmax layer. The loss criterion was set as cross-entropy, one-fifth of the training steps were calculated as warm-up steps and the optimizer was Adam, with a learning rate of 0.00002.
4.5. Ensemble Learning
Following our unimodal and bimodal experiments for sentiment analysis, ensemble learning methods were employed to further enhance the model’s performance. Four different ensemble learning methods were used, including max voting, averaging, weighted averaging, and our proposed neural-network-based ensemble learning method.
Max voting is a classification method that utilizes multiple models to make predictions for each data point. Each model’s prediction is considered a ‘vote’, and the final prediction is determined by the majority of the models. A similar approach is taken in the averaging method, where predictions from all models are averaged to generate the final prediction.
Weighted averaging extends the averaging method by assigning different weights to each model, based on their importance and accuracy. In our proposed neural-network-based ensemble learning method, a neural network model was created and trained using the predictions of all six models for 250 epochs and a batch size of 10.
To perform these ensemble methods, the predictions from each of the six models were saved and then loaded as a single dataset. The ensemble methods were then applied to this dataset to generate the final prediction.
6. Conclusions and Future Work
In this paper, we presented multiple techniques for classifying sentiment using different types of data. As illustrated in
Table 8, a set of experiments was conducted to compare the performance of different models, including state-of-the-art models, for sentiment classification using uni- and bimodal datasets and variations in those models. We calculated weighted accuracy, loss, precision, recall, and F1 score for evaluating the best-performing models in our experiments. According to the experimental results, RoBERTa achieved the highest accuracy compared to other models in the text-only setting, whereas 2D CNN trained on Mel-spectrogram features achieved the highest in the audio-only setting. In our bimodal approach—based on the output of the model trained on RoBERTa’s concatenated last four hidden layers along with Wav2Vec 2.0 features—this version showed higher performance than the other approach adopted. Lastly, to overcome the shortcomings of models with lower accuracy, we proposed simple neural-network-based ensemble learning. To evaluate our ensemble learning approach, we considered other ensemble learning techniques in our final set of experiments. Our proposed ensemble learning approach outperformed the second-best technique by 3.12%.
Our proposed approach is well-suited for analyzing bimodal data, which encompasses sentiment expressed through both spoken language and nonverbal cues, a common feature of CC interactions. By combining the results of both text-based and audio-based sentiment analysis, ensemble learning bimodal sentiment analysis can achieve a more comprehensive and nuanced understanding of the sentiment expressed, leading to more reliable insights for decision-making purposes. It offers various potential applications in different domains, particularly in identifying the sentiment of customer conversations within the CC domain. Additionally, it can be used in social media analysis to monitor the sentiment of online conversations related to a particular topic or brand, helping companies to identify and respond to customer complaints or concerns.
The main limitation of this work currently lies in the fact that it relies extensively on the quality, as well as the number of distinctive models, for generating a good-performing neural-network-based ensemble learning model. An interesting avenue to explore in the future could be relying on a few highly performing models for this experiment.
In the future, we would like to use our method to reproduce the results of this study on other datasets and ensure our proposed method is consistent. Further, as progress is made in the field of deep learning techniques, our work can provide a basis to enhance bimodal sentiment analysis, particularly audio sentiment analysis, and explore the benefit of implementing ensemble learning on such bimodal datasets.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}