For our modeling work, we employed the User-Centered System Design [
49] by Norman and Draper and the Unified Modeling Language (UML) [
50]. The central use case for our modeling work is
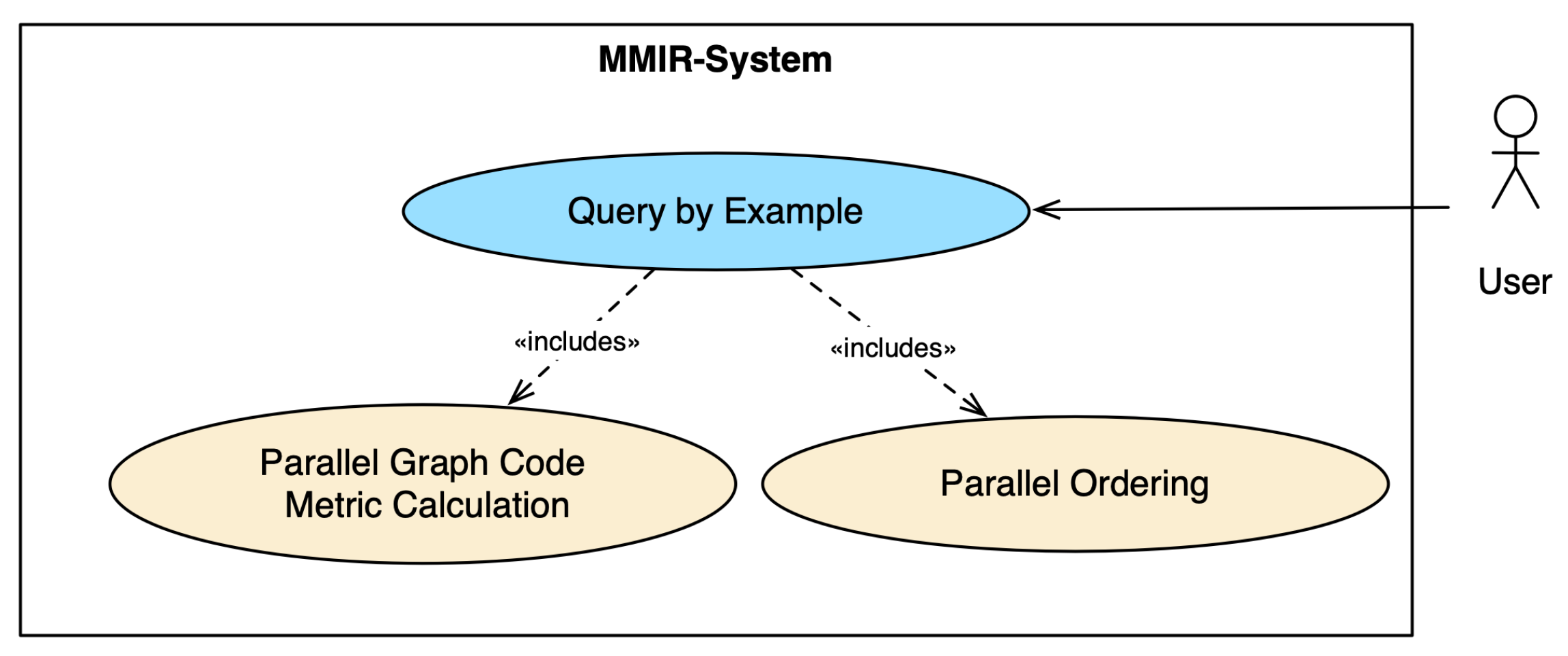
similarity search, as shown in
Figure 3. The objective of similarity search is to discover objects that bear a resemblance to a designated query object, adhering to a specific similarity criterion provided. With the user in focus, we aimed for an optimized user experience in terms of reducing runtimes for the implementation of the use case. In the case of
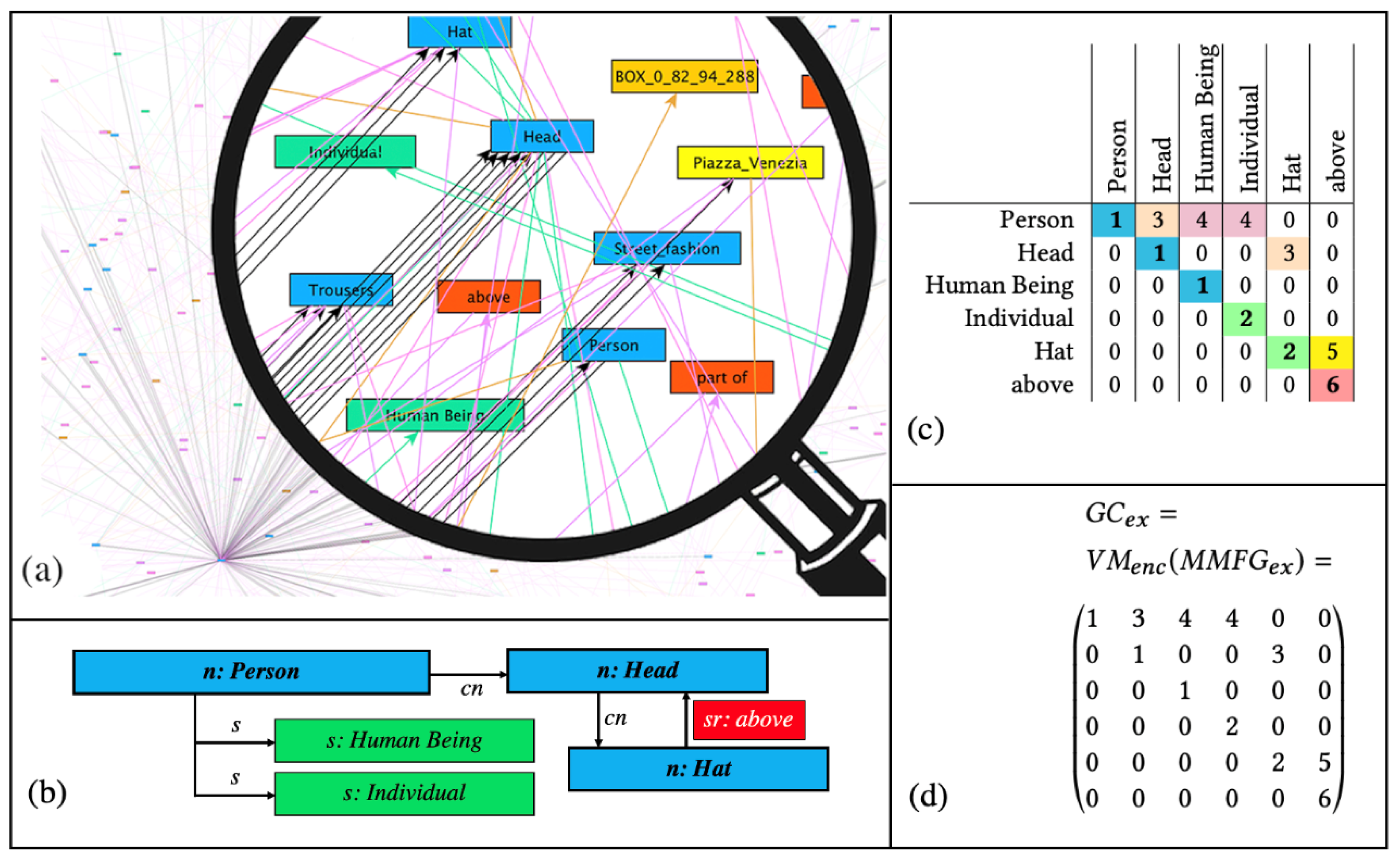
MMFGs and
Graph Codes, in the first use case,
Parallel Graph Code Metric Calculation, the calculation of the metrics’ values for the query
Graph Code and all
Graph Codes in the collection
is happening. In the use case
Parallel Ordering, the list of items and metrics is ordered by the highest similarity by comparing the metric values. Parallel algorithms are explored for both steps.
In the following sections, we employ the described decomposition techniques for the Graph Code algorithms and model different parallel approaches. The modeled approaches are examined for their theoretical speedup and applicability to parallelization technologies.
3.1. Parallel Graph Code Algorithms
The similarity search based on
Graph Codes calculates the metric values for each
Graph Code in the collection against the query
Graph Code and orders the results. The pseudocode of
Section 2.3 describes the algorithm. We applied the decomposition techniques (
Section 2.4) to the algorithm and modeled a Task Dependency Graph (TDG).
Starting with the first step, the iteration over all items n in the Graph Code collection can be decomposed by the divide-and-conquer method. As the individual metric calculations do not have dependencies, they can be split into n parallel steps. Next, the calculation of intersection matrices and metric calculation contain comparison of the elements in both matrices. Hence, the data decomposition can be used, and each comparison step can be done in parallel. In a consecutive step, the individual comparison results are used to calculate the Graph Code metric values. The calculation of the three metric values could also be parallelized, but compared to the rest of the algorithm, the number of instructions is low and, therefore, the potential is also low. Finally, the ordering of the results can be parallelized.
In summary, the decomposition identified three tasks:
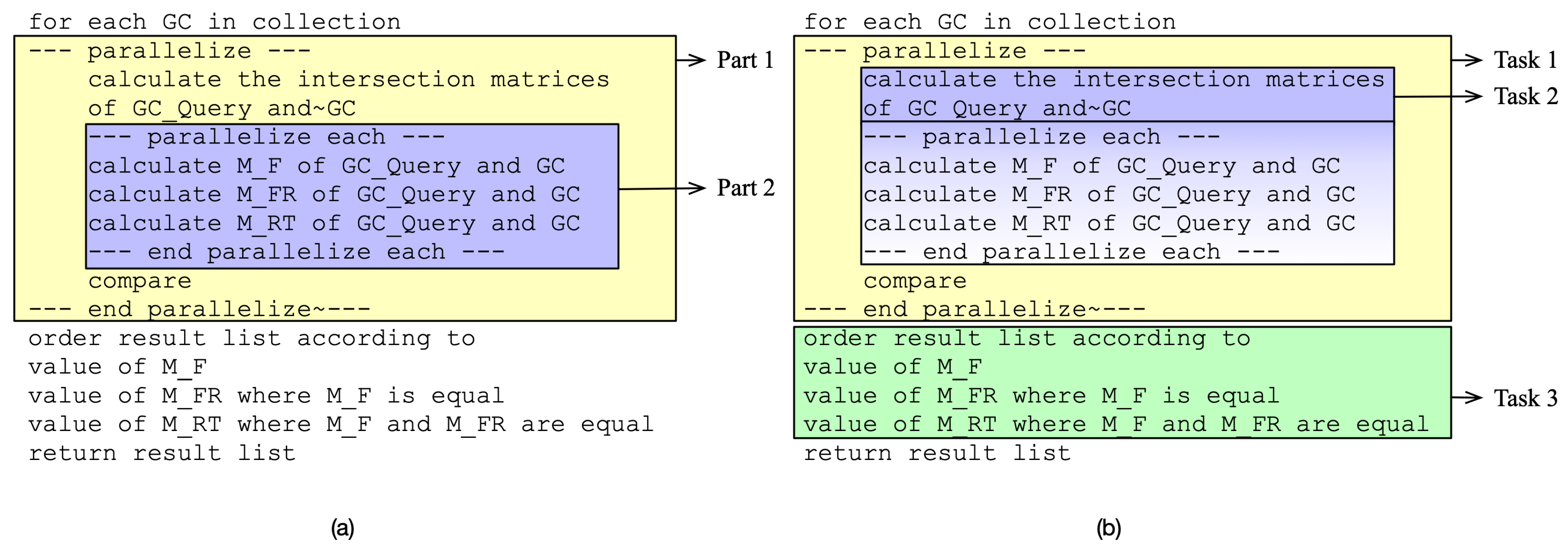
Compared to the parallelization points indicated in the pseudocode, the identified tasks are different, as shown in
Figure 6, where the initial version shows two parallel parts (
Figure 6a), and the new version shows the three decomposed tasks (
Figure 6b).
Task 1 and
Task 2 are part of the sub-use case
Parallel Graph Code Metric calculation of the use case
similarity search.
Task 3 maps to the use case Parallel Ordering of the use case
similarity search.
The identified tasks can, but do not need to, run in parallel, regardless of whether the other tasks are sequential or parallel. Hence, different versions can be modeled. The remainder of this section discusses different models.
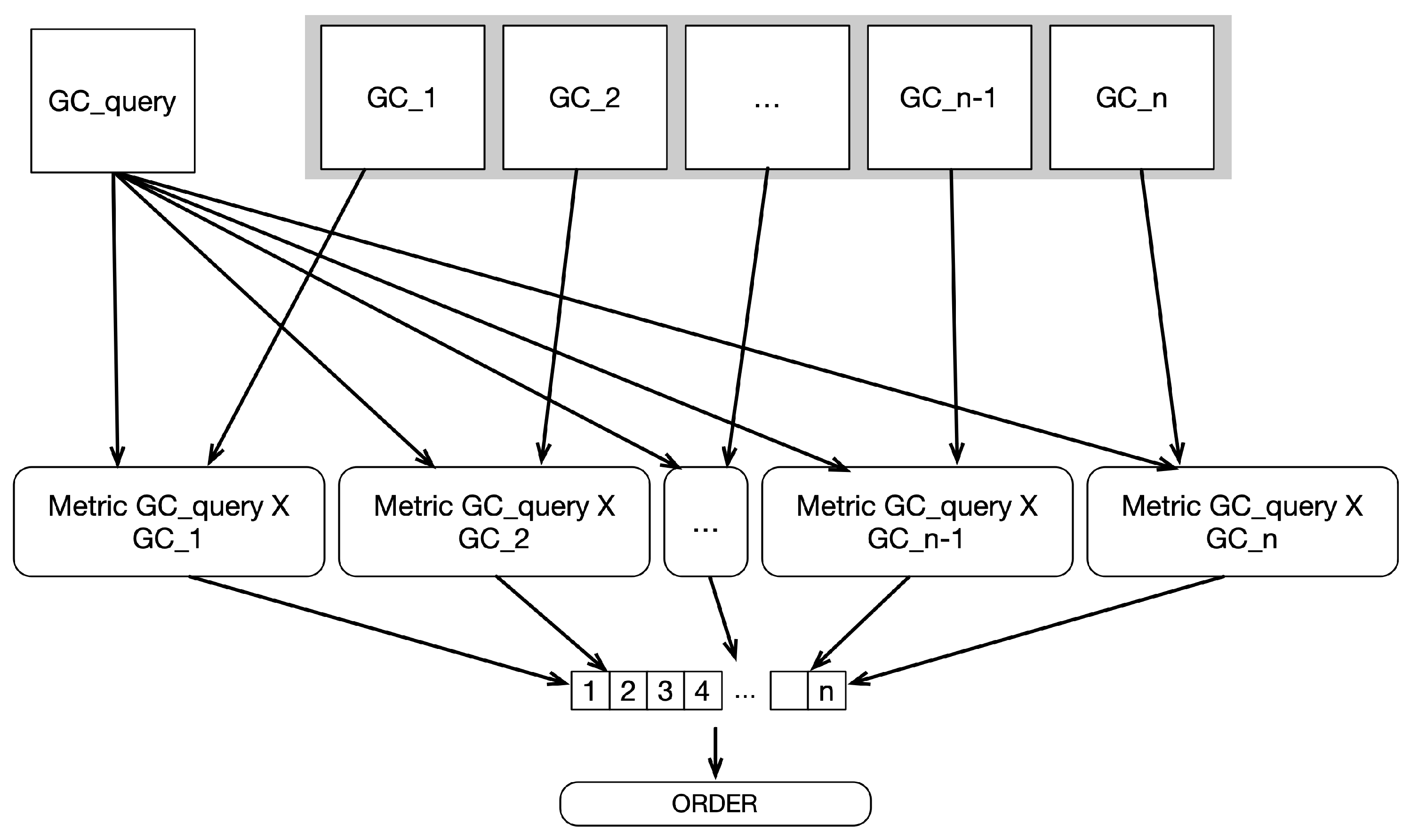
Task 1, the iteration over the collection, is an obvious task to run in parallel and has no interdependencies between each calculation of the metric, as shown in the TDG in
Figure 4. A metric calculation uses two
Graph Codes as input. For a similarity search, one of the inputs is the reference
Graph Code , and the other is an element
from the collection
. Each of these calculations can be executed independently and thus arbitrarily in parallel. The calculated metric values will be stored in a result array; the position is correlated with the position in the collection. The parallelization can be done on thread-level parallelization and, therefore, run on multicore CPUs and GPUs, as well as with distributed processing. Listing 1 shows the start and end of the parallelization for
Task 1 parallelization.
| Listing 1. Pseudocode of Task 1 parallelization. |
| 1 --- START TASK 1 -> TLP parallelise --- |
| 2 for each GC in collection |
| 3 --- calculate the intersection of GC_Query and~GC --- |
| 4 for each element in GC_Q->VM |
| 5 Check Intersection with GC_Q |
| 6 Calculate M_F, M_FR, M_RT from m_res array values |
| 7 --- END Task 1 TLP parallelize --- |
| 8 order result list according to |
| 9 value of M_F |
| 10 value of M_FR where M_F is equal |
| 11 value of M_RT where M_F and M_FR are equal |
| 12 return result list |
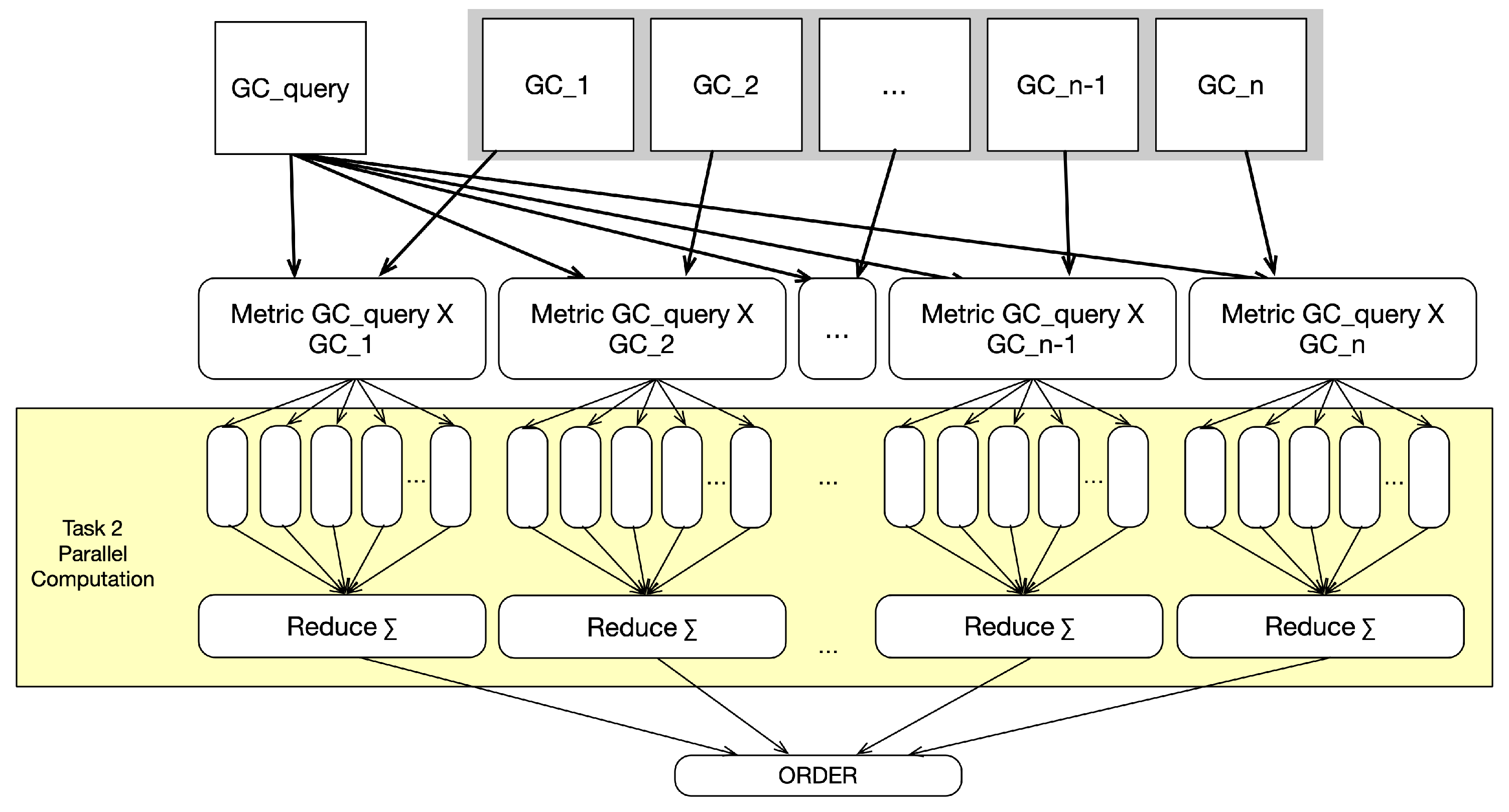
For
Task 2, finding intersections in the two matrices can be processed in parallel, but the findings, as well as the check for the feature relationship metric and feature relationship type metric, need to be stored in intermediate storage, as shown in
Figure 5. This part of
Task 2 is named
Task 2a. As a subsequent step, the storage is summed up and the values are used for the calculation of the final metric values. This step is
Task 2b. For large matrices in the millions, due to the high LOD, summing up the values can be done in parallel with reduction approaches [
51]. Listing 2 shows the start and end of the parallelization in the case of
Task 2.
| Listing 2. Pseudocode of Task 2 parallelization. |
| 1 for each GC in collection |
| 2 --- calculate the intersection of GC_Query and~GC --- |
| 3 --- START TASK 2a -> SIMD parallelize --- |
| 4 for each element in GC_Q->VM |
| 5 Check Intersection with GC_Q, store in m_res array |
| 6 ... |
| 7 --- END TASK 2a SIMD parallelize --- |
| 8 --- START TASK 2b -> TLP parallelize |
| 9 reduce m_res arrays |
| 10 --- END TASK 2b TLP parallelize --- |
| 11 Calculate M_F, M_FR, M_RT from m_res array values |
| 12 order result list according to |
| 13 value of M_F |
| 14 value of M_FR where M_F is equal |
| 15 value of M_RT where M_F and M_FR are equal |
| 16 return result list |
The final
Task 3, the ordering of the metrics, has a dependency on all preceding tasks because it needs all the calculated metrics as input. The task itself can be done with parallel versions of QuickSort [
52] or RadixSort [
53].
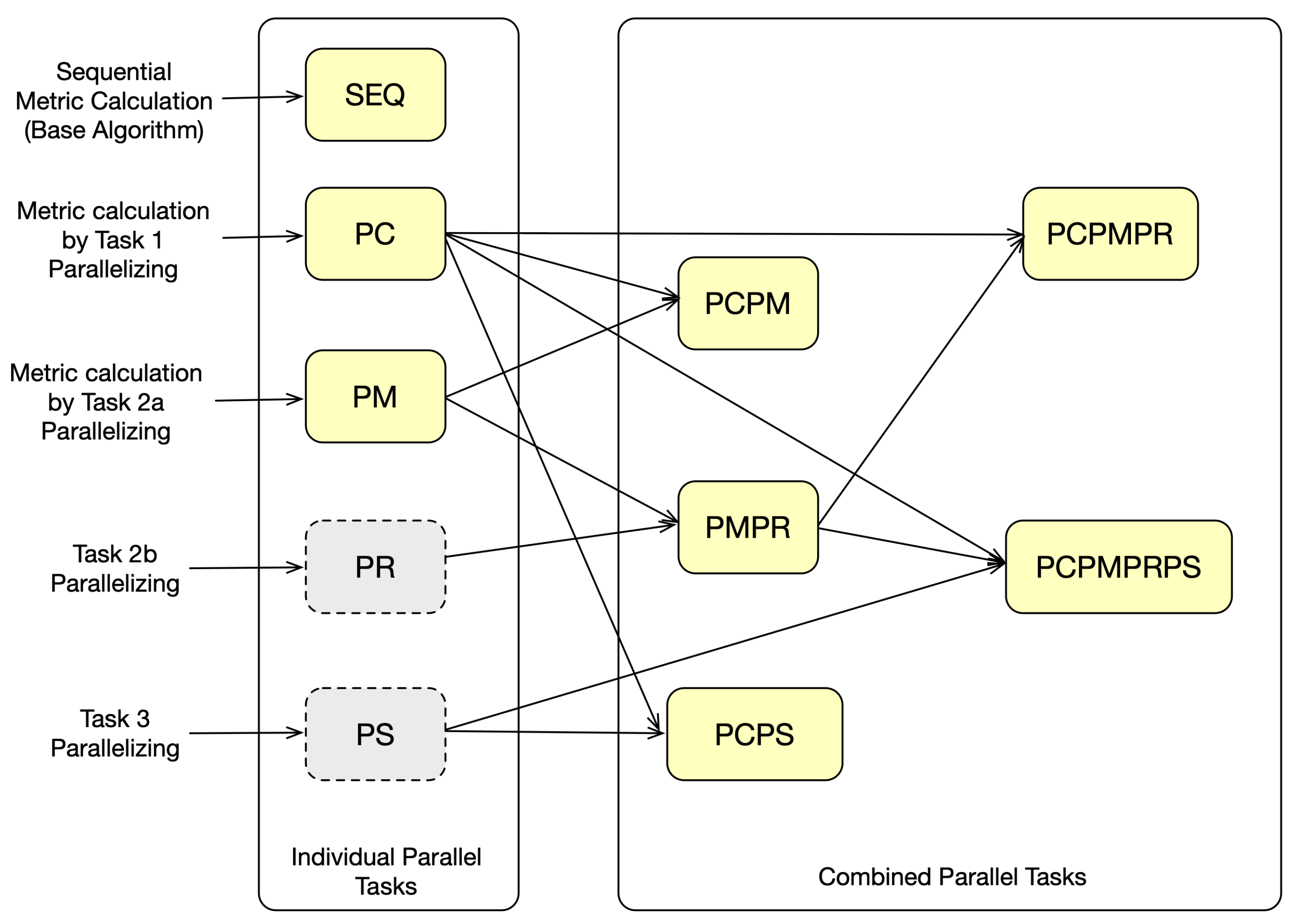
Task 1 can run in parallel with a sequential metric calculation, or in parallel, as described with
Task 2, as shown in
Figure 7. Executing
Task 1 in sequence and only running
Task 2 in parallel is also possible, as shown before in
Figure 5. The following Listing 3 shows the start and end of the tasks and the type of parallelization for all the tasks.
| Listing 3. Pseudocode of Task 1, 2, and 3 parallelization. |
| 1 --- START TASK 1 -> TLP parallelise --- |
| 2 for each GC in collection |
| 3 --- calculate the intersection of GC_Query and~GC --- |
| 4 --- START TASK 2a -> SIMD parallelize --- |
| 5 for each element in GC_Q->VM |
| 6 Check Intersection with GC_Q, store in m_res array |
| 7 ... |
| 8 --- END TASK 2a SIMD parallelize --- |
| 9 --- START TASK 2b -> TLP parallelize |
| 10 reduce m_res arrays |
| 11 --- END TASK 2b TLP parallelize --- |
| 12 Calculate M_F, M_FR, M_RT from m_res array values |
| 13 --- END Task 1 TLP parallelize --- |
| 14 --- START TASK 3 -> TLP parallelize --- |
| 15 order result list according to |
| 16 value of M_F |
| 17 value of M_FR where M_F is equal |
| 18 value of M_RT where M_F and M_FR are equal |
| 19 --- END TASK 3 TLP parallelize --- |
| 20 return result list |
Overall, the initial algorithm can be broken down into three tasks, and each task can be parallelized or in sequence. In the next section, we define algorithms from the different combinations.
3.3. Potential Parallelization on Modern Processors
Modern processors are designed as multicore processors. They can execute instructions in parallel, but the execution model differs. While MIMD processors have an individual instruction counter for each core, SIMD processors share an instruction counter. A shared instruction counter means that every core executes all statements for all paths of input data. If a branch of the code (e.g., if statement) is not executed in one parallel path, the core omits the instruction step and cannot execute other instructions. This effect is called thread divergence. The branching characteristics of parallel tasks impact the utilization of a SIMD processor and, hence, the efficiency of the algorithm. However, SIMD processor designs can have many more cores and can achieve massive parallelization.
The characteristics of the modeled parallel Graph Code algorithms are both advantageous and disadvantageous for parallelization. The individual tasks have a low degree of dependency and show a gather pattern, which means that inputs can be grouped and processed individually, and each output can be stored in an individual place. This indicates the applicability for SIMD. On the other hand, the calculation of metrics implies the creation of intersections of two Graph Codes. The number of intersections depends on the size and similarity of the Graph Code. This indicates that thread divergence is likely.
The algorithm
can be parallelized at thread level, which means that every calculation can be put into a thread and executed in parallel. This is suitable for both types of processors: multicore CPUs (MIMD) and modern GPUs (SIMD). As
Task 2 algorithms constitute data-level parallelization, it loads the data once and processes each item. Data-level parallelization is more suitable for GPUs, but in the case of heterogeneous
Graph Codes, thread divergence can limit the effectiveness. However, the low degree of dependency allows for processing many calculations in parallel, employing all available cores. Given a processor with 16,000 cores, such as the Nvida H100 [
54], 16,000
Graph Code metric calculations can be performed in parallel.
To reduce or even eliminate the possible performance impact of thread divergence, the
Graph Codes can be grouped by size. Executing same-size groups could reduce thread divergence. This method has been used in similar cases [
55]. Another approach is to employ the previously described Feature Relevance [
24].
Graph Codes with only relevant features should increase the performance with a minimal loss of accuracy. The impact on parallel
Graph Code algorithms works as follows.
Depending on the vocabulary width (LOD) used in the MMFGs, the resulting Graph Codes can be sparse or dense. With a high LOD, Graph Codes tend to be large and sparse. For the calculation, this leads to many unnecessary comparisons to obtain the intersections of two Graph Codes. For a similarity search, it is questionable to have many terms used in only one Graph Code or in every Graph Code. By applying techniques such as TFIDF, the density of the information in the resulting SMMFGs and the semantic Graph Codes increases. The resulting semantic Graph Codes have similar dimensions and a similar number of intersections. Both may be beneficial to the effect of thread divergence and, hence, to the efficiency of parallel Graph Code algorithms.
A further approach for
Task 2a could replace the search of corresponding feature vocabulary terms in the
Graph Code to compare with a lookup table, such as an inverted list [
56]. This approach could be applied to the sequential and parallel versions of the algorithms.
A benefit of the modeled algorithms is that no more pre-processing is needed than producing the Graph Codes. The approaches Semantic Graph Codes and inverted lists require further pre-processing.
In summary, the characteristics of the parallel algorithm show high potential for acceleration. In the next section, we deduce the theoretical speedup.
3.4. Theoretical Speedup
The performance of parallel
Graph Code algorithms can be compared with the sequential version. The improvement is measured as speedup
S, which is the ratio of parallel to sequential runtime, where
p is the number of processors around a problem of size
n.
is the execution time of the best serial implementation and
is the parallel implementation. In this subsection, we will focus on the algorithm
.
The calculation of the metric values is performed on a collection of
Graph Codes . This corresponds to
The value
n corresponds to the number of
Graph Codes in a collection
Each
Graph Code has a variable word list
with a length
l corresponding to the dimension of the
Graph Code value matrix
.
Regarding the sequential metric computation of two
Graph Codes and
, the runtime
can be mainly described by the sizes
l of the respective
Graph Codes with the following factors. For each element in the matrix of
Graph Code , the corresponding values of
Graph Code must be searched and compared.
as the number of elements in the word list of the query vector
and corresponding
is the length of the word list in the vector to compare
.
When calculating the metrics of a collection of
Graph Codes , the calculation is performed for
Graph Code against each element in the collection. Hence, the calculation happens
n times, the number of
Graph Codes in the collection. Since the GCs vary in length, the individual runtimes are summed up.
In consideration of the parallel algorithm,
can now be divided by the number of execution units (CPU cores or CUDA cores)
c. This results in
By parallelizing the steps for each element of the Graph Code matrix , this can be divided among the number of execution units c. To form the sum, the buffer size l must be calculated.
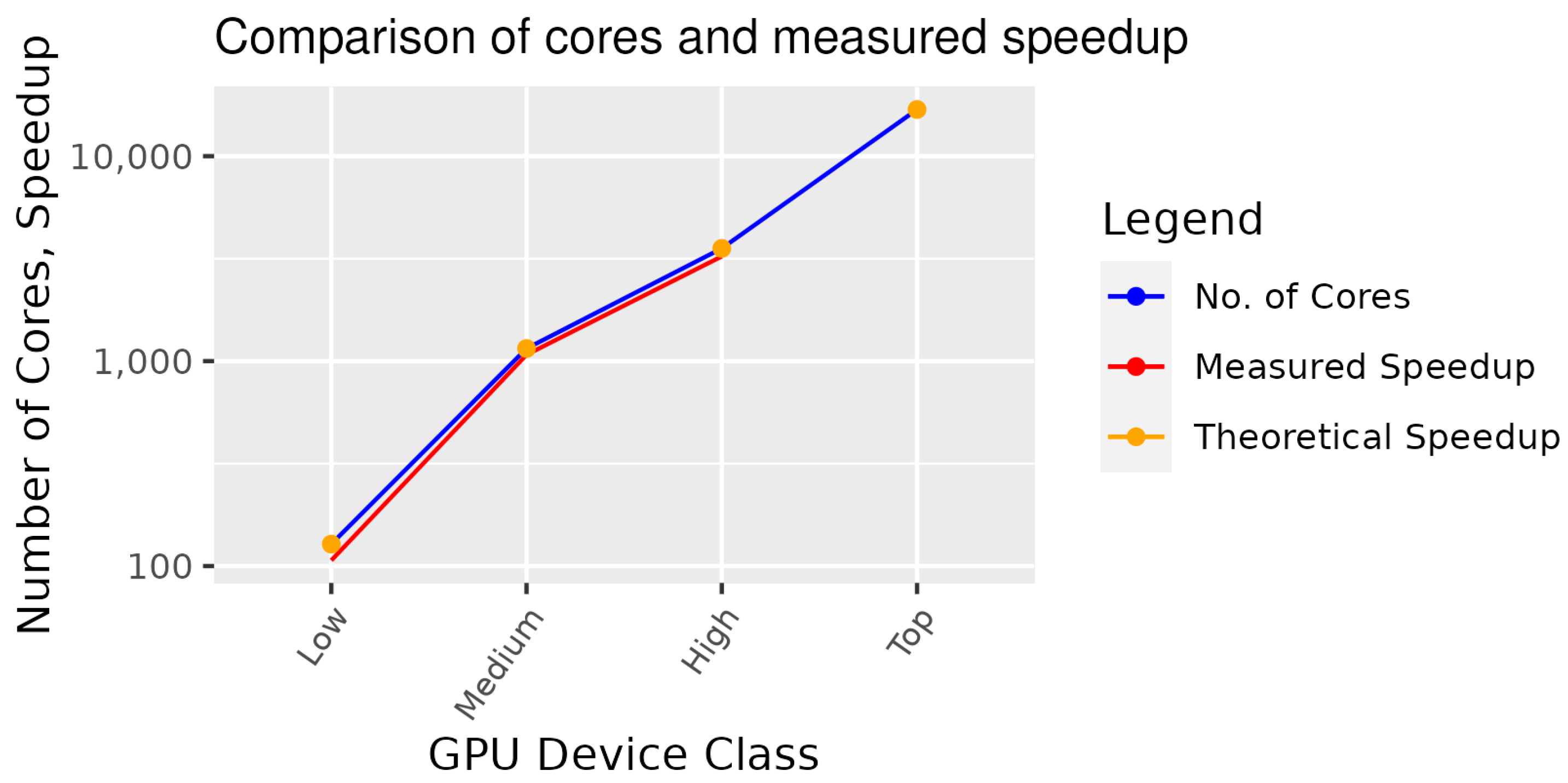
Looking at current top-end GPUs such as the Nvidia H100 with 16,896 cores,
As measured in previously published experiments (source), the calculation of 720,000
Graph Codes took 635 s in an instance using a single thread. Hence, employing the parallel algorithms could lead to a reduction in the processing time down to 0.038 s or a theoretical speedup of 16.711.
Graph Codes and the modeled algorithms show high potential for massive parallel processing. Next, we summarize the section and discuss the implementation and evaluation of the algorithms.
3.5. Discussion
In this section, we present the conceptual details of parallel Graph Code algorithms, their mathematical background and formalization, and the conceptual transfer of parallel algorithms to processors. The application of the decomposition methods showed that the Graph Code metric calculation is massively parallelizable. In theory, the only limiting factor is the number of available cores and memory.
The algorithm variants show huge speedup potential on different multicore processor systems. Considering an implementation for SIMD GPUs with a shared instruction counter, the heterogeneity of Graph Codes in a collection could lead to the inefficient utilization of GPU resources. We presented the options of grouping Graph Codes by size or homogenization with TFIDF. As it is a theoretical examination, an implementation of the parallel algorithm and an evaluation of the efficiency is needed.
With regard to distributed computing, the algorithm could be used because Tasks 1 and 2 are without dependencies. If the collection is distributed, all nodes can calculate their portions; only the final Task 3 (ordering) needs to be computed on one node with all intermediate results. Implementing and evaluating this remains an open challenge.
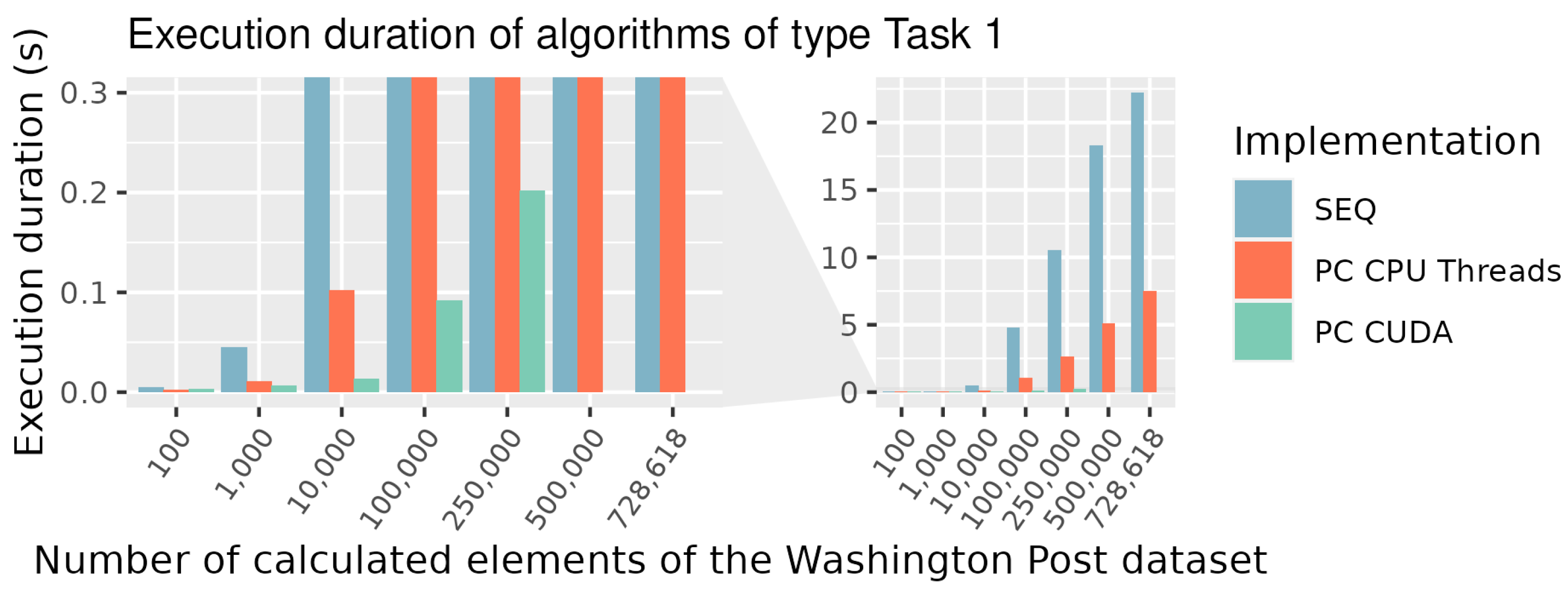
For an evaluation of real performance, we decided to implement some variants of the algorithms. To compare speedups on CPU and GPU, we decided to implement
for Threads and CUDA. In the case of a very high LOD, algorithms
and
could be beneficial. To test their efficiency, they were implemented in CUDA. For a comparison of ordering the result list (
Task 3) on the GPU and CPU,
was implemented for CUDA. Our implementation is discussed in
Section 4 and the evaluation results given in
Section 5.



 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}