

Enhancing Digital Health Services with Big Data Analytics


Abstract
1. Introduction
1.1. Motivation
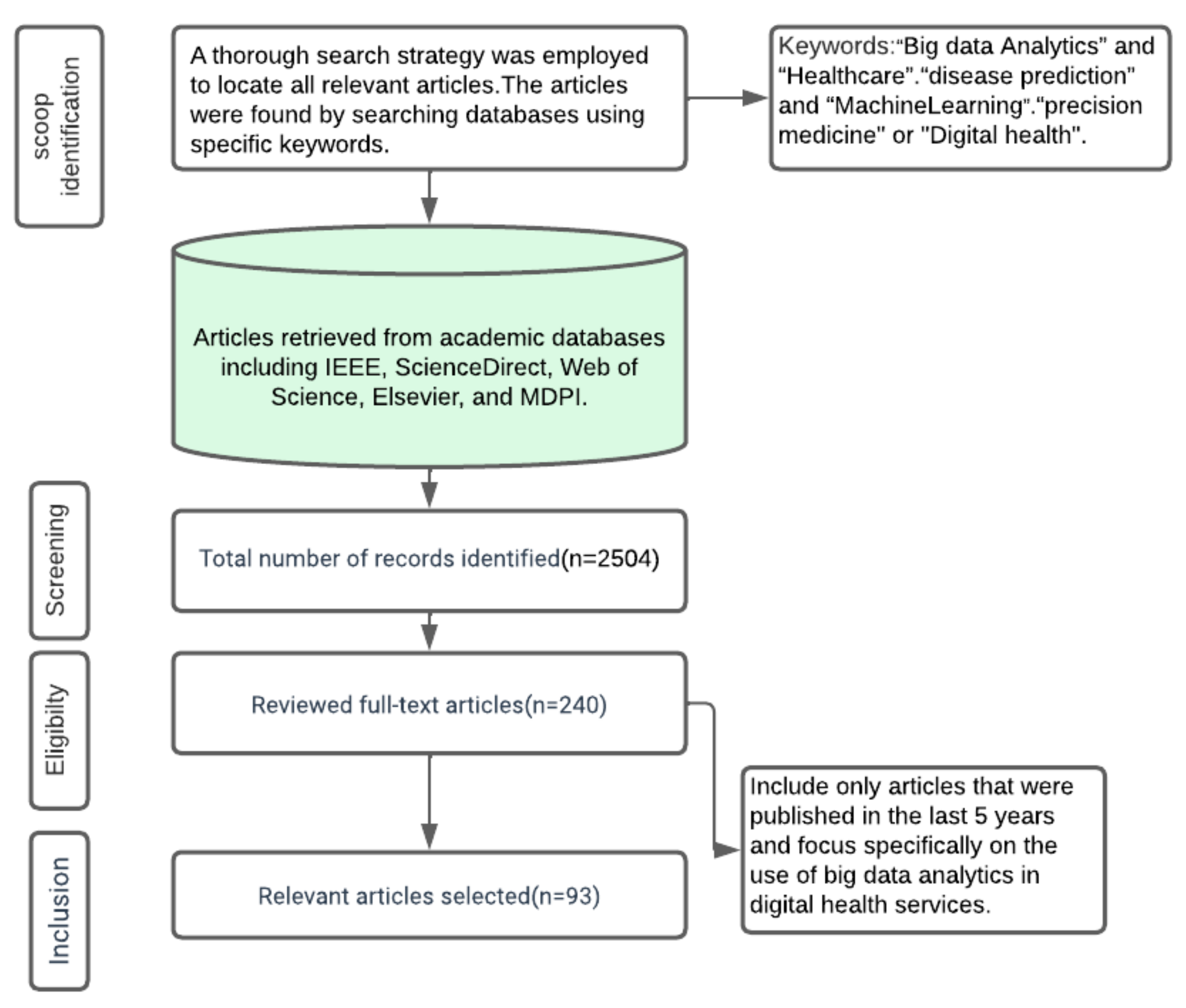
1.2. Research Methodology
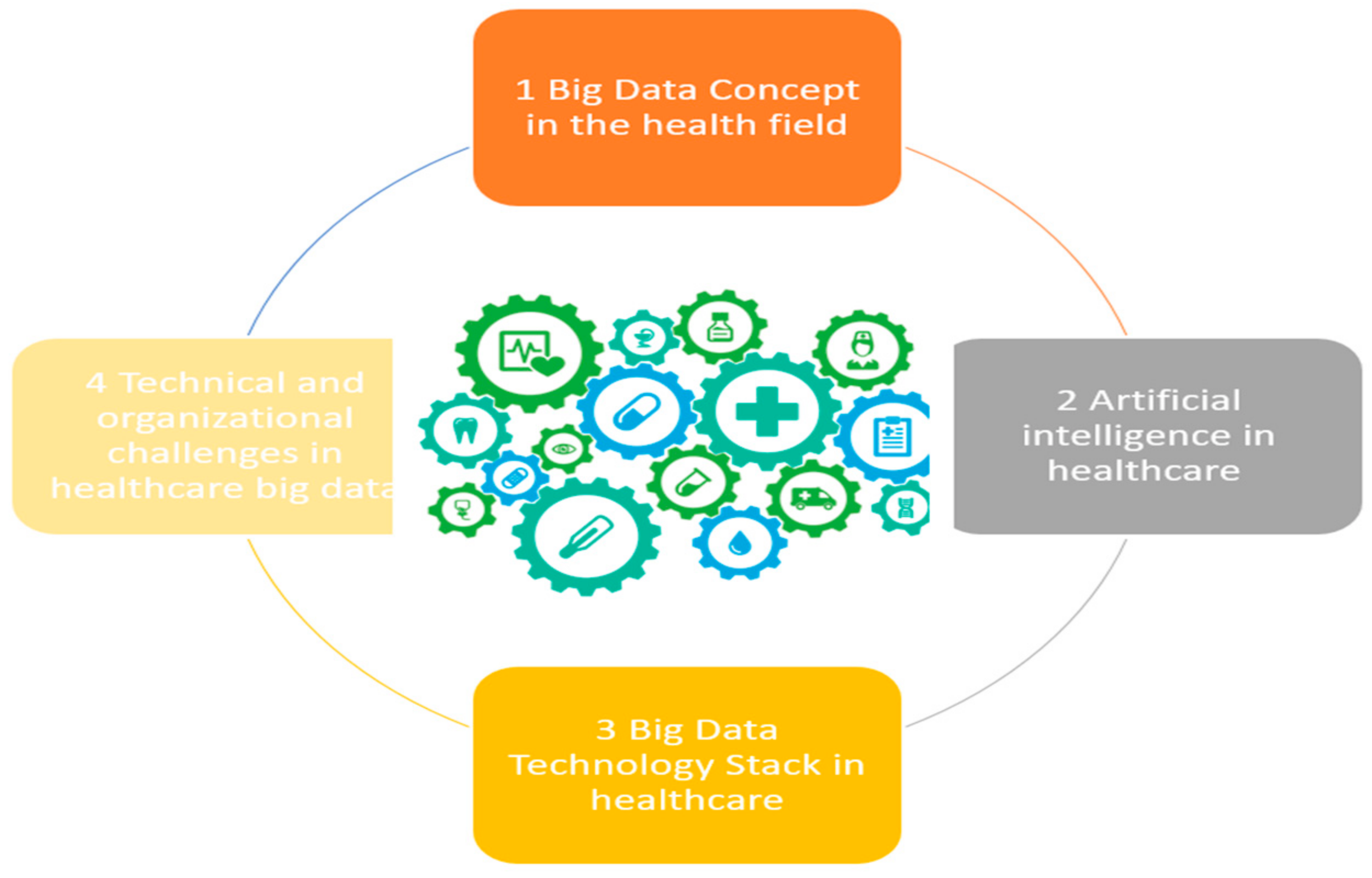
1.3. Paper Organization
1.4. Existing Surveys
1.5. Current Survey
2. Big Data Concepts in the Health Field
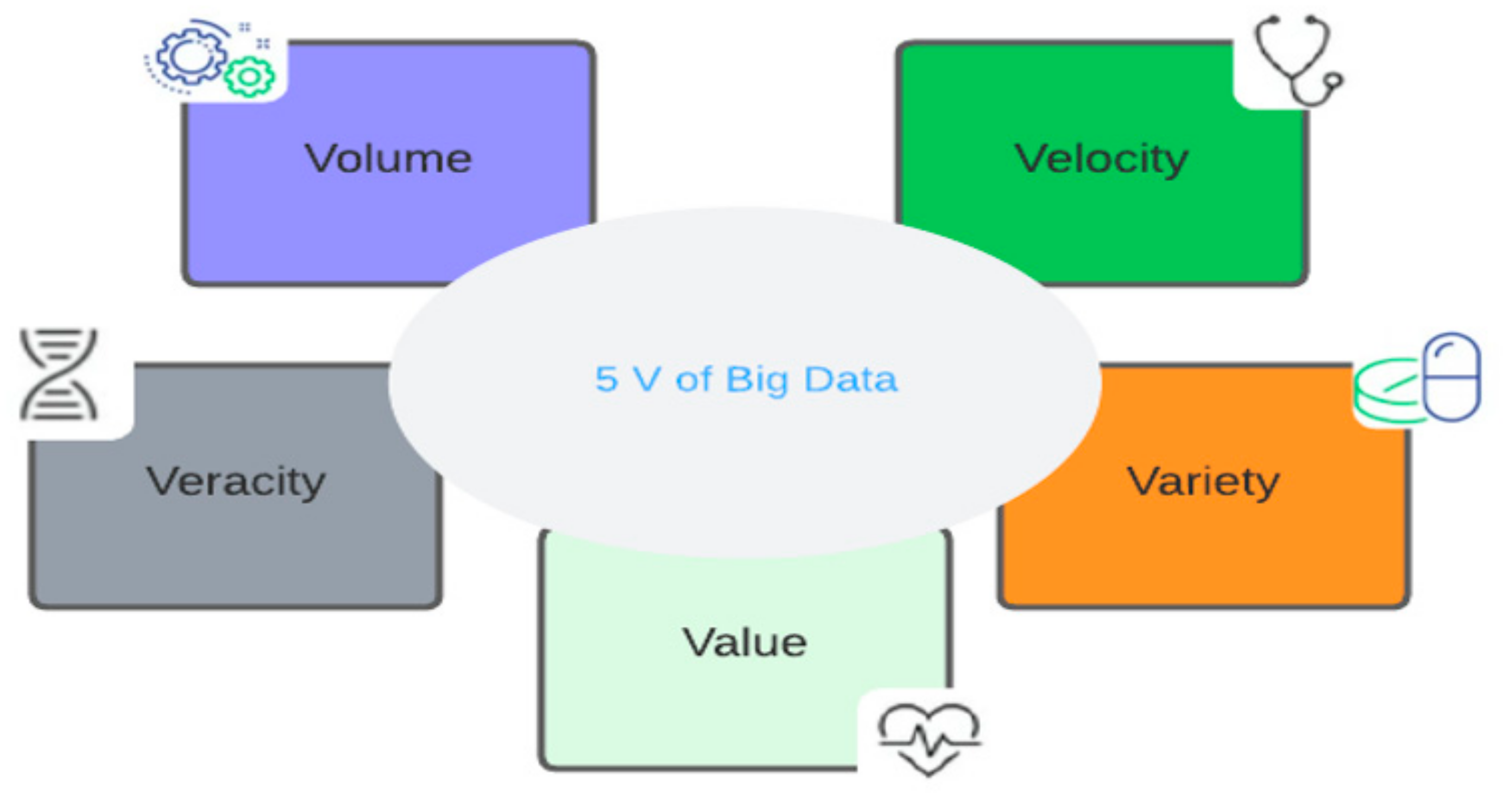
2.1. Features of Big Data in Healthcare
- Volume
- Variety
- Velocity
- Veracity
- Value
2.2. Data Sources
- Electronic Health Records
- Social networks
- Internet of Things
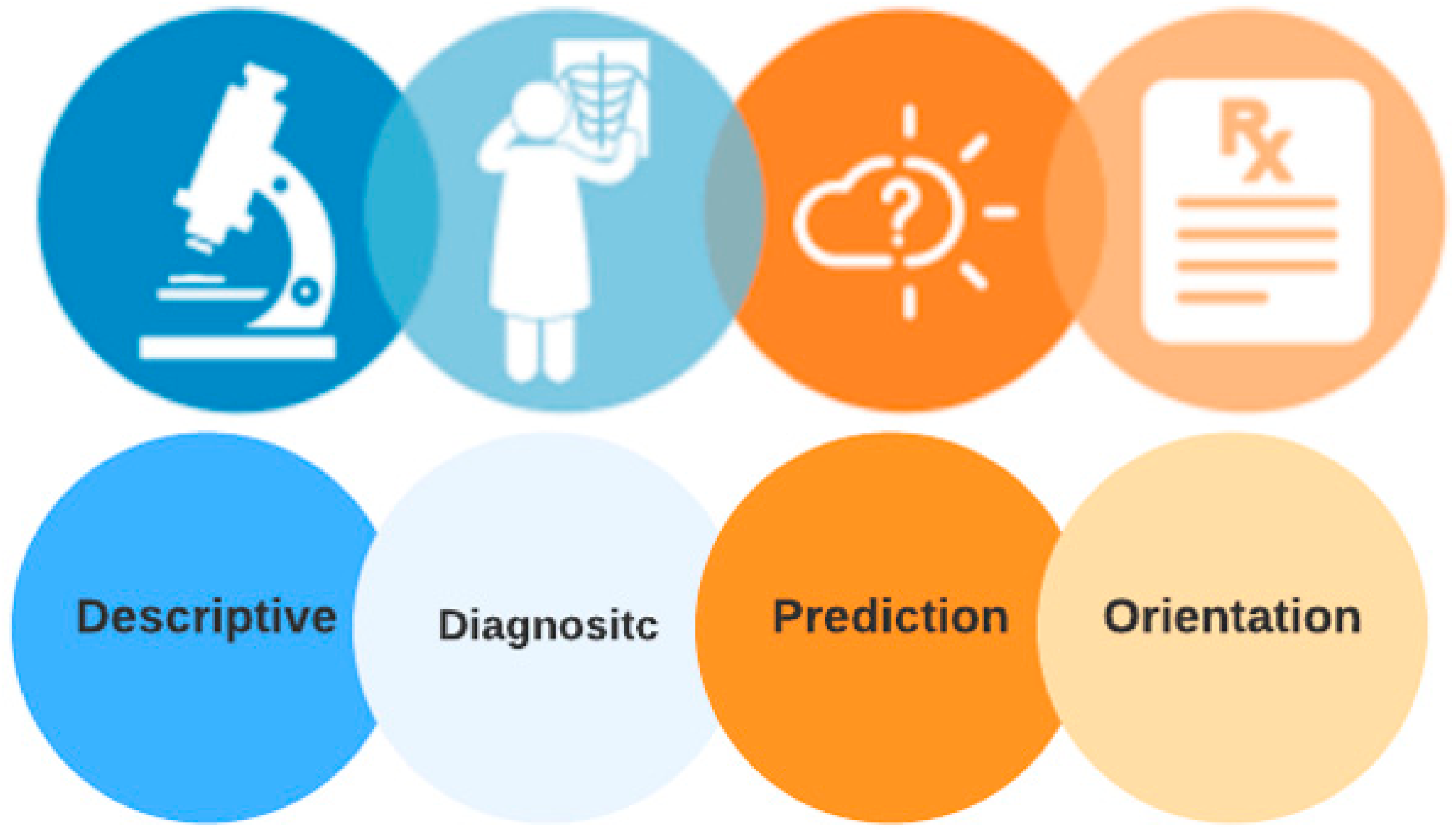
2.3. Healthcare Big Data Analytics Classification
- (a)
- Descriptive Analytics
- (b)
- Diagnostic Analytics
- (c)
- Predictive Analytics
- (d)
- Prescriptive Analytics
3. Artificial Intelligence in Medical Field
- K-Nearest Neighbor Algorithm
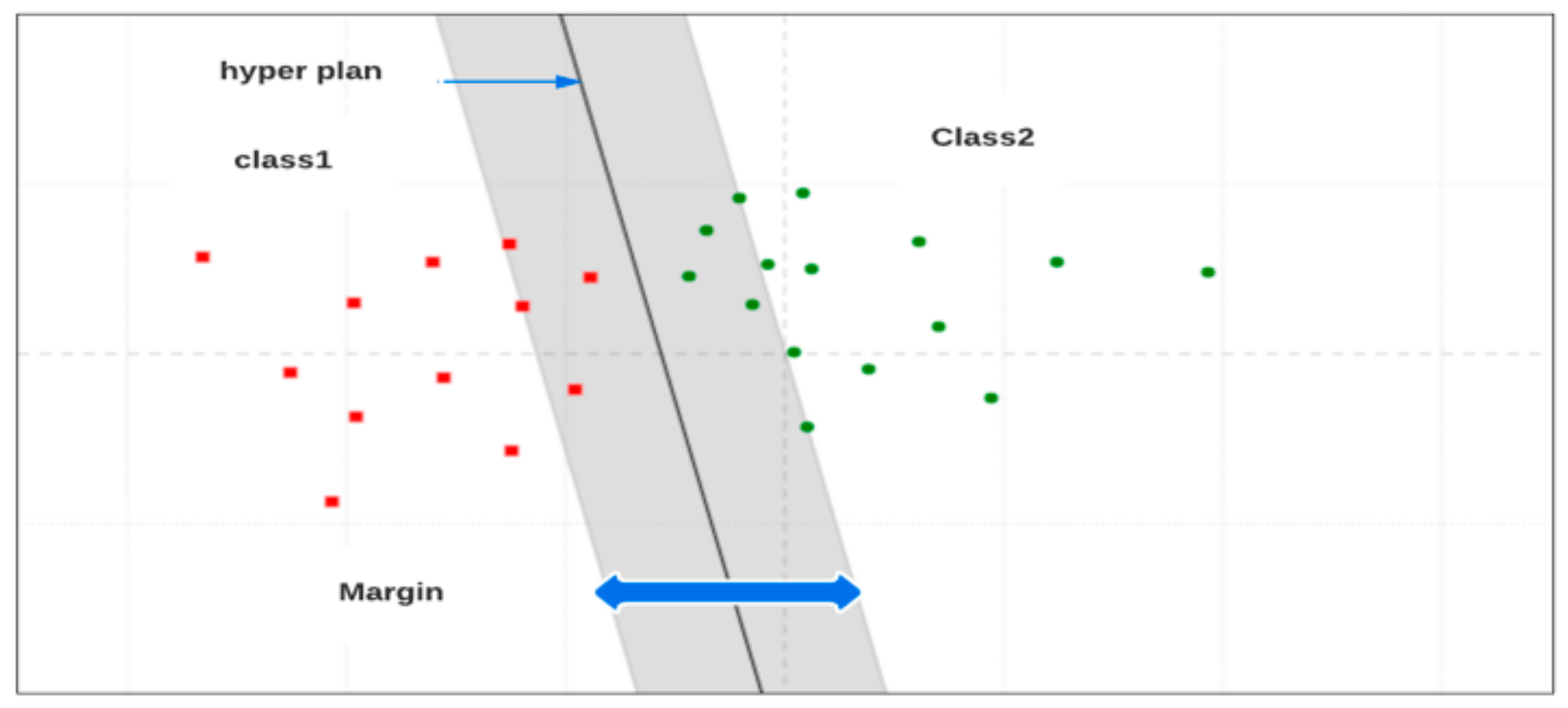
- Support Vector Machines (SVM)
- K-Means Clustering Techniques
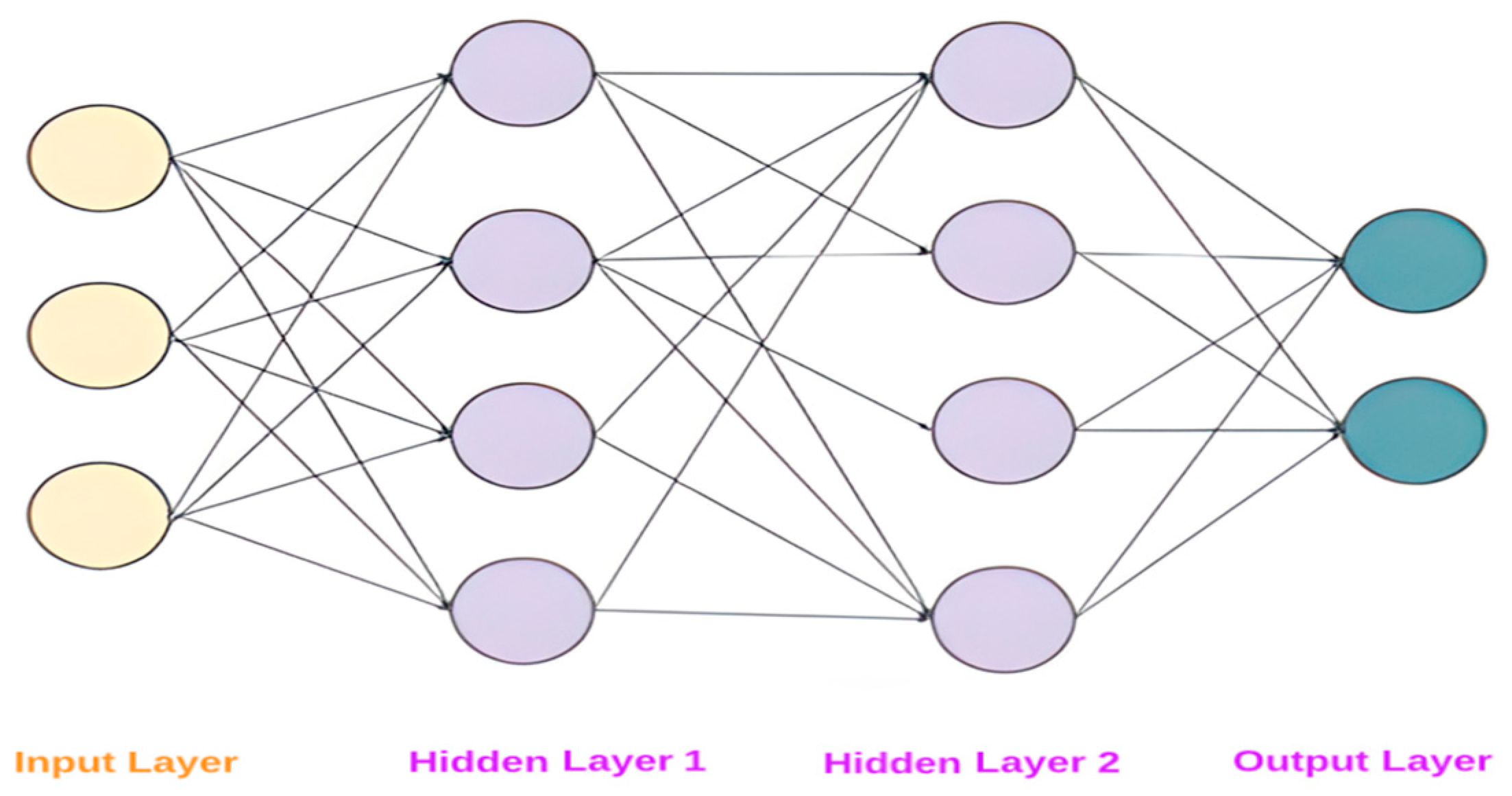
- Artificial Neural Networks
- Application of Machine Learning in Healthcare
4. Big Data Technology Stack in Healthcare
4.1. Infrastructure and Virtualization
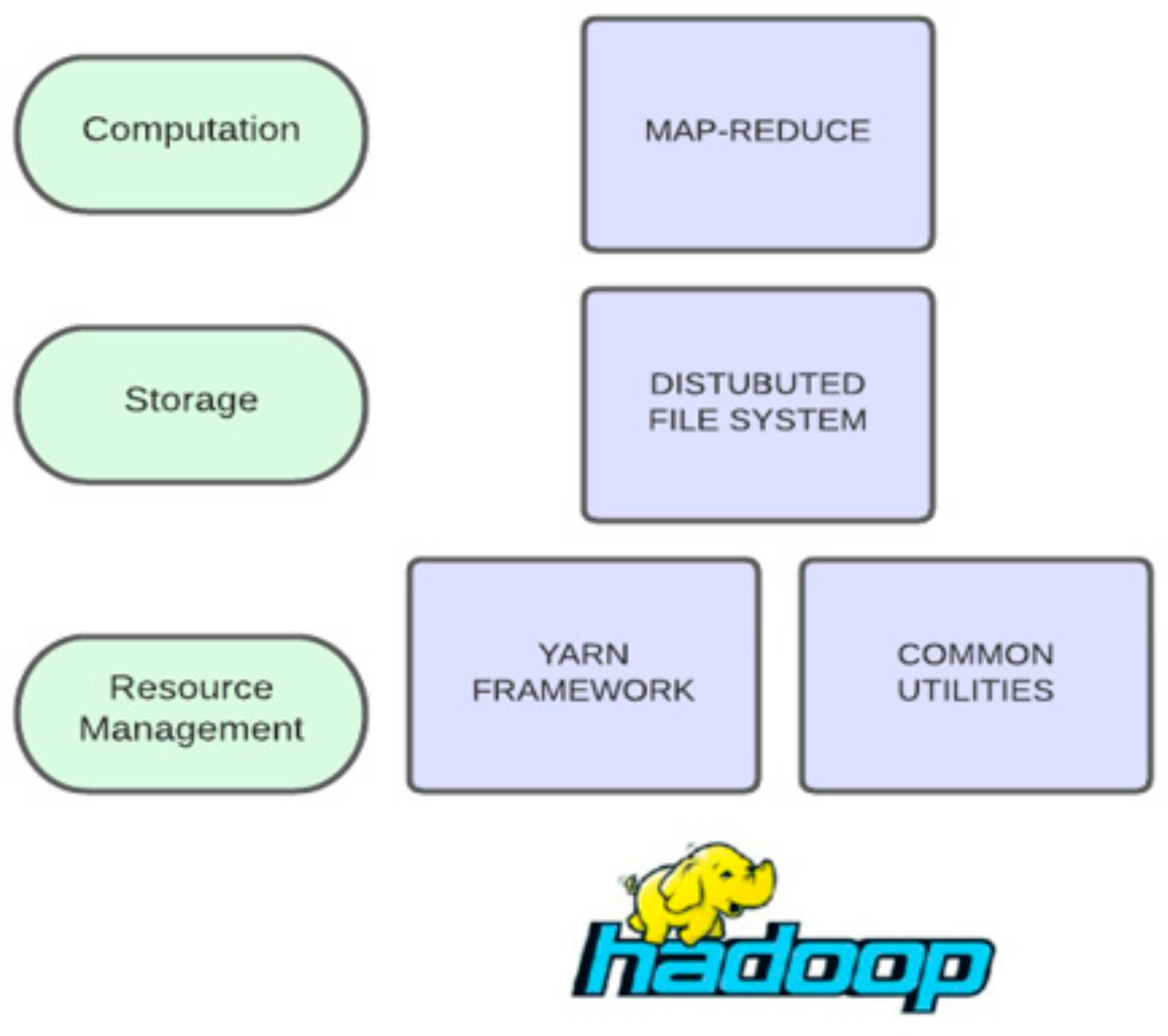
4.1.1. Apache Hadoop
4.1.2. Apache Spark
- Spark SQL: allows queries to be performed on data using SQL in conjunction with the Java, Scala, Python, and R programming languages.
- Spark Streaming: allows for the processing of streaming data, i.e., data that enters the system while calculations are already underway on the previous data. This feature is very important because in Hadoop, new data cannot be preprocessed during processing, but the entire data set must be available when a MapReduce process is started. Java, Scala, and Python programming languages are supported.
- MLlib: This is a machine learning library that allows this type of algorithm to run up to 100 times faster than Hadoop.
- GraphX: Provides an API (application programming interface) for graphical data, allowing for productive computations using iterative algorithms.
4.2. The Use of NoSQL Databases
- The creation of a complete patient profile that includes all tests performed on the patient and extracts useful relationships between them using data mining techniques. It is easy to modify and add new test data to the profile and compare old and new data.
- Early detection and containment of epidemics: big data has the potential to save human lives in situations where no other method can. Collecting data on emerging diseases, which have the potential to spread, widely, could be leveraged by applications that could serve as a tool for medical personnel and the extraction of risk indicators, such as the speed of spread, the number of people affected, symptoms, comparisons with data from previous epidemics, and suggesting the possibility of rapidly implementing population containment measures if necessary.
- The early diagnosis of rare diseases: it is possible to identify rare diseases that may have a common set of symptoms, but each of them or a subset of them is not a formidable indication. This observation is especially important because medical practitioners make their diagnoses primarily based on the experience and history of the patients they have examined in the past, which makes the process of early diagnosis of rare diseases extremely difficult, given the nature of human reasoning. Applications that have a large statistical dataset make it very easy to extract indicators to identify a disease and are an extremely useful tool for medical staff.
- Immediate consultation in real-time: in the case of laboratory data from patient tests, it is possible for medical personnel to draw immediate quantitative conclusions. As measurements from all types and sources of data can be visually displayed in single tables via graphs, there is no need for an independent review of individual tests by attending physicians.
4.3. Commercial Platforms for Healthcare Data Analytics
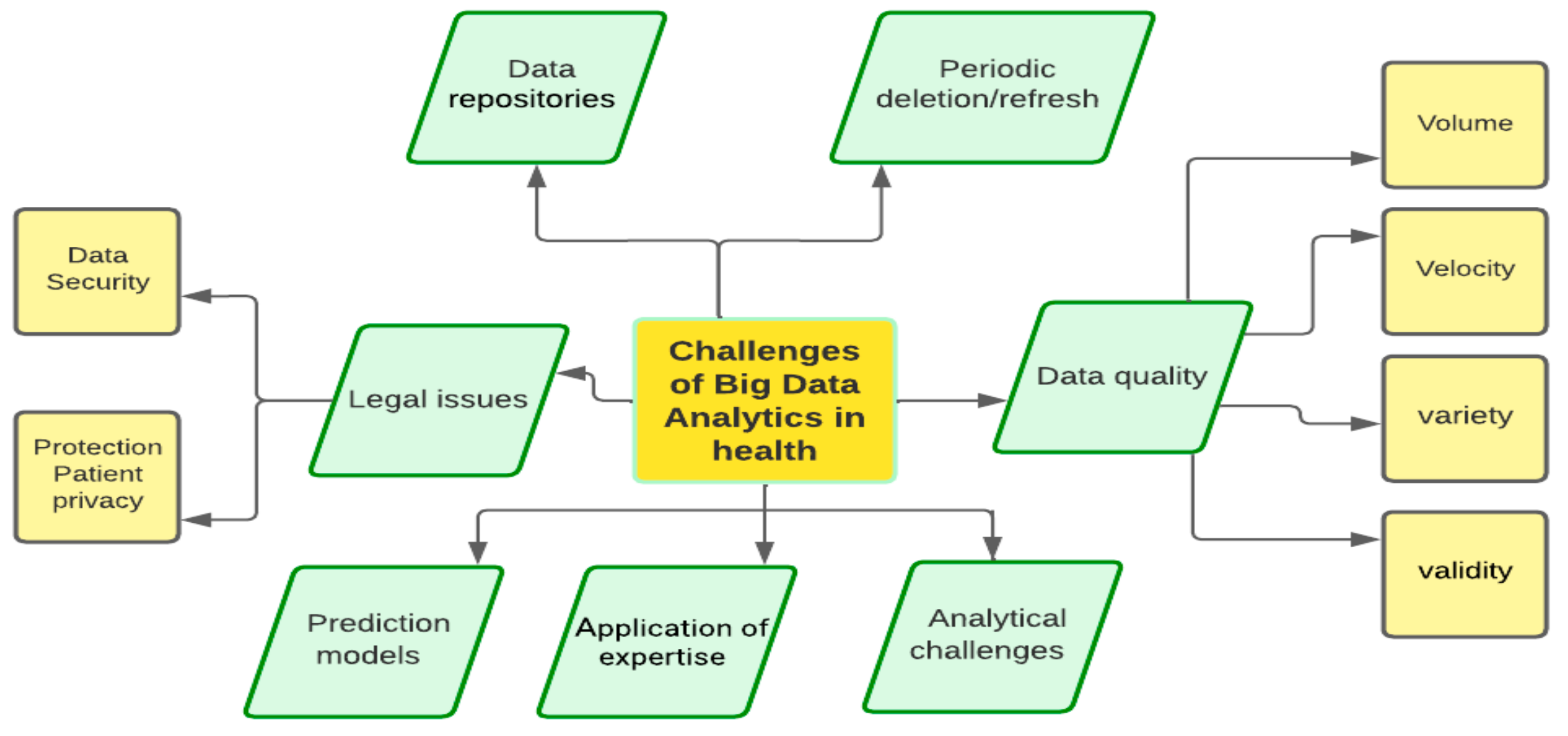
5. Technical and Organizational Challenges in Healthcare Big Data
- (a)
- Data repositories
- (b)
- Data quality
- Volume: For efficient exploitation of data, the ability to manage and store the volume of data as well as determine their size must be ensured. Scalability is almost always required, as needs are constantly increasing, as is the volume to be exploited.
- Velocity: Any organization must consider the speed with which it can store, process, and use available data and continuously improve its performance, especially when the rate of data arrival is fast.
- Validity: Ensuring the validity of the data is critical to the project’s needs and is a demanding process.
- Variety: Identifying all data sources, the technical challenges that each source imposes, and managing them effectively is an integral part of any big data analysis effort and is a major challenge.
- (c)
- Periodic data refresh
- (d)
- Analytics challenges
- (e)
- Application of expertise
- (f)
- Prediction models
- (g)
- Legal issues
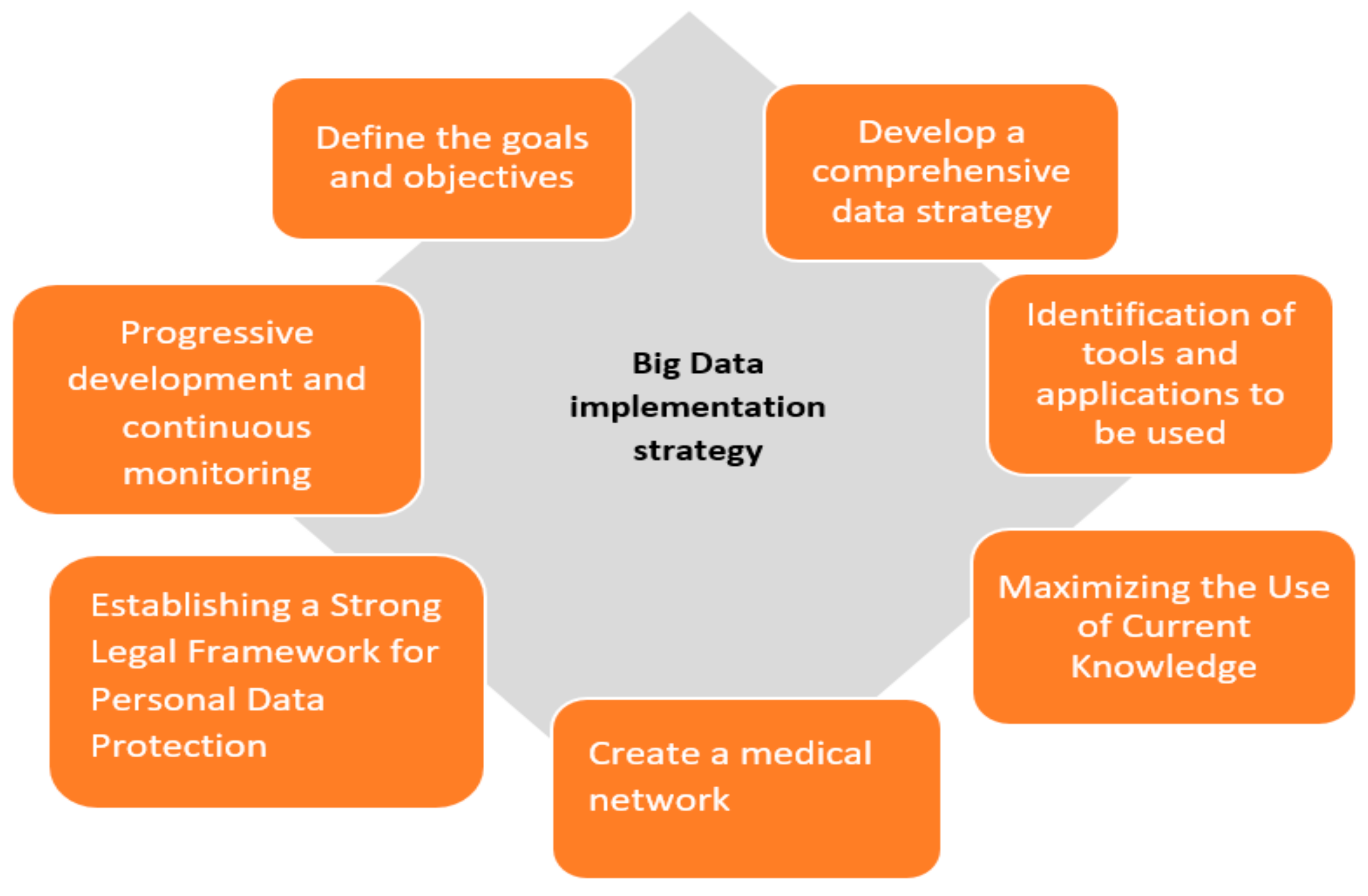
6. Proposed Strategies for Implementing Big Data Analytics in Healthcare for Smart City
- ✓
- Define the goals and objectives: Clearly define the goals and objectives of the big data analytics initiative, such as improving patient outcomes, reducing healthcare costs, or enhancing the quality of care.
- ✓
- Develop a comprehensive data strategy: Develop a comprehensive data strategy that outlines how the data will be collected, stored, processed, and analyzed to support the big data analytics initiative.
- ✓
- The identification of tools and applications to be used: Invest in the right technology and infrastructure to support big data analytics, such as cloud computing, data warehouses, and data analytics tools. The effective use of big data technologies has many benefits, including the ability to measure the effectiveness and efficiency of interventions in real clinical practice. At the same time, it offers the possibility of aggregating epidemiological, clinical, economic, and management data that can contribute to the generation of correlation information between the health of humans, economic resources, and health outcomes.
- ✓
- Maximizing the Use of Current Knowledge: It is imperative to adopt a perspective that integrates and uses existing knowledge. This approach will enhance data comprehension, facilitate the systematic generation of novel insights, and foster a data-driven culture within the medical institution.
- ✓
- Create a medical network: Collaborate with patients, healthcare providers, and researchers to ensure that the big data analytics project aligns with their needs and goals.
- ✓
- Establishing a Strong Legal Framework for Personal Data Protection: Data protection, in particular, plays a key role in the successful implementation of big data. Particular attention must be paid to the processing of personal data, and it is important to take into account the legal framework conditions and technological possibilities for its implementation.
- ✓
- Progressive development and continuous monitoring: A progressive integration can help better monitor and continually evaluate the big data analytics initiative to ensure that it is delivering value and positively impacting patient care.
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Manogaran, G.; Thota, C.; Lopez, D.; Vijayakumar, V.; Abbas, K.M.; Sundarsekar, R. Big Data Knowledge System in Healthcare. In Internet of Things and Big Data Technologies for Next Generation Healthcare; Bhatt, C., Dey, N., Ashour, A.S., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 133–157. [Google Scholar] [CrossRef]
- Munawar, H.S.; Qayyum, S.; Ullah, F.; Sepasgozar, S. Big Data and Its Applications in Smart Real Estate and the Disaster Management Life Cycle: A Systematic Analysis. Big Data Cogn. Comput. 2020, 4, 4. [Google Scholar] [CrossRef]
- Raghupathi, W.; Raghupathi, V. Big data analytics in healthcare: Promise and potential. Health Inf. Sci. Syst. 2014, 2, 3. [Google Scholar] [CrossRef] [PubMed]
- Bhaskaran, K.L.; Osei, R.S.; Kotei, E.; Agbezuge, E.Y.; Ankora, C.; Ganaa, E.D. A Survey on Big Data in Pharmacology, Toxicology and Pharmaceutics. Big Data Cogn. Comput. 2022, 6, 161. [Google Scholar] [CrossRef]
- Dash, S.; Shakyawar, S.K.; Sharma, M.; Kaushik, S. Big data in healthcare: Management, analysis and future prospects. J. Big Data 2019, 6, 54. [Google Scholar] [CrossRef]
- Strickland, N.H. PACS (picture archiving and communication systems): Filmless radiology. Arch. Dis. Child. 2000, 83, 82–86. [Google Scholar] [CrossRef]
- Janke, A.T.; Overbeek, D.L.; Kocher, K.E.; Levy, P.D. Exploring the Potential of Predictive Analytics and Big Data in Emergency Care. Ann. Emerg. Med. 2016, 67, 227–236. [Google Scholar] [CrossRef]
- Batko, K.; Ślęzak, A. The use of Big Data Analytics in healthcare. J. Big Data 2022, 9, 3. [Google Scholar] [CrossRef]
- Wang, L.; Alexander, C.A. Big Data in Medical Applications and Health Care. Curr. Res. Med. 2015, 6, 1–8. [Google Scholar] [CrossRef]
- Tresp, V.; Overhage, J.M.; Bundschus, M.; Rabizadeh, S.; Fasching, P.A.; Yu, S. Going Digital: A Survey on Digitalization and Large-Scale Data Analytics in Healthcare. Proc. IEEE 2016, 104, 2180–2206. [Google Scholar] [CrossRef]
- Harerimana, G.; Jang, B.; Kim, J.W.; Park, H.K. Health Big Data Analytics: A Technology Survey. IEEE Access 2018, 6, 65661–65678. [Google Scholar] [CrossRef]
- Bahri, S.; Zoghlami, N.; Abed, M.; Tavares, J.M.R.S. BIG DATA for Healthcare: A Survey. IEEE Access 2019, 7, 7397–7408. [Google Scholar] [CrossRef]
- Dhayne, H.; Haque, R.; Kilany, R.; Taher, Y. In Search of Big Medical Data Integration Solutions—A Comprehensive Survey. IEEE Access 2019, 7, 91265–91290. [Google Scholar] [CrossRef]
- Wang, L.; Alexander, C.A. Big data analytics in medical engineering and healthcare: Methods, advances and challenges. J. Med. Eng. Technol. 2020, 44, 267–283. [Google Scholar] [CrossRef]
- Shafqat, S.; Kishwer, S.; Rasool, R.U.; Qadir, J.; Amjad, T.; Ahmad, H.F. Big data analytics enhanced healthcare systems: A review. J. Supercomput. 2020, 76, 1754–1799. [Google Scholar] [CrossRef]
- Imran, S.; Mahmood, T.; Morshed, A.; Sellis, T. Big data analytics in healthcare A systematic literature review and roadmap for practical implementation. IEEE/CAA J. Autom. Sinica 2021, 8, 1–22. [Google Scholar] [CrossRef]
- Chattu, V.K. A Review of Artificial Intelligence, Big Data, and Blockchain Technology Applications in Medicine and Global Health. Big Data Cogn. Comput. 2021, 5, 41. [Google Scholar] [CrossRef]
- Al-Sai, Z.A.; Husin, M.H.; Syed-Mohamad, S.M.; Abdin, R.M.S.; Damer, N.; Abualigah, L.; Gandomi, A.H. Explore Big Data Analytics Applications and Opportunities: A Review. Big Data Cogn. Comput. 2022, 6, 157. [Google Scholar] [CrossRef]
- Zhou, H. Developing Natural Language Processing to Extract Complementary and Integrative Health Information from Electronic Health Record Data. In Proceedings of the 2022 IEEE 10th International Conference on Healthcare Informatics (ICHI), Rochester, MN, USA, 11–14 June 2022; pp. 474–475. [Google Scholar] [CrossRef]
- Piedrahita-Valdés, H.; Piedrahita-Castillo, D.; Bermejo-Higuera, J.; Guillem-Saiz, P.; Bermejo-Higuera, J.R.; Guillem-Saiz, J.; Sicilia-Montalvo, J.A.; Machío-Regidor, F. Vaccine Hesitancy on Social Media: Sentiment Analysis from June 2011 to April 2019. Vaccines 2021, 9, 28. [Google Scholar] [CrossRef]
- Khaloufi, H.; Abouelmehdi, K.; Beni-hssane, A.; Saadi, M. Security model for Big Healthcare Data Lifecycle. Procedia Comput. Sci. 2018, 141, 294–301. [Google Scholar] [CrossRef]
- Kumar, D.R.; Rajkumar, K.; Lalitha, K.; Dhanakoti, V. Bigdata in the Management of Diabetes Mellitus Treatment. In Internet of Things for Healthcare Technologies 73; Chakraborty, C., Banerjee, A., Kolekar, M.H., Garg, L., Chakraborty, B., Eds.; Springer Singapore: Singapore, 2021; pp. 293–324. [Google Scholar] [CrossRef]
- Alfred, R.; Obit, J.H. The roles of machine learning methods in limiting the spread of deadly diseases: A systematic review. Heliyon 2021, 7, e07371. [Google Scholar] [CrossRef]
- Wang, H.; Cui, Z.; Chen, Y.; Avidan, M.; Abdallah, A.B.; Kronzer, A. Predicting Hospital Readmission via Cost-Sensitive Deep Learning. IEEE/ACM Trans. Comput. Biol. Bioinf. 2018, 15, 1968–1978. [Google Scholar] [CrossRef] [PubMed]
- Leff, D.R.; Yang, G.-Z. Big Data for Precision Medicine. Engineering 2015, 1, 277–279. [Google Scholar] [CrossRef]
- Weitzman, E.R.; Kelemen, S.; Mandl, K.D. Surveillance of an Online Social Network to Assess Population-level Diabetes Health Status and Healthcare Quality. Online J. Public Health Inform. 2011, 3, ojphi.v3i3.3797. [Google Scholar] [CrossRef] [PubMed]
- Ram, S.; Zhang, W.; Williams, M.; Pengetnze, Y. Predicting Asthma-Related Emergency Department Visits Using Big Data. IEEE J. Biomed. Health Inform. 2015, 19, 1216–1223. [Google Scholar] [CrossRef] [PubMed]
- Odlum, M.; Yoon, S. What can we learn about the Ebola outbreak from tweets? Am. J. Infect. Control 2015, 43, 563–571. [Google Scholar] [CrossRef]
- Ma, Y.; Wang, Y.; Yang, J.; Miao, Y.; Li, W. Big Health Application System based on Health Internet of Things and Big Data. IEEE Access 2017, 5, 7885–7897. [Google Scholar] [CrossRef]
- Darwish, A.; Sayed, G.I.; Hassanien, A.E. The Impact of Implantable Sensors in Biomedical Technology on the Future of Healthcare Systems. In Intelligent Pervasive Computing Systems for Smarter Healthcare, 1st ed.; Sangaiah, A.K., Shantharajah, S., Theagarajan, P., Eds.; Wiley: Hoboken, NJ, USA, 2019; pp. 67–89. [Google Scholar] [CrossRef]
- Islam, M.S.; Hasan, M.M.; Wang, X.; Germack, H.D.; Noor-E-Alam, M. A Systematic Review on Healthcare Analytics: Application and Theoretical Perspective of Data Mining. Healthcare 2018, 6, 54. [Google Scholar] [CrossRef]
- Fisahn, C.; Sanders, F.H.; Moisi, M.; Page, J.; Oakes, P.C.; Wingerson, M.; Dettori, J.; Tubbs, R.S.; Chamiraju, P.; Nora, P.; et al. Descriptive analysis of unplanned readmission and reoperation rates after intradural spinal tumor resection. J. Clin. Neurosci. 2017, 38, 32–36. [Google Scholar] [CrossRef]
- Yu, Y.; Li, M.; Liu, L.; Li, Y.; Wang, J. Clinical big data and deep learning: Applications, challenges, and future outlooks. Big Data Min. Anal. 2019, 2, 288–305. [Google Scholar] [CrossRef]
- Simpao, A.F.; Ahumada, L.M.; Gálvez, J.A.; Rehman, M.A. A review of analytics and clinical informatics in health care. J. Med. Syst. 2014, 38, 45. [Google Scholar] [CrossRef]
- Khalifa, M. Health Analytics Types, Functions and Levels: A Review of Literature. Stud. Health Technol. Inform. 2018, 251, 137–140. [Google Scholar]
- Alharthi, H. Healthcare predictive analytics: An overview with a focus on Saudi Arabia. J. Infect. Public Health 2018, 11, 749–756. [Google Scholar] [CrossRef]
- Mosavi, N.S.; Santos, M.F. How Prescriptive Analytics Influences Decision Making in Precision Medicine. Procedia Comput. Sci. 2020, 177, 528–533. [Google Scholar] [CrossRef]
- Dicuonzo, G.; Galeone, G.; Shini, M.; Massari, A. Towards the Use of Big Data in Healthcare: A Literature Review. Healthcare 2022, 10, 1232. [Google Scholar] [CrossRef]
- Khan, P.; Kader, F.; Islam, S.M.R.; Rahman, A.B.; Kamal, S.; Toha, M.U.; Kwak, K.-S. Machine Learning and Deep Learning Approaches for Brain Disease Diagnosis: Principles and Recent Advances. IEEE Access 2021, 9, 37622–37655. [Google Scholar] [CrossRef]
- Chauhan, N.K.; Singh, K. A Review on Conventional Machine Learning vs. Deep Learning. In Proceedings of the 2018 International Conference on Computing, Power and Communication Technologies (GUCON), Greater Noida, India, 28–29 September 2018; pp. 347–352. [Google Scholar] [CrossRef]
- Xing, W.; Bei, Y. Medical Health Big Data Classification Based on KNN Classification Algorithm. IEEE Access 2020, 8, 28808–28819. [Google Scholar] [CrossRef]
- Wang, L.; Liu, J.; Zhu, S.; Gao, Y. Prediction of Linear B-Cell Epitopes Using AAT Scale. In Proceedings of the 2009 3rd International Conference on Bioinformatics and Biomedical Engineering, Beijing, China, 11–13 June 2009; pp. 1–4. [Google Scholar] [CrossRef]
- Venkatesan, C.; Karthigaikumar, P.; Paul, A.; Satheeskumaran, S.; Kumar, R. ECG Signal Preprocessing and SVM Classifier-Based Abnormality Detection in Remote Healthcare Applications. IEEE Access 2018, 6, 9767–9773. [Google Scholar] [CrossRef]
- Li, Y.; Wu, H. A Clustering Method Based on K-Means Algorithm. Phys. Procedia 2012, 25, 1104–1109. [Google Scholar] [CrossRef]
- Hasson, U.; Nastase, S.A.; Goldstein, A. Direct Fit to Nature: An Evolutionary Perspective on Biological and Artificial Neural Networks. Neuron 2020, 105, 416–434. [Google Scholar] [CrossRef]
- Thapa, S.; Adhikari, S.; Ghimire, A.; Aditya, A. Feature Selection Based Twin-Support Vector Machine for the Diagnosis of Parkinson’s Disease. In Proceedings of the 2020 IEEE 8th R10 Humanitarian Technology Conference (R10-HTC), Kuching, Malaysia, 1–3 December 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Xu, L.; Liang, G.; Liao, C.; Chen, G.-D.; Chang, C.-C. An Efficient Classifier for Alzheimer’s Disease Genes Identification. Molecules 2018, 23, 3140. [Google Scholar] [CrossRef]
- Ahmed, U.; Issa, G.F.; Khan, M.A.; Aftab, S.; Said, R.A.T.; Ghazal, T.M.; Ahmad, M. Prediction of Diabetes Empowered with Fused Machine Learning. IEEE Access 2022, 10, 8529–8538. [Google Scholar] [CrossRef]
- Wang, W.; Bu, F.; Lin, Z.; Zhai, S. Learning Methods of Convolutional Neural Network Combined with Image Feature Extraction in Brain Tumor Detection. IEEE Access 2020, 8, 152659–152668. [Google Scholar] [CrossRef]
- Zheng, B.; Yoon, S.W.; Lam, S.S. Breast cancer diagnosis based on feature extraction using a hybrid of K-means and support vector machine algorithms. Expert Syst. Appl. 2014, 41, 1476–1482. [Google Scholar] [CrossRef]
- van der Burgh, H.K.; Schmidt, R.; Westeneng, H.-J.; de Reus, M.A.; van den Berg, L.H.; van den Heuvel, M.P. Deep learning predictions of survival based on MRI in amyotrophic lateral sclerosis. Neuroimage Clin. 2016, 13, 361–369. [Google Scholar] [CrossRef] [PubMed]
- Ghiasi, M.M.; Zendehboudi, S.; Mohsenipour, A.A. Decision tree-based diagnosis of coronary artery disease: CART model. Comput. Methods Programs Biomed. 2020, 192, 105400. [Google Scholar] [CrossRef]
- Brinati, D.; Campagner, A.; Ferrari, D.; Locatelli, M.; Banfi, G.; Cabitza, F. Detection of COVID-19 Infection from Routine Blood Exams with Machine Learning: A Feasibility Study. J. Med. Syst. 2020, 44, 135. [Google Scholar] [CrossRef]
- Yao, L.-H.; Leung, K.-C.; Hong, J.-H.; Tsai, C.-L.; Fu, L.-C. A System for Predicting Hospital Admission at Emergency Department Based on Electronic Health Record Using Convolution Neural Network. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Toronto, ON, Canada, 11–14 October 2020; pp. 546–551. [Google Scholar] [CrossRef]
- Ambesange, S.; Vijayalaxmi, A.; Uppin, R.; Patil, S.; Patil, V. Optimizing Liver disease prediction with Random Forest by various Data balancing Techniques. In Proceedings of the 2020 IEEE International Conference on Cloud Computing in Emerging Markets (CCEM), Bengaluru, India, 6–7 November 2020; pp. 98–102. [Google Scholar] [CrossRef]
- Wadekar, A. Predicting Opioid Use Disorder (OUD) Using A Random Forest. In Proceedings of the 2019 IEEE 43rd Annual Computer Software and Applications Conference (COMPSAC), Milwaukee, WI, USA, 15–19 July 2019; Volume 1, pp. 960–961. [Google Scholar] [CrossRef]
- Aprilliani, U.; Rustam, Z. Osteoarthritis Disease Prediction Based on Random Forest. In Proceedings of the 2018 International Conference on Advanced Computer Science and Information Systems (ICACSIS), Yogyakarta, Indonesia, 27–28 October 2018; pp. 237–240. [Google Scholar] [CrossRef]
- Jamthikar, A.D.; Gupta, D.; Mantella, L.E.; Saba, L.; Johri, A.M.; Suri, J.S. Ensemble Machine Learning and Its Validation for Prediction of Coronary Artery Disease and Acute Coronary Syndrome Using Focused Carotid Ultrasound. IEEE Trans. Instrum. Meas. 2022, 71, 2503810. [Google Scholar] [CrossRef]
- Kaur, S.; Aggarwal, H.; Rani, R. Neurological disease prediction using ensembled Machine Learning Model. In Proceedings of the 2020 Sixth International Conference on Parallel, Distributed and Grid Computing (PDGC), Waknaghat, India, 6–8 November 2020; pp. 410–414. [Google Scholar] [CrossRef]
- Mienye, I.D.; Sun, Y.; Wang, Z. An improved ensemble learning approach for the prediction of heart disease risk. Inform. Med. Unlocked 2020, 20, 100402. [Google Scholar] [CrossRef]
- Alshamlan, H.; Taleb, H.B.; Al Sahow, A. A Gene Prediction Function for Type 2 Diabetes Mellitus using Logistic Regression. In Proceedings of the 2020 11th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 7–9 April 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Prodanova, K.; Uzunova, Y. Prediction of Graft Dysfunction in Pediatric Liver Transplantation by Logistic Regression. In Proceedings of the 2020 International Conference on Mathematics and Computers in Science and Engineering (MACISE), Madrid, Spain, 14–16 January 2020; pp. 260–263. [Google Scholar] [CrossRef]
- Lei, L. Prediction of Score of Diabetes Progression Index Based on Logistic Regression Algorithm. In Proceedings of the 2020 International Conference on Virtual Reality and Intelligent Systems (ICVRIS), Zhangjiajie, China, 18–19 July 2020; pp. 954–956. [Google Scholar] [CrossRef]
- Bhagyashree, S.R. Clinical Diagnosis of Alzheimer’s Disease Employing Support Vector Machine. In Proceedings of the 2022 IEEE International Conference on Distributed Computing and Electrical Circuits and Electronics (ICDCECE), Ballari, India, 23–24 April 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Shahajad, M.; Gambhir, D.; Gandhi, R. Features extraction for classification of brain tumor MRI images using support vector machine. In Proceedings of the 2021 11th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 28–29 January 2021; pp. 767–772. [Google Scholar] [CrossRef]
- Eke, C.S.; Jammeh, E.; Li, X.; Carroll, C.; Pearson, S.; Ifeachor, E. Early Detection of Alzheimer’s Disease with Blood Plasma Proteins Using Support Vector Machines. IEEE J. Biomed. Health Inform. 2021, 25, 218–226. [Google Scholar] [CrossRef]
- Sathiyanarayanan, P.; Pavithra, S.; Saranya, M.S.A.; Makeswari, M. Identification of Breast Cancer Using The Decision Tree Algorithm. In Proceedings of the 2019 IEEE International Conference on System, Computation, Automation and Networking (ICSCAN), Pondicherry, India, 29–30 March 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Fu, B.; Liu, P.; Lin, J.; Deng, L.; Hu, K.; Zheng, H. Predicting Invasive Disease-Free Survival for Early Stage Breast Cancer Patients Using Follow-Up Clinical Data. IEEE Trans. Biomed. Eng. 2019, 66, 2053–2064. [Google Scholar] [CrossRef]
- Ambesange, S.; Nadagoudar, R.; Uppin, R.; Patil, V.; Patil, S.; Patil, S. Liver Diseases Prediction using KNN with Hyper Parameter Tuning Techniques. In Proceedings of the 2020 IEEE Bangalore Humanitarian Technology Conference (B-HTC), Vijiyapur, India, 8–10 October 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Sandag, G.A.; Tedry, N.E.; Lolong, S. Classification of Lower Back Pain Using K-Nearest Neighbor Algorithm. In Proceedings of the 2018 6th International Conference on Cyber and IT Service Management (CITSM), Parapat, Indonesia, 7–9 August 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Pawlovsky, A.P. An Ensemble Based on Distances for a kNN Method for Heart Disease Diagnosis. In Proceedings of the 2018 International Conference on Electronics, Information, and Communication (ICEIC), Honolulu, HI, USA, 24–27 January 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Ripan, R.C.; Sarker, I.H.; Hossain, S.M.M.; Anwar, M.; Nowrozy, R.; Hoque, M.M.; Furhad, H. A Data-Driven Heart Disease Prediction Model Through K-Means Clustering-Based Anomaly Detection. SN Comput. Sci. 2021, 2, 112. [Google Scholar] [CrossRef]
- Vadyala, S.R.; Betgeri, S.N.; Sherer, E.A.; Amritphale, A. Prediction of the number of COVID-19 confirmed cases based on K-means-LSTM. Array 2021, 11, 100085. [Google Scholar] [CrossRef]
- Manivannan, P.; Devi, P.I. Dengue Fever Prediction Using K-Means Clustering Algorithm. In Proceedings of the 2017 IEEE International Conference on Intelligent Techniques in Control, Optimization and Signal Processing (INCOS), Srivilliputtur, India, 23–25 March 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Sarkar, A.; Hossain, S.K.S.; Sarkar, R. Human activity recognition from sensor data using spatial attention-aided CNN with genetic algorithm. Neural Comput. Appl. 2022, 35, 5165–5191. [Google Scholar] [CrossRef]
- Xu, Q.; Wang, X.; Jiang, H. Convolutional neural network for breast cancer diagnosis using diffuse optical tomography. Visual Computing for Industry, Biomed. Art 2019, 2, 6. [Google Scholar] [CrossRef]
- Mohammed, M.A.; Ghani, M.K.A.; Hamed, R.I.; Ibrahim, D.A.; Abdullah, M.K. Artificial neural networks for automatic segmentation and identification of nasopharyngeal carcinoma. J. Comput. Sci. 2017, 21, 263–274. [Google Scholar] [CrossRef]
- Costa, F.F. Big data in biomedicine. Drug Discov. Today 2014, 19, 433–440. [Google Scholar] [CrossRef]
- Landset, S.; Khoshgoftaar, T.M.; Richter, A.N.; Hasanin, T. A survey of open source tools for machine learning with big data in the Hadoop ecosystem. J. Big Data 2015, 2, 24. [Google Scholar] [CrossRef]
- Shvachko, K.; Kuang, H.; Radia, S.; Chansler, R. The Hadoop Distributed File System. In Proceedings of the 2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST), Incline Village, NV, USA, 3–7 May 2010; pp. 1–10. [Google Scholar] [CrossRef]
- Azeroual, O.; Fabre, R. Processing Big Data with Apache Hadoop in the Current Challenging Era of COVID-19. Big Data Cogn. Comput. 2021, 5, 12. [Google Scholar] [CrossRef]
- Fu, J.; Sun, J.; Wang, K. SPARK—A Big Data Processing Platform for Machine Learning. In Proceedings of the 2016 International Conference on Industrial Informatics—Computing Technology, Intelligent Technology, Industrial Information Integration (ICIICII), Wuhan, China, 3–4 December 2016; pp. 48–51. [Google Scholar] [CrossRef]
- Salloum, S.; Dautov, R.; Chen, X.; Peng, P.X.; Huang, J.Z. Big data analytics on Apache Spark. Int. J. Data Sci. Anal. 2016, 1, 145–164. [Google Scholar] [CrossRef]
- Liu, W.; Li, Q.; Cai, Y.; Li, Y.; Li, X. A Prototype of Healthcare Big Data Processing System Based on Spark. In Proceedings of the 2015 8th International Conference on Biomedical Engineering and Informatics (BMEI), Shenyang, China, 14–16 October 2015; pp. 516–520. [Google Scholar] [CrossRef]
- Ed-daoudy, A.; Maalmi, K. Application of Machine Learning Model on Streaming Health Data Event in Real-Time to Predict Health Status Using Spark. In Proceedings of the 2018 International Symposium on Advanced Electrical and Communication Technologies (ISAECT), Rabat, Morocco, 21–23 November 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Ed-Daoudy, A.; Maalmi, K. Real-Time Machine Learning for Early Detection of Heart Disease Using Big Data Approach. In Proceedings of the 2019 International Conference on Wireless Technologies, Embedded and Intelligent Systems (WITS), Fez, Morocco, 3–4 April 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Chandra, D.G. BASE analysis of NoSQL database. Future Gener. Comput. Syst. 2015, 52, 13–21. [Google Scholar] [CrossRef]
- Williams, A.J.; Harland, L.; Groth, P.; Pettifer, S.; Chichester, C.; Willighagen, E.L.; Evelo, C.T.; Blomberg, N.; Ecker, G.; Goble, C.; et al. Open PHACTS: Semantic interoperability for drug discovery. Drug Discov. Today 2012, 17, 1188–1198. [Google Scholar] [CrossRef] [PubMed]
- Khazaei, H.; Mench-Bressan, N.; McGregor, C.; Pugh, J.E. Health Informatics for Neonatal Intensive Care Units: An Analytical Modeling Perspective. IEEE J. Transl. Eng. Health Med. 2015, 3, 1–9. [Google Scholar] [CrossRef] [PubMed]
- McGregor, C.; Inibhunu, C.; Glass, J.; Doyle, I.; Gates, A.; Madill, J.; Pugh, J.E. Health Analytics as a Service with Artemis Cloud: Service Availability. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020; pp. 5644–5648. [Google Scholar] [CrossRef]
- Salvi, E.; Parimbelli, E.; Basadonne, A.; Viani, N.; Cavallini, A.; Micieli, G.; Quaglini, S.; Sacchi, L. Exploring IBM Watson to Extract Meaningful Information from the List of References of a Clinical Practice Guideline. In Artificial Intelligence in Medicine; Springer: Cham, Switzerland, 2017; pp. 193–197. [Google Scholar] [CrossRef]
- Contractor, D.; Telang, A. (Eds.) Applications of Cognitive Computing Systems and IBM Watson; Springer: Singapore, 2017. [Google Scholar] [CrossRef]
- Koutkias, V. From Data Silos to Standardized, Linked, and FAIR Data for Pharmacovigilance: Current Advances and Challenges with Observational Healthcare Data. Drug Saf. 2019, 42, 583–586. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Reference | Year | Overview |
|---|---|---|---|
| 1 | [9] | 2015 | This survey examines the utilization of big data in healthcare and explores the benefits it can bring to the healthcare industry. It delves into the various data sources that should be utilized and brought together for analysis. Numerous difficulties with big healthcare data are also addressed. |
| 2 | [10] | 2016 | This paper addresses both the difficulties and potential of big data in the medical industry, including the pipeline for processing it. It also presents a variety of machine-learning techniques for mining and analyzing data. |
| 3 | [11] | 2018 | This paper gives an in-depth look at the technologies and techniques used to create analytical applications in healthcare. It examines the progression of healthcare big data and the data mining algorithms used, including their general usage and specific applications in healthcare. Additionally, it covers the essential platforms and technologies needed for a successful health analytics solution. |
| 4 | [12] | 2019 | This paper discusses the significant impacts of big data on various medical actors and healthcare providers, as well as the difficulties in utilizing all of this big data and the applications that are already accessible. |
| 5 | [13] | 2019 | In this article, the authors investigate the various technologies, tools, and applications used for data integration in healthcare. They also address the current difficulties encountered when integrating large amounts of healthcare data and explore potential future research opportunities in this field. |
| 6 | [14] | 2020 | This paper covers technological advances and advancements in big data analytics in healthcare as well as infrastructure, artificial intelligence (AI), and cloud computing. In addition, it also explores the primary techniques, frameworks, and resources for big healthcare data analytics in medical engineering. |
| 7 | [15] | 2020 | This paper provides an overview of big data analytics systems used in healthcare and highlights the various algorithms, techniques, and tools that can be implemented in cloud, wireless, and internet of things environments. The authors propose the concept of SmartHealth as a way to bring all these platforms together and have a unified standard learning healthcare system for the future. |
| 8 | [16] | 2021 | This study places particular emphasis on applications of big data analytics for the healthcare field, especially NoSQL databases. The authors also propose a BDA architecture dubbed Med-BDA for the healthcare industry to address BDA’s issues in this field. They also present strategies to make their proposals successful, and the authors in this article also make a comparison with the literature to justify the importance of their work. |
| 9 | [17] | 2021 | This article discusses the use of ML, big data, and blockchain technology in medicine, healthcare, public health surveillance, and case prediction during the COVID-19 pandemic and other epidemics. It also covers potential challenges for medical professionals and health technologists in creating future-oriented models to enhance human life. |
| 10 | [5] | 2022 | This paper examines the fundamental concepts of big data, its management, analysis, and potential applications, specifically in the field of health. |
| 11 | [8] | 2022 | The primary objective of this paper is to gather and categorize the utilization of big data from various perspectives and to provide a comprehensive analysis of the application of big data analytics within medical institutions in Poland. |
| 12 | [18] | 2022 | This study examines the literature on big data applications in the context of the COVID-19 pandemic, specifically focusing on their use in four key industries, including healthcare. By comparing the utilization of big data applications before and during the pandemic, the paper provides an overview of the current significance of big data in the COVID-19 era and how these applications align with relevant big data analytics models. |
| 13 | [4] | 2022 | This survey explores the utilization of big data (BD) in the fields of pharmacy, pharmacology, and toxicology. It examines how researchers have employed BD to address issues and discover solutions. The survey uses a comparative analysis to examine the application of big data in these three domains. |
| Data | Format of Representation |
|---|---|
| First and Last Name | Text |
| Gender | Code |
| Date of birth | Date |
| Clinical notes | Text |
| Laboratory tests, X-ray tests | Code/Number |
| Radiological examinations | Image/Signal |
| Medications | Number/code/Text |
| Vaccines | Code |
| Application of Machine Learning in Medicine | ||
|---|---|---|
| Year | Context of Research | Technique Used |
| 2020 | Using various data balancing techniques to improve liver disease prediction [55] | Random Forest |
| 2019 | Predicting Opioid Use Disorder [56] | |
| 2018 | Prediction of osteoarthritis disease [57] | |
| 2022 | Prediction of Coronary Artery Disease and Acute Coronary Syndrome [58] | Ensemble Learning |
| 2020 | Neurological disease prediction [59] | |
| 2020 | Prediction of heart disease risk [60] | |
| 2022 | A Gene Prediction Function for Type 2 Diabetes Mellitus [61] | Logistic regression |
| 2020 | Prediction of graft dysfunction in pediatric liver transplantation [62] | |
| 2020 | Diabetes Progression Index Score Prediction [63] | |
| 2022 | Clinical Diagnosis of Alzheimer’s Disease [64] | Support vector Machines |
| 2021 | Classification of MRI images of brain tumors [65] | |
| 2021 | Early Alzheimer’s Disease Detection Using Blood Plasma Proteins [66] | |
| 2019 | Breast Cancer Detection Using the Decision Tree [67] | Decision trees |
| 2019 | Predicting breast cancer survivability [68] | |
| 2020 | Liver Diseases Prediction using KNN [69] | K nearest Neighbors |
| 2018 | Lower Back Pain Classification [70] | |
| 2018 | Heart disease diagnosis [71] | |
| 2021 | Prediction of cardiovascular disease via anomaly detection based on grouping [72] | K-means |
| 2021 | Estimated number of confirmed COVID-19 cases [73] | |
| 2017 | Dengue fever forecast [74] | |
| 2022 | Recognizing human activity from sensor data [75] | Neural Networks |
| 2019 | Classify lesions in optical tomographic images of breast masses [76] | |
| 2017 | Automatic identification of nasopharyngeal carcinoma [77] | |
| Hadoop | Spark | IBM Watson | Artemis | Open PHACTS | |
|---|---|---|---|---|---|
| Data Storage | HDFS (Hadoop Distributed File System) | RDDs (Resilient Distributed Datasets) | IBM Cloud Object Storage | MySQL, PostgreSQL, Oracle | Virtuoso Universal Server |
| Data Processing | Map Reduce, Hadoop Ecosystem (Pig, Hive, HBase, etc.) | Spark Core, Spark SQL, Spark Streaming, GraphX, MLlib | Watson Studio, SPSS Modeler | Cypher Query Language, RDF triplestores | SPARQL, RDF triplestores |
| Data Integration | Apache Nifi, Talend, Pentaho | Apache Nifi, Talend, Pentaho | IBM InfoSphere DataStage, Talend | ETL tools, REST APIs | ETL tools, REST APIs |
| Healthcare Applications | Clinical Decision Support, Drug Discovery, Genomics, Imaging Analytics | Predictive Analytics, Electronic Health Records Analysis, Clinical Decision Support | Drug Discovery, Genomics, Precision Medicine | Clinical Trials, Patient Data Management | Drug Discovery, Pharmacovigilance, Disease Networks |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Berros, N.; El Mendili, F.; Filaly, Y.; El Bouzekri El Idrissi, Y. Enhancing Digital Health Services with Big Data Analytics. Big Data Cogn. Comput. 2023, 7, 64. https://doi.org/10.3390/bdcc7020064
Berros N, El Mendili F, Filaly Y, El Bouzekri El Idrissi Y. Enhancing Digital Health Services with Big Data Analytics. Big Data and Cognitive Computing. 2023; 7(2):64. https://doi.org/10.3390/bdcc7020064
Chicago/Turabian StyleBerros, Nisrine, Fatna El Mendili, Youness Filaly, and Younes El Bouzekri El Idrissi. 2023. "Enhancing Digital Health Services with Big Data Analytics" Big Data and Cognitive Computing 7, no. 2: 64. https://doi.org/10.3390/bdcc7020064
APA StyleBerros, N., El Mendili, F., Filaly, Y., & El Bouzekri El Idrissi, Y. (2023). Enhancing Digital Health Services with Big Data Analytics. Big Data and Cognitive Computing, 7(2), 64. https://doi.org/10.3390/bdcc7020064