
A Mirror to Human Question Asking: Analyzing the Akinator Online Question Game


Abstract
1. Introduction
2. Materials and Methods
2.1. Dataset
2.2. Methods
2.2.1. Question Analysis
2.2.2. Topic Modelling
LDA Topic Modelling
BERT Topic Modelling
3. Results
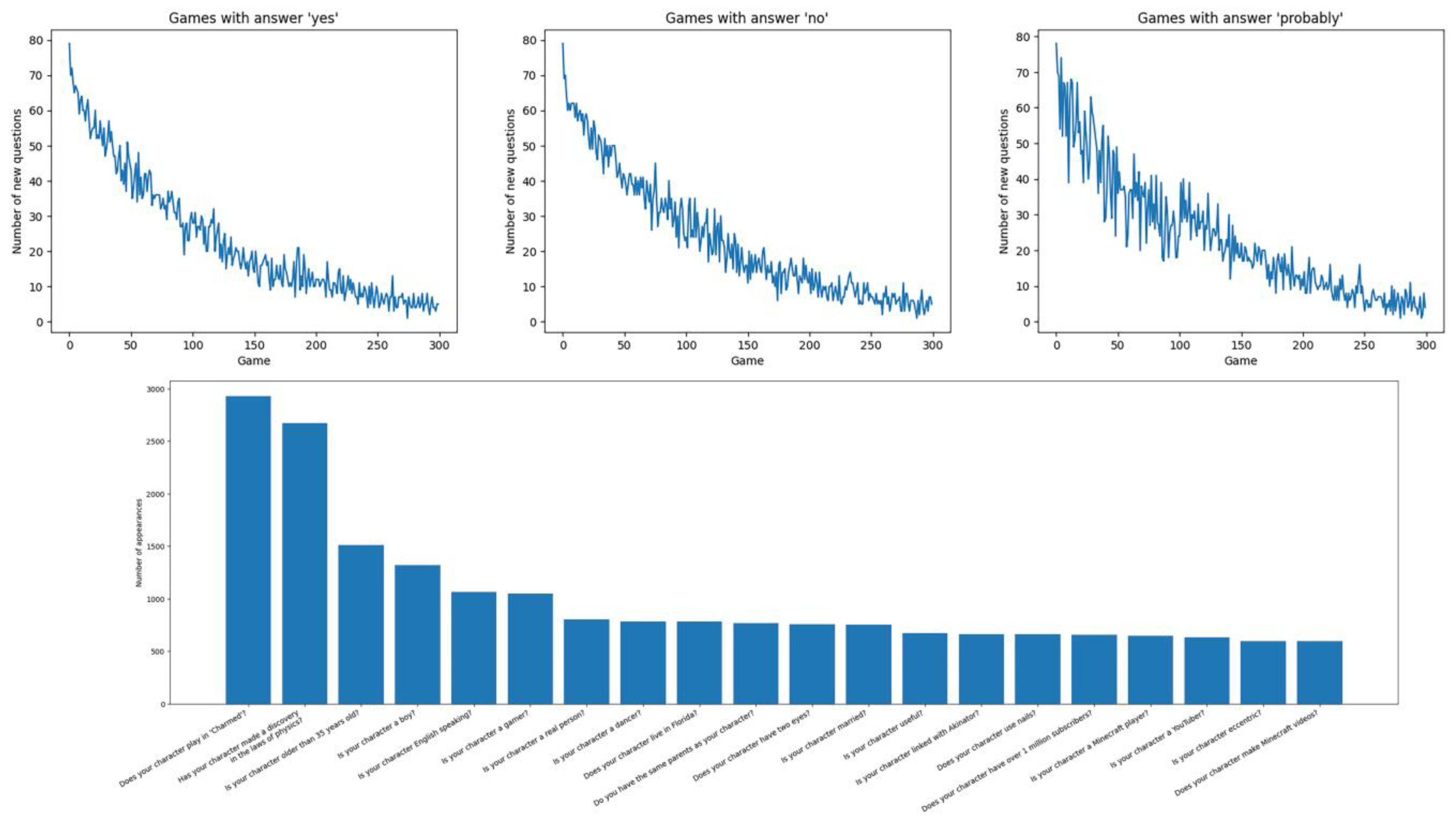
3.1. Question Analysis
3.2. LDA Topic Modelling Analysis
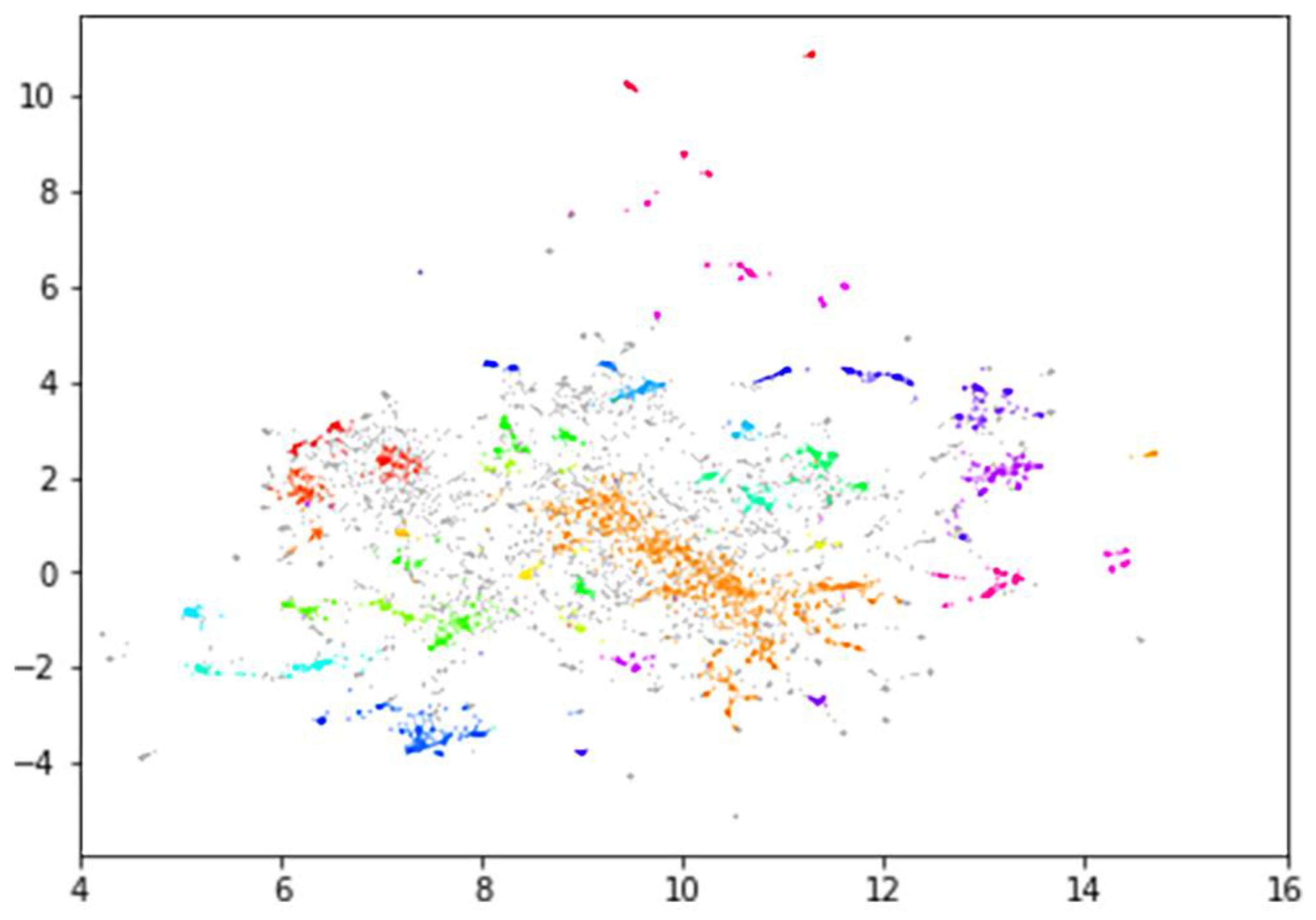
3.3. BERT Topic Modelling Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ruggeri, A.; Xu, F.; Lombrozo, T. Effects of explanation on children’s question asking. Cognition 2019, 191, 103966. [Google Scholar] [CrossRef]
- De Simone, C.; Ruggeri, A. What is a good question asker better at? From unsystematic generalization to adult-like selectivity across childhood. Cogn. Dev. 2021, 59, 101082. [Google Scholar] [CrossRef]
- Ruggeri, A.; Lombrozo, T.; Griffiths, T.L.; Xu, F. Sources of developmental change in the efficiency of information search. Dev. Psychol. 2016, 52, 2159–2173. [Google Scholar] [CrossRef] [PubMed]
- Rothe, A.; Lake, B.M.; Gureckis, T.M. Do people ask good questions? Comput. Brain Behav. 2018, 1, 69–89. [Google Scholar] [CrossRef]
- Getzels, J.W. The problem of the problem. New Dir. Methodol. Soc. Behav. Sci. Quest. Fram. Response Consistency 1982, 11, 37–49. [Google Scholar]
- Gottlieb, J. The effort of asking good questions. Nat. Hum. Behav. 2021, 5, 823–824. [Google Scholar] [CrossRef]
- Nelson, J.D. Finding useful questions: On Bayesian diagnosticity, probability, impact, and information gain. Psychol. Rev. 2005, 112, 979–999. [Google Scholar] [CrossRef]
- Wang, Z.; Lake, B.M. Modeling question asking using neural program generation. arXiv 2019, arXiv:1907.09899. [Google Scholar]
- Crupi, V.; Nelson, J.D.; Meder, B.; Cevolani, G.; Tentori, K. Generalized information theory meets human cognition: Introducing a unified framework to model uncertainty and information search. Cogn. Sci. 2018, 42, 1410–1456. [Google Scholar] [CrossRef]
- Coenen, A.; Nelson, J.D.; Gureckis, T.M. Asking the right questions about the psychology of human inquiry: Nine open challenges. Psychon. Bull. Rev. 2019, 26, 1548–1587. [Google Scholar] [CrossRef]
- Hawkins, R.; Goodman, N. Why do you ask? The informational dynamics of questions and answers. PsyArXiv 2017. [Google Scholar] [CrossRef]
- Boyce-Jacino, C.; DeDeo, S. Cooperation, interaction, search: Computational approaches to the psychology of asking and answering questions. PsyArXiv 2021. [Google Scholar] [CrossRef]
- Myung, J.I.; Pitt, M.A. Optimal experimental design for model discrimination. Psychol. Rev. 2009, 116, 499–518. [Google Scholar] [CrossRef] [PubMed]
- Gureckis, T.M.; Markant, D.B. Self-directed learning: A cognitive and computational perspective. Perspect. Psychol. Sci. 2012, 7, 464–481. [Google Scholar] [CrossRef] [PubMed]
- Damassino, N. The questioning Turing test. Minds Mach. 2020, 30, 563–587. [Google Scholar] [CrossRef]
- Bloom, B.S.; Engelhart, M.D.; Furst, E.J.; Hill, W.H.; Krathwohl, D.R. Taxonomy of Educational Objectives: The Classification of Educational Goals: Handbook 1: Cognitive Domain; David McKay Company, Inc.: New York, NY, USA, 1956. [Google Scholar]
- Hu, W.; Shi, Q.Z.; Han, Q.; Wang, X.; Adey, P. Creative scientific problem finding and its developmental trend. Creat. Res. J. 2010, 22, 46–52. [Google Scholar] [CrossRef]
- Zhangozha, A.R. On techniques of expert systems on the example of the Akinator program. Artif. Intell. Sci. J. 2020, 25, 7–13. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Hass, R. Modeling Topics in the Alternative Uses Task. PsyArXiv 2018. [Google Scholar] [CrossRef]
- Vayansky, I.; Kumar, S.A.P. A review of topic modeling methods. Inf. Syst. 2020, 94, 101582. [Google Scholar] [CrossRef]
- Rehurek, R.; Sojka, P. Gensim—Python Framework for Vector Space Modelling; NLP Centre, Faculty of Informatics, Masaryk University: Brno, Czech Republic, 2011; Volume 3. [Google Scholar]
- Bianchi, F.; Terragni, S.; Hovy, D. Pre-training is a hot topic: Contextualized document embeddings improve topic coherence. arXiv 2020, arXiv:2004.03974. [Google Scholar]
- Angelov, D. Top2Vec: Distributed representations of topics. arXiv 2020, arXiv:2008.09470. [Google Scholar]
- Grootendorst, M. BERTopic: Neural topic modeling with a class-based TF-IDF procedure. arXiv 2022, arXiv:2203.05794. [Google Scholar]
- Zope, B.; Mishra, S.; Shaw, K.; Vora, D.R.; Kotecha, K.; Bidwe, R.V. Question answer system: A state-of-art representation of quantitative and qualitative analysis. Big Data Cogn. Comput. 2022, 6, 109. [Google Scholar] [CrossRef]
- Daoud, M. Topical and non-topical approaches to measure similarity between Arabic questions. Big Data Cogn. Comput. 2022, 6, 87. [Google Scholar] [CrossRef]
- Simanjuntak, L.F.; Mahendra, R.; Yulianti, E. We know you are living in bali: Location prediction of Twitter users using BERT language model. Big Data Cogn. Comput. 2022, 6, 77. [Google Scholar] [CrossRef]
- Rafner, J.; Biskjær, M.M.; Zana, B.; Langsford, S.; Bergenholtz, C.; Rahimi, S.; Carugati, A.; Noy, L.; Sherson, J. Digital games for creativity assessment: Strengths, weaknesses and opportunities. Creat. Res. J. 2022, 34, 28–54. [Google Scholar] [CrossRef]
- Kumar, A.A. Semantic memory: A review of methods, models, and current challenges. Psychon. Bull. Rev. 2021, 28, 40–80. [Google Scholar] [CrossRef] [PubMed]
- Kumar, A.A.; Steyvers, M.; Balota, D.A. A critical review of network-based and distributional approaches to semantic memory structure and processes. Top. Cogn. Sci. 2022, 14, 54–77. [Google Scholar] [CrossRef]
- Abraham, A.; Bubic, A. Semantic memory as the root of imagination. Front. Psychol. 2015, 6, 325. [Google Scholar] [CrossRef] [PubMed]
- Beaty, R.E.; Kenett, Y.N.; Hass, R.W.; Schacter, D.L. Semantic memory and creativity: The costs and benefits of semantic memory structure in generating original ideas. Think. Reason. 2022, 1–35. [Google Scholar] [CrossRef]
- Kenett, Y.N.; Faust, M. A semantic network cartography of the creative mind. Trends Cogn. Sci. 2019, 23, 271–274. [Google Scholar] [CrossRef]
- Kenett, Y.N.; Humphries, S.; Chatterjee, A. A thirst for knowledge: Grounding creativity, curiosity, and aesthetic experience in memory and reward neural systems. Creat. Res. J. 2023, 1–15. [Google Scholar] [CrossRef]
- Arreola, N.J.; Reiter-Palmon, R. The effect of problem construction creativity on solution creativity across multiple everyday problems. Psychol. Aesthet. Creat. Arts 2016, 10, 287–295. [Google Scholar] [CrossRef]
- Paravizo, E.; Crilly, N. Computer games for design creativity research: Opportunities and challenges. In Proceedings of the International Conference on-Design Computing and Cognition, Glasgow, UK, 4–6 July 2022; pp. 379–396. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Question | Run 1—November 2021 | Run 2—December 2021 | Total |
|---|---|---|---|
| Is your character a girl? | 1132 | 2164 | 3296 |
| Is your character a Youtuber? | 1603 | 8 | 1611 |
| Does your character make Youtube videos? | 1115 | 0 | 1115 |
| Is your character known for making Youtube videos? | 1007 | 0 | 1007 |
| Is your character a woman? | 143 | 42 | 185 |
| Is your character real? | 0 | 268 | 268 |
| Is your character a real person? | 0 | 413 | 413 |
| Does your character know your name? | 0 | 337 | 337 |
| Is your character a female? | 0 | 920 | 920 |
| Does your character personally know you? | 0 | 651 | 651 |
| Have you ever talked to your character? | 0 | 8 | 8 |
| Is your character a make? | 0 | 189 | 189 |
| 5000 | 5000 | 10,000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sasson, G.; Kenett, Y.N. A Mirror to Human Question Asking: Analyzing the Akinator Online Question Game. Big Data Cogn. Comput. 2023, 7, 26. https://doi.org/10.3390/bdcc7010026
Sasson G, Kenett YN. A Mirror to Human Question Asking: Analyzing the Akinator Online Question Game. Big Data and Cognitive Computing. 2023; 7(1):26. https://doi.org/10.3390/bdcc7010026
Chicago/Turabian StyleSasson, Gal, and Yoed N. Kenett. 2023. "A Mirror to Human Question Asking: Analyzing the Akinator Online Question Game" Big Data and Cognitive Computing 7, no. 1: 26. https://doi.org/10.3390/bdcc7010026
APA StyleSasson, G., & Kenett, Y. N. (2023). A Mirror to Human Question Asking: Analyzing the Akinator Online Question Game. Big Data and Cognitive Computing, 7(1), 26. https://doi.org/10.3390/bdcc7010026