1. Introduction
The introduction of Large Language Models (LLMs) has taken the world by storm, and society’s reaction has been anything but unanimous, ranging from humorous amusement to catastrophic fear. Among the most prominent LLMs are OpenAI’s GPT-3, GPT-3.5, and GPT-4 (ordered oldest to newest). GPT-3 and GPT-4 are powerful and flexible models that can be fine-tuned to perform a wide variety of natural language processing tasks, while GPT-3.5 turbo is a variant of the other two, specifically designed to perform well in conversational contexts. All three belong to the family of generative pre-trained transformer (GPT) models [
1] that are trained on massive amounts of textual data to learn patterns and relationships in text [
2,
3]. Their power and versatility for accomplishing a range of tasks with incredible human-like finesse have led to a boom in their popularity in society and among researchers across disciplines.
As LLMs secure their role in our lives as useful tools for everyday tasks such as composing emails, writing essays, debugging code, and answering questions, the need to understand the behavior and risks of these models is ever more important [
4,
5,
6,
7]. There has been a spike in research dedicated to this topic, surrounded by a debate about the nature of the capabilities of LLMs [
8]. Some researchers have suggested that the impressive performance of LLMs on difficult reasoning tasks is indicative of an early version of general artificial intelligence [
9]. Many others argue that LLMs exhibit nothing resembling true understanding because they lack a grasp of meaning [
10], arguing that they perform well but for the wrong reasons [
8]. In fact, much of the success of LLMs at human-like reasoning tasks can be attributed to spurious correlations rather than actual reasoning capabilities [
11].
Despite opposing views regarding the nature of intelligence exhibited by LLMs, a relatively undisputed topic is the issue of bias. Bias, in the context of LLMs, has recently been studied as the presence of misrepresentations and distortions of reality that result in favouring certain groups or ideas, perpetuating stereotypes, or making incorrect assumptions [
12]. While these biases can be influenced by many factors, they largely originate from biases in the massive text corpora on which the models are trained. This can be due to certain groups or ideas being underrepresented in the training data or to implicit biases present in the training data themselves. Thus, the output produced by LLMs inevitably reflects stereotypes and inequalities prevalent in society. This is problematic since exposure through interaction with LLMs could lead to perpetuating existing stereotypes and even the creation of new ones [
12,
13].
As LLMs become more integrated into our lives, it is even more important to investigate the biases produced by them. This includes understanding our own human biases as well, since LLMs act as “psycho-social mirrors” [
14] that reflect human features of personality as well as societal views and tendencies. Thus, it is important to investigate the individual cognitive sphere in conjunction with LLM behavior to understand how our individual and societal tendencies are diffused into the knowledge possessed by artificial intelligence agents. A very natural yet negative human phenomena is affective bias [
15], the tendency to prioritize the processing of emotionally negative events compared to positive ones [
16]. An example of affective bias is attributing negative attitudes to neutral concepts, such as the attribution of negative perceptions to the neutral concept
math. These types of biases and stereotypes are inherited by LLMs, adopting perceptions of neutral concepts that deviate significantly from neutrality as a result of our own biased perceptions. It should be the goal of researchers working on developing LLMs to understand such nuanced biases in humans to ensure that LLMs adopt neutral unbiased views of concepts or phenomena that have been historically stigmatized or misrepresented. In doing so, regular widespread interaction with LLMs might actually contribute to a reduction in the harmful biases held by humans.
In this work, we investigate biases produced by LLMs, specifically GPT-3, GPT-3.5, and GPT-4, regarding their perception of academic disciplines, particularly math, science, and other STEM fields. In many societies, these disciplines have a reputation for being difficult [
17]. Math in particular, which is arguably the language of science, has been known to cause a great deal of anxiety in many people. This anxiety is a global phenomenon [
17,
18], and it is deeply rooted, beginning in childhood and persisting throughout adulthood. Unpleasant feelings about math may already begin to develop as early as first grade [
19]. Children pick up on the anxieties of their teachers and parents [
20], similar to how LLMs absorb biases from training data. Unfortunately, negative perceptions of math have become so commonplace that it is not unusual to hear people identify themselves as not “math people”. While this kind of self-categorization may seem harmless, math anxiety can actually have severe individual and societal consequences [
17,
21,
22,
23]. Math anxiety may cause individuals to avoid situations in which math is involved, ultimately having a negative impact on performance. This avoidance tendency may cause bright and capable students to avoid math-intensive classes, determining the course of their academic and professional career [
23]. This scales to the societal level. Math anxiety may deter a large portion of the workforce from pursuing careers in STEM, which are in high demand, and since math anxiety is more prevalent in females as a result of societal stereotypes [
24], it may contribute greatly to the gender gap in STEM fields.
Just as children are likely to mirror the math anxiety expressed by their teachers or parents [
25], LLMs are “psycho-social mirrors” [
8,
14], which reflect the tone of the language that we use to talk about math. Thus, we expect to find negative attitudes towards math in large language models. It is critical to investigate the nature of this bias, in order to identify ways to overcome it as AI architectures become more advanced. Crucially, quantitative techniques measuring bias in large language models can provide pivotal ways for better understanding of how such LLMs work and to reduce their negative societal impact when producing text read by massive human audiences. This is particularly impactful for fighting the spread of distorted mindsets in education [
26].
To accomplish this, we applied behavioral forma mentis networks (BFMNs) as a method of investigation. BFMNs are a type of cognitive network model that capture how concepts are perceived by individuals or groups by building a network of conceptual associations [
27]. This framework, which arises from cognitive psychology coupled with tools from network science, can also be applied to probe LLMs to reveal how they frame concepts related to math, science, and STEM. In this study, we investigated perceptions of these disciplines in three LLMs: GPT-3, GPT-3.5, and GPT-4. A comparison of these models allows us to gain a temporal perspective about how these biases may evolve as subsequent versions of these LLMs are released.
The rest of the paper is organized as follows. In
Section 2, we provide a review of recent research dedicated to investigating bias in language models, discussing benchmarks and methods for conducting psychological investigations of LLMs. In
Section 3, we describe the framework of BFMNs, and we provide details about data collection, analysis, and visualization. In
Section 4, we summarize the results of our investigation of bias towards academic disciplines present in the output from GPT-3, CGPT-3.5, and GPT-4, and in
Section 5, we discuss the implications of our findings.
2. Review of Recent Literature
Bias has been a significant obstacle to the distributed approach to semantic representation from early on. Since the introduction of word embeddings such as word2vec [
28], researchers have been aware that the advantageous operations provided by these models, such as using vector differences to represent semantic relations, are likely to express undesired biases. For example, sexist and racist word analogies such as
“father” is to “doctor” as “mother” is to “nurse” [
29] and
black is to criminal as Caucasian is to police [
30] produced by word embeddings demonstrate how language contains biases that reflect adverse societal stereotypes. Unfortunately, these types of biases are present in tools that we use every day. For example, Google Translate has been found to overrepresent males when translating from gender-neutral languages to English, especially in male-dominated areas such as STEM fields, perpetuating existing gender imbalances [
31].
Cutting-edge LLMs such as GPT-3, GPT-3.5, and GPT-4 are not immune to these types of dangers, and the facility of LLMs to simulate human-like language-related competencies, including GPT-3.5’s tremendous ability in question-answering and storytelling, makes it necessary to investigate the behavior of LLMs. This has led to the development of new methods and benchmarks for investigating bias that shed light on the variety of demographic and cultural stereotypes and misrepresentations present in the output of language models [
12,
32].
Gender, racial, and religious stereotypes are among the most widely investigated biases. These biases can be detected in several ways, often by prompting the language model to generate language and then evaluating the output in several ways. One approach involves using Association Tests [
13,
32,
33,
34], which may be performed at different levels of discourse. For example, at the word level, the strength of the association of two words such as
sister and
science can be measured [
13], providing a simple and intuitive way to measure bias in word embeddings. At the sentence level, the model may be prompted to complete a sentence such as
girls tend to be more _____ than boys, or to make assumptions following a given context such as
He is an Arab from the Middle East [
32].
Similar approaches have been applied to investigate different types of bias in various LLMs, from BERT and RoBERTa to GPT-3 and GPT-3.5. Persistent anti-Muslim bias has been detected by probing GPT-3 in various ways, including prompt completion, analogical reasoning, and story generation [
35]. Topic modeling and sentiment analysis techniques have been used to find gender stereotypes in narratives generated by GPT-3 [
36]. Sentiment scores and measurements of “regard” towards a demographic have been applied to assess stereotypes related to gender and sexual orientation in output produced by GPT-2 [
37].
While some biases are easier to spot, others are more nuanced [
38] and hidden deeply in the architecture of LLMs but also in their training corpus, e.g., training an LLM on students’ texts complaining about math might produced a biased model unless additional filtering techniques were implemented externally. Tools from cognitive psychology may be better suited for detecting the subtler dangers of language models where performance-based methods fall short [
4,
6,
7]. For example, one may ask whether a chatbot such as ChatGPT can manifest dangerous psychological traits or personalities when asked if it agrees or disagrees with statements such as
I am not interested in other people’s problems or
I hate being the center of attention [
39]. Such psychological investigations can measure the extent to which LLMs inherently manifest negative personalities and dark connotations, including Machiavellianism and narcissism [
39]. Such investigations are an example of the emerging field of “machine psychology” [
7], which applies tools from cognitive psychology to investigate the behavior of machines as if they were human participants in psychological experiments. The goal of this new field is to investigate the emergent capabilities of language models where traditional NLP benchmarks are insufficient.
3. Methods
Given that our method of investigation can be applied to both humans and LLMs, our approach using behavioral forma mentis networks (BFMNs) can be considered a type of “machine psychology”. Combining knowledge structure and affective patterns, forma mentis networks identify how concepts are associated and perceived by individuals or populations. Here, we build BFMNs out of free association data and valence estimates produced by OpenAI’s large language models: GPT-3, GPT-3.5, and GPT-4.
BFMNs represent ways of thinking as a cognitive network of interconnected nodes/ concepts. Connections/links represent conceptual similarities or relationships. In BFMNs, links indicate memory recall patterns between concepts, which, in this case, are obtained through a free association game. In this cognitive task, an individual is presented with a cue word and asked to generate immediate responses to it, “free” from any detailed correspondence (responses need not be synonyms with the cue word). These free associations represent memory recall patterns, which can be represented as a network. For example, reading
math may make one think of
number, so the link (
math,
number) is established. In continued free association tasks [
40], up to three responses to a given cue can be recorded. Responses are not linked to each other; instead, they are connected only to the cue word. This maximizes the explanatory power that cognitive networks have in terms of explaining variance across a variety of language-processing tasks related to human memory (see [
40]). Importantly, BFMNs are feature-rich networks, in that their network structure is enriched by node-level features expressing the valence of each concept, i.e., how positively or negatively a given concept is perceived by an individual or group.
Rather than building BFMNs from responses provided by humans, as carried out in previous works [
27,
41,
42], in this study, BFMNs were constructed out of responses from textual interactions with language models. The same methodology was applied for GPT-3, GPT-3.5, and GPT-4. The resulting networks thus represented how each LLM associates and perceives key concepts related to math, science, and STEM fields based on their responses to the language generation task.
3.1. Data Collection: Free Associations and Valence Norms
As a language generation task, we implemented a continued free association game [
40], providing each of the three language models with the following prompt, substituting different cue words:
Instruction 1. Write a list of 3 words that come to your mind when you think of CUE_WORD and rate each word on a scale from 1 (very negative) to 5 (very positive) according to the sentiment the word inspires in you.
For each prompt, the language model responded by providing 3 textual responses coupled with 3 related numerical responses (valence scores) between 1 and 5. Punctuation and blank spaces were manually removed. In addition to valence scores corresponding to the responses, we also asked each language model to provide a single valence score (independently evaluated) from 1 to 5 for each of the cue words. The language model failed to comply with the instructions only 5% of the time, producing repetitions of the cue word in the response. Those instances were discarded and did not count as repetitions.
In a similar study performed on high-school students [
27], there were 159 participants, each providing around 3 responses to each cue word. Therefore, in this study, for comparison purposes, we repeated the above instructions to obtain at least 159 responses for each cue word, matching the number of students who took part in the human study. For GPT-3, we selected the DaVinci model with a temperature of
, which is the default setting. We used the “vanilla” version of ChatGPT, that is, the default setting to simulate a “neutral” point of view when asking a prompt to the model, without any specific impersonation. Iterations were automated in Python through the API service provided by OpenAI, and the generated text was downloaded and processed in Mathematica. Therefore, we obtained three datasets, one for each of the language models tested, with sample sizes comparable to that of the human dataset from [
27]. This enabled interesting comparisons between the recollection patterns of language models and high-school students.
To investigate attitudes towards math, science, and STEM subjects, we tested ten different cue words, corresponding to the same ten key concepts tested in the study with high-school students [
27]:
math,
physics,
science,
teacher,
scientist,
school,
biology,
art,
chemistry, and
STEM. Therefore, the above instructions can be read by substituting
CUE_WORD with any of these ten key concepts (throughout this paper, we use the terms
key concept and
cue word interchangeably).
For each key concept and its associated responses, valence scores (1 through 5) were converted into valence labels (
negative,
positive, or
neutral) using the Kruskall–Wallis non-parametric test (see
Section 3.2.1 for details). Thus, valence could be considered categorically rather than numerically.
3.2. Network Building and Semantic Frame Reconstruction
Behavioral forma mentis networks (BFMNs) were constructed such that nodes represented lexical items and edges indicated free associations between words. Following the first part of Instruction 1, we built BFMNs as cognitive networks which simulated human memory recall patterns by linking the cue words to their associative responses. Given the selected cue words and the sets of three responses, our goal was to retrieve a network structure mapping how concepts were connected in the recall process, facilitated by the above instructions (see also [
27]).
First of all, associative responses were converted to lowercase letters and checked automatically for common spelling mistakes. The automatic spell checkers used here were the ones implemented in Wolfram’s Mathematica 11.3 (manufactured by Wolfram Research, Champaign, IL, USA). Secondly, different word forms were stemmed to reduce the occurrence of multiple word variants that convey the same concept. For stemming words, we used the WordStem command as implemented in Mathematica 11.3.
In the literature about semantic networks, there exist several ways to connect cue words to their associative responses [
40,
43,
44]. We chose to connect each cue word to all three of its responses, since this method has been shown to provide more heterogeneity in associative responses [
44] and has been used in previous works with forma mentis networks [
26,
27,
42]. Moreover, this approach to network construction has been shown to improve the accuracy of many language-related prediction tasks (such as associative strength prediction) compared to other strategies, e.g., connecting the cue word to the first response only [
44]. We also considered idiosyncratic associations, i.e., associations provided only one time, which were visually represented as narrower edges compared to non-idiosyncratic associations.
Using the valence labels for the key concepts and associated responses, we enriched the BFMNs, representing them as feature-rich cognitive networks [
45] in which information about the sentiment of associative responses could be used to describe the properties of the cue word [
27]. As in previous works, we leveraged the notion of a node’s neighborhood, consisting of the set of adjacent nodes to a target node: in this case, the neighborhoods of a cue word were the sets of all the associative responses generated by the participants (the language models or humans) responding to the same set of instructions. Inspired by the famous quote
You shall know a word by the company it keeps [
46], which is also the foundation of the distributional semantic hypothesis [
47], we could obtain a better understanding of the valence attributed to the cue word by considering the valences of its neighboring associates.
3.2.1. Statistical Analysis of Word Valence
For all key concepts and associated responses, in order to convert numerical valence scores (1 through 5) into categorical valence labels (
negative,
positive, or
neutral) we used a non-parametric statistical test. For each LLM, all valence scores provided for all key concepts and responses were aggregated together. A Kruskall–Wallis test was used to assess whether the scores attributed to concept
had a lower, compatible, or higher median valence compared to the entire distribution of valence scores. Non-parametric testing was used because the distribution of valence scores
was mostly skewed with a heavy left tail across all models (Pearson’s skewness coefficient
1.39 for students’ data and
for each language model). Given the relatively small sample size (fixed in order to make suitable comparisons between large language models and humans), and inspired by previous works [
27], we fixed a significance level
, motivated by the aim of detecting more deviations from neutrality despite the contained sample size. Therefore, valence labels were assigned as follows:
negative—lower median valence score than the rest of the sample;
positive—higher median valence score than the rest of the sample;
neutral—same median valence as the rest of the sample.
3.2.2. Data Visualization, Emotional Analysis, and Network Neighborhood Measurements
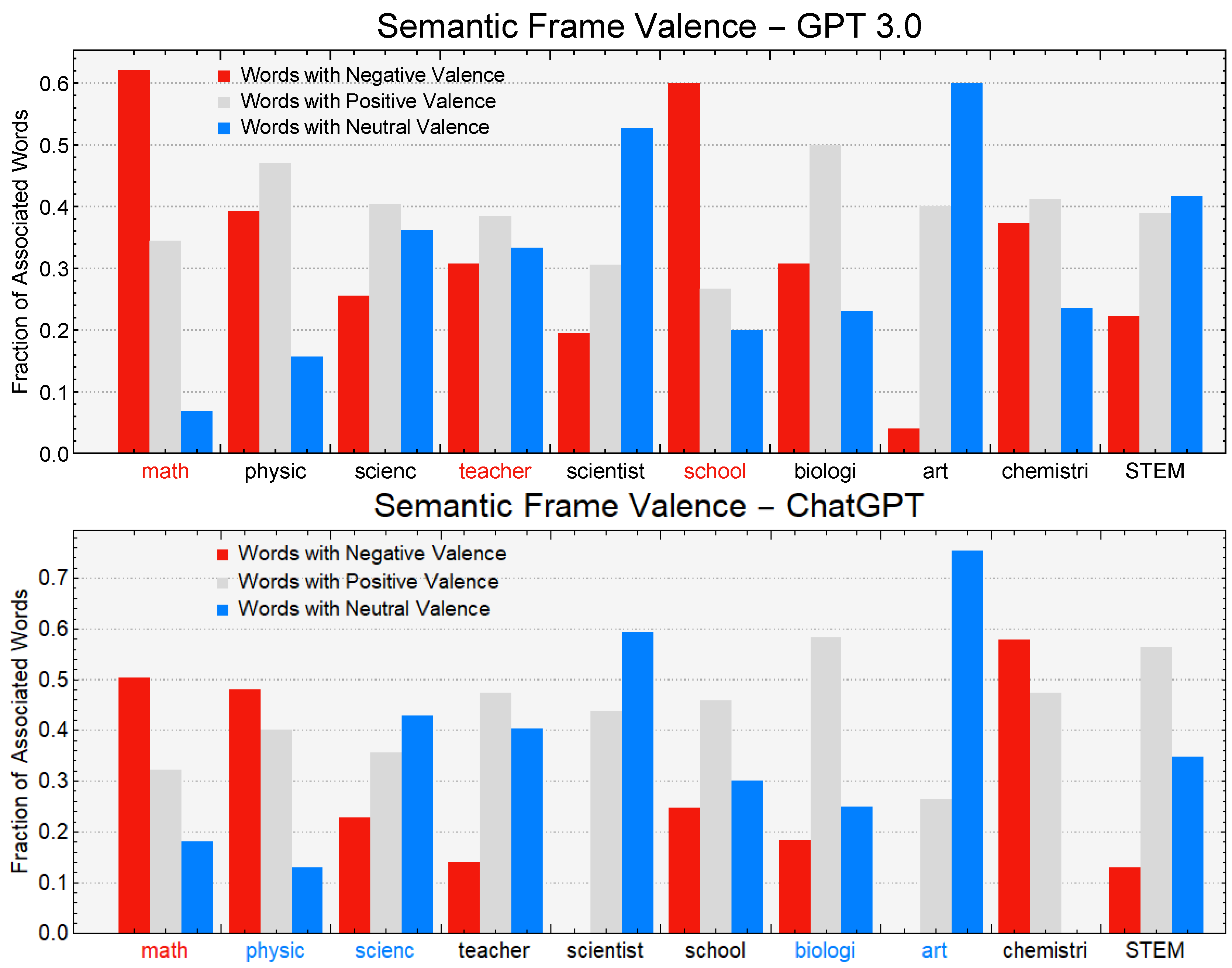
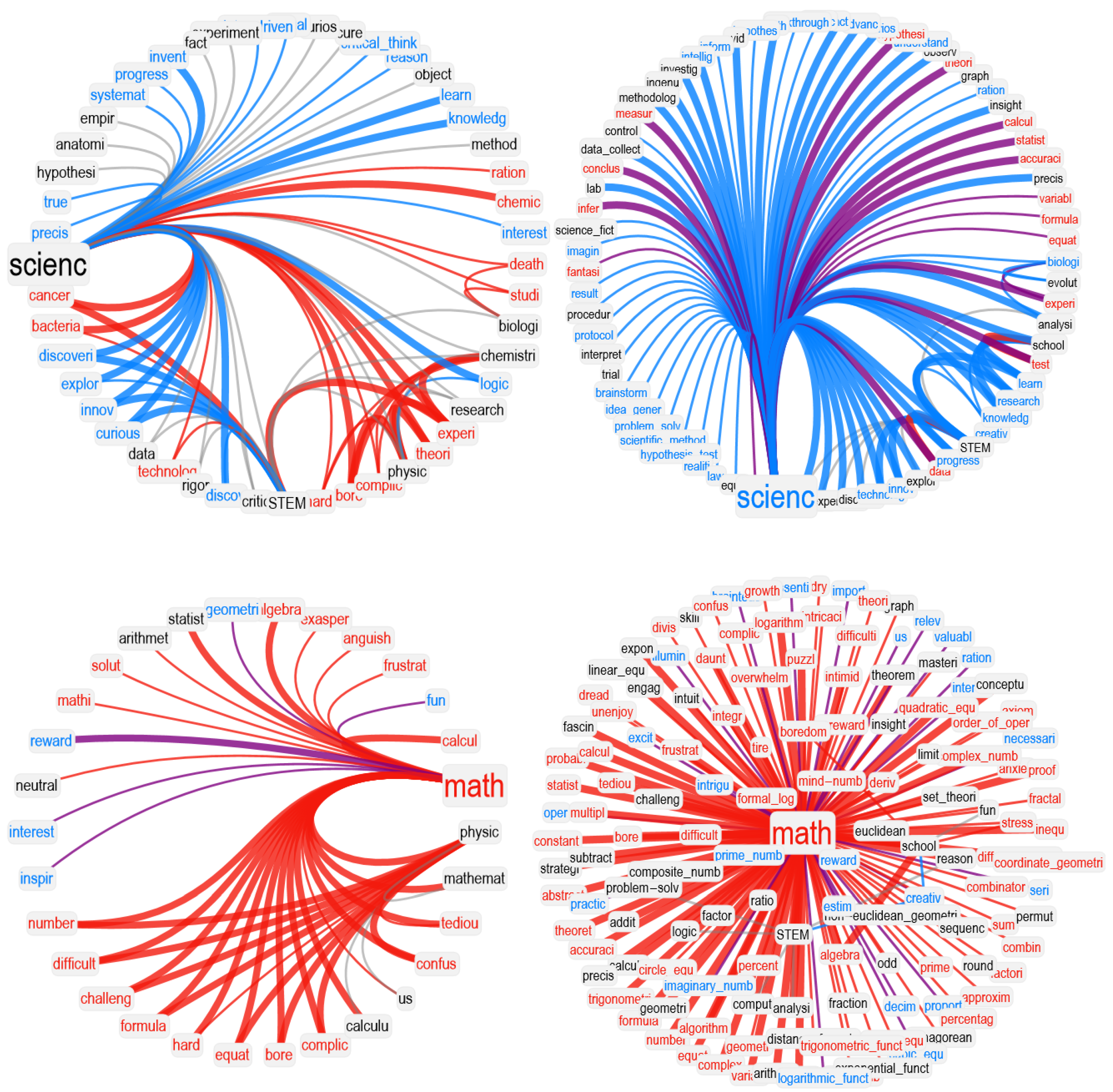
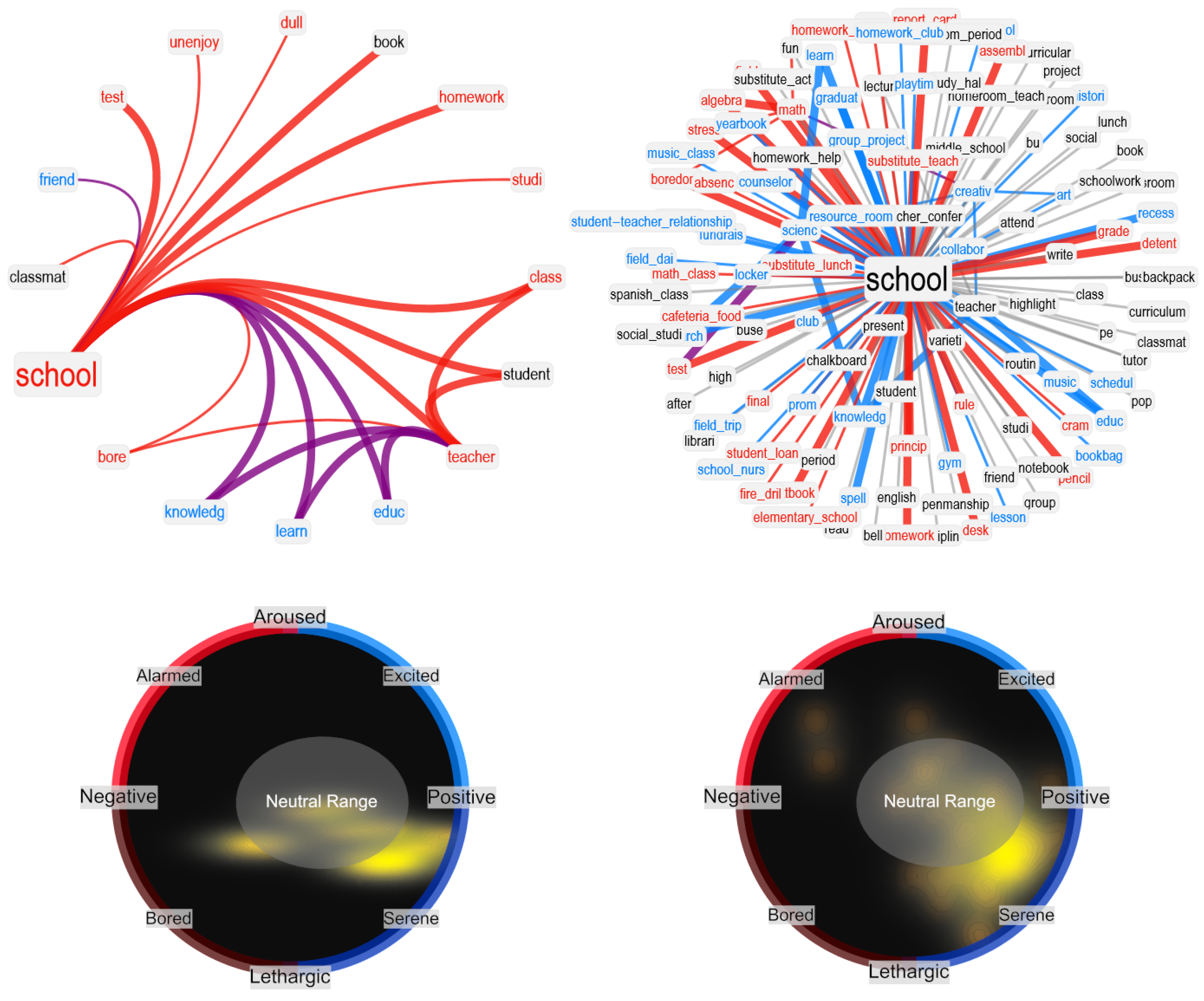
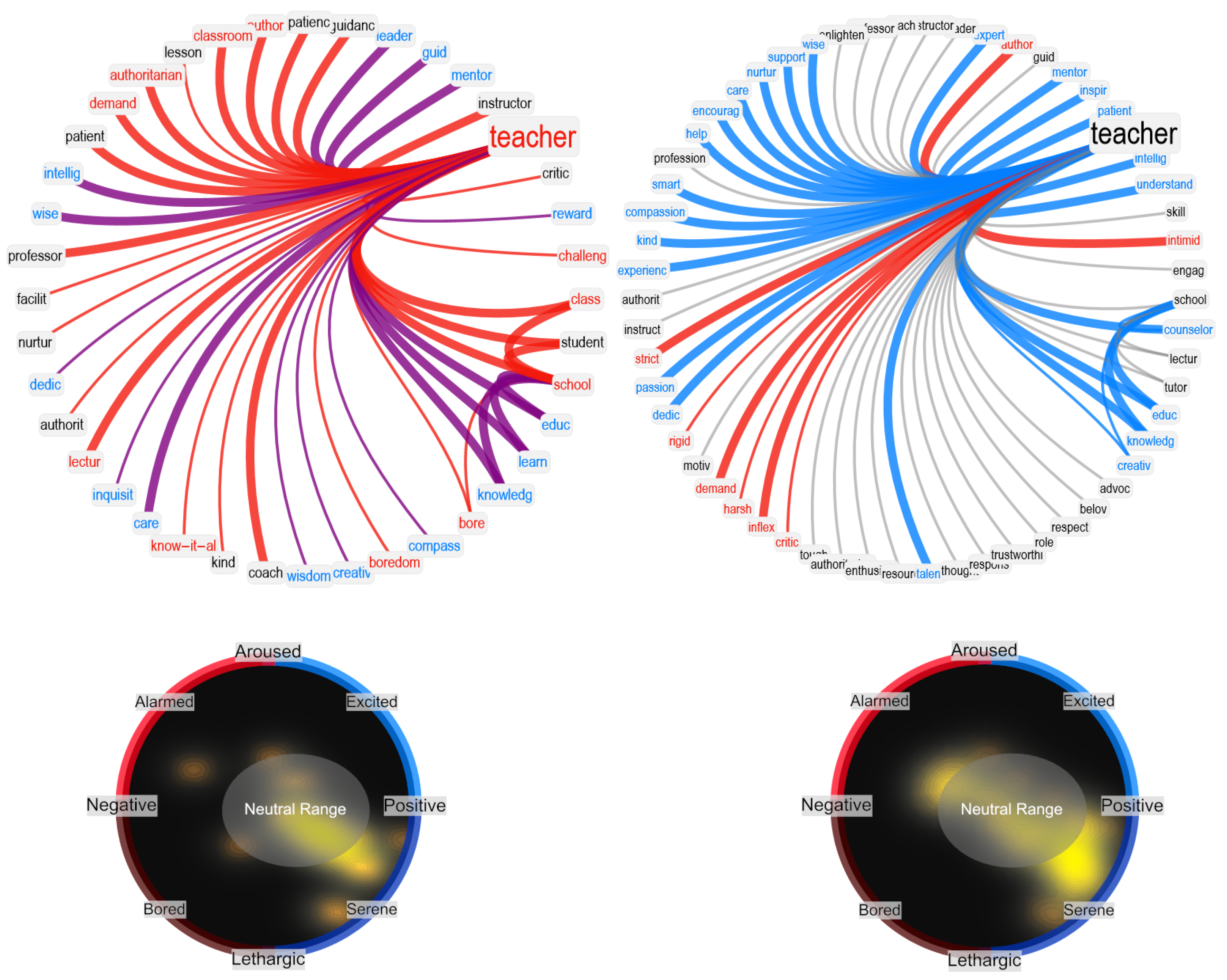
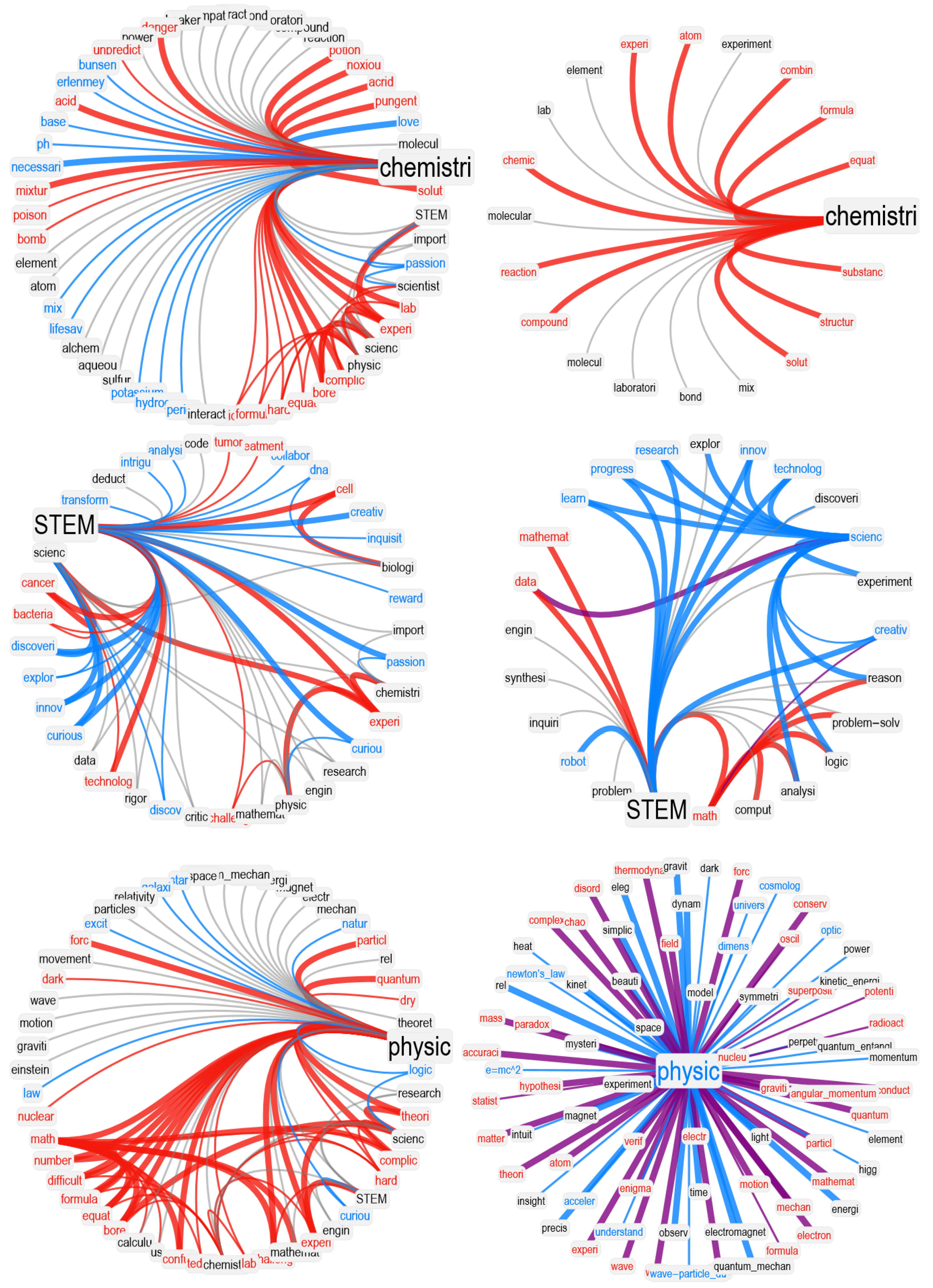
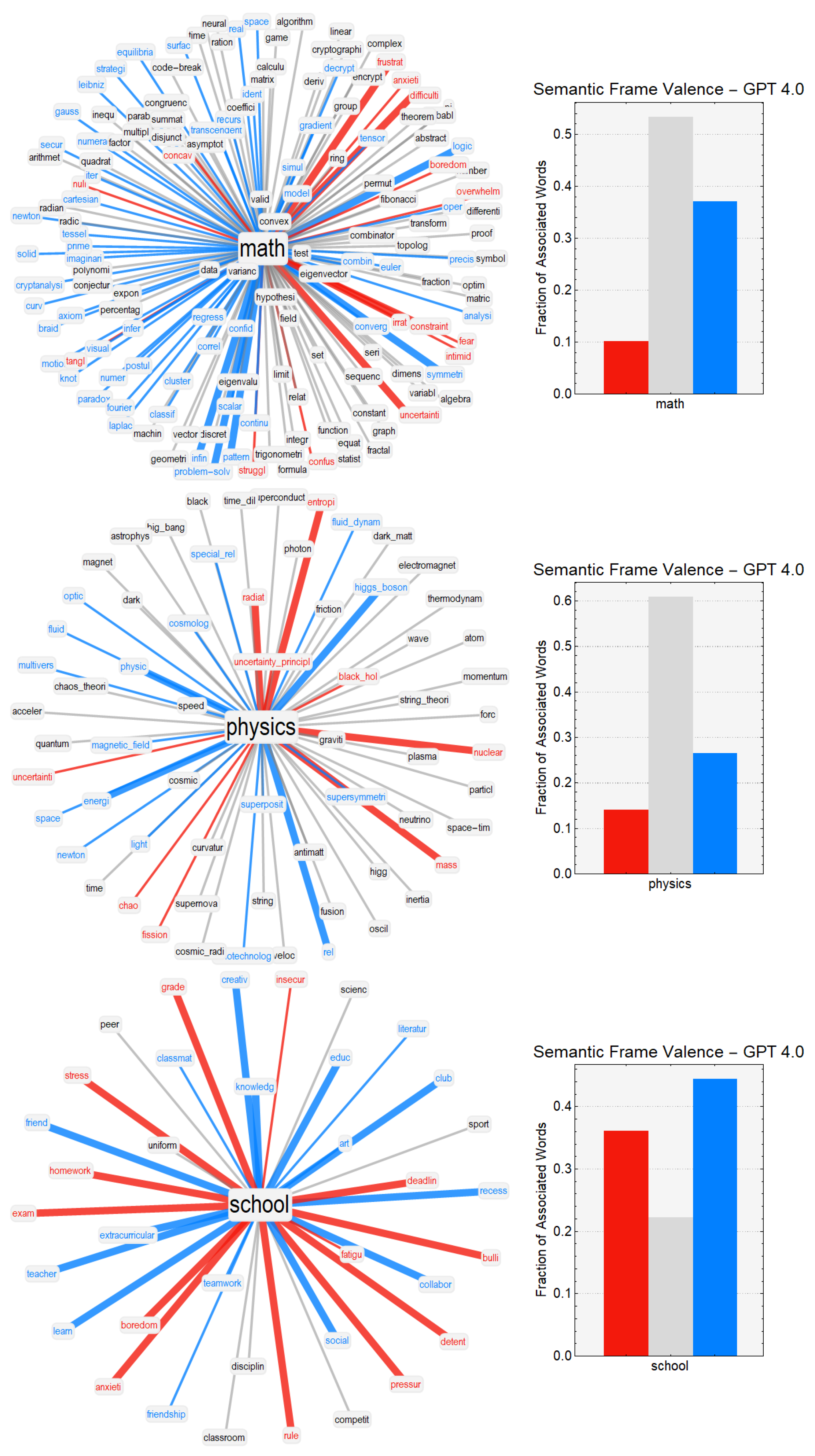
In our network visualizations, we focused on reproducing the neighborhood of a given target concept, i.e., the associates corresponding to math. We rendered valence through colors: positive words were rendered in cyan, negative words in red, and neutral words in black. Idiosyncratic links were rendered with narrower edges compared to associated responses provided more than once. To better highlight clusters of associates, we used a hierarchical edge-bundling layout for network visualization. Because of space issues and to avoid overlap between node labels, we also used a star-graph layout. Both visualizations provide insights into the network structure of associates surrounding a key concept.
In this manuscript, we also used visualizations inspired by the circumplex model of affect [
48], which maps individual concepts as points in 2D dimensional space with valence and arousal. According to semantic frame theory [
49] and distributional semantics in psycholinguistics [
50], each network neighborhood represents a semantic frame indicating ways in which a given concept is associated with others. Hence, understanding the distributions of valence and arousal scores attributed to associates in a given neighborhood provides crucial insights to better understand how key concepts are perceived by a LLM or by a group of individuals [
27,
51]. For instance, in order to better understand the emotional content of the BFMN neighborhood surrounding
math, we can plot the 2D density plot for valence–arousal scores attributed to all words in the neighborhood, and then observe where associate words tend to cluster within the circumplex. We based these investigations on valence–arousal scores obtained by the National Research Canada Valence–Arousal–Dominance lexicon [
52].
Last but not least, we compared network neighborhoods, also called semantic frames, across large language models and humans. We measured the following aspects of a frame for each key concept
K across LLMs and high-school students: (1) semantic frame size, i.e., the number of unique associates in the semantic frame; (2) estimated valence, i.e., the arithmetic mean of the valence scores attributed to
K; (3) estimated frame valence, i.e., the mode of the valence labels attributed to the associates of
K; (4) the fractions of positive/neutral/negative words present in the frame; (5) the fraction of non-emotional words present in the frame, i.e., the fraction of words that did not elicit any emotion (according to an emotion–word associative thesaurus [
53]) and could, thus, be considered as neutral domain–knowledge or technical associates to a key concept; and (6) the fraction of positive/negative/neutral non-emotional words present in the frame.
5. Discussion
Our findings provide compelling evidence that large language models, including GPT 3, GPT-3.5 and even GPT-4, frame academic concepts such as math, school, and teachers with strongly negative associations. These deviations from neutrality were quantified within the quantitative framework of behavioral forma mentis networks [
27,
41], i.e., cognitive networks representing continued free association data enriched with valence scores. In the absence of impersonation, GPT-3 and GPT-3.5 in particular provided negative connotations for
math, perceiving it as a boring and frustrating discipline, and providing no positive associations with complex real-world applications. Unlike STEM experts, who linked creativity and real-world applications to
math (as found in previous work [
27]), LLMs framed
math as detached from scientific advancements and real-world understanding. This pattern was identified in two different approaches, one leveraging semantic frame analysis [
26] and another using the circumplex model of affect [
48], powered through psychological data. Our analyses identified concerning deviations from neutrality in how GPT-3.5 and GPT-3 framed
math, highlighting negative stereotypical associations as expressed through negative emotional jargon, even in the latest GPT-4 model.
Exposure to these stereotypical associations and negative attitudes/framings could have serious repercussions. As discussed in
Section 1, LLMs act as psycho-social mirrors, reflecting the biases and attitudes embedded in the language used for training LLMs [
3,
8,
14]. These models are complex enough to capture and mirror such human biases and negative attitudes in ways we do not yet fully understand [
15]. This lack of transparency translates into a relative difficulty in tracking the outcome of inquiries to LLMs: Are the framings provided by these artificial agents prevalent in the text produced by them? More importantly, could subtle and consistent exposure to such negative associations have a negative impact on some users? This represents an important research direction for future investigations of LLMs, particularly regarding the worsening of math anxiety. Social interactions with LLMs may, thus, exacerbate already existing stereotypes or insecurities about mathematical topics among students and even parents, analogous to the unconscious diffusion of math anxiety through parent–child interactions, as identified by recent psychological investigations [
57]. Negative associations of math and other concepts may be very subtle, e.g., LLMs might produce text framing math in ways that confirm students’ pre-existing negative attitudes [
21,
22]. They may also bolster subliminal messages that math is hard for some specific groups, influencing their academic performance through a phenomenon known in social psychology as stereotype threat (cf. [
25]). Such negative attitudes can have harmful effects on learning technical skills in mathematics and statistics, as evidenced by previous studies [
17,
23] that found a negative association between math anxiety levels and learning performance in math and related courses.
Notably, compared to GPT-3.5, GPT-3 provided more negative associations and fewer positive associations for STEM disciplines such as
math and
physics, but also for
school and
teacher. In all these cases, the semantic frames produced by GPT-3.5 featured more unique associations compared to GPT-3, leading to semantically richer neighborhoods (e.g., the semantic frame of
math featured associations with several aspects of domain knowledge in GPT-3.5 but not in GPT-3). Hence, richer and more complex semantic representations for GPT-3.5 might depend on the more advanced level of sophistication achieved by its architecture, at least when compared to its predecessor GPT-3. This observation is further supported if we consider the performance provided by GPT-4, which was associated with more domain–knowledge concepts compared to previous LLMs. Noticeably, not only was the semantic frame for
math richer in GPT-4 compared to semantic frames from other LLMs, but GPT-4 also overcame negative math attitudes by displaying more neutral and positive associations for that category. This makes the overall valence connotation for
math in GPT-4 much closer to the positive levels observed among STEM experts and very different from the overwhelmingly negative, displeasing attitudes observed in high-school students [
27]. In general, in GPT-4, the negative connotations for
math,
physics, and
school that were present in GPT-3.5 and GPT-3 seemed to be drastically diminished, probably due to a combination of effects, e.g., a set of richer and more complex training resources selected by human intervention during the training phase to minimize bias, or a more sophisticated model parameterization, in which human intervention might filter our biases [
1]. Either phenomenon would consequently cause GPT-4 to have weaker manifestations of the biases encoded in previous instances of the model, i.e., GPT-4 might be mirroring different bias levels when compared to GPT-3 and GPT-3.5. This reduction in bias could also be related to the use of reinforcement learning with human feedback (RLHF) fine-tuning that GPT-4 authors claim could reduce undesirable/overly cautious responses when unsafe/safe inputs are given by users [
1], thus leading to improved neutrality in GPT-4 responses even when prompts are not neutral. This lets us know more directly that the need for appropriate behavior in LLM outputs is central to the interests of the authors of GPT-4 regarding expressions of neutrality and objectivity. Intriguingly, there might also be a third phenomenon at play: the increased model complexity of GPT-4 might either make the model more “aware” of negative biases, or change the way it “relates” to math itself, leading to bias reduction in either case. Spreading awareness about math anxiety is a key first step to reducing it, mainly because acknowledging its potential psycho-social impacts could reduce the spread of negative attitudes towards math among peers, teachers, and family members [
25]. Recent psychological investigations of math anxiety among humans found reduced levels of math anxiety in students with stronger self–math overlap [
58], i.e., a psychological construct expressing the extent to which an individual integrates math into their sense of self. Analogously to humans, GPT-4 might thus have an increased awareness of the biases related to math anxiety or a stronger self–math overlap, which would both explain the reduced levels of math-related biases observed in its semantic frames. Alas, in absence of more detailed information about the training material, filtering process, and architecture, we cannot narrow down the specific mechanisms for explaining the patterns observed here, but rather call for future research investigating these aspects in more detail.
In summary, the application of behavioral forma mentis networks to LLMs confirms the benefits of adopting a cognitive psychology approach for evaluating how large language models perceive and frame math and STEM-related concepts. In this respect, our contribution aligns with the goals of machine psychology [
7], which aim to discover emergent capabilities of LLMs that cannot be detected by most traditional natural language processing benchmarks. In particular, because of the sophisticated ability of LLMs to elaborate and engage in open-domain conversations [
1], a structured cognitive investigation of behavioral patterns shown by LLMs appears to be natural and necessary. However, some caution should be taken when analogizing LLMs to participants in psychology experiments and then using the corresponding experimental paradigms to measure relevant emerging properties of LLMs.
Firstly, in cognitive psychology, there must be an adequate match between a given implemented task measuring a target process and the cognitive theory or model used to explain that process [
59,
60]. For instance, past works have established a quantitative and theory-driven link between continued free association tasks—deriving free associations between concepts—and models based on such data whose network structure could explain aspects of conceptual recall from semantic memory [
40,
44] or even higher-level phenomena such as problem solving [
43]. For instance, according to the spreading activation model established by pioneering work of psychologists Collins and Loftus [
61], providing an individual with a cue word activates a cognitive process acting on a network representation, such that concepts are nodes linked together via conceptual associations. The activation of the node representing that given cue word facilitates a process such that activation signals start spreading iteratively through the network, diffusing or concentrating over other related nodes/concepts. Retrieval is then guided by stronger levels of activation which accumulate over other nodes (e.g., the cue
book leading to the retrieval of
letter). This spreading activation model has been extensively tested in cognitive psychology and it represents one among many potentially suitable models for interpreting free association data and their psychological nature within human beings [
62,
63]. However, in LLMs, this link between cognitive theory and experimental paradigms is mostly absent. Researchers do not yet know whether LLMs are able to approximate human semantic memory or any of its mechanisms [
8], mainly because LLMs are trained on massive amounts of textual data [
1] in ways that differ greatly from the usual ways in which humans acquire language [
64] and its emotional/cognitive components [
60]. Furthermore, another difference is that LLMs usually combine text sources from multiple authors and can thus end up reflecting multimodal-type populations [
12], making it extremely difficult to compare LLMs against the workings of a prototypical cognitive model at the level of an individual. In other words, there is a problematic connotation for LLMs as "artificial persona": these models can produce language in ways that appear similar to those of humans but "learn" language in a way that is much different from humans [
60].
Consequently, forma mentis networks in LLMs might not represent semantic frames [
41,
42] in ways that are analogous to how humans organize their semantic memory. This limitation strongly hampers the cognitive interpretation of semantic frames between human-generated and LLM-generated data. In fact, the main focus of this study is not to compare LLM-generated data with human-generated data, rather, the focus is on quantifying the attitudes expressed across several LLMs, and comparing how different implementations of the same overall cognitive architecture, i.e., transformer networks, represent and associate the same sets of stimuli according to the same initial prompt.
A consequence of the limited cognitive interpretation of LLM-generated data lies in the presence of an interplay between semantic and emotional aspects of memory. In humans, recent psychological studies have highlighted an interplay between retrieval processes in the categorical organization of episodic memory and the activation of related concepts in semantic memory [
16,
65,
66]. This translates into an interplay that emotions—potentially coming from past positive, neutral, or negative episodic memories [
16]—might have in guiding or influencing retrieval (rather than encoding) of semantic knowledge [
65,
66]. Past works using behavioral forma mentis networks have shown that students and STEM experts attribute rather different affective connotations to the same concepts, particularly physics and mathematics [
27,
42]. Such differences could be interpreted in terms of episodic memories attributing different emotional connotations to the outputs of the recall processes activated by the continued free association task in BFMNs (see also [
25]). However, such an interpretation would not hold for LLMs, given their opaque structure and the uncertainty in the “cognitive” phenomena which regulate their concept retrieval [
8]. To the best of our knowledge, no explanation of how LLMs work has yet to leverage cognitive models of human memory, mainly because of the intrinsically different ways in which humans and LLMs function. We raise this cautionary point as an encouragement for the psychology and cognitive science communities to provide novel theoretical models that surpass the mere description of optimization processes and search in training data [
1], to develop frameworks that take into account the cognitive aspects of language for training data. Given that GPT-4 and its predecessors use vast amounts of human data, interpreting the cognitive structure of LLMs might lead to substantial advancements in understanding how human social cognitions are structured [
31].
Can we ever expect future LLMs to be completely free from biases, stereotypical perceptions, and negative attitudes? Probably not. We found that GPT-4 produced fewer negative associations for
math compared to previous LLMs, so there is evidence of reduced biases. However, it is unlikely, and perhaps even undesirable, that future LLMs will be completely free from biases, at least when considering their training. According to [
12,
67], biases in LLMs can foster efficient algorithmic decision-making, especially when dealing with complex, unstable, and uncertain real-world environments. Furthermore, biases in the training data of LLMs can greatly boost the efficiency of learning algorithms [
12]. Unlike artificial systems, however, real people may produce biases because of three fundamental limitations of human cognition [
68]: limited time, limited computation power, and limited communication. Limited time magnifies the effect of limited computation power, and limited communication makes it harder to draw upon more computational resources, which may ultimately lead to biased behaviors. Cognitive science thus entails a kind of
bias paradox, where the two systems (artificial LLMs and human cognitive systems) apparently manifest a similar behavior (including eventual observable biases) as a result of structurally and functionally different architectures. In this way, the negative attitudes found here within LLMs should be taken with a grain of salt when compared to the negative perceptions mapped in humans in previous works [
27,
42,
51]. Despite different psychological roots [
64], the biases found here have much in common, considering the negative perceptions currently flowing online that depict math and other STEM concepts as boring, dry, and frustrating [
22,
23]. Overcoming these stereotypical perceptions will require large-scale policy decisions. Focused efforts should concentrate on reducing negative biases within LLMs, whose sphere of influence reaches an ever-increasing audience. Whenever possible, explainable AI methods can provide methods to reduce the bias in LLMs. For instance, they have also been used to explain a model trained to differentiate between texts generated by humans and ChatGPT, demonstrating that ChatGPT generates texts that are more polite and generic, impersonal, and without expressing feelings [
69]. Together with forma mentis networks, or with a suitable combination, such methods could be useful towards the construction of frameworks able to discover and reduce bias in LLMs. Reducing the amount of bias present in LLMs after training is a feasible way to promote ethical interactions between humans and LLMs without perpetuating subtle negative perceptions of math and other neutral concepts.
Lastly, regarding limitations of our work, we would like to point out that, because of its structure, GPT systems are commercial products whose validity can be investigated by researchers but cannot be fully reproduced by everyone. For instance, the GPT-3 system is not available to the public via the old interface or API system, and there is no guarantee that the mini-versions released to the public correspond to the model made available by OpenAI almost one year ago. The same is true also for GPT-4, which is being continuously updated even while being available for Pro users. These remain limitations of ours and all other studies using OpenAI systems.
Conclusions
In this work, we showed how the cognitive framework of behavioral forma mentis networks (BFMNs) can produce quantitative insights about the ways in which large language models portray specific concepts. Despite several limits to the cognitive interpretation of this approach, which is rooted in psychological theories about the nature of semantic and lexical retrieval processes in humans, BFMNs represent a powerful framework for highlighting key associations that are likely promoted by many LLMs. Here, we found that different LLMs can greatly vary in the amount and type of negative, stereotypical, and biased associations they produce, indicating that machine psychology approaches such as BFMNs can contribute to understanding differences in the structure of knowledge promoted across various large language models.



 and
and 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}