
Multimodal Emotional Classification Based on Meaningful Learning



Abstract
:1. Introduction
2. Related Works
3. Materials and Methods
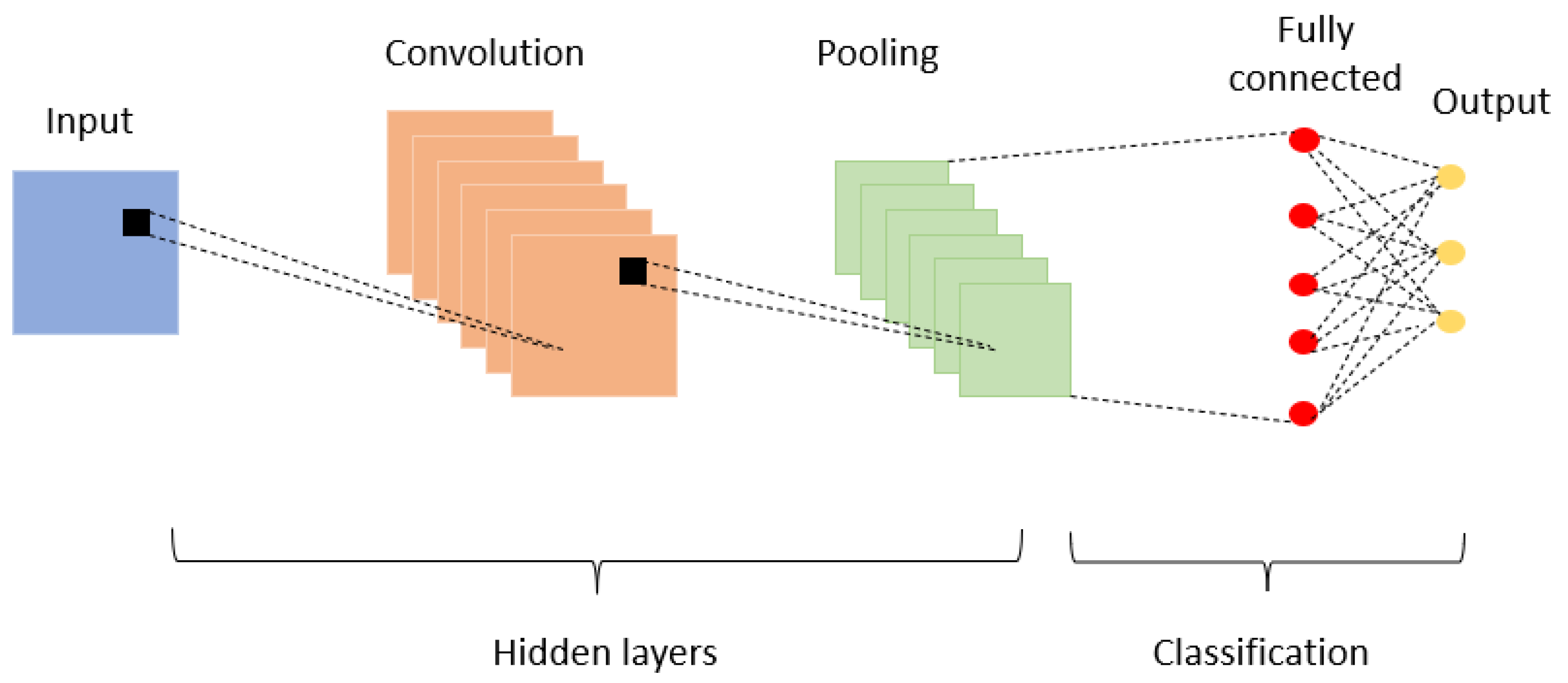
3.1. Convolutional Neural Networks
- Max pooling: replaces the input region with its maximum value.
- Average pooling (weighted average pooling): pools the input region by taking its average or a weighted sum, which can be based on the distance from the region center.
- The Fully Connected (FC) layer, which is at the end of the CNN design and is fully connected to every output neuron, is used for classification. To classify the input image, the FC layer first applies a linear combination and then an activation function after receiving an input vector. In the end, it returns a vector of size d, where d is the number of classes and each component is the likelihood that the input image belongs to a particular class.
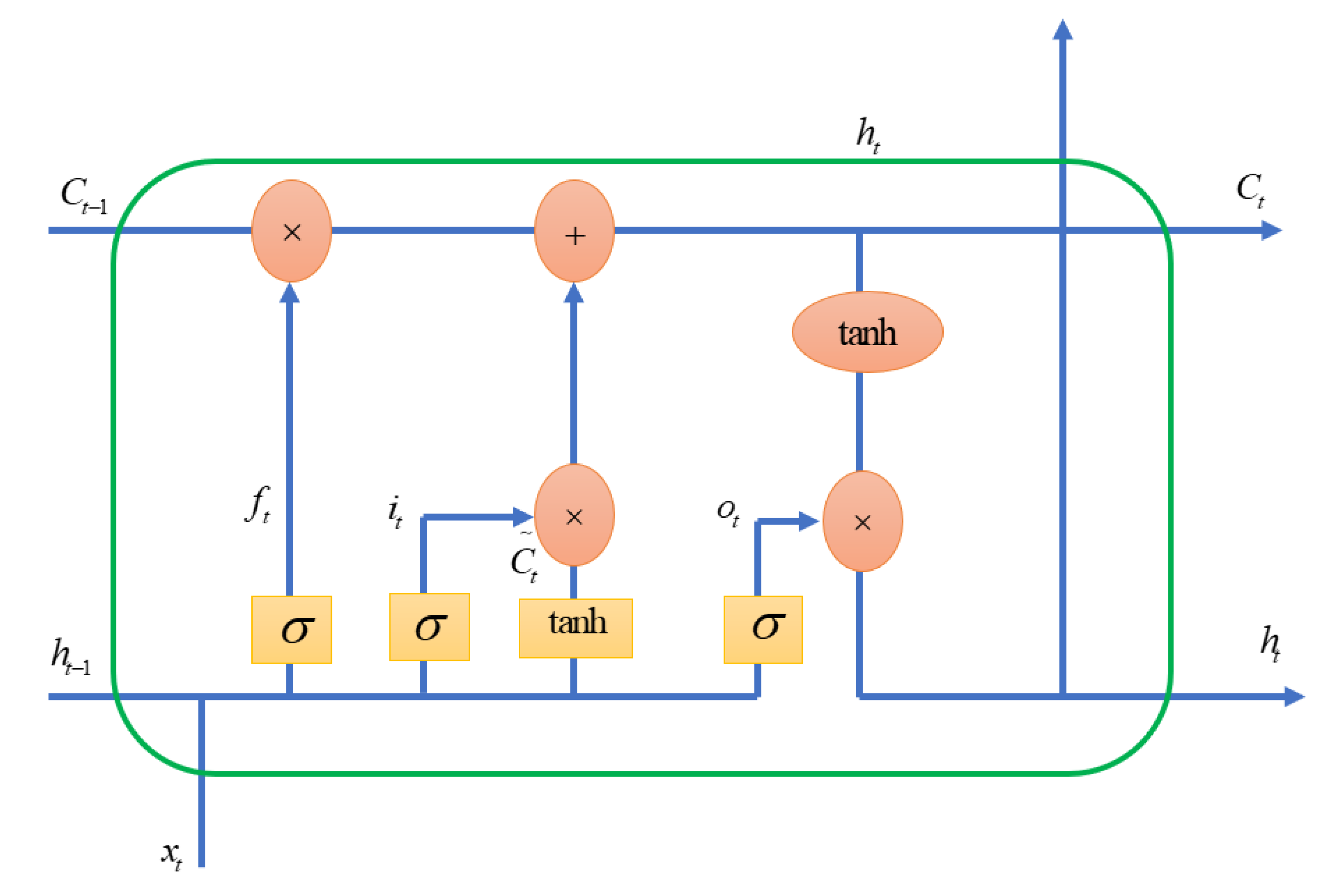
3.2. Long Short-Term Memory
- Identifying pertinent information from the past, taken from the cell state through the forget gate;
- Using the input gate to choose from the current input those items that will be important in the long term. The cell state, which serves as long-term memory, will be added to these;
- Select the crucial short-term information from the newly created cell state and use the output gate to create the subsequent hidden state.
- Forget gate:The forget gate determines what information must be remembered and what can be forgotten. Data derived from the current input and hidden state are absorbed by the sigmoid function. The values that Sigmoid produces range from 0 to 1. It draws a conclusion regarding the necessity of the old output’s part (by giving the output closer to 1). The cell will eventually use this value of for point-by-point multiplication.: timestep, : forget gate at , : input, : previous hidden state, : weight matrix between forget gate and input gate, : connection bias at .
- Input gate:Updates to the cell state are made by the input gate using the following operations. To begin with, the second sigmoid function receives the current state, , and the previously hidden information, . The values are specified to range from 0 (important) to 1 (not important).The same data from the current state and concealed state will then be transferred through the tanh function. The network will be controlled by the tanh operator, which will produce a vector containing every conceivable value between −1 and 1. Point-by-point multiplication can be performed on the output values produced by the activation functions.: timestep, : input gate at , : input, : weight matrix of sigmoid operator between input gate and output gate, : bias vector at , : value generated by tanh, : weight matrix of tanh operator between cell state information and network output, : bias vector at .The input gate and forget gate have provided the network with sufficient data. Making a decision and storing the data from the new state in the cell state come next. The forget vector multiplies the previous cell state . Values will be removed from the cell state if the result is 0. The network then executes point-by-point addition on the output value of the input vector , which updates the cell state and gives the network a new cell state .: timestep, : input gate at , : value generated by tanh, : forget gate at t, : previous timestep.
- Output gate:The value of the following hidden state is decided by the output gate. Information about prior inputs is contained in this state.First, the third sigmoid function receives the values of the current state and the prior concealed state. The tanh function is then applied to the new cell state that was created from the original cell state. These two results are multiplied one by one. The network determines which information the hidden state should carry based on the final value. For prediction, this hidden state is used.: timestep, : output gate at , : weight matrix of output gate, : bias vector, : LSTM output.
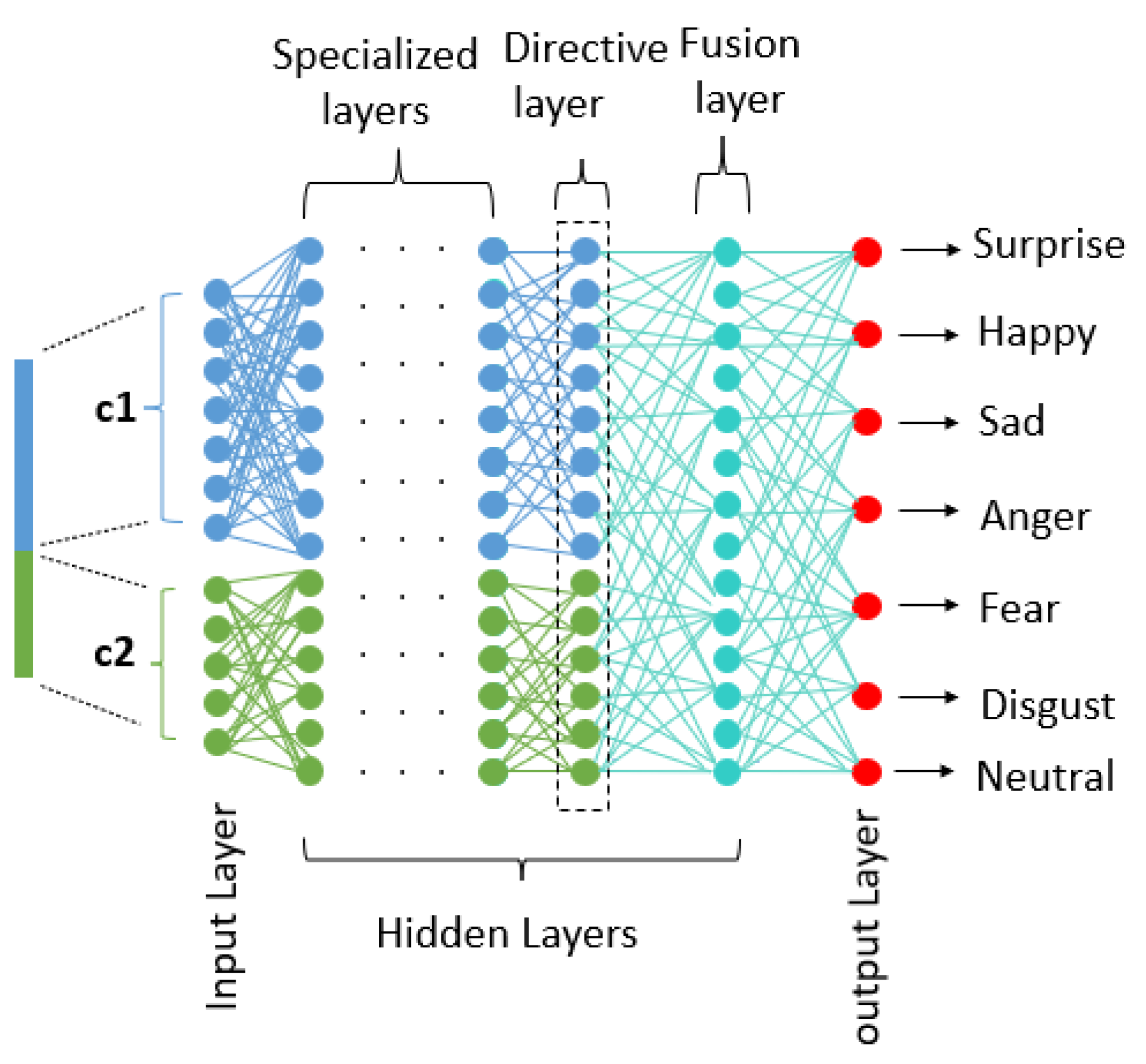
3.3. The Meaningful Neural Network
- Specialized layers: Sets of neurons that are trained specifically to extract and learn the representations of the input vector components are present in each of these layers. Depending on how many components the input vector contains, we can often have any number of neuron sets. The weights’ calculation and updating during the gradient backpropagation step can be expressed as follows:Forward Propagation:: the component numbers, : the number of neurons belonging to the layer that concerns the component , : the weight that connects the neuron j belonging to the layer that concerns the component with the neuron belonging to the layer of the component , : the output of the neuron k belonging to layer of the component , : the bias connected to the neuron j and belonging to layer of component .Backward Propagation:
- Directive layer: One directive layer is present in the suggested architecture. While the other side is fully connected, the left side is semi-connected. By taking into consideration the two sets of neurons for the specialized layers, this layer enables the control of error propagation.Forward Propagation:Backward Propagation:
- Fusing Layer: This layer is completely connected. It enables the merging of learned representations from earlier levels.Forward Propagation:: the component numbers, : the number of neurons belonging to the layer that concerns the component c, : the weight that connects the neuron belonging to the layer that concerns the component with the neuron belonging to the layer of the component c, : the output of the neuron k belonging to layer , : the bias connected to the neuron j and belonging to layer of component c.Backward Propagation:
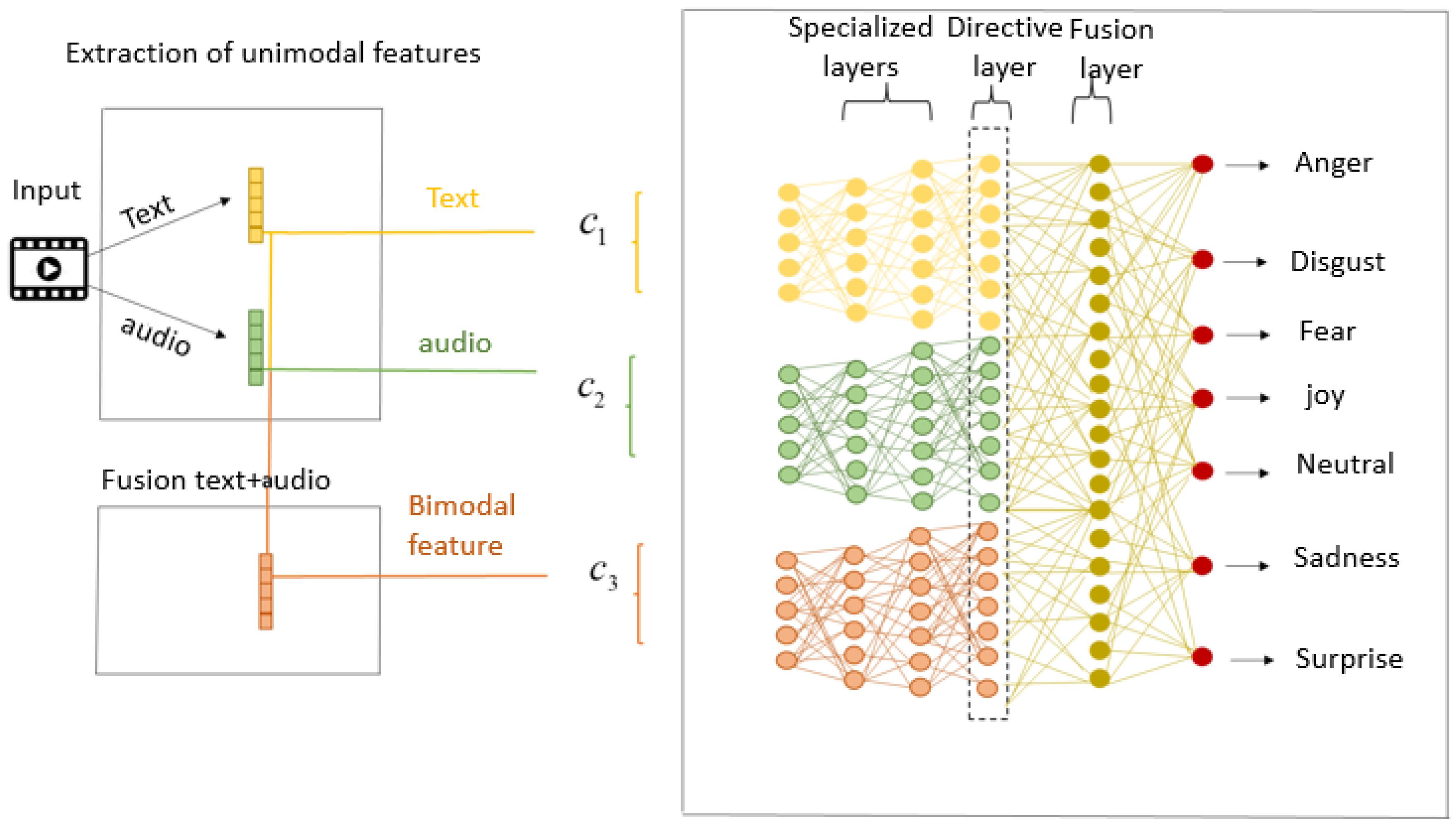
4. Proposed Method
4.1. Extraction of Unimodal Features
4.1.1. Extraction of Text Modality
4.1.2. Extraction of Audio Modality
4.2. The Fusion of Text and Audio Modalities
4.3. Classification
5. Proposed Experimental Results and Discussion
5.1. Computational Environment
5.2. Dataset
5.3. Evaluation Metrics
- Accuracy: the easiest performance metric to understand is accuracy, which is just the proportion of correctly predicted observations to all observations.
- Recall: is a metric for how well a model detects True Positives.
- Precision: is the ratio of accurately anticipated positive observations to all actual class observations—yes.
- F1-score: is the average of Precision and Recall, weighted.
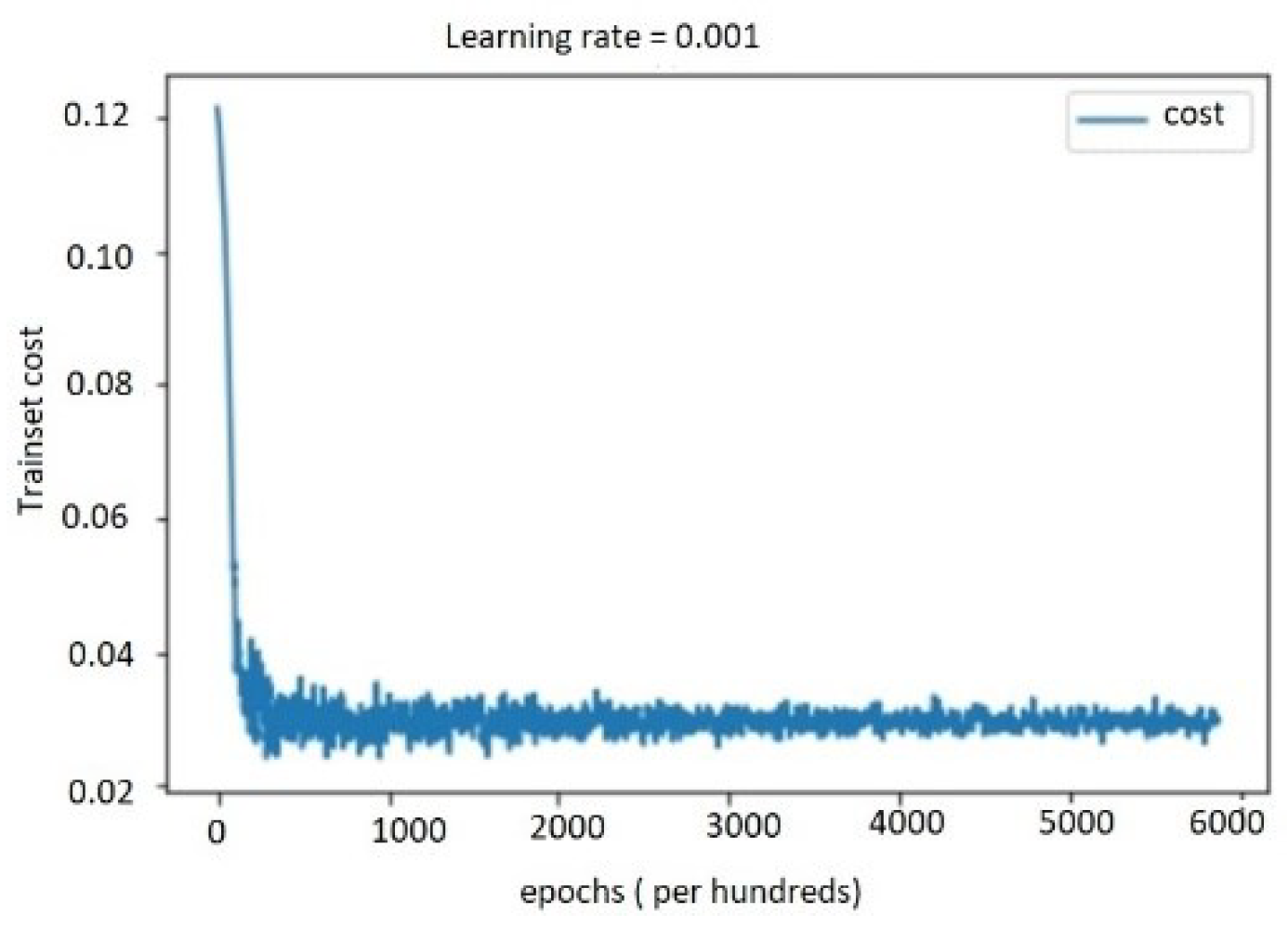
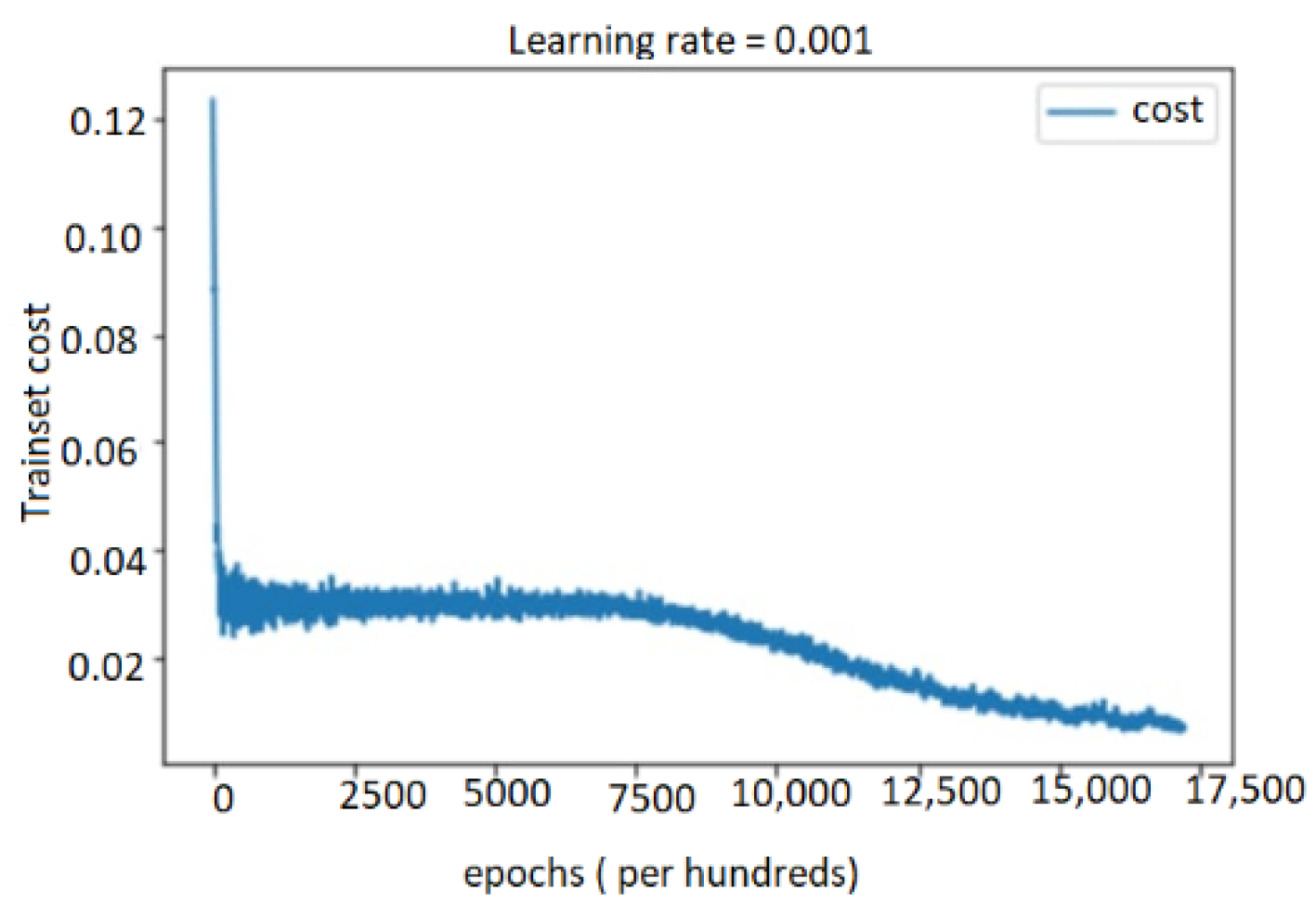
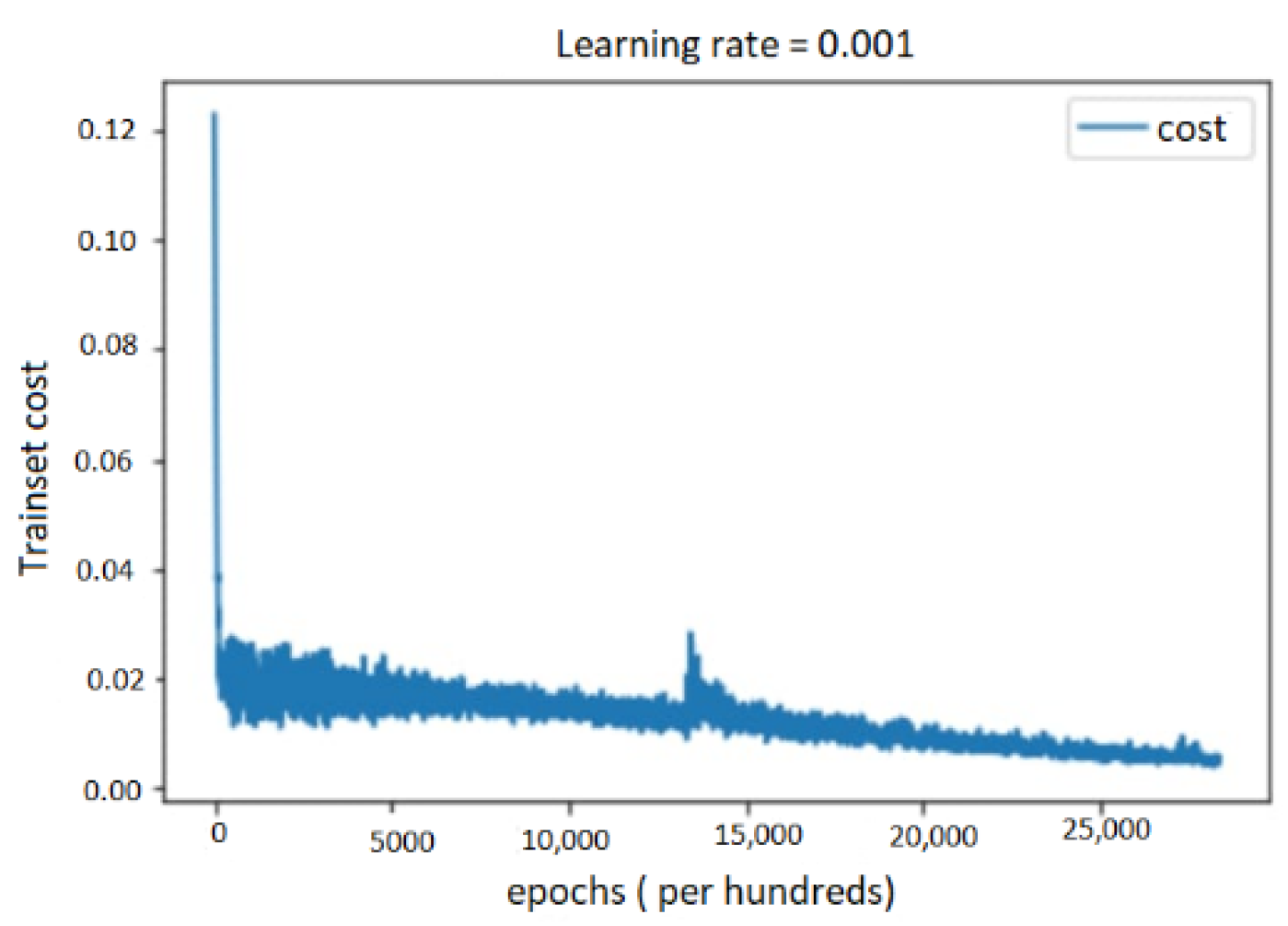
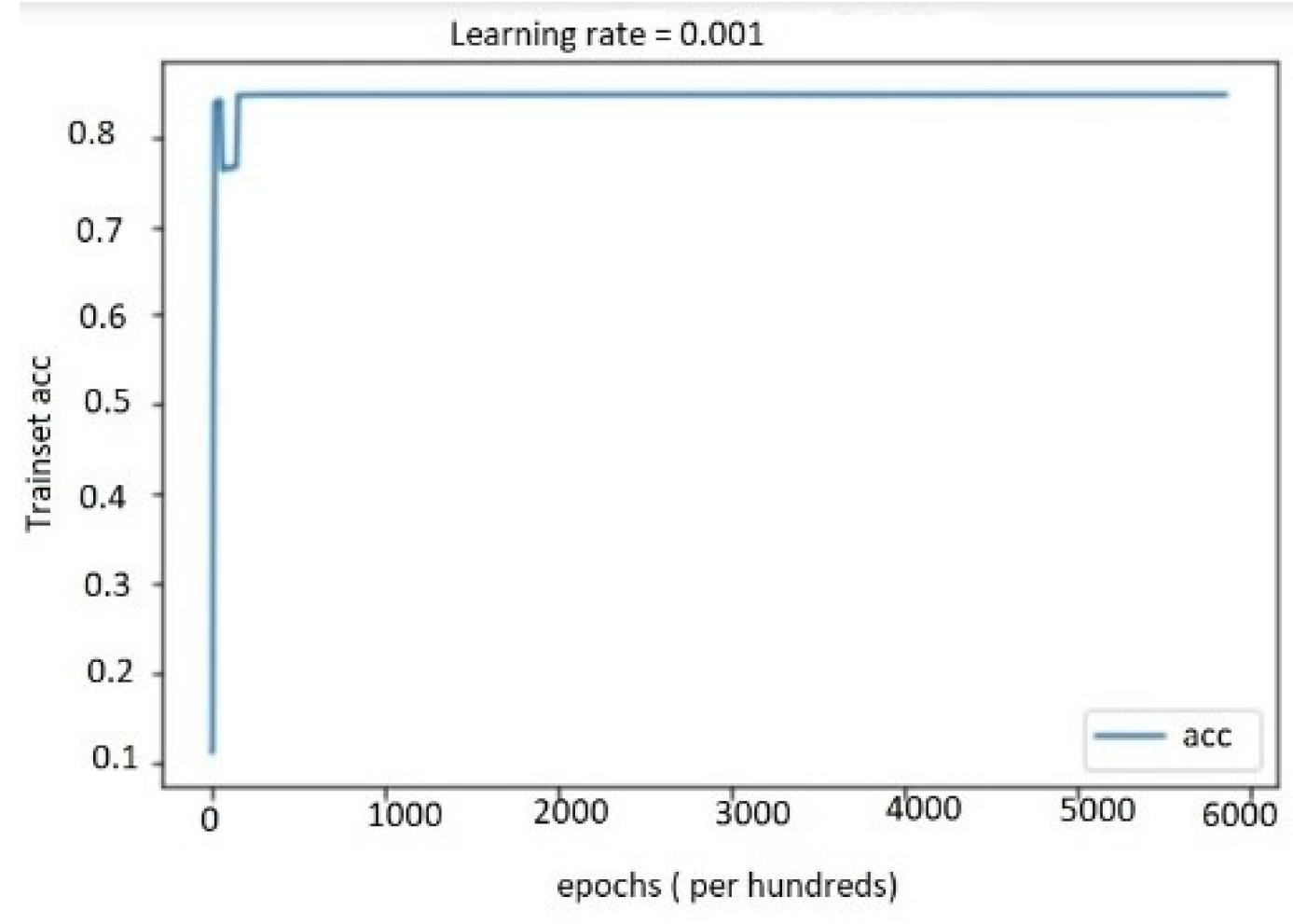
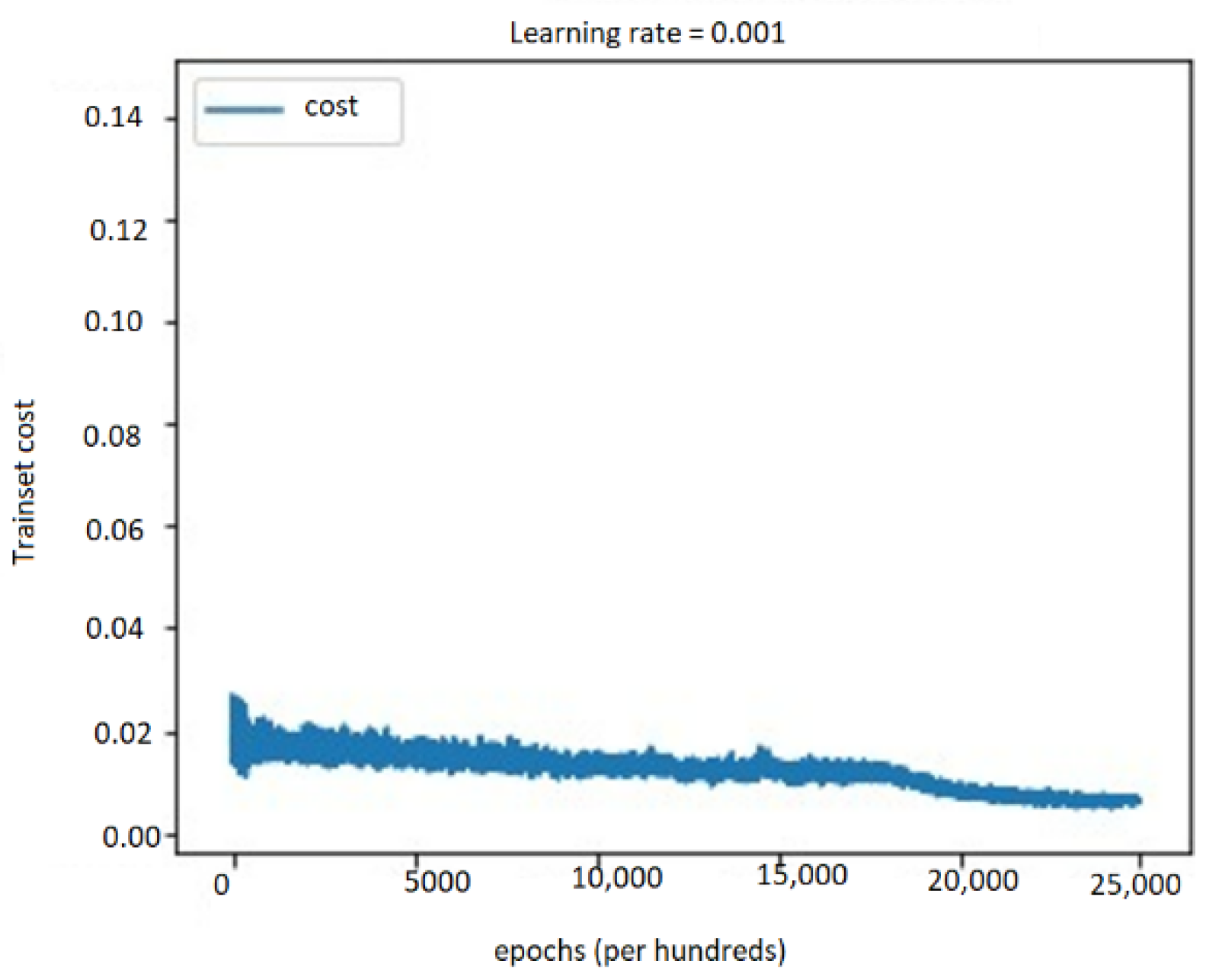
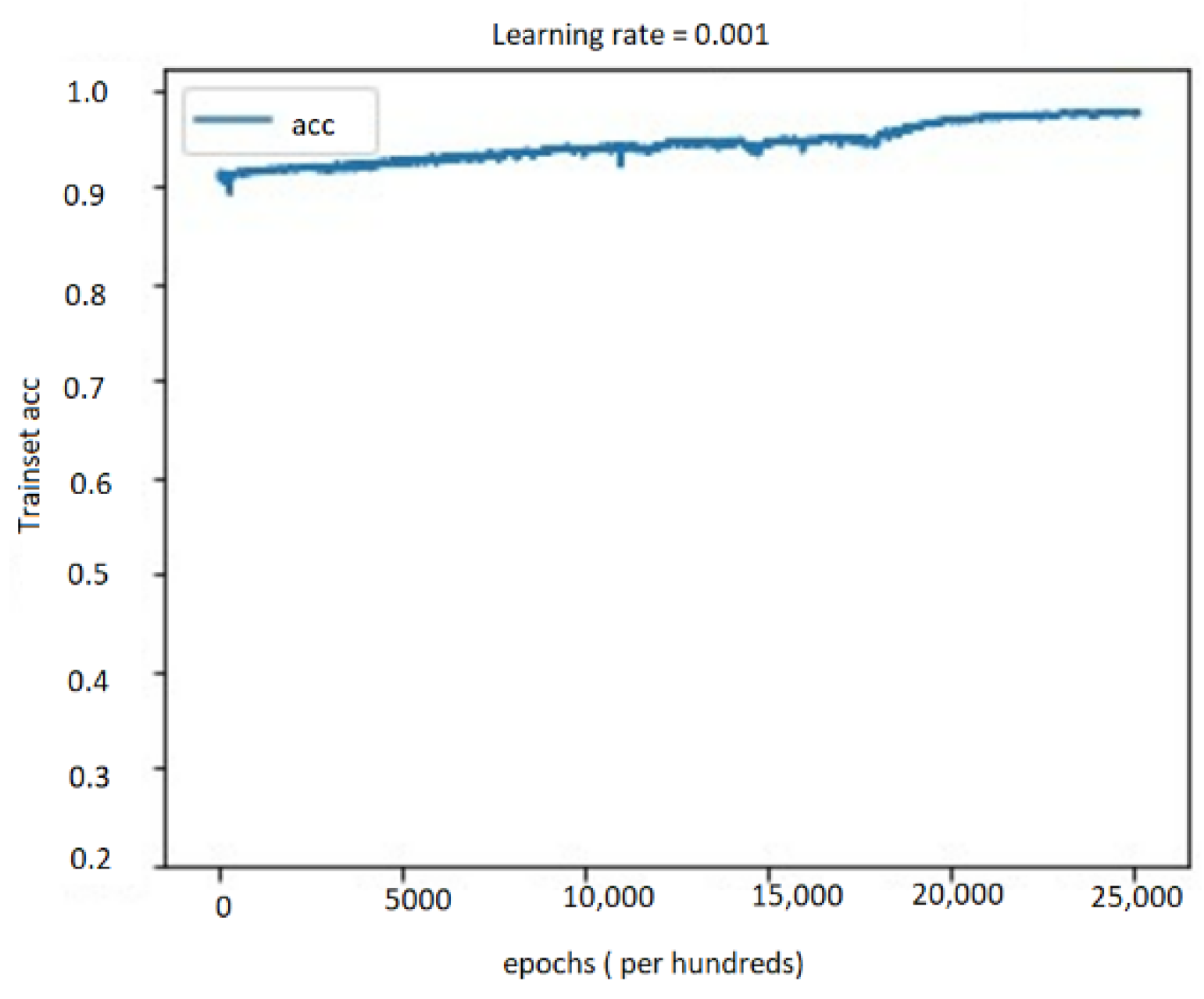
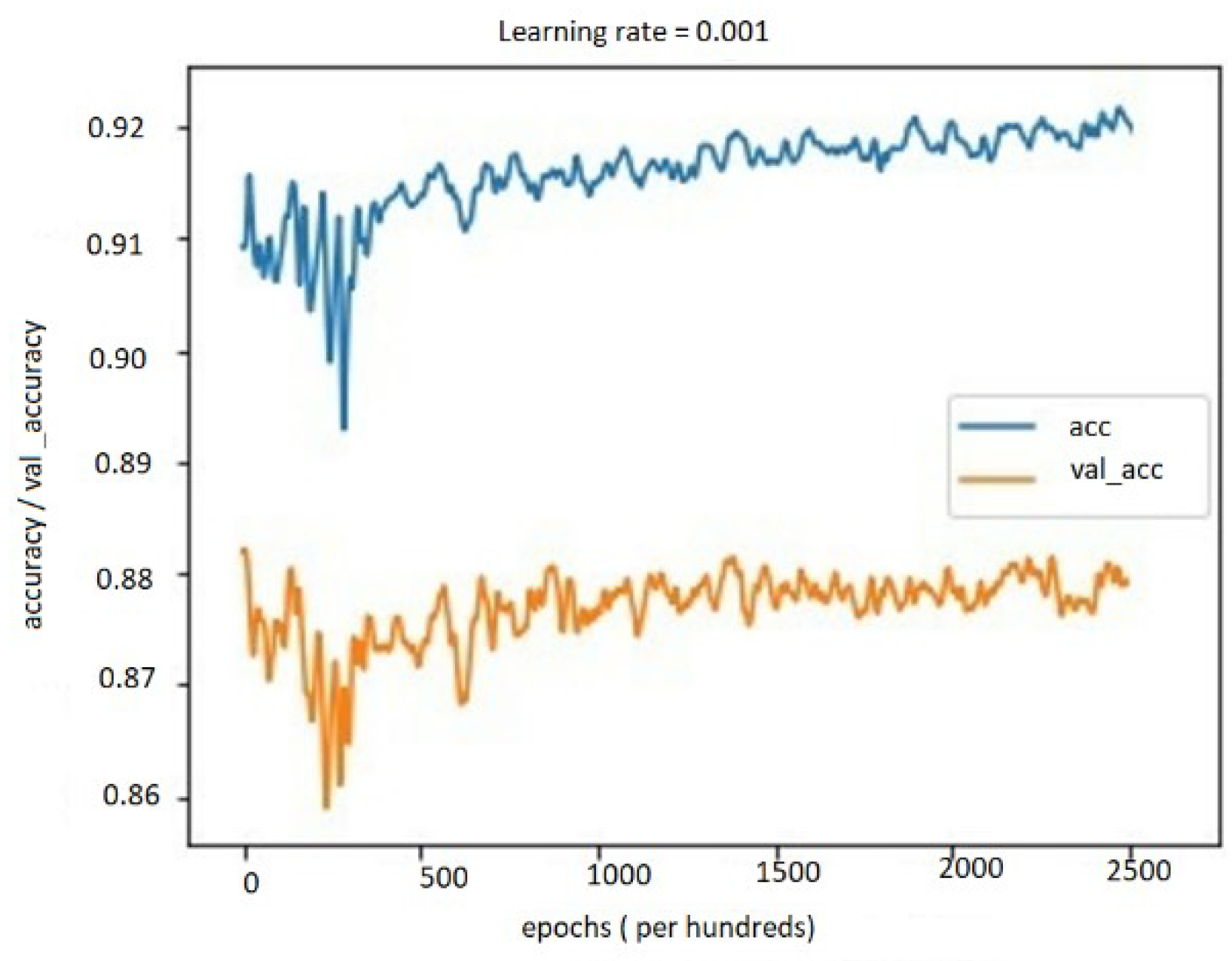
5.4. Performance Evaluation
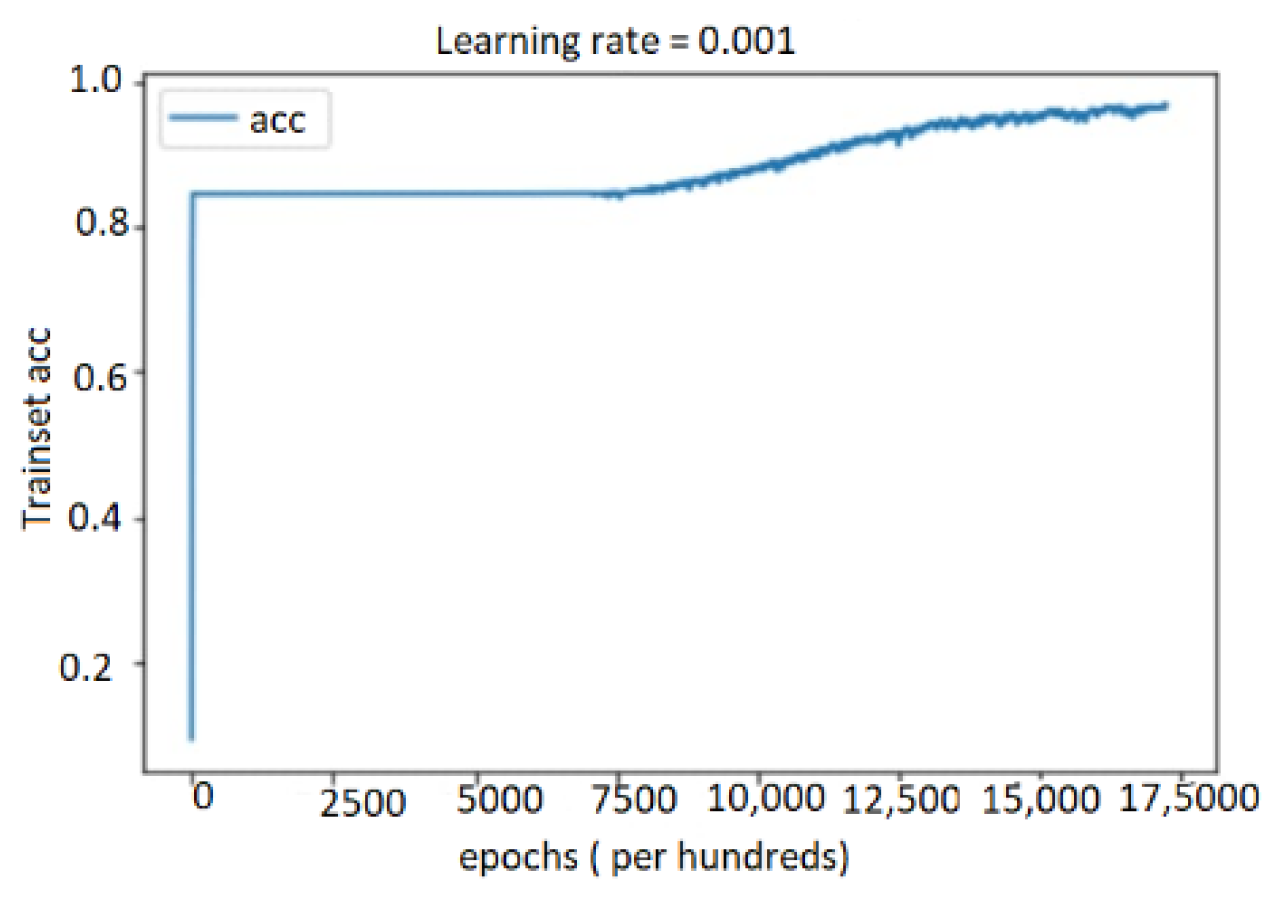
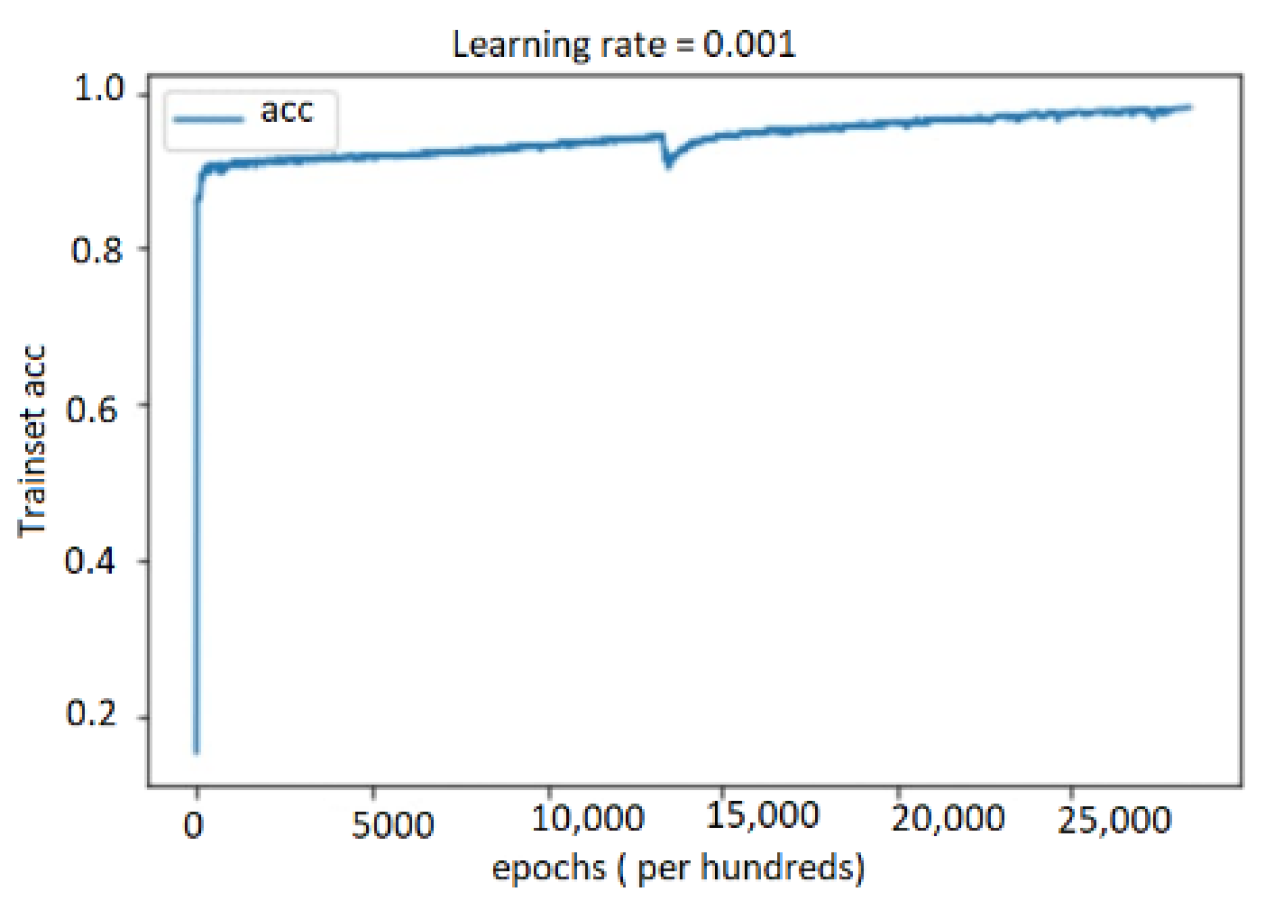
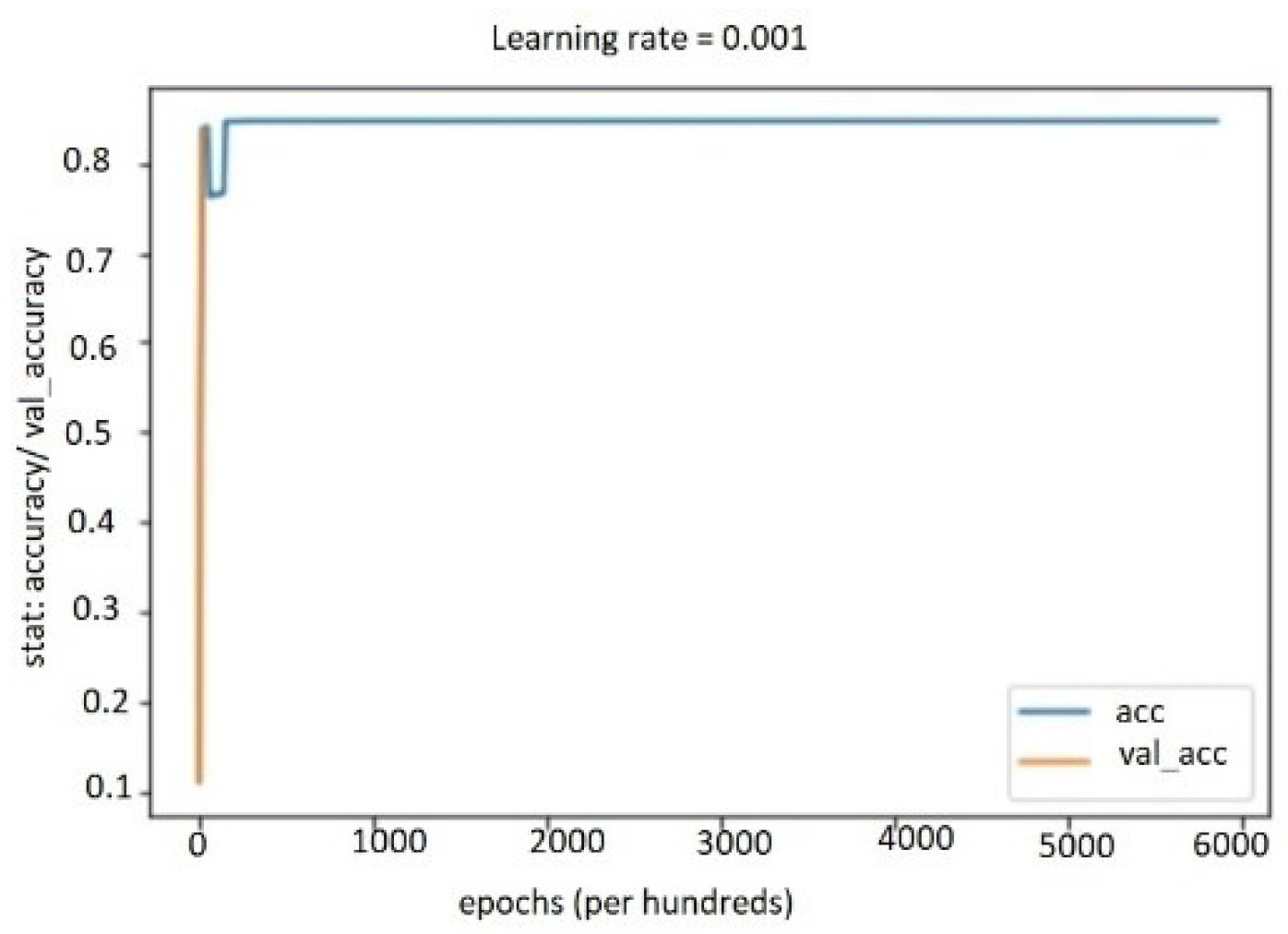
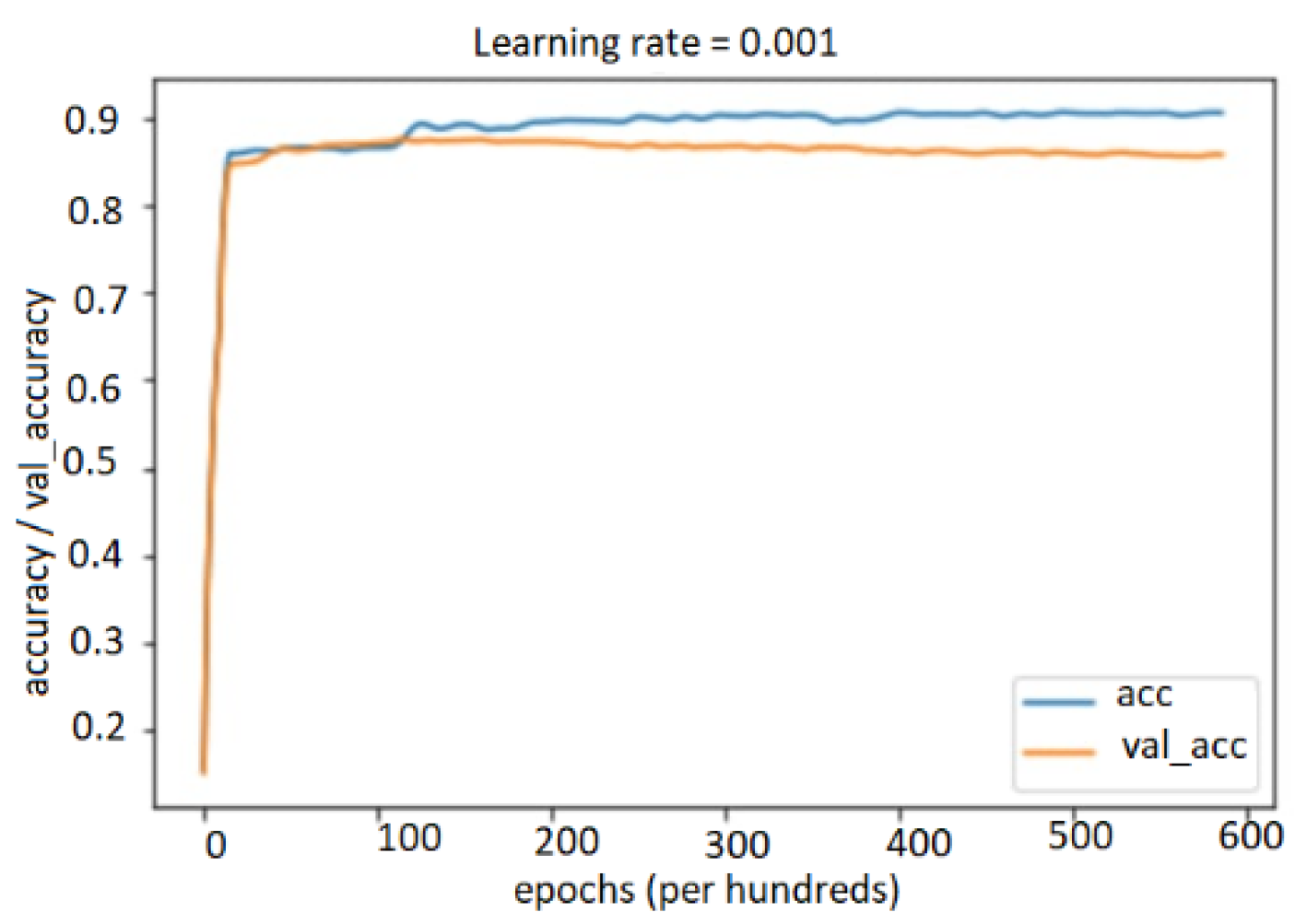
5.4.1. Performance Study on Audio, Text, and Bimodal Modalities
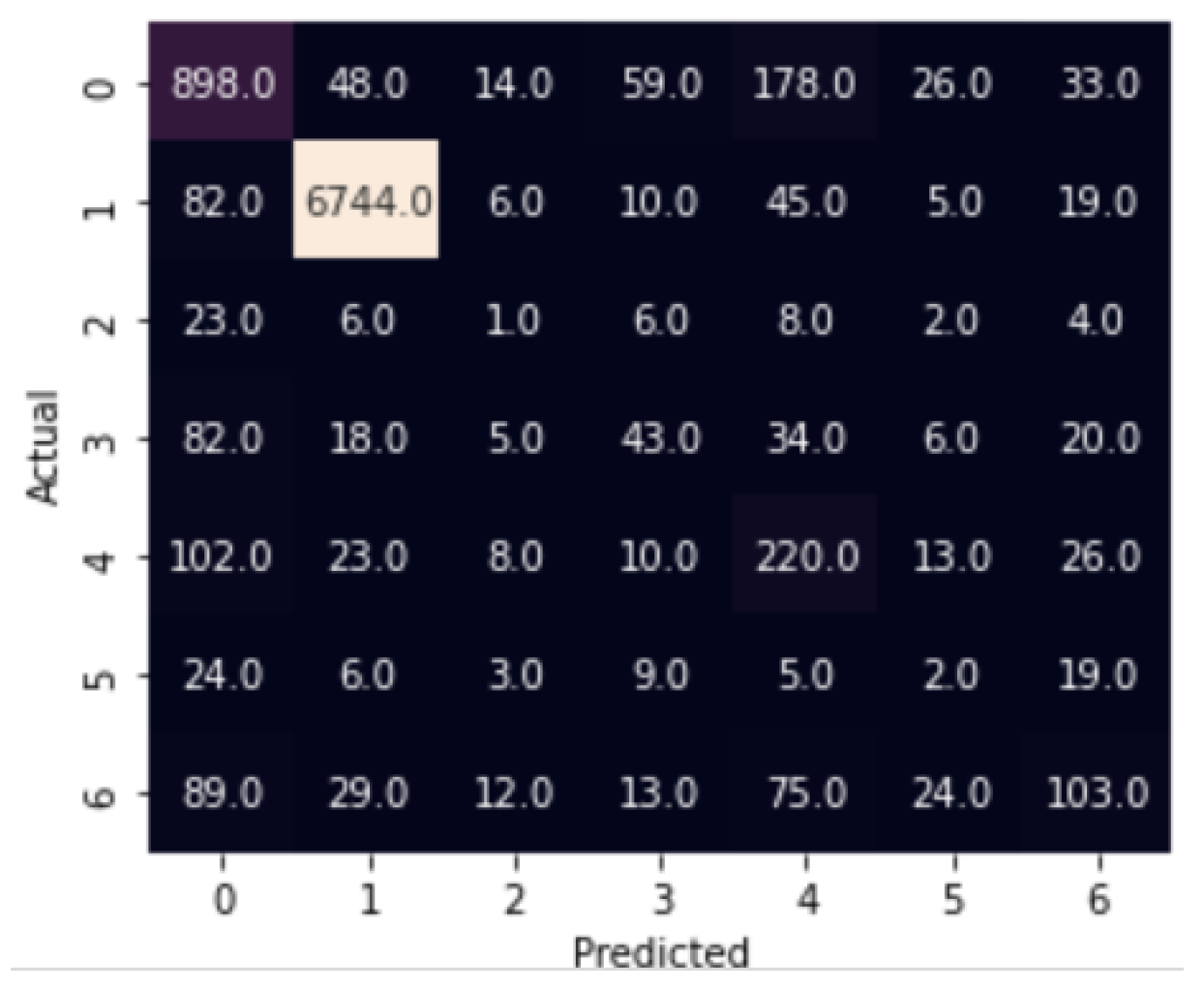
5.4.2. Performance Results on Multimodal System
5.5. Comparison with State-of-the-Art Methods
6. Conclusions and Futures Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Definition of ‘Emotion’. In Merriam-Webster Dictionary; Merriam-Webster: Springfield, MA, USA, 2012.
- Perveen, N.; Roy, D.; Chalavadi, K.M. Facial Expression Recognition in Videos Using Dynamic Kernels. IEEE Trans. Image Process. 2020, 29, 8316–8325. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Ouyang, Y.; Zeng, Y.; Li, Y. Dynamic Facial Expression Recognition Model Based on BiLSTM-Attention. In Proceedings of the 2020 15th International Conference on Computer Science & Education (ICCSE), IEEE, Delft, The Netherlands, 18–22 August 2020; pp. 828–832. [Google Scholar]
- Zeebaree, S.; Ameen, S.; Sadeeq, M. Social Media Networks Security Threats, Risks and Recommendation: A Case Study in the Kurdistan Region. Int. J. Innov. Creat. Change 2020, 13, 349–365. [Google Scholar]
- Al-Sultan, M.R.; Ameen, S.Y.; Abduallah, W.M. Real Time Implementation of Stegofirewall System. Int. J. Comput. Digit. Syst. 2019, 8, 498–504. [Google Scholar]
- Baimbetov, Y.; Khalil, I.; Steinbauer, M.; Anderst-Kotsis, G. Using Big Data for Emotionally Intelligent Mobile Services through Multi-Modal Emotion Recognition. In Proceedings of the International Conference on Smart Homes and Health Telematics, Denver, CO, USA, 25–27 June 2014; Springer: Berlin/Heidelberg, Germany, 2015; pp. 127–138. [Google Scholar]
- Bianchi-Berthouze, N.; Lisetti, C.L. Modeling Multimodal Expression of User’s Affective Subjective Experience. User Model. User-Adapt. Interact. 2002, 12, 49–84. [Google Scholar] [CrossRef]
- Abdullah, S.M.S.A.; Ameen, S.Y.A.; Sadeeq, M.A.M.; Zeebaree, S. Multimodal Emotion Recognition Using Deep Learning. J. Appl. Sci. Technol. Trends 2021, 2, 52–58. [Google Scholar] [CrossRef]
- Said, Y.; Barr, M. Human Emotion Recognition Based on Facial Expressions via Deep Learning on High-Resolution Images. Multimed. Tools Appl. 2021, 80, 25241–25253. [Google Scholar] [CrossRef]
- Anagnostopoulos, C.-N.; Iliou, T.; Giannoukos, I. Features and Classifiers for Emotion Recognition from Speech: A Survey from 2000 to 2011. Artif. Intell. Rev. 2015, 43, 155–177. [Google Scholar] [CrossRef]
- Thakur, N.; Han, C.Y. An Exploratory Study of Tweets about the SARS-CoV-2 Omicron Variant: Insights from Sentiment Analysis, Language Interpretation, Source Tracking, Type Classification, and Embedded URL Detection. COVID 2022, 2, 1026–1049. [Google Scholar] [CrossRef]
- Alarcao, S.M.; Fonseca, M.J. Emotions Recognition Using EEG Signals: A Survey. IEEE Trans. Affect. Comput. 2017, 10, 374–393. [Google Scholar] [CrossRef]
- Poria, S.; Hazarika, D.; Majumder, N.; Naik, G.; Cambria, E.; Mihalcea, R. MELD: A Multimodal Multi-Party Dataset for Emotion Recognition in Conversations. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Florence, Italy, 2019; pp. 527–536. [Google Scholar]
- Chen, S.-Y.; Hsu, C.-C.; Kuo, C.-C.; Ku, L.-W. EmotionLines: An Emotion Corpus of Multi-Party Conversations. arXiv 2018, arXiv:1802.08379. [Google Scholar]
- Busso, C.; Bulut, M.; Lee, C.-C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Chang, J.N.; Lee, S.; Narayanan, S.S. IEMOCAP: Interactive Emotional Dyadic Motion Capture Database. Lang. Resour. Eval. 2008, 42, 335–359. [Google Scholar] [CrossRef]
- Zadeh, A.; Zellers, R.; Pincus, E.; Morency, L.-P. MOSI: Multimodal Corpus of Sentiment Intensity and Subjectivity Analysis in Online Opinion Videos. arXiv 2016, arXiv:1606.06259. [Google Scholar]
- Choi, W.Y.; Song, K.Y.; Lee, C.W. Convolutional Attention Networks for Multimodal Emotion Recognition from Speech and Text Data. In Proceedings of the Grand Challenge and Workshop on Human Multimodal Language (Challenge-HML), Melbourne, Australia, 20 July 2018; pp. 28–34. [Google Scholar]
- Tzirakis, P.; Trigeorgis, G.; Nicolaou, M.A.; Schuller, B.W.; Zafeiriou, S. End-to-End Multimodal Emotion Recognition Using Deep Neural Networks. IEEE J. Sel. Top. Signal Process. 2017, 11, 1301–1309. [Google Scholar] [CrossRef]
- Poria, S.; Chaturvedi, I.; Cambria, E.; Hussain, A. Convolutional MKL Based Multimodal Emotion Recognition and Sentiment Analysis. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining (ICDM), IEEE, Barcelona, Spain, 12–15 December 2016; pp. 439–448. [Google Scholar]
- Maat, L.; Pantic, M. Gaze-X: Adaptive, Affective, Multimodal Interface for Single-User Office Scenarios. In Artifical Intelligence for Human Computing, Proceedings of the 8th International Conference on Multimodal Interfaces, Banff, AB, Canada, 2–4 November 2006; Springer: Berlin/Heidelberg, Germany, 2007; pp. 251–271. [Google Scholar]
- Su, Q.; Chen, F.; Li, H.; Yan, N.; Wang, L. Multimodal Emotion Perception in Children with Autism Spectrum Disorder by Eye Tracking Study. In Proceedings of the 2018 IEEE-EMBS Conference on Biomedical Engineering and Sciences (IECBES), IEEE, Sarawak, Malaysia, 3–6 December 2018; pp. 382–387. [Google Scholar]
- Nemati, S.; Rohani, R.; Basiri, M.E.; Abdar, M.; Yen, N.Y.; Makarenkov, V. A Hybrid Latent Space Data Fusion Method for Multimodal Emotion Recognition. IEEE Access 2019, 7, 172948–172964. [Google Scholar] [CrossRef]
- Prasad, G.; Dikshit, A.; Lalitha, S. Sentiment and Emotion Analysis for Effective Human-Machine Interaction during Covid-19 Pandemic. In Proceedings of the 2021 8th International Conference on Signal Processing and Integrated Networks (SPIN), IEEE, Noida, India, 26–27 August 2021; pp. 909–915. [Google Scholar]
- Priyasad, D.; Fernando, T.; Denman, S.; Sridharan, S.; Fookes, C. Attention Driven Fusion for Multi-Modal Emotion Recognition. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, Barcelona, Spain, 4–8 May 2020; pp. 3227–3231. [Google Scholar]
- Sun, B.; Li, L.; Zhou, G.; Wu, X.; He, J.; Yu, L.; Li, D.; Wei, Q. Combining Multimodal Features within a Fusion Network for Emotion Recognition in the Wild. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, Seattle, WA, USA, 9–13 November 2015; pp. 497–502. [Google Scholar]
- Schuller, B.; Valster, M.; Eyben, F.; Cowie, R.; Pantic, M. Avec 2012: The Continuous Audio/Visual Emotion Challenge. In Proceedings of the 14th ACM International Conference on Multimodal Interaction, Santa Monica, CA, USA, 22–26 October 2012; pp. 449–456. [Google Scholar]
- Cevher, D.; Zepf, S.; Klinger, R. Towards Multimodal Emotion Recognition in German Speech Events in Cars Using Transfer Learning. arXiv 2019, arXiv:1909.02764. [Google Scholar]
- Georgiou, E.; Papaioannou, C.; Potamianos, A. Deep Hierarchical Fusion with Application in Sentiment Analysis. In Proceedings of the Interspeech, Graz, Austria, 15–19 September 2019; pp. 1646–1650. [Google Scholar]
- Bahreini, K.; Nadolski, R.; Westera, W. Data Fusion for Real-Time Multimodal Emotion Recognition through Webcams and Microphones in e-Learning. Int. J. Hum. Comput. Interact. 2016, 32, 415–430. [Google Scholar] [CrossRef]
- Slavova, V. Towards Emotion Recognition in Texts–a Sound-Symbolic Experiment. Int. J. Cogn. Res. Sci. Eng. Educ. (IJCRSEE) 2019, 7, 41–51. [Google Scholar] [CrossRef]
- Pan, Z.; Luo, Z.; Yang, J.; Li, H. Multi-Modal Attention for Speech Emotion Recognition. arXiv 2020, arXiv:2009.04107. [Google Scholar]
- Krishna, D.N.; Patil, A. Multimodal Emotion Recognition Using Cross-Modal Attention and 1D Convolutional Neural Networks. In Proceedings of the Interspeech, Shanghai, China, 25–29 October 2020; pp. 4243–4247. [Google Scholar]
- Huang, J.; Li, Y.; Tao, J.; Lian, Z.; Wen, Z.; Yang, M.; Yi, J. Continuous Multimodal Emotion Prediction Based on Long Short Term Memory Recurrent Neural Network. In Proceedings of the 7th Annual Workshop on Audio/Visual Emotion Challenge, Mountain View, CA, USA, 23–27 October 2017; pp. 11–18. [Google Scholar]
- Lian, Z.; Liu, B.; Tao, J. CTNet: Conversational Transformer Network for Emotion Recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 985–1000. [Google Scholar] [CrossRef]
- Ma, H.; Wang, J.; Lin, H.; Pan, X.; Zhang, Y.; Yang, Z. A Multi-View Network for Real-Time Emotion Recognition in Conversations. Knowl. Based Syst. 2022, 236, 107751. [Google Scholar] [CrossRef]
- Siriwardhana, S.; Kaluarachchi, T.; Billinghurst, M.; Nanayakkara, S. Multimodal Emotion Recognition with Transformer-Based Self Supervised Feature Fusion. IEEE Access 2020, 8, 176274–176285. [Google Scholar] [CrossRef]
- Xie, B.; Sidulova, M.; Park, C.H. Robust Multimodal Emotion Recognition from Conversation with Transformer-Based Crossmodality Fusion. Sensors 2021, 21, 4913. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to Forget: Continual Prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef]
- Filali, H.; Riffi, J.; Aboussaleh, I.; Mahraz, A.M.; Tairi, H. Meaningful Learning for Deep Facial Emotional Features. Neural Process. Lett. 2022, 54, 387–404. [Google Scholar] [CrossRef]
- Poria, S.; Cambria, E.; Hazarika, D.; Majumder, N.; Zadeh, A.; Morency, L.-P. Context-Dependent Sentiment Analysis in User-Generated Videos. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 873–883. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Eyben, F.; Wöllmer, M.; Schuller, B. Opensmile: The Munich Versatile and Fast Open-Source Audio Feature Extractor. In Proceedings of the 18th ACM International Conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 1459–1462. [Google Scholar]
- Reynolds, D.A. Gaussian Mixture Models. Encycl. Biom. 2009, 741, 659–663. [Google Scholar]
- Eddy, S.R. Hidden Markov Models. Curr. Opin. Struct. Biol. 1996, 6, 361–365. [Google Scholar] [CrossRef]
- Wang, S.-C. Artificial Neural Network. In Interdisciplinary Computing in Java Programming; Springer: Berlin/Heidelberg, Germany, 2003; pp. 81–100. [Google Scholar]
- Noble, W.S. What Is a Support Vector Machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef]
- Schapire, R.E. Explaining Adaboost. In Empirical Inference; Springer: Berlin/Heidelberg, Germany, 2013; pp. 37–52. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Components | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| C1 Text | C2 Audio | C3 Bimodal | |||||||
| Dimension | Number of Neurones | Activation Function | Dimension | Number of Neurones | Activation Function | Dimension | Number of Neurones | Activation Function | |
| Input | 1611 | 500 | ReLu | 49 | 50 | ReLu | 898 | 300 | ReLu |
| Specialized layer 1 | 200 | ReLu | 20 | ReLu | 200 | ReLu | |||
| Specialized layer 2 | 50 | ReLu | 7 | Softmax | 50 | ReLu | |||
| Directive Layer | 7 | Softmax | - | - | 7 | Softmax | |||
| Fusion layer | 21 | 7 | Softmax | 21 | 7 | Softmax | 21 | 7 | Softmax |
| Output | 7 | Softmax | 7 | Softmax | 7 | Softmax | |||
| Anger | Disgust | Fear | Joy | Neutral | Sadness | Surprise | |
|---|---|---|---|---|---|---|---|
| Train | 1109 | 271 | 268 | 1743 | 4710 | 683 | 1205 |
| Dev | 153 | 22 | 40 | 163 | 470 | 111 | 150 |
| Test | 345 | 68 | 50 | 402 | 1256 | 208 | 281 |
| Emotion | Modality | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Text Only | Audio Only | Bimodal (Text + Audio) | |||||||
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | Precision | Recall | F1-Score | |
| Anger | 90 | 87 | 88 | 55 | 58 | 56 | 72 | 72 | 72 |
| Disgust | 68 | 80 | 74 | 98 | 97 | 97 | 98 | 98 | 98 |
| Fear | 60 | 35 | 44 | 0 | 0 | 0 | 4 | 10 | 6 |
| Joy | 76 | 36 | 48 | 9 | 18 | 12 | 23 | 18 | 20 |
| Neutral | 88 | 88 | 88 | 17 | 19 | 18 | 44 | 46 | 45 |
| Sadness | 82 | 40 | 54 | 3 | 1 | 2 | 6 | 9 | 7 |
| Surprise | 84 | 95 | 89 | 27 | 14 | 19 | 39 | 29 | 33 |
| Macro avg | 78 | 66 | 69 | 30 | 30 | 29 | 41 | 40 | 40 |
| Weighted avg | 84 | 84 | 83 | 82 | 82 | 82 | 87 | 87 | 87 |
| Modality | Accuracy (%) |
|---|---|
| Audio only | 81.79 |
| Text only | 83.98 |
| Bimodal (text + audio) | 86.51 |
| Emotion | Multimodal | |||
|---|---|---|---|---|
| Precision | Recall | F1-Score | Accuracy | |
| Anger | 69 | 71 | 70 | 86.69 |
| Disgust | 98 | 98 | 98 | |
| Fear | 2 | 2 | 2 | |
| Joy | 29 | 21 | 24 | |
| Neutral | 39 | 55 | 46 | |
| Sadness | 3 | 3 | 3 | |
| Surprise | 46 | 30 | 36 | |
| Macro avg | 41 | 40 | 40 | |
| Weighted avg | 87 | 87 | 87 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Filali, H.; Riffi, J.; Boulealam, C.; Mahraz, M.A.; Tairi, H. Multimodal Emotional Classification Based on Meaningful Learning. Big Data Cogn. Comput. 2022, 6, 95. https://doi.org/10.3390/bdcc6030095
Filali H, Riffi J, Boulealam C, Mahraz MA, Tairi H. Multimodal Emotional Classification Based on Meaningful Learning. Big Data and Cognitive Computing. 2022; 6(3):95. https://doi.org/10.3390/bdcc6030095
Chicago/Turabian StyleFilali, Hajar, Jamal Riffi, Chafik Boulealam, Mohamed Adnane Mahraz, and Hamid Tairi. 2022. "Multimodal Emotional Classification Based on Meaningful Learning" Big Data and Cognitive Computing 6, no. 3: 95. https://doi.org/10.3390/bdcc6030095
APA StyleFilali, H., Riffi, J., Boulealam, C., Mahraz, M. A., & Tairi, H. (2022). Multimodal Emotional Classification Based on Meaningful Learning. Big Data and Cognitive Computing, 6(3), 95. https://doi.org/10.3390/bdcc6030095