This section includes a detailed description of the methodology and steps of the experiment.
3.1. Dataset
Twitter, Facebook, Instagram, and YouTube are considered popular social networking platforms in the Arab world. Researchers stated that Twitter is the most popular social media platform in Gulf countries compared to the rest of the Arab world [
10]. The researchers also found that, when compared to other Arab world nations, the Gulf countries have the lowest Facebook usage [
10]. It was also found that most researchers used the Twitter and Facebook platforms to create Arabic text datasets [
6].
The number of active social media accounts in the UAE amounted to about 20.85 million accounts, according to Alittihad newspaper, which reported that the number of active social media accounts in the UAE amounted to about 8.8 million Facebook accounts, 4 million LinkedIn accounts, 3.7 million Instagram accounts, 2.3 million Twitter accounts, and nearly 2 million active Snapchat accounts [
9]. It is worth noting that Instagram witnessed an increase in active accounts in recent years [
39]. Researchers stated that, in terms of active users, Instagram is the third most popular social networking platform [
39]. It is also the most popular social media platform among teenagers, as well as the most popular platform for influencer marketing.
Instagram is a well-known photo- and video-sharing social media platform. It is one of the most widely used social media platforms in the UAE. People can leave comments on Instagram posts, as well as like or dislike the photographs and videos that have been posted [
8]. We focus here on gathering comments on Instagram posts written in Arabic dialects, with a particular concentration on the Emirati dialect due to many reasons: (a) the authors’ goal is to collect texts written in the Emirati dialect from popular Emirati Instagram accounts. Based on our findings while investigating Twitter, Facebook, and Instagram, we discovered that the number of comments left on the same posts by the same account owners on Instagram was much higher than the number of comments left on the same posts by the same account owners on Twitter and Facebook. (b) According to [
40], Instagram is one of the top three social media platforms in the United Arab Emirates; Instagram is popular social media site in UAE and its popularity is increasing day after day. (c) Finally, while reviewing research papers, most of the constructed datasets used Twitter and Facebook platforms to construct datasets of Arabic texts; however, a limited number of studies targeted the Instagram platform for collecting comments and constructing datasets from the collected comments [
6].
Below is our methodology, which was followed for collecting the dataset:
We were granted a “Facebook for Developers” account, through which we were able to collect comments from Instagram posts written in Arabic.
We identified public Instagram accounts of Emirati government authorities, Emirati news accounts, and Emirati bloggers to collect comments written in the Emirati dialect.
Comments in the form of Arabic texts were collected from different kinds of posts whether they were pictures or videos. The collected comments were stored in an Excel datasheet.
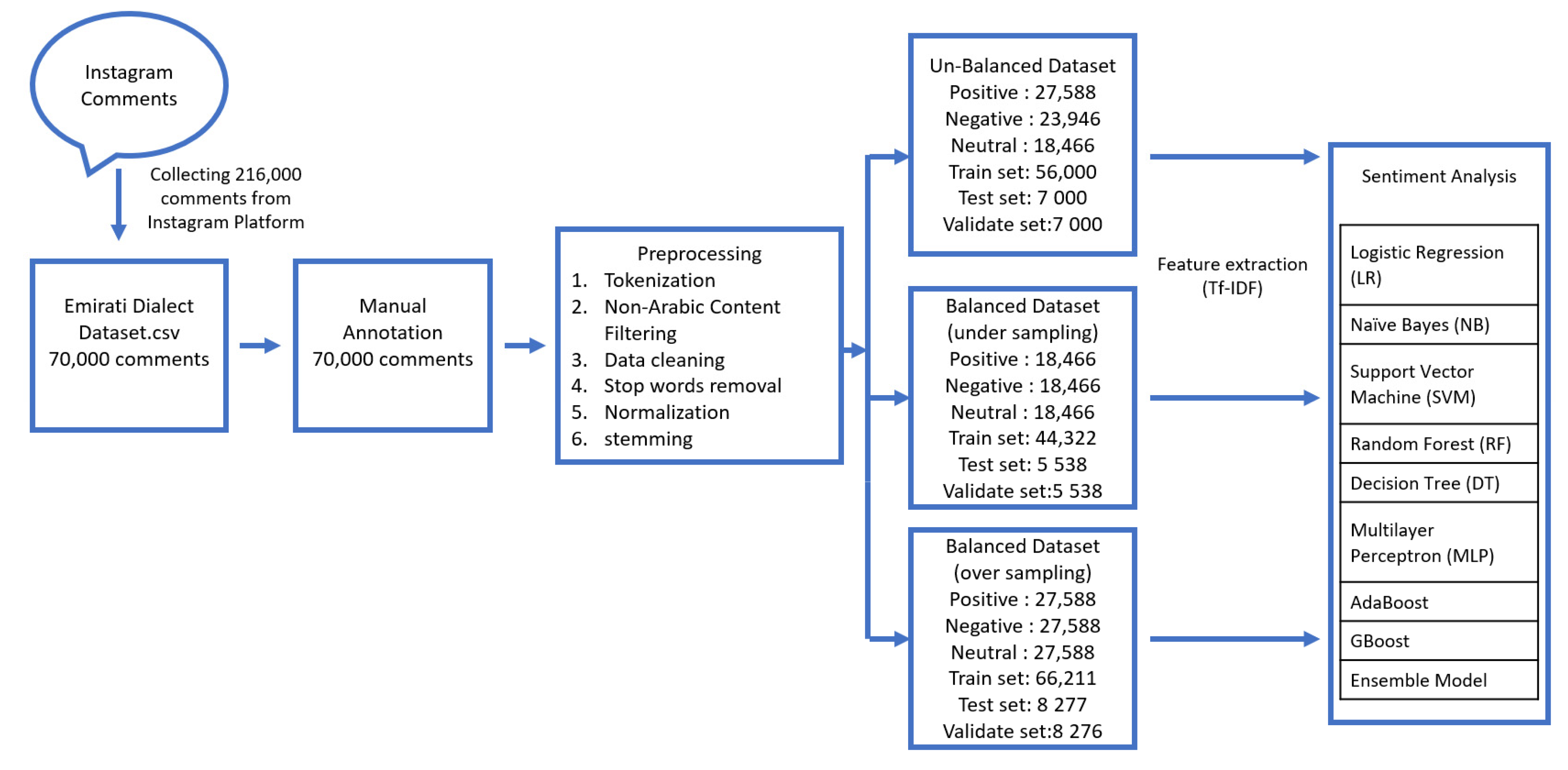
We were able to initially collect around 216,000 comments; after that, around 70,000 comments were annotated and categorized as positive, negative, or neutral. Moreover, the comments were annotated based on dialect type: either the Emirati dialect or other Arabic dialects. The criterion for the annotation will be further mentioned below.
It was reported that most of the comments were written in the Emirati dialect; however, some comments were written in MSA and other Arabic dialects. In total, 459 comments were written in other Arabic dialects, 1 comment was written in MSA, and the remaining 69,540 comments were written in the Emirati dialect. No occurrences of Arabic writing with Roman characters were reported in the dataset.
Table 4 illustrates a description of our collected corpus of the Emirati dialect. We named our corpus ESAAD, which stands for Emirati Sentiment Analysis Annotated Dataset.
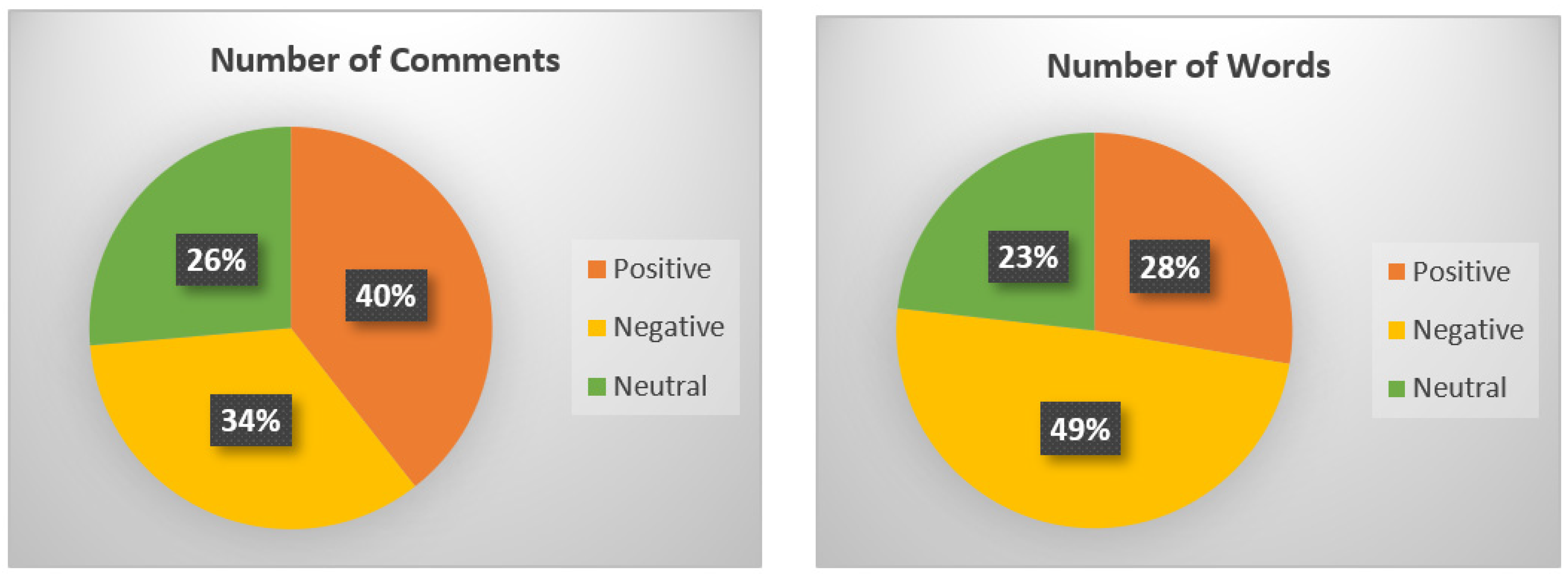
Figure 2 illustrates a comparison of the sentiment score values of Instagram comments in terms of the number of neutral, positive, and negative comments.
Ethics: The comments gathered are from public accounts, and this action is lawful and approved under the website’s Terms of Use Policies. The collected comments are in the form of small sentences that are not protected by copyright requirements, and to ensure adherence to the privacy rules, the identities of account owners, from which the texts were obtained, are disguised.
3.2. Annotating the Dataset
A sentiment annotation of a text involves labeling the text based on the sentiment presented in that text. Three approaches can be utilized for sentiment annotation: automatic annotation, semi-automatic annotation, and manual annotation [
41]. In this research paper, the constructed dataset was manually annotated by three annotators. Each of the annotators agreed on a set of constraints and signed a contract with the author. Each annotator was given an annotation guideline to follow, which was based upon annotation principles developed by V. Batanović, M. Cvetanović, and B. Nikolić [
42]. The annotation guideline principles are as follows:
The annotator must enter the term “positive” for the comment, which expresses a positive sentiment. Similarly, if the comment expresses a negative sentiment, the annotator must enter the term “negative”, which signifies a negative sentiment. If the comment does not represent any sentiment, then the annotator must enter the word “neutral”.
Each comment is individually evaluated, with no recourse to the surrounding comments. The only difficulty that the annotators faced mostly revolved around the uncertainty about whether a given comment is sarcastic. Researchers dealt with this difficulty by approving the sentiments of certain comments that the majority of annotators agreed on.
A predefined list with several positive, negative, and neutral words was identified and handed to annotators to help them in their annotations.
The researchers used a composite scoring system when a comment had several different statements. This indicates that each sentence was independently assessed, with the final sentiment label derived by merging the partial labels. In this experiment, the strength of the sentiment is not considered, and texts of a certain polarity had the same sentiment label regardless of the strength of the polarity they represented.
For sentiment labeling, only comments in which the author was the speaker were considered. Other people’s points of view indicated in the comment were only taken into account if they indirectly exposed the speaker’s position; otherwise, they were viewed as neutral. Comments that presented questions, requests, advertisements, follow requests, suggestions, pleas, intent, or ambiguous statements were labeled as neutral sentiments. Comments that represented news, factual statements, or any kind of information were labeled as neutral sentiments. Comments that represented regrets and sarcasm were labeled as negative sentiments. Humorous comments were labeled as positive sentiments, as humor indicates happiness, unless this humor was followed by any negative words, then the sentiment of the sentence was calculated based upon the composite scoring system mentioned earlier. Emojis were considered when annotating comments, and the weights given to the emoji’s polarity were less than the weights given to the text’s polarity as this method could deal with the weaknesses that were related to the misuse of emojis [
1]. It was found that emoticons or emojis could lead to several errors while analyzing the sentiment of texts, as they were more likely to be used in social media texts that utilized emojis or emoticons that contradicted the text [
43]. Comments that contained verses from the Holy Qur’an or hadiths from the Sunnah were labeled with neutral sentiments.
The annotation process:
- 1.
Each comment was annotated by the three annotators, then the sentiment for the comment was approved by determining the sentiment that the majority of annotators agreed on.
- 2.
If there was no consensus between the three annotators, another expert annotator was assigned.
- 3.
Annotators successfully annotated 70,000 comments that were extracted from the Instagram platform.
- 4.
To measure the quality of annotation, an inter-annotator agreement was calculated for 3000 selected comments. The authors utilized Cohen’s kappa coefficient to measure the agreement between the annotators using SPSS software.
It is worth noting that SPSS software restricted the following rules for correctly implementing Cohen’s kappa coefficient: (1) The raters’ responses were graded on a nominal scale, and the categories must be mutually exclusive (in our experiment: positive, negative, or neutral). (2) The response data were made up of paired observations of the same phenomena, which meant that both raters evaluated the identical observations (in our experiment, annotators evaluated the same comments, i.e., text). (3) The two raters were independent, which meant that one rater’s decision did not influence the decision of the other (in our experiment, the annotators were independent). (4) All observations were judged by the same raters, meaning that the raters were fixed or unique (in our experiment, the annotators were fixed, meaning that the same annotators evaluated the same text).
For example, both annotators evaluated the same 3000 comments, i.e., text. Additionally, the ratings of the annotators (i.e., either “Positive”, “Negative” or “Neutral” sentiments) were compared for the same comments (i.e., text; the rating given by annotator 1 for comment 1 was compared to the rating given by annotator 2 for comment 1, and so forth).
Cohen’s kappa coefficient was utilized to measure the inter-annotator agreement, and the result was 93%.
3.5. Sentiment Analysis Experiment Setup
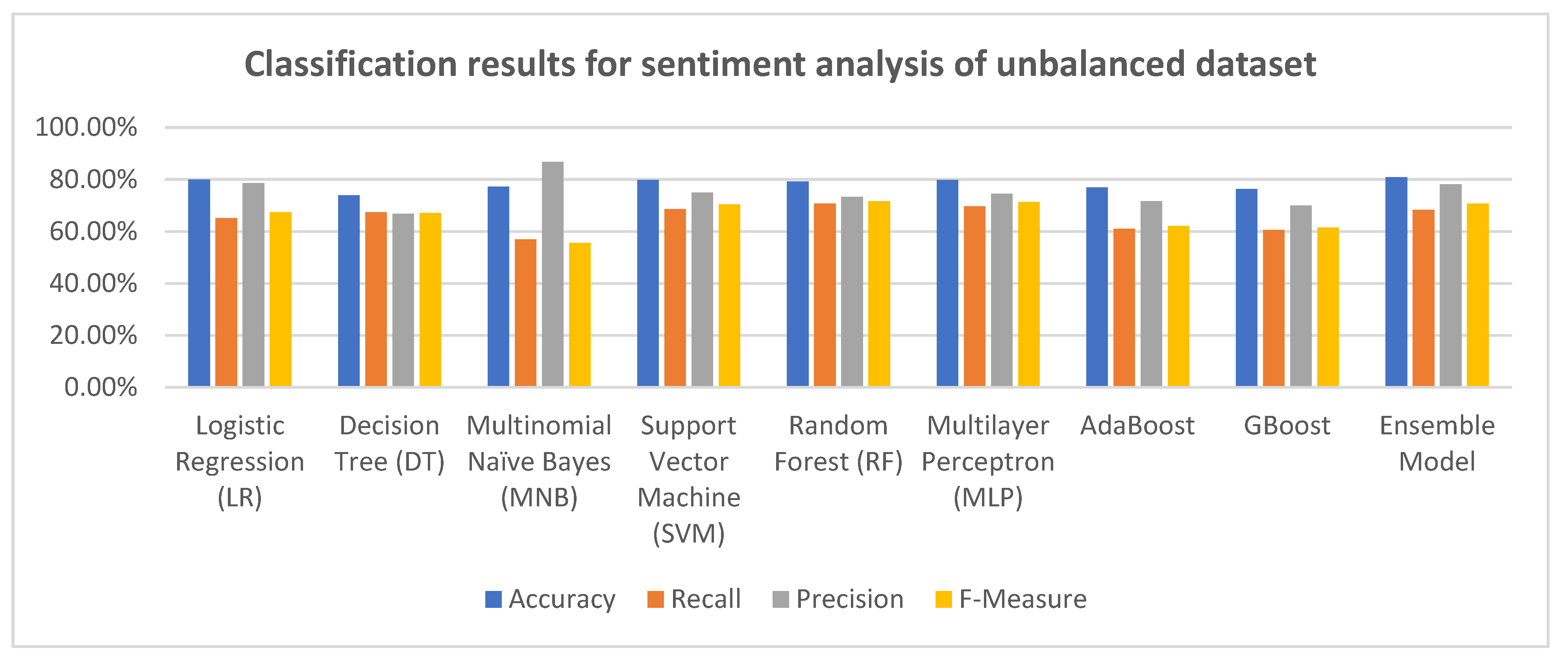
We used the following classifiers after converting the dataset into TfidfVectorizer: logistic regression (LR), multinomial Naïve Bayes (MNB), support vector machine (SVM), decision tree (DT), random forest (RF), multilayer perceptron (MLP), AdaBoost, GBoost, and an ensemble model. SciKit-Learn (SKLearn) library and Natural Language Tool Kit (NLTK) library were utilized in the experiment. These libraries are open-source and free, allowing programmers to use a variety of machine learning techniques.
As mentioned earlier, the dataset consisted of 70,000 comments extracted from the Instagram platform, and most of the comments were written in the Emirati dialect. In the experiment, the dataset was divided into a train set, test set, and validation set.
We used the pandas API in Python to upload the dataset (.csv file), and then used the TfidfVectorizer to train the dataset. Various classification experiments were conducted on the dataset to compare the classification results obtained using different machine learning algorithms. We used 80% of the dataset as training data, 10% of the dataset as test data, and 10% of the dataset as a validation set. All of the experiments were conducted using the TF-IDF feature referred to in
Section 3.4.
Figure 3 illustrates the experiment model.
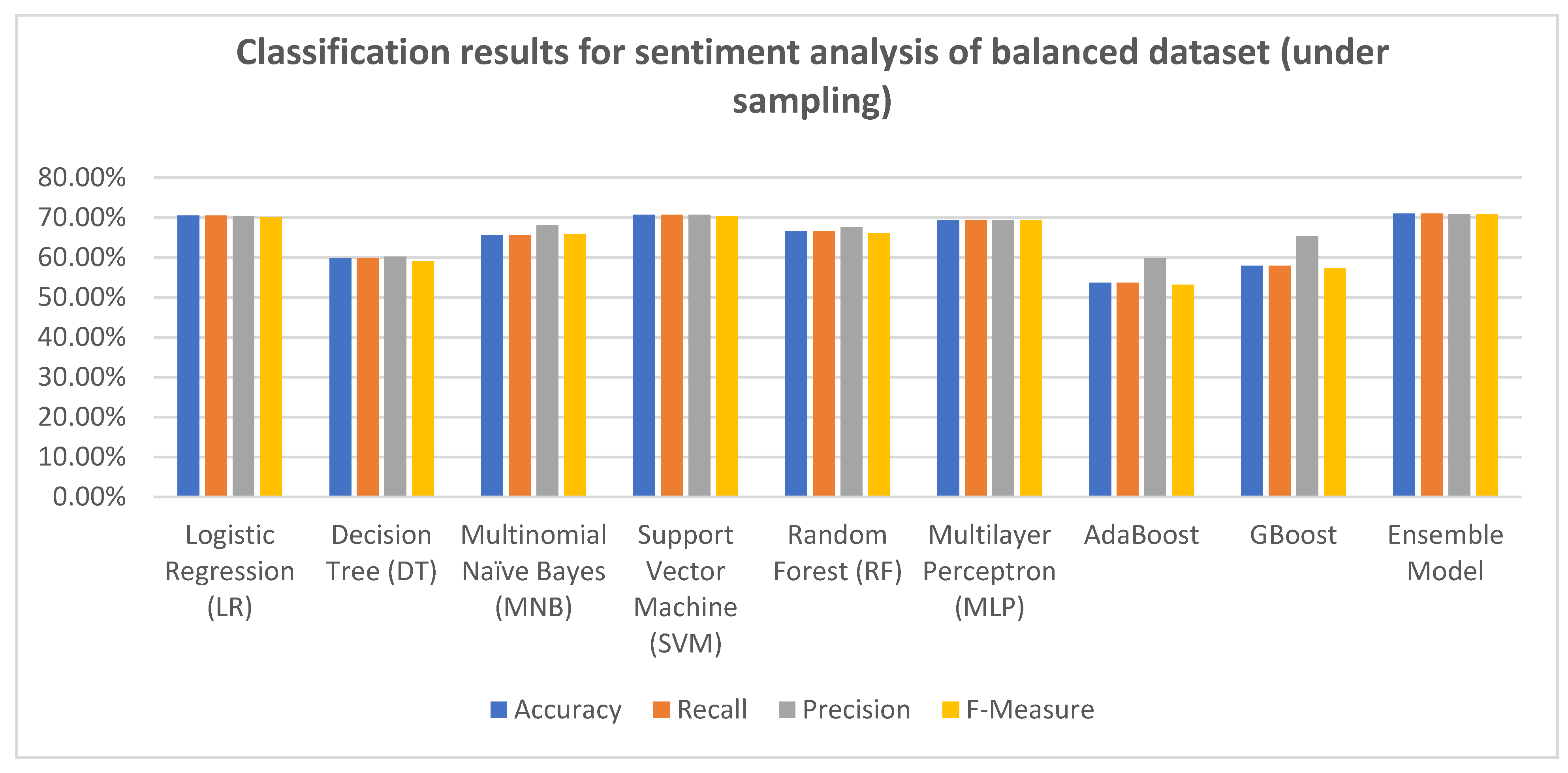
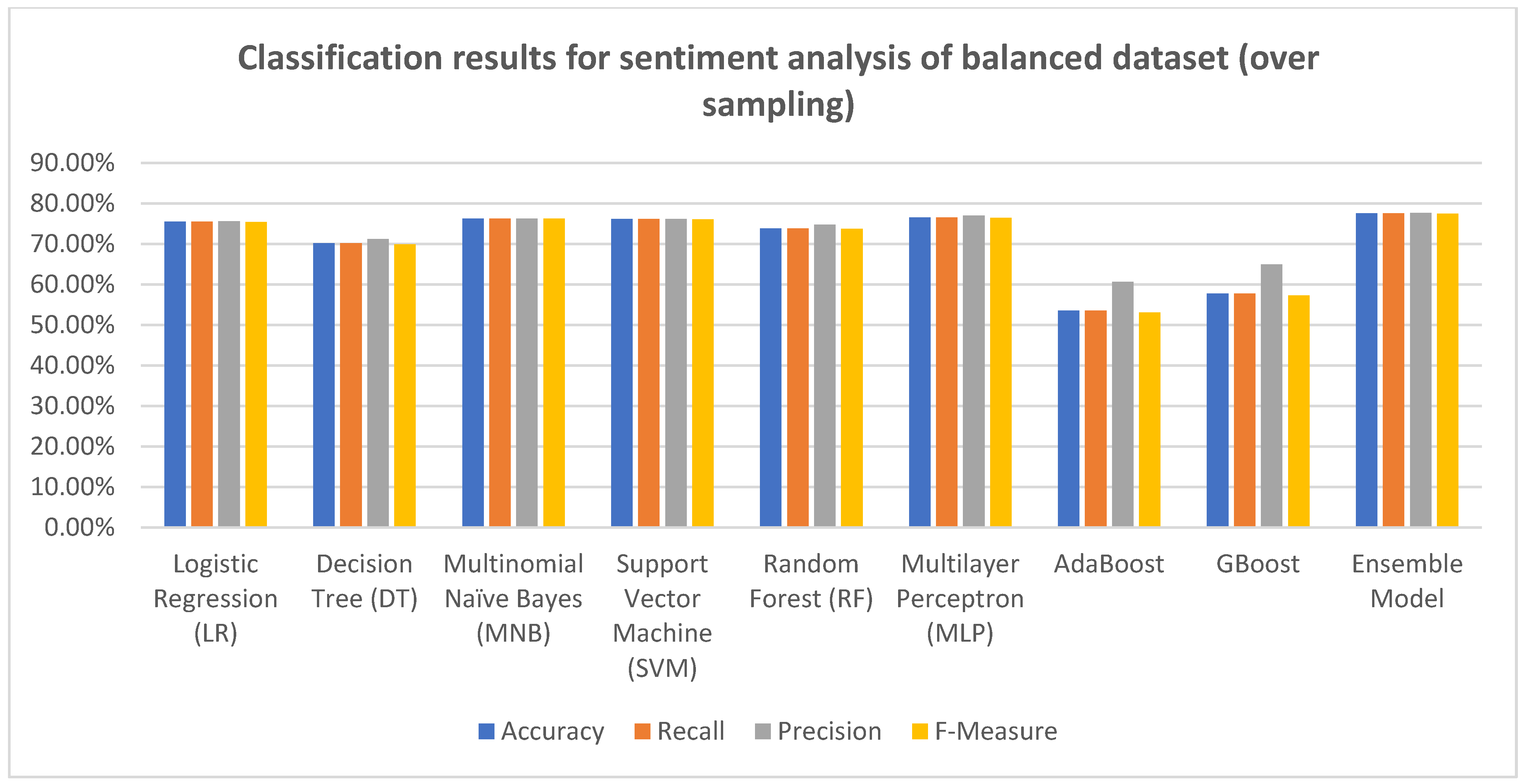
We utilized machine learning algorithms for both balanced and unbalanced datasets. In order to handle the unbalanced dataset and convert it into a balanced dataset, both undersampling and oversampling techniques were applied.
Undersampling involves reducing the number of majority target instances or samples., i.e., reducing the number of comments in each sentiment class to reach the minority class instances [
51]. Oversampling, on the other hand, created new examples of existing comments to increase the number of minority class instances or samples [
51].
Further details about the utilized classifiers and the dataset are described below.
Logistic regression (LR) is a linear classifier that uses a straight line to try to differentiate between positive and negative cases [
52]. LR is one of the most elegant and widely used classification algorithms and it generally does not overfit data. LR is commonly trained using the gradient descent optimization approach to obtain the model parameters or coefficients [
52].
Multinomial naïve Bayes (MNB): The naïve Bayes NB theorem is the foundation of the multinomial naïve Bayes classifier. Although NB is extremely efficient, its assumptions have an impact on the quality of the findings [
50]. The multinominal naïve Bayes (MNB) approach was developed to overcome NB disadvantages. MNB uses a multinomial model to represent the distribution of words in a corpus. MNB treats the text as if it were a series of words, assuming that the placement of words is independently determined of one another [
50].
Support vector machine (SVM): The SVM algorithm is a supervised technique that may be used for both classification and regression [
49]. By identifying the nearest points, it calculates the distance between the differences between the two classes [
49].
Random forest (RF): The random forest classifier is a supervised technique that may be used for classification and regression [
49]. It is a collection of several independent decision trees put together as a whole [
53]. It makes a decision based on the results of numerous decision trees with the maximum scores [
49].
Multilayer perceptron (MLP): Multi-layer perceptron is a popular artificial neural network (ANN). It is a strong modeling tool that uses examples of data with known outcomes to apply a supervised training approach. This approach creates a nonlinear functional model that allows output data to be predicted from input data [
54].
Decision tree (DT): One of the most often utilized approaches in classification is the decision tree algorithm. A DT’s goal is to create a model that uses input data to predict the correct label for target variables [
50]. It is a supervised method that builds a tree to hierarchically build a model. Each decision node in the tree is connected with an attribute [
53]. A decision node has two or more branches, each with an associated attribute value or a range of values. The target value is contained in a leaf node, which has no branches [
53]. To achieve maximal homogeneity at each node, the algorithm divides the training data into smaller sections. The method starts at the root node and works its way down the tree using the decision rules specified for each decision node to obtain the outcome for a sample [
53].
AdaBoost: AdaBoost is a boosting algorithm that creates a resilient model that is less biased than its constituents by employing a large number of weak learners (base estimators) [
53]. The base estimators are trained in a way that each base model is dependent on the prior one, and the predictions are merged using a deterministic approach [
53]. When fitting each base model, additional weight was assigned to samples that were handled inaccurately by previous models in the sequence. A strong learner with little bias was obtained at the end of the procedure [
53].
GBoost: GBoost is a boosting algorithm, as previously discussed. The gradient boosting (GBoost) approach employs an iterative optimization procedure to create the ensemble model as a weighted sum of several weak learners, similar to AdaBoost [
53]. The distinction derives from the sequential optimization process’ definition [
53]. The GBoost technique uses gradient descent to describe the issue. At each step, a base estimator is fitted opposite to the gradient of the current ensemble’s error curve [
53]. GBoost utilizes gradient descent, whereas AdaBoost tries to solve the optimization issue locally at each step [
53].
Ensemble Model: Ensemble learning is a type of machine learning that involves training several different classifiers, and then selecting a few to use in an ensemble [
55]. It has been proven that combining classifiers is more successful than using each one separately [
55]. In our experiment, we utilized an ensemble model of RF, MNB, LR, SMV, and MLP, and it presented the best result in terms of accuracy.
Dataset description:
Table 5 summarizes the balanced and unbalanced datasets.
- 1.
Description of the unbalanced dataset:
Total positive comments: 27,588; total negative comments: 23,946; total neutral comments: 18,466; train set: 56,000; test set: 7000; and validation set: 7000.
- 2.
Description of the balanced dataset (undersampling):
Dataset size: 55,398 comments (18,466 positive comments; 18,466 negative comments; 18466 neutral comments);
Train set: 44,322 comments (14,774 positive comments; 14,774 negative comments; 14774 neutral comments);
Test set: 5538 comments (1846 positive comments; 1846 negative comments; 1846 neutral comments);
Validation set: 5538 comments (1846 positive comments; 1846 negative comments; 1846 neutral comments).
- 3.
Description of the balanced dataset (oversampling):
Dataset size: 82,764 comments (total positive comments: 27,588; total negative comments: 27,588; total neutral comments: 27,588);
Train set: 66,211, Test set: 8277, and validation set: 8276.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}