
COVID-19 Tweets Classification Based on a Hybrid Word Embedding Method


Abstract
:1. Introduction
- 1.
- We present five different extant feature extraction methods: TF-IDF N-gram, TF-IDF uni-gram, Word2vec, Glove, and FastText. We also present two novel methods: hybrid TF-IDF with Glove, and hybrid TF-IDF-based FastText.
- 2.
- We compare machine learning methods performance with different features extraction for English-language tweets classification.
- 3.
- We choose the best methods combination and fusion to enhance the previously compared performances of machine learning classifiers.
2. Literature Review
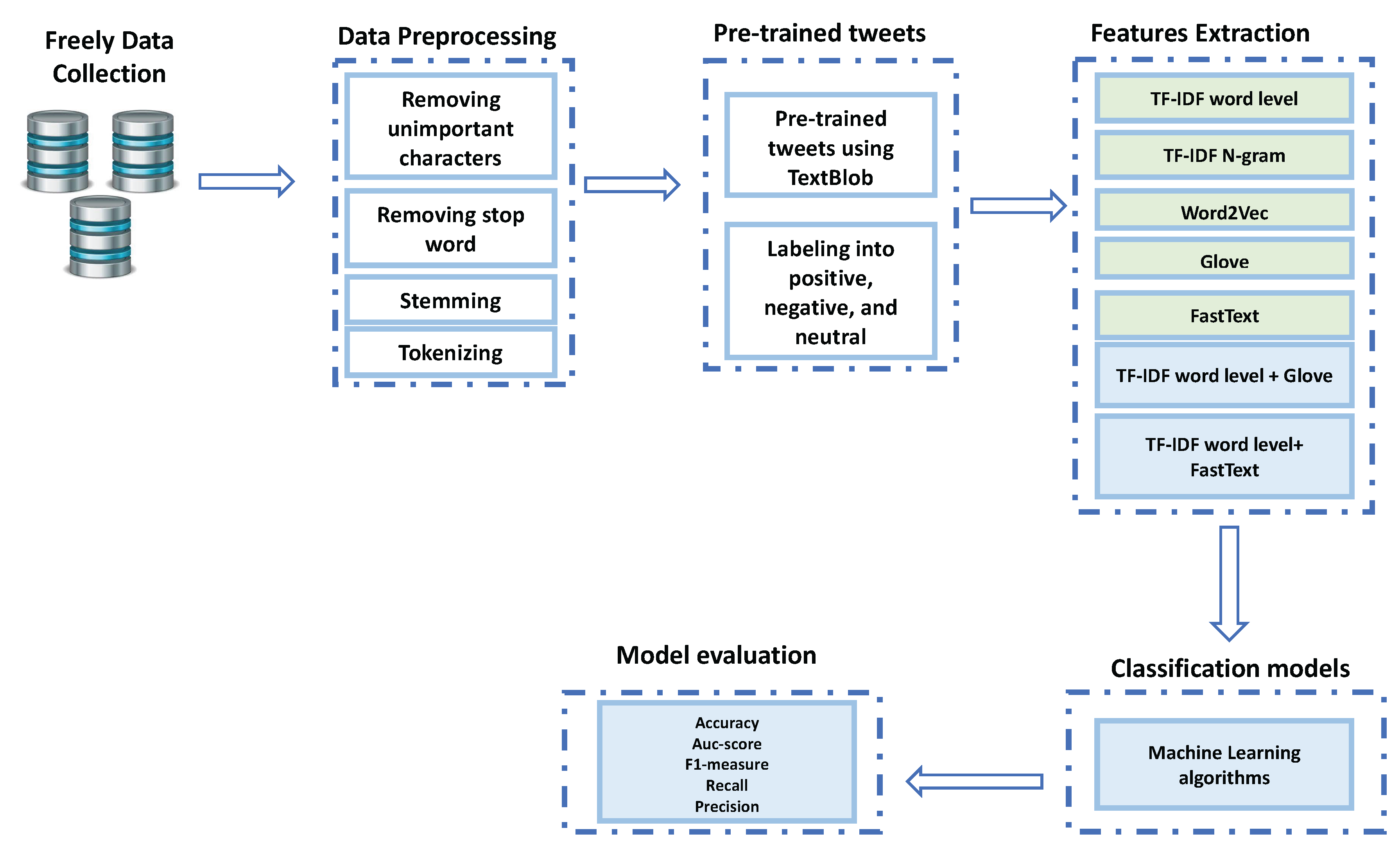
3. Materials and Methods
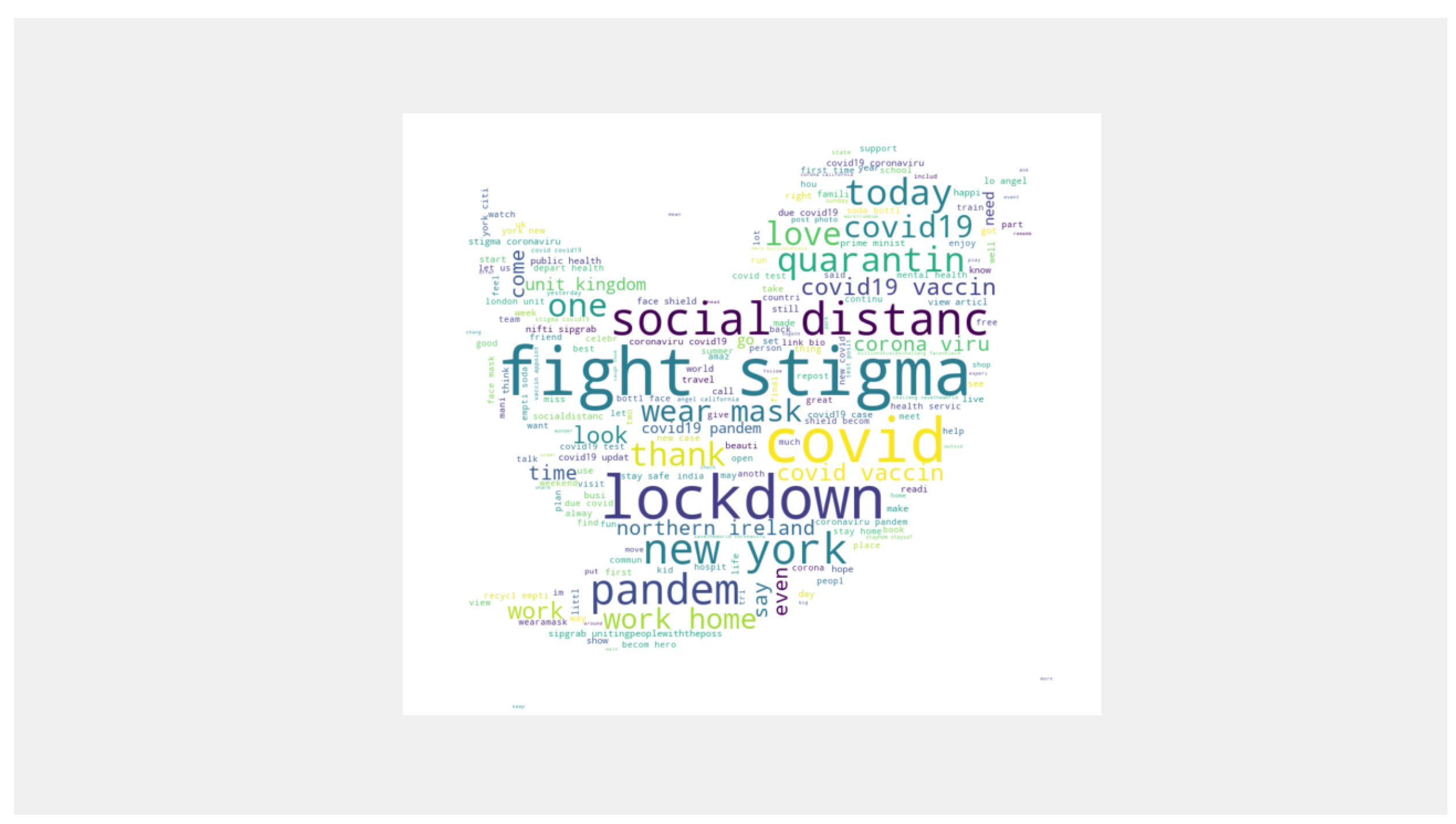
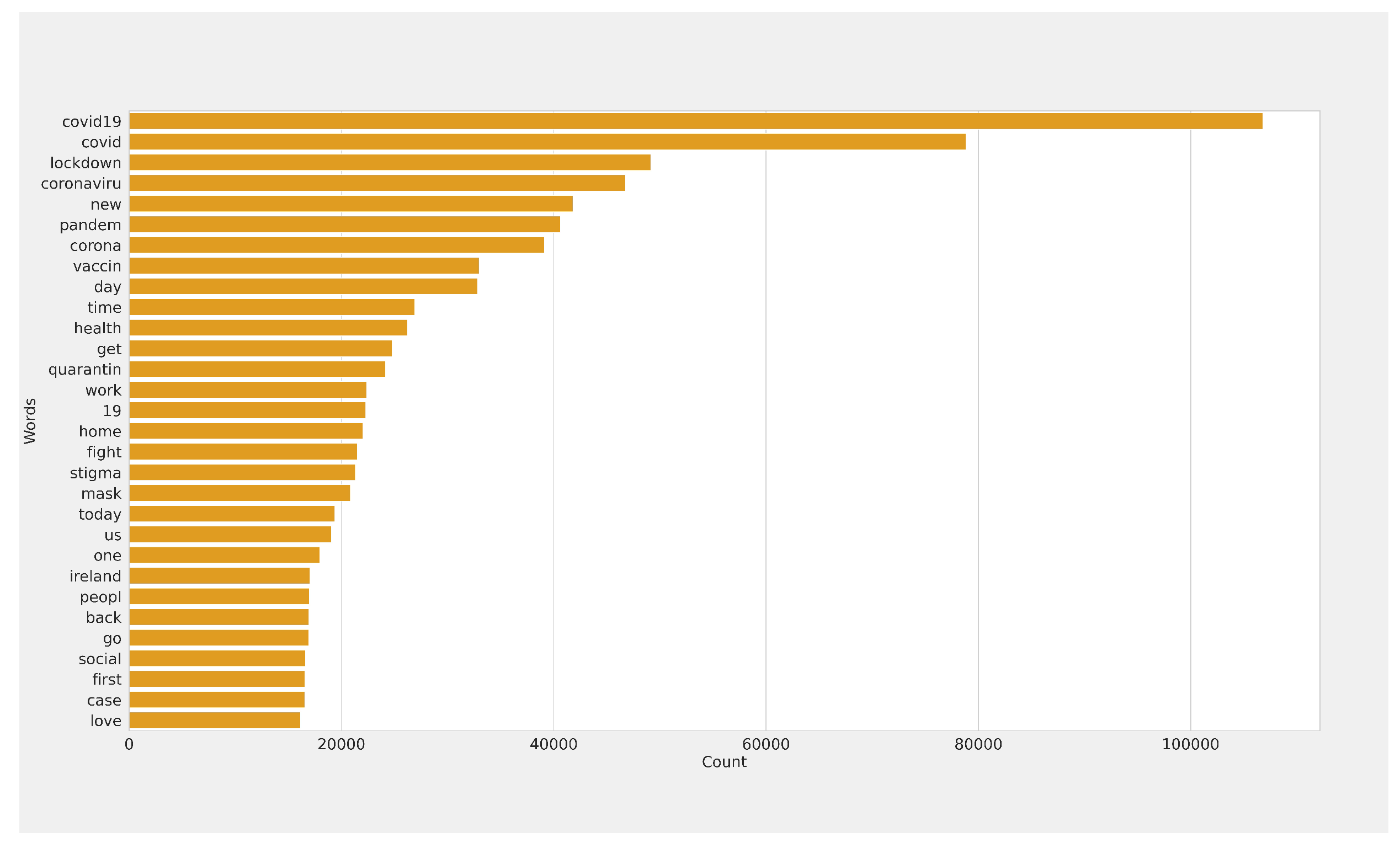
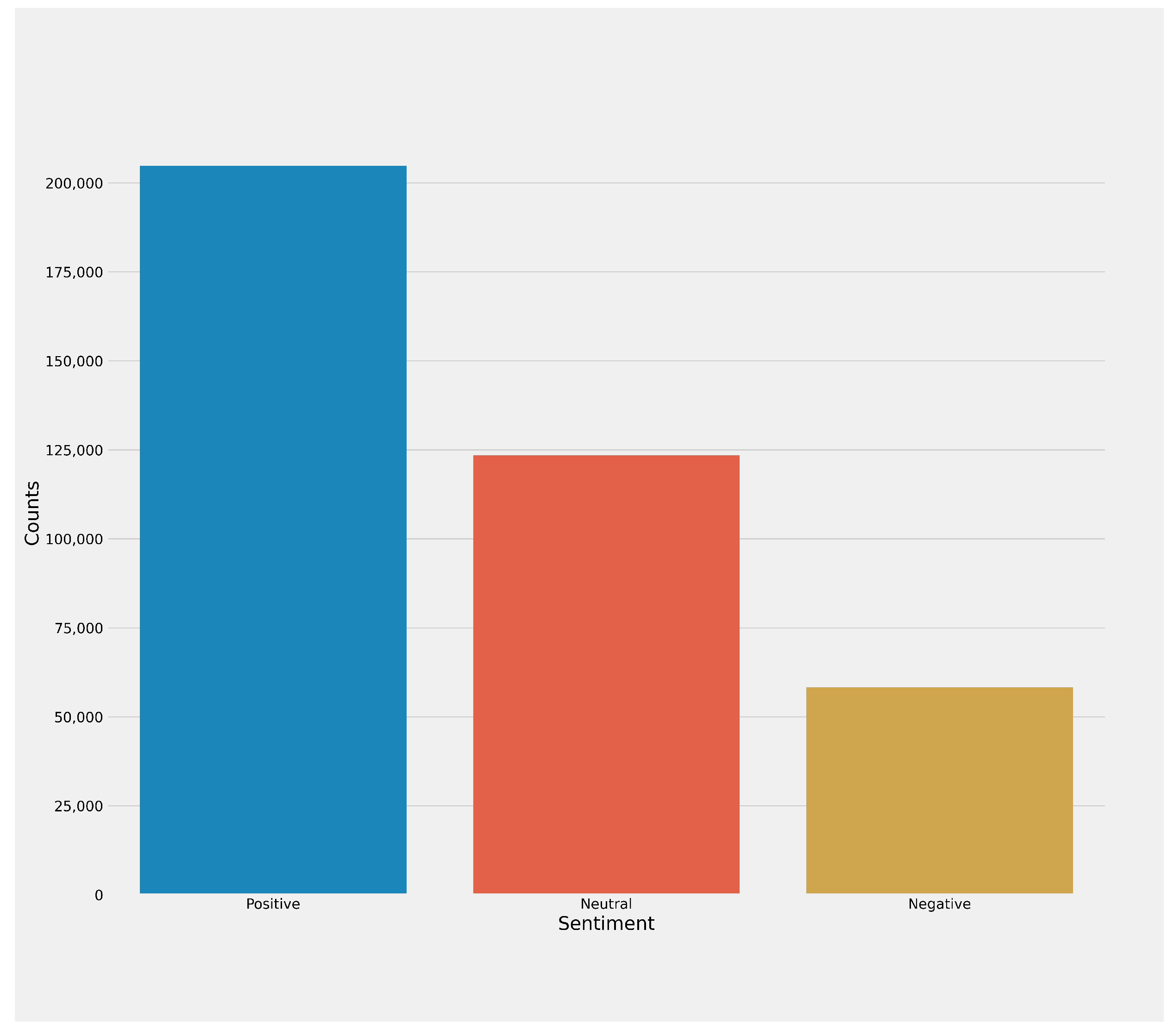
3.1. Data Collection
3.2. Data Preprocessing
3.3. Feature Extraction
3.3.1. Term Frequency-Inverse Document Frequency (TF-IDF)
3.3.2. Word2Vec
3.3.3. FastText
3.3.4. Glove
3.3.5. Hybrid Word Embedding Techniques with TF-IDF
3.4. Classification
3.4.1. Decision Tree
3.4.2. Random Forest
3.4.3. XGBoost
3.4.4. AdaBoost
3.4.5. Naïve Bayes
3.4.6. Logistic Regression
3.4.7. SVM
3.4.8. Convolutional Neural Network
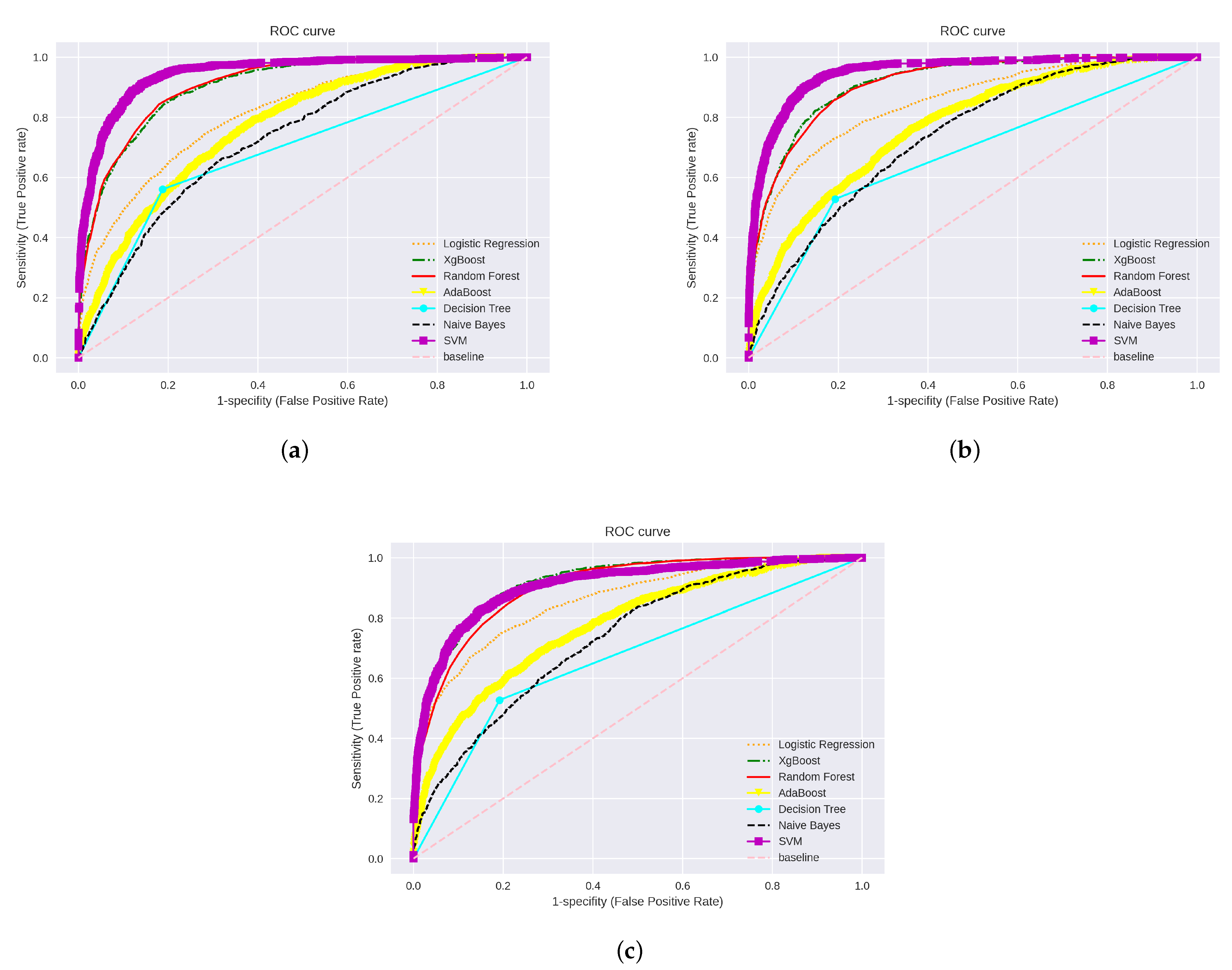
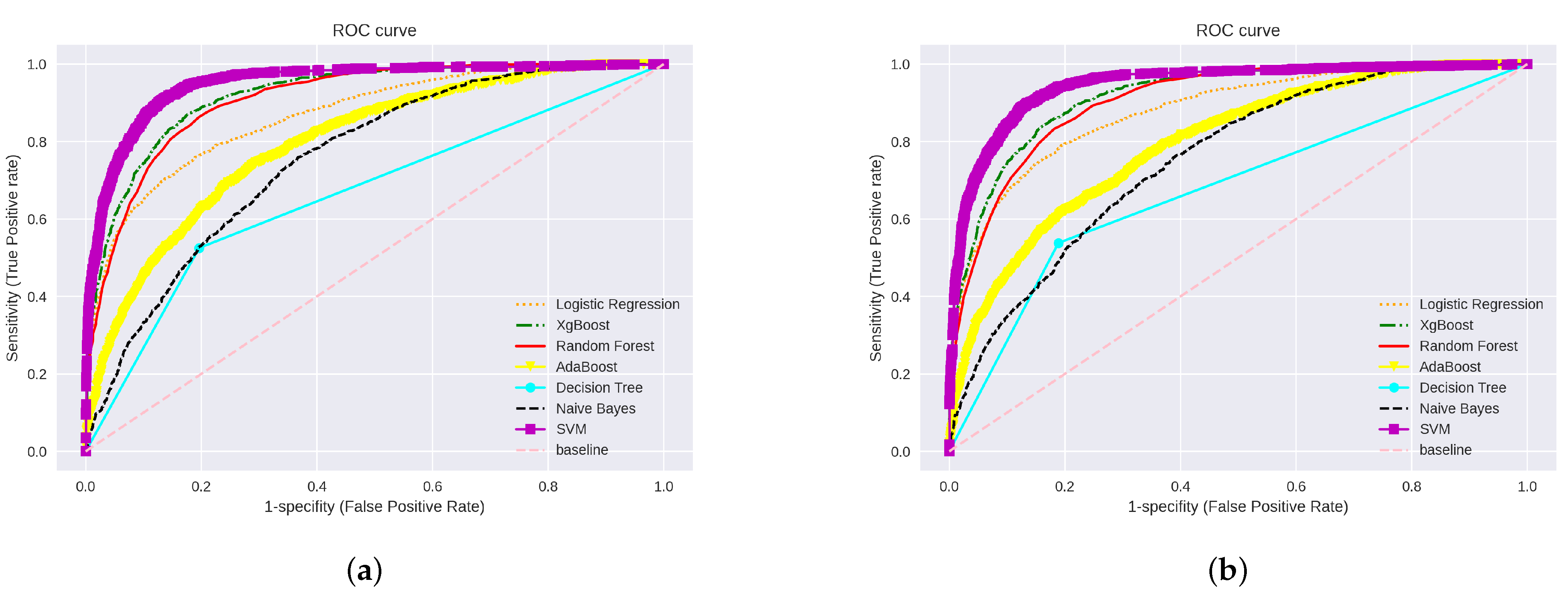
4. Experimental Results
- Accuracy indicates the weighted harmonic mean of both precision and recall. The accuracy equation is as follows:
- Precision score represents the percentage of positively classified tweets that actually correct. The precision is mathematically expressed as follows:
- Recall score indicates the ability of the classifiers to classify all positive instances correctly. The recall is mathematically expressed as follows:
- F1-score indicates the weighted harmonic mean of both precision and recall. The F1-score is mathematically expressed as follows:
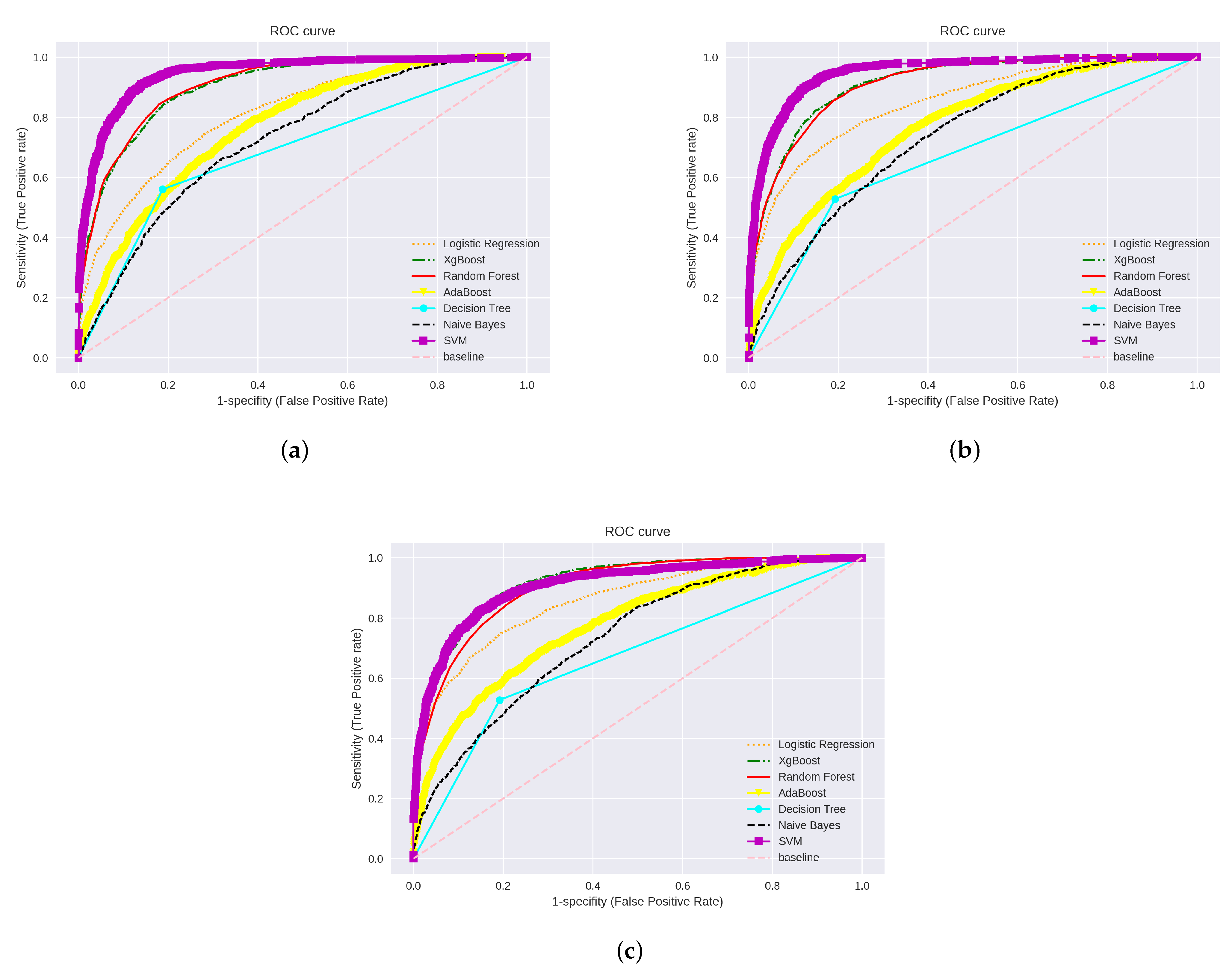
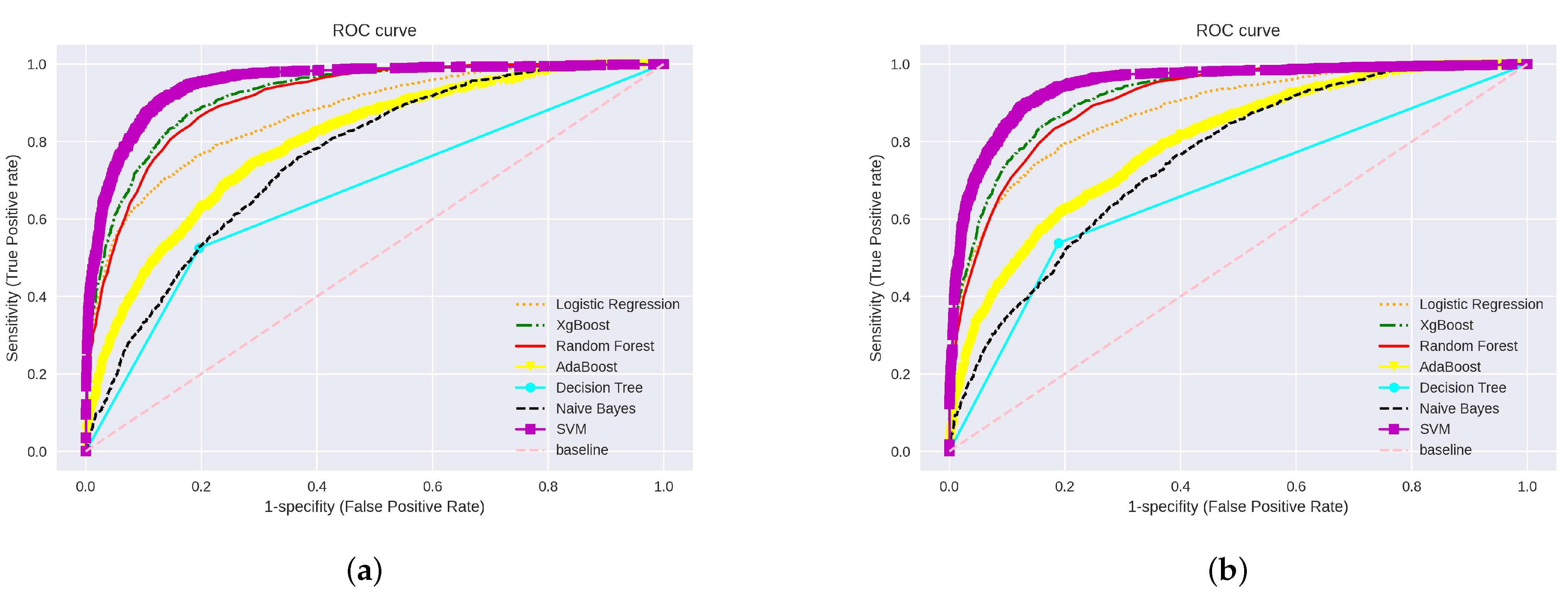
- AUCC score indicates the classifiers’ ability to distinguish between classes through the probability curve (ROC). The AUCC is defined as follows:where refers to true positives: the correct prediction number of positive class. is true negatives: the correct predictions number of negative class. refers to false positives: the incorrect positive predictions number of a class. Furthermore, refers to false negatives: the incorrect negative predictions number of a class.
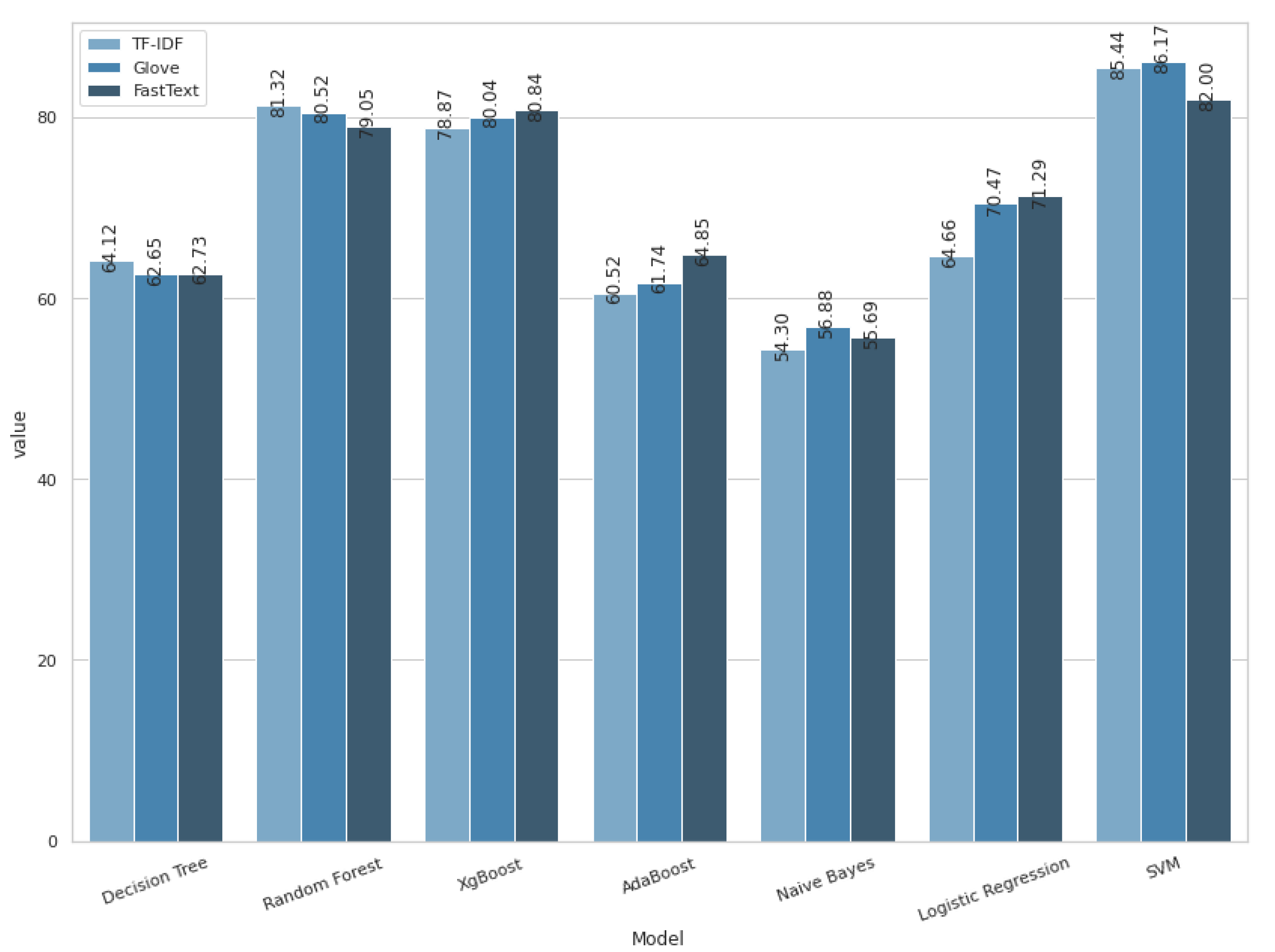
4.1. Machine Learning Algorithms with Simple Feature Extraction Methods
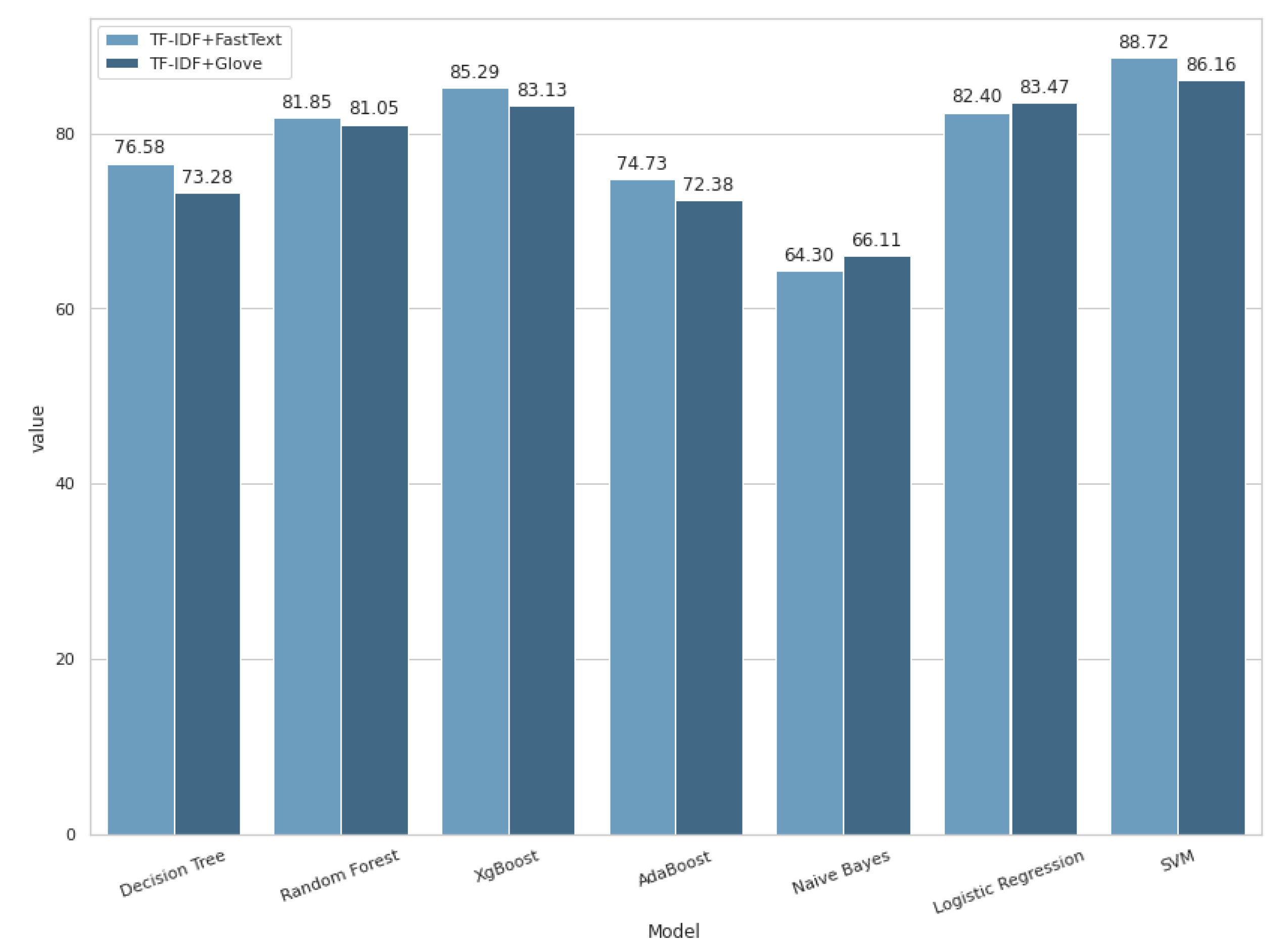
4.2. Machine Learning Algorithms with Hybrid Feature Extraction Techniques
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AdaBoost | adaptive boosting |
| AI | artificial intelligence |
| CNN | convolutional neural network |
| DT | decision tree |
| FP | false positives |
| FN | false negatives |
| KNN | k-nearest neighbours |
| LR | logistic regression |
| LSTM | long short-term memory |
| ML | machine learning |
| NB | naïve Bayes |
| NLP | natural language processing |
| RF | random forest |
| SA | sentiment analysis |
| SGD | stochastic gradient descent |
| SMOTE | synthetic minority oversample technique |
| SNS | social network sites |
| SVM | support vector machine |
| TF-IDF | term frequency-inverse document frequency |
| TP | true positives |
| TN | true negatives |
| URL | uniform resource locator |
| XGBoost | extreme gradient boosting |
References
- Worldometer. Available online: https://www.worldometers.info/coronavirus (accessed on 26 May 2021).
- Adamu, H.; Lutfi, S.L.; Malim, N.H.A.H.; Hassan, R.; Di Vaio, A.; Mohamed, A.S.A. Framing twitter public sentiment on Nigerian government COVID-19 palliatives distribution using machine learning. Sustainability 2021, 13, 3497. [Google Scholar] [CrossRef]
- Huang, H.; Peng, Z.; Wu, H.; Xie, Q. A big data analysis on the five dimensions of emergency management information in the early stage of COVID-19 in China. J. Chin. Gov. 2020, 5, 213–233. [Google Scholar] [CrossRef]
- Chakraborty, K.; Bhatia, S.; Bhattacharyya, S.; Platos, J.; Bag, R.; Hassanien, A.E. Sentiment Analysis of COVID-19 tweets by Deep Learning Classifiers—A study to show how popularity is affecting accuracy in social media. Appl. Soft Comput. 2020, 97, 106754. [Google Scholar] [CrossRef] [PubMed]
- Depoux, A.; Martin, S.; Karafillakis, E.; Preet, R.; Wilder-Smith, A.; Larson, H. The pandemic of social media panic travels faster than the COVID-19 outbreak. J. Travel Med. 2020, 27, taaa031. [Google Scholar] [CrossRef] [Green Version]
- Pappa, S.; Ntella, V.; Giannakas, T.; Giannakoulis, V.G.; Papoutsi, E.; Katsaounou, P. Prevalence of depression, anxiety, and insomnia among healthcare workers during the COVID-19 pandemic: A systematic review and meta-analysis. Brain Behav. Immun. 2020, 88, 901–907. [Google Scholar] [CrossRef]
- Kabir, M.; Madria, S. CoronaVis: A real-time COVID-19 tweets data analyzer and data repository. arXiv 2020, arXiv:2004.13932. [Google Scholar]
- Taboada, M. Sentiment analysis: An overview from linguistics. Annu. Rev. Linguist. 2016, 2, 325–347. [Google Scholar] [CrossRef] [Green Version]
- Beigi, G.; Hu, X.; Maciejewski, R.; Liu, H. An overview of sentiment analysis in social media and its applications in disaster relief. In Sentiment Analysis and Ontology Engineering; Springer: Berlin/Heidelberg, Germany, 2016; pp. 313–340. [Google Scholar]
- Sailunaz, K.; Alhajj, R. Emotion and sentiment analysis from Twitter text. J. Comput. Sci. 2019, 36, 101003. [Google Scholar] [CrossRef] [Green Version]
- Samuel, J.; Ali, G.; Rahman, M.; Esawi, E.; Samuel, Y. COVID-19 public sentiment insights and machine learning for tweets classification. Information 2020, 11, 314. [Google Scholar] [CrossRef]
- Liu, R.; Shi, Y.; Ji, C.; Jia, M. A survey of sentiment analysis based on transfer learning. IEEE Access 2019, 7, 85401–85412. [Google Scholar] [CrossRef]
- Tyagi, P.; Tripathi, R. A review towards the sentiment analysis techniques for the analysis of twitter data. In Proceedings of the 2nd International Conference on Advanced Computing and Software Engineering (ICACSE), Sultanpur, India, 8–9 February 2019. [Google Scholar]
- Saura, J.R.; Palacios-Marqués, D.; Ribeiro-Soriano, D. Exploring the boundaries of open innovation: Evidence from social media mining. Technovation 2022, 102447. [Google Scholar] [CrossRef]
- Mackey, T.; Purushothaman, V.; Li, J.; Shah, N.; Nali, M.; Bardier, C.; Liang, B.; Cai, M.; Cuomo, R. Machine learning to detect self-reporting of symptoms, testing access, and recovery associated with COVID-19 on Twitter: Retrospective big data infoveillance study. JMIR Public Health Surveill. 2020, 6, e19509. [Google Scholar] [CrossRef] [PubMed]
- Wan, S.; Yi, Q.; Fan, S.; Lv, J.; Zhang, X.; Guo, L.; Lang, C.; Xiao, Q.; Xiao, K.; Yi, Z.; et al. Relationships among lymphocyte subsets, cytokines, and the pulmonary inflammation index in coronavirus (COVID-19) infected patients. Br. J. Haematol. 2020, 189, 428–437. [Google Scholar] [CrossRef] [PubMed]
- Rajput, N.K.; Grover, B.A.; Rathi, V.K. Word frequency and sentiment analysis of twitter messages during coronavirus pandemic. arXiv 2020, arXiv:2004.03925. [Google Scholar]
- Muthusami, R.; Bharathi, A.; Saritha, K. COVID-19 outbreak: Tweet based analysis and visualization towards the influence of coronavirus in the world. Gedrag Organ. Rev. 2020, 33, 8–9. [Google Scholar]
- Jelodar, H.; Wang, Y.; Orji, R.; Huang, S. Deep sentiment classification and topic discovery on novel coronavirus or COVID-19 online discussions: Nlp using lstm recurrent neural network approach. IEEE J. Biomed. Health Inform. 2020, 24, 2733–2742. [Google Scholar] [CrossRef] [PubMed]
- Aljameel, S.S.; Alabbad, D.A.; Alzahrani, N.A.; Alqarni, S.M.; Alamoudi, F.A.; Babili, L.M.; Aljaafary, S.K.; Alshamrani, F.M. A sentiment analysis approach to predict an individual’s awareness of the precautionary procedures to prevent COVID-19 outbreaks in Saudi Arabia. Int. J. Environ. Res. Public Health 2021, 18, 218. [Google Scholar] [CrossRef]
- Ghadeer, A.S.; Aljarah, I.; Alsawalqah, H. Enhancing the Arabic sentiment analysis using different preprocessing operators. New Trends Inf. Technol. 2017, 113, 113–117. [Google Scholar]
- Imran, A.S.; Daudpota, S.M.; Kastrati, Z.; Batra, R. Cross-cultural polarity and emotion detection using sentiment analysis and deep learning on COVID-19 related tweets. IEEE Access 2020, 8, 181074–181090. [Google Scholar] [CrossRef]
- Alam, F.; Dalvi, F.; Shaar, S.; Durrani, N.; Mubarak, H.; Nikolov, A.; Martino, G.D.S.; Abdelali, A.; Sajjad, H.; Darwish, K.; et al. Fighting the COVID-19 infodemic in social media: A holistic perspective and a call to arms. arXiv 2020, arXiv:2007.07996. [Google Scholar]
- Alqurashi, S.; Hamoui, B.; Alashaikh, A.; Alhindi, A.; Alanazi, E. Eating garlic prevents COVID-19 infection: Detecting misinformation on the arabic content of twitter. arXiv 2021, arXiv:2101.05626. [Google Scholar]
- Naseem, U.; Razzak, I.; Khushi, M.; Eklund, P.W.; Kim, J. Covidsenti: A large-scale benchmark Twitter data set for COVID-19 sentiment analysis. IEEE Trans. Comput. Soc. Syst. 2021, 8, 1003–1015. [Google Scholar] [CrossRef]
- Basiri, M.E.; Nemati, S.; Abdar, M.; Asadi, S.; Acharrya, U.R. A novel fusion-based deep learning model for sentiment analysis of COVID-19 tweets. Knowl.-Based Syst. 2021, 228, 107242. [Google Scholar] [CrossRef]
- Rustam, F.; Khalid, M.; Aslam, W.; Rupapara, V.; Mehmood, A.; Choi, G.S. A performance comparison of supervised machine learning models for COVID-19 tweets sentiment analysis. PLoS ONE 2021, 16, e0245909. [Google Scholar] [CrossRef] [PubMed]
- Nemes, L.; Kiss, A. Social media sentiment analysis based on COVID-19. J. Inf. Telecommun. 2021, 5, 1–15. [Google Scholar] [CrossRef]
- Loria, S. Textblob Documentation. Available online: https://buildmedia.readthedocs.org/media/pdf/textblob/dev/textblob.pdf (accessed on 8 July 2021).
- Kaur, H.; Ahsaan, S.U.; Alankar, B.; Chang, V. A proposed sentiment analysis deep learning algorithm for analyzing COVID-19 tweets. Inf. Syst. Front. 2021, 23, 1417–1429. [Google Scholar] [CrossRef]
- Li, X.; Zhang, J.; Du, Y.; Zhu, J.; Fan, Y.; Chen, X. A Novel Deep Learning-based Sentiment Analysis Method Enhanced with Emojis in Microblog Social Networks. Enterp. Inf. Syst. 2022, 1–22. [Google Scholar] [CrossRef]
- Balli, C.; Guzel, M.S.; Bostanci, E.; Mishra, A. Sentimental Analysis of Twitter Users from Turkish Content with Natural Language Processing. Comput. Intell. Neurosci. 2022, 2022, 2455160. [Google Scholar] [CrossRef]
- Zemberek, NLP Tools for Turkish. Available online: https://github.com/ahmetaa/zemberek-nlp (accessed on 20 September 2021).
- Sitaula, C.; Shahi, T.B. Multi-channel CNN to classify nepali COVID-19 related tweets using hybrid features. arXiv 2022, arXiv:2203.10286. [Google Scholar]
- Singh, C.; Imam, T.; Wibowo, S.; Grandhi, S. A Deep Learning Approach for Sentiment Analysis of COVID-19 Reviews. Appl. Sci. 2022, 12, 3709. [Google Scholar] [CrossRef]
- Parimala, M.; Swarna Priya, R.; Praveen Kumar Reddy, M.; Lal Chowdhary, C.; Kumar Poluru, R.; Khan, S. Spatiotemporal-based sentiment analysis on tweets for risk assessment of event using deep learning approach. Softw. Pract. Exp. 2021, 51, 550–570. [Google Scholar] [CrossRef]
- Lamsal, R. Coronavirus (COVID-19) Geo-Tagged Tweets Dataset. 2020. Available online: https://ieee-dataport.org/open-access/coronavirus-covid-19-geo-tagged-tweets-dataset (accessed on 26 May 2021).
- Loper, E.; Bird, S. Nltk: The natural language toolkit. arXiv 2002, arXiv:0205028. [Google Scholar]
- Lamsal, R. Design and analysis of a large-scale COVID-19 tweets dataset. Appl. Intell. 2021, 51, 2790–2804. [Google Scholar] [CrossRef] [PubMed]
- Documenting the Now. [Computer Software]. 2020. Available online: https://github.com/docnow/hydrator (accessed on 7 July 2021).
- Hedderich, M.A.; Lange, L.; Adel, H.; Strötgen, J.; Klakow, D. A survey on recent approaches for natural language processing in low-resource scenarios. arXiv 2020, arXiv:2010.12309. [Google Scholar]
- Python for NLP: Sentiment Analysis with Scikit-Learn. Available online: https://stackabuse.com/python-for-nlp-sentimentanalysis-with-scikit-learn/ (accessed on 30 May 2021).
- Willett, P. The Porter stemming algorithm: Then and now. Program Electron. Libr. Inf. Syst. 2006, 40, 219–223. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Douze, M.; Jégou, H.; Mikolov, T. Fasttext. zip: Compressing text classification models. arXiv 2016, arXiv:1612.03651. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of tricks for efficient text classification. arXiv 2016, arXiv:1607.01759. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Yang, H.; Fong, S. Optimized very fast decision tree with balanced classification accuracy and compact tree size. In Proceedings of the 3rd International Conference on Data Mining and Intelligent Information Technology Applications, Macao, China, 24–26 October 2011; pp. 57–64. [Google Scholar]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Singer, G.; Marudi, M. Ordinal decision-tree-based ensemble approaches: The case of controlling the daily local growth rate of the COVID-19 epidemic. Entropy 2020, 22, 871. [Google Scholar] [CrossRef]
- Kowsari, K.; Jafari Meimandi, K.; Heidarysafa, M.; Mendu, S.; Barnes, L.; Brown, D. Text classification algorithms: A survey. Information 2019, 10, 150. [Google Scholar] [CrossRef] [Green Version]
- Cox, D.R. The regression analysis of binary sequences. J. R. Stat. Soc. Ser. B 1958, 20, 215–232. [Google Scholar] [CrossRef]
- Naz, S.; Sharan, A.; Malik, N. Sentiment classification on twitter data using support vector machine. In Proceedings of the 2018 IEEE/WIC/ACM International Conference on Web Intelligence (WI), Santiago, Chile, 3–6 December 2018; pp. 676–679. [Google Scholar]
- Implementing SVM and Kernel SVM with Python’s Scikit-Learn. Available online: https://stackabuse.com/implementing-svmand-kernel-svm-with-pythons-scikit-learn (accessed on 30 June 2021).
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 1746–1751. [Google Scholar] [CrossRef] [Green Version]
- Jabeur, S.B.; Sadaaoui, A.; Sghaier, A.; Aloui, R. Machine learning models and cost-sensitive decision trees for bond rating prediction. J. Oper. Res. Soc. 2020, 71, 1161–1179. [Google Scholar] [CrossRef]
- Antunes, F.; Ribeiro, B.; Pereira, F. Probabilistic modeling and visualization for bankruptcy prediction. Appl. Soft Comput. 2017, 60, 831–843. [Google Scholar] [CrossRef] [Green Version]
- Gholamy, A.; Kreinovich, V.; Kosheleva, O. Why 70/30 or 80/20 Relation between Training and Testing Sets: A Pedagogical Explanation. 2018. Available online: https://www.cs.utep.edu/vladik/2018/tr18-09.pdf (accessed on 31 July 2021).
- Farquad, M.; Bose, I. Preprocessing unbalanced data using support vector machine. Decis. Support Syst. 2012, 53, 226–233. [Google Scholar] [CrossRef]
- Singh, M.; Jakhar, A.K.; Pandey, S. Sentiment analysis on the impact of coronavirus in social life using the BERT model. Soc. Netw. Anal. Min. 2021, 11, 1–11. [Google Scholar] [CrossRef]
- Pota, M.; Ventura, M.; Catelli, R.; Esposito, M. An effective BERT-based pipeline for Twitter sentiment analysis: A case study in Italian. Sensors 2020, 21, 133. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Machine Learning Algorithms | ||||||||
|---|---|---|---|---|---|---|---|---|
| DT | RF | XGBoost | AdaBoost | NB | LR | SVM | ||
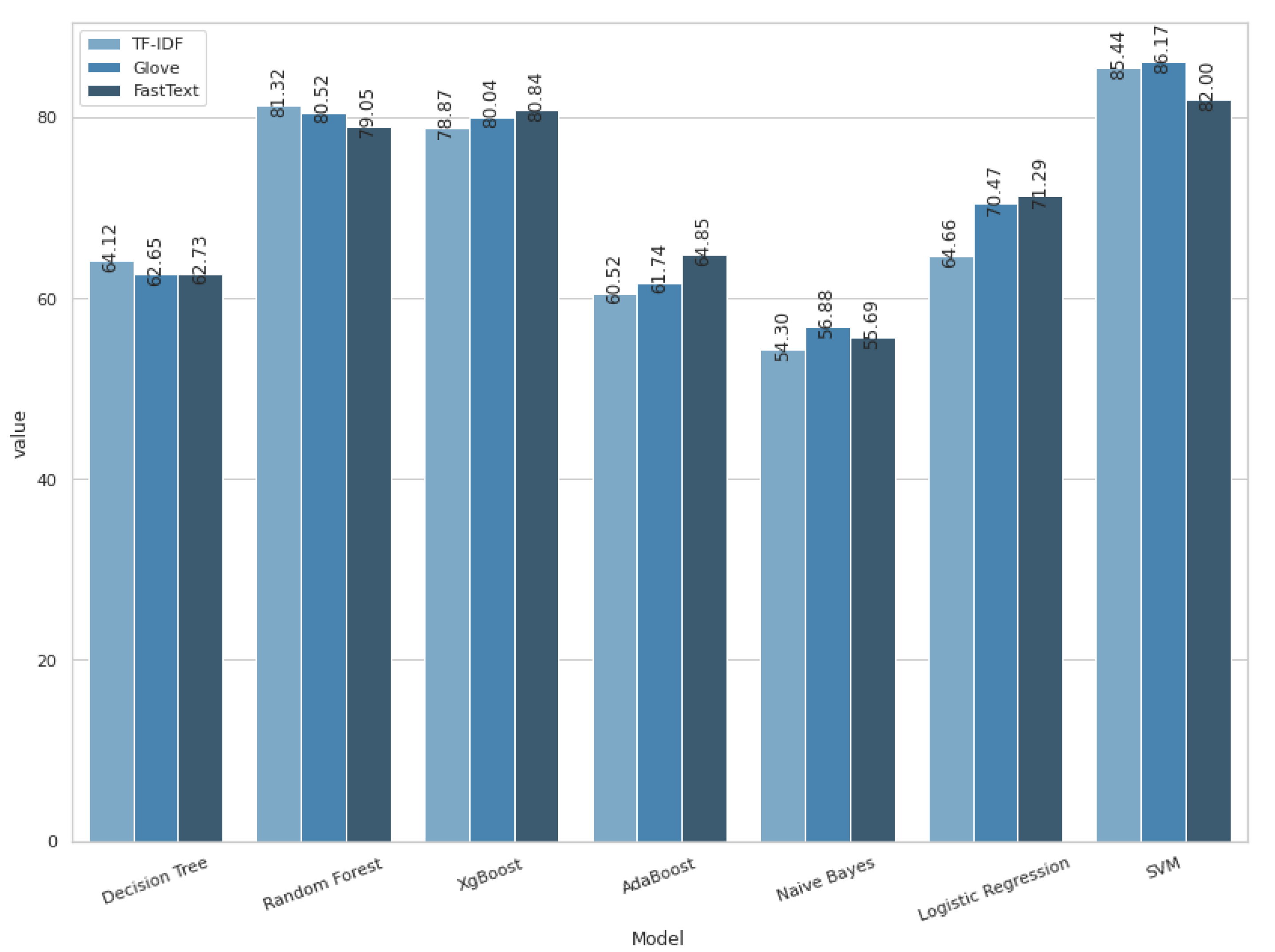
| TF-IDF word-level | Accuracy | 64.12% | 81.32% | 78.87% | 60.52% | 54.3% | 64.66% | 85.44% |
| AUCC | 73.09% | 93.38% | 92.76% | 76.05% | 71.84% | 83.36% | 96.07% | |
| F1-Score | 0.64 | 0.81 | 0.79 | 0.61 | 0.52 | 0.65 | 0.85 | |
| Precision | 0.64 | 0.81 | 0.79 | 0.61 | 0.56 | 0.65 | 0.85 | |
| Recall | 0.64 | 0.81 | 0.79 | 0.61 | 0.54 | 0.64 | 0.85 | |
| TF-IDF N-gram level | Accuracy | 63.99% | 81.02% | 80.11% | 60.24% | 53.12% | 63.84% | 85.2% |
| AUCC | 72.99% | 92% | 92.98% | 75.39% | 71.03% | 82.04% | 95.7% | |
| F1-Score | 0.64 | 0.81 | 0.80 | 0.60 | 0.51 | 0.64 | 0.85 | |
| Precision | 0.64 | 0.82 | 0.80 | 0.60 | 0.56 | 0.64 | 0.85 | |
| Recall | 0.64 | 0.81 | 0.80 | 0.60 | 0.53 | 0.64 | 0.85 | |
| Machine Learning Algorithms | ||||||||
|---|---|---|---|---|---|---|---|---|
| DT | RF | XGBoost | AdaBoost | NB | LR | SVM | ||
| Word2Vec | Accuracy | 59.34% | 71.04% | 69.69% | 66.25% | 58% | 74.09% | 69.72% |
| AUCC | 63.23% | 82.65% | 80.1% | 75.89% | 73.12% | 84.12% | 81.45% | |
| F1-Score | 0.59 | 0.67 | 0.64 | 0.62 | 0.48 | 0.72 | 0.69 | |
| Precision | 0.59 | 0.75 | 0.71 | 0.63 | 0.56 | 0.72 | 0.69 | |
| Recall | 0.59 | 0.71 | 0.69 | 0.66 | 0.58 | 0.74 | 0.69 | |
| Glove | Accuracy | 62.65% | 80.52% | 80.04% | 61.74% | 56.88% | 70.47% | 86.17% |
| AUCC | 71.98% | 93.19% | 93.22% | 79.54% | 75.48% | 86.7% | 96.22% | |
| F1-Score | 0.62 | 0.81 | 0.80 | 0.62 | 0.57 | 0.70 | 0.86 | |
| Precision | 0.62 | 0.81 | 0.80 | 0.62 | 0.57 | 0.70 | 0.86 | |
| Recall | 0.63 | 0.81 | 0.80 | .0.62 | 0.57 | 0.70 | 0.86 | |
| FastText | Accuracy | 62.73% | 79.05% | 80.84% | 64.85% | 55.69% | 71.29% | 82% |
| AUCC | 72.05% | 92.54% | 93.66% | 80.64% | 75.02% | 87.7% | 93.21% | |
| F1-Score | 0.63 | 0.79 | 0.81 | 0.64 | 0.55 | 0.71 | 0.80 | |
| Precision | 0.63 | 0.80 | 0.81 | 0.64 | 0.57 | 0.71 | 0.81 | |
| Recall | 0.63 | 0.79 | 0.81 | 0.64 | 0.56 | 0.71 | 0.81 | |
| Deep Learning Classifier CNN | |||||
|---|---|---|---|---|---|
| Accuracy | AUCC | F1-Score | Precision | Recall | |
| TF-IDF word-level | 76.01% | 86.52% | 0.76 | 0.76 | 0.76 |
| Word2Vec | 74.33% | 81.42% | 0.74 | 0.74 | 0.74 |
| Glove | 79.83% | 82.18% | 0.79 | 0.79 | 0.79 |
| FastText | 73.59% | 80.45% | 0.71 | 0.71 | 0.71 |
| Machine Learning Algorithms | ||||||||
|---|---|---|---|---|---|---|---|---|
| DT | RF | XGBoost | AdaBoost | NB | LR | SVM | ||
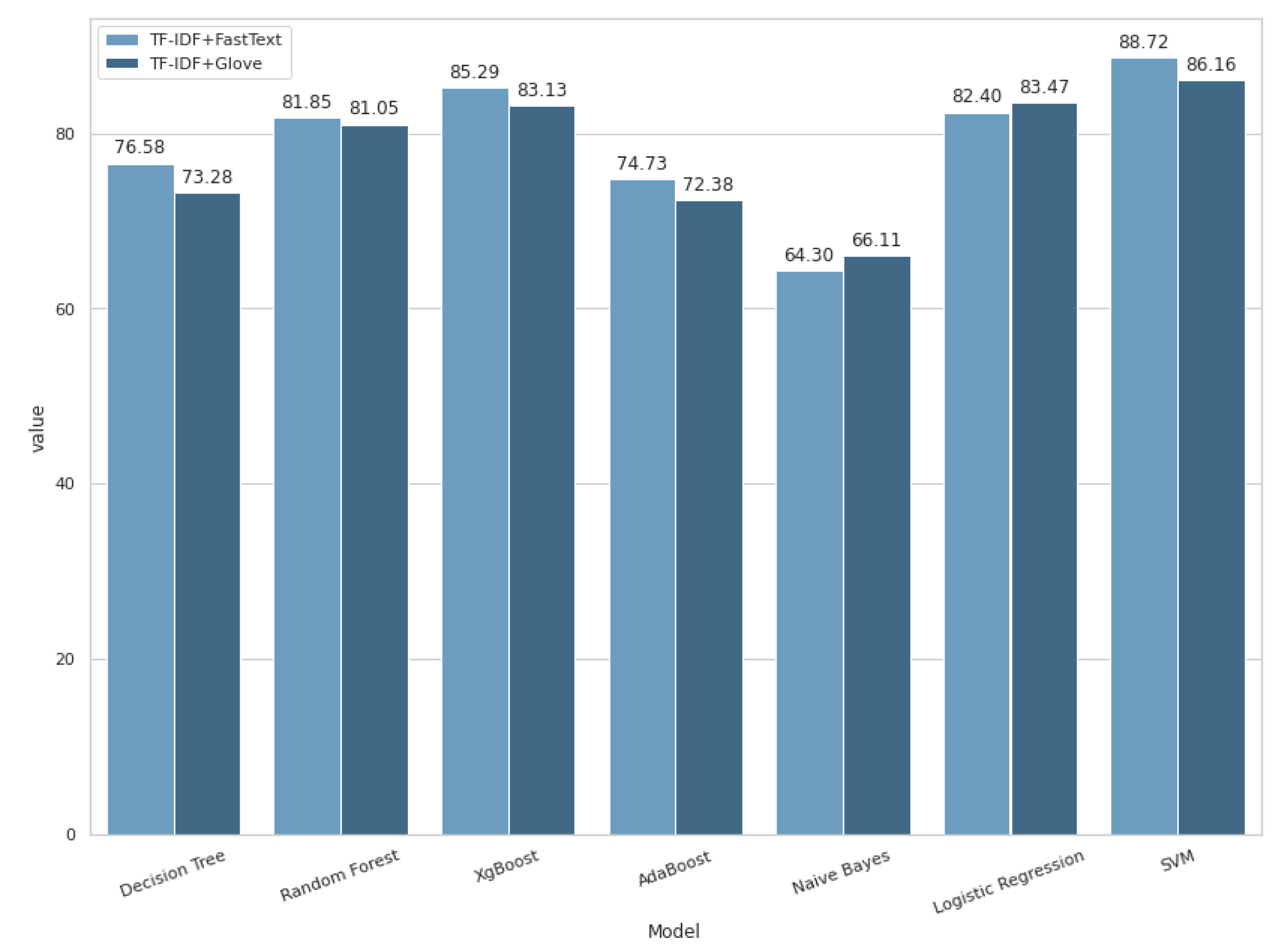
| Hybrid 1 1 | Accuracy | 76.58% | 81.85% | 85.29% | 74.73% | 64.30% | 82.40% | 88.72% |
| AUCC | 74.68% | 87.74% | 89.63% | 82.54% | 74.07% | 87.03% | 95.88% | |
| F1-Score | 0.75 | 0.82 | 0.84 | 0.74 | 0.62 | 0.81 | 0.85 | |
| Precision | 0.76 | 0.81 | 0.85 | 0.74 | 0.69 | 0.82 | 0.85 | |
| Recall | 0.76 | 0.81 | 0.85 | 0.74 | 0.64 | 0.82 | 0.85 | |
| Hybrid 2 2 | Accuracy | 73.28% | 81.05% | 83.13% | 72.38% | 66.11% | 83.47% | 86.16% |
| AUCC | 72.46% | 87.66% | 88.58% | 80.02% | 77.99% | 88.72% | 96.42% | |
| F1-Score | 0.72 | 0.81 | 0.83 | 0.72 | 0.63 | 0.83 | 0.86 | |
| Precision | 0.73 | 0.81 | 0.83 | 0.72 | 0.74 | 0.83 | 0.86 | |
| Recall | 0.63 | 0.71 | 0.73 | 0.62 | 0.56 | 0.73 | 0.86 | |
| Study | Classifier Name | Accuracy | AUCC Score | F1-Score |
|---|---|---|---|---|
| Alqurashi et al. [24] | FastText + XGBoost | 86.8% | 85.4% | 0.39 |
| Naseem et al. [25] | TF-IDF + RF | 84.5% | NA 3 | NA 3 |
| Imran et al. [22] | FastText + LSTM | 82.4% | NA 3 | 0.82 |
| Sitaula and Shahi [34] | FastText + ds + BOW + MCNN | 71.3% | NA 3 | 0.50 |
| Singh et al. [35] | Improved LSTM-RNN with attention mechanisms | 84.56% | NA 3 | 0.81 |
| Hybrid Method 1 1 | TF-IDF and Glove + SVM | 86.16% | 96.42% | 0.86 |
| Hybrid Method 2 2 | TF-IDF and FastText + SVM | 88.72% | 95.88% | 0.86 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Didi, Y.; Walha, A.; Wali, A. COVID-19 Tweets Classification Based on a Hybrid Word Embedding Method. Big Data Cogn. Comput. 2022, 6, 58. https://doi.org/10.3390/bdcc6020058
Didi Y, Walha A, Wali A. COVID-19 Tweets Classification Based on a Hybrid Word Embedding Method. Big Data and Cognitive Computing. 2022; 6(2):58. https://doi.org/10.3390/bdcc6020058
Chicago/Turabian StyleDidi, Yosra, Ahlam Walha, and Ali Wali. 2022. "COVID-19 Tweets Classification Based on a Hybrid Word Embedding Method" Big Data and Cognitive Computing 6, no. 2: 58. https://doi.org/10.3390/bdcc6020058
APA StyleDidi, Y., Walha, A., & Wali, A. (2022). COVID-19 Tweets Classification Based on a Hybrid Word Embedding Method. Big Data and Cognitive Computing, 6(2), 58. https://doi.org/10.3390/bdcc6020058