
New Efficient Approach to Solve Big Data Systems Using Parallel Gauss–Seidel Algorithms


Abstract
:1. Introduction
2. Solving Linear Regression Using Factorized Matrices and Gauss–Seidel Algorithm
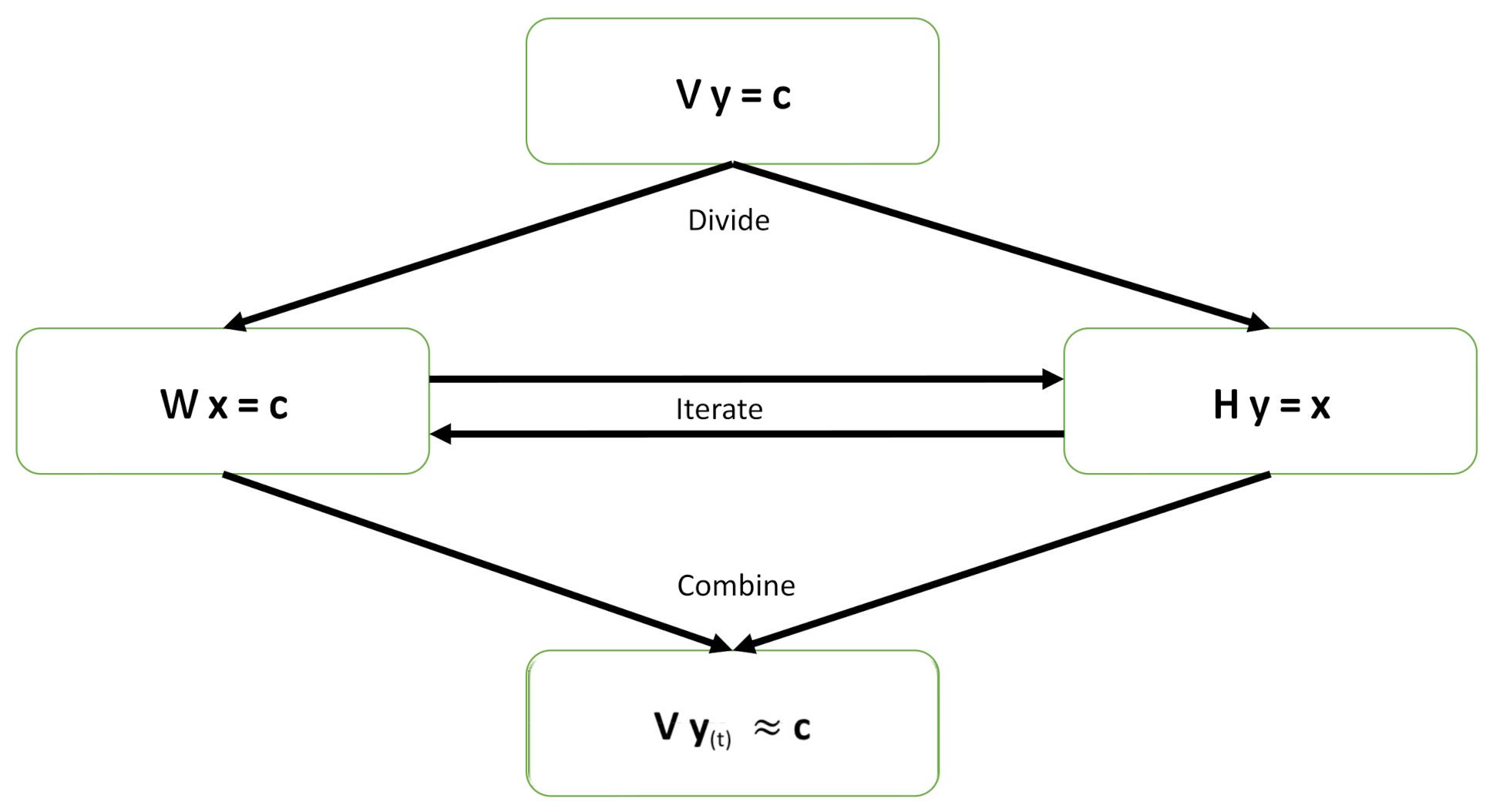
2.1. Linear Regression: Divide-and-Iterate Approach
2.2. Gauss–Seidel Algorithm and Its Extensions
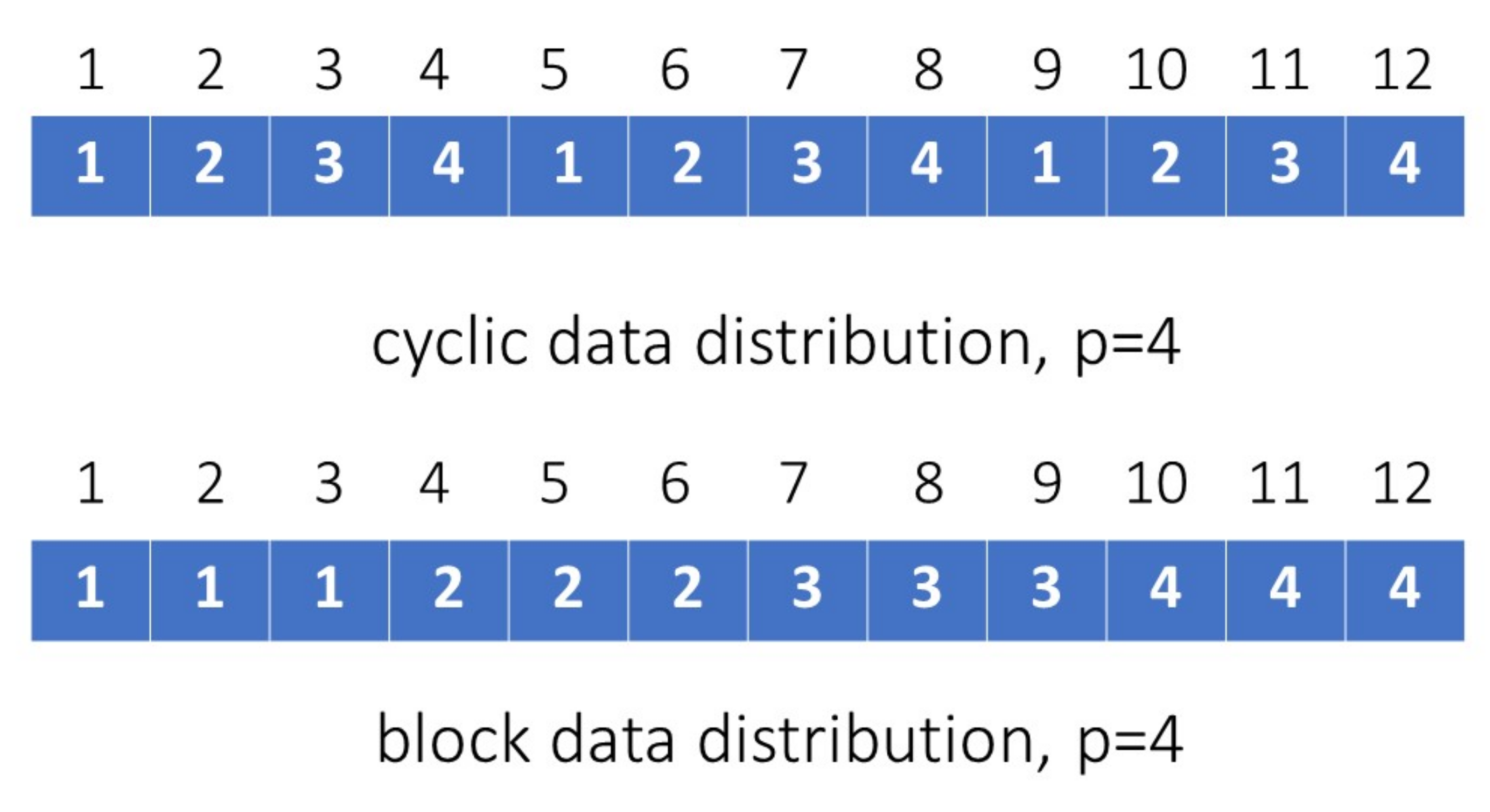
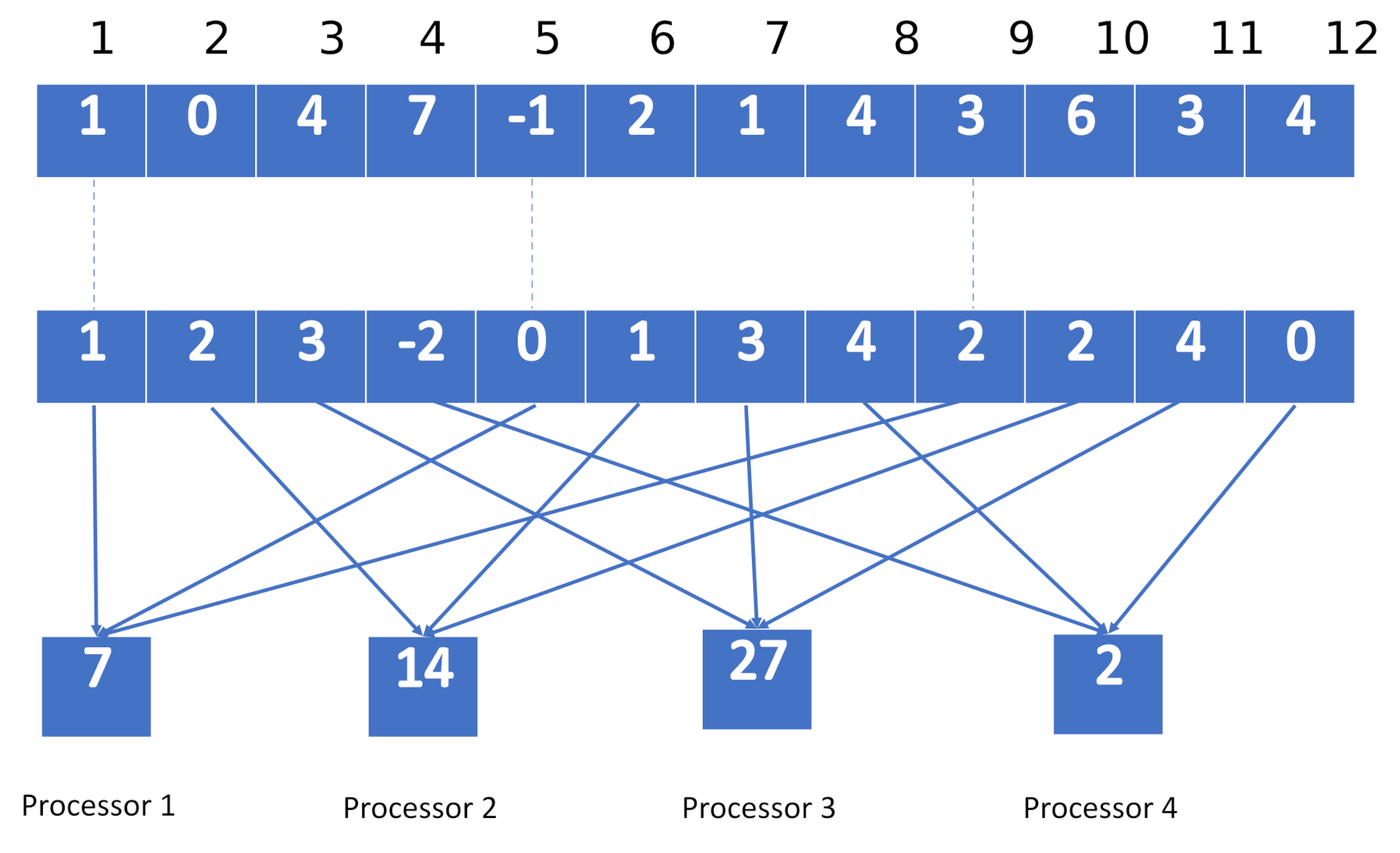
3. Parallel Random Iterative Approach for Linear Systems
3.1. Consistent Linear Systems
| Algorithm 1 The Parallel GSA |
| Result: |
| Input: , , , ; while do |
| Pick up column with probability ; |
| Update ; |
| Pick up column with probability ; |
| Update ; |
| end |
3.2. Inconsistent Linear Systems
| Algorithm 2 The Parallel EGSA |
| Result: Input: , , , |
| whiledo |
| Pick up column with probability |
| Update |
| Pick up row with probability |
| Update |
| Pick up column with probability |
| Update |
| end |
4. Convergence Studies
4.1. Auxiliary Lemmas
4.2. Convergence Analysis
5. Complexity Analysis
5.1. Time-Complexity Analysis
5.2. Memory-Complexity Analysis
6. Numerical Evaluation
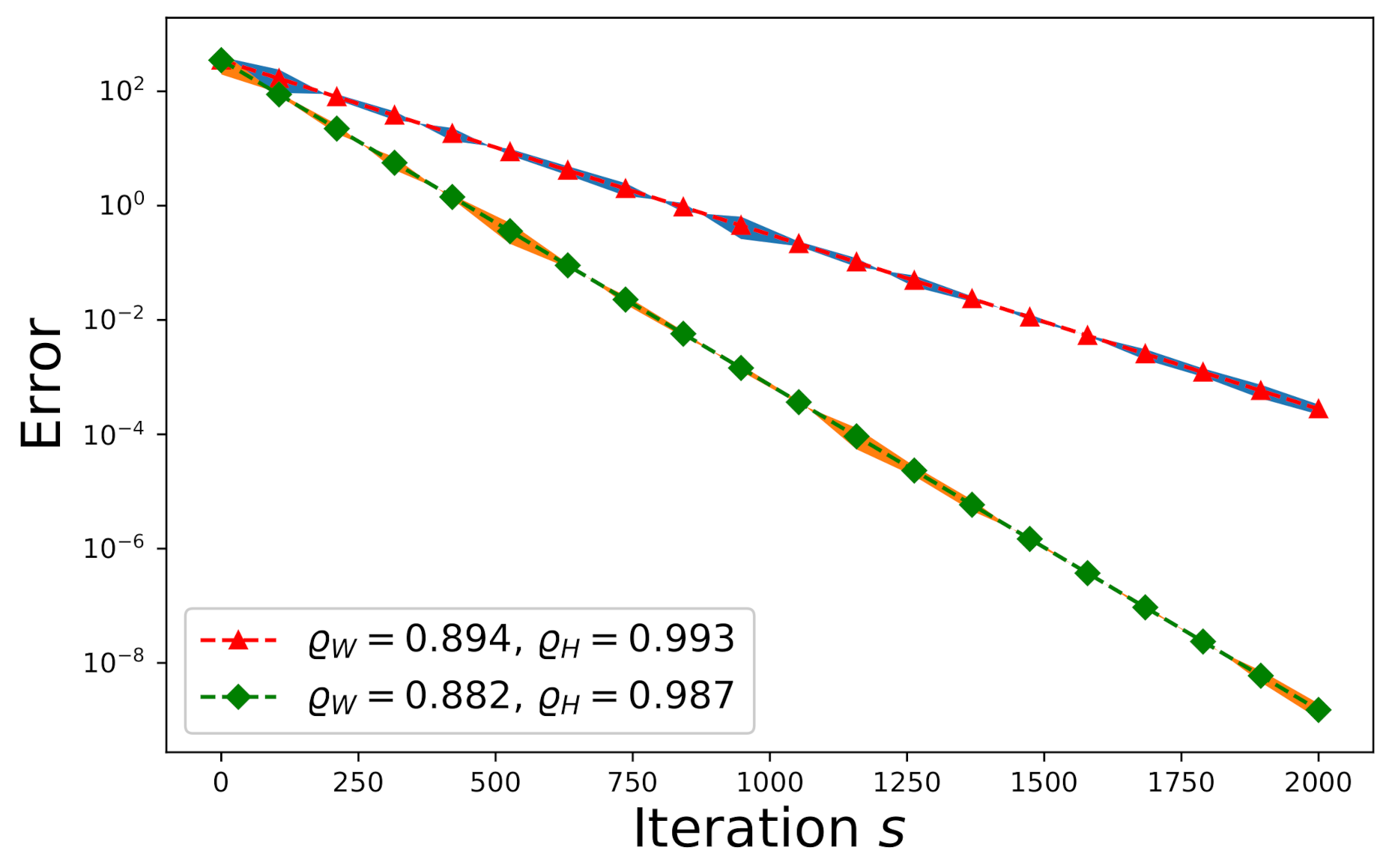
6.1. Convergence Study
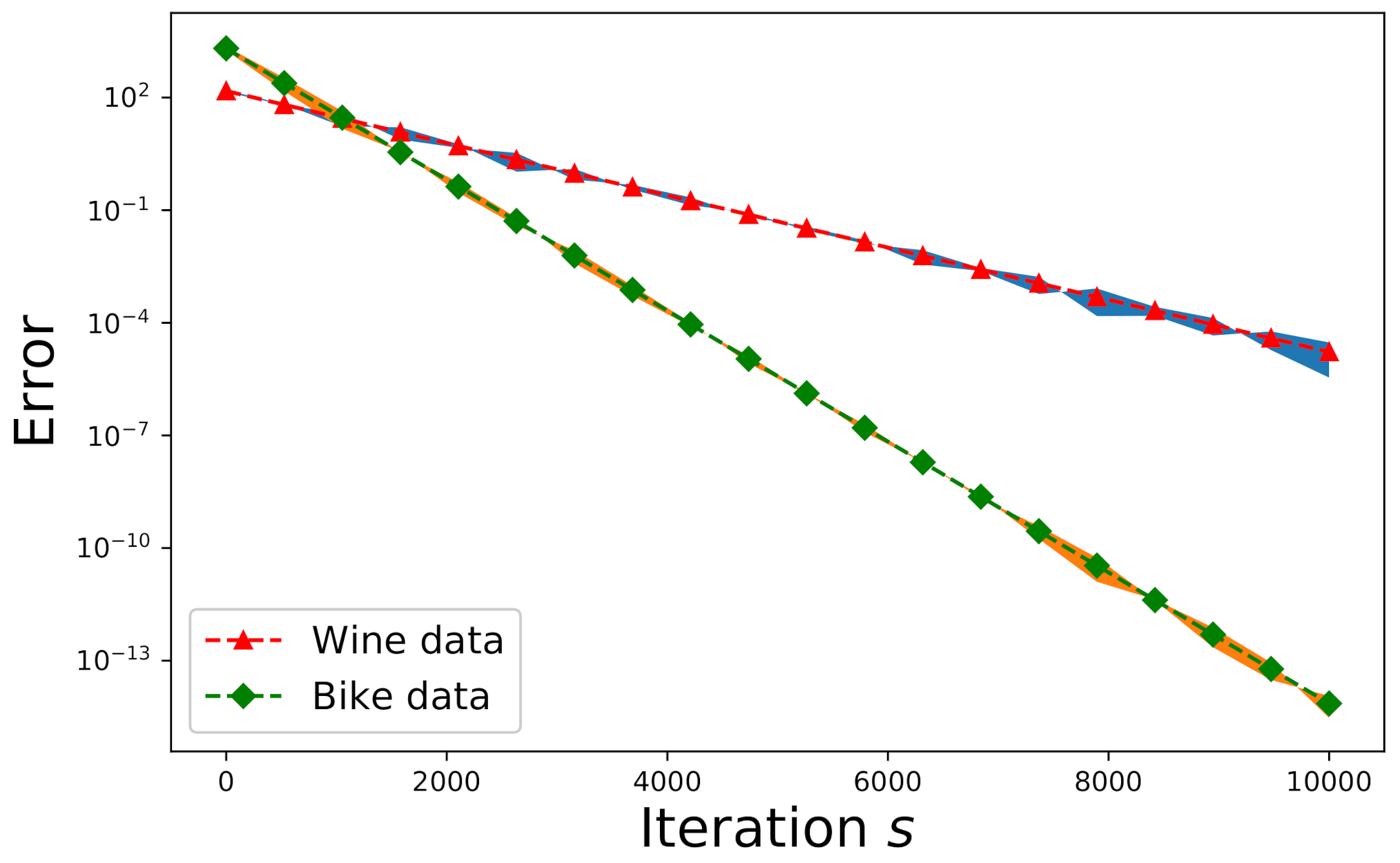
6.2. Validation Using Real-World Data
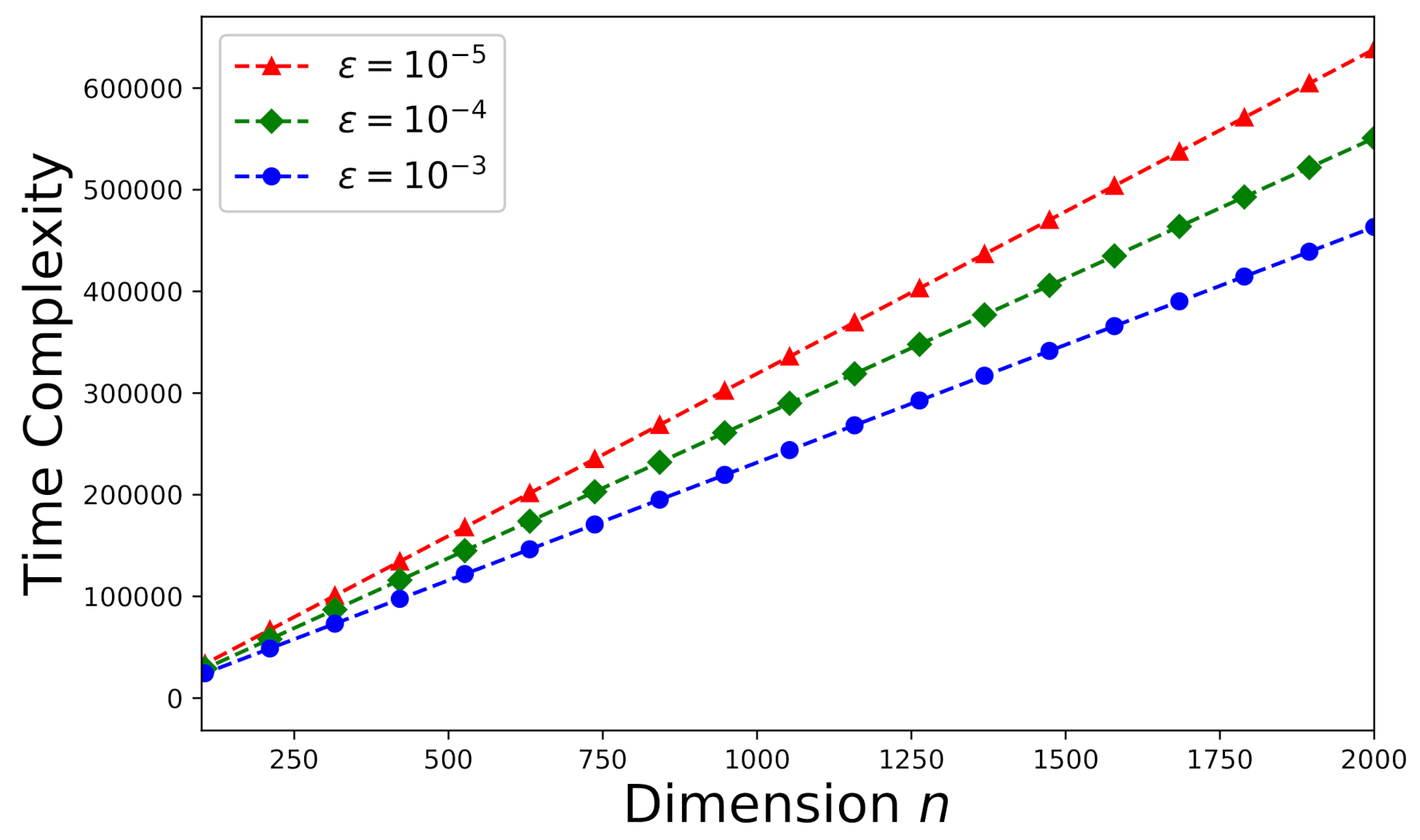
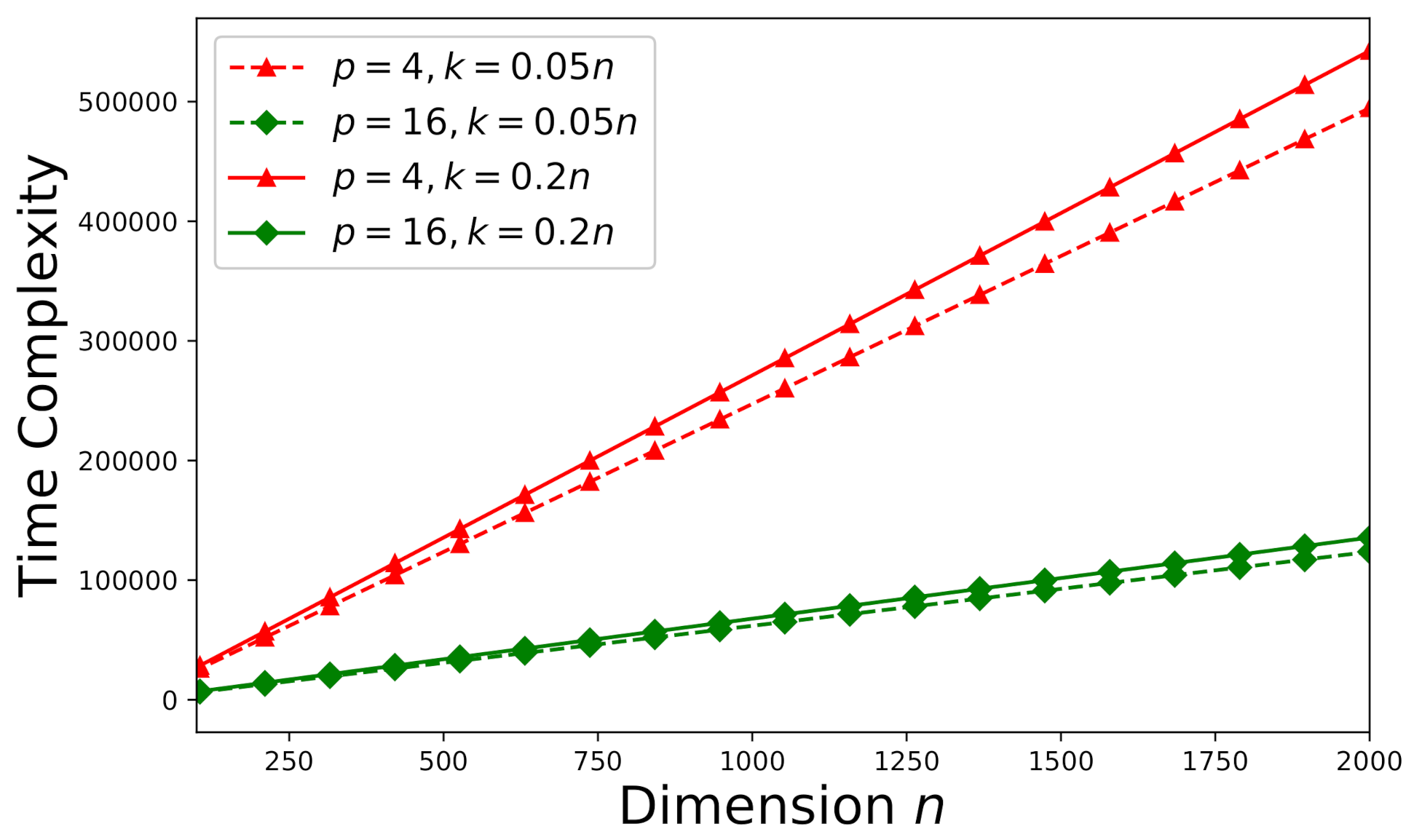
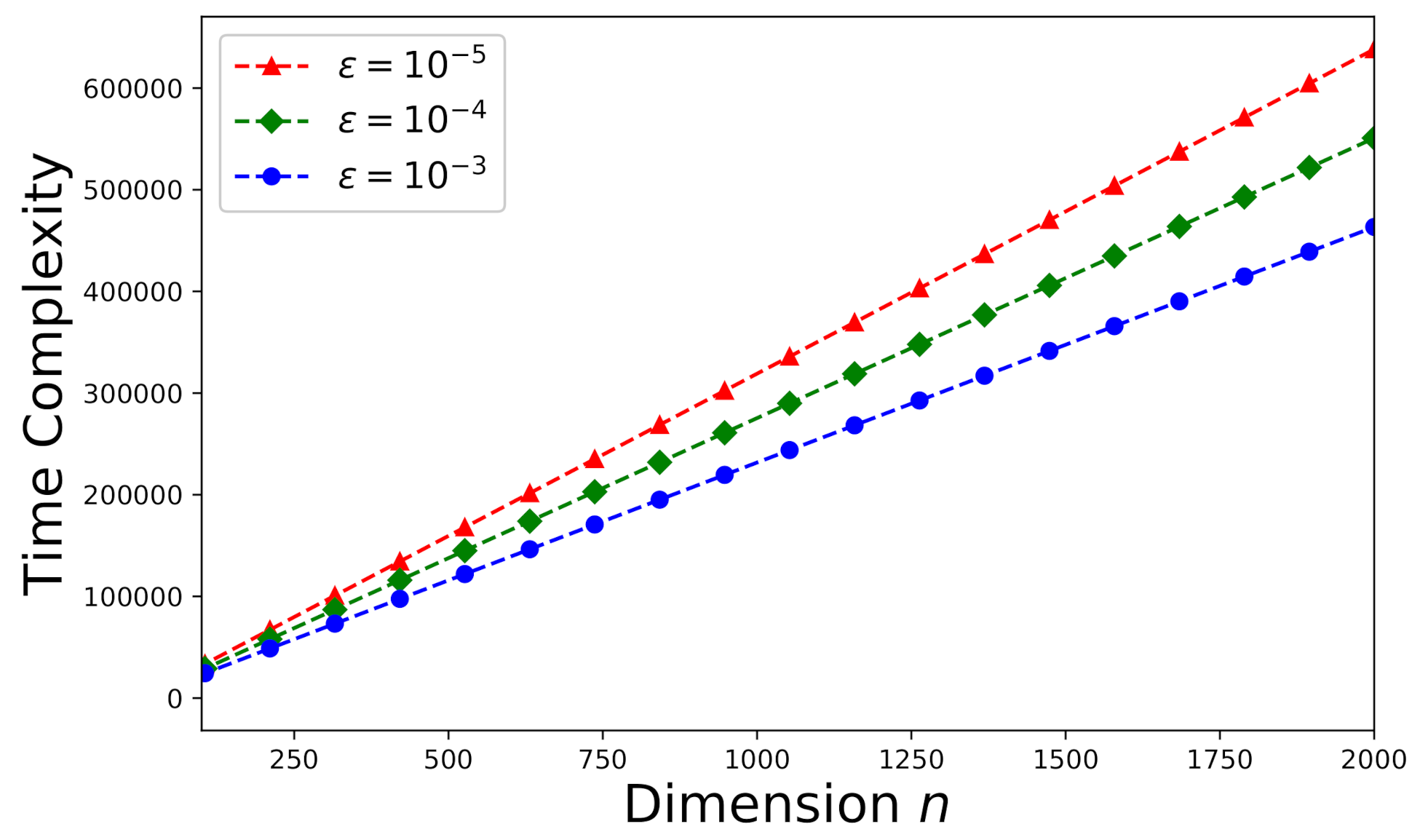
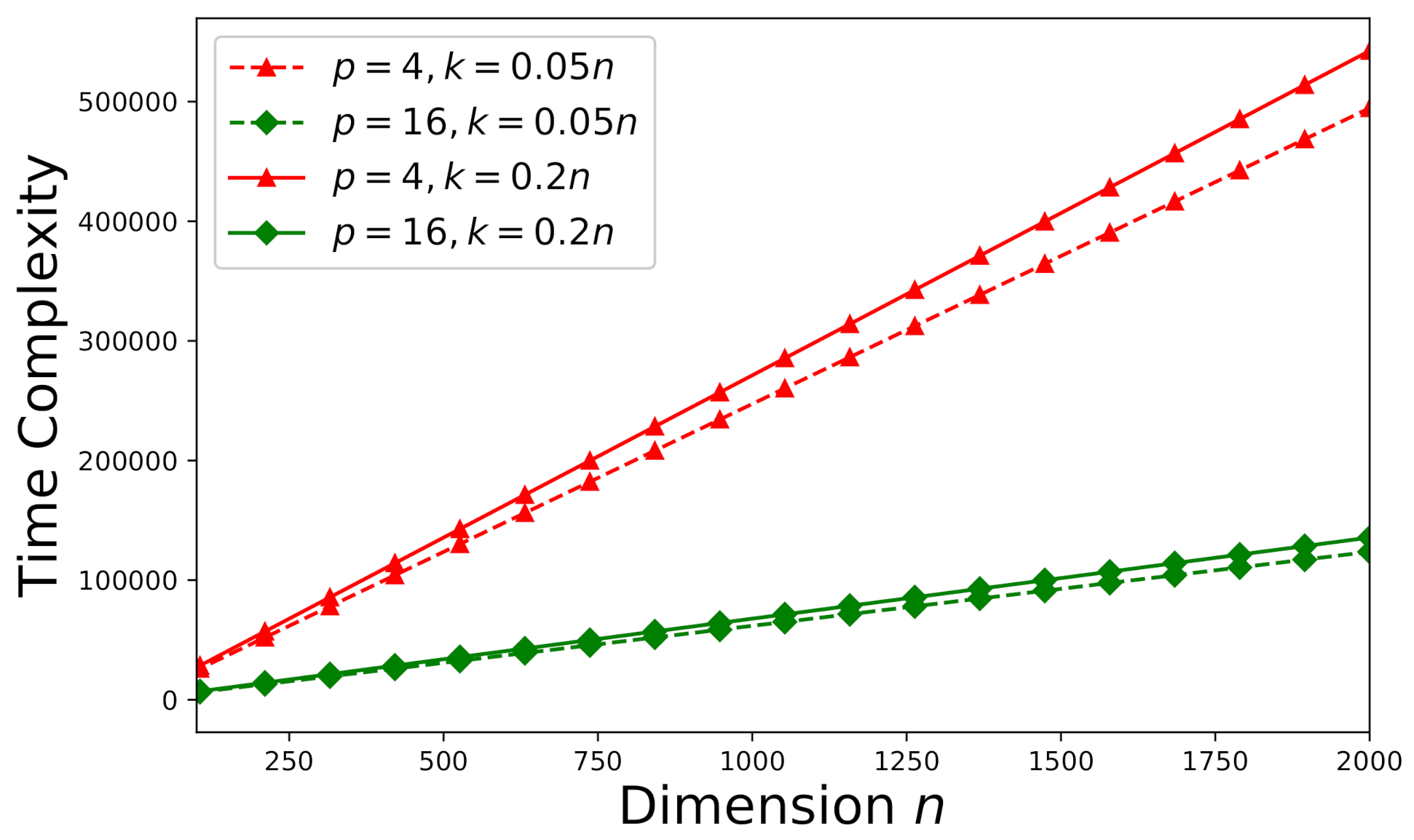
6.3. Time-Complexity Study
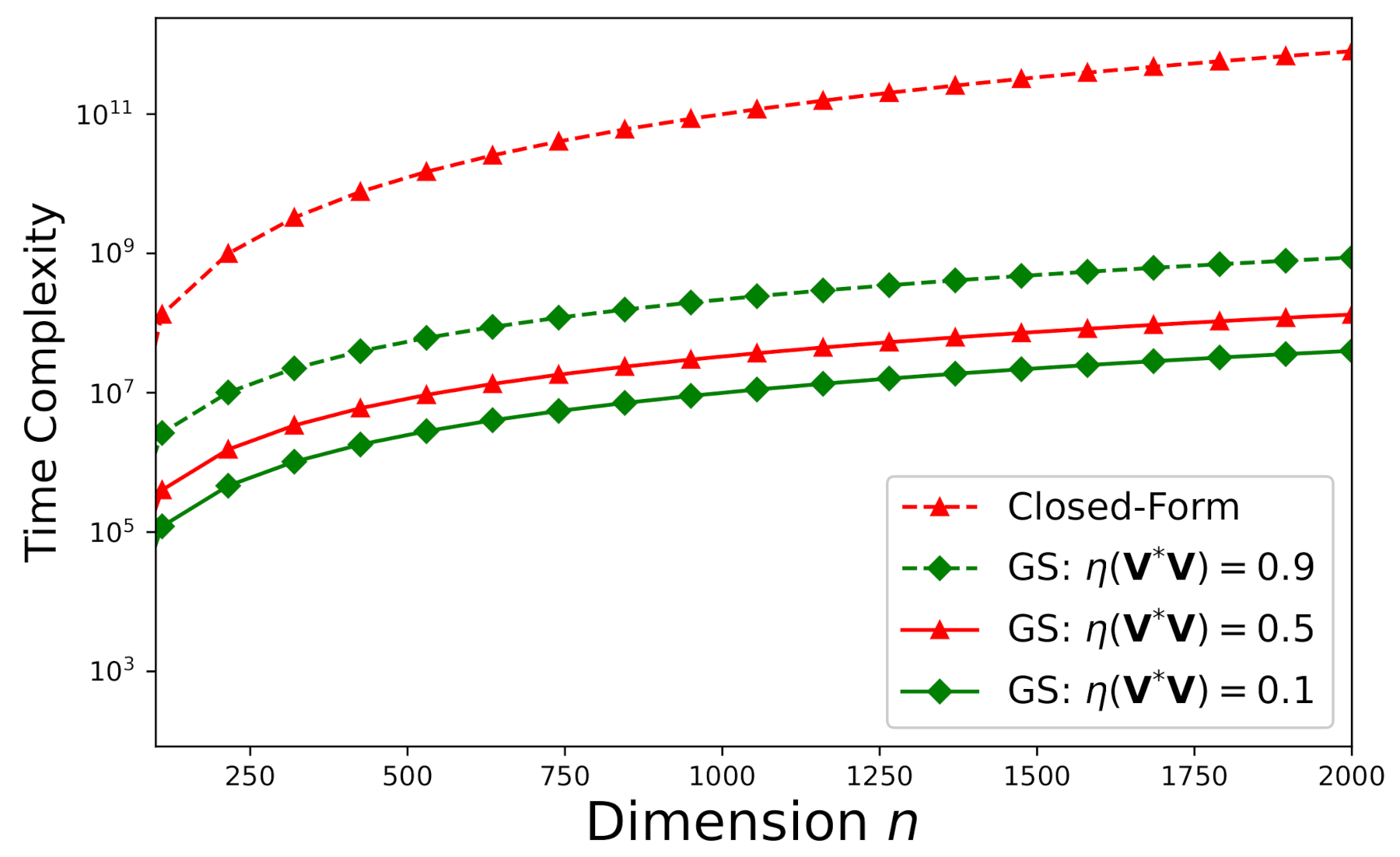
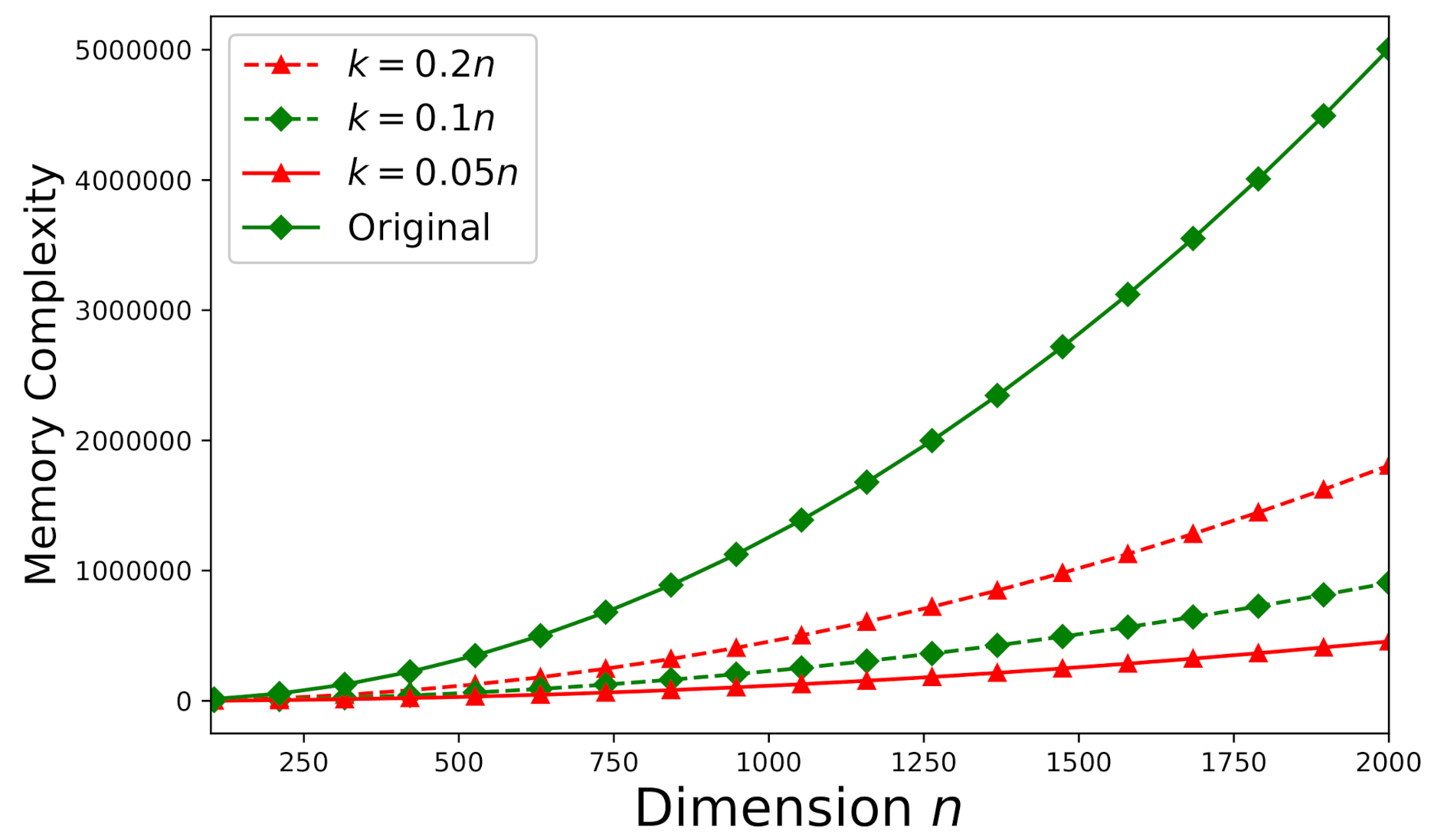
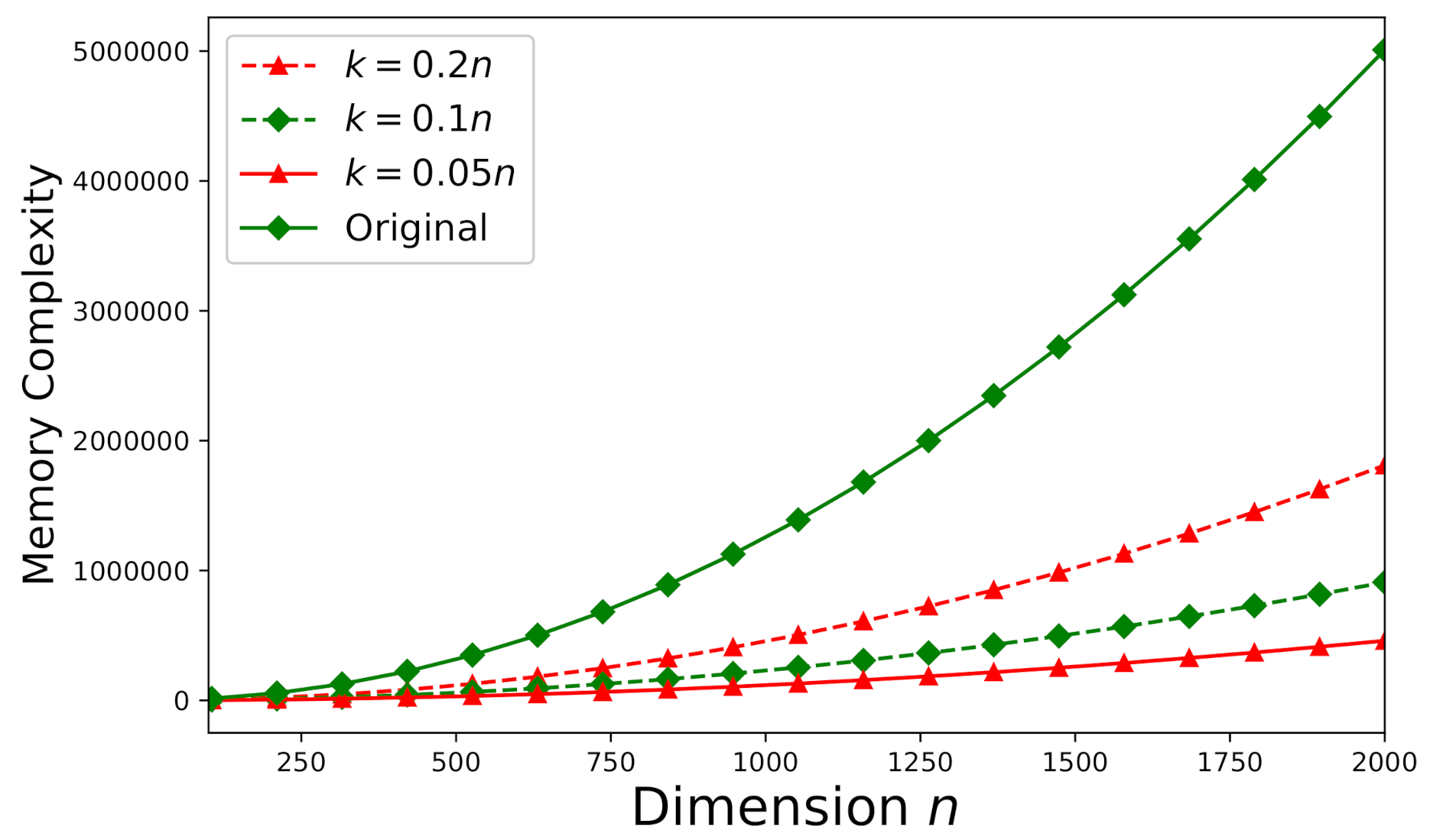
6.4. Memory-Complexity Study
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Thakur, N.; Han, C.Y. An ambient intelligence-based human behavior monitoring framework for ubiquitous environments. Information 2021, 12, 81. [Google Scholar] [CrossRef]
- Chen, Y.; Ho, P.H.; Wen, H.; Chang, S.Y.; Real, S. On Physical-Layer Authentication via Online Transfer Learning. IEEE Internet Things J. 2021, 9, 1374–1385. [Google Scholar] [CrossRef]
- Tariq, F.; Khandaker, M.; Wong, K.-K.; Imran, M.; Bennis, M.; Debbah, M. A speculative study on 6G. arXiv 2019, arXiv:1902.06700. [Google Scholar] [CrossRef]
- Gu, R.; Tang, Y.; Tian, C.; Zhou, H.; Li, G.; Zheng, X.; Huang, Y. Improving execution concurrency of large-scale matrix multiplication on distributed data-parallel platforms. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 2539–2552. [Google Scholar] [CrossRef]
- Dass, J.; Sarin, V.; Mahapatra, R.N. Fast and communication-efficient algorithm for distributed support vector machine training. IEEE Trans. Parallel Distrib. Syst. 2018, 30, 1065–1076. [Google Scholar] [CrossRef]
- Yu, Z.; Xiong, W.; Eeckhout, L.; Bei, Z.; Mendelson, A.; Xu, C. MIA: Metric importance analysis for big data workload characterization. IEEE Trans. Parallel Distrib. Syst. 2017, 29, 1371–1384. [Google Scholar] [CrossRef]
- Zhang, T.; Liu, X.-Y.; Wang, X.; Walid, A. cuTensor-Tubal: Efficient primitives for tubal-rank tensor learning operations on GPUs. IEEE Trans. Parallel Distrib. Syst. 2019, 31, 595–610. [Google Scholar] [CrossRef]
- Zhang, T.; Liu, X.-Y.; Wang, X. High performance GPU tensor completion with tubal-sampling pattern. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 1724–1739. [Google Scholar] [CrossRef]
- Hu, Z.; Li, B.; Luo, J. Time-and cost-efficient task scheduling across geo-distributed data centers. IEEE Trans. Parallel Distrib. Syst. 2017, 29, 705–718. [Google Scholar] [CrossRef]
- Jaulmes, L.; Moreto, M.; Ayguade, E.; Labarta, J.; Valero, M.; Casas, M. Asynchronous and exact forward recovery for detected errors in iterative solvers. IEEE Trans. Parallel Distrib. Syst. 2018, 29, 1961–1974. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Wu, J.; Lin, J.; Liu, R.; Zhang, H.; Ye, Z. Affinity regularized non-negative matrix factorization for lifelong topic modeling. IEEE Trans. Knowl. Data Eng. 2019, 32, 1249–1262. [Google Scholar] [CrossRef]
- Kannan, R.; Ballard, G.; Park, H. MPI-FAUN: An MPI-based framework for alternating-updating nonnegative matrix factorization. IEEE Trans. Knowl. Data Eng. 2017, 30, 544–558. [Google Scholar] [CrossRef]
- Wang, S.; Chen, H.; Cao, J.; Zhang, J.; Yu, P. Locally balanced inductive matrix completion for demand-supply inference in stationless bike-sharing systems. IEEE Trans. Knowl. Data Eng. 2019, 32, 2374–2388. [Google Scholar] [CrossRef]
- Sharma, S.; Powers, J.; Chen, K. PrivateGraph: Privacy-preserving spectral analysis of encrypted graphs in the cloud. IEEE Trans. Knowl. Data Eng. 2018, 31, 981–995. [Google Scholar] [CrossRef]
- Liu, Z.; Vandenberghe, L. Interior-point method for nuclear norm approximation with application to system identification. SIAM J. Matrix Anal. Appl. 2009, 31, 1235–1256. [Google Scholar] [CrossRef]
- Borg, I.; Groenen, P. Modern multidimensional scaling: Theory and applications. J. Educ. Meas. 2003, 40, 277–280. [Google Scholar] [CrossRef]
- Biswas, P.; Lian, T.-C.; Wang, T.-C.; Ye, Y. Semidefinite programming based algorithms for sensor network localization. ACM Trans. Sens. Netw. 2006, 2, 188–220. [Google Scholar] [CrossRef]
- Yan, K.; Wu, H.-C.; Xiao, H.; Zhang, X. Novel robust band-limited signal detection approach using graphs. IEEE Commun. Lett. 2017, 21, 20–23. [Google Scholar] [CrossRef]
- Yan, K.; Yu, B.; Wu, H.-C.; Zhang, X. Robust target detection within sea clutter based on graphs. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7093–7103. [Google Scholar] [CrossRef]
- Costa, J.A.; Hero, A.O. Geodesic entropic graphs for dimension and entropy estimation in manifold learning. IEEE Trans. Signal Process. 2004, 52, 2210–2221. [Google Scholar] [CrossRef] [Green Version]
- Sandryhaila, A.; Moura, J.M. Big data analysis with signal processing on graphs. IEEE Signal Process. Mag. 2014, 31, 80–90. [Google Scholar] [CrossRef]
- Sandryhaila, A.; Moura, J.M. Discrete signal processing on graphs. IEEE Trans. Signal Process. 2013, 61, 1644–1656. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, A.; Romberg, J. Compressive multiplexing of correlated signals. IEEE Trans. Inf. Theory 2014, 61, 479–498. [Google Scholar] [CrossRef] [Green Version]
- Davies, M.E.; Eldar, Y.C. Rank awareness in joint sparse recovery. IEEE Trans. Inf. Theory 2012, 58, 1135–1146. [Google Scholar] [CrossRef] [Green Version]
- Cong, Y.; Liu, J.; Fan, B.; Zeng, P.; Yu, H.; Luo, J. Online similarity learning for big data with overfitting. IEEE Trans. Big Data 2017, 4, 78–89. [Google Scholar] [CrossRef]
- Zhu, X.; Suk, H.-I.; Huang, H.; Shen, D. Low-rank graph-regularized structured sparse regression for identifying genetic biomarkers. IEEE Trans. Big Data 2017, 3, 405–414. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.-Y.; Wang, X. LS-decomposition for robust recovery of sensory big data. IEEE Trans. Big Data 2017, 4, 542–555. [Google Scholar] [CrossRef]
- Fan, J.; Zhao, M.; Chow, T.W.S. Matrix completion via sparse factorization solved by accelerated proximal alternating linearized minimization. IEEE Trans. Big Data 2018, 6, 119–130. [Google Scholar] [CrossRef]
- Hou, D.; Cong, Y.; Sun, G.; Dong, J.; Li, J.; Li, K. Fast multi-view outlier detection via deep encoder. IEEE Trans. Big Data 2020, 1–11. [Google Scholar] [CrossRef]
- Hotelling, H. Analysis of a complex of statistical variables into principal components. J. Educ. Psychol. 1933, 24, 417–441. [Google Scholar] [CrossRef]
- Landauer, T.K.; Foltz, P.W.; Laham, D. An introduction to latent semantic analysis. Discourse Process. 1998, 25, 259–284. [Google Scholar] [CrossRef]
- Obozinski, G.; Taskar, B.; Jordan, M.I. Joint covariate selection and joint subspace selection for multiple classification problems. Stat. Comput. 2010, 20, 231–252. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.; Wu, J.; Liu, T.; Tao, D.; Fu, Y. Spectral ensemble clustering via weighted k-means: Theoretical and practical evidence. IEEE Trans. Knowl. Data Eng. 2017, 29, 1129–1143. [Google Scholar] [CrossRef]
- Jiang, X.; Zeng, W.-J.; So, H.C.; Zoubir, A.M.; Kirubarajan, T. Beamforming via nonconvex linear regression. IEEE Trans. Signal Process. 2015, 64, 1714–1728. [Google Scholar] [CrossRef]
- Kallummil, S.; Kalyani, S. High SNR consistent linear model order selection and subset selection. IEEE Trans. Signal Process. 2016, 64, 4307–4322. [Google Scholar] [CrossRef]
- Kallummil, S.; Kalyani, S. Residual ratio thresholding for linear model order selection. IEEE Trans. Signal Process. 2018, 67, 838–853. [Google Scholar] [CrossRef]
- So, H.C.; Zeng, W.-J. Outlier-robust matrix completion via lp-minimization. IEEE Trans. Signal Process. 2018, 66, 1125–1140. [Google Scholar]
- Berberidis, D.; Kekatos, V.; Giannakis, G.B. Online censoring for large-scale regressions with application to streaming big data. IEEE Trans. Signal Process. 2016, 64, 3854–3867. [Google Scholar] [CrossRef] [Green Version]
- Boloix-Tortosa, R.; Murillo-Fuentes, J.J.; Tsaftaris, S.A. The generalized complex kernel least-mean-square algorithm. IEEE Trans. Signal Process. 2019, 67, 5213–5222. [Google Scholar] [CrossRef]
- Widrow, B. Adaptive Signal Processing; Prentice Hall: Hoboken, NJ, USA, 1985. [Google Scholar]
- Sonneveld, P.; Van Gijzen, M.B. IDR (s): A family of simple and fast algorithms for solving large nonsymmetric systems of linear equations. SIAM J. Sci. Comput. 2009, 31, 1035–1062. [Google Scholar] [CrossRef] [Green Version]
- Bavier, E.; Hoemmen, M.; Rajamanickam, S.; Thornquist, H. Amesos2 and Belos: Direct and iterative solvers for large sparse linear systems. Sci. Program. 2012, 20, 241–255. [Google Scholar] [CrossRef] [Green Version]
- Chang, S.Y.; Wu, H.-C. Divide-and-Iterate approach to big data systems. IEEE Trans. Serv. Comput. 2020. [Google Scholar] [CrossRef]
- Hageman, L.; Young, D. Applied Iterative Methods; Academic Press: Cambridge, MA, USA, 1981. [Google Scholar]
- Leventhal, D.; Lewis, A.S. Randomized methods for linear constraints: Convergence rates and conditioning. Math. Oper. Res. 2010, 35, 641–654. [Google Scholar] [CrossRef] [Green Version]
- Ma, A.; Needell, D.; Ramdas, A. Convergence properties of the randomized extended Gauss–Seidel and Kaczmarz methods. SIAM J. Matrix Anal. Appl. 2015, 36, 1590–1604. [Google Scholar] [CrossRef] [Green Version]
- Weiss, N.A. A Course in Probability; Addison-Wesley: Boston, MA, USA, 2006. [Google Scholar]
- Harremoës, P. Bounds on tail probabilities in exponential families. arXiv 2016, arXiv:1601.05179. [Google Scholar]
- Dua, D.; Graff, C. UCI Machine Learning Repository. 2017. Available online: http://archive.ics.uci.edu/ml (accessed on 3 March 2022).
- Li, C.-K.; Tam, T.-Y.; Tsing, N.-K. The generalized spectral radius, numerical radius and spectral norm. Linear Multilinear Algebra 1984, 16, 215–237. [Google Scholar] [CrossRef]
- Mittal, R.; Al-Kurdi, A. LU-decomposition and numerical structure for solving large sparse nonsymmetric linear systems. Comput. Math. Appl. 2002, 43, 131–155. [Google Scholar] [CrossRef] [Green Version]
- Kroonenberg, P.M.; De Leeuw, J. Principal component analysis of three-mode data by means of alternating least squares algorithms. Psychometrika 1980, 45, 69–97. [Google Scholar] [CrossRef]
- Kågström, B.; Poromaa, P. LAPACK-style algorithms and software for solving the generalized Sylvester equation and estimating the separation between regular matrix pairs. ACM Trans. Math. Softw. 1996, 22, 78–103. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dimensions, n | 100 | 1000 | 10,000 | 100,000 |
|---|---|---|---|---|
| LU | 5.31 | 8.18 × 10 | 2.18 × 10 | 7.01 × 10 |
| ALS | 4.31 | 17.81 | 9.18 × 10 | 4.81 × 10 |
| Dimensions, n | 100 | 1000 | 10,000 | 100,000 |
|---|---|---|---|---|
| = , LAPACK | 5.71 | 25.1 | 2.4 × 10 | 9.2× 10 |
| = , Fac. Inc. | 6.63 | 41.61 | 8.08 × 10 | 2.30 × 10 |
| = , Fac. Exc. | 2.32 | 23.8 | 7.18 × 10 | 1.91 × 10 |
| = , LAPACK | 5.31 | 23.1 | 2.28 × 10 | 9.01 × 10 |
| = , Fac. Inc. | 4.43 | 20.1 | 1.71 × 10 | 7.60 × 10 |
| = , Fac. Exc. | 0.13 | 2.31 | 8.18 × 10 | 2.81 × 10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, S.Y.; Wu, H.-C.; Wang, Y. New Efficient Approach to Solve Big Data Systems Using Parallel Gauss–Seidel Algorithms. Big Data Cogn. Comput. 2022, 6, 43. https://doi.org/10.3390/bdcc6020043
Chang SY, Wu H-C, Wang Y. New Efficient Approach to Solve Big Data Systems Using Parallel Gauss–Seidel Algorithms. Big Data and Cognitive Computing. 2022; 6(2):43. https://doi.org/10.3390/bdcc6020043
Chicago/Turabian StyleChang, Shih Yu, Hsiao-Chun Wu, and Yifan Wang. 2022. "New Efficient Approach to Solve Big Data Systems Using Parallel Gauss–Seidel Algorithms" Big Data and Cognitive Computing 6, no. 2: 43. https://doi.org/10.3390/bdcc6020043
APA StyleChang, S. Y., Wu, H.-C., & Wang, Y. (2022). New Efficient Approach to Solve Big Data Systems Using Parallel Gauss–Seidel Algorithms. Big Data and Cognitive Computing, 6(2), 43. https://doi.org/10.3390/bdcc6020043