
A Hierarchical Hadoop Framework to Process Geo-Distributed Big Data



Abstract
:1. Introduction
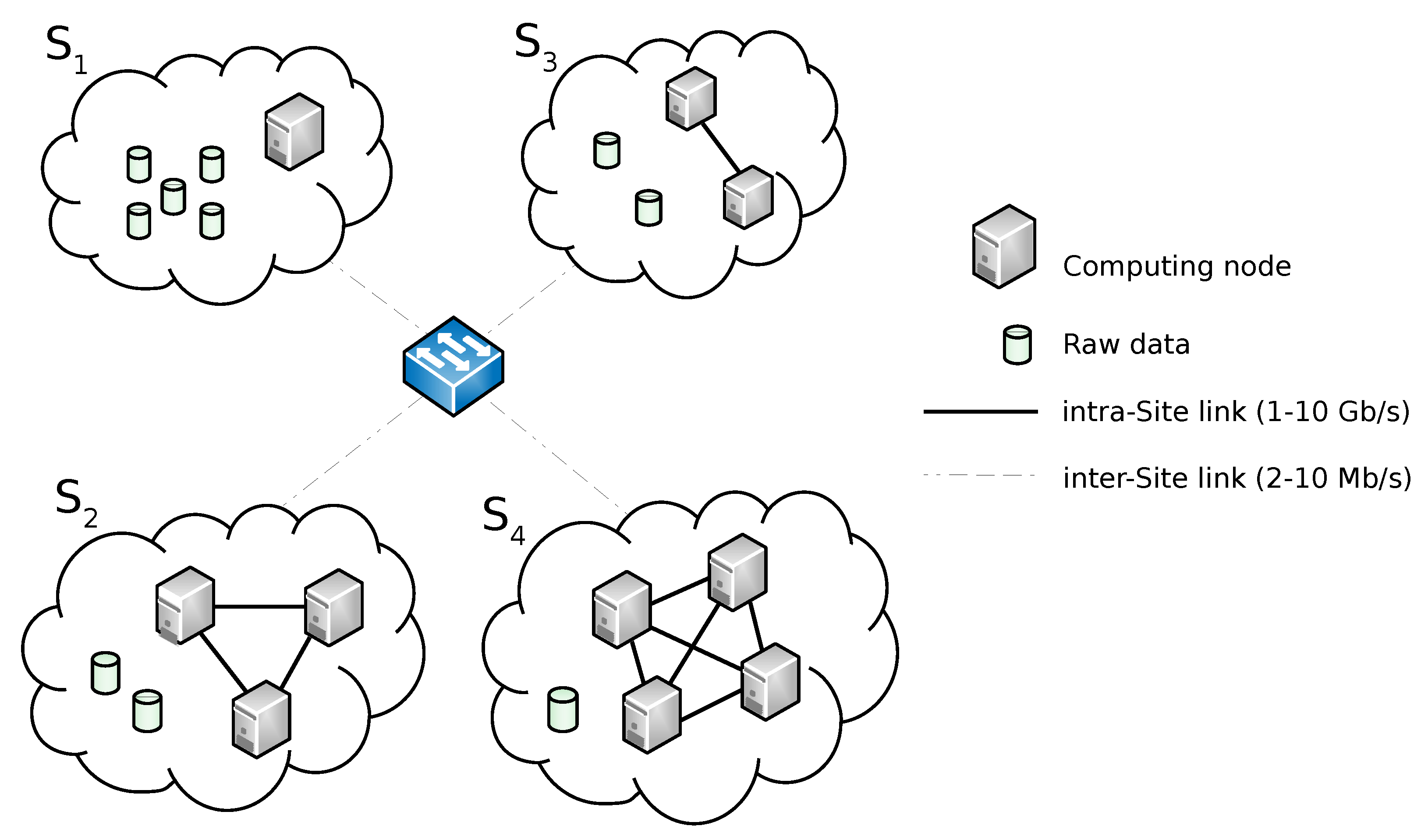
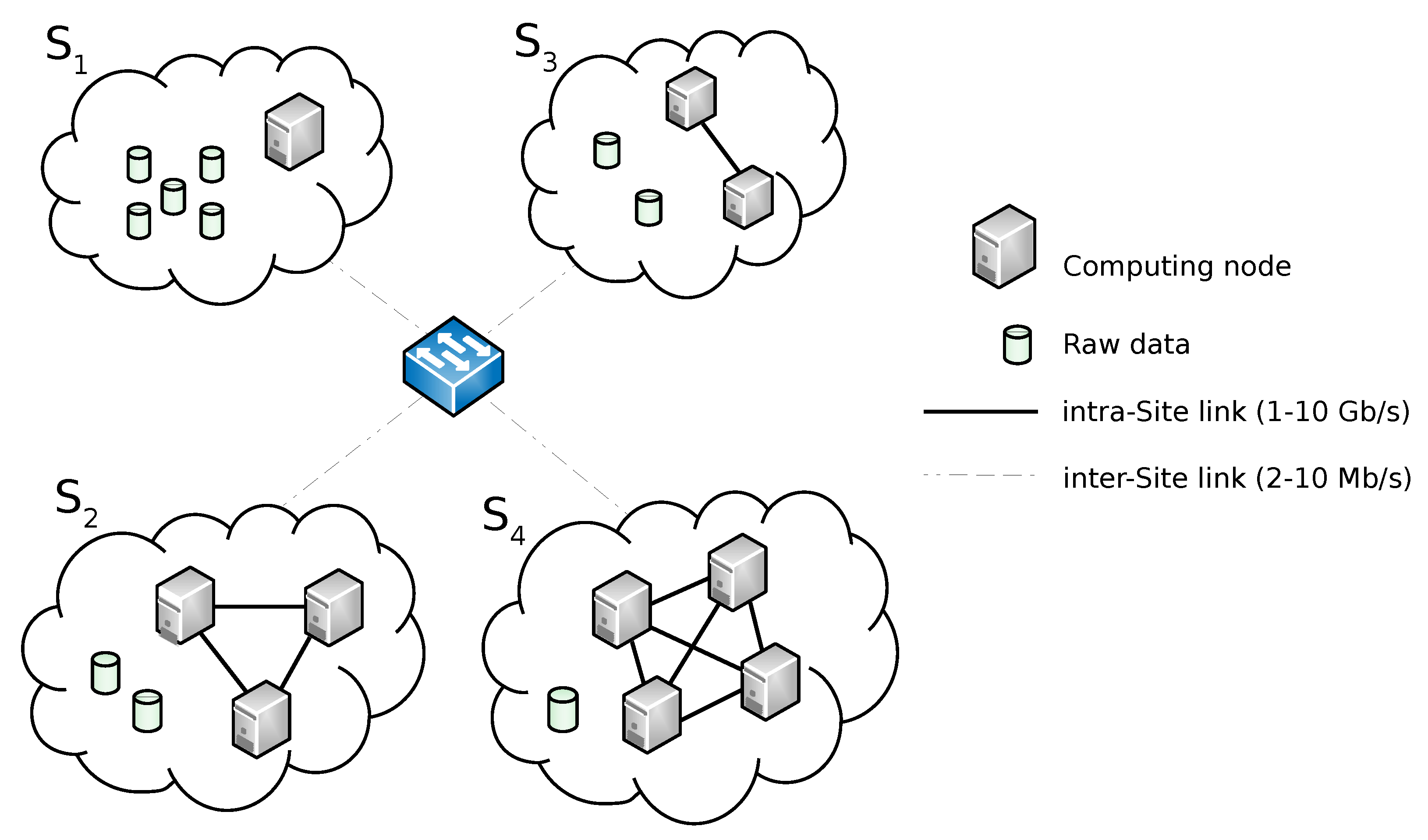
2. Background and Motivating Scenario
3. Hierarchical Hadoop Framework Design
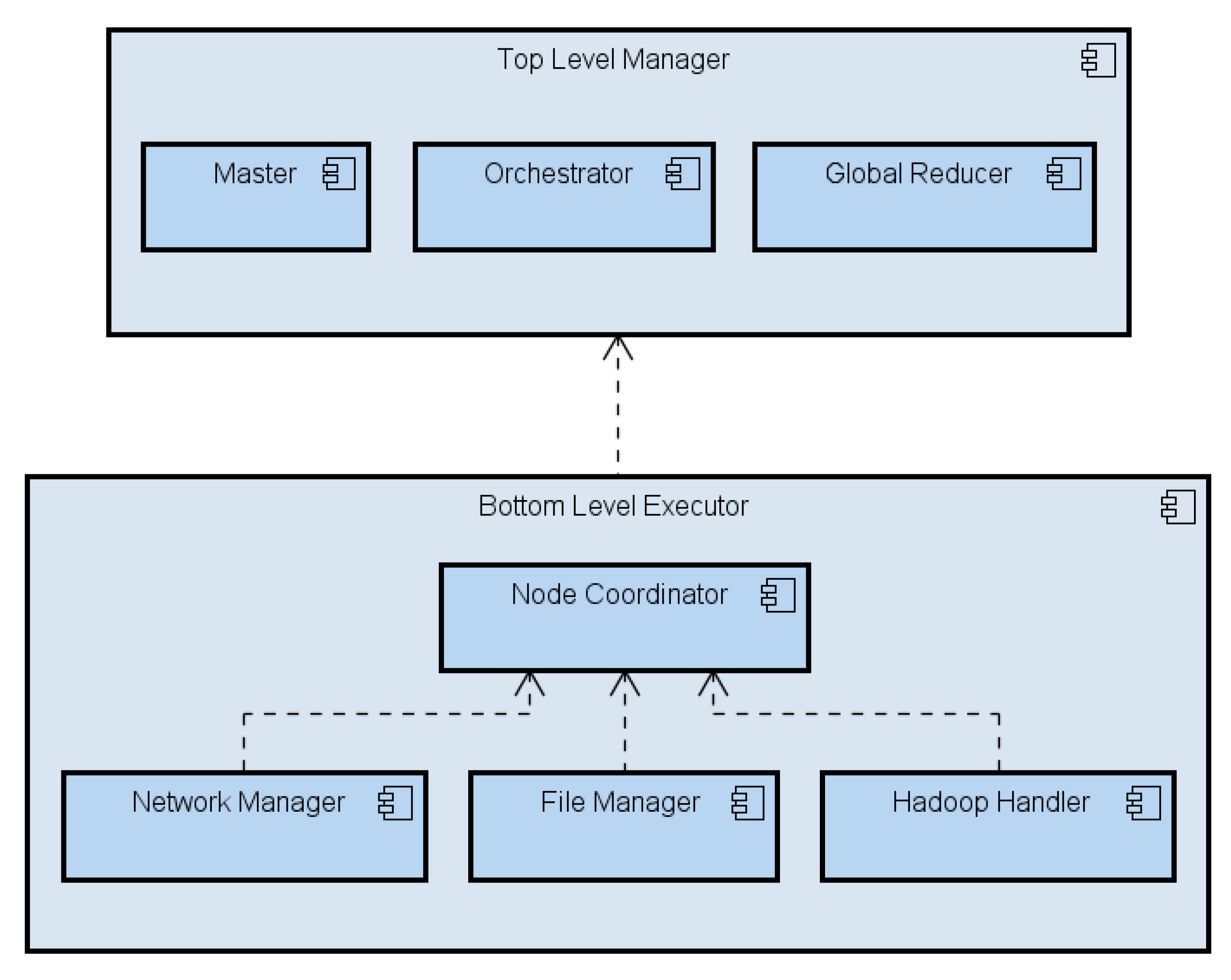
3.1. System Architecture
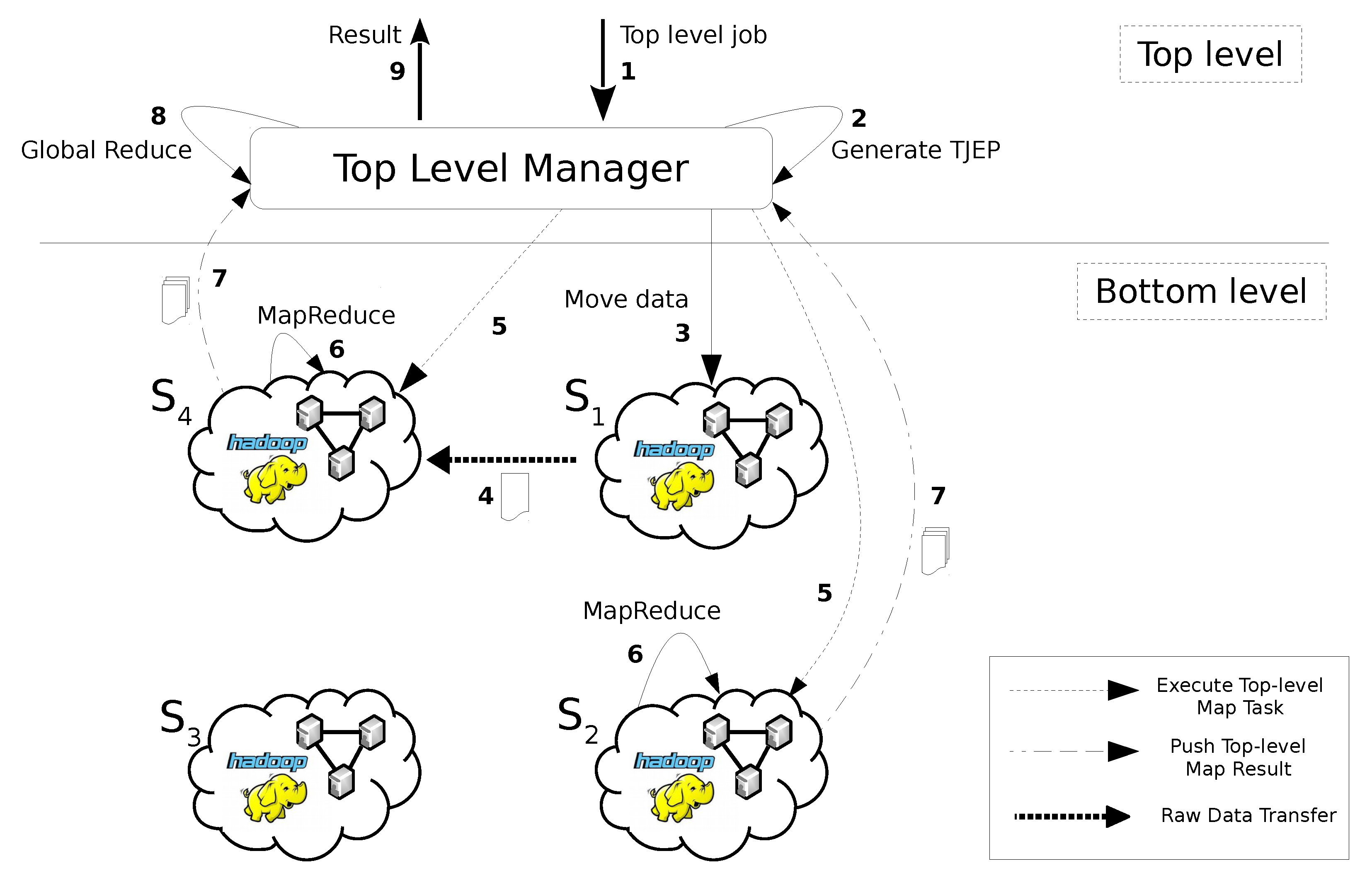
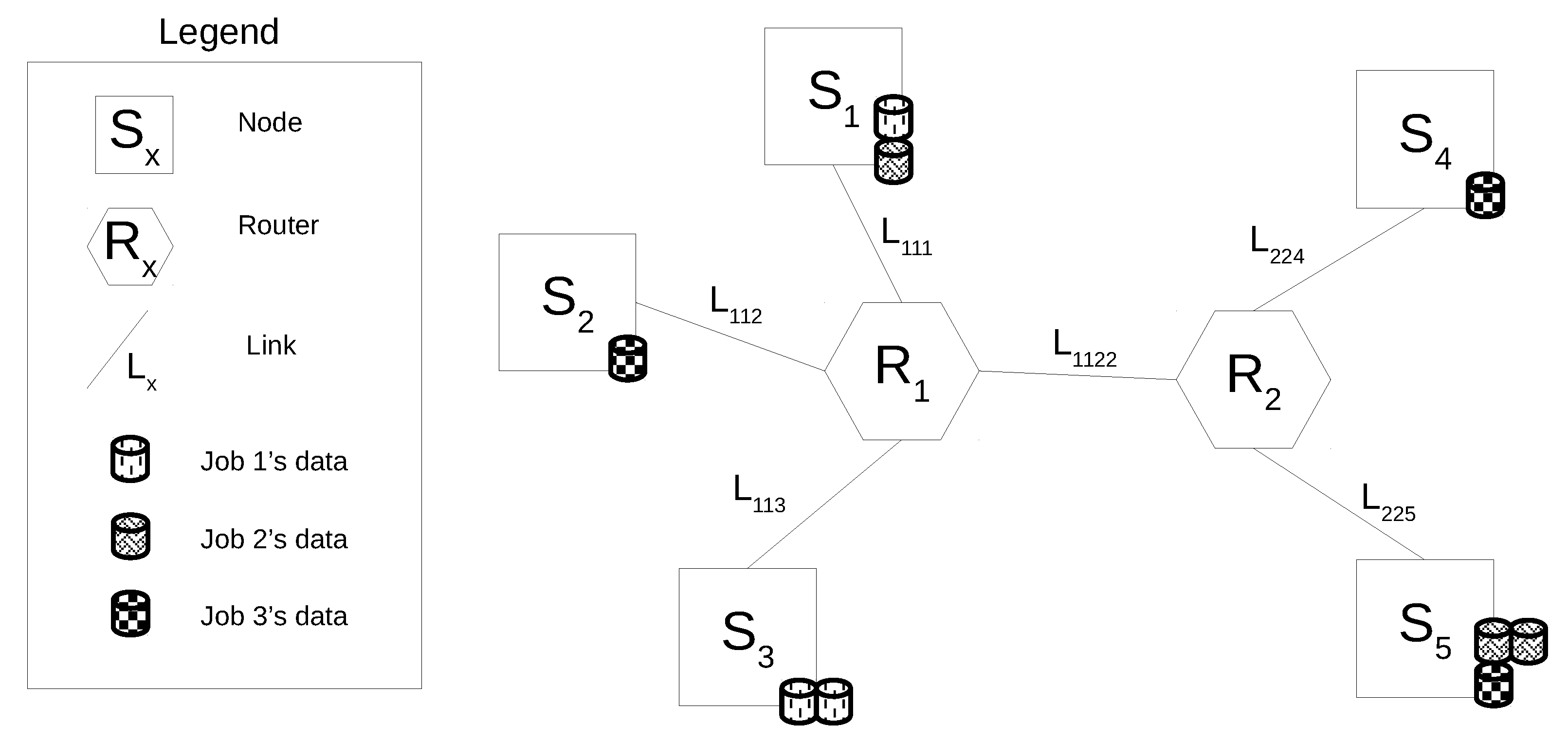
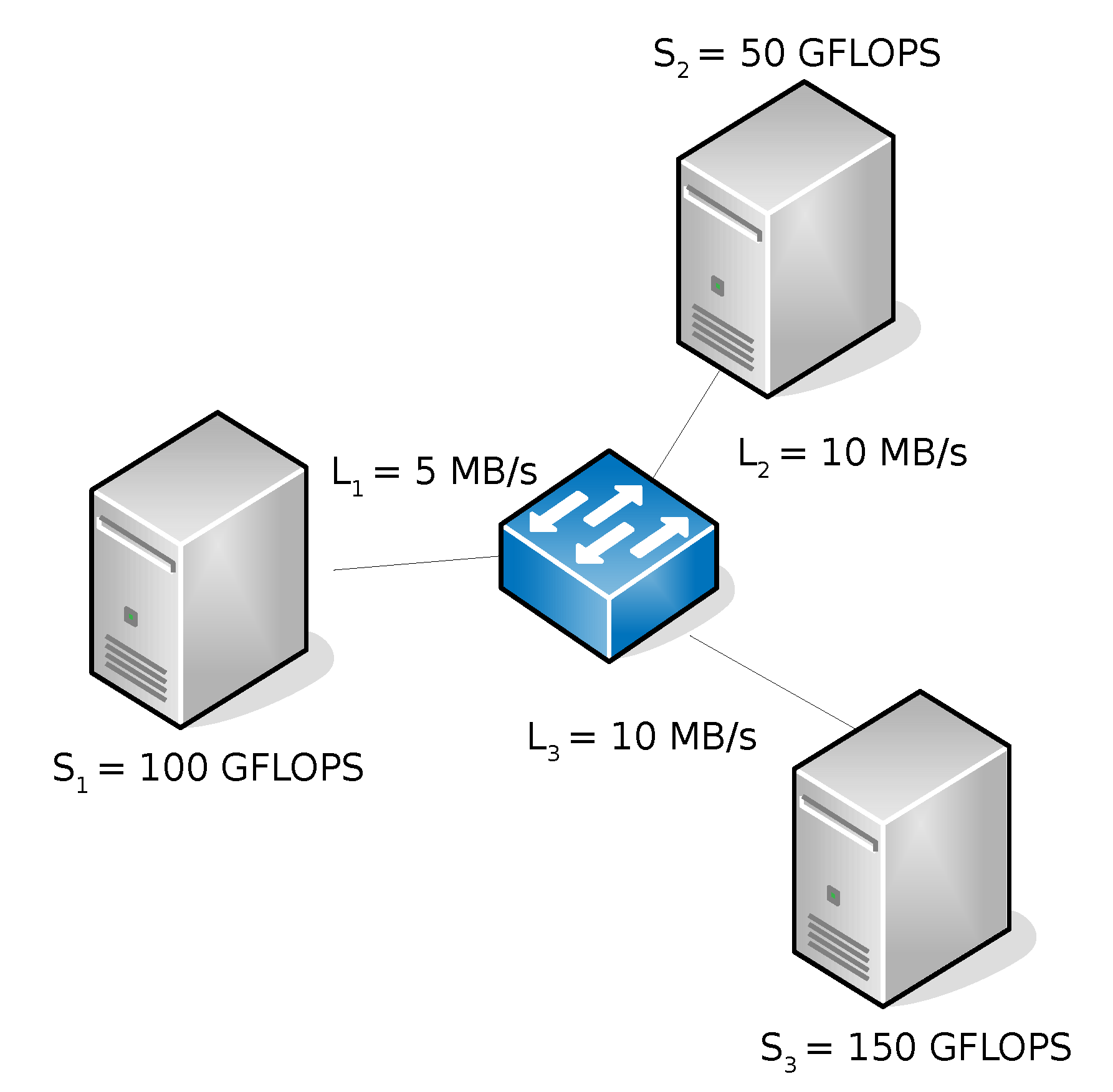
- The Top-Level Manager receives a job submission which requires computation of data residing on , and , respectively.
- A Top-level Job Execution Plan (TJEP) is generated using information on (a) the status of the Bottom-level layer such as the distribution of the data set among Sites, (b) the current computing availability of Sites, (c) the topology of the network and (d) the current capacity of its links.
- The Top-Level Manager executes the TJEP. Following the plan instructions, it orders to shift its own data to .
- The actual data shift from to happens.
- According to the plan, the Top-Level Manager sends a message to activate the run of sub-jobs on the Sites where the interested data are currently stored. In particular, Top-level Map tasks are triggered to run on and , respectively, (we reiterate that a Top-Level Map task corresponds to a MapReduce sub-job).
- and executes local Hadoop sub-jobs on their respective data sets.
- and send the output of their local executions to the Top-Level Manager.
- A procedure run by the Top-Level Manager is fed with the partial results elaborated by the Bottom-Level layer and performs a global data reduction.
- The final output is returned to the requester.

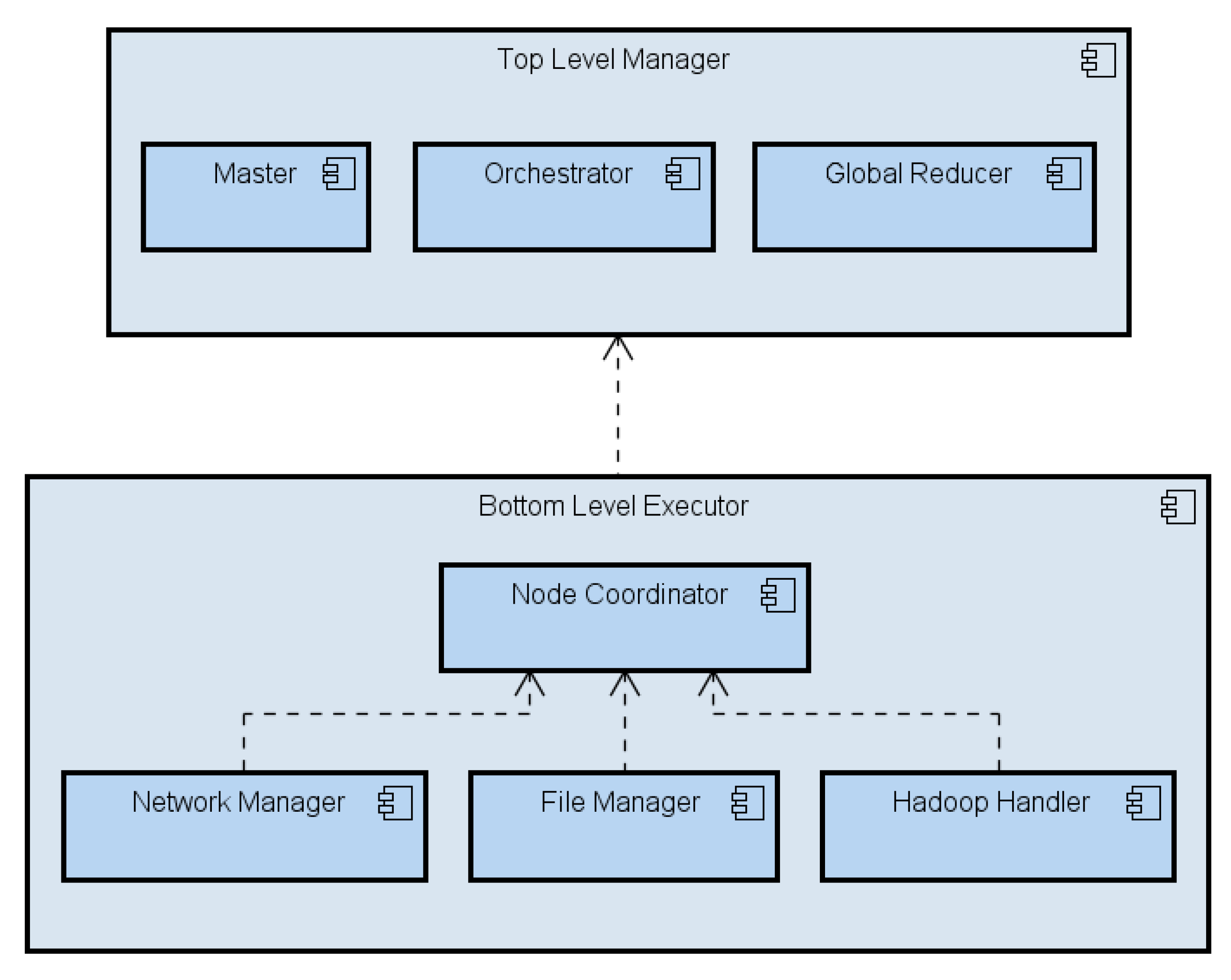
- Master: it receives the Top-level job execution request, extracts the job information and passes it to the Orchestrator, which in its turn uses it to build the TJEP. The Master is in charge of enforcing the TJEP and, once the job has been processed by the Global Reducer, of delivering the final result to the requester.
- Orchestrator: it builds the TJEP by combining information from the the submitted job and the execution context (such as, e.g., the Sites’ available computing power and inter-Site network capacity.
- Global Reducer: it receives the output of the sub-jobs computation from the local Sites and runs the final reduction.
- Node Coordinator: owns all the information on the node (Site) status.
- File Manager: it handles data blocks loading and storage of data blocks, while also keeping track of files namespace.
- Hadoop Handler: it exposes vanilla Hadoop’s APIs. Basically, this module decouples the system from the underlying Hadoop-based computing platform. This way, the framework stays independent of the Hadoop flavor deployed in the local Site.
- Network Manager: it handles inter-Sites communication.
3.2. Jobs Scheduling
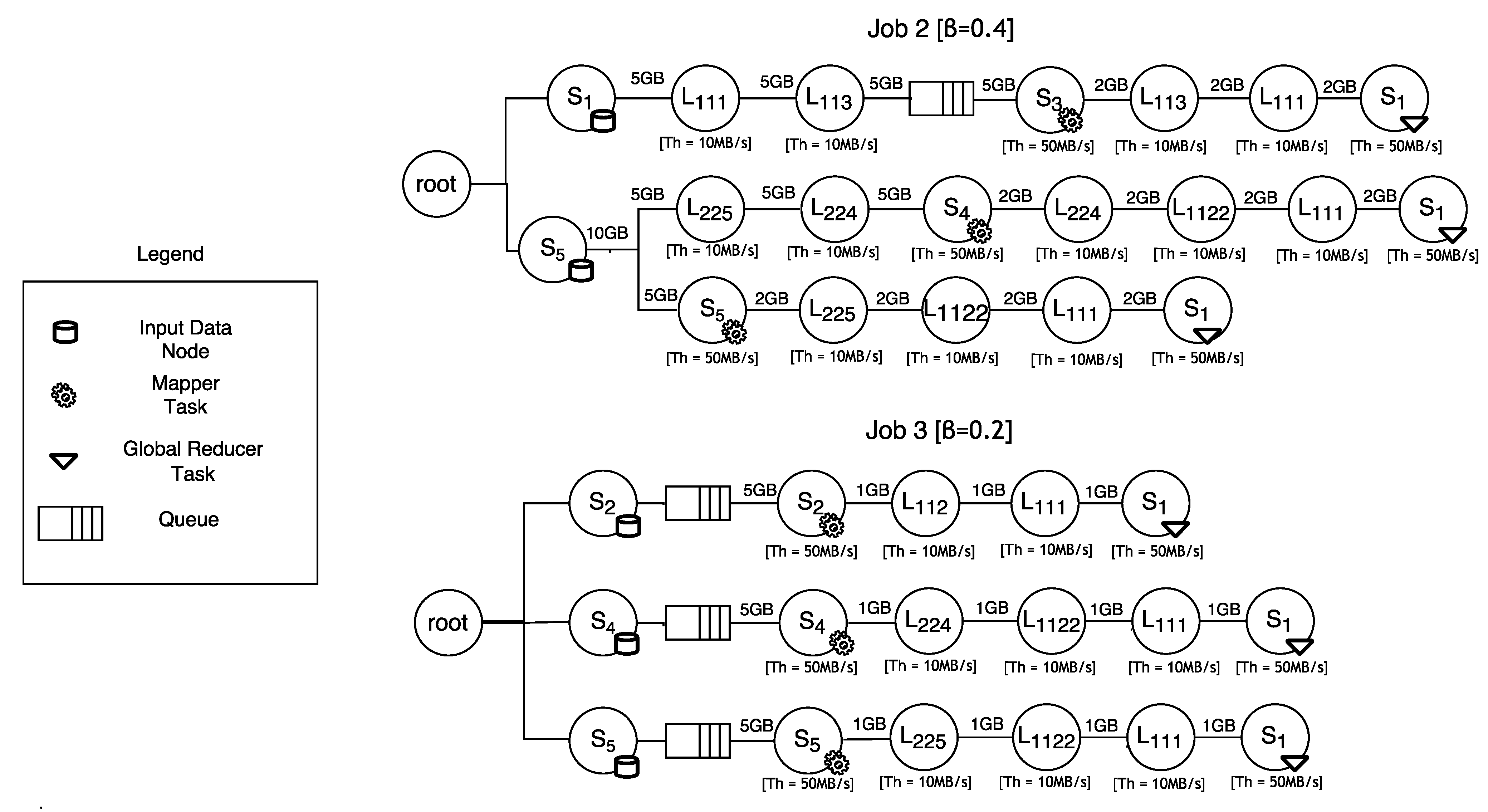
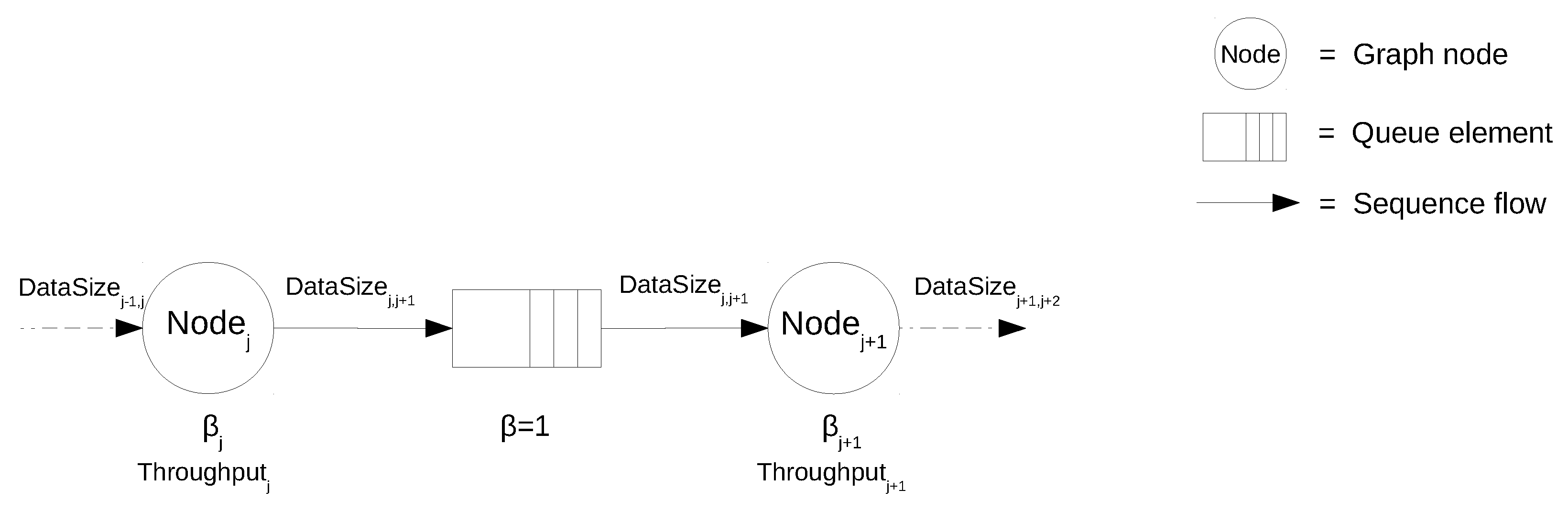
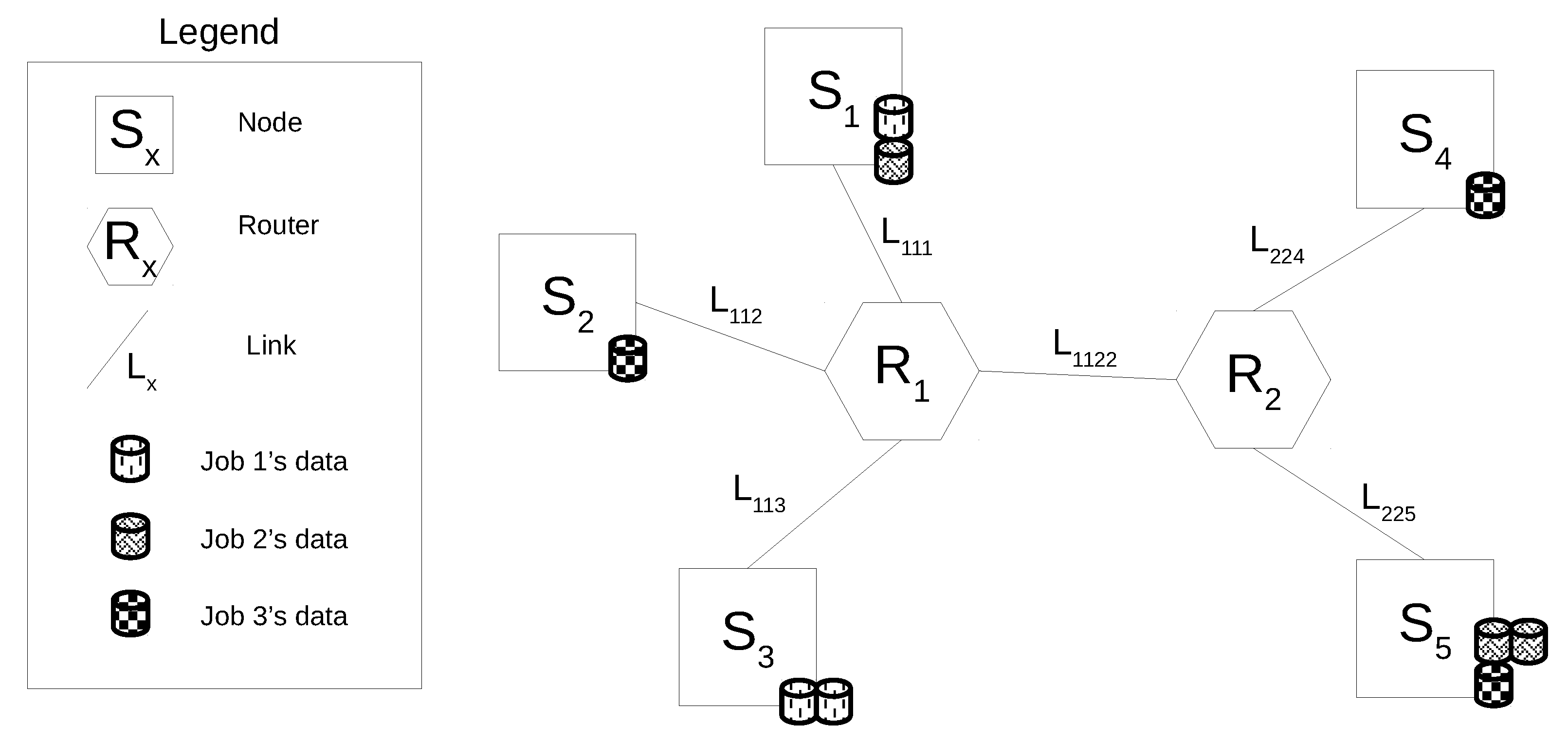
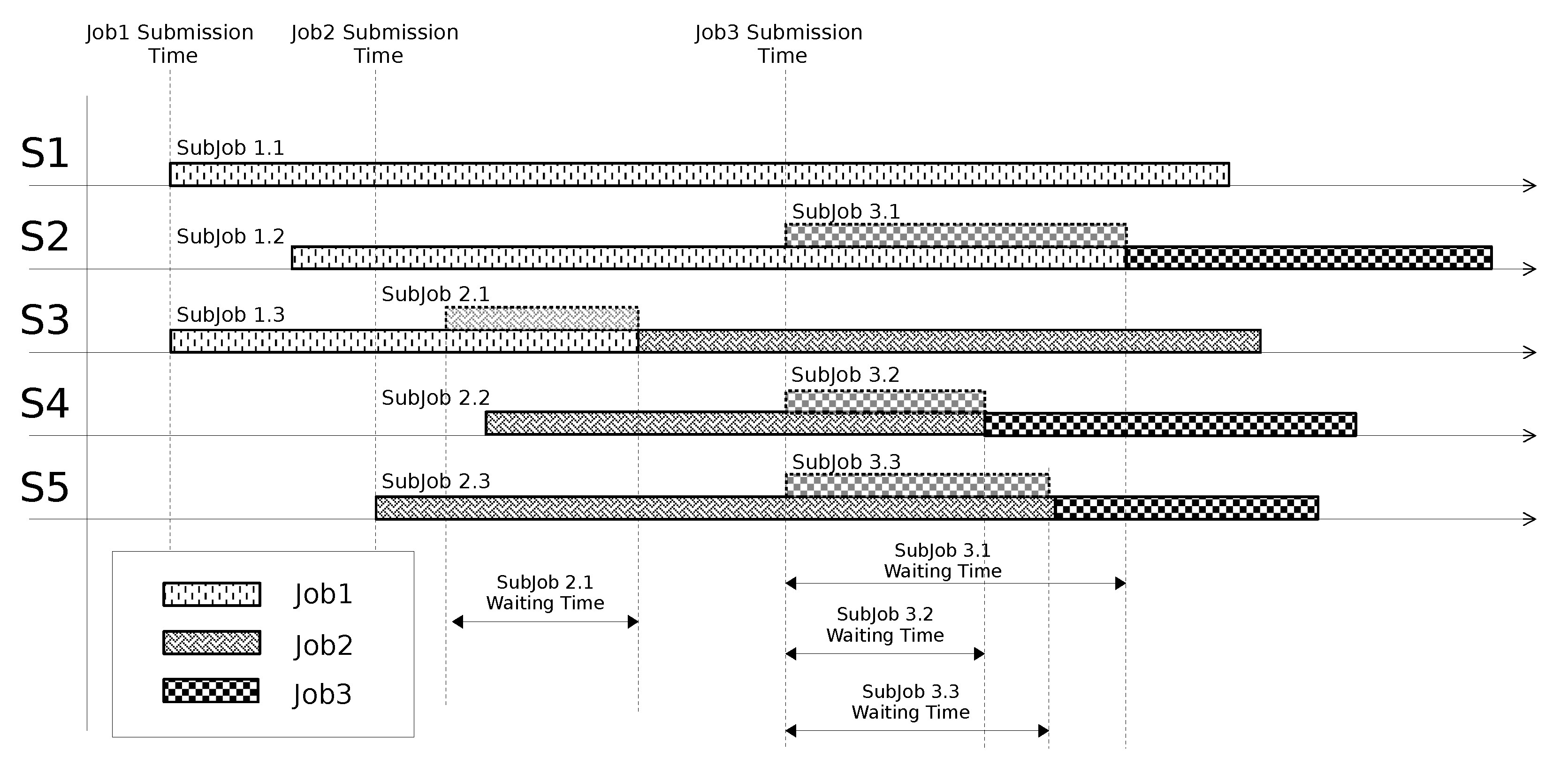
3.2.1. Modeling Job’s Execution Paths
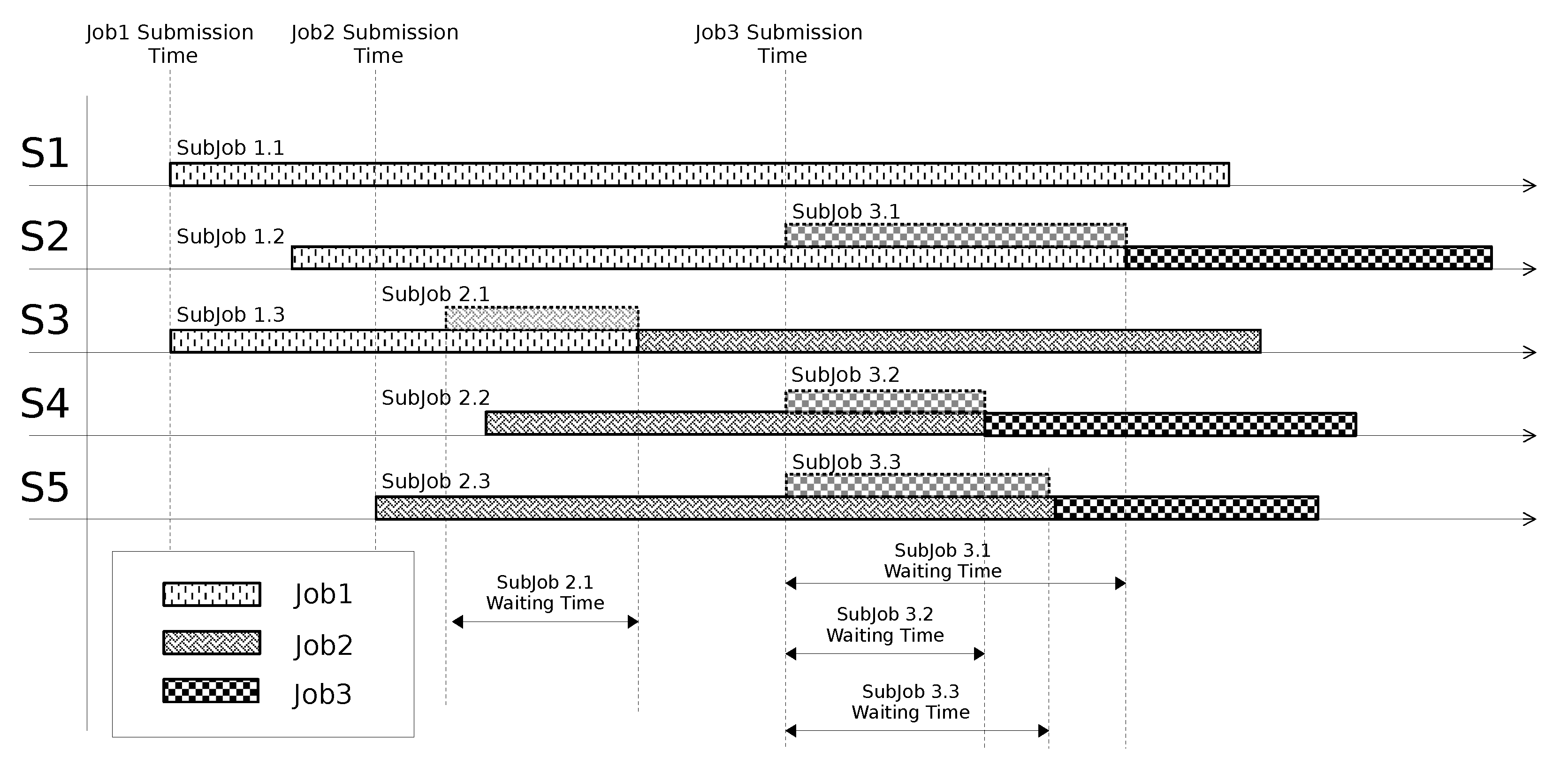
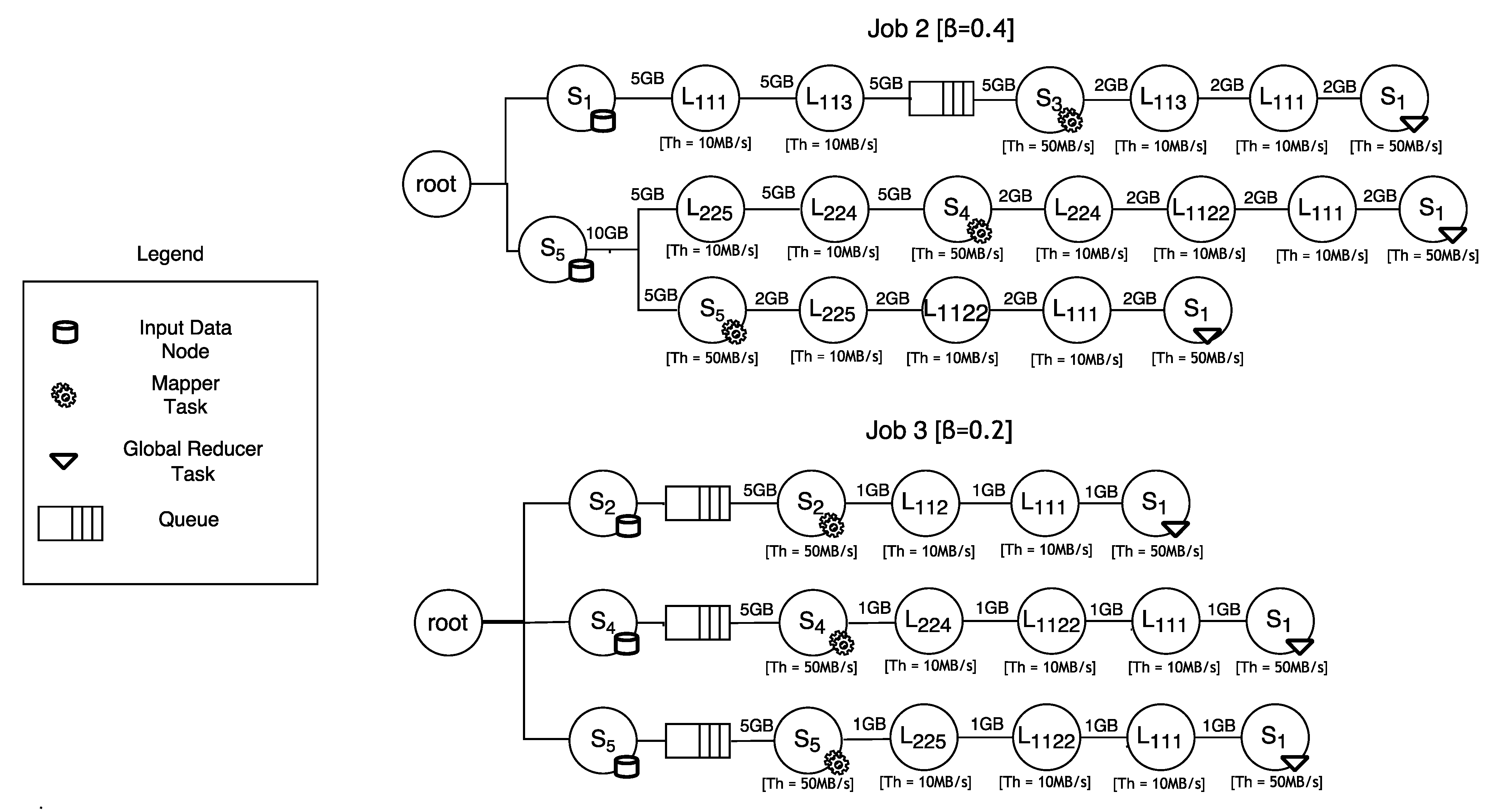
- a data block is moved from to through the links and ; here, sub-job suffers a delay because the resource is used by sub-job (see Figure 5); once has been released, gains it and elaborates the data block; the output of the elaboration is shifted to through the links and ; here, the global reduction can take place (note that the global reduction step starts only after all the data elaborated by the sub-jobs have been gathered in .).
- a data block is shifted from to traversing the links and ; here, immediately gains the computing resource () and elaborates the data block; the output of the elaboration is moved to through the links , and ; here, the global reduction can take place.
- accesses and elaborates the data block residing in ; the output of the elaboration is shifted to through the links , and ; here, the global reduction can take place.
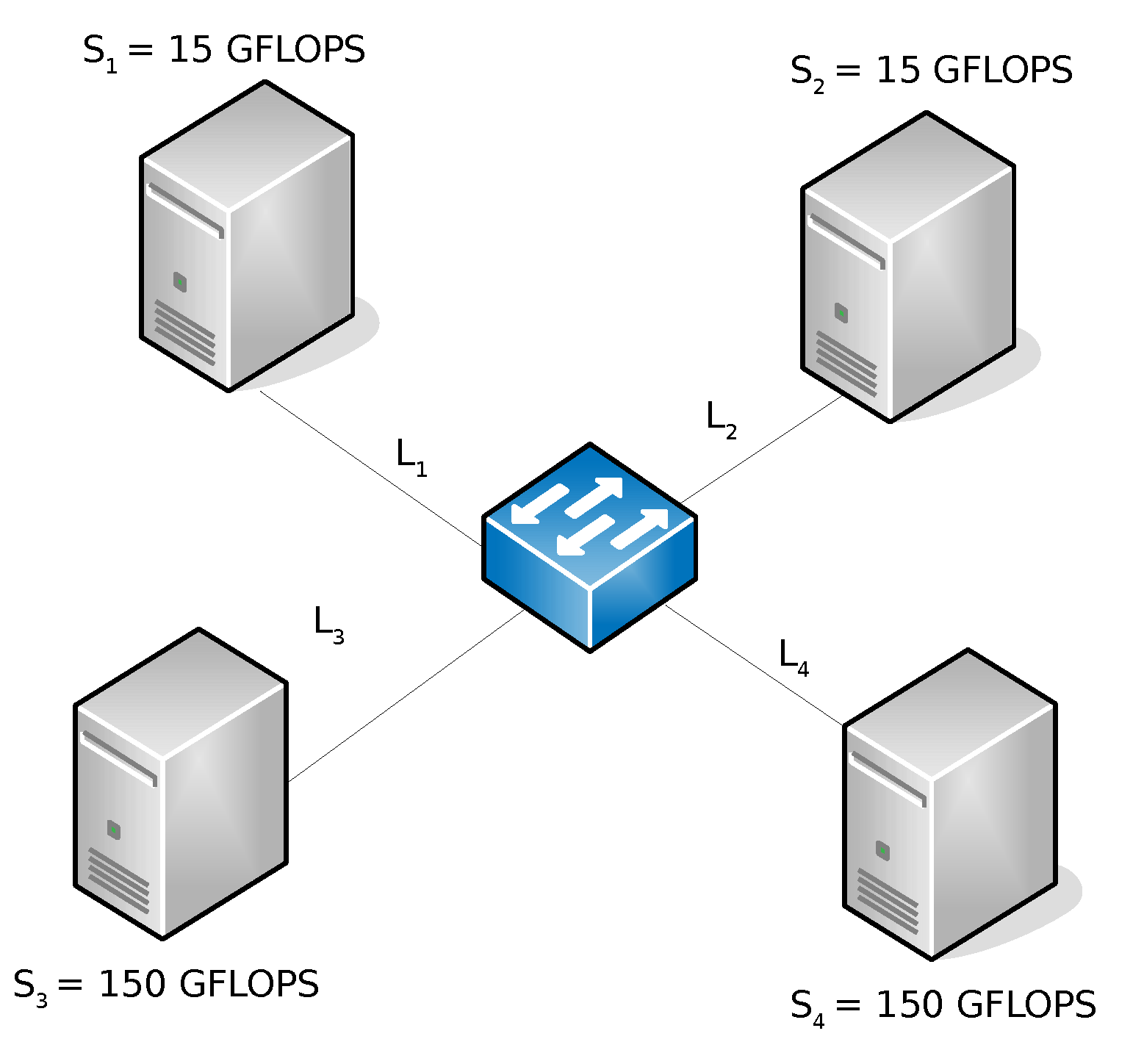
4. Optimal Data Fragmentation
- is the Site’s computing power normalized to the overall context’s computing power.
- represents the capability of the Site to exchange data with other sites in the computing context.
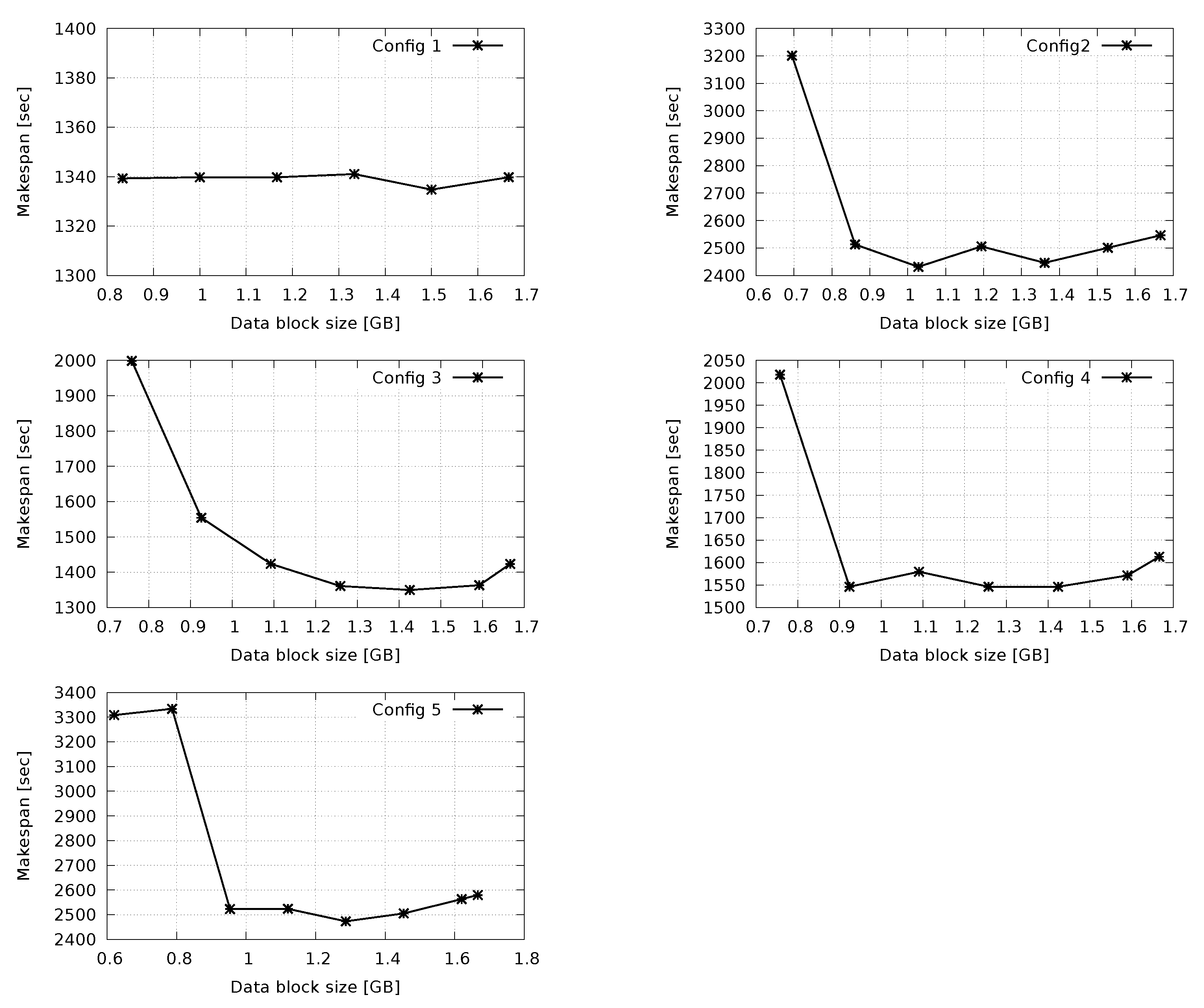
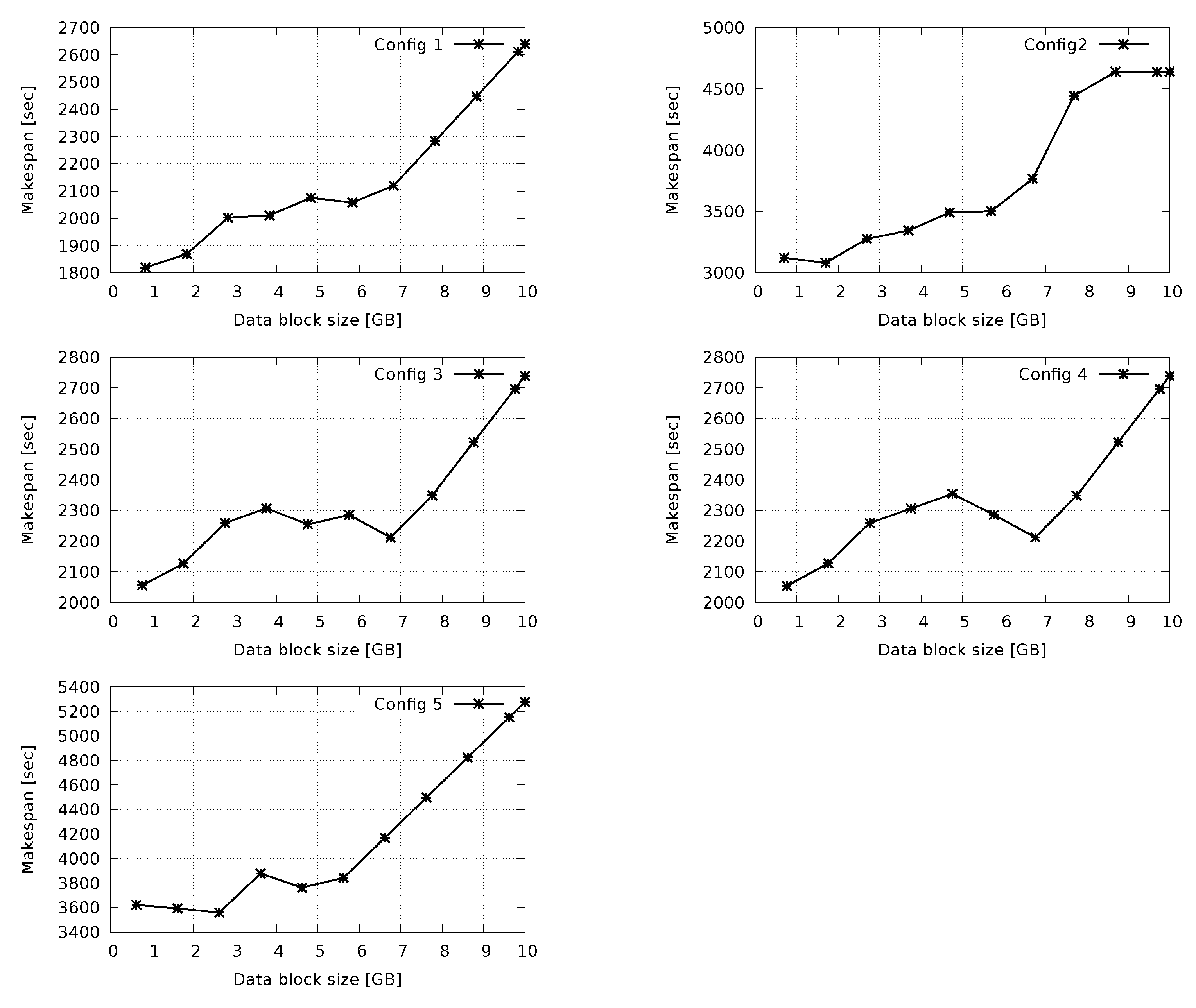
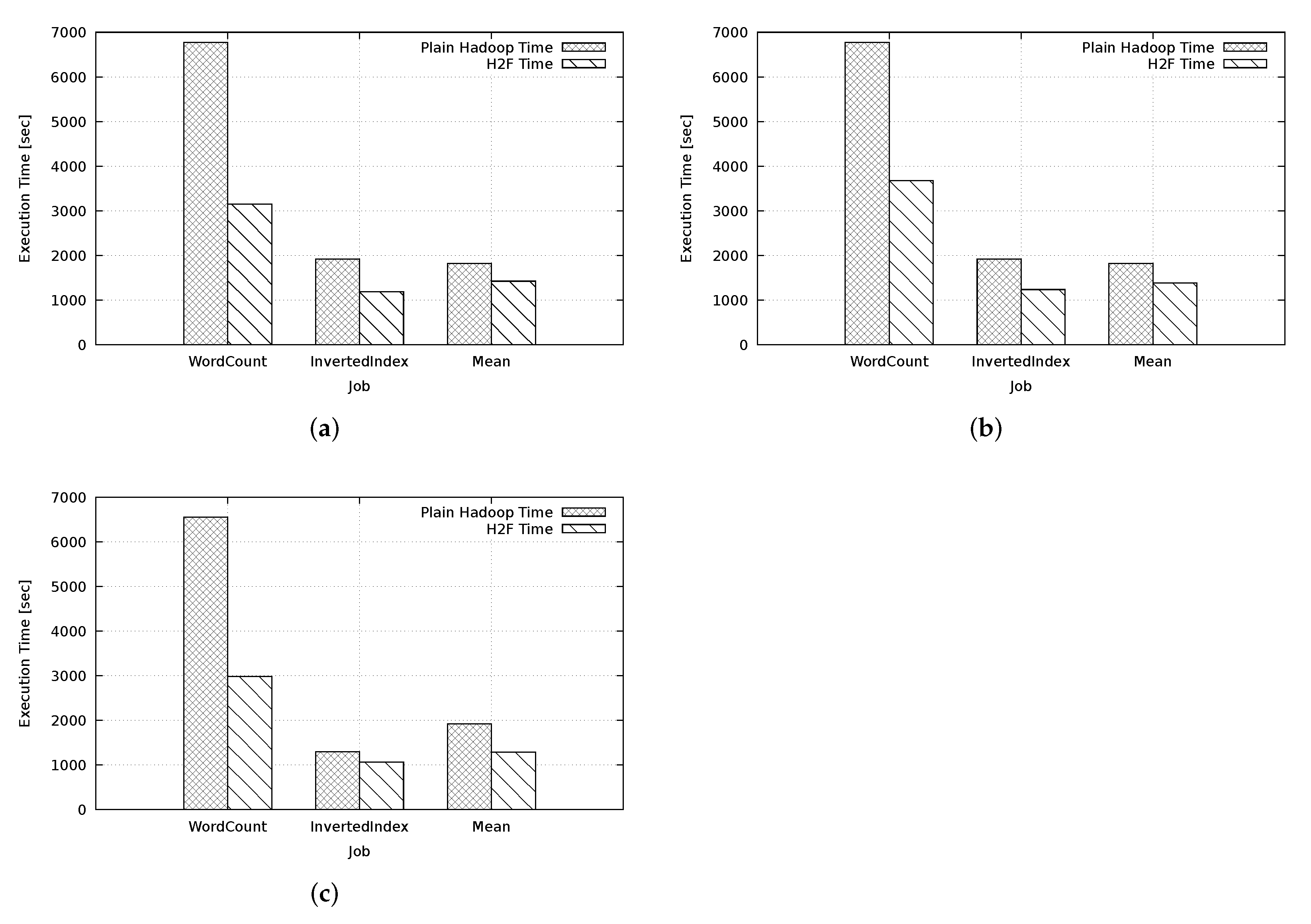
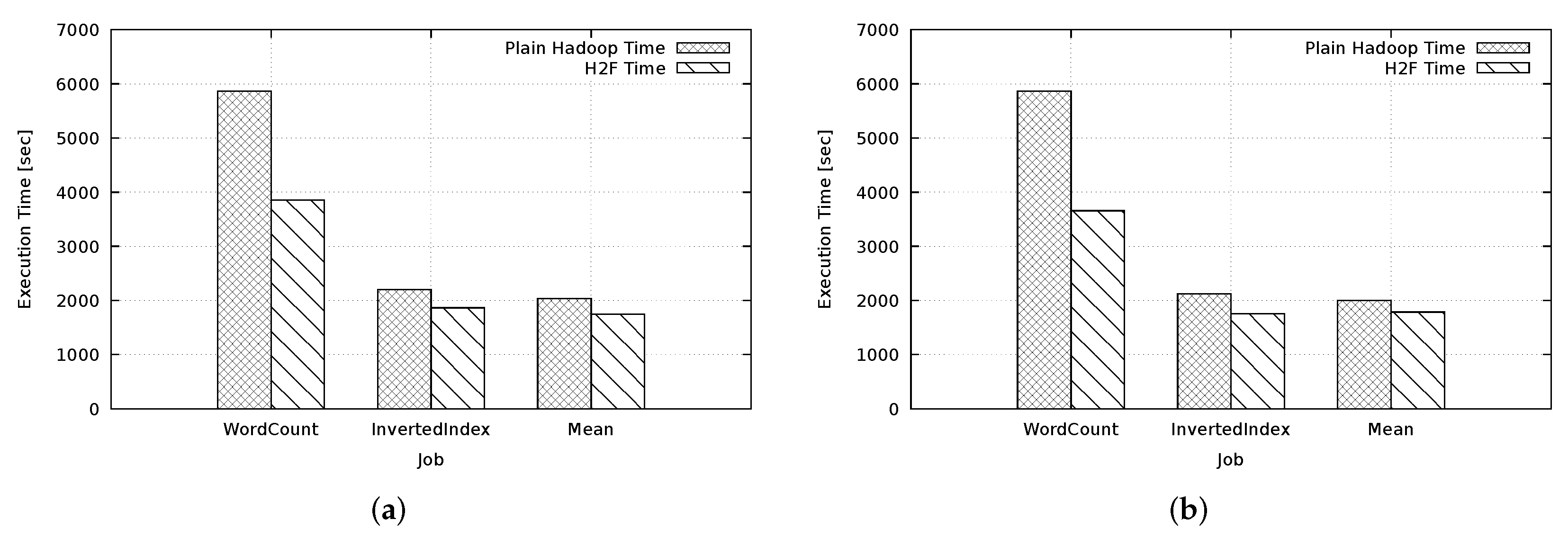
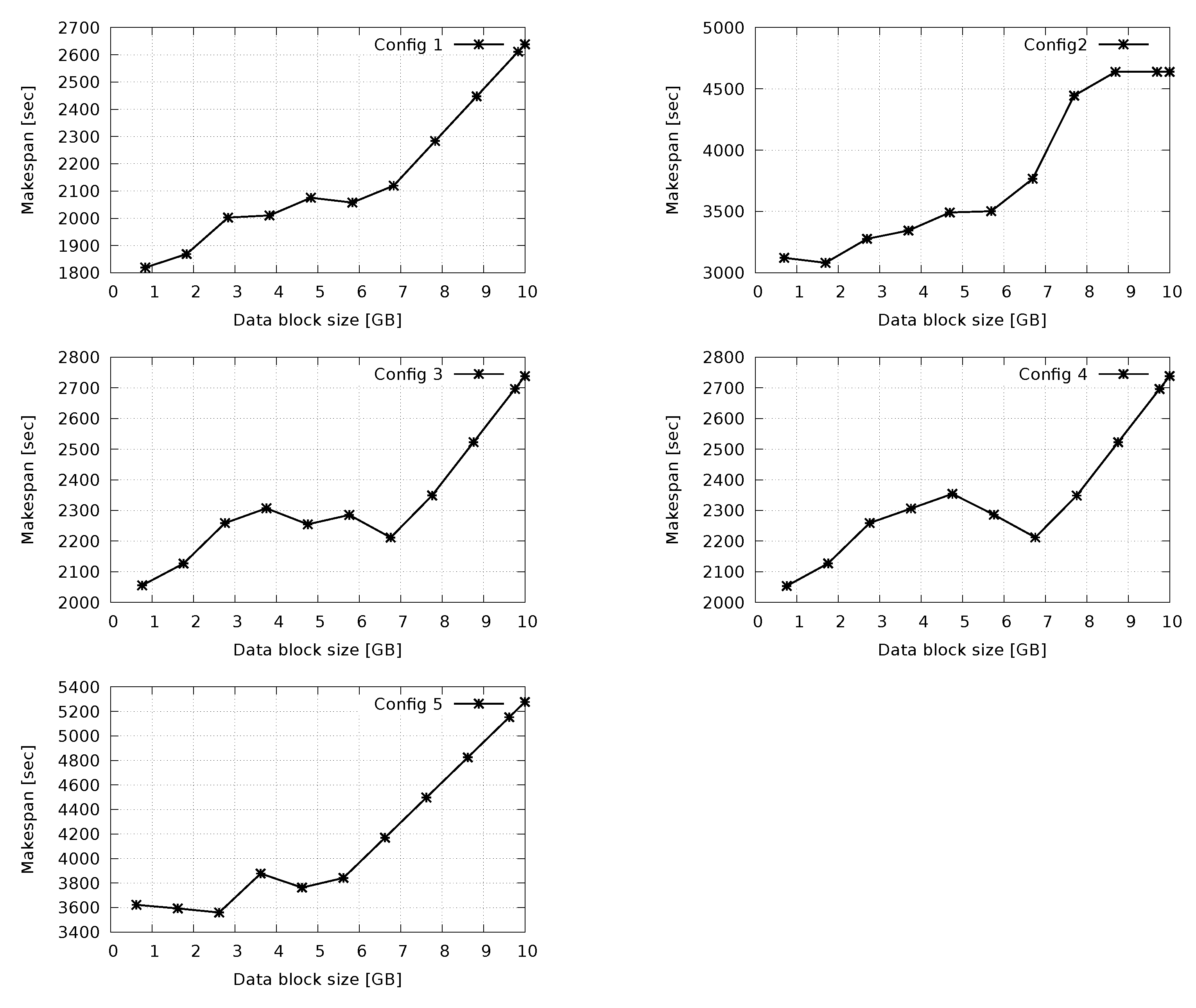
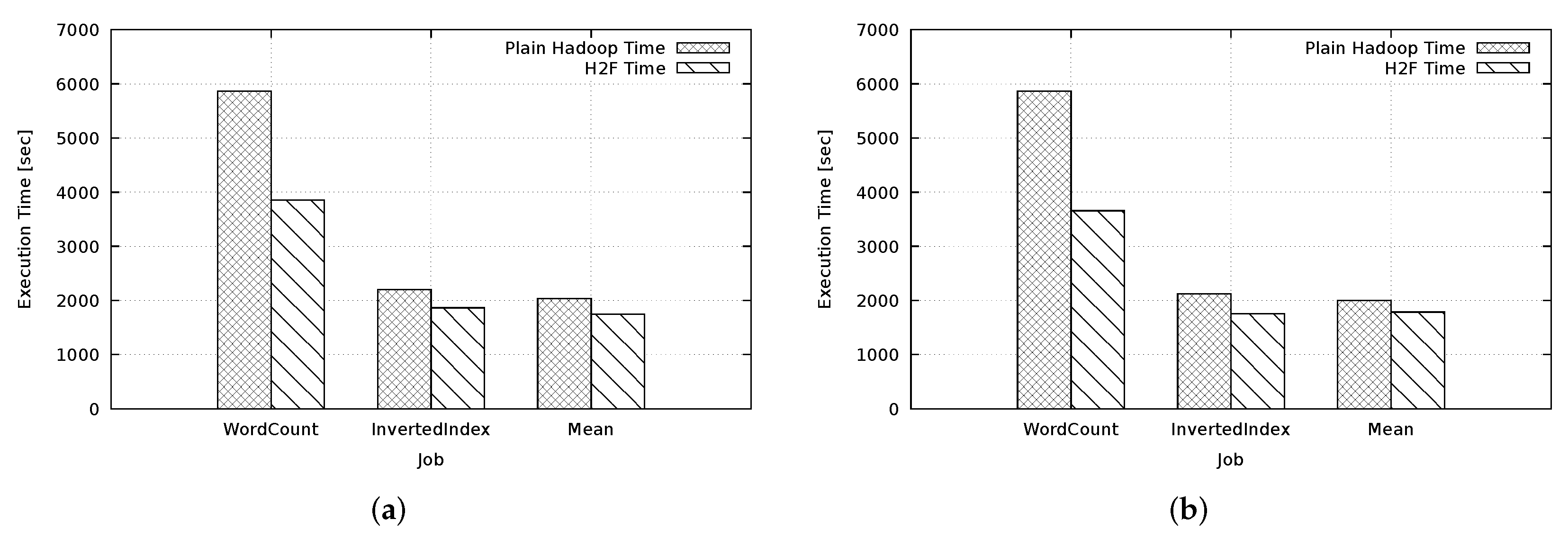
5. Experiment: H2F vs. Hadoop
Concluding Remarks on Performance Results
6. Literature Review
6.1. Geo-Hadoop Approach
6.2. Hierarchical Approach
6.3. Comparative Analysis
- Context of the computing scenario. The context encompasses elements such as (a) the number and the capability of the available computing nodes, (b) the topology of the network interconnecting the computing nodes as well as the bandwidth available at each network link, and (c) the amount of data residing at each node involved in the computation.
- Job scheduling objective. The objective of the scheduling algorithm (optimization of cost, execution time, etc.).
- Application profiling. Each job encapsulates a specific application that elaborates data according to a given algorithm. The application profile is the “fingerprint” of the application that captures the way the application behaves in terms of data manipulation.
- Compatibility with MapReduce frameworks. This refers to the possibility of reusing existing software frameworks specifically designed for clusters of close nodes.
- Data fragmentation. It refers to the opportunity of the fragmenting data of a data center into smaller pieces (blocks) and migrating groups of them to other data centers.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
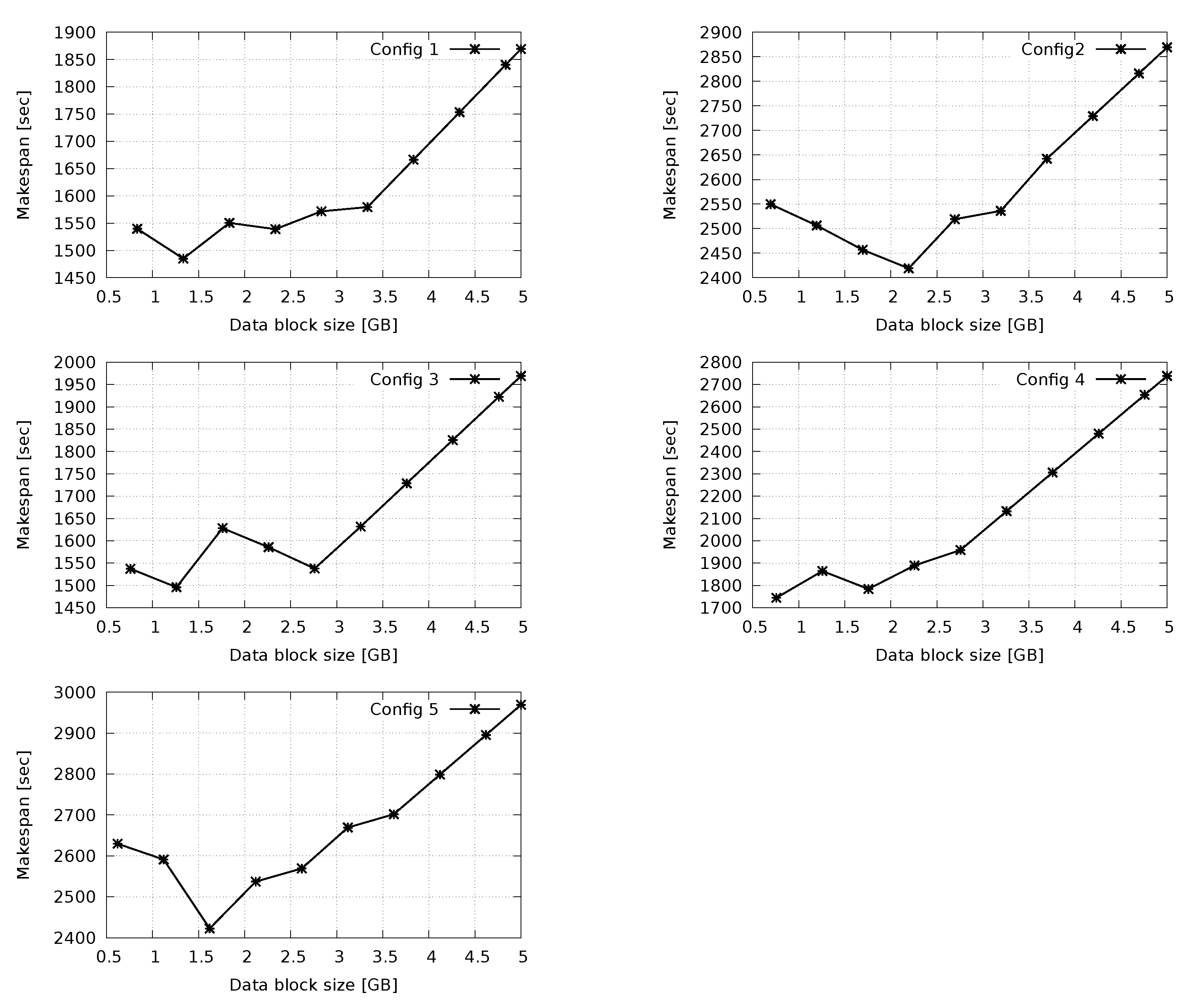{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Computing Context | Job Scheduling Objective | Application Profiling | Developed Software | Compatibility with MapReduce Frameworks | Data Fragmentation | |
|---|---|---|---|---|---|---|
| Kim et al. [23] | CPU | Makespan | - | Hadoop Extension | - | - |
| Wang et al. [28] | - | Makespan, Network usage | - | Hadoop Extension | - | - |
| Mattess et al. [24] | - | Monetary cost | - | Hadoop Extension | - | - |
| Heinz et al. [7] | - | Map execution time | Map phase | Hadoop Extension | - | - |
| Zhang et al. [10] | - | Makespan | - | Hadoop Extension | - | - |
| Fahmy et al. [25] | - | Makespan, Network usage | - | HDFS Extension | Hadoop 0.20 | - |
| You et al. [29] | CPU | Makespan | - | Hadoop Extension | - | - |
| Cheng et al. [31] | CPU | Makespan | - | Hadoop Extension | - | - |
| Li et al. [30] | Network, Data | Makespan | - | Hadoop Extension | - | - |
| Convolbo et al. [32] | Data | Makespan | - | Hadoop Extension | - | - |
| Yu et al. [33] | Data | Makespan | - | Simulator | - | - |
| Luo et al. [11] | CPU, Data | Makespan | - | Hadoop Extension | - | - |
| Jayalath et al. [12] | Network, Data | Makespan, Monetary cost | - | Software prototype | Hadoop | Yes |
| Yang et al. [13] | Data | Makespan | - | Software prototype | - | - |
| H2F | CPU, Network, Data | Makespan | MapReduce | Software prototype | Hadoop (any version) | Yes |
7. Conclusions and Final Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Jin, X.; Wah, B.W.; Cheng, X.; Wang, Y. Significance and Challenges of Big Data Research. Big Data Res. 2015, 2, 59–64. [Google Scholar] [CrossRef]
- Kambatla, K.; Kollias, G.; Kumar, V.; Grama, A. Trends in big data analytics. J. Parallel Distrib. Comput. 2014, 74, 2561–2573. [Google Scholar] [CrossRef]
- Hashem, I.A.T.; Yaqoob, I.; Anuar, N.B.; Mokhtar, S.; Gani, A.; Khan, S.U. The rise of “big data” on cloud computing: Review and open research issues. Inf. Syst. 2015, 47, 98–115. [Google Scholar] [CrossRef]
- Pääkkönen, P.; Pakkala, D. Reference Architecture and Classification of Technologies, Products and Services for Big Data Systems. Big Data Res. 2015, 2, 166–186. [Google Scholar] [CrossRef] [Green Version]
- Hilty, L.M.; Aebischer, B. ICT for Sustainability: An Emerging Research Field. In ICT Innovations for Sustainability; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 3–36. [Google Scholar] [CrossRef] [Green Version]
- Cardosa, M.; Wang, C.; Nangia, A.; Chandra, A.; Weissman, J. Exploring MapReduce Efficiency with Highly-Distributed Data. In Proceedings of the Second International Workshop on MapReduce and Its Applications, San Jose, CA, USA, 8 June 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 27–34. [Google Scholar] [CrossRef] [Green Version]
- Heintz, B.; Chandra, A.; Sitaraman, R.; Weissman, J. End-to-end Optimization for Geo-Distributed MapReduce. IEEE Trans. Cloud Comput. 2016, 4, 293–306. [Google Scholar] [CrossRef]
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. In Proceedings of the 6th Conference on Symposium on Operating Systems Design and Implementation, USENIX Association, OSDI’04, San Francisco, CA, USA, 6–8 December 2004. [Google Scholar]
- The Apache Software Foundation. The Apache Hadoop Project. 2011. Available online: hadoop.apache.org (accessed on 29 December 2021).
- Zhang, Q.; Liu, L.; Lee, K.; Zhou, Y.; Singh, A.; Mandagere, N.; Gopisetty, S.; Alatorre, G. Improving Hadoop Service Provisioning in a Geographically Distributed Cloud. In Proceedings of the 2014 IEEE 7th International Conference on Cloud Computing (CLOUD’14), Anchorage, AK, USA, 27 June–2 July 2014; pp. 432–439. [Google Scholar] [CrossRef] [Green Version]
- Luo, Y.; Guo, Z.; Sun, Y.; Plale, B.; Qiu, J.; Li, W.W. A Hierarchical Framework for Cross-domain MapReduce Execution. In Proceedings of the Second International Workshop on Emerging Computational Methods for the Life Sciences (ECMLS ’11), Trento, Italy, 29 September–1 October 2011; pp. 15–22. [Google Scholar] [CrossRef]
- Jayalath, C.; Stephen, J.; Eugster, P. From the Cloud to the Atmosphere: Running MapReduce across Data Centers. IEEE Trans. Comput. 2014, 63, 74–87. [Google Scholar] [CrossRef]
- Yang, H.; Dasdan, A.; Hsiao, R.; Parker, D.S. Map-reduce-merge: Simplified Relational Data Processing on Large Clusters. In Proceedings of the 2007 ACM SIGMOD International Conference on Management of Data (SIGMOD’07), Beijing, China, 11–14 June 2017; pp. 1029–1040. [Google Scholar] [CrossRef]
- Cavallo, M.; Di Modica, G.; Polito, C.; Tomarchio, O. H2F: A Hierarchical Hadoop Framework for big data processing in geo-distributed environments. In Proceedings of the 3rd IEEE/ACM International Conference on Big Data Computing, Applications and Technologies (BDCAT 2016), Shanghai, China, 6–9 December 2016; pp. 27–35. [Google Scholar] [CrossRef]
- Cavallo, M.; Di Modica, G.; Polito, C.; Tomarchio, O. Fragmenting Big Data to boost the performance of MapReduce in geographical computing contexts. In Proceedings of the 3rd International Conference on Big Data Innovations and Applications (Innovate-Data 2017), Prague, Czech Republic, 21–23 August 2017; pp. 17–24. [Google Scholar] [CrossRef]
- Facebook. Project PRISM. 2012. Available online: www.wired.com/2012/08/facebook-prism (accessed on 29 December 2021).
- Dastjerdi, A.V.; Gupta, H.; Calheiros, R.N.; Ghosh, S.K.; Buyya, R. Fog Computing: Principles, architectures, and applications. In Internet of Things: Principles and Paradigms; Morgan Kaufmann: Burlington, MA, USA, 2016; pp. 61–75. [Google Scholar] [CrossRef] [Green Version]
- Cavallo, M.; Di Modica, G.; Polito, C.; Tomarchio, O. Application Profiling in Hierarchical Hadoop for Geo-distributed Computing Environments. In Proceedings of the IEEE Symposium on Computers and Communications (ISCC 2016), Messina, Italy, 27–30 June 2016; pp. 555–560. [Google Scholar] [CrossRef]
- Cavallo, M.; Di Modica, G.; Polito, C.; Tomarchio, O. A LAHC-based Job Scheduling Strategy to Improve Big Data Processing in Geo-distributed Contexts. In Proceedings of the 2nd International Conference on Internet of Things, Big Data and Security (IoTBDS 2017), Porto, Portugal, 24–26 April 2017; pp. 92–101. [Google Scholar] [CrossRef]
- Zhao, L.; Yang, Y.; Munir, A.; Liu, A.X.; Li, Y.; Qu, W. Optimizing Geo-Distributed Data Analytics with Coordinated Task Scheduling and Routing. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 279–293. [Google Scholar] [CrossRef]
- Huang, Y.; Shi, Y.; Zhong, Z.; Feng, Y.; Cheng, J.; Li, J.; Fan, H.; Li, C.; Guan, T.; Zhou, J. Yugong: Geo-Distributed Data and Job Placement at Scale. Proc. VLDB Endow. 2019, 12, 2155–2169. [Google Scholar] [CrossRef]
- Oh, K.; Chandra, A.; Weissman, J. A Network Cost-aware Geo-distributed Data Analytics System. In Proceedings of the 20th IEEE/ACM International Symposium on Cluster, Cloud and Internet Computing (CCGRID 2020), Melbourne, Australia, 11–14 May 2020; pp. 649–658. [Google Scholar] [CrossRef]
- Kim, S.; Won, J.; Han, H.; Eom, H.; Yeom, H.Y. Improving Hadoop Performance in Intercloud Environments. SIGMETRICS Perform. Eval. Rev. 2011, 39, 107–109. [Google Scholar] [CrossRef]
- Mattess, M.; Calheiros, R.N.; Buyya, R. Scaling MapReduce Applications Across Hybrid Clouds to Meet Soft Deadlines. In Proceedings of the 2013 IEEE 27th International Conference on Advanced Information Networking and Applications (AINA’13), Barcelona, Spain, 25–28 March 2013; pp. 629–636. [Google Scholar] [CrossRef]
- Fahmy, M.M.; Elghandour, I.; Nagi, M. CoS-HDFS: Co-locating Geo-distributed Spatial Data in Hadoop Distributed File System. In Proceedings of the 3rd IEEE/ACM International Conference on Big Data Computing, Applications and Technologies (BDCAT 2016), Shanghai, China, 6–9 December 2016; pp. 123–132. [Google Scholar] [CrossRef]
- Afrati, F.; Dolev, S.; Sharma, S.; Ullman, J. Meta-MapReduce: A Technique for Reducing Communication in MapReduce Computations. In Proceedings of the 17th International Symposium on Stabilization, Safety, and Security of Distributed Systems (Springer-SSS), Edmonton, AB, Canada, 18–21 August 2015. [Google Scholar]
- He, C.; Weitzel, D.; Swanson, D.; Lu, Y. HOG: Distributed Hadoop MapReduce on the Grid. In Proceedings of the 2012 SC Companion: High Performance Computing, Networking Storage and Analysis, Salt Lake City, UT, USA, 10–16 November 2012; pp. 1276–1283. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Tao, J.; Ranjan, R.; Marten, H.; Streit, A.; Chen, J.; Chen, D. G-Hadoop: MapReduce across distributed data centers for data-intensive computing. Future Gener. Comput. Syst. 2013, 29, 739–750. [Google Scholar] [CrossRef]
- You, H.H.; Yang, C.C.; Huang, J.L. A Load-aware Scheduler for MapReduce Framework in Heterogeneous Cloud Environments. In Proceedings of the 2011 ACM Symposium on Applied Computing (SAC 2011), TaiChung, Taiwan, 21–24 March 2011; pp. 127–132. [Google Scholar] [CrossRef]
- Li, P.; Guo, S.; Miyazaki, T.; Liao, X.; Jin, H.; Zomaya, A.Y.; Wang, K. Traffic-Aware Geo-Distributed Big Data Analytics with Predictable Job Completion Time. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 1785–1796. [Google Scholar] [CrossRef]
- Cheng, D.; Rao, J.; Guo, Y.; Jiang, C.; Zhou, X. Improving Performance of Heterogeneous MapReduce Clusters with Adaptive Task Tuning. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 774–786. [Google Scholar] [CrossRef]
- Convolbo, M.W.; Chou, J.; Lu, S.; Chung, Y.C. DRASH: A Data Replication-Aware Scheduler in Geo-Distributed Data Centers. In Proceedings of the 2016 IEEE International Conference on Cloud Computing Technology and Science (CloudCom), Luxembourg, 12–15 December 2016; pp. 302–309. [Google Scholar] [CrossRef]
- Yu, B.; Pan, J. Location-aware associated data placement for geo-distributed data-intensive applications. In Proceedings of the 2015 IEEE Conference on Computer Communications (INFOCOM 2015), Kowloon, Hong Kong, 26 April–1 May 2015; pp. 603–611. [Google Scholar] [CrossRef]
- Dolev, S.; Florissi, P.; Gudes, E.; Sharma, S.; Singer, I. A Survey on Geographically Distributed Big-Data Processing using MapReduce. IEEE Trans. Big Data 2019, 5, 60–80. [Google Scholar] [CrossRef] [Green Version]
- Bergui, M.; Najah, S.; Nikolov, N.S. A survey on bandwidth-aware geo-distributed frameworks for big-data analytics. J. Big Data 2021, 8, 1–26. [Google Scholar] [CrossRef]

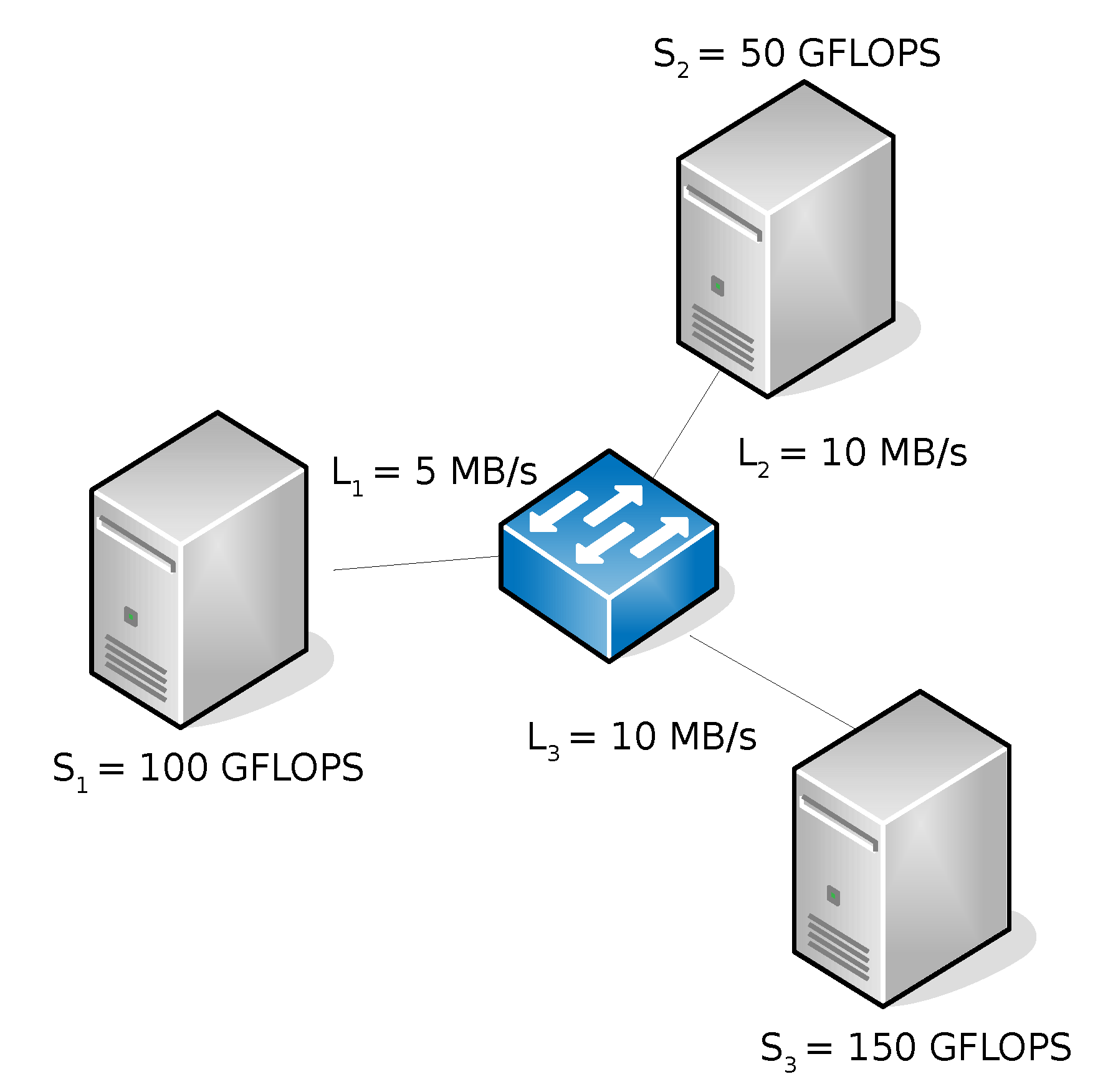
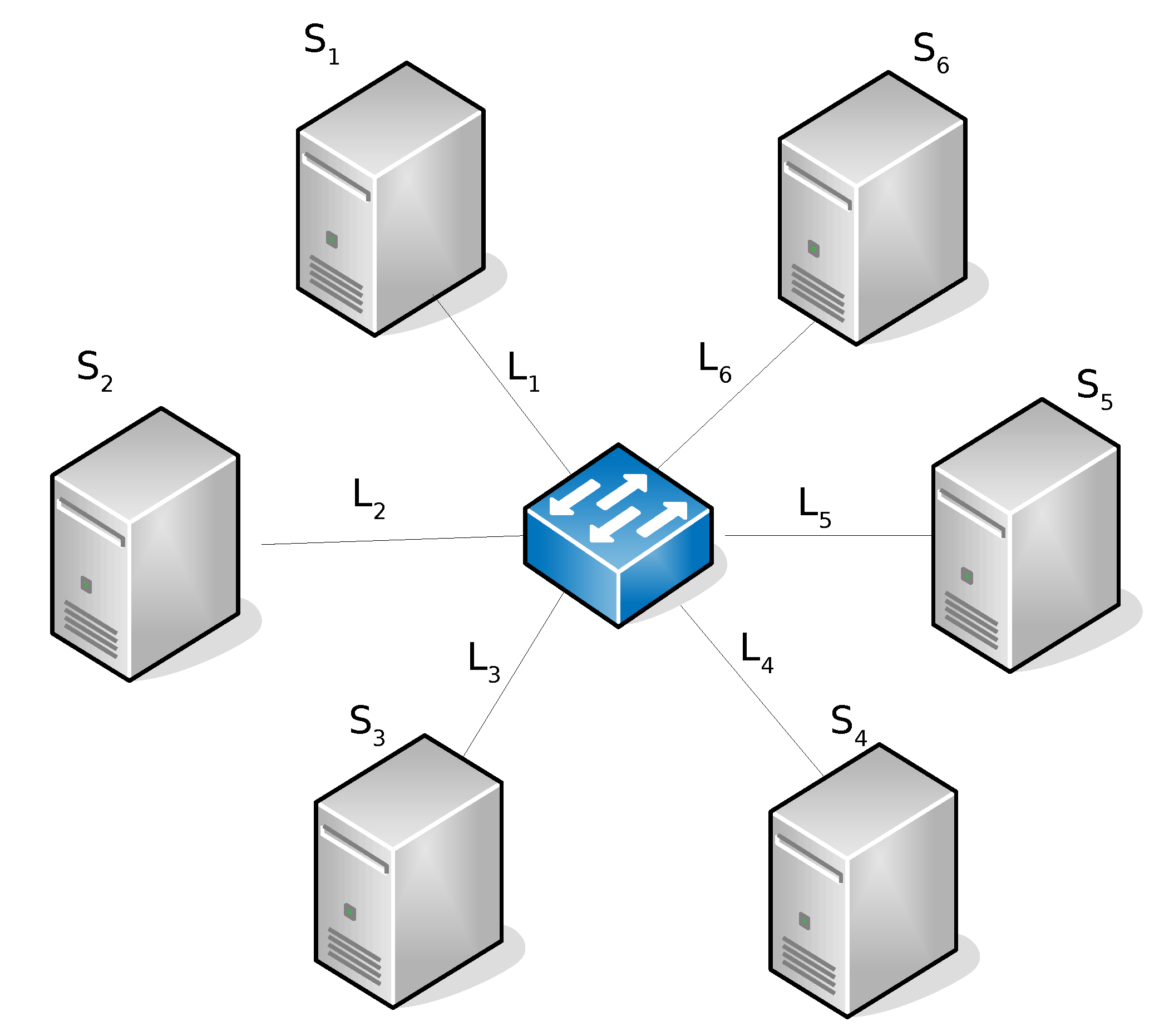

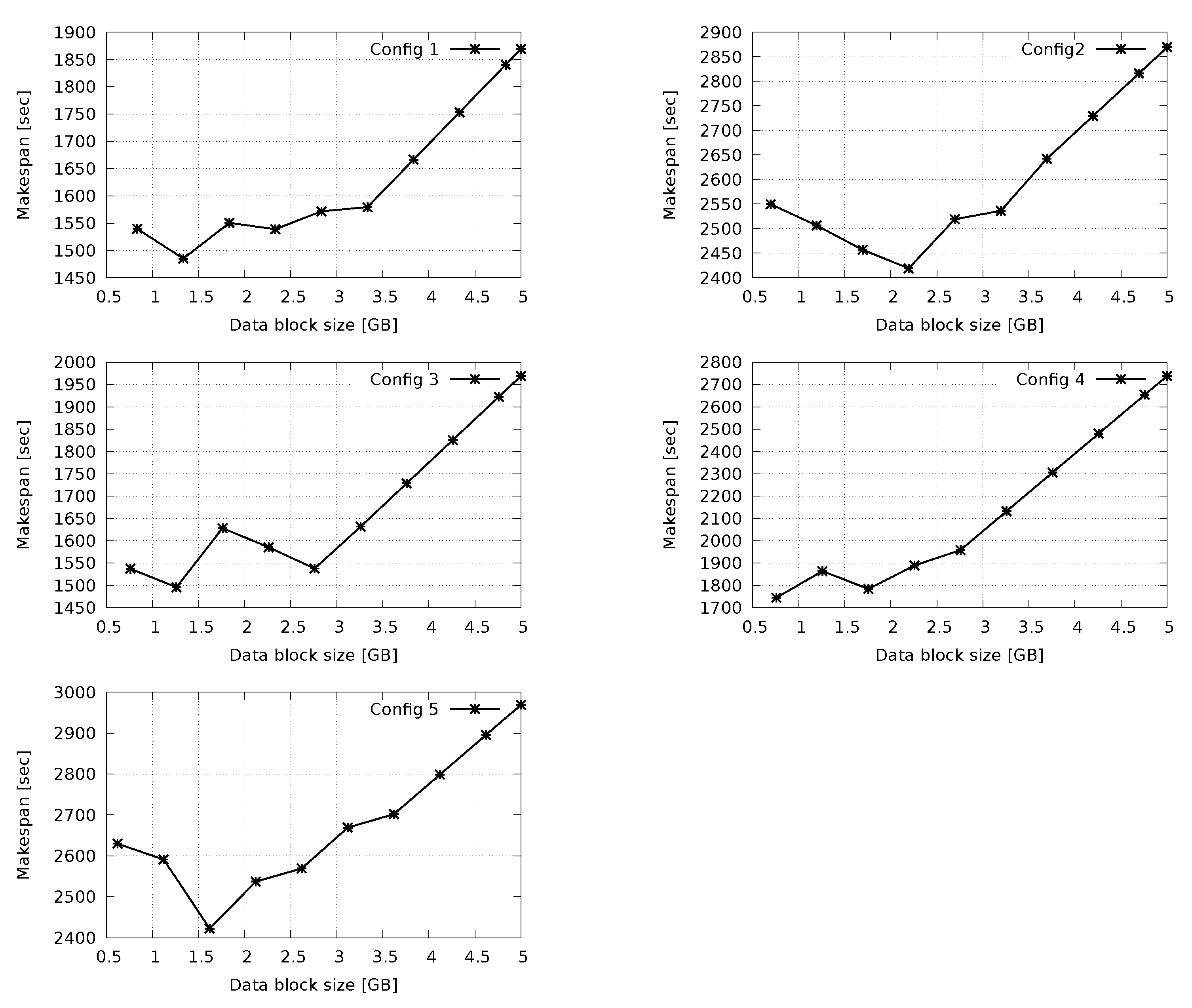
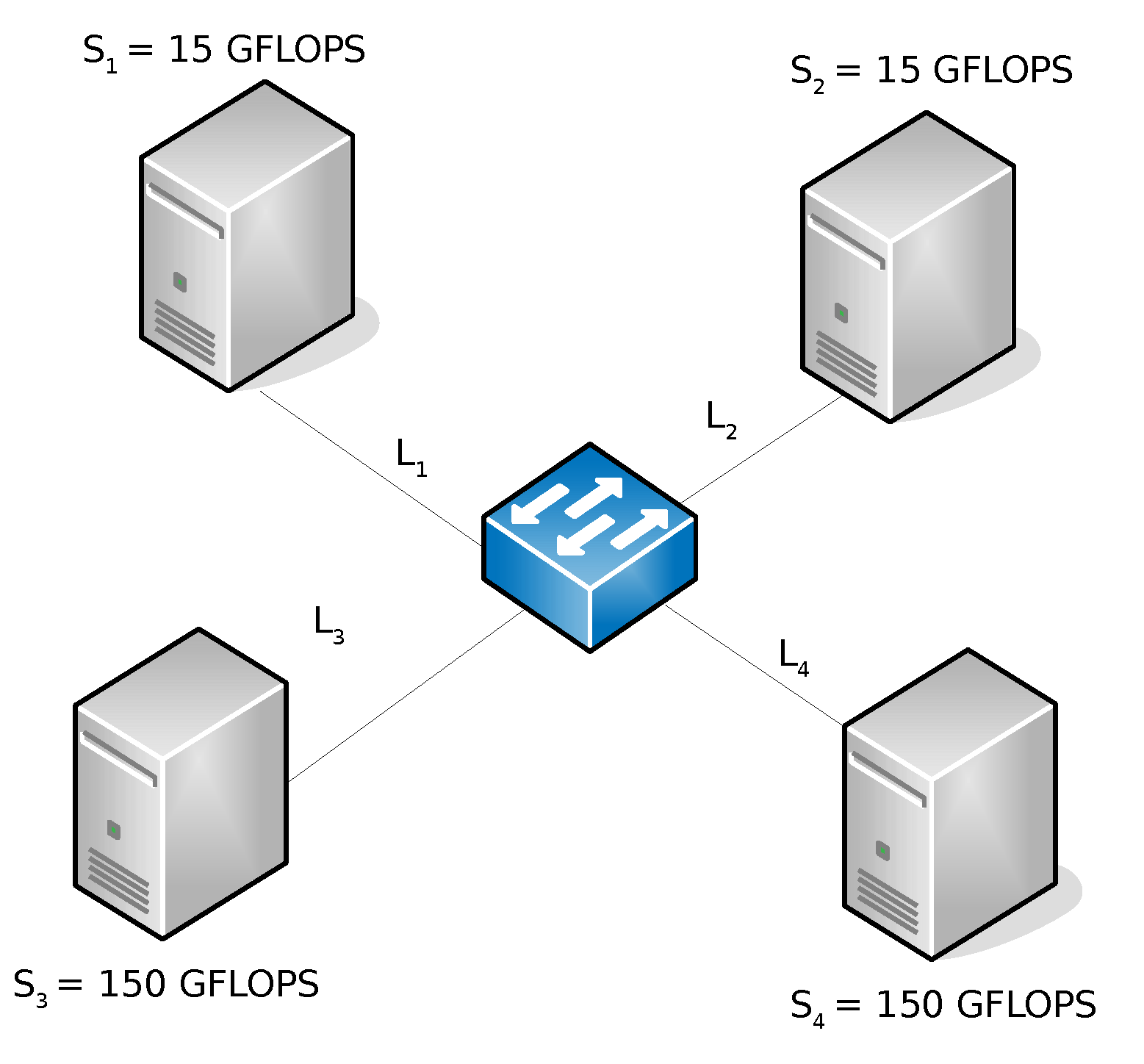


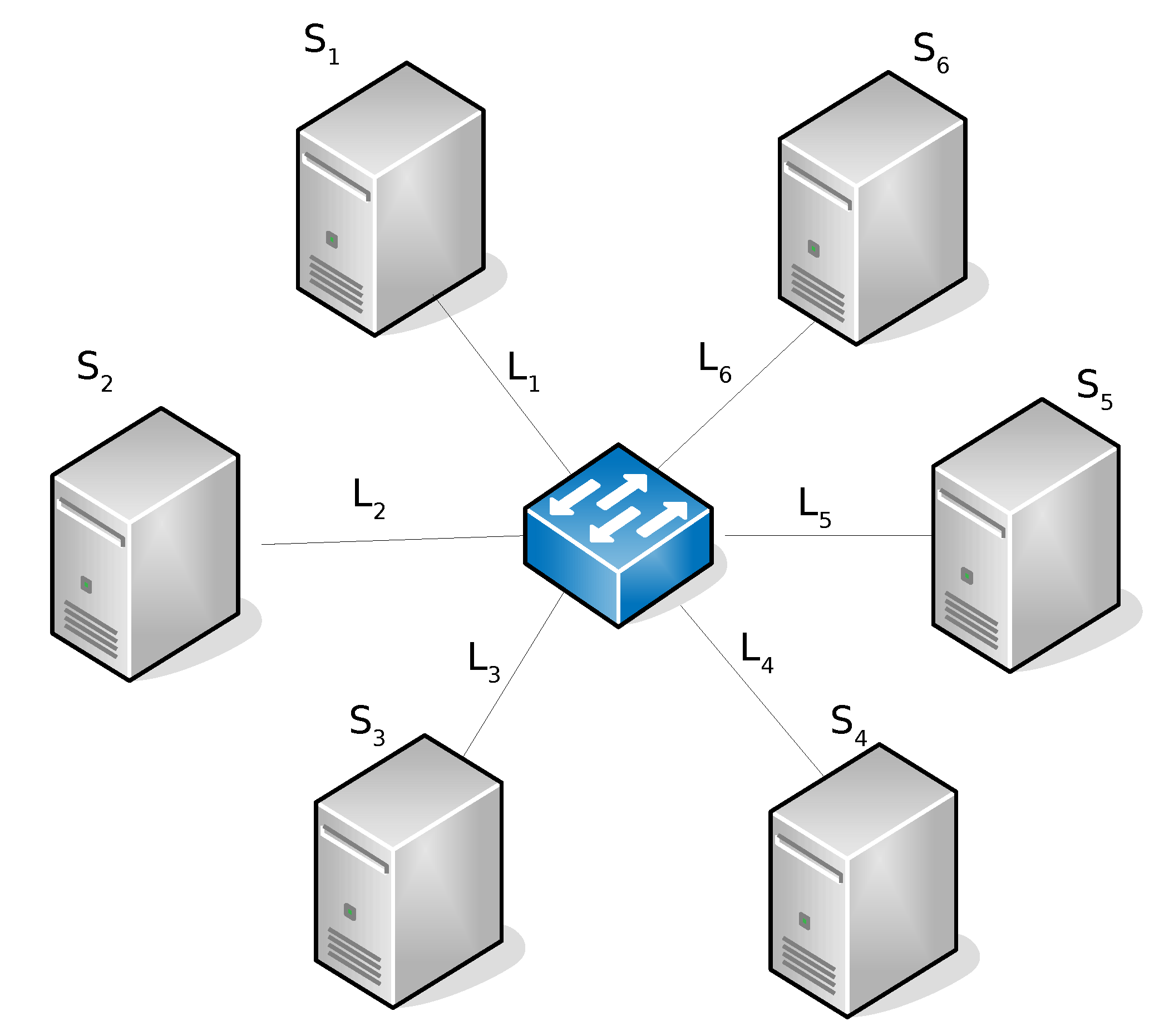
| Sites [GFLOPS] | Links [MB/s] | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Config | ||||||||||||
| 1 | 50 | 50 | 50 | 50 | 50 | 50 | 10 | 10 | 10 | 10 | 10 | 10 |
| 2 | 50 | 25 | 50 | 25 | 50 | 25 | 10 | 10 | 10 | 10 | 10 | 10 |
| 3 | 50 | 50 | 50 | 50 | 50 | 50 | 5 | 10 | 5 | 10 | 5 | 10 |
| 4 | 25 | 50 | 25 | 50 | 25 | 50 | 10 | 5 | 10 | 5 | 10 | 5 |
| 5 | 50 | 25 | 50 | 25 | 50 | 25 | 10 | 5 | 10 | 5 | 10 | 5 |
| 1.67 GB | 1.38 GB | 1.52 GB | 1.52 GB | 1.24 GB |
| 40% | 30% | 20% | 10% | |
| 40% | 40% | 20% | 0% | |
| 30% | 0% | 70% | 0% |
| 20 | 20 | 40 | 40 | |
| 20 | 40 | 20 | 40 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Di Modica, G.; Tomarchio, O. A Hierarchical Hadoop Framework to Process Geo-Distributed Big Data. Big Data Cogn. Comput. 2022, 6, 5. https://doi.org/10.3390/bdcc6010005
Di Modica G, Tomarchio O. A Hierarchical Hadoop Framework to Process Geo-Distributed Big Data. Big Data and Cognitive Computing. 2022; 6(1):5. https://doi.org/10.3390/bdcc6010005
Chicago/Turabian StyleDi Modica, Giuseppe, and Orazio Tomarchio. 2022. "A Hierarchical Hadoop Framework to Process Geo-Distributed Big Data" Big Data and Cognitive Computing 6, no. 1: 5. https://doi.org/10.3390/bdcc6010005
APA StyleDi Modica, G., & Tomarchio, O. (2022). A Hierarchical Hadoop Framework to Process Geo-Distributed Big Data. Big Data and Cognitive Computing, 6(1), 5. https://doi.org/10.3390/bdcc6010005