4.1. Unit A
As mentioned in
Section 3.2, in Unit A, for the International Relations course, 29 students were considered. From these, 24 were females and 5 were male; 12 students were 18 years old, and 17 were over 18 years old.
Regarding the grades, two students were graded in the low-negative range (below 5 values), six were graded in the negative range (between 5 and 10 values), thirteen were graded in the positive range (between 10 and 15 values), and eight students were graded in the high-positive range over 15 values out of 20.
The DOT average for the first assessment moment was −3.85, with a standard deviation of 4.13, a minimum of −11.88, and a maximum of 7.5. The DOT average for the second assessment moment was −1.65, with a standard deviation of 2.83, a minimum of −6.59, and a maximum of 3.89. The p-values obtained were 0.000, 0.741, and 0.629 for grade, gender, and age, respectively.
4.2. Unit B
In Unit B, for the Computer Science and Computer Engineering courses, 50 students were considered. From these, 5 were female and 45 were male; 24 students were 18 years old and 26 were over 18 years old.
Regarding the grades, thirteen students were graded in the low-negative range (below 5 values), ten were graded in the negative range (between 5 and 10 values), twenty were graded in the positive range (between 10 and 15 values), and seven students were graded in the high-positive range (over 15 values out of 20).
The DOT average for the first assessment moment was 0.78, with a standard deviation of 2.99, a minimum of −6.9, and a maximum of 7.5. The DOT average for the second assessment moment was −1.75, with a standard deviation of 1.89, a minimum of −5.6, and a maximum of 2.5. The p-values obtained were 0.000, 0.257, and 0.472 for grade, gender, and age, respectively.
4.4. T-Test Results
The
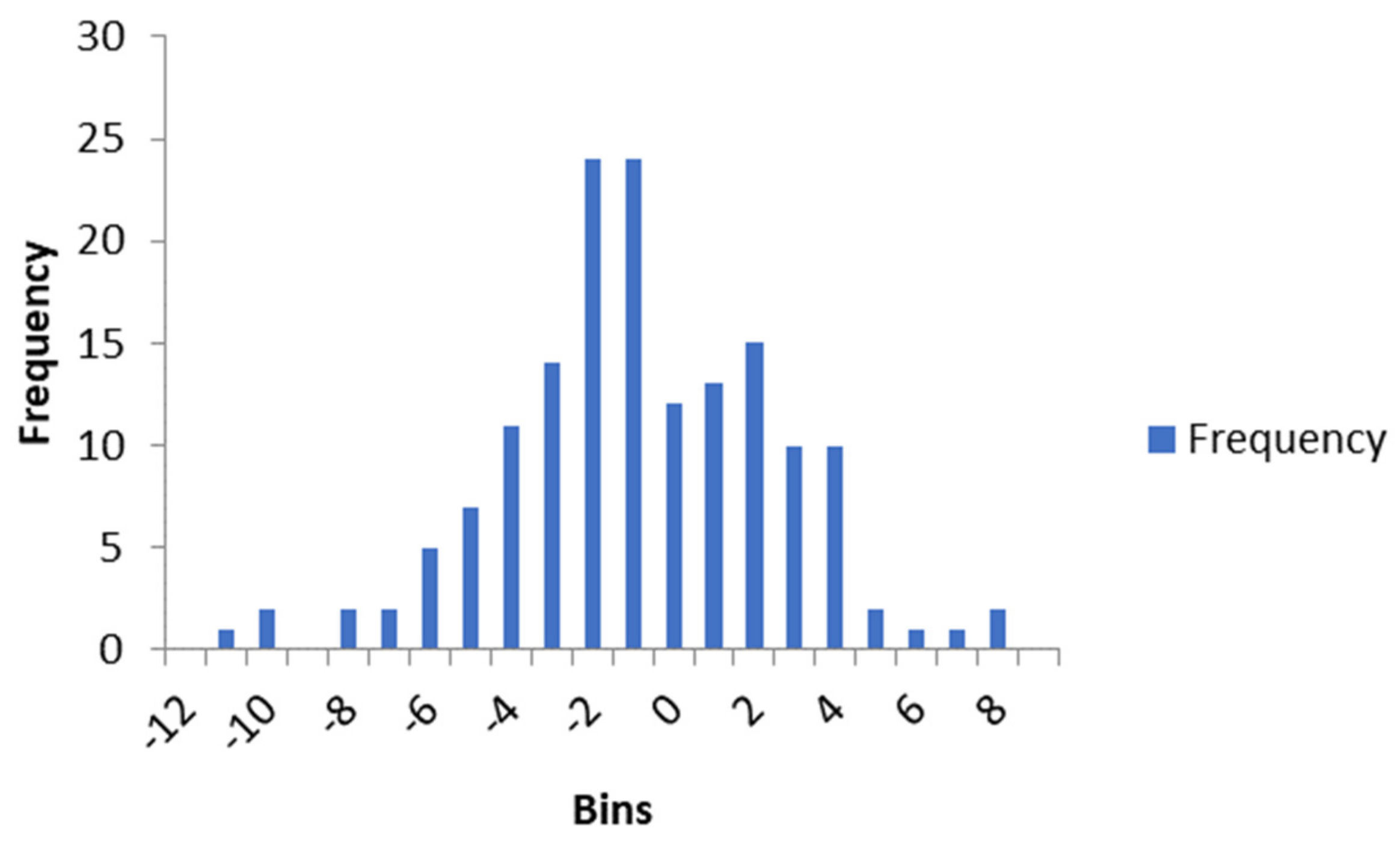
t-test was performed considering a set of data composed by the DOT for every student of both units, on both assessment moments. There are 158 observations, with average DOT of −1.316 and standard deviation of 3.361. The data’s t value is −4.921. By plotting a histogram of the data (
Figure 3), we can see that we need to consider the critical values for the two tailed t distribution table.
With a t value of −4.921, we can state, for this sample with size 158, with 157 degrees of freedom, and a significance of ate least 99.9% (), that we can reject the null hypothesis (), and so, that the students cannot accurately assess their work. In addition, as it is a negative value, students tend to over-assess their work.
We have also performed the
t-test for each unit’s assessment moment. These results are presented in
Table 3, which presents, for each unit’s assessment moment, the mean, standard deviation, number of observations, the t value found, and the significance that we can reject the null hypothesis (
), and so, that the students cannot accurately assess their work.
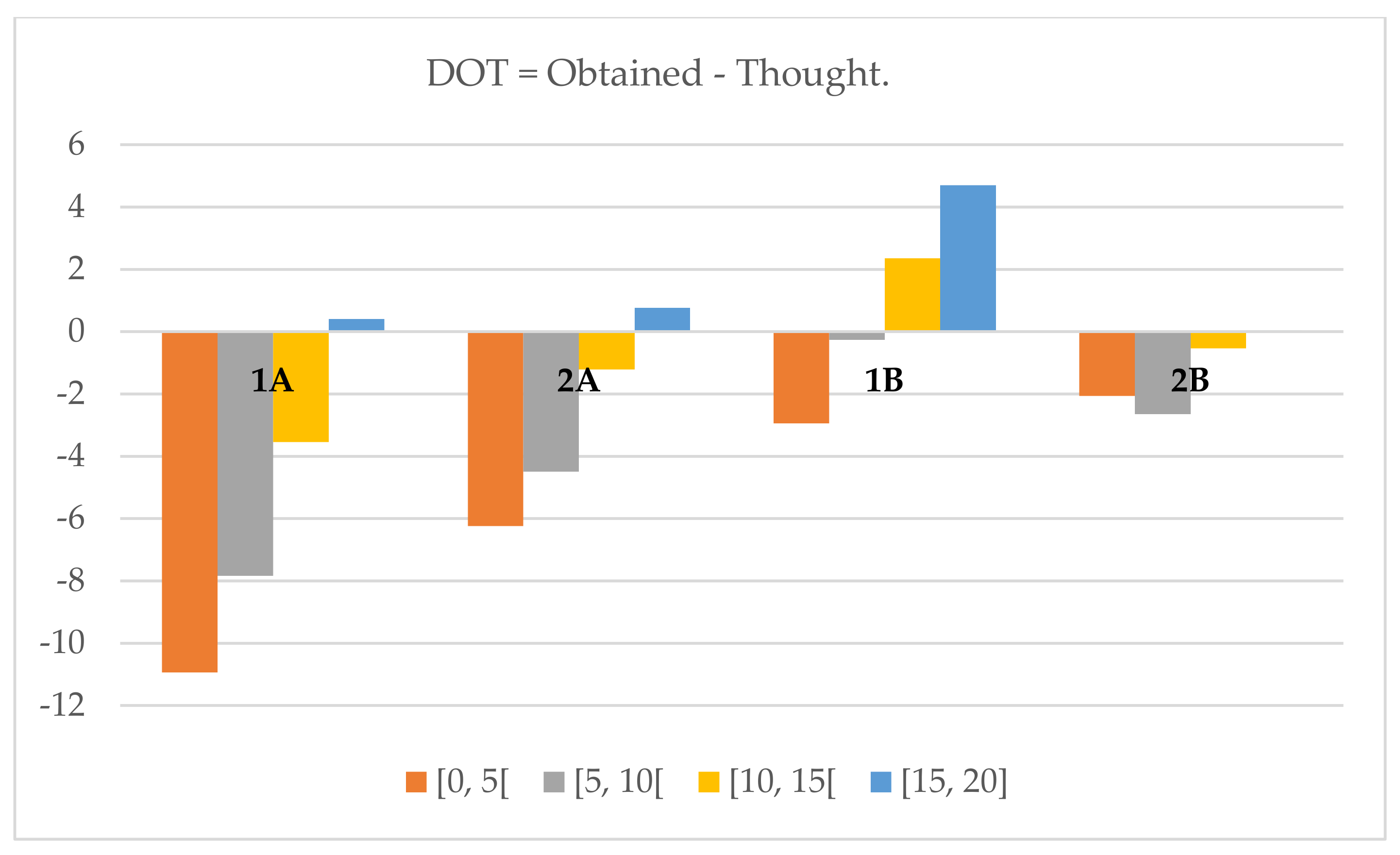
In Unit A’s first moment, we can state with 99.9% certainty that the students cannot accurately assess their work, and in the second moment we can also state that with 99% certainty. As the t values are negative, we can also state that the students tend do over-assess their work, but that, by the time of the second assessment moment, the difference is lower.
In Unit B we can state, with 90% certainty that the students cannot accurately assess their work, and in the second moment we can state the same with 99.9% certainty. In the first moment, as the t value is greater than zero, we see that students tend to under-assess their work, but on the second moment they tend to over-assess it (as the t value is lower than zero).
4.5. Clustering Results
The first clustering was performed using the K-means algorithm in Python, with K = 3. Four different datasets were used: the two assessment moments in each of the two different courses. Each dataset considered three variables: predicted grade, obtained grade, and DOT (the difference between the obtained and the predicted grades). For each dataset, we present a figure and a table. The figure visually represents the clusters found, and the table represents some information available for each cluster (group of students): number of students, cluster SSE, and average and standard deviation of the predicted grade, the obtained grade, and the DOT. In the figures, the circles represent the students, the xx coordinates are each student’s predicted grade on self-assessment, the yy coordinates are each student’s obtained grade, and the zz coordinates are each student’s DOT. Each cluster of students is represented by a different color (blue, green, and red) and the centroid of each cluster is represented by a triangle.
We can see in
Table 4 the information regarding the dataset that considers the first assessment moment for Unit A.
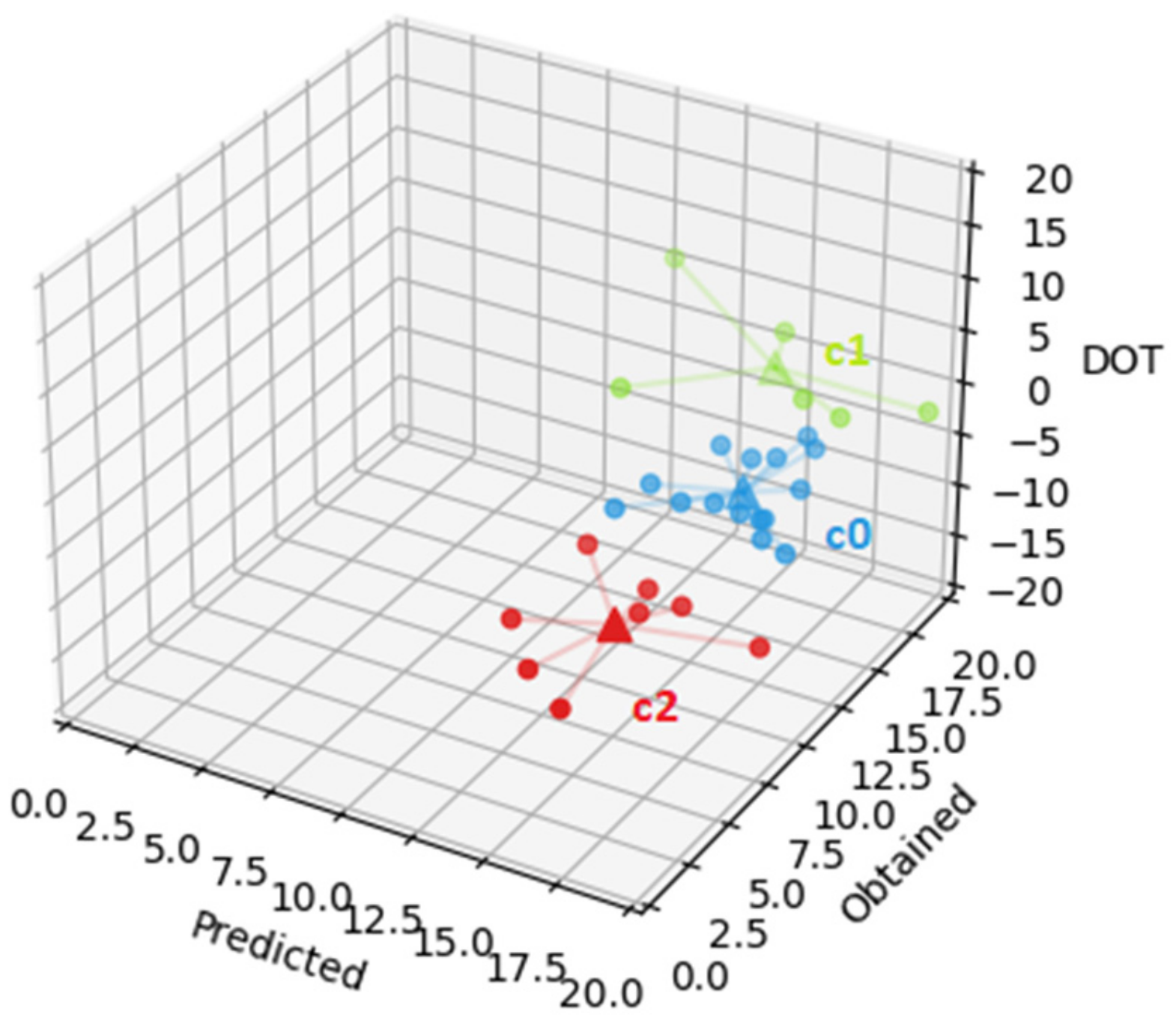
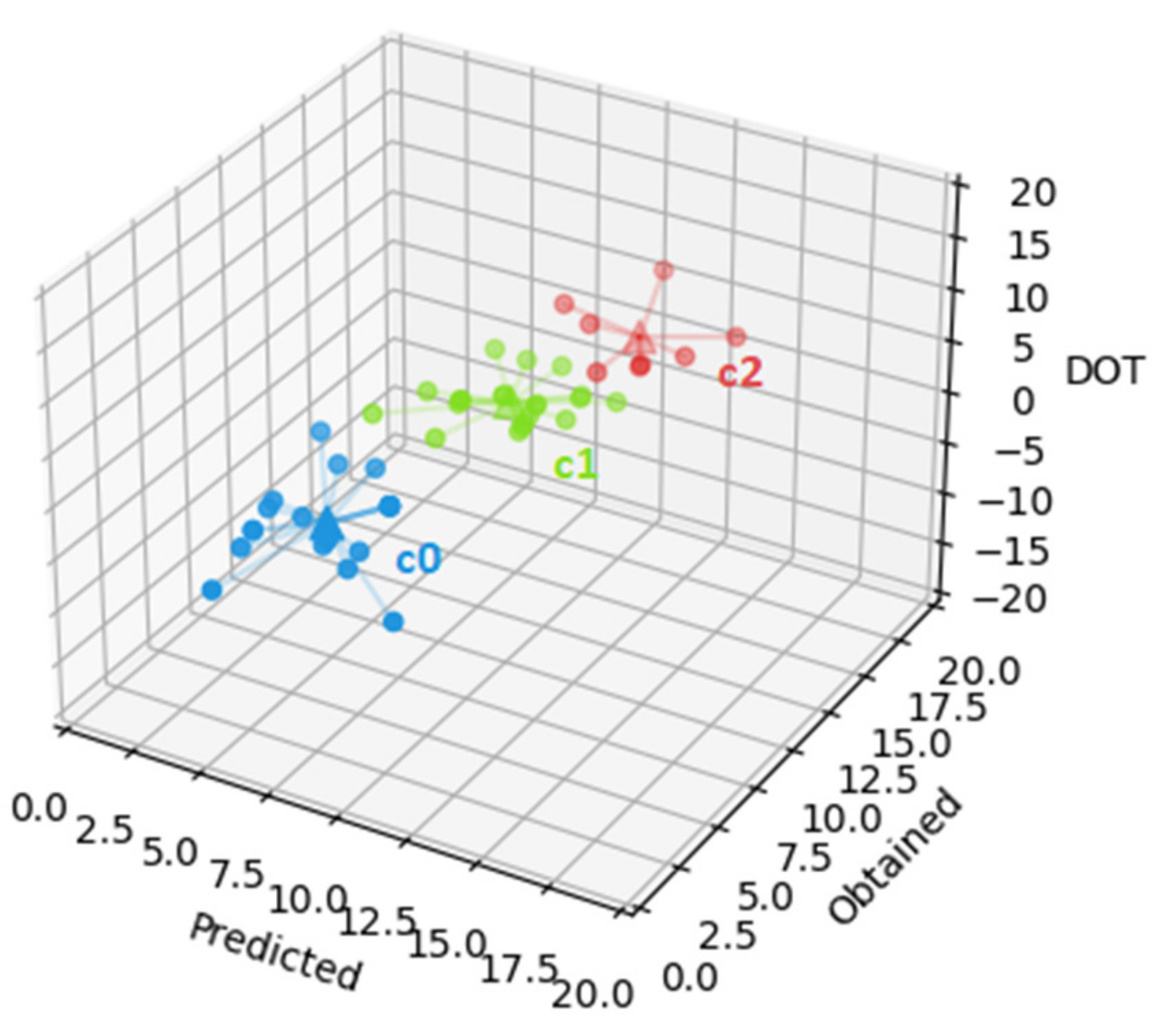
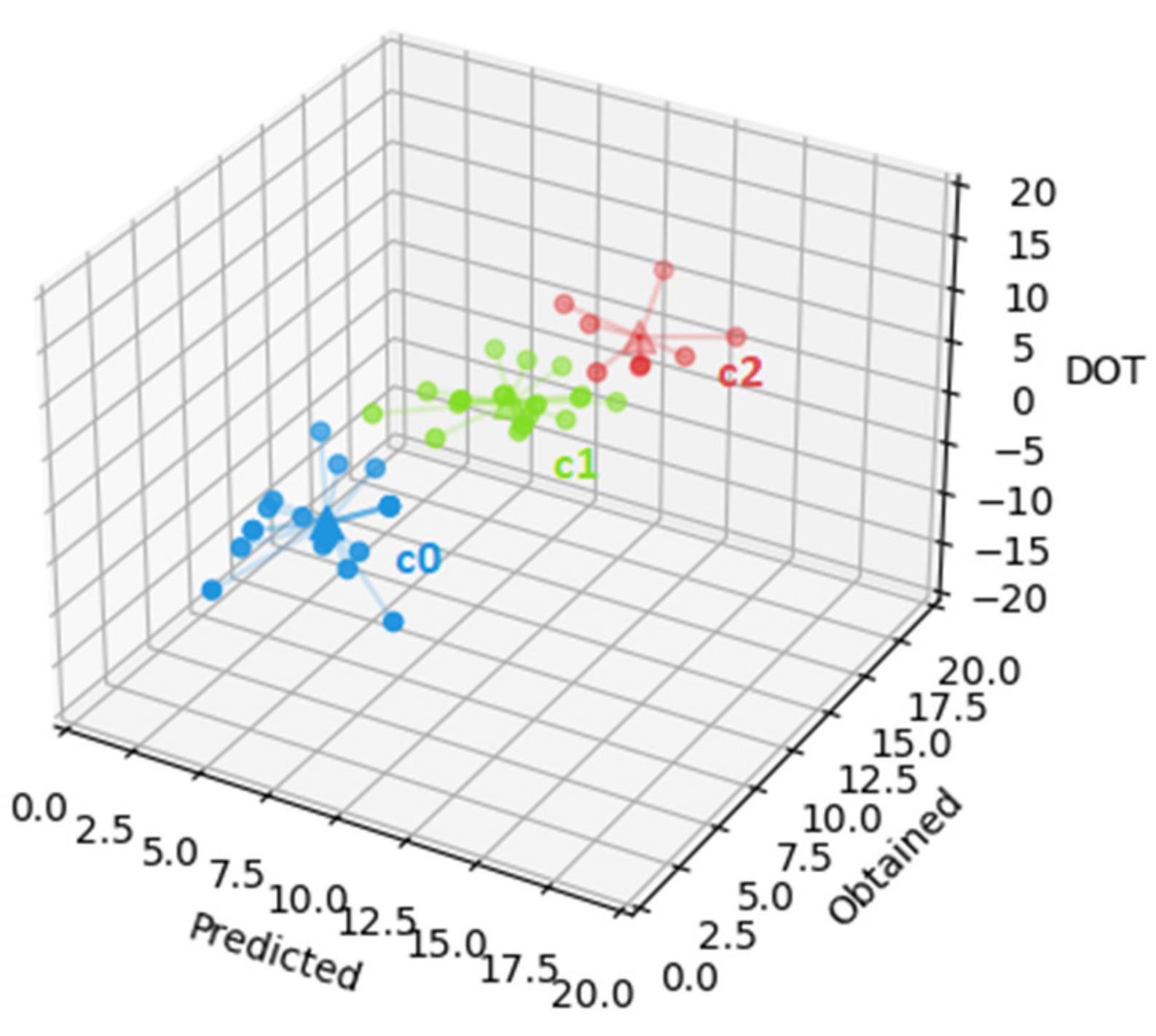
The first cluster (cluster 0, the cluster represented by c0, in blue in
Figure 4, with an SSE of 149.7) groups the 15 students with average predicted grade of 16.5 with a standard deviation of 1.4, average obtained grade of 13.0 with standard deviation of 1.6, and average DOT of −3.6 with standard deviation 1.5. The second cluster (cluster 1, the cluster represented by c1, in green in
Figure 4, with an SSE of 76.0) groups the 6 students with average predicted grade of 15.4 with standard deviation of 3.2, average obtained grade of 17.2 with standard deviation of 1.8, and average DOT of 1.8 with standard deviation of 3.0. Finally, the third cluster (cluster 2, the cluster represented by c2, in red in
Figure 4, with an SSE of 140.4) groups the 8 students with average predicted grade of 15.4 with standard deviation of 1.9, average obtained grade of 6.8 with standard deviation of 2.1, and average DOT of −8.6 with standard deviation of 2.0. Cluster c1 has the lowest SSE, which indicates a higher resemblance among the cluster’s elements. However, in this case, it can also be related to having less students. The most relevant information gathered in this dataset is that students in clusters 1 and 2 predicted, on average, a grade of 15.4. However, students on cluster 1 obtained, on average, a grade of 17.2 with average DOT of 1.8, while students on cluster 2 obtained, on average, a grade of 6.8 with average DOT of −8.6. This shows that students with low grades (as in cluster 2) will predict much higher grades, while students with higher grades will predict slightly lower grades.
Concerning the second test for Unit A, the results are presented in
Table 5.
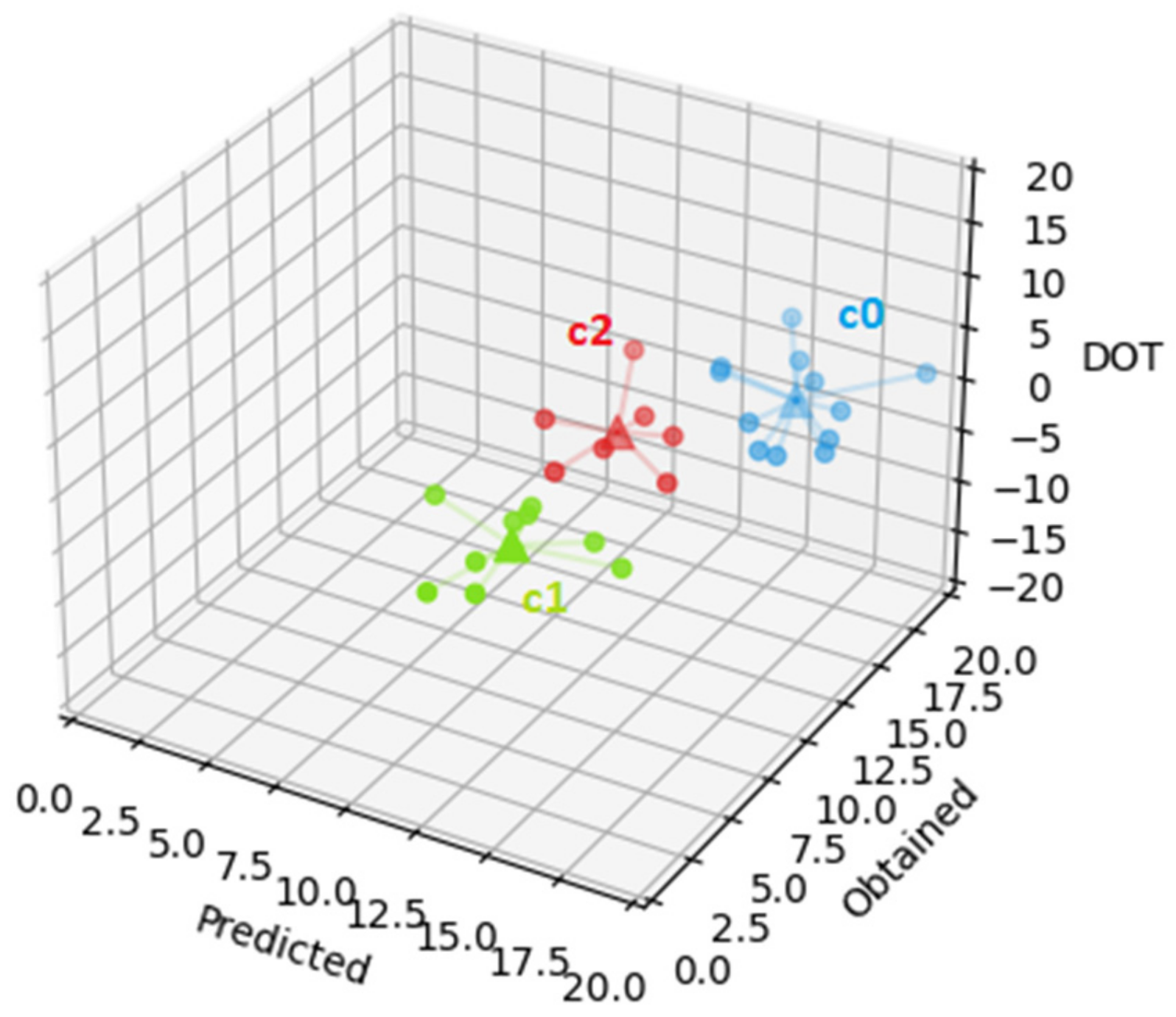
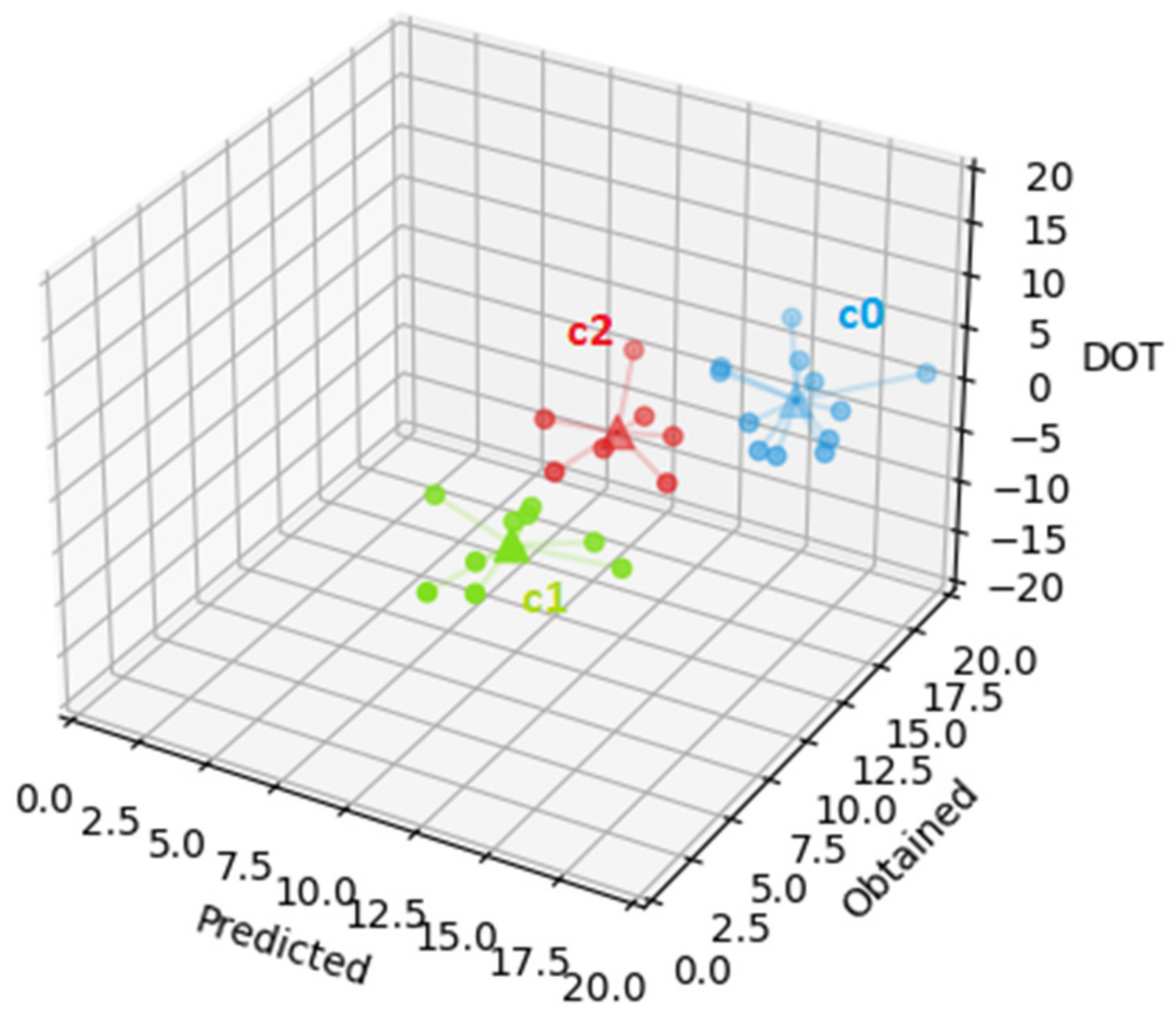
In this case, the first cluster (cluster 0, the cluster represented by c0, in blue in
Figure 5, with an SSE of 131.4) groups the 12 students with average predicted grade of 16.4 with a standard deviation of 2.6, average obtained grade of 16.5 with standard deviation of 3.9, and average DOT of 0.1 with standard deviation 2.9. The second cluster (cluster 1, the cluster represented by c1, in green in
Figure 5, with an SSE of 88.6) groups the 10 students with average predicted grade of 11.6 with standard deviation of 2.7, average obtained grade of 6.9 with standard deviation of 4.7, and average DOT of −4.7 with standard deviation of 2.6. Finally, the third cluster (cluster 2, the cluster represented by c2, in red in
Figure 5, with an SSE of 66.0) groups the 7 students with average predicted grade of 12.4 with standard deviation of 2.8, average obtained grade of 12.1 with standard deviation of 4.9, and average DOT of −0.3 with standard deviation of 2.9. Cluster c2 has the lowest SSE (66.0), followed by cluster c1 (88.6). As the number of students per cluster is more uniform than for the previous results presented, in this case this must indicate a higher resemblance among the elements of each cluster. The most relevant information gathered in this dataset is that students in clusters 0 and 2 have, on average, grades above 10, and their DOT is much lower than that of the students on cluster 1, which obtain, on average, a lower grade. This suggests, on one hand, that students improve their self-assessment by the time of the second test and, on the other hand, that students with lower grades still predict much higher grades than the obtained, although the DOT here is lower than for the first test.
Table 6 represents the information regarding the dataset that considers the first test for Unit B.
The first cluster (cluster 0, the cluster represented by c0, in blue in
Figure 6, with an SSE of 240.8) groups the 21 students with average predicted grade of 6.7 with a standard deviation of 1.5, average obtained grade of 4.6 with standard deviation of 1.7, and average DOT of −2.1 with standard deviation 1.8. The second cluster (cluster 1, the cluster represented by c1, in green in
Figure 6, with an SSE of 152.5) groups the 21 students with average predicted grade of 9.3 with standard deviation of 1.5, average obtained grade of 11.6 with standard deviation of 1.3, and average DOT of 2.3 with standard deviation of 1.0. Finally, the third cluster (cluster 2, the cluster represented by c2, in red in
Figure 6, with an SSE of 62.5) groups the 8 students with average predicted grade of 11.5 with standard deviation of 1.5, average obtained grade of 16.0 with standard deviation of 1.4, and average DOT of 4.5 with standard deviation of 1.6. The cluster with the lowest SSE is c2 which, as happened for the clustering of the first assessment for Unit A (
Table 3 and
Figure 2), can be due to the smaller size of this cluster. The most relevant information gathered in this dataset is that students with very low grades (cluster 0) will predict a slightly higher grade, students with grades slightly above 10 (cluster 1) will predict slightly lower grades, and students with higher grades (cluster 2) will predict lower grades. In addition, when compared to the results for Unit A, the DOT in this case is slightly lower, suggesting a different ability of self-assessment depending on the course.
Finally,
Table 7 represents the information regarding the dataset that considers the second test for Unit B.
The first cluster (cluster 0, the cluster represented by c0, in blue in
Figure 7, with an SSE of 47.3) groups the 15 students with average predicted grade of 4.1 with a standard deviation of 1.5, average obtained grade of 2.0 with standard deviation of 0.9, and average DOT of −2.1 with standard deviation 1.2. The second cluster (cluster 1, the cluster represented by c1, in green in
Figure 7, with an SSE of 396.9) groups the 13 students with average predicted grade of 15.7 with standard deviation of 2.6, average obtained grade of 15.4 with standard deviation of 2.8, and average DOT of −0.3 with standard deviation of 1.9. Finally, the third cluster (cluster 2, the cluster represented by c2, in red in
Figure 7, with an SSE of 297.0) groups the 22 students with average predicted grade of 9.8 with standard deviation of 1.2, average obtained grade of 7.4 with standard deviation of 1.8, and average DOT of −2.4 with standard deviation of 1.8. Here, cluster c0′s SSE is much lower than the other clusters’ SSE. Again, as happened for the second assessment moment for Unit A (
Table 4 and
Figure 3), this indicates a higher resemblance between this cluster’s elements. The most relevant information gathered in this dataset is that students with lower grades (clusters 0 and 2) will still predict a slightly higher grade, while students with higher grades (cluster 1) will predict a grade that is very close to the one the students in fact obtained. Besides, as happened in Unit A, by the second test, students have improved their self-assessment ability.
The second clustering was performed using the K-prototypes algorithm in Python, with K = 3. It was performed in a single dataset, containing four variables: the DOT, the grade level (low-negative (below 5 values: [0,5]), negative (between 5 and 10 values: [5,10[), positive (between 10 and 15 values: [10,15]), high-positive (over 15 values: [15,20]), the assessment moment (first, or second), and the unit (A, or B).
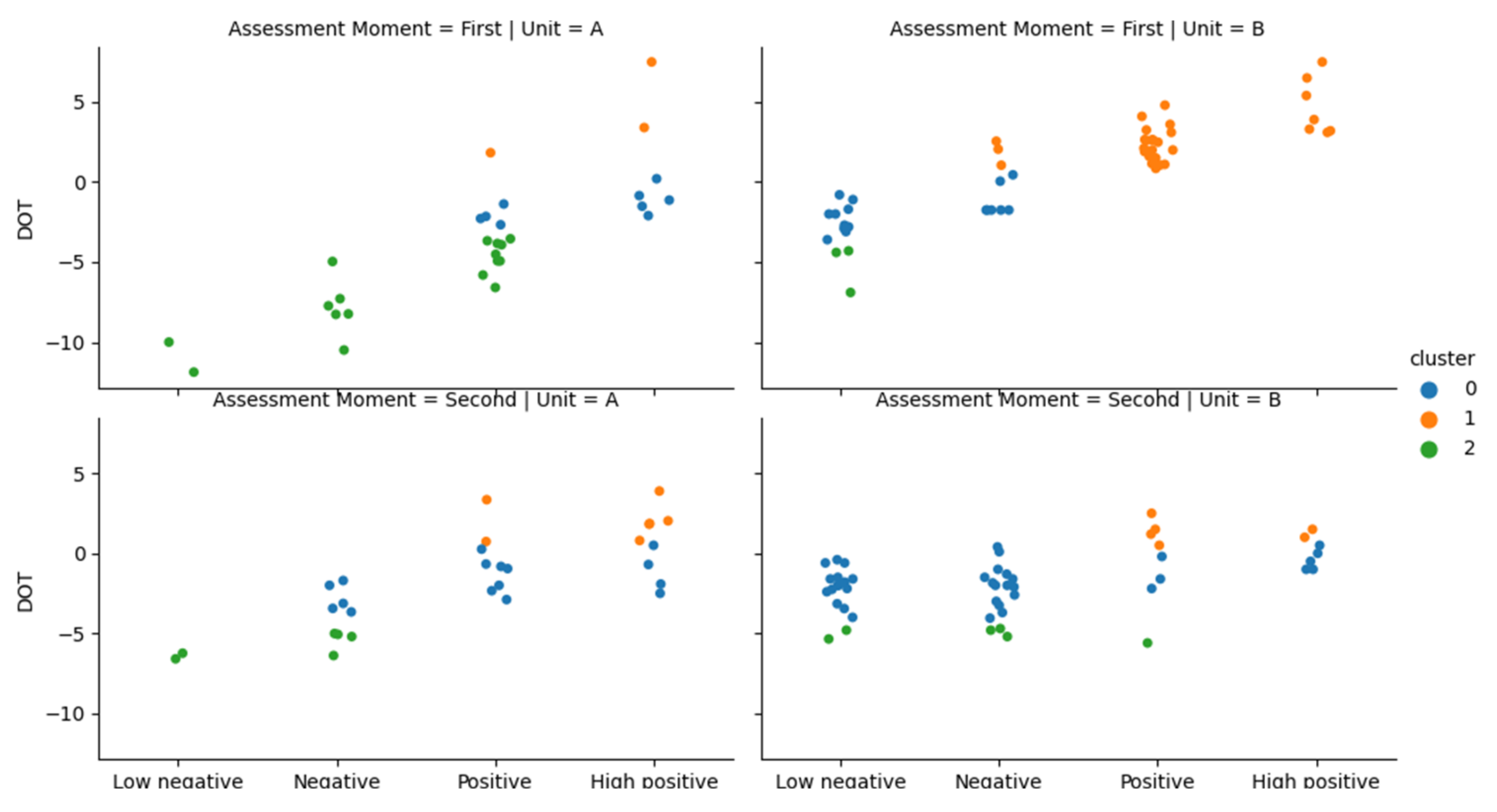
Figure 8 presents the clusters found in this process.
In the figure the clusters are presented by unit, assessment moment, and grade level. The clustering basically grouped the elements by their DOT: cluster 0 groups the students who can almost accurately assess their work; cluster 1 groups the students who under-assess their work; and cluster 2 groups the students who over-assess their work. In the first assessment moment there are more over-assessing students in Unit A (cluster 2, in green in the figure) and more under-assessing students in Unit B (cluster 1, in orange in the figure). In the second assessment moment, most students are included in cluster 0 (in blue in the figure), meaning that their assessment is more accurate.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}