
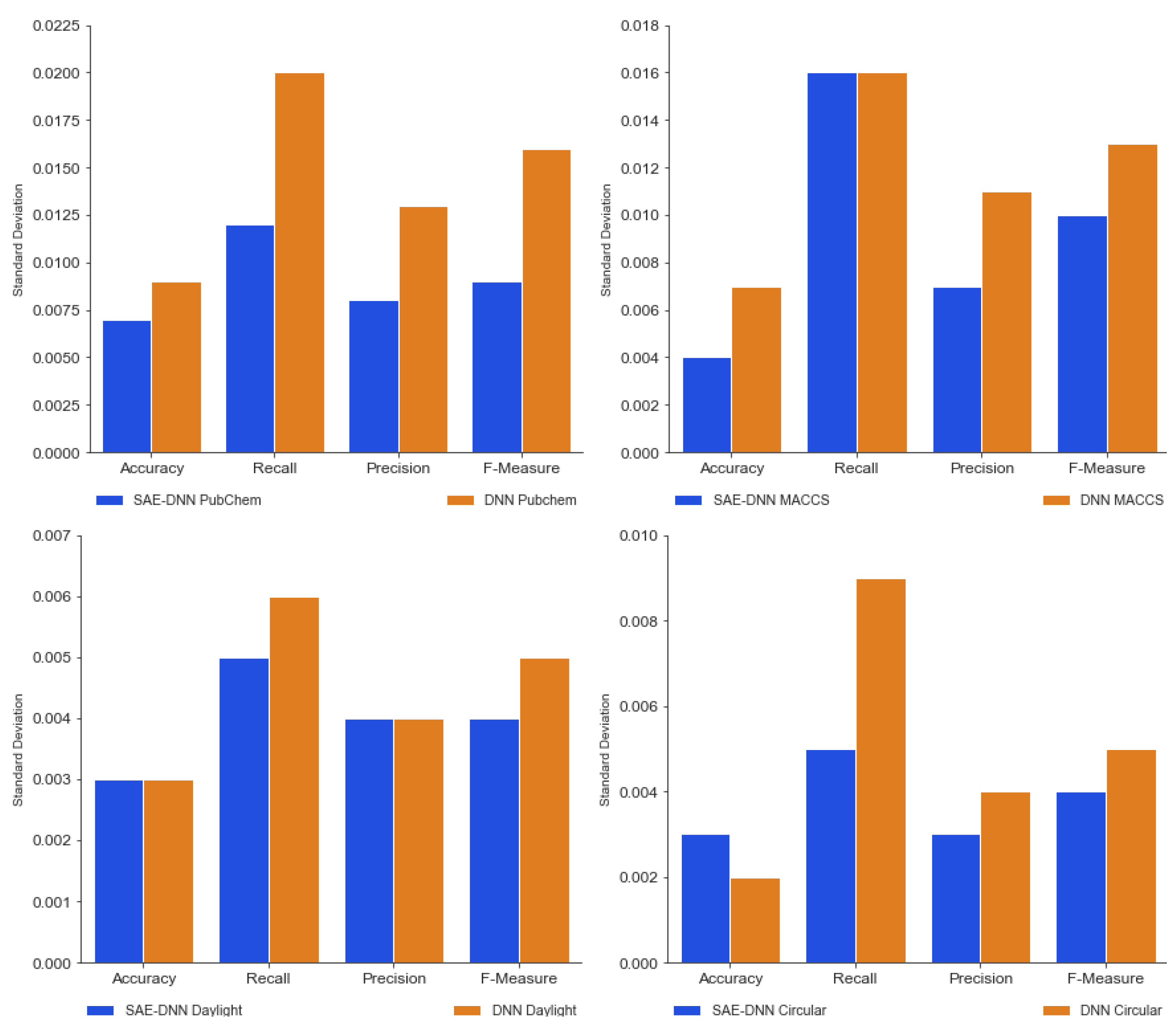
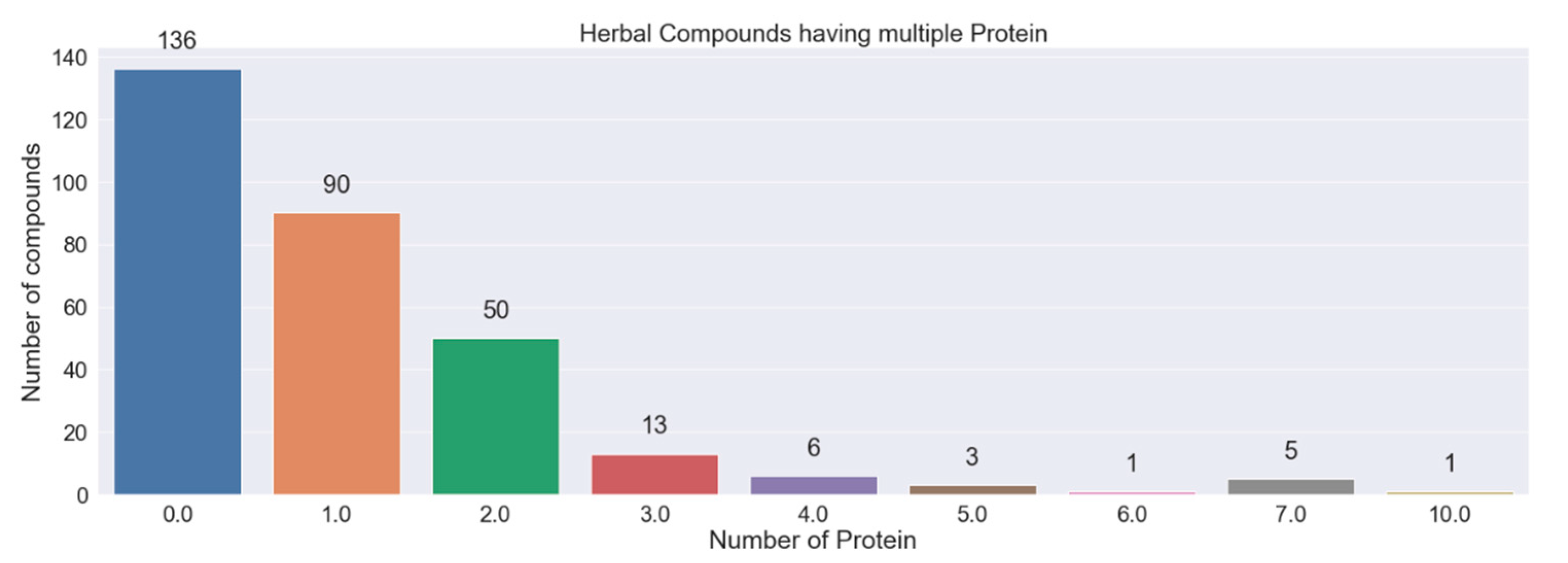
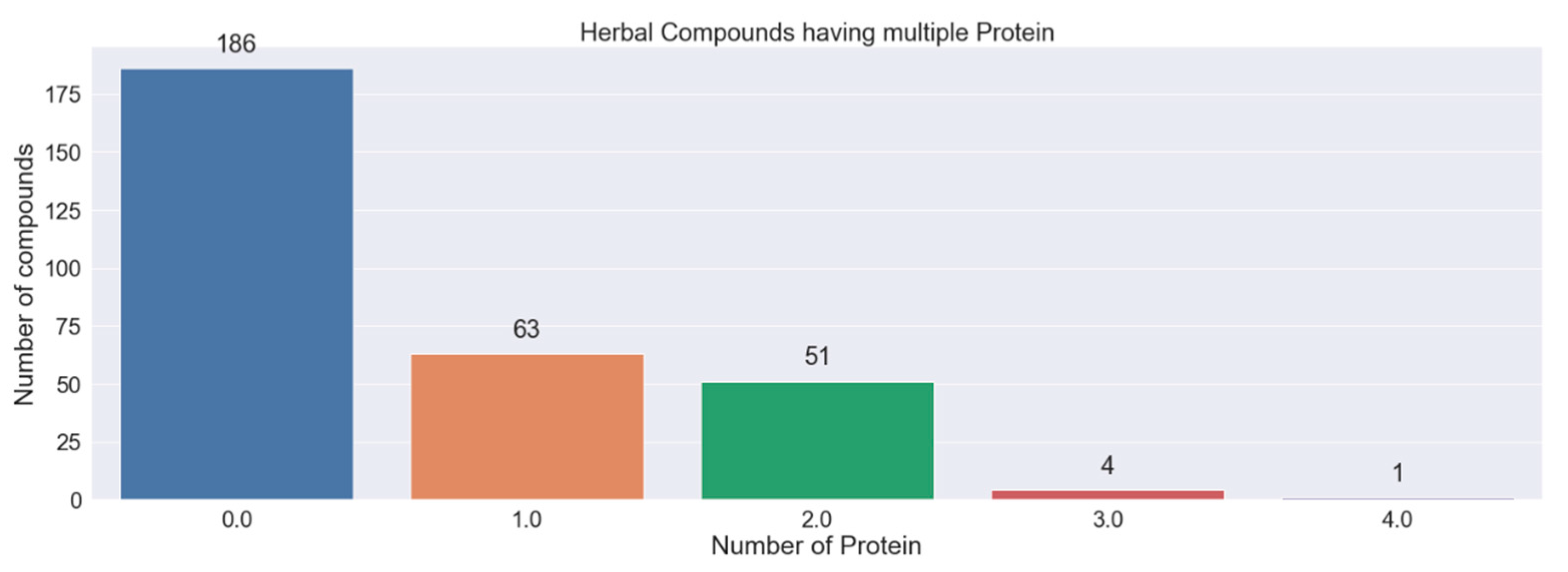
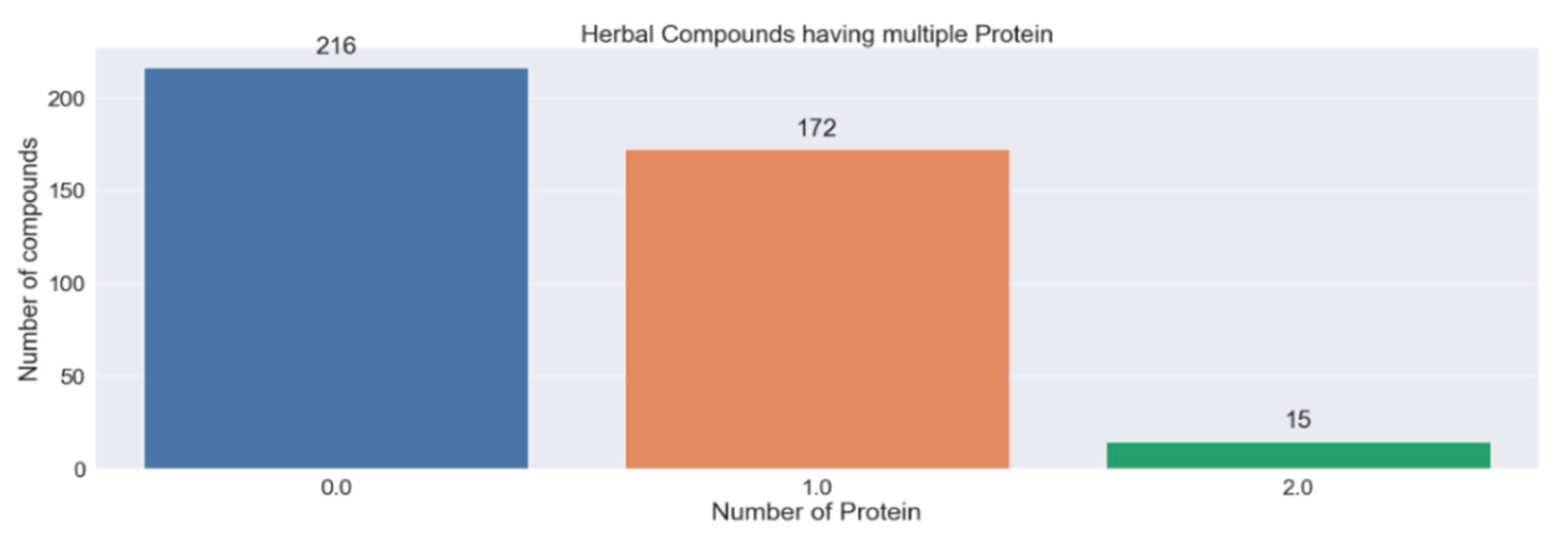
Screening of Potential Indonesia Herbal Compounds Based on Multi-Label Classification for 2019 Coronavirus Disease


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
Share and Cite
Fadli, A.; Kusuma, W.A.; Annisa; Batubara, I.; Heryanto, R. Screening of Potential Indonesia Herbal Compounds Based on Multi-Label Classification for 2019 Coronavirus Disease. Big Data Cogn. Comput. 2021, 5, 75. https://doi.org/10.3390/bdcc5040075
Fadli A, Kusuma WA, Annisa, Batubara I, Heryanto R. Screening of Potential Indonesia Herbal Compounds Based on Multi-Label Classification for 2019 Coronavirus Disease. Big Data and Cognitive Computing. 2021; 5(4):75. https://doi.org/10.3390/bdcc5040075
Chicago/Turabian StyleFadli, Aulia, Wisnu Ananta Kusuma, Annisa, Irmanida Batubara, and Rudi Heryanto. 2021. "Screening of Potential Indonesia Herbal Compounds Based on Multi-Label Classification for 2019 Coronavirus Disease" Big Data and Cognitive Computing 5, no. 4: 75. https://doi.org/10.3390/bdcc5040075
APA StyleFadli, A., Kusuma, W. A., Annisa, Batubara, I., & Heryanto, R. (2021). Screening of Potential Indonesia Herbal Compounds Based on Multi-Label Classification for 2019 Coronavirus Disease. Big Data and Cognitive Computing, 5(4), 75. https://doi.org/10.3390/bdcc5040075