
Networks and Stories. Analyzing the Transmission of the Feminist Intangible Cultural Heritage on Twitter




{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- -
- We will argue the generational importance of hashtag feminism and the fourth feminist wave, and we will especially focus on explaining why working with Twitter data gives us access to a privileged vantage point from which to observe the dynamics of self-definition of the movement itself that are taking place during these same years.
- -
- We will outline the main characteristics of big data as a socio-technical paradigm and highlight the opportunities it offers to social scientists who approach it with a hybrid analytical perspective: mathematically and technically solvent as well as phenomenologically grounded;
- -
- We will also discuss the universe of technical opportunities and the legal limits we face when we want to work with massive data from social media to understand the dynamics that occur in them;
- -
- We will present a particular methodological proposal based on Network Analysis and Machine Learning techniques. We will argue in favor of the implementation of a series of unsupervised algorithms to provide analytical context to big data, and then we will defend the articulation of Data Engineering techniques to facilitate further analysis;
- -
- We will present four different investigations that we have already developed in the framework of the broad project that also gives rise to this article with a more methodological orientation. In these four investigations we have deployed the methodology we present, giving epistemological priority to the analysis of the context by means of inductive logics, without renouncing causal reasoning and hypothetico-deductive logic;
- -
- Finally, we will elaborate a series of concluding reflections.
2. Objectives
2.1. Analyzing the Shaping of the Current Feminist Wave through Twitter
2.2. Related Works
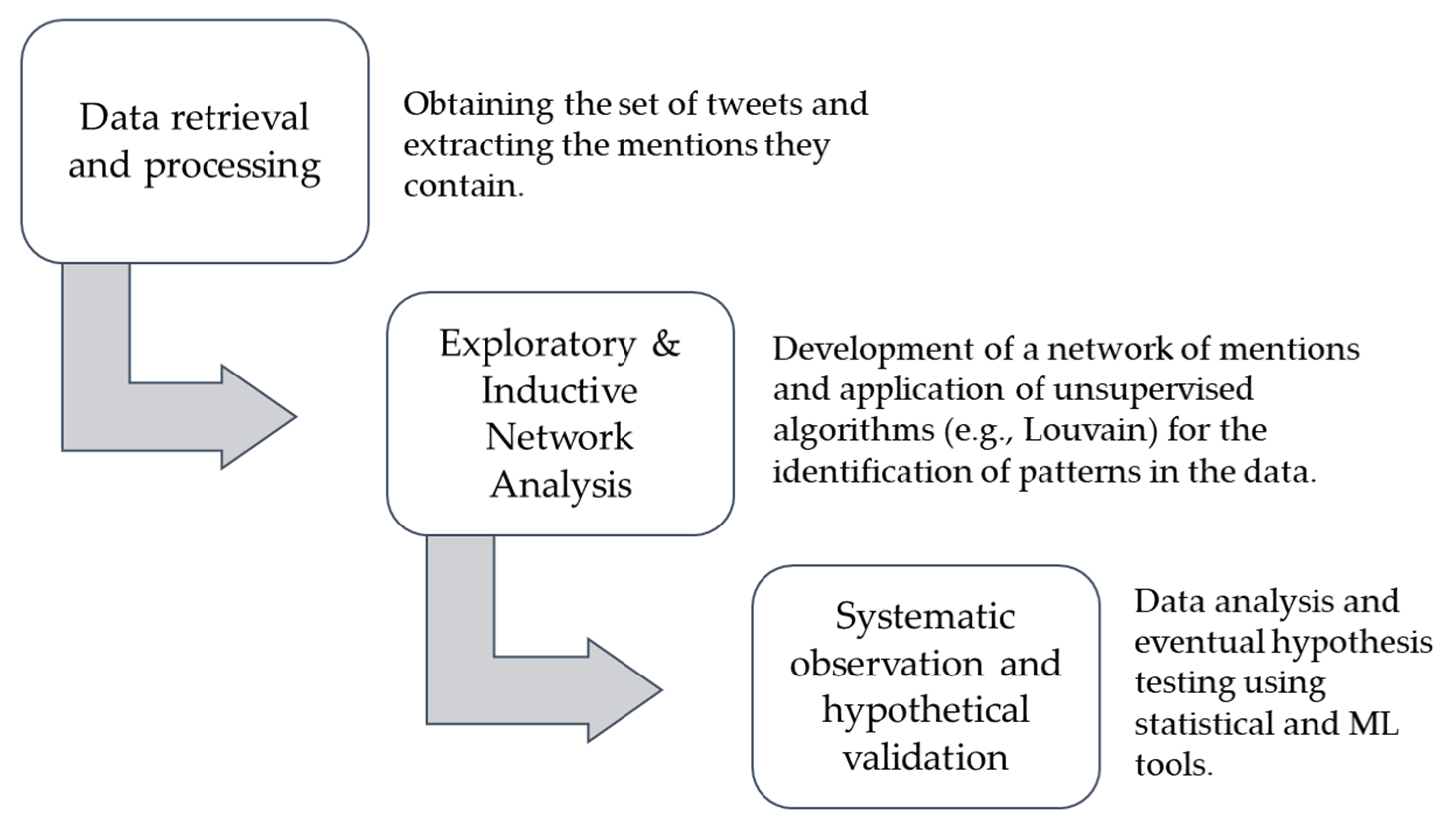
3. Methodology
3.1. Big Data and Interpretative Perspectives
3.2. Social Media as Relational and Textual Big Data Sources: Possibilities and Legal Limits
4. Results
4.1. Network Analysis and Machine Learning as Assistants for the Interpretation of Dynamics in Virtual Networks
4.2. Combining Induction and Deduction to Understand the Current Feminist Wave
4.2.1. Feminisms Outraged at Justice
4.2.2. Digital Prospects of the Contemporary Feminist Movement for Dialogue and International Mobilization
4.2.3. Feminist Hashtag Activism in Spain
4.2.4. Influence of Gender in Electoral Debates in Spain
5. Conclusions with Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fernández-Ferández, M.; Tardivo, V. La sociología de la Comunicación y la Mass Coomunication Research: Tradición y actualidad. Espac. Abierto Cuad. Venez. Sociol. 2016, 25, 133–142. [Google Scholar]
- Castillo, A. Neologismos y Sociedad del Conocimiento; Ariel: Barcelona, Spain, 2007. [Google Scholar]
- García-Estévez, N. La convergencia activista en Hong Kong: Del ciberactivismo de ‘Occupy Central’ al hacktivismo de ‘Operación Hong Kong’. In Move.Net: Actas del I Congreso Internacional Move.Net Sobre Movimientos Sociales y TIC (139–156); Grupo Interdisciplinario de Estudios en Comunicación, Política y Cambio Social de la Universidad de Sevilla: Seville, Spain, 2015. [Google Scholar]
- Dery, M. Velocidad de Escape. La Cibercultura en el Final del Siglo; Siruela: Madrid, Spain, 1998. [Google Scholar]
- Joyanes, L. Cibersociedad, los Retos Sociales Ante un Nuevo Mundo Digital; McGraw-Hill: Madrid, Spain, 1997. [Google Scholar]
- Lévy, P. Cibercultura. La Cultura de la Sociedad Digital; Anthropos: Mexico City, Mexico, 2007. [Google Scholar]
- Van Dijck, J. La Cultura de la Conectividad. Una Historia Crítica de las Redes Sociales; Siglo Veintiuno Editores: Buenos Aires, Argentina, 2016. [Google Scholar]
- Toret, J. Tecnopolítica: La Potencia de las Multitudes Conectadas. El Sistema Red 15M, un Nuevo Paradigma de la Política Distribuida; IN3 Working Paper Series; Universitat Oberta de Catalunya: Barcelona, Spain, 2013. [Google Scholar]
- Castells, M. Comunicación, poder y contrapoder en la sociedad red (I). Los medios y la política. Telos 2008, 74, 1–19. [Google Scholar]
- Castells, M. Comunicación y Poder; Alianza Editorial: Madrid, Spain, 2009. [Google Scholar]
- Melucci, A. Acción Colectiva, Vida Cotidiana y Democracia; Centro de Estudios Sociológicos: Mexico City, Mexico, 1999. [Google Scholar]
- Candón-Mena, J.I. Internet en Movimiento: Nuevos Movimientos Sociales y Nuevos Medios en la Sociedad de la Información; Universidad Complutense de Madrid, Servicio de Publicaciones: Madrid, Spain, 2011. [Google Scholar]
- Romero, U.P.M. Movimientos Sociales y la Autocomunicación de Masas. Una Revisión del Movimiento 15-M; Colegio San Luis: San Luis Potosí, Mexico, 2012. [Google Scholar]
- Rovira-Sancho, G. Movimientos Sociales y Comunicación: La Red Como Paradigma. Anàlisi: Quad. Comun. Cult. 2012, 45, 91–104. [Google Scholar]
- Withers, D. Feminism, Digital Culture and the Politics of Transmission: Theory, Practice and Cultural Heritage; Rowman & Littlefield: Lanham, MA, USA, 2015. [Google Scholar]
- Congosto, M.L.; Fernández, M.; Moro Egido, E. Twitter y Política: Información, Opinión y ¿Predicción? Cuad. Comun. Evoca 2011, 4, 11–16. [Google Scholar]
- Campos-Domínguez, E. Twitter y la comunicación política. El Prof. Inf. 2017, 26, 785–793. [Google Scholar] [CrossRef]
- Rodríguez, R.; Ureña, D. Diez razones para el uso de Twitter como herramienta en la comunicación política y electoral. Comun. Plur. 2011, 5, 89–116. [Google Scholar]
- Piscitelli, A. Prólogo: Twitter, la revolución y los enfoques ni-ni. In Mundo Twitter: Una Guía Para Comprender y Dominar la Plataforma que Cambió la Red; Orihuela, J.L., Ed.; Alienta: Barcelona, Spain, 2011; pp. 15–20. [Google Scholar]
- Pariser, E. The Filter Bubble: What the Internet Is Hiding from You; Penguin: London, UK, 2011. [Google Scholar]
- Page, R. The linguistics of self-branding and micro-celebrity in Twitter: The role of hashtags. Discourse Commun. 2012, 6, 181–201. [Google Scholar] [CrossRef]
- Carr, D. Hashtag Activism and Its Limits. The New York Times, 25 March 2012. [Google Scholar]
- Marwick, A. Status Update: Celebrity, Publicity, and Branding in the Social Media Age; Yale University Press: New Haven, CT, USA, 2013. [Google Scholar]
- Fuchs, C. Social Media. A Critical Introduction; Sage: Thousand Oaks, CA, USA, 2014. [Google Scholar]
- Giraldo-Luque, S.; Fernández-García, N.; Pérez-Arce, J.C. La centralidad temática de la movilización #NiUnaMenos en Twitter. El Prof. Inf. 2018, 27, 1–226. [Google Scholar]
- Anduiza, E.; Cristancho, C.; Sabucedo, J.M. Mobilization through online social networks: The political protest of the indignados in Spain. Inf. Commun. Soc. 2014, 17, 750–764. [Google Scholar] [CrossRef]
- Bennett, W.L.; Segerberg, A. The logic of connective action: Digital media and the personalization of contentious politics. Inf. Commun. Soc. 2012, 15, 739–768. [Google Scholar] [CrossRef]
- Dixon, K. Feminist online identity: Analyzing the presence of hashtag feminism. J. Arts Humanit. 2014, 3, 34–40. [Google Scholar]
- Zimmerman, T. #Intersectionality: The Fourth Wave Feminist Twitter Community. Atlantis Crit. Stud. Gend. Cult. Soc. Justice 2017, 38, 54–70. [Google Scholar]
- Shiva, N.; Nosrat Kharazmi, Z. The fourth wave of feminism and the lack of social realism in cyberspace. J. Cyberspace Stud. 2019, 3, 129–146. [Google Scholar]
- Mendes, K.; Ringrose, J.; Keller, J. # MeToo and the promise and pitfalls of challenging rape culture through digital feminist activism. Eur. J. Women’s Stud. 2018, 25, 236–246. [Google Scholar]
- Worthington, N. Celebrity-bashing or# MeToo contribution? New York Times Online readers debate the boundaries of hashtag feminism. Commun. Rev. 2020, 23, 46–65. [Google Scholar]
- Zhou, Q.; Qiu, H. Predicting online feminist engagement after MeToo: A study combining resource mobilization and integrative social identity paradigms. Chin. J. Commun. 2020, 13, 351–369. [Google Scholar] [CrossRef]
- Clark-Parsons, R. I see you, I believe you, I stand with you:# MeToo and the performance of networked feminist visibility. Fem. Media Stud. 2021, 21, 362–380. [Google Scholar]
- Thelwall, M. International Women’s Day 2009–2020 on Twitter: Postfeminist or Fourth Wave Feminism? SSRN 2021, 3846542. [Google Scholar] [CrossRef]
- Sanchez-Duarte, J.M.; Fernandez-Romero, D. Feminist sub-activism and digital collective repertoires: Cyberfeminist practices on Twitter. El Prof. Inf. 2017, 26, 894–902. [Google Scholar]
- Navarro, C.; Coromina, Ò. Discussion and mediation of social outrage on Twitter: The reaction to the judicial sentence of “La Manada”. Commun. Soc. 2020, 33, 93–106. [Google Scholar] [CrossRef]
- Idoiaga-Mondragon, N.; Berasategi-Sancho, N.; Beloki-Arizti, N.; Belasko-Txertudi, M. # 8M women’s strikes in Spain: Following the unprecedented social mobilization through twitter. J. Gend. Stud. 2021, 1–16. [Google Scholar] [CrossRef]
- Birhane, A. Algorithmic injustice: A relational ethics approach. Patterns 2021, 2, 100205. [Google Scholar] [CrossRef]
- Graham, S.S.; Hopkins, H.R. AI for Social Justice: New Methodological Horizons in Technical Communication. Tech. Commun. Q. 2021, 1–14. [Google Scholar] [CrossRef]
- Kuo, R. Racial justice activist hashtags: Counterpublics and discourse circulation. New Media Soc. 2018, 20, 495–514. [Google Scholar] [CrossRef]
- Almazor, M.G.; Canteli, M.J.P.; de la Cal Barredo, M.L. New approaches to the propagation of the antifeminist backlash on Twitter. Investig. Fem. 2020, 11, 221–237. [Google Scholar] [CrossRef]
- Laney, D. 3D data management: Controlling data volume, velocity and variety. META Group Res. Note 2001, 6, 1. [Google Scholar]
- Khan, M.A.; Uddin, M.F.; Gupta, N. Seven V’s of Big Data understanding Big Data to extract value. In Proceedings of the 2014 Zone 1 Conference of the American Society for Engineering Education, Bridgeport, CT, USA, 3–5 April 2014; pp. 1–5. [Google Scholar]
- Oguntimilehin, A.; Ademola, O. A Review of Big Data Management, Benefits and Challenges. J. Emerg. Trends Comput. Inf. Sci. 2014, 5, 433–438. [Google Scholar]
- Patgiri, R.; Ahmed, A. Big data: The v’s of the game changer paradigm. In Proceedings of the IEEE 18th International Conference on High Performance Computing and Communications, Sydney, Australia, 12–14 December 2016; pp. 17–24. [Google Scholar]
- Anderson, C. The end of theory: The data deluge makes the scientific method obsolete. Wired Mag. 2008, 16, 16–17. [Google Scholar]
- DiFonzo, N. The Echo-Chamber Effect. The New York Times, 22 April 2011. [Google Scholar]
- Sweeney, L. Discrimination in online ad delivery. Queue 2013, 11, 10–29. [Google Scholar] [CrossRef]
- Datta, A.; Tschantz, M.C.; Datta, A. Automated experiments on ad privacy settings: A tale of opacity, choice, and discrimination. Proc. Priv. Enhancing Technol. 2015, 1, 92–112. [Google Scholar] [CrossRef]
- Metz, R. Why Microsoft Accidently Unleashed a Neo-Nazi Sexbot. Available online: https://www.technologyreview.com/2016/03/24/161424/why-microsoft-accidentally-unleashed-a-neo-nazi-sexbot/ (accessed on 23 November 2021).
- Arcila-Calderón, C.; Barbosa-Caro, E.; Cabezuelo-Lorenzo, F. Técnicas big data: Análisis de textos a gran escala para la investigación científica y periodística. El Prof. Inf. 2016, 25, 623–631. [Google Scholar] [CrossRef][Green Version]
- Campolo, A.; Sanfilippo, M.; Whittaker, M.; Crawford, K. AI Now 2017 Report; AI Now Institute at New York University: New York, NY, USA, 2017. [Google Scholar]
- Edizel, B.; Bonchi, F.; Hajian, S.; Panisson, A.; Tassa, T. FaiRecSys: Mitigating algorithmic bias in recommender systems. Int. J. Data Sci. Anal. 2020, 9, 197–213. [Google Scholar] [CrossRef]
- Morales-i-Gras, J. Datos Masivos y Minería de Datos Sociales, Conceptos y Herramientas Básicas; Fundació Universitat Oberta de Catalunya: Barcelona, Spain, 2020. [Google Scholar]
- Garcia-Alsina, M. Big Data: Gestión y Explotación de Grandes Volúmenes de Datos; Editorial UOC-El Profesional de la Información: Barcelona, Spain, 2017. [Google Scholar]
- Morales-i-Gras, J. Minería de Datos de los Social Media, Técnicas Para el Análisis de Datos Masivos; Fundació Universitat Oberta de Catalunya: Barcelona, Spain, 2020. [Google Scholar]
- Crossley, N. The social world of the network. Combining qualitative and quantitative elements in social network analysis. Sociologica 2010, 4. [Google Scholar] [CrossRef]
- Edwards, G. Mixed-Method Approaches to Social Network Analysis; Routledge: Abingdon-on-Thames, UK, 2010. [Google Scholar]
- Karamshuk, D.; Shaw, F.; Brownlie, J.; Sastry, N. Bridging big data and qualitative methods in the social sciences: A case study of Twitter responses to high profile deaths by suicide. Online Soc. Netw. Media 2017, 1, 33–43. [Google Scholar] [CrossRef]
- Chen, N.C.; Drouhard, M.; Kocielnik, R.; Suh, J.; Aragon, C.R. Using machine learning to support qualitative coding in social science: Shifting the focus to ambiguity. ACM Trans. Interact. Intell. Syst. 2018, 8, 1–20. [Google Scholar] [CrossRef]
- Twitter. Standard Search—Twitter Developers; Twitter Developers: San Francisco, CA, USA, 2018. [Google Scholar]
- Ediger, D.; Jiang, K.; Riedy, J.; Bader, D.A.; Corley, C.; Farber, R.; Reynolds, W.N. Massive social network analysis: Mining Twitter for social good. In Proceedings of the 39th International Conference on Parallel Processing Workshops, San Diego, CA, USA, 13–16 September 2010; pp. 583–593. [Google Scholar]
- Chatfield, A.; Brajawidagda, U. Twitter tsunami early warning network: A social network analysis of Twitter information flows. In Proceedings of the 23rd Australasian Conference on Information Systems, Melbourne, Australia, 3–5 December 2012; Volume 56. [Google Scholar]
- Tremayne, M. Anatomy of protest in the digital era: A network analysis of Twitter and Occupy Wall Street. Soc. Mov. Stud. 2014, 13, 110–126. [Google Scholar] [CrossRef]
- Congosto, M.L. Elecciones Europeas 2014: Viralidad de los mensajes en Twitter. Redes Rev. Hisp. Para Análisis Redes Soc. 2015, 26, 23–52. [Google Scholar]
- Del Fresno García, M.; Daly, A.J.; Supovitz, J. Desvelando climas de opinión por medio del Social Media Mining y Análisis de Redes Sociales en Twitter. El caso de los Common Core State Standards. Redes Rev. Hisp. Para Análisis Redes Soc. 2015, 26, 53–75. [Google Scholar]
- Morales-i-Gras, J. Desenredando las identidades soberanistas vasca y catalana: Un Análisis de Redes Sociales de las etiquetas de Twitter# BasquesDecide y #Up4Freedom. Pap. CEIC Int. J. Collect. Identity Res. 2015, 2, 1–37. [Google Scholar]
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R.; Lefebvre, E. Fast Unfolding of Communities in Large Networks. J. Stat. Mech. Theory Exp. 2008, 2008, 10. [Google Scholar] [CrossRef]
- Zhao, Y. Analysing Twitter data with text mining and social network analysis. In Proceedings of the 11th Australasian Data Mining and Analytics Conference, Camberra, Australia, 13–15 November 2013; Volume 146. [Google Scholar]
- Gualda, E.; Borrero, J.D. La ‘Spanish Revolution’ en Twitter (2): Redes de hashtags (#) y actores individuales y colectivos respecto a los desahucios en España. Redes Rev. Hisp. Para Análisis Redes Soc. 2015, 26, 1–22. [Google Scholar]
- Himelboim, I.; Smith, M.A.; Rainie, L.; Shneiderman, B.; Espina, C. Classifying Twitter topic-networks using social network analysis. Soc. Media Soc. 2017, 3, 2056305117691545. [Google Scholar] [CrossRef]
- Gerlach, M.; Peixoto, T.P.; Altmann, E.G. A network approach to topic models. Sci. Adv. 2018, 4. [Google Scholar] [CrossRef] [PubMed]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit; O’Reilly Media Inc.: London, UK, 2009. [Google Scholar]
- Ray, P.; Chakrabarti, A. A mixed approach of deep learning method and rule-based method to improve aspect level sentiment analysis. Appl. Comput. Inform. 2019. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Myers, S.A.; Sharma, A.; Gupta, P.; Lin, J. Information network or social network? The structure of the Twitter follow graph. In Proceedings of the 23rd International Conference on World Wide Web, Seoul, Korea, 7–11 April 2014; pp. 493–498. [Google Scholar]
- Grandjean, M. A social network analysis of Twitter: Mapping the digital humanities community. Cogent Arts Humanit. 2016, 3, 1171458. [Google Scholar] [CrossRef]
- Lozares-Colina, C. La teoría de redes sociales. Pap. Rev. Sociol. 1996, 48, 103–126. [Google Scholar]
- Louch, H. Personal network integration: Transitivity and homophily in strong-tie relations. Soc. Netw. 2000, 22, 45–64. [Google Scholar] [CrossRef]
- Isaak, J.; Hanna, M.J. User data privacy: Facebook, Cambridge Analytica, and privacy protection. Computer 2018, 51, 56–59. [Google Scholar] [CrossRef]
- Lykousas, N.; Patsakis, C. Large-scale analysis of grooming in modern social networks. arXiv 2020, arXiv:2004.08205. [Google Scholar] [CrossRef]
- Boulanger, M. Scraping the Bottom of the Barrel: Why It Is No Surprise That Data Scrapers Can Have Access to Public Profiles on LinkedIn. Sci. Technol. Law Rev. 2018, 21, 77. [Google Scholar]
- Newman, M.E. Modularity and community structure in networks. Proc. Natl. Acad. Sci. USA 2006, 103, 8577–8582. [Google Scholar] [CrossRef]
- Lambiotte, R.; Delvenne, J.C.; Barahona, M. Laplacian dynamics and multiscale modular structure in networks. arXiv 2008, arXiv:0812.1770. [Google Scholar]
- Morales-i-Gras, J. Soberanías Enredadas: Una Perspectiva Reticular, Constructural y Agéntica Hacia los Relatos Soberanistas Vasco y Catalán Contemporáneos en Twitter. Ph.D. Dissertation, Universidad del País Vasco-Euskal Herriko Unibertsitatea, Leioa, Spain, 2017. [Google Scholar]
- Munro, E. Feminism: A fourth wave? Political Insight 2013, 4, 22–25. [Google Scholar] [CrossRef]
- Larrondo Ureta, A.; Orbegozo Terradillos, J.; Morales i Gras, J. Digital Prospects of the Contemporary Feminist Movement for Dialogue and International Mobilization: A Case Study of the 25 November Twitter Conversation. Soc. Sci. 2021, 10, 84. [Google Scholar] [CrossRef]
- Gaspar, R.; Pedro, C.; Panagiotopoulos, P.; Seibt, B. Beyond positive or negative: Qualitative sentiment analysis of social media reactions to unexpected stressful events. Comput. Hum. Behav. 2016, 56, 179–191. [Google Scholar] [CrossRef]
- Orbegozo-Terradillos, J.; Morales-i-Gras, J.; Larrondo, A. Feminismos indignados ante la justicia: La conversación digital en el caso de La Manada. IC Rev. Científica Inf. Comun. 2019, 16, 249–283. [Google Scholar]
- Krackhardt, D.; Stern, R.N. Informal networks and organizational crises: An experimental simulation. Soc. Psychol. Q. 1988, 51, 123–140. [Google Scholar] [CrossRef]
- Larrondo, A.; Morales-i-Gras, J.; Orbegozo-Terradillos, J. Feminist hashtag activism in Spain: Measuring the degree of politicisation of online discourse on #YoSíTeCreo, #HermanaYoSíTeCreo, #Cuéntalo y #NoEstásSola. Commun. Soc. 2019, 32, 207–221. [Google Scholar]
- Freeman, L.C. Centrality in social networks conceptual clarification. Soc. Netw. 1978, 1, 215–239. [Google Scholar] [CrossRef]
- Orbegozo-Terradillos, J.; Larrondo-Ureta, A.; Morales-i-Gras, J. Influencia del género en los debates electorales en España: Análisis de la audiencia social en #ElDebateDecisivo y# L6Neldebate. El Prof. Inf. 2020, 29, 12. [Google Scholar]
- Noguera, J.M. Redes y Periodismo. Cuando las Noticias se Socializan; Editorial UOC: Barcelona, Spain, 2012. [Google Scholar]
- Martínez-Nicolás, M.; Sapera-Lapiedra, E.; Carrasco-Campos, A. La investigación sobre comunicación en España en los últimos 25 años (1990–2014). Objetos de estudio y métodos aplicados en los trabajos publicados en revistas españolas especializadas. Empiria Rev. Metodol. Cienc. Soc. 2019, 42, 37–69. [Google Scholar] [CrossRef]
- Ruiz-Soler, J. Twitter research for social scientists: A brief introduction to the benefits, limitations and tools for analysing Twitter data. Digitos 2017, 3, 17–31. [Google Scholar]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Morales-i-Gras, J.; Orbegozo-Terradillos, J.; Larrondo-Ureta, A.; Peña-Fernández, S. Networks and Stories. Analyzing the Transmission of the Feminist Intangible Cultural Heritage on Twitter. Big Data Cogn. Comput. 2021, 5, 69. https://doi.org/10.3390/bdcc5040069
Morales-i-Gras J, Orbegozo-Terradillos J, Larrondo-Ureta A, Peña-Fernández S. Networks and Stories. Analyzing the Transmission of the Feminist Intangible Cultural Heritage on Twitter. Big Data and Cognitive Computing. 2021; 5(4):69. https://doi.org/10.3390/bdcc5040069
Chicago/Turabian StyleMorales-i-Gras, Jordi, Julen Orbegozo-Terradillos, Ainara Larrondo-Ureta, and Simón Peña-Fernández. 2021. "Networks and Stories. Analyzing the Transmission of the Feminist Intangible Cultural Heritage on Twitter" Big Data and Cognitive Computing 5, no. 4: 69. https://doi.org/10.3390/bdcc5040069
APA StyleMorales-i-Gras, J., Orbegozo-Terradillos, J., Larrondo-Ureta, A., & Peña-Fernández, S. (2021). Networks and Stories. Analyzing the Transmission of the Feminist Intangible Cultural Heritage on Twitter. Big Data and Cognitive Computing, 5(4), 69. https://doi.org/10.3390/bdcc5040069