
A Semantic Web Framework for Automated Smart Assistants: A Case Study for Public Health



Abstract
:1. Introduction
Relevant Work
- Can natural-language question answering be democratized for under-resourced organizations and teams?
- Can a voice-enabled smart assistant be realized and function with client-side computational resources?
- Is it possible to ensure data privacy while using voice assistants?
- Can a caching mechanism be employed for offline chatbot usage?
2. Methods

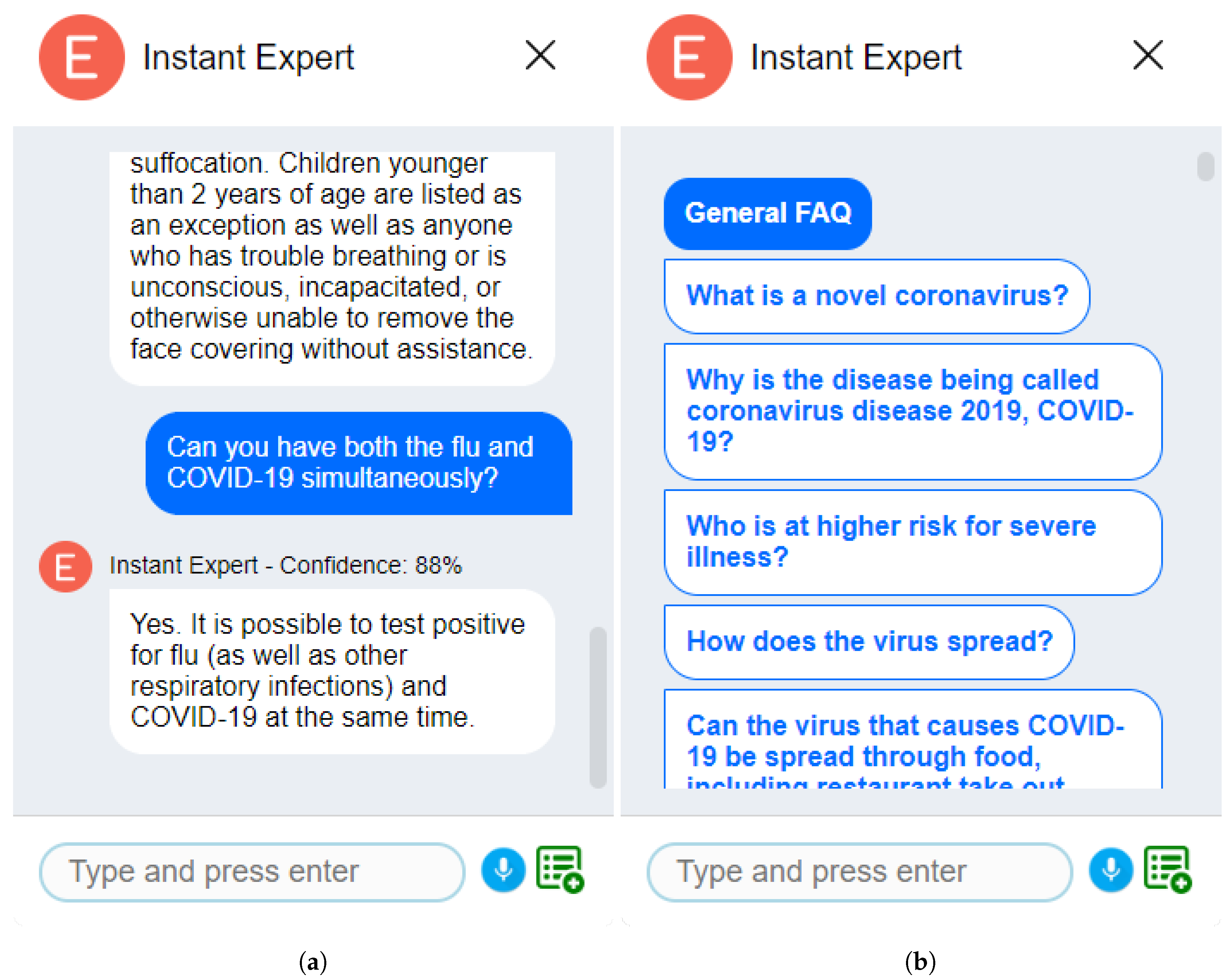
2.1. User Interaction and Interface
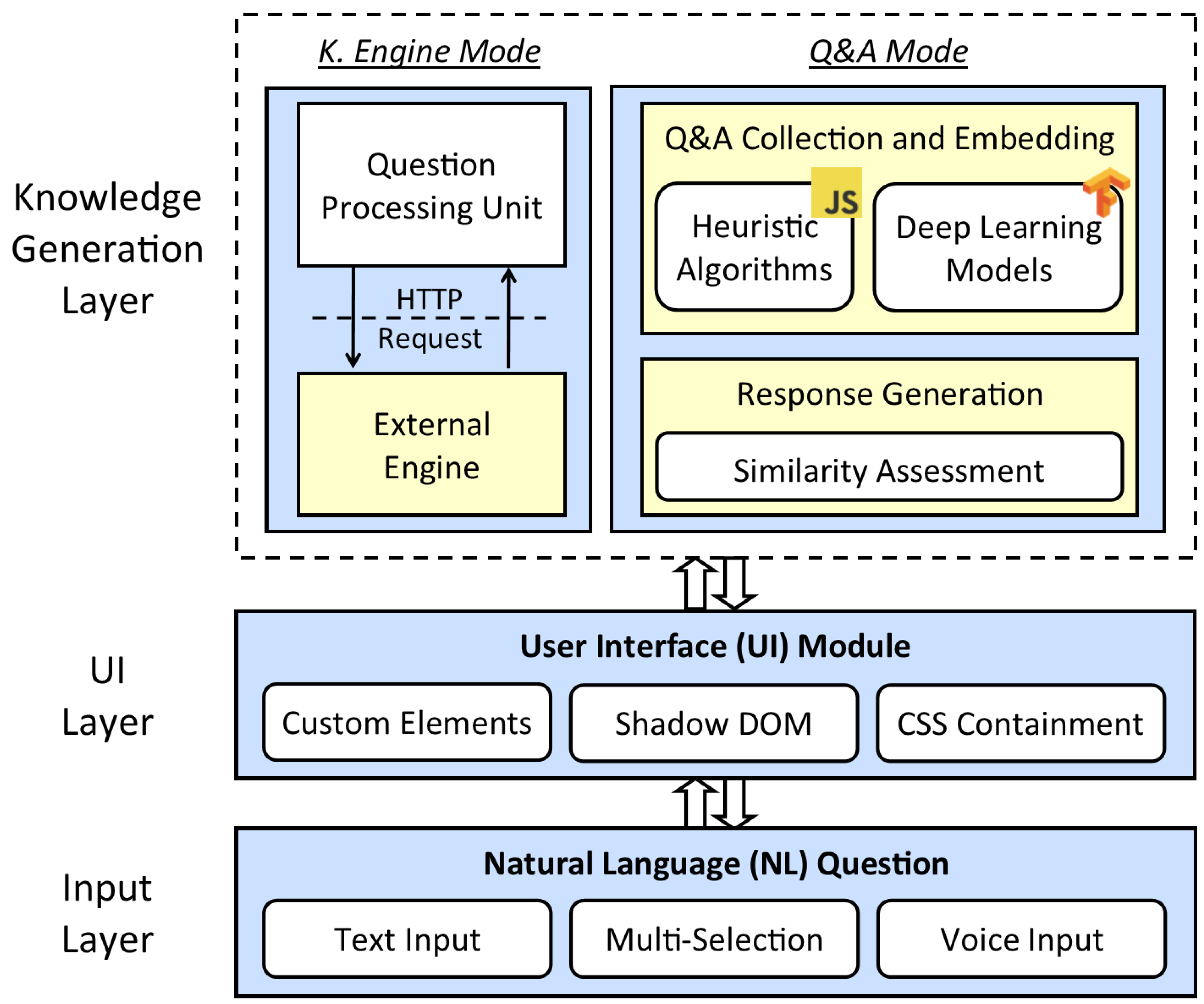
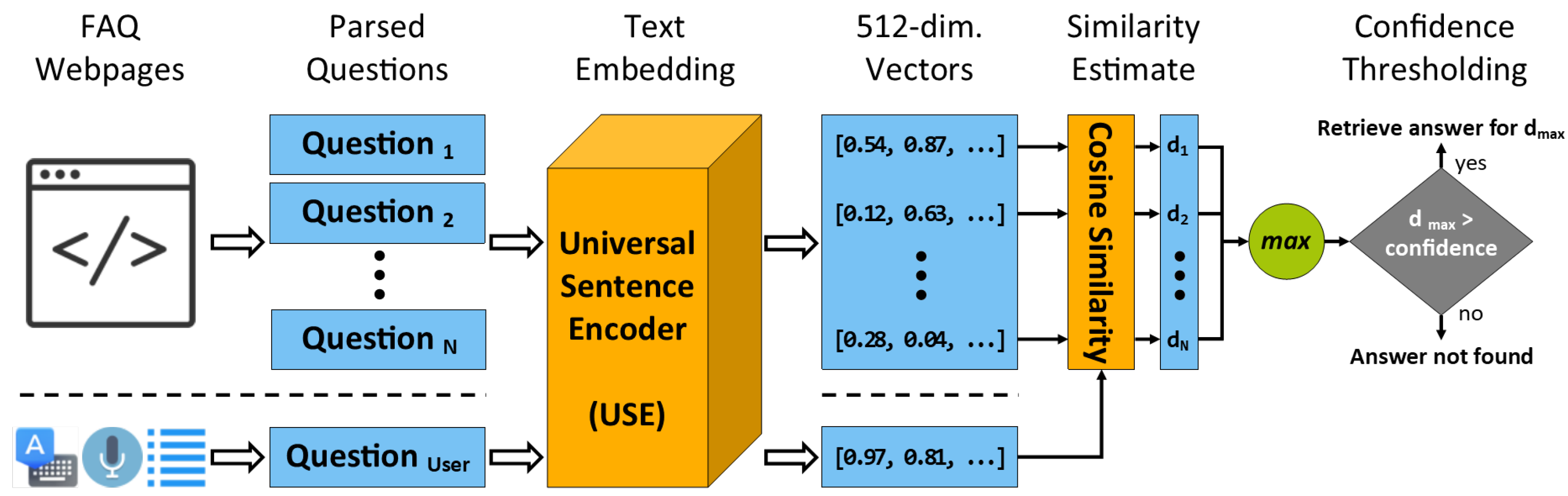
2.2. Knowledge Generation Module
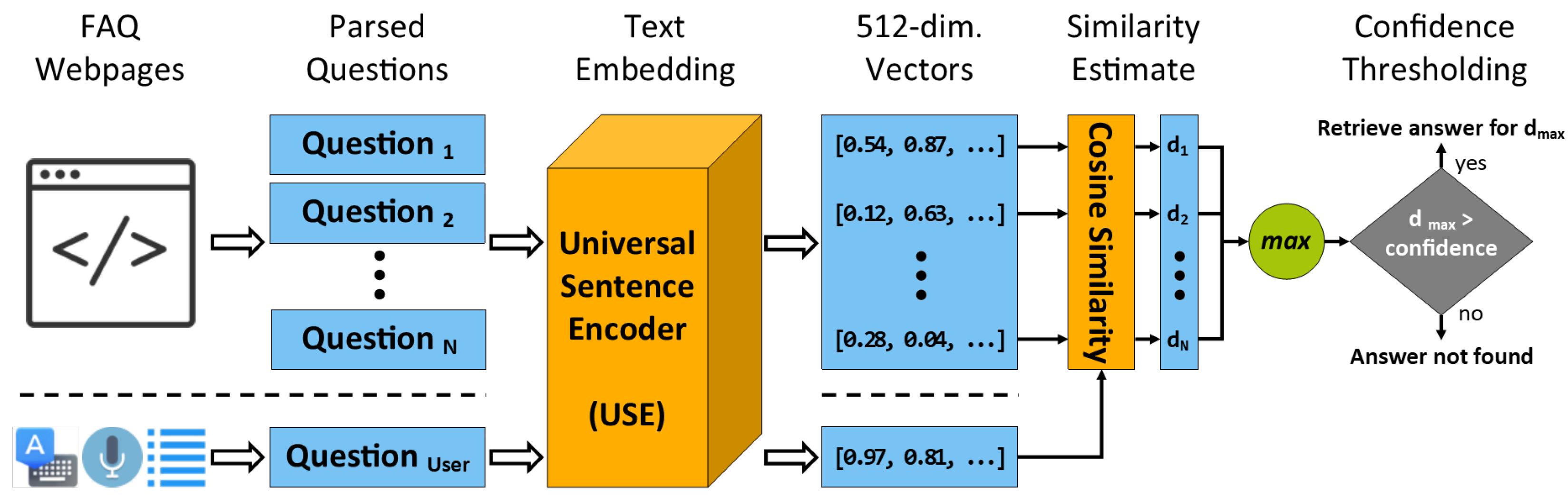
2.2.1. Q&A Mode
 or simply have been coded sequentially in the same scope with other questions and answers:
or simply have been coded sequentially in the same scope with other questions and answers:

2.2.2. Knowledge-Engine Mode
3. Results
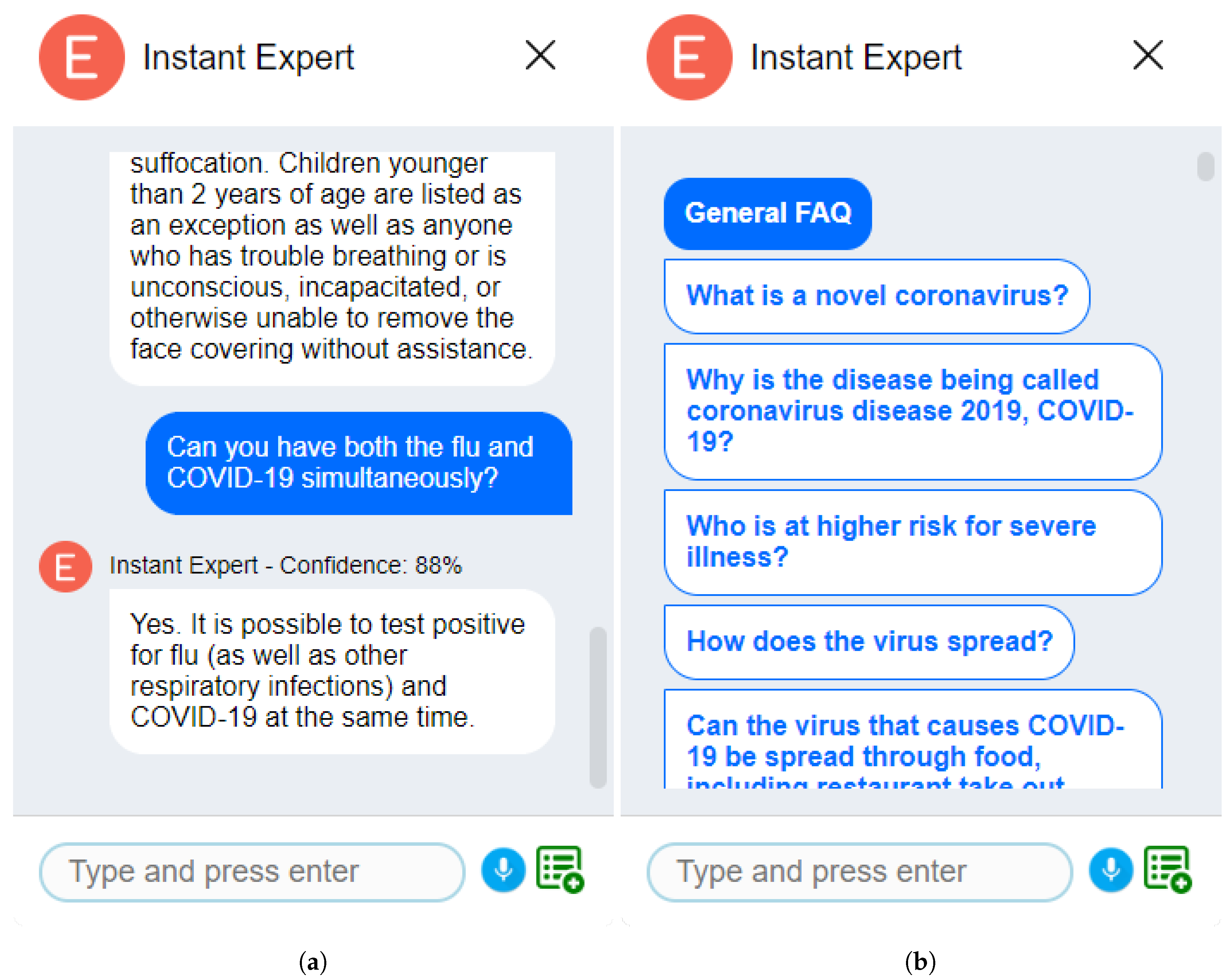
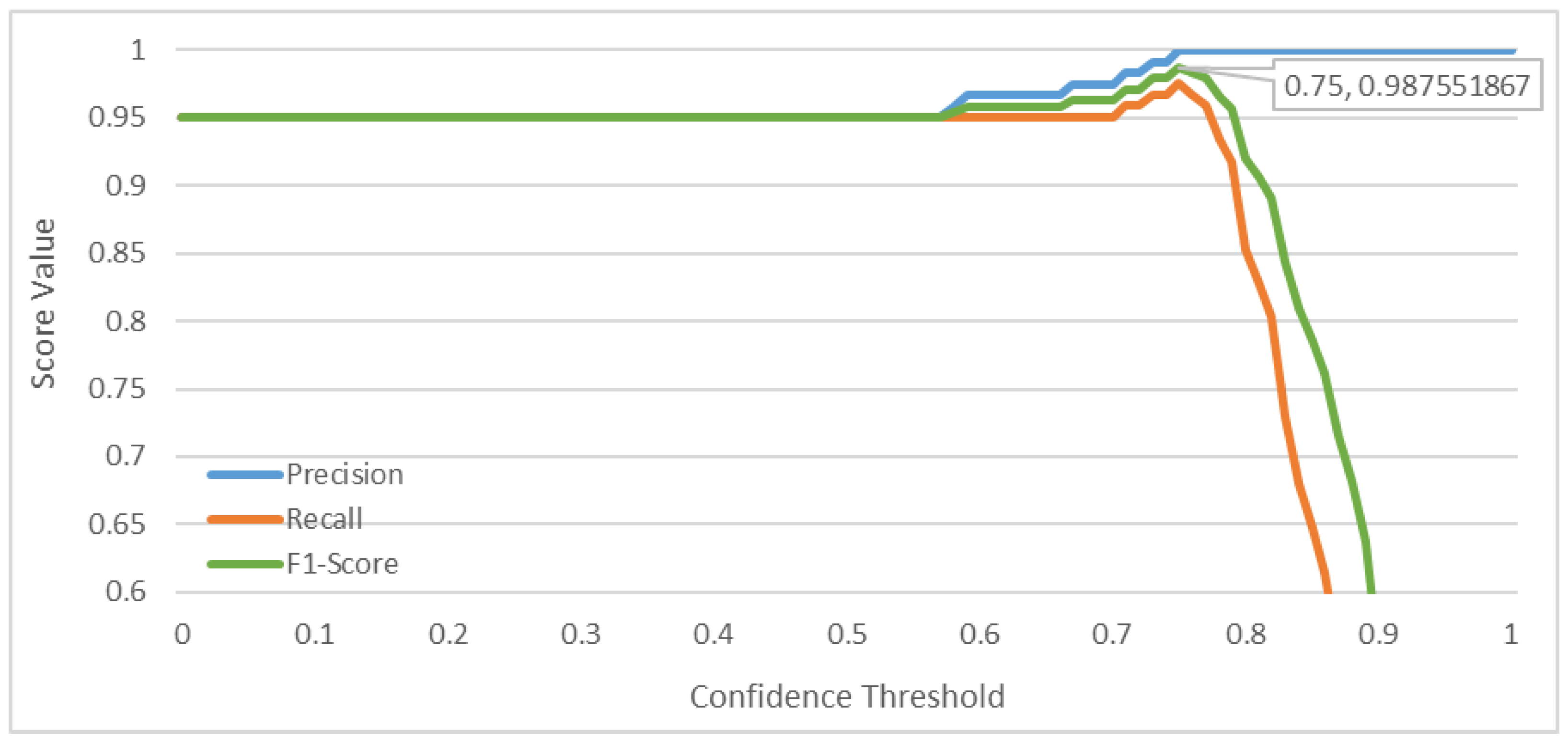
3.1. Q&A Mode–Public Health Case Study
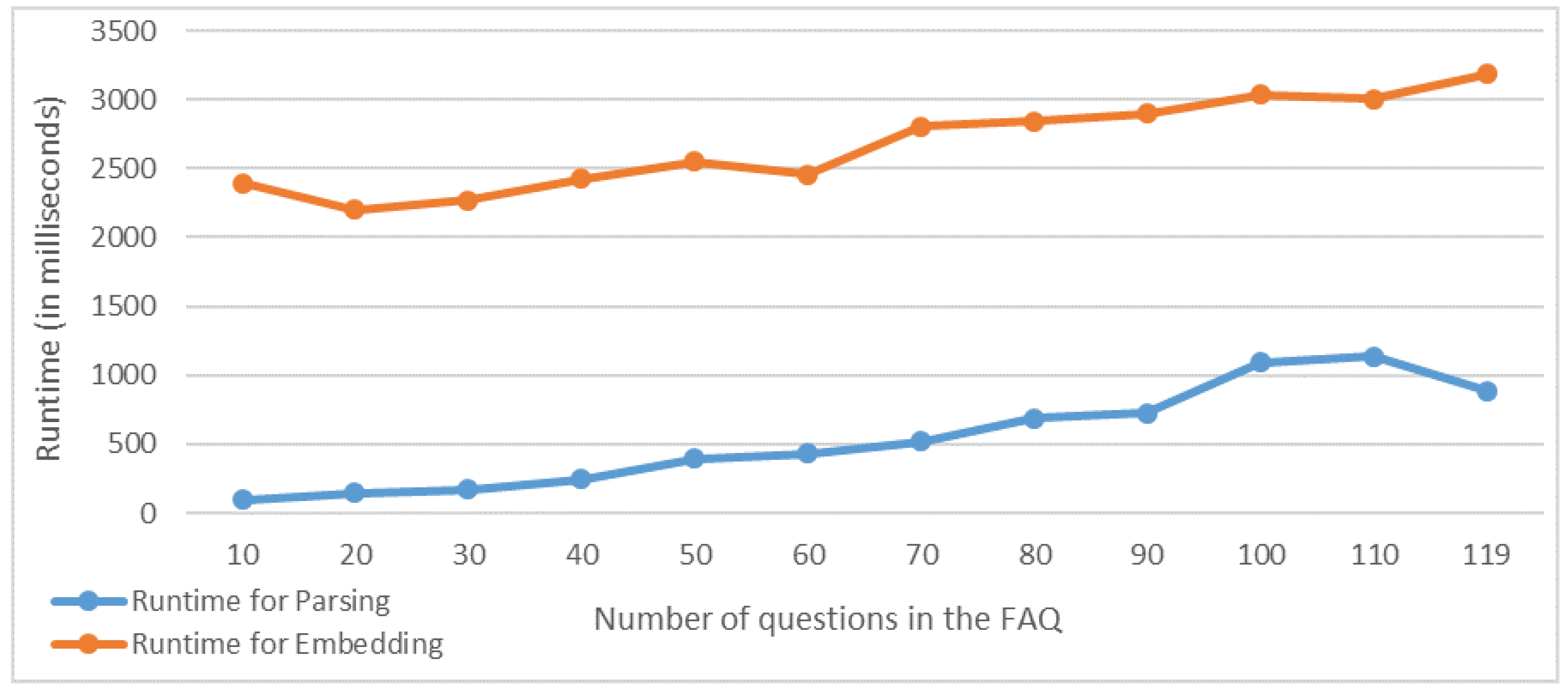
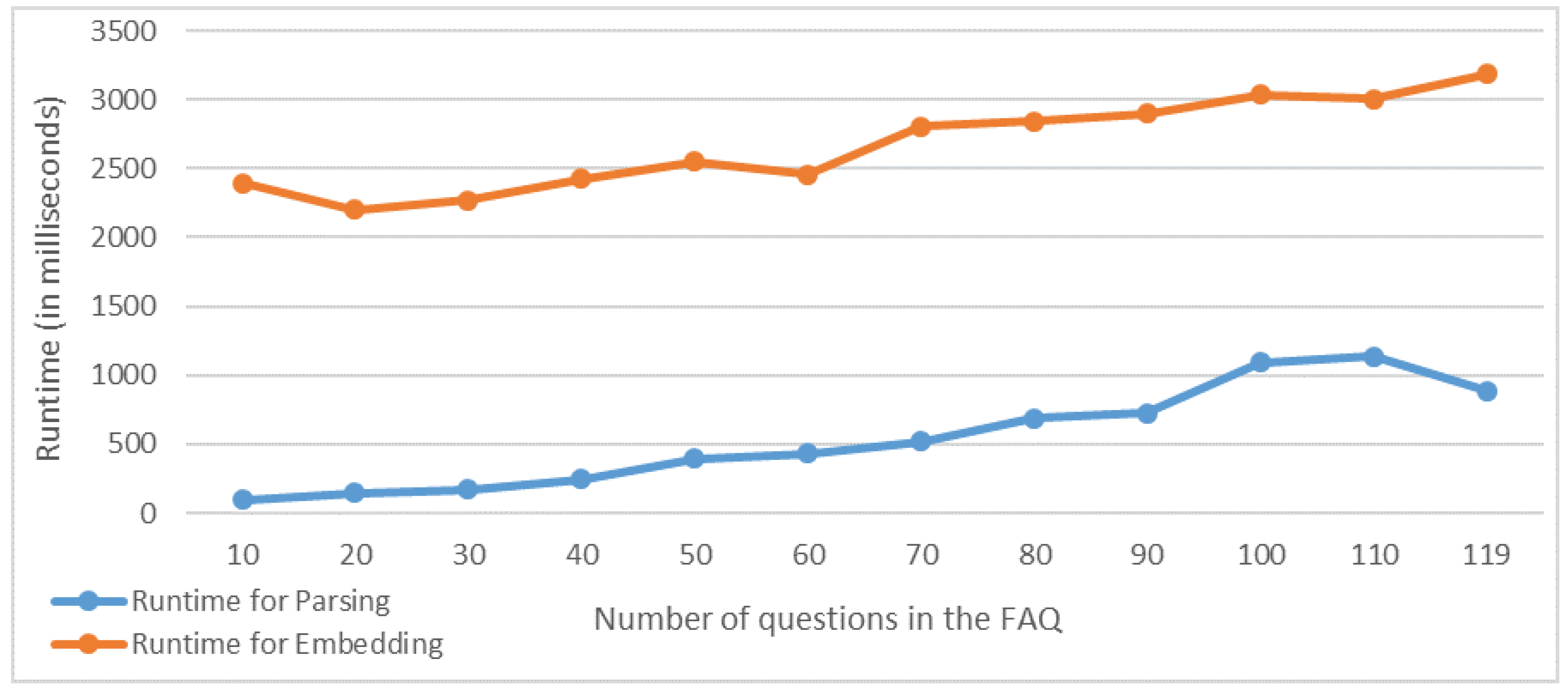
3.1.1. FAQ from a Web Page

3.1.2. FAQ from a Custom List

3.1.3. FAQ from a Model

3.2. Knowledge-Engine Mode-Web Search Use Case
4. Discussions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sermet, Y.; Villanueva, P.; Sit, M.A.; Demir, I. Crowdsourced approaches for stage measurements at ungauged locations using smartphones. Hydrol. Sci. J. 2020, 65, 813–822. [Google Scholar] [CrossRef]
- Wu, X.; Zhu, X.; Wu, G.Q.; Ding, W. Data mining with big data. IEEE Trans. Knowl. Data Eng. 2013, 26, 97–107. [Google Scholar]
- Sit, M.; Sermet, Y.; Demir, I. Optimized watershed delineation library for server-side and client-side web applications. Open Geospat. Data Softw. Stand. 2019, 4, 8. [Google Scholar] [CrossRef] [Green Version]
- Demir, I.; Yildirim, E.; Sermet, Y.; Sit, M.A. FLOODSS: Iowa flood information system as a generalized flood cyberinfrastructure. Int. J. River Basin Manag. 2018, 16, 393–400. [Google Scholar] [CrossRef]
- Peppard, J.; Ward, J. The Strategic Management of Information Systems: Building a Digital Strategy; John Wiley & Sons: Hoboken, NJ, USA, 2016. [Google Scholar]
- Carson, A.; Windsor, M.; Hill, H.; Haigh, T.; Wall, N.; Smith, J.; Olsen, R.; Bathke, D.; Demir, I.; Muste, M. Serious gaming for participatory planning of multi-hazard mitigation. Int. J. River Basin Manag. 2018, 16, 379–391. [Google Scholar] [CrossRef]
- Alberts, I. Challenges of information system use by knowledge workers: The email productivity paradox. Proc. Am. Soc. Inf. Sci. Technol. 2013, 50, 1–10. [Google Scholar] [CrossRef]
- Sermet, M.Y.; Demir, I.; Kucuksari, S. Overhead power line sag monitoring through augmented reality. In Proceedings of the 2018 North American Power Symposium (NAPS), Fargo, ND, USA, 9–11 September 2018; pp. 1–5. [Google Scholar]
- Xu, H.; Windsor, M.; Muste, M.; Demir, I. A web-based decision support system for collaborative mitigation of multiple water-related hazards using serious gaming. J. Environ. Manag. 2020, 255, 109887. [Google Scholar] [CrossRef] [PubMed]
- Sermet, Y.; Demir, I.; Muste, M. A serious gaming framework for decision support on hydrological hazards. Sci. Total Environ. 2020, 728, 138895. [Google Scholar] [CrossRef] [Green Version]
- Liao, S.H. Expert system methodologies and applications—A decade review from 1995 to 2004. Expert Syst. Appl. 2005, 28, 93–103. [Google Scholar] [CrossRef]
- Brandtzaeg, P.B.; Følstad, A. Why people use chatbots. In International Conference on Internet Science; Springer: Berlin/Heidelberg, Germany, 2017; pp. 377–392. [Google Scholar]
- Sit, M.; Demiray, B.Z.; Xiang, Z.; Ewing, G.J.; Sermet, Y.; Demir, I. A comprehensive review of deep learning applications in hydrology and water resources. Water Sci. Technol. 2020, 82, 2635–2670. [Google Scholar] [CrossRef] [PubMed]
- IMARCGroup Intelligent Virtual Assistant Market: Global Industry Trends, Share, Size, Growth, Opportunity and Forecast 2019–2024. 2019. Available online: https://www.researchandmarkets.com/reports/4775648/intelligent-virtual-assistant-market-global (accessed on 11 October 2021).
- Schoemaker, P.J.; Tetlock, P.E. Building a more intelligent enterprise. MIT Sloan Manag. Rev. 2017, 58, 28. [Google Scholar]
- Jain, M.; Kumar, P.; Kota, R.; Patel, S.N. Evaluating and informing the design of chatbots. In Proceedings of the 2018 Designing Interactive Systems Conference, Hong Kong, China, 9–13 June 2018; pp. 895–906. [Google Scholar]
- Chung, K.; Park, R.C. Chatbot-based heathcare service with a knowledge base for cloud computing. Clust. Comput. 2019, 22, 1925–1937. [Google Scholar] [CrossRef]
- Yildirim, E.; Demir, I. An integrated web framework for HAZUS-MH flood loss estimation analysis. Nat. Hazards 2019, 99, 275–286. [Google Scholar] [CrossRef]
- Androutsopoulou, A.; Karacapilidis, N.; Loukis, E.; Charalabidis, Y. Transforming the communication between citizens and government through AI-guided chatbots. Gov. Inf. Q. 2019, 36, 358–367. [Google Scholar] [CrossRef]
- Vaidyam, A.N.; Wisniewski, H.; Halamka, J.D.; Kashavan, M.S.; Torous, J.B. Chatbots and conversational agents in mental health: A review of the psychiatric landscape. Can. J. Psychiatry 2019, 64, 456–464. [Google Scholar] [CrossRef]
- USACE Virtual Assistant Technology Holds Promise for USACE. 2019. Available online: https://www.usace.army.mil/Media/News-Archive/Story-Article-View/Article/2014053/virtual-assistant-technology-holds-promise-for-usace/ (accessed on 11 October 2021).
- Miner, A.S.; Laranjo, L.; Kocaballi, A.B. Chatbots in the fight against the COVID-19 pandemic. NPJ Digit. Med. 2020, 3, 1–4. [Google Scholar] [CrossRef]
- Sohrabi, C.; Alsafi, Z.; O’Neill, N.; Khan, M.; Kerwan, A.; Al-Jabir, A.; Iosifidis, C.; Agha, R. World Health Organization declares global emergency: A review of the 2019 novel coronavirus (COVID-19). Int. J. Surg. 2020, 76, 71–76. [Google Scholar] [CrossRef]
- Laranjo, L.; Dunn, A.G.; Tong, H.L.; Kocaballi, A.B.; Chen, J.; Bashir, R.; Surian, D.; Gallego, B.; Magrabi, F.; Lau, A.Y.; et al. Conversational agents in healthcare: A systematic review. J. Am. Med. Inform. Assoc. 2018, 25, 1248–1258. [Google Scholar] [CrossRef] [Green Version]
- Hwang, S.; Kim, J. Toward a Chatbot for Financial Sustainability. Sustainability 2021, 13, 3173. [Google Scholar] [CrossRef]
- Sermet, Y.; Demir, I. An intelligent system on knowledge generation and communication about flooding. Environ. Model. Softw. 2018, 108, 51–60. [Google Scholar] [CrossRef]
- Kolenik, T.; Gams, M. Intelligent Cognitive Assistants for Attitude and Behavior Change Support in Mental Health: State-of-the-Art Technical Review. Electronics 2021, 10, 1250. [Google Scholar] [CrossRef]
- Lee, K.; Jo, J.; Kim, J.; Kang, Y. Can Chatbots Help Reduce the Workload of Administrative Officers?-Implementing and Deploying FAQ Chatbot Service in a University. In International Conference on Human-Computer Interaction; Springer: Berlin/Heidelberg, Germany, 2019; pp. 348–354. [Google Scholar]
- Abdellatif, A.; Costa, D.; Badran, K.; Abdalkareem, R.; Shihab, E. Challenges in chatbot development: A study of stack overflow posts. In Proceedings of the 17th International Conference on Mining Software Repositories, Seoul, Korea, 29–30 June 2020; pp. 174–185. [Google Scholar]
- Daniel, G.; Cabot, J.; Deruelle, L.; Derras, M. Xatkit: A multimodal low-code chatbot development framework. IEEE Access 2020, 8, 15332–15346. [Google Scholar] [CrossRef]
- Singh, A.; Ramasubramanian, K.; Shivam, S. Introduction to Microsoft Bot, RASA, and Google Dialogflow. In Building an Enterprise Chatbot; Springer: Berlin/Heidelberg, Germany, 2019; pp. 281–302. [Google Scholar]
- Radziwill, N.M.; Benton, M.C. Evaluating quality of chatbots and intelligent conversational agents. arXiv 2017, arXiv:1704.04579. [Google Scholar]
- Schmidt, B.; Borrison, R.; Cohen, A.; Dix, M.; Gärtler, M.; Hollender, M.; Klöpper, B.; Maczey, S.; Siddharthan, S. Industrial Virtual Assistants: Challenges and Opportunities. In Proceedings of the 2018 ACM International Joint Conference and 2018 International Symposium on Pervasive and Ubiquitous Computing and Wearable Computers, Singapore, 8–12 October 2018; pp. 794–801. [Google Scholar]
- MindCommerce Virtual Personal Assistants (VPA) and Smart Speaker Market: Artificial Intelligence Enabled Smart Advisers, Intelligent Agents, and VPA Devices 2019–2024. 2019. Available online: https://mindcommerce.com/reports/virtual-personal-assistant-market/ (accessed on 11 October 2021).
- Adam, M.; Wessel, M.; Benlian, A. AI-based chatbots in customer service and their effects on user compliance. Electron. Mark. 2020, 9, 204. [Google Scholar] [CrossRef] [Green Version]
- Sermet, Y.; Demir, I. Virtual and augmented reality applications for environmental science education and training. In New Perspectives on Virtual and Augmented Reality: Finding New Ways to Teach in a Transformed Learning Environment; Routledge: Abingdon, UK, 2020. [Google Scholar]
- Oh, J.; Ahn, W.H.; Kim, T. Web app restructuring based on shadow DOMs to improve maintainability. In Proceedings of the 2017 8th IEEE International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 24–26 November 2017; pp. 118–122. [Google Scholar]
- De Ryck, P.; Nikiforakis, N.; Desmet, L.; Piessens, F.; Joosen, W. Protected web components: Hiding sensitive information in the shadows. IT Prof. 2015, 17, 36–43. [Google Scholar] [CrossRef] [Green Version]
- Atkins, T.; Rivoal, F. CSS Containment Module Level 1. 2018. Available online: https://www.w3.org/TR/css-contain-1/ (accessed on 11 October 2021).
- Damani, S.; Narahari, K.N.; Chatterjee, A.; Gupta, M.; Agrawal, P. Optimized Transformer Models for FAQ Answering. In Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2020; pp. 235–248. [Google Scholar]
- Jijkoun, V.; de Rijke, M. Retrieving answers from frequently asked questions pages on the web. In Proceedings of the 14th ACM International Conference on Information and Knowledge Management, Bremen, Germany, 31 October–5 November 2005; pp. 76–83. [Google Scholar]
- Farouk, M. Measuring Text Similarity Based on Structure and Word Embedding. Cogn. Syst. Res. 2020, 63, 1–10. [Google Scholar] [CrossRef]
- Cer, D.; Yang, Y.; Kong, S.Y.; Hua, N.; Limtiaco, N.; John, R.S.; Constant, N.; Guajardo-Cespedes, M.; Yuan, S.; Tar, C.; et al. Universal sentence encoder. arXiv 2018, arXiv:1803.11175. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Sermet, Y.; Demir, I. Towards an information centric flood ontology for information management and communication. Earth Sci. Inform. 2019, 12, 541–551. [Google Scholar] [CrossRef]
- CNBC. Microsoft is Launching a ‘Plasmabot’ to Encourage People Who Recovered from the Virus to Donate Their Plasma as a Possible Treatment. Available online: https://www.cnbc.com/2020/04/18/microsoft-plasmabot-encourages-covid-19-survivors-to-donate-plasma.html (accessed on 11 October 2021).
- Espinoza, J.; Crown, K.; Kulkarni, O. A Guide to Chatbots for COVID-19 Screening at Pediatric Health Care Facilities. JMIR Public Health Surveill. 2020, 6, e18808. [Google Scholar] [CrossRef]
- Judson, T.J.; Odisho, A.Y.; Young, J.J.; Bigazzi, O.; Steuer, D.; Gonzales, R.; Neinstein, A.B. Case Report: Implementation of a Digital Chatbot to Screen Health System Employees during the COVID-19 Pandemic. J. Am. Med. Inform. Assoc. 2020, 27, 1450–1455. [Google Scholar] [CrossRef] [PubMed]
- Martin, A.; Nateqi, J.; Gruarin, S.; Munsch, N.; Abdarahmane, I.; Knapp, B. An artificial intelligence-based first-line defence against COVID-19: Digitally screening citizens for risks via a chatbot. bioRxiv 2020. [Google Scholar] [CrossRef] [PubMed]
- Sharma, M.; Yadav, K.; Yadav, N.; Ferdinand, K.C. Zika virus pandemic—Analysis of Facebook as a social media health information platform. Am. J. Infect. Control 2017, 45, 301–302. [Google Scholar] [CrossRef]
- Vergadia, P. How Can Chatbots Help during Global Pandemic (COVID-19)? Available online: https://medium.com/google-cloud/how-can-chatbots-help-during-global-pandemic-covid-19-9c1a4428d8c2 (accessed on 11 October 2021).
- SimilarWeb. Coronavirus Data, Insights, and Trends. Available online: https://www.similarweb.com/coronavirus/ (accessed on 11 October 2021).
- Centers for Disease Control and Prevention (CDC). Coronavirus (COVID-19) Frequently Asked Questions. 2021. Available online: https://www.cdc.gov/coronavirus/2019-ncov/faq.html (accessed on 11 October 2021).
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- He, H.; Ma, Y. Imbalanced Learning: Foundations, Algorithms, and Applications; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Ross, C. I Asked Eight Chatbots Whether I Had COVID-19. The Answers Ranged from ‘Low’ Risk to ‘Start Home Isolation’. Available online: https://www.statnews.com/2020/03/23/coronavirus-i-asked-eight-chatbots-whether-i-had-covid-19/ (accessed on 11 October 2021).
- Microsoft. Project Answer Search. Available online: https://labs.cognitive.microsoft.com/en-us/project-answer-search (accessed on 11 October 2021).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Original Question | Generated Test Question |
|---|---|
| “Should I make my own hand sanitizer if I cannot find it in the stores?” | There are no hand sanitizer left in stores. Should I make one myself? |
| “What should I do if there is an outbreak in my community?” | What are you suggesting me to do if my community suffers from an outbreak? |
| “Should I go to work if there is an outbreak in my community?” | Am I supposed to continue working if we have an outbreak in my street? |
| “Can CDC tell me or my employer when it is safe for me to go back to work/school after recovering from or being exposed to COVID-19?” | If I am exposed to COVID-19, when can I safely go back to work? |
| “My family member died from COVID-19 while overseas. What are the requirements for returning the body to the United States?” | What is the policy on bringing my relative back to US who passed away due to COVID-19? |
| “What is routine cleaning? How frequently should facilities be cleaned to reduce the potential spread of COVID-19?” | How often should I clean my place to prevent COVID-19? |
| “What should I do if there are pets at my long-term care facility or assisted living facility?” | What steps I should take if my nursing home has pets? |
| N/A (CDC’s FAQ does not have this question) | Am I at risk of serious complications from COVID-19 if I smoke cigarettes? |
| N/A (CDC’s FAQ does not have this question) | Are there any vaccines to prevent COVID-19? |
| N/A (CDC’s FAQ does not have this question) | Are antibiotics effective in preventing or treating COVID-19? |
| Original Question | Test Question | Commentary |
|---|---|---|
| “Limit time with older adults, including relatives, and people with chronic medical conditions.” | “Should I avoid spending time with the elderly, especially those with health conditions?” | The structure of the original question is not in the form of a question, and rather a recommendation. Especially since there are similar questions exist in the FAQ on dealing with people with underlying conditions, the mapping process could not complete with a satisfactory confidence. |
| “Will businesses and schools close or stay closed in my community and for how long? Will there be a “stay at home” or “shelter in place” order in my community?” | “For how much longer the business will stay closed?” | This FAQ item is too broad, and in fact entails three different questions for business or schools. The test question only asks a portion of the FAQ item concerning the businesses, which results in unsatisfactory confidence. |
| “What about imported animals or animal products?” | “Do animal products pose risk?” | This FAQ question is incomplete as its meaning depend on a previous question in the FAQ list. |
| FAQ Source | No of Q&A | No of Parsed Q&A | Precision | Recall |
|---|---|---|---|---|
| FDA COVID-19 FAQ (fda.gov) | 78 | 78 | 100% | 100% |
| World Health Organization (WHO)—Q&A on coronaviruses (who.int) | 24 | 24 | ||
| United Nations COVID-19 FAQ (un.org) | ||||
| (in English) | 40 | 40 | ||
| (in French) | 37 | 37 | ||
| (in Spanish) | 38 | 38 | ||
| Stanford COVID-19 FAQ (stanfordhealthcare.org) | 16 | 16 | ||
| Robert Koch Institut COVID-19 FAQ (rki.de) | ||||
| (in German) | 43 | 43 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sermet, Y.; Demir, I. A Semantic Web Framework for Automated Smart Assistants: A Case Study for Public Health. Big Data Cogn. Comput. 2021, 5, 57. https://doi.org/10.3390/bdcc5040057
Sermet Y, Demir I. A Semantic Web Framework for Automated Smart Assistants: A Case Study for Public Health. Big Data and Cognitive Computing. 2021; 5(4):57. https://doi.org/10.3390/bdcc5040057
Chicago/Turabian StyleSermet, Yusuf, and Ibrahim Demir. 2021. "A Semantic Web Framework for Automated Smart Assistants: A Case Study for Public Health" Big Data and Cognitive Computing 5, no. 4: 57. https://doi.org/10.3390/bdcc5040057
APA StyleSermet, Y., & Demir, I. (2021). A Semantic Web Framework for Automated Smart Assistants: A Case Study for Public Health. Big Data and Cognitive Computing, 5(4), 57. https://doi.org/10.3390/bdcc5040057