
Advances in Convolution Neural Networks Based Crowd Counting and Density Estimation



Abstract
:
1. Introduction
2. Related Work and Motivation
2.1. Detection-Based Approaches
2.2. Regression-Based Approaches
2.3. Traditional Density Estimation Based Approaches
2.4. CNN-Based Density Estimation
3. Related Previous Surveys
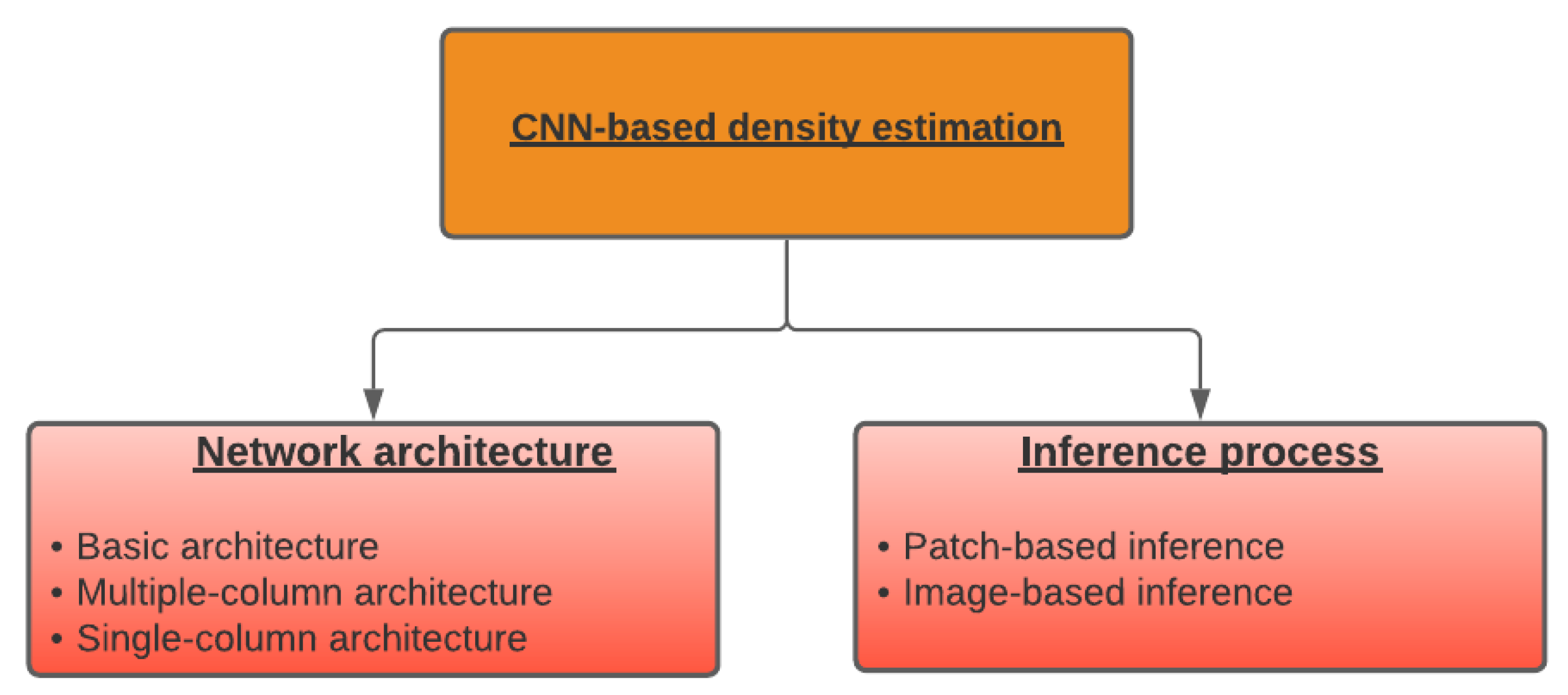
4. Taxonomy for CNN-Based Density Estimation
4.1. Typical CNN Architecture for Density Estimation and Crowd Counting
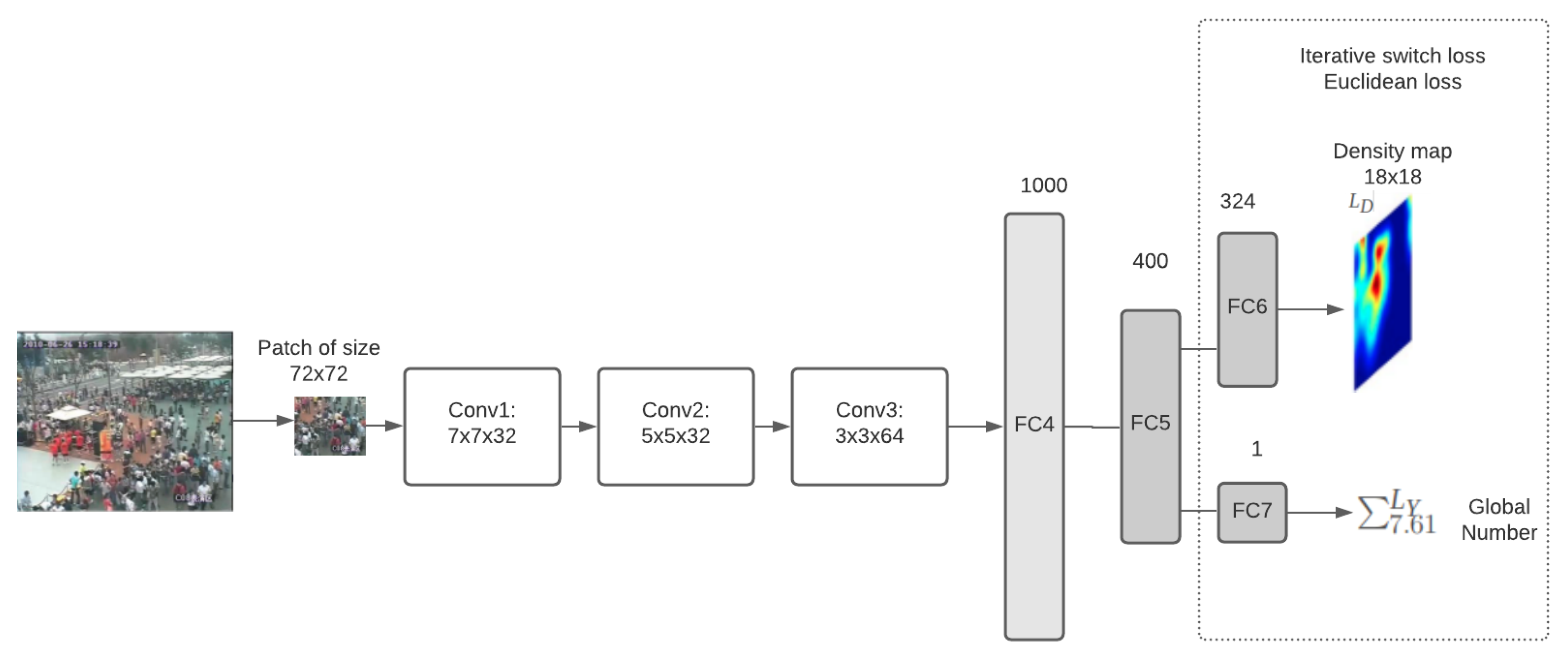
4.1.1. Basic Network Architecture
4.1.2. Multiple-Column Architecture
4.1.3. Single-Column Architecture
4.2. Typical Inference Paradigm
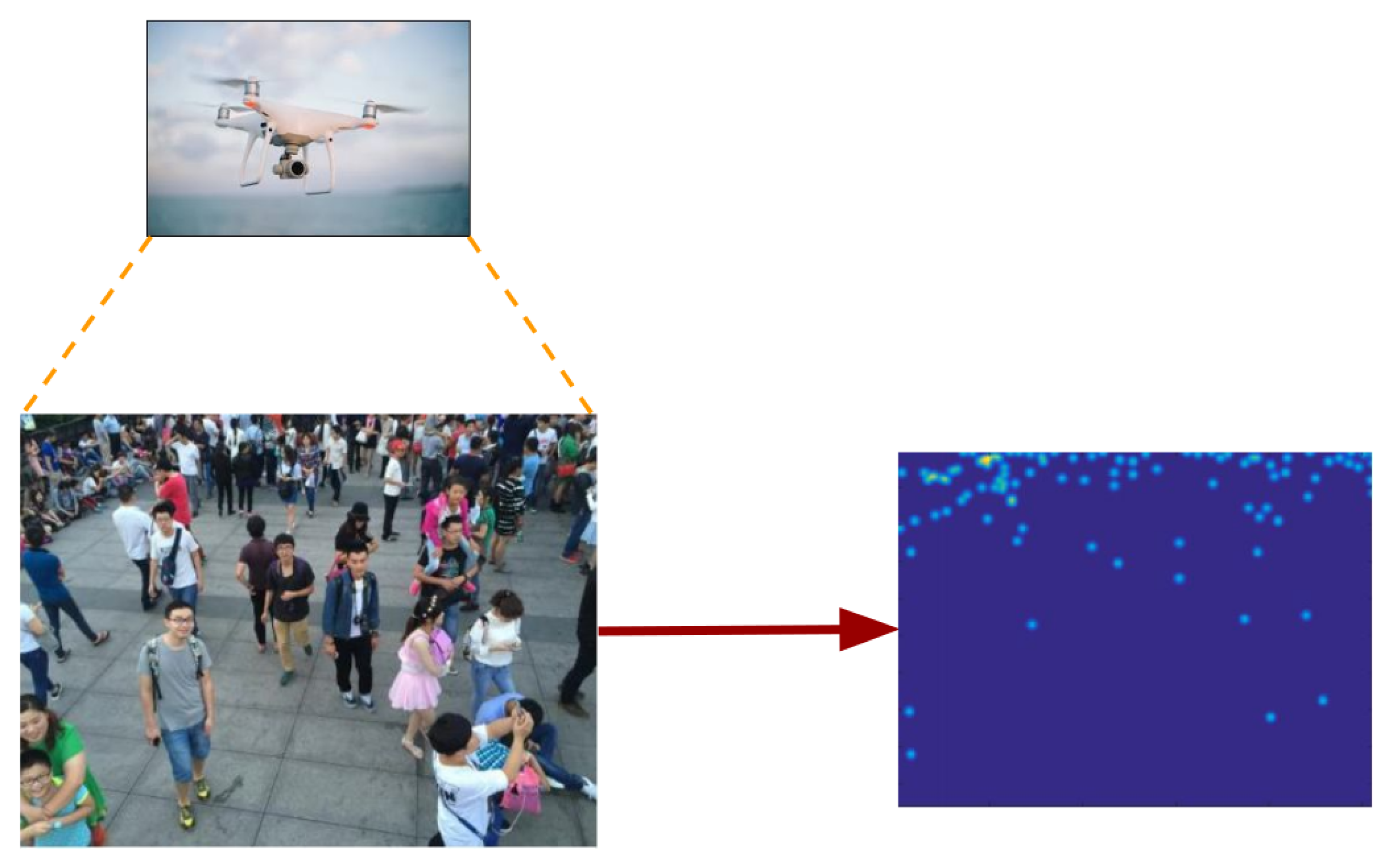
4.2.1. Patch-Based Inference
4.2.2. Image-Based Inference
5. Datasets and Results
- UCSD [69]: It was among the first datasets to be collected to count people. It was acquired with a stationary camera mounted at an elevated position, overlooking pedestrian walkways. The dataset contains 2000 frames of size 158 × 512 along with annotations of pedestrians in every 1/5 frames, while the other frames are annotated using linear interpolation. It provides also the bounding box coordinates for every pedestrian. The dataset has 49,885 person instances, which are split into training and test subsets. UCSD has a low-density crowd with an average of 25 pedestrian instances, and the perspective across images does not change greatly since all images are captured from the same location.
- Mall [70]: This dataset is collected from a publicly accessible webcam in a shopping mall. The video sequence of the dataset contains over 2000 frames of size 640 × 480 in which 62,325 heads were annotated with an average of 25 heads per image. By comparing to UCSD, the Mall dataset was created with higher crowd densities as well as more significant changes in illumination conditions and different activity patterns (static vs. moving people). The scene has severe perspective distortion along the video sequence, which results in large variations in scale and appearance of objects. In addition, there exist severe occlusions caused by different objects in the mall.
- UCF_CC_50 [13]: It is the first challenging dataset, which was created by directly scraping publicly web images. The dataset presents a wide range of crowd densities along with large varying perspective distortion. It contains only 50 images whose size is 2101 × 2888 pixels. These images contain a total of 241,677 head instances with an average of 1279 heads in each image. Due to its small size, the performance of recent CNN-based models is far from optimal.
- WorldExpo’10 [54]: Zhang et al. [54] remarked that most existing crowd counting methods are scene-specific and their performance drops significantly when they are applied to unseen scenes with different layouts. To deal with this, they introduced the WorldExpo’10 dataset to perform a data-driven cross-scene crowd counting. They collected the data from Shanghai 2010 World-Expo, which contains 1132 video sequences captured by 108 cameras with an image resolution of 576 × 720 pixels. The dataset contains 3980 frames that contain a total of 200,000 annotated heads for an average of 50 heads by frame.
- AHU-Crowd [71]: It is composed of diverse video sequences representing dense crowds in different public places including stations, stadiums, rallies, marathons, and pilgrimage. The sequences have different perspective views, resolutions, and crowd densities and cover a large multitude of motion behaviors for both obvious and subtle instabilities. The dataset contains 107 frames whose size is 720 × 576 pixels, and 45,000 annotated heads.
- ShanghaiTechRGBD [72]: It is a large-scale dataset composed of 2193 for a total of 144,512 annotated head count. The images are captured by a stereo camera with a valid depth ranging from 0 to 20 m. The images are captured in very busy streets of metropolitan areas and crowded public parks, while the light conditions vary from very bright to very dark.
- CityUHK-X [73]: It contains 55 scenes captured using a moving camera with a tilt angle range of [−10°, −65°] and a height range of [2.2, 16.0] meters. The dataset is split into training and test subsets. The training subset is composed of 43 scenes for a total of 2503 images and 78,592 people, while the test subset is composed of 12 scenes for a total of 688 images and 28,191 people.
- SmartCity [47]: It consists of 50 images, collected from 10 different cities for outdoor scenes of different places, such as shopping malls, office entrances, sidewalks, and atriums.
- Crowd Surveillance [74]: It is composed of 13,945 high-resolution images. It is split into 10,880 images for training and 3065 images for testing for a total of 386,513 head count.
- DroneCrowd [75]: It was captured using a drone-mounted camera and recorded at 25 frames per second with a resolution of 1920 × 1080 pixels. It contains 112 video clips with 33,600 frames. The annotation was performed by over 20 experts for more than two months so that more than 4.8 million heads are annotated on 20,800 people trajectories.
- DLR-ACD [76]: It is a collection of 33 aerial images for crowd counting and density estimation. It was captured through 16 different flights and over various urban scenes including sports events, city centers, and festivals.
- Fudan-ShanghaiTech [77]: It is a large-scale video crowd counting dataset, and it is the largest dataset for crowd counting and density estimation. It is composed of 100 videos captured from 13 different scenes. It contains 150,000 images for a total of 394,081 annotated head count.
- Venice [78]: It is a small dataset acquired in Piazza San Marco in Venice (Italy). It contains four different sequences for a total of 167 annotated images with a resolution of 1280 × 720 pixels.
- CityStreet [79]: It was collected from a busy city street using a multiview camera system, which is composed of five synchronized cameras. The dataset contains a total of 500 multi-view images in total.
- DISCO [80]: It was collected to jointly utilize ambient sounds and visual contexts for crowd counting. The dataset contains a total of 248 video clips, where each clip was recorded at 25 frames per second with a resolution of 1920 × 1080.
- DroneVehicle [81]: It consists of 15,532 pairs of RGB and infrared images for a total of 441,642 annotated objects. The images were acquired by a drone-mounted camera over various urban areas, including different types of urban roads, residential areas, and parking lots from day to night.
- NWPU-Crowd [82]: It contains 5109 images for a total of 2,133,375 annotated heads with point and box labels. Compared to existing datasets, it has negative samples and a large appearance variation.
- JHU-CROWD++ [83]: It is composed of 4372 images and 1.51 million annotations and acquired under various scenarios and environmental conditions. Labeling is provided in different formats, including dots, approximate bounding boxes, and blur levels.
6. Results and Discussions
- N: is the number of test samples.
- is the ground truth result corresponding to sample i.
- is the estimated result corresponding to sample i.
7. Potential Application of Crowd Counting
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xiong, F.; Shi, X.; Yeung, D.Y. Spatiotemporal modeling for crowd counting in videos. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5151–5159. [Google Scholar]
- Zhang, S.; Wu, G.; Costeira, J.P.; Moura, J.M. Fcn-rlstm: Deep spatio-temporal neural networks for vehicle counting in city cameras. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3667–3676. [Google Scholar]
- Dollar, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian Detection: An Evaluation of the State of the Art. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 743–761. [Google Scholar] [CrossRef]
- Xu, H.; Lv, P.; Meng, L. A people counting system based on head-shoulder detection and tracking in surveillance video. In Proceedings of the 2010 International Conference on Computer Design and Applications, Qinhuangdao, China, 25–27 June 2010; Volume 1, pp. V1-394–V1-398. [Google Scholar]
- Subburaman, V.; Descamps, A.; Carincotte, C. Counting People in the Crowd Using a Generic Head Detector. In Proceedings of the 2012 9th IEEE International Conference on Advanced Video and Signal Based Surveillance, IEEE Computer Society, Beijing, China, 18–21 September 2012; pp. 470–475. [Google Scholar] [CrossRef]
- Topkaya, I.S.; Erdogan, H.; Porikli, F. Counting people by clustering person detector outputs. In Proceedings of the 2014 11th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Seoul, Korea, 26–29 August 2014; pp. 313–318. [Google Scholar]
- Girshick, R.B.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R.B. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A. SSD: Single Shot MultiBox Detector. arXiv 2016, arXiv:1512.02325. [Google Scholar]
- Oñoro-Rubio, D.; López-Sastre, R.J. Towards Perspective-Free Object Counting with Deep Learning. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 615–629. [Google Scholar]
- Idrees, H.; Saleemi, I.; Seibert, C.; Shah, M. Multi-source Multi-scale Counting in Extremely Dense Crowd Images. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 25–27 June 2013; pp. 2547–2554. [Google Scholar]
- Chen, K.; Loy, C.C.; Gong, S.; Xiang, T. Feature Mining for Localised Crowd Counting. Available online: http://www.bmva.org/bmvc/2012/BMVC/paper021/paper021.pdf (accessed on 16 September 2021).
- Tota, K.; Idrees, H. Counting in Dense Crowds using Deep Features. Available online: https://www.crcv.ucf.edu/REU/2015/Tota/Karunya_finalreport.pdf (accessed on 16 September 2021).
- Ma, Z.; Chan, A.B. Crossing the Line: Crowd Counting by Integer Programming with Local Features. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 25–27 June 2013; pp. 2539–2546. [Google Scholar]
- Wang, Z.; Liu, H.; Qian, Y.; Xu, T. Crowd Density Estimation Based on Local Binary Pattern Co-Occurrence Matrix. In Proceedings of the 2012 IEEE International Conference on Multimedia and Expo Workshops, Melbourne, Australia, 9–13 July 2012; pp. 372–377. [Google Scholar]
- Balbin, J.R.; Garcia, R.G.; Fernandez, K.E.D.; Golosinda, N.P.G.; Magpayo, K.D.G.; Velasco, R.J.B. Crowd counting system by facial recognition using Histogram of Oriented Gradients, Completed Local Binary Pattern, Gray-Level Co-Occurrence Matrix and Unmanned Aerial Vehicle. In Third International Workshop on Pattern Recognition; Jiang, X., Chen, Z., Chen, G., Eds.; International Society for Optics and Photonics, SPIE: Bellingham, WA, USA, 2018; Volume 10828, pp. 238–242. [Google Scholar] [CrossRef]
- Ghidoni, S.; Cielniak, G.; Menegatti, E. Texture-Based Crowd Detection and Localisation. In Intelligent Autonomous Systems 12; Springer: Berlin/Heidelberg, Germany, 2013; Volume 193. [Google Scholar] [CrossRef] [Green Version]
- Chan, A.B.; Vasconcelos, N. Counting People With Low-Level Features and Bayesian Regression. IEEE Trans. Image Process. 2012, 21, 2160–2177. [Google Scholar] [CrossRef] [Green Version]
- Huang, X.; Zou, Y.; Wang, Y. Cost-sensitive sparse linear regression for crowd counting with imbalanced training data. In Proceedings of the 2016 IEEE International Conference on Multimedia and Expo (ICME), Seattle, WA, USA, 11–15 July 2016; pp. 1–6. [Google Scholar]
- Lempitsky, V.; Zisserman, A. Learning To Count Objects in Images. In Advances in Neural Information Processing Systems 23; Lafferty, J.D., Williams, C.K.I., Shawe-Taylor, J., Zemel, R.S., Culotta, A., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2010; pp. 1324–1332. [Google Scholar]
- Pham, V.; Kozakaya, T.; Yamaguchi, O.; Okada, R. COUNT Forest: CO-Voting Uncertain Number of Targets Using Random Forest for Crowd Density Estimation. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015; pp. 3253–3261. [Google Scholar]
- Silveira Jacques Junior, J.C.; Musse, S.R.; Jung, C.R. Crowd Analysis Using Computer Vision Techniques. IEEE Signal Process. Mag. 2010, 27, 66–77. [Google Scholar] [CrossRef] [Green Version]
- Li, T.; Chang, H.; Wang, M.; Ni, B.; Hong, R.; Yan, S. Crowded Scene Analysis: A Survey. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 367–386. [Google Scholar] [CrossRef] [Green Version]
- Zitouni, M.S.; Bhaskar, H.; Dias, J.; Al-Mualla, M. Advances and trends in visual crowd analysis: A systematic survey and evaluation of crowd modelling techniques. Neurocomputing 2016, 186, 139–159. [Google Scholar] [CrossRef]
- Loy, C.C.; Chen, K.; Gong, S.; Xiang, T. Crowd counting and profiling: Methodology and evaluation. In Modeling, Simulation and Visual Analysis of Crowds; Springer: Berlin/Heidelberg, Germany, 2013; pp. 347–382. [Google Scholar]
- Saleh, S.A.M.; Suandi, S.A.; Ibrahim, H. Recent survey on crowd density estimation and counting for visual surveillance. Eng. Appl. Artif. Intell. 2015, 41, 103–114. [Google Scholar] [CrossRef]
- Sindagi, V.A.; Patel, V.M. A survey of recent advances in cnn-based single image crowd counting and density estimation. Pattern Recognit. Lett. 2018, 107, 3–16. [Google Scholar] [CrossRef] [Green Version]
- Gao, G.; Gao, J.; Liu, Q.; Wang, Q.; Wang, Y. CNN-based Density Estimation and Crowd Counting: A Survey. arXiv 2020, arXiv:2003.12783. [Google Scholar]
- Fu, M.; Xu, P.; Li, X.; Liu, Q.; Ye, M.; Zhu, C. Fast crowd density estimation with convolutional neural networks. Eng. Appl. Artif. Intell. 2015, 43, 81–88. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, H.; Yang, L.; Liu, S.; Cao, X. Deep People Counting in Extremely Dense Crowds. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 1299–1302. [Google Scholar] [CrossRef]
- Sermanet, P.; Chintala, S.; LeCun, Y. Convolutional neural networks applied to house numbers digit classification. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; pp. 3288–3291. [Google Scholar]
- Xue, Y.; Ray, N.; Hugh, J.; Bigras, G. Cell Counting by Regression Using Convolutional Neural Network. In Computer Vision–ECCV 2016 Workshops; Hua, G., Jégou, H., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 274–290. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Walach, E.; Wolf, L. Learning to Count with CNN Boosting. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Zhang, Y.; Zhou, D.; Chen, S.; Gao, S.; Ma, Y. Single-image crowd counting via multi-column convolutional neural network. In Proceedings of the IEEEConference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 589–597. [Google Scholar]
- Boominathan, L.; Kruthiventi, S.S.; Babu, R.V. Crowdnet: A deep convolutional network for dense crowd counting. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 640–644. [Google Scholar]
- Babu Sam, D.; Surya, S.; Venkatesh Babu, R. Switching convolutional neural network for crowd counting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5744–5752. [Google Scholar]
- Sam, D.B.; Babu, R.V. Top-down feedback for crowd counting convolutional neural network. arXiv 2018, arXiv:1807.08881. [Google Scholar]
- Liu, L.; Wang, H.; Li, G.; Ouyang, W.; Lin, L. Crowd counting using deep recurrent spatial-aware network. arXiv 2018, arXiv:1807.00601. [Google Scholar]
- Zhang, A.; Shen, J.; Xiao, Z.; Zhu, F.; Zhen, X.; Cao, X.; Shao, L. Relational attention network for crowd counting. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6788–6797. [Google Scholar]
- Hossain, M.; Hosseinzadeh, M.; Chanda, O.; Wang, Y. Crowd counting using scale-aware attention networks. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 7–11 January 2019; pp. 1280–1288. [Google Scholar]
- Guo, D.; Li, K.; Zha, Z.J.; Wang, M. Dadnet: Dilated-attention-deformable convnet for crowd counting. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1823–1832. [Google Scholar]
- Jiang, X.; Zhang, L.; Xu, M.; Zhang, T.; Lv, P.; Zhou, B.; Yang, X.; Pang, Y. Attention Scaling for Crowd Counting. Available online: https://openaccess.thecvf.com/content_CVPR_2020/papers/Jiang_Attention_Scaling_for_Crowd_Counting_CVPR_2020_paper.pdf (accessed on 16 September 2021).
- Li, Y.; Zhang, X.; Chen, D. Csrnet: Dilated convolutional neural networks for understanding the highly congested scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1091–1100. [Google Scholar]
- Zhang, L.; Shi, M.; Chen, Q. Crowd Counting via Scale-Adaptive Convolutional Neural Network. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1113–1121. [Google Scholar]
- Wang, Z.; Xiao, Z.; Xie, K.; Qiu, Q.; Zhen, X.; Cao, X. In defense of single-column networks for crowd counting. arXiv 2018, arXiv:1808.06133. [Google Scholar]
- Cao, X.; Wang, Z.; Zhao, Y.; Su, F. Scale Aggregation Network for Accurate and Efficient Crowd Counting. In Computer Vision–ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 757–773. [Google Scholar]
- Valloli, V.K.; Mehta, K. W-Net: Reinforced U-Net for Density Map Estimation. arXiv 2019, arXiv:1903.11249. [Google Scholar]
- Jiang, X.; Xiao, Z.; Zhang, B.; Zhen, X.; Cao, X.; Doermann, D.; Shao, L. Crowd counting and density estimation by trellis encoder–decoder networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 6133–6142. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent models of visual attention. Available online: https://proceedings.neurips.cc/paper/2014/file/09c6c3783b4a70054da74f2538ed47c6-Paper.pdf (accessed on 16 September 2021).
- Liu, N.; Long, Y.; Zou, C.; Niu, Q.; Pan, L.; Wu, H. Adcrowdnet: An attention-injective deformable convolutional network for crowd understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3225–3234. [Google Scholar]
- Zhang, C.; Li, H.; Wang, X.; Yang, X. Cross-scene crowd counting via deep convolutional neural networks. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015; pp. 833–841. [Google Scholar]
- Tian, Y.; Lei, Y.; Zhang, J.; Wang, J.Z. PaDNet: Pan-Density Crowd Counting. IEEE Trans. Image Process. 2020, 29, 2714–2727. [Google Scholar] [CrossRef] [Green Version]
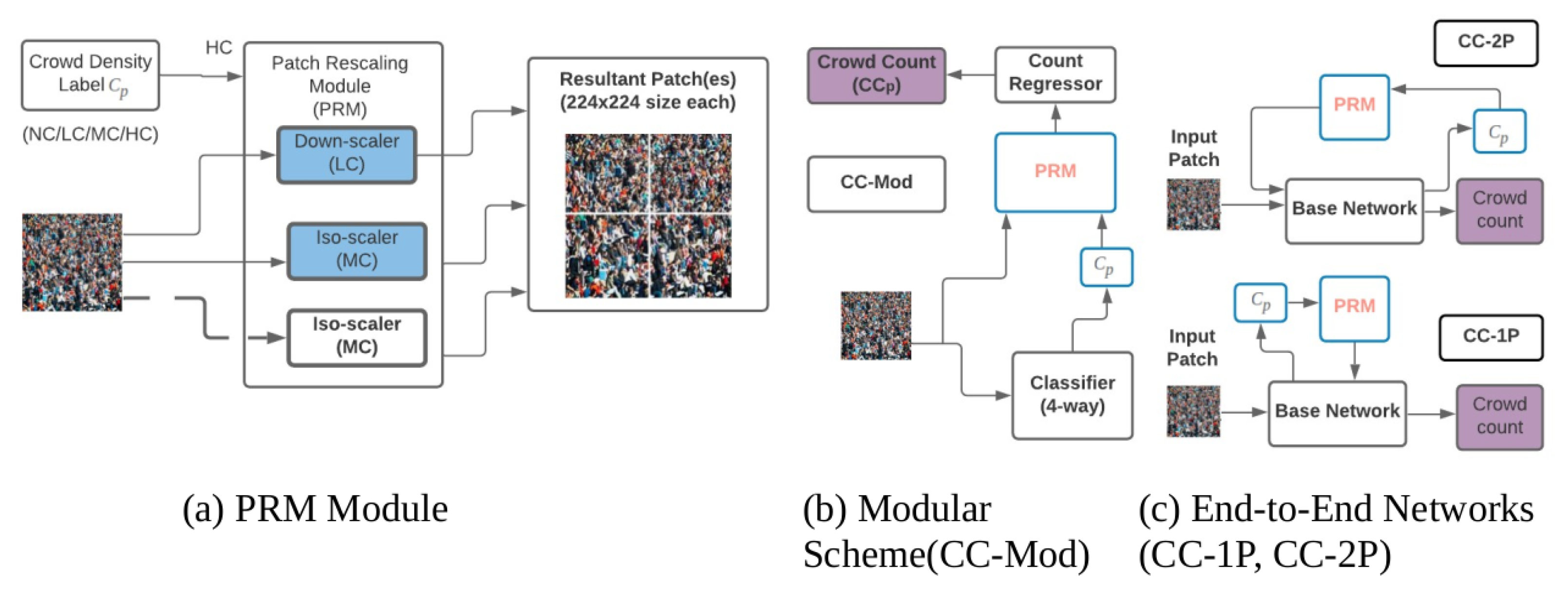
- Sajid, U.; Wang, G. Plug-and-play rescaling based crowd counting in static images. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 2287–2296. [Google Scholar]
- Shang, C.; Ai, H.; Bai, B. End-to-end crowd counting via joint learning local and global count. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 1215–1219. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial transformer networks. Available online: https://proceedings.neurips.cc/paper/2015/file/33ceb07bf4eeb3da587e268d663aba1a-Paper.pdf (accessed on 16 September 2021).
- Liu, J.; Gao, C.; Meng, D.; Hauptmann, A.G. DecideNet: Counting Varying Density Crowds through Attention Guided Detection and Density Estimation. arXiv 2018, arXiv:1712.06679. [Google Scholar]
- Liu, X.; van de Weijer, J.; Bagdanov, A.D. Leveraging Unlabeled Data for Crowd Counting by Learning to Rank. arXiv 2018, arXiv:1803.03095. [Google Scholar]
- Shi, M.; Yang, Z.; Xu, C.; Chen, Q. Revisiting Perspective Information for Efficient Crowd Counting. arXiv 2019, arXiv:1807.01989. [Google Scholar]
- Liang, D.; Chen, X.; Xu, W.; Zhou, Y.; Bai, X. TransCrowd: Weakly-Supervised Crowd Counting with Transformer. arXiv 2021, arXiv:2104.09116. [Google Scholar]
- Sun, G.; Liu, Y.; Probst, T.; Paudel, D.P.; Popovic, N.; Gool, L.V. Boosting Crowd Counting with Transformers. arXiv 2021, arXiv:2105.10926. [Google Scholar]
- Gao, J.; Gong, M.; Li, X. Congested Crowd Instance Localization with Dilated Convolutional Swin Transformer. arXiv 2021, arXiv:2108.00584. [Google Scholar]
- Shi, Z.; Zhang, L.; Liu, Y.; Cao, X.; Ye, Y.; Cheng, M.M.; Zheng, G. Crowd Counting with Deep Negative Correlation Learning. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5382–5390. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015; pp. 1–9. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Sam, D.B.; Sajjan, N.N.; Babu, R.V. Divide and Grow: Capturing Huge Diversity in Crowd Images with Incrementally Growing CNN. arXiv 2018, arXiv:1807.09993. [Google Scholar]
- Chan, A.; Morrow, M.; Vasconcelos, N. Analysis of Crowded Scenes using Holistic Properties. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.214.8754&rep=rep1&type=pdf (accessed on 16 September 2021).
- Loy, C.C.; Gong, S.; Xiang, T. From Semi-supervised to Transfer Counting of Crowds. Available online: https://personal.ie.cuhk.edu.hk/~ccloy/files/iccv_2013_crowd.pdf (accessed on 16 September 2021).
- Lim, M.K.; Kok, V.J.; Loy, C.C.; Chan, C.S. Crowd Saliency Detection via Global Similarity Structure. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 3957–3962. [Google Scholar]
- Lian, D.; Li, J.; Zheng, J.; Luo, W.; Gao, S. Density Map Regression Guided Detection Network for RGB-D Crowd Counting and Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Kang, D.; Dhar, D.; Chan, A. Incorporating Side Information by Adaptive Convolution. In Advances in Neural Information Processing Systems 30; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NJ, USA, 2017; pp. 3867–3877. [Google Scholar]
- Yan, Z.; Yuan, Y.; Zuo, W.; Tan, X.; Wang, Y.; Wen, S.; Ding, E. Perspective-Guided Convolution Networks for Crowd Counting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Zhu, P.; Wen, L.; Bian, X.; Ling, H.; Hu, Q. Vision meets drones: A challenge. arXiv 2018, arXiv:1804.07437. [Google Scholar]
- Bahmanyar, R.; Vig, E.; Reinartz, P. MRCNet: Crowd Counting and Density Map Estimation in Aerial and Ground Imagery. arXiv 2019, arXiv:1909.12743. [Google Scholar]
- Fang, Y.; Zhan, B.; Cai, W.; Gao, S.; Hu, B. Locality-constrained Spatial Transformer Network for Video Crowd Counting. arXiv 2019, arXiv:1907.07911. [Google Scholar]
- Liu, W.; Salzmann, M.; Fua, P. Context-Aware Crowd Counting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Zhang, Q.; Chan, A.B. Wide-Area Crowd Counting via Ground-Plane Density Maps and Multi-View Fusion CNNs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 8297–8306. [Google Scholar]
- Hu, D.; Mou, L.; Wang, Q.; Gao, J.; Hua, Y.; Dou, D.; Zhu, X. Ambient Sound Helps: Audiovisual Crowd Counting in Extreme Conditions. arXiv 2020, arXiv:2005.07097. [Google Scholar]
- Zhu, P.; Sun, Y.; Wen, L.; Feng, Y.; Hu, Q. Drone Based RGBT Vehicle Detection and Counting: A Challenge. arXiv 2020, arXiv:2003.02437. [Google Scholar]
- Wang, Q.; Gao, J.; Lin, W.; Li, X. NWPU-Crowd: A Large-Scale Benchmark for Crowd Counting and Localization. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef]
- Sindagi, V.A.; Yasarla, R.; Patel, V.M. Pushing the frontiers of unconstrained crowd counting: New dataset and benchmark method. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1221–1231. [Google Scholar]
- Idrees, H.; Tayyab, M.; Athrey, K.; Zhang, D.; Al-Máadeed, S.; Rajpoot, N.; Shah, M. Composition Loss for Counting, Density Map Estimation and Localization in Dense Crowds. arXiv 2018, arXiv:1808.01050. [Google Scholar]
- Liu, W.; Luo, W.D.L.; Gao, S. Future Frame Prediction for Anomaly Detection—A New Baseline. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Tayara, H.; Gil Soo, K.; Chong, K.T. Vehicle Detection and Counting in High-Resolution Aerial Images Using Convolutional Regression Neural Network. IEEE Access 2018, 6, 2220–2230. [Google Scholar] [CrossRef]
- Amato, G.; Ciampi, L.; Falchi, F.; Gennaro, C. Counting Vehicles with Deep Learning in Onboard UAV Imagery. In Proceedings of the 2019 IEEE Symposium on Computers and Communications (ISCC), Barcelona, Spain, 29 June–3 July 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Chen, J.; Xiu, S.; Chen, X.; Guo, H.; Xie, X. Flounder-Net: An efficient CNN for crowd counting by aerial photography. Neurocomputing 2021, 420, 82–89. [Google Scholar] [CrossRef]
- Castellano, G.; Castiello, C.; Mencar, C.; Vessio, G. Crowd Counting from Unmanned Aerial Vehicles with Fully-Convolutional Neural Networks. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Wu, J.; Yang, G.; Yang, X.; Xu, B.; Han, L.; Zhu, Y. Automatic counting of in situ rice seedlings from UAV images based on a deep fully convolutional neural network. Remote Sens. 2019, 11, 691. [Google Scholar] [CrossRef] [Green Version]
- Oh, S.; Chang, A.; Ashapure, A.; Jung, J.; Dube, N.; Maeda, M.; Gonzalez, D.; Landivar, J. Plant Counting of Cotton from UAS Imagery Using Deep Learning-Based Object Detection Framework. Remote Sens. 2020, 12, 2981. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Kitano, B.T.; Mendes, C.C.; Geus, A.R.; Oliveira, H.C.; Souza, J.R. Corn plant counting using deep learning and UAV images. IEEE Geosci. Remote Sens. Lett. 2019. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | ||
|---|---|---|
| Methods | Network Architecture | Inference Paradigm |
| Wang et al [32] | Basic | Patch-based |
| Fu et al [31] | Basic | Patch-based |
| Yao et al. [34] | Basic | Pacth-based |
| Elad et al. [36] | Basic | Patch-based |
| Zhang et al. [37] | Multiple-column | Patch-based |
| Boominathan et al. [38] | Multiple-column | Patch-based |
| Oñoro-Rubio et al. [12] | Multiple-column | Patch-based |
| Deepak et al. [39] | Multiple-column | Patch-based |
| Deepak et al. [40] | Multiple-column | Patch-based |
| Liu et al. [41] | Multiple-column | Patch-based |
| Zhang et al [42] | Multiple-column | Patch-based |
| Hossain et al. [43] | Multiple-column | Patch-based |
| Guo et al. [44] | Multiple-column | Patch-based |
| Jiang et al. [45] | Multiple-column | Patch-based |
| Li et al. [46] | Single-column | Whole-image |
| Zhang et al. [47] | Signle-column | Patch-based |
| Wang et al. [48] | Single-column | Patch-based |
| Cao et al. [49] | Single-column | Patch-based |
| Varun et al. [50] | Single-column | Patch-based |
| Xiaolong et al. [51] | Single-column | Patch-based |
| Mohammed et al. [52] | Single-column | Patch-based |
| Liu et al. [53] | Single-column | Patch-based |
| Zhang et al. [54] | Multiple-column | Patch-based |
| Tian et al. [55] | Multiple-column | Patch-based |
| Sajid et al. [56] | Multiple-column | Patch-based |
| Chong et al. [57] | Multiple-column | Patch-based |
| Name | Year | Attributes | Avg. Resolution | No. Samples | No. Instances | Avg. Count |
|---|---|---|---|---|---|---|
| Free view datasets | ||||||
| NWPU-Crowd [82] | 2020 | Congested, Localization | 2191 × 3209 | 5109 | 2,133,375 | 418 |
| JHU-CROWD++ [83] | 2020 | Congested | 1430 × 910 | 4372 | 1,515,005 | 346 |
| JHU-CROWD++ [84] | 2018 | Congested | 2013 × 2902 | 1535 | 1,251,642 | 815 |
| ShanghaiTech Part A [85] | 2016 | Congested | 589 × 868 | 482 | 241,677 | 501 |
| UCF_CC_50 [13] | 2013 | Congested | 2101 × 2888 | 50 | 241,677 | 1279 |
| Crowd Surveillance-view | ||||||
| DISCO [80] | 2020 | Audiovisual, extreme conditions | 1080 × 1920 | 1935 | 170,270 | 88 |
| Crowd Surveillance [74] | 2019 | Free scenes | 840 × 1342 | 13,945 | 386,513 | 28 |
| ShanghaiTechRGBD [72] | 2019 | Depth | 1080 × 1920 | 2193 | 144,512 | 65.9 |
| Fudan-ShanghaiTech [77] | 2019 | 400 Fixed Scenes, Synthetic | 1080 × 1920 | 15,211 | 7,625,843 | 501 |
| Venice [78] | 2019 | 4 Fixed Scenes | 720 × 1280 | 167 | - | - |
| CityStreet [79] | 2019 | Multi-view | 1520 × 2704 | 500 | - | - |
| SmartCity [47] | 2018 | - | 1080 × 1920 | 50 | 369 | 7 |
| CityUHK-X [73] | 2017 | 55 Fixed Scenes | 384 × 512 | 3191 | 106,783 | 33 |
| ShanghaiTech Part B [71] | 2016 | Free Scenes | 768 × 1024 | 716 | 88,488 | 123 |
| AHU-Crowd [71] | 2016 | - | 720 × 576 | 107 | 45,000 | 421 |
| WorldExpo’10 [54] | 2015 | 108 Fixed Scenes | 576 × 720 | 3980 | 199,923 | 50 |
| Mall [70] | 2012 | 1 Fixed Scene | 480 × 640 | 2000 | 62,325 | 31 |
| UCSD [69] | 2008 | 1 Fixed Scene | 158 × 238 | 2000 | 49,885 | 25 |
| Drone-View | ||||||
| DroneVehicle [81] | 2020 | Vehicle | 840 × 712 | 31,064 | 441,642 | 14.2 |
| DroneCrowd [75] | 2019 | Video | 1080 × 1920 | 33,600 | 4,864,280 | 145 |
| DLR-ACD [76] | 2019 | - | - | 33 | 226,291 | 6857 |
| Approach Type | Dataset | Mall | UCF CC 50 | WorldExpo 10 | UCSD | UCF-QNRF | ShanghaiTech Part A | ShanghaiTech Part B | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | |
| Traditional approach | Learning To Count Objects in Images [22] | - | - | - | - | - | - | 1.59 | - | - | - | - | - | - | - |
| COUNT Forest [23] | 2.5 | 10.0 | - | - | - | - | 1.61 | 4.40 | - | - | - | - | - | - | |
| Multi-source Multi-scale Counting [13] | - | - | 468.0 | 590.3 | - | - | - | - | - | - | - | - | - | - | |
| Multiple-column approaches | MCNN [37] | - | - | 377.6 | 509.1 | 11.6 | - | 1.07 | 1.35 | - | - | 110.2 | 173.2 | 26.4 | 41.3 |
| Cross-scene crowd counting [54] | - | - | 467.0 | 498.5 | 12.9 | - | 1.60 | 3.31 | - | - | 181.8 | 277.7 | 32.0 | 49.8 | |
| Hydra-CNN [12] | - | - | 333.7 | 425.2 | - | - | - | - | - | - | - | - | - | - | |
| Switching-CNN [39] | - | - | 318.1 | 439.2 | 9.4 | - | 1.62 | 2.10 | 228 | 445 | 90.4 | 135 | 21.6 | 33.4 | |
| Crowd counting using deep recurrent net. [41] | 1.72 | 2.1 | 219.2 | 250.2 | 7.76 | - | - | - | - | - | 69.3 | 96.4 | 11.1 | 18.2 | |
| RANet [42] | - | - | 239.8 | 319.4 | - | - | - | - | 111 | 190 | 59.4 | 102.0 | 7.9 | 12.9 | |
| DADNet [44] | - | - | 285.5 | 389.7 | - | - | - | - | - | - | 64.2 | 99.9 | - | - | |
| DANet [45] | - | - | 268.3 | 373.2 | - | - | - | - | - | - | 71.4 | 120.6 | 9.1 | 14.7 | |
| Single-column approach | CRSNet [46] | - | - | 266.1 | 397.5 | - | - | - | - | - | - | 68.2 | 115 | 10.6 | 16 |
| SaCNN [47] | - | - | 314.9 | 424.8 | 8.5 | - | - | - | - | - | 86.8 | 139.2 | 16.2 | 25.8 | |
| SCNet [48] | - | - | 280.5 | 332.8 | 8.4 | - | - | - | - | - | 71.9 | 117.9 | 9.3 | 14.4 | |
| SANet [49] | - | - | 258.4 | 334.9 | - | - | - | - | - | - | 67.0 | 104.5 | 8.4 | 13.6 | |
| ADCrowdNet (AMG-attn-DME) [53] | - | - | 273.6 | 362.0 | 7.3 | - | 1.09 | 1.35 | - | - | 70.9 | 115.2 | 7.7 | 12.9 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gouiaa, R.; Akhloufi, M.A.; Shahbazi, M. Advances in Convolution Neural Networks Based Crowd Counting and Density Estimation. Big Data Cogn. Comput. 2021, 5, 50. https://doi.org/10.3390/bdcc5040050
Gouiaa R, Akhloufi MA, Shahbazi M. Advances in Convolution Neural Networks Based Crowd Counting and Density Estimation. Big Data and Cognitive Computing. 2021; 5(4):50. https://doi.org/10.3390/bdcc5040050
Chicago/Turabian StyleGouiaa, Rafik, Moulay A. Akhloufi, and Mozhdeh Shahbazi. 2021. "Advances in Convolution Neural Networks Based Crowd Counting and Density Estimation" Big Data and Cognitive Computing 5, no. 4: 50. https://doi.org/10.3390/bdcc5040050
APA StyleGouiaa, R., Akhloufi, M. A., & Shahbazi, M. (2021). Advances in Convolution Neural Networks Based Crowd Counting and Density Estimation. Big Data and Cognitive Computing, 5(4), 50. https://doi.org/10.3390/bdcc5040050