
ADD: Attention-Based DeepFake Detection Approach


Abstract
:1. Introduction
- We considered the Deepfake detection task as an FGVC problem and proposed a digital video authentication system, ADD, built based on an attention mechanism.
- ADD first locates potentially manipulated areas of the input image and extracts discriminative features from those regions. Second, the detection model is made to pay more attention to these forgery regions for decision-making by imposing additional supervision on instance interpretation in the learning procedure through attention-based data augmentation.
- The performance of the ADD is evaluated against two challenging DeepFake forensic datasets. Experimental results demonstrate that ADD could achieve a detection rate of 98.37% on Celeb-DF (V2), outperforming state-of-the-art DeepFake detection methods.
2. Related Work
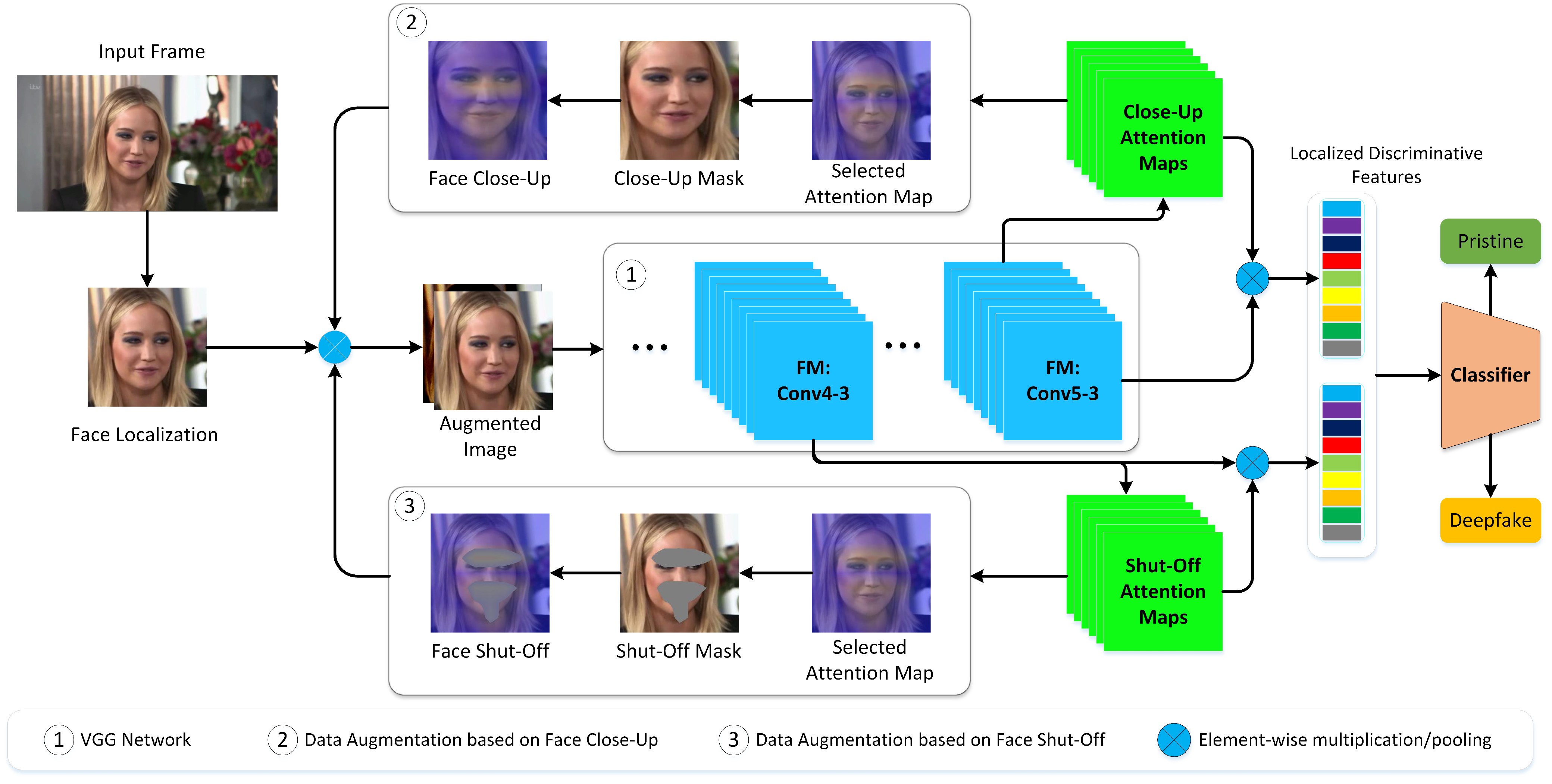
3. ADD: Methods
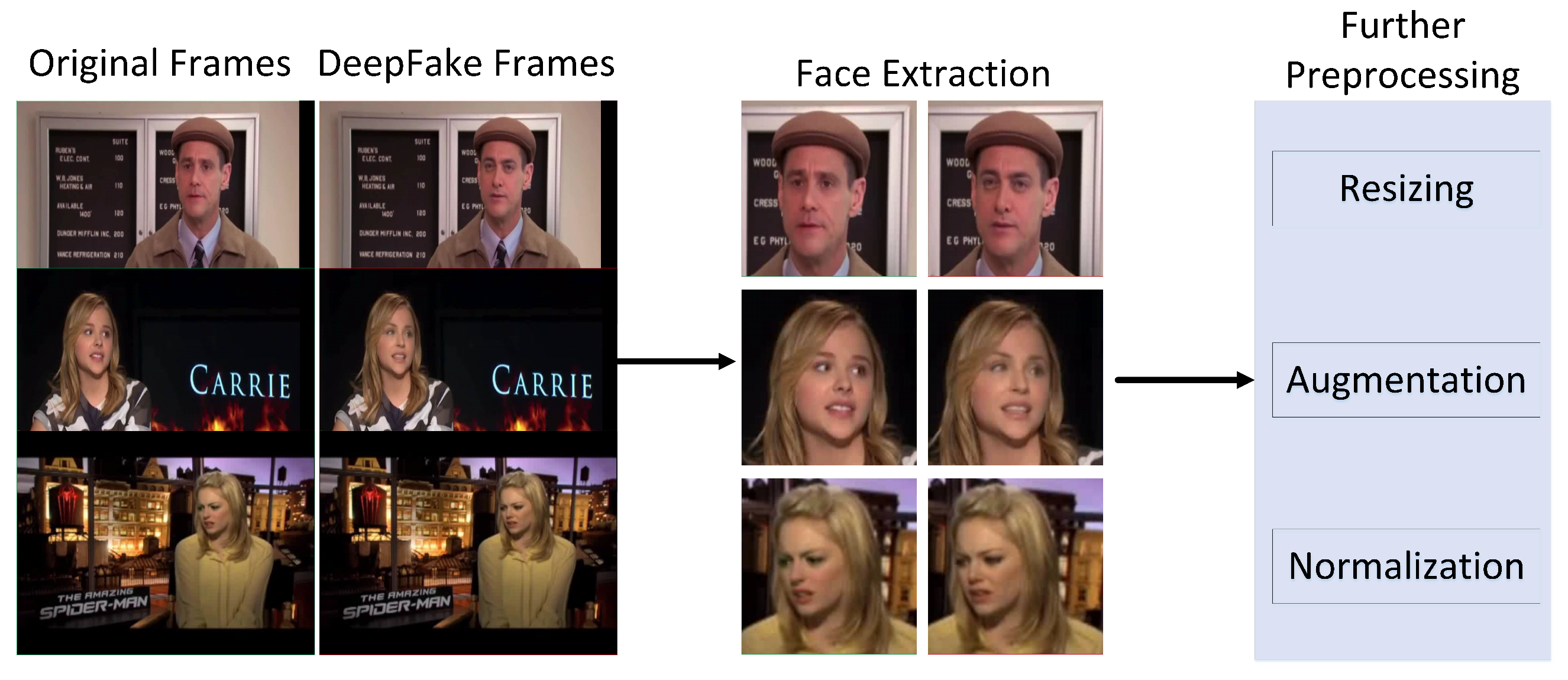
3.1. Face Localization and Preprocessing
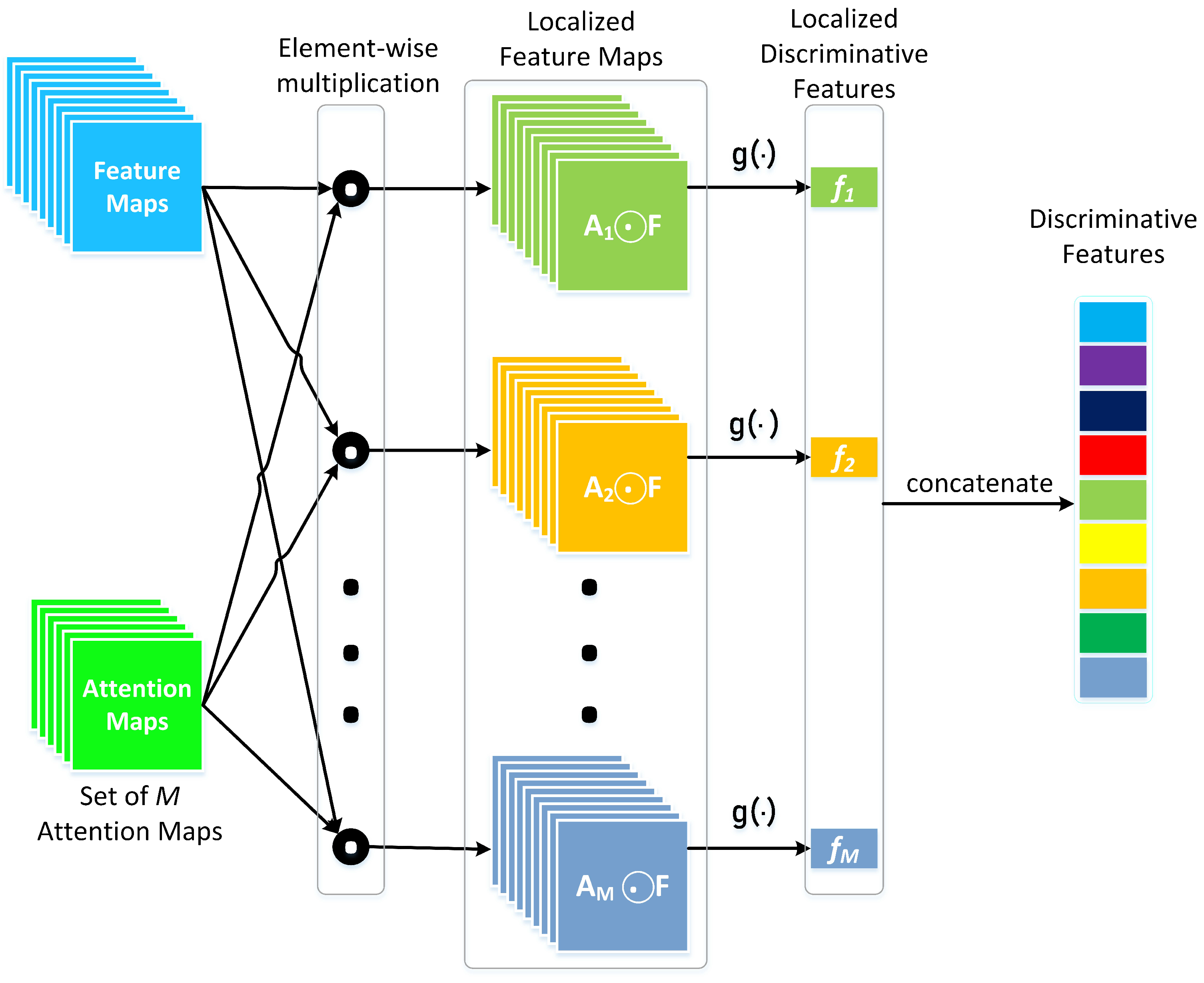
3.2. Localized Discriminative Features
3.3. Attention-Based Data Augmentation
4. Evaluation Settings
4.1. Datasets
4.2. Baseline Architectures
4.3. Implementation Specifics
4.4. Evaluation Metrics
5. Results & Discussion
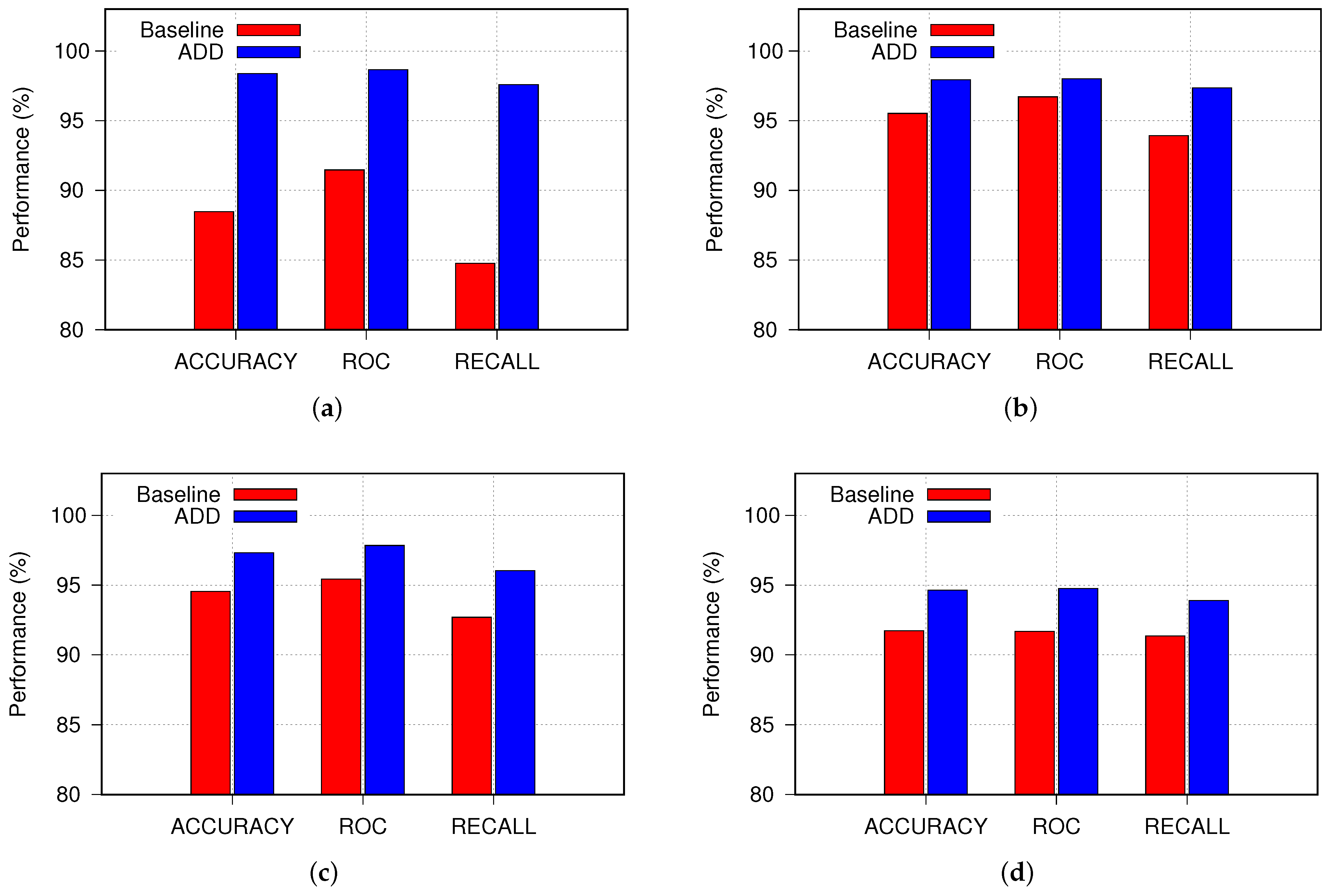
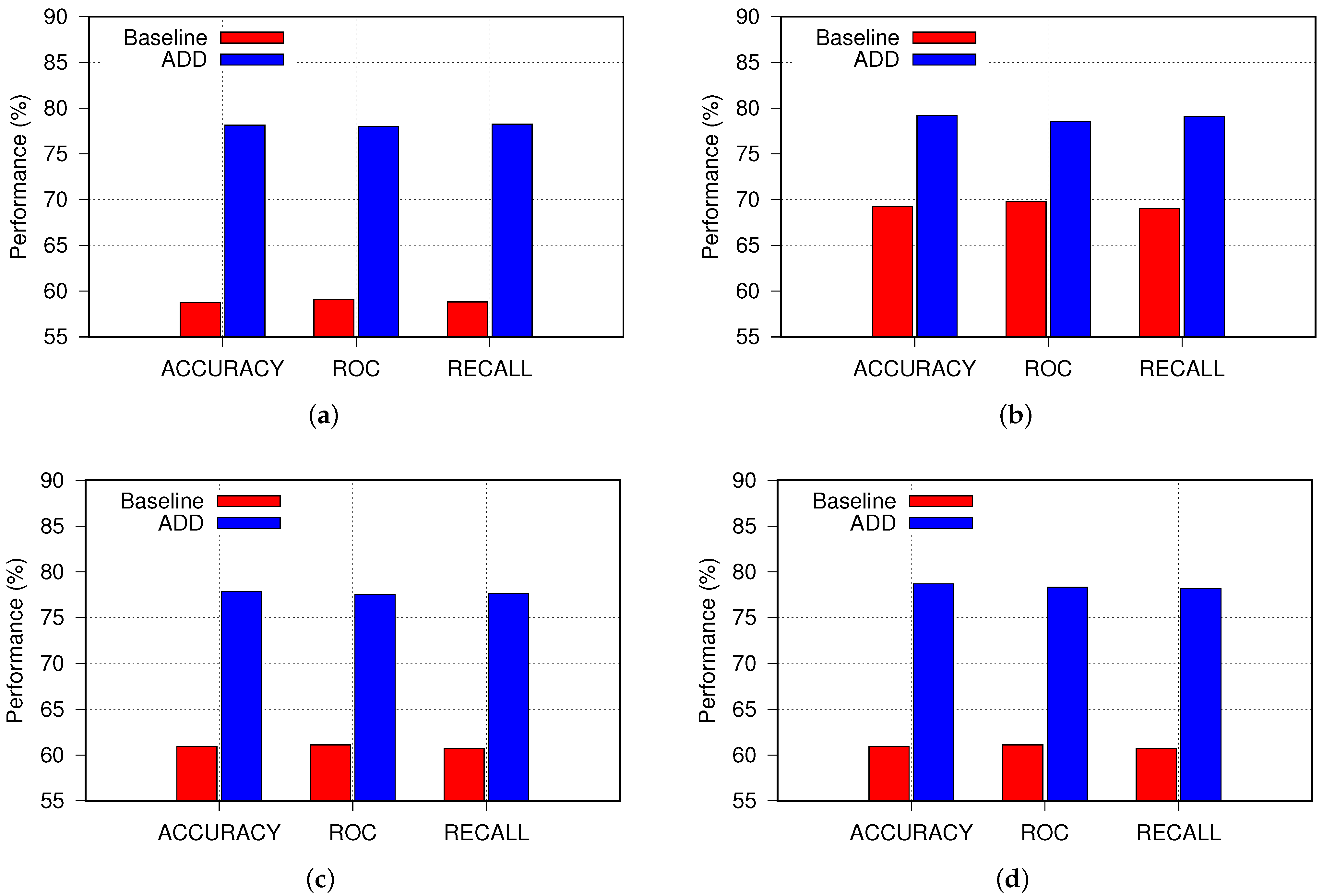
5.1. ADD’s Impact
5.2. Comparison with State-of-the-Art Methods
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Antipov, G.; Baccouche, M.; Dugelay, J.L. Face aging with conditional generative adversarial networks. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 2089–2093. [Google Scholar]
- Thies, J.; Zollhofer, M.; Stamminger, M.; Theobalt, C.; Nießner, M. Face2face: Real-time face capture and reenactment of rgb videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2387–2395. [Google Scholar]
- Vaccari, C.; Chadwick, A. Deepfakes and disinformation: Exploring the impact of synthetic political video on deception, uncertainty, and trust in news. Soc. Media+ Soc. 2020, 6. [Google Scholar] [CrossRef] [Green Version]
- Toews, R. Deepfakes Are Going to Wreak Havoc on Society. We Are not Prepared. 2020. Available online: https://www.forbes.com/sites/robtoews/2020/05/25/deepfakes-are-going-to-wreak-havoc-on-society-we-are-not-prepared (accessed on 15 January 2021).
- Turton, W.; Martin, A. How Deepfakes Make Disinformation More Real Than Ever. Bloomberg 2020, 199–217. Available online: https://www.bloombergquint.com/technology/how-deepfakes-make-disinformation-more-real-than-ever-quicktake (accessed on 15 January 2021).
- Ingram, D. A Face-Swapping App Takes off in China, Making Ai-Powered Deepfakes for Everyone. 2019. Available online: https://www.wautom.com/2019/09/zao-a-face-swapping-app-takes-off-in-china-making-ai-powered-deepfakes-for-everyone/ (accessed on 15 January 2021).
- Greengard, S. Will deepfakes do deep damage? Commun. ACM 2019, 63, 17–19. [Google Scholar] [CrossRef]
- Korshunov, P.; Marcel, S. Deepfake Detection: Humans vs. Machines; The European Association for Biometrics (EAB): Bussum, The Netherlands, 2020. [Google Scholar]
- Guarnera, L.; Giudice, O.; Battiato, S. DeepFake Detection by Analyzing Convolutional Traces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 666–667. [Google Scholar]
- Li, Y.; Lyu, S. Exposing DeepFake Videos By Detecting Face Warping Artifacts. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 46–52. [Google Scholar]
- Maras, M.H.; Alexandrou, A. Determining authenticity of video evidence in the age of artificial intelligence and in the wake of Deepfake videos. Int. J. Evid. Proof 2019, 23, 255–262. [Google Scholar] [CrossRef]
- Day, C. The future of misinformation. IEEE Ann. Hist. Comput. 2019, 21, 108. [Google Scholar] [CrossRef]
- Fletcher, J. Deepfakes, Artificial Intelligence, and Some Kind of Dystopia: The New Faces of Online Post-Fact Performance. Theatre J. 2018, 70, 455–471. [Google Scholar] [CrossRef]
- Chesney, B.; Citron, D. Deep fakes: A looming challenge for privacy, democracy, and national security. Calif. L. Rev. 2019, 107, 1753. [Google Scholar] [CrossRef] [Green Version]
- Thies, J.; Zollhöfer, M.; Nießner, M. Deferred neural rendering: Image synthesis using neural textures. ACM Trans. Graph. (TOG) 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Nirkin, Y.; Masi, I.; Tuan, A.T.; Hassner, T.; Medioni, G. On face segmentation, face swapping, and face perception. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 98–105. [Google Scholar]
- Masi, I.; Tran, A.T.; Hassner, T.; Leksut, J.T.; Medioni, G. Do we really need to collect millions of faces for effective face recognition? In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 579–596. [Google Scholar]
- Masi, I.; Tran, A.T.; Hassner, T.; Sahin, G.; Medioni, G. Face-specific data augmentation for unconstrained face recognition. Int. J. Comput. Vis. 2019, 127, 642–667. [Google Scholar] [CrossRef]
- Suwajanakorn, S.; Seitz, S.M.; Kemelmacher-Shlizerman, I. Synthesizing obama: Learning lip sync from audio. ACM Trans. Graph. (TOG) 2017, 36, 1–13. [Google Scholar] [CrossRef]
- Pumarola, A.; Agudo, A.; Martinez, A.M.; Sanfeliu, A.; Moreno-Noguer, F. Ganimation: Anatomically-aware facial animation from a single image. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 818–833. [Google Scholar]
- Nirkin, Y.; Keller, Y.; Hassner, T. FSGAN: Subject agnostic face swapping and reenactment. In Proceedings of the IEEE International Conference on COMPUTER Vision, Seoul, Korea, 27–28 October 2019; pp. 7184–7193. [Google Scholar]
- Kim, H.; Garrido, P.; Tewari, A.; Xu, W.; Thies, J.; Niessner, M.; Pérez, P.; Richardt, C.; Zollhöfer, M.; Theobalt, C. Deep video portraits. ACM Trans. Graph. (TOG) 2018, 37, 1–14. [Google Scholar] [CrossRef]
- Natsume, R.; Yatagawa, T.; Morishima, S. Fsnet: An identity-aware generative model for image-based face swapping. In Asian Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2018; pp. 117–132. [Google Scholar]
- Li, Y.; Sun, P.; Qi, H.; Lyu, S. Celeb-DF: A Large-scale Challenging Dataset for DeepFake Forensics. In Proceedings of the IEEE Conference on Computer Vision and Patten Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Du, M.; Pentyala, S.; Li, Y.; Hu, X. Towards Generalizable Deepfake Detection with Locality-aware AutoEncoder. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Gold Coast, Australia, 1–5 November 2020; pp. 325–334. [Google Scholar]
- Yadav, D.; Salmani, S. Deepfake: A Survey on Facial Forgery Technique Using Generative Adversarial Network. In Proceedings of the 2019 International Conference on Intelligent Computing and Control Systems (ICCS), Madurai, India, 15–17 May 2019; pp. 852–857. [Google Scholar]
- Shelke, N.A.; Kasana, S.S. A comprehensive survey on passive techniques for digital video forgery detection. Multimed. Tools Appl. 2021, 80, 6247–6310. [Google Scholar] [CrossRef]
- Mirsky, Y.; Lee, W. The creation and detection of deepfakes: A survey. ACM Comput. Surv. (CSUR) 2021, 54, 1–41. [Google Scholar] [CrossRef]
- Li, Y.; Chang, M.C.; Lyu, S. In ictu oculi: Exposing ai created fake videos by detecting eye blinking. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 11–13 December 2018; pp. 1–7. [Google Scholar]
- Huh, M.; Liu, A.; Owens, A.; Efros, A.A. Fighting fake news: Image splice detection via learned self-consistency. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 101–117. [Google Scholar]
- Nguyen, H.H.; Yamagishi, J.; Echizen, I. Capsule-forensics: Using capsule networks to detect forged images and videos. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2307–2311. [Google Scholar]
- Afchar, D.; Nozick, V.; Yamagishi, J.; Echizen, I. Mesonet: A compact facial video forgery detection network. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 11–13 December 2018; pp. 1–7. [Google Scholar]
- Faceswap. Faceswap: Deepfakes Software for All. Available online: https://faceswap.dev/ (accessed on 15 January 2021).
- FakeApp. FakeApp 2.2.0—Download for PC Free. 2019. Available online: https://www.malavida.com/en/soft/fakeapp/ (accessed on 15 January 2021).
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Kim, T.; Cha, M.; Kim, H.; Lee, J.K.; Kim, J. Learning to discover cross-domain relations with generative adversarial networks. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, Sydney, Australia, 17 July 2017; pp. 1857–1865. [Google Scholar]
- Lu, Y.; Tai, Y.W.; Tang, C.K. Attribute-guided face generation using conditional cyclegan. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 282–297. [Google Scholar]
- Shaoan, L. Faceswap-GAN. 2020. Available online: https://github.com/shaoanlu/faceswap-GAN (accessed on 15 January 2021).
- Wang, T.C.; Liu, M.Y.; Tao, A.; Liu, G.; Kautz, J.; Catanzaro, B. Few-shot video-to-video synthesis. In Proceedings of the Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Liu, G.; Tao, A.; Kautz, J.; Catanzaro, B. Video-to-Video Synthesis. Adv. Neural Inf. Process. Syst. 2018, 1144–1156. [Google Scholar]
- Siarohin, A.; Lathuilière, S.; Tulyakov, S.; Ricci, E.; Sebe, N. First order motion model for image animation. Adv. Neural Inf. Process. Syst. 2019, 32, 7137–7147. [Google Scholar]
- Li, L.; Bao, J.; Yang, H.; Chen, D.; Wen, F. Faceshifter: Towards high fidelity and occlusion aware face swapping. arXiv 2019, arXiv:1912.13457. [Google Scholar]
- Ciftci, U.A.; Demir, I.; Yin, L. Fakecatcher: Detection of synthetic portrait videos using biological signals. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef]
- Matern, F.; Riess, C.; Stamminger, M. Exploiting visual artifacts to expose deepfakes and face manipulations. In Proceedings of the 2019 IEEE Winter Applications of Computer Vision Workshops (WACVW), Waikoloa, HI, USA, 7–11 January 2019; pp. 83–92. [Google Scholar]
- Cozzolino, D.; Thies, J.; Rössler, A.; Riess, C.; Nießner, M.; Verdoliva, L. Forensictransfer: Weakly-supervised domain adaptation for forgery detection. arXiv 2018, arXiv:1812.02510. [Google Scholar]
- Nguyen, H.H.; Fang, F.; Yamagishi, J.; Echizen, I. Multi-task Learning for Detecting and Segmenting Manipulated Facial Images and Videos. In Proceedings of the 2019 IEEE 10th International Conference on Biometrics: Theory, Applications and Systems (BTAS), Tampa, FL, USA, 23–26 September 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Rana, M.S.; Sung, A.H. Deepfakestack: A deep ensemble-based learning technique for deepfake detection. In Proceedings of the 2020 7th IEEE International Conference on Cyber Security and Cloud Computing (CSCloud)/2020 6th IEEE International Conference on Edge Computing and Scalable Cloud (EdgeCom), New York, NY, USA, 1–3 August 2020; pp. 70–75. [Google Scholar]
- Güera, D.; Delp, E.J. Deepfake video detection using recurrent neural networks. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; pp. 1–6. [Google Scholar]
- Sabir, E.; Cheng, J.; Jaiswal, A.; AbdAlmageed, W.; Masi, I.; Natarajan, P. Recurrent convolutional strategies for face manipulation detection in videos. Interfaces (GUI) 2019, 3, 80–87. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Yu, N.; Davis, L.S.; Fritz, M. Attributing fake images to gans: Learning and analyzing gan fingerprints. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 7556–7566. [Google Scholar]
- Đorđević, M.; Milivojević, M.; Gavrovska, A. DeepFake Video Analysis using SIFT Features. In Proceedings of the 2019 27th Telecommunications Forum (TELFOR), Belgrade, Serbia, 26–27 November 2019; pp. 1–4. [Google Scholar]
- Kaur, S.; Kumar, P.; Kumaraguru, P. Deepfakes: Temporal sequential analysis to detect face-swapped video clips using convolutional long short-term memory. J. Electron. Imaging 2020, 29, 033013. [Google Scholar] [CrossRef]
- Mittal, T.; Bhattacharya, U.; Chandra, R.; Bera, A.; Manocha, D. Emotions Don’t Lie: An Audio-Visual Deepfake Detection Method using Affective Cues. In Proceedings of the 28th ACM International Conference on Multimedia; 2020; pp. 2823–2832. [Google Scholar]
- Zi, B.; Chang, M.; Chen, J.; Ma, X.; Jiang, Y.G. WildDeepfake: A Challenging Real-World Dataset for Deepfake Detection. In Proceedings of the 28th ACM International Conference on Multimedia; 2020; pp. 2382–2390. [Google Scholar]
- Rossler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Nießner, M. Faceforensics++: Learning to detect manipulated facial images. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 1–11. [Google Scholar]
- Deng, J.; Guo, J.; Ververas, E.; Kotsia, I.; Zafeiriou, S. RetinaFace: Single-Shot Multi-Level Face Localisation in the Wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5203–5212. [Google Scholar]
- Kazemi, V.; Sullivan, J. One millisecond face alignment with an ensemble of regression trees. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1867–1874. [Google Scholar]
- Yang, X.; Li, Y.; Lyu, S. Exposing deep fakes using inconsistent head poses. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8261–8265. [Google Scholar]
- Korshunov, P.; Marcel, S. Deepfakes: A new threat to face recognition? assessment and detection. arXiv 2018, arXiv:1812.08685. [Google Scholar]
- Dolhansky, B.; Howes, R.; Pflaum, B.; Baram, N.; Ferrer, C.C. The deepfake detection challenge (dfdc) preview dataset. arXiv 2019, arXiv:1910.08854. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide residual networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the importance of initialization and momentum in deep learning. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1139–1147. [Google Scholar]
- Zhou, P.; Han, X.; Morariu, V.I.; Davis, L.S. Two-stream neural networks for tampered face detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1831–1839. [Google Scholar]
- Nguyen, H.H.; Yamagishi, J.; Echizen, I. Use of a capsule network to detect fake images and videos. arXiv 2019, arXiv:1910.12467. [Google Scholar]
- Masi, I.; Killekar, A.; Mascarenhas, R.M.; Gurudatt, S.P.; AbdAlmageed, W. Two-Branch Recurrent Network for Isolating Deepfakes in Videos. In Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 667–684. [Google Scholar]
- Li, L.; Bao, J.; Zhang, T.; Yang, H.; Chen, D.; Wen, F.; Guo, B. Face X-ray for more general face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 5001–5010. [Google Scholar]
- Charitidis, P.; Kordopatis-Zilos, G.; Papadopoulos, S.; Kompatsiaris, I. Investigating the Impact of Pre-processing and Prediction Aggregation on the DeepFake Detection Task. In Proceedings of the Truth and Trust Conference, Virtual, 15–17 October 2020. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In the Proceedings of the International Conference on Learning Representation, San Diego, CA, USA,, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 630–645. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Class | Videos | Frames | Source | Train | Test | Val. |
|---|---|---|---|---|---|---|---|
| Celeb-DF (V2) | Pristine | 590 | 225.4 K | YouTube | 632 | 62 | 196 |
| DeepFake | 5639 | 2116.8 K | DF | 4736 | 536 | 340 | |
| WildDeepFake | Pristine | 3805 | 680 K | Internet | 3044 | 380 | 381 |
| DeepFake | 3509 | 500 K | Internet | 2807 | 350 | 351 |
| Backbone | Method | Celeb-DF (V2) | WildDeepFake | ||||
|---|---|---|---|---|---|---|---|
| ACC | ROC | Recall | ACC | ROC | Recall | ||
| ResNet | Baseline | 88.47 | 91.47 | 84.76 | 58.73 | 59.12 | 58.81 |
| ADD | 98.37 | 98.65 | 97.59 | 78.15 | 78.01 | 78.24 | |
| Xception | Baseline | 94.54 | 95.42 | 92.69 | 69.25 | 69.78 | 69.01 |
| ADD | 97.32 | 97.84 | 96.03 | 80.13 | 80.31 | 79.93 | |
| VGG | Baseline | 95.53 | 96.71 | 93.93 | 60.92 | 61.12 | 60.71 |
| ADD | 97.93 | 98.01 | 97.35 | 77.83 | 77.54 | 77.61 | |
| MobileNet | Baseline | 91.72 | 91.68 | 91.35 | 61.78 | 61.54 | 61.23 |
| ADD | 94.63 | 94.76 | 93.89 | 78.67 | 78.31 | 78.15 | |
| Models | AUC (%) |
|---|---|
| Two-stream [68] | 53.8 |
| Meso4 [33] | 54.8 |
| HeadPose [61] | 54.6 |
| FWA [11] | 56.9 |
| VA-MLP [45] | 55.0 |
| Xception-c40 [58] | 65.5 |
| Multi-task [47] | 54.3 |
| Capsule [69] | 57.5 |
| TBRN [70] | 73.41 |
| Face X-ray [71] | 80.58 |
| PPA [72] | 83.10 |
| FakeCatcher [44] | 91.50 |
| ADD-ResNet (ours) | 98.37 |
| ADD-Xception (ours) | 97.32 |
| ADD-VGG (ours) | 97.93 |
| ADD-MobileNet (ours) | 94.63 |
| Models | ACC (%) |
|---|---|
| AlexNet [73] | 60.37 |
| VGG16 [74] | 60.92 |
| ResNetV2-50 [75] | 63.99 |
| ResNetV2-101 [75] | 58.73 |
| ResNetV2-152 [75] | 59.33 |
| Inception-v2 [76] | 62.12 |
| MesoNet-1 [33] | 60.51 |
| MesoNet-4 [33] | 64.47 |
| MesoNet-inception [33] | 66.03 |
| XceptionNet [77] | 69.25 |
| ADDNet-2D [57] | 76.25 |
| ADDNet-3D [57] | 65.50 |
| ADD-ResNet (ours) | 78.15 |
| ADD-Xception (ours) | 79.23 |
| ADD-VGG (ours) | 77.83 |
| ADD-MobileNet (ours) | 78.67 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khormali, A.; Yuan, J.-S. ADD: Attention-Based DeepFake Detection Approach. Big Data Cogn. Comput. 2021, 5, 49. https://doi.org/10.3390/bdcc5040049
Khormali A, Yuan J-S. ADD: Attention-Based DeepFake Detection Approach. Big Data and Cognitive Computing. 2021; 5(4):49. https://doi.org/10.3390/bdcc5040049
Chicago/Turabian StyleKhormali, Aminollah, and Jiann-Shiun Yuan. 2021. "ADD: Attention-Based DeepFake Detection Approach" Big Data and Cognitive Computing 5, no. 4: 49. https://doi.org/10.3390/bdcc5040049
APA StyleKhormali, A., & Yuan, J.-S. (2021). ADD: Attention-Based DeepFake Detection Approach. Big Data and Cognitive Computing, 5(4), 49. https://doi.org/10.3390/bdcc5040049