
Uncovering Active Communities from Directed Graphs on Distributed Spark Frameworks, Case Study: Twitter Data

Abstract
:1. Introduction
- (1)
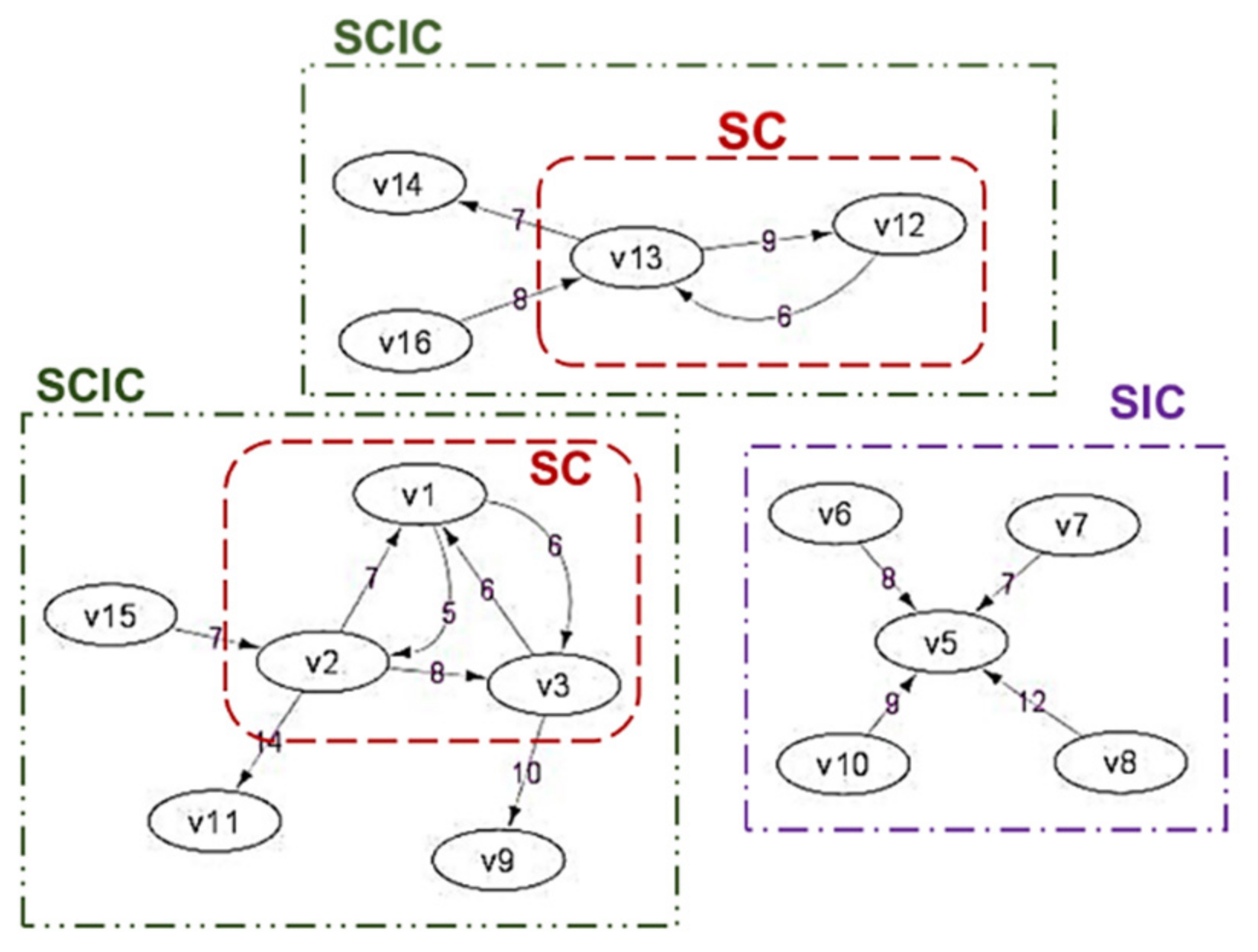
- The concept of temporal active communities suitable for social networks, where the communities are formed based on the measure of their interactions only (for every specific period of time). There are three communities defined: similar interest communities (SIC), strong-interacting communities (SC), and strong-interacting communities with their “inner circle” neighbors (SCIC).
- (2)
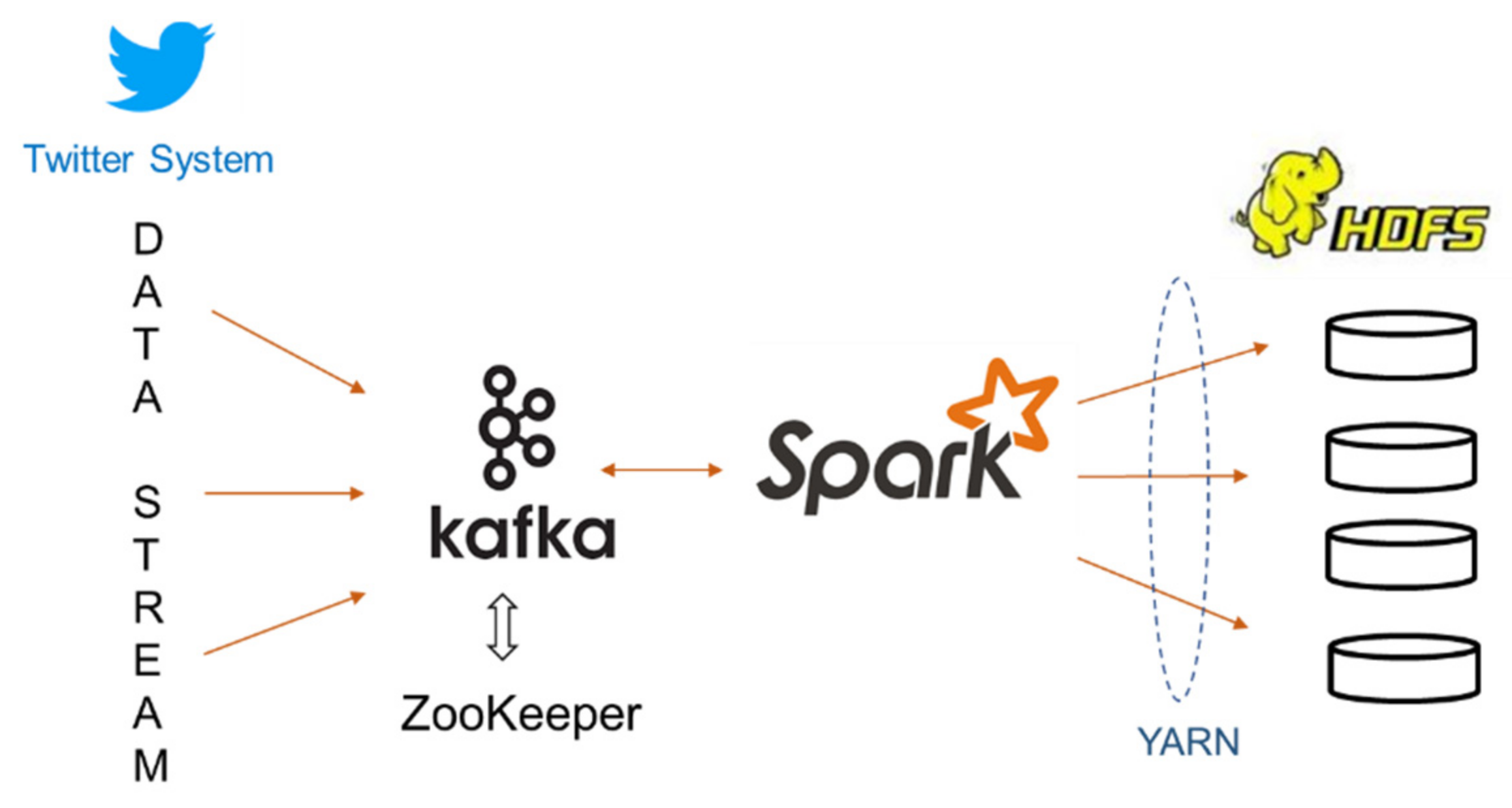
- The algorithms to detect SIC, SC and SCIC from directed graphs in an Apache Spark framework using DataFrames, GraphX and GraphFrames API. As Spark provides data stream processing (using Spark Streaming as well as Kafka), the algorithms can potentially be used for analyzing the stream via the off-line computation approach for processing batches of data stream.
- (3)
- The use of motif finding in GraphFrames to discover temporal active communities. When the interaction patterns are known in advance, motif finding can be employed to find strongly connected component subgraphs. This process can be very efficient when the patterns are simple.
2. Literature Review
2.1. Related Works
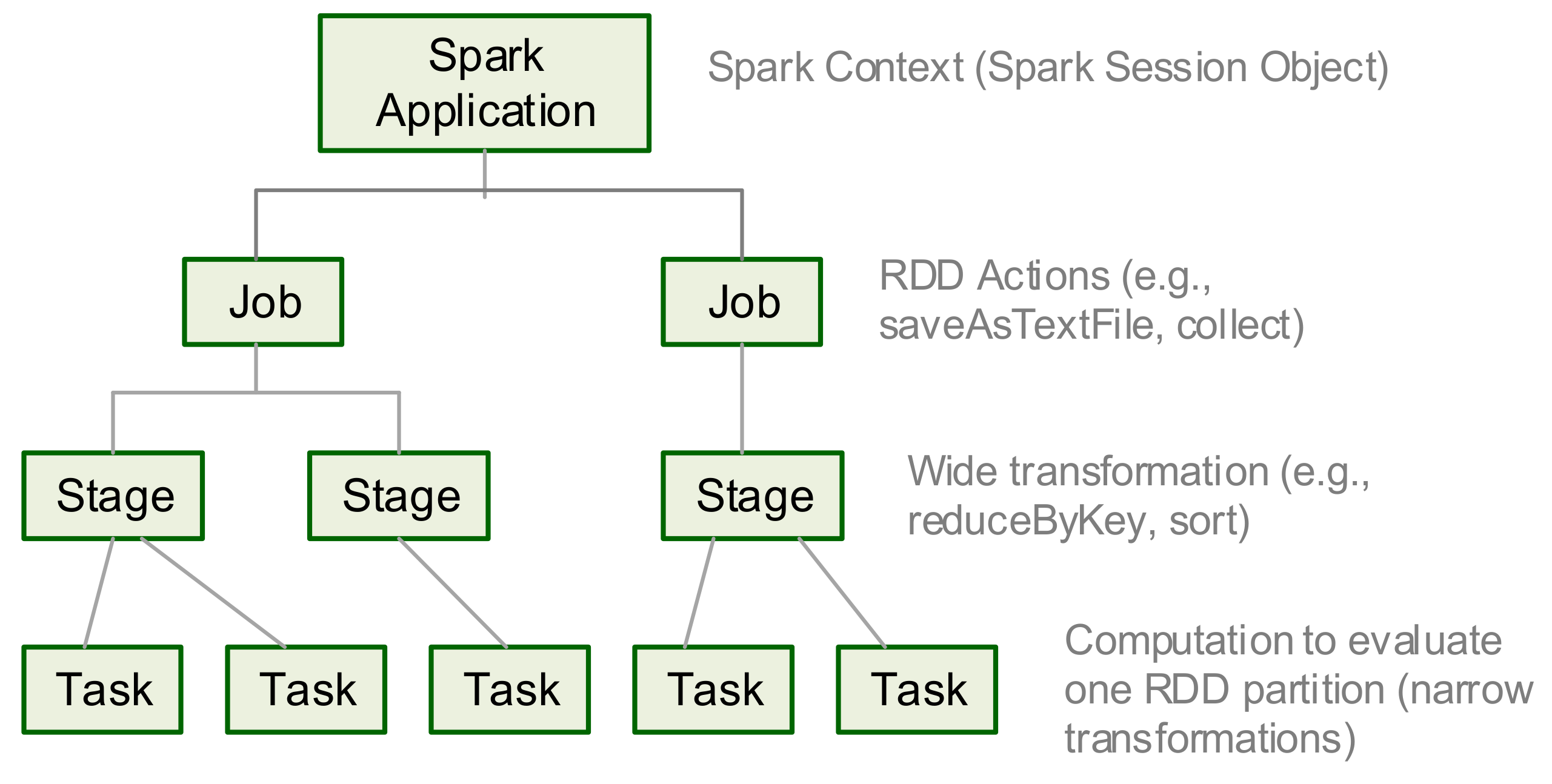
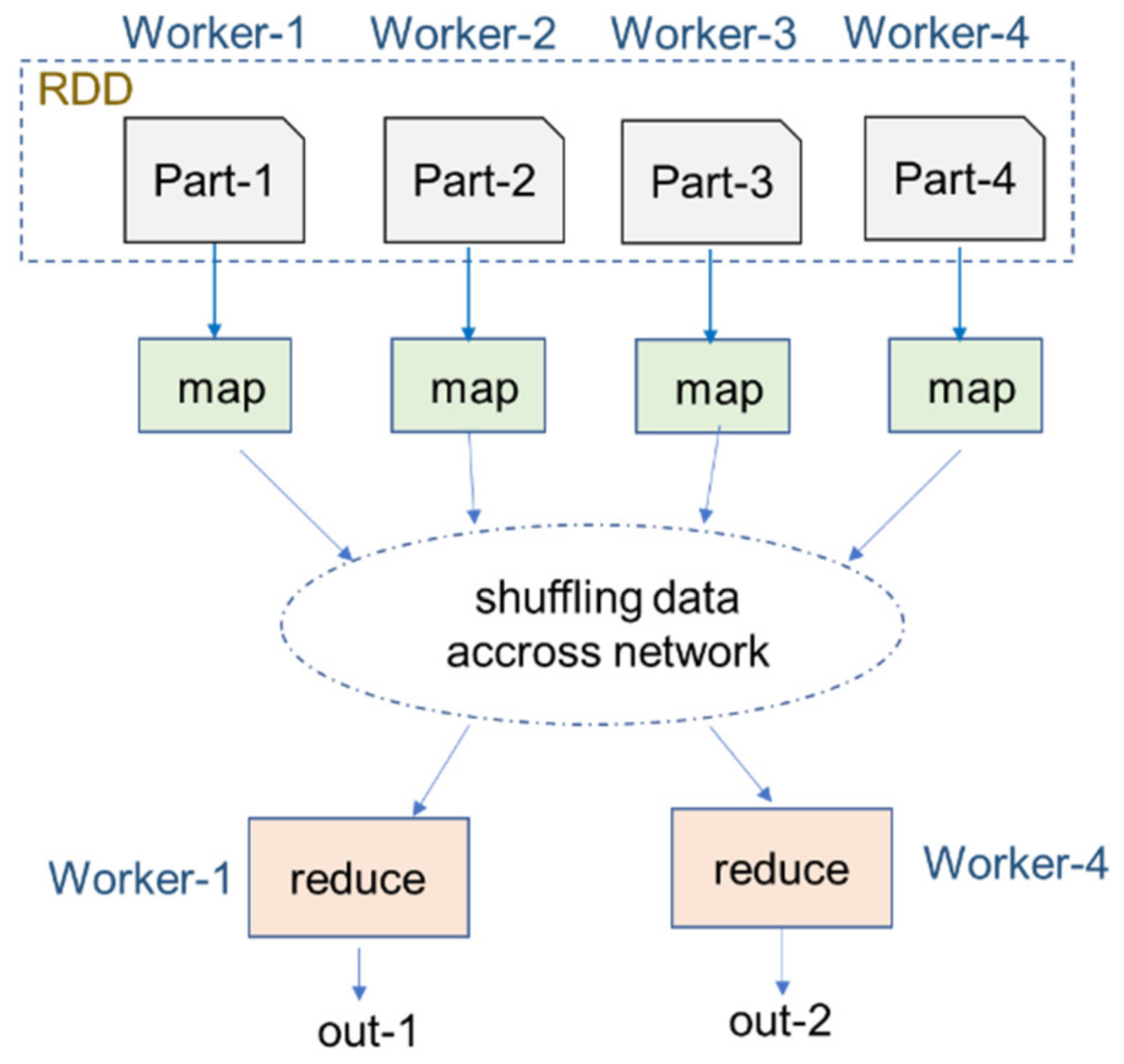
2.2. Spark, GraphX and GraphFrames
2.2.1. Apache Spark
2.2.2. GraphX and GraphFrames
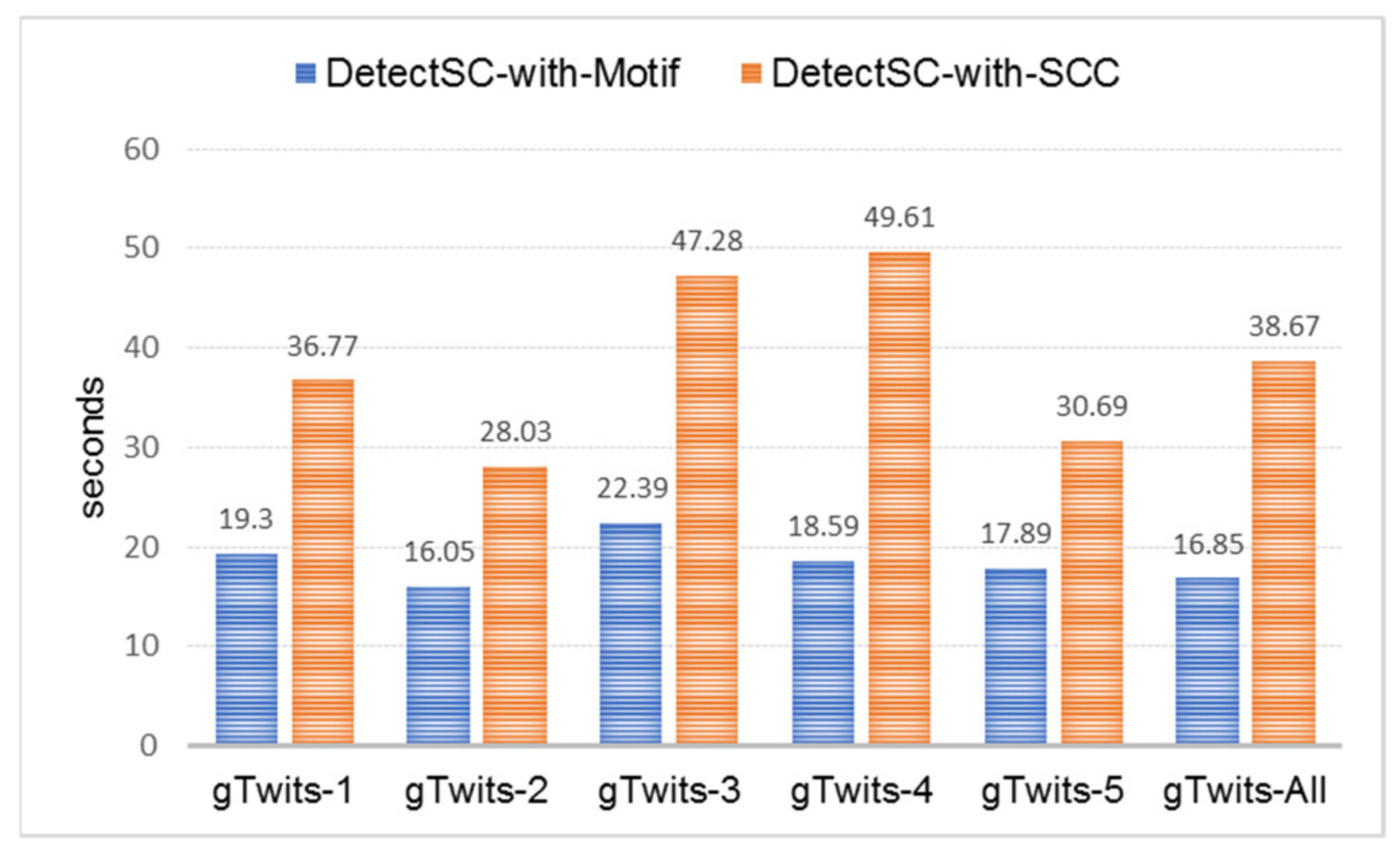
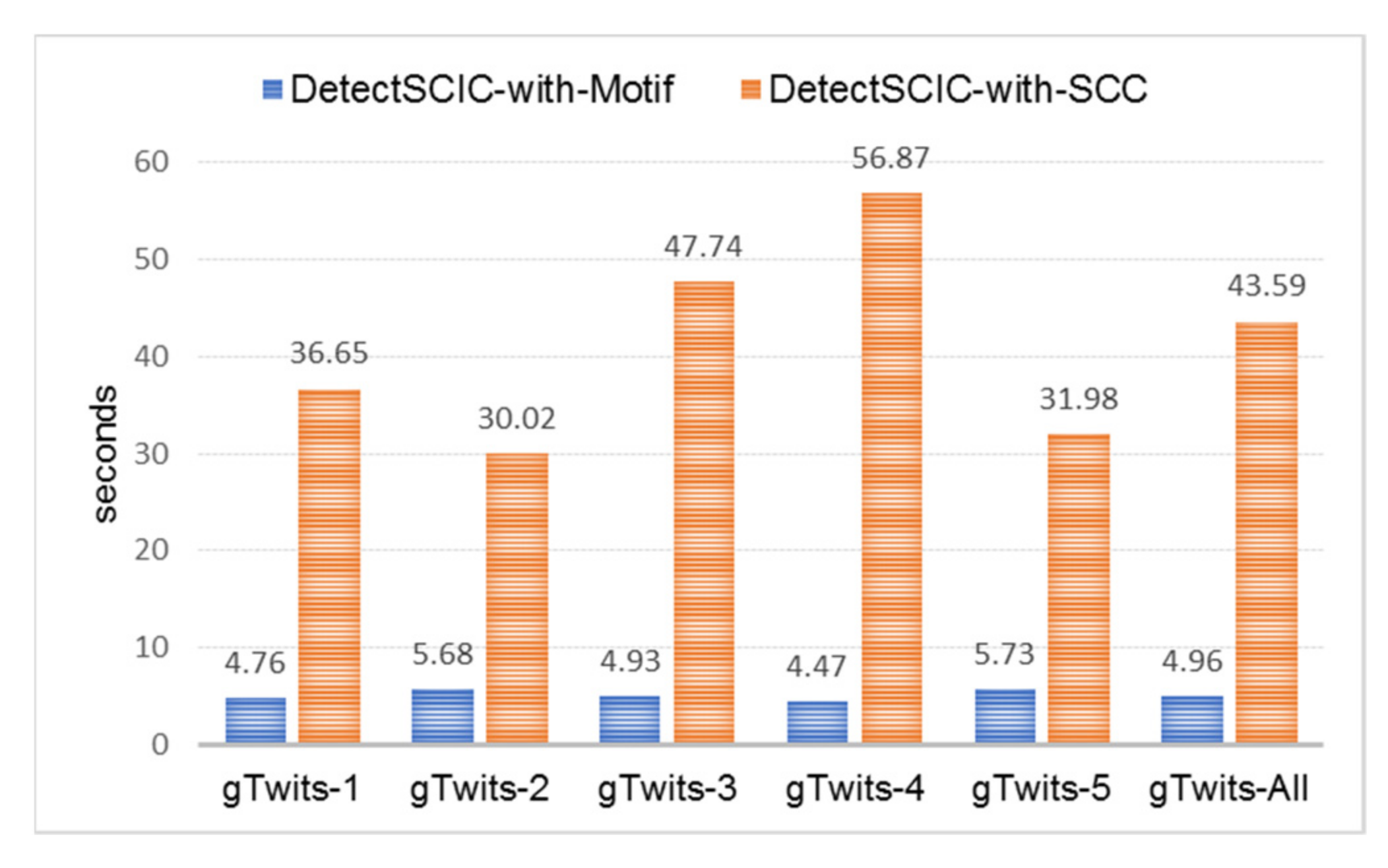
3. Comparing SCC Algorithm and Motif Finding on Spark
- (1)
- An instance of GraphFrame for each graph dataset was created;
- (2)
- SCC algorithm was used to detect SCCs from the graph instance;
- (3)
- A set of patterns was searched from the graph instance. The pattern set searched on g1 was “(a)-[e1]->(b); (b)-[e2]->(a)”, g2 was “(a)-[e1]->(b); (b)-[e2]->(c); (c)-[e3]->(a)”, g3 was “(a)-[e1]->(b); (b)-[e2]->(c); (c)-[e3]->(d); (d)-[e4]->(a)”, g4 was “(a)-[e1]->(b); (b)-[e2]->(c); (c)-[e3]->(b); (b)-[e4]->(a)”, g5 was “(a)-[e1]->(b); (b)-[e2]->(c); (c)-[e3]->(d); (d)-[e4]->(e); (e)-[e5]->(a)”, and g6 was “(a)-[e1]->(b); (b)-[e2]->(c); (c)-[e3]->(b); (b)-[e4]->(a);(c)-[e5]->(d); (d)-[e6]->(c)”. For g7, all of the patterns were combined.
4. Proposed Techniques
4.1. Active Communities Definition
- (1)
- Similar interest communities (SIC): A group of people responding to the same event. Real world examples: (a) Twitter users who frequently retweet or reply or quote a user’s tweets, which means that those users have the same interest toward the tweet content; (b) forum users who frequently give comments or reply to posts/threads posted by certain user/users, which means those users have the same interest in discussion subjects.
- (2)
- Strong-interacting communities (SC): A group of people who interact with each other frequently in a period of time. Real world example: a group of people who reply/call/email/tweet/message each other.
- (3)
- Strong-interacting communities with their “inner circle” neighbors (SCIC): The extension of SC, where SC members become the core of the communities, added by the “external” people who are frequently directly contacted by the core members, as well as “external” people who directly contact the core members. Real world example: as in the aforementioned SC, now also including the surrounding people who actively communicate with them.
4.2. Proposed Algorithms
- (a)
- Detecting SIC from directed graphs
| Algorithm 1: DetectSIC |
| Descriptions: Detecting SIC from a directed graph using GraphFrame Input: Directed graph G, thWC1 = threshold of w; thIndeg = threshold of vertices in-degree Output: Communities stored in map structure, comSIC = map(CenterId, list of member Ids); a vertex can be member of more than one community. Steps: (1) Graph preparation: (a) filteredE = E in G with w > thWC1 //Only edges having w > thWC1 is used to construct the graph; (b) GFil = (V, filteredE) (2) Compute inDeg for every vertex in GFil, store into dataframe, inD(Id, inDegree) (3) selInD (IdF, inDegree) = inD where inDeg > thIndeg (4) Find communities: (a) dfCom = (GFil where its nodes having Id = selInD.IdF) inner join with E on Id = dstId, order by Id; (b) Collect partitions of dfCom from every worker (coalesce) then iterate on each record: read Id and srcId column, map the pair value of (Id, srcId) into comSIC |
- (b)
- Detecting SC using motif finding
| Algorithm 2: DetectSC-with-MotifFinding |
| Descriptions: Detecting SC using motif finding Input: Directed graph G; thWC1 = threshold of w; thDeg = threshold of vertices degree; motifs = {motif1, motif2, …, motifn} where motif1 = 1st pattern of SC, motif2 = 2nd pattern of SC, motifn = the nth pattern of SC Output: Communities stored in map structure, comSCMotif = map(member_Ids: String, member_count: Int) where member_Ids contains list of Id. A vertex can be member of more than one community. Steps: (1) Graph preparation: (a) filteredE = E in G with w > thWC1; (b) GFil = (V, filteredE) (2) Compute degrees for every vertex in GFil, store into a dataframe, deg(Id, degree) (3) selDeg (IdF, degree) = deg where degree > thDeg (4) Gsel = subgraph of GFil where its nodes having Id = selInD.IdF (5) For each motifi in motifs, execute Gsel.find(motifi), store the results in dfMi, filter records in dfMi to discard repetitive set of nodes (6) Collect partitions of dfMi from every worker (coalesce), then call findComDFM(dfMi) |
| Algorithm 3: findComDFM |
| Descriptions: Formatting communities from dataframe dfMi Input: dfMi Output: Communities stored in map structure, comSCMotif: map(member_Ids: String, member_count: Int). member_Ids: string of sorted Ids (separated by space) in a community, member_count: count of Ids in a community Steps: (1) For each row in collected dfMi: (2) line = row (3) parse line and find every vertex Id in str with space to separate between Id, with the count of Ids store in member_count (4) sort Ids in str in ascending order (5) add (str, Id) into comMotif // as str is the key in comMotif, only unique value of str will be successfully added |
- (c)
- Detecting SC using SCC algorithm
| Algorithm 4: DetectSC-with-SCC |
| Descriptions: Detecting SC using SCC algorithm Input: Directed graph G; thWC1 = threshold of w; thDeg = threshold of vertices degree; thCtMember = threshold of member counts in an SCC Output: Communities stored in map structure, comSIC = map(CenterId, list of member Ids). A vertex can be member of more than one community. Steps: (1) Graph preparation: (a) filteredE = E in G with w > thWC1; (b) GFil = (V, filteredE) (2) filteredG = subgraph of GFil where each vertex has degree > thDeg (3) Find strongly connected components from filteredG, store as sccs dataframe (4) Using group by, create dataframe dfCt(idCom,count), then filter with count > thCtMember // The SCC algorithm record every vertex as a member of an SCC (SCC may contain one vertex only) (5) Join sccs and dfCt on Id = IdCom store into sccsSel // sccsSel contains only records in a community having more than one member (6) Collect partitions of sccsSel from every worker, sort the records by idCom in ascending order, then call findComSC(sccsSel) |
| Algorithm 5: findComSC |
| Descriptions: Formatting communities from sccsSel Input: Dataframe containing connected vertices, sccs(id, idCom) Output: Communities stored in map structure, comSCC: map(idCom: String, ids_count: String). idCom: string of community Id, Ids_count: strings of list of vertex Ids in a community separated by space and count of Ids. Steps: (1) prevIdCom = “”; keyStr = “”; addStatus = false; nMember = 0 (2) For each row in sccsSel (3) line = row; parse line; strId = line[0]; idC = line[1] (4) if line is the first line: add strId to keyStr; prevIdCom = idC; nMember = nMember + 1 (5) else if prevIdCom == idC and line is not the last line: add strId to keyStr; nMember = nMember + 1 (6) else if prevIdCom != idC and line is not the last line: add strId to keyStr, nMember = nMember + 1; add (keyStr, nMember) to comSCC; keyStr =””; nMember = 0; addStatus = true; //Final check (7) if addStatus == false and line is the last line: add (keyStr, nMember) to comSCC; addStatus = true; |
- (d)
- Detecting SCIC
| Algorithm 6: DetectSCIC-with-SCC |
| Descriptions: Detecting SCIC using SCC algorithm Input: Directed graph G; thWC1 = threshold of w; thDeg = threshold of vertices degree; thCtMember = threshold of member counts in an SCC Output: Communities stored in map structure, comSCIC = map(idCom: String, ids_count: String). A vertex can be member of more than one community. Steps: Step 1 to 6 is the same with the ones in DetectSC-with-SCC. (7) Join sccsSel with filteredE based on sccsSel.id = filteredE.dst store as dfIntoSCC with src column renamed as friendId //neighbor nodes contact SCC nodes (8) Join sccsSel with filteredE based on sccsSel.id = filteredE.src store as dfFromSCC with dst column renamed as friendId // neighbor nodes contacted by SCC nodes (9) Merge dfIntoSCC and dfFromSCC into dfComExpand dataframe using union operation (10) Collect partitions of dfComExpand from every worker, sort the records by IdCom in ascending order, then call findComSCIC(dfComExpand) // The schema is: dfComExpand(id, idCom, friendId) |
| Algorithm 7: findComSCIC |
| Descriptions: Formatting communities from dfComExpand Input: Dataframe containing connected vertices, dfComExpand (id, idCom, friendId ) Output: Communities stored in map structure, comSCIC: map(idCom: String, ids_count: String). idCom: string of community Id, Ids_count: strings of vertex Ids in a community separated by space and count of Ids the community. Steps: (1) prevIdCom = “”; keyStr = “”; addStatus = false; nMember = 0 (2) For each row in dfComExpand (3) line = row; parse line; strId = line[0]; idC = line[1]; idFr = line[2] (4) if line is the first line: add strId and idFr to keyStr; prevIdCom = idC; nMember = nMember + 2 (5) else if prevIdCom == idC and line is not the last line: add idFr to keyStr; nMember = nMember + 1 (6) else if prevIdCom != idC and line is not the last line: add idFr to keyStr, nMember = nMember + 1; add (keyStr, nMember) to comSCC; keyStr =””; nMember = 0; addStatus = true; //Final check (7) if addStatus == false and line is the last line: add (keyStr, nMember) to comSCC; addStatus = true; |
| Algorithm 8: DetectSCIC-with-Motif |
| Descriptions: Detecting SCIC using motif finding Input: Directed graph G; thWC1 = threshold of w; thDeg = threshold of vertices degree; thCtMember = threshold of member counts in an SCC Output: Communities stored in map structure, comSCICMotif = map(IdCom, list of member Ids). A vertex can be member of more than one community. Steps: Step 1 to 6 is the same with the ones in DetectSC-with- Motif (7) Initialize an array, arrCom(IdCom, IdM) where IdCom is Id of the community, IdM is Id of the member; IdC = 0 (8) for each pair of (member_Ids, member_count) from comSCMotif: (9) IdC = IdC + 1 (10) parse member_Ids then for each Id add(IdC, Id) into arrCom (11) create a dataframe, dfCom(IdCom, id) from arrCom (12) Join dfCom with filteredE based on dfCom.id = filteredE.dst store as dfIntoSCC with src column renamed as friendId //neighbor nodes contact SCC nodes (13) Join dfCom with filteredE based on dfCom.id = filteredE.src store as dfFromSCC with dst column renamed as friendId // neighbor nodes contacted by SCC nodes (14) Merge dfIntoSCC and dfFromSCC into dfComExpand dataframe using union operation (15) Collect partitions of dfComExpand from every worker, sort the records by IdCom in ascending order, then call findComSCIC(dfComExpand) // The schema is: dfComExpand(id, idCom, friendId) |
5. Experiments and Results
5.1. Public Big Graphs
5.2. Real Tweets
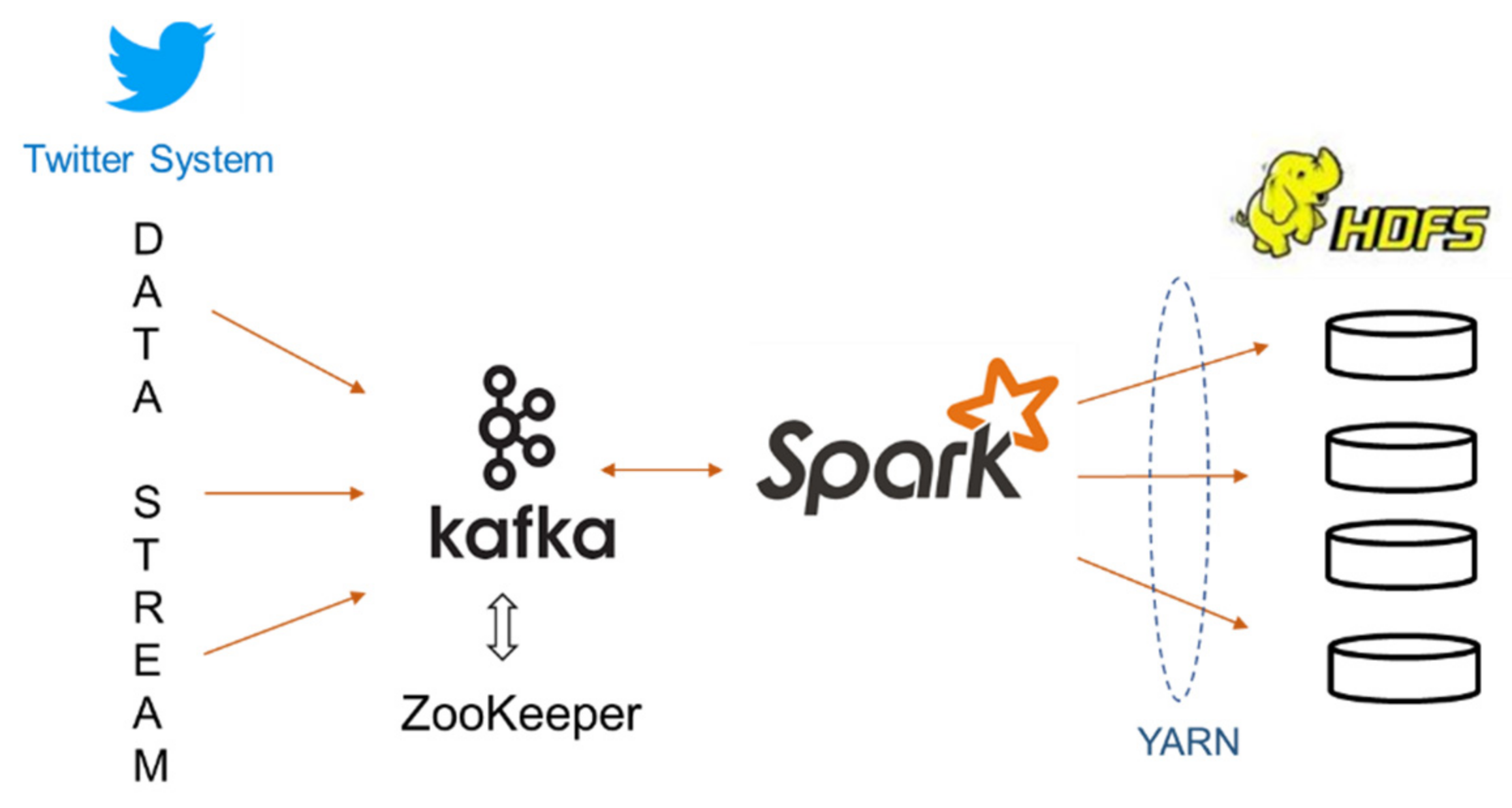
5.3. Data Collection and Preparation
- (1)
- Create a dataframe (edgesDF) from half-hourly tweet streams (48 × 7 parquet files per day)
- (2)
- Filter the edgesDF to include only quote and reply tweets
- (3)
- Clean edgesDF by removing tweets having self reply/quote or screennames with null values.
- (4)
- Create a dataframe of edgesWDF from edgesDF using edgesDF.groupBy(“src”,”dst”).count()
- (5)
- Filter edgesWDF to include only records having count > thWeight, which means that only users who have actively replied or quoted tweets in the period are included as graph vertices. Here, the threshold used is three. Thus, all users that reply or quote tweets more than three times a week are considered active users. The statistics of the data preparation are depicted in Table 2.
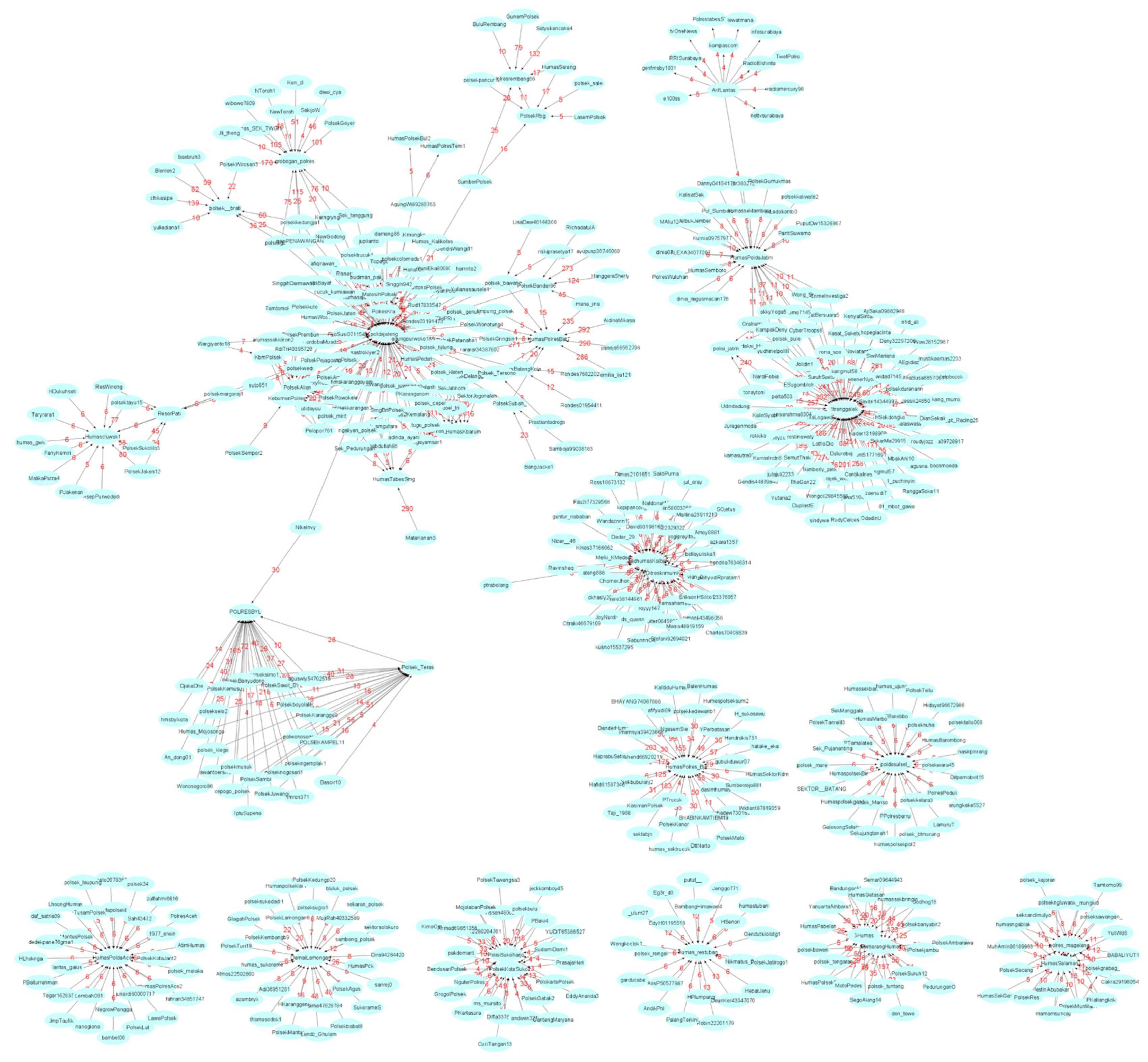
5.4. Finding and Discussion of SICs
Discussion and Analysis of the SICs
5.5. Finding and Discussion of SCs and SICs
5.5.1. Discussion and Analysis of the SCs and SCICs
- (1)
- 24–30 January and 14–20 March 202: civilian-only communities were formed.
- (2)
- 21–27 February 2021: civilian-only and police officer-only communities were formed.
- (3)
- 28 February–6 March and 7–13 March 2021: civilian-only and civilian-police officer communities were formed.
5.5.2. The Scalability Issue
6. Conclusions and Further Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| //GraphFrame instance creation |
| val edges1 = spark.read.option(“header”,true).csv(path-csv-file) |
| val vert1 = spark.read.option(“header”,true).csv(“path-csv-file “) |
| val g1 = GraphFrame(vert1, edges1) |
| //Detecting SCCs using SCC algorithm on a graph instance |
| val scc = g1.stronglyConnectedComponents.maxIter(10).run() |
| //Motif findings (patterns searched) towards each graph instance |
| (a)val Cyclic_2 = g1.find(“(a)-[e1]->(b); (b)-[e2]->(a)”) |
| (b)val Circle_3 = g2.find(“(a)-[e1]->(b); (b)-[e2]->(c); (c)-[e3]->(a)”) |
| (c)val Circle_4 = g3.find(“(a)-[e1]->(b); (b)-[e2]->(c); (c)-[e3]->(d); (d)-[e4]->(a)”) |
| (d)val Cyclic_22 = g4.find(“(a)-[e1]->(b); (b)-[e2]->(c); (c)-[e3]->(b); (b)-[e4]->(a)”) |
| (e)val Circle_5 = g5.find(“(a)-[e1]->(b); (b)-[e2]->(c); (c)-[e3]->(d); (d)-[e4]->(e); (e)-[e5]->(a)”) |
| (f)val Cyclic_222 = g6.find(“(a)-[e1]->(b); (b)-[e2]->(c); (c)-[e3]->(b); (b)-[e4]->(a);(c)-[e5]->(d); (d)-[e6]->(c)”) |
| //For detecting all motifs, the codes in (a) to (f) are combined. |
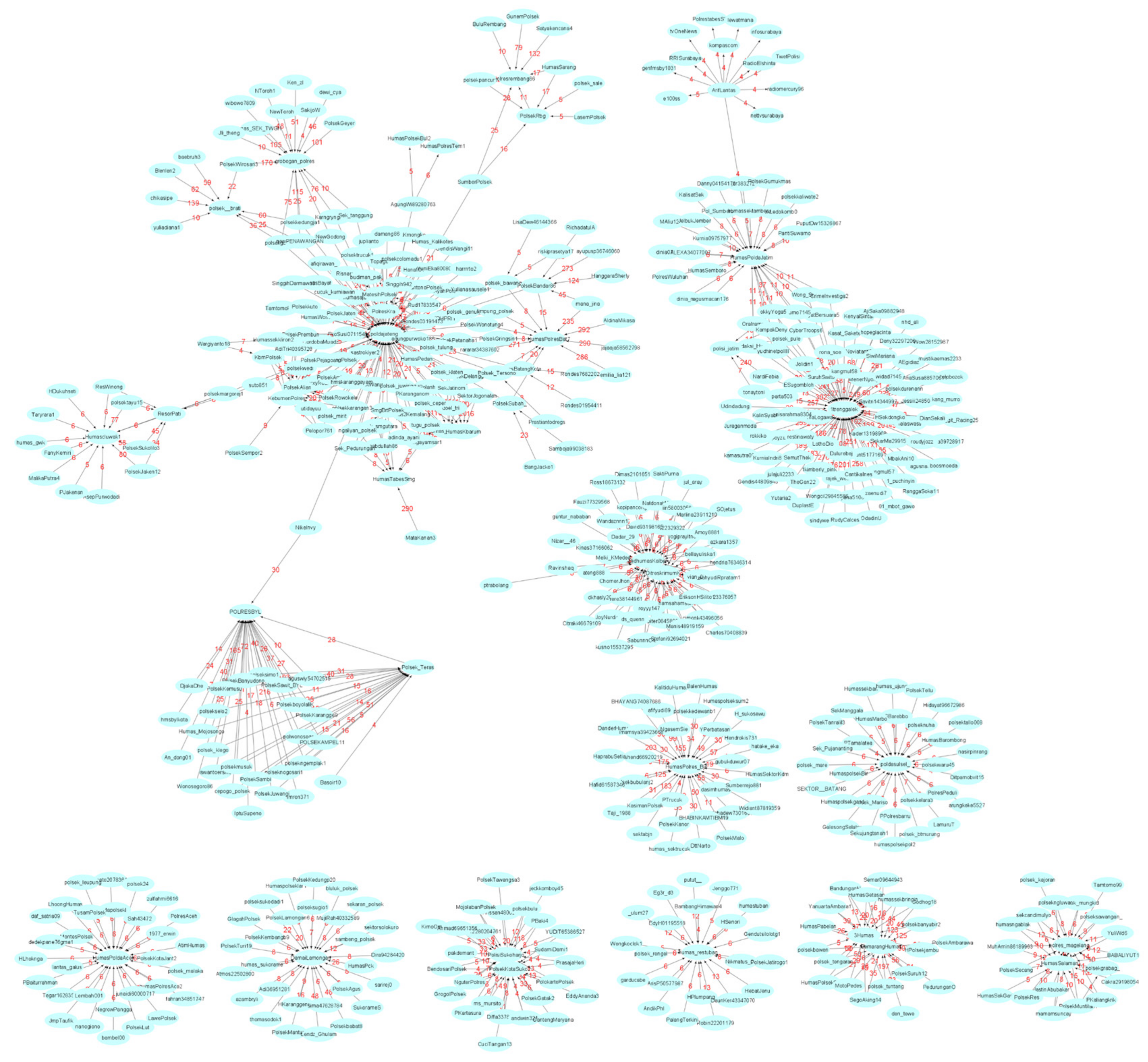
| Graphs/#Communities | SC: #Members: Id Members | SCIC: #Members: Id Members |
|---|---|---|
| gTweets-3/ 4 | 2: PolresKra MatesihPolsek; 2: dfitriani1 Trikus2012; 2: sek_pemalang polres_pemalang; 2: putu_ardikabali KakBejo | 10: MatesihPolsek polsekcolomadu1 Hanafi0101 PolresKra poldajateng_ Rud17833547 Sek_Mojogedang Topage19 agungpurwoko186 cucuk_kurniawan; 3: dfitriani1 HannyValenciaa Trikus2012; 10: Jonatan77875470 Warungpring1 poldajateng_ tyas_aldian Wiekha5 sek_pemalang HumasWatukumpul polres_pemalang Anto60king sakila2021 3_Martha23 TiaraJelita20; 2: putu_ardikabali KakBejo |
| gTweets-4/ 4 | 2: 3Humas SemarangHumas; 2: Kfaizureen Mat_Erk; 3: HumasPoldaRiau BastianusRicar3 Hans77759603; 2: rokandt Alva47831808 | 20: 3Humas BandunganH PolsekAmbarawa PedurunganO TeloGodhog18 polsek_tengaran PolsekSuruh12 den_tewe SegoAking14 SemarangHumas HumasPolsekSum7 polsekbanyubir2 polsek_tuntang HPolsekjambu HumasGetasan polsekbawen YanuartaAmbara1 HumasPabelan humassekbringin Semar09644943 MotoPedes, 3: Kfaizureen ffiekahishak Mat_Erk; 3: HumasPoldaRiau BastianusRicar3 Hans77759603; 2: rokandt Alva47831808 |
| gTweets-5/ 3 | 2: ___327____ syarlothsita; 2: tejomament BabylonGate1; 2: equalgame97 chibicatsaurus | 4: ___327____ syarlothsita rokandt arifbsantoso; 2: tejomament BabylonGate1; 2: equalgame97 chibicatsaurus |
References
- Bae, S.-H.; Halperin, D.; West, J.D.; Rosvall, M.; Howe, B. Scalable and Efficient Flow-Based Community Detection for Large-Scale Graph Analysis. ACM Trans. Knowl. Discov. Data 2017, 11, 1–30. [Google Scholar] [CrossRef]
- Fortunato, S. Community detection in graphs. In Complex Networks and Systems Lagrange Laboratory; ISI Foundation: Torino, Italy, 2010. [Google Scholar]
- Makris, C.; Pispirigos, G. Stacked Community Prediction: A Distributed Stacking-Based Community Extraction Methodology for Large Scale Social Networks. Big Data Cogn. Comput. 2021, 5, 14. [Google Scholar] [CrossRef]
- Yao, K.; Papadias, D.; Bakiras, S. Density-based Community Detection in Geo-Social Networks. In Proceedings of the 16th International Symposium on Spatial and Temporal Databases (SSTD’19), Vienna, Austria, 19–21 August 2019. [Google Scholar]
- Malak, M.S.; East, R. Spark GraphX in Action; Manning Publ. Co.: Shelter Island, NY, USA, 2016. [Google Scholar]
- Chambers, B.; Zaharia, M. Spark: The Definitive Guide, Big Data Processing Made Simple; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2018. [Google Scholar]
- Atastina, I.; Sitohang, B.; Saptawati, G.A.P.; Moertini, V.S. An Implementation of Graph Mining to Find the Group Evolution in Communication Data Record. In Proceedings of the DSIT2018, Singapore, 20–22 July 2018. [Google Scholar] [CrossRef]
- Dave, A.; Jindal, A.; Li, L.E.; Xin, R.; Gonzalez, J.; Zaharia, M. GraphFrames: An Integrated API for Mixing Graph and Relational Queries. In Proceedings of the Fourth International Workshop on Graph Data Management Experiences and Systems, Redwood Shores, CA, USA, 24 June 2016. [Google Scholar] [CrossRef]
- Tran, D.H.; Gaber, M.M.; Sattler, K.U. Change Detection in Streaming Data in the Era of Big Data: Models and Issues. SIGKDD Explorations. 2014. Available online: https://www.kdd.org/explorations/view/june-2014-volume-16-issue-1 (accessed on 27 February 2021).
- Moertini, V.S.; Adithia, M.T. Pengantar Data Science dan Aplikasinya bagi Pemula; Unpar Press: Bandung, Indonesia, 2020. [Google Scholar]
- Fung, P.K. InfoFlow: A Distributed Algorithm to Detect Communities According to the Map Equation. Big Data Cogn. Comput. 2019, 3, 42. [Google Scholar] [CrossRef] [Green Version]
- Bhatt, S.; Padhee, S.; Sheth, A.; Chen, K.; Shalin, V.; Doran, D.; Minnery, B. Knowledge Graph Enhanced Community Detection and Characterization. In Proceedings of the 12th ACM International Conference on Web Search and Data Mining (WSDM ’19), Melbourne, VIC, Australia, 11–15 February 2019. [Google Scholar] [CrossRef]
- Jia, Y.; Zhang, Q.; Zhang, W.; Wang, X. CommunityGAN: Community Detection with Generative Adversarial Nets. In Proceedings of the International World Wide Web Conference (WWW ’19), San Francisco, CA, USA, 13–17 May 2019. [Google Scholar]
- Roghani, H.; Bouyer, A.; Nourani, E. PLDLS: A novel parallel label diffusion and label selection-based community detection algorithm based on Spark in social networks. Expert Syst. Appl. 2021, 183, 115377. [Google Scholar] [CrossRef]
- Zhang, Y.; Yin, D.; Wu, B.; Long, F.; Cui, Y.; Bian, X. PLinkSHRINK: A parallel overlapping community detection algorithm with Link-Graph for large networks. Soc. Netw. Anal. Min. 2019, 9, 66. [Google Scholar] [CrossRef]
- Corizzo, R.; Pio, G.; Ceci, M.; Malerba, D. DENCAST: Distributed density-based clustering for multi-target regression. J. Big Data 2019, 6, 43. [Google Scholar] [CrossRef]
- Krishna, R.J.; Sharma, D.P. Review of Parallel and Distributed Community Detection Algorithms. In Proceedings of the the 2nd International Conference on Information Management and Machine Intelligence (ICIMMI), Jaipur, Rajasthan, India, 24–25 July 2020. [Google Scholar] [CrossRef]
- Sadri, A.M.; Hasan, S.; Ukkusuri, S.V.; Lopez, J.E.S. Analyzing Social Interaction Networks from Twitter for Planned Special Events; Lyles School of Civil Engineering, Purdue University: West Lafayette, IN, USA, 2017. [Google Scholar]
- Karau, H.; Warren, R. High Performance Spark; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2017. [Google Scholar]
- Holmes, A. Hadoop in Practice; Manning Publications, Co.: Shelter Island, NY, USA, 2012. [Google Scholar]
- White, T. Hadoop: The Definitive Guide, 4th ed.; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2015. [Google Scholar]
- Karau, H.; Konwinski, A.; Wendell, P.; Zaharia, M. Learning Spark; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2015. [Google Scholar]
- Moertini, V.S.; Ariel, M. Scalable Parallel Big Data Summarization Technique Based on Hierarchical Clustering Algorithm. J. Theor. Appl. Inf. Technol. 2020, 98, 3559–3581. [Google Scholar]
- Gonzalez, J.E.; Xin, R.S.; Dave, A.; Crankshaw, D. GraphX: Graph Processing in a Distributed Dataflow Framework. In Proceedings of the 11th USENIX Symposium on Operating Systems Design and Implementation (OSDI’14), USENIX Association, Denver (Broomfield), CO, USA, 6–8 October 2014; pp. 599–613. [Google Scholar]
- Yan, D.; Cheng, J.; Xing, K.; Lu, Y.; Ng, W.S.H.; Bu, Y. Pregel Algorithms for Graph Connectivity Problems with Performance Guarantees. In Proceedings of the 40th International Conference on Very Large Data Bases, Hangzhou, China, 1–5 September 2014. [Google Scholar]
- Bahrami, R.A.; Gulati, J.; Abulaish, M. Efficient Processing of SPARQL Queries Over GraphFrames. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence (WI’17), Leipzig, Germany, 23–26 August 2017; pp. 678–685. [Google Scholar]
- Balkesen, C.; Teubner, J.; Alonso, G.; Ozsu, M.T. Main-Memory Hash Joins on Modern Processor Architectures. IEEE Trans. Knowl. Data Eng. 2015, 27, 1754–1766. [Google Scholar] [CrossRef] [Green Version]
- McAuley, J.; Leskovec, J. Learning to Discover Social Circles in Ego Networks; Stanford University: Stanford, CA, USA, 2012. [Google Scholar]
- Djalante, R.; Lassa, J.; Setiamarga, D.; Sudjatma, A.; Indrawan, M.; Haryanto, B.; Mahfud, C.; Sinapoy, M.S.; Djalante, S.; Rafliana, I.; et al. Review and analysis of current responses to COVID-19 in Indonesia: Period of January to March 2020. Prog. Disaster Sci. 2020, 6, 100091. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.J.; Ng, C.; Brook, R.H. Response to COVID-19 in Taiwan, Big Data Analytics, New Technology, and Proactive Testing. JAMA 2020, 323, 1341. [Google Scholar] [CrossRef] [PubMed]
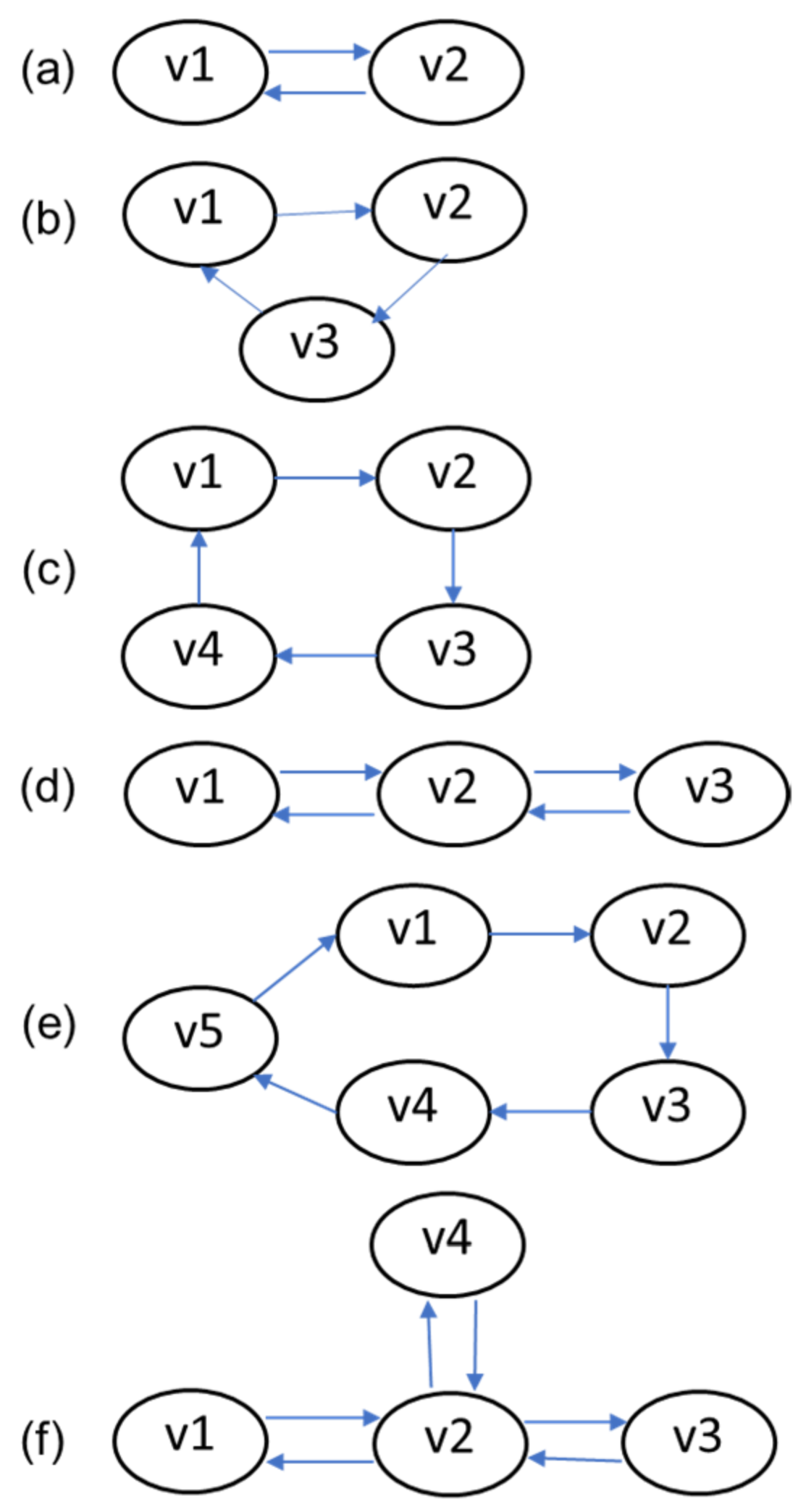
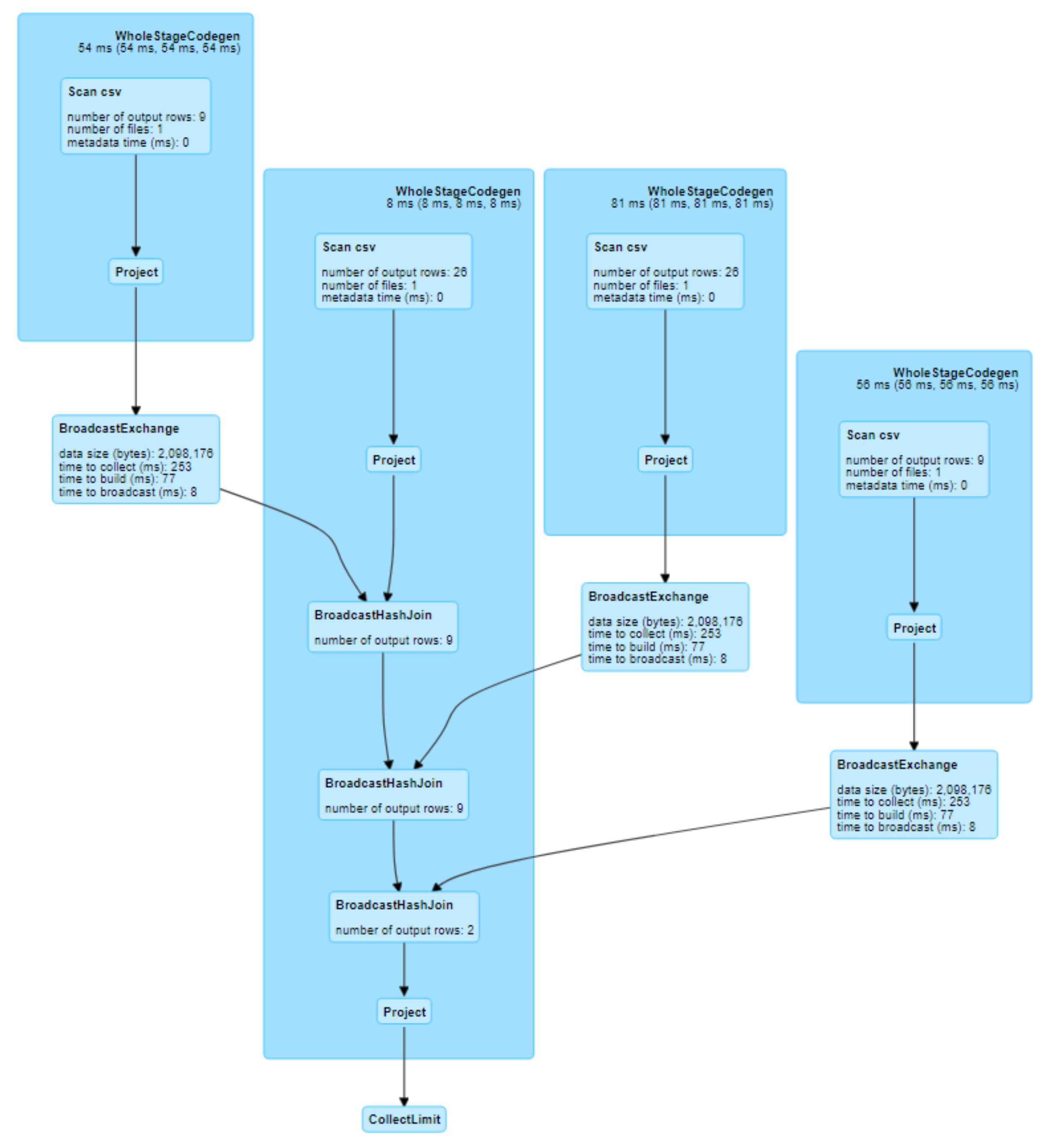
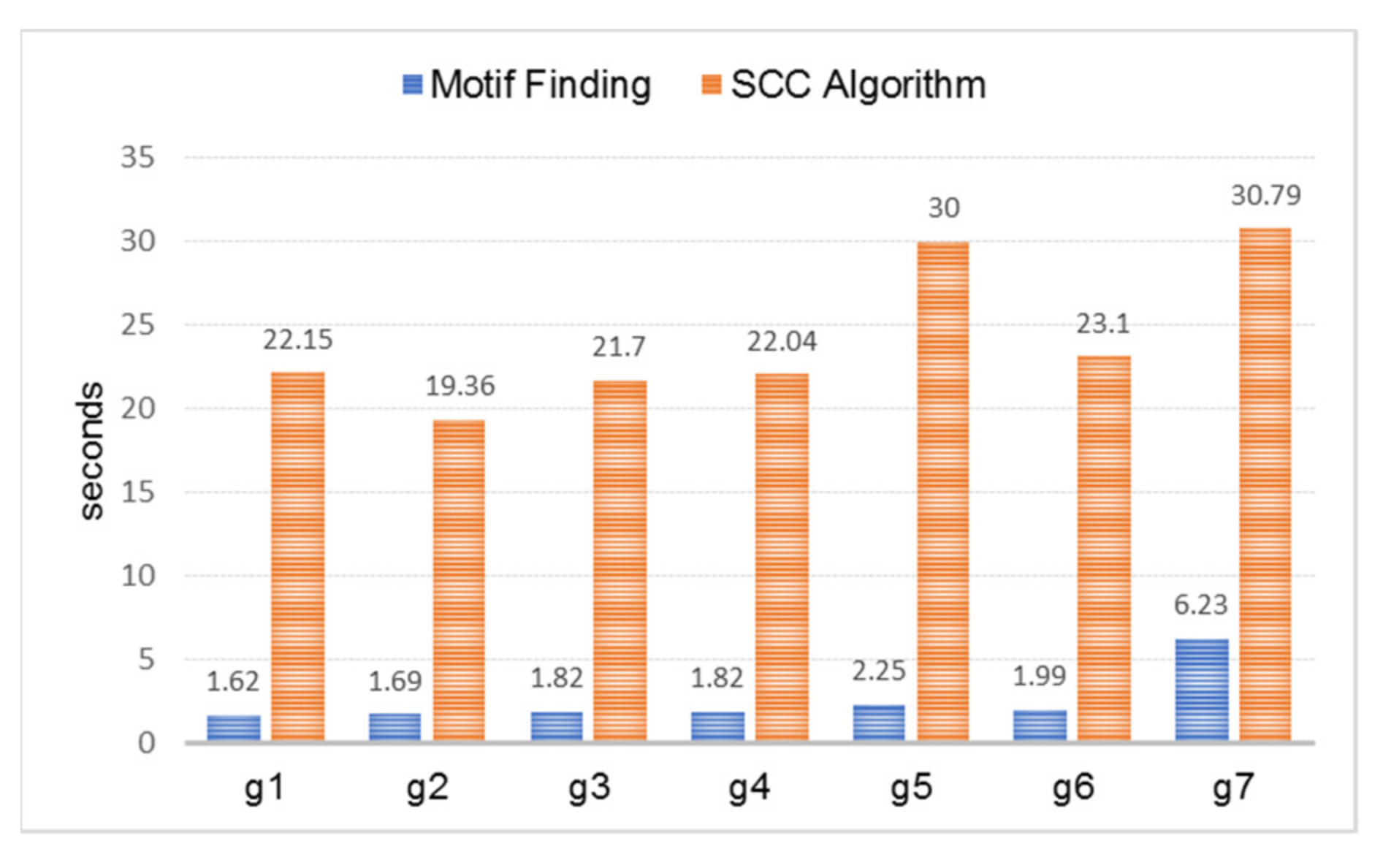
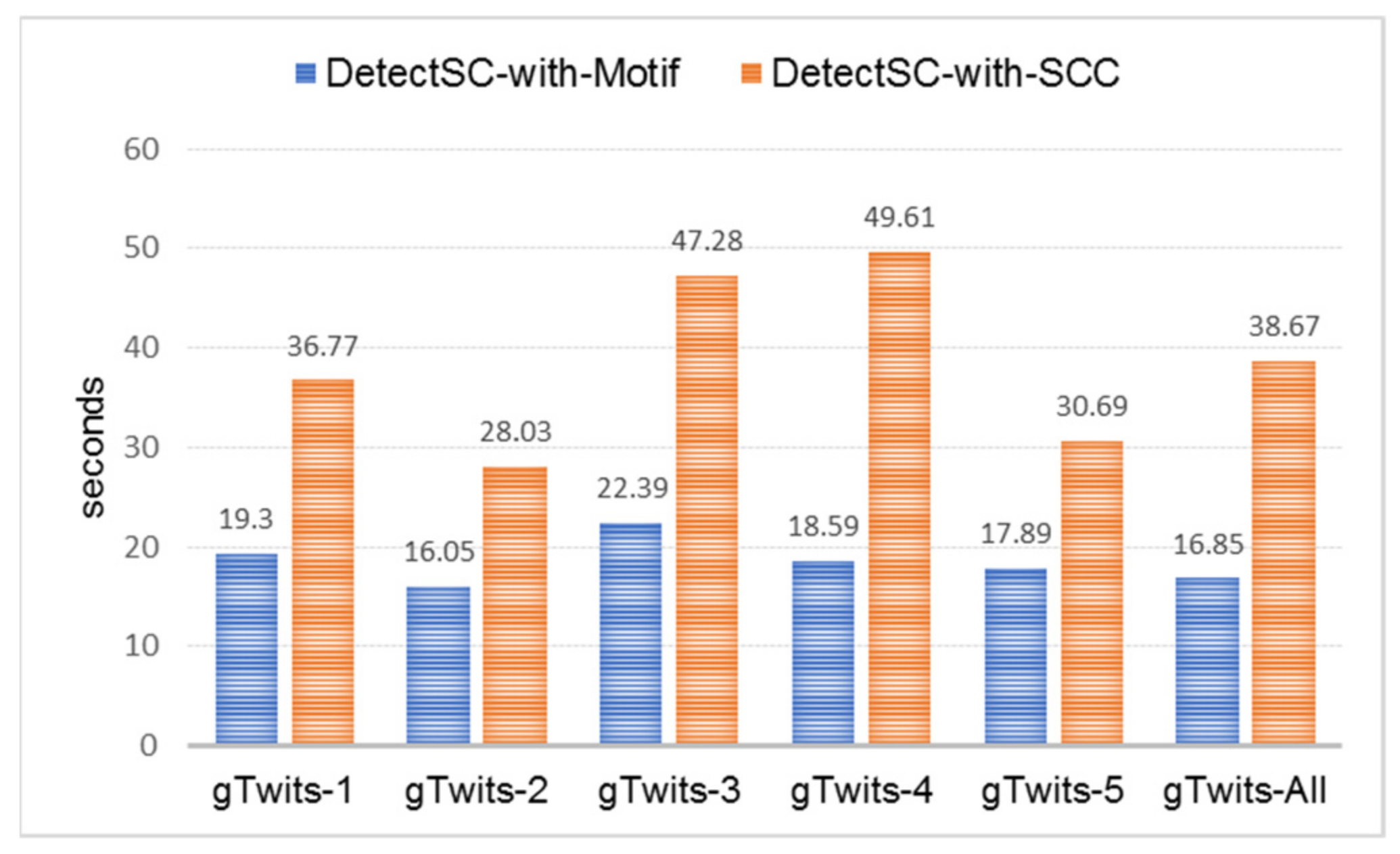
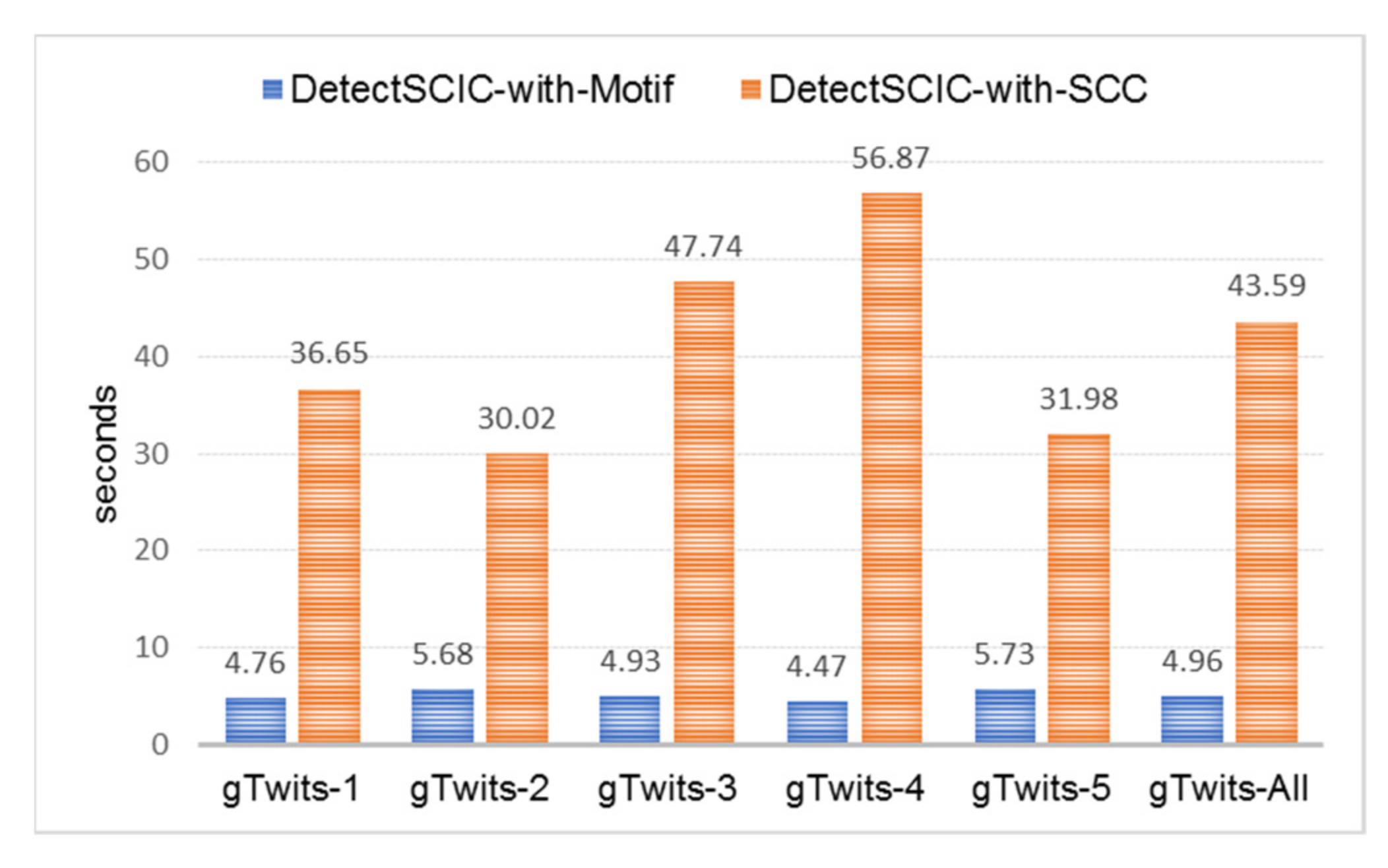
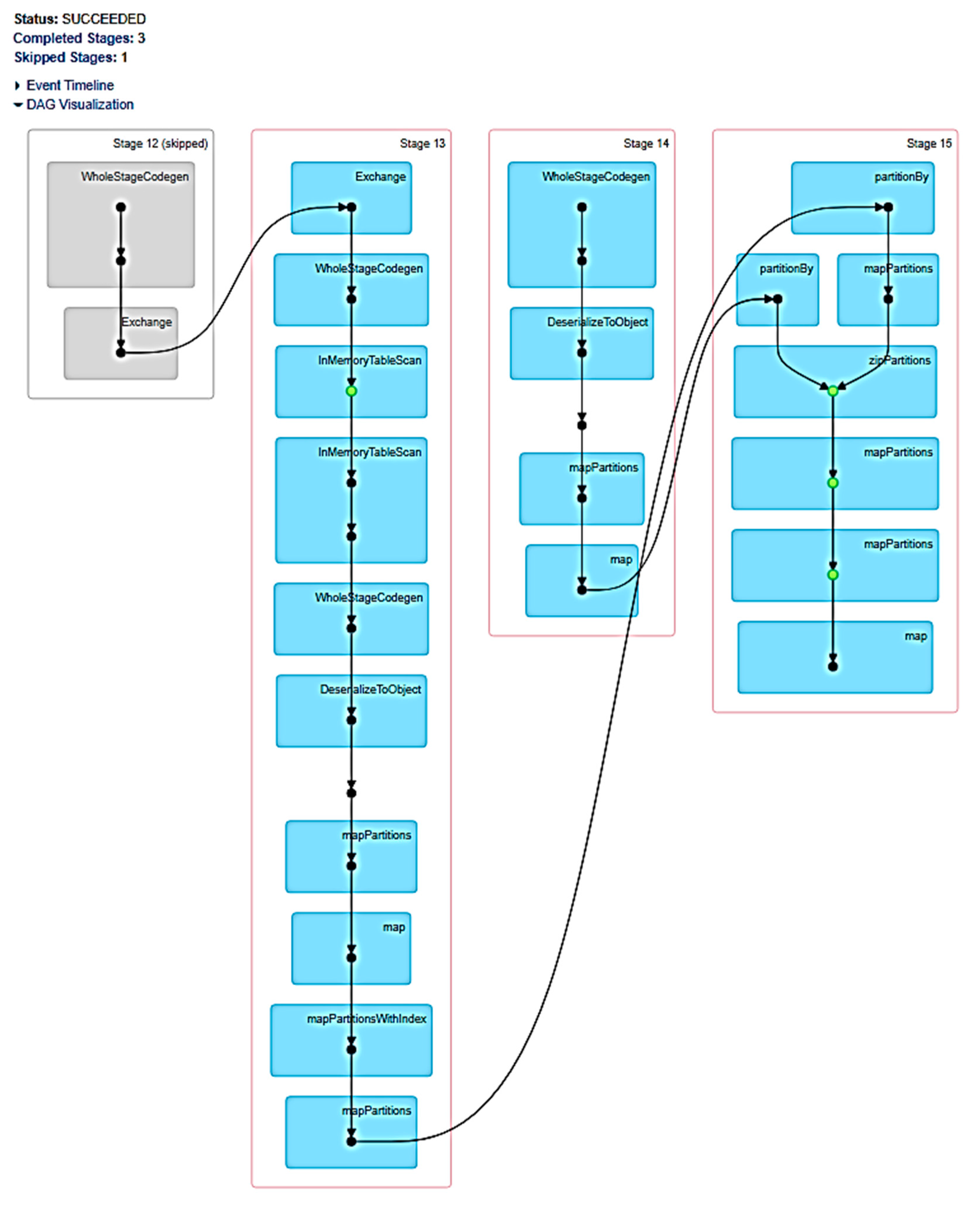
| Case | Graph | Motif Finding | SCC Algorithm | ||
|---|---|---|---|---|---|
| #Jobs | #Stages | #Jobs | #Stages | ||
| (a) | g1 | 4 | 4 | 29 | 75 |
| (b) | g2 | 6 | 6 | 28 | 75 |
| (c) | g3 | 8 | 8 | 30 | 83 |
| (d) | g4 | 7 | 7 | 32 | 80 |
| (e) | g5 | 10 | 10 | 38 | 105 |
| (f) | g6 | 10 | 10 | 37 | 98 |
| (g) | g7 | 45 | 45 | 41 | 114 |
| Weekly Period | #Tweets | #Quote & Reply Tweets | #Clean Edges (*) | #Weighted Edges/WE (**) | #Filtered WE (***) | #Vertices | Graph Created | #CC |
|---|---|---|---|---|---|---|---|---|
| 24–30 January 2021 | 470.250 | 56.764 | 47.800 | 44.655 | 198 | 261 | gTweets-1 | 81 |
| 21–27 February 2021 | 321.927 | 37.235 | 30.875 | 28.682 | 130 | 190 | gTweets-2 | 65 |
| 28 February–6 March 2021 | 266.743 | 58.490 | 46.961 | 28.037 | 839 | 750 | gTweets-3 | 92 |
| 7–13 March 2021 | 199.613 | 63.234 | 50.782 | 20.373 | 1.172 | 1027 | gTweets-4 | 103 |
| 14–20 March 2021 | 225.231 | 35.846 | 29.947 | 25.880 | 205 | 264 | gTweets-5 | 70 |
| Graph | Degree | Indegree | Outdegree | Neighborhood Connectivity | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ma | Mi | Av | Ma | Mi | Av | Ma | Mi | Av | Ma | Mi | Av | |
| gTweets-1 | 21 | 1 | 1.52 | 21 | 0 | 0.76 | 8 | 0 | 0.76 | 21 | 1 | 4.69 |
| gTweets-2 | 11 | 1 | 1.37 | 6 | 0 | 0.68 | 11 | 0 | 0.68 | 11 | 1 | 2.50 |
| gTweets-3 | 139 | 1 | 2.39 | 139 | 0 | 1.27 | 12 | 0 | 1.13 | 139 | 1 | 23.02 |
| gTweets-4 | 92 | 1 | 2.34 | 92 | 0 | 1.20 | 92 | 1 | 22.72 | 13 | 0 | 1.15 |
| gTweets-5 | 23 | 1 | 1.64 | 23 | 0 | 0.87 | 23 | 1 | 5.16 | 5 | 0 | 0.79 |
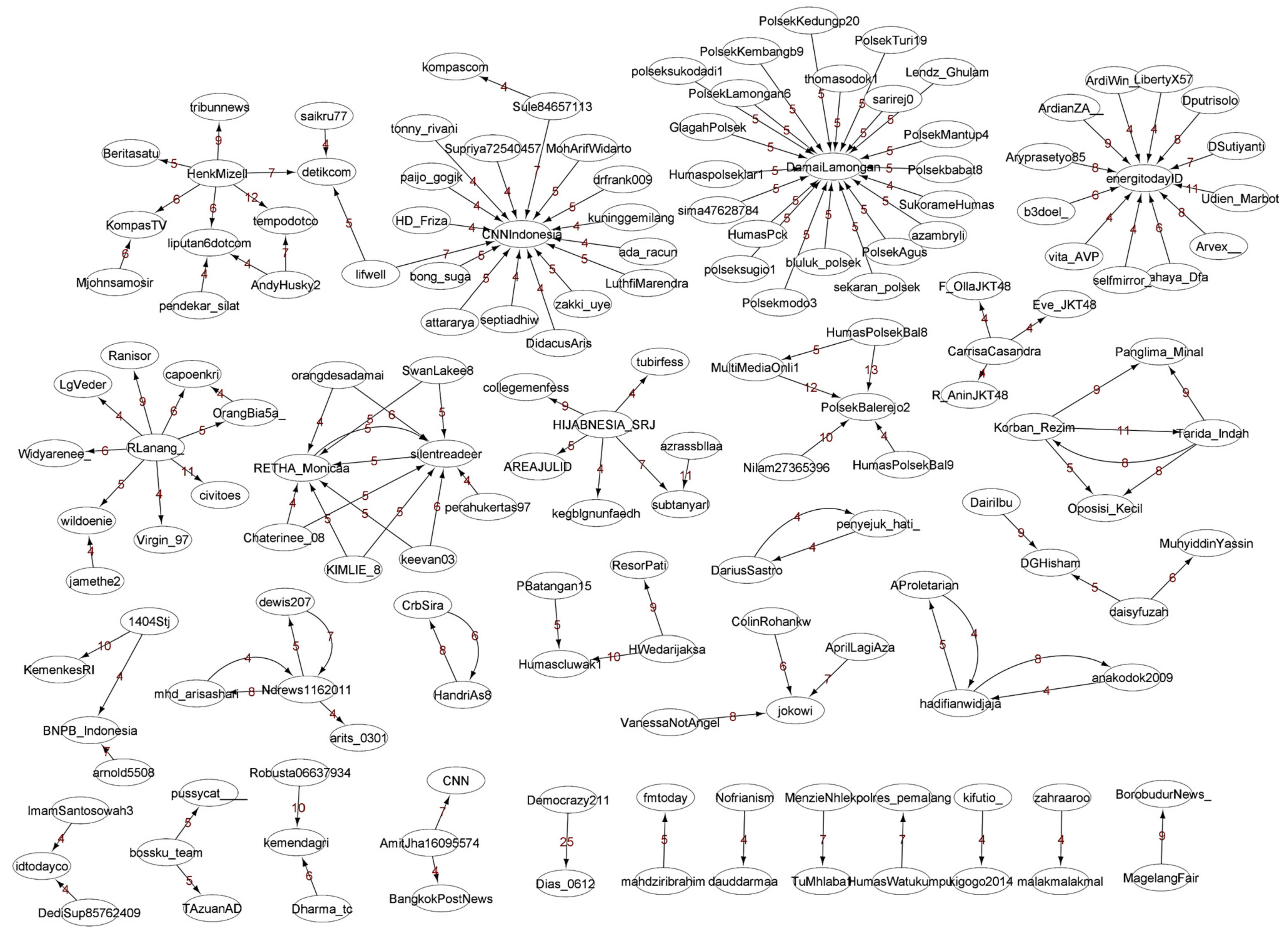
| Graph | thInDeg | #SICs | Sample of SICs | |
|---|---|---|---|---|
| Center Id | #Members | |||
| gTweets-1 | 5 | 5 | DamaiLamongan | 21 |
| silentreadeer | 7 | |||
| energitodayID | 12 | |||
| CNNIndonesia | 16 | |||
| RETHA_Monicaa | 6 | |||
| gTweets-2 | 5 | 1 | restulungagung | 6 |
| gTweets-3 | 10 | 21 | PolisiInfo | 15 |
| humas_restuban | 19 | |||
| Polres_Bwi | 12 | |||
| Hpanunggalan | 14 | |||
| HumasPolres_Bjn | 24 | |||
| gTweets-4 | 10 | 32 | DitreskrimumK | 33 |
| HumasPoldaAceh | 30 | |||
| MatesihPolsek | 11 | |||
| poldajateng | 92 | |||
| poldasulsel_ | 30 | |||
| gTweets-5 | 5 | 4 | PolisiInfo | 12 |
| HumasPolres_Bjn | 16 | |||
| 1trenggalek | 10 | |||
| poldajateng | 23 | |||
| Graphs/#Communities | SC: #Members: Id Members | SCIC: #Members: Id Members |
|---|---|---|
| gTweets-1/ 6 | 2: penyejuk_hati_ DariusSastro; 2: RETHA_Monicaa silentreadeer; 3: mhd_arisashari Ndrews1162011 dewis207; 2: HandriAs8 CrbSira, 3: AProletarian anakodok2009 hadifianwidjaja; 2: Korban_Rezim Tarida_Indah | 2: penyejuk_hati_ DariusSastro, 8: orangdesadamai SwanLakee8 KIMLIE_8 RETHA_Monicaa keevan03 silentreadeer Chaterinee_08 perahukertas97; 4: mhd_arisashari arits_0301 Ndrews1162011 dewis207; 2: HandriAs8 CrbSira; 3: AProletarian anakodok2009 hadifianwidjaja; 4: Panglima_Minal Korban_Rezim Tarida_Indah Oposisi_Kecil |
| gTweets-2/ 3 | 2: akundihackmulu jtuvanyx; 2: sek_pemalang polres_pemalang; 2: Fido_Dildo emha_baraja | 2: akundihackmulu jtuvanyx; 2: sek_pemalang polres_pemalang; 2: Fido_Dildo emha_baraja |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moertini, V.S.; Adithia, M.T. Uncovering Active Communities from Directed Graphs on Distributed Spark Frameworks, Case Study: Twitter Data. Big Data Cogn. Comput. 2021, 5, 46. https://doi.org/10.3390/bdcc5040046
Moertini VS, Adithia MT. Uncovering Active Communities from Directed Graphs on Distributed Spark Frameworks, Case Study: Twitter Data. Big Data and Cognitive Computing. 2021; 5(4):46. https://doi.org/10.3390/bdcc5040046
Chicago/Turabian StyleMoertini, Veronica S., and Mariskha T. Adithia. 2021. "Uncovering Active Communities from Directed Graphs on Distributed Spark Frameworks, Case Study: Twitter Data" Big Data and Cognitive Computing 5, no. 4: 46. https://doi.org/10.3390/bdcc5040046
APA StyleMoertini, V. S., & Adithia, M. T. (2021). Uncovering Active Communities from Directed Graphs on Distributed Spark Frameworks, Case Study: Twitter Data. Big Data and Cognitive Computing, 5(4), 46. https://doi.org/10.3390/bdcc5040046