NLA-Bit: A Basic Structure for Storing Big Data with Complexity O(1)


Abstract
1. Introduction
1.1. Graph Databases
- With explicit schema, such as Gram [6], GMOD [7], PaMaL [8], GOOD [8,9], GOAL [10], GDM [11,12], Logical Data Model (LDM) [13,14], Hypernode Mode (HyM) [15,16,17], and GROOVY [18]. The explicit schema exists separately from the data in the database and is used as an external pattern for data organization.
- With implicit schema such as RDF [19,20,21], GGL [22,23,24,25], Simatic-XT [26], and Object Exchange Model (OEM) [27]. Implicit schema is integrated in the database as a root of the data structure. In other words, the first data structure which can be accessed is the schema from which all other structures may be traversed, using it as a pattern.
1.2. Resource Description Framework
- Popular relational databases (ICS-FORTH RDF Suite [42,43], Semantics Platform 2.0 of Intellidimension Inc., Belfast, ME, USA [44], Ontopia Knowledge Suite [45], Hexastore [36], Jena [37,38], 3store [46], 4store [47], Kowari [48], Oracle [49], RDF-3X [50], RDFSuite [42], Virtuoso [51], and Sesame [40,41]);
1.3. Technologies for Storing RDF Data
- (1)
- General schemes, i.e., schemes that do not support certain structures and run on third-party databases, such as Jena SDB, which can connect to almost all relational databases, such as MySQL, PostsgreSQL and Oracle;
- (2)
- Specific to schemas that provide storing with their own database structures (Virtuoso, Mulgara, AllegroGraph and Garlik JXT).
1.3.1. General Schemes
Vertical Presentation
Normalized Triple Store
1.3.2. Specific Schemas
Horizontal Presentation
Vertical Decomposition
Multi-Indexing
- Triples with the same Subject;
- Triples with equal Relations;
- List of Subjects or Relations related to an Object.
1.4. The Goal of This Paper
- The reduction of the amount of occupied memory due to the complete absence of additional indexes, absolute addresses, pointers and additional files;
- Reduction of processing time due to the complete lack of demand—the data are stored/extracted to/from a direct address.
1.5. Organization of the Paper
2. NLA-Bit
2.1. Natural Language Addressing (NLA)
| document identifier: | A519701/2 |
| document data: | letter of conformance of agreement for collaboration |
2.2. Advantages of NLA
- The function that uses the encoding of letters with integers locates unambiguously and there is no way to get collisions;
- This function can be used recursively for each string character and to build perfect hash tables on many levels and thus to have quick access to the data.
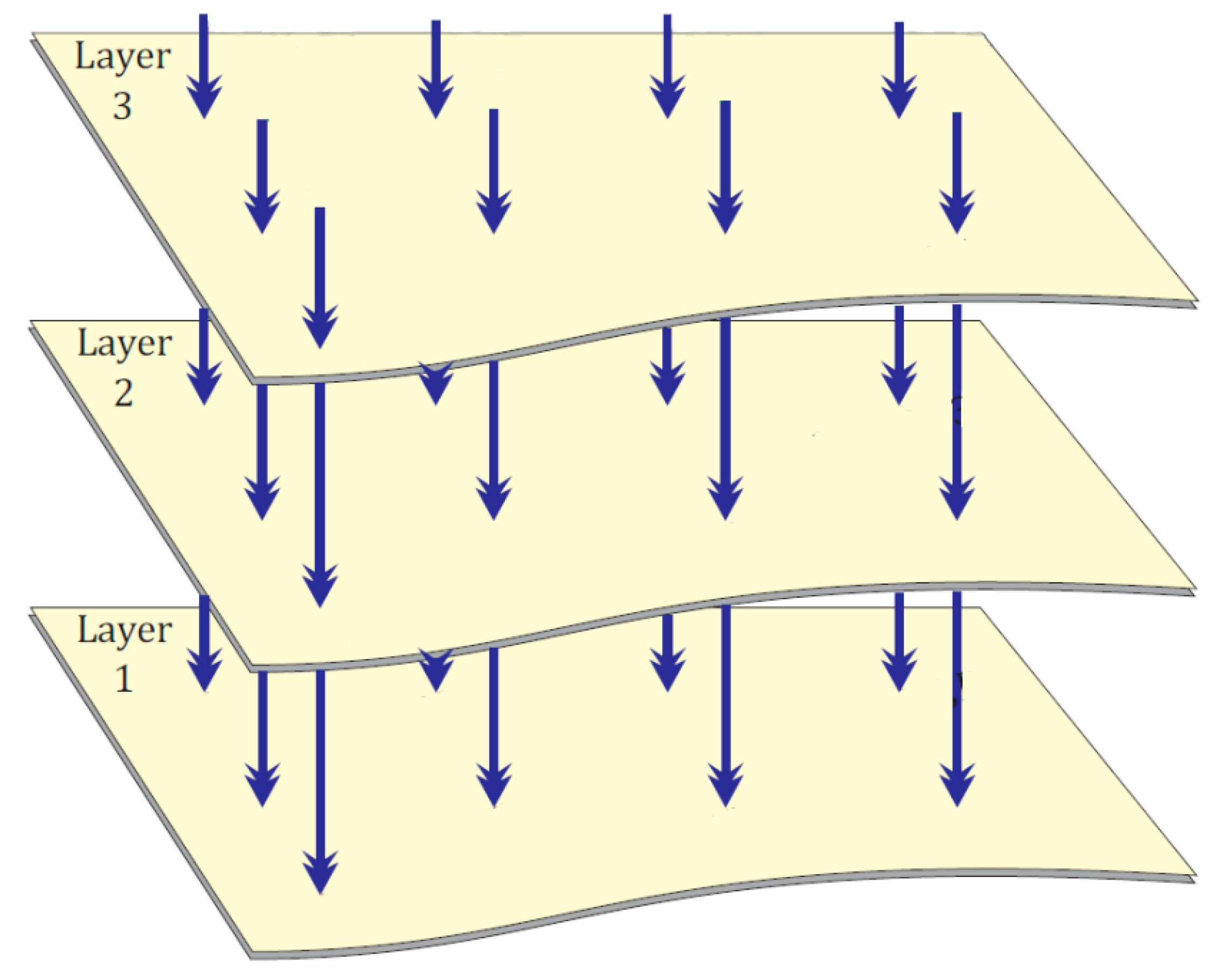
2.3. NLA-Bit
3. Results
3.1. Use Case: The Document Flow
3.1.1. Administrative Document and Document Flow
- Organizational and administrative documents—order, decision and decree; reference, etc.;
- Information documents—report, memorandum, information, official letter, report, protocol, list, reference, etc.
3.1.2. Administrative Information System
3.1.3. Information Objects
3.1.4. Electronic Correspondence
3.1.5. Metadata for Documents
3.1.6. Example of a System from Practice: DocuWare System
3.2. Experimental System Design
3.2.1. The NLA_Doc System
3.2.2. NLA_Doc Data Structures
3.2.3. NLA_Doc Functions
- Converts <document ID> and <metadata ID> into spatial addresses;
- Stores <data> in the point located at the address <document ID> in a layer specified by <metadata ID> in the triple.
- Converts <document ID> and <metadata ID> into spatial addresses;
- Retrieves <data> from the container located at the address <document ID> from a layer specified by <metadata ID>.
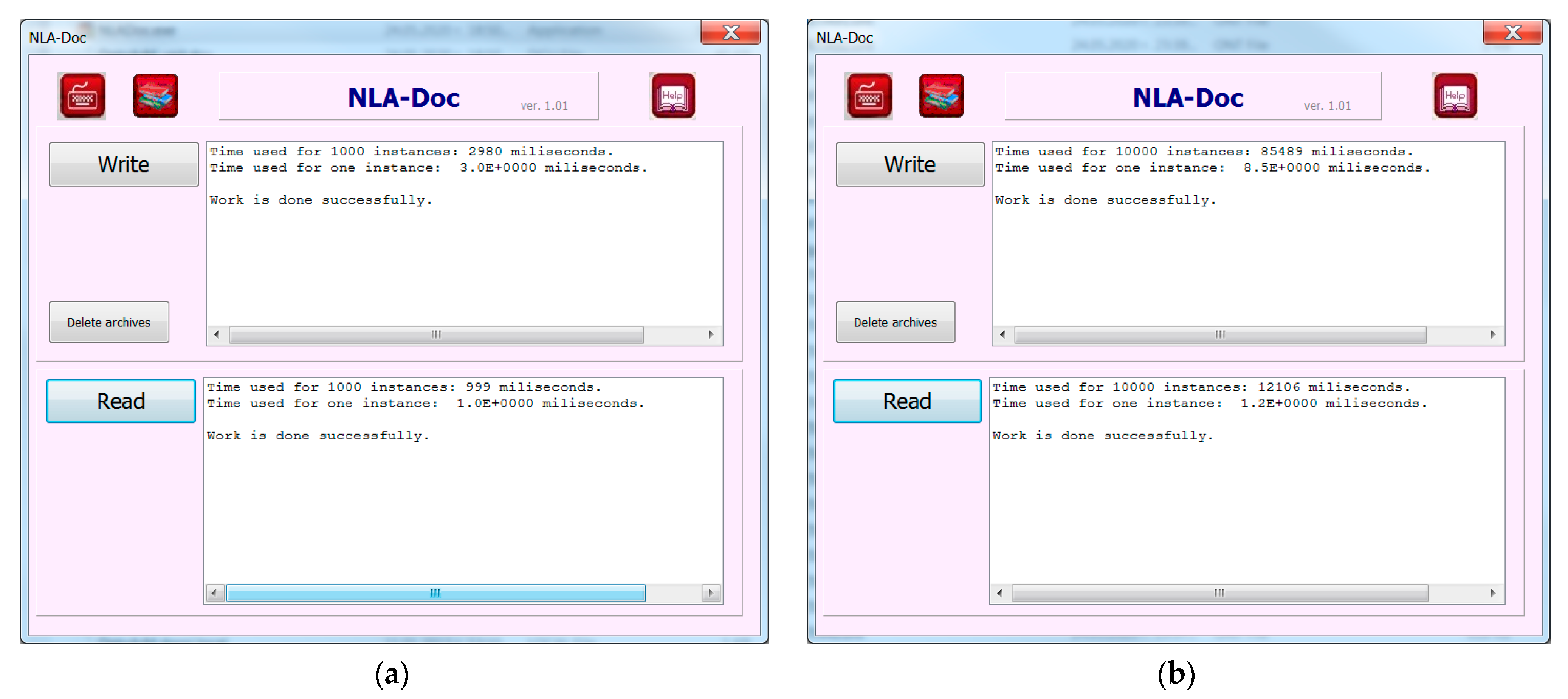
3.3. Basic Measurements
- Processor: Intel Core2 Duo T9550 2.66 GHz; CPU Launched: 2009, Average CPU Mark: 1810 (PK = 1810);
- Physical Memory: 4.00 GB (MK = 4);
- Hard Disk: 100 GB data partition; 2 GB swap (DK = 100);
- Operating System: 64-bit operating system Windows 7 Ultimate SP1.
4. Discussion
- The reduction of the amount of occupied memory due to the complete absence of additional indexes, absolute addresses, pointers and additional files;
- Reduction of processing time due to the complete lack of demand—the data are stored/extracted to/from a direct address.
5. Conclusions and Further Work
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
| Layer | Objects |
|---|---|
| URI | A519701/2 (unique registration identifier) |
| About | letter of conformance of agreement for collaboration |
| address of the recipient | Bulgaria, Sofia, 1000, PO Box 775 |
| on your № | B436213/73 |
| to № | |
| Address | |
| Application | |
| compiled | Peter Dimov |
| agreed | Damian Ivanov |
| signature | |
| resolution | Simon Nikolov |
| read | <A519701/2: read> |
| note | to be discussed on the board of directors |
| transcript | |
| type | letter of conformance |
| concerning | a brief presentation of the essence through text |
| data on the authorized person | Stefan Stanev (authorized to sign the respective type of document) |
| correspondent | name/title; address; pin/uic, etc. |
| data on the storing of the document from the departmental nomenclature: | 20 February 2020 |
| the type of file format | docx |
| attached files | path1, short description1; path2, short description2; path3, short description3; path4, short description4; … |
| additional comment | |
| additional data | |
| deadline for completion | 20 May 2020 |
| employee | Nikola Atanasov |
| e-signature | e-signatures of the employees who prepared and agreed on the document |
| recipient registration number | |
| method of sending/receiving | |
| creating software | |
| volume | 18 MB |
| case index | CS2468/FG83 |
| chronology | paths to descriptions of the activities related to the storing and audit of the document |
| Subject | Relation | Object |
|---|---|---|
| A519701 | URI | A519701/2 (unique registration identifier) |
| A519701 | About | letter of conformance of agreement for collaboration |
| A519701 | address of the recipient | Bulgaria, Sofia, 1000, PO Box 775 |
| A519701 | on your № | B436213/73 |
| A519701 | to № | |
| A519701 | Address | |
| A519701 | Application | |
| A519701 | Compiled | Peter Dimov |
| A519701 | Agreed | Damian Ivanov |
| A519701 | Signature | |
| A519701 | Resolution | Simon Nikolov |
| A519701 | Read | <A519701/2: read> |
| A519701 | Note | to be discussed on the board of directors |
| A519701 | Transcript | |
| A519701 | Type | letter of conformance |
| A519701 | concerning | a brief presentation of the essence through text |
| A519701 | data on the authorized person | Stefan Stanev (authorized to sign the respective type of document) |
| A519701 | correspondent | name/title; address; pin/uic, etc. |
| A519701 | data on the storing of the document from the departmental nomenclature: | 20 February 2020 |
| A519701 | the type of file format | docx |
| A519701 | attached files | path1, short description1; path2, short description2; path3, short description3; path4, short description4; … |
| A519701 | additional comment | |
| A519701 | additional data | |
| A519701 | deadline for completion | 20 May 2020 |
| A519701 | Employee | Nikola Atanasov |
| A519701 | e-signature | e-signatures of the employees who prepared and agreed on the document |
| A519701 | recipient registration number | |
| A519701 | method of sending/receiving | |
| A519701 | creating software | |
| A519701 | volume | 18 MB |
| A519701 | case index | CS2468/FG83 |
| A519701 | chronology | paths to descriptions of the activities related to the storing and audit of the document |
| Layer | Objects |
|---|---|
| 23 January 2021; 13:15:52 | Sami Mogamad Alchalian |
| 29 January 2021; 08:24:18 | Viviyan Venelinova Valkova |
| 2 February 2021; 16:38:44 | Martin Borislavov Borisov |
| 4 February 2021; 09:16:27 | Viviyan Venelinova Valkova |
| 5 February 2021; 11:52:45 | Gabriel Metodiev Krumov |
| 6 February 2021; 23:38:36 | Sami Mogamad Alchalian |
| Subject | Relation | Object |
|---|---|---|
| A519701: read | 23 January 2021; 13:15:52 | Sami Mogamad Alchalian |
| A519701: read | 29 January 2021; 08:24:18 | Viviyan Venelinova Valkova |
| A519701: read | 2 February 2021; 16:38:44 | Martin Borislavov Borisov |
| A519701: read | 4 February 2021; 09:16:27 | Viviyan Venelinova Valkova |
| A519701: read | 5 February 2021; 11:52:45 | Gabriel Metodiev Krumov |
| A519701: read | 6 February 2021; 23:38:36 | Sami Mogamad Alchalian |
Appendix B
| A519701/2; META62; NIKOLA BRANIMIROV IVANOV B436213/73; META82; GRIGOR GAVRILOV GRANDZHEV C531719/36; META68; LACHEZAR VENTSISLAVOV IVANOV D448266/7; META43; SAMI MOGAMAD ALCHALIAN E847955/73; META38; VIVIYAN VENELINOVA VALKOVA F326742/15; META32; MARTIN BORISLAVOV BORISOV G356217/15; META50; GABRIEL METODIEV KRUMOV H430291/27; META71; ANGEL ALEKSANDROV BOYADZHIEV I239507/17; META95; STANISLAV SVETLOZAROV ZLATEV J31634/40; META39; MARTIN MITKOV DIMITROV … |
| (a) sample Input data |
| A519701/2; META62; B436213/73, META82; C531719/36, META68; D448266/7, META43; E847955/73, META38; F326742/15, META32; G356217/15; META50; H430291/27, META71; I239507/17; META95; J31634/40, META39; … |
| (b) sample test data |
| A519701/2; META62; NIKOLA BRANIMIROV IVANOV; B436213/73; META82; GRIGOR GAVRILOV GRANDZHEV; C531719/36; META68; LACHEZAR VENTSISLAVOV IVANOV; D448266/7; META43; SAMI MOGAMAD ALCHALIAN; E847955/73; META38; VIVIAN VENELINOVA VALKOVA; F326742/15; META32; MARTIN BORISLAVOV BORISOV; G356217/15; META50; GABRIEL METODIEV KRUMOV; H430291/27; META71; ANGEL ALEXANDROV BOYADZHIEV; I239507/17; META95; STANISLAV SVETLOZAROV ZLATEV; J31634/40; META39; MARTIN MITKOV DIMITROV; … |
| (c) sample extracted data |

References
- David, C.F.; Olivier, C.; Guillaume, B. A survey of RDF storage approaches. ARIMA J. 2012, 15, 11–35. [Google Scholar]
- Mendelzon, A.; Schwentick, T.; Suciu, D. Foundations of Semistructured Data. 2001. Available online: http://www.dagstuhl.de/Reports/01/01361.pdf (accessed on 20 July 2013).
- Bhadkamkar, M.; Farfan, F.; Hristidis, V.; Rangaswami, R. Storing Semi-Structured Data on Disk Drives. ACM Trans. Storage 2009, 5, 6. [Google Scholar] [CrossRef]
- Buneman, P. Semi-Structured Data; Department of Computer and Information Science University of Pennsylvania: Philadelphia, PA, USA, 2001. [Google Scholar]
- Angles, R.; Gutierrez, C. Survey of Graph Database Models. ACM Comput. Surv. 2008, 40, 1–39. [Google Scholar] [CrossRef]
- Amann, B.; Scholl, M. Gram: A graph data model and query language. In Proceedings of the European Conference on Hypertext Technology (ECHT), ACM, Milan, Italy, 30 November–4 December 1992; pp. 201–211. [Google Scholar]
- Andries, M.; Gemis, M.; Paredaens, J.; Thyssens, I.; den Bussche, J.V. Concepts for graph-oriented object manipulation. In Proceedings of the 3rd International Conference on Extending Database Technology (EDBT) LNCS, Vienna, Austria, 23–27 March 1992; Volume 580, pp. 21–38. [Google Scholar]
- Gemis, M.; Paredaens, J. An object-oriented pattern matching language. In Proceedings of the First JSSST International Symposium on Object Technologies for Advanced Software, Kanazawa, Japan, 4–6 November 1993; pp. 339–355. [Google Scholar]
- Gyssens, M.; Paredaens, J.; den Bussche, J.V.; Gucht, D.V.A. Graph-oriented object database model. In Proceedings of the 9th Symposium on Principles of Database Systems (PODS), Nashville, TN, USA, 2–4 April 1990; pp. 417–424. [Google Scholar]
- Hidders, J.; Paredaens, J. GOAL A graph-based object and association language. In Advances in Database Systems: Implementations and Applications; CISM: Brussels, Belgium, 1993; pp. 247–265. [Google Scholar]
- Hidders, J.A. Graph-Based Update Language for Object-Oriented Data Models. Ph.D. Thesis, Technische Universiteit, Eindhoven, The Netherlands, December 2001. [Google Scholar]
- Hidders, J. Typing graph-manipulation operations. In Proceedings of the 9th International Conference on Database Theory (ICDT), Siena, Italy, 8–10 January 2002; pp. 394–409. [Google Scholar]
- Kuper, G.M.; Vardi, M.Y. A new approach to database logic. In Proceedings of the 3rd Symposium on Principles of Database Systems (PODS), Waterloo, ON, Canada, 25–27 March 1984; pp. 86–96. [Google Scholar]
- Kuper, G.M.; Vardi, M.Y. The Logical Data Model. ACM Trans. Database Syst. (TODS) 1993, 18, 379–413. [Google Scholar] [CrossRef]
- Levene, M.; Loizou, G. A Graph-Based Data Model and its Ramifications. IEEE Trans. Knowl. Data Eng. (TKDE) 1995, 7, 809–823. [Google Scholar] [CrossRef][Green Version]
- Levene, M.; Poulovassilis, A. The hypernode model and its associated query language. In Proceedings of the 5th Jerusalem Conference on Information Technology, Jerusalem, Israel, 22–25 October 1990; pp. 520–530. [Google Scholar]
- Poulovassilis, A.; Levene, M. A Nested-Graph Model for the Representation and Manipulation of Complex Objects. ACM Trans. Inf. Syst. (TOIS) 1994, 12, 35–68. [Google Scholar] [CrossRef]
- Levene, M.; Poulovassilis, A. An Object-Oriented Data Model Formalised Through Hypergraphs. Data Knowl. Eng. (DKE) 1991, 6, 205–224. [Google Scholar] [CrossRef]
- Klyne, G.; Carroll, J.J. Resource Description Framework (RDF): Concepts and Abstract Syntax; W3C Recommendation; W3C: Canberra, Australia, 2004. [Google Scholar]
- Angles, R.; Gutierrez, C. Querying RDF data from a graph database perspective. In Proceedings of the 2nd European Semantic Web Conference (ESWC), Heraklion, Greece, 29 May–1 June 2005; pp. 346–360. [Google Scholar]
- Hayes, J.; Gutierrez, C. Bipartite graphs as intermediate model for RDF. In Proceedings of the 3rd International Semantic Web Conference (ISWC), Hiroshima, Japan, 7–11 November 2004; pp. 47–61. [Google Scholar]
- Graves, M.; Bergeman, E.R.; Lawrence, C.B. Querying a genome database using graphs. In Proceedings of the 3rd International Conference on Bioinformatics and Genome Research, Tallahassee, FL, USA, 1–4 June 1994. [Google Scholar]
- Graves, M.; Bergeman, E.R.; Lawrence, C.B. A graph-theoretic data model for genome mapping databases. In Proceedings of the 28th Hawaii International Conference on System Sciences (HICSS), IEEE Computer Society, Maui, HI, USA, 4–7 January 1995a; p. 32. [Google Scholar]
- Graves, M.; Bergeman, E.; Lawrence, C.B. Graph Database Systems for Genomics: Special issue on Managing Data for the Human Genome Project. IEEE Eng. Med. Biol. 1995, 11, 737–745. [Google Scholar] [CrossRef]
- Graves, M. Theories and Tools for Designing Application-Specific Knowledge Base Data Models. Ph.D. Thesis, University of Michigan, Ann Arbor, MI, USA, January 1993. [Google Scholar]
- Mainguenaud, M.; Simatic, X.T. A Data Model to Deal with Multi-scaled Networks. Comput. Environ. Urban Syst. 1992, 16, 281–288. [Google Scholar] [CrossRef]
- Papakonstantinou, Y.; Garcia-Molina, H.; Widom, J. Object exchange across heterogeneous information sources. In Proceedings of the 11th International Conference on Data Engineering (ICDE), Taipei, Taiwan, 6–10 March 1995; pp. 251–260. [Google Scholar]
- Hayes, P. RDF Semantics: W3C Recommendation. 10 February 2004. Available online: http://www.w3.org/TR/rdf-mt/ (accessed on 21 January 2021).
- Muys, A. Building an Enterprise Scale Database for RDF Data; Seminar; Netymon: Sydney, Australia, 2007. [Google Scholar]
- RDF. Available online: http://www.w3.org/RDF/#specs (accessed on 21 February 2021).
- Owens, A. An Investigation into Improving RDF Store Performance an Investigation into Improving RDF Store Performance. Ph.D. Thesis, University of Southampton, Southampton, UK, March 2009. [Google Scholar]
- Rohloff, K.; Dean, M.; Emmons, I.; Ryder, D.; Sumner, J. An evaluation of triple-store technologies for large data stores. In On the Move to Meaningful Internet Systems 2007: OTM 2007 Workshops; Meersman, R., Tari, Z., Herrero, P., Eds.; OTM 2007: Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4806. [Google Scholar] [CrossRef]
- Magkanaraki, A.; Karvounarakis, G.; Anh, T.T.; Christophides, V.; Plexousakis, D. Ontology Storage and Querying; Technical Report. No 308; Foundation for Research and Technology, Hellas Institute of Computer Science, Information Systems Laboratory: Heraklion, Greece, 2002. [Google Scholar]
- Sintek, M.; Decker, S. TRIPLE-an RDF query, inference, and transformation language. In Proceedings of the Deductive Databases and Knowledge Management Workshop (DDLP’ 2001), Tokyo, Japan, 20–22 October 2001. [Google Scholar]
- Atre, M.; Srinivasan, J.; Hendler, A.J. BitMat: A Main Memory RDF Triple Store; Technical Report; Tetherless World Constellation, Rensselaer Polytechnic Institute: Troy, NY, USA, 2009. [Google Scholar]
- Weiss, C.; Karras, P.; Bernstein, A. Hexastore: Sextuple indexing for semantic web data management. In Proceedings of the 34th Very Large Data Bases (VLDB) Conference, Auckland, New Zealand, 24–30 August 2008. [Google Scholar]
- Jena2 Database Interface—Database Layout. Available online: http://jena.sourceforge.net/DB/layout.html (accessed on 21 January 2021).
- Wilkinson, K.; Sayers, C.; Kuno, H.; Reynolds, D. Efficient RDF Storage and Retrieval in Jena2; SWDB: Berkeley, CA, USA, 2003. [Google Scholar]
- Harth, A.; Decker, S. Optimized Index Structures for Querying RDF from the Web; Digital Enterprise Research Institute (DERI), National University of Galway: Galway, Ireland, 2013. [Google Scholar]
- Sesame, OpenRDF. Available online: https://www.w3.org/2001/sw/wiki/Sesame (accessed on 21 January 2021).
- Broekstra, J.; Kampman, A.; van Harmelen, F. Lecture notes in computer science. In Sesame: A Generic Architecture for Storing and Querying RDF and RDF Schema, Proceedings of the Semantic Web—ISWC 2002, Sardinia, Italy, 9–12 June 2002; Horrocks, I., Hendler, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2002; pp. 54–68. [Google Scholar] [CrossRef]
- Alexaki, S.; Christophides, V.; Karvounarakis, G.; Plexousakis, D.; Tolle, K. The ICS-FORTH RDFSuite: Managing voluminous RDF description bases. In Proceedings of the 2nd International Workshop on the Semantic Web (SemWeb’01), Hong Kong, China, 30–31 July 2001. [Google Scholar]
- Alexaki, S.; Christophides, V.; Karvounarakis, G.; Plexousakis, D. On storing voluminous RDF descriptions: The case of web portal catalogs. In Proceedings of the 4th International Workshop on the Web and Databases (WebDB’01), In Conjunction with ACM SIGMOD/PODS, Santa Barbara, CA, USA, 24–25 May 2001. [Google Scholar]
- Intellidimension Inc. Semantics Platform 2.0. Available online: http://www.intellidimension.com/products/semantics-platform/ (accessed on 21 January 2021).
- The Ontopia Knowledge Suite: An Introduction, White Paper (V. 1.3), 2002. Available online: http://www.regnet.org/members/demo/ontopia/doc/misc/atlas-tech.html (accessed on 21 January 2021).
- Harris, S.; Gibbins, N. 3store: Efficient bulk RDF storage. In Proceedings of the 1st International Workshop on Practical and Scalable Semantic Systems, PSSS 2003, Sanibel Island, FL, USA, 20 October 2003. [Google Scholar]
- Harris, S.; Lamb, N.; Shadbolt, N. 4store: The design and implementation of a clustered RDF store. In Proceedings of the SSWS2009 5th International Workshop on Scalable Semantic Web Knowledge Base Systems, Washington DC, USA, 26 October 2009. [Google Scholar]
- Wood, D.; Gearon, P.; Adams, A. Kowari: A platform for semantic web storage and analysis. In Proceedings of the XTech 2005 Conference, Chiba, Japan, 10–14 May 2005. [Google Scholar]
- ORACLE. Available online: http://www.oracle.com/technetwork/ (accessed on 21 January 2021).
- Neumann, T.; Weikum, G. RDF-3X: A RISC-Style Engine for RDF; JDMR; VLDB Endowment: Auckland, New Zealand, 2008. [Google Scholar]
- Erling, O.; Mikhailov, I. RDF support in the virtuoso DBMS. In Proceedings of the Conference on Social Semantic Web, Leipzig, Germany, 26–28 September 2007. [Google Scholar]
- Dumbill, E. Putting RDF to Work. Article on XML.com, 09.08.2000. Available online: http://www.xml.com/pub/a/2000/08/09/rdfdb (accessed on 21 January 2021).
- RDFStore. Available online: http://rdfstore.sourceforge.net/documentation/api.html (accessed on 21 January 2021).
- Beckett, D. The design and implementation of the Redland RDF application framework. In Proceedings of the WWW’01: 10th International Conference on World Wide Web, Hong Kong, China, 1–5 April 2001. [Google Scholar]
- McBride, B. Jena: Implementing the RDF model and syntax specification. In Proceedings of the Second International Workshop on the Semantic Web-SemWeb2001, Hongkong, China, 1 May 2001. [Google Scholar]
- Kolas, D.; Emmons, I.; Dean, M. Efficient Linked-List RDF Indexing in Parliament. Available online: https://www.researchgate.net/publication/228910462_Efficient_Linked-List_RDF_Indexing_in_Parliament (accessed on 21 January 2021).
- Matono, A.; Pahlevi, M.S.; Kojima, I. RDFCube: A P2P-based three-dimensional index for structural joins on distributed triple stores. In Databases, Information Systems, and Peer-to-Peer Computing; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Hertel, A.; Broekstra, J.; Stuckenschmidt, H. RDF storage and retrieval systems. In Handbook on Ontologies, International Handbooks on Information Systems; Staab, S., Studer, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 489–508. [Google Scholar] [CrossRef]
- Agrawal, R.; Somani, A.; Xu, Y. Storage and querying of e-commerce data. In Proceedings of the 27th Conference on Very Large Data Bases (VLDB), Rome, Italy, 11–14 September 2001. [Google Scholar]
- Chong, I.E.; Das, S.; Eadon, G.; Srinivasan, J. An efficient SQL-based RDF querying scheme. In Proceedings of the 31st International Conference on Very Large Data Bases (VLDB’05), Trondheim, Norway, 30 August–2 September 2005. [Google Scholar]
- OracleDB. Available online: http://www.oracle.com/technetwork/database/options/semantic-tech/index.html (accessed on 21 January 2021).
- Guha, R.V. RdfDB: An RDF Database. Available online: http://www.cs.cmu.edu/afs/cs/usr/niu/rdf/ (accessed on 21 January 2021).
- Broekstra, J. Storage, Querying and Inferencing for Semantic Web Languages. Ph.D. Thesis, Vrije Universiteit, Amsterdam, The Netherlands, December 2005. [Google Scholar]
- Gabel, T.; Sure, Y.; Voelker, J. KAON—An Overview; Insititute AIFB, University of Karlsruhe: Karlsruhe, Germany, 2004. [Google Scholar]
- Pan, Z.; Heflin, J. DLDB: Extending Relational Databases to Support Semantic Web Queries; Technical Report LU-CSE-04-006; Department of Computer Science and Engineering, Lehigh University: Bethlehem, PA, USA, 2004. [Google Scholar]
- Broekstra, J.; Kampman, A.; van Harmelen, F. Sesame: A generic architecture for storing and querying RDF and RDF. In Proceedings of the Semantic Web—ISWC 2002, First International Semantic Web Conference, Sardinia, Italy, 9–12 June 2002. [Google Scholar]
- Fletcher, G.H.L.; Beck, P.W. Scalable indexing of RDF graphs for efficient joins processing. In Proceedings of the 18th ACM Conference on Information and Knowledge Management (CIKM’09), Hong Kong, China, 2–6 November 2009. [Google Scholar]
- Janik, M.; Kochut, K. BRAHMS: A WorkBench RDF store and high-performance memory system for semantic association discovery. In Proceedings of the Fourth International Semantic Web Conference, Galway, Ireland, 6–10 November 2005. [Google Scholar]
- McGlothlin, J.P.; Khan, L.R. RDFJoin: A Scalable of Data Model for Persistence and Efficient Querying of RDF Datasets; UTDCS-08-09; University of Texas at Dallas: Richardson, TX, USA, 2009; pp. 1–12. [Google Scholar]
- McGlothlin, J.P.; Khan, L.R. DFKB: Efficient support for RDF inference queries and knowledge management. In Proceedings of the 2009 International Database Engineering Applications Symposium (IDEAS’09), Cetraro-Calabria, Italy, 16–18 September 2009. [Google Scholar]
- Tran, T.; Ladwig, G.; Rudolph, S. iStore: Efficient RDF Data Management Using Structure Indexes for General Graph Structured Data; Institute AIFB, Karlsruhe Institute of Technology: Karlsruhe, Germany, 2009. [Google Scholar]
- Markov, K.; Ivanova, K.; Vanhoof, K.; Velychko, V.; Castellanos, J. Natural Language Addressing; ITHEA: Hasselt, Belgium; Kyiv, Ukraine; Madrid, Spain; Sofia, Bulgaria, 2015; p. 315. ISBN 978-954-16-0070-2/978-954-16-0071-9. [Google Scholar]
- Markov, K.; Ivanova, K.; Vanhoof, K.; Depaire, B.; Velychko, V.; Castellanos, J.; Aslanyan, L.; Karastanev, S. Storing big data using natural language addressing. In Proceedings of the International Scientific Conference Informatics in the Scientific Knowledge: VFU, Varna, Bulgaria, 27–29 June 2014; Lyutov, N., Ed.; pp. 147–164. [Google Scholar]
- Markov, K.; Vanhoof, K.; Mitov, I.; Depaire, B.; Ivanova, K.; Velychko, V.; Gladun, G. Intelligent data processing based on multi-dimensional numbered memory structures. In Data Mining: Concepts, Methodologies, Tools, and Applications; IGI Global: Hershey, PA, USA, 2013; pp. 445–473. ISBN 13 978-1-4666-2455-9. [Google Scholar] [CrossRef]
- Briggs, M. DB2 NoSQL graph store. In What, Why & Overview, A presentation, Information Management software IBM; IBM: Endicott, NY, USA, 2012. [Google Scholar]
- WordNet. Available online: http://WordNet.princeton.edu (accessed on 21 January 2021).
- OASIS Open Document Format for Office Applications (OpenDocument) TC. Available online: https://www.oasis-open.org/committees/tc_home.php?wg_abbrev=office (accessed on 21 January 2021).
- Complete System for Digital Management of Information and Processes; Nemetschek Bulgaria Ltd.: Sofia, Bulgaria, 2019; Available online: https://www.edocument.bg/?gclid=EAIaIQobChMIoYGVy5yv6QIVGLLtCh1cMgMKEAMYASAAEgKqoPD_BwE (accessed on 21 January 2021). (In Bulgarian)
- BadgerDB. Available online: https://dgraph.io/docs/badger/ (accessed on 21 January 2021).
- Haskell. Available online: https://www.haskell.org/ (accessed on 21 January 2021).

| Triples: | Resources: | Literals: | |||||
|---|---|---|---|---|---|---|---|
| Subject | Relation | Is Literal | Object | ID | URI | ID | Value |
| r1 | r2 | False | r3 | r1 | …#1 | l1 | Value1 |
| r1 | r4 | True | l1 | r2 | …#2 | … | … |
| … | … | … | … | … | … | … | … |
| ClassA: | Relation1: | ClassB: | |
|---|---|---|---|
| ID | Subject | Object | ID |
| …#1 | …#1 | …#3 | …#3 |
| … | … | … | … |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ivanova, K.B. NLA-Bit: A Basic Structure for Storing Big Data with Complexity O(1). Big Data Cogn. Comput. 2021, 5, 8. https://doi.org/10.3390/bdcc5010008
Ivanova KB. NLA-Bit: A Basic Structure for Storing Big Data with Complexity O(1). Big Data and Cognitive Computing. 2021; 5(1):8. https://doi.org/10.3390/bdcc5010008
Chicago/Turabian StyleIvanova, Krasimira Borislavova. 2021. "NLA-Bit: A Basic Structure for Storing Big Data with Complexity O(1)" Big Data and Cognitive Computing 5, no. 1: 8. https://doi.org/10.3390/bdcc5010008
APA StyleIvanova, K. B. (2021). NLA-Bit: A Basic Structure for Storing Big Data with Complexity O(1). Big Data and Cognitive Computing, 5(1), 8. https://doi.org/10.3390/bdcc5010008