PerTract: Model Extraction and Specification of Big Data Systems for Performance Prediction by the Example of Apache Spark and Hadoop



Abstract
:1. Introduction
- A DSL for modeling performance-relevant factors of big data systems,
- An automatic extraction of system structure, behavior, resource demands, and data workload from Apache Spark and Apache Hadoop,
- Transformations from DSL instances to model- and simulation-based performance evaluation tools,
- Tool support for this approach.
- A formalism and DSL to model big data applications,
- A lightweight Java agent to sample stack traces and CPU times from applications,
- Automatic extraction of DSL instances,
- Detailed evaluation against complex applications of the HiBench benchmark suite.
2. Related Work
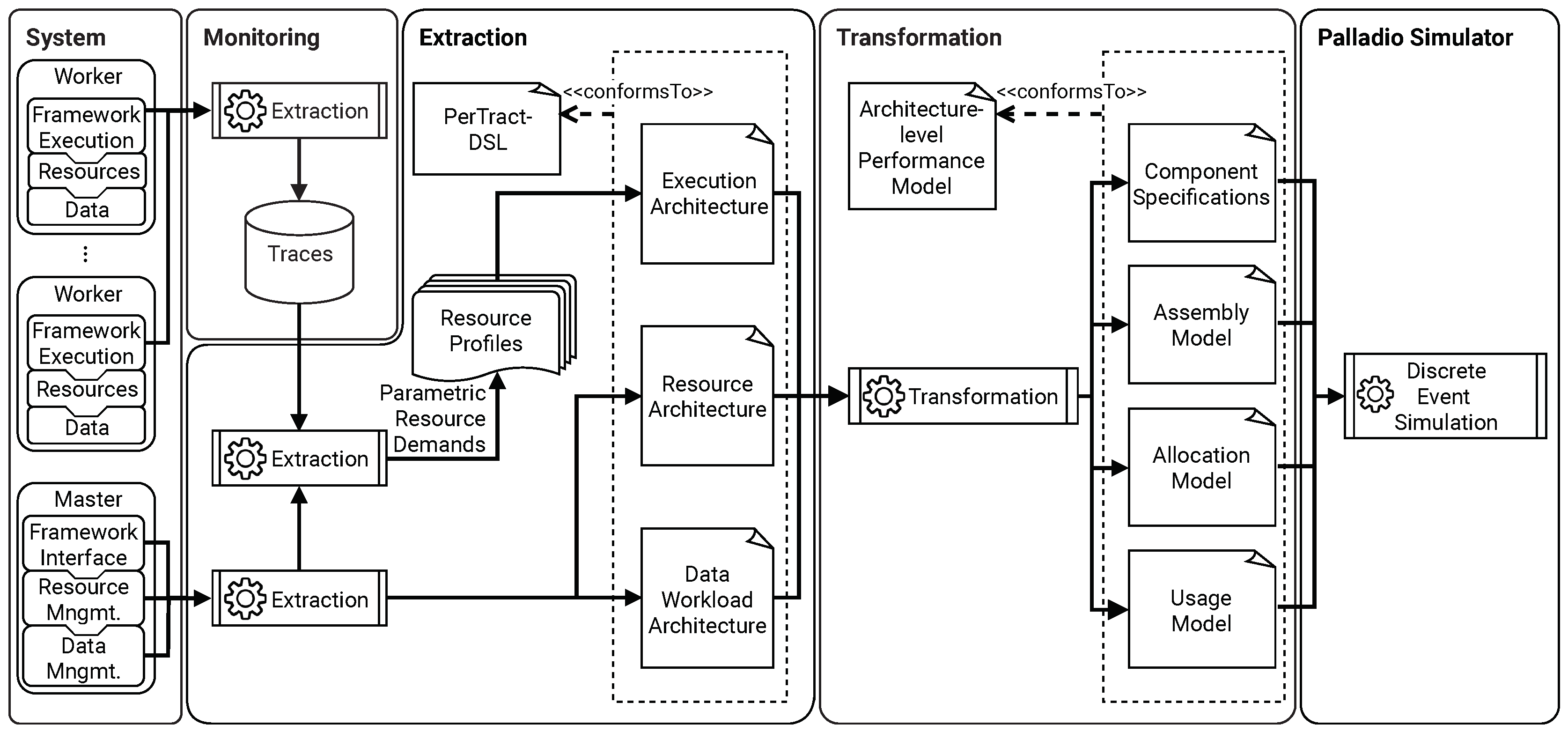
3. Modeling Approach
3.1. Formalism
- An Execution Architecture of the application, specifying nested directed graphs for execution components,
- A set of Resource Profiles, providing demands of different resources with parametric dependencies for the nodes of a graph,
- A Data Workload Architecture, specifying the underlying data model and type of data source
- A Resource Architecture, specifying a cluster of resource nodes, each with several resource units
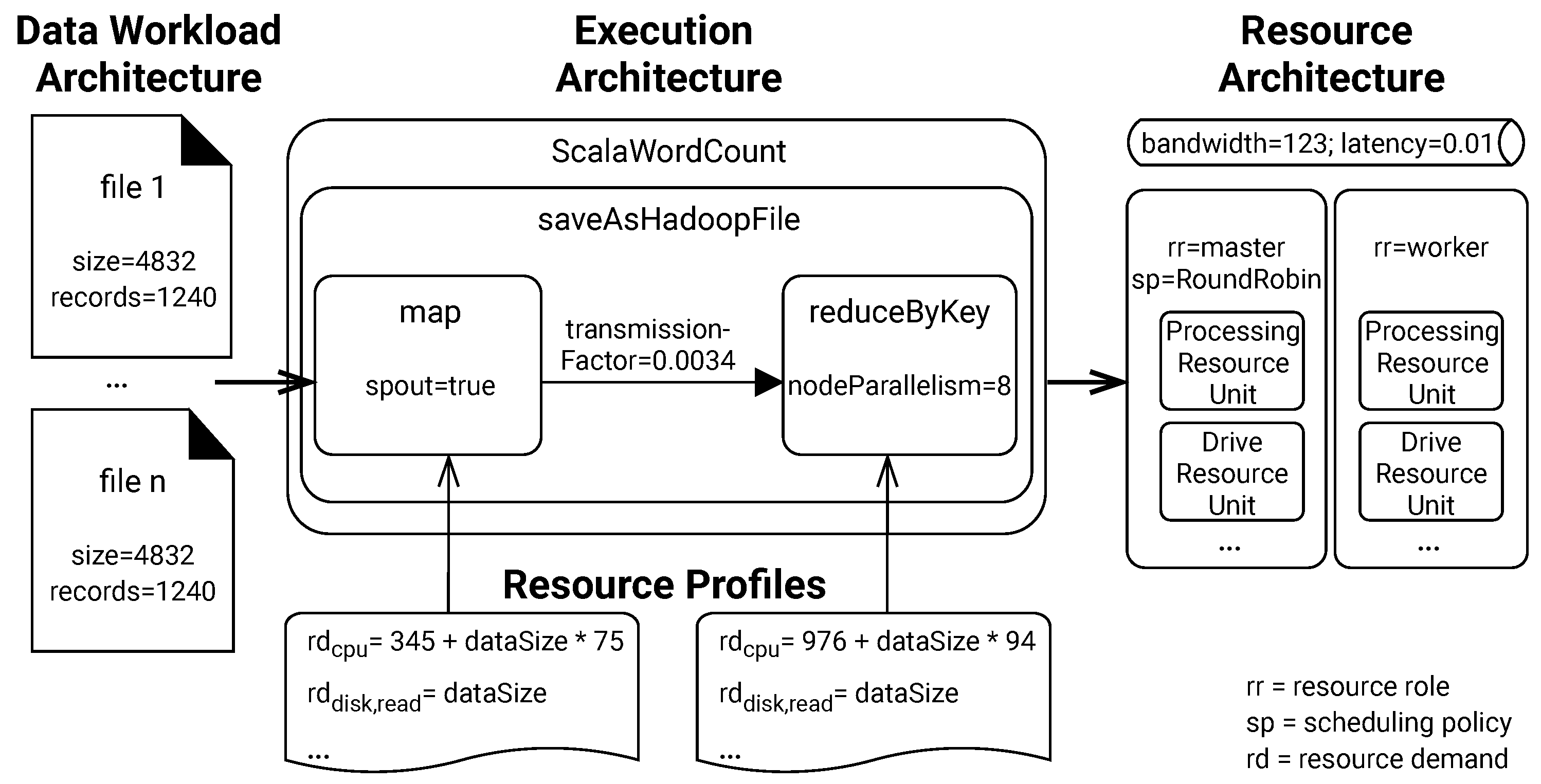
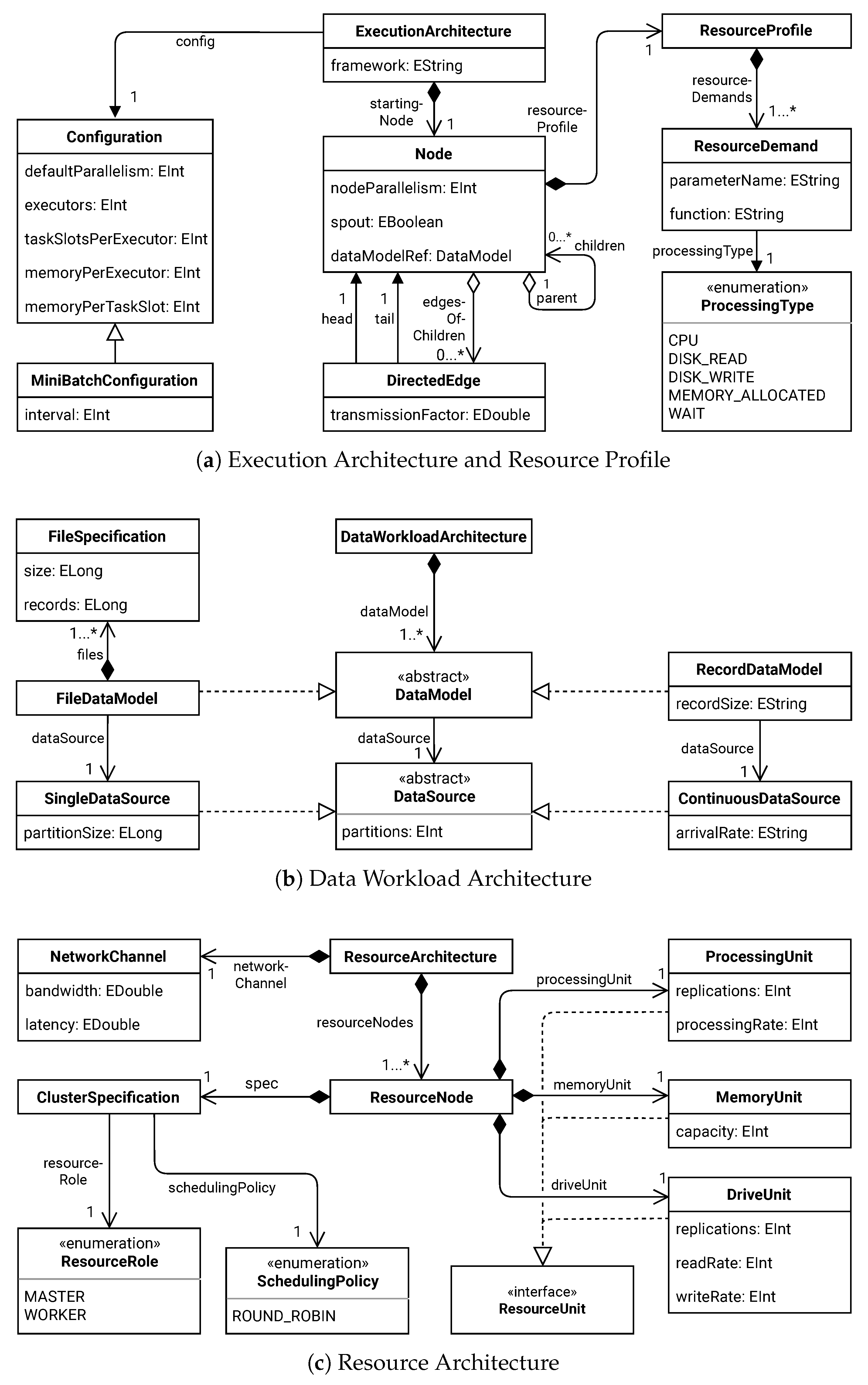
3.1.1. Application Execution Architecture
3.1.2. Resource Profile
3.1.3. Data Workload Architecture
3.1.4. Resource Architecture
3.2. PerTract-DSL
4. Extracting Model Instances by the Example of Apache Spark, Apache YARN and Apache HDFS
4.1. Extraction of Resource Demands
| Algorithm 1: Sampling thread groups and CPU values. |
 |
4.2. Extraction of Execution Architectures
4.3. Extraction and Estimation of Resource Profiles
4.4. Extraction of Data Workload Architectures
4.5. Extraction of Resource Architectures
5. Transformation to Performance Models
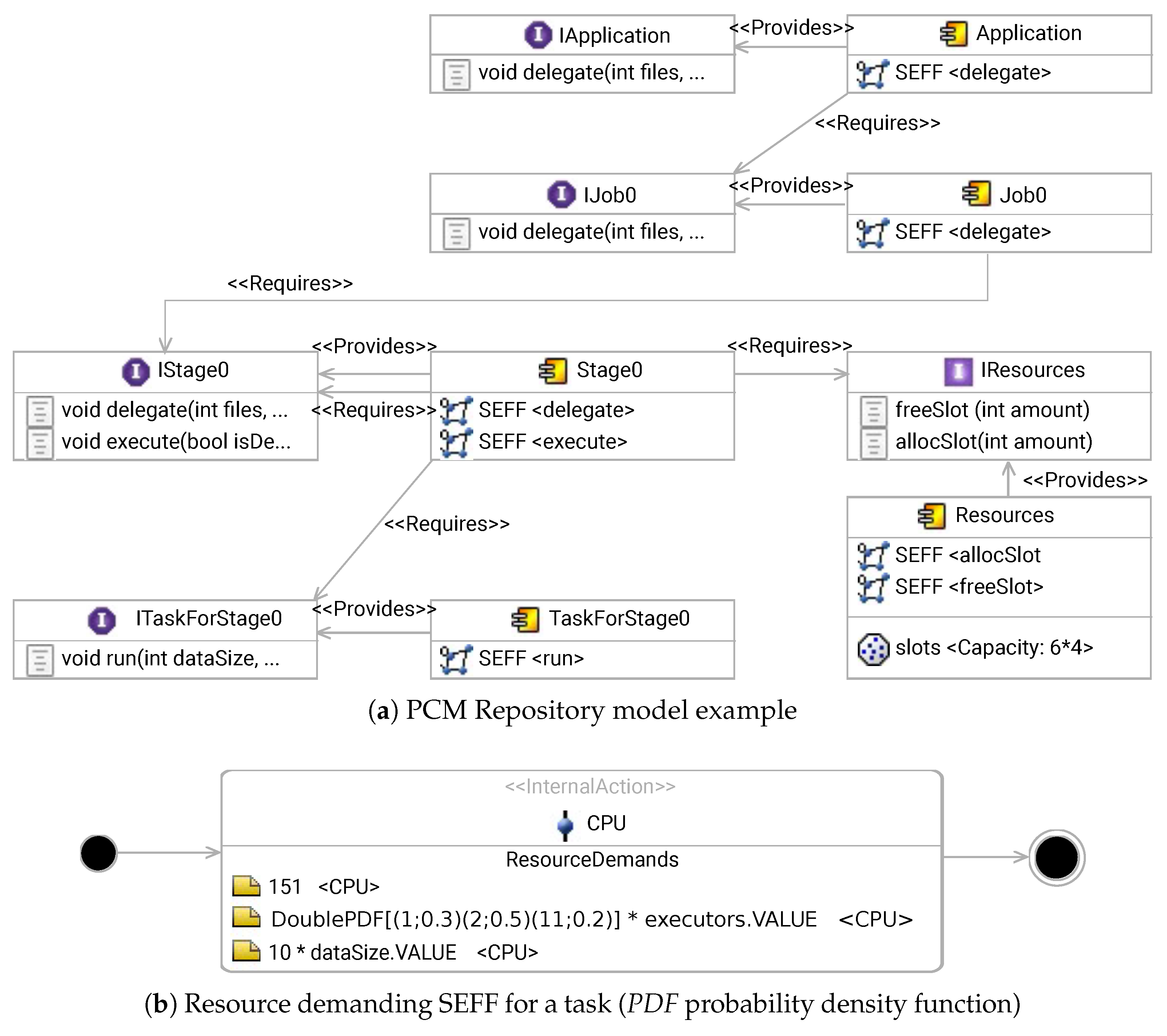
5.1. Palladio Component Model
5.2. Transformation to PCM
6. Evaluation
6.1. Research Methodology
6.2. HiBench Benchmark Suite
6.3. Experiment Setup
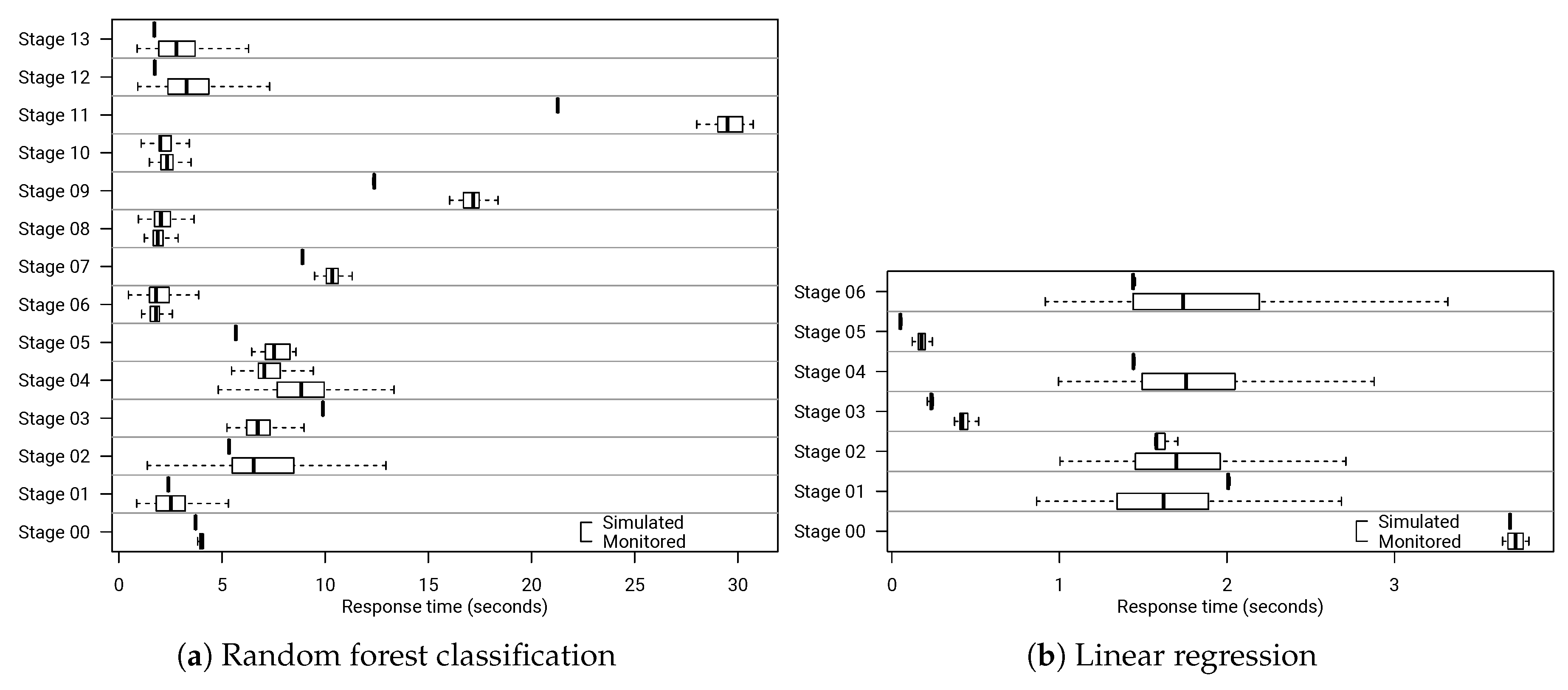
6.4. Collecting Resource Demands and Extracting Execution Architectures
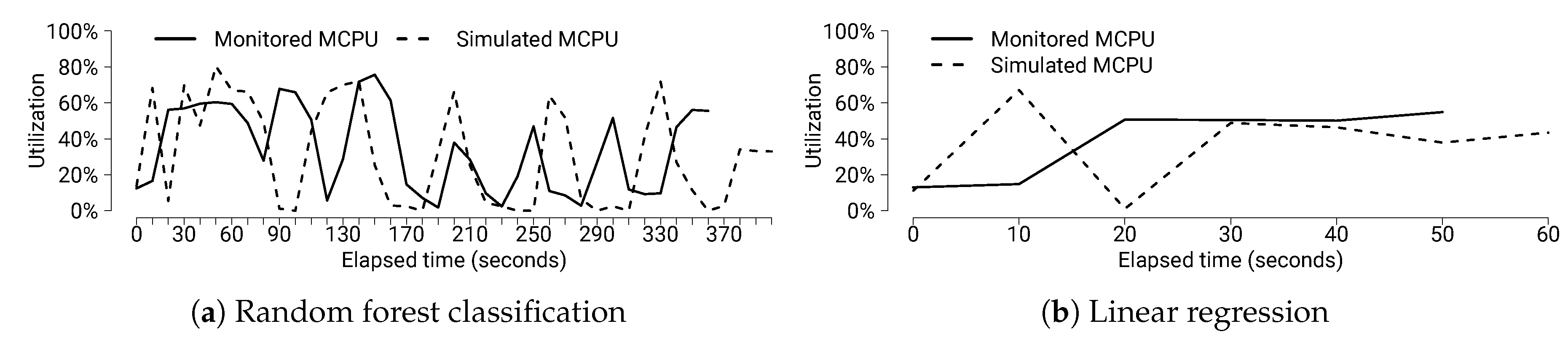
6.5. Evaluating Data Workload Changes
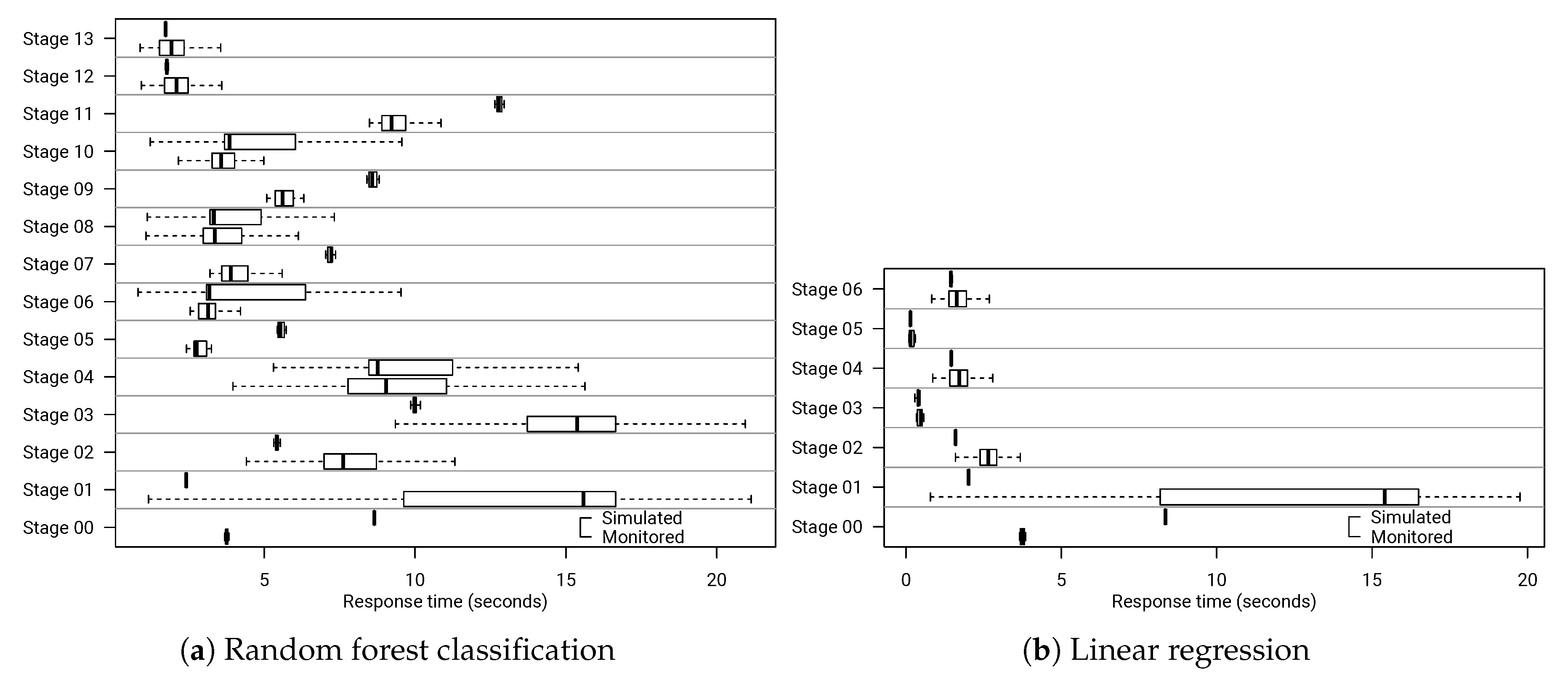
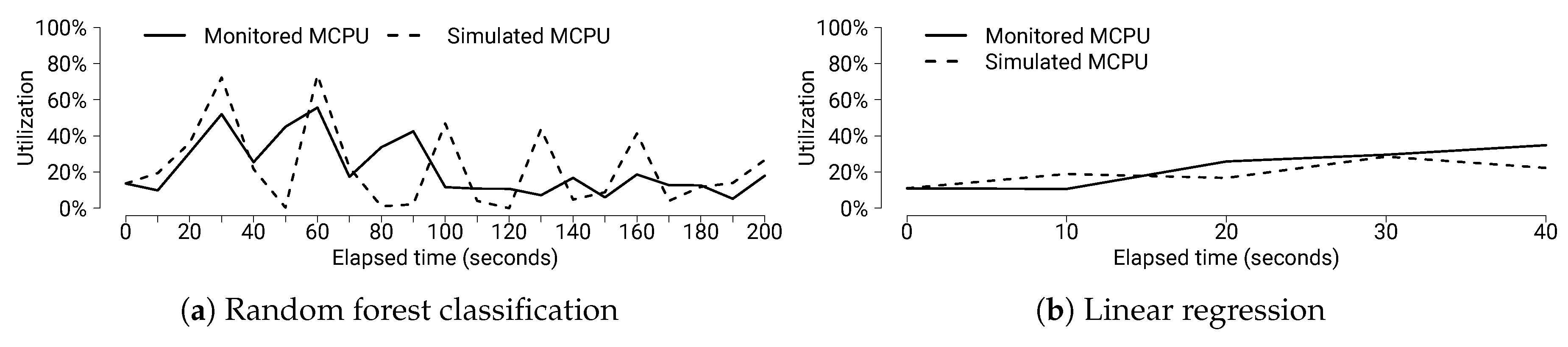
6.6. Evaluating Resource Changes
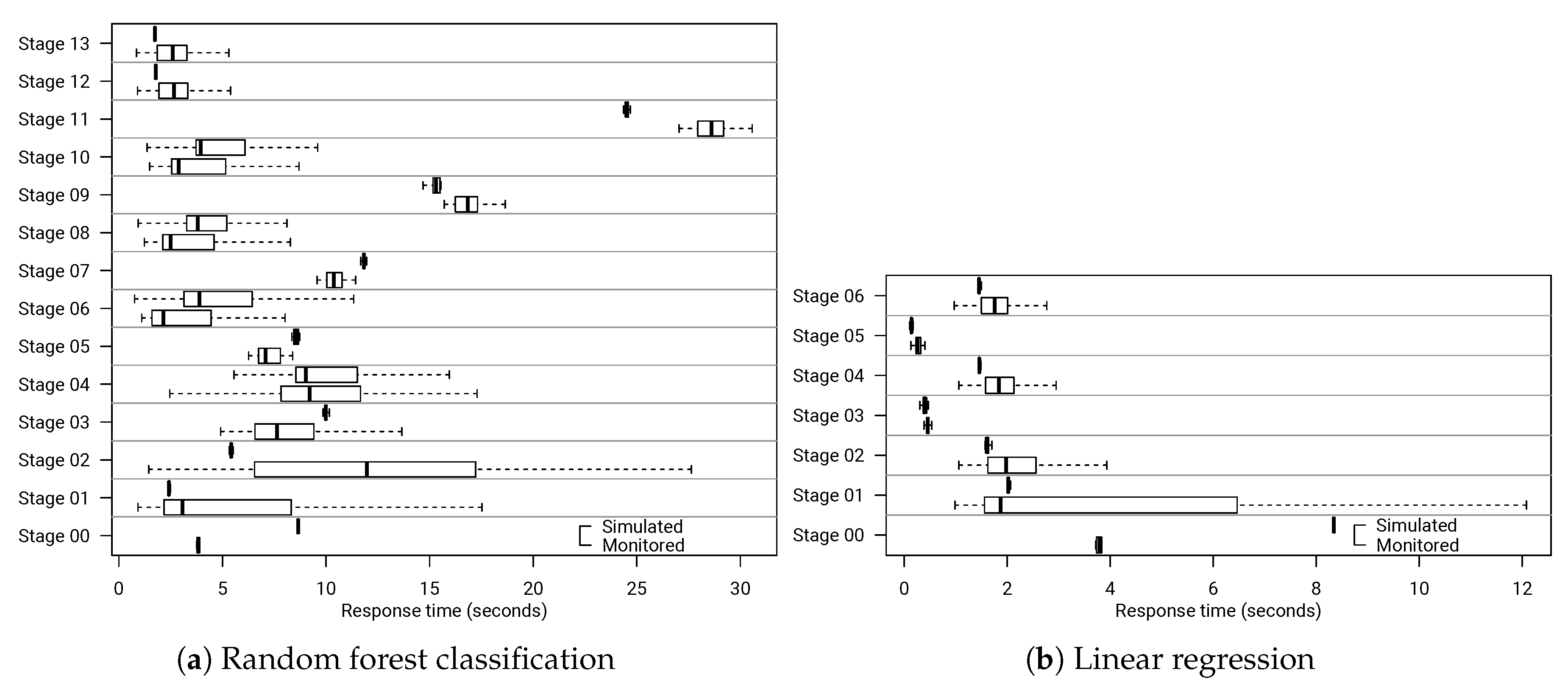
6.7. Evaluating Data Workload and Resource Changes
6.8. Threats to Validity
6.9. Assumptions and Limitations
7. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| CPU | Central processing unit |
| DSL | Domain-specific language |
| EMF | Eclipse modeling framework |
| GB | Gigabyte |
| HDFS | Hadoop distributed file system |
| LAN | Local area network |
| LR | Linear regression |
| MB | Megabytes |
| MCPU | Mean CPU utilization |
| MRT | Mean response time |
| PCM | Palladio component model |
| Probability density function | |
| RDD | Resilient distributed dataset |
| RDSEFF | Resource demanding service effect specification |
| RFC | Random forest classification |
| RMSE | Root mean square error |
| VM | Virtualized machine |
References
- Schermann, M.; Hemsen, H.; Buchmüller, C.; Bitter, T.; Krcmar, H.; Markl, V.; Hoeren, T. Big Data—An interdisciplinary opportunity for information systems research. Bus. Inf. Syst. Eng. 2014, 6, 261–266. [Google Scholar] [CrossRef]
- Brunnert, A.; Vögele, C.; Danciu, A.; Pfaff, M.; Mayer, M.; Krcmar, H. Performance management work. Bus. Inf. Syst. Eng. 2014, 6, 177–179. [Google Scholar] [CrossRef]
- Wang, K.; Khan, M.M.H. Performance Prediction for Apache Spark Platform. In Proceedings of the 17th International Conference on High Performance Computing and Communications, New York, NY, USA, 24–26 August 2015; pp. 166–173. [Google Scholar]
- Brosig, F.; Meier, P.; Becker, S.; Koziolek, A.; Koziolek, H.; Kounev, S. Quantitative Evaluation of Model-Driven Performance Analysis and Simulation of Component-Based Architectures. IEEE Trans. Softw. Eng. 2015, 41, 157–175. [Google Scholar] [CrossRef]
- Brunnert, A.; van Hoorn, A.; Willnecker, F.; Danciu, A.; Hasselbring, W.; Heger, C.; Herbst, N.; Jamshidi, P.; Jung, R.; von Kistowski, J.; et al. Performance-Oriented DevOps: A Research Agenda; Technical Report SPEC-RG-2015-01; SPEC Research Group—DevOps Performance Working Group, Standard Performance Evaluation Corporation (SPEC): Gainesville, FL, USA, 2015; Available online: http://research.spec.org/fileadmin/user_upload/documents/wg_devops/endorsed_publications/SPEC-RG-2015-001-DevOpsPerformanceResearchAgenda.pdf (accessed on 8 August 2019).
- Becker, S.; Koziolek, H.; Reussner, R. The Palladio component model for model-driven performance prediction. J. Syst. Softw. 2009, 82, 3–22. [Google Scholar] [CrossRef]
- Kroß, J. PerTract. Available online: https://github.com/johanneskross/pertract (accessed on 7 August 2019).
- Kroß, J.; Brunnert, A.; Prehofer, C.; Runkler, T.; Krcmar, H. Stream Processing on Demand for Lambda Architectures. In Computer Performance Engineering; Beltrán, M., Knottenbelt, W., Bradley, J., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2015; Volume 9272, pp. 243–257. [Google Scholar]
- Kroß, J.; Brunnert, A.; Krcmar, H. Modeling Big Data Systems by Extending the Palladio Component Model. In Proceedings of the 2015 Symposium on Software Performance, Munich, Germany, 4–6 November 2015. [Google Scholar]
- Kroß, J.; Krcmar, H. Modeling and Simulating Apache Spark Streaming Applications. In Proceedings of the 2016 Symposium on Software Performance, Kiel, Germany, 8–9 November 2016. [Google Scholar]
- Kroß, J.; Krcmar, H. Model-based Performance Evaluation of Batch and Stream Applications for Big Data. In Proceedings of the IEEE 25th International Symposium on Modeling, Analysis and Simulation of Computer and Telecommunication Systems (MASCOTS), Banff, AB, Canada, 20–22 September 2017; pp. 80–86. [Google Scholar]
- Vianna, E.; Comarela, G.; Pontes, T.; Almeida, J.; Almeida, V.; Wilkinson, K.; Kuno, H.; Dayal, U. Analytical Performance Models for MapReduce Workloads. Int. J. Parallel Program. 2013, 41, 495–525. [Google Scholar] [CrossRef]
- Verma, A.; Cherkasova, L.; Campbell, R.H. Profiling and evaluating hardware choices for MapReduce environments: An application-aware approach. Perform. Eval. 2014, 79, 328–344. [Google Scholar] [CrossRef]
- Zhang, Z.; Cherkasova, L.; Loo, B.T. Benchmarking Approach for Designing a Mapreduce Performance Model. In Proceedings of the ACM/SPEC International Conference on Performance Engineering, Prague, Czech Republic, 21–24 April 2013; ACM Press: New York, NY, USA, 2013; pp. 253–258. [Google Scholar]
- Zhang, Z.; Cherkasova, L.; Loo, B.T. Performance Modeling of MapReduce Jobs in Heterogeneous Cloud Environments. In Proceedings of the 2013 IEEE Sixth International Conference on Cloud Computing, Santa Clara, CA, USA, 28 June–3 July 2013; IEEE: Washington, DC, USA, 2013; pp. 839–846. [Google Scholar] [Green Version]
- Zhang, Z.; Cherkasova, L.; Loo, B.T. Exploiting Cloud Heterogeneity to Optimize Performance and Cost of MapReduce Processing. SIGMETRICS Perform. Eval. Rev. 2015, 42, 38–50. [Google Scholar] [CrossRef]
- Barbierato, E.; Gribaudo, M.; Iacono, M. Performance evaluation of NoSQL big-data applications using multi-formalism models. Future Gener. Comput. Syst. 2014, 37, 345–353. [Google Scholar] [CrossRef]
- Ardagna, D.; Bernardi, S.; Gianniti, E.; Karimian Aliabadi, S.; Perez-Palacin, D.; Requeno, J.I. Modeling Performance of Hadoop Applications: A Journey from Queueing Networks to Stochastic Well Formed Nets. In Algorithms and Architectures for Parallel Processing; Carretero, J., Garcia-Blas, J., Ko, R.K., Mueller, P., Nakano, K., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; pp. 599–613. [Google Scholar] [Green Version]
- Lehrig, S. Applying Architectural Templates for Design-Time Scalability and Elasticity Analyses of SaaS Applications. In Proceedings of the 2nd International Workshop on Hot Topics in Cloud Service Scalability, Dublin, Ireland, 22 March 2014; pp. 2:1–2:8. [Google Scholar]
- Ardagna, D.; Barbierato, E.; Evangelinou, A.; Gianniti, E.; Gribaudo, M.; Pinto, T.B.M.; Guimarães, A.; da Silva, A.P.C.; Almeida, J.M. Performance Prediction of Cloud-Based Big Data Applications. In Proceedings of the ACM/SPEC International Conference on Performance Engineering, Berlin, Germany, 9–13 April 2018; pp. 192–199. [Google Scholar]
- Singhal, R.; Singh, P. Performance Assurance Model for Applications on SPARK Platform. In Performance Evaluation and Benchmarking for the Analytics Era; Nambiar, R., Poess, M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2018; pp. 131–146. [Google Scholar]
- Venkataraman, S.; Yang, Z.; Franklin, M.; Recht, B.; Stoica, I. Ernest: Efficient Performance Prediction for Large-Scale Advanced Analytics. In Proceedings of the 13th USENIX Symposium on Networked Systems Design and Implementation (NSDI 16), Santa Clara, CA, USA, 13–17 March 2016; USENIX Association: Santa Clara, CA, USA, 2016; pp. 363–378. [Google Scholar]
- Alipourfard, O.; Liu, H.H.; Chen, J.; Venkataraman, S.; Yum, M.; Zhang, M. CherryPick: Adaptively Unearthing the Best Cloud Configurations for Big Data Analytics. In Proceedings of the 14th USENIX Symposium on Networked Systems Design and Implementation (NSDI 17), Boston, MA, USA, 27–29 March 2017; USENIX Association: Boston, MA, USA, 2017; pp. 469–482. [Google Scholar]
- Witt, C.; Bux, M.; Gusew, W.; Leser, U. Predictive performance modeling for distributed batch processing using black box monitoring and machine learning. Inf. Syst. 2019, 82, 33–52. [Google Scholar] [CrossRef] [Green Version]
- Castiglione, A.; Gribaudo, M.; Iacono, M.; Palmieri, F. Modeling performances of concurrent big data applications. Softw. Pract. Exp. 2014, 45, 1127–1144. [Google Scholar] [CrossRef]
- Niemann, R. Towards the Prediction of the Performance and Energy Efficiency of Distributed Data Management Systems. In Proceedings of the ACM/SPEC International Conference on Performance Engineering, Delft, The Netherlands, 12–16 March 2016; pp. 23–28. [Google Scholar]
- Casale, G.; Ardagna, D.; Artac, M.; Barbier, F.; Nitto, E.D.; Henry, A.; Iuhasz, G.; Joubert, C.; Merseguer, J.; Munteanu, V.I.; et al. DICE: Quality-driven Development of Data-intensive Cloud Applications. In Proceedings of the Seventh International Workshop on Modeling in Software Engineering, Florence, Italy, 16–24 May 2015; pp. 78–83. [Google Scholar]
- Guerriero, M.; Tajfar, S.; Tamburri, D.A.; Di Nitto, E. Towards a Model-driven Design Tool for Big Data Architectures. In Proceedings of the 2nd International Workshop on BIG Data Software Engineering, Austin, TX, USA, 2016; pp. 37–43. [Google Scholar]
- Gómez, A.; Merseguer, J.; Di Nitto, E.; Tamburri, D.A. Towards a UML Profile for Data Intensive Applications. In Proceedings of the 2Nd International Workshop on Quality-Aware DevOps, Saarbrücken, Germany, 21 July 2016; pp. 18–23. [Google Scholar]
- Ginis, R.; Strom, R.E. Method for Predicting Performance of Distributed Stream Processing Systems. U.S. Patent 7,818,417, 19 October 2010. [Google Scholar]
- Steinberg, D.; Budinsky, F.; Paternostro, M.; Merks, E. EMF: Eclipse Modeling Framework, 2nd ed.; Addison-Wesley: Boston, MA, USA, 2009. [Google Scholar]
- King, B. Performance Assurance for IT Systems; Auerbach Publications: Boston, MA, USA, 2004. [Google Scholar]
- Brandl, R.; Bichler, M.; Ströbel, M. Cost accounting for shared IT infrastructures. Wirtschaftsinformatik 2007, 49, 83–94. [Google Scholar] [CrossRef]
- Brunnert, A.; Krcmar, H. Continuous Performance Evaluation and Capacity Planning Using Resource Profiles for Enterprise Applications. J. Syst. Softw. 2017, 123, 239–262. [Google Scholar] [CrossRef]
- Zaharia, M.; Chowdhury, M.; Das, T.; Dave, A.; Ma, J.; McCauley, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Resilient Distributed Datasets: A Fault-tolerant Abstraction for In-memory Cluster Computing. In Proceedings of the 9th USENIX Conference on Networked Systems Design and Implementation, San Jose, CA, USA, 25–27 April 2012; USENIX Association: Berkeley, CA, USA, 2012; p. 2. [Google Scholar]
- Apache Spark. Lightning-Fast Cluster Computing. Available online: https://spark.apache.org (accessed on 19 February 2018).
- Ousterhout, K.; Rasti, R.; Ratnasamy, S.; Shenker, S.; Chun, B.G. Making Sense of Performance in Data Analytics Frameworks. In Proceedings of the 12th USENIX Symposium on Networked Systems Design and Implementation, Oakland, CA, USA, 4–6 May 2015; USENIX Association: Oakland, CA, USA, 2015; pp. 293–307. [Google Scholar]
- Apache Hadoop. Welcome to Apache Hadoop! Available online: https://hadoop.apache.org/ (accessed on 1 January 2017).
- Dean, J.; Ghemawat, S. MapReduce: Simplified Data Processing on Large Clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Hevner, A.R.; March, S.T.; Park, J.; Ram, S. Design Science in Information Systems Research. MIS Q. 2004, 28, 75–105. [Google Scholar] [CrossRef]
- Huang, S.; Huang, J.; Dai, J.; Xie, T.; Huang, B. The HiBench benchmark suite: Characterization of the MapReduce-based data analysis. In Proceedings of the 26th International Conference on Data Engineering Workshops, Long Beach, CA, USA, 1–6 March 2010; pp. 41–51. [Google Scholar]
- Wohlin, C.; Runeson, P.; Höst, M.; Ohlsson, M.C.; Regnell, B.; Wesslén, A. Experimentation in Software Engineering; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Heinrich, R.; Eichelberger, H.; Schmid, K. Performance Modeling in the Age of Big Data—Some Reflections on Current Limitations. In Proceedings of the 3rd International Workshop on Interplay of Model-Driven and Component-Based Software Engineering, Saint-Malo, France, 2 October 2016; pp. 37–38. [Google Scholar]
- Kistowski, J.V.; Herbst, N.; Kounev, S.; Groenda, H.; Stier, C.; Lehrig, S. Modeling and Extracting Load Intensity Profiles. ACM Trans. Auton. Adapt. Syst. 2017, 11, 23:1–23:28. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PerTract-DSL | PCM Model Elements |
|---|---|
| Execution Architecture | Repository Model |
| Nodes | Interface, Basic Component |
| Edges | RDSEFF |
| Configuration | Parameters, Infrastructure Component |
| Resource Profile | Distributed Call Action, RDSEFF |
| Resource Architecture | Resource Environment Model |
| Resource Node | Resource Container |
| Cluster Specification | Cluster Specification |
| Network Channel | Linking Resource |
| Data Workload Architecture | Usage Model |
| Data Model | Entry Level SystemCall, Parameters |
| Data Source | Workload |
| Software platform | Hortonworks Data Platform (2.6.3.0-235) | ||
| 4× | - Apache Spark (2.2.0) | ||
| - Apache Hadoop (2.7.3) | |||
| - Apache Ambari (2.6.0) | |||
| Java virtual machine | Oracle JDK (1.8.0_60) | ||
| Operating system | CentOS Linux (7.2.1511) | ||
| Virtualization | VMware ESXi (5.1.0), 8 cores, 36 GB RAM | ||
| CPU cores | 5× | 48 × 2.1 GHz | |
| CPU sockets | 4 × AMD Opteron 6172 | ||
| Random access memory (RAM) | 256 gigabyte (GB) | ||
| Hardware system | IBM System X3755M3 | ||
| Application | Scenario | File Size | Files | Partitions | Total Size |
|---|---|---|---|---|---|
| Random forest classification | Small | 1.89 gigabyte | 8 | 128 | 15.12 gigabyte |
| Large | 3.58 gigabyte | 8 | 232 | 28.64 gigabyte | |
| Huge | 5.52 gigabyte | 8 | 360 | 44.16 gigabyte | |
| Linear regression | Small | 1.86 gigabyte | 8 | 120 | 14.88 gigabyte |
| Large | 3.49 gigabyte | 8 | 224 | 27.92 gigabyte | |
| Huge | 5.59 gigabyte | 8 | 360 | 44.72 gigabyte |
| Random Forest Classification Application | Linear Regression Application | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Worker | Data | Monitored | Simulated | Prediction | Monitored | Simulated | Prediction | ||
| Nodes | Workload | MRT | MRT | RMSE | Error | MRT | MRT | RMSE | Error |
| 4 | Small | 264.79 | 262.71 | 4.47 | 0.78% | 42.15 | 43.09 | 1.19 | 2.23% |
| Large | 502.09 | 462.41 | 40.26 | 7.90% | 71.96 | 76.60 | 4.73 | 6.45% | |
| Huge | 755.05 | 696.70 | 59.65 | 7.73% | 124.21 | 116.38 | 13.39 | 6.30% | |
| 8 | Small | 222.46 | 199.04 | 24,92 | 10.53% | 35.28 | 32.95 | 2.65 | 6.59% |
| Large | 378.31 | 322.54 | 56.62 | 14.74% | 52.24 | 49.74 | 3.66 | 4.79% | |
| Huge | 534.12 | 486.34 | 48.48 | 8.94% | 76.73 | 73.54 | 4.60 | 4.15% | |
| 16 | Small | 196.62 | 196.46 | 4.34 | 0.08% | 37.84 | 37.33 | 2.22 | 1.34% |
| Large | 287.38 | 285.20 | 11.56 | 0.76% | 40.86 | 45.24 | 4.48 | 10.74% | |
| Huge | 373.74 | 396.38 | 25.97 | 6.06% | 53.27 | 56.96 | 4.05 | 6.93% | |
| Random Forest Classification Application | Linear Regression Application | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Worker | Data | Monitored | Simulated | Prediction | Monitored | Simulated | Prediction | ||
| Nodes | Workload | MCPU | MCPU | RMSE | Error | MCPU | MCPU | RMSE | Error |
| 4 | Small | 48.96% | 45.69% | 3.31% | 6.69% | 48.86% | 47.43% | 2.53% | 2.94% |
| Large | 56.93% | 48.70% | 8.23% | 14.45% | 57.55% | 52.06% | 5.62% | 9.53% | |
| Huge | 56.06% | 49.66% | 6.43% | 11.42% | 56.32% | 55.45% | 4.02% | 1.54% | |
| 8 | Small | 35.23% | 34.83% | 0.91% | 1,13% | 36.03% | 32.48% | 3.72% | 9.86% |
| Large | 44.64% | 39.60% | 5.31% | 11.29% | 46.13% | 42.51% | 3.85% | 7.85% | |
| Huge | 47.27% | 40.66% | 6.61% | 13.98% | 52.93% | 48.15% | 4.81% | 9.04% | |
| 16 | Small | 22.65% | 22.12% | 0.84% | 2.32% | 22.05% | 19.34% | 2.91% | 12.26% |
| Large | 31.23% | 27.61% | 3.65% | 11.57% | 31.85% | 28.99% | 3.06% | 8.97% | |
| Huge | 34.00% | 30.72% | 3.39% | 9.63% | 38.22% | 35.59% | 3.13% | 6.89% | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kroß, J.; Krcmar, H. PerTract: Model Extraction and Specification of Big Data Systems for Performance Prediction by the Example of Apache Spark and Hadoop. Big Data Cogn. Comput. 2019, 3, 47. https://doi.org/10.3390/bdcc3030047
Kroß J, Krcmar H. PerTract: Model Extraction and Specification of Big Data Systems for Performance Prediction by the Example of Apache Spark and Hadoop. Big Data and Cognitive Computing. 2019; 3(3):47. https://doi.org/10.3390/bdcc3030047
Chicago/Turabian StyleKroß, Johannes, and Helmut Krcmar. 2019. "PerTract: Model Extraction and Specification of Big Data Systems for Performance Prediction by the Example of Apache Spark and Hadoop" Big Data and Cognitive Computing 3, no. 3: 47. https://doi.org/10.3390/bdcc3030047
APA StyleKroß, J., & Krcmar, H. (2019). PerTract: Model Extraction and Specification of Big Data Systems for Performance Prediction by the Example of Apache Spark and Hadoop. Big Data and Cognitive Computing, 3(3), 47. https://doi.org/10.3390/bdcc3030047