Mapping Distributional Semantics to Property Norms with Deep Neural Networks

Abstract
1. Introduction
- by thinking of concepts whose meaning is similar;
- by completing an analogy;
- based on properties, including properties people did not previously realize characterized that concept;
- by deductive reasoning based on related concepts.
- We predict properties for new concepts by learning a nonlinear mapping from a distributional semantic space to human-annotated property space based on multilayer perceptrons.
- We explore the performances of distribution models with different types of contexts on this task by qualitative and quantitative analyses.
- Using a publicly available dataset of property norms, we show that high-quality property norms can indeed be induced from standard distributional data.
2. Related Work
3. Distributional Models and Property Norms
4. Learning Properties of Concepts from Distributional Models with Multilayer Perceptrons
5. Experiments and Evaluation
5.1. Data Preparation
5.2. Baselines
- PLSR: refs. [16,18] estimate the function (1) in Section 4 using PLSR. PLSR, a bilinear factor model, is used to find the fundamental relations between the distributional semantic space and the property semantic space by modeling the covariance structures in these two spaces. In our experiments, we set the number of components to 50 and 100, respectively.
- KNN: For each concept in the test dataset, we choose the k most similar concepts from the training dataset based on their cosine similarities in the distributional semantic space. Then the property vector of the concept in the test dataset is represented by the average of property vectors of these k most similar concepts. We set k to 5 and 10 in our experiments.
5.3. Quantitative Evaluation
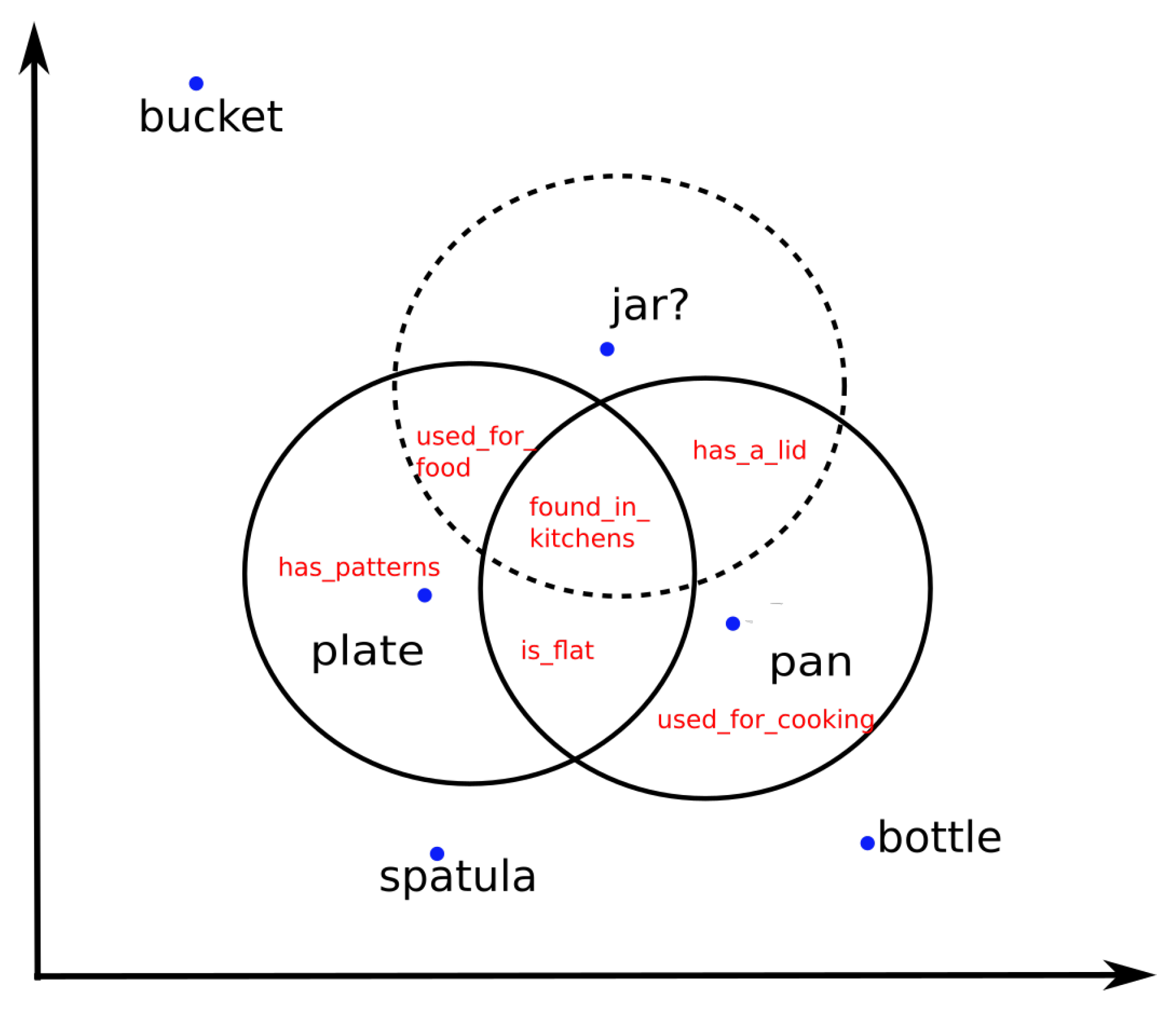
5.4. Qualitative Evaluation
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Levy, O.; Goldberg, Y. Dependency-based word embeddings. In Proceedings of the 52nd Anua Meeting of the Associations for Computational Linguistics (Short Papers), Baltimore, MD, USA, 23–25 June 2014; pp. 302–308. [Google Scholar]
- McRae, K.; Cree, G.S.; Seidenberg, M.S.; McNorgan, C. Semantic feature production norms for a large set of living and nonliving things. Behav. Res. Methods 2005, 37, 547–559. [Google Scholar] [CrossRef] [PubMed]
- Devereux, B.J.; Tyler, L.K.; Geertzen, J.; Randall, B. The Centre for Speech, Language and the Brain (CSLB) concept property norms. Behav. Res. Methods 2014, 46, 1119–1127. [Google Scholar] [CrossRef] [PubMed]
- Gupta, A.; Boleda, G.; Baroni, M.; Padó, S. Distributional vectors encode referential attributes. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 12–21. [Google Scholar]
- Baroni, M.; Murphy, B.; Barbu, E.; Poesio, M. Strudel: A Corpus-Based Semantic Model Based on Properties and Types. Cogn. Sci. 2010, 34, 222–254. [Google Scholar] [CrossRef] [PubMed]
- Harris, Z.S. Distributional structure. Word 1954, 10, 146–162. [Google Scholar] [CrossRef]
- Firth, J.R. A synopsis of linguistic theory 1930–1955. In Studies in Linguistic Analysis; Longmans: London, UK, 1957; pp. 1–32. [Google Scholar]
- Murphy, G. The Big Book of Concepts; The MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Mintz, M.; Bills, S.; Snow, R.; Jurafsky, D. Distant supervision for relation extraction without labeled data. In Proceedings of the 47th Annual Meeting of the ACL and the 4th IJCNLP of the AFNLP, Suntec, Singapore, 2–7 August 2009; pp. 1003–1011. [Google Scholar]
- Socher, R.; Chen, D.; Manning, C.D.; Ng, A.Y. Reasoning with neural tensor networks for knowledge base completion. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 926–934. [Google Scholar]
- Speer, R.; Chin, J.; Havasi, C. ConceptNet 5.5: An Open Multilingual Graph of General Knowledge. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17), San Francisco, CA, USA, 4–9 February 2017; pp. 4444–4451. [Google Scholar]
- Devereux, B.; Pilkington, N.; Poibeau, T.; Korhonen, A. Towards Unrestricted, Large-Scale Acquisition of Feature-Based Conceptual Representations from Corpus Data. Res. Lang. Comput. 2009, 7, 137–170. [Google Scholar] [CrossRef]
- Summers-Stay, D.; Voss, C.; Cassidy, T. Using a Distributional Semantic Vector Space with a Knowledge Base for Reasoning in Uncertain Conditions. Biol. Inspired Cogn. Archit. 2016, 16, 34–44. [Google Scholar] [CrossRef]
- Herbelot, A.; Vecchi, E.M. Building a shared world: Mapping distributional to model-theoretic semantic spaces. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (Best Paper Award), Lisbon, Portugal, 17–21 September 2015; pp. 22–32. [Google Scholar]
- Dernoncourt, F. Mapping distributional to model-theoretic semantic spaces: A baseline. arXiv 2016, arXiv:1607.02802. [Google Scholar]
- Făgărăşan, L.; Vecchi, E.M.; Clark, S. From distributional semantics to feature norms: Grounding semantic models in human perceptual data. In Proceedings of the 11th International Conference on Computational Semantics, London, UK, 15–17 April 2015; pp. 52–57. [Google Scholar]
- Baroni, M.; Lenci, A. Concepts and Properties in Word Spaces. Ital. J. Linguist. 2008, 9, 1–36. [Google Scholar]
- Rubinstein, D.; Levi, E.; Schwartz, R.; Rappoport, A. How Well Do Distributional Models Capture Different Types of Semantic Knowledge? In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; pp. 726–730. [Google Scholar]
- Erk, K. What do you know about an alligator when you know the company it keeps? Semant. Pragmat. 2016, 9, 1–63. [Google Scholar] [CrossRef]
- Boleda, G.; Herbelot, A. Formal Distributional Semantics: Introduction to the Special Issue. Spec. Issue Comput. Linguist. Form. Distrib. Semant. 2017, 42, 619–635. [Google Scholar] [CrossRef]
- Bulat, L.; Kiela, D.; Clark, S. Vision and Feature Norms: Improving automatic feature norm learning through cross-modal maps. In Proceedings of the NAACL-HLT, San Diego, CA, USA, 12–17 June 2016; pp. 579–588. [Google Scholar]
- Frome, A.; Corrado, G.S.; Shlens, J.; Bengio, S.; Dean, J.; Ranzato, M.; Mikolov, T. DeViSE: A Deep Visual-Semantic Embedding Model. In Proceedings of the NIPS 2013: Neural Information Processing Systems Conference, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 2121–2129. [Google Scholar]
- Silberer, C.; Ferrari, V.; Lapata, M. Visually Grounded Meaning Representations. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2284–2297. [Google Scholar] [CrossRef] [PubMed]
- Zellers, R.; Choi, Y. Zero-Shot Activity Recognition with Verb Attribute Induction. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 946–958. [Google Scholar]
- Peirsman, Y. Word Space Models of Semantic Similarity and Relatedness. In Proceedings of the 13th ESSLLI Student Session, Sofia, Bulgaria, 6–17 August 2008; pp. 143–152. [Google Scholar]
- Melamud, O.; McClosky, D.; Patwardhan, S.; Bansal, M. The Role of Context Types and Dimensionality in Learning Word Embeddings. In Proceedings of the NAACL-HLT, San Diego, CA, USA, 12–17 June 2016; pp. 1030–1040. [Google Scholar]
- Cybenko, G. Approximation by Superpositions of a Sigmoidal Function. Math. Control Signals Syst. 1989, 2, 303–314. [Google Scholar] [CrossRef]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Kingma, D.P.; Ba, J.L. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Han, L.; Kashyap, A.L.; Finin, T.; Mayfield, J.; Weese, J. UMBC EBIQUITY-CORE: Semantic textual similarity systems. In Proceedings of the Second Joint Conference on Lexical and Computational Semantics. Association for Computational Linguistics, Atlanta, GA, USA, 13–14 June 2013. [Google Scholar]
- Parker, R.; Graff, D.; Kong, J.; Chen, K.; Maeda, K. English Gigaword, 5th ed.; Linguistic Data Consortium, LDC2011T07; Linguistic Data Consortium: Philadelphia, PA, USA, 2011. [Google Scholar]
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.; Bethard, S.J.; McClosky, D. The Stanford CoreNLP natural language processing toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 22–27 June 2014; pp. 55–60. [Google Scholar]


{kind=link}
| Distributional Models | Contexts |
|---|---|
| W2V1 | careful, discovered |
| W2V3 | a, careful, discovered, something, funky |
| DEP | careful/amod, discovered/nsubj−1 |
| Concept | Top 5 Properties | Production Frequency |
|---|---|---|
| basket | is_weaved | 18 |
| used_for_holding_things | 18 | |
| has_a_handle | 17 | |
| made_of_wicker | 10 | |
| made_of_wood | 9 |
| Description | Value |
|---|---|
| Model Type | Multilayer Perceptron (MLP) |
| Number of Layers | 5 (3 hidden layers) |
| Number of Units in Each Layer | 300:800:1500:2000:2526 |
| Hidden Layer Activation Function | ReLU |
| Output Layer Activation Function | Softmax |
| Regularization | Dropout |
| Loss Function | Categorical Cross Entropy |
| Optimizer | Adam |
| Methods | Parameters | Distributional Models (Precision) | |||
|---|---|---|---|---|---|
| W2V1 | W2V5 | W2V10 | DEP | ||
| MLP | Dropout | 42.46 | 42.10 | 41.15 | 41.59 |
| No Dropout | 40.72 | 40.65 | 40.86 | 40.79 | |
| PLSR | c = 50 | 38.26 | 37.75 | 37.75 | 37.53 |
| c = 100 | 37.31 | 38.26 | 38.18 | 37.68 | |
| KNN | k = 5 | 36.01 | 34.63 | 34.85 | 35.79 |
| k = 10 | 36.01 | 35.86 | 36.37 | 36.66 | |
| Methods | Parameters | Distributional Models (Recall) | |||
|---|---|---|---|---|---|
| W2V1 | W2V5 | W2V10 | DEP | ||
| MLP | Dropout | 32.40 | 32.06 | 31.28 | 31.95 |
| No Dropout | 30.90 | 30.86 | 31.27 | 31.11 | |
| PLSR | c = 50 | 29.04 | 28.43 | 28.72 | 29.01 |
| c = 100 | 28.60 | 29.06 | 29.12 | 28.98 | |
| KNN | k = 5 | 27.76 | 26.47 | 26.74 | 27.26 |
| k = 10 | 27.89 | 27.73 | 27.95 | 28.08 | |
| Concept | Method | Top 5 Predicted Properties |
|---|---|---|
| jar | McRae | has_a_lid, made_of_glass, used_for_holding_things, a_container, is_breakable, |
| MLP | used_for_holding_things, made_of_plastic, made_of_glass, has_a_lid, is_breakable | |
| PLSR | made_of_plastic, ∗found_in_kitchens, ∗made_of_metal, ∗is_round, used_for_holding_things | |
| KNN | ∗made_of_metal, made_of_plastic, ∗found_in_kitchens, used_for_holding_things, ∗a_utensil | |
| sparrow | McRae | a_baby_bird, beh_flies, has_feathers, beh_lays_eggs, has_wings |
| MLP | a_baby_bird, beh_flies, has_wings, has_feathers, beh_lays_eggs | |
| PLSR | a_baby_bird, beh_flies, has_feathers, has_wings, has_a_beak | |
| KNN | a_baby_bird, beh_flies, has_feathers, has_wings, has_a_beak | |
| spatula | McRae | a_utensil, has_a_handle, made_of_plastic, used_for_cooking, is_flat, |
| MLP | a_utensil, made_of_plastic, made_of_metal, found_in_kitchens, ∗used_for_eating | |
| PLSR | made_of_metal, found_in_kitchens, made_of_plastic, ∗a_tool, a_utensil | |
| KNN | made_of_metal, found_in_kitchens, ∗a_tool, made_of_plastic, has_a_handle | |
| sofa | McRae | found_in_living_rooms, furniture, is_comfortable, used_by_sitting_on, has_cushions |
| MLP | is_comfortable, furniture, is_soft, used_by_sitting_on, has_cushions | |
| PLSR | is_comfortable, ∗made_of_wood, is_soft, used_by_sitting_on, used_for_sleeping | |
| KNN | is_comfortable, is_soft, ∗made_of_wood, ∗worn_for_warmth, used_for_sleeping | |
| bracelet | McRae | worn_on_wrists, made_of_gold, made_of_silver, a_fashion_accessory, a_jewelry |
| MLP | ∗worn_around_neck, made_of_silver, a_fashion_accessory, a_jewelry, made_of_gold | |
| PLSR | made_of_metal, made_of_gold, made_of_silver, ∗worn_around_neck, is_round, | |
| KNN | ∗worn_for_warmth, ∗clothing, ∗is_long, ∗worn_by_women, ∗different_colours | |
| doll | McRae | has_own_clothes, used_for_playing, a_toy, used_by_girls, has_hair |
| MLP | ∗is_small, ∗is_soft, ∗is_white, ∗is_comfortable, ∗is_large | |
| PLSR | ∗is_small, ∗is_white, ∗worn_by_women, ∗different_colours, ∗clothing | |
| KNN | ∗is_comfortable, ∗worn_for_warmth, ∗worn_at_night, ∗is_warm, ∗clothing | |
| walrus | McRae | an_animal, is_large, beh_swims, lives_in_water, is_fat |
| MLP | an_animal, a_mammal, hunted_by_people, ∗has_a_tail, beh_swims | |
| PLSR | an_animal, is_large, lives_in_water, beh_swims, ∗a_baby_bird | |
| KNN | an_animal, ∗has_a_tail, has_teeth, ∗is_green, ∗is_furry | |
| platypus | McRae | an_animal, lives_in_water, a_mammal, beh_swims, has_a_bill |
| MLP | an_animal, beh_swims, ∗has_a_tail, ∗has_4_legs, ∗is_brown | |
| PLSR | an_animal, ∗is_small, ∗has_a_tail, ∗has_4_legs, ∗is_large | |
| KNN | an_animal, ∗is_green, ∗has_4_legs, ∗beh_eats, ∗has_a_tail |
| Concept | Method | Top 5 Neighbors |
|---|---|---|
| jar | MLP | jar, bucket, plate, spatula, whistle |
| PLSR | bucket, spatula, plate, pan, skillet | |
| KNN | spatula, tongs, bucket, grater, pan | |
| sparrow | MLP | sparrow, raven, finch, buzzard, parakeet |
| PLSR | raven, sparrow, finch, buzzard, parakeet | |
| KNN | sparrow, raven, finch, buzzard, parakeet | |
| spatula | MLP | spatula, fork, tongs, grater, bucket |
| PLSR | spatula, tongs, grater, pan, hatchet | |
| KNN | spatula, tongs, hatchet, grater, bucket | |
| sofa | MLP | sofa, cushion, bench, jeans, cabinet |
| PLSR | sofa, cushion, cabinet, bench, jeans | |
| KNN | sofa, cushion, socks, bench, cabinet | |
| bracelet | MLP | bracelet, tie, crown, fork, plate |
| PLSR | bracelet, tongs, bucket, crown, thimble | |
| KNN | skirt, socks, cape, tie, jacket | |
| doll | MLP | rice, cottage, cushion, shrimp, bear |
| PLSR | sparrow, finch, butterfly, sheep, raven | |
| KNN | socks, bracelet, cape, skirt, bench | |
| walrus | MLP | platypus, buffalo, elk, walrus, caribou |
| PLSR | walrus, ox, buffalo, platypus, otter | |
| KNN | walrus, ox, platypus, otter, cougar | |
| platypus | MLP | otter, platypus, walrus, ox, buffalo |
| PLSR | ox, walrus, platypus, buffalo, elk | |
| KNN | cougar, ox, buffalo, elk, walrus |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, D.; Summers-Stay, D. Mapping Distributional Semantics to Property Norms with Deep Neural Networks. Big Data Cogn. Comput. 2019, 3, 30. https://doi.org/10.3390/bdcc3020030
Li D, Summers-Stay D. Mapping Distributional Semantics to Property Norms with Deep Neural Networks. Big Data and Cognitive Computing. 2019; 3(2):30. https://doi.org/10.3390/bdcc3020030
Chicago/Turabian StyleLi, Dandan, and Douglas Summers-Stay. 2019. "Mapping Distributional Semantics to Property Norms with Deep Neural Networks" Big Data and Cognitive Computing 3, no. 2: 30. https://doi.org/10.3390/bdcc3020030
APA StyleLi, D., & Summers-Stay, D. (2019). Mapping Distributional Semantics to Property Norms with Deep Neural Networks. Big Data and Cognitive Computing, 3(2), 30. https://doi.org/10.3390/bdcc3020030