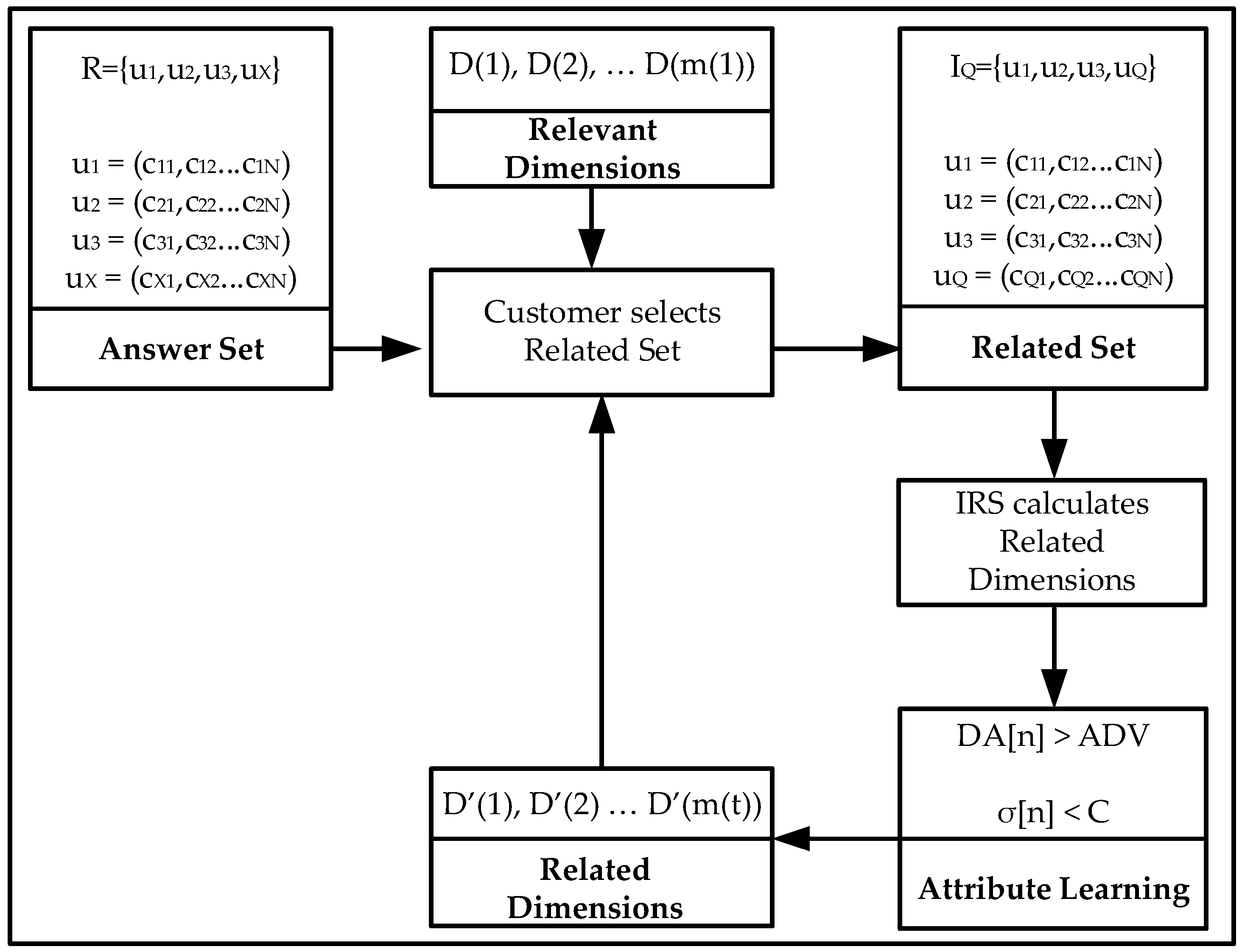
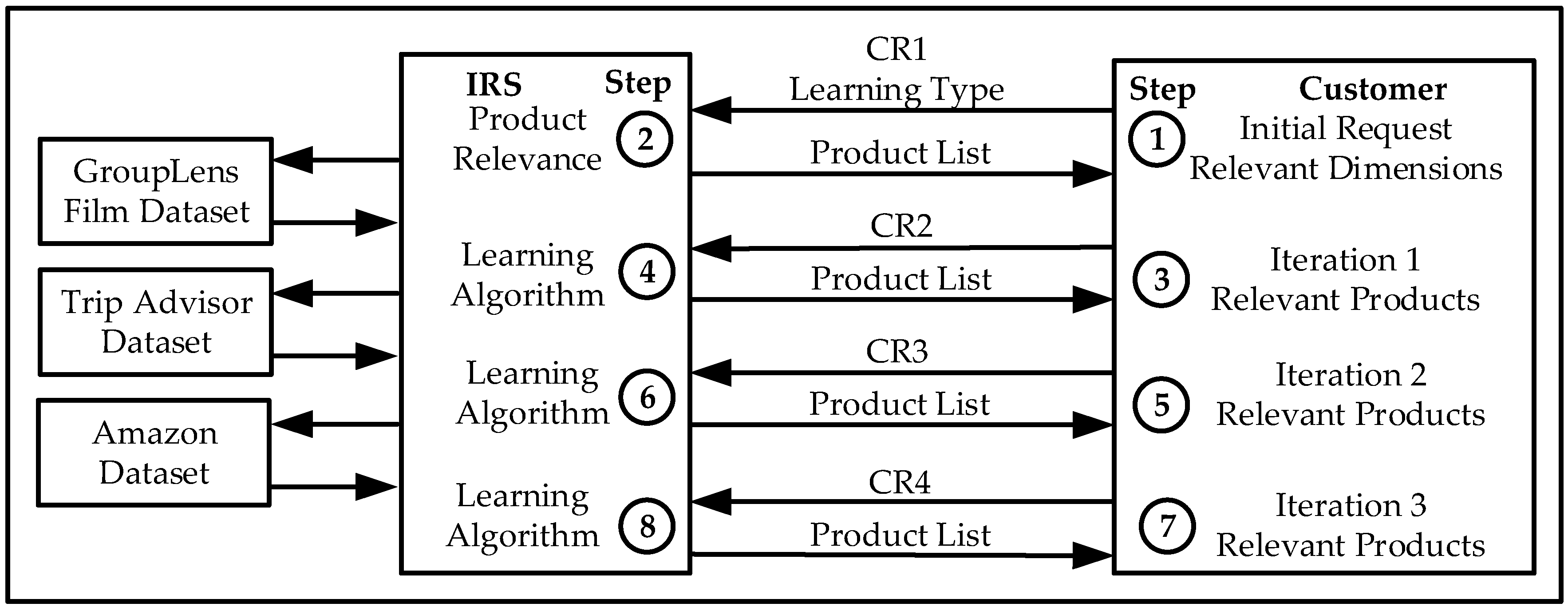
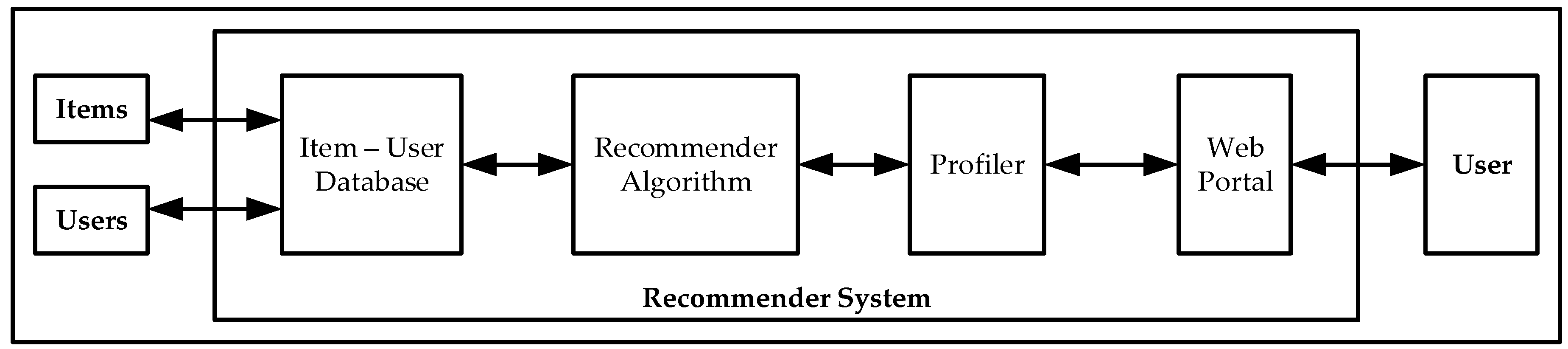
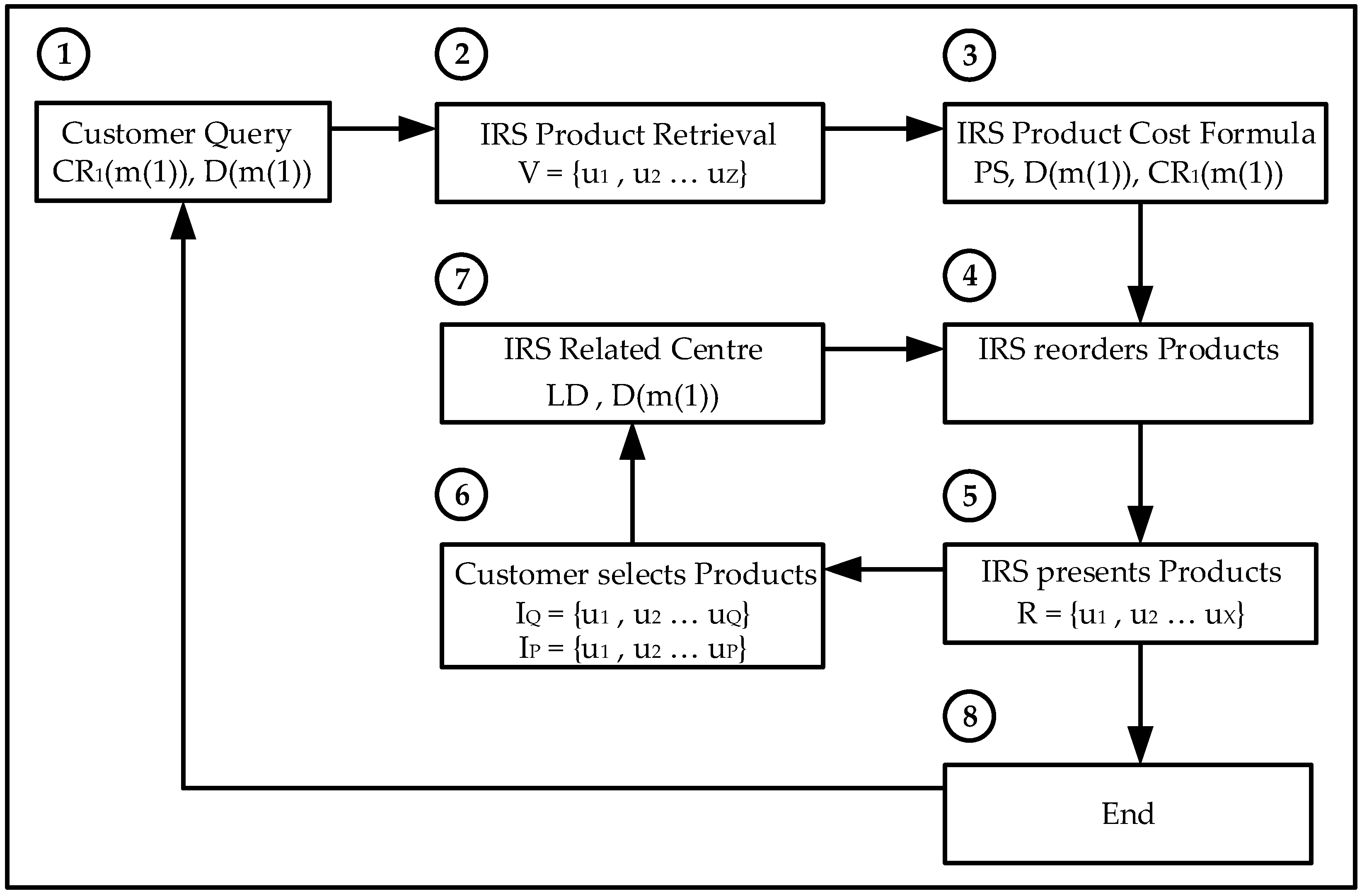
In the evaluation, validators are asked to select relevant products, not to rank them, as they normally do when using a Recommender System therefore a product is considered as either relevant or irrelevant. Validators are 15 personal friends from Imperial College students, researchers and London young professionals degree educated.
5.2.1. GroupLens Film Data Set
GroupLens is a research group in the Department of Computer Science and Engineering at the University of Minnesota. Since its creation in 1992 GroupLens’ research projects have consisted on Recommender Systems, Online Communities, Mobile Technologies, Digital Libraries and Local Geographic Information Systems. The data set is based on a 5-star rating and genre tagging from MovieLens. It contains 21063128 ratings and 470509 tags across 27303 films. The data set was created by 229060 users between January-1995 and March-2015.
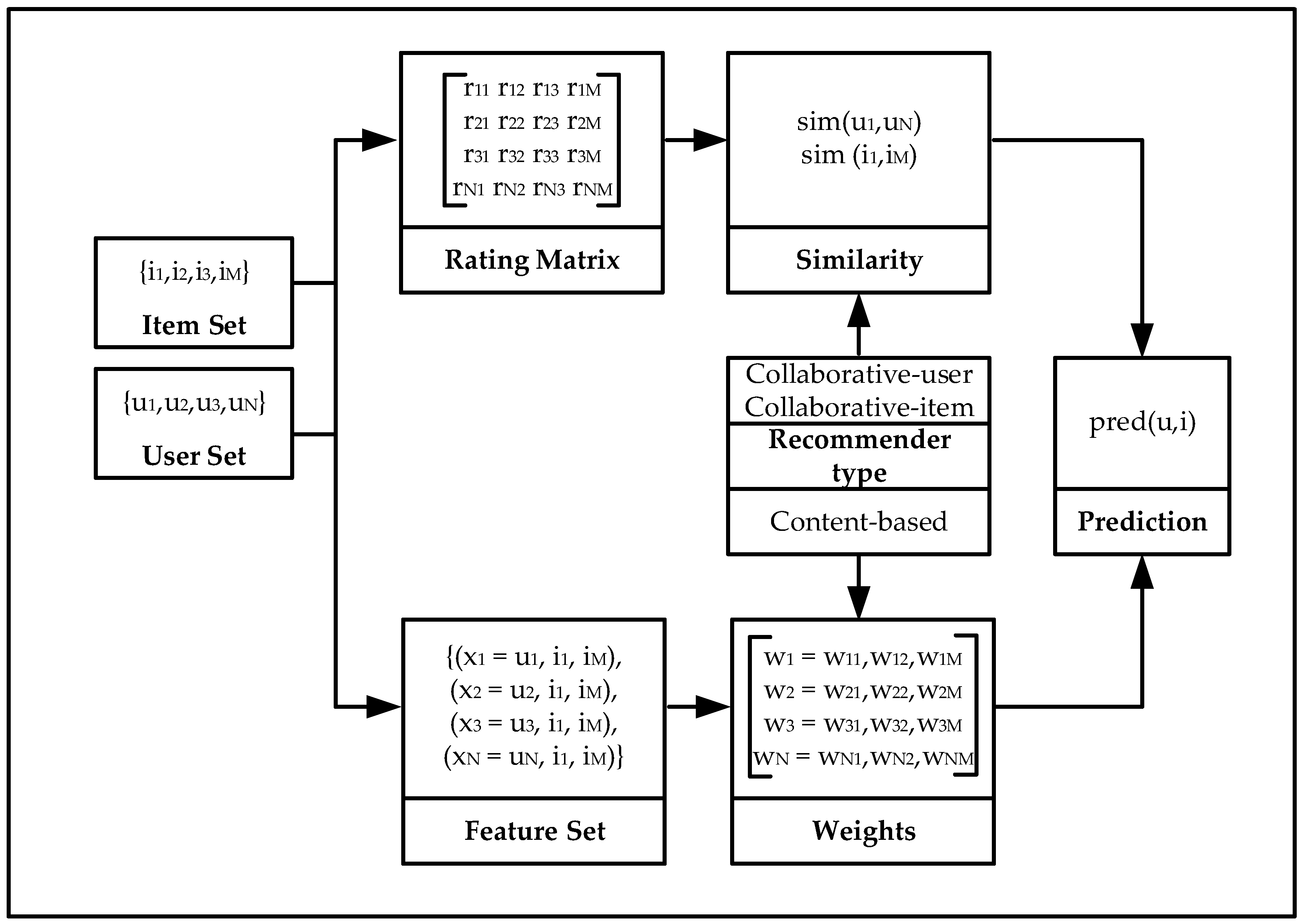
The data sets files are written as comma-separated values, csv extension. The files are encoded as UTF-8. The ratings data file consists of userId, movieId, rating and timestamp, whereas the film data file consists on movieId, title, genres. Genres are: Action, Adventure, Animation, Children, Comedy, Crime, Documentary, Drama, Fantasy, Film-Noir, Horror, Musical, Mystery, Romance, Sci-Fi, Thriller, War, Western and IMAX. The data set is processed by extracting the relevant information; movieId, rating title and genres. All the ratings from individual customers are combined to the same different products where the average value is the final product rating. Each film is considered as a multidimensional vector consisting on the different genres. The film relevance is the averaged film rating which is equally divided between the different genres it is classified.
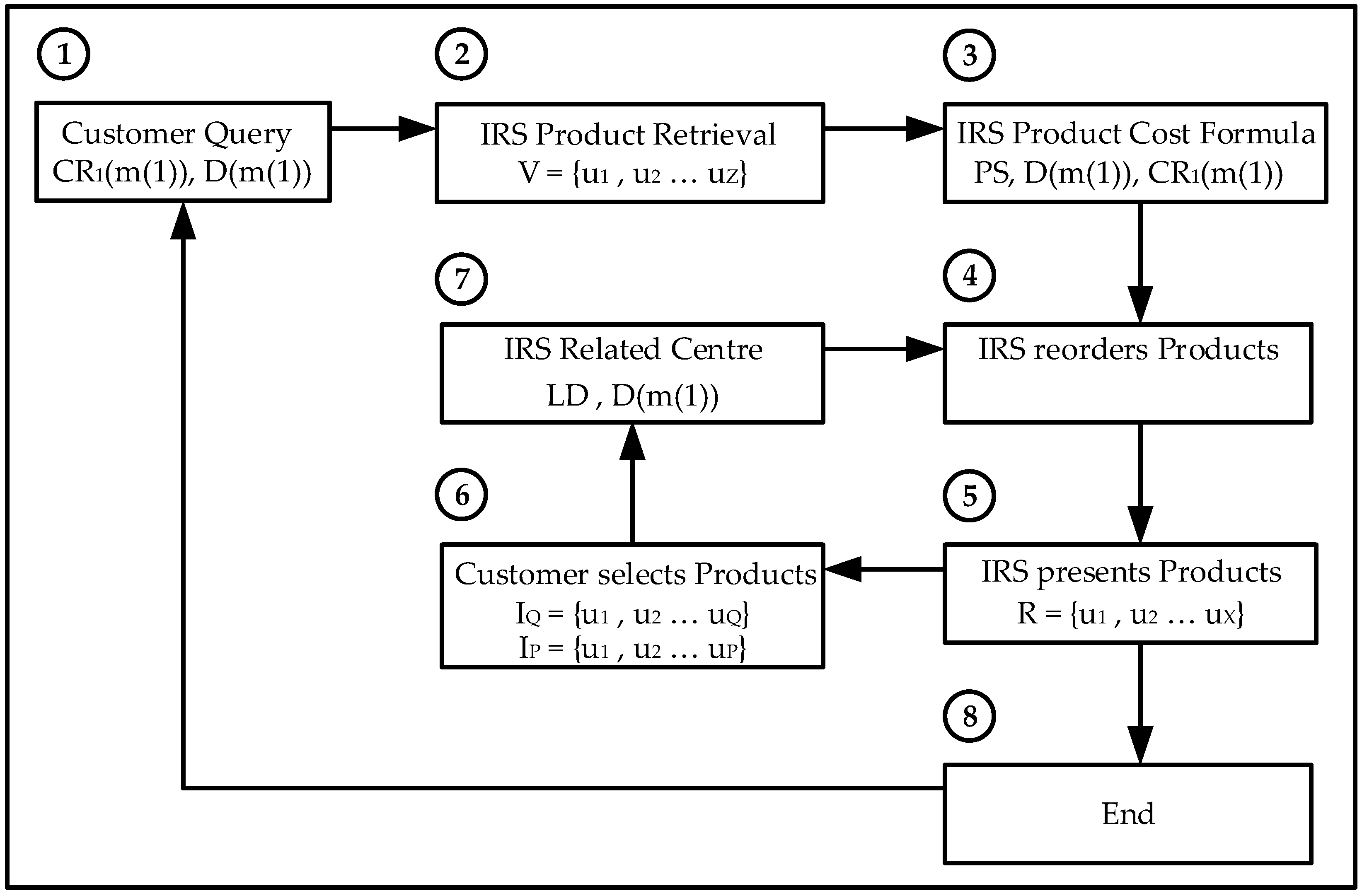
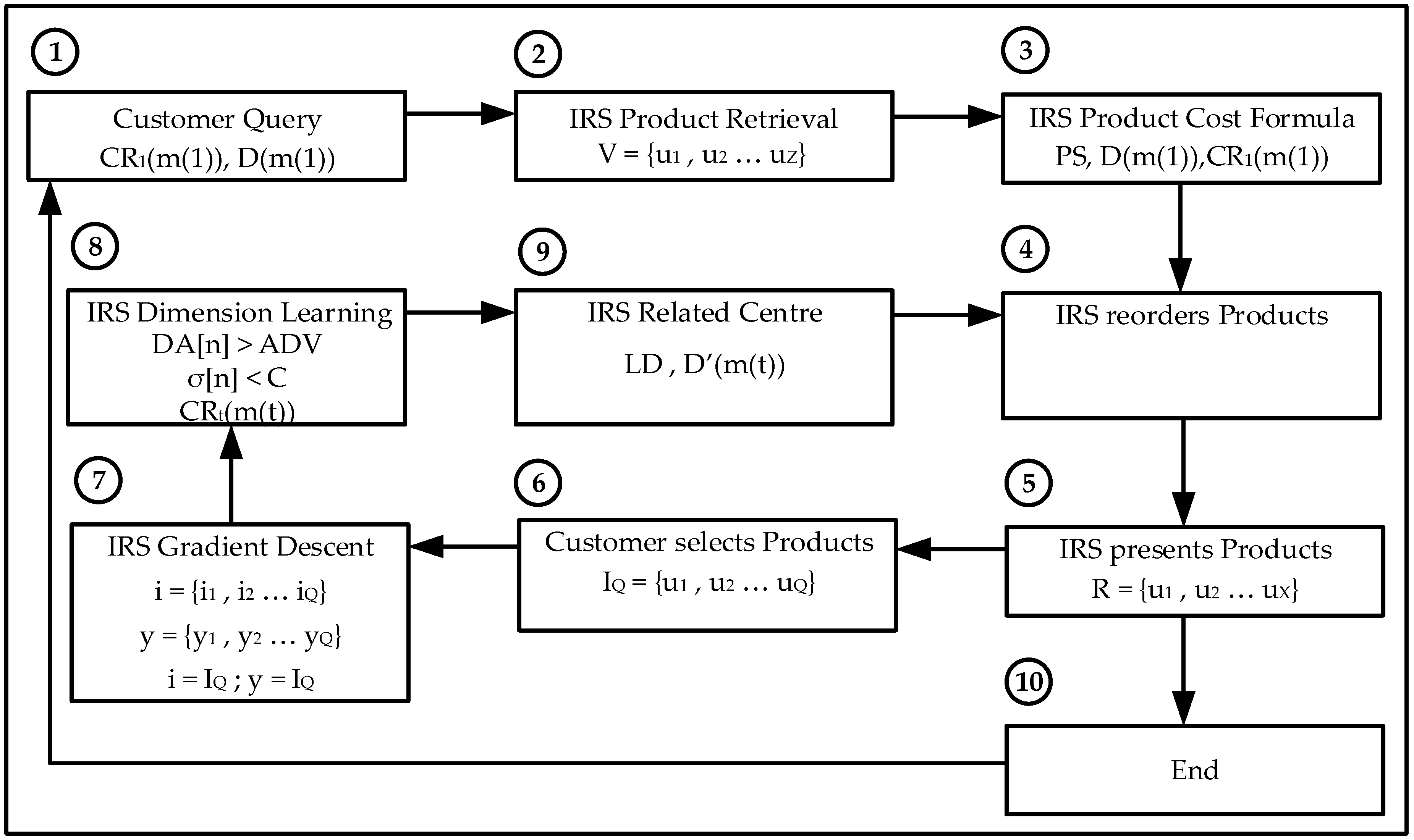
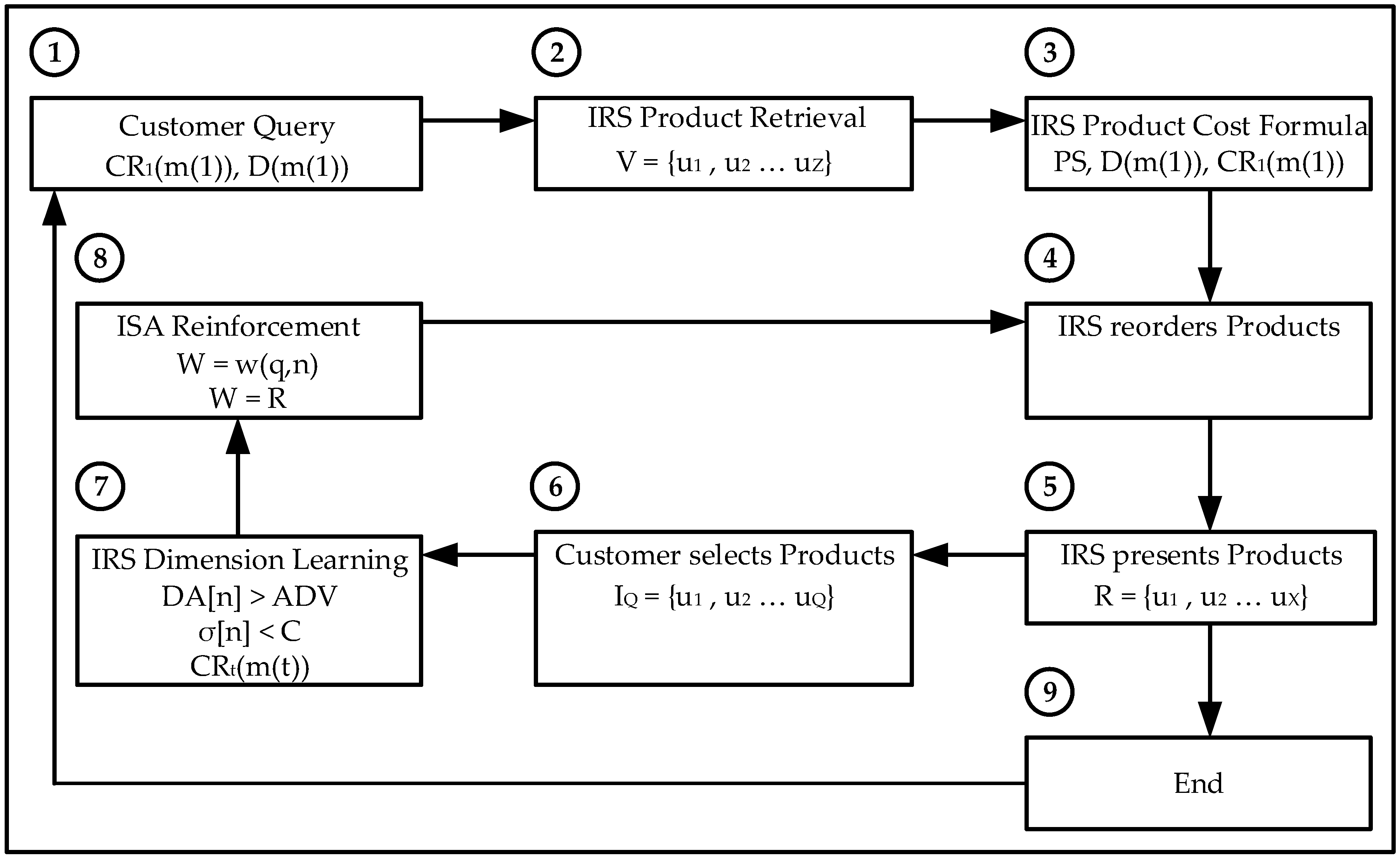
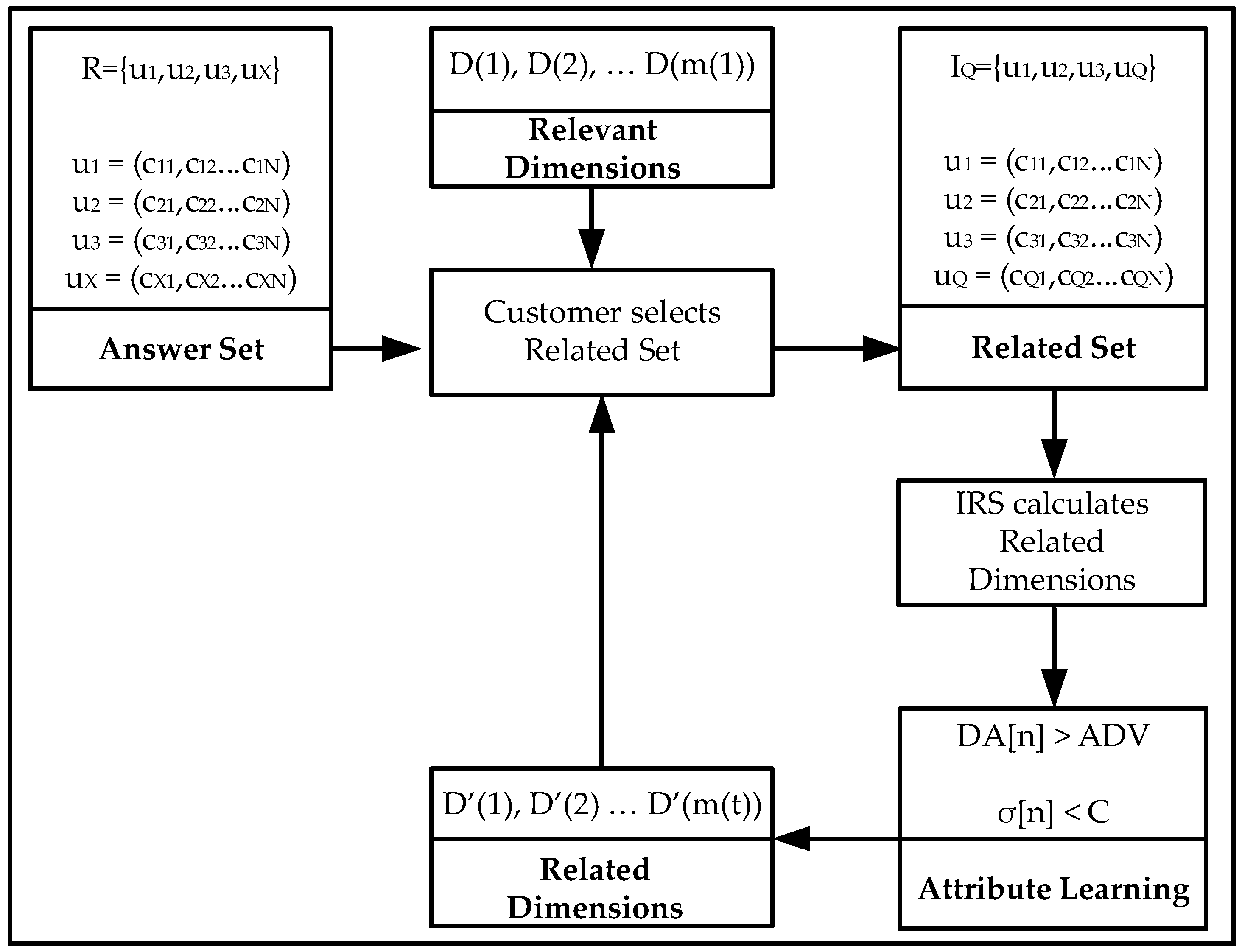
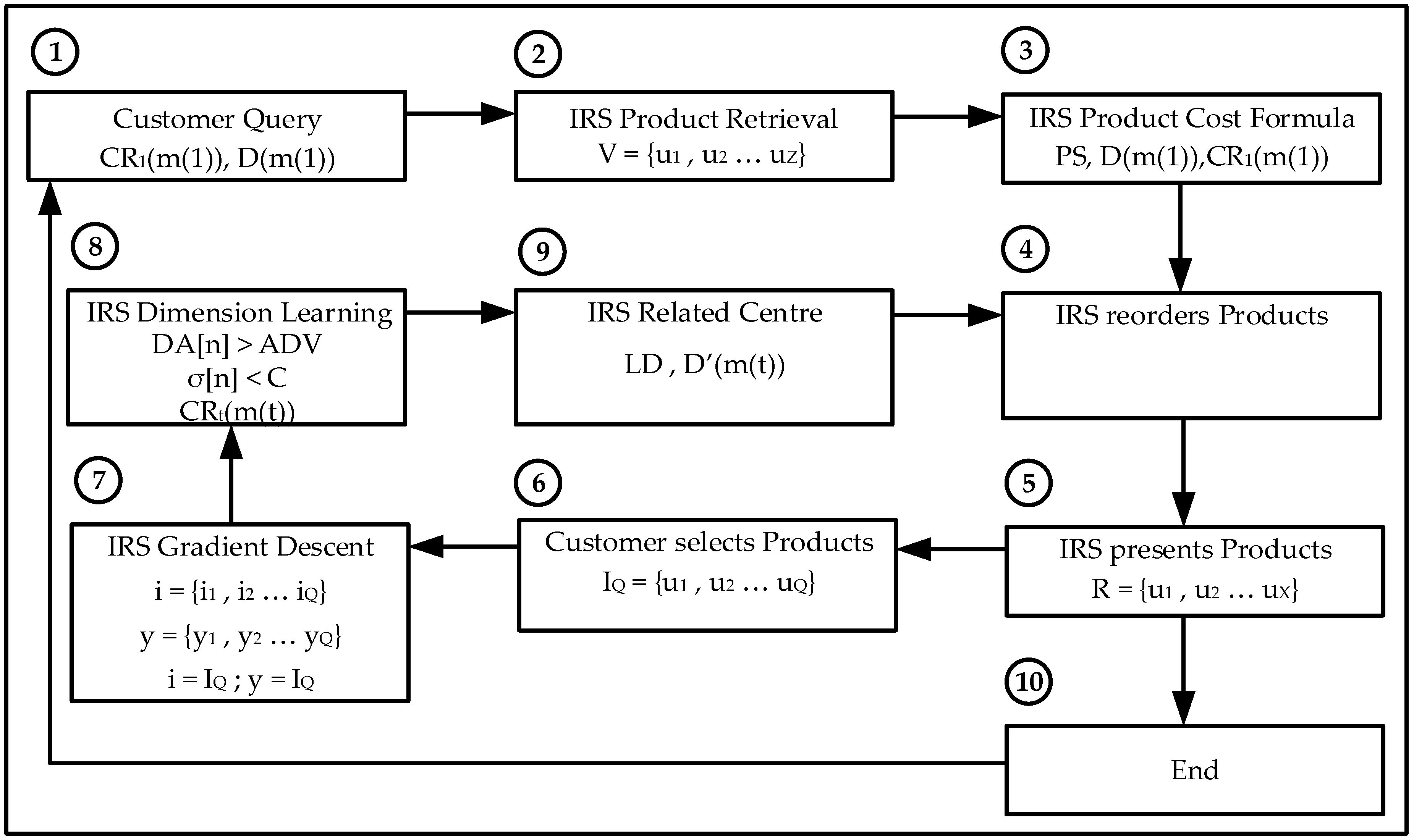
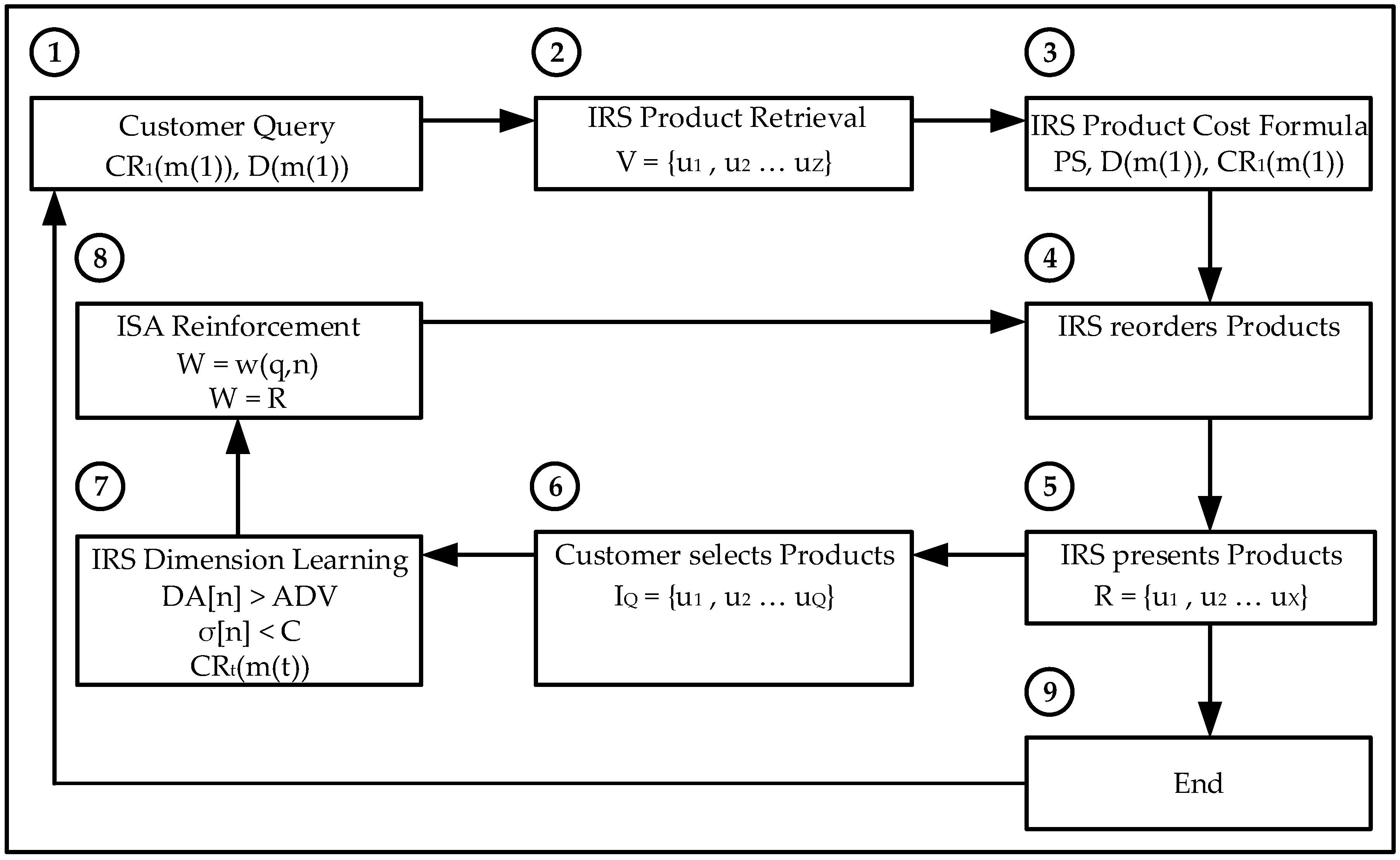
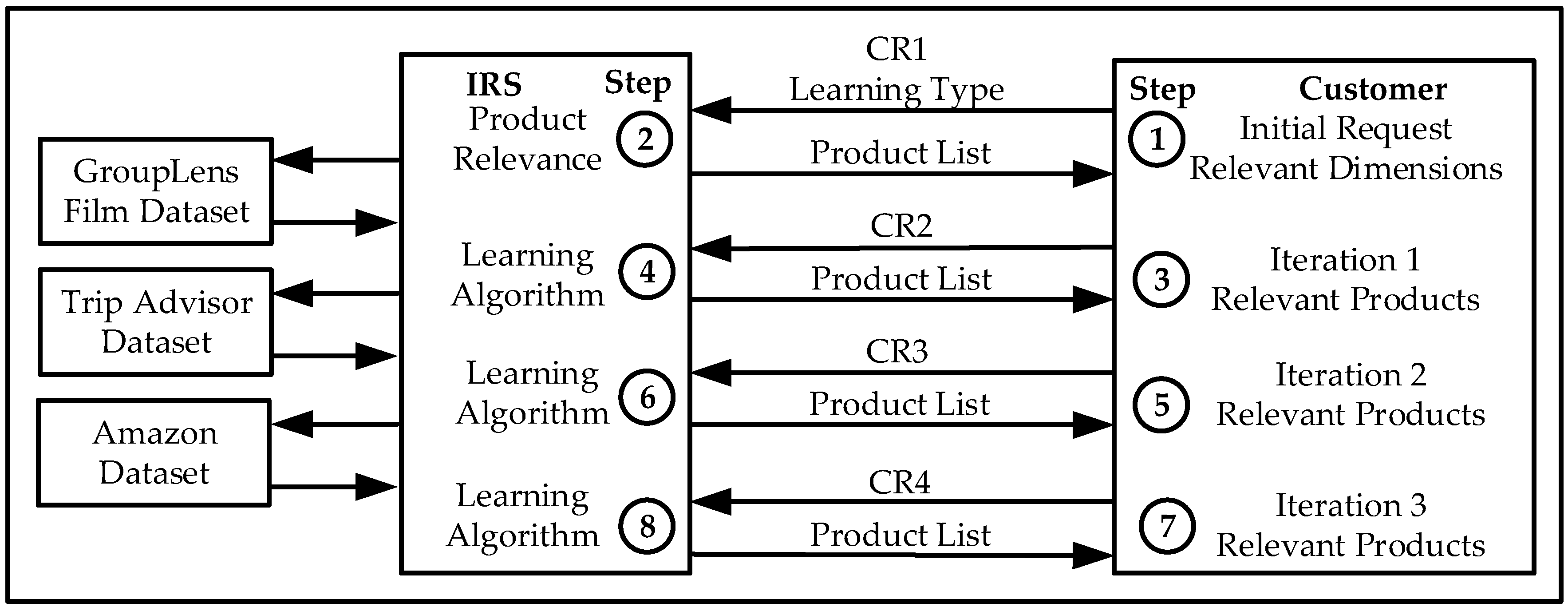
The IRS is programmed to retrieve the user’s relevant film genres and the type of learning (Gradient Descent or Reinforcement Learning). The IRS then reorders the films based on their relevance which is the combined value of the user selected genres only. The Intelligent Recommender System provides a reordered list of film titles to the user based on the higher values of the selected genres; the customer then selects the most relevant products with a higher overall rating; the IRS then continues the recommendation iterative process or provides with the final film titles.
Gradient Descent and Reinforcement Learning have been validated independently for five different queries with ten recommendations in total.
Table 1 and
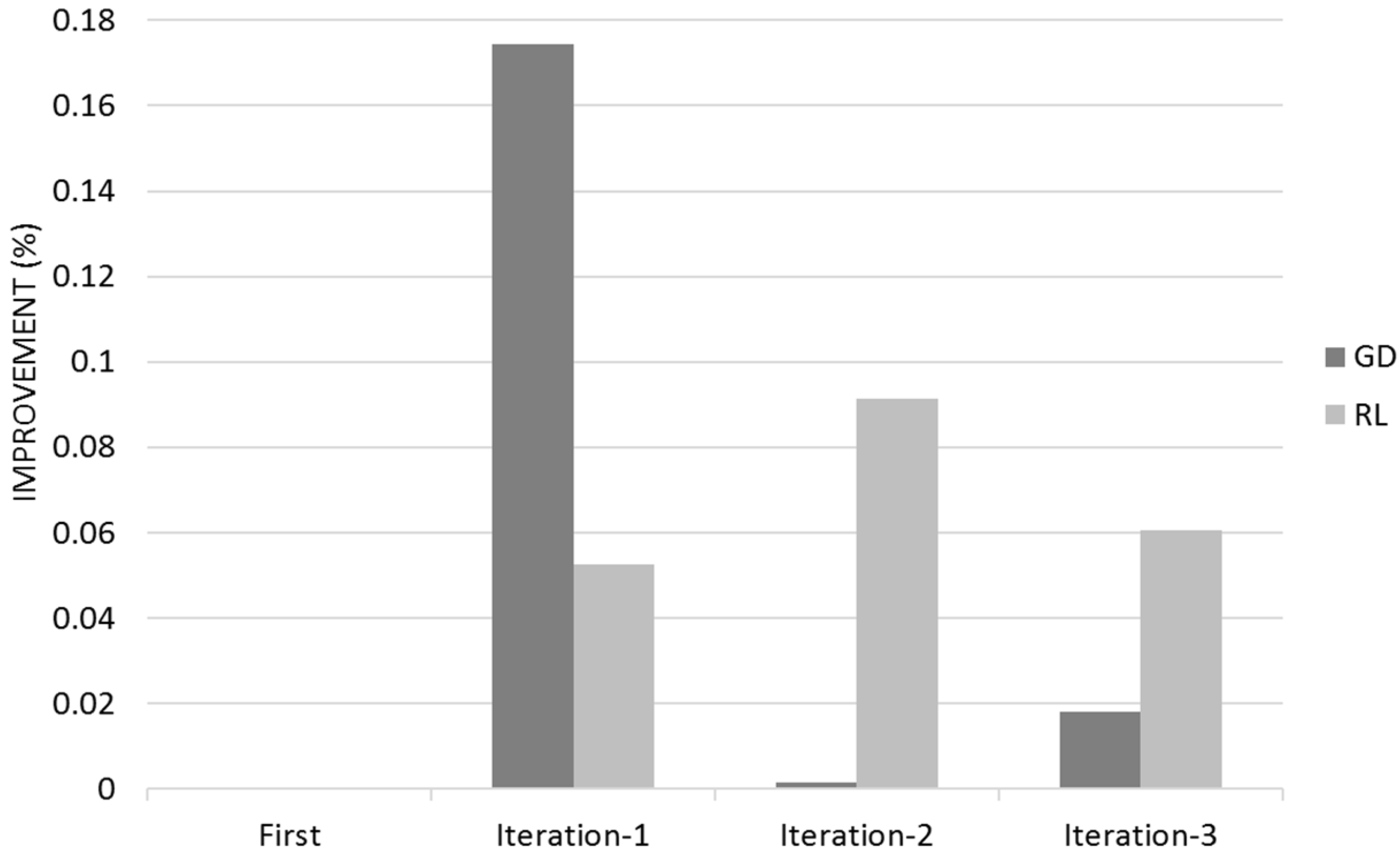
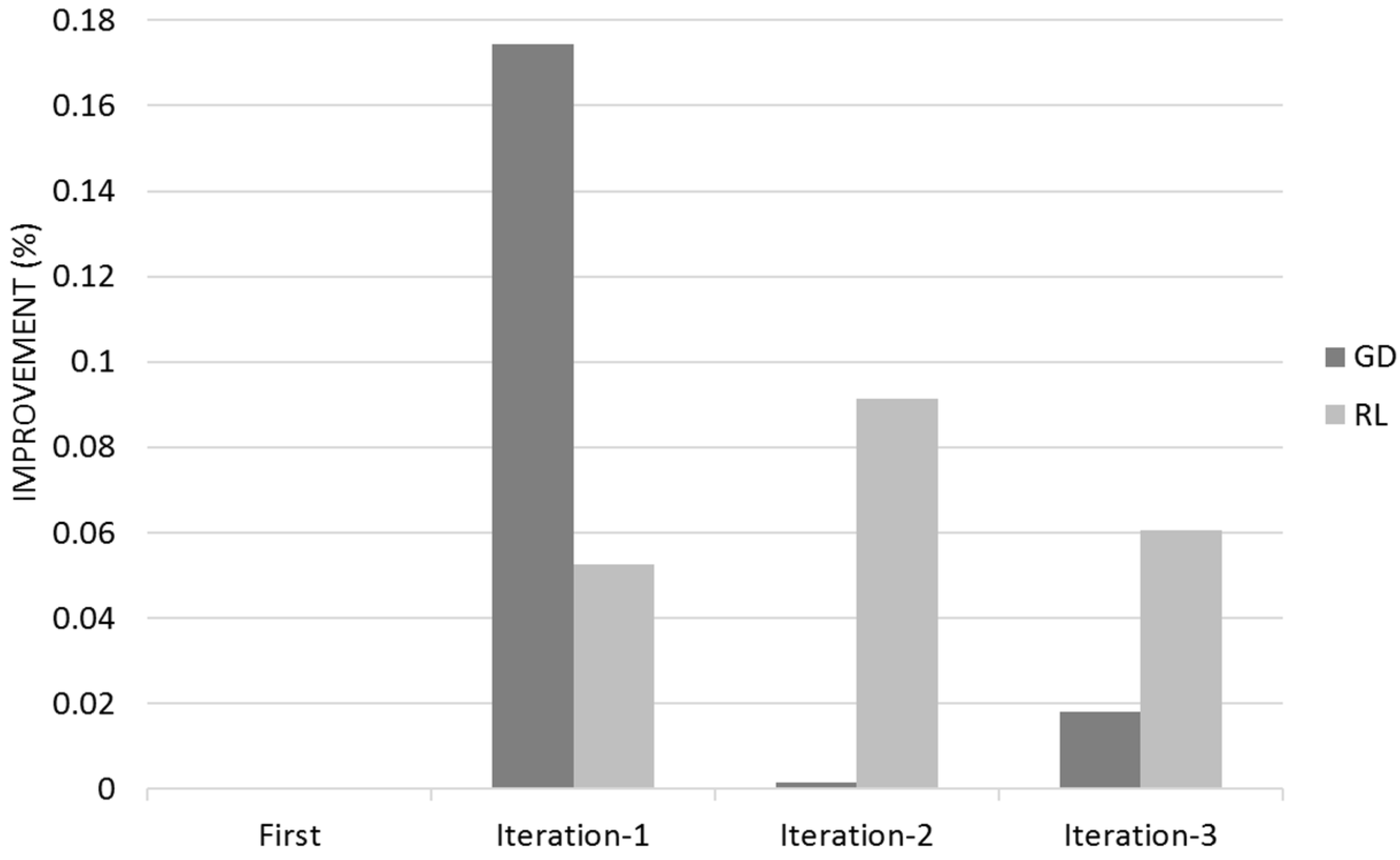
Table 2 show the Quality for the different iterations with its associated 95% Confidence Range. I represents the improvement from IRS against the Recommender System; the second I is between IRS iterations 2 and 1 and finally the third I is between IRS iterations 3 and 2.
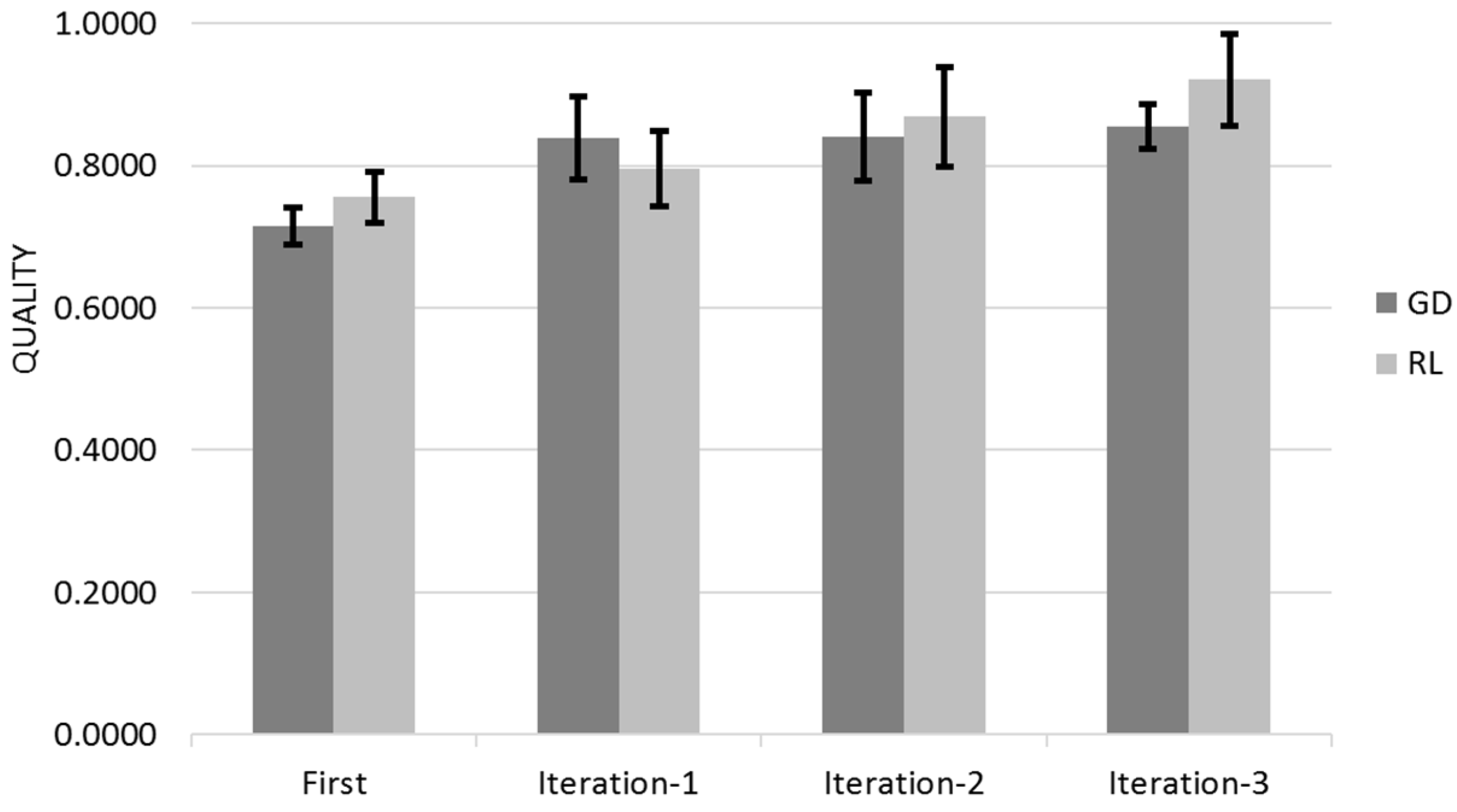
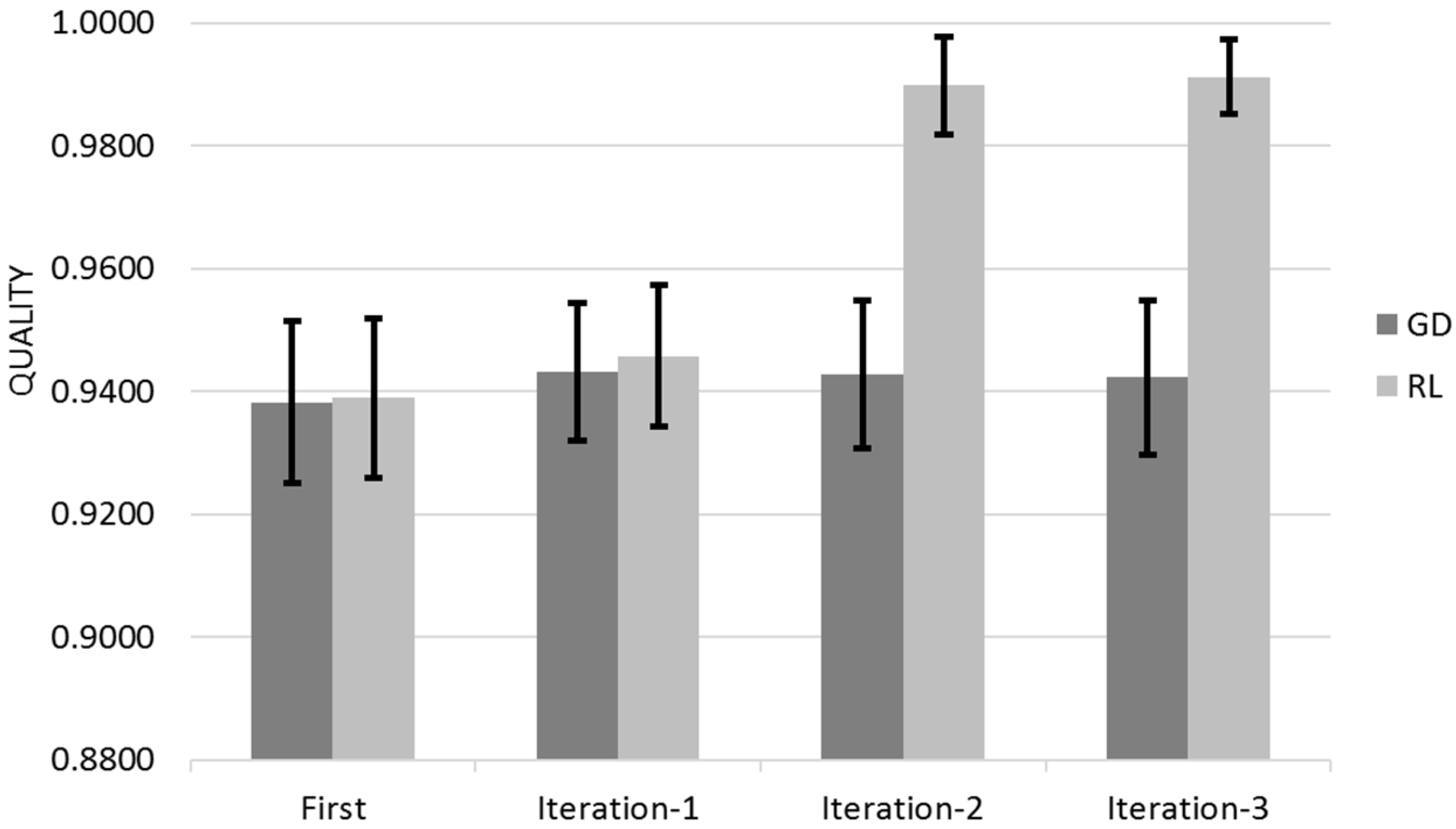
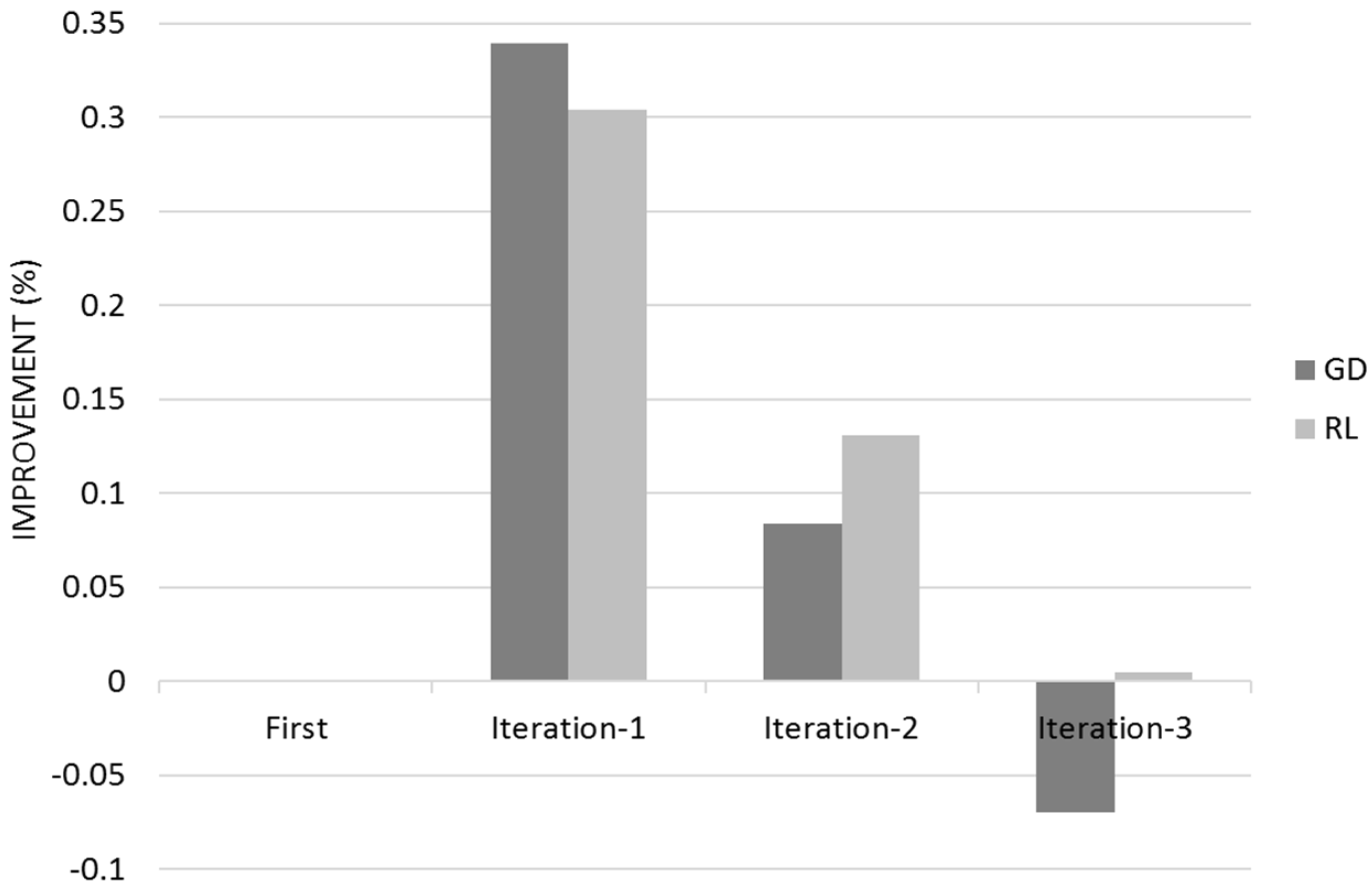
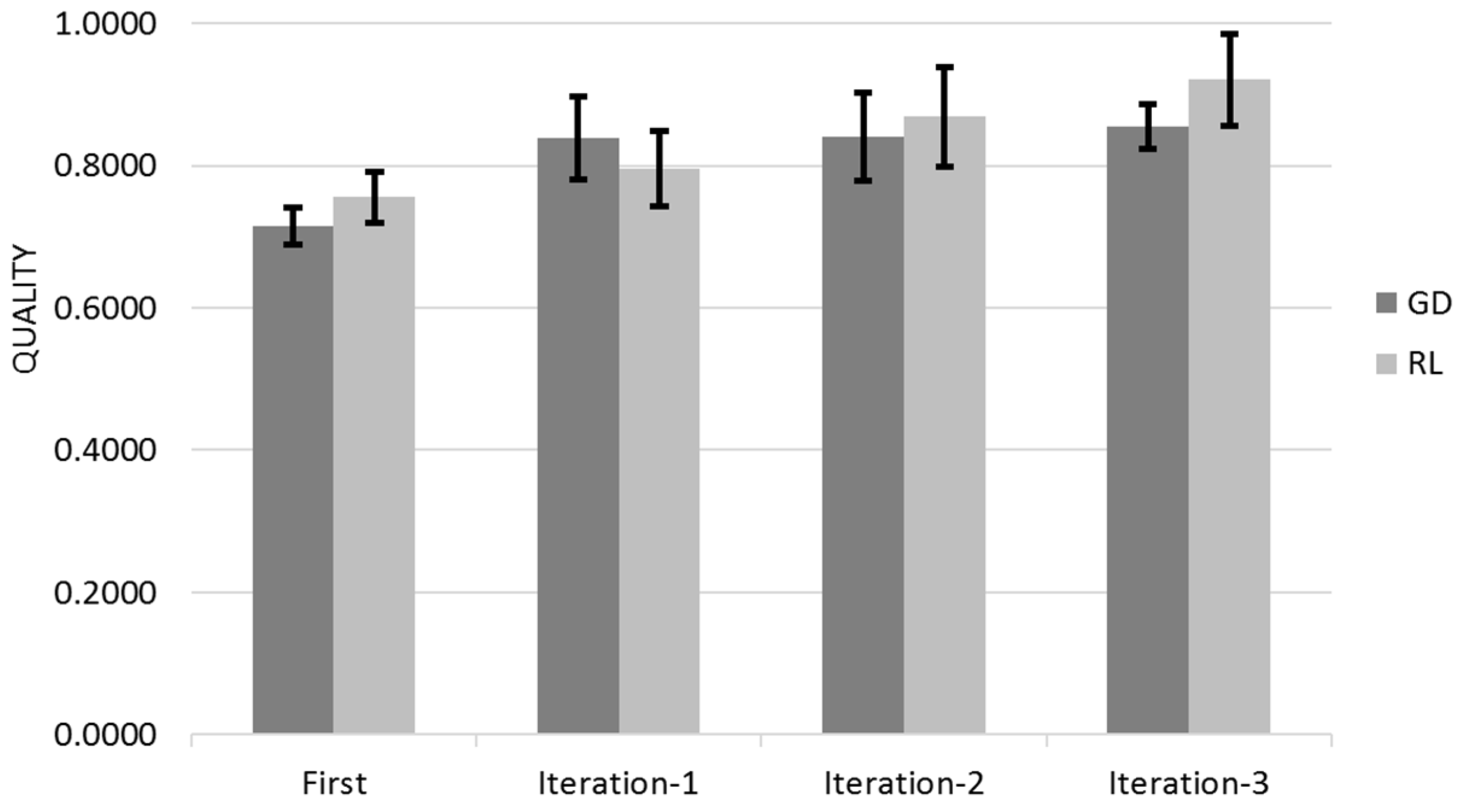
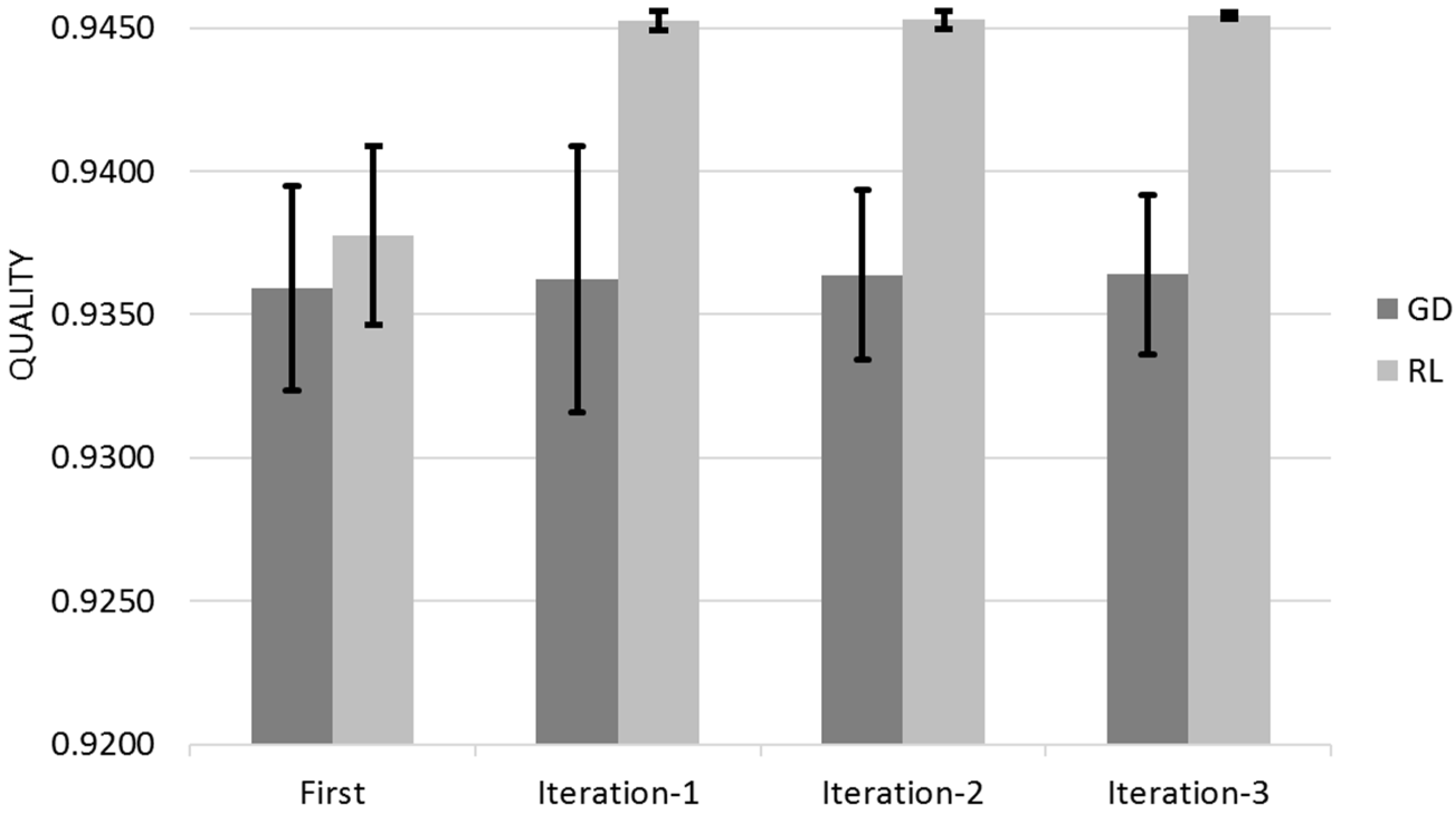
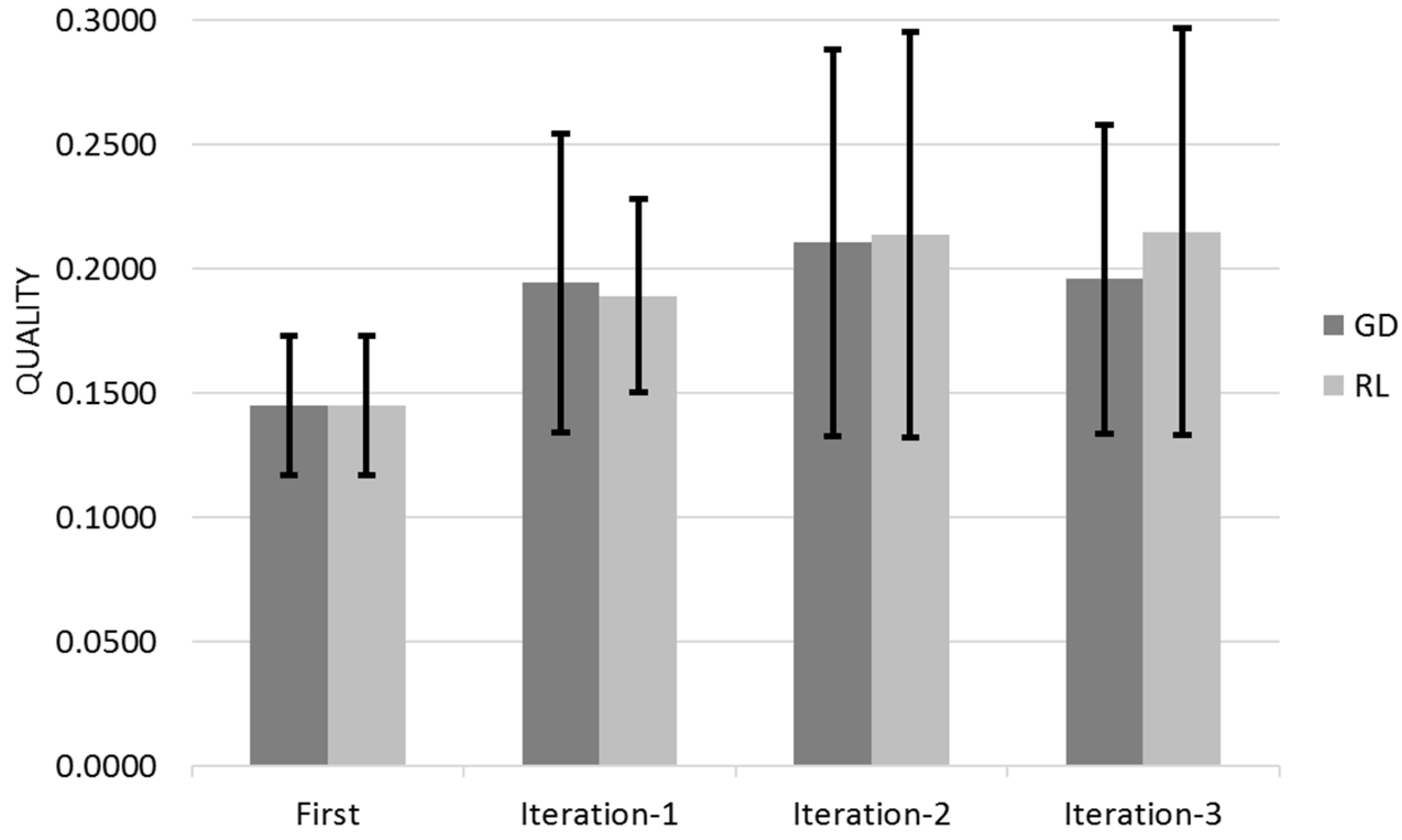
Figure 12 shows the Quality for across the three different iterations for Gradient Descent (GD) and Reinforcement Learning (RL) Algorithms with the 95% Confidence Interval that corresponds to Q ± 95%CR.
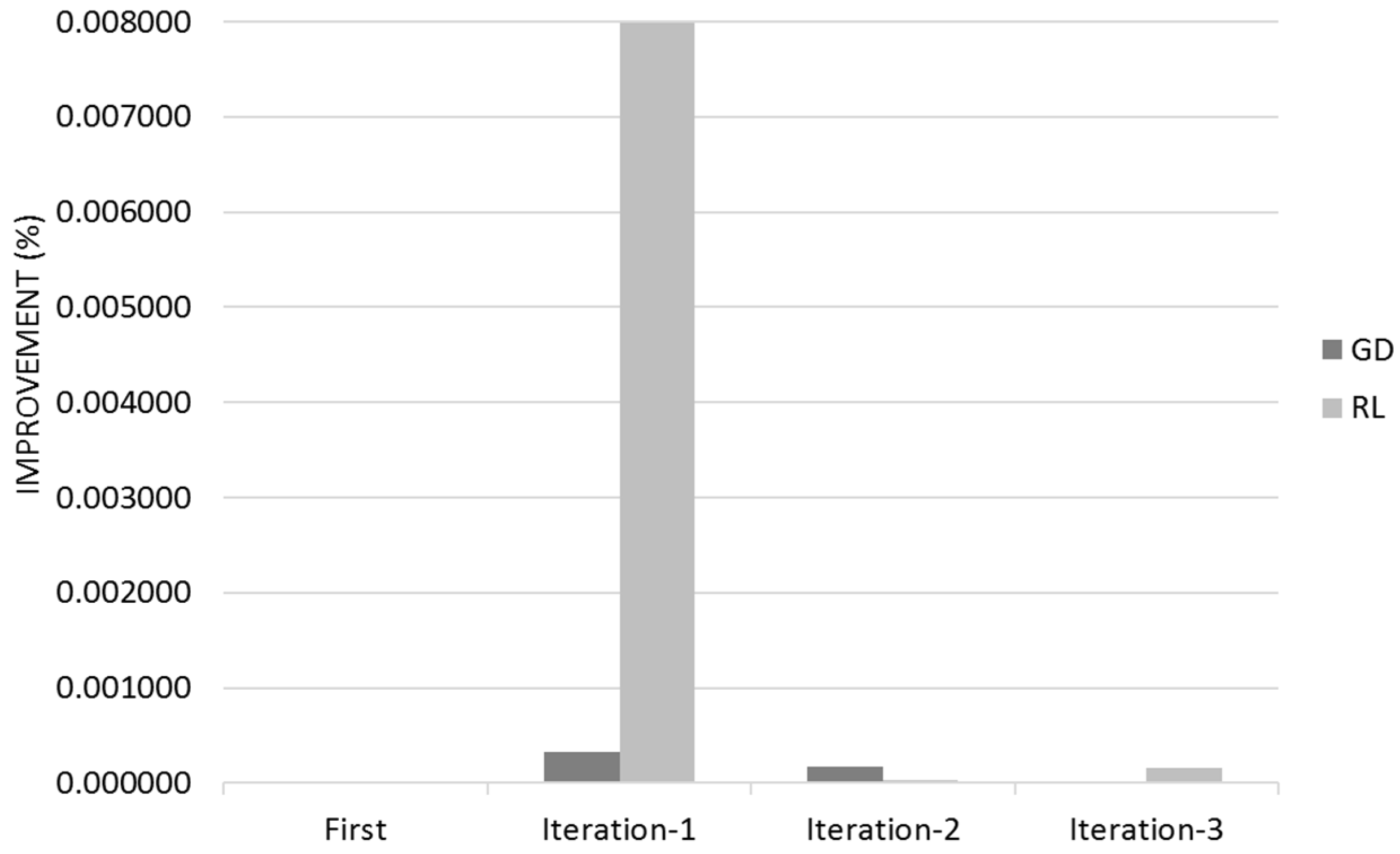
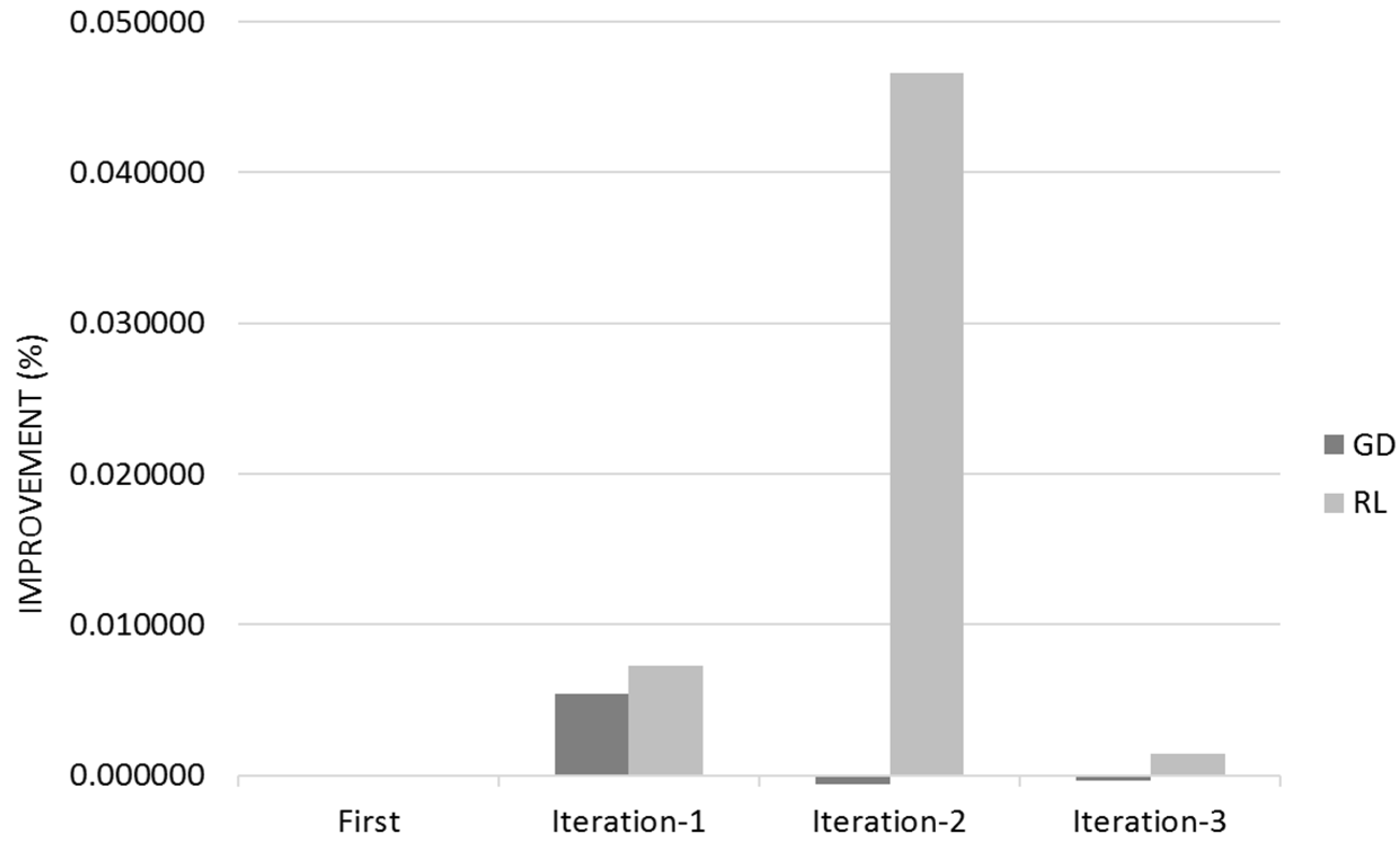
Gradient Descent learns mostly on its first customer iteration whereas Reinforcement Learning improvement is dispersed between the different user iterations (
Figure 12 and
Figure 13). The 95% Confidence Interval product regions overlaps. Gradient Descent outperforms Reinforcement Learning in the first iteration however Reinforcement Learning overtakes Gradient Descent due its continued learning rate.
5.2.2. Trip Advisor Data Set
Trip Advisor data set has been obtained from University of California-Irvine (UCI), Machine Learning repository, Centre for Machine Learning and Intelligent Systems. It is formed on two data sets; car and hotels reviews.
The car data set is the full review of cars for model years 2007, 2008 and 2009. There are approximately from 140 to 250 different cars for each model year. The total number of reviews is approximately 42,230, (Year 2007: 18,903 reviews, Year 2008: 15,438 reviews and Year 2009: 7947 reviews). The data set format is car model, year, number of reviews, Fuel, Interior, Exterior, Build, Performance, Comfort, Reliability, Fun and overall rating.
The Hotel data set is the full reviews of hotels in 10 different cities (Dubai, Beijing, London, New York City, New Delhi, San Francisco, Shanghai, Montreal, Las Vegas, Chicago). There are approximately from 80 to 700 hotels in each city. The total number of reviews is approximately 259,000. The data set format is hotel id, hotel name, hotel url, street, city, state, country, post code, number of reviews, Cleanliness, Room, Service, Location, Value, Comfort and overall rating.
The data set is processed by extracting its relevant information; the ratings from different years are combined into the same car type. The hotel and car data sets are joined into one where the average rating value is the final product (hotel or car) rating. Each product is a multidimensional vector consisting on the different variables the user can select; the product relevance is the product rating which it is equally divided between the different variables that is classified.
The IRS is programmed to retrieve the recommendation product (hotel or car) related attributes and the type of learning (Gradient Descent or Reinforcement Learning). The IRS then reorders the products based on their relevance which is the combined value of the user selected variables only. The IRS provides to the customer a reordered list of either hotels or cars re-ranked based on the higher values for the related attributes using the Random Neural Network; the customer then selects the most relevant products and the IRS continues the user feedback iterative process or provides the final hotel or car products.
Gradient Descent and Reinforcement Learning are evaluated independently for five different queries with ten recommendations in total for cars.
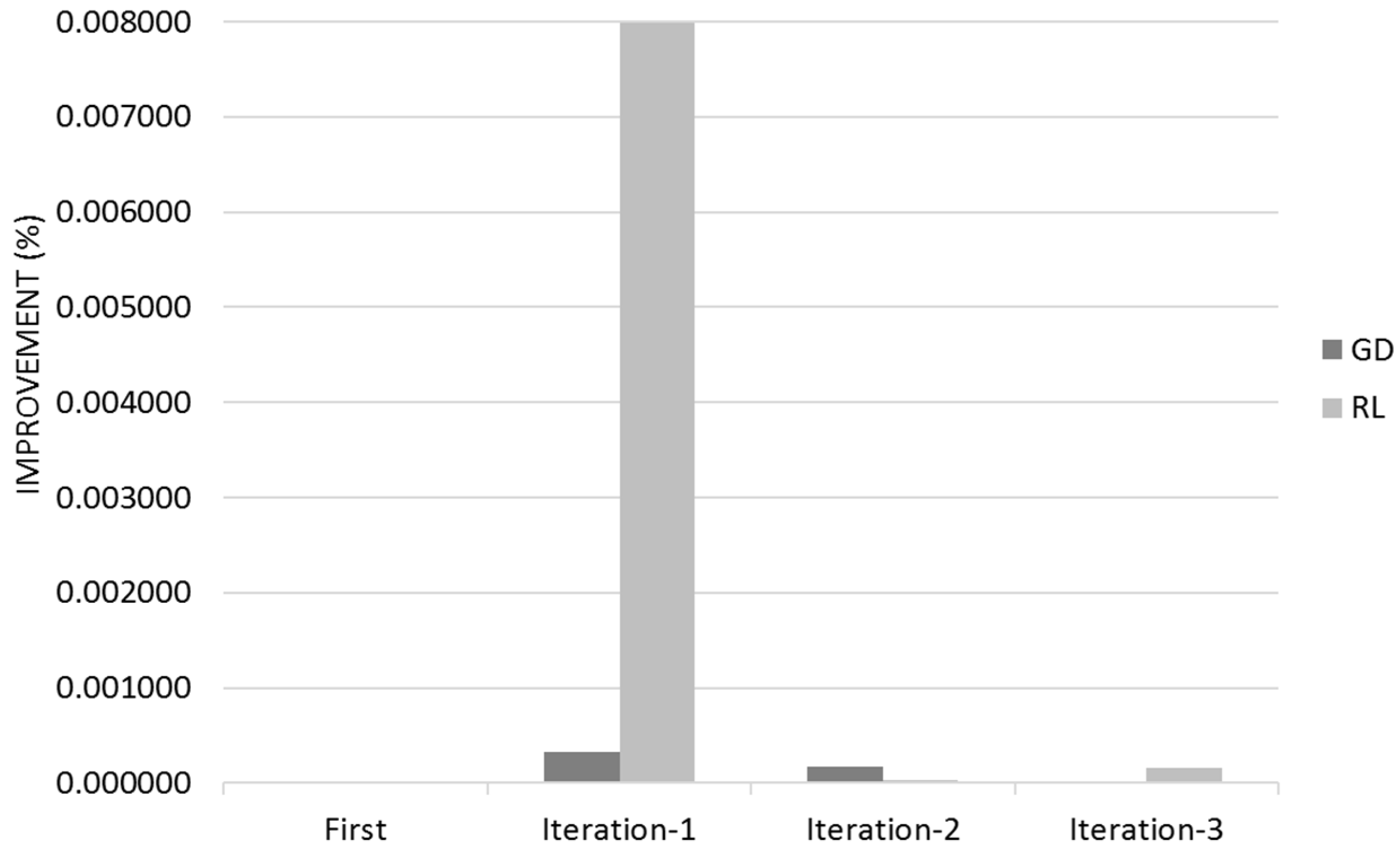
Table 3 and
Table 4 show the Quality for different iterations with the associated 95% Confidence Range. I represents the improvement from IRS against the Recommender Systems; the second I is between IRS iterations 2 and 1 and finally the third I is between IRS iterations 3 and 2.
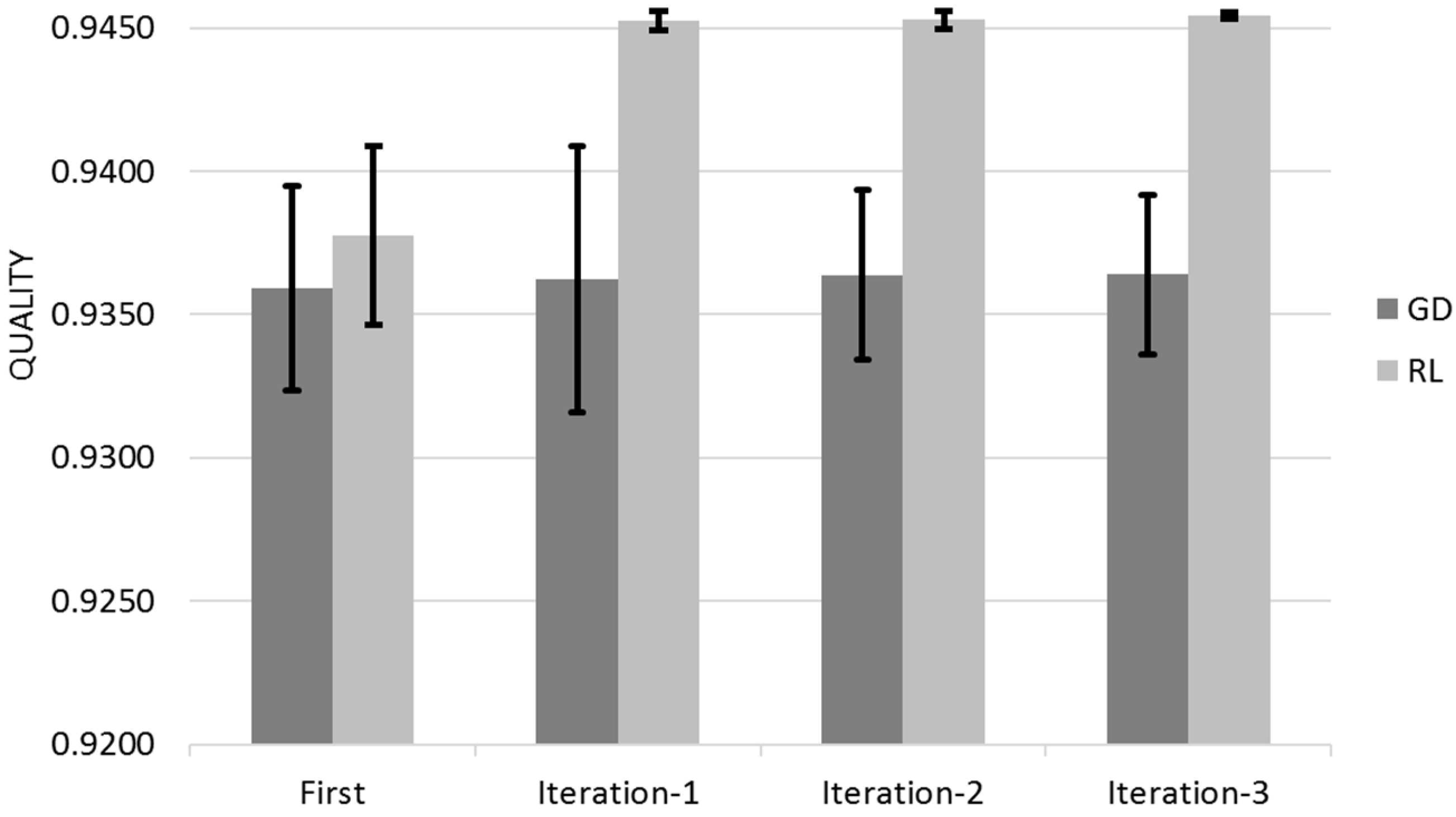
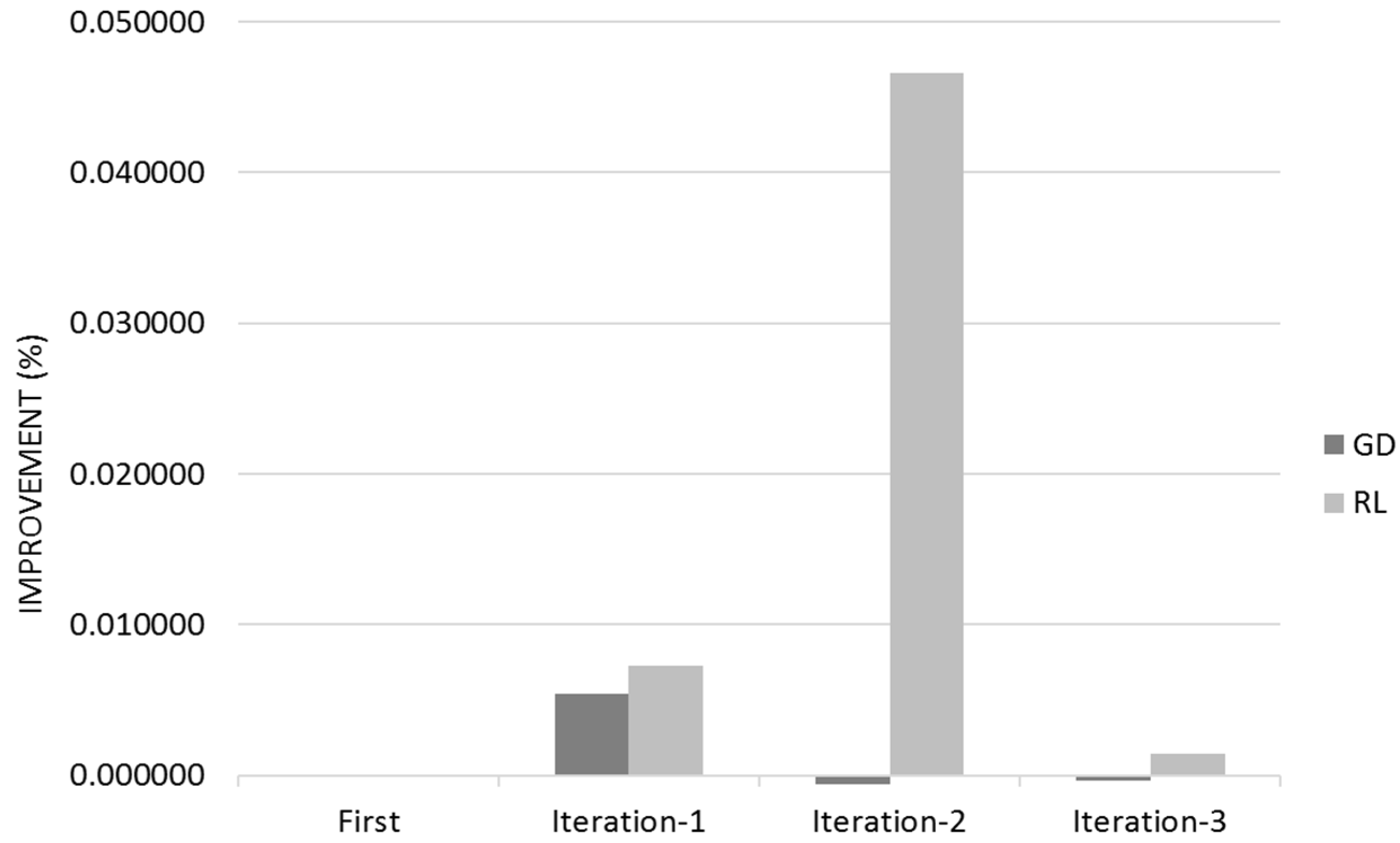
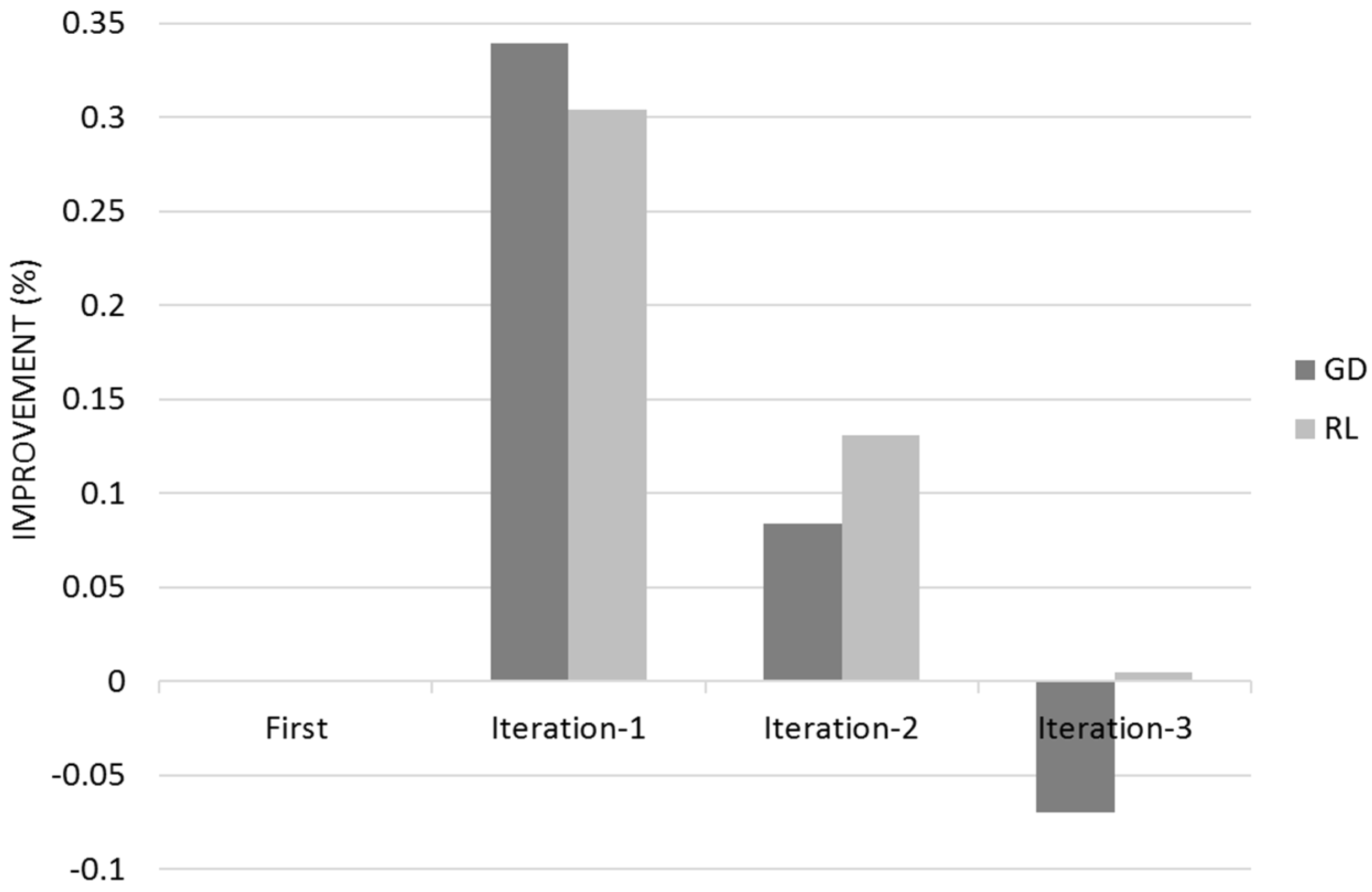
Figure 14 shows the Quality for across the three different iterations for Gradient Descent (GL) and Reinforcement Learning (RL) Algorithms with the 95% Confidence Interval that corresponds to Q ± 95%CR.
Both Gradient Descent and Reinforcement learn mostly on their customer first iteration with a residual learning on their successive iterations (
Figure 14 and
Figure 15). This learning rate is mostly because the initial quality was very high therefore difficult to improve. The 95% Confidence Interval is reduced and negligible when Reinforcement Learning reaches its optimum value; Reinforcement Learning manages to obtain a higher value of quality than Gradient Descent.
Gradient Descent and Reinforcement Learning are independently evaluated for five different queries with ten recommendations in total for hotels.
Table 5 and
Table 6 show the Quality for different iterations with the associated 95% Confidence Range. I represents the improvement from IRS against the Recommender Systems; the second I is between IRS iterations 2 and 1 and finally the third I is between IRS iterations 3 and 2.
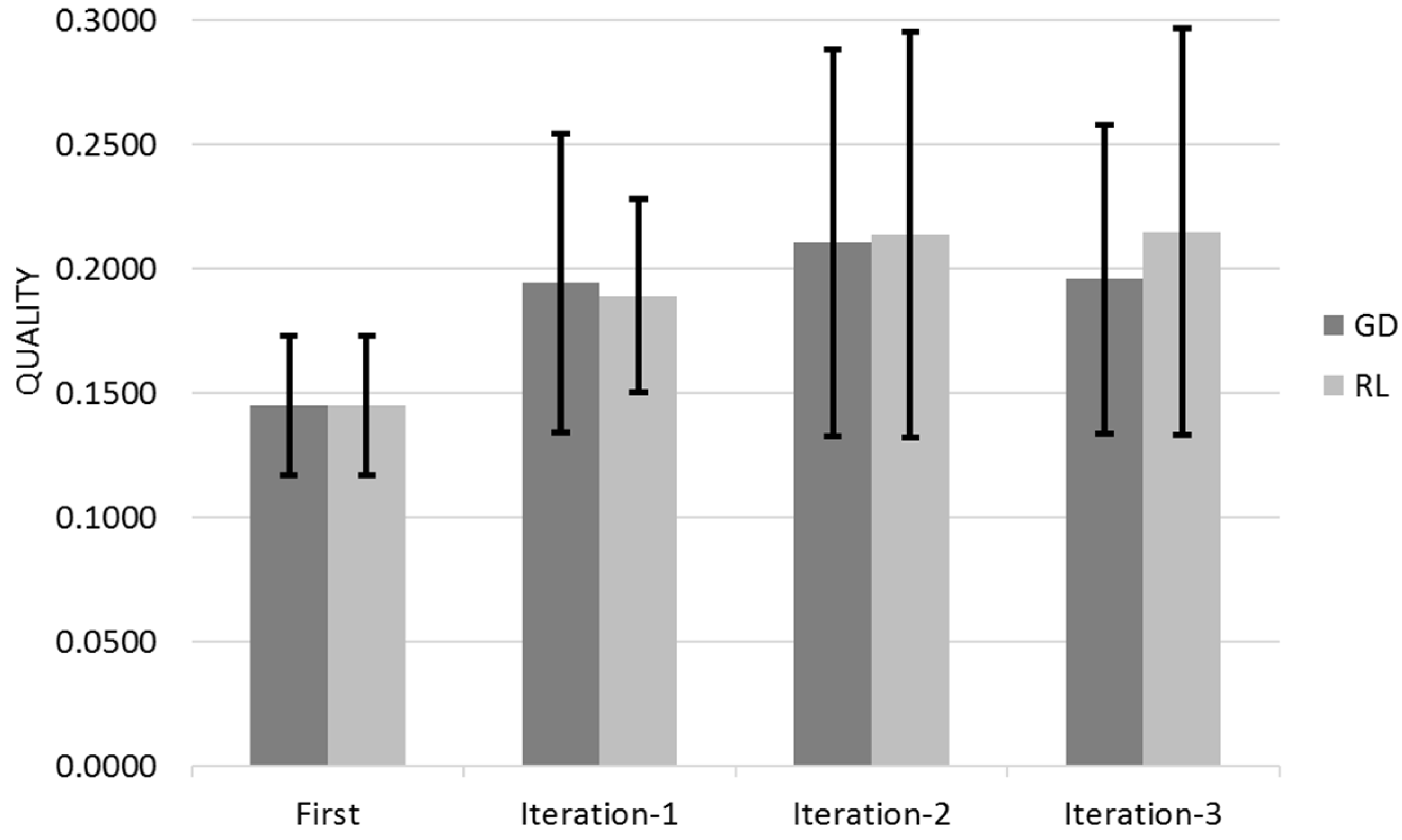
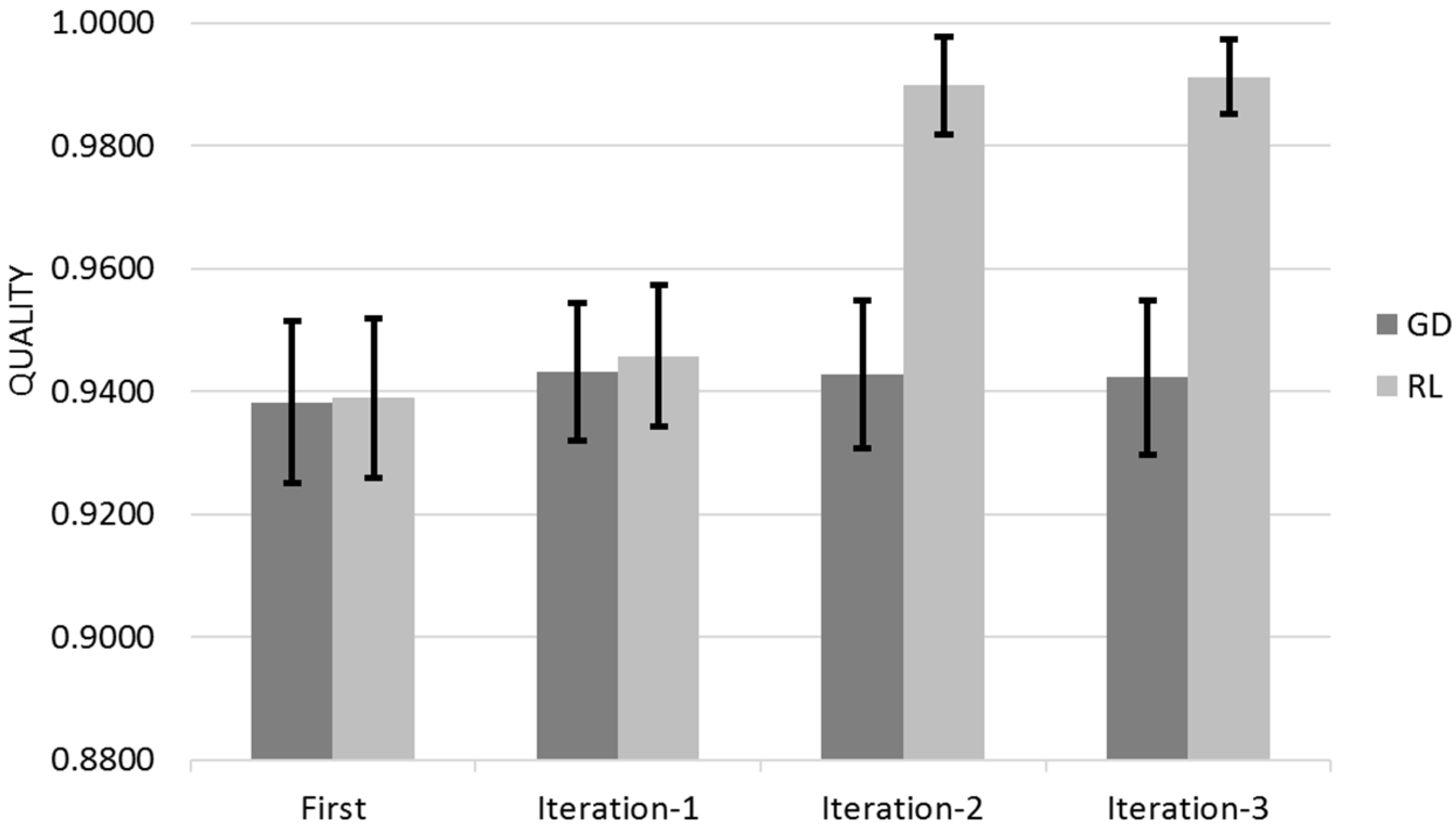
Figure 16 shows the Quality for across the three different iterations for Gradient Descent (GL) and Reinforcement Learning (RL) Algorithms with the 95% Confidence Interval that corresponds to Q ± 95%CR.
The obtained results are consisting with the previous evaluation; Both Gradient Descent and Reinforcement algorithms learn mostly on their customer first iteration with a residual learning on their successive iterations (
Figure 16 and
Figure 17). Reinforcement Learning has a learning peak on its second iteration, this is because it provides the best scoring hotels in all cities whereas Gradient Descent still provides the best scoring hotels in the selected city only.
5.2.3. Amazon Data Set
The Amazon data set contains product reviews and metadata, including 143.7 million reviews spanning from May 1996 to July 2014; the review data is an 18 GByte file. The subsets are: Books; Electronics; Movies and TV; CDs and Vinyl; Clothing; Shoes and Jewellery; Home and Kitchen; Kindle Store; Sports and Outdoors; Cell Phones and Accessories; Health and Personal Care; Toys and Games; Video Games; Tools and Home; Improvement; Beauty; Apps for Android; Office Products; Pet Supplies; Automotive; Grocery and Gourmet Food; Patio, Lawn and Garden; Baby; Digital Music; Musical Instruments and Amazon Instant Video.
Due the large processing time to analyse the entire data set, only the Films & TV subset is selected. Each Amazon subclass data set is form of two different sub sets:
The review set contains the reviewerID, productID, reviewer name, rating of the review, review text, rating of the product, summary of the review, time of the review.
The metadata set contains productID, name of the product, price, url of the product image, related products (also bought, also viewed, bought together, buy after viewing), sales rank information, brand name and the list of categories the product belongs to.
The data set is processed by extracting its relevant information and combining all the ratings from individual customers to the same products; the average value is the final product rating. Each product is a multidimensional vector consisting of the different properties or dimensions defined by the customer on its request. The Intelligent Recommender System provides to the customer a reordered list of products re-ranked; the customer then selects the most relevant products and the IRS continues the customer feedback iterative process or provides the final products.
Gradient Descent and Reinforcement Learning are independently validated for five different queries with ten recommendations in total.
Table 7 and
Table 8 show the Quality for different iterations with its associated 95% Confidence Range. I represents the improvement from IRS against the Recommender System; the second I is between IRS iterations 2 and 1 and finally the third I is between IRS iterations 3 and 2.
Figure 18 shows the Quality for across the three different iterations for Gradient Descent (GD) and Reinforcement Learning (RL) Algorithms with the 95% Confidence Interval that corresponds to Q ± 95%CR.
Gradient Descent learns predominantly during its first customer iteration whereas Reinforcement Learning improvement is more dispersed among the different user iterations (
Figure 18 and
Figure 19). The 95% Confidence Interval is greater in the amazon data set with a significant product overlap. Gradient Descent outperforms Reinforcement Learning in the first iteration however Reinforcement Learning overtakes Gradient Descent because of its continued learning speed. The Related Centre learned by Gradient Descent has defocused on its third iteration producing a decrement on Quality.
Overall, Gradient Descent predominantly acquires relevance on its first customer iteration with a decreasing learning speed in further stages. Reinforcement algorithm learns gradually with a learning speed dispersed within the customer iteration stages until it reaches its largest quality. IRS algorithm provides very high quality with the Trip Advisor data set at its first customer iteration stage therefore the learning speed decreased significantly in further iterations, however it maintained equal learning pattern: Gradient Descent learns better on its first customer iteration while Reinforcement Learning progressively maintains its learning speed.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}