
A Machine Learning Approach to Improve Turbulence Modelling from DNS Data Using Neural Networks †

 , ,
, , 
Abstract
1. Introduction
2. Aims and Objectives
3. The Test Cases
3.1. Turbulent Channel Flow
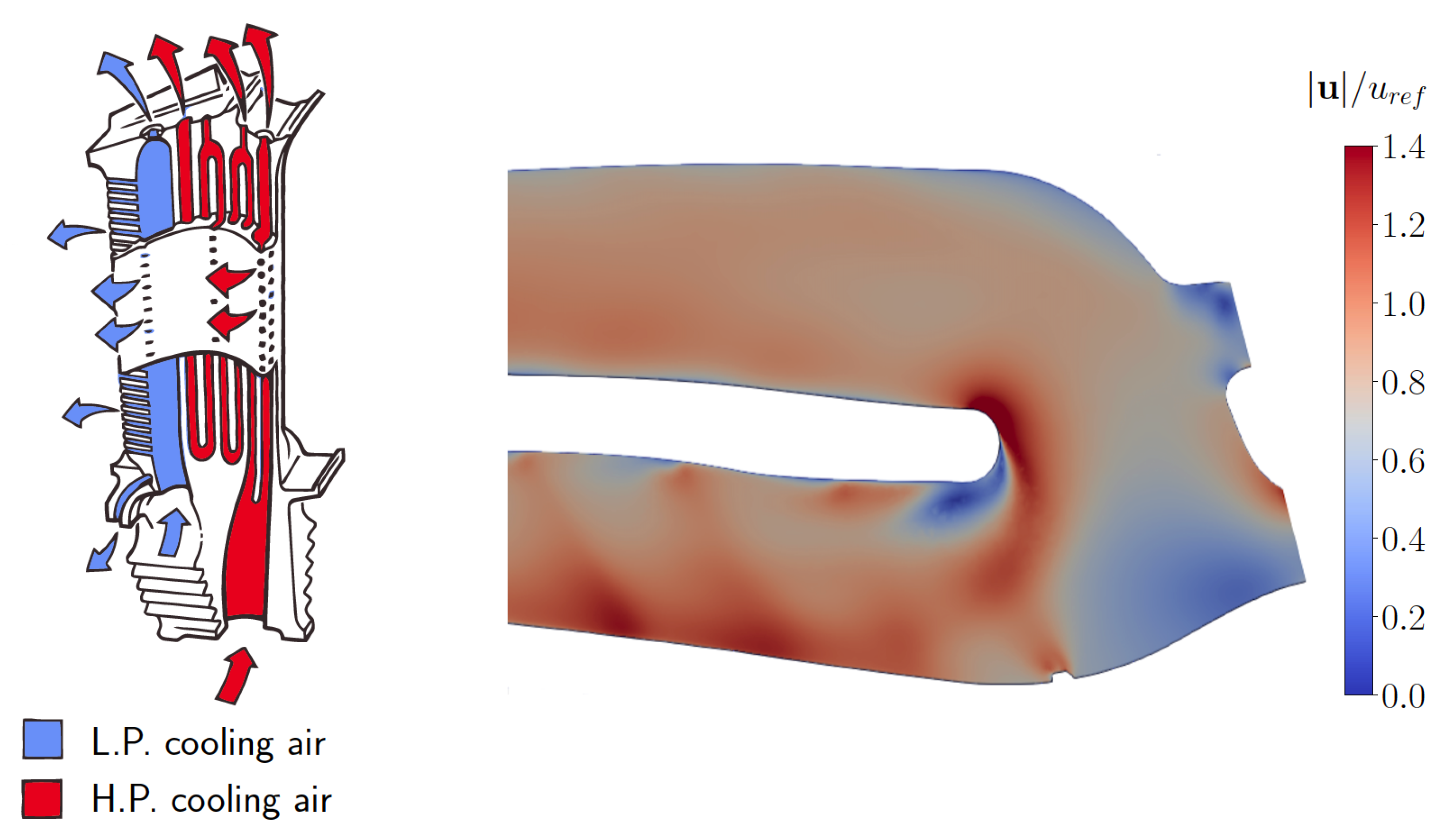
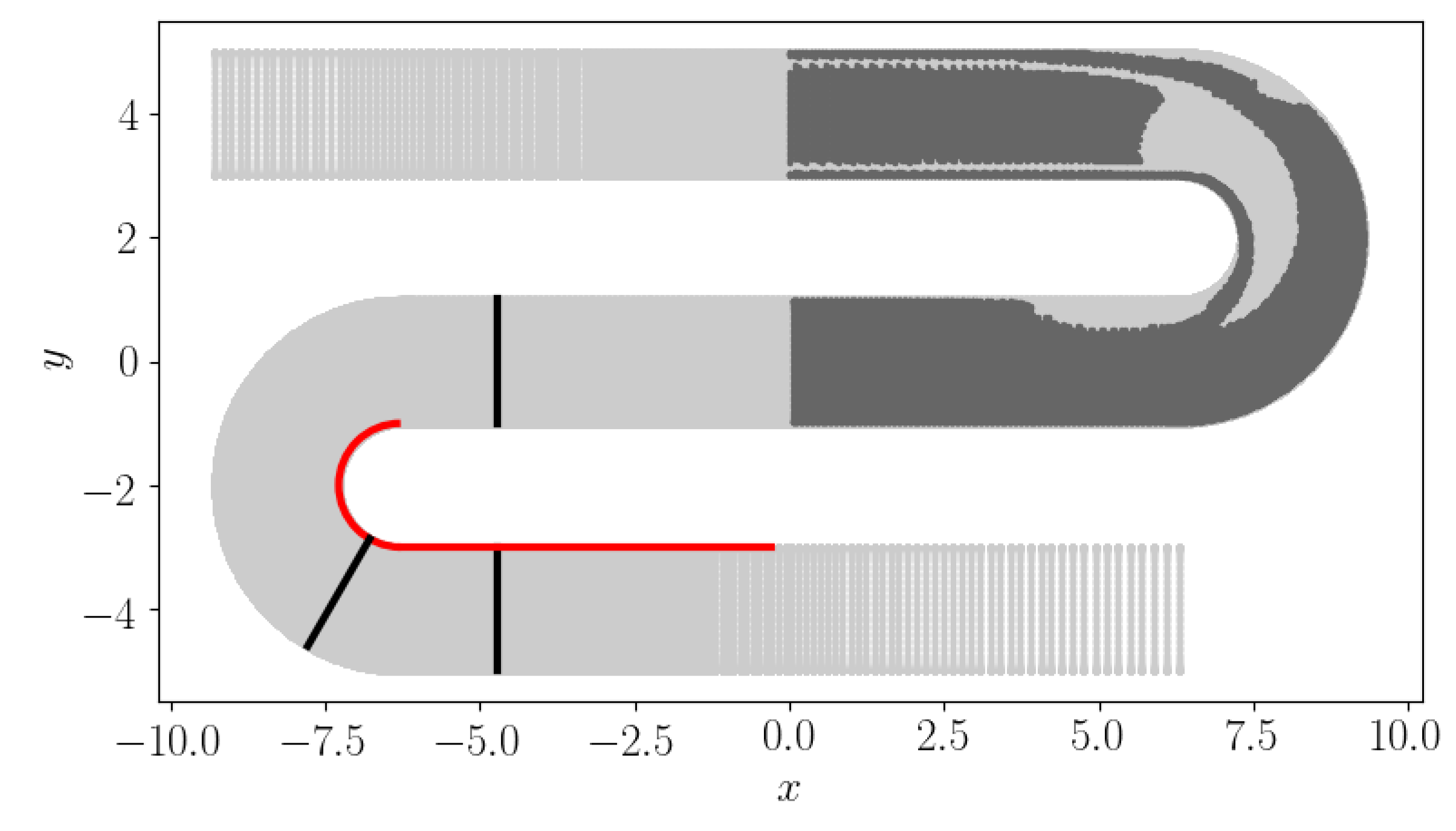
3.2. Serpentine Passage
4. The DNS-ML Framework
- 1.
- High fidelity CFD calculations are run until statistical convergence is reached. Average velocities and Reynolds stresses are sampled at the RANS mesh nodes and exported.
- 2.
- 3.
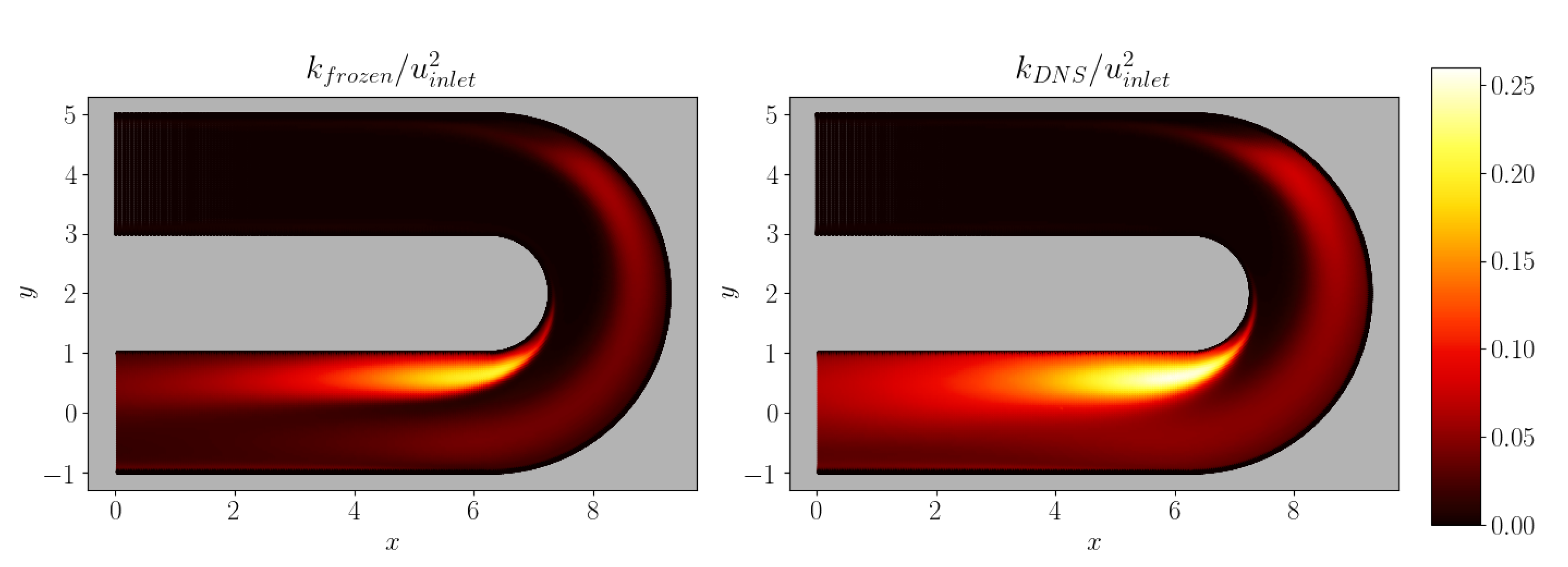
- At each node of the RANS mesh, velocity components and their gradients from the DNS calculation, as well as k and from the frozen field, are used to compute non-dimensional input features, including the first two velocity gradient invariants, the viscosity ratio, a local turbulent Reynolds number based on the distance from the wall and the turbulence intensity:
- 4.
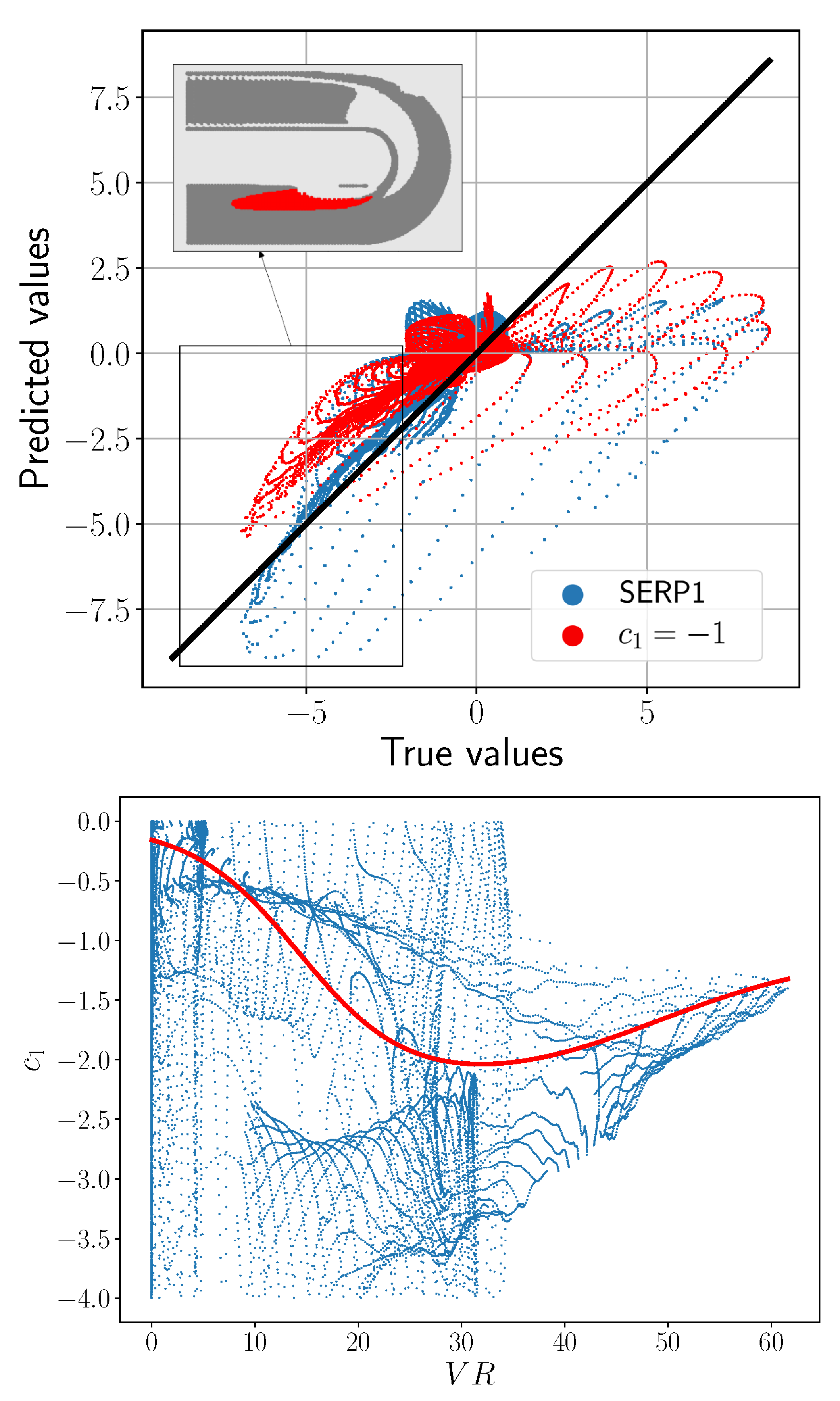
- These features form the input layer of the ANN, whose outputs are the coefficients . During training, predicted Reynolds stresses are computed applying (2) and their difference to the DNS values summed over all points defines the loss function for the ANN. At each iteration the ANN weights and biases are updated to reduce the loss function, until a minimum is stably reached. The comparison between and is referred to as the a priori assessment.
- 5.
- The functional mapping between input features and coefficients is exported as a look-up table of equispaced points, whose range is based on the maximum and minimum input features for the training points.
- 6.
- A RANS calculation with the new model using the Rolls-Royce code HYDRA is performed. At each point of the mesh it computes the flow features, performs a bilinear interpolation on the look-up table and estimates the coefficients. Outside of the table the value at last point within the range is returned, in order to avoid extrapolations that could easily result in RANS instabilities. These are then used to compute the Reynolds stresses that enter the RANS equations.
- 7.
- Results are compared a posteriori to the DNS and the baseline RANS, by looking at the velocity field and other key flow features. This is a central aspect of the process: we can easily check that solving the RANS after imposing the DNS values of results in very accurate predictions of the flow field, but once are approximated by the constitutive relationship (2), it is hard to provide a quantitative estimate of how Reynolds stress errors lead to flow field inaccuracies without running the calculation.
Flow Classification and Model Training
5. Results
5.1. Turbulent Channel Flow
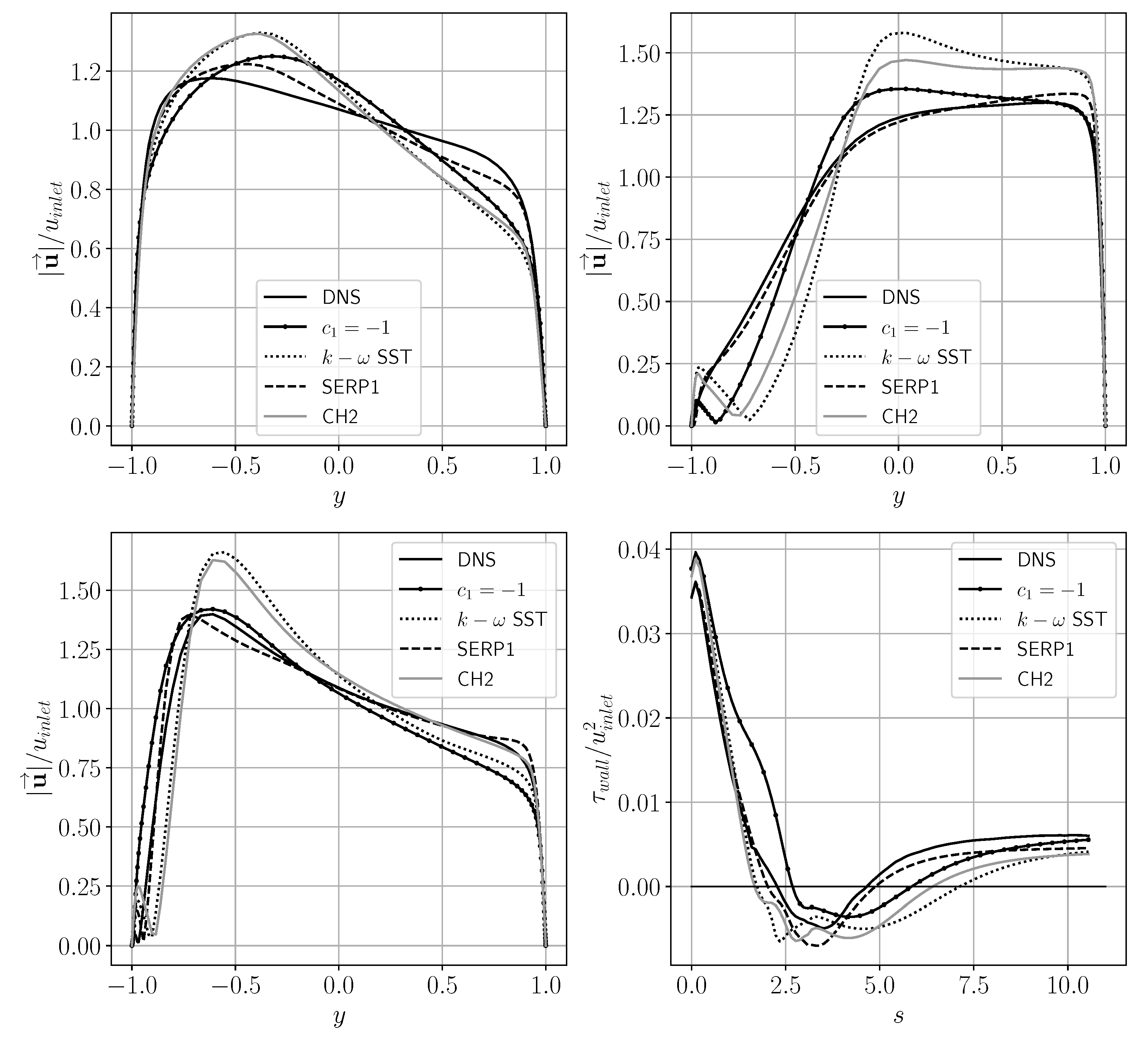
5.2. Serpentine Passage
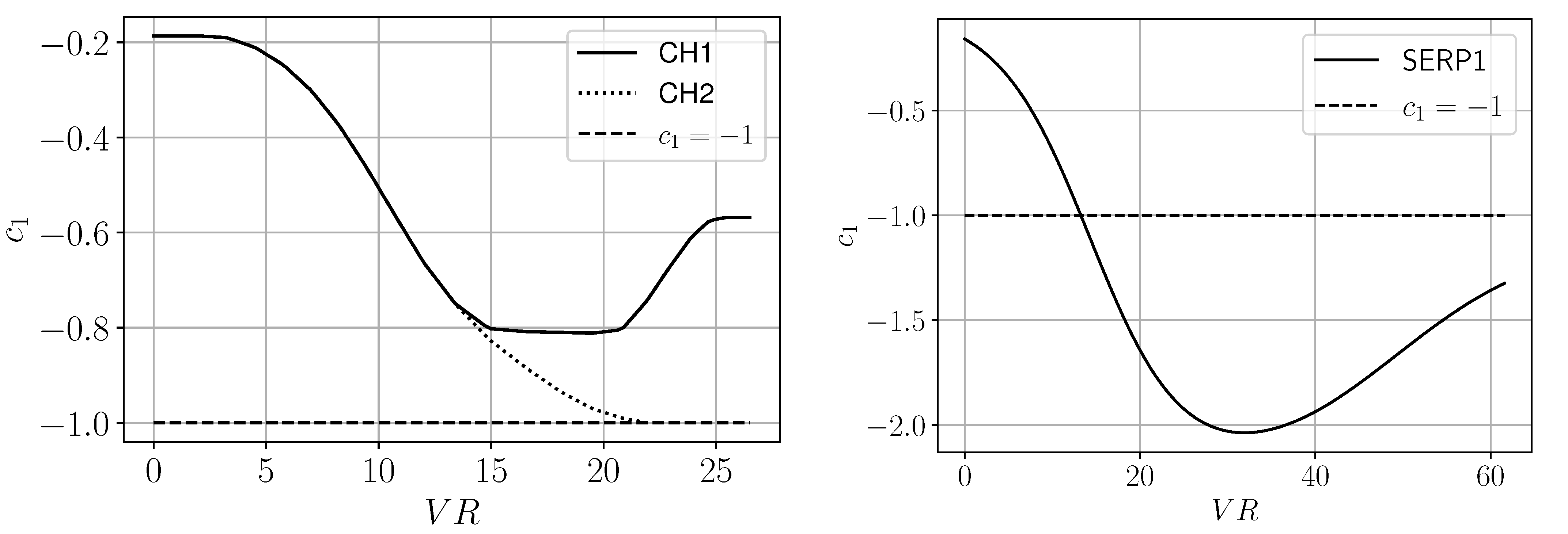
- The input flow feature that performed best is again , as seen for the channel. Up to the qualitative behaviour of the best serpentine model, referred to as SERP1, is similar to CH1; however, after that, the coefficient becomes even stronger () before settling at around (Figure 4, right).
- Regularisation is essential to guarantee sufficient smoothing; less regularised models that seem to have a good performance a priori failed to meet expectations when assessed a posteriori.
- The best results were found with two hidden layers, with 4 and 5 neurons, respectively. This illustrates that significant improvements can be achieved even with relatively simple ANN structures.
6. Discussion
7. Conclusions
- The channel flow velocity profile predictions reached a discrepancy (based on Equation (5)) to the DNS of 0.026 for CH1 and 0.019 for CH2 from a value of 0.041 for the SST and 0.213 for the SST without the limiter on .
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Abbreviations
| DNS | Direct Numerical Simulation |
| RANS | Reynolds-Averaged Navier–Stokes |
| CFD | Computational Fluid Dynamics |
| ML | Machine Learning |
| GEP | Gene Expression Programming |
| ANN | Artificial Neural Network |
| Nomenclature | |
| k | turbulent kinetic energy |
| turbulent specific dissipation | |
| density | |
| turbulent dissipation | |
| Reynolds stress tensor: | |
| isotropic Reynolds stress | |
| anisotropy tensor | |
| turbulent viscosity | |
| strain rate tensor | |
| tensor expansion coefficients | |
| tensor basis | |
| non dimensional strain rate tensor | |
| non dimensional rotation rate tensor | |
| velocity gradient tensor | |
| velocity fluctuations | |
| laminar viscosity | |
| distance from the wall | |
| velocity components | |
| velocity gradient invariants | |
| viscosity ratio | |
| local turbulent Reynolds number | |
| turbulence intensity | |
| k production | |
| SST model constants |
References
- Launder, B.; Spalding, D.B. The Numerical Computation of Turbulent Flows. Comput. Methods Appl. Mech. Eng. 1974, 3, 269–289. [Google Scholar] [CrossRef]
- Wilcox, D. Turbulence Modeling for CFD; Number v. 1 in Turbulence Modeling for CFD; DCW Industries: La Canada, CA, USA, 2006. [Google Scholar]
- Weatheritt, J.; Sandberg, R. A novel evolutionary algorithm applied to algebraic modifications of the RANS stress-strain relationship. J. Comput. Phys. 2016, 325, 22–37. [Google Scholar] [CrossRef]
- Pope, S.B. A more general effective-viscosity hypothesis. J. Fluid Mech. 1975, 72, 331–340. [Google Scholar] [CrossRef]
- Weatheritt, J.; Pichler, R.; Sandberg, R.; Laskowski, G.; Michelassi, V. Machine learning for turbulence model development using a high-fidelity HPT cascade simulation. In Proceedings of the ASME Turbo Expo, Charlotte, NC, USA, 26–30 June 2017. [Google Scholar]
- Moxey, D.; Cantwell, C.; Bao, Y.; Cassinelli, A.; Castiglioni, G.; Chun, S.; Juda, E.; Kazemi, E.; Lackhove, K.; Marcon, J.; et al. Nektar++: Enhancing the capability and application of high-fidelity spectral/hp element methods. Comput. Phys. Commun. 2020, 249, 107110. [Google Scholar] [CrossRef]
- Mansour, N.N.; Kim, J.; Moin, P. Reynolds-stress and dissipation-rate budgets in a turbulent channel flow. J. Fluid Mech. 1988, 194, 15–44. [Google Scholar] [CrossRef]
- Cassinelli, A.; Montomoli, F.; Adami, P.; Sherwin, S.J. High Fidelity Spectral Hp Element Methods For Turbomachinery. In Proceedings of the ASME Turbo Expo, Oslo, Norway, 11–15 June 2018. [Google Scholar]
- Laskowski, G.; Durbin, P.A. Direct numerical simulations of turbulent flow through a stationary and rotating infinite serpentine passage. Phys. Fluids 2007, 19, 015101. [Google Scholar] [CrossRef]
- Cassinelli, A.; Xu, H.; Montomoli, F.; Adami, P.; Vazquez Diaz, R.; Sherwin, S.J. On the Effect of Inflow Disturbances on the Flow Past a Linear LPT Vane Using Spectral/hp Element Methods. In Proceedings of the ASME Turbo Expo 2019, Phoenix, AZ, USA, 17–21 June 2019. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DNS | SST | CH1 | CH2 | ||
|---|---|---|---|---|---|
| u | - | 0.213 | 0.041 | 0.026 | 0.019 |
| - | 0.214 | 0.106 | 0.025 | 0.038 |
| DNS | SST | SERP1 | CH2 | ||
|---|---|---|---|---|---|
| Sep. bubble length | 2.37 | 3.16 | 5.32 | 2.84 | 4.67 |
| 1st traverse | - | 0.0804 | 0.1075 | 0.0375 | 0.1014 |
| 2nd traverse | - | 0.0856 | 0.1262 | 0.0327 | 0.1066 |
| 3rd traverse | - | 0.0904 | 0.2445 | 0.0284 | 0.1893 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY-NC-ND) license (https://creativecommons.org/licenses/by-nc-nd/4.0/).
Share and Cite
Frey Marioni, Y.; de Toledo Ortiz, E.A.; Cassinelli, A.; Montomoli, F.; Adami, P.; Vazquez, R. A Machine Learning Approach to Improve Turbulence Modelling from DNS Data Using Neural Networks. Int. J. Turbomach. Propuls. Power 2021, 6, 17. https://doi.org/10.3390/ijtpp6020017
Frey Marioni Y, de Toledo Ortiz EA, Cassinelli A, Montomoli F, Adami P, Vazquez R. A Machine Learning Approach to Improve Turbulence Modelling from DNS Data Using Neural Networks. International Journal of Turbomachinery, Propulsion and Power. 2021; 6(2):17. https://doi.org/10.3390/ijtpp6020017
Chicago/Turabian StyleFrey Marioni, Yuri, Enrique Alvarez de Toledo Ortiz, Andrea Cassinelli, Francesco Montomoli, Paolo Adami, and Raul Vazquez. 2021. "A Machine Learning Approach to Improve Turbulence Modelling from DNS Data Using Neural Networks" International Journal of Turbomachinery, Propulsion and Power 6, no. 2: 17. https://doi.org/10.3390/ijtpp6020017
APA StyleFrey Marioni, Y., de Toledo Ortiz, E. A., Cassinelli, A., Montomoli, F., Adami, P., & Vazquez, R. (2021). A Machine Learning Approach to Improve Turbulence Modelling from DNS Data Using Neural Networks. International Journal of Turbomachinery, Propulsion and Power, 6(2), 17. https://doi.org/10.3390/ijtpp6020017