Abstract
The rapid expansion of virtual education has highlighted both its opportunities and limitations. Conventional virtual learning environments tend to lack flexibility, often applying standardized methods that do not account for individual learning differences. In contrast, Artificial Intelligence (AI) empowers the creation of customized educational experiences that address specific student needs. Such personalization is essential to mitigate educational inequalities, particularly in areas with limited infrastructure, scarce access to trained educators, and varying levels of digital literacy. This study explores the role of AI in advancing virtual education, with particular emphasis on supporting differentiated learning. It begins by selecting an appropriate pedagogical model to guide personalization strategies and proceeds to investigate the application of AI techniques across three key areas: the characterization of educational resources, the detection of learning styles, and the recommendation of tailored content. The primary contribution of this research is the development of a scalable framework that can be adapted to a variety of educational contexts, with the goal of enhancing the effectiveness and personalization of virtual learning environments through AI.
1. Introduction
The digitalization of education has greatly broadened access to learning beyond the confines of conventional classroom environments. While virtual education, enabled by digital platforms, provides increased flexibility, it also presents persistent challenges, including limited student engagement, a lack of tailored learning experiences, and insufficiently effective assessment strategies. AI offers promising solutions to these issues by enabling intelligent automation, fostering adaptive and personalized learning, and promoting more interactive educational experiences [1].
Conventional virtual learning environments often fail to accommodate diverse learning preferences and do not sufficiently address regional variations in educational needs. A large number of e-learning platforms are built upon rigid instructional frameworks that often prove inadequate for students coming from varied educational contexts. The integration of AI-driven adaptive learning systems allows educational institutions to customize content in real time, aligning it with the unique needs of each student. This type of personalization is especially crucial in marginalized or remote areas, where uniform teaching strategies may fall short due to cultural nuances and infrastructural limitations [2].
Maintaining student engagement remains a major challenge in virtual learning settings. Many students experience difficulties with motivation and self-regulation in online environments, which often leads to elevated dropout rates. AI-based solutions—such as real-time feedback mechanisms, intelligent chatbots, and interactive learning dashboards—offer promising strategies to boost engagement by providing tailored recommendations and instant support. These technologies contribute to a more immersive and responsive learning experience, enabling students to engage with educational content in ways that reflect their individual preferences and learning styles [3].
AI also offers significant potential to transform educational management and assessment practices. By incorporating predictive analytics into virtual learning platforms, institutions can proactively identify students at risk of underperformance, adjust the complexity of course materials in real time, and refine instructional approaches to better support diverse learning needs [4]. Through the application of machine learning algorithms to student performance data, AI can create individualized learning trajectories, allowing each learner to advance at a pace that best suits their abilities and progress.
In this context, AI serves as a driving force for innovation in education by reshaping conventional instructional models into personalized, adaptive, and data-informed learning experiences. AI-based systems continuously analyze student performance, learning preferences, and engagement patterns to deliver timely feedback and individualized recommendations [5]. Additionally, AI technologies have the potential to enhance various components of digital education, including automated assessment tools, intelligent tutoring systems, and predictive analytics. These tools can support educators in identifying specific learning needs and tailoring interventions accordingly. However, the extent to which these systems improve educational outcomes depends on multiple factors such as the quality of the data, instructional design, and the context of implementation. Recent studies have explored these benefits and suggested promising applications, while also highlighting the need for further validation and critical reflection on pedagogical effectiveness [6].
This paper outlines the methodological framework and initial findings of the project titled “Didactic Innovation Strategy with an Adaptive Approach Supported by Artificial Intelligence Techniques”. Supported by Colombia’s General Royalties System, the project sought to enhance the department of Antioquia’s capabilities in the areas of Science, Technology, and Innovation (STI). Its central objective was to advance research efforts aimed at designing adaptive didactic strategies powered by AI technologies.
The project had two primary objectives: (1) to evaluate the pedagogical implications of personalized learning by analyzing how students’ interactions aligned with their identified learning styles, and (2) to develop and implement an AI-based framework to support this personalization in virtual environments. The integration of the AI-based framework with pedagogical analysis within a single study was intentional, as the effectiveness of the personalization model depends on both its technological performance and its impact on student learning behavior.
2. Conceptual Framework for AI-Enhanced Differentiated Learning
Differentiated learning emphasizes adapting instructional content and strategies to address the diverse needs, preferences, and prior knowledge of students. In this context, adaptive or personalized e-learning systems are designed to identify and address the unique needs of each student by delivering tailored educational experiences. To support this objective, researchers have created a range of content recommendation systems that align instructional resources with individual learner preferences.
2.1. Pedagogical Elements Related to Differentiated Learning
Learning styles have been widely explored as a means of categorizing individual preferences in acquiring and processing information. Although various definitions exist [7], they are generally understood as cognitive, affective, and physiological patterns that serve as indicators of how learners perceive, interact with, and understand educational content. Several influential models have guided the development of adaptive systems, notably the VARK model [8], which classifies students based on sensory preferences into four categories: visual, aural, reading/writing, and kinesthetic.
Experiential learning theories have further shaped the conceptualization of learning styles. Kolb’s model (1984) outlines a four-stage learning cycle—concrete experience, reflective observation, abstract conceptualization, and active experimentation—which defines four corresponding styles: convergers, divergers, assimilators, and accommodators [9,10]. Honey and Mumford (1992) extended this perspective by proposing four styles—active, reflective, theoretical, and pragmatic—grounded in how learners absorb and transform information [11,12].
A prominent framework in this field is the Felder-Silverman Learning Style Model (FSLSM), which categorizes learners into four key dimensions: processing (active vs. reflective), perception (sensing vs. intuitive), input (verbal vs. visual), and understanding (sequential vs. global) [13]. Kouis et al. implemented FSLSM within a Learning Management System (LMS), designing a framework that measures alignment between educational content and students’ learning styles [14]. Their results showed that personalized alignment improved learner satisfaction and content effectiveness.
Similarly, M. M. El-Bishouty et al. [15] explored how the Felder-Silverman learning style model can be utilized to design online courses that better cater to diverse student learning preferences, effectively improving their learning experience. These studies demonstrate the pedagogical relevance of using learning styles as a basis for differentiated instruction in virtual environments.
Table 1 provides a comparative synthesis of learning style models considered in this study. This comparison highlights the rationale for selecting FSLSM, due to its structured bipolar dimensions, adaptability to AI algorithms, and proven integration in learning environments.

Table 1.
Comparative Overview of Selected Learning Style Models.
2.2. AI to Strengthen Differentiated Learning
AI is transforming the educational landscape by enabling adaptive, data-informed, and intelligent learning environments that enrich both instructional practices and student learning. A model of educational innovation driven by AI incorporates machine learning, natural language processing (NLP), and predictive analytics to provide personalized learning experiences aligned with each student’s unique needs. Tools such as intelligent tutoring systems, automated assessments, and content recommendation engines enhance learner engagement and facilitate student-centered approaches.
AI also supports institutional decision-making by analyzing learning patterns, identifying at-risk students early, and enabling timely interventions. In doing so, AI helps address disparities in learning, improve access, and foster educational equity, thus reshaping traditional models into dynamic and inclusive ecosystems.
To enhance the precision of content recommendations, researchers have adopted advanced AI techniques. For example, Venkatesh and Sathyalakshmi introduced a recommender system based on Bee Colony Optimization, integrating web crawling and indexing to dynamic model content [16]. Similarly, Sianturi and Yuhana applied algorithms such as Decision Trees, Naïve Bayes, and K-Nearest Neighbor to predict learning styles based on student behavior, achieving accuracy rates of up to 96% [17].
Beyond conventional machine learning, some models incorporate fuzzy logic and expert systems to personalize instruction further. Hwang et al. developed a fuzzy-based expert system combining cognitive and emotional variables to adapt content delivery [18], while Kolekar et al. created an interface that dynamically adapted learning pathways using concept maps and behavioral analysis [19].
Hybrid AI models also show promise. For instance, Tarus et al. combined domain ontologies and sequential pattern mining with collaborative filtering, achieving high satisfaction rates among learners and an accuracy of 0.65 in predictions [20].
By integrating these technologies, educational institutions can deliver more relevant and engaging content, optimize learning pathways, and enhance student performance. The evolution of AI-powered personalized learning tools promises to further transform digital education by offering responsive, inclusive, and effective learning experiences tailored to each student’s profile.
3. Methodological Approach
Our proposed system was composed of pedagogical and technological components, wired together with the goal of adapting the content of an online course to the learning style of the students.
3.1. Pedagogical Components
Although the pedagogical components are not the focus of this paper, we briefly describe them here to provide enough context for the technological components. The pedagogical model that guided this work is the FSLSM.
The pedagogical components were developed by our collaborators, experts in education and pedagogy. A more detailed explanation of their work is available in a paper that is currently under review. We list our collaborators expert in education in the Acknowledgements section.
3.1.1. Mapping Learning Object Features to FSLSM Learning Styles
To assess the degree of alignment between the educational resources used in the Moodle course “Preparación para la Vida Universitaria”, specifically the Logical Reasoning module (PPVU), available here https://udearroba.udea.edu.co/home/aspirantes/ (accessed on 26 June 2025) and the dimensions defined by FSLSM, each resource was labeled according to the model’s four dichotomies. Using content analysis techniques combined with instructional design criteria, we assigned quantitative scores that reflect the degree to which each resource represents a particular FSLSM dimension, for example, video lectures received high scores for the visual preference. In this way, we built a matrix of weights that maps the contribution of each feature in a learning object to each pole in the Felder-Silverman model. In Table 2, we present a sample of such a matrix. The weight indicates whether the presence of the feature might positively (‘1’) or negatively (‘−1’) impact the learning of students who have a preference aligned with that pole, or there is no impact (‘0’). For example, the presence of images in the learning object has a positive impact (‘1’) on students with a visual learning style.
Table 2.
A sample of the mapping from learning object characteristics to FS learning styles.
3.1.2. Adaptive SCORM Objects
Nine SCORM objects covered several mathematical concepts, and each object had four variations in the way it presented content, each designed to favor one of four learning styles: (1) visual-sensing, (2) visual-intuitive, (3) verbal-sensing, and (4) verbal-intuitive.
3.1.3. Human-Expert Annotated Learning Objects
A group of human experts in information science annotated the learning objects present in the PPVU course, which resulted in a matrix with the counts of each of the features listed in the weight matrix described in Section 3.1.1. These feature counts were then transformed into a vector of four elements, one per FSLM dimension, taking values in the set {−11, −9, …, −1, 1, …, 9, 11}, which is the set of values used in the Index of Learning Styles (ILS) questionnaire. In this way, we have a learning style vector for each object in the course. This structured labeling facilitates the identification of potential learning style tendencies during the analysis phase and enables the dynamic selection of the learning style of the SCORM objects described in Section 3.1.2 to match the learning style of the student.
3.2. Technological Components
We developed multiple technological components that take as input the pedagogical components described above and the interaction data from the students to solve a set of problems that enable the personalization of content delivery in an online course: (1) the identification of a student learning style, (2) the identification of a learning object’s learning style, (3) Moodle plugins to enable the adaptation of content to a student’s learning style, and (4) the extraction of learning object metadata.
3.2.1. Index of Learning Styles Questionnaire on Moodle
One of the most important steps in our methodology involves identifying students’ learning styles. To this end, we apply the FSLSM, which classifies learners across four key dimensions: perception (Sensing vs. Intuitive), processing (Active vs. Reflective), input (Visual vs. Verbal), and understanding (Sequential vs. Global). Widely acknowledged for its effectiveness in capturing cognitive preferences, this model provides a robust foundation for designing personalized learning experiences. By administering an FSLSM-based assessment, we determine each student’s dominant learning style, enabling the customization of educational content to better align with individual profile. This approach marks a significant shift from standardized teaching methods toward more personalized, learner-centered pedagogy [1].
To identify students’ learning styles based on the FSLSM, a Moodle-based component was developed and deployed. This module, compatible with Moodle version 4.2+, allowed the administration of the original ILS questionnaire through three distinct formats: (1) direct textual questions, (2) questions supported by illustrative images, and (3) experience-based scenarios with visual support. This multi-visualization strategy aimed to enhance accessibility, accommodate different learner preferences, and foster reflection on individual learning processes.
The inclusion of multiple visual formats was not intended as a mechanism for rigid classification, but rather to support metacognitive engagement. By allowing students to choose their preferred questionnaire visualization and switch between them at any time, the system offers a flexible interface that respects learner autonomy. This design supports the idea that learning style awareness is better cultivated through reflective choice than through prescriptive assessment.
Each visualization targeted different learner characteristics. The text-only format aligned with learners favoring verbal, reflective, and sequential processing, offering a clear and structured presentation. The image-supported format introduced graphical elements to aid comprehension, catering particularly to visual, sensing, and active learners. Lastly, the experiential visualization adapted the questionnaire into real-life scenarios, appealing to intuitive, global, and active learners who benefit from context-rich and holistic prompts. A comparative overview of the three visualization modalities is presented in Table 3.
Table 3.
Comparison of Questionnaire Visualization Modalities.
Additionally, Figure 1 illustrates the first question of the FSLSM questionnaire in each of the three visualization modes, exemplifying the practical implementation of this flexible assessment design.
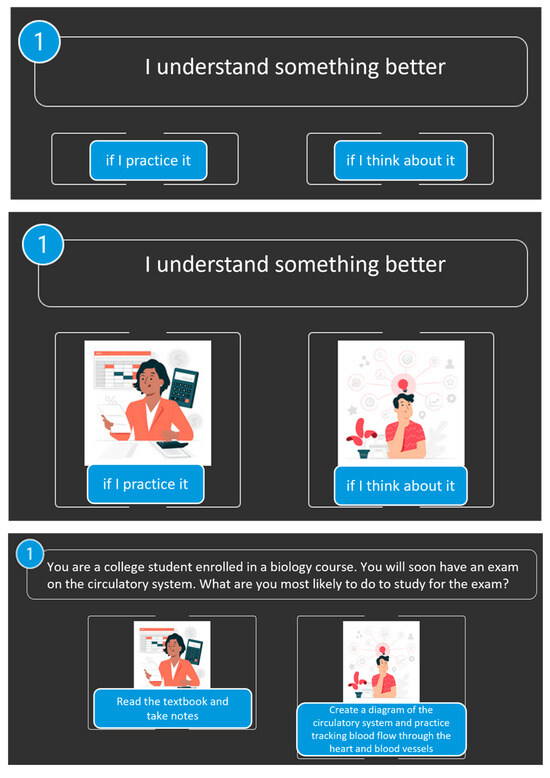
Figure 1.
Visualization Modalities of the FSLSM Questionnaire. Note: The first image shows the direct textual question, the second displays the same question with an image, and the third presents an experiential adaptation with visual context.
Figure 2 presents a sample output of a student’s learning style profile based on the FSLSM. The visual representation shows the learner’s position on each of the four FSLSM dimensions. In this case, the student demonstrated a strong preference for the Sensory style over Intuitive, along with moderate inclinations toward Sequential, Visual, and Active modes of learning. These results suggest that the student may benefit more from concrete, practical examples, visual aids, and step-by-step instructional strategies, rather than abstract concepts, verbal materials, or exploratory learning tasks. By identifying this profile, the system can recommend educational resources aligned with the student’s dominant cognitive preferences, thereby enhancing engagement and content assimilation.
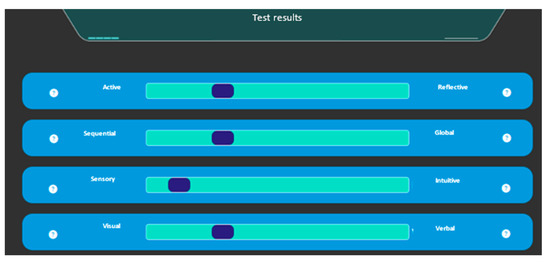
Figure 2.
Sample result of a student’s learning style/cognitive preferences classification via FSLSM.
3.2.2. Automatic Inference of Students’ Learning Style
The estimation of the learning style of a student using their answers to the ILS questionnaire, as described above, has some implicit assumptions that could make them unreliable: (a) the student has enough awareness of their learning attitudes, (b) the student answers in a truthful and careful manner, not rushing the answers to quickly move to the course content, and (c) the student’s learning style does not change during the development of the course. For these reasons, we trained a machine learning model that learned from interaction data of a previous version of the course, to predict the learning style of a student in the current course, using their daily interaction data.
Figure 3 presents an overview of our proposed method, illustrating the process from student interaction to the identification of individual learning styles. We employed K-means clustering to analyze behavioral data from students enrolled in the course PPVU offered through the Ude@ Moodle platform during the 2025-1 academic semester. By examining interaction patterns, such as navigation sequences, time spent on activities, and resource usage; we were able to cluster students and align the resulting profiles with FSLSM dimensions. We provide in the next paragraphs a detailed description of the main components of our system.
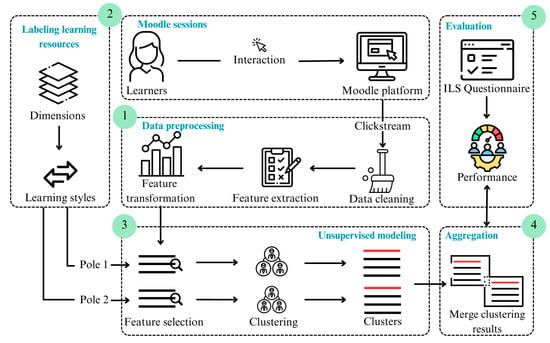
Figure 3.
Overview of the proposed method.
Data Cleaning
In this approach, learner interactions are captured primarily through clickstream data generated within the Moodle platform, providing a detailed trace of student behavior essential for subsequent analysis. As a widely adopted open-source LMS, Moodle records extensive user activity in the form of clickstream data, which captures various platform interactions such as page visits, resource views, forum contributions, and other user actions [21].
Due to its high volume, complexity, and unstructured nature, the raw data captured by Moodle is not directly suitable for predictive modeling. Therefore, a preprocessing stage is necessary to transform the dataset into a structured matrix of dimensions M × N, where M denotes the number of students and N represents the set of extracted features per student. This transformation involves two main steps: data cleaning and feature extraction, as described below.
The data cleaning step focused on selecting the most relevant tables and columns from the Moodle database, with particular emphasis on those that reflect students’ interactions with learning resources. Our primary source was the logstore_standard_log table, which provides detailed records of user activity. From this table, we extracted only the columns that directly relate to engagement with educational materials. Non-instructional data fields—such as objecttable or system-level metadata—were excluded to minimize noise and improve processing efficiency. This targeted extraction strategy ensured that the resulting dataset retained only high-value interaction records, optimizing it for subsequent modeling of learning behaviors.
Feature Extraction
Given the objective of identifying students’ learning styles dynamically as they progress through the course, we partitioned the interactions of the students into sessions. Due to the absence of explicit login and logout event markers in the Moodle activity logs, we defined a session as a continuous sequence of learner interactions. A new session was started if the time gap between two consecutive events exceeds eight hours, as illustrated in Figure 4.
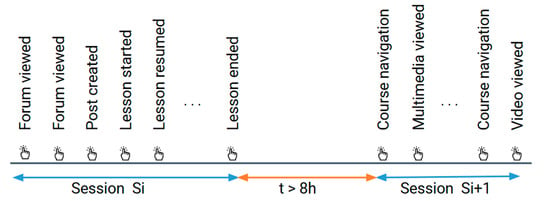
Figure 4.
A new session starts after an 8 h gap between events.
We then aggregated interaction metrics across a session for each student to compute two key engagement metrics:
- Time spent per resource—Calculated as the time difference between successive events occurring within the same session.
- Number of accesses per resource—Determined by counting the frequency of interactions with each learning object.
As mentioned in Section 3.1.3, each learning object is characterized by a vector of four elements, one for each FLSM dimension, taking values in {−11, −9, …, −1, 1, …, 9, 11}. This vector is referred to as the learning object’s learning style, representing the learning style with which the object has the most affinity. The sign of each element indicates the preferred pole within the corresponding FLSM dimension (e.g., for the ‘input’ dimension, negative values represent the ‘visual’ pole and positive values represent the ‘verbal’ pole).
Since the learning style vector of each object is available, the objects can be grouped according to the FLSM pole with which they have affinity. For example, all objects with negative values in the ‘input’ dimension are aligned with the ‘visual’ pole. A weighted average of time spent and number of accesses was then computed, with weights based on each object’s value on that pole. These two weighted averages form a two-dimensional feature representation of each student, which was then used to cluster students and predict their preference for that pole.
Unsupervised Modeling
The student’s learning style was predicted by estimating their preference on each pole. Since each pole can take six possible values on the ILS scale, k-means clustering with k = 6 was applied to group learners into six distinct clusters per pole. The resulting clusters were labeled by sorting the L2-norms of their centroids from lowest to highest, then assigning the corresponding ILS values (e.g., for the ‘visual’ pole, −1 was assigned to the cluster with the lowest L2-norm centroid, and −11 to the one with the highest).
The labels of the two poles for each FLSM dimension were summed to obtain a unique value for that dimension. If the resulting value falls outside the ILS range {−11, …, 11}, it was adjusted to the nearest value within the range, in the direction of the pole with the greatest magnitude or the largest L2-norm of the centroid. This process resulted in the student’s learning style vector.
3.2.3. Automatic Classification of Learning Resources Using AI
Following the identification of students’ learning styles through the FSLSM-based module, the next methodological step focused on the automated extraction of structural and semantic features from digital learning resources embedded in web-based platforms and mapping them to dimensions of the FSLSM, as shown in Figure 5. This classification process serves as the foundation for delivering adaptive learning pathways, ensuring that each learner receives content aligned with their cognitive profile.
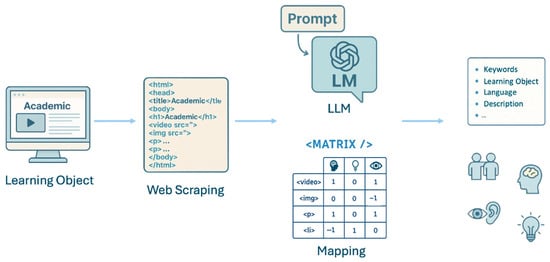
Figure 5.
Overview of the automatic classification method.
To accomplish this task, we developed a classification system that combined structural HTML analysis with advanced NLP via large language models (LLMs). The structural analysis began with the extraction of HTML elements from open educational resources using automated dynamic web scraping techniques. Specific tags such as <video>, <ul>, <form>, <img>, and <table> were mapped to pedagogically meaningful features based on a predefined semantic matrix. Each tag was associated with one or more FSLSM dimensions, for instance, <video> with visual learners, <form> with active learners, and <ul> with sequential learners, enabling the derivation of a resource’s potential alignment with learning styles.
Complementing this structural mapping, we employed LLMs accessed via API to conduct semantic analysis of the textual content within each object. Tailored prompts were used to extract latent pedagogical indicators such as intended learning outcomes, cognitive load, interactivity level, and instructional strategy, as well as resource metadata according to IEEE LOM and SCORM metadata schemes, ensuring compatibility with institutional repositories and LMS.
Each learning object was subsequently aggregated to generate a four-dimensional learning style vector for the analyzed resource. A scoring matrix aligned with the FSLSM dimensions was applied: a score of +1 was assigned to features that explicitly supported a given learning style, 0 to those considered neutral, and −1 to those potentially incongruent with the style. An example is provided below.
Visual vs. Verbal: presence of videos, images, or dominant text.
Sensing vs. Intuitive: examples, definitions, or exploratory content.
Sequential vs. Global: structured or hypertext-based organization.
Active vs. Reflective: use of interactive tools such as quizzes, forms, or forums.
That way, each detected feature was mapped to a FSLSM dimension and assigned a value on a scale from −11 to 11. This allowed each resource to be represented as a four-dimensional vector, capturing its instructional alignment with learner preferences.
This classification model, designed to be SCORM-compatible, ensured interoperability with existing LMS and facilitates the reuse and recommendation of resources across platforms. Additionally, it leveraged automated classification to reduce the need for the tedious manual process described in Section 3.1.3.
The resulting resource vectors were linked to the individual FSLSM profiles generated in the previous phase. This alignment enabled the development of a personalized recommendation engine capable of dynamically selecting and suggesting resources based on the best pedagogical match for each student.
3.2.4. Automatic Generation of Learning Object Metadata
Building on the classification pipeline, we next implemented an automated metadata generation module to enrich each learning object with interoperable descriptions and cataloging fields.
This operational workflow integrated seamlessly into our parsing pipeline. In the first stage, the full text and structural features previously parsed from the resource’s HTML are consolidated into a clean input string. This string included the concatenated text content, a summary of detected HTML elements, and a list of prominent keywords. By combining raw content and structural markers, we provide the downstream language model with both semantic and contextual cues necessary for accurate metadata formulation.
The second stage leverages an LLM accessed via API as it was implemented in the classification section. We crafted a system prompt that assigns the model the role of “an expert educational cataloguer”, and defined user prompts that explicitly request metadata of our interest, including the following: (1) five to ten thematic keywords prioritizing conceptual relevance; (2) a concise learning objective formulated as “Upon completion, the learner will be able to …”; (3) automatic detection of the resource’s language; and (4) a recommended educational level (elementary, secondary, or tertiary), inferred from vocabulary complexity and conceptual density. The prompt further instructed the model to output all metadata fields in JSON format, conformant with SCORM data element sets and IEEE LOM XML schemas.
By enriching each learning object with both a four-dimensional FSLSM vector and high-quality, standards-compliant metadata, this module streamlines resource discovery, bolsters interoperability, and underpins advanced, learner-centered recommendation strategies.
4. Results
4.1. Data
The results presented in this section were obtained in a case study conducted during the first academic semester of 2025 in the Logical and Mathematical Reasoning PPVU course. The course spanned eight weeks and was designed for an estimated total workload of 48 h, with a recommended study time of six hours per week. It was structured into five thematic units, each containing a combination of educational resources and assessment activities.
A total of 12,212 undergraduate students were enrolled in the same virtual classroom within the institutional LMS. Participants were randomly assigned to four groups of approximately equal size, comprising one control group and three experimental groups. The distribution of participants is presented in Table 4.
Table 4.
Participant Allocation by Experimental Group.
All groups had access to the same base course structure, including instructional materials, activities, and assessments. However, in the experimental groups, the content corresponding to specific topics was replaced by SCORM packages with differentiated presentation formats according to group assignment:
- Adaptive SCORM Group: Each student was shown only the version of the learning object that corresponded to their learning style, as identified through the Felder-Silverman Learning Styles Questionnaire (FSLSQ). The system displayed a single version per topic, aligned with the learning preferences indicated in the questionnaire.
- Balanced SCORM Group: All versions of the learning objects were made available simultaneously to each student. No personalization was applied based on learning style, and the student could freely select their preferred version.
- AI-Suggested SCORM Group: In this group, the system initially selected the version of the learning object corresponding to the student’s FSLSQ-identified learning style. Subsequently, the system re-evaluated interaction data at fixed intervals and updated the learning style classification based on behavioral indicators. Recommendations were adjusted accordingly over the duration of the course.
From an ethical standpoint, all students enrolled in the course were informed about the study and asked to provide their voluntary consent to participate. Upon accessing the course for the first time, students were presented with a message explaining the objectives of the research, followed by a consent question regarding their willingness to participate. This procedure ensured that students’ autonomy and decision to participate were fully respected. Only the data of students who explicitly agreed to participate were included in the analysis. Furthermore, all data were anonymized to ensure the protection of participants’ personal information and to comply with institutional and ethical research standards.
4.2. Survey Results on Learning Styles
A total of 2616 out of 12,212 enrolled students completed the FSLSQ, distributed across the four experimental groups as follows: Control (n = 610), Adaptive SCORM (n = 661), Balanced SCORM (n = 656), and AI-Suggested SCORM (n = 689). The responses revealed consistent tendencies in learning style preferences across all dimensions of the FSLSM.
- Perception Dimension: A dominant preference for the Sensing style was evident in all groups, ranging from 70.5% to 71.7%. This suggested a general inclination among students toward concrete information, practical examples, and real-world applications in their learning.
- Input Dimension: Most students preferred Visual information formats, with percentages between 58.4% and 62.7%. This reinforced the importance of integrating visual resources such as diagrams, videos, and charts to support comprehension.
- Processing Dimension: The Active style was more prevalent than the Reflective style across all groups (58.7–62.5%), indicating that many students favor learning by doing, through collaboration, experimentation, and interaction.
- Understanding Dimension: The Sequential learning preference prevailed in all groups, with the Balanced SCORM group showing the highest proportion (68.2%). This points to a preference for logically ordered, step-by-step instruction.
These results collectively underscored the pedagogical relevance of adapting learning experiences to accommodate dominant learning preferences, particularly those favoring sensory-rich, visually supported, and actively engaged content delivered in a logical sequence.
The analysis of student interaction with SCORM-based learning objects across all four experimental groups revealed variations in usage patterns, completion rates, and content preferences. Table 5 presents the number and percentage of users who accessed each SCORM-based learning object across the four groups in the case study: Adaptive SCORM, Balanced SCORM, AI-Suggested SCORM, and the Control group. The data revealed differences in content engagement patterns by topic and group, allowing comparisons between personalized and non-personalized resource delivery approaches.
Table 5.
Distribution of Users by Topic and Experimental Group Based on Learning Object Access.
Notably, while all groups had access to the same course content, the way it was presented—particularly in the AI-Suggested group, which dynamically adapted based on interaction data—appeared to influence engagement. This group maintained comparable levels of resource use and completion with the Adaptive and Balanced groups, although topic-specific differences emerged.
These observations suggested that adaptive personalization, particularly when updated dynamically through AI, holds potential for enhancing content relevance and improving user interaction. Furthermore, the consistency in engagement across groups reinforces the value of differentiated content delivery, aligned with student preferences, to support deeper learning and more effective use of instructional resources.
In addition, after completing the course, the student was invited to evaluate how much studying the materials helped them in their development on the course topics according to their learning preferences. The survey aimed to explore students’ perceptions regarding the alignment between course materials and their learning preferences, as well as their study behaviors and awareness of learning styles. Figure 6 presents the results of a survey, the grouped bar chart summarizes responses to five key questions: perceived alignment of materials with learning styles, sufficiency of resources, use of external materials, consideration of learning styles in resource selection, and identification of personal presentation preferences. The results offered insight into the relevance of adaptive content and the metacognitive engagement of learners in virtual learning environments.
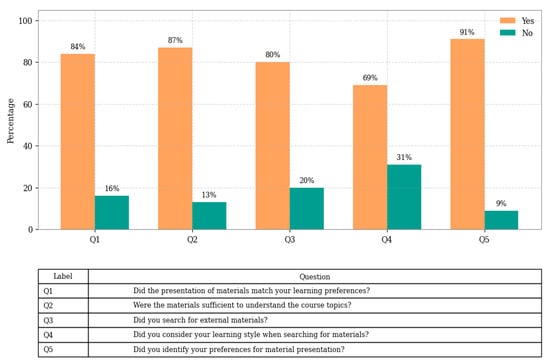
Figure 6.
Student Perceptions on Learning Styles and Course Material Use. Each question is represented by a label (Q1–Q5), with full descriptions listed in the accompanying table.
The survey administered revealed predominantly positive perceptions from students regarding the adaptation of course materials to their individual learning preferences. Specifically, 84% of respondents indicated that the way materials were presented aligned with their preferred learning styles. This suggests a strong level of perceived relevance and adequacy in the instructional design among participants in the experimental groups.
In addition, 87% of students considered the materials available on the platform sufficient to support their understanding of course content. Interestingly, 80% reported seeking external materials to further deepen their learning. This behavior did not contradict the perception of sufficiency but rather indicated proactive engagement and a desire to enrich understanding beyond the provided content.
A significant finding was that nearly 70% of the students who sought external resources reported doing so based on the results of their FSLSQ. This implies that the instrument served not only as a diagnostic tool but also as a metacognitive aid, enabling students to make more informed decisions about resource selection.
Moreover, 91% of students stated they had identified their preferences regarding content presentation formats. The most frequently preferred formats were visual and interactive, with the Visual category (117 students) and the Sensing category (67 students) being most prominent. This was followed by Intuitive (39) and Verbal (35) styles. These preferences highlighted a tendency towards learning objects that include graphic, dynamic, and contextually applicable elements.
These results are more deeply understood when contextualized alongside the classification of resources and qualitative analysis of course content. In the area of mathematics, a significant number of materials were delivered through video formats, reflecting a broader trend found in educational platforms like YouTube. This modality appeared particularly effective for students with visual, sensing, and sequential learning styles due to its capacity to convey mathematical procedures step-by-step in a visual manner.
However, this trend also underscored a limitation in traditional mathematics instruction, which often prioritizes abstract and theoretical approaches. The underuse of sensory-rich resources, interactive simulations, and real-world problem-solving contexts limits engagement for students with more active, intuitive, or global learning preferences. The data suggests the need to reconceptualize mathematics instruction, incorporating resources that promote practical engagement and conceptual visualization.
Visual representations that illustrate procedural sequences were especially valued. In such cases, images functioned as didactic tools rather than decorative elements. Conversely, visuals that lacked clear relevance to content were perceived as superficial. Additionally, formats like audio and podcasts received lower preference ratings, likely due to the abstract and symbolic nature of mathematical language, which relies heavily on visual and spatial processing.
It is worth noting that not all students reported a clear alignment between their learning style and resource preferences. This disconnection may result from limited understanding of learning style concepts or skepticism regarding the accuracy of the FSLSQ profile. These findings emphasized the importance of coupling diagnostic tools with metacognitive development to help students interpret and apply their learning preferences effectively.
4.3. Automatic Identification of Student’s Learning Styles
The training data comprised 1321 interactions from 371 students who took the PPVU course during the second semester of 2024, and the test data were 390 interactions from 117 students who took the PPVU course during the first semester of 2025. We present in Figure 7 the distribution of the learning styles assigned to the 34 learning objects available during the 2024-2 cohort. The objects had a clear bias towards the (visual, sensing, reflective, global) learning style, and we will see later how that influences the predictions of our model on the train and test data.
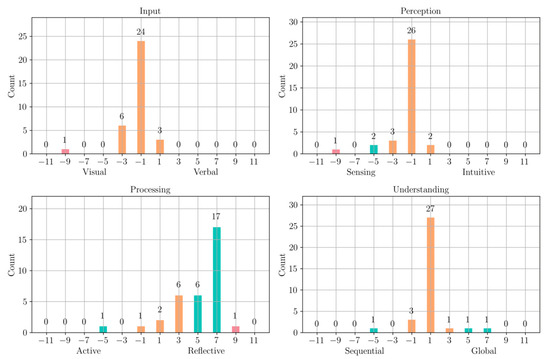
Figure 7.
Distribution of Learning Styles of Learning Objects.
Figure 8 shows the distribution of learning styles of students from the training data, according to the results of the ILS questionnaire. The distribution was, in general, well balanced among the poles of each dimension. In contrast, as it is shown on Figure 9, the distribution of the learning styles predicted by our algorithm is more biased in the ‘input’, ‘perception’, and ‘processing’ towards one of the poles, following the same bias introduced by the learning style of the objects, and more balanced in the ‘understanding’ dimension. We quantify the agreement between the binarized FLSM labels obtained through the ILS questionnaire () and the ones predicted by our algorithm () as
where is the number of students. Table 6 shows moderate alignment between behavioral indicators and ILS-reported preferences on the training data, especially for the Input and Perception dimensions. Lower agreement in Processing and Understanding may stem from their more abstract nature, which is harder to capture through log data. However, these results should be interpreted cautiously, as the work [22] highlights low reliability for these exact dimensions in the ILS, which raises questions about their validity as a ground truth. Given these limitations, we utilize the ILS as a comparative reference rather than a definitive standard, with our clustering approach providing a scalable alternative for inferring learning tendencies from behavior.
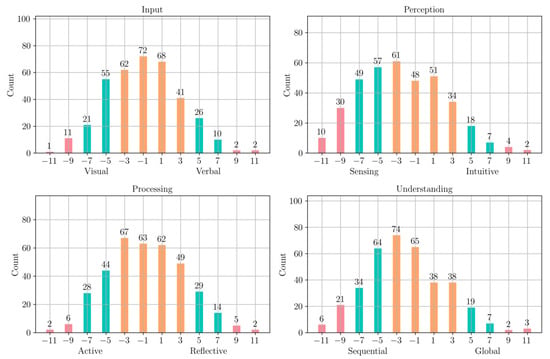
Figure 8.
Distribution of Learning Styles of Students on the training data, according to the ILS questionnaire.
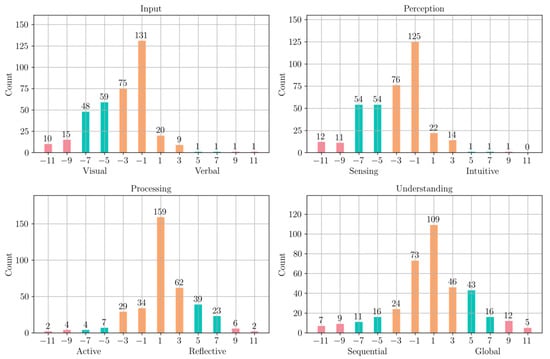
Figure 9.
Distribution of learning styles of the students in the training data, according to our prediction algorithm.
Table 6.
Overlap between ILS-based and predicted labels on the train set.
For the 2025-1 cohort, 9 of the 34 objects were replaced by SCORM objects with four variations in content format, to align with four learning style combinations: (1) visual-sensing, (2) visual-intuitive, (3) verbal-sensing, and (4) verbal-intuitive. These nine SCORM objects were the elements in the course that allowed us to provide a personalized and adaptive learning experience, as the content format of each SCORM can be changed to match the learning style predicted by our algorithm.
Figure 10 and Figure 11 show the distribution of student learning styles in the test data, according to the ILS questionnaire and our prediction algorithm, respectively. As in the training data, the distribution of questionnaire-based styles was well balanced but showed a strong bias in the ‘input’ and ‘perception’ dimensions, likely influenced by the bias in the learning styles of the objects. However, while the distribution of predicted styles in the ‘processing’ dimension was more biased toward the ‘reflective’ pole in the training data, it was more biased toward the ‘active’ pole in the test data. Similarly, while the distribution of the ‘understanding’ dimension was balanced in the training data, it was heavily biased toward the ‘sequential’ pole in the test data. Table 7 again shows moderate agreement between the two sets of labels in the test set, with improved alignment in the ‘processing’ and ‘understanding’ dimensions.
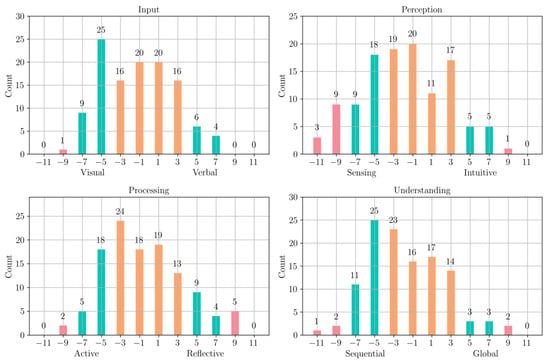
Figure 10.
Distribution of Learning Styles of Students on the test data, according to the ILS questionnaire.
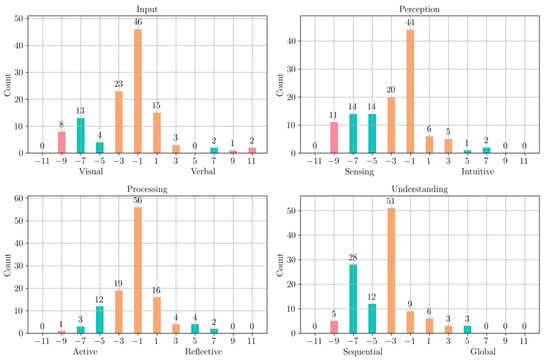
Figure 11.
Distribution of learning styles of the students in the test data, according to our prediction algorithm.
Table 7.
Overlap between ILS-based and predicted labels on the test set.
Finally, we analyzed the performance of two exams the students take at the beginning (pre-mock) and at the end (mock) of the course. Table 8 shows the results for the three student groups that were described in Table 4: the Balanced SCORM Group (Balanced), the Adaptive SCORM Group (ILS), and the AI-Suggested SCORM Group (IA). Although the size of each group is small and it is, thus, not possible to draw any conclusion with statistical significance, it is worth noting that the group of students with the biggest gain on average from the pre-mock exam to the mock exam was the group whose SCORM content changed according to the predictions of our algorithm. This result provided evidence that a learning environment whose content adapts to the learning style of the student could have the potential to improve learning outcomes.
Table 8.
Comparison of grades between the three SCORM-based groups described in Table 4.
4.4. Automatic Classification of Learning Resources
The automated pipeline described in Section 3.2.3 was applied to a corpus of 38 digital learning objects, extracted from the publicly accessible educational repository https://boa.udea.edu.co/innovacionesdidacticas/ (accessed on 26 June 2025). We successfully retrieved and parsed raw HTML for 97.4% of those resources, extracting on average 27.4 ± 6.3 unique tags and 1183 ± 421 words of text content per resource. This initial step provided a detailed structural and textual footprint for each object, far exceeding the granularity offered by conventional metadata fields.
From these parsed features, we integrated binary and frequency-based indicators aligned with the FSLSM, as well as semantic analysis of textual content. Taken together, these results affirmed that an HTML-driven, rule-based extraction pipeline can deliver comprehensive FSLSM-aligned vectors at scale, with over 19% of LOs exhibited multi-style profiles scoring ≥ |4| in two or more dimensions. These vectors were normalized and interpreted using a threshold-based decision rule to identify dominant, secondary, or neutral styles. The distribution of dominant learning styles among the corpus was visual 42.1%, sequential 28.9%, active 26.3%, and verbal 5.3%.
This distribution highlighted a notable bias in existing resources toward visual and procedural content structures, potentially reflecting underlying design trends in open educational resource creation. Conversely, intuitive and global learning preferences were significantly underrepresented, suggesting potential gaps in the availability of resources for these learner types.
The resulting resource vectors were stored in a centralized database and linked to the individual FSLSM profiles generated in the first phase. This alignment enabled the development of a personalized recommendation engine capable of dynamically selecting and suggesting resources based on the best pedagogical match for each student.
Overall, this automatic classification framework represents an advancement over traditional metadata-based approaches. It leverages both the structural and semantic dimensions of digital content to produce informed representation of learning resources, which is essential for the implementation of reliable recommendations systems.
4.5. Automatic Generation of Learning Object Metadata
To illustrate the outcomes of the automatic generation automatic metadata generation module , and to demonstrate how it can be applied to different thematics, in Figure 12 is shown an example of an online learning object interface from a course of historical evolution of engineering education.

Figure 12.
Example of a learning object.
After HTML parsing, the module consolidated the resource full text and structural summaries into a single prompt sent to the LLM. It then returned standards-compliant metadata in JSON format, which can be directly ingested by an LSM.
The following JSON exemplifies the metadata produced for the learning object in Figure 10. It includes ten thematic keywords, a concise learning objective, automatic language detection, a recommended educational level, and a description of the interactive component
- {“topic”: “Evolution of Engineering Education”,“keywords”: [“engineering origins”,“ancient civilizations”,“craftsmanship”,“technology evolution”,“educational practices”,“Mesopotamia”,“Egypt”,“Greece”,“Rome”,“Inca”],“learning_objective”: “Upon completion, the learner will be able to describe how early craftsmen and ancient civilizations contributed to the development of engineering as a distinct discipline.”,“language”: “English”,“educational_level”: “Secondary”,“interactivity_type”: “Interactive modal triggered by click”}
When evaluated against a human-annotated sample, the automated workflow demonstrated strong agreement with expert reviewers. The resulting JSON outputs can be seamlessly imported to LMS repositories, enabling immediate indexing, searchability, and personalized recommendation without manual tagging. These results confirmed that our AI-driven metadata generation module reliably produces high-quality, interoperable descriptors; greatly enhancing resource discoverability and supporting adaptive, learner-centered educational ecosystems.
4.6. Discussion
The personalized learning model developed in this study exhibits considerable potential for adaptation across a broad spectrum of educational settings beyond its initial implementation context. The combination of AI-powered recommendation systems and differentiated instructional strategies can be effectively applied at various educational levels, including primary and secondary education, vocational training programs, and higher education institutions.
In these diverse learning environments, identifying the unique characteristics of each student, such as cognitive preferences and learning objectives, is essential for delivering impactful instruction. The pipeline can be adjusted to gather and process this information through direct assessments or by analyzing learner interactions within digital learning platforms. This data-driven methodology enables the creation of tailored learning trajectories that address the distinct needs and contextual conditions of different educational systems.
Likewise, the techniques used for metadata annotation and the classification of learning resources are highly adaptable. Educational institutions can leverage these methods to structure digital content based on curriculum requirements, instructional goals, and individual learner profiles. This contributes to more effective resource organization and ensures that learners are provided with content that is pedagogically relevant and aligned with their learning styles.
One of the model’s key strengths lies in its capacity for real-time adaptation. As students engage with learning platforms, their profiles are continually updated, allowing the system to refine its recommendations and interventions dynamically. This level of adaptability is particularly beneficial in formal educational contexts, where monitoring student progress and providing timely support are crucial for preventing disengagement or failure.
Moreover, the deployment of AI-driven recommendation strategies can significantly boost learner engagement by delivering content that is both relevant and personalized. When tailored to different educational environments, these strategies promote more inclusive and effective learning experiences, fostering academic success and advancing educational equity.
A distinctive contribution of this model is the integration of HTML-based semantic analysis and metadata-driven content classification. The use of HTML parsers and rule-based feature mapping allowed for the automatic characterization of learning objects along the Felder-Silverman dimensions, supporting a deeper alignment between content properties and learner profiles.
Additionally, the unsupervised modeling of learning style preferences (derived from clickstream data, session segmentation, and engagement metrics) showcased the feasibility of scalable personalization without relying exclusively on self-reported assessments. The fusion of clustering techniques with instructional design theory bridges a critical gap in many LMS environments that still operate under static, one-size-fits-all frameworks.
In summary, the model presented in this study offers a flexible and scalable approach that can be adapted to a variety of instructional settings. Its implementation has the potential to transform conventional pedagogical models by encouraging student-centered learning, improving the alignment of educational resources, and enabling timely, data-informed instructional interventions. Furthermore, the methodological framework developed provides a replicable blueprint for other institutions aiming to leverage AI and behavioral data for meaningful personalization in digital education.
5. Conclusions
This study highlights the transformative potential of AI in driving personalized learning in virtual education environments. By applying AI techniques to classify learning objects and generate tailored content recommendations, we developed a dynamic and adaptive learning model capable of addressing the individual needs of students at scale. Our findings demonstrate that the integration of AI into educational systems can improve instructional efficiency and facilitate the construction of personalized learning pathways, ultimately leading to better academic outcomes.
The use of the FSLSM for structuring and labeling learning resources provided a solid pedagogical foundation for content adaptation. By aligning instructional materials with cognitive preferences through real-time analysis of learner behavior, the model ensures greater relevance and pedagogical impact. This alignment not only supports deeper content comprehension and retention but also promotes a greater level of satisfaction and motivation.
A key strength of the model lies in its capacity for continuous self-optimization. Through a dynamic feedback loop that captures interaction data and performance metrics, the system can iteratively refine both content delivery and instructional strategies. This responsiveness allows the learning environment to evolve alongside student progress, ensuring timely support and fostering sustained engagement throughout the learning process.
Furthermore, the flexibility and scalability of the pipeline make it more applicable than traditional academic settings. Its architecture supports adaptation to vocational training, professional development programs, and other lifelong learning contexts where personalization and responsiveness are critical. By relying on real-time behavioral data rather than static profiles, the model offers a practical pathway for implementing equitable, learner-centered instruction across diverse populations.
The integration of AI into personalized learning represents not just a technological advancement, but a fundamental pedagogical shift. It enables data-informed decision-making, enhances instructional effectiveness, and promotes inclusive educational practices. The framework and evidence presented in this study provide a replicable model for institutions aiming to build more adaptive, equitable, and effective digital learning ecosystems.
In conclusion, the methodological approach adopted in this project constituted an advancement in educational innovation. By integrating AI with the pedagogical foundations of differentiated instruction, the system seeks to promote a virtual learning environment that is more personalized, adaptive, and responsive to students’ individual needs. While further empirical validation is required, this approach may contribute to enhancing student engagement and academic performance. It represents a promising step toward the development of more effective virtual education models grounded in pedagogical theory.
Author Contributions
Conceptualization, L.F. and C.M.-C.; methodology, L.F. and C.M.-C.; software, J.M. and A.G.; validation, J.M., A.G. and C.M.-C.; formal analysis, J.M., A.G. and C.M.-C.; investigation, L.F., J.M., A.G. and C.M.-C.; resources, L.F.; data curation, J.M., A.G. and C.M.-C.; writing—original draft preparation, L.F., J.M., A.G. and C.M.-C.; writing—review and editing, L.F., J.M., A.G. and C.M.-C.; visualization, J.M. and A.G.; supervision, L.F. and C.M.-C.; project administration, L.F.; funding acquisition, L.F. All authors have read and agreed to the published version of the manuscript.
Funding
This work is funded by General Royalty System of Colombia (SGR—Sistema General de Regalías) BPIN-2021000100186.
Institutional Review Board Statement
This project was approved by the Collegiate Body of Administration and Decision (OCAD) for Science, Technology, and Innovation (CTeI) of the General Royalty System (SGR), under project code BPIN 2021000100186, in accordance with Agreement No. 14 dated 31 January 2022. Additionally, the project—including all ethical considerations—was authorized for execution by the Universidad de Antioquia through the Vice-Rector’s Office for Research and the Committee for Research Development (CODI), as documented in ACTA 2022-53069 for Registration and Intellectual Property.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
Indeed, we used a new dataset derived from our Moodle courses. Unfortunately, due to privacy concerns related to student data, we are unable to make this dataset publicly available.
Acknowledgments
We thank the Didactic and New Technologies UdeA Research Group for their contributions to the pedagogical components of this paper, especially Doris Ramírez, Ángela Vergara, Diana Oviedo, Lorena Quiroz, and David Bernal. We also express our gratitude to graduate student Lina M. Montoya for her valuable contributions to the research objectives that supported the development of this paper.
Conflicts of Interest
Author Carlos Mendoza-Cardenas was employed by the company Twitch Interactive. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Bernacki, M.L.; Greene, M.J.; Lobczowski, N.G. A systematic review of research on personalized learning: Personalized by whom, to what, how, and for what purpose (s)? Educ. Psychol. Rev. 2021, 33, 1675–1715. [Google Scholar] [CrossRef]
- Fu, Y.; Weng, Z.; Wang, J. Examining AI Use in Educational Contexts: A Scoping Meta-Review and Bibliometric Analysis. Int. J. Artif. Intell. Educ. 2024. [Google Scholar] [CrossRef]
- Adnan, M.; Habib, A.; Ashraf, J.; Mussadiq, S.; Raza, A.A.; Abid, M.; Bashir, M.; Khan, S.U. Predicting at-risk students at different percentages of course length for early intervention using machine learning models. IEEE Access 2021, 9, 7519–7539. [Google Scholar] [CrossRef]
- Tomasevic, N.; Gvozdenovic, N.; Vranes, S. An overview and comparison of supervised data mining techniques for student exam performance prediction. Comput. Educ. 2020, 143, 103676. [Google Scholar] [CrossRef]
- Zerkouk, M.; Mihoubi, M.; Chikhaoui, B.; Wang, S. Predicting Online Education Dropout: A new Machine Learning Model based on Sentiment Analysis, Socio-demographic, and Behavioral Data. Int. J. Artif. Intell. Educ. 2025. [Google Scholar] [CrossRef]
- Chen, L.; Chen, P.; Lin, Z. Artificial Intelligence in Education: A Review. IEEE Access 2020, 8, 75264–75278. [Google Scholar] [CrossRef]
- Dantas, L.A.; Cunha, A. An Integrative Debate on Learning Styles and the Learning Process. Soc. Sci. Humanit. Open 2020, 2, 100017. [Google Scholar] [CrossRef]
- Fleming, N.; Baume, D. Learning Styles Again: Varking Up the Right Tree! Educational Developments, SEDA Ltd.: Birmingham, UK, 2006; pp. 4–7. [Google Scholar]
- Kolb, A.Y.; Kolb, D.A. Learning Styles and Learning Spaces: Enhancing Experiential Learning in Higher Education Experience-Based Learning Systems. Acad. Manag. Learn. Educ. 2005, 4, 193–212. [Google Scholar] [CrossRef]
- Freiberg, A.; Fernández, M. Honey-Alonso Learning Styles Questionnaire: An Analysis of its Psychometric Properties in College Students. Summa Psicológica Ust. 2012, 10, 103–117. [Google Scholar]
- Swailes, S.; Senior, B. The Dimensionality of Honey and Mumford’s Learning Styles Questionnaire. Int. J. Sel. Assess. 1999, 7, 1–11. [Google Scholar] [CrossRef]
- Coffield, F.; Moseley, D.; Hall, E.; Ecclestone, K. Learning Styles and Pedagogy in Post-16 Learning: A Systematic and Critical Review; Learning and Skills Research Centre: London, UK, 2004. [Google Scholar]
- Felder, R.M. Learning and Teaching Styles in Engineering Education. Available online: http://www.ncsu.edu/felder-public/ILSpage.html (accessed on 26 June 2025).
- Kouis, D.; Kyprianos, K.; Ermidou, P.; Kaimakis, P.; Koulouris, A. A framework for assessing lmss e-courses content type compatibility with learning styles dimensions. J. E-Learn. Knowl. Soc. 2020, 16, 73–86. [Google Scholar]
- El-Bishouty, M.M.; Aldraiweesh, A.; Alturki, U.; Tortorella, R.; Yang, J.; Chang, T.-W.; Graf, S.; Kinshuk. Use of Felder and Silverman learning style model for online course design. Educ. Technol. Res. Dev. 2019, 67, 161–177. [Google Scholar] [CrossRef]
- Venkatesh, M.; Sathyalakshmi, S. Smart learning using personalised recommendations in web-based learning systems using artificial bee colony algorithm to improve learning performance. Electron. Gov. Int. J. 2020, 16, 101–117. [Google Scholar] [CrossRef]
- Sianturi, S.T.; Yuhana, U.L. Student behaviour analysis to detect learning styles using decision tree, naive bayes, and k-nearest neighbor method in moodle learning management system. IPTEK J. Technol. Sci. 2022, 33, 94–104. [Google Scholar] [CrossRef]
- Hwang, G.-J.; Sung, H.-Y.; Chang, S.-C.; Huang, X.-C. A fuzzy expert system-based adaptive learning approach to improving students’ learning performances by considering affective and cognitive factors. Comput. Educ. Artif. Intell. 2020, 1, 100003. [Google Scholar] [CrossRef]
- Kolekar, S.V.; Pai, R.M.; MM, M.P. Rule based adaptive user interface for adaptive e-learning system. Educ. Inf. Technol. 2019, 24, 613–641. [Google Scholar] [CrossRef]
- Tarus, J.K.; Niu, Z.; Yousif, A. A hybrid knowledge-based recommender system for e-learning based on ontology and sequential pattern mining. Future Gener. Comput. Syst. 2017, 72, 37–48. [Google Scholar] [CrossRef]
- Moodle Docs. Database Schema Introduction. Available online: https://moodledev.io/docs/apis/core/dml/database-schema (accessed on 5 April 2025).
- Al-Azawei, A.; Parslow, P.; Lundqvist, K. A psychometric analysis of reliability and validity of the index of learning styles (ILS). Int. J. Psychol. Stud. 2015, 7, 46–57. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).