


A Systematic Review on Artificial Intelligence-Based Multimodal Dialogue Systems Capable of Emotion Recognition




Abstract
1. Introduction
2. Materials and Methods
2.1. Research Questions
2.2. Eligibility Criteria
2.3. Sources of Information
2.4. Search Strategy
2.5. Study Selection Process
3. Results
3.1. Selection of Studies
3.2. Designation of Studies
3.3. What Input Data and Categories Are Present in Multimodal Dialogue Systems?
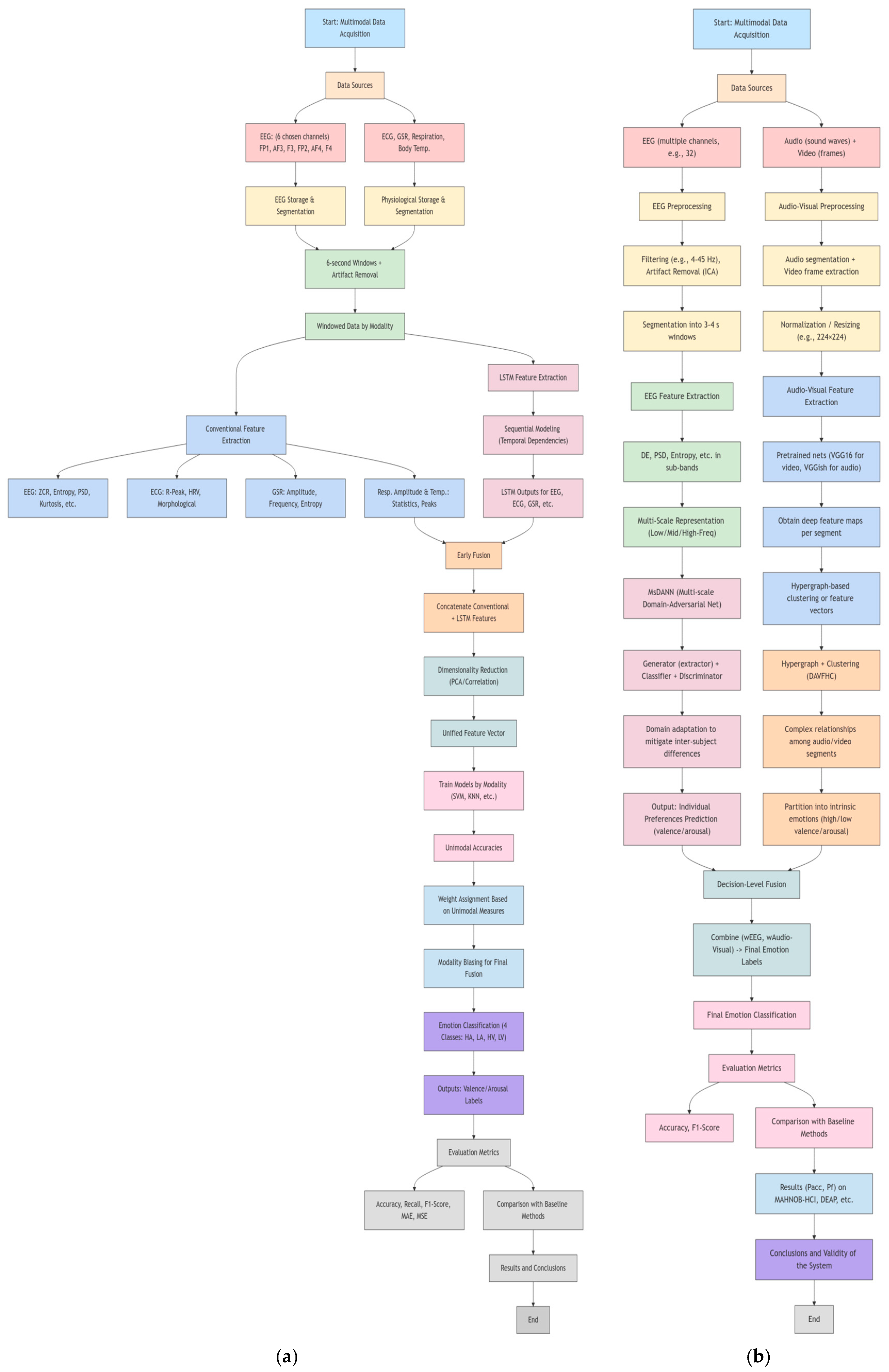
3.4. What Are the Models and Architectures in Emotion Recognition Through Signals?




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Data Combination Methods in the Proposed Models |
|---|---|
| Li et al. [2] | Weighting Enumerator: This approach involves attributing a numerical value, called a “weight”, to each data element, indicating its importance within an information set. This technique demonstrated optimal accuracy in the valence and excitation dimensions in experiments using the DEAP and MAHNOB-HCI databases. It competently integrates SVM results applied to EEG and CNN data used for facial expression analysis. |
| Tang et al. [47] | Modality-level fusion: the paper discusses a modality-level fusion that processes peripheral signals and EEG independently before integration, thus preserving the distinctive features of each modality. Global fusion: after modality-level integration, a global fusion phase is executed, which consists of mapping the combined features into a lower-dimensional space using fully connected layers, thus amalgamating information from several modalities into a singular vector for emotion classification. |
| Umair et al. [41] | Early fusion integrates features from modalities such as ECG, GSR, EEG, respiration amplitude, and body temperature into a unified feature vector, which improves the capture of complementary information. Late fusion (decision-level fusion): The system employs late fusion, or decision-level fusion (DLF), which combines the results of several classifiers. This approach allows individual classification of each modality using several classifiers, such as Support Vector Machines, Logistic Regression, KNN, and Naïve Bayes. Combining the results of these classifiers according to specific rules poses design challenges. |
| Liang et al. [43] | Fusion techniques: The text examines two main fusion methodologies: EEG–Video Fusion and EEG–Visual–Audio Fusion. EEG–Video Fusion integrates EEG metrics with video data, while EEG–Visual–Audio Fusion fuses EEG, visual, and audio data independently. Weight assignment: Both fusion approaches use weight assignments for various modalities. In electroencephalographic and video fusion, weights are designated to illustrate the importance of EEG and video data in emotion detection. In electroencephalographic, visual, and audio–visual fusion, the weights for electroencephalographic, visual, and audio modalities are distributed evenly. |
| Du et al. [48] | Multimodal fusion: 3FACRNN synergistically integrates EEG and visual data through a multi-tasking loss function rather than simple feature concatenation, improving performance across modality strengths. Feature construction: EEG signals are decomposed into frequency bands through a 3D feature construction module, which captures spatial, temporal, and band-specific information essential for emotion recognition. Attentional mechanism: the model employs attentional mechanisms to prioritize frequency bands in EEG data, which enhances the network’s focus on crucial features to accurately predict emotion recognition. Cascade networks: the visual network is designed as a convolutional cascade neural network (CNN-TCN), which efficiently processes visual data before integrating it with EEG data. |
| Razzaq et al. [42] | Multimodal feature fusion: the framework incorporates features from various modalities, such as facial expressions, body language, and sound cues, by concatenating their feature vectors into a unified global representation of emotional state. Decision-level fusion: the paper highlights the importance of decision-level fusion, which consolidates the results of classifiers using different modalities, facilitating independent operation and improving the flexibility and robustness of classification. Generalized mixture functions (GM): the framework uses genetic modification functions to fuse features and decisions, which allows dynamic weighting of contributions to modalities to address data sparsity and variability of emotional expressions, thus improving classification accuracy. Implementation of fusion techniques: implementation involves preprocessing the data to extract relevant features from each modality and fuse them into equal-sized vectors to ensure consistency and efficient integration of multimodal decisions. |
| Gahlan and Sethia [34] | Function-level fusion (FLF): The framework employs function-level fusion, extracting and concatenating features from different physiological signals (EEG, ECG, and GSR) separately. This method maintains the integrity of the relevant information for each signal modality. |
3.5. What Are the Models and Architectures in Traditional Multimodal Dialogue Systems?
3.6. What Are the Metrics and Their Value in Emotion Recognition Models and Multimodal Dialogue Systems?
| Author | Proposed Models |
|---|---|
| Liu et al. [49] | Transformer-based multimodal infusion dialogue (TMID) system |
| Heo et al. [50] | Dialogue system with audiovisual scene recognition |
| Chen et al. [35] | DKMD, which stands for Dual Knowledge Generative Pretrained Language Model, is designed for task-oriented multimodal dialogue systems |
| Liu et al. [51] | Modality-aligned chain of thought reasoning (MatCR) is designed for the generation of task-oriented multimodal dialogues |
| Kumar et al. [10] | Uses an end-to-end audio classification subnet, ACLnet |
| Chen et al. [52] | MDS-S2, which stands for Dual Semantic Knowledge Composed Multimodal Dialog System, uses the pretrained generative language model BART as its backbone |
| Author | Data Combination Methods in the Proposed Models |
|---|---|
| Liu et al. [49] |
|
| Heo et al. [50] | The proposed system uses an advanced data fusion technique that combines audio, visual, and textual modalities. The following are the key aspects of the data fusion method:
|
| Chen et al. [35] | The data fusion method integrates textual and visual information to improve the performance of the dialogue system. Key aspects include the following:
|
| Liu et al. [51] | The MatCR framework’s data fusion method integrates multimodal information to improve the understanding of user intent and response optimization.
|
| Kumar et al. [10] | Data fusion methods are vital for multimodal dialogue systems, particularly in audiovisual scene-aware dialogue (AVSD). The key points of data fusion methods are described below:
|
| Chen et al. [52] | The data fusion method integrates several types of knowledge to improve the performance of the dialogue system. These are the key points of this method:
|
| Metrics | Precision | Recall Rate | F1-Score | Accuracy | |||||
|---|---|---|---|---|---|---|---|---|---|
| Author\ Dimension | Valence (%) | Arousal (%) | Valence (%) | Arousal (%) | Valence (%) | Arousal (%) | Valence (%) | Arousal (%) | |
| Proposed Models for Emotion Recognition | [2] | - | - | 68.18 | 69.28 | - | - | 78.56 | 77.22 |
| [47] | - | - | - | - | - | - | 74.17 | 74.34 | |
| [41] | 97 | 85 | 92 | 91 | 95 | 88 | - | 92.62 | |
| [43] | - | - | - | - | 90.45 | 86.55 | 90.21 | 85.59 | |
| [48] | 99.13 | 98.89 | 97.26 | 96.42 | 97.33 | 97.38 | 98.37 | 97.55 | |
| [42] | - | - | - | - | - | - | 98.19 | 98.19 | |
| [34] | - | - | - | - | - | - | 88.3 | 88.3 | |
| Author\Metrics | BLEU1 | BLEU2 | BLEU3 | BLEU4 | METEOR | ROUGE-L | CIDEr | NIST | |
|---|---|---|---|---|---|---|---|---|---|
| Proposed Models | [49] | 64.81 | 58.09 | 54.24 | 51.59 | - | - | - | 8.8317 |
| [50] K = 4 | 0.6455 | 0.4889 | 0.3796 | 0.2986 | 0.2253 | 0.503 | 0.7868 | - | |
| [35] | 39.59 | 31.95 | 27.26 | 23.72 | - | - | - | 4.0004 | |
| [51] | 29.03 | 24.69 | 22.43 | - | - | 27.79 | - | - | |
| [10] | 0.632 | 0.499 | 0.402 | 0.329 | 0.223 | 0.488 | 0.762 | - | |
| [52] | 41.4 | 32.91 | 27.74 | 23.89 | - | - | - | 4.2142 |
4. Discussion
Critical Analysis
- Robustness and Improved Generalization
- Advanced Understanding of Complex Emotions
- Emotional Detection in High-Stress Scenarios
- Cultural Inclusion and Linguistic Diversity in Emotional Recognition
- Emotional Recognition in Real Driving Contexts
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- De Andrade, I.M.; Tumelero, C. Increasing customer service efficiency through artificial intelligence chatbot. Rege-Rev. Gest. 2022, 29, 238–251. [Google Scholar] [CrossRef]
- Li, R.; Liang, Y.; Liu, X.; Wang, B.; Huang, W.; Cai, Z.; Ye, Y.; Qiu, L.; Pan, J. MindLink-Eumpy: An Open-Source Python Toolbox for Multimodal Emotion Recognition. Front. Hum. Neurosci. 2021, 15, 621493. [Google Scholar] [CrossRef] [PubMed]
- Pinochet, L.H.C.; de Gois, F.S.; Pardim, V.I.; Onusic, L.M. Experimental study on the effect of adopting humanized and non-humanized chatbots on the factors measure the intensity of the user’s perceived trust in the Yellow September campaign. Technol. Forecast. Soc. Change 2024, 204, 123414. [Google Scholar] [CrossRef]
- Karani, R.; Desai, S. IndEmoVis: A Multimodal Repository for In-Depth Emotion Analysis in Conversational Contexts. Procedia Comput. Sci. 2024, 233, 108–118. [Google Scholar] [CrossRef]
- Kim, H.; Hong, T. Enhancing emotion recognition using multimodal fusion of physiological, environmental, personal data. Expert Syst. Appl. 2024, 249, 123723. [Google Scholar] [CrossRef]
- Zou, B.; Wang, Y.; Zhang, X.; Lyu, X.; Ma, H. Concordance between facial micro-expressions and physiological signals under emotion elicitation. Pattern Recognit. Lett. 2022, 164, 200–209. [Google Scholar] [CrossRef]
- Taware, S.; Thakare, A. Critical Analysis on Multimodal Emotion Recognition in Meeting the Requirements for Next Generation Human Computer Interactions. Int. J. Recent Innov. Trends Comput. Commun. 2023, 11, 523–534. [Google Scholar] [CrossRef]
- Zhou, H.; Liu, Z. Realization of Self-Adaptive Higher Teaching Management Based Upon Expression and Speech Multimodal Emotion Recognition. Front. Psychol. 2022, 13, 857924. [Google Scholar] [CrossRef] [PubMed]
- Yang, Z.; Wang, Y.; Yamashita, K.S.; Khatibi, E.; Azimi, I.; Dutt, N.; Borelli, J.L.; Rahmani, A.M. Integrating wearable sensor data and self-reported diaries for personalized affect forecasting. Smart Health 2024, 32, 100464. [Google Scholar] [CrossRef]
- Kumar, S.H.; Okur, E.; Sahay, S.; Huang, J.; Nachman, L. Investigating topics, audio representations and attention for multimodal scene-aware dialog. Comput. Speech Lang. 2020, 64, 101102. [Google Scholar] [CrossRef]
- Hazer-Rau, D.; Meudt, S.; Daucher, A.; Spohrs, J.; Hoffmann, H.; Schwenker, F.; Traue, H.C. The uulmMAC Database—A Multimodal Affective Corpus for Affective Computing in Human-Computer Interaction. Sensors 2020, 20, 2308. [Google Scholar] [CrossRef]
- Khan, M.; Gueaieb, W.; El Saddik, A.; Kwon, S. MSER: Multimodal speech emotion recognition using cross-attention with deep fusion. Expert Syst. Appl. 2024, 245, 122946. [Google Scholar] [CrossRef]
- Shang, Y.; Fu, T. Multimodal fusion: A study on speech-text emotion recognition with the integration of deep learning. Intell. Syst. Appl. 2024, 24, 200436. [Google Scholar] [CrossRef]
- Moore, P. Do We Understand the Relationship between Affective Computing, Emotion and Context-Awareness? Machines 2017, 5, 16. [Google Scholar] [CrossRef]
- Shinde, S.; Kathole, A.; Wadhwa, L.; Shaikha, A.S. Breaking the silence: Innovation in wake word activation. Multidiscip. Sci. J. 2023, 6, 2024021. [Google Scholar] [CrossRef]
- Shi, X.; She, Q.; Fang, F.; Meng, M.; Tan, T.; Zhang, Y. Enhancing cross-subject EEG emotion recognition through multi-source manifold metric transfer learning. Comput. Biol. Med. 2024, 174, 108445. [Google Scholar] [CrossRef] [PubMed]
- Pei, G.; Shang, Q.; Hua, S.; Li, T.; Jin, J. EEG-based affective computing in virtual reality with a balancing of the computational efficiency and recognition accuracy. Comput. Hum. Behav. 2024, 152, 108085. [Google Scholar] [CrossRef]
- Hsu, S.-H.; Lin, Y.; Onton, J.; Jung, T.-P.; Makeig, S. Unsupervised learning of brain state dynamics during emotion imagination using high-density EEG. NeuroImage 2022, 249, 118873. [Google Scholar] [CrossRef]
- Na Jo, H.; Park, S.W.; Choi, H.G.; Han, S.H.; Kim, T.S. Development of an Electrooculogram (EOG) and Surface Electromyogram (sEMG)-Based Human Computer Interface (HCI) Using a Bone Conduction Headphone Integrated Bio-Signal Acquisition System. Electronics 2022, 11, 2561. [Google Scholar] [CrossRef]
- Zhu, B.; Zhang, D.; Chu, Y.; Zhao, X.; Zhang, L.; Zhao, L. Face-Computer Interface (FCI): Intent Recognition Based on Facial Electromyography (fEMG) and Online Human-Computer Interface with Audiovisual Feedback. Front. Neurorobot. 2021, 15, 692562. [Google Scholar] [CrossRef]
- Kim, J.; Cho, D.; Lee, K.J.; Lee, B. A Real-Time Pinch-to-Zoom Motion Detection by Means of a Surface EMG-Based Human-Computer Interface. Sensors 2014, 15, 394–407. [Google Scholar] [CrossRef]
- Jekauc, D.; Burkart, D.; Fritsch, J.; Hesenius, M.; Meyer, O.; Sarfraz, S.; Stiefelhagen, R. Recognizing affective states from the expressive behavior of tennis players using convolutional neural networks. Knowl.-Based Syst. 2024, 295, 111856. [Google Scholar] [CrossRef]
- Islam, M.; Nooruddin, S.; Karray, F.; Muhammad, G. Human activity recognition using tools of convolutional neural networks: A state of the art review, data sets, challenges, and future prospects. Comput. Biol. Med. 2022, 149, 106060. [Google Scholar] [CrossRef] [PubMed]
- Diep, Q.B.; Phan, H.Y.; Truong, T.-C. Crossmixed convolutional neural network for digital speech recognition. PLoS ONE 2024, 19, e0302394. [Google Scholar] [CrossRef]
- Annamalai, B.; Saravanan, P.; Varadharajan, I. ABOA-CNN: Auction-based optimization algorithm with convolutional neural network for pulmonary disease prediction. Neural Comput. Appl. 2023, 35, 7463–7474. [Google Scholar] [CrossRef]
- Yang, Y.; Liu, J.; Zhao, L.; Yin, Y. Human-Computer Interaction Based on ASGCN Displacement Graph Neural Networks. Informatica 2024, 48, 195–208. [Google Scholar] [CrossRef]
- Bi, W.; Xie, Y.; Dong, Z.; Li, H. Enterprise Strategic Management from the Perspective of Business Ecosystem Construction Based on Multimodal Emotion Recognition. Front. Psychol. 2022, 13, 857891. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Zhai, Y.; Xu, G.; Wang, N. Multi-Modal Affective Computing: An Application in Teaching Evaluation Based on Combined Processing of Texts and Images. Trait. Signal 2023, 40, 533–541. [Google Scholar] [CrossRef]
- Dang, X.; Chen, Z.; Hao, Z.; Ga, M.; Han, X.; Zhang, X.; Yang, J. Wireless Sensing Technology Combined with Facial Expression to Realize Multimodal Emotion Recognition. Sensors 2022, 23, 338. [Google Scholar] [CrossRef]
- Tashu, T.M.; Hajiyeva, S.; Horvath, T. Multimodal Emotion Recognition from Art Using Sequential Co-Attention. J. Imaging 2021, 7, 157. [Google Scholar] [CrossRef]
- Liu, W.; Cao, S.; Zhang, S. Multimodal consistency-specificity fusion based on information bottleneck for sentiment analysis. J. King Saud Univ.-Comput. Inf. Sci. 2024, 36, 101943. [Google Scholar] [CrossRef]
- Makhmudov, F.; Kultimuratov, A.; Cho, Y.-I. Enhancing Multimodal Emotion Recognition through Attention Mechanisms in BERT and CNN Architectures. Appl. Sci. 2024, 14, 4199. [Google Scholar] [CrossRef]
- Gifu, D.; Pop, E. Smart Solutions to Keep Your Mental Balance. Procedia Comput. Sci. 2022, 214, 503–510. [Google Scholar] [CrossRef]
- Gahlan, N.; Sethia, D. AFLEMP: Attention-based Federated Learning for Emotion recognition using Multi-modal Physiological data. Biomed. Signal Process. Control 2024, 94, 106353. [Google Scholar] [CrossRef]
- Chen, X.; Song, X.; Jing, L.; Li, S.; Hu, L.; Nie, L. Multimodal Dialog Systems with Dual Knowledge-enhanced Generative Pretrained Language Model. arXiv 2024, arXiv:2207.07934. [Google Scholar] [CrossRef]
- Singla, C.; Singh, S.; Sharma, P.; Mittal, N.; Gared, F. Emotion recognition for human–computer interaction using high-level descriptors. Sci. Rep. 2024, 14, 12122. [Google Scholar] [CrossRef]
- Chen, W. A Novel Long Short-Term Memory Network Model for Multimodal Music Emotion Analysis in Affective Computing. J. Appl. Sci. Eng. 2022, 26, 367–376. [Google Scholar] [CrossRef]
- Garcia-Garcia, J.M.; Lozano, M.D.; Penichet, V.M.R.; Law, E.L.-C. Building a three-level multimodal emotion recognition framework. Multimed. Tools Appl. 2023, 82, 239–269. [Google Scholar] [CrossRef]
- Polydorou, N.; Edalat, A. An interactive VR platform with emotion recognition for self-attachment intervention. EAI Endorsed Trans. Pervasive Health Technol. 2021, 7, e5. [Google Scholar] [CrossRef]
- Bieńkiewicz, M.M.; Smykovskyi, A.P.; Olugbade, T.; Janaqi, S.; Camurri, A.; Bianchi-Berthouze, N.; Björkman, M.; Bardy, B.G. Bridging the gap between emotion and joint action. Neurosci. Biobehav. Rev. 2021, 131, 806–833. [Google Scholar] [CrossRef]
- Umair, M.; Rashid, N.; Khan, U.S.; Hamza, A.; Iqbal, J. Emotion Fusion-Sense (Emo Fu-Sense)—A novel multimodal emotion classification technique. Biomed. Signal Process. Control 2024, 94, 106224. [Google Scholar] [CrossRef]
- Razzaq, M.A.; Hussain, J.; Bang, J.; Hua, C.-H.; Satti, F.A.; Rehman, U.U.; Bilal, H.S.M.; Kim, S.T.; Lee, S. A Hybrid Multimodal Emotion Recognition Framework for UX Evaluation Using Generalized Mixture Functions. Sensors 2023, 23, 4373. [Google Scholar] [CrossRef] [PubMed]
- Liang, Z.; Zhang, X.; Zhou, R.; Zhang, L.; Li, L.; Huang, G.; Zhang, Z. Cross-individual affective detection using EEG signals with audio-visual embedding. Neurocomputing 2022, 510, 107–121. [Google Scholar] [CrossRef]
- Yu, S.; Androsov, A.; Yan, H.; Chen, Y. Bridging computer and education sciences: A systematic review of automated emotion recognition in online learning environments. Comput. Educ. 2024, 220, 105111. [Google Scholar] [CrossRef]
- Bianco, S.; Celona, L.; Ciocca, G.; Marelli, D.; Napoletano, P.; Yu, S.; Schettini, R. A Smart Mirror for Emotion Monitoring in Home Environments. Sensors 2021, 21, 7453. [Google Scholar] [CrossRef]
- Tan, X.; Fan, Y.; Sun, M.; Zhuang, M.; Qu, F. An emotion index estimation based on facial action unit prediction. Pattern Recognit. Lett. 2022, 164, 183–190. [Google Scholar] [CrossRef]
- Tang, J.; Ma, Z.; Gan, K.; Zhang, J.; Yin, Z. Hierarchical multimodal-fusion of physiological signals for emotion recognition with scenario adaption and contrastive alignment. Inf. Fusion 2024, 103, 102129. [Google Scholar] [CrossRef]
- Du, Y.; Li, P.; Cheng, L.; Zhang, X.; Li, M.; Li, F. Attention-based 3D convolutional recurrent neural network model for multimodal emotion recognition. Front. Neurosci. 2024, 17, 1330077. [Google Scholar] [CrossRef]
- Liu, B.; He, L.; Liu, Y.; Yu, T.; Xiang, Y.; Zhu, L.; Ruan, W. Transformer-Based Multimodal Infusion Dialogue Systems. Electronics 2022, 11, 3409. [Google Scholar] [CrossRef]
- Heo, Y.; Kang, S.; Seo, J. Natural-Language-Driven Multimodal Representation Learning for Audio-Visual Scene-Aware Dialog System. Sensors 2023, 23, 7875. [Google Scholar] [CrossRef]
- Liu, Y.; Li, L.; Zhang, B.; Huang, S.; Zha, Z.-J.; Huang, Q. MaTCR: Modality-Aligned Thought Chain Reasoning for Multimodal Task-Oriented Dialogue Generation. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 5776–5785. [Google Scholar]
- Chen, X.; Song, X.; Wei, Y.; Nie, L.; Chua, T.-S. Dual Semantic Knowledge Composed Multimodal Dialog Systems. arXiv 2023, arXiv:2305.09990. [Google Scholar]
- Aguilera, A.; Mellado, D.; Rojas, F. An Assessment of In-the-Wild Datasets for Multimodal Emotion Recognition. Sensors 2023, 23, 5184. [Google Scholar] [CrossRef] [PubMed]
- Richet, N.; Belharbi, S.; Aslam, H.; Schadt, M.E.; González-González, M.; Cortal, G.; Koerich, A.L.; Pedersoli, M.; Finkel, A.; Bacon, S.; et al. Textualized and Feature-based Models for Compound Multimodal Emotion Recognition in the Wild. arXiv 2024, arXiv:2407.12927. [Google Scholar]
- Deschamps-Berger, T.; Lamel, L.; Devillers, L. Exploring Attention Mechanisms for Multimodal Emotion Recognition in an Emergency Call Center Corpus. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Ruan, Y.P.; Zheng, S.K.; Huang, J.; Zhang, X.; Liu, Y.; Li, T. CH-MEAD: A Chinese Multimodal Conversational Emotion Analysis Dataset with Fine-Grained Emotion Taxonomy. In Proceedings of the 2023 Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Taipei, Taiwan, 31 October–3 November 2023; pp. 498–505. [Google Scholar]
- Oh, G.; Jeong, E.; Kim, R.C.; Yang, J.H.; Hwang, S.; Lee, S.; Lim, S. Multimodal Data Collection System for Driver Emotion Recognition Based on Self-Reporting in Real-World Driving. Sensors 2022, 22, 4402. [Google Scholar] [CrossRef]






| Code | Questions |
|---|---|
| P: RQ1 | What types of input data and categories are present in multimodal dialogue systems? |
| I: RQ2 | What are the models and architectures used in emotion recognition through physiological signals? |
| C: RQ3 | What are the models and architectures used in traditional multimodal dialogue systems? |
| O: RQ4 | What are the metrics and their value in emotion recognition models and multimodal dialogue systems? |
| Criterion | Code | Description |
|---|---|---|
| Inclusion | IC1 | Research related to multimodal dialogue systems and emotion recognition. |
| IC2 | Research demonstrating metrics as outcomes. | |
| IC3 | Research presenting the origin of data sources. | |
| IC4 | Research presenting solution proposal architecture. | |
| Exclusion | EC1 | Studies not related to artificial intelligence. |
| EC2 | Studies not published between 2020 and 2024. | |
| EC3 | Studies unrelated to multimodal dialogue systems | |
| EC4 | Studies not written in English. | |
| EC5 | Duplicate articles. |
| Code | Keyword String | Chain Search Title/Abstract |
|---|---|---|
| P: RQ1 | dialogue interaction, multimodal dialogue features, types of multimodal dialogue, multimodal data entry, models in dialog system, models with emotion, human computation, affective dialog | (“dialog system” AND multimodal) OR (dialog AND “human computation”) OR (multimodal AND methods) OR (dialogue interaction AND emotion) OR (“emotional AND dialog”) OR (multimodal dialogue features AND emotion) (“affective dialog” AND multimodal) |
| I: RQ2 | affective computing, AI models, emotion recognition, physiological signals, dialogue with emotion, multimodal emotion, emotion detection, effective dialogue | (“affective computing “AND models) OR (“emotion recognition” AND dialog) OR (“physiological signals” AND models) OR (“dialogue with emotion” AND multimodal) (“multimodal emotion” and dialog) OR (effective AND dialog) |
| C: RQ3 | Dialogue, multimodal, communication, dialogue models, neural networks, artificial intelligence, dialog architecture | (dialogue AND multimodal) OR (dialogue AND multimodal AND models) OR (dialogue AND “neural networks”) OR (dialogue AND “artificial intelligence) OR (“dialog architecture” and models) |
| O: RQ4 | Metrics, dialog, dialogue system, Communication, models, neural networks, Affective, emotional, recognition | (metrics AND dialog) OR (“dialogue system” and metrics) OR (metrics AND models AND emotion) OR (metrics AND recognition AND models) OR (communication AND metrics AND models) OR (“neural networks” AND metrics) |
| Author | Year | Entry Type | Dataset | Category |
|---|---|---|---|---|
| Li et al. [2] | 2021 | Mixed | DEAP, MAHNOB-HCI | Emotion |
| Tang et al. [47] | 2024 | Mixed | DEAP, SEED-IV y SEED-V. | Emotion |
| Umair et al. [41] | 2024 | Physiological | MAHNOB-HCI | Emotion |
| Liang et al. [43] | 2022 | Mixed | MAHNOB-HCI y DEAP | Emotion |
| Du et al. [48] | 2024 | Mixed | DEAP y MAHNOB-HCI | Emotion |
| Razzaq et al. [42] | 2023 | Physical | EXPERIMENTOS PROPIOS | Emotion |
| Gahlan and Sethia [34] | 2024 | Physiological | AMIGOS Y DREAMER | Emotion |
| Liu et al. [49] | 2022 | Physical | MMD | Dialogue |
| Heo et al. [50] | 2023 | Physical | AUDIOVISUAL SCENE-AWARE DIALOG (AVSD) | Dialogue |
| Chen et al. [35] | 2022 | Physical | MMConv | Dialogue |
| Liu et al. [51] | 2023 | Physical | JDDC 2.1 | Dialogue |
| Kumar et al. [10] | 2020 | Physical | AVSD | Dialogue |
| Chen et al. [52] | 2023 | Physical | MMConv | Dialogue |
| Questions | Number of Studies | Designated Studies |
|---|---|---|
| P: RQ1 | 13 | Li et al. [2], Tang et al. [47], Umair et al. [41], Liang et al. [43], Du et al. [48], Razzaq et al. [42], Gahlan and Sethia [34], Liu et al. [49], Heo et al. [50], Chen et al. [35], Liu et al. [51], Kumar et al. [10], Chen et al. [52]. |
| I: RQ2 | 7 | Li et al. [2], Tang et al. [47], Umair et al. [41], Liang et al. [43], Du et al. [48], Razzaq et al. [42], Gahlan and Sethia [34]. |
| C: RQ3 | 6 | Liu et al. [49], Heo et al. [50], Chen et al. [35], Liu et al. [51], Kumar et al. [10], Chen et al. [52]. |
| O: RQ4 | 13 | Li et al. [2], Tang et al. [47], Umair et al. [41], Liang et al. [43], Du et al. [48], Razzaq et al. [42], Gahlan and Sethia [34], Liu et al. [49], Heo et al. [50], Chen et al. [35], Liu et al. [51], Kumar et al. [10], Chen et al. [52]. |
| Author | Type of Entry | Category |
|---|---|---|
| Li et al. [2] | Images, EEG signals, electroencephalograms | Physiological–physical 1 |
| Tang et al. [47] | Electroencephalogram signal, EEG; electromyogram EMG; eye movement; body temperature; galvanic skin response, GSR; electrocardiogram, ECG; respiration | Physiological–physical |
| Umair et al. [41] | ECG, GSR, EEG signal, respiration amplitude, body temperature | Physiological 2 |
| Liang et al. [43] | EEG, videos | Physiological–physical |
| Du et al. [48] | EEG, videos | Physiological–physical |
| Razzaq et al. [42] | Video, audio, and image | Physical 3 |
| Gahlan and Sethia [34] | EEG, ECG Y, GSR | Physiological |
| Liu et al. [49] | Text and image | Physical |
| Heo et al. [50] | Audio and video | Physical |
| Chen et al. [35] | Image and text | Physical |
| Liu et al. [51] | Image and text | Physical |
| Kumar et al. [10] | Text and audiovisual | Physical |
| Chen et al. [52] | Image and text | Physical |
| Author | Proposed Models |
|---|---|
| Li et al. [2] | Mindlink-Eumpy is an open-source Python toolbox, AdaBoost, that improves accuracy by combining predictions from SVM and CNN. |
| Tang et al. [47] | Heterogeneous Robust Physiological Representations Network (RHPRnet) |
| Umair et al. [41] | Emo Fu-Sense employs LSTM and Recurrent Neural Networks (RNNs) |
| Liang et al. [43] | EEG-AVE, which stands for EEG with audiovisual embedding, is designed for interindividual affective detection. |
| Du et al. [48] | 3FACRNN, designed for multimodal emotion recognition, integrating visual and EEG networks |
| Razzaq et al. [42] | Hybrid multimodal emotion recognition (H-MMER) |
| Gahlan and Sethia [34] | AFLEMP (attention-based federated learning for emotion recognition using multimodal physiological data) |
| Feature | Traditional Systems | AI-Based Systems |
|---|---|---|
| Processing Type | Rules and heuristics | Deep learning and generative models |
| Integrated Modalities | Separate text, audio, or video | Integration of multiple signals simultaneously (vision, audio, EEG, EMG) |
| Adaptability | Limited to predefined rules | Adaptive through training with large volumes of data |
| Accuracy in Recognition | Dependent on the quality of the rules implemented | High precision based on big data and neural networks |
| Generalization to New Environments | Low, requires manual adjustments | High, adjusted by transfer learning |
| Scalability | Limited, requires manual reconfiguration | High, trainable in multiple languages and contexts |
| Examples of Models | Systems based on HMM, decision trees | Models based on CNN, LSTM, BERT, and multimodal Transformers |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bravo, L.; Rodriguez, C.; Hidalgo, P.; Angulo, C. A Systematic Review on Artificial Intelligence-Based Multimodal Dialogue Systems Capable of Emotion Recognition. Multimodal Technol. Interact. 2025, 9, 28. https://doi.org/10.3390/mti9030028
Bravo L, Rodriguez C, Hidalgo P, Angulo C. A Systematic Review on Artificial Intelligence-Based Multimodal Dialogue Systems Capable of Emotion Recognition. Multimodal Technologies and Interaction. 2025; 9(3):28. https://doi.org/10.3390/mti9030028
Chicago/Turabian StyleBravo, Luis, Ciro Rodriguez, Pedro Hidalgo, and Cesar Angulo. 2025. "A Systematic Review on Artificial Intelligence-Based Multimodal Dialogue Systems Capable of Emotion Recognition" Multimodal Technologies and Interaction 9, no. 3: 28. https://doi.org/10.3390/mti9030028
APA StyleBravo, L., Rodriguez, C., Hidalgo, P., & Angulo, C. (2025). A Systematic Review on Artificial Intelligence-Based Multimodal Dialogue Systems Capable of Emotion Recognition. Multimodal Technologies and Interaction, 9(3), 28. https://doi.org/10.3390/mti9030028