


diaLogic: A Multi-Modal Framework for Automated Team Behavior Modeling Based on Speech Acquisition



Abstract
1. Introduction
2. Related Work
3. Modeling Human Behavior Using Invariants
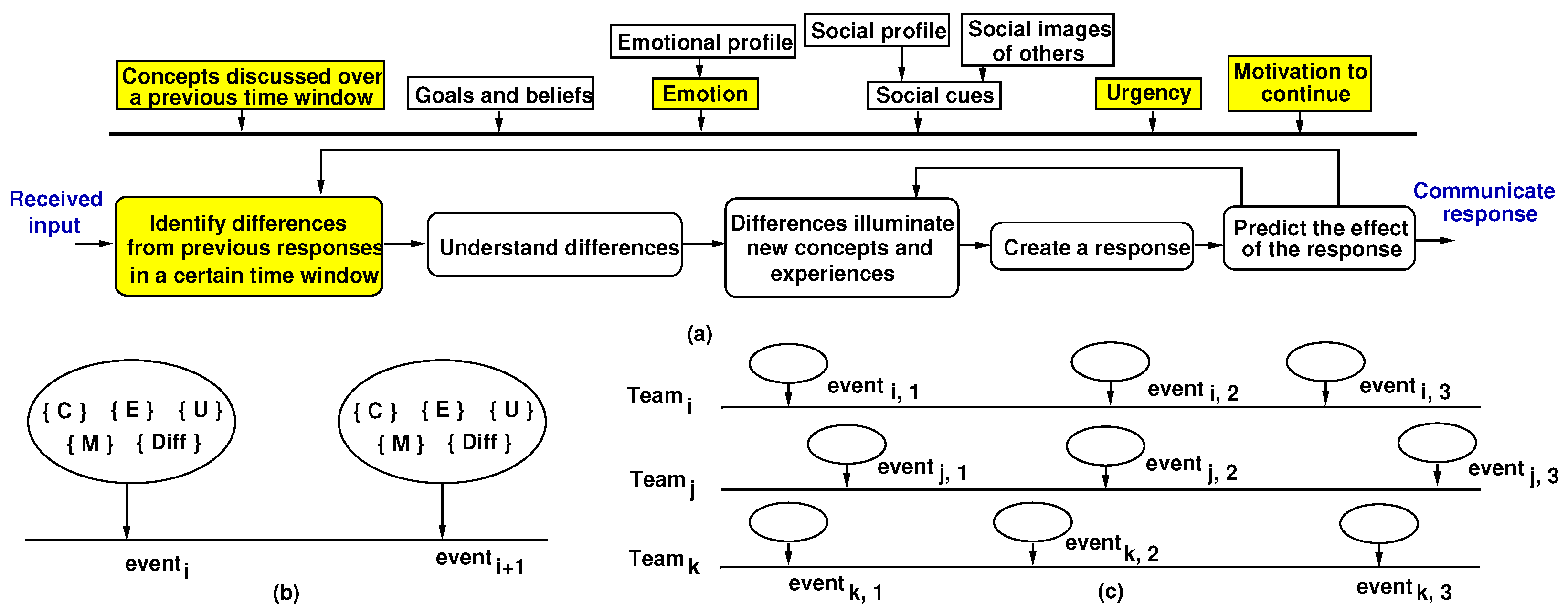
3.1. Invariants and Hypothesis Extraction
3.2. Metrics, Similarity, and Dissimilarity
4. System Design and Metrics
4.1. Speaker Diarization
| Algorithm 1 Temporal smoothing algorithm |
|
4.2. Speaker Interaction Detection
4.3. Speech Emotion Recognition
4.4. Speech-to-Text Conversion
4.5. Speech Clause Detection
- Each word is marked with the verb associated with it and whether it occurs before or after the verb. This double word tagging is used to determine the clause types.
- Clauses correspond to each of the detected subjects: who and for who clauses correspond to the PERSON category; what clauses are represented by the ORGANIZATION and MISC categories; when clauses relate to the DATE, TIME, DURATION, and SET categories; and where clauses are represented by the LOCATION category. The first instance of words in what, where, and when clauses are recorded.
- If a noun with the PERSON label comes before the corresponding verb in a sentence, the word is marked as a who clause.
- If the same noun comes after the verb, the word is labeled as a for who clause.
- How clauses are represented by words that are adverbs. Descriptor words for how clauses are recorded if they are associated with a verb, and one instance of descriptor words is recorded for each verb.
- Why clauses are represented as the following sentence structures: Because [blank] [verb] [blank] [descriptor] is used if two nouns are associated with a verb and a descriptor is present; otherwise, Because [blank] [verb] [descriptor] is used if a descriptor is present but a second noun is not. Similarly, Because [blank] [verb] [blank] is utilized if a second noun is present but a descriptor is not. Some examples of a coherent why sentence are “Because they did programming well” and “Because I took courses sparingly”. An attempt is made to build one why clause for each verb in the original sentence.
- Assuming the same sentence structures as for why clauses, for consequence clauses, the verb, along with the noun or descriptor in the second blank, is formed into a separate sentence. From the examples above, the consequences would be did programming and took courses, respectively. One consequence cause is built for every verb in the original sentence.
- Sentences that do not contain verbs in a multi-sentence utterance are ignored, and the speech clauses are detected for the next sentence.
- Utterances that do not contain text are ignored.
4.6. Hypothesis Extraction
5. Experimental Results
5.1. Performance Data
5.2. Speaker Diarization
5.3. Speaker Interaction Graph Generation
5.4. Speaker Emotion Recognition
5.5. Speech-to-Text Conversion and Words-per-Minute Estimation
5.6. Speech Clause Detection
5.7. Team Behavior Hypothesis Extraction
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wu, X.; Xiao, L.; Sun, Y.; Zhang, J.; Ma, T.; He, L. A Survey of Human-in-the-Loop for Machine Learning. Future Gener. Comput. Syst. 2022, 135, 364–381. [Google Scholar] [CrossRef]
- Hong, J.; Hong, Y.-G.; de Foy, X.; Kovatsch, M.; Schooler, E.; Kutscher, D. Internet of Things (IoT) Edge Challenges and Functions. Internet Research Task Force (IRTF) 2024, RFC: 556, April.
- Tehrani, B.M.; Wang, J.; Wang, C. Review of Human-in-the-Loop Cyber-Physical Systems (HiLCPS): The Current Status from Human Perspective. In Proceedings of the ASCE International Conference on Computing in Civil Engineering, Atlanta, GA, USA, 17–19 June 2019; pp. 470–478. [Google Scholar]
- Doboli, A.; Doboli, S. A Novel Agent-based, Evolutionary Model for Expressing the Dynamics of Creative Open-Problem Solving in Small Groups. Appl. Intell. 2021, 51, 2094–2127. [Google Scholar] [CrossRef]
- Cutler, R.; Davis, L. Look Who’s Talking: Speaker Detection Using Video and Audio Correlation. In Proceedings of the IEEE International Conference on Multimedia and Expo., New York, NY, USA, 30 July–2 August 2000; Volume 3, pp. 1589–1592. [Google Scholar]
- Kumar, M.; Kim, S.H.; Lord, C.; Narayanan, S. Improving Speaker Diarization for Naturalistic Child-Adult Conversational Interactions Using Contextual Information. J. Acoust. Soc. Am. 2020, 147, EL196. [Google Scholar] [CrossRef] [PubMed]
- Cabrera, A.; Cabrera, E. Knowledge-sharing dilemmas. Organ. Stud. 2002, 23, 687–710. [Google Scholar] [CrossRef]
- Fischbacher, U.; Gachter, S.; Fehr, E. Are People Conditionally Cooperative? Evidence from a Public Goods Experiment. Econ. Lett. 2001, 71, 397–404. [Google Scholar] [CrossRef]
- Edmondson, A. Psychological safety and learning behavior in work teams. Adm. Sci. Q. 1999, 44, 350–383. [Google Scholar] [CrossRef]
- Edmondson, A.; Kramer, R.; Cook, K. Psychological Safety, Trust, and Learning in Organizations: A Group-level Lens. Trust. Distrust Organ. Dilemmas Approaches 2004, 12, 239–272. [Google Scholar]
- Duke, R.; Doboli, A. diaLogic: Interaction-Focused Speaker Diarization. In Proceedings of the IEEE International Systems Conference (SysCon), Vancouver, BC, Canada, 15 April–15 May 2021; pp. 1–8. [Google Scholar]
- Duke, R.; Doboli, A. diaLogic: Non-Invasive Speaker-Focused Data Acquisition for Team Behavior Modeling. arXiv 2022, arXiv:2209.00619. [Google Scholar]
- Fauconnier, G.; Turner, T. The Way We Think: Conceptual Blending and the Mind’s Hidden Complexities; Basic Books: New York, NY, USA, 2002. [Google Scholar]
- Doboli, A.; Curiac, D.-I. Studying Consensus and Disagreement during Problem Solving in Teams through Learning and Response Generation Agents Model. Mathematics 2023, 11, 2602. [Google Scholar] [CrossRef]
- Duke, R.; Doboli, A. Applications of diaLogic System in Individual and Team-based Problem-Solving Applications. In Proceedings of the IEEE International Symposium on Smart Electronic Systems (iSES), Warangal, India, 18–22 December 2022; pp. 706–711. [Google Scholar]
- Radford, A.; Kim, J.W.; Xu, T.; Brockman, G.; McLeavey, C.; Sutskever, I. Robust Speech Recognition via Large-Scale Weak Supervision. arXiv 2022, arXiv:2212.04356. [Google Scholar]
- Manning, C.; Surdeanu, M.; Bauer, J.; Finkel, J.; Bethard, S.; McClosky, D. The Stanford CoreNLP Natural Language Processing Toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 23–24 June 2014; pp. 55–60. [Google Scholar]
- Tan, L. Pywsd: Python Implementations of Word Sense Disambiguation (WSD) Technologies [software]. 2014. Available online: https://github.com/alvations/pywsd (accessed on 9 March 2025).
- Jurafsky, D.; Martin, J. Speech and Language Processing; Pearson Prentice Hall: Old Bridge, NJ, USA, 2009. [Google Scholar]
- Park, T.J.; Kanda, N.; Dimitriadis, D.; Han, K.J.; Watanabe, S.; Narayanan, S. A Review of Speaker Diarization: Recent Advances with Deep Learning. Comput. Speech Lang. 2022, 72, 101317. [Google Scholar] [CrossRef]
- Sun, L.; Du, J.; Jiang, C.; Zhang, X.; He, S.; Yin, B.; Lee, C.-H. Speaker Diarization with Enhancing Speech for the First DIHARD Challenge. In Proceedings of the INTERSPEECH, Hyderabad, India, 2–6 September 2018; pp. 2793–2797. [Google Scholar]
- Cyrta, P.; Trzcinski, T.; Stokowiec, W. Speaker Diarization using Deep Recurrent Convolutional Neural Networks for Speaker Embeddings. In Advances in Intelligent Systems and Computing; Springer: Cham, Switzerland, 2017; pp. 107–117. [Google Scholar]
- Aronowitz, H.; Zhu, W.; Suzuki, M.; Kurata, G.; Hoory, R. New Advances in Speaker Diarization. In Proceedings of the INTERSPEECH, Shanghai, China, 25–29 October 2020; pp. 279–283. [Google Scholar]
- Siracusa, M.; Fisher, J. Dynamic Dependency Tests for Audio-Visual Speaker Association. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Honolulu, HI, USA, 16–20 April 2007; pp. 457–460. [Google Scholar]
- Capozzi, F.; Beyan, C.; Pierro, A.; Koul, A.; Murino, V.; Livi, S.; Bayliss, A.; Ristic, J.; Becchio, C. Tracking the Leader: Gaze Behavior in Group Interactions. iScience 2019, 16, 242–249. [Google Scholar] [CrossRef] [PubMed]
- Pierro, A.; Mannetti, L.; De Grada, E.; Livi, S.; Kruglanski, A.W. Autocracy Bias in Informal Groups under Need for closure. Personal. Soc. Psychol. Bull. 2003, 29, 405–417. [Google Scholar] [CrossRef]
- Risko, E.F.; Richardson, D.C.; Kingstone, A. Breaking the Fourth Wall of Cognitive Science: Real-World Social Attention and the Dual Function of Gaze. Curr. Dir. Psychol. Sci. 2016, 25, 70–74. [Google Scholar] [CrossRef]
- Wang, W.; Yaman, S.; Precoda, K.; Richey, C. Automatic Identification of Speaker Role and Agreement/Disagreement in Broadcast Conversation. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 5556–5559. [Google Scholar]
- Burkhardt, F.; Paeschke, A.; Rolfes, M.; Sendlmeier, W.; Weiss, B. A Database of German Emotional Speech. In Proceedings of the INTERSPEECH, Lisbon, Portugal, 4–8 September 2005. [Google Scholar] [CrossRef]
- Semwal, N.; Kumar, A.; Narayanan, S. Automatic Speech Emotion Detection System using Multi-Domain Acoustic Feature Selection and Classification Models. In Proceedings of the IEEE International Conference on Identity, Security and Behavior Analysis (ISBA), New Delhi, India, 22–24 February 2017; pp. 1–6. [Google Scholar]
- Kanth, N.R.; Saraswathi, S. Efficient Speech Emotion Recognition Using Binary Support Vector Machines & Multiclass SVM. In Proceedings of the IEEE International Conference on Computational Intelligence and Computing Research, Madurai, India, 10–12 December 2015; pp. 1–6. [Google Scholar]
- Sun, T.-W. End-to-End Speech Emotion Recognition With Gender Information. IEEE Access 2020, 8, 152423–152438. [Google Scholar] [CrossRef]
- Zhong, S.; Yu, B.; Zhang, H. Exploration of an Independent Training Framework for Speech Emotion Recognition. IEEE Access 2020, 8, 222533–222543. [Google Scholar] [CrossRef]
- Suganya, S.; Charles, E. Speech Emotion Recognition Using Deep Learning on Audio Recordings. In Proceedings of the International Conference on Advances in ICT for Emerging Regions, Colombo, Sri Lanka, 3–4 September 2019; pp. 1–6. [Google Scholar]
- Del Corro, L.; Gemulla, R. ClausIE: Clause-Based Open Information Extraction. In Proceedings of the International Conference World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 355–366. [Google Scholar]
- Chen, X.; Alexopoulou, T.; Tsimpli, I. Automatic Extraction of Subordinate Clauses and Its Application in Second Language Acquisition Research. Behav. Res. Methods 2022, 53, 803–817. [Google Scholar] [CrossRef]
- Gagnon, M.; Sylva, L. Text Summarization by Sentence Extraction and Syntactic Pruning. In Proceedings of the Computational Linguistics in the North East, Storrs, CT, USA, 22–24 October 2004; Available online: https://api.semanticscholar.org/CorpusID:58920425 (accessed on 9 March 2025).
- Heilman, M.; Smith, N. Extracting Simplified Statements for Factual Question Generation. In Proceedings of the Third Workshop on Question Generation, Tenth International Conference on Intelligent Tutoring Systems, Pittsburgh, PA, USA, 18 June 2010; Available online: https://api.semanticscholar.org/CorpusID:2123424 (accessed on 9 March 2025).
- Atabuzzaman, M.; Shajalal, M.; Ahmed, M.E.; Afjal, M.I.; Aono, M. Leveraging Grammatical Roles for Measuring Semantic Similarity Between Texts. IEEE Access 2021, 9, 62972–62983. [Google Scholar] [CrossRef]
- Dornescu, I.; Evans, R.; Orasan, C. Relative Clause Extraction for Syntactic Simplification. In Proceedings of the Workshop on Automatic Text Simplification—Methods and Applications in the Multilingual Society, Dublin, Ireland, 24 August 2014; pp. 1–10. [Google Scholar]
- Doboli, A.; Umbarkar, A.; Doboli, S.; Betz, J. Modeling Semantic Knowledge Structures for Creative Problem Solving: Studies on Expressing Concepts, Categories, Associations, Goals and Context. Knowl.-Based Syst. 2015, 78, 34–50. [Google Scholar] [CrossRef]
- Fellbaum, C. WordNet and Wordnets. In Encyclopedia of Language and Linguistics, 2nd ed.; Brown, K., Ed.; Elsevier: Oxford, UK, 2005; pp. 665–670. [Google Scholar]
- Ravanelli, M.; Parcollet, T.; Plantinga, P.; Rouhe, A.; Cornell, S.; Lugosch, L.; Subakan, C.; Dawalatabad, N.; Heba, A.; Zhong, J.; et al. SpeechBrain: A General-Purpose Speech Toolkit. arXiv 2021, arXiv:2106.04624. [Google Scholar]
- Bredin, H.; Yin, R.; Coria, J.; Gelly, G.; Korshunov, P.; Lavechin, M.; Fustes, D.; Titeux, H.; Bouaziz, W.; Gill, M. pyannote.audio: Neural Building Blocks for Speaker Diarization. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Barcelona, Spain, 4–8 May 2020; pp. 7124–7128. [Google Scholar]
- webrtc/common_audio/vad-external/webrtc. Available online: https://chromium.googlesource.com/external/webrtc/stable/src/+/b34066b0ebe4a9adc6df603090afdf6a2b2a986b/common_audio/vad/vad_core.h (accessed on 9 March 2025).
- Clevert, D.-A.; Unterthiner, T.; Hochreiter, S. Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs). arXiv 2016, arXiv:1511.07289. [Google Scholar]
- Xia, W.; Lu, H.; Wang, Q.; Tripathi, A.; Huang, Y.; Lopez Moreno, I.; Sak, H. Turn-to-Diarize: Online Speaker Diarization Constrained by Transformer Transducer Speaker Turn Detection. arXiv 2022, arXiv:2109.11641. [Google Scholar]
- Bredin, H.; Laurent, A. End-to-end Speaker Segmentation for Overlap-aware Resegmentation. In Proceedings of the Interspeech, Annual Conference of the International Speech Communication Association, Brno, Czech Republic, 30 August–3 September 2021; Available online: https://api.semanticscholar.org/CorpusID:233204561 (accessed on 9 March 2025).
- Lyu, K.; Lyu, R.; Chang, H. Real-time Multilingual Speech Recognition and Speaker Diarization System based on Whisper Segmentation. PeerJ Comput. Sci. 2024, 10, e1973. [Google Scholar] [CrossRef] [PubMed]
- Yella, S.; Valente, F. Speaker diarization of overlapping speech based on silence distribution in meeting recordings. In Proceedings of the Interspeech, Portland, OR, USA, 9–13 September 2012; pp. 490–493. [Google Scholar]
- Le Prell, C.; Clavier, O. Effects of noise on speech recognition: Challenges for communication by service members. Hear. Res. 2017, 349, 76–89. [Google Scholar] [CrossRef] [PubMed]
- Castiblanco Jimenez, I.A.; Olivetti, E.C.; Vezzetti, E.; Moos, S.; Celeghin, A.; Marcolin, F. Effective Affective EEG-based Indicators in Emotion-Evoking VR Environments: An Evidence from Machine Learning. Neural Comput. Applic. 2024, 36, 22245–22263. [Google Scholar] [CrossRef]
- Valenza, G.; Citi, L.; Lanata, A.; Scilingo, E.P.; Barbieri, R. Revealing Real-Time Emotional Responses: A Personalized Assessment based on Heartbeat Dynamics. Sci. Rep. 2014, 4, 4998. [Google Scholar] [CrossRef]
- Google. Speech-to-Text: Automatic Speech Recognition|Google Cloud. Available online: https://cloud.google.com/speech-to-text (accessed on 2 May 2022).
- Microsoft Azure. Speech to Text Audio to Text Translation|Microsoft Azure. Available online: https://azure.microsoft.com/en-us/services/cognitive-services/speech-to-text/#overview (accessed on 2 May 2022).
- CABank English CallHome Corpus. Cabank English Callhome Corpus. Available online: https://ca.talkbank.org/access/CallHome/eng.html (accessed on 9 March 2025).
- Bredin, H. pyannote.metrics: A Toolkit for Reproducible Evaluation, Diagnostic, and Error Analysis of Speaker Diarization Systems. In Proceedings of the Interspeech, Annual Conference of the International Speech Communication Association, Stockholm, Sweden, 20–24 August 2017; pp. 3587–3591. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Neural Network Model | Training Time (h:mm:ss) |
|---|---|
| Speaker Diarization | 6 days 11 h |
| SER | 5:01:08 |
| Data Segmentation (h:mm:ss) | CNN Predictions (h:mm:ss) | Spectral Clustering (h:mm:ss) | Temporal Smoothing (h:mm:ss) | Resegmentation |
|---|---|---|---|---|
| 0:02:54 | 0:03:36 | 0:00:08 | 0:00:01 | 0:02:29 |
| Correct (%) | Conf. (%) | Missed (%) | FA (%) | DER (%) |
|---|---|---|---|---|
| 88.0 | 9.2 | 2.8 | 3.5 | 15.5 |
| Video | # Int. | # Inter. | # Adj. Inter. | Inter. (%) | Adj. Inter. (%) |
|---|---|---|---|---|---|
| G2 T1 | 207 | 26 | 14 | 12 | 6 |
| G6 T1 | 157 | 28 | 20 | 17 | 12 |
| G110 T2 | 208 | 52 | 44 | 25 | 21 |
| Data Segmentation (h:mm:ss) | CNN Predictions (h:mm:ss) | Data Concatenation (h:mm:ss) |
|---|---|---|
| 0:00:08 | 0:06:21 | 0:00:07 |
| Video | # Senten. | # Senten. w/Ambig. Error | Senten. w/Ambig. Error (%) | # Senten. w/Alg. Error | Senten. w/Alg. Error (%) |
|---|---|---|---|---|---|
| G7T1 | 50 | 7 | 14 | 8 | 16 |
| G8T1 | 50 | 10 | 20 | 5 | 10 |
| G9T1 | 50 | 12 | 24 | 6 | 12 |
| G10T1 | 50 | 8 | 16 | 8 | 16 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Duke, R.; Doboli, A. diaLogic: A Multi-Modal Framework for Automated Team Behavior Modeling Based on Speech Acquisition. Multimodal Technol. Interact. 2025, 9, 26. https://doi.org/10.3390/mti9030026
Duke R, Doboli A. diaLogic: A Multi-Modal Framework for Automated Team Behavior Modeling Based on Speech Acquisition. Multimodal Technologies and Interaction. 2025; 9(3):26. https://doi.org/10.3390/mti9030026
Chicago/Turabian StyleDuke, Ryan, and Alex Doboli. 2025. "diaLogic: A Multi-Modal Framework for Automated Team Behavior Modeling Based on Speech Acquisition" Multimodal Technologies and Interaction 9, no. 3: 26. https://doi.org/10.3390/mti9030026
APA StyleDuke, R., & Doboli, A. (2025). diaLogic: A Multi-Modal Framework for Automated Team Behavior Modeling Based on Speech Acquisition. Multimodal Technologies and Interaction, 9(3), 26. https://doi.org/10.3390/mti9030026