3.1. Datasets
In choosing the datasets, we are interested in having Italian and English versions of data, with textual descriptions long enough to fit the purpose, and possibly tagged. Here a brief description of the four datasets used.
FilmTV movies dataset (
https://www.kaggle.com/stefanoleone992/filmtv-movies-dataset), from now on referred to as Movie, provides the information on movies with data on how users from different countries rate the movies compared to each other. Data has been scraped from the publicly available website
https://www.filmtv.it (accessed on 24 November 2019). Each row represents a movie available on FilmTV.it, with the original title, year, genre, duration, country, director, actors, average vote, and votes. Both versions (English and Italian) contain 53,497 movies, and the Italian version contains one extra-attribute for the local title used when the movie was published in Italy. The “description” of the movie has been used for extracting keywords. The length of the text is variable, ranging from a simple phrase, that gives some hints of the plot, to a more detailed explanation of the movie. The language, both in Italian and in English, is plain, without jargon or technicalities.
Food.com Recipes and Interactions dataset (
https://www.kaggle.com/shuyangli94/food-com-recipes-and-user-interactions), from now on referred to as Recipe (English version), consists of 180K+ recipes and 700K+ recipe reviews covering 18 years of user interactions and uploads on Food.com (formerly GeniusKitchen). For our purpose, this dataset is perfect, having each recipe a textual description of the steps involved, and tags associated. The language used to outline the procedure is simple, but the nouns of kitchen ingredients and tools are rarely used in ordinary conversation.
Recipe (Italian version) is a dataset with 28,200 Italian recipes, with ingredients, and food preparation steps. The dataset was created by Giorgio Musilli (
https://www.dbricette.it). The preparation steps, used as input to extract keywords, use a basic language, with verbs to infinitive and some essential information on how to combine, cut, cook the ingredients.
The summary of the main information on the 4 datasets used, two in Italian and two in English, is shown in
Table 2. The datasets are rather different, both in the length of the sentences and in the number of candidate words present.
3.2. Experiments
The method depicted in
Figure 1 has been implemented, according to the steps defined in
Table 3, described in depth in their computational aspects.
The data have been pre-processed according to the standard pipeline, presented previously.
This preprocessing phase aims to extract from phases in plain language noun or noun phrases. The tool(s) identified and possibly integrated should, therefore, be able to understand the phrases structures and dependencies structure, to correctly identify noun phrases.
Tools present in the literature have been identified and tested: for the English language, datasets were processed using standard tools, such as Stanford’s core NLP suite, Natural Language Toolkit NLTK [
30] of Python, with PENN Treebank [
31] as a POS tagger and tokenizer.
Stanford’s core NLP suite offers a set of tools for managing natural Languages. It can give the base forms of words, their parts of speech (POS), normalize dates, times, and numeric quantities, and identify noun phrases and mark up the structure of sentences in terms of phrases and syntactic dependencies [
32].
Natural Language Toolkit NLTK is a tool able to work with human language data. It provides a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning.
SpaCy is an open-source software library for advanced NLP and features convolutional neural network models for part-of-speech tagging, dependency parsing, and named entity recognition (NER). It offers pre-built statistical neural network models (also for the Italian language) as well as tools to train custom models on their own datasets.
Pattern, developed by Clips (Computational Linguistics & Psycholinguistics) at the University of Antwerp, is a Python package for web mining, natural language processing, machine learning, and network analysis, with a focus on ease-of-use [
33].
For the preprocessing of the Italian datasets, some preliminary tests have been performed with the NLTK package, the Pattern python package specific for Italian, and Spacy (with pre-trained Italian model), but they do not provide acceptable results. Stanford core NLP has not developed tools for the Italian language.
The main problems are encountered with POS tagging, probably due to an incorrect syntactic interpretation of the sentence: for example, adjectives, which have the same form of a verb, are misinterpreted, and therefore possible noun phrases are not identified.
The tool that proved to work best is the TreeTagger [
21], a free tool developed by Helmut Schmid at the Institute for Computational Linguistics of the University of Stuttgart, using the standard Italian tagset, although it still has some issues for both POS tagging and lemmatization.
To identify n-gram words, different procedures and tools were tested. In the end, based on experimental evaluations, we started from a grammatical analysis by TreeTagger, able to identify grammatical structures in sentences and dependencies, and integrated the results with NLTK and dependency parsing tools: in this way, integrating NLTK and TreeTagger, it was possible to identify n-grams words that appear in documents.
After POS tagging, single words that are nouns and compound words that are nouns and adjectives (according to the grammatical rules of each language) were held on the four datasets.
Table 4 reports the total number of candidate keywords and the number of different words, either single or compound.
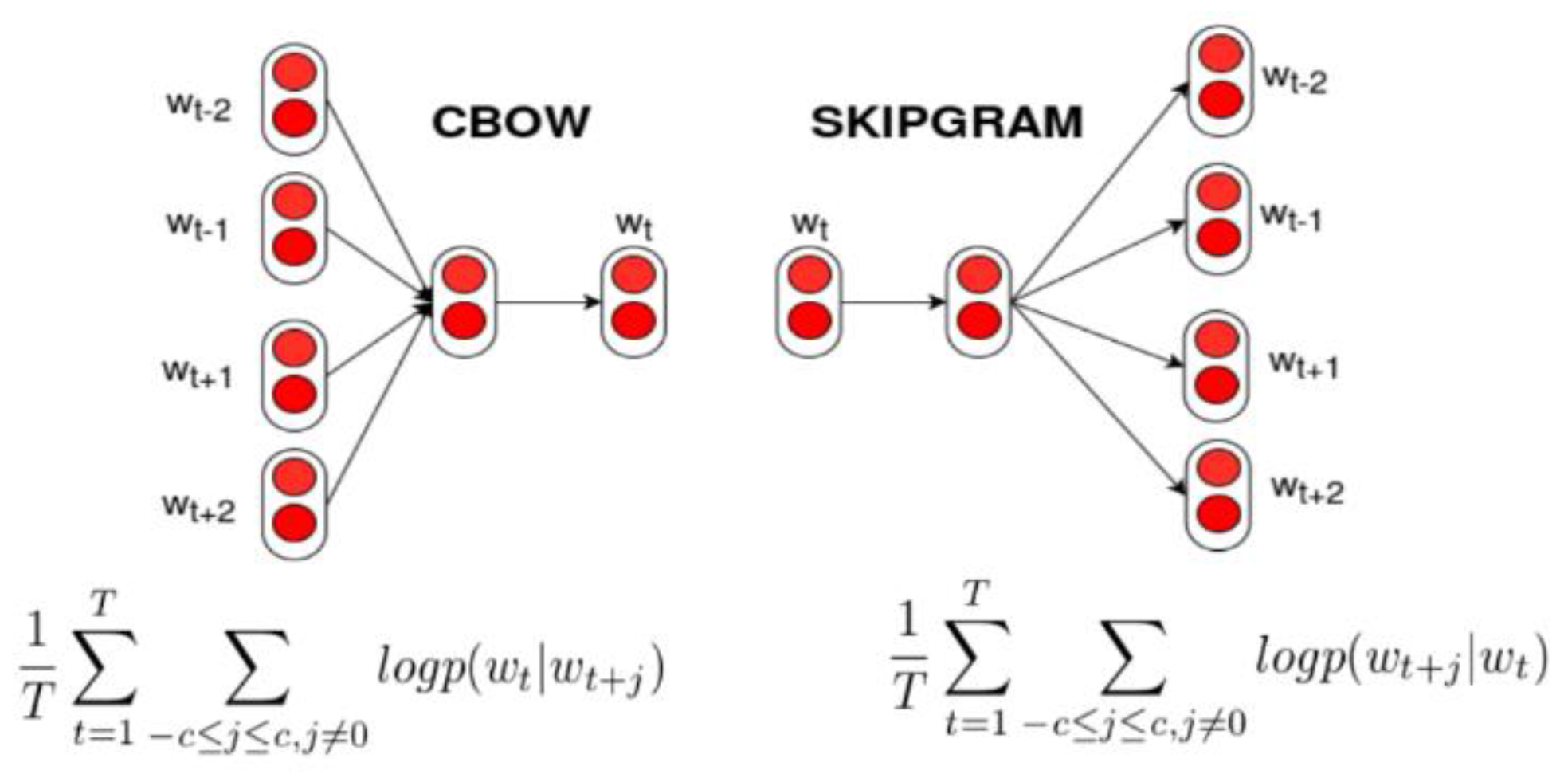
To estimate the semantic relatedness of words and to compute their similarity, we have used Word2Vec and GloVe pre-trained models in English and Italian. In detail the models used:
In
Table 4, the dimension of pre-trained word embedding models used is shown.
For all models used, the vector length is 300 features.
From the pre-trained models, the vectors corresponding to the candidate keywords have been extracted. The vectors of the n-gram words have been calculated as an average of the vectors of the single words, if present in the model, according to the formula defined above in Equation (3).
In
Appendix B,
Table A5 details the percentage of coverage, that is how many candidate keywords are present in the word embedding model considered, how many terms are present in the model (in model), and how many are out of vocabulary (oo vocab) terms.
Table A5 reports data for 1-g and
n-grams, respectively.
The out of vocabulary terms, that terms not present in the models, can be grouped in three main categories:
Terms with some typos, as “washignton” or “agosciosa”, the n of “angosciosa” is missing (anguished) or “areoporto” misspelled for airport. This category of terms can be automatically corrected using a tool able to measure the distance of two words, e.g., based on character exchange.
Technicalities or sector-specific terms, such as “chorizos” from recipe/en or “brunoise” (of French origin, indicating a technique for cutting vegetables) from recipe/it. A training phase to add these terms to the word embedding models should be undergone to deal with these cases.
Diminutives or nicknames, which are very frequent in Italian, as “padellino” (that mean little saucepan) or “ziette”, aunts or “storiellina”, nice little stories. A lemmatization/stemmer tool should be trained to be able to deal with these kinds of modification of words.
It is worth noting that in general w2v wiki and GloVe have greater coverage, while w2v google has many terms outside the vocabulary, due probably to the low number of terms in the models. This is especially valid for the pre-trained model on google news in Italian. The movie datasets, both in Italian and English, show a very high percentage of coverage, because of the common words used in the description, while the recipes, to different extents, suffer the problem of the kitchen-specific words. The recipe/en generally exceeds for out-of-vocabulary terms and is the only case where the number of oo terms is higher for the w2vwiki model than for GloVe.
Then, semantic relatedness matrices were calculated, based respectively on the measurement of cosine similarity and Euclidean distance, able to measure the relatedness of any two words, based on embedded vectors.
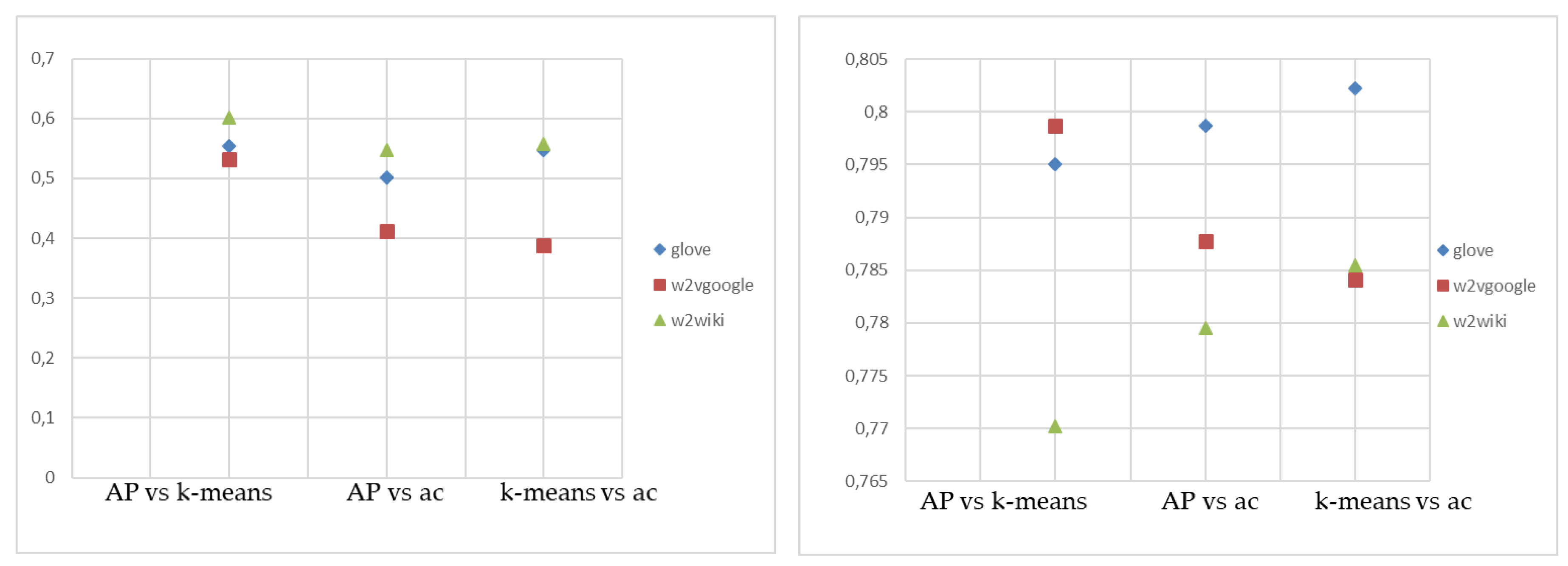
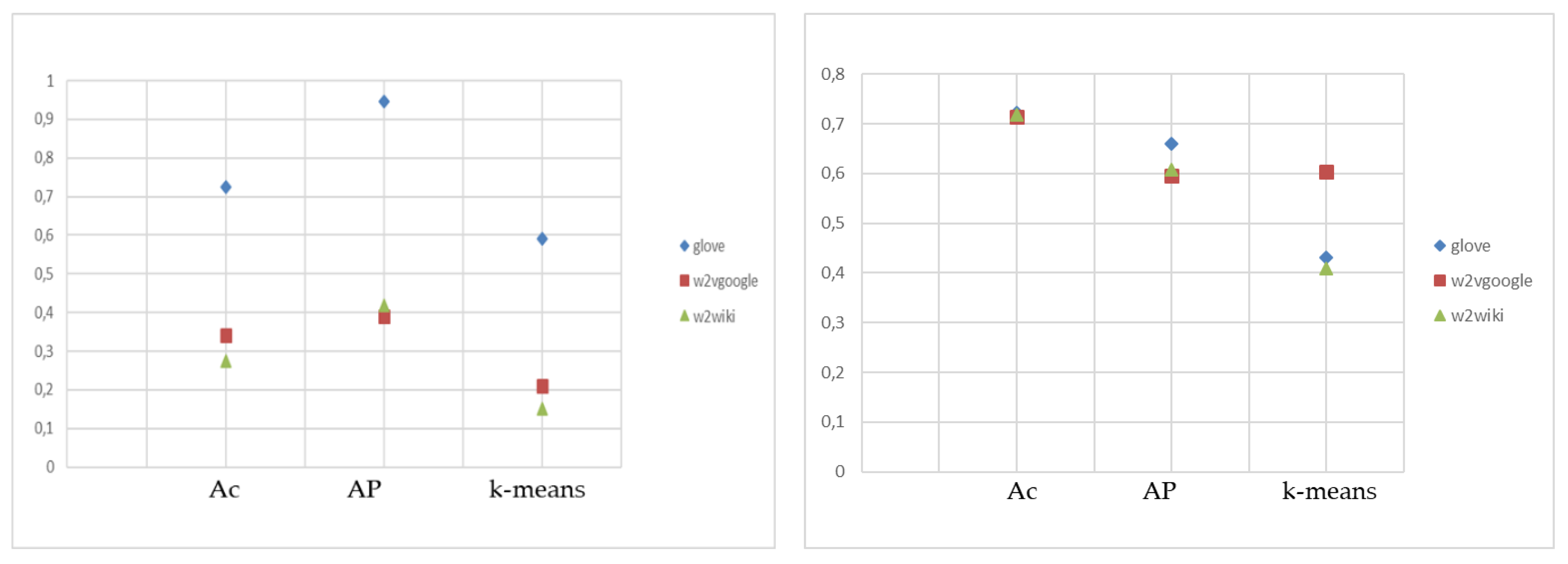
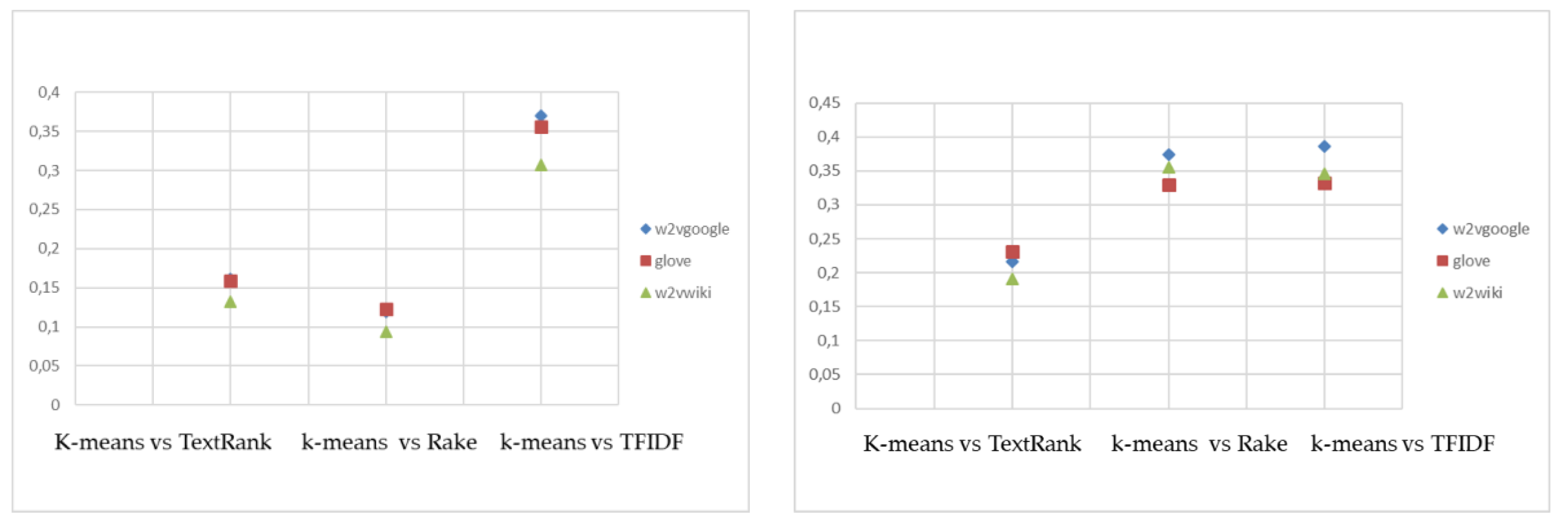
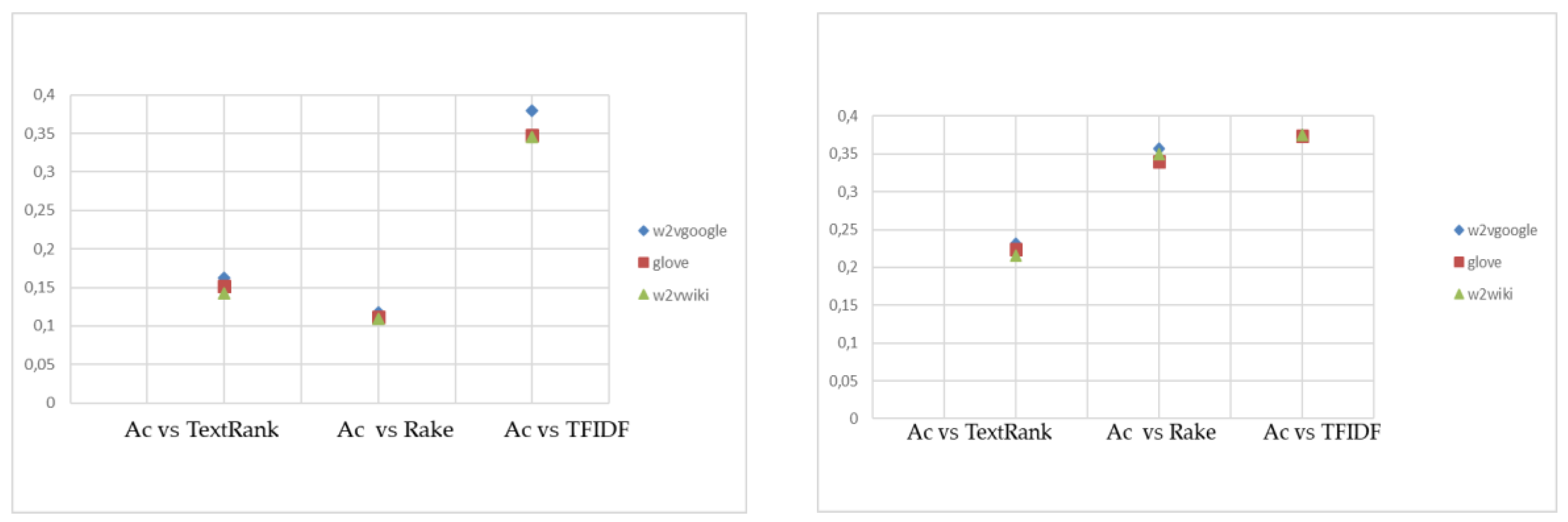
The cluster algorithms have been applied to the similarity matrices, related to the terms (and their vectors) of the candidate keywords, using different criteria of similarity, cosine similarity, and Euclidean distance. The algorithms used were: Affinity Propagation, K-means, and hierarchical clustering. K-means and hierarchical clustering algorithms require the number of clusters as input: therefore, the number of clusters obtained by the Affinity Propagation on cosine similarity measurements and Euclidean distance has been inserted in these cases.
Table 5 reports results on the clustering process, using the clustering algorithms on the four datasets, with the word embedding models.
Our method, starting from candidate keywords, identifies those words that are centroid or n terms (1-g or n-gram) closer to the centroid. If the number of clusters is higher, the extracted keywords are more numerous.
In general, it can be noted that the number of clusters obtained depends greatly from the word embedding model used, hence on the number of terms usable, and is higher for the Cosine similarity matrix with respect to Euclidian distance.
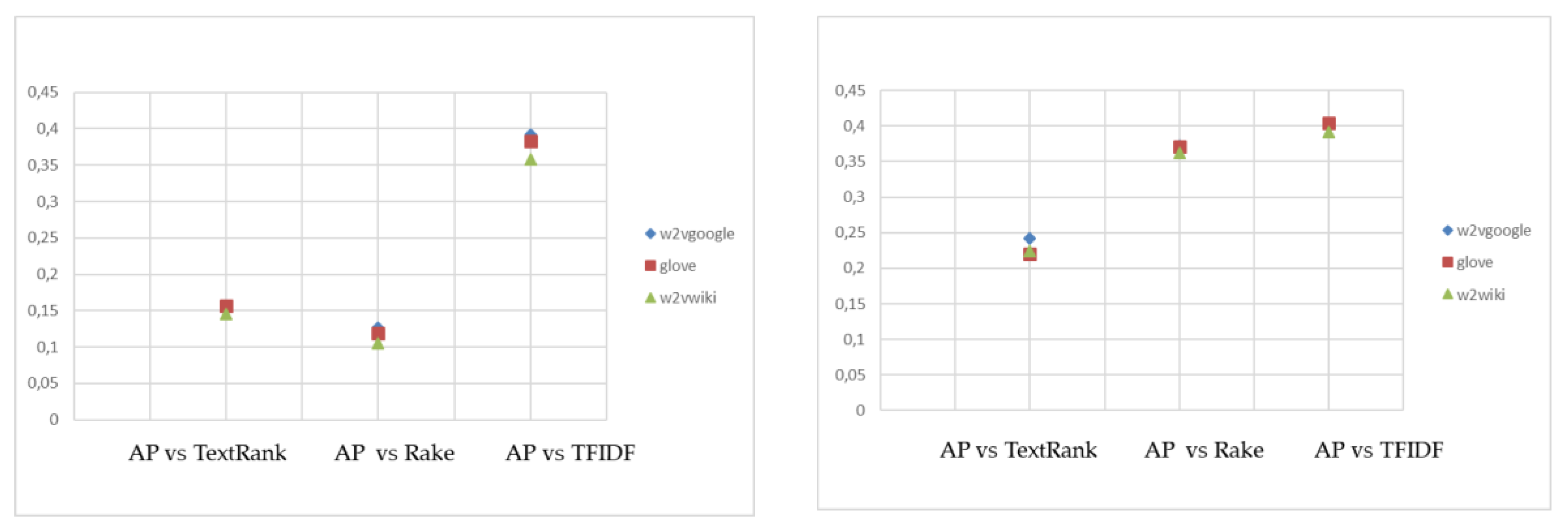
The last step is the extraction of keyphrases to be associated with each text. We have matched candidate keywords/keyphrases extracted from the text, eventually in the form of (1) or (2), with the term(s) closest to the centroid of the clustering algorithms. In particular, for Affinity Propagation, the centroid is exactly the exemplar, while for K-mean and hierarchical clustering, the k terms closest to the centroid (calculated, if not available, as the average of its members) have been identified. For greater homogeneity and to allow a better comparison among the algorithms, also for Affinity Propagation have been extracted, besides the exemplar, the k-1 closest terms.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






