Prediction of Who Will Be Next Speaker and When Using Mouth-Opening Pattern in Multi-Party Conversation †



Abstract
:1. Introduction
2. Related Work
2.1. Prediction of Next Speaker and Utterance Interval
2.2. Mouth-Opening Movement and Speaking
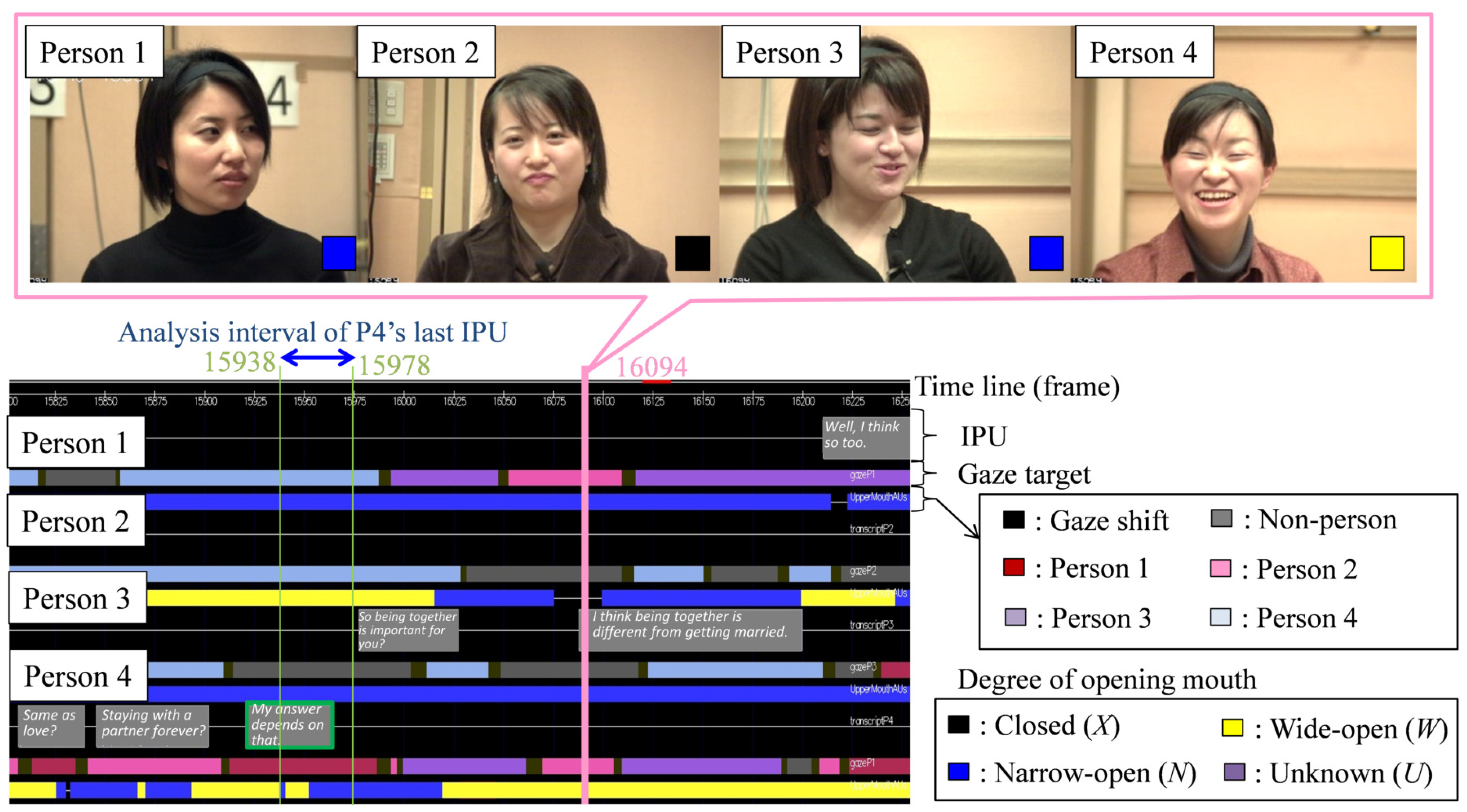
3. Corpus Data of Multi-Party Conversation
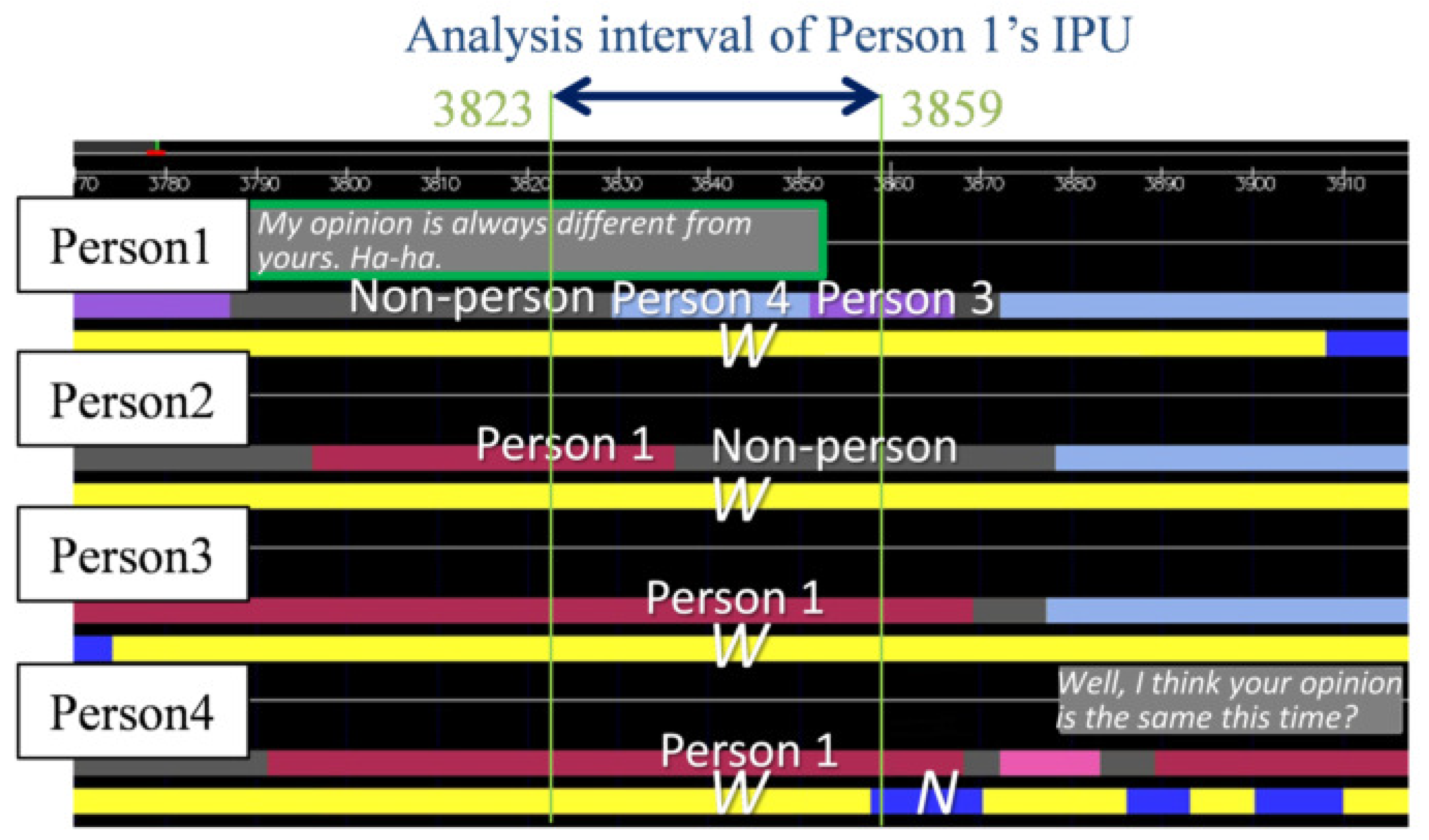
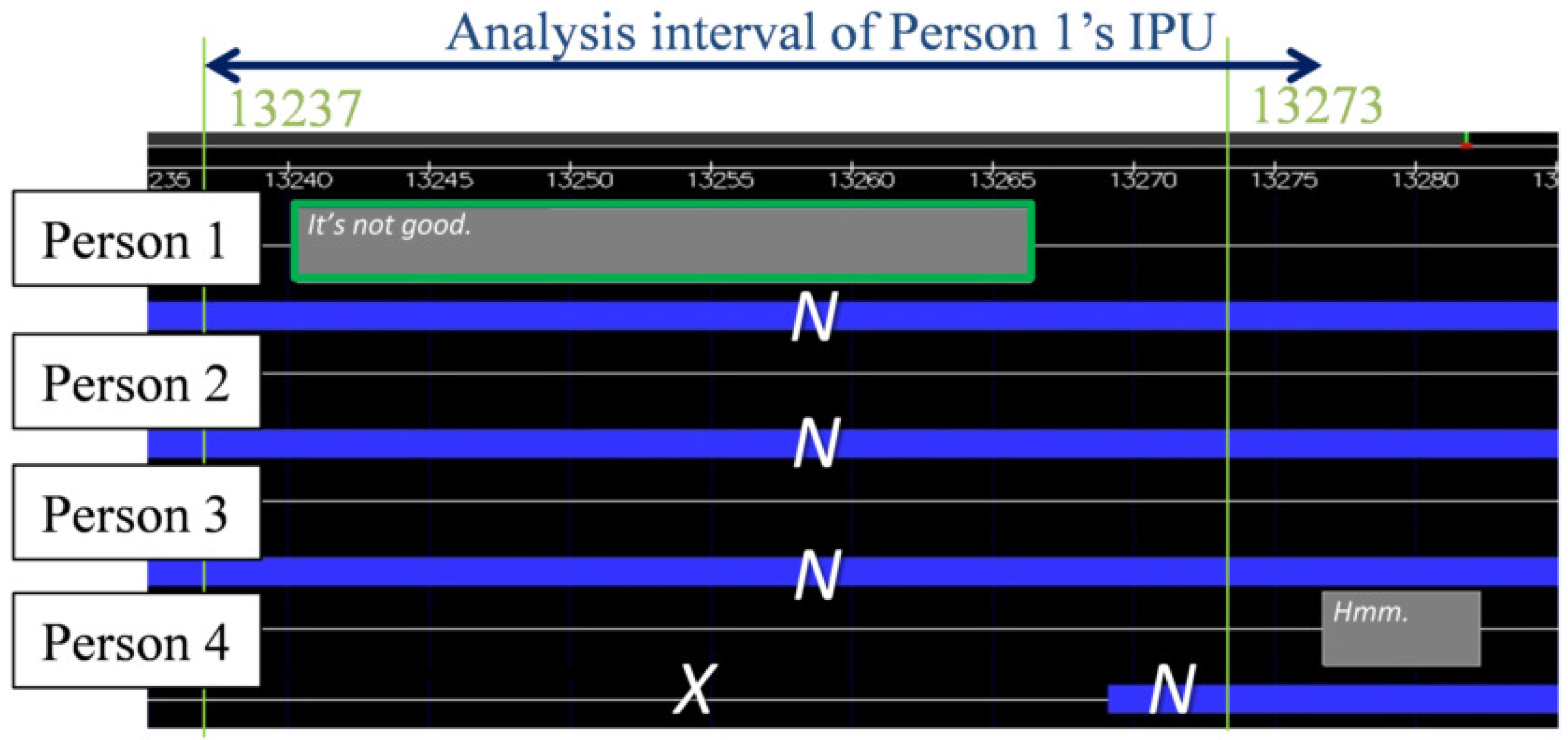
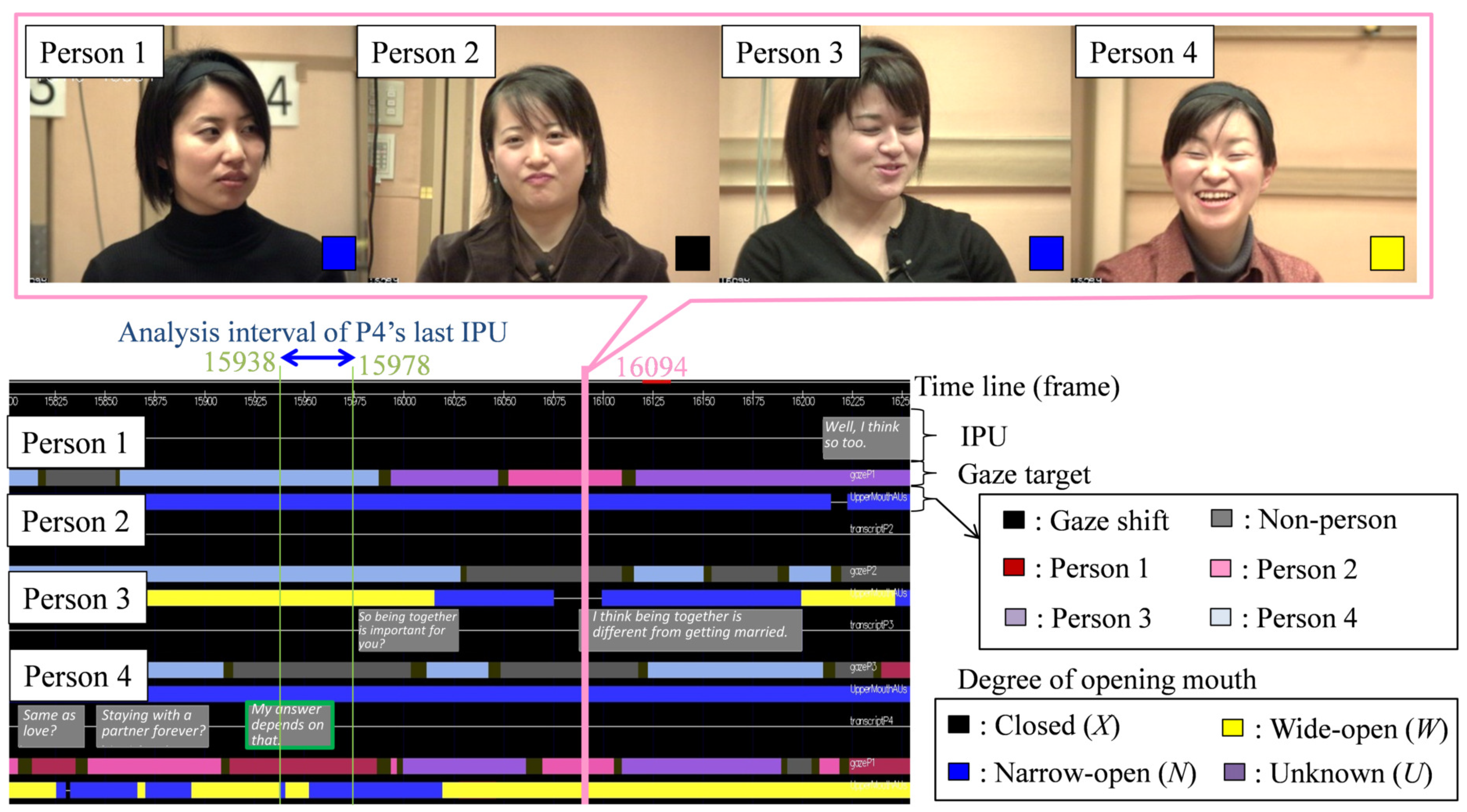
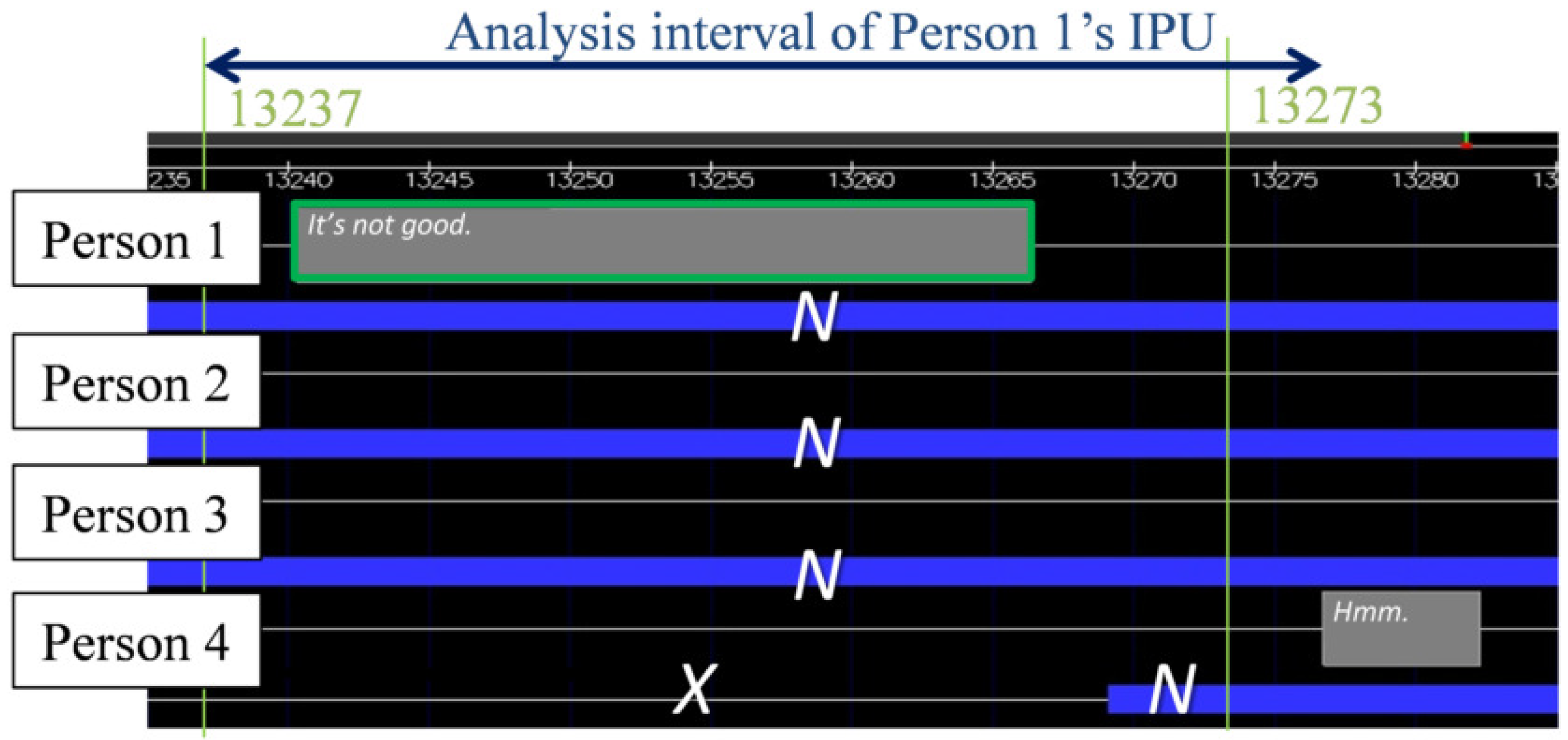
- Utterance: We designed the utterance unit on the basis of the inter-pausal unit (IPU) [38]. Specifically, the start and end of each utterance was denoted as an IPU. When a silence interval of 200 ms or more occurred, the utterance was separated. Therefore, if an utterance was made after a silent period of 200 ms or less, it was determined that one utterance was continued. Since this IPU can determine the start and end of an utterance using only the duration of the silent section, it is very convenient when performing real-time utterance section detection. We excluded back-channels without specific utterance content from the extracted IPUs. Later, we considered the same person’s continued IPU as one utterance turn. We considered that IPU pairs by the same person in the temporally adjacent IPU pairs are turn-keeping and IPU pairs by different persons are turn-changing. The total number of IPU pairs was 904 for turn-keeping and 126 for turn-changing. Our analysis excluded overlap of utterances, that is, when the listener interrupted while the current speaker was speaking or when two or more participants spoke at the same time. Specifically, data was excluded when the IPU pair utterance interval was less than 200 ms. All told, there were 904 IPU pairs during turn-keeping and 105 IPU pairs during turn-changing.
- Degrees of mouth-opening: We define the three degrees of mouth-opening as follows.
- -
- Closed (X): The mouth is closed.
- -
- Narrow-open (N): The mouth opening is narrower than one front tooth.
- -
- Wide-open (W): The mouth opening is wider than one front tooth.
- -
- Unknown (U): A state where the opening of the mouth cannot be determined. For example, a participant has covered her mouth with her hand.
Figure 2 shows an example of the X, N and W. This classification of degree of mouth-opening is a simplified version of the AU 25 (lip part), AU 26 (chin lowering) and AU 27 (mouth stretch) of the Facial Action Coding System (FACS), which is a comprehensive, anatomically based system for describing all visually discernible facial movements [39]. We focused on lip opening and ensured quantitative annotations even in non-frontal views. A skilled annotator carefully observed the person’s face image and manually annotated the degree of mouth-opening for each time frame. - Eye-gaze target: The eye-gaze target was annotated manually using bust/head and overhead views in each frame of the videos by a skilled annotator. The eye-gaze objects were the four participants (Persons 1, 2, 3 and 4) and non-persons. Three annotators labeled the eye-gaze targets. We calculated the Conger’s kappa coefficient [40] to evaluate an inter-coder agreement of the three annotators. The result was 0.887, which is a quite high value indicating the high reliability of the annotated eye-gaze targets. We used the eye-gaze targets annotated by one annotator who had the most experience.
4. Analysis of Next Speaker and MOTPs
4.1. Analysis Method
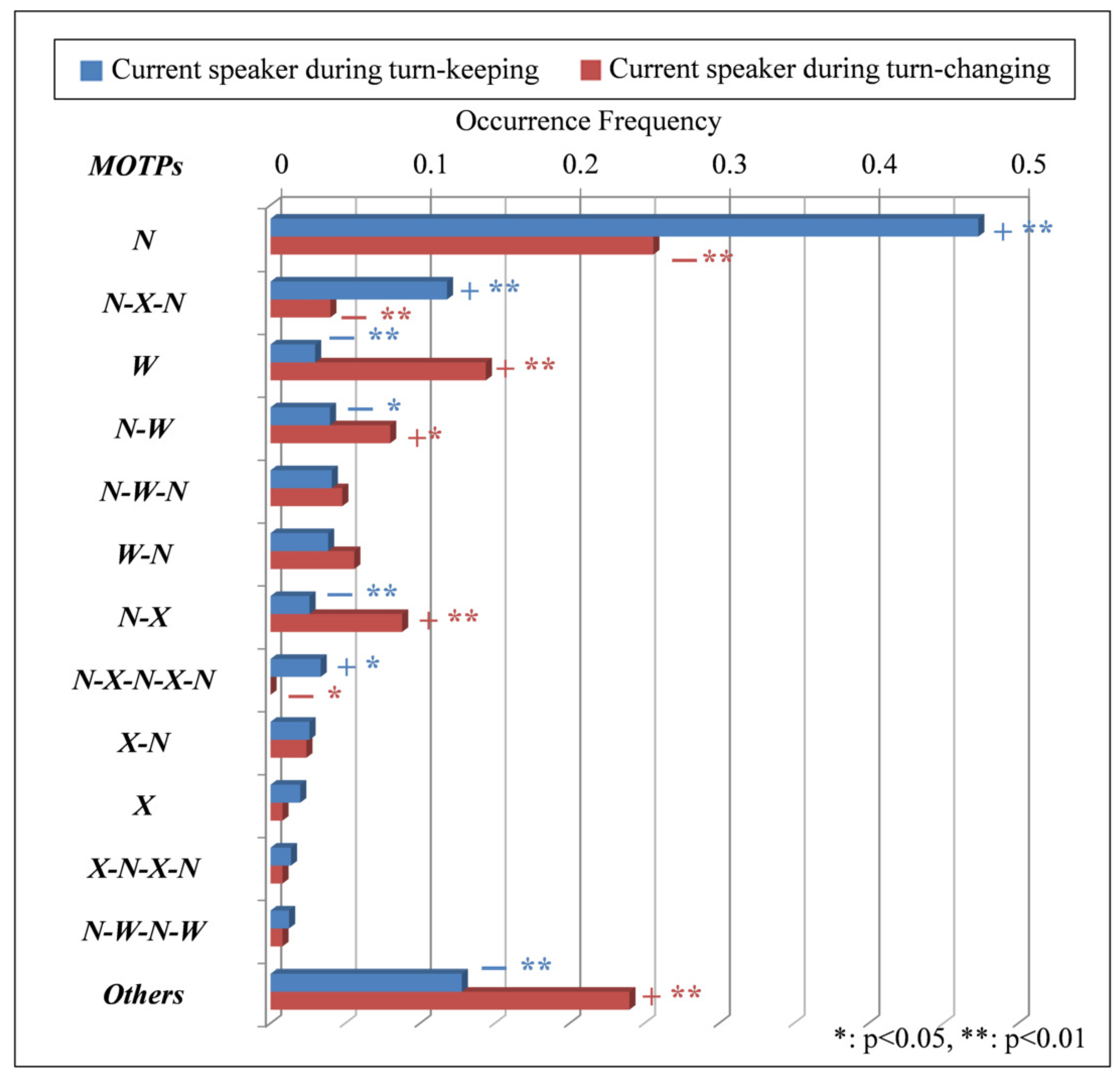
4.2. Analysis of Current Speaker’s MOTPs and Turn-Keeping/Changing
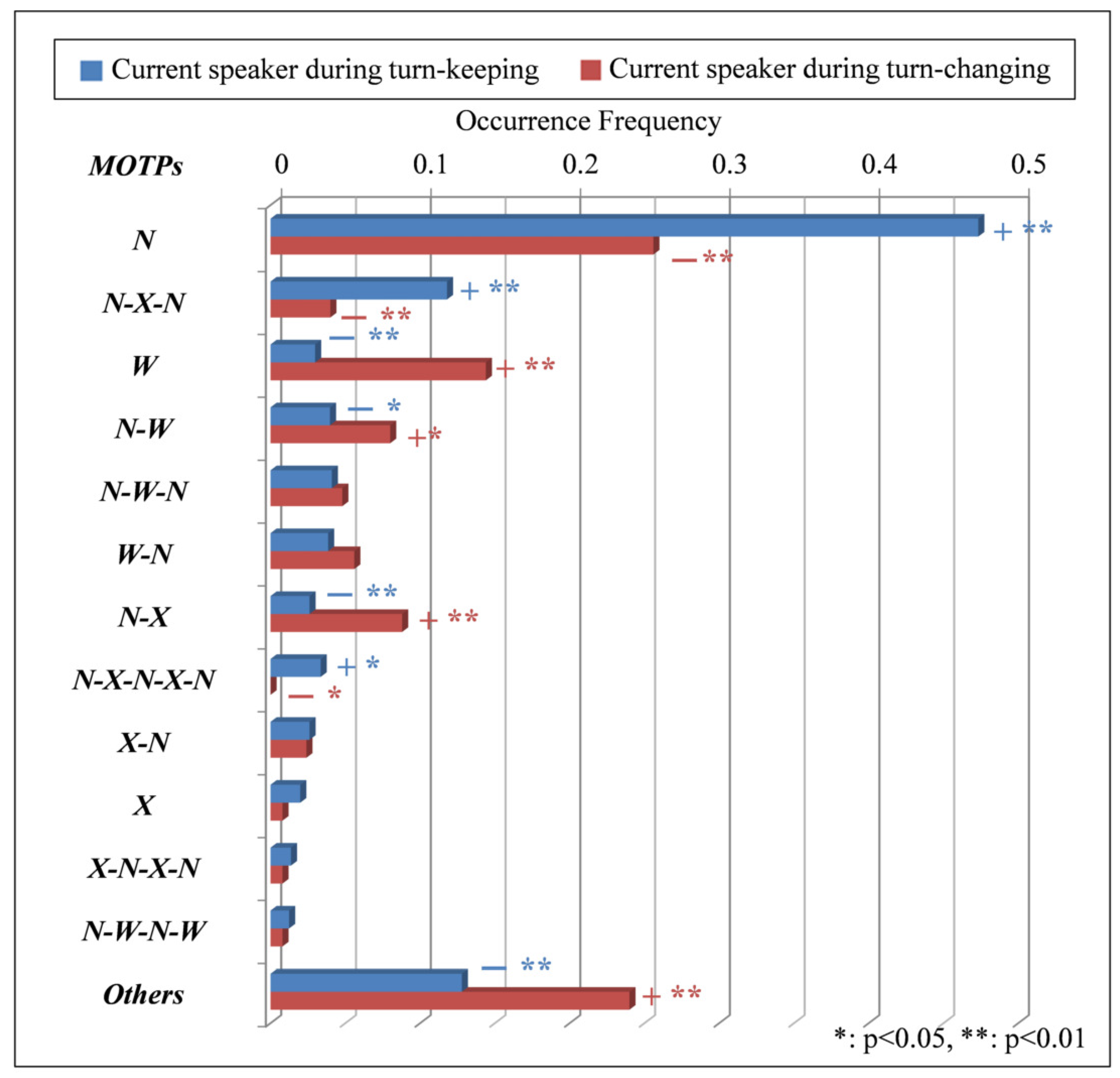
- The occurrence frequencies of N, N-X-N and N-X-N-X-N of the current speaker’s MOTPs are significantly higher during turn-keeping than during turn-changing. That is, the occurrence frequency at which the current speaker continues to open her mouth narrowly (N), open it narrowly after closing it from opening it narrowly (N-X-N) and open it narrowly after closing it again from opening it narrowly (N-X-N-X-N) is higher during turn-keeping than during turn-changing. The N has the highest frequency, which is 0.47, of all the MOTPs whose occurrence frequency is significantly higher during turn-keeping than during turn-changing. There is a big difference in the occurrence frequency of N during turn-keeping compared to during turn-changing, which is approximately twice as high. The representative results indicate that the current speaker more often continues to open her mouth narrowly during turn-keeping than during turn-changing.
- The occurrence frequencies of W, N-W, N-X and of the current speaker’s MOTPs are significantly higher during turn-changing than during turn-keeping. That is, the occurrence frequency at which the current speaker continues to open her mouth widely (W), opens widely from narrowly (N-W), closes it from opening it narrowly (N-X) and performs a mouth-opening pattern with the occurrence frequency of 1% or less () is higher during turn-changing than during turn-keeping. The W and N-W have the highest frequencies, 0.14 and 0.08, respectively, of all the MOTPs excepting , whose occurrence frequency is significantly higher during turn-changing than during turn-keeping. There is a big difference in the occurrence frequency of W and N-W during turn-changing compared to during turn-keeping, which is approximately five times and three times as high, respectively. The representative results indicate that the current speaker more often continues to open her mouth widely or starts to close it from opening it narrowly during turn-changing than during turn-keeping.
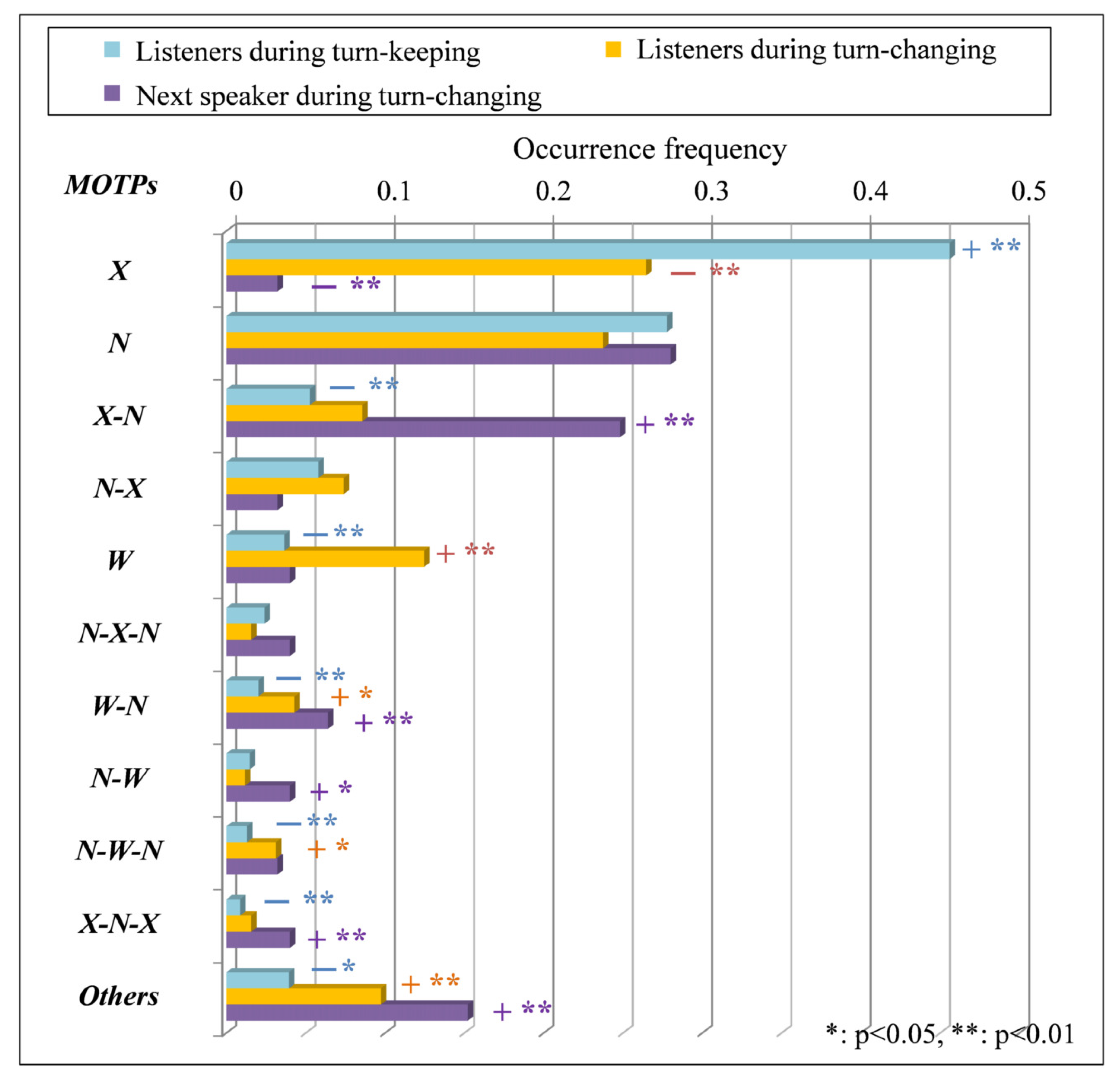
4.3. Analysis of Listeners’ MOTPs and Next Speaker
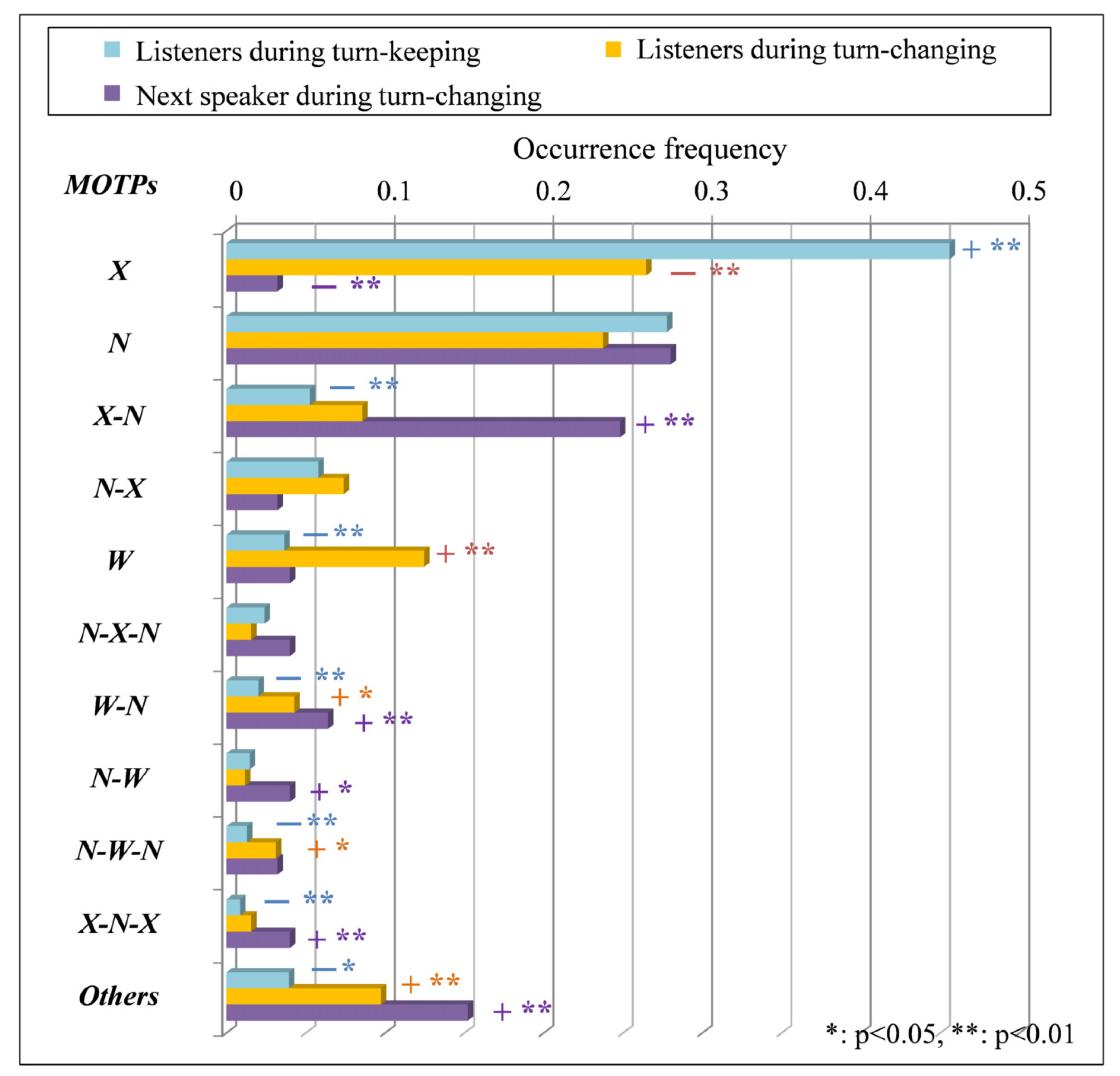
- The occurrence frequencies of X of the MOTPs of listeners during turn-keeping are significantly higher than those of listeners and the next speaker during turn-changing. That is, the occurrence frequency at which listeners during turn-keeping continue to close their mouths (X) is high. There is a big difference in the occurrence frequency of X of listeners in turn-keeping, 0.45, compared to listeners and the next speaker during turn-changing, which are approximately twice and 15 times as high. In contrast, the occurrence frequencies of X-N, W, W-N, N-W-N, X-N-X and of the MOTPs of listeners during turn-keeping are significantly lower than those of the listeners and the next speaker during turn-changing. That is, the occurrence frequencies at which the listeners during turn-keeping start opening their mouths narrowly after closing them (X-N), continue to open them widely (W), start opening them narrowly after opening them widely (W-N), start opening them narrowly after opening them narrowly and then widely (N-W-N), start closing them after closing them and opening them narrowly (X-N-X) and perform a mouth-opening pattern with the occurrence frequency of 1% or less () are low.The representative results indicate that the listeners during turn-keeping more often continue to close their mouth than the listeners and the next speaker during turn-changing.
- The occurrence frequencies of W, W-N, N-W-N and of the MOTPs of listeners during turn-changing are significantly higher than those of listeners during turn-keeping. That is, the occurrence frequency at which listeners during turn-changing continue to open their mouths widely (W), start to open them narrowly from widely (W-N), start to open them narrowly after opening them narrowly and then widely (N-W-N) and perform a mouth-opening pattern with the occurrence frequency of 1% or less () is higher than that of listeners during turn-keeping. The W has the highest frequency, about 0.12, among the MOTPs of the listeners during turn-changing. There is a big difference in the occurrence frequency of W of listeners in turn-changing compared to listeners during turn-keeping, which is approximately four times as high. In contrast, the occurrence frequency of X of the MOTPs of listeners during turn-changing is significantly lower than that of listeners during turn-keeping. That is, the occurrence frequency at which listeners during turn-changing continue to close their mouths (X) is lower than that of listeners during turn-keeping.The representative results indicate that the listeners during turn-changing more often continue to open their mouth widely than the listeners during turn-keeping.
- The occurrence frequencies of X-N, W-N, N-W, X-N-X and of the MOTPs of the next speaker during turn-changing are significantly higher than those of listeners during turn-keeping and turn-changing. That is, the occurrence frequencies when the next speaker during turn-changing starts opening her mouth narrowly after closing it (X-N), opening it narrowly from widely (W-N) and vice versa (N-W), starts closing it after closing it and opening it narrowly (X-N-X) and performs a mouth-opening pattern with the occurrence frequency of 1% or less () are higher than those of listeners during turn-keeping and turn-changing. The X-N has the highest frequency, about 0.24, among the MOTPs of the next speaker during turn-changing. There is a big difference in the occurrence frequency of W of the next speaker in turn-changing compared to listeners during turn-keeping and turn-changing, which are approximately four times as high. In contrast, the occurrence frequency of X of the next speaker during turn-changing is significantly lower than that of listeners during turn-keeping and turn-changing. That is, the occurrence frequency at which the next speaker during turn-changing continues to close her mouth (X) is lower than that of listeners during turn-keeping and turn-changing.The representative results indicate that the next speaker during turn-changing more often starts to open her mouth narrowly from closing it than listeners during turn-keeping and turn-changing.
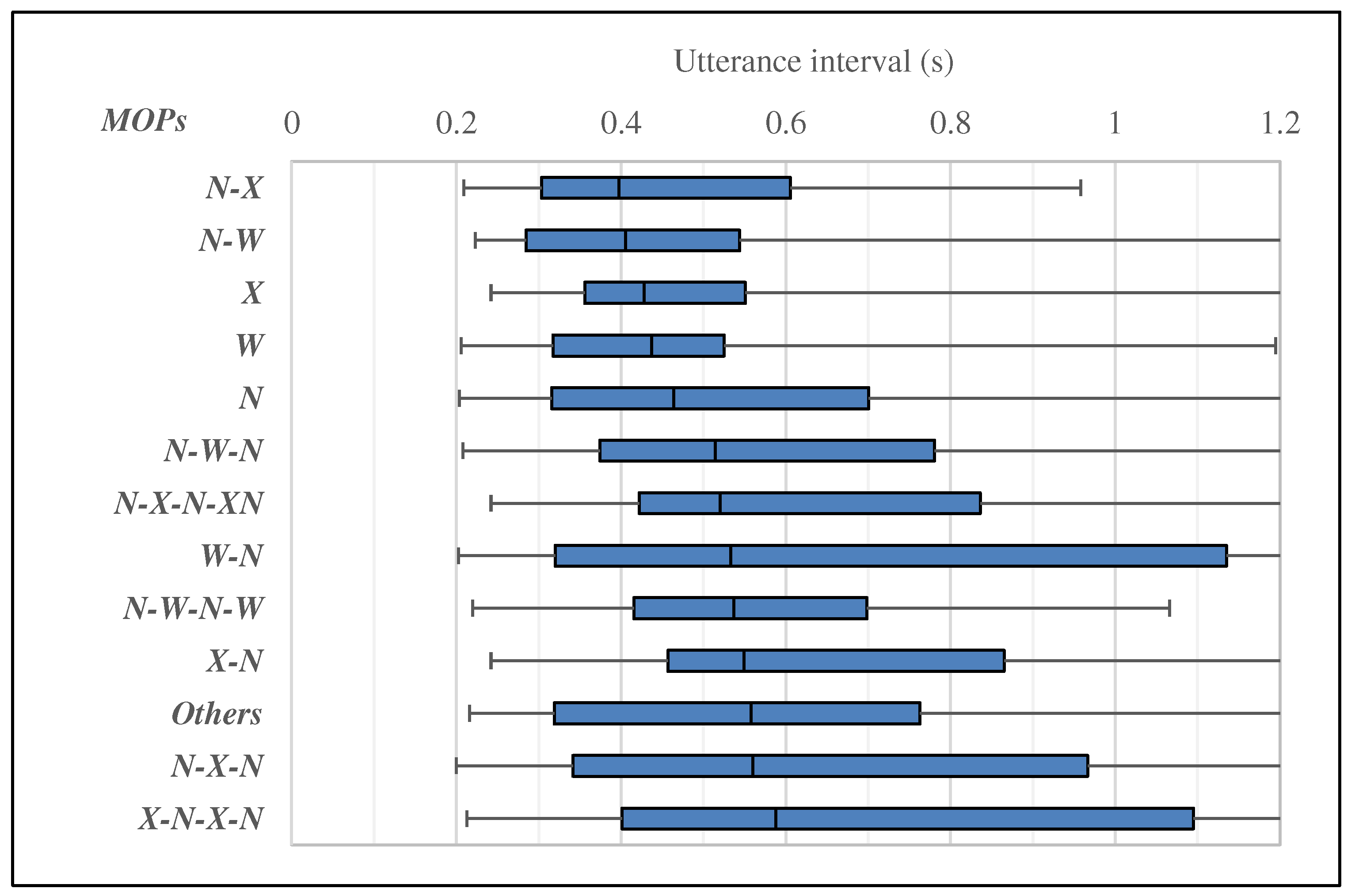
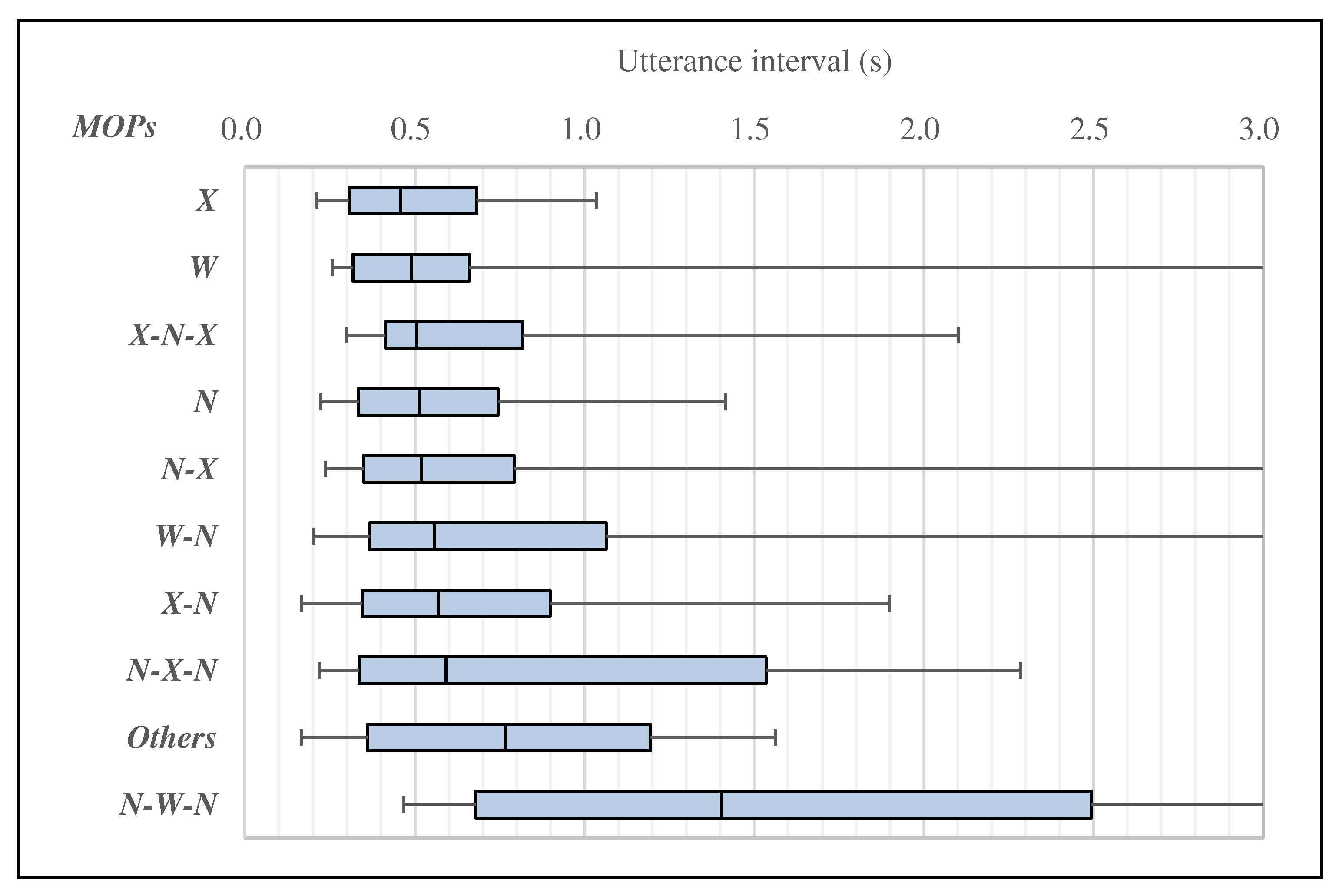
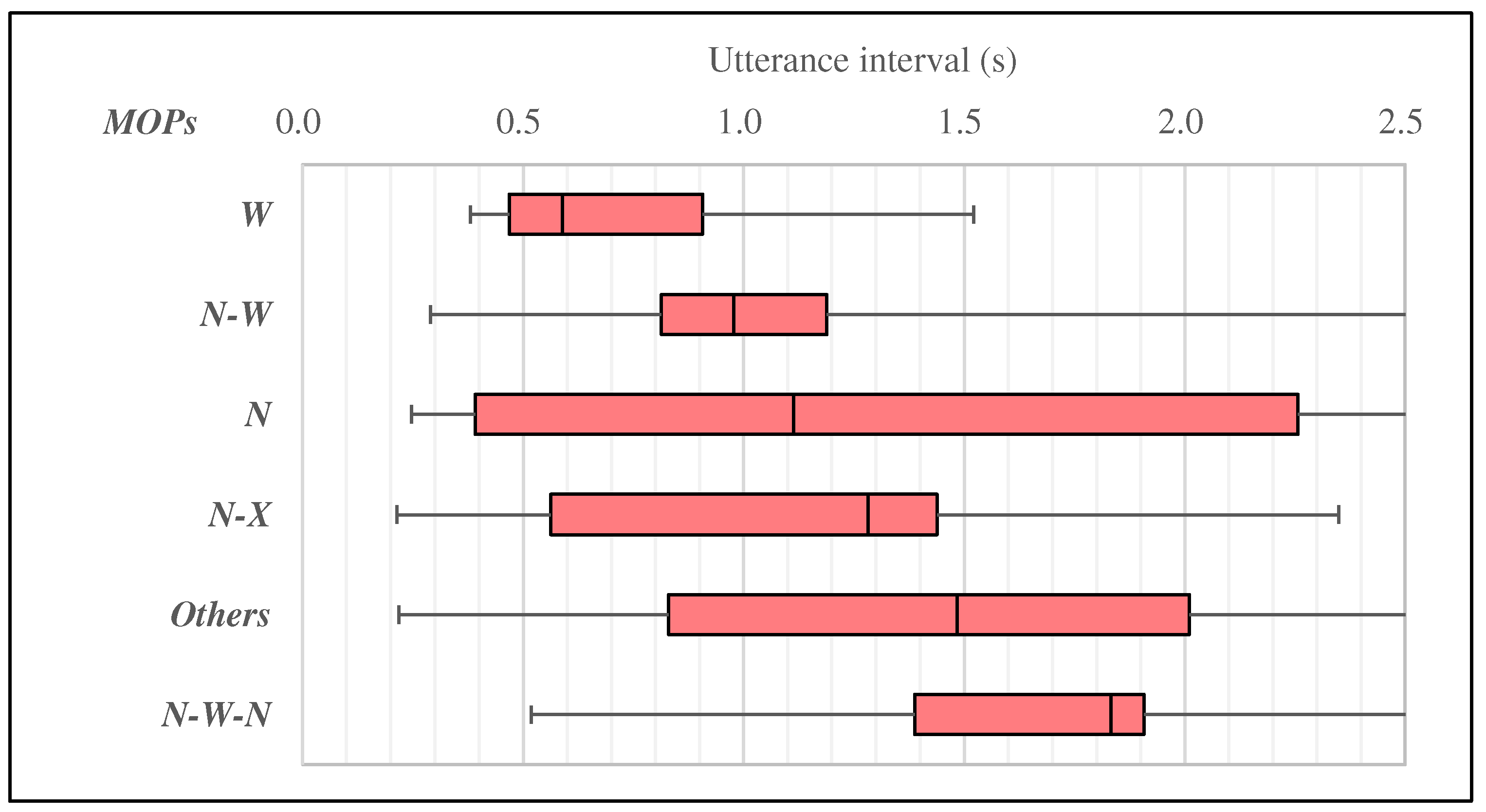
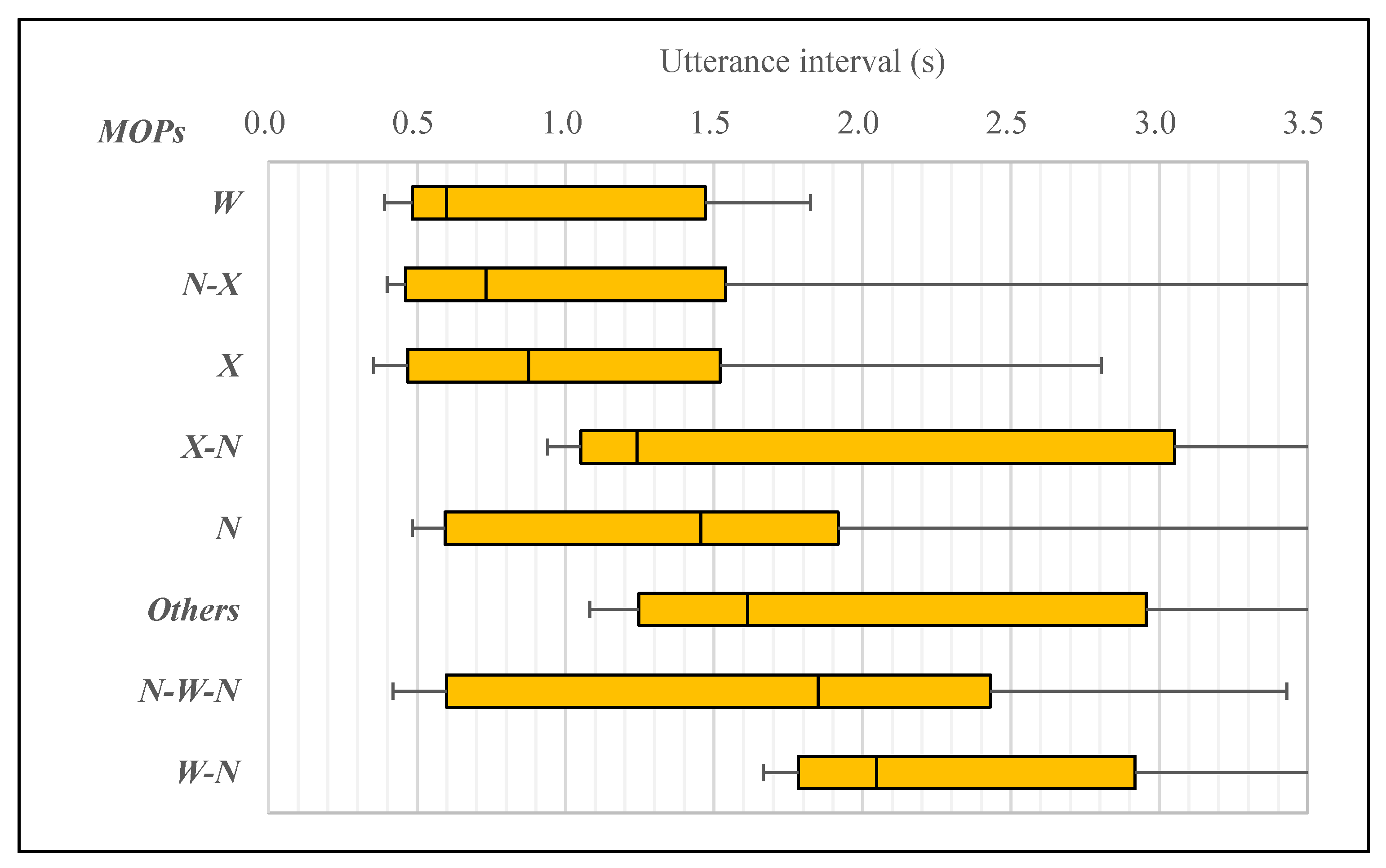
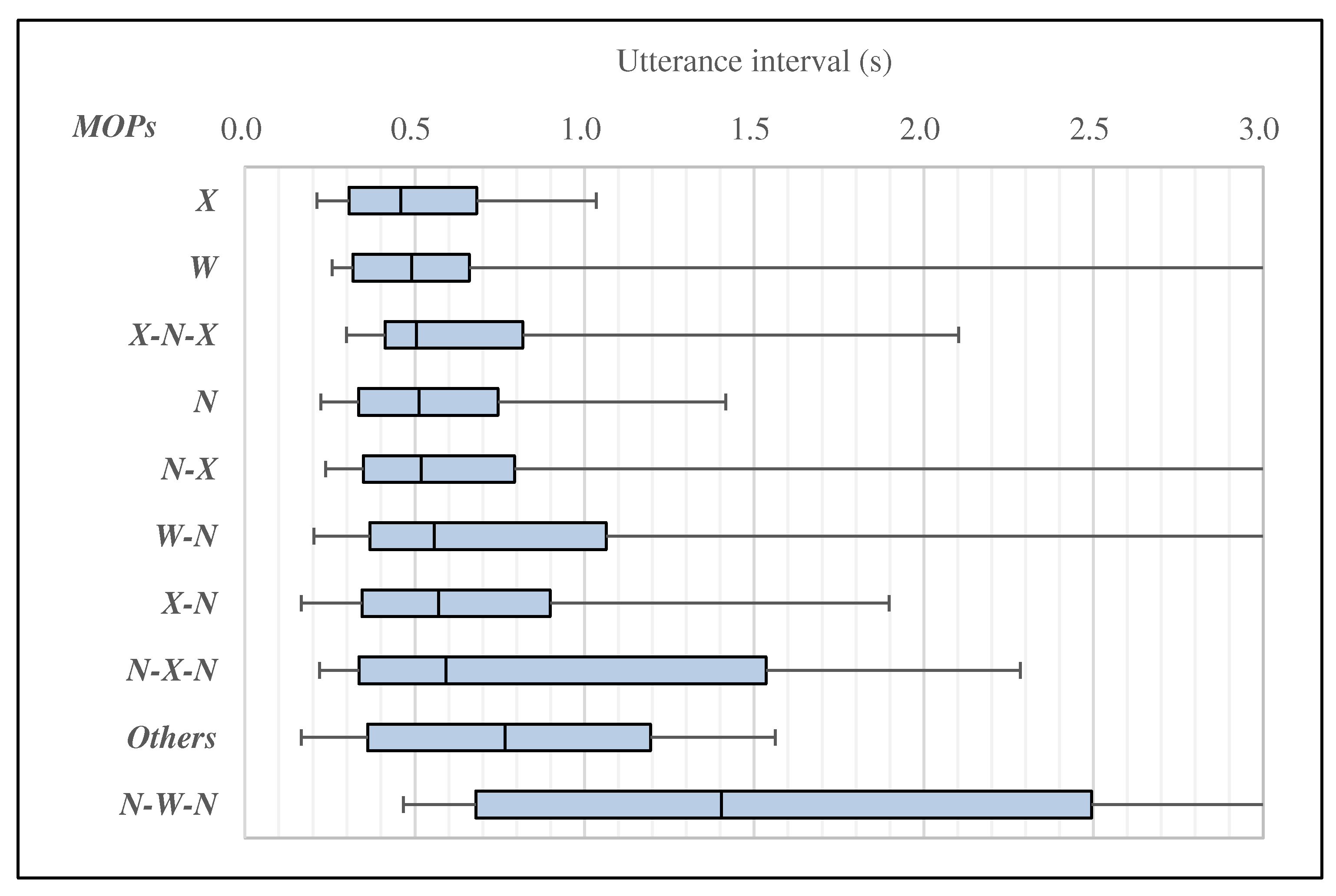
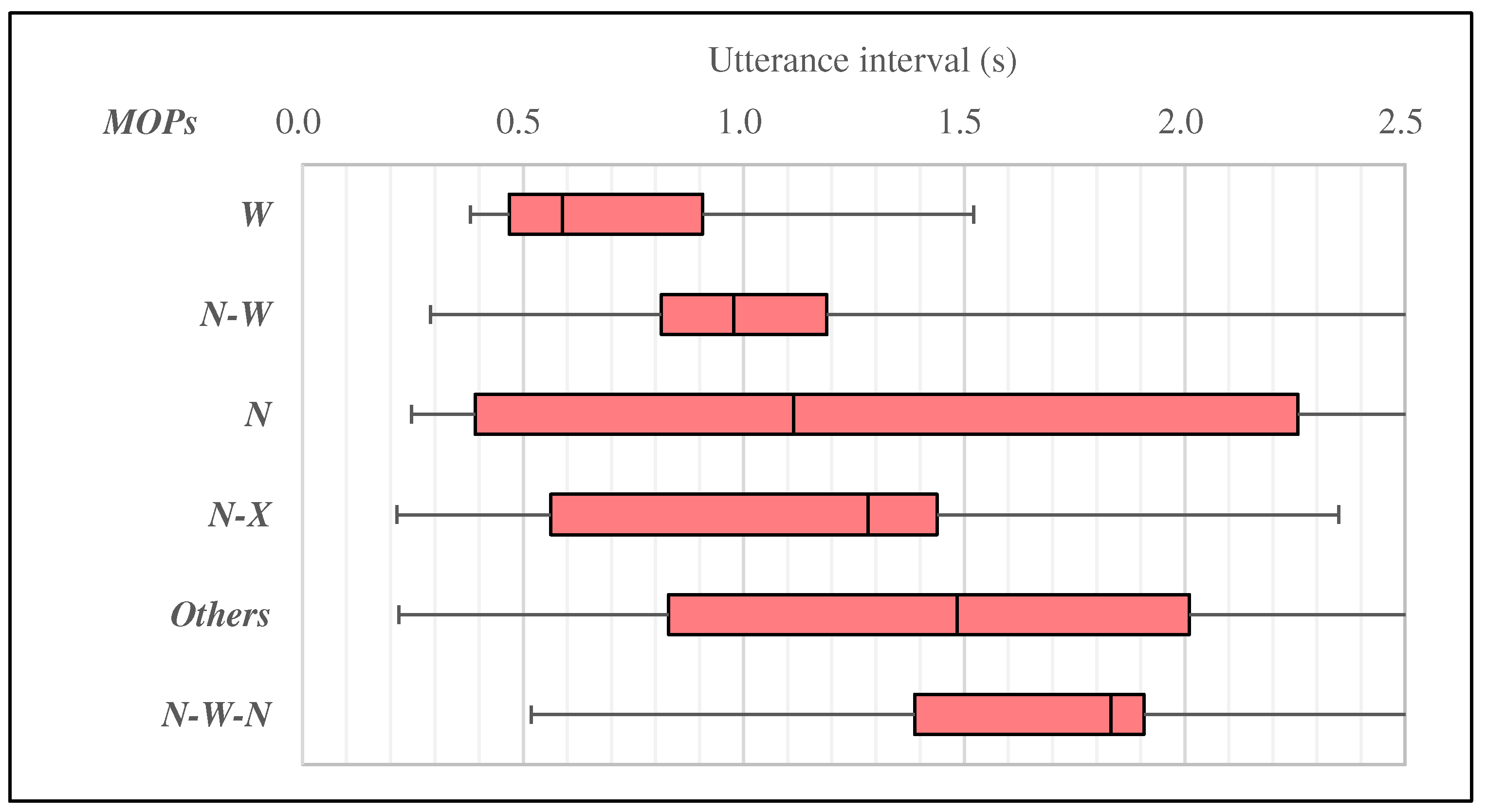
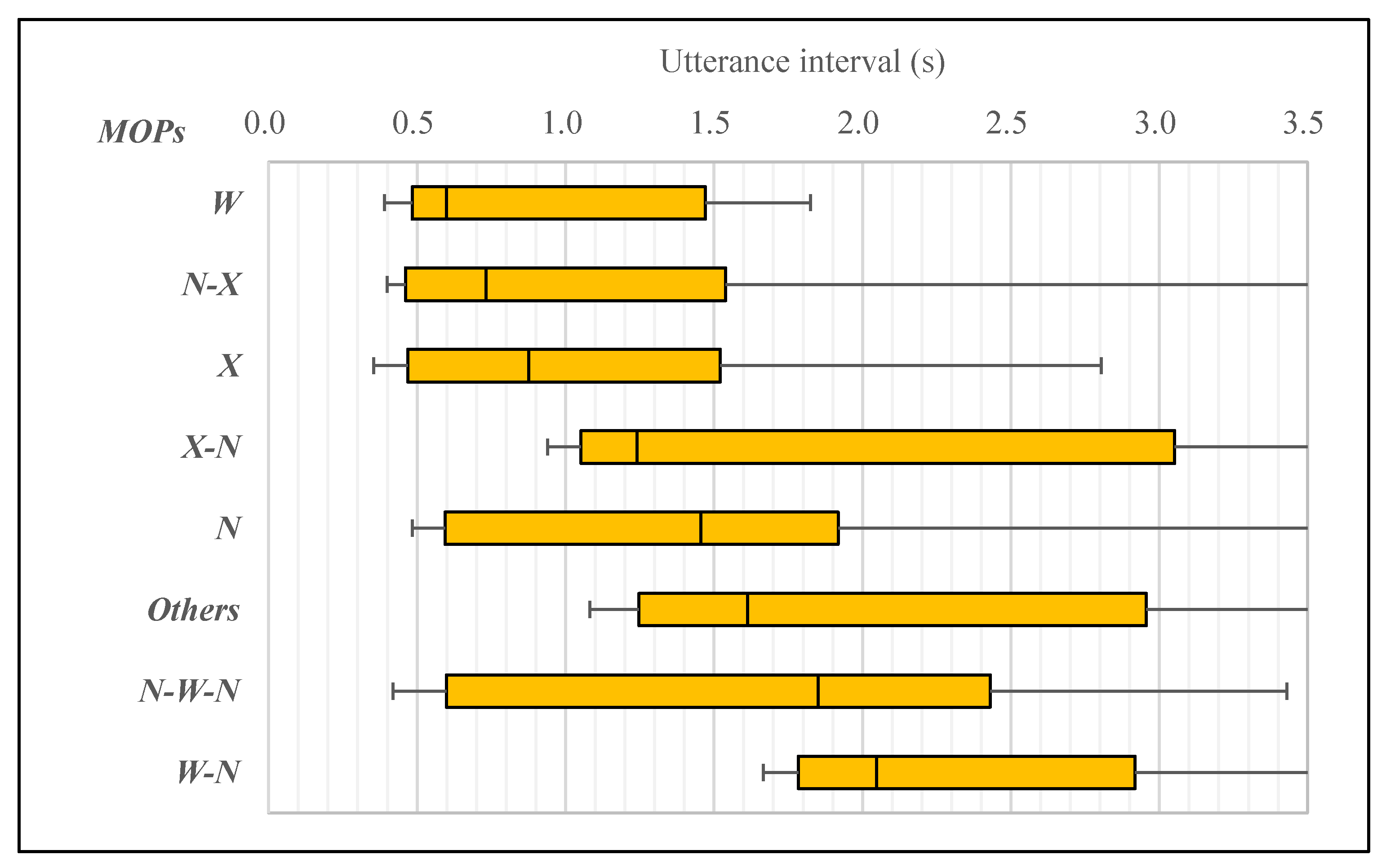
5. Analysis of MOTPs and Utterance Interval
5.1. Analysis of MOTPs and Utterance Interval in Turn-Keeping
5.2. Analysis of MOTPs and Utterance Interval in Turn-Changing
6. Prediction Models of Next Speaker and Utterance Interval
6.1. Design Guidelines for Creating Prediction Models
6.2. Prediction Model of Turn-Keeping or Turn-Changing
- Current speaker’s mouth model (SmM): This model uses the current speaker’s MOTPs as feature values. Specifically, among the 13 types of MOTPs obtained in the analysis in Section 4.2, the MOTPs of the current speaker that appeared at the end of the utterance are used. The feature values are expressed as a 13-dimensional one-hot vector.
- Listeners’ mouth model (LmM): This model uses the three listeners’ MOTPs as feature values. Specifically, among the 11 types of MOTPs obtained in the analysis in Section 4.3, the GTP of the three listeners that appeared at the end of the utterance is used. The feature values are expressed as an 11-dimensional vector that contains information on the number of appearances of each of the 11 MOTPs.
- All-mouth model (AmM): This model uses both the current speaker’s and listeners’ MOTPs as feature values. The feature values are expressed as a 24-dimensional vector that combines the 13-dimensional vector of the current speaker’s MOTPs and the 11-dimensional vector of the listeners’ MOTPs.
- Eye-gaze model (EgM): This model uses the GTPs of the current speaker and listeners as feature values. With reference to our previous research on GTPs [5,15,16], we created a GTP that contains n-gram information of eye-gaze objects including mutual gaze information. The GTPs are created using eye-gaze targets between 1000 ms before the IPU and 200 ms after the end of IPU, the same as the MOTPs. There are 11 types of current speaker’s GTPs and 14 types of listeners’ GTPs. The feature values are expressed as a 25-dimensional vector that contains information on the number of appearances of each of the 25 GTPs.
- Multimodal-feature model (MuM): This model uses all the current speaker’s and listeners’ MOTPs and GTPs as feature values. These feature values are fused early. The feature values are expressed as a 49-dimensional vector that contains information on the number of appearances of each of the 24 MOTPs and 25 GTPs.
6.3. Prediction of Next Speaker during Turn-Changing
6.4. Prediction of Utterance Interval
7. Discussion
8. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Gatica-Perez, D. Analyzing group interactions in conversations: A review. In Proceedings of the MFI, Heidelberg, Germany, 3–6 September 2006; pp. 41–46. [Google Scholar]
- Otsuka, K. Conversational scene analysis. IEEE Signal Process. Mag. 2011, 28, 127–131. [Google Scholar] [CrossRef]
- Ishii, R.; Kumano, S.; Otsuka, K. Multimodal Fusion using Respiration and Gaze for Predicting Next Speaker in Multi-Party Meetings. In Proceedings of the ICMI, Tokyo, Japan, 12–16 November 2016; pp. 99–106. [Google Scholar]
- Ishii, R.; Kumano, S.; Otsuka, K. Predicting Next Speaker Using Head Movement in Multi-party Meetings. In Proceedings of the ICASSP, Queensland, Australia, 19–24 April 2015; pp. 2319–2323. [Google Scholar]
- Ishii, R.; Otsuka, K.; Kumano, S.; Yamamoto, J. Predicting of Who Will Be the Next Speaker and When Using Gaze Behavior in Multiparty Meetings. ACM TiiS 2016, 6, 4. [Google Scholar]
- Ishii, R.; Otsuka, K.; Kumano, S.; Yamato, J. Analysis of Respiration for Prediction of Who Will Be Next Speaker and When? In Proceedings of the ICMI, Istanbul, Turkey, 12–16 November 2014; pp. 18–25. [Google Scholar]
- Ishii, R.; Otsuka, K.; Kumano, S.; Yamamoto, J. Using Respiration to Predict Who Will Speak Next and When in Multiparty Meetings. ACM TiiS 2016, 6, 20. [Google Scholar] [CrossRef]
- Gracco, V.L.; Lofqvist, A. Speech Motor Coordination and Control: Evidence from Lip, Jaw, and Laryngeal Movements. J. Neurosci. 1994, 14, 6585–6597. [Google Scholar] [CrossRef]
- Sacks, H.; Schegloff, E.A.; Jefferson, G. A simplest systematics for the organisation of turn taking for conversation. Language 1974, 50, 696–735. [Google Scholar] [CrossRef]
- Kendon, A. Some functions of gaze direction in social interaction. Acta Psychol. 1967, 26, 22–63. [Google Scholar] [CrossRef]
- Lammertink, I.; Casillas, M.; Benders, T.; Post, B.; Fikkert, P. Dutch and English toddlers’ use of linguistic cues in predicting upcoming turn transitions. Front. Psychol. 2015, 6, 495. [Google Scholar] [CrossRef]
- Levinson, S.C. Turn-taking in human communication—Origins and implications for language processing. Trends Cogn. Sci. 2016, 20, 6–14. [Google Scholar] [CrossRef]
- Kawahara, T.; Iwatate, T.; Takanashii, K. Prediction of turn-taking by combining prosodic and eye-gaze information in poster conversations. In Proceedings of the INTERSPEECH, Portland, OR, USA, 9–13 September 2012. [Google Scholar]
- Jokinen, K.; Furukawa, H.; Nishida, M.; Yamamoto, S. Gaze and turn-taking behavior in casual conversational interactions. ACM TiiS 2013, 3, 12. [Google Scholar] [CrossRef]
- Ishii, R.; Otsuka, K.; Kumano, S.; Matsuda, M.; Yamato, J. Predicting Next Speaker and Timing from Gaze Transition Patterns in Multi-Party Meetings. In Proceedings of the ICMI, Sydney, Australia, 9–13 December 2013; pp. 79–86. [Google Scholar]
- Ishii, R.; Otsuka, K.; Kumano, S.; Yamato, J. Analysis and Modeling of Next Speaking Start Timing based on Gaze Behavior in Multi-party Meetings. In Proceedings of the ICASSP, Florence, Italy, 4–9 May 2014; pp. 694–698. [Google Scholar]
- Holler, J.; Kendrick, H. Unaddressed participants’ gaze in multi-person interaction: optimizing recipiency. Front. Psychol. 2015, 6, 515–535. [Google Scholar] [CrossRef]
- Hömke, P.; Holler, J.; Levinson, S.C. Eye blinking as addressee feedback in face-to-face conversation. Res. Lang. Soc. Interact. 2017, 50, 54–70. [Google Scholar] [CrossRef]
- Ishii, R.; Kumano, S.; Otsuka, K. Prediction of Next-Utterance Timing using Head Movement in Multi-Party Meetings. In Proceedings of the HAI, Bielefeld, Germany, 17–20 October 2017; pp. 181–187. [Google Scholar]
- Holler, J.; Kendrick, K.H.; Levinson, S.C. Processing language in face-to-face conversation: Questons with gestures get faster responses. Psychon. Bull. Rev. 2018, 6, 25. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Harper, M.P. Multimodal floor control shift detection. In Proceedings of the ICMI, Cambridge, MA, USA, 2–4 November 2009; pp. 15–22. [Google Scholar]
- de Kok, I.; Heylen, D. Multimodal end-of-turn prediction in multi-party meetings. In Proceedings of the ICMI, Cambridge, MA, USA, 2–4 November 2009; pp. 91–98. [Google Scholar]
- Ferrer, L.; Shriberg, E.; Stolcke, A. Is the speaker done yet? Faster and more accurate end-of-utterance detection using prosody in human-computer dialog. In Proceedings of the INTERSPEECH, Denver, CO, USA, 16–20 September 2002; Volume 3, pp. 2061–2064. [Google Scholar]
- Laskowski, K.; Edlund, J.; Heldner, M. A single-port non-parametric model of turn-taking in multi-party conversation. In Proceedings of the ICASSP, Prague, Czech Republic, 22–27 May 2011; pp. 5600–5603. [Google Scholar]
- Schlangen, D. From reaction to prediction: experiments with computational models of turn-taking. In Proceedings of the INTERSPEECH, Pittsburgh, PA, USA, 17–21 September 2006; pp. 17–21. [Google Scholar]
- Dielmann, A.; Garau, G.; Bourlard, H. Floor holder detection and end of speaker turn prediction in meetings. In Proceedings of the INTERSPEECH, Makuhari, Japan, 26–30 September 2010; pp. 2306–2309. [Google Scholar]
- Itoh, T.; Kitaoka, N.; Nishimura, R. Subjective experiments on influence of response timing in spoken dialogues. In Proceedings of the ISCA, Brighton, UK, 6–10 September 2009; pp. 1835–1838. [Google Scholar]
- Inoue, M.; Yoroizawa, I.; Okubo, S. Human Factors Oriented Design Objectives for Video Teleconferencing Systems. ITS 1984, 66–73. [Google Scholar]
- Matthews, I.; Cootes, T.F.; Bangham, J.A.; Cox, S.; Harvey, R. Extraction of visual features for lipreading. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 198–213. [Google Scholar] [CrossRef]
- Chakravarty, P.; Mirzaei, S.; Tuytelaars, T. Who’s speaking?: Audio-supervised classification of active speakers in video. In Proceedings of the ICMI, Seattle, WA, USA, 9–13 November 2015. [Google Scholar]
- Chakravarty, P.; Zegers, J.; Tuytelaars, T.; hamme, H.V. Active speaker detection with audio-visual co-training. In Proceedings of the ICMI, Tokyo, Japan, 12–16 November 2016; pp. 312–316. [Google Scholar]
- Cech, J.; Mittal, R.; Deleforge, A.; Sanchez-Riera, J.; AlamedaPineda, X.; Horaud, R. Active-speaker detection and localization with microphones and cameras embedded into a robotic head. In Proceedings of the Humanoids, Atlanta, GA, USA, 15–17 October 2013; pp. 203–210. [Google Scholar]
- Cutler, R.; Davis, L. Look who’s talking: Speaker detection using video and audio correlation. In Proceedings of the ICME, New York, NY, USA, 30 July–2 August 2000; pp. 1589–1592. [Google Scholar]
- Haider, F.; Luz, S.; Campbell, N. Active speaker detection in human machine multiparty dialogue using visual prosody information. In Proceedings of the GlobalSIP, Washington, DC, USA, 7–9 December 2016; pp. 1207–1211. [Google Scholar]
- Haider, F.; Luz, S.; Vogel, C.; Campbell, N. Improving Response Time of Active Speaker Detection using Visual Prosody Information Prior to Articulation. In Proceedings of the INTERSPEECH, Hyderabad, India, 2–6 September 2018; pp. 1736–1740. [Google Scholar]
- Murai, K. Speaker Predicting Apparatus, Speaker Predicting Method, and Program Product for Predicting Speaker. U.S. Patent 20070120966, 2011. [Google Scholar]
- Cheunga, Y.; Liua, X.; You, X. A local region based approach to lip tracking. Pattern Recognit. 2012, 45, 3336–3347. [Google Scholar] [CrossRef]
- Koiso, H.; Horiuchi, Y.; Tutiya, S.; Ichikawa, A.; Den, Y. An analysis of turn-taking and backchannels based on prosodic and syntactic features in Japanese Map Task dialogs. Lang. Speech 1998, 41, 295–321. [Google Scholar] [CrossRef]
- Ekman, P.; Friesen, W.V. The Facial Action Coding System: A Technique for the Measurement of Facial Movement; Consulting Psychologists Press: Palo Alto, CA, USA, 1978. [Google Scholar]
- Conger, A. Integration and generalisation of Kappas for multiple raters. Psychol. Bull. 1980, 88, 322–328. [Google Scholar] [CrossRef]
- Otsuka, K.; Araki, S.; Mikami, D.; Ishizuka, K.; Fujimoto, M.; Yamato, J. Realtime meeting analysis and 3D meeting viewer based on omnidirectional multimodal sensors. In Proceedings of the ICMI, Cambridge, MA, USA, 2–4 November 2009; pp. 219–220. [Google Scholar]
- Haberman, S.J. The analysis of residuals in cross-classified tables. Biometrics 1973, 29, 205–220. [Google Scholar] [CrossRef]
- Keerthi, S.S.; Shevade, S.; Bhattacharyya, C.; Murthy, K.K. Improvements to Platt’s SMO Algorithm for SVM Classifier Design. Neural Comput. 2001, 13, 637–649. [Google Scholar] [CrossRef]
- Bouckaert, R.R.; Frank, E.; Hall, M.A.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. WEKA–Experiences with a Java Open-Source Project. J. Mach. Learn. Res. 2010, 11, 2533–2541. [Google Scholar]
- Amos, B.; Ludwiczuk, B.; Satyanarayanan, M. OpenFace: A General-Purpose Face Recognition Library with Mobile Applications; Technical Report, CMU-CS-16-118; CMU School of Computer Science: Pittsburgh, PA, USA, 2016. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | F-Measure |
|---|---|
| Chance level (CL) | |
| Current speaker’s mouth model (SmM) | |
| Listeners’ mouth model (LmM) | |
| All-mouth model (AmM) | |
| Eye-gaze model (EgM) | |
| Multimodal-feature model (MuM) |
| Models | F-Measure |
|---|---|
| Chance level (CL) | |
| Listeners’ mouth model (LmM) | |
| Eye-gaze model (EgM) | |
| Multimodal-feature model (MuM) |
| Models | Turn-Keeping | Turn-Changing |
|---|---|---|
| Chance level (CL) | ||
| Mouth model (MoM) | ||
| Eye-gaze model (EgM) | ||
| Multimodal-feature model (MuM) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ishii, R.; Otsuka, K.; Kumano, S.; Higashinaka, R.; Tomita, J. Prediction of Who Will Be Next Speaker and When Using Mouth-Opening Pattern in Multi-Party Conversation. Multimodal Technol. Interact. 2019, 3, 70. https://doi.org/10.3390/mti3040070
Ishii R, Otsuka K, Kumano S, Higashinaka R, Tomita J. Prediction of Who Will Be Next Speaker and When Using Mouth-Opening Pattern in Multi-Party Conversation. Multimodal Technologies and Interaction. 2019; 3(4):70. https://doi.org/10.3390/mti3040070
Chicago/Turabian StyleIshii, Ryo, Kazuhiro Otsuka, Shiro Kumano, Ryuichiro Higashinaka, and Junji Tomita. 2019. "Prediction of Who Will Be Next Speaker and When Using Mouth-Opening Pattern in Multi-Party Conversation" Multimodal Technologies and Interaction 3, no. 4: 70. https://doi.org/10.3390/mti3040070
APA StyleIshii, R., Otsuka, K., Kumano, S., Higashinaka, R., & Tomita, J. (2019). Prediction of Who Will Be Next Speaker and When Using Mouth-Opening Pattern in Multi-Party Conversation. Multimodal Technologies and Interaction, 3(4), 70. https://doi.org/10.3390/mti3040070