Graph-Based Prediction of Meeting Participation


Abstract
:1. Introduction
Related Work
2. Social Network Models
2.1. Turn-Taking Graphs
- The betweenness centrality, degree centrality, and closeness centrality of the target speaker in the current window (, , and , respectively).
- The minimum, maximum and mean betweenness centrality of the other (non-target) participants in the current window (, , and , respectively).
- The minimum, maximum and mean degree centrality of the other (non-target) participants in the current window (, , and , respectively).
- The minimum, maximum and mean closeness centrality of the other (non-target) participants in the current window (, , and , respectively).
2.2. Language Graphs
- The linguistic centrality of the target speaker (, rescaled by participant frequency.
- The minimum, maximum, and mean linguistic centrality scores of the other (non-target) participants (, , and , respectively), again rescaled based on participant frequency.
- The total number of communities ().
- The number of communities represented by sentences in the current window (). This will range from 1 (all sentences in the current window belong to one community) to 20 (each sentence in the window is in a different community).
- The number of communities containing speakers (). For this corpus, this feature will range between 1 (all speakers in the same community) to 4 (each speaker in a separate community).
- The change in density of the language network between the previous and current windows (). Density is a measure of how connected the graph is, e.g., a graph with the maximum possible number of edges has a density of 1.
2.3. Other Features
- The frequency (number of dialogue act units) of the target speaker in the current window ().
- The minimum, maximum and mean frequency of the other (non-target) participants in the current window (, , and , respectively).
- The feature is the current index/location in the conversation.
3. Experimental Setup
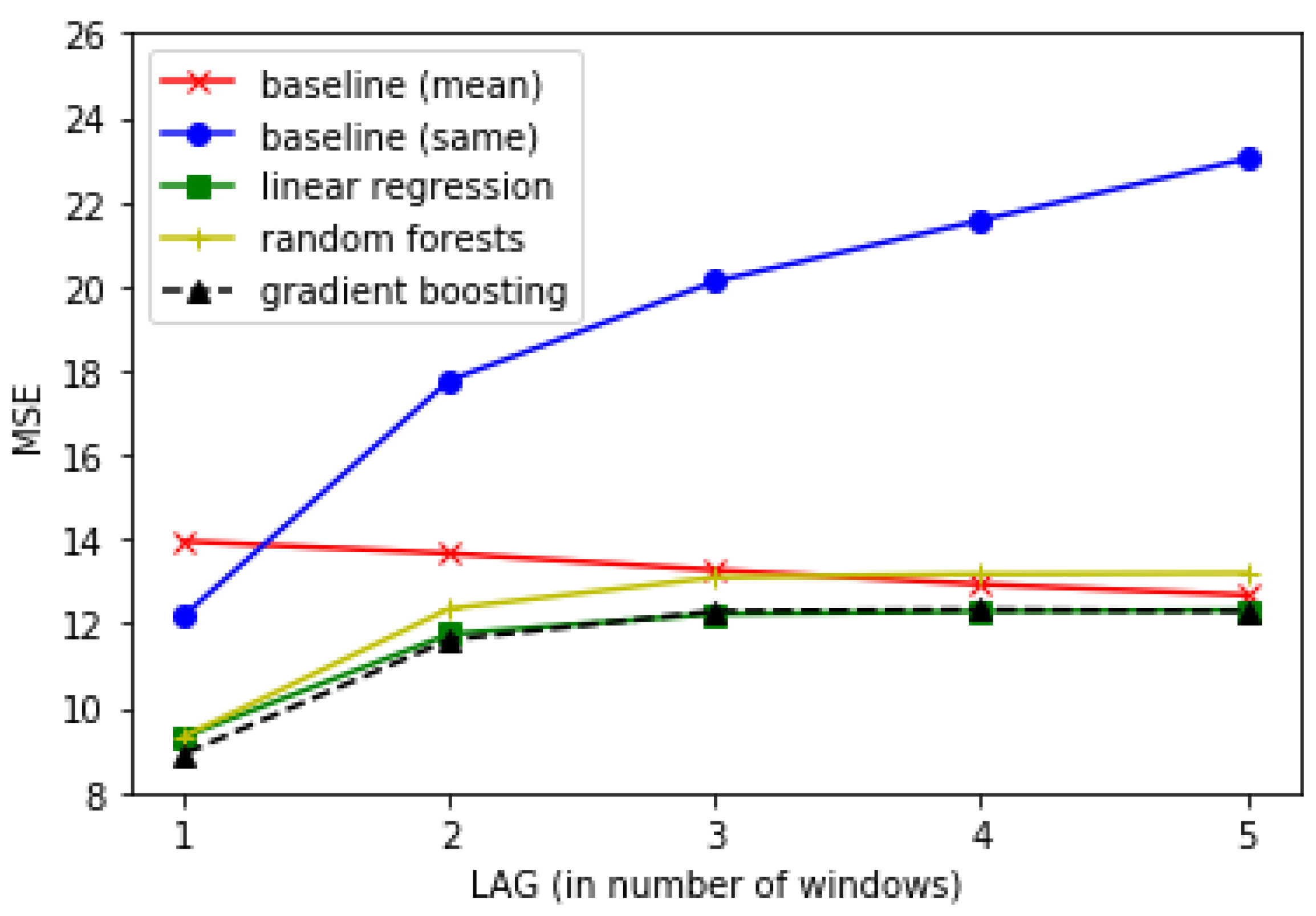
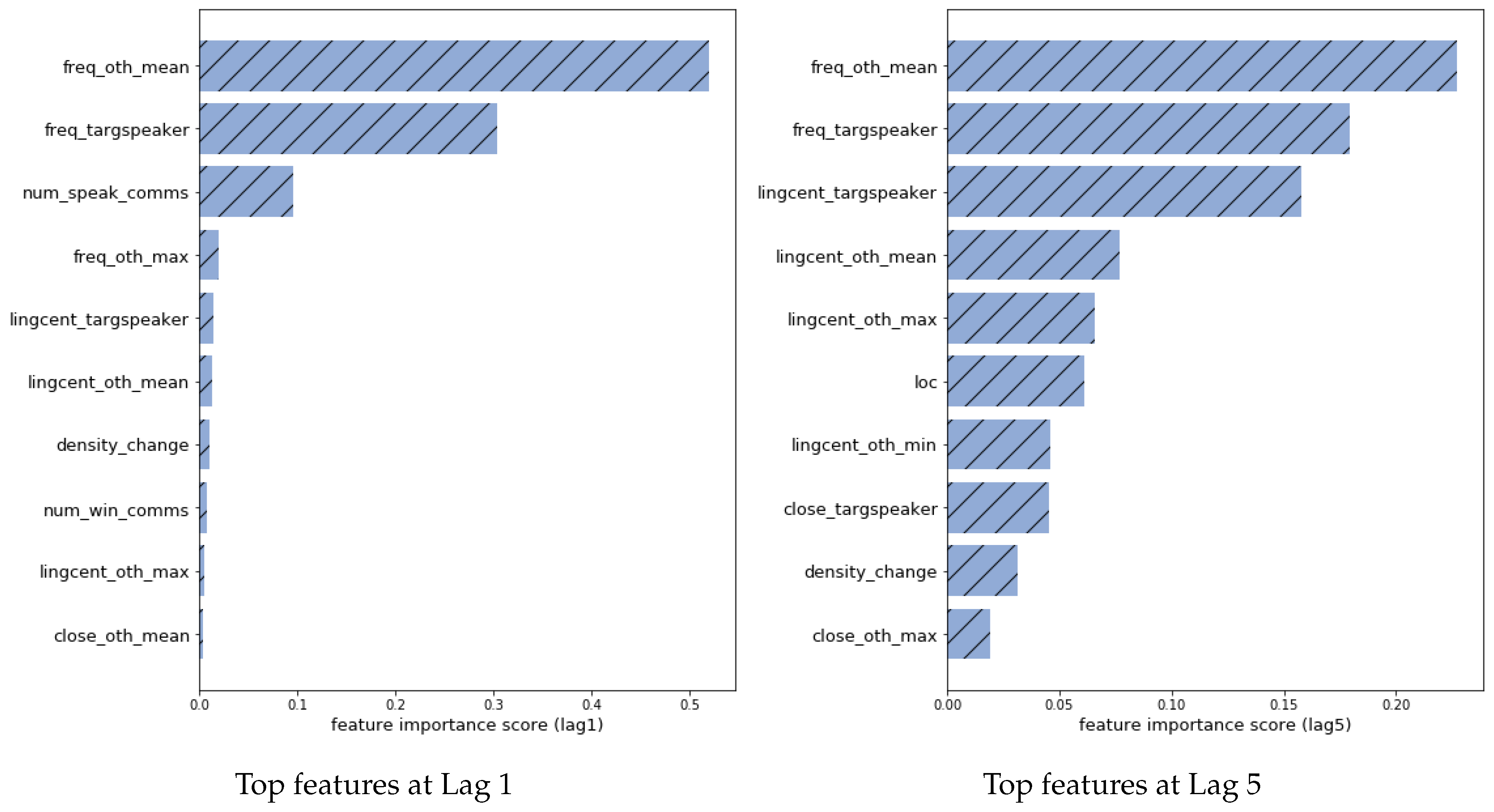
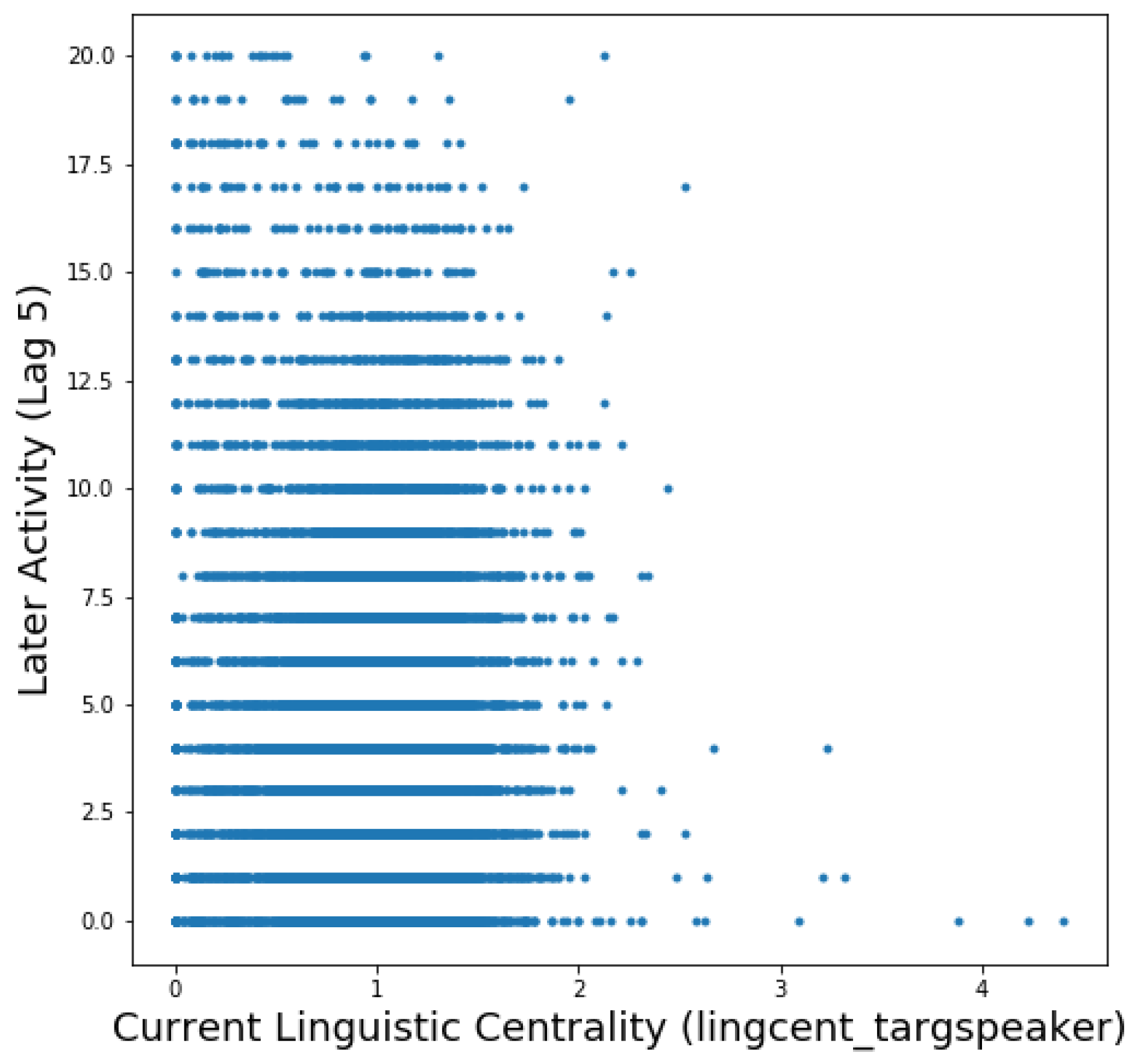
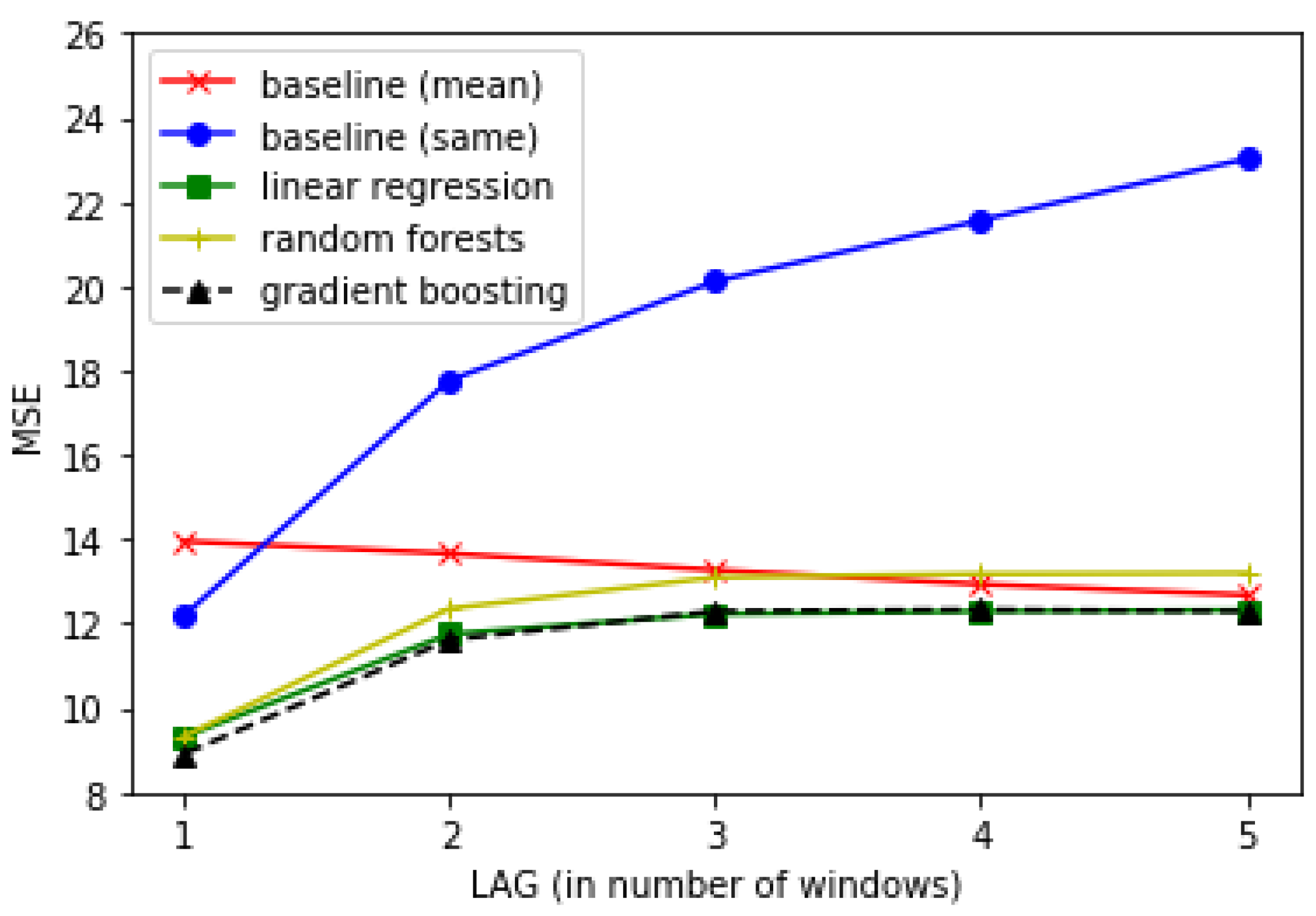
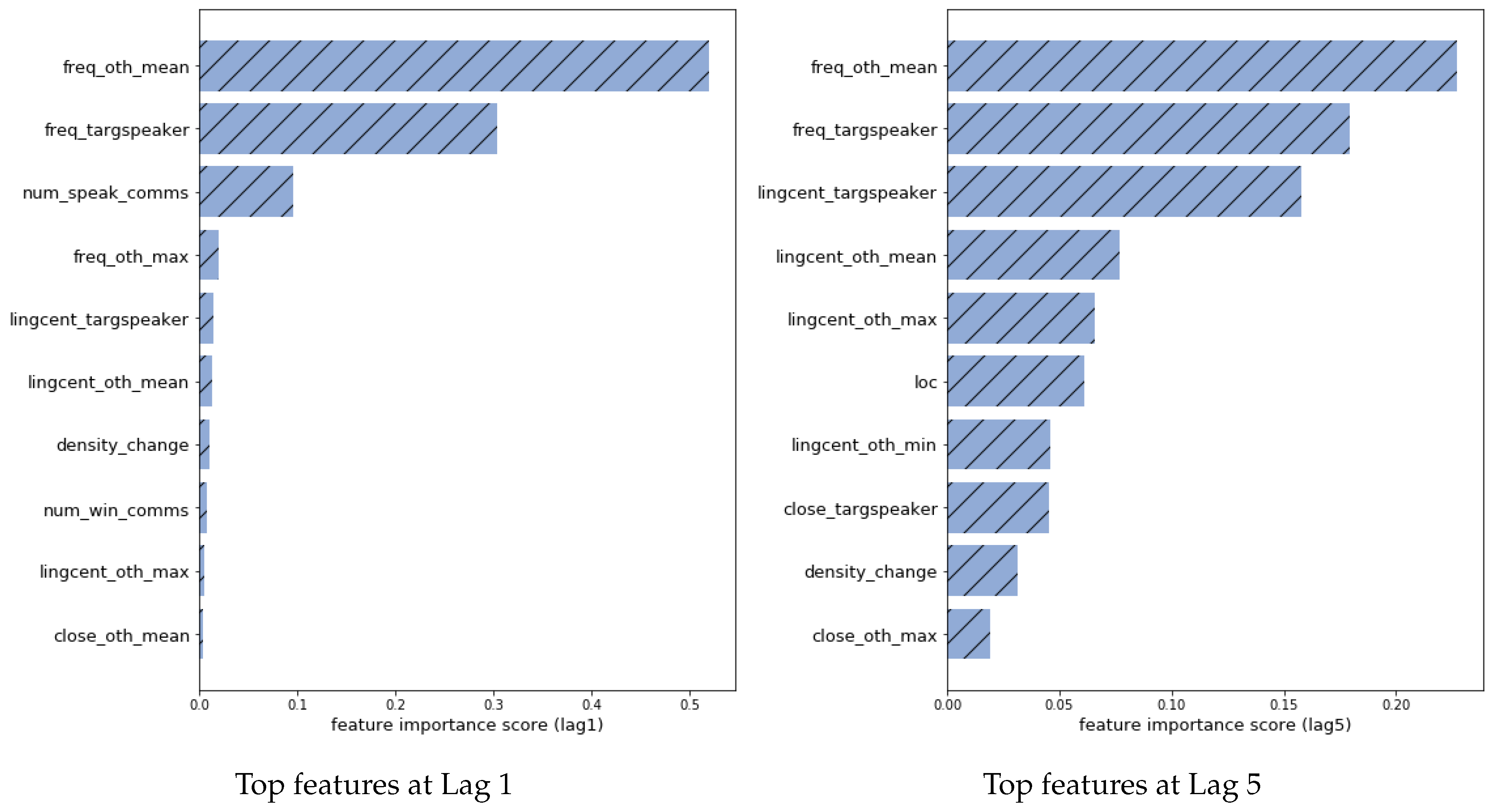
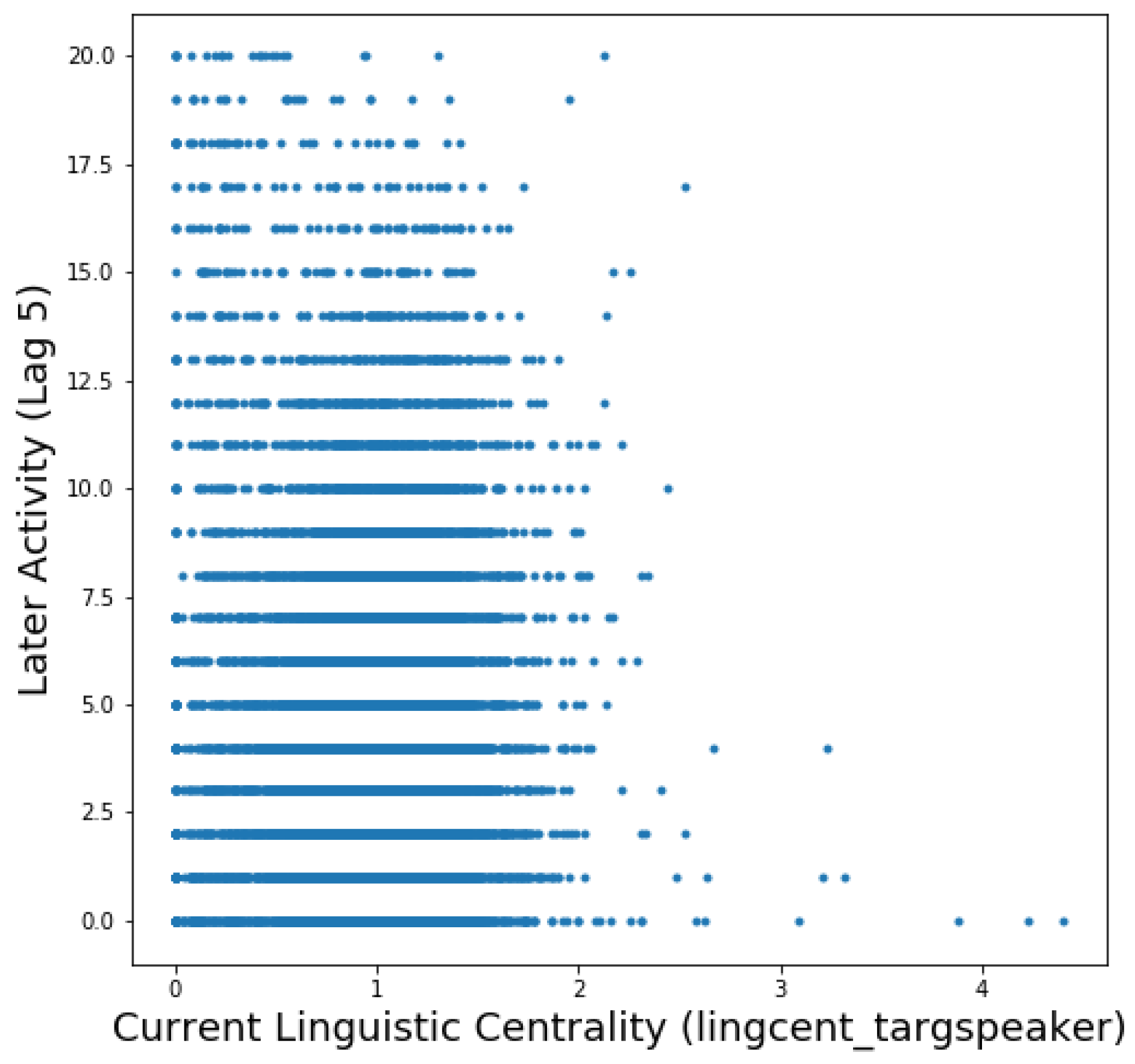
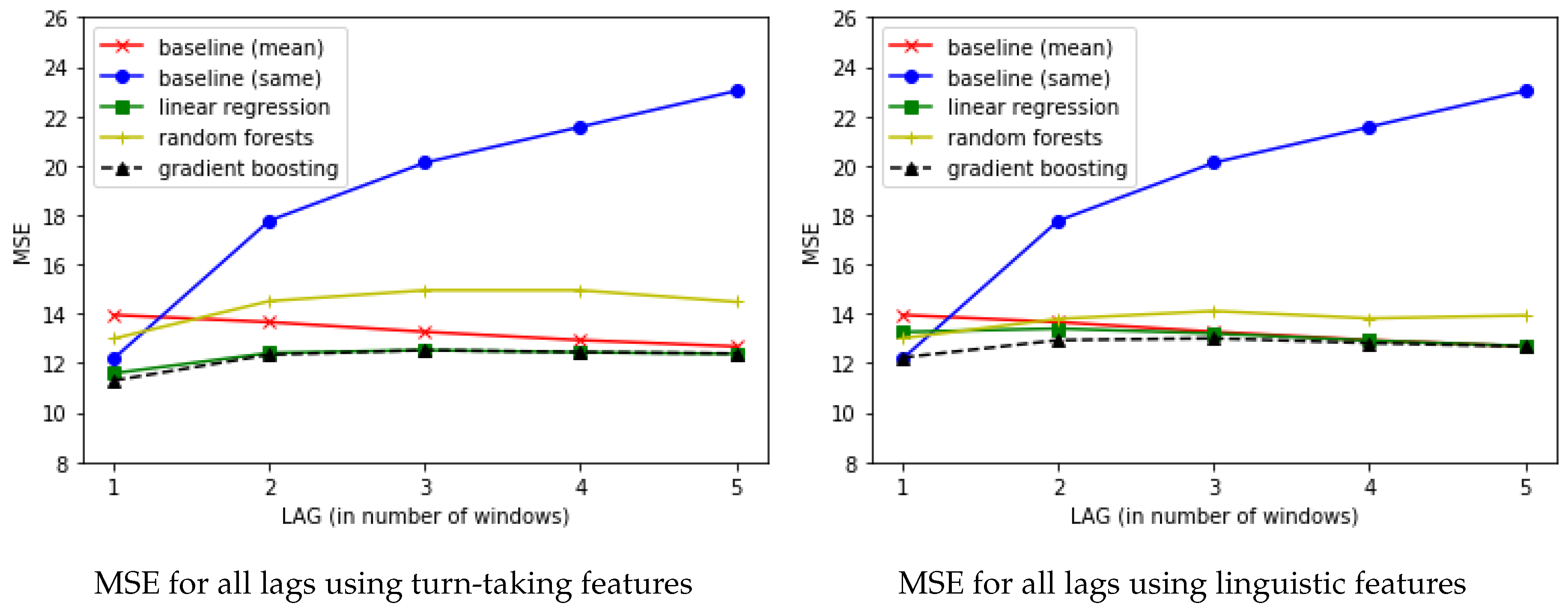
4. Results
5. Conclusions
Acknowledgments
Conflicts of Interest
References
- Stewart, A.; Keirn, Z.; D’Mello, S. Multimodal Modeling of Coordination and Coregulation Patterns in Speech Rate during Triadic Collaborative Problem Solving. In Proceedings of the ICMI, Boulder, CO, USA, 16 October 2018; pp. 21–30. [Google Scholar]
- Murray, G. Predicting Small Group Interaction Dynamics with Social Network Analysis. In Proceedings of the International Conference on Computational Social Science (IC2S2), Amsterdam, The Netherlands, 17–20 July 2019. [Google Scholar]
- Ishii, R.; Otsuka, K.; Kumano, S.; Yamato, J. Analysis of respiration for prediction of who will be next speaker and when? in multi-party meetings. In Proceedings of the 16th International Conference on Multimodal Interaction; ACM: New York, NY, USA, 2014; pp. 18–25. [Google Scholar]
- Magyari, L.; de Ruiter, J.P. Prediction of turn-ends based on anticipation of upcoming words. Front. Psychol. 2012, 3, 376. [Google Scholar] [CrossRef] [PubMed]
- Kim, B.; Rudin, C. Learning about meetings. Data Min. Knowl. Discov. 2014, 28, 1134–1157. [Google Scholar] [CrossRef] [Green Version]
- Grothendieck, J.; Gorin, A.; Borges, N. Social correlates of turn-taking behavior. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 4745–4748. [Google Scholar]
- Vinciarelli, A. Capturing order in social interactions [social sciences]. IEEE Signal Process. Mag. 2009, 26, 133–152. [Google Scholar] [CrossRef]
- Escalera, S.; Baró, X.; Vitria, J.; Radeva, P.; Raducanu, B. Social network extraction and analysis based on multimodal dyadic interaction. Sensors 2012, 12, 1702–1719. [Google Scholar] [CrossRef] [PubMed]
- Wrede, B.; Shriberg, E. Spotting “hot spots” in meetings: Human judgments and prosodic cues. In Proceedings of the Eurospeech 2003, Geneva, Switzerland, 1–4 September 2003. [Google Scholar]
- Lai, C.; Carletta, J.; Renals, S. Detecting summarization hot spots in meetings using group level involvement and turn-taking features. In Proceedings of the Interspeech 2013, Lyon, France, 25–29 August 2013. [Google Scholar]
- Vinciarelli, A.; Pantic, M.; Bourlard, H. Social signal processing: Survey of an emerging domain. Image Vis. Comput. 2009, 27, 1743–1759. [Google Scholar] [CrossRef] [Green Version]
- Avci, U.; Aran, O. Predicting the performance in decision-making tasks: From individual cues to group interaction. IEEE Trans. Multimed. 2016, 18, 643–658. [Google Scholar] [CrossRef]
- Murray, G.; Oertel, C. Predicting Group Performance in Task-Based Interaction. In Proceedings of the ICMI 2018, Boulder, CO, USA, 2–4 November 2018; pp. 14–20. [Google Scholar]
- Lai, C.; Murray, G. Predicting group satisfaction in meeting discussions. In Proceedings of the Workshop on Modeling Cognitive Processes from Multimodal Data, ICMI, Boulder, CO, USA, 16–20 October 2018. [Google Scholar]
- Sanchez-Cortes, D.; Aran, O.; Mast, M.S.; Gatica-Perez, D. A nonverbal behavior approach to identify emergent leaders in small groups. IEEE Trans. Multimed. 2011, 14, 816–832. [Google Scholar] [CrossRef]
- Müller, P.; Bulling, A. Emergent Leadership Detection Across Datasets. arXiv 2019, arXiv:1905.02058. [Google Scholar]
- Fusaroli, R.; Bahrami, B.; Olsen, K.; Roepstorff, A.; Rees, G.; Frith, C.; Tylén, K. Coming to terms: Quantifying the benefits of linguistic coordination. Psychol. Sci. 2012, 23, 931–939. [Google Scholar] [CrossRef] [PubMed]
- Reitter, D.; Moore, J.D. Alignment and task success in spoken dialogue. J. Mem. Lang. 2014, 76, 29–46. [Google Scholar] [CrossRef]
- Rahimi, Z.; Kumar, A.; Litman, D.J.; Paletz, S.; Yu, M. Entrainment in Multi-Party Spoken Dialogues at Multiple Linguistic Levels. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017; pp. 1696–1700. [Google Scholar]
- Beňuš, Š. Social aspects of entrainment in spoken interaction. Cogn. Comput. 2014, 6, 802–813. [Google Scholar] [CrossRef]
- Carletta, J. Unleashing the killer corpus: Experiences in creating the multi-everything AMI Meeting Corpus. Lang. Resour. Eval. 2007, 41, 181–190. [Google Scholar] [CrossRef]
- Clauset, A.; Newman, M.E.; Moore, C. Finding community structure in very large networks. Phys. Rev. 2004, 70, 066111. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gerlach, M.; Peixoto, T.P.; Altmann, E.G. A network approach to topic models. Sci. Adv. 2018, 4, eaaq1360. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Braley, M.; Murray, G. The Group Affect and Performance (GAP) Corpus. In Proceedings of the Group Interaction Frontiers in Technology workshop, ICMI, Boulder, CO, USA, 16–20 October 2018; ACM: New York, NY, USA, 2018; p. 2. [Google Scholar]
- Oertel, C.; Cummins, F.; Edlund, J.; Wagner, P.; Campbell, N. D64: A corpus of richly recorded conversational interaction. J. Multimodal User Interfaces 2013, 7, 19–28. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Lag | |
|---|---|
| 1 | 0.35 |
| 2 | 0.17 |
| 3 | 0.11 |
| 4 | 0.08 |
| 5 | 0.08 |
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Murray, G. Graph-Based Prediction of Meeting Participation. Multimodal Technol. Interact. 2019, 3, 54. https://doi.org/10.3390/mti3030054
Murray G. Graph-Based Prediction of Meeting Participation. Multimodal Technologies and Interaction. 2019; 3(3):54. https://doi.org/10.3390/mti3030054
Chicago/Turabian StyleMurray, Gabriel. 2019. "Graph-Based Prediction of Meeting Participation" Multimodal Technologies and Interaction 3, no. 3: 54. https://doi.org/10.3390/mti3030054
APA StyleMurray, G. (2019). Graph-Based Prediction of Meeting Participation. Multimodal Technologies and Interaction, 3(3), 54. https://doi.org/10.3390/mti3030054