

Driving Domain Classification Based on Kernel Density Estimation of Urban Land Use and Road Network Scaling Models


Abstract
1. Introduction
1.1. Motivation
1.2. Related Research
1.3. Urban Metrics and Urban Sprawl
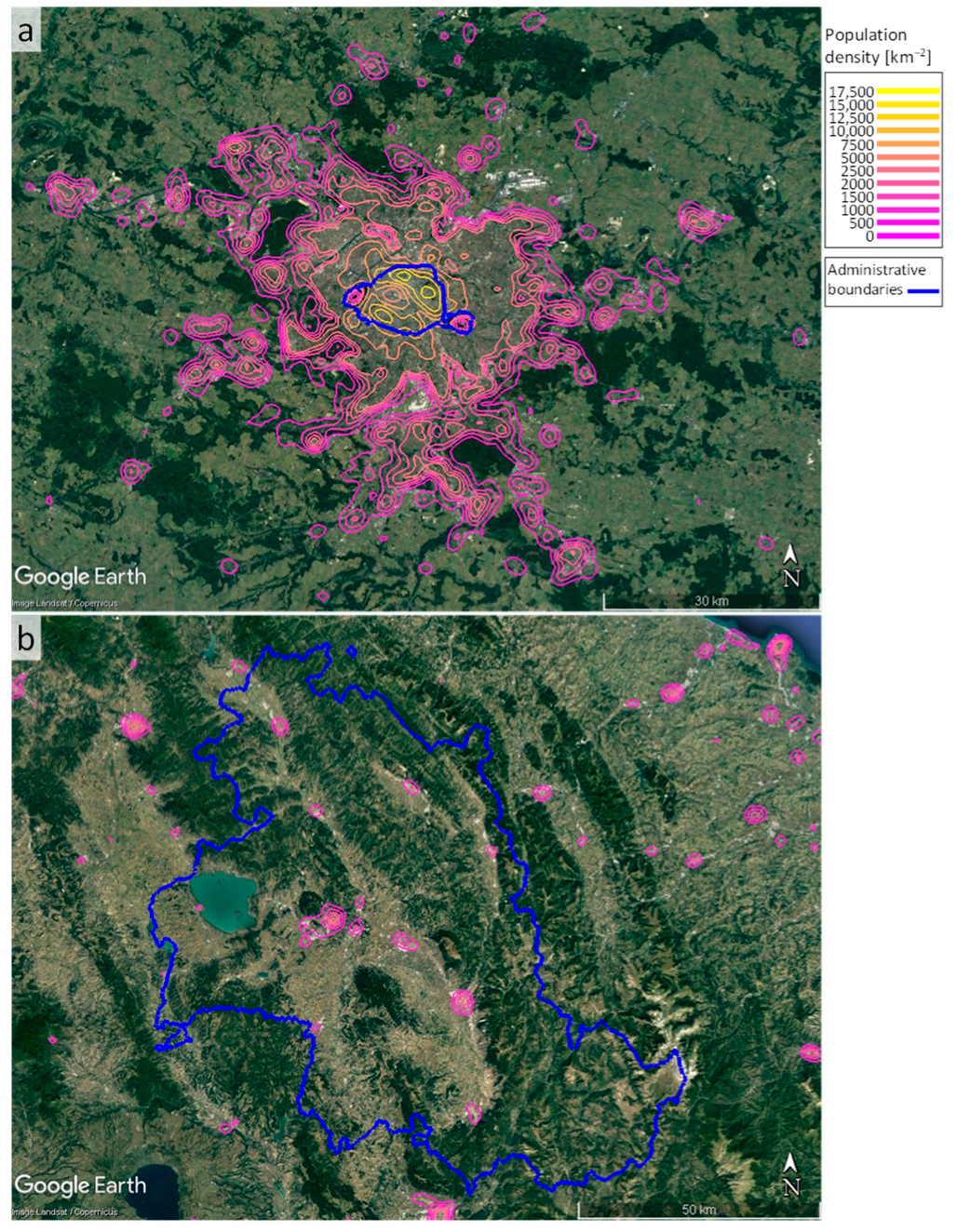
1.4. Land-Use Analyses and Urban Density Estimation
1.5. Relationship between Road Network and City Size
1.6. Summary of the Related Research
2. Methodology
2.1. Overview
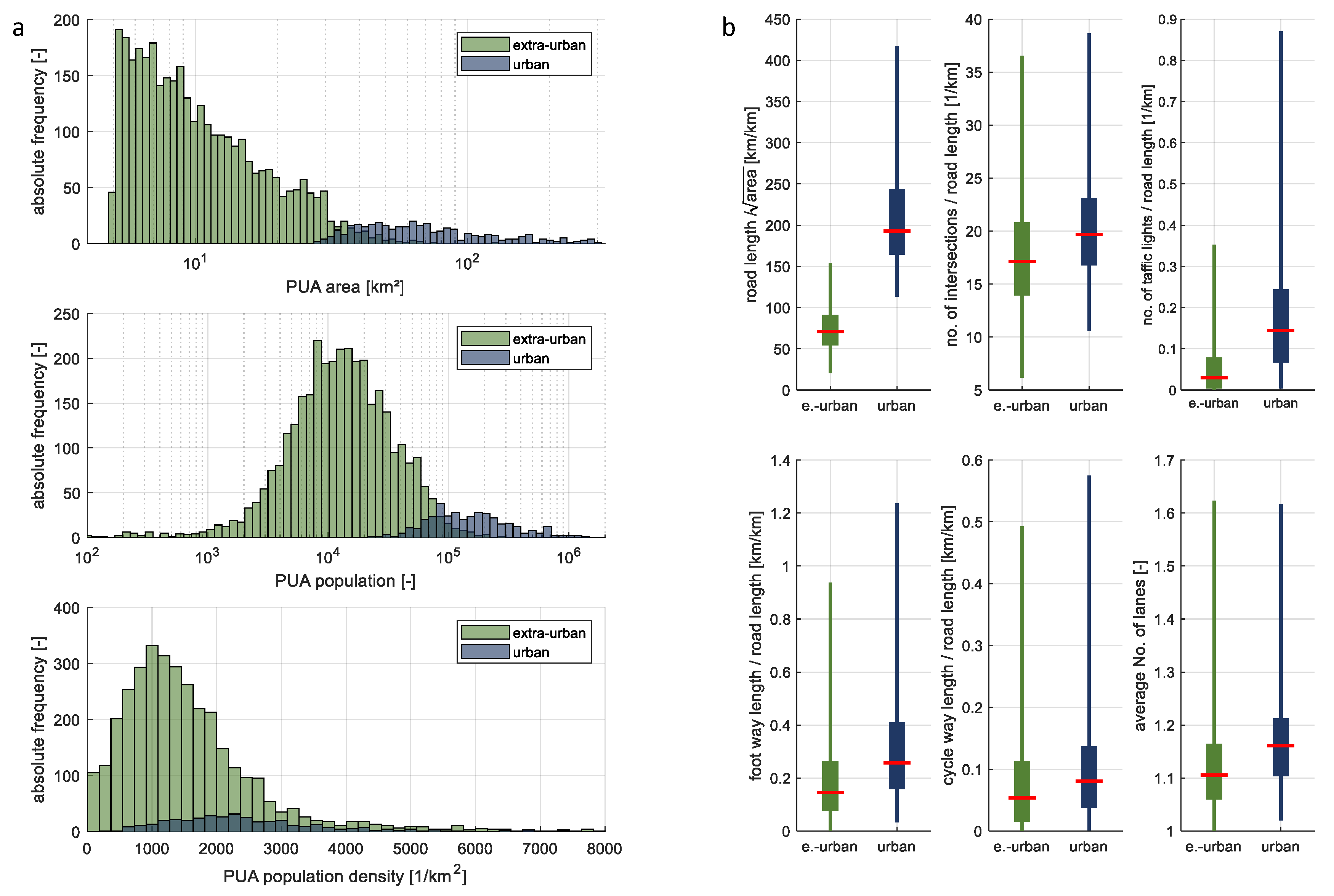
2.2. Urban Land-Use Categories in OSM
2.3. Kernel Density Estimation of Urban Land Use and Population Density
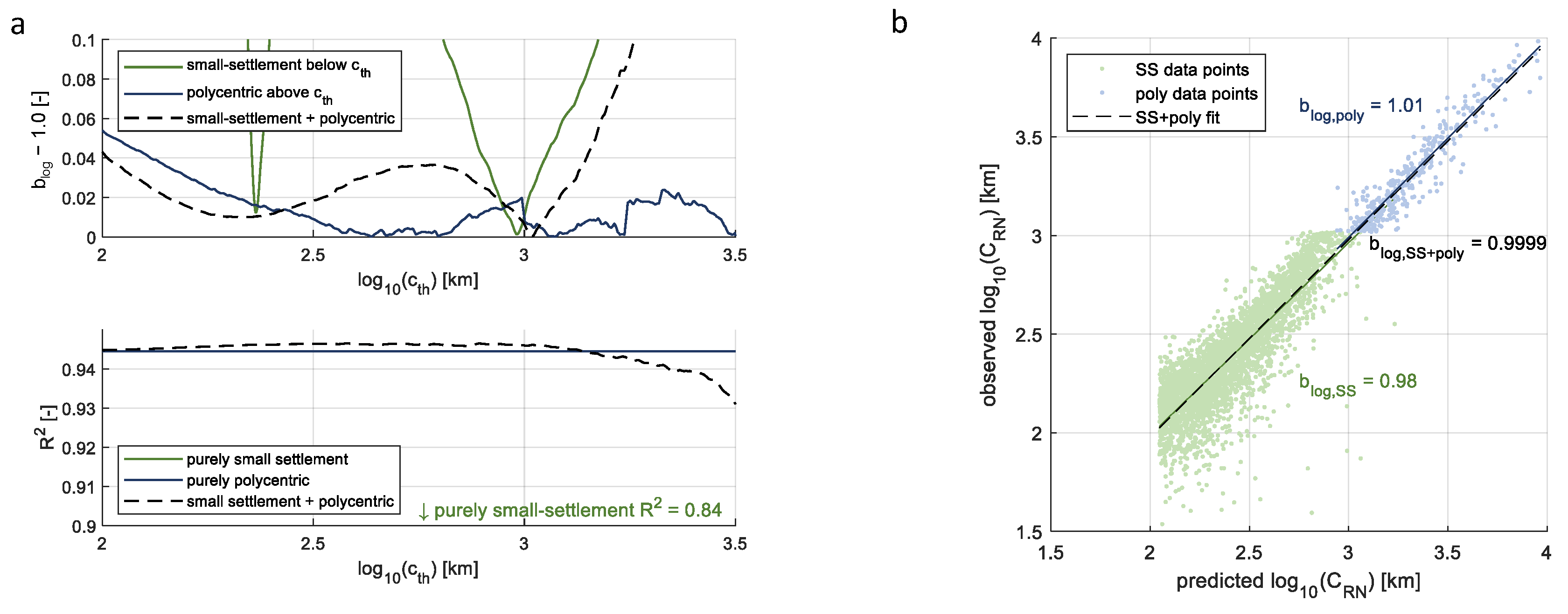
2.4. Road Network Scaling Model
3. Results and Discussion
4. Summary and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- SAE International/ISO. Surface Vehicle Recommended Practice: Taxonomy and Definitions for Terms Related to Driving Automation Systems for On-Road Motor Vehicles, 2021-04; SAE. (J3016). 2021. Available online: https://www.researchgate.net/publication/355980391_SURFACE_VEHICLE_RECOMMENDED_PRACTICE_R_Taxonomy_and_Definitions_for_Terms_Related_to_Driving_Automation_Systems_for_On-Road_Motor_Vehicles (accessed on 26 November 2023).
- PAS 1883:2020; Operational Design Domain (ODD) Taxonomy for an Automated Driving System (ADS): Specification. The British Standards Institution, BSI Standards Limited: London, UK, 2020.
- ISO 34503:2023; Road Vehicles—Test Scenarios for Automated Driving Systems—Specification for Operational Design Domain. International Organization for Standardization: Geneva, Switzerland, 2023.
- Ye, X.; Wang, X. Operational design domain of automated vehicles at freeway entrance terminals. Accid. Anal. Prev. 2022. [Google Scholar] [CrossRef]
- Vreeswijk, J.; Wijbenga, A.; Schindler, J. Cooperative Automated Driving for managing Transition Areas and the Operational Design Domain (ODD). In Proceedings of the 8th Transport Research Arena TRA, Rethinking Transport. TRA2020, Helsinki, Finland, 27–30 April 2020. [Google Scholar]
- Bernstein, D.; Kornhauser, D. An Introduction to Map Matching for Personal Navigation Assistants; New Jersey Institute of Technology: Newark, NJ, USA, 1996. [Google Scholar]
- Quddus, M.A.; Ochieng, W.Y.; Zhao, L.; Noland, R.B. A general map matching algorithm for transport telematics applications. GPS Solut. 2003, 7, 157–167. [Google Scholar] [CrossRef]
- Yang, H.; Cheng, S.; Jiang, H.; An, S. An Enhanced Weight-based Topological Map Matching Algorithm for Intricate Urban Road Network. Procedia—Soc. Behav. Sci. 2013, 96, 1670–1678. [Google Scholar] [CrossRef]
- Lou, Y.; Zhang, C.; Zheng, Y.; Xie, X.; Wang, W.; Huang, Y. Map-matching for low-sampling-rate GPS trajectories. In Proceedings of the 17th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems; Association for Computing Machinery: New York, NY, USA, 2009. [Google Scholar] [CrossRef]
- Uni Münster. Definitionen: Stadtbegriff. Available online: https://www.uni-muenster.de/Staedtegeschichte/portal/einfuehrung/Definitionen.html (accessed on 9 November 2023).
- Bhagat, R.B. Rural-urban classification and municipal governance in India. Singap. J. Trop. Geogr. 2005, 26, 61–73. [Google Scholar] [CrossRef]
- Bundesinstitut für Bau-, Stadt- und Raumforschung. Raumbeobachtung: Stadt- und Gemeindetypen in Deutschland. Available online: https://www.bbsr.bund.de/BBSR/DE/forschung/raumbeobachtung/Raumabgrenzungen/deutschland/gemeinden/StadtGemeindetyp/StadtGemeindetyp.html (accessed on 9 November 2023).
- Geography Revision. Hierarchy of Settlements. Available online: https://geography-revision.co.uk/a-level/human/hierarchy-of-settlements/#Introduction_to_hierarchy_of_settlements (accessed on 9 November 2023).
- Tarrant, J.R. A Note concerning the Definition of Groups of Settlements for a Central Place Hierarchy. Econ. Geogr. 1968, 44, 144–151. [Google Scholar] [CrossRef]
- Lynch, K.A. What Is the Form of a City, and How Is It Made? In Urban Ecology: An International Perspective on the Interaction between Humans and Nature; Marzluff, J.M., Shulenberger, E., Endlicher, W., Alberti, M., Bradley, G., Ryan, C., zum Brunnen, C., Simon, U., Eds.; Springer: New York, NY, USA, 2008; pp. 677–690. ISBN 978-0-387-73411-8. [Google Scholar]
- Müller-Ibold, K. Einführung in die Stadtplanung: Band 1: Definitionen und Bestimmungsfaktoren; W. Kohlhammer: Stuttgart, Germany, 1996; ISBN 978-3-8348-1632-0. [Google Scholar]
- OpenStreetMap Contributors. Planet Dump. Available online: https://planet.osm.org (accessed on 5 July 2023).
- Eurostat. NUTS 2021 Classification. Table. 2023. Available online: https://ec.europa.eu/eurostat/documents/345175/629341/NUTS2021.xlsx (accessed on 2 December 2023).
- Lowry, J.H.; Lowry, M.B. Comparing spatial metrics that quantify urban form. Comput. Environ. Urban Syst. 2014, 44, 59–67. [Google Scholar] [CrossRef]
- Saksena, S.; Fox, J.; Spencer, J.; Castrence, M.; DiGregorio, M.; Epprecht, M.; Sultana, N.; Finucane, M.; Nguyen, L.; Vien, T.D. Classifying and mapping the urban transition in Vietnam. Appl. Geogr. 2014, 50, 80–89. [Google Scholar] [CrossRef]
- Chettry, V. A Critical Review of Urban Sprawl Studies. J. Geovisualization Spat. Anal. 2023, 7, 28. [Google Scholar] [CrossRef]
- Lopez, R. Urban Sprawl in the United States: 1970–2010. Cities Environ. (CATE) 2014, 7. Available online: https://digitalcommons.lmu.edu/cgi/viewcontent.cgi?article=1131&context=cate (accessed on 25 April 2024).
- Hennig, E.I.; Schwick, C.; Soukup, T.; Orlitová, E.; Kienast, F.; Jaeger, J.A. Multi-scale analysis of urban sprawl in Europe: Towards a European de-sprawling strategy. Land Use Policy 2015, 49, 483–498. [Google Scholar] [CrossRef]
- OpenStreetMap Wiki Contributors. About OpenStreetMap: OpenStreetMap Wiki. Available online: https://wiki.openstreetmap.org/w/index.php?title=About_OpenStreetMap&oldid=2310396 (accessed on 12 November 2023).
- Eurostat. Data of the 2021 Population and Housing Census in the EU. GeoPackage (gpkg). 2023. Available online: https://gisco-services.ec.europa.eu/census/2021/Eurostat_Census-GRID_2021_V1-0.zip (accessed on 13 November 2023).
- Yue, W.; Zhang, L.; Liu, Y. Measuring sprawl in large Chinese cities along the Yangtze River via combined single and multidimensional metrics. Habitat Int. 2016, 57, 43–52. [Google Scholar] [CrossRef]
- Dutta, I.; Das, A. Application of geo-spatial indices for detection of growth dynamics and forms of expansion in English Bazar Urban Agglomeration, West Bengal. J. Urban Manag. 2019, 8, 288–302. [Google Scholar] [CrossRef]
- Jiao, L. Urban land density function: A new method to characterize urban expansion. Landsc. Urban Plan. 2015, 139, 26–39. [Google Scholar] [CrossRef]
- Li, Z.; Jiao, L.; Zhang, B.; Xu, G.; Liu, J. Understanding the pattern and mechanism of spatial concentration of urban land use, population and economic activities: A case study in Wuhan, China. Geo-Spat. Inf. Sci. 2021, 24, 678–694. [Google Scholar] [CrossRef]
- Goldblatt, R.; You, W.; Hanson, G.; Khandelwal, A. Detecting the Boundaries of Urban Areas in India: A Dataset for Pixel-Based Image Classification in Google Earth Engine. Remote Sens. 2016, 8, 634. [Google Scholar] [CrossRef]
- Tabassum, A.; Basak, R.; Shao, W.; Haque, M.M.; Chowdhury, T.A.; Dey, H. Exploring the Relationship between Land Use Land Cover and Land Surface Temperature: A Case Study in Bangladesh and the Policy Implications for the Global South. J. Geovisualization Spat. Anal. 2023, 7, 25. [Google Scholar] [CrossRef]
- Cianfarani, F.; Abdelkarim, M.; Richards, D.; Kedarisetty, R.K. Assessing the Urban Vacant Land Potential for Infill Housing: A Case Study in Oklahoma City, USA. Urban Sci. 2023, 7, 101. [Google Scholar] [CrossRef]
- Samaniego, H.; Moses, M.E. Cities as organisms: Allometricscalingofurbanroad networks. J. Transp. Land Use 2008, 1, 21–39. [Google Scholar] [CrossRef]
- Taillanter, E.; Barthelemy, M. Evolution of road infrastructure in large urban areas. Phys. Rev. E 2023, 107, 34304. [Google Scholar] [CrossRef]
- Boeing, G. OSMnx: A Python package to work with graph-theoretic OpenStreetMap street networks. JOSS 2017, 2, 215. [Google Scholar] [CrossRef]
- OpenStreetMap Wiki Contributors. DE:Key:landuse: OpenStreetMap Wiki. Available online: https://wiki.openstreetmap.org/w/index.php?title=DE:Key:landuse&oldid=2338525 (accessed on 12 November 2023).
- Eurostat Press Office. The 2021 Population and Housing Censuses in the EU. Available online: https://ec.europa.eu/eurostat/documents/4031688/14081269/KS-09-21-344-EN-N.pdf/5907978a-011d-52fc-100e-f6a67735d938?t=1641392358489 (accessed on 26 November 2023).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S. No. | Key | Value | Comment | Classification |
|---|---|---|---|---|
| 1 | landuse | commercial | - | urban |
| 2 | construction | - | ||
| 3 | education | - | ||
| 4 | fairground | - | ||
| 5 | industrial | - | ||
| 6 | residential | - | ||
| 7 | retail | - | ||
| 8 | institutional | - | ||
| 9 | cemetery | old cemeteries are often found inside urban areas | ||
| 10 | garages | - | ||
| 11 | port | high spatial share of port cities is part of the port area | ||
| 12 | leisure | park | many metropolitan areas include parks for leisure | |
| 13 | landuse | aquaculture | - | non-urban |
| 14 | allotments | allotments are mainly placed at the rim of urban areas | ||
| 15 | farmland | - | ||
| 16 | farmyard | - | ||
| 17 | paddy | - | ||
| 18 | animal_keeping | - | ||
| 19 | flowerbed | - | ||
| 20 | forest | - | ||
| 21 | greenhouse_horticulture | built-up land but in extra-urban areas | ||
| 22 | meadow | - | ||
| 23 | orchard | - | ||
| 24 | plant_nursery | - | ||
| 25 | vineyard | - | ||
| 26 | basin | - | ||
| 27 | reservoir | - | ||
| 28 | salt_pond | - | ||
| 29 | brownfield | - | ||
| 30 | conservation | - | ||
| 31 | depot | - | ||
| 32 | grass | - | ||
| 33 | greenfield | - | ||
| 34 | landfill | - | ||
| 35 | military | - | ||
| 36 | quarry | - | ||
| 37 | railway | - | ||
| 38 | recreation_ground | - | ||
| 39 | religious | - | ||
| 40 | village_green | - | ||
| 41 | winter_sports | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Brandes, G.; Sieg, C.; Sander, M.; Henze, R. Driving Domain Classification Based on Kernel Density Estimation of Urban Land Use and Road Network Scaling Models. Urban Sci. 2024, 8, 48. https://doi.org/10.3390/urbansci8020048
Brandes G, Sieg C, Sander M, Henze R. Driving Domain Classification Based on Kernel Density Estimation of Urban Land Use and Road Network Scaling Models. Urban Science. 2024; 8(2):48. https://doi.org/10.3390/urbansci8020048
Chicago/Turabian StyleBrandes, Gerrit, Christian Sieg, Marcel Sander, and Roman Henze. 2024. "Driving Domain Classification Based on Kernel Density Estimation of Urban Land Use and Road Network Scaling Models" Urban Science 8, no. 2: 48. https://doi.org/10.3390/urbansci8020048
APA StyleBrandes, G., Sieg, C., Sander, M., & Henze, R. (2024). Driving Domain Classification Based on Kernel Density Estimation of Urban Land Use and Road Network Scaling Models. Urban Science, 8(2), 48. https://doi.org/10.3390/urbansci8020048