

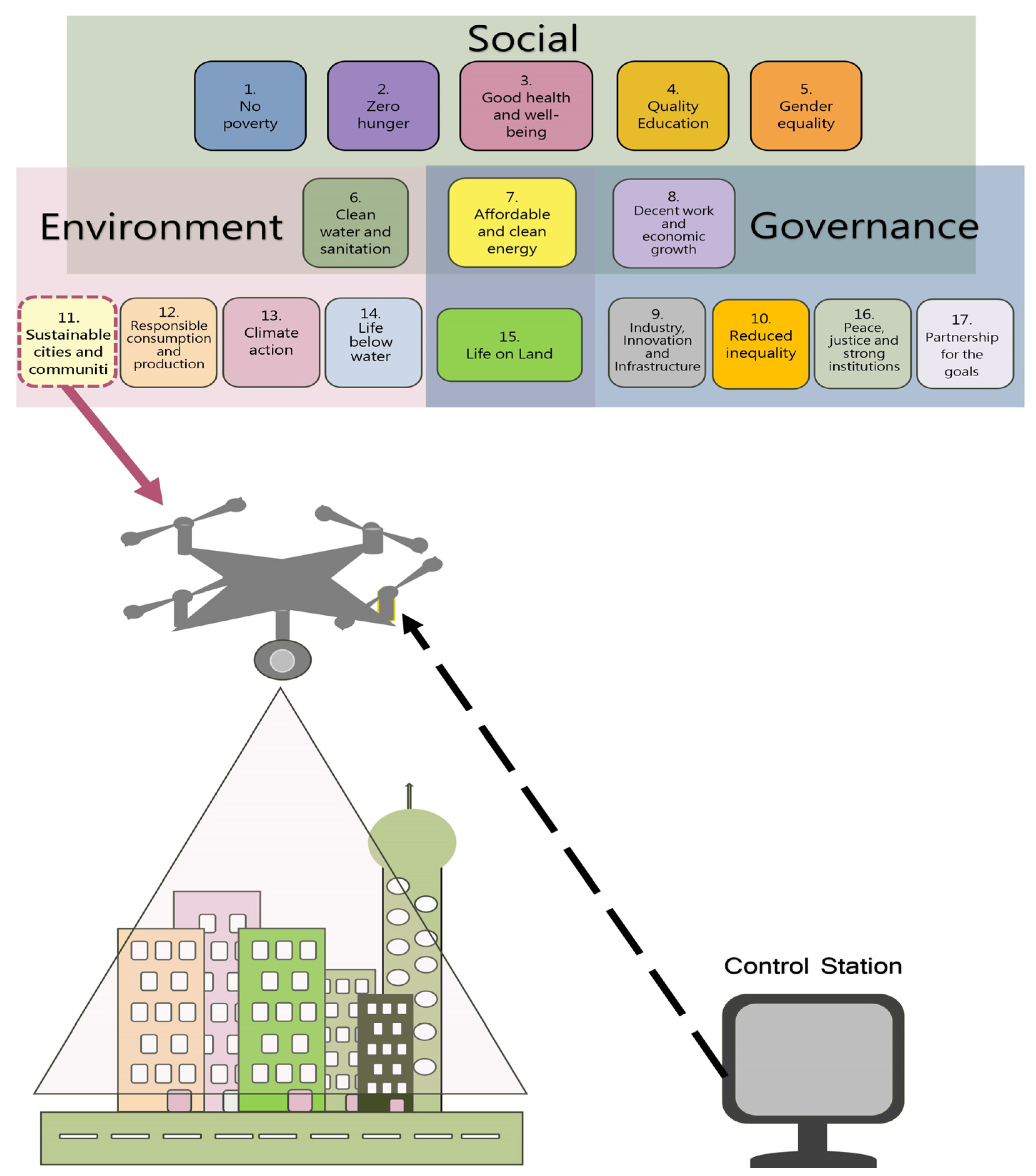
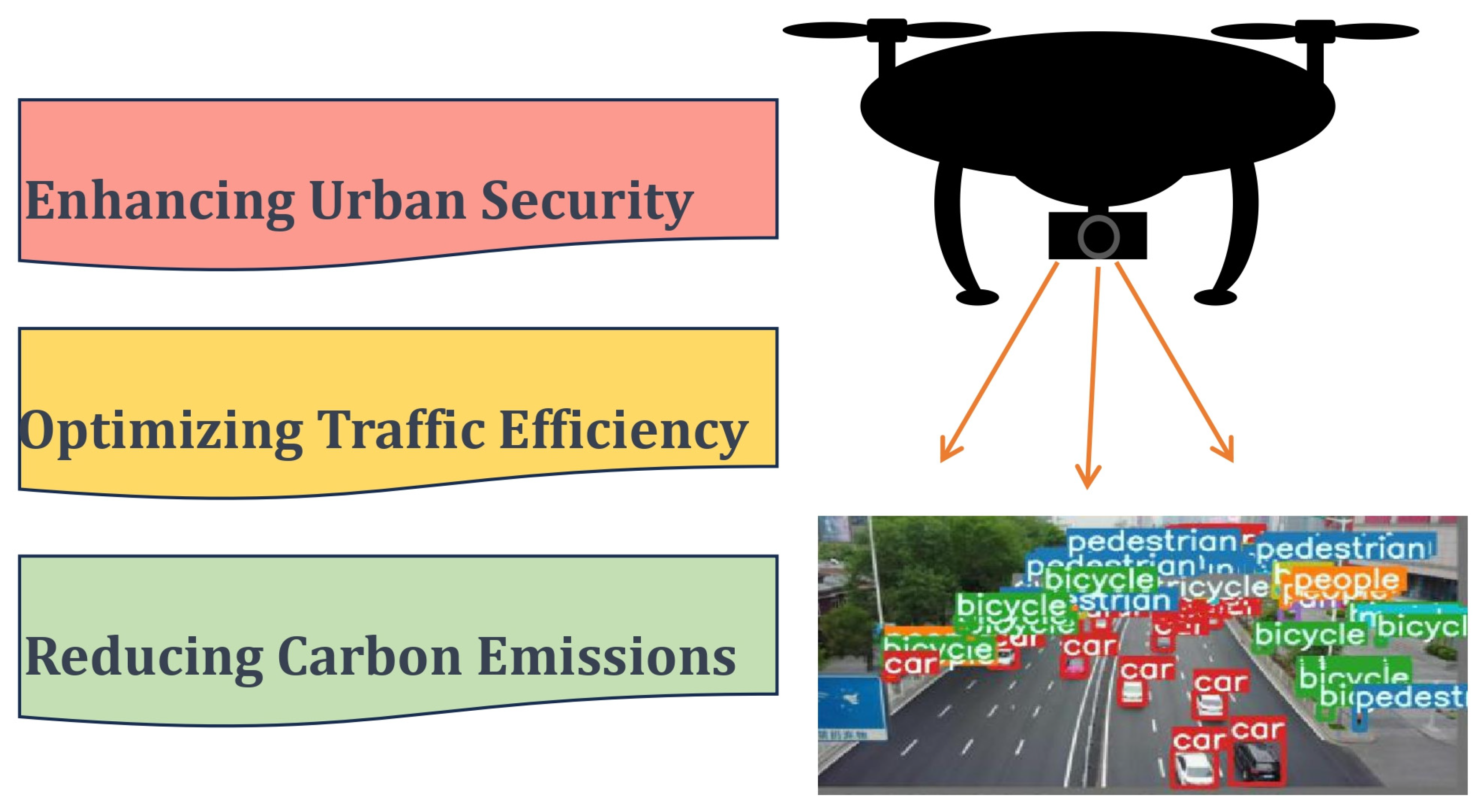
Advancing ESG and SDGs Goal 11: Enhanced YOLOv7-Based UAV Detection for Sustainable Transportation in Cities and Communities


Abstract
:1. Introduction
2. Related Work
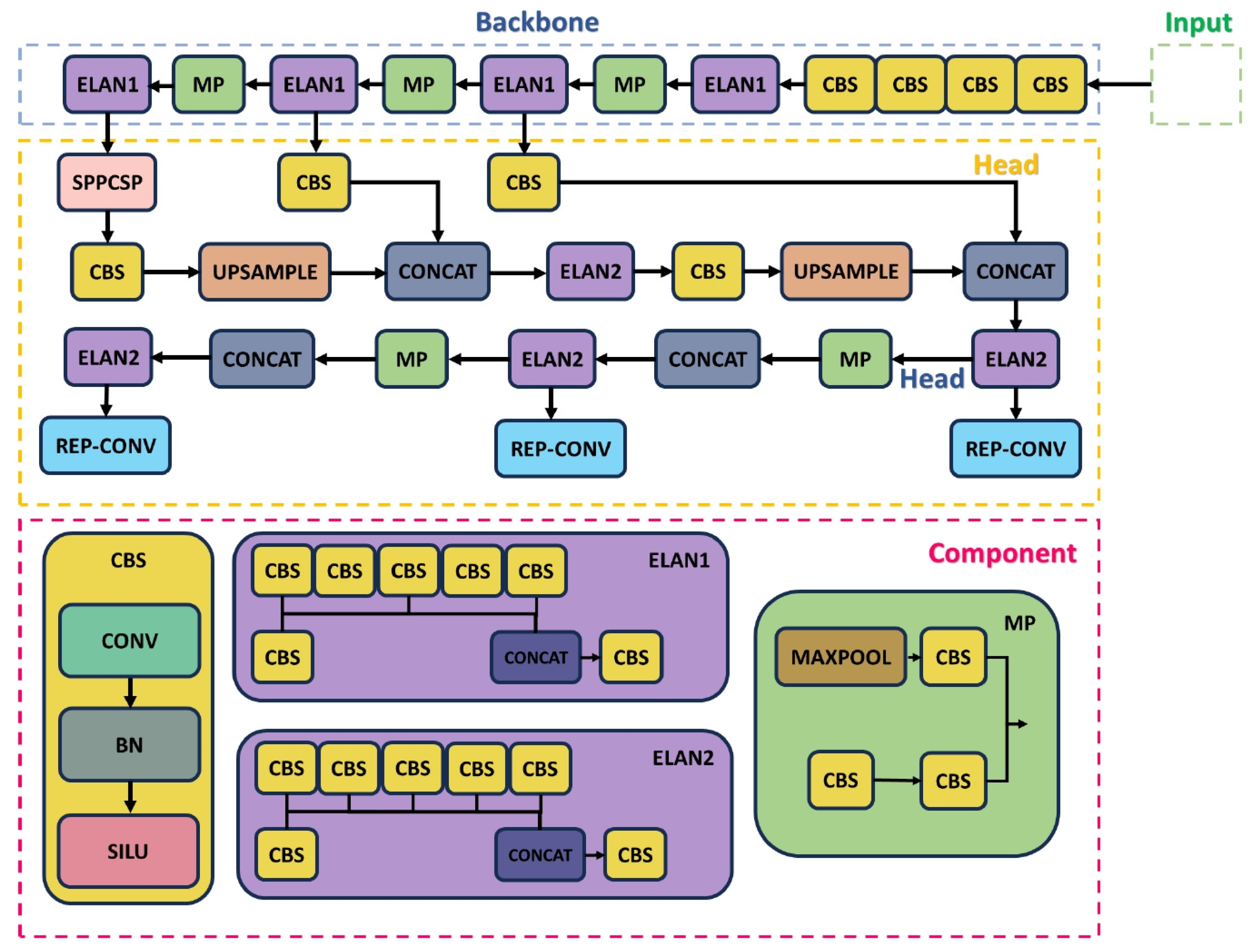
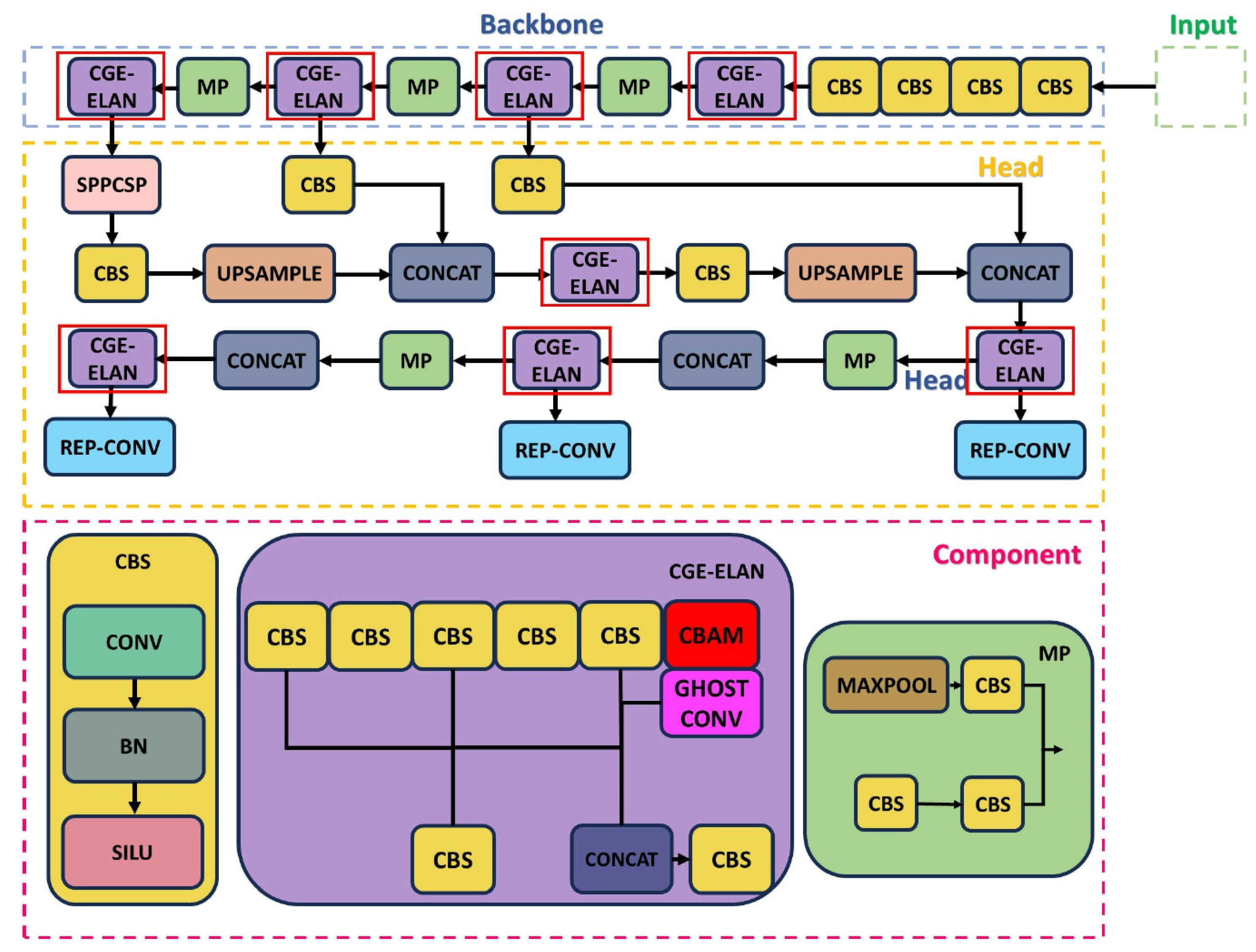
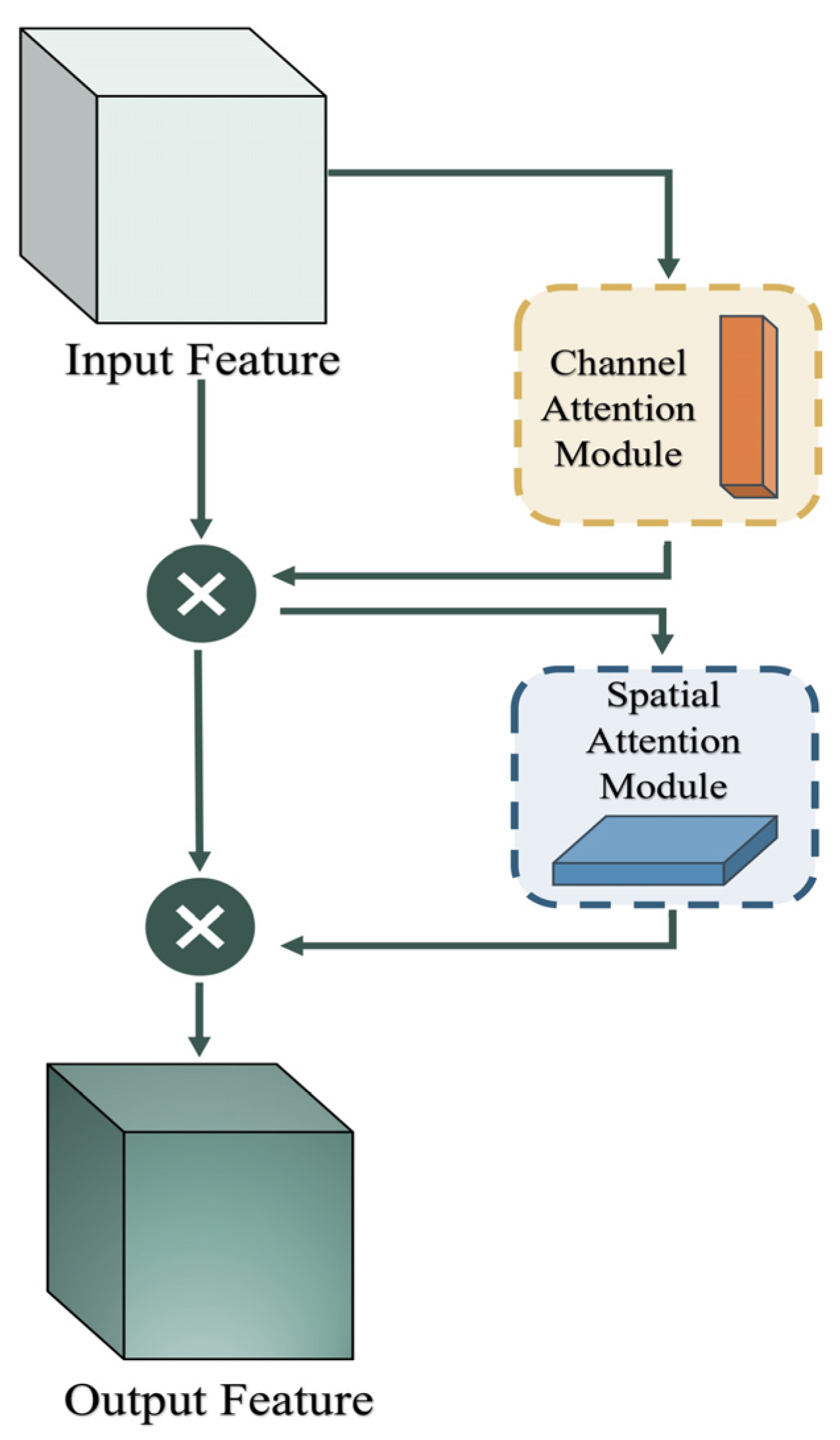
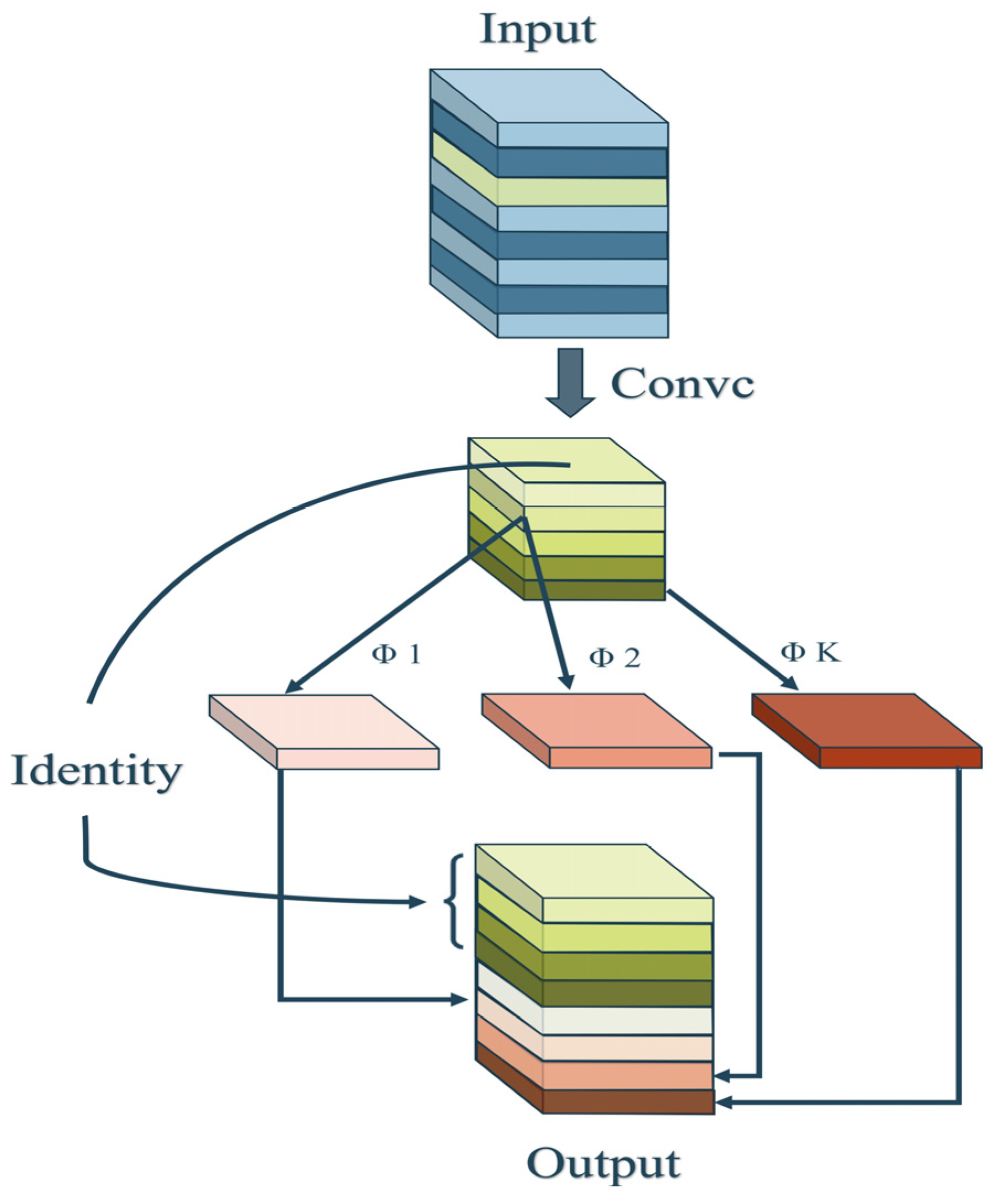
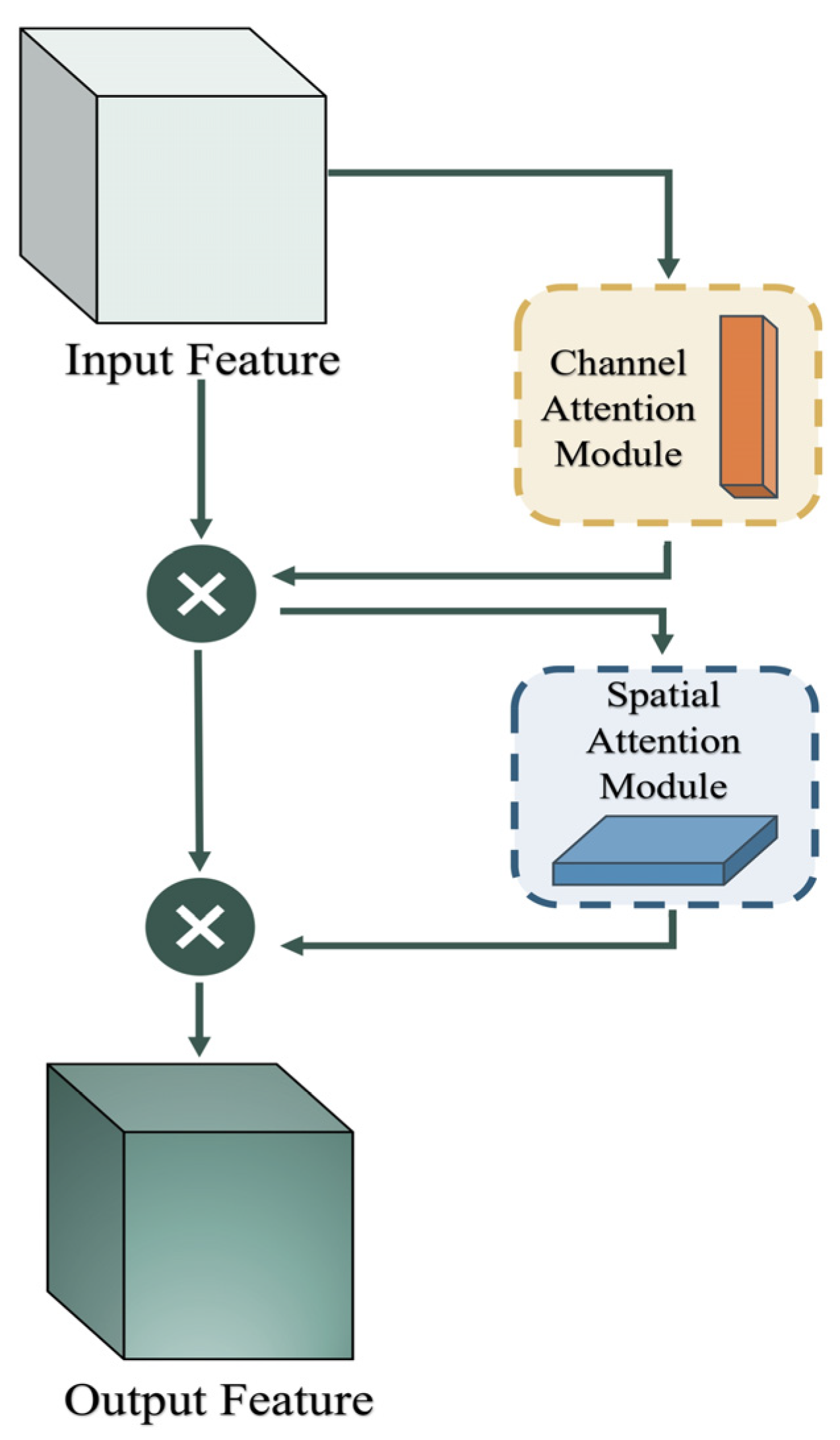
3. Materials and Methods
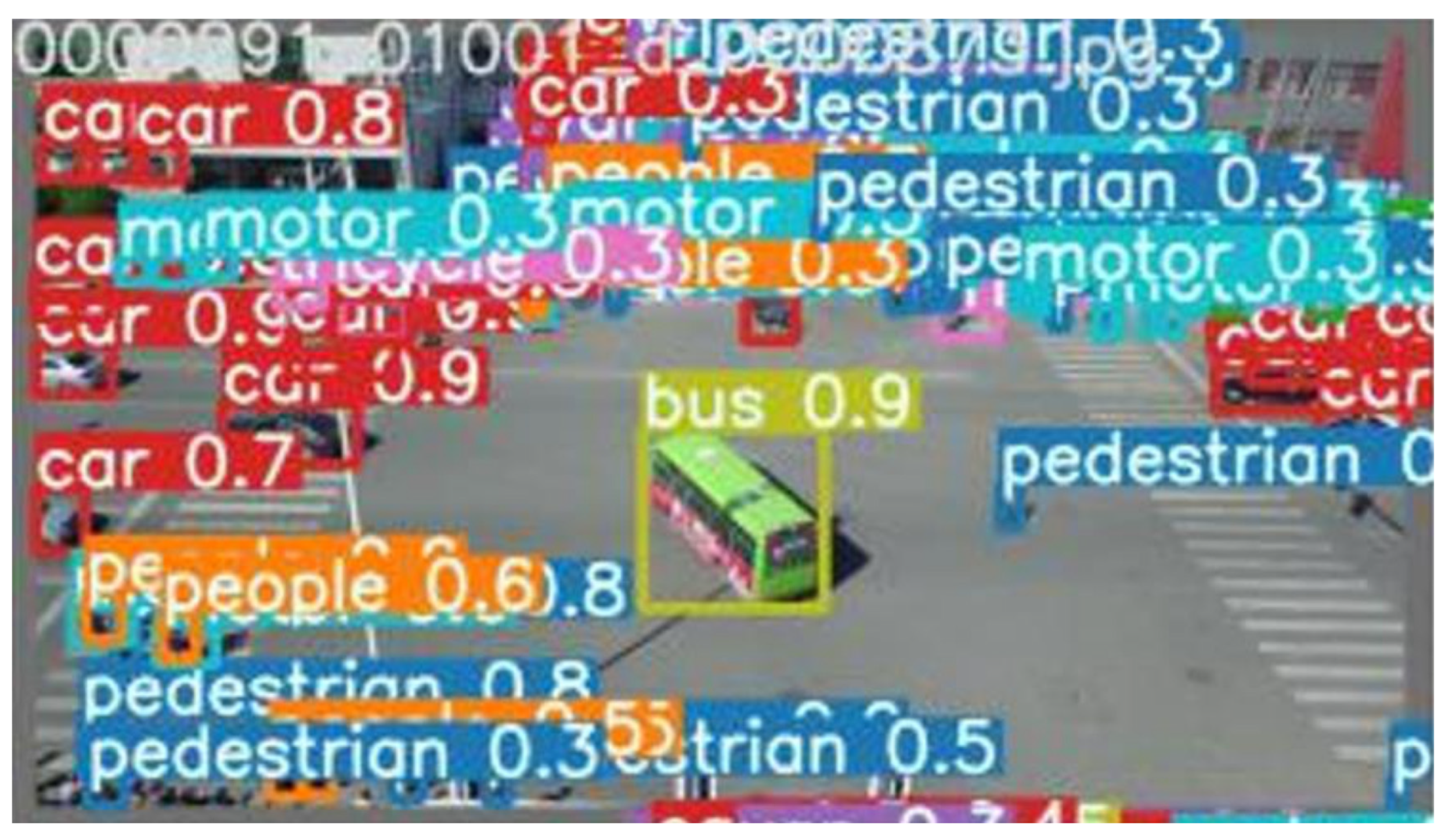
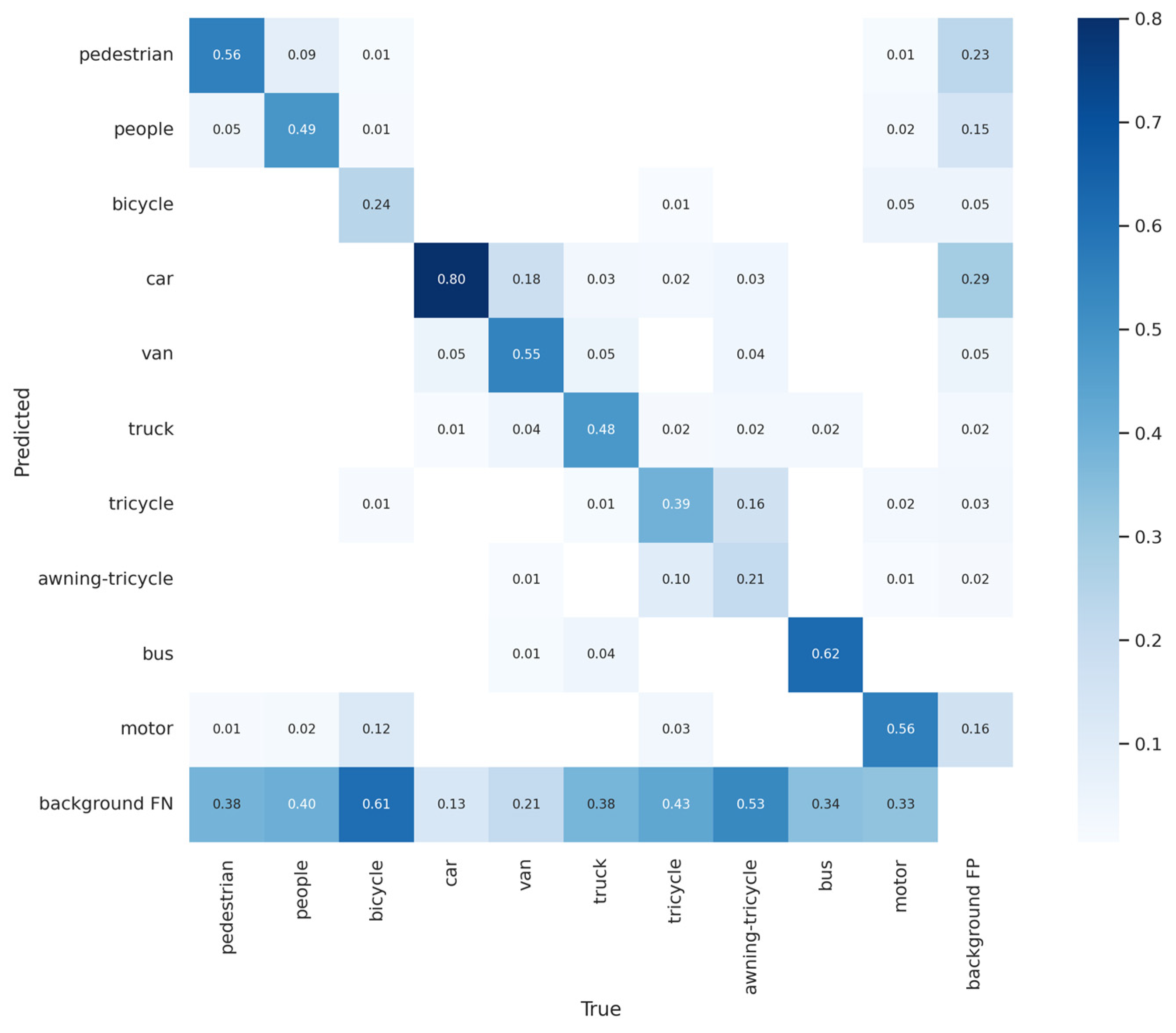
4. Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Alandejani, M.; Al-Shaer, H. Macro Uncertainty Impacts on ESG Performance and Carbon Emission Reduction Targets. Sustainability 2023, 15, 4249. [Google Scholar] [CrossRef]
- Baratta, A.; Cimino, A.; Longo, F.; Solina, V.; Verteramo, S. The Impact of ESG Practices in Industry with a Focus on Carbon Emissions: Insights and Future Perspectives. Sustainability 2023, 15, 6685. [Google Scholar] [CrossRef]
- De La Torre, R.; Corlu, C.G.; Faulin, J.; Onggo, B.S.; Juan, A.A. Simulation, Optimization, and Machine Learning in Sustainable Transportation Systems: Models and Applications. Sustainability 2021, 13, 1551. [Google Scholar] [CrossRef]
- Bamwesigye, D.; Hlavackova, P. Analysis of Sustainable Transport for Smart Cities. Sustainability 2019, 11, 2140. [Google Scholar] [CrossRef]
- Kostrzewski, M.; Marczewska, M.; Uden, L. The Internet of Vehicles and Sustainability—Reflections on Environmental, Social, and Corporate Governance. Energies 2023, 16, 3208. [Google Scholar] [CrossRef]
- Barykin, S.; Strimovskaya, A.; Sergeev, S.; Borisoglebskaya, L.; Dedyukhina, N.; Sklyarov, I.; Sklyarova, J.; Saychenko, L. Smart City Logistics on the Basis of Digital Tools for ESG Goals Achievement. Sustainability 2023, 15, 5507. [Google Scholar] [CrossRef]
- Bartniczak, B.; Raszkowski, A. Implementation of the Sustainable Cities and Communities Sustainable Development Goal (SDG) in the European Union. Sustainability 2022, 14, 16808. [Google Scholar] [CrossRef]
- Kalfas, D.; Kalogiannidis, S.; Chatzitheodoridis, F.; Toska, E. Urbanization and Land Use Planning for Achieving the Sustainable Development Goals (SDGs): A Case Study of Greece. Urban Sci. 2023, 7, 43. [Google Scholar] [CrossRef]
- Terama, E.; Peltomaa, J.; Mattinen-Yuryev, M.; Nissinen, A. Urban Sustainability and the SDGs: A Nordic Perspective and Opportunity for Integration. Urban Sci. 2019, 3, 69. [Google Scholar] [CrossRef]
- Weymouth, R.; Hartz-Karp, J. Principles for Integrating the Implementation of the Sustainable Development Goals in Cities. Urban Sci. 2018, 2, 77. [Google Scholar] [CrossRef]
- Lobner, N.; Seixas, P.C.; Dias, R.C.; Vidal, D.G. Urban Compactivity Models: Screening City Trends for the Urgency of Social and Environmental Sustainability. Urban Sci. 2021, 5, 83. [Google Scholar] [CrossRef]
- Moslem, S.; Duleba, S. Sustainable Urban Transport Development by Applying a Fuzzy-AHP Model: A Case Study from Mersin, Turkey. Urban Sci. 2019, 3, 55. [Google Scholar] [CrossRef]
- Tsouros, D.C.; Bibi, S.; Sarigiannidis, P.G. A Review on UAV-Based Applications for Precision Agriculture. Information 2019, 10, 349. [Google Scholar] [CrossRef]
- Gupta, A.; Afrin, T.; Scully, E.; Yodo, N. Advances of UAVs toward Future Transportation: The State-of-the-Art, Challenges, and Opportunities. Future Transp. 2021, 1, 326–350. [Google Scholar] [CrossRef]
- Butilă, E.V.; Boboc, R.G. Urban Traffic Monitoring and Analysis Using Unmanned Aerial Vehicles (UAVs): A Systematic Literature Review. Remote Sens. 2022, 14, 620. [Google Scholar] [CrossRef]
- Liu, Z.; Gao, X.; Wan, Y.; Wang, J.; Lyu, H. An Improved YOLOv5 Method for Small Object Detection in UAV Capture Scenes. IEEE Access 2023, 11, 14365–14374. [Google Scholar] [CrossRef]
- Wang, Y.; Feng, W.; Jiang, K.; Li, Q.; Lv, R.; Tu, J. Real-Time Damaged Building Region Detection Based on Improved YOLOv5s and Embedded System From UAV Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 4205–4217. [Google Scholar] [CrossRef]
- Robakowska, M.; Ślęzak, D.; Żuratyński, P.; Tyrańska-Fobke, A.; Robakowski, P.; Prędkiewicz, P.; Zorena, K. Possibilities of Using UAVs in Pre-Hospital Security for Medical Emergencies. Int. J. Environ. Res. Public Health 2022, 19, 10754. [Google Scholar] [CrossRef]
- Raheem, D.; Dayoub, M.; Birech, R.; Nakiyemba, A. The Contribution of Cereal Grains to Food Security and Sustainability in Africa: Potential Application of UAV in Ghana, Nigeria, Uganda, and Namibia. Urban Sci. 2021, 5, 8. [Google Scholar] [CrossRef]
- Jin, R.; Lv, J.; Li, B.; Ye, J.; Lin, D. Toward Efficient Object Detection in Aerial Images Using Extreme Scale Metric Learning. IEEE Access 2021, 9, 56214–56227. [Google Scholar] [CrossRef]
- Li, M.; Zhao, X.; Li, J.; Nan, L. ComNet: Combinational Neural Network for Object Detection in UAV-Borne Thermal Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 6662–6673. [Google Scholar] [CrossRef]
- Shao, Z.; Cheng, G.; Ma, J.; Wang, Z.; Wang, J.; Li, D. Real-Time and Accurate UAV Pedestrian Detection for Social Distancing Monitoring in COVID-19 Pandemic. IEEE Trans. Multimed. 2022, 24, 2069–2083. [Google Scholar] [CrossRef] [PubMed]
- Zhou, L.-Q.; Sun, P.; Li, D.; Piao, J.-C. A Novel Object Detection Method in City Aerial Image Based on Deformable Convolutional Networks. IEEE Access 2022, 10, 31455–31465. [Google Scholar] [CrossRef]
- Xu, X.; Zhang, X.; Yu, B.; Hu, X.S.; Rowen, C.; Hu, J.; Shi, Y. DAC-SDC Low Power Object Detection Challenge for UAV Applications. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 392–403. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Feng, Y.; Zhang, S.; Wang, N.; Mei, S. Finding Nonrigid Tiny Person With Densely Cropped and Local Attention Object Detector Networks in Low-Altitude Aerial Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4371–4385. [Google Scholar] [CrossRef]
- Karagulian, F.; Liberto, C.; Corazza, M.; Valenti, G.; Dumitru, A.; Nigro, M. Pedestrian Flows Characterization and Estimation with Computer Vision Techniques. Urban Sci. 2023, 7, 65. [Google Scholar] [CrossRef]
- Verma, D.; Jana, A.; Ramamritham, K. Quantifying Urban Surroundings Using Deep Learning Techniques: A New Proposal. Urban Sci. 2018, 2, 78. [Google Scholar] [CrossRef]
- Nguyen, D.D.; Rohacs, J.; Rohacs, D. Autonomous Flight Trajectory Control System for Drones in Smart City Traffic Management. ISPRS Int. J. Geo-Inf. 2021, 10, 338. [Google Scholar] [CrossRef]
- Veeranampalayam Sivakumar, A.N.; Li, J.; Scott, S.; Psota, E.; Jhala, A.J.; Luck, J.D.; Shi, Y. Comparison of Object Detection and Patch-Based Classification Deep Learning Models on Mid- to Late-Season Weed Detection in UAV Imagery. Remote Sens. 2020, 12, 2136. [Google Scholar] [CrossRef]
- Hildmann, H.; Kovacs, E. Review: Using Unmanned Aerial Vehicles (UAVs) as Mobile Sensing Platforms (MSPs) for Disaster Response, Civil Security and Public Safety. Drones 2019, 3, 59. [Google Scholar] [CrossRef]
- Mohan, M.; Silva, C.; Klauberg, C.; Jat, P.; Catts, G.; Cardil, A.; Hudak, A.; Dia, M. Individual Tree Detection from Unmanned Aerial Vehicle (UAV) Derived Canopy Height Model in an Open Canopy Mixed Conifer Forest. Forests 2017, 8, 340. [Google Scholar] [CrossRef]
- Alsamhi, S.H.; Shvetsov, A.V.; Kumar, S.; Shvetsova, S.V.; Alhartomi, M.A.; Hawbani, A.; Rajput, N.S.; Srivastava, S.; Saif, A.; Nyangaresi, V.O. UAV Computing-Assisted Search and Rescue Mission Framework for Disaster and Harsh Environment Mitigation. Drones 2022, 6, 154. [Google Scholar] [CrossRef]
- Silva, L.A.; Leithardt, V.R.Q.; Batista, V.F.L.; Villarrubia González, G.; De Paz Santana, J.F. Automated Road Damage Detection Using UAV Images and Deep Learning Techniques. IEEE Access 2023, 11, 62918–62931. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 8, 1–25. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 26–27 July 2017; pp. 2117–2125. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Zhu, P.; Wen, L.; Du, D.; Bian, X.; Fan, H.; Hu, Q.; Ling, H. Detection and Tracking Meet Drones Challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 7380–7399. [Google Scholar] [CrossRef]
- Du, D.; Zhu, P.; Wen, L.; Bian, X.; Lin, H.; Hu, Q.; Peng, T.; Zheng, J.; Wang, X.; Zhang, Y. VisDrone-DET2019: The vision meets drone object detection in image challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 213–226. [Google Scholar]
- Character, L.; Ortiz Jr, A.; Beach, T.; Luzzadder-Beach, S. Archaeologic Machine Learning for Shipwreck Detection Using Lidar and Sonar. Remote Sens. 2021, 13, 1759. [Google Scholar] [CrossRef]
- Guth, S.; Sapsis, T.P. Machine Learning Predictors of Extreme Events Occurring in Complex Dynamical Systems. Entropy 2019, 21, 925. [Google Scholar] [CrossRef]
- Liu, K.; Sun, Q.; Sun, D.; Peng, L.; Yang, M.; Wang, N. Underwater Target Detection Based on Improved YOLOv7. J. Mar. Sci. Eng. 2023, 11, 677. [Google Scholar] [CrossRef]
- Gallo, I.; Rehman, A.U.; Dehkordi, R.H.; Landro, N.; La Grassa, R.; Boschetti, M. Deep Object Detection of Crop Weeds: Performance of YOLOv7 on a Real Case Dataset from UAV Images. Remote Sens. 2023, 15, 539. [Google Scholar] [CrossRef]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; Kwon, Y.; Michael, K.; Fang, J.; Yifu, Z.; Wong, C.; Montes, D. Ultralytics/yolov5: v7. 0-YOLOv5 Sota Realtime Instance Segmentation. Zenodo 2022. Available online: https://ui.adsabs.harvard.edu/abs/2022zndo...7347926J/abstract, (accessed on 22 November 2022).
- Nepal, U.; Eslamiat, H. Comparing YOLOv3, YOLOv4 and YOLOv5 for autonomous landing spot detection in faulty UAVs. Sensors 2022, 22, 464. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Hong, Y. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Chen, J.; Bai, S.; Wan, G.; Li, Y. Research on YOLOv7-based defect detection method for automotive running lights. Syst. Sci. Control Eng. 2023, 11, 2185916. [Google Scholar] [CrossRef]
- Jiang, K.; Xie, T.; Yan, R.; Wen, X.; Li, D.; Jiang, H.; Jiang, N.; Feng, L.; Duan, X.; Wang, J. An attention mechanism-improved YOLOv7 object detection algorithm for hemp duck count estimation. Agriculture 2022, 12, 1659. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Yan, Q.; Liu, H.; Zhang, J.; Sun, X.; Xiong, W.; Zou, M.; Xia, Y.; Xun, L. Cloud Detection of Remote Sensing Image Based on Multi-Scale Data and Dual-Channel Attention Mechanism. Remote Sens. 2022, 14, 3710. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Chen, J.; Liu, H.; Zhang, Y.; Zhang, D.; Ouyang, H.; Chen, X. A multiscale lightweight and efficient model based on YOLOv7: Applied to citrus orchard. Plants 2022, 11, 3260. [Google Scholar] [CrossRef]
- Yao, J.; Qi, J.; Zhang, J.; Shao, H.; Yang, J.; Li, X. A real-time detection algorithm for Kiwifruit defects based on YOLOv5. Electronics 2021, 10, 1711. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, H.; Xin, Z. Efficient detection model of steel strip surface defects based on YOLO-V7. IEEE Access 2022, 10, 133936–133944. [Google Scholar] [CrossRef]
- Gevorgyan, Z. SIoU loss: More powerful learning for bounding box regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Precision | Recall | mAP50 | mAP50-95 | FPS |
|---|---|---|---|---|---|
| YOLOv3 | 0.259 | 0.183 | 0.154 | 0.069 | 144.927 |
| YOLOv5 | 0.425 | 0.322 | 0.308 | 0.165 | 52.9 |
| YOLOv7 | 0.584 | 0.479 | 0.480 | 0.274 | 166 |
| Proposed Method | 0.592 | 0.481 | 0.490 | 0.28 | 45.04 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chung, M.-A.; Wang, T.-H.; Lin, C.-W. Advancing ESG and SDGs Goal 11: Enhanced YOLOv7-Based UAV Detection for Sustainable Transportation in Cities and Communities. Urban Sci. 2023, 7, 108. https://doi.org/10.3390/urbansci7040108
Chung M-A, Wang T-H, Lin C-W. Advancing ESG and SDGs Goal 11: Enhanced YOLOv7-Based UAV Detection for Sustainable Transportation in Cities and Communities. Urban Science. 2023; 7(4):108. https://doi.org/10.3390/urbansci7040108
Chicago/Turabian StyleChung, Ming-An, Tze-Hsun Wang, and Chia-Wei Lin. 2023. "Advancing ESG and SDGs Goal 11: Enhanced YOLOv7-Based UAV Detection for Sustainable Transportation in Cities and Communities" Urban Science 7, no. 4: 108. https://doi.org/10.3390/urbansci7040108
APA StyleChung, M.-A., Wang, T.-H., & Lin, C.-W. (2023). Advancing ESG and SDGs Goal 11: Enhanced YOLOv7-Based UAV Detection for Sustainable Transportation in Cities and Communities. Urban Science, 7(4), 108. https://doi.org/10.3390/urbansci7040108