
The Influence of Transportation Accessibility on Traffic Volumes in South Korea: An Extreme Gradient Boosting Approach



Abstract
:1. Introduction
2. Related Works
2.1. Traffic and Accessibility
2.2. Machine Learning in Urban Sciences
2.3. Research Gaps
3. Materials and Methods
3.1. Variable
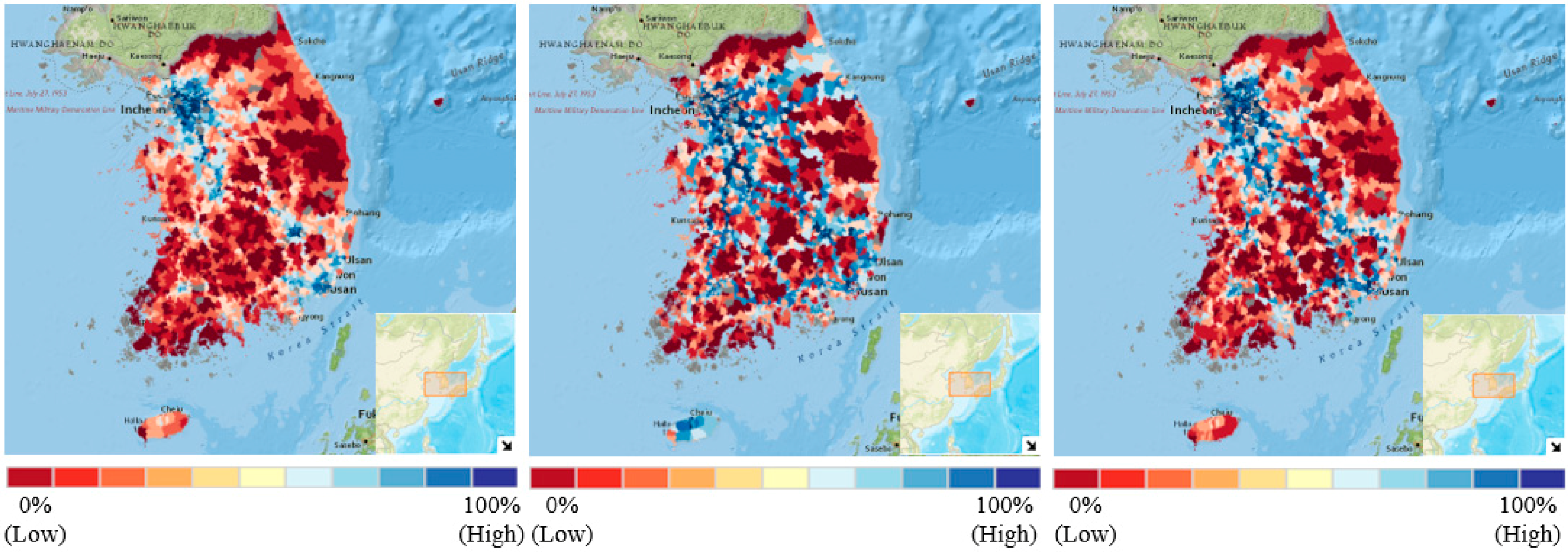
3.1.1. Dependent Variable: Traffic Volumes
3.1.2. Independent Variables
3.2. Methodological Approach
3.2.1. Extreme Gradient Boosting Decision Tree Model
3.2.2. Interpretable Machine Learning: Shapley Value
4. Results
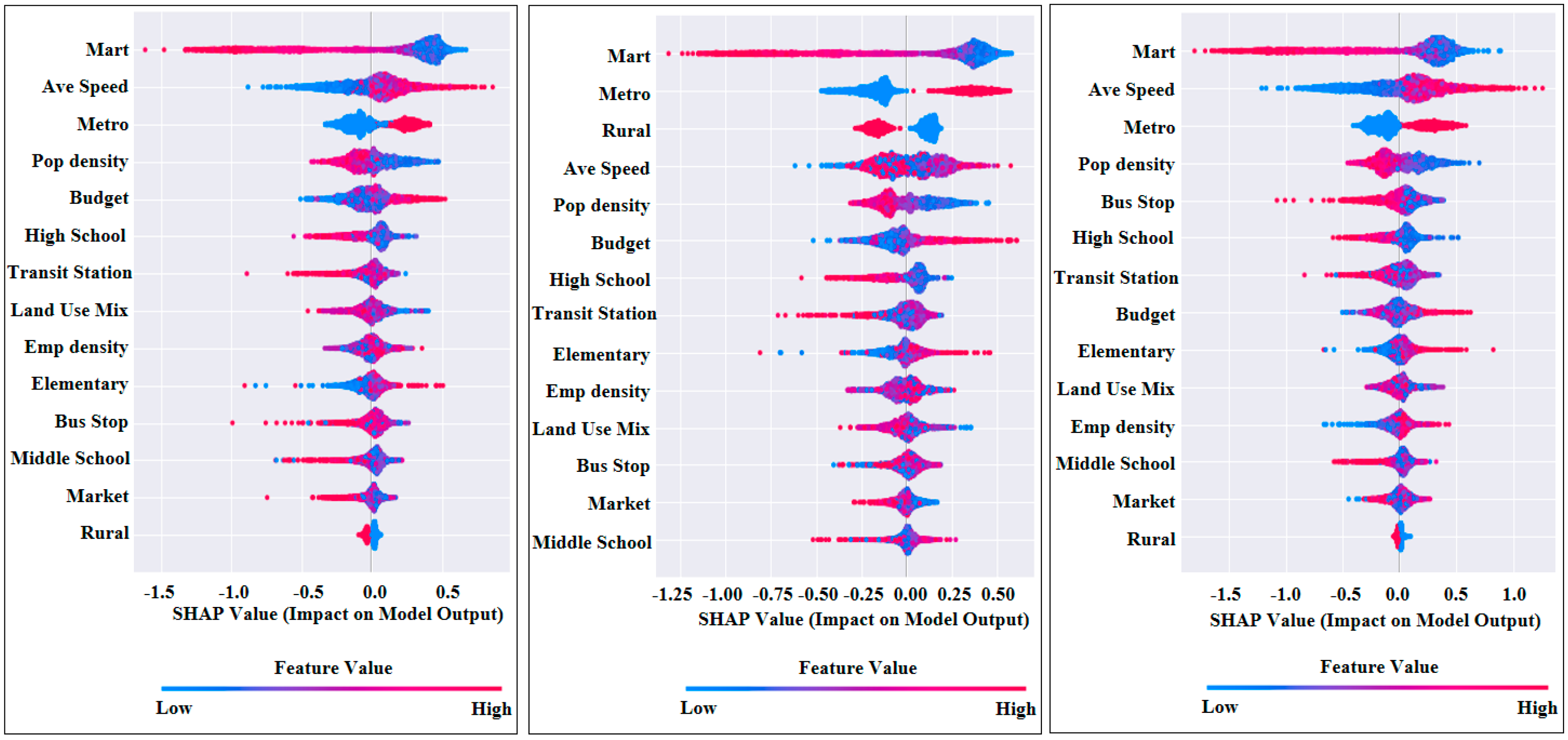
4.1. Feature Importance and Summary Plot
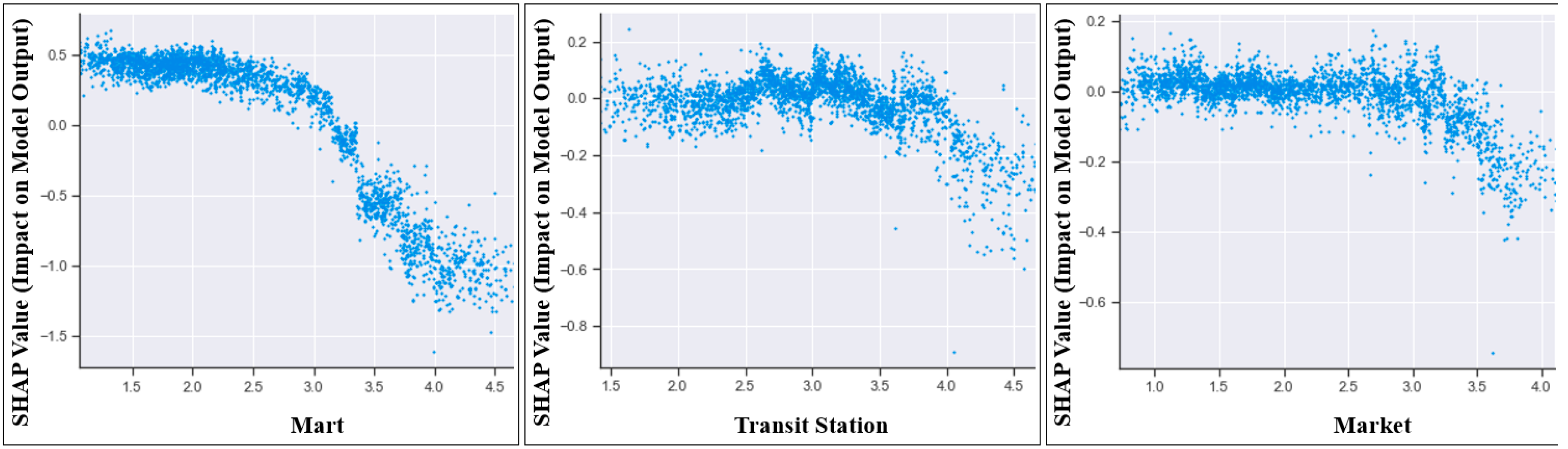
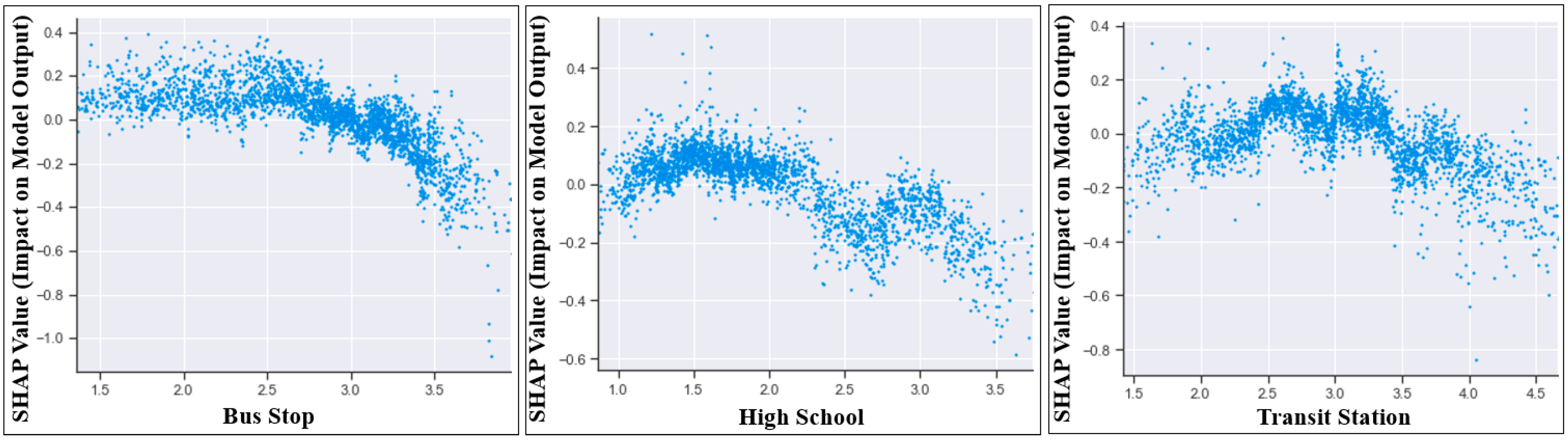
4.2. Dependence Plot
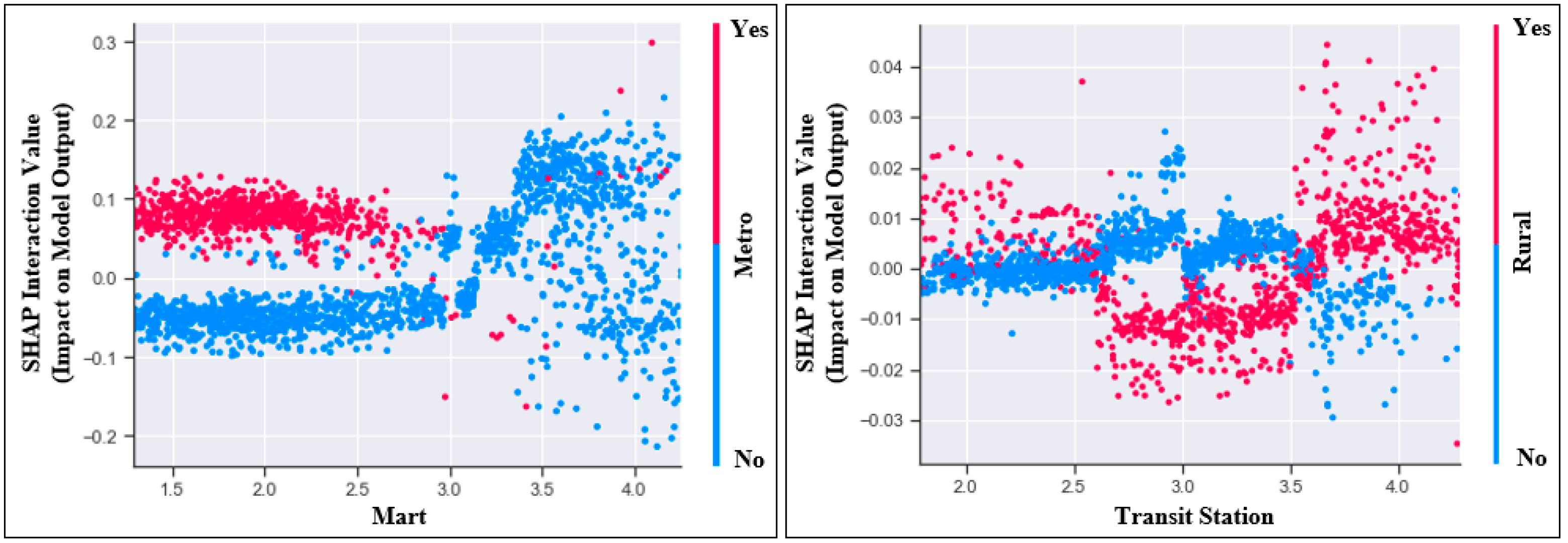
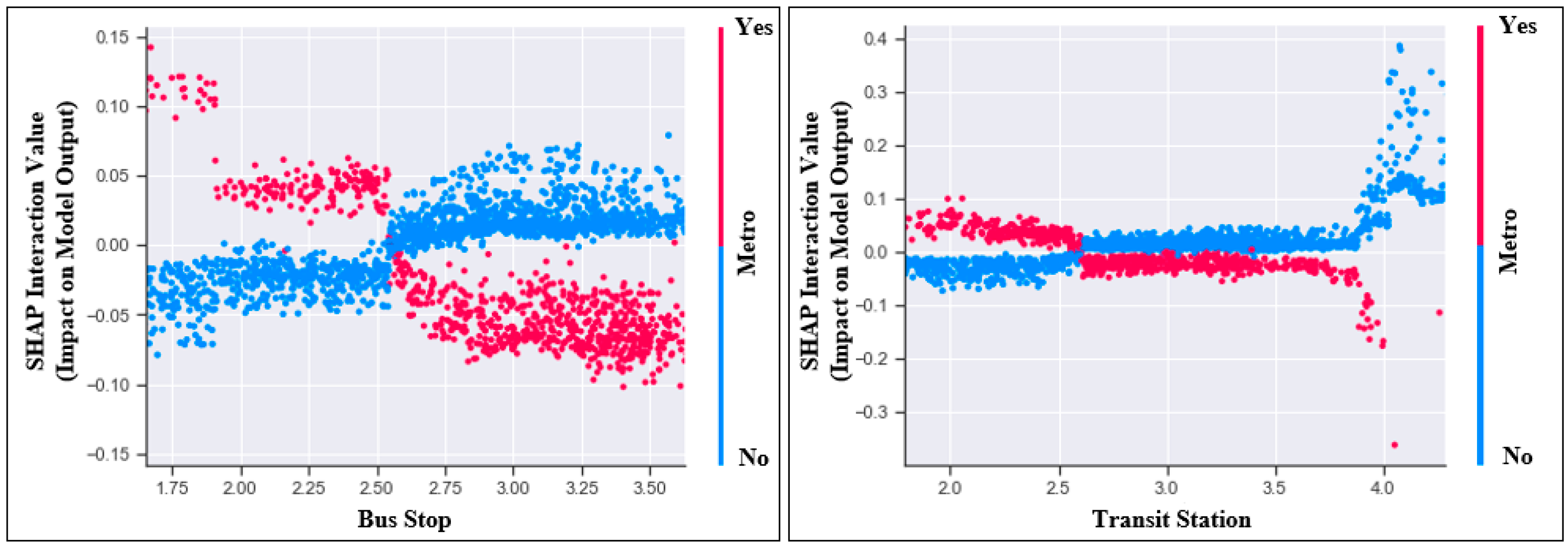
4.3. Interaction Value Plot
5. Discussion
5.1. Key Findings
5.2. Implication
5.3. Limitation of this Study and Future Research Direction
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Arnott, R.; Small, K. The Economics of Traffic Congestion. Am. Sci. 1994, 82, 446–455. [Google Scholar]
- Mondschein, A.; Taylor, B.D. Is traffic congestion overrated? Examining the highly variable effects of congestion on travel and accessibility. J. Transp. Geogr. 2017, 64, 65–76. [Google Scholar] [CrossRef]
- Boarnet, M.G. A Broader Context for Land Use and Travel Behavior, and a Research Agenda. J. Am. Plan. Assoc. 2011, 77, 197–213. [Google Scholar] [CrossRef]
- Ewing, R.; Cervero, R. Travel and the Built Environment. J. Am. Plan. Assoc. 2010, 76, 265–294. [Google Scholar] [CrossRef]
- El-Assi, W.; Salah Mahmoud, M.; Nurul Habib, K. Effects of built environment and weather on bike sharing demand: A station level analysis of commercial bike sharing in Toronto. Transportation 2017, 44, 589–613. [Google Scholar] [CrossRef]
- Ding, C.; Cao, X.; Wang, Y. Synergistic effects of the built environment and commuting programs on commute mode choice. Transp. Res. Part A Policy Pract. 2018, 118, 104–118. [Google Scholar] [CrossRef]
- Guan, X.; Wang, D. Influences of the built environment on travel: A household-based perspective. Transp. Res. Part A: Policy Pract. 2019, 130, 710–724. [Google Scholar] [CrossRef]
- Bai, S.; Jiao, J. Dockless E-scooter usage patterns and urban built Environments: A comparison study of Austin, TX, and Minneapolis, MN. Travel Behav. Soc. 2020, 20, 264–272. [Google Scholar] [CrossRef]
- Frank, L.D.; Sallis, J.F.; Saelens, B.E.; Leary, L.; Cain, K.; Conway, T.L.; Hess, P.M. The development of a walkability index: Application to the Neighborhood Quality of Life Study. Br. J. Sports Med. 2010, 44, 924–933. [Google Scholar] [CrossRef]
- Duranton, G.; Turner, M.A. Urban Growth and Transportation. Rev. Econ. Stud. 2012, 79, 1407–1440. [Google Scholar] [CrossRef]
- Lavieri, P.S.; Dai, Q.; Bhat, C.R. Using virtual accessibility and physical accessibility as joint predictors of activity-travel behavior. Transp. Res. Part A Policy Pract. 2018, 118, 527–544. [Google Scholar] [CrossRef]
- Wang, C.-H.; Chen, N.; Tian, G. Do accessibility and clustering affect active travel behavior in Salt Lake City? Transp. Res. Part D Transp. Environ. 2021, 90, 102655. [Google Scholar] [CrossRef]
- Yan, X. Toward Accessibility-Based Planning: Addressing the Myth of Travel Cost Savings. J. Am. Plan. Assoc. 2021, 87, 409–423. [Google Scholar] [CrossRef]
- Lee, S. Exploring Associations between Multimodality and Built Environment Characteristics in the U.S. Sustainability 2022, 14, 6629. [Google Scholar] [CrossRef]
- Alzubi, J.; Nayyar, A.; Kumar, A. Machine Learning from Theory to Algorithms: An Overview. J. Phys. Conf. Ser. 2018, 1142, 012012. [Google Scholar] [CrossRef]
- Bhavsar, P.; Safro, I.; Bouaynaya, N.; Polikar, R.; Dera, D. Machine Learning in Transportation Data Analytics. In Data Analytics for Intelligent Transportation Systems; Elsevier: Amsterdam, The Netherlands, 2017; pp. 283–307. ISBN 978-0-12-809715-1. [Google Scholar]
- Bhat, C.R.; Gossen, R. A mixed multinomial logit model analysis of weekend recreational episode type choice. Transp. Res. Part B Methodol. 2004, 38, 767–787. [Google Scholar] [CrossRef]
- Lee, S.; Wang, L. Intermediate Effect of the COVID-19 Pandemic on Prices of Housing near Light Rail Transit: A Case Study of the Portland Metropolitan Area. Sustainability 2022, 14, 9107. [Google Scholar] [CrossRef]
- Lao, Y.; Qi, F.; Zhou, J.; Fang, X. A Prediction Method Based on Extreme Gradient Boosting Tree Model and its Application. J. Phys. Conf. Ser. 2021, 1995, 012017. [Google Scholar] [CrossRef]
- Chang, Y.-C.; Chang, K.-H.; Wu, G.-J. Application of eXtreme gradient boosting trees in the construction of credit risk assessment models for financial institutions. Appl. Soft Comput. 2018, 73, 914–920. [Google Scholar] [CrossRef]
- Liu, J.; Wang, B.; Xiao, L. Non-linear associations between built environment and active travel for working and shopping: An extreme gradient boosting approach. J. Transp. Geogr. 2021, 92, 103034. [Google Scholar] [CrossRef]
- Feng, D.-C.; Wang, W.-J.; Mangalathu, S.; Taciroglu, E. Interpretable XGBoost-SHAP Machine-Learning Model for Shear Strength Prediction of Squat RC Walls. J. Struct. Eng. 2021, 147, 04021173. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Bibal, A.; Frénay, B. Interpretability of Machine Learning Models and Representations: An Introduction. In Proceedings of the 24th European Symposium on Artificial Neural Networks ESANN, Bruges, Belgium, 27–29 April 2016; pp. 77–82. [Google Scholar]
- Molnar, C. Interpretable Machine Learning: A Guide for Making Black Box Models Explainable; Leanpub: Victoria, BC, Canada, 2021. [Google Scholar]
- Sundararajan, M.; Najmi, A. The Many Shapley Values for Model Explanation. In Proceedings of the 37th International Conference on Machine Learning, Vienna, Austria, 21 November 2020; pp. 9269–9278. [Google Scholar]
- Lundberg, S.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. arXiv 2017, arXiv:1705.07874. [Google Scholar]
- Rodríguez-Pérez, R.; Bajorath, J. Interpretation of machine learning models using shapley values: Application to compound potency and multi-target activity predictions. J. Comput. Aided Mol. Des. 2020, 34, 1013–1026. [Google Scholar] [CrossRef]
- Ndichu, S.; Kim, S.; Ozawa, S.; Ban, T.; Takahashi, T.; Inoue, D. Detecting Web-Based Attacks with SHAP and Tree Ensemble Machine Learning Methods. Appl. Sci. 2022, 12, 60. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.-I. Explainable AI for Trees: From Local Explanations to Global Understanding. arXiv 2019, arXiv:1905.04610. [Google Scholar] [CrossRef] [PubMed]
- Ding, C.; Cao, X.; Næss, P. Applying gradient boosting decision trees to examine non-linear effects of the built environment on driving distance in Oslo. Transp. Res. Part A Policy Pract. 2018, 110, 107–117. [Google Scholar] [CrossRef]
- Molnar, C.; Freiesleben, T.; König, G.; Casalicchio, G.; Wright, M.N.; Bischl, B. Relating the Partial Dependence Plot and Permutation Feature Importance to the Data Generating Process. arXiv 2021, arXiv:2109.01433. [Google Scholar]
- Papa, E. Transport and Mobility Planning; Parker, G., Ed.; Macmillan: London, UK, 2021; ISBN 978-1-352-01192-0. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Description | Source | Mean | St. Dev |
|---|---|---|---|---|
| Dependent Variables (Target Features) | ||||
| Truck | Log-transformed the amount of truck traffic in annual average daily traffic (AADT) in vehicles per day at the Eup/Myeon/Dong (EMD) level (dependent variable for the truck model) | KTI | 6.595 | 1.030 |
| Car | Log-transformed the amount of car traffic in annual average daily traffic (AADT) in vehicles per day at the EMD level (dependent variable for the car model) | KTI | 8.038 | 1.108 |
| Bus | Log-transformed the amount of bus traffic in annual average daily traffic (AADT) in vehicles per day at the EMD level (dependent variable for the bus model) | KTI | 3.805 | 1.136 |
| Independent Variables (Input Features) | ||||
| Transportation Accessibility | ||||
| Elementary | Log-transformed averaged travel time from each home to the nearest elementary school in minutes at the EMD level where is an EMD, denotes population size, and represents aggregated travel time from the population-weighted centroid of EMD to the facility. The equation is from KTI. | KTI | 1.388 | 0.473 |
| Middle School | Log-transformed averaged travel time from each home to the nearest middle school in minutes at the EMD level | KTI | 1.699 | 0.552 |
| High School | Log-transformed averaged travel time from each home to the nearest high school in minutes at the EMD level | KTI | 2.025 | 0.715 |
| Mart | Log-transformed averaged travel time from each home to the nearest mart in minutes at the EMD level | KTI | 2.570 | 0.962 |
| Market | Log-transformed averaged travel time from each home to the nearest market in minutes at the EMD level | KTI | 2.224 | 0.886 |
| Bus Stop | Log-transformed averaged travel time from each home to the nearest bus stop in minutes at the EMD level | KTI | 2.805 | 0.611 |
| Transit Station | Log-transformed averaged travel time from each home to the nearest train station in minutes at the EMD level | KTI | 3.010 | 0.740 |
| Control Factors | ||||
| Ave Speed | The log-transformed average speed of cars at the EMD level | KTI | 3.539 | 0.357 |
| Pop Density | The log-transformed population density in persons per km2 at the Si/Gun/Gu (SGG) level | SK | 12.635 | 0.631 |
| Emp Density | Log-transformed employment density in jobs per km2 at the SGG level | SK | 11.776 | 0.564 |
| Land Use Mix | Land use diversity index at the SGG level where is areas of residential use permits in km2, is areas of commercial/industrial use permits in km2, is areas of other land use permits in km2, and is [17,18]. | SK | 0.572 | 0.138 |
| Budget | Log-transformed total budgets in 10,000 Won at the SGG level | SK | 13.811 | 0.582 |
| Metro | 1 if EMD is located in metropolitan areas, such as Seoul and Busan, 0 otherwise | NSDIP | 0.328 | 0.470 |
| Rural | 1 if EMD is located in rural areas (Eup and Myeon), 0 otherwise | NSDIP | 0.411 | 0.492 |
| Variables | Truck | Car | Bus | |||
|---|---|---|---|---|---|---|
| Estimates (p-Value) | VIF | Estimates | VIF | Estimates | VIF | |
| Elementary | 0.109 ** (0.027) | 3.277 | −0.016 (0.702) | 3.277 | 0.010 (0.863) | 3.277 |
| Middle School | −0.072 * (0.079) | 3.108 | −0.018 (0.619) | 2.108 | −0.085 * 0.089) | 2.108 |
| High School | −0.183 *** (<0.001) | 3.002 | −0.182 *** (<0.001) | 2.002 | −0.193 *** (<0.001) | 3.002 |
| Mart | −0.405 *** (<0.001) | 4.603 | −0.418 *** (<0.001) | 4.603 | −0.535 *** (<0.001) | 4.603 |
| Market | −0.067 *** (0.008) | 3.052 | −0.107 *** (<0.001) | 3.052 | −0.022 (0.482) | 3.052 |
| Bus Stop | 0.033 (0.193) | 1.459 | 0.093 *** (<0.001) | 1.459 | −0.165 *** (<0.001) | 1.459 |
| Transit Station | −0.041 * (0.052) | 1.440 | −0.016 (0.385) | 1.440 | −0.045 * (0.078) | 1.440 |
| Ave Speed | 0.916 *** (<0.001) | 5.022 | 0.564 *** (<0.001) | 5.022 | 1.824 *** (<0.001) | 5.022 |
| Pop Density | −0.339 *** (<0.001) | 4.080 | −0.303 *** (<0.001) | 4.080 | −0.391 *** (<0.001) | 4.080 |
| Emp Density | 0.164 *** (<0.001) | 4.226 | 0.122 *** (0.002) | 4.226 | 0.182 *** (0.001) | 4.226 |
| Land Use Mix | −0.123 (0.219) | 1.154 | −0.170 ** (0.049) | 1.154 | 0.005 (0.965) | 1.154 |
| Budget | 0.435 *** (<0.001) | 1.881 | 0.423 *** (<0.001) | 1.881 | 0.386 *** (<0.001) | 1.881 |
| Metro | 0.946 *** (<0.001) | 2.925 | 1.063 *** (<0.001) | 2.925 | 1.124 *** (<0.001) | 2.925 |
| Rural | −0.310 *** (<0.001) | 5.116 | −0.349 *** (<0.001) | 5.116 | −0.279 *** (<0.001) | 5.116 |
| Constant | 1.137 * (0.069) | 3.995 *** (<0.001) | −2.903 *** (<0.001) | |||
| Model Performance | ||||||
| Observation | 3278 | 3278 | 3278 | |||
| Adj. R squared | 0.485 | 0.669 | 0.382 | |||
| Algorithms | Truck | Car | Bus | |||
|---|---|---|---|---|---|---|
| R Squared | Explained Variance | R Squared | Explained Variance | R Squared | Explained Variance | |
| LR | 0.492 | 0.495 | 0.670 | 0.671 | 0.389 | 0.392 |
| DT | 0.534 | 0.536 | 0.710 | 0.711 | 0.403 | 0.405 |
| RF | 0.655 | 0.657 | 0.803 | 0.804 | 0.525 | 0.527 |
| GB | 0.662 | 0.663 | 0.807 | 0.809 | 0.538 | 0.539 |
| XGB | 0.664 | 0.666 | 0.809 | 0.810 | 0.543 | 0.545 |
| Variables | Truck | Car | Bus | |||
|---|---|---|---|---|---|---|
| Mag. | Rank | Mag. | Rank | Mag. | Rank | |
| Elementary | 6.25% | 10 | 6.16% | 9 | 7.04% | 9 |
| Middle School | 6.11% | 12 | 3.80% | 14 | 6.49% | 12 |
| High School | 9.17% | 6 | 8.44% | 7 | 9.88% | 6 |
| Mart | 48.27% | 1 | 42.61% | 1 | 46.22% | 1 |
| Market | 5.19% | 13 | 4.08% | 13 | 6.15% | 13 |
| Bus Stop | 6.12% | 11 | 4.83% | 12 | 11.70% | 5 |
| Transit Station | 6.94% | 7 | 6.92% | 8 | 9.85% | 7 |
| Pop Density | 11.70% | 4 | 11.68% | 5 | 15.57% | 4 |
| Emp Density | 6.40% | 9 | 6.15% | 10 | 6.57% | 11 |
| Land Use Mix | 6.58% | 8 | 5.79% | 11 | 6.81% | 10 |
| Budget | 11.26% | 5 | 10.44% | 6 | 9.50% | 8 |
| Metro | 15.85% | 3 | 24.16% | 2 | 19.75% | 3 |
| Rural | 2.72% | 14 | 14.07% | 3 | 1.66% | 14 |
| Ave Speed | 17.49% | 2 | 13.49% | 4 | 28.25% | 2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, S.; Yang, J.; Cho, K.; Cho, D. The Influence of Transportation Accessibility on Traffic Volumes in South Korea: An Extreme Gradient Boosting Approach. Urban Sci. 2023, 7, 91. https://doi.org/10.3390/urbansci7030091
Lee S, Yang J, Cho K, Cho D. The Influence of Transportation Accessibility on Traffic Volumes in South Korea: An Extreme Gradient Boosting Approach. Urban Science. 2023; 7(3):91. https://doi.org/10.3390/urbansci7030091
Chicago/Turabian StyleLee, Sangwan, Jicheol Yang, Kuk Cho, and Dooyong Cho. 2023. "The Influence of Transportation Accessibility on Traffic Volumes in South Korea: An Extreme Gradient Boosting Approach" Urban Science 7, no. 3: 91. https://doi.org/10.3390/urbansci7030091
APA StyleLee, S., Yang, J., Cho, K., & Cho, D. (2023). The Influence of Transportation Accessibility on Traffic Volumes in South Korea: An Extreme Gradient Boosting Approach. Urban Science, 7(3), 91. https://doi.org/10.3390/urbansci7030091