
Quality of Crowdsourced Data on Urban Morphology—The Human Influence Experiment (HUMINEX)

 , , , , ,
, , , , ,  , ,
, ,  and
and
Abstract
:
1. Introduction
2. Description of the Human Influence Experiment
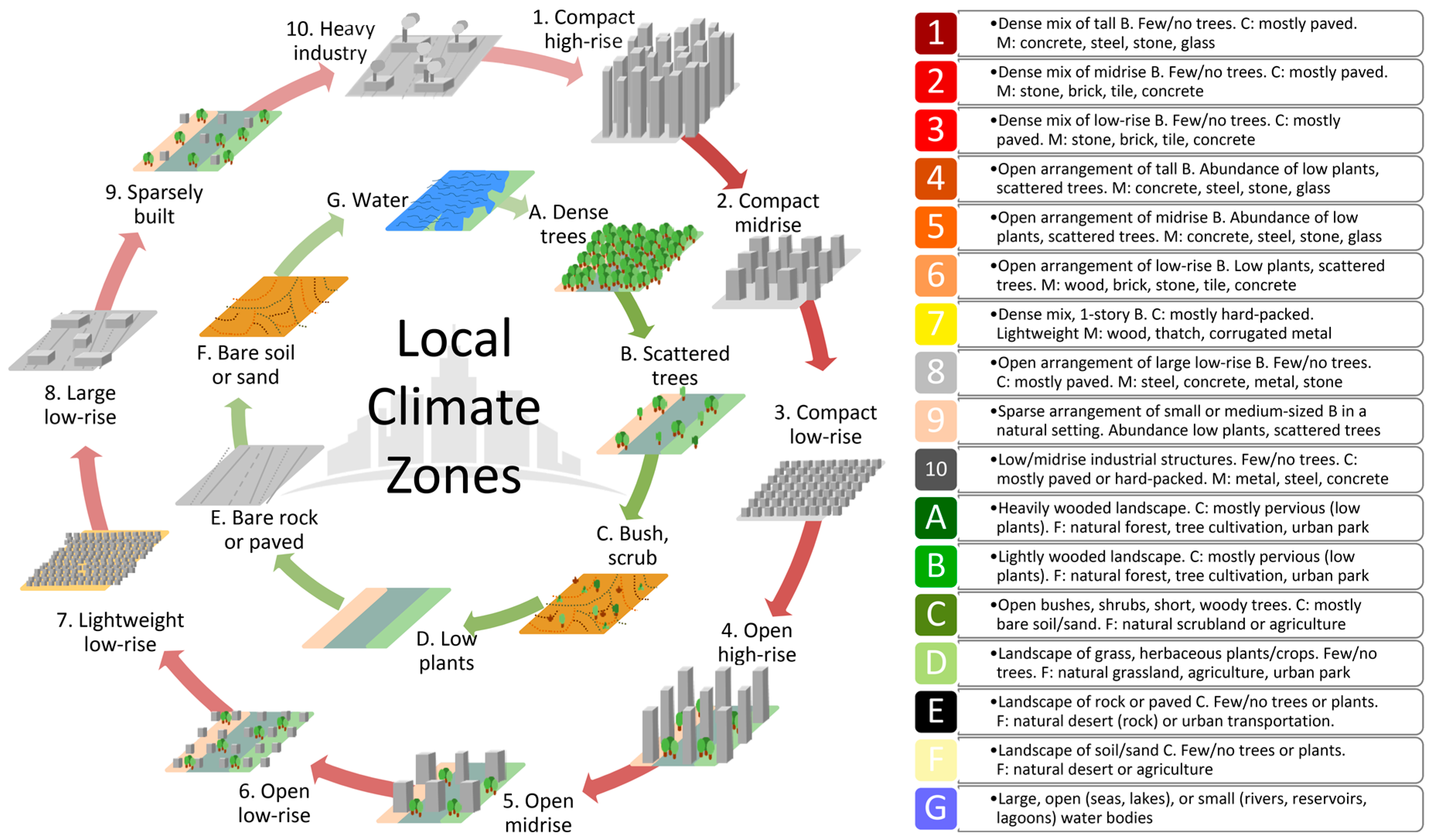
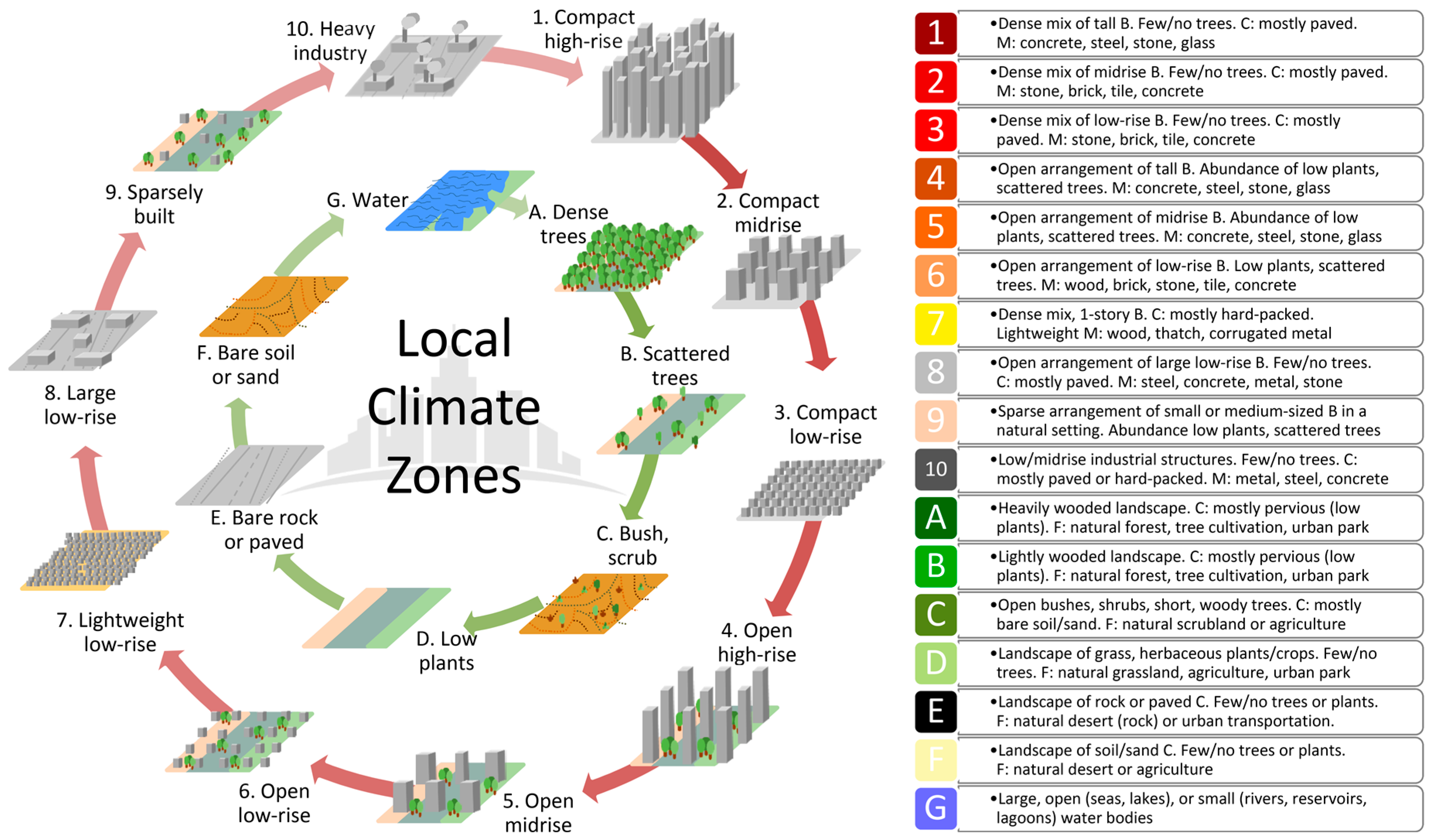
2.1. The LCZ Scheme
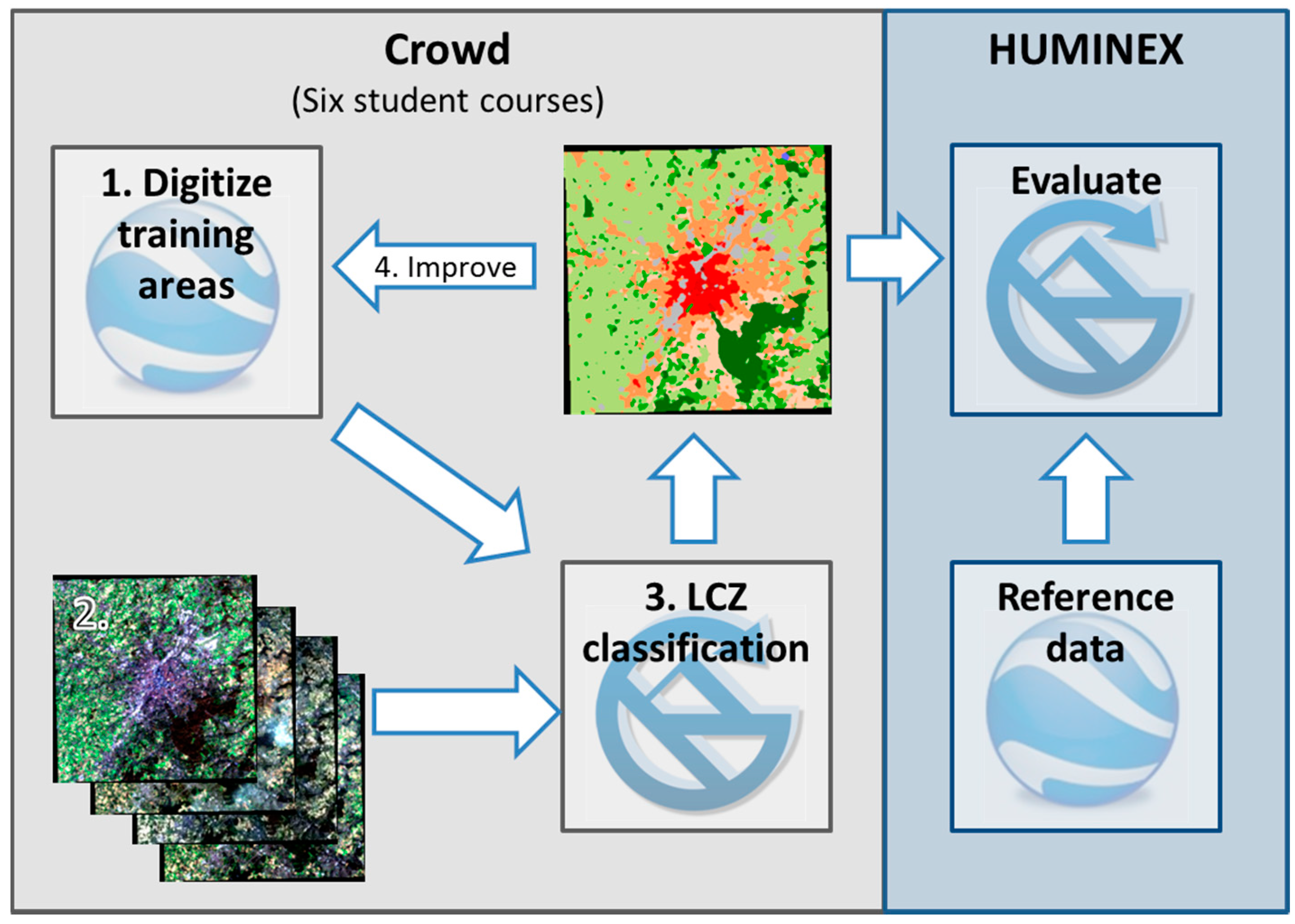
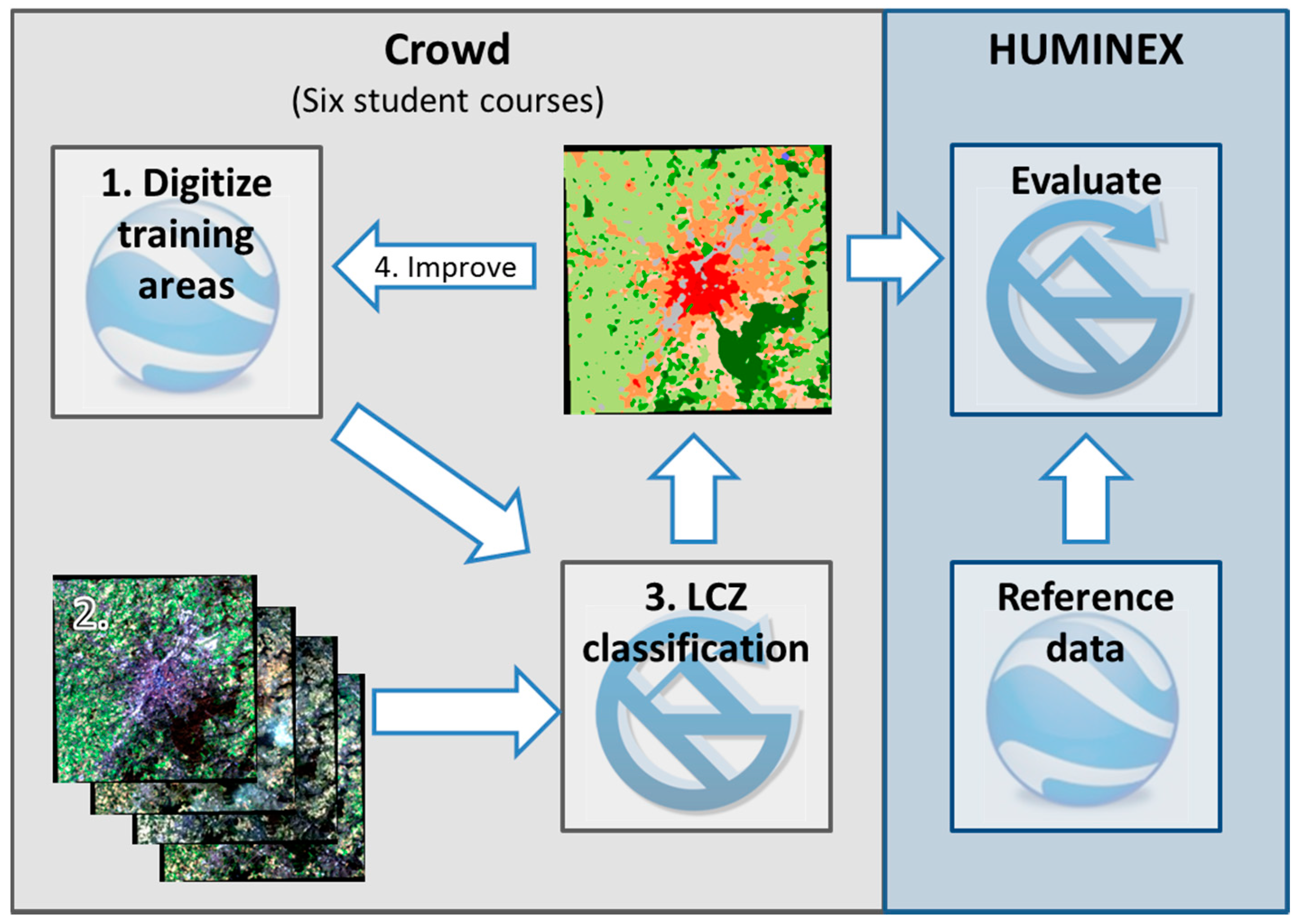
2.2. LCZ Classification Workflow
2.3. Collection of Metadata on Individual Operators
3. Data and Methods
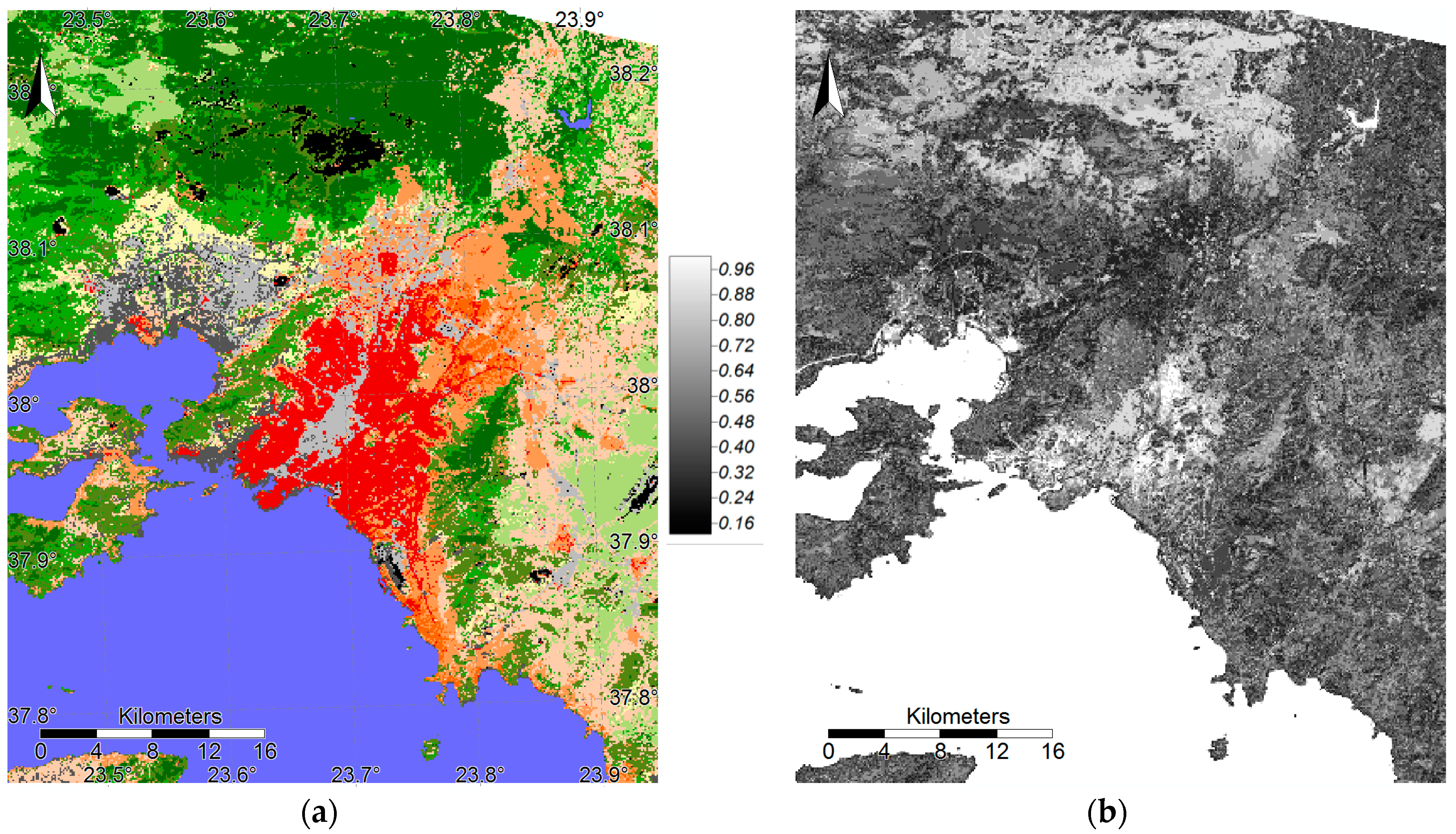
3.1. TAs and LCZ Maps Collected during HUMINEX
3.2. Accuracy Assessment of the LCZ Maps
4. Results
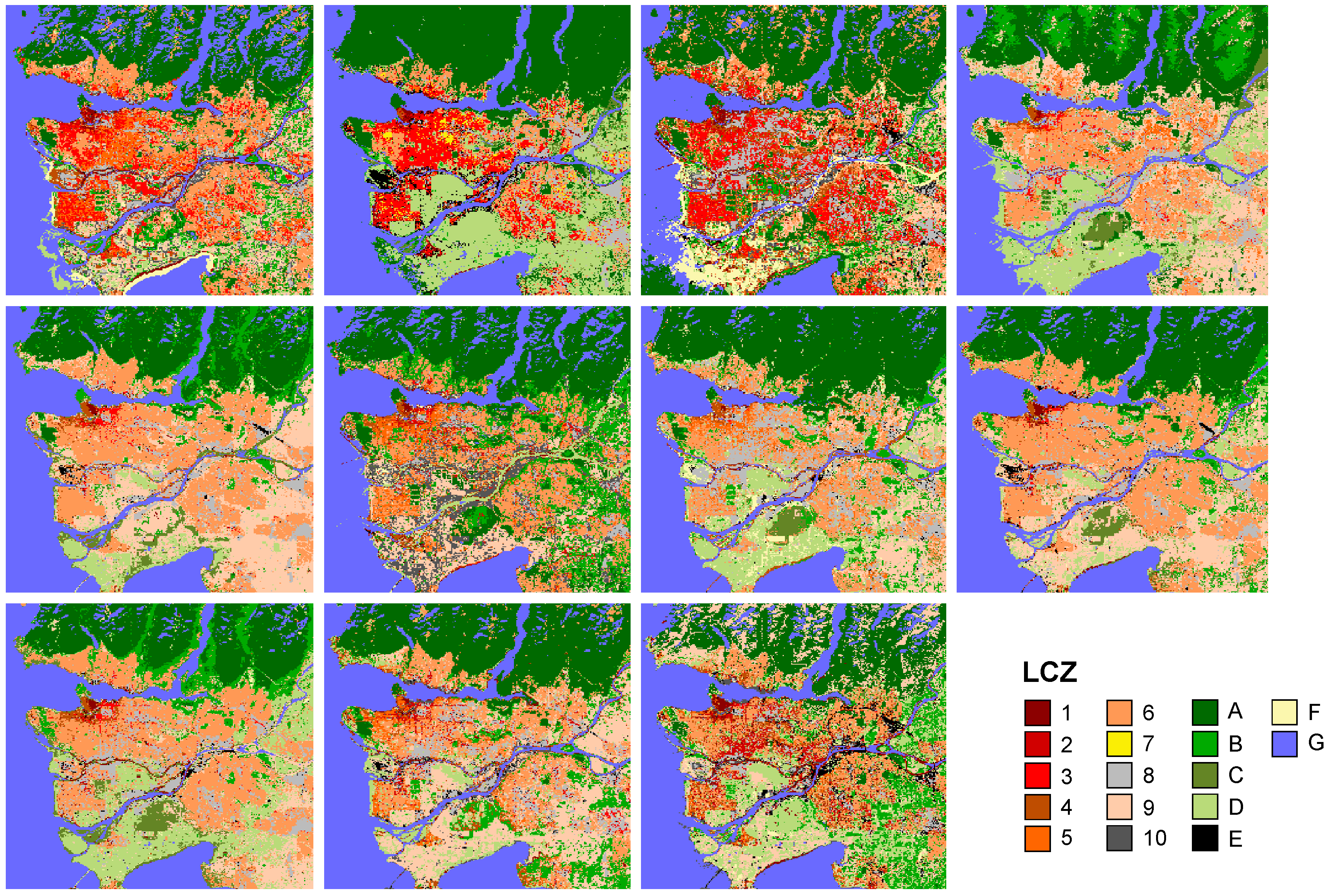
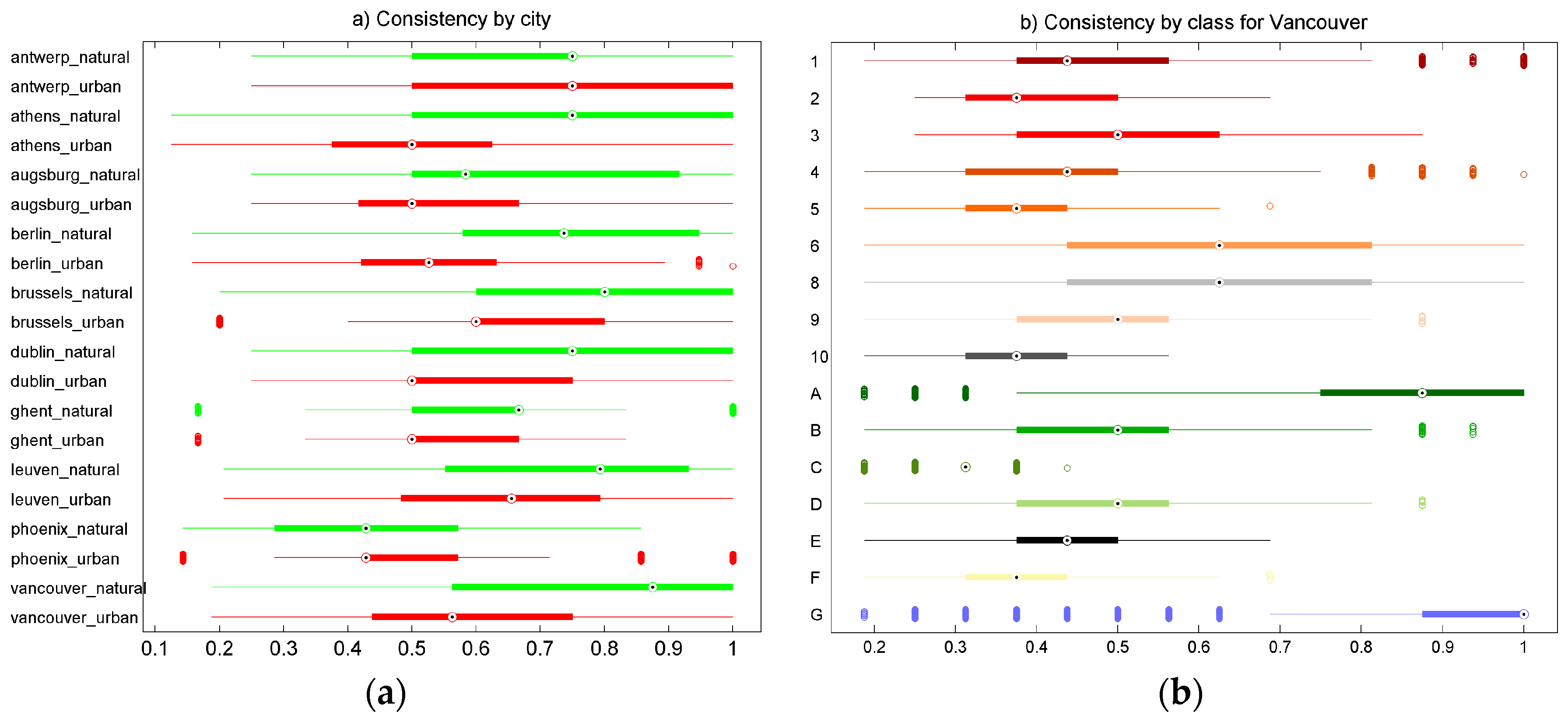
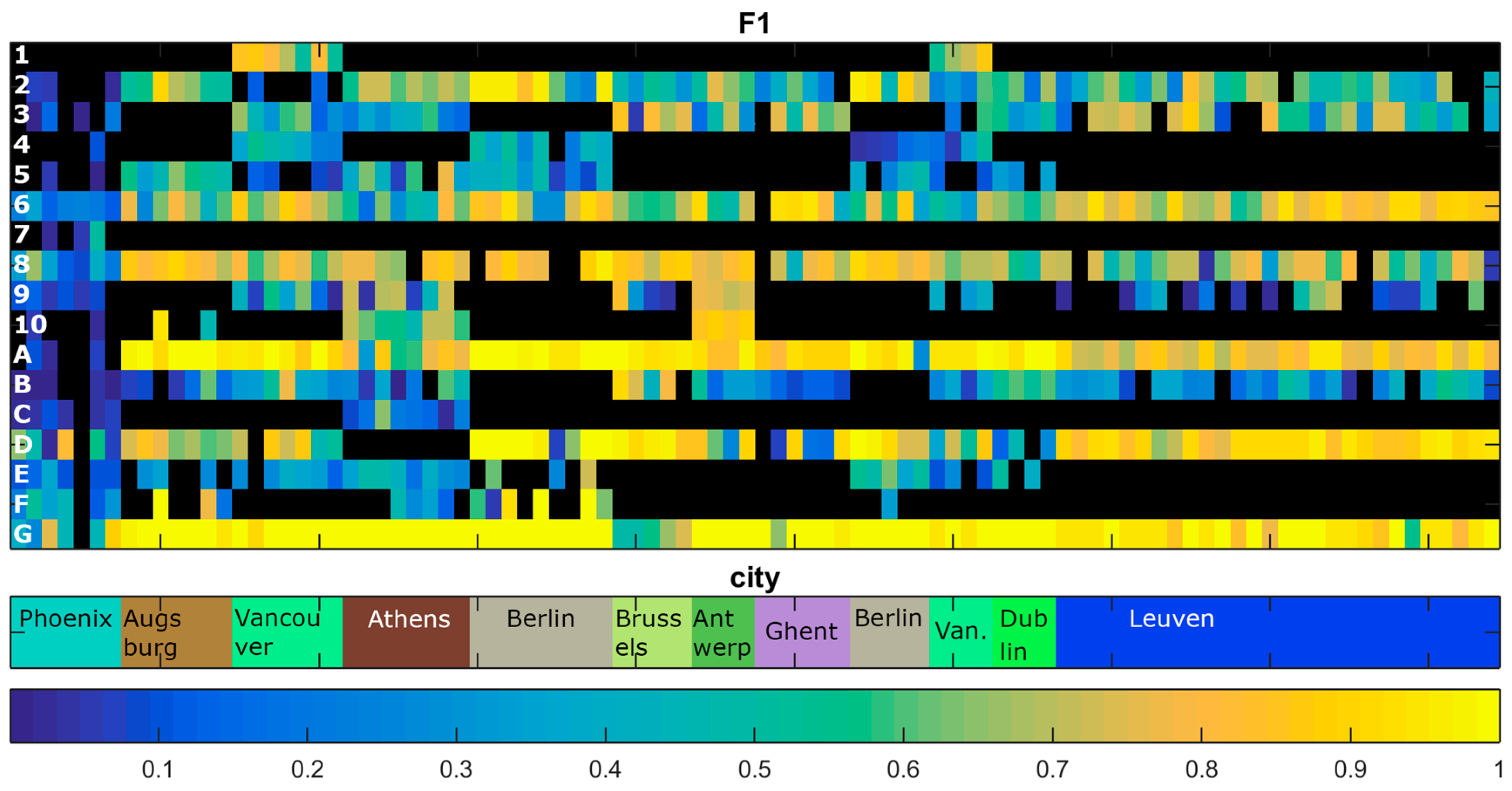
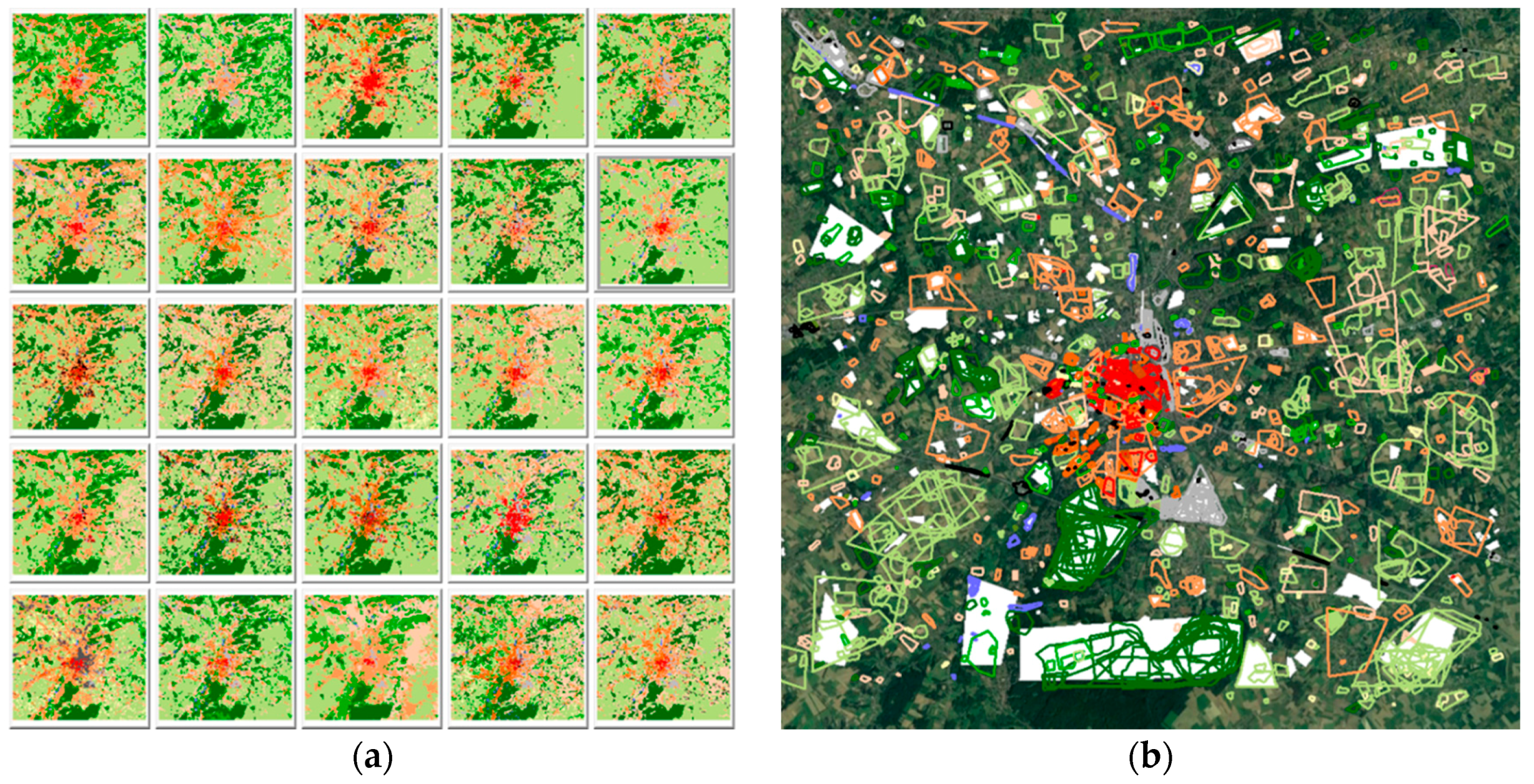
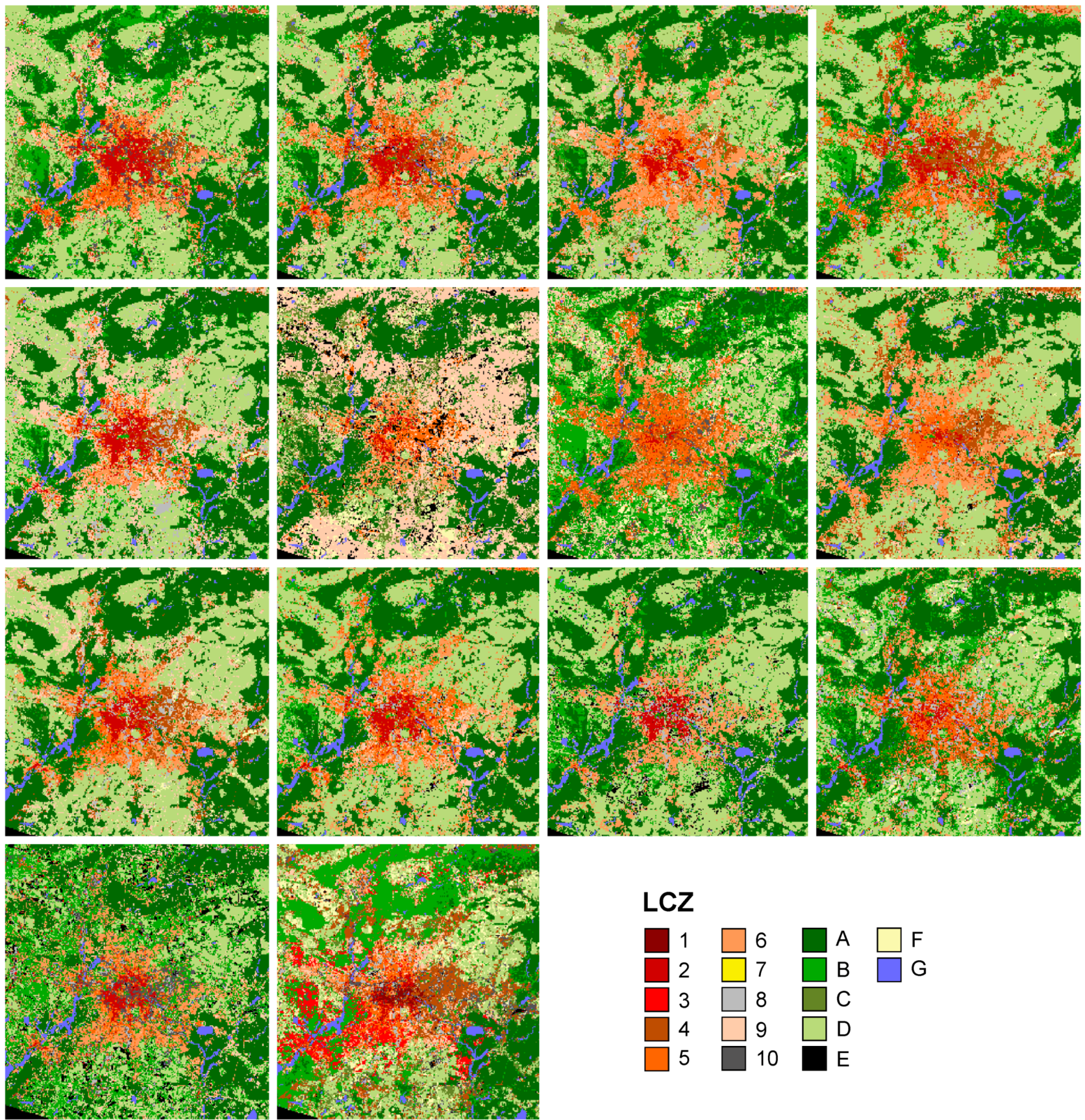
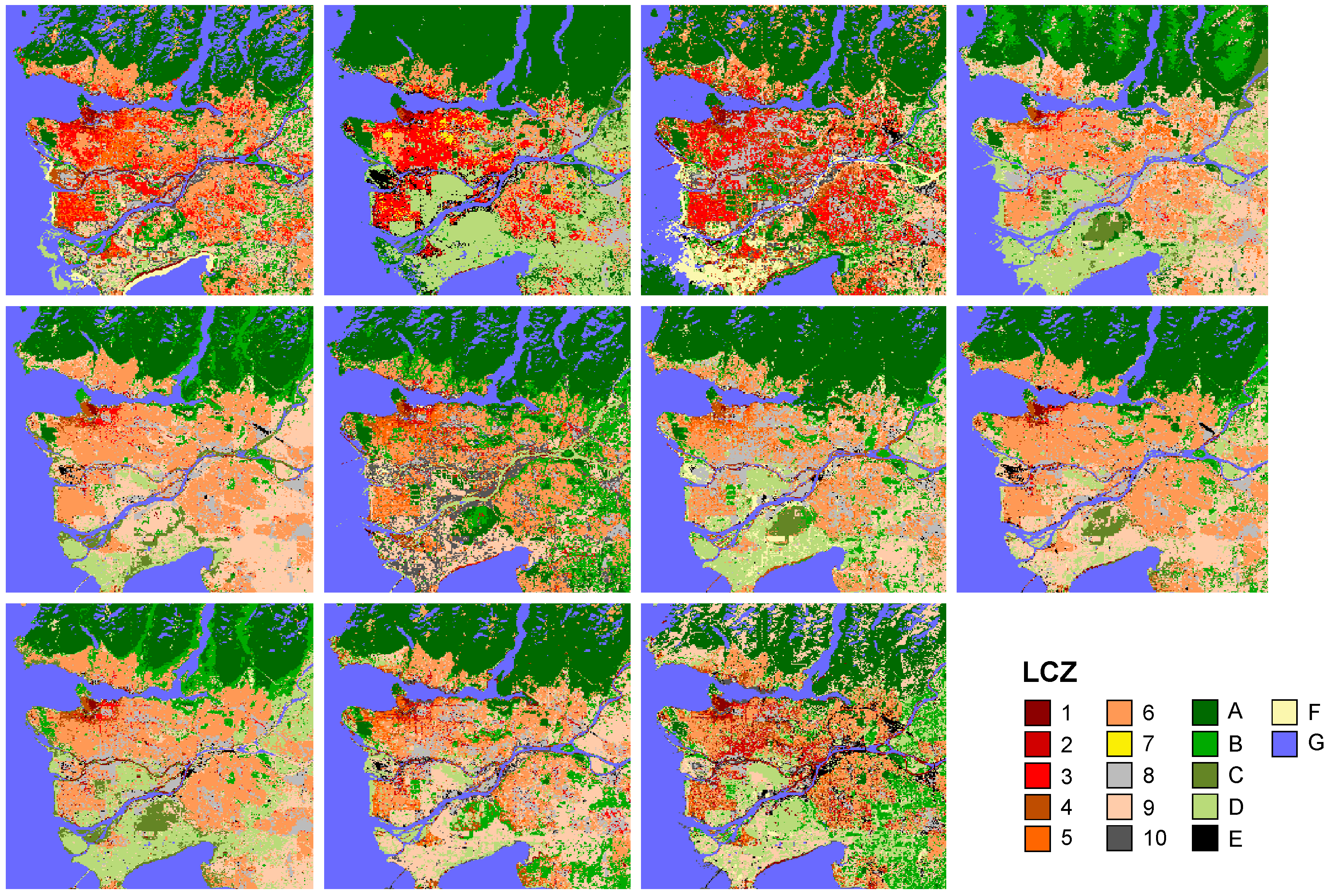
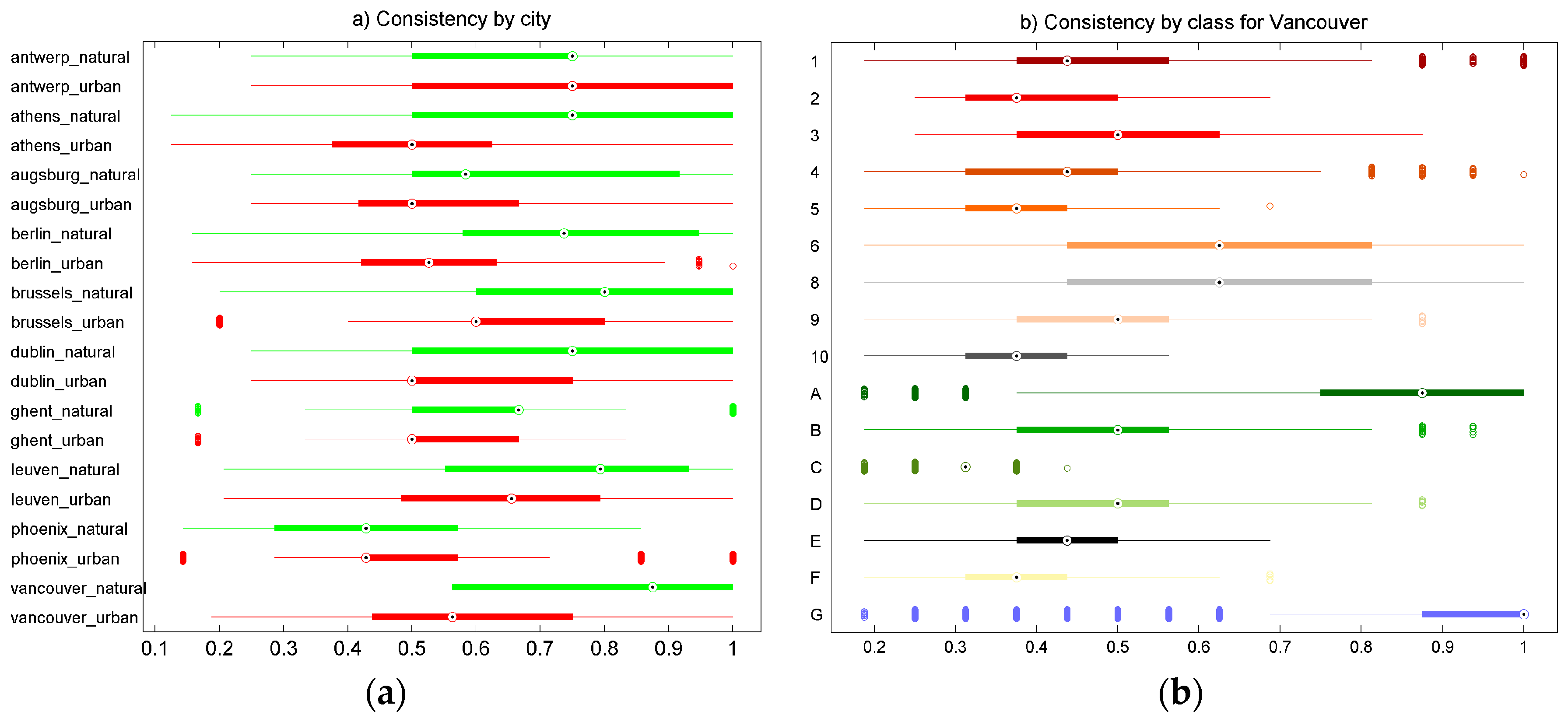
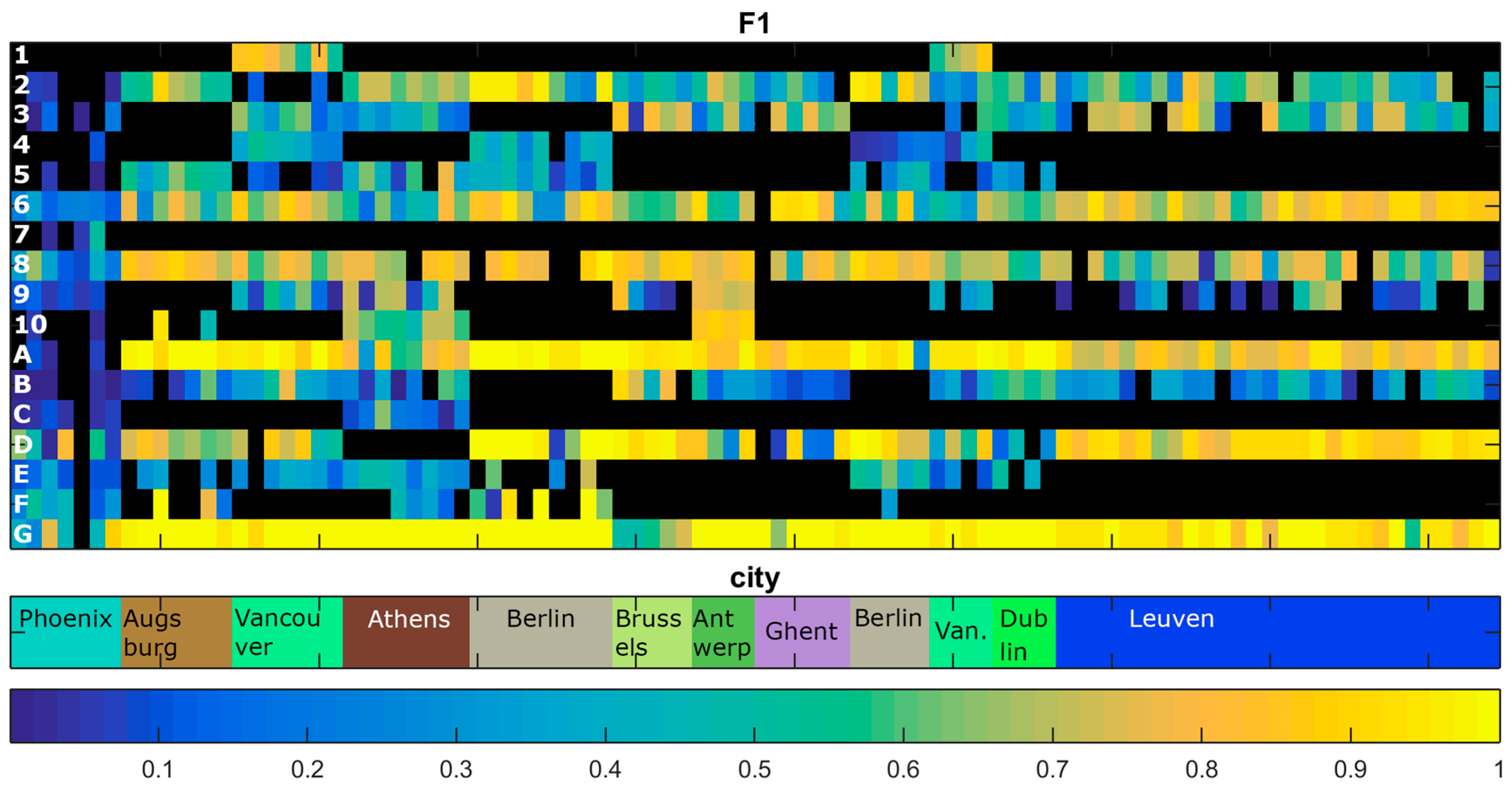
4.1. Variation in Classification Results
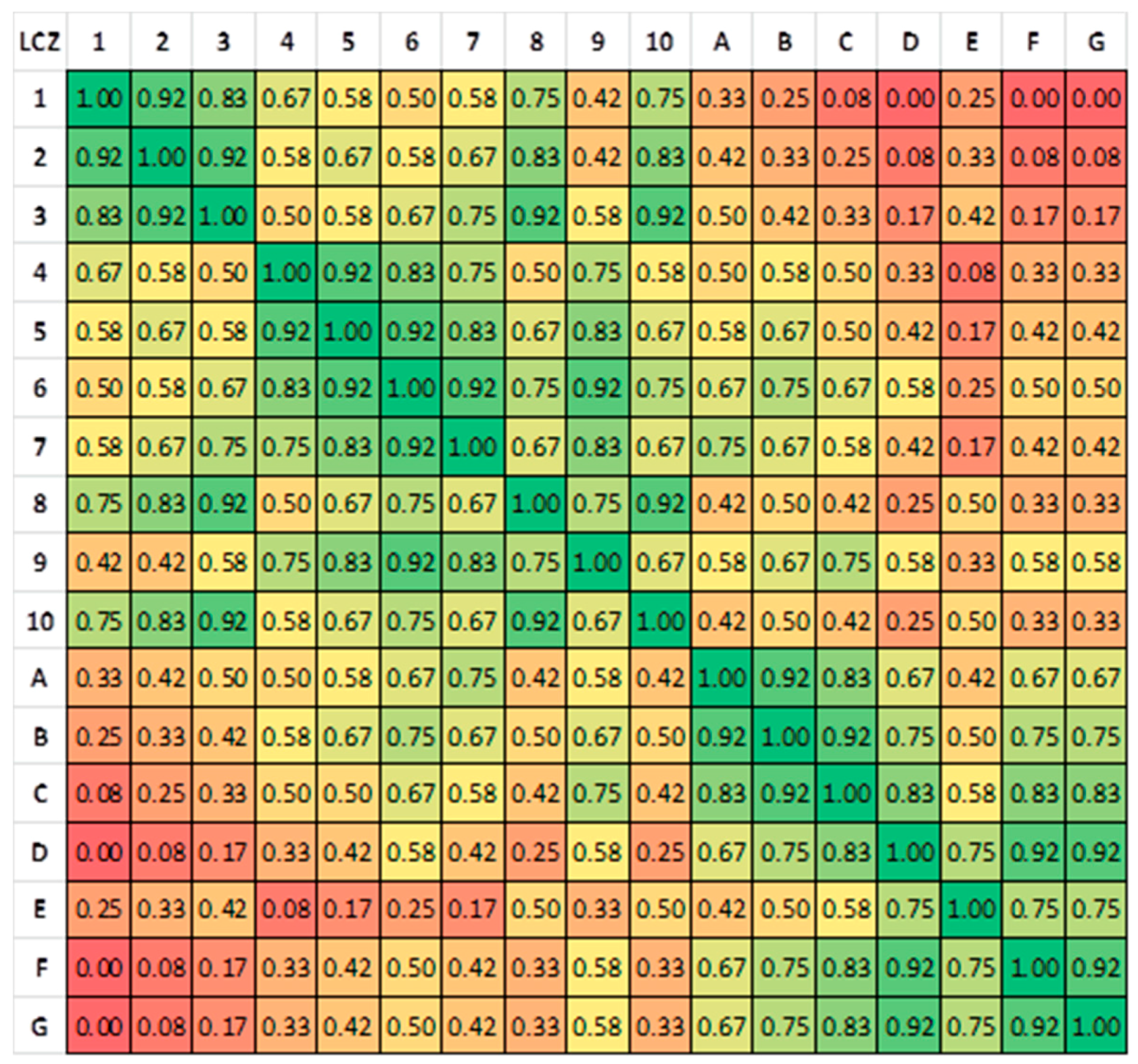
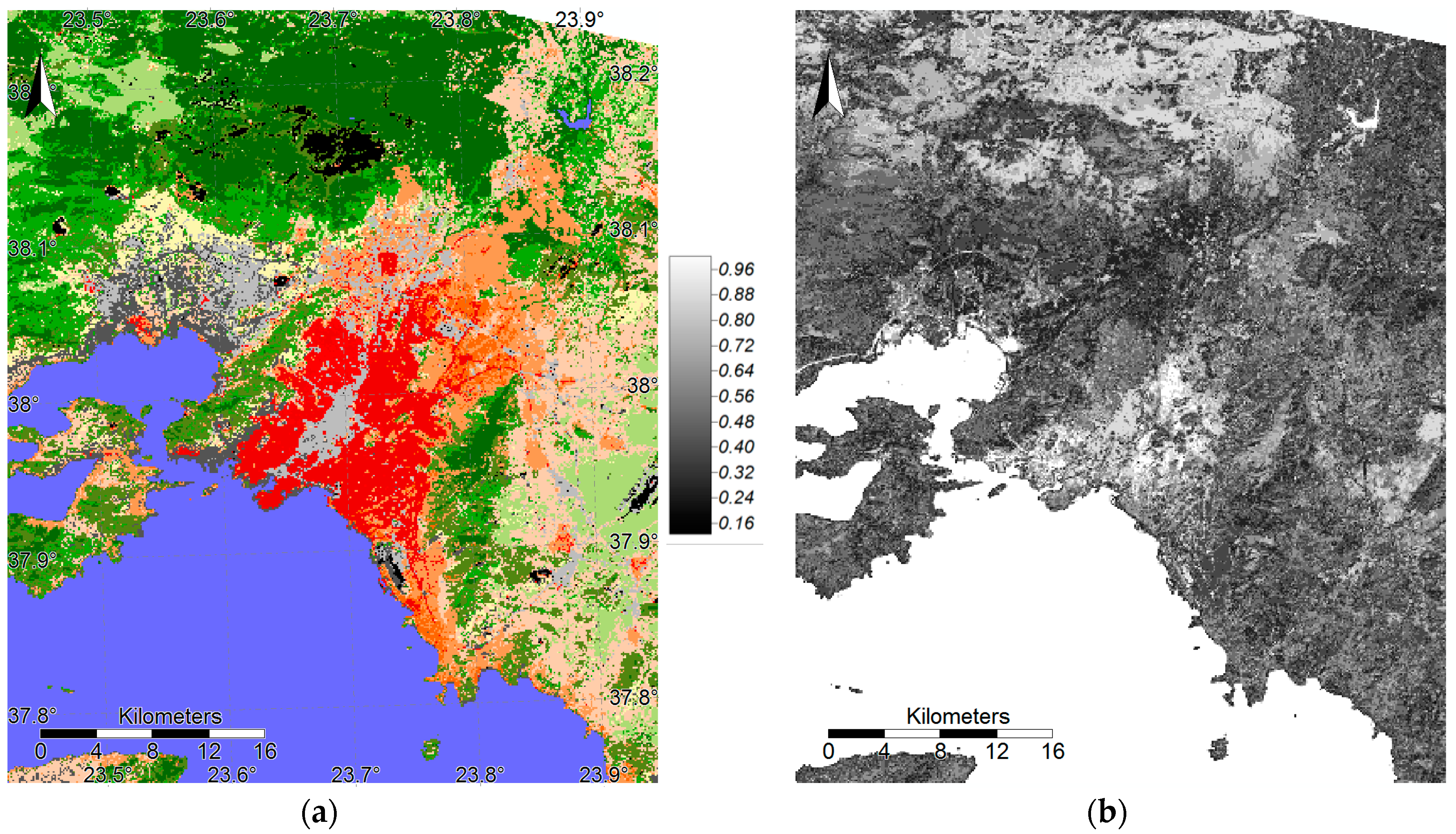
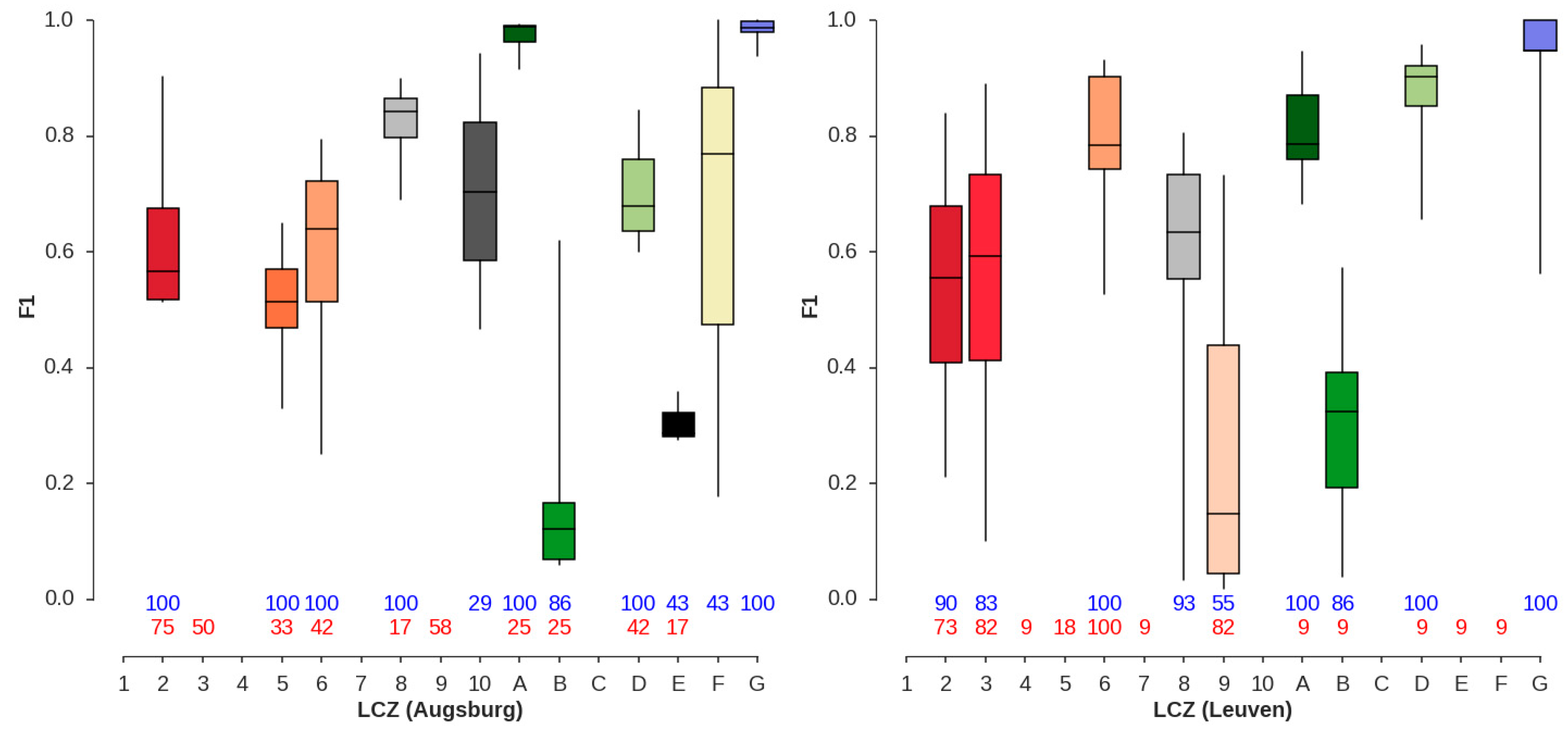
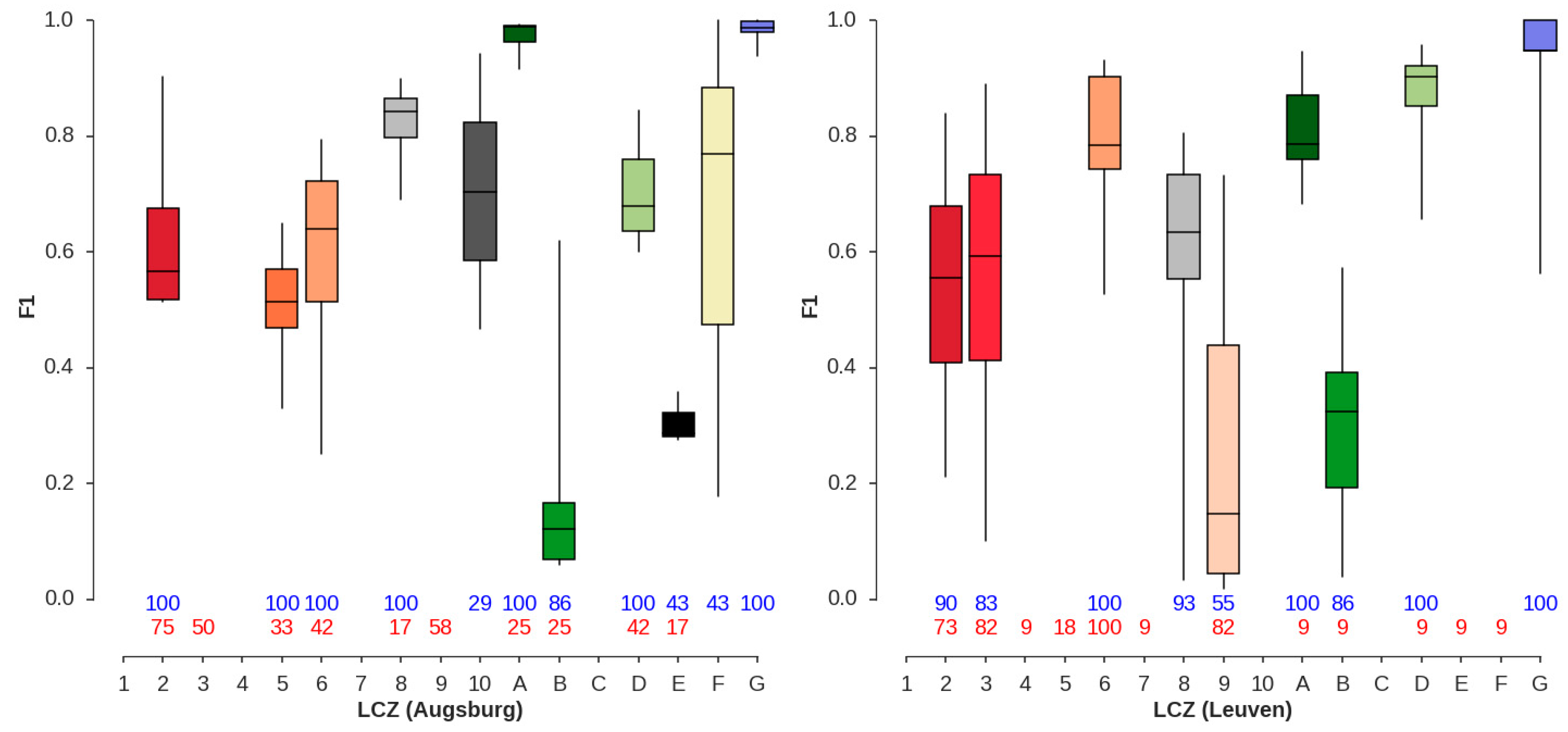
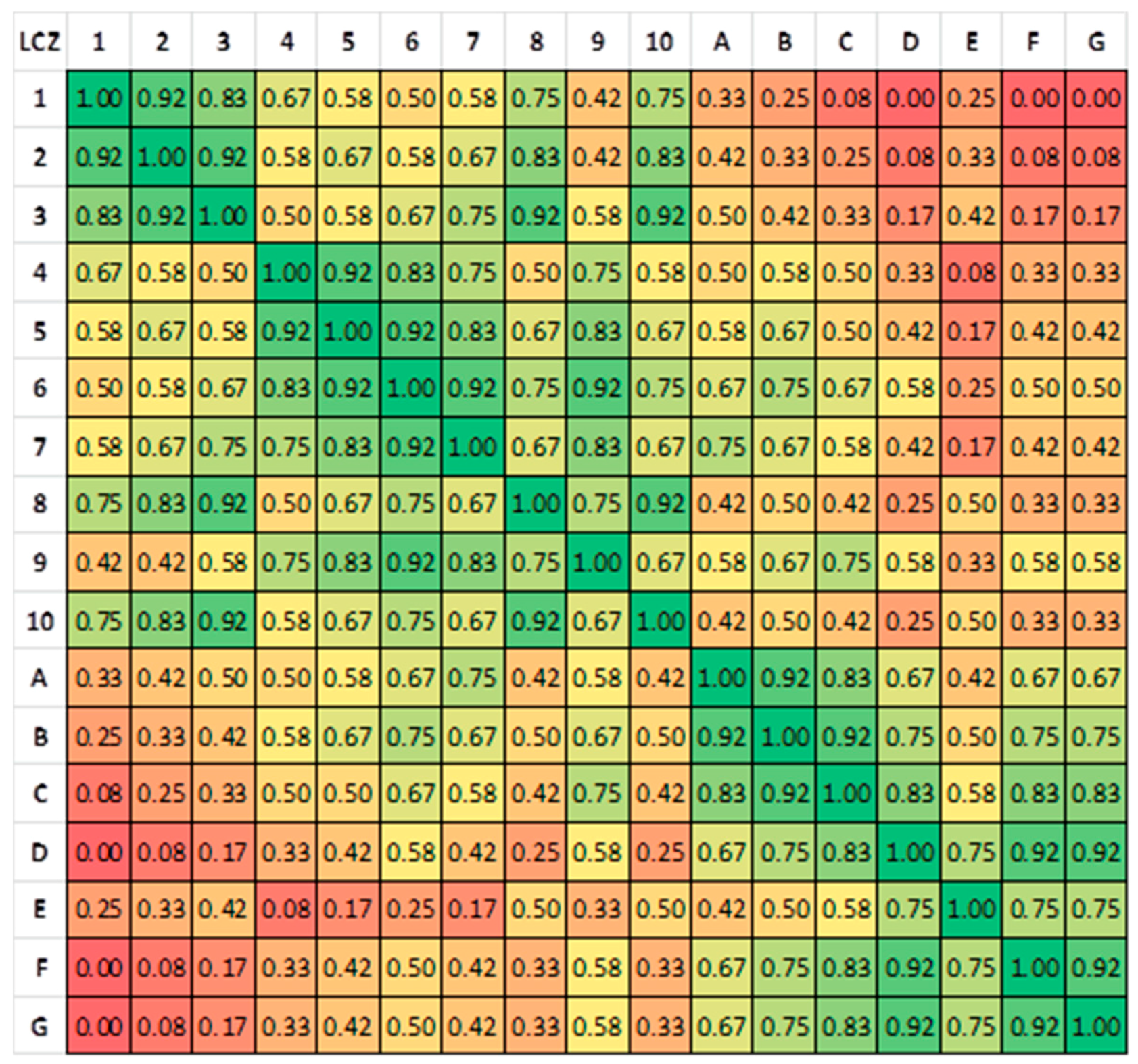
4.2. LCZ Type Specific Accuracies
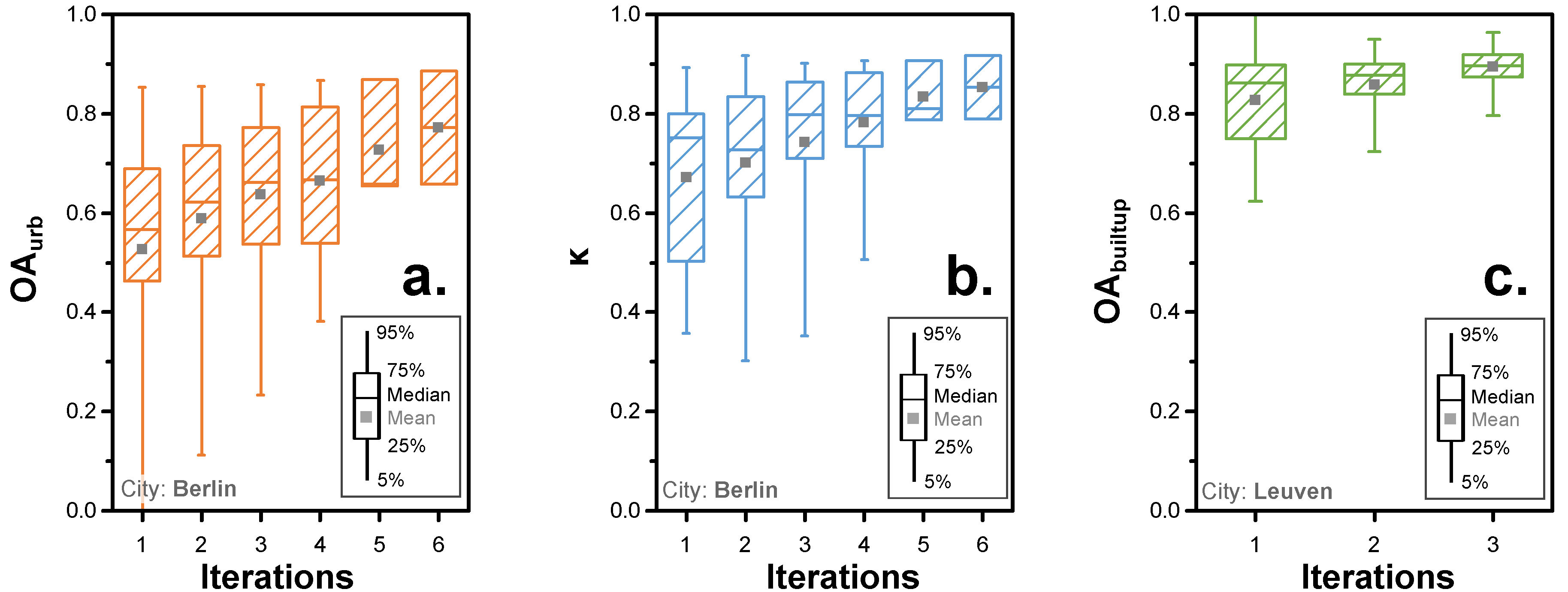
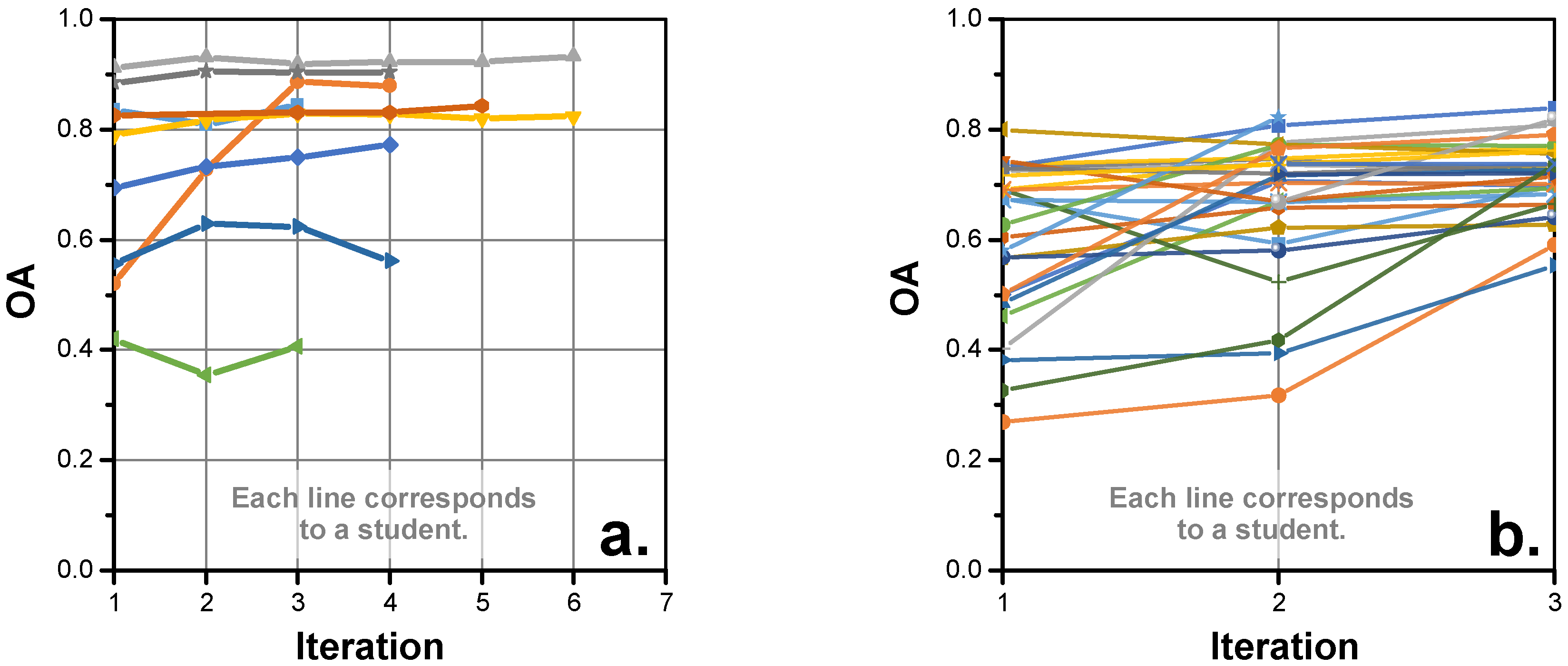
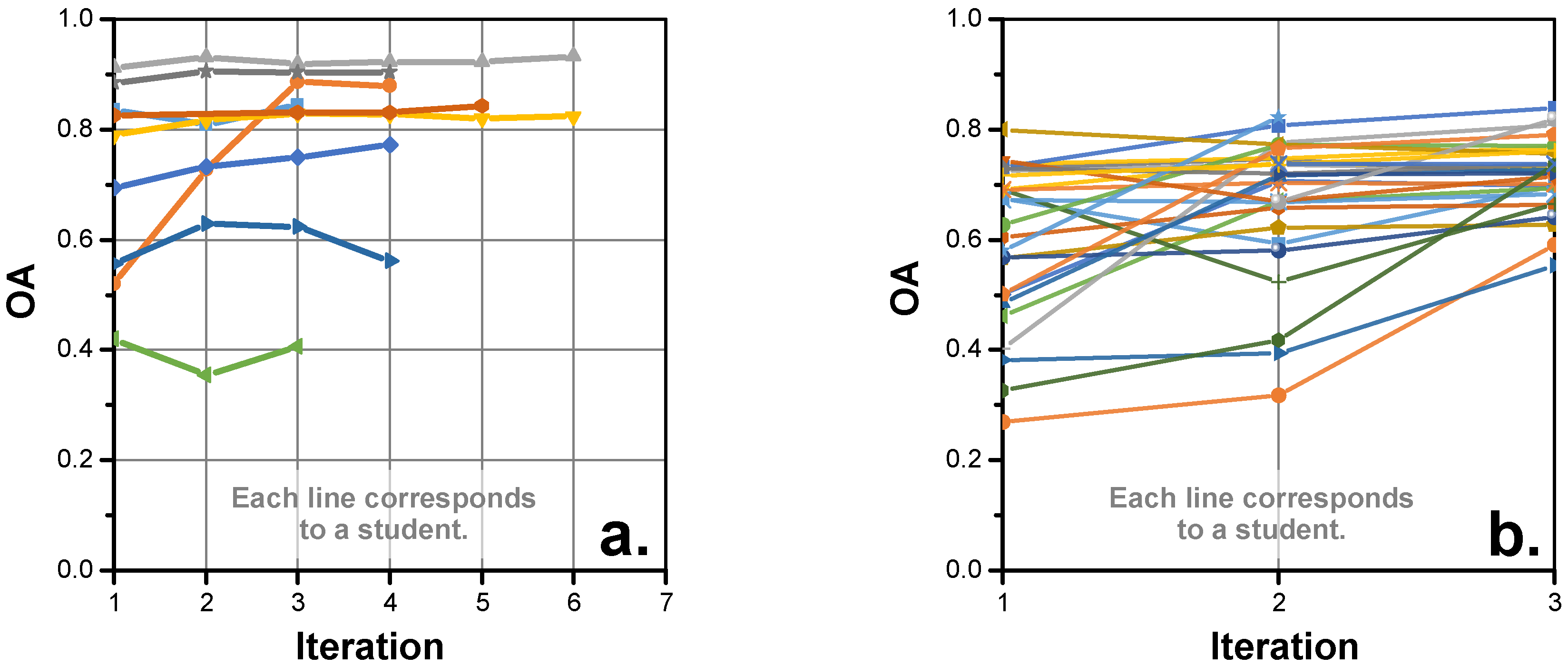
4.3. Iterations
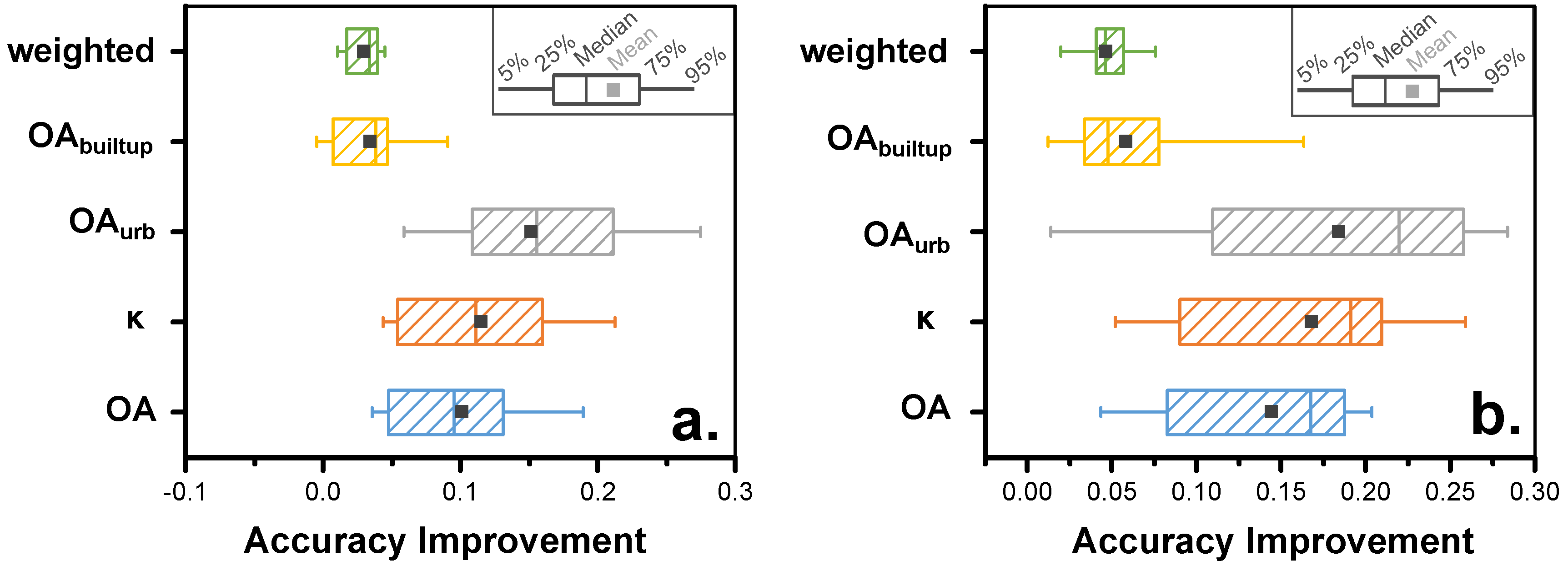
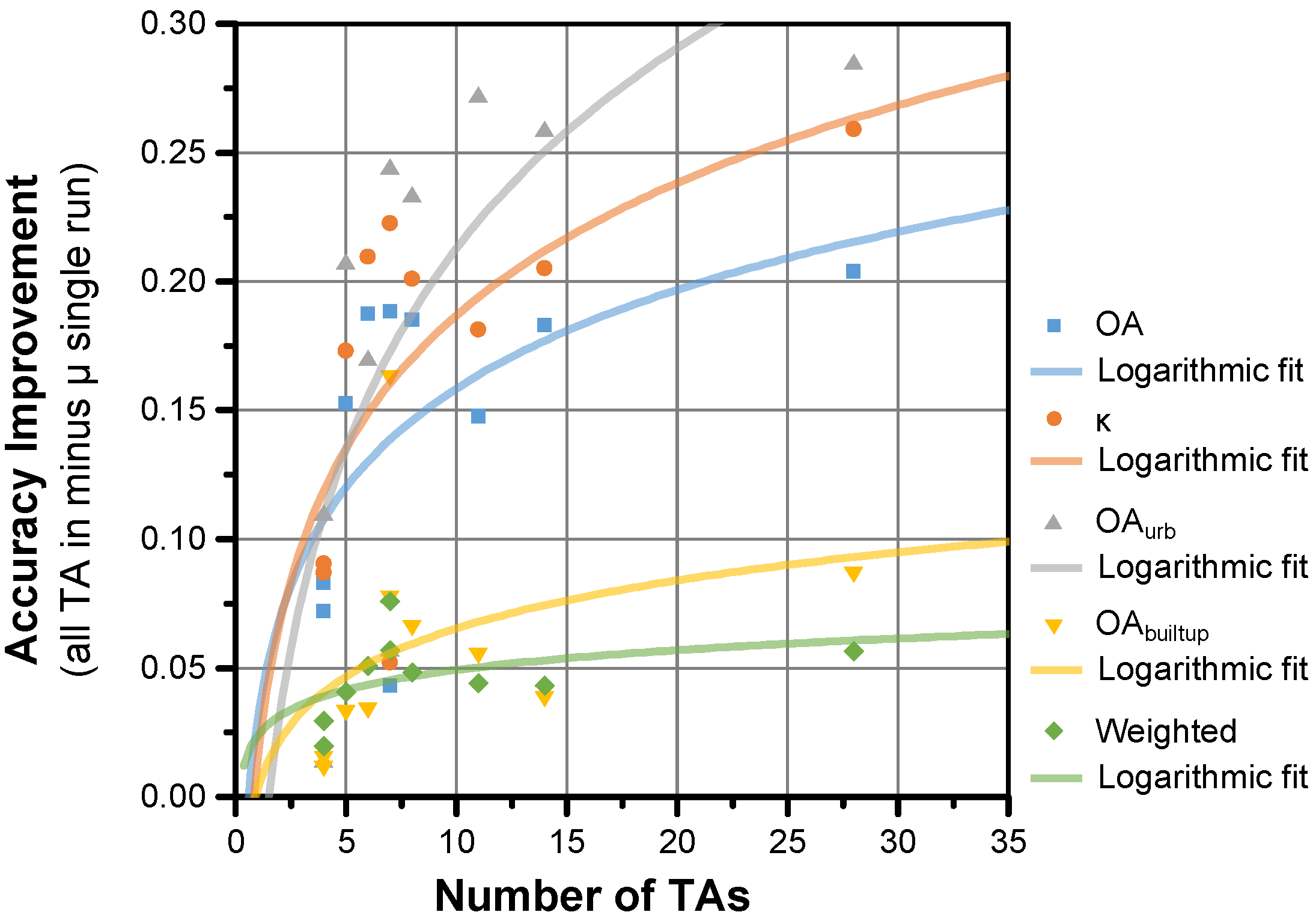
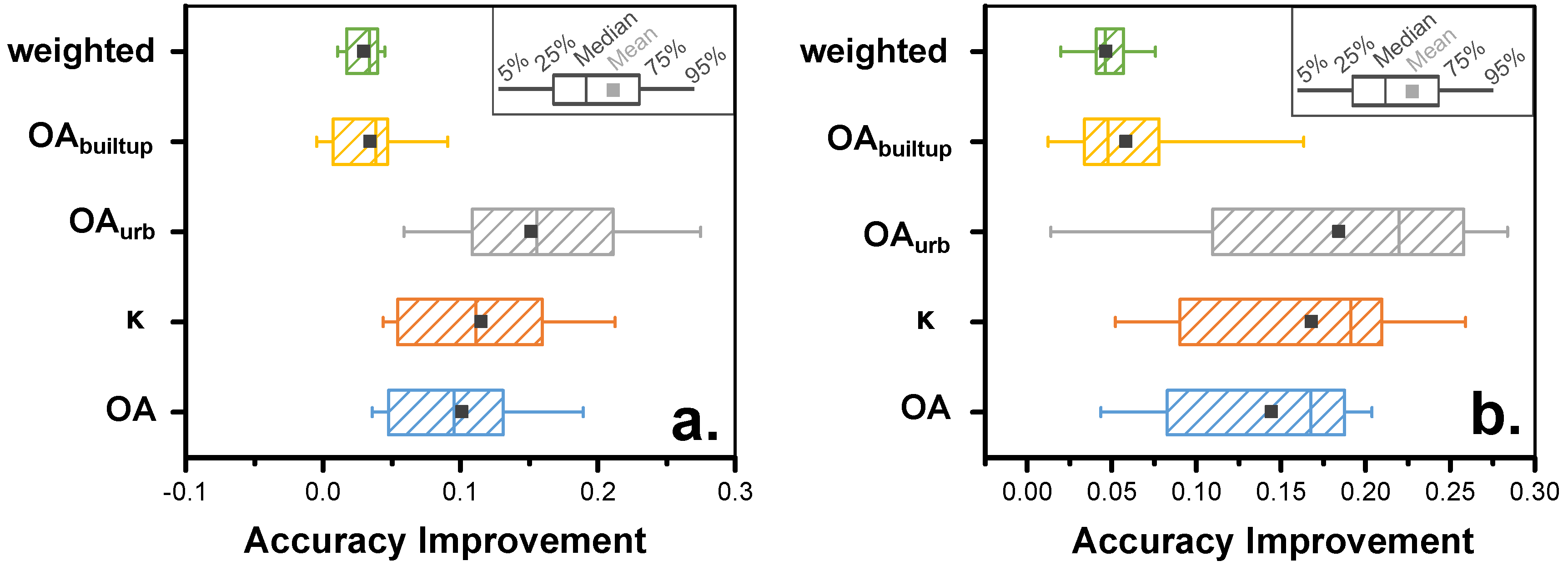
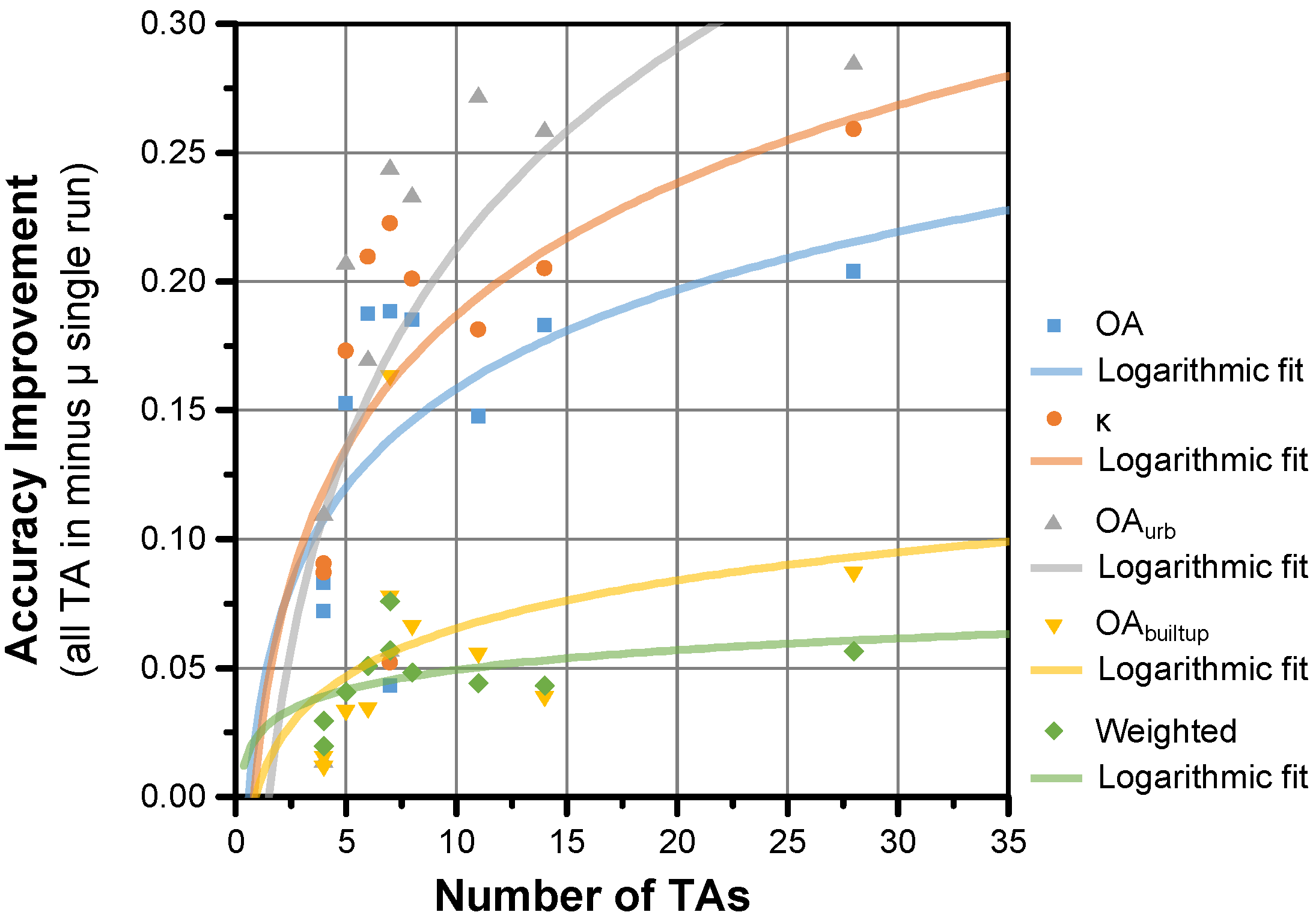
4.4. Multiple Training Sets
- (1)
- the mean accuracies achieved across individual runs, i.e., the LCZ maps created with one TA set as shown in Figure 12a for Leuven (=µ of individual runs);
- (2)
- the best accuracies achieved across the individual runs, which requires prior knowledge and therefore cannot be done without reference data (=best run);
- (3)
- the accuracies achieved when selecting the most frequently chosen category across the individual maps (=modal LCZ); and
- (4)
- the accuracies achieved when combining all TAs into a single LCZ classification per city.
5. Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A
References
- Makse, H.A.; Havlin, S.; Stanley, H.E. Modelling urban growth patterns. Nature 1995, 377, 608–612. [Google Scholar] [CrossRef]
- Batty, M. Cities and Complexity: Understanding Cities with Cellular Automata, Agent-Based Models, and Fractals; MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Schneider, A.; Woodcock, C.E. Compact, dispersed, fragmented, extensive? A comparison of urban growth in twenty-five global cities using remotely sensed data, pattern metrics and census information. Urban Stud. 2008, 45, 659–692. [Google Scholar] [CrossRef]
- Jha, A.K.; Miner, T.W.; Stanton-Geddes, Z. Building Urban Resilience: Principles, Tools, and Practice; World Bank Publications: Washington, DC, USA, 2013. [Google Scholar]
- Satterthwaite, D.; Dodman, D. Towards resilience and transformation for cities within a finite planet. Environ. Urban. 2013, 25, 291–298. [Google Scholar] [CrossRef]
- Meerow, S.; Newell, J.P.; Stults, M. Defining urban resilience: A review. Landsc. Urban Plan. 2016, 147, 38–49. [Google Scholar] [CrossRef]
- Batty, M. The New Science of Cities; MIT Press: Cambridge, MA, USA, 2013. [Google Scholar]
- Kitchin, R. The real-time city? Big data and smart urbanism. GeoJournal 2014, 79, 1–14. [Google Scholar] [CrossRef]
- White, L.; Burger, K.; Yearworth, M. Smart Cities: Big Data and Behavioral Operational Research. In Behavioral Operational Research; Kunc, M., Malpass, J., White, L., Eds.; Palgrave Macmillan: London, UK, 2016; pp. 303–318. [Google Scholar]
- Esch, T.; Marconcini, M.; Felbier, A.; Roth, A.; Heldens, W.; Huber, M.; Schwinger, M.; Taubenbock, H.; Muller, A.; Dech, S. Urban footprint processor—Fully automated processing chain generating settlement masks from global data of the TanDEM-X mission. IEEE Geosci. Remote Sens. Lett. 2013, 10, 1617–1621. [Google Scholar] [CrossRef]
- Pesaresi, M.; Ferri, S.; Ehrlich, D.; Florczyk, A.J.; Freire, S.; Halkia, M.; Julena, A.; Kemper, T.; Soille, P.; Syrris, V. Operating Procedure for the Production of the Global Human Settlement Layer from Landsat Data of the Epochs 1975, 1990, 2000, and 2014; JRC Technical Report; Publications Office of the European Union: Luxembourg, 2016; Volume EUR 27741 EN. [Google Scholar]
- Bechtel, B.; Pesaresi, M.; See, L.; Mills, G.; Ching, J.; Alexander, P.J.; Feddema, J.J.; Florczyk, A.J.; Stewart, I. Towards consistent mapping of urban structures—Global human settlement layer and local climate zones. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inform. Sci. 2016, XLI-B8, 1371–1378. [Google Scholar] [CrossRef]
- Mills, G.; Ching, J.; See, L.; Bechtel, B.; Feddema, J.; Masson, V.; Stewart, I.; Neophytou, M.; O’Connor, M.; Chen, F.; et al. Introduction to the WUDAPT project. In Proceedings of the 9th International Conference on Urban Climate, Toulouse, France, 20–24 July 2015. [Google Scholar]
- Stewart, I.D.; Oke, T.R. Local Climate Zones for Urban Temperature Studies. Bull. Am. Meteorol. Soc. 2012, 93, 1879–1900. [Google Scholar] [CrossRef]
- Stewart, I.D.; Oke, T.R.; Krayenhoff, E.S. Evaluation of the “local climate zone” scheme using temperature observations and model simulations. Int. J. Climatol. 2014, 34, 1062–1080. [Google Scholar] [CrossRef]
- Alexander, P.J.; Mills, G. Local climate classification and Dublin’s urban heat island. Atmosphere 2014, 5, 755–774. [Google Scholar] [CrossRef]
- Lehnert, M.; Geletič, J.; Husák, J.; Vysoudil, M. Urban field classification by “local climate zones” in a medium-sized Central European city: The case of Olomouc (Czech Republic). Theor. Appl. Climatol. 2015, 122, 531–541. [Google Scholar] [CrossRef]
- Fenner, D.; Meier, F.; Scherer, D.; Polze, A. Spatial and temporal air temperature variability in Berlin, Germany, during the years 2001–2010. Urban Clim. 2014, 10(Part 2), 308–331. [Google Scholar] [CrossRef]
- Arnds, D.; Böhner, J.; Bechtel, B. Spatio-temporal variance and meteorological drivers of the urban heat island in a European city. Theor. Appl. Climatol. 2017, 128, 43–61. [Google Scholar] [CrossRef]
- Brousse, O.; Martilli, A.; Foley, M.; Mills, G.; Bechtel, B. WUDAPT, an efficient land use producing data tool for mesoscale models? Integration of urban LCZ in WRF over Madrid. Urban Clim. 2016, 17, 116–134. [Google Scholar] [CrossRef]
- Alexander, P.J.; Bechtel, B.; Chow, W.T.L.; Fealy, R.; Mills, G. Linking urban climate classification with an urban energy and water budget model: Multi-site and multi-seasonal evaluation. Urban Clim. 2016, 17, 196–215. [Google Scholar] [CrossRef]
- Wouters, H.; Demuzere, M.; Blahak, U.; Fortuniak, K.; Maiheu, B.; Camps, J.; Tielemans, D.; van Lipzig, N.P.M. The efficient urban canopy dependency parametrization (SURY) v1.0 for atmospheric modelling: description and application with the COSMO-CLM model for a Belgian summer. Geosci. Model Dev. 2016, 9, 3027–3054. [Google Scholar] [CrossRef]
- Bechtel, B.; Daneke, C. Classification of Local Climate Zones based on multiple Earth Observation data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 1191–1202. [Google Scholar] [CrossRef]
- Lelovics, E.; Unger, J.; Gál, T.; Gál, C. Design of an urban monitoring network based on Local Climate Zone mapping and temperature pattern modelling. Clim. Res. 2014, 60, 51–62. [Google Scholar] [CrossRef]
- Gal, T.; Bechtel, B.; Lelovics, E. Comparison of two different Local Climate Zone mapping methods. In Proceedings of the ICUC9, Toulouse, France, 20–24 July 2015. [Google Scholar]
- Geletič, J.; Lehnert, M. GIS-based delineation of local climate zones: The case of medium-sized Central European cities. Morav. Geogr. Rep. 2016, 24. [Google Scholar] [CrossRef]
- Weng, Q. (Ed.) Global Urban Monitoring and Assessment through Earth Observation; Remote Sensing Applications Series; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]
- Casonne, A. Deriving Local Climate Zones from Remote Sensing Data. Master’s Thesis, University of Strasbourg, Strasbourg, France, 2016. [Google Scholar]
- Bechtel, B.; Alexander, P.J.; Böhner, J.; Ching, J.; Conrad, O.; Feddema, J.; Mills, G.; See, L.; Stewart, I. Mapping Local Climate Zones for a worldwide database of the form and function of cities. ISPRS Int. J. Geo-Inf. 2015, 4, 199–219. [Google Scholar] [CrossRef]
- Conrad, O.; Bechtel, B.; Bock, M.; Dietrich, H.; Fischer, E.; Gerlitz, L.; Wehberg, J.; Wichmann, V.; Böhner, J. System for Automated Geoscientific Analyses (SAGA) v. 2.1.4. Geosci. Model Dev. 2015, 8, 1991–2007. [Google Scholar] [CrossRef]
- Bechtel, B.; See, L.; Mills, G.; Foley, M. Classification of Local Climate Zones using SAR and multi-spectral data in an arid environment. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 3097–3105. [Google Scholar] [CrossRef]
- Danylo, O.; See, L.; Bechtel, B.; Schepaschenko, D.; Fritz, S. Contributing to WUDAPT: A Local Climate Zone classification of two cities in Ukraine. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sen. 2016, 9, 1841–1853. [Google Scholar] [CrossRef]
- Kaloustian, N.; Bechtel, B. Local climatic zoning and urban heat island in Beirut. Proced. Eng. 2016, 169, 216–223. [Google Scholar] [CrossRef]
- Xu, Y.; Ren, C.; Meng, C.; Ng, E.; Wu, T. Classification of local climate zones using ASTER and Landsat data for high-density cities. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017. [Google Scholar] [CrossRef]
- Tuia, D.; Moser, G.; Saux, B.L.; Bechtel, B.; See, L. 2017 IEEE GRSS Data Fusion Contest: Open Data for Global Multimodal Land Use Classification [Technical Committees]. IEEE Geosci. Remote Sens. Mag. 2017, 5, 70–73. [Google Scholar] [CrossRef]
- Mitraka, Z.; Frate, F.D.; Chrysoulakis, N.; Gastellu-Etchegorry, J.P. Exploiting Earth Observation data products for mapping Local Climate Zones. In Proceedings of the 2015 Joint Urban Remote Sensing Event (JURSE), Ecublens, Switzerland, 30 March–1 April 2015; pp. 1–4. [Google Scholar]
- Bechtel, B.; Demuzere, M.; Xu, Y.; Verdonck, M.L.; Lopes, P.; See, L.; Ren, C.; Van Coillie, F.M.B.; Tuia, D.; Fonte, C.C.; et al. Beyond the Urban Mask: Local Climate Mask Zones as a Generic Descriptor of Urban Areas—Potential and Recent Developments. In Proceedings of the IEEE 2017 Joint Urban Remote Sensing Event (JURSE), Dubai, UAE, 6–8 March 2017. [Google Scholar]
- Tuia, D.; Moser, G.; Wurm, M.; Taubenbock, H. Land Use Modelling in North Rhine-Westphalia with Interaction and Scaling Laws. In Proceedings of the IEEE 2017 Joint Urban Remote Sensing Event (JURSE), Dubai, UAE, 6–8 March 2017. [Google Scholar]
- Perera, N.G.R.; Emmanuel, R. A “Local Climate Zone” based approach to urban planning in Colombo, Sri Lanka. Urban Clim. 2016. [Google Scholar] [CrossRef]
- Goodchild, M.F. Citizens as sensors: The world of volunteered geography. GeoJournal 2007, 69, 211–221. [Google Scholar] [CrossRef]
- See, L.; Mooney, P.; Foody, G.; Bastin, L.; Comber, A.; Estima, J.; Fritz, S.; Kerle, N.; Jiang, B.; Laakso, M.; et al. Crowdsourcing, citizen science or Volunteered Geographic Information? The current state of crowdsourced geographic information. ISPRS Int. J. Geo-Inf. 2016, 5, 55. [Google Scholar] [CrossRef]
- Howe, J. The rise of crowdsourcing. Wired Mag. 2006, 14, 1–4. [Google Scholar]
- International Association for Urban Climate. Available online: http://www.urban-climate.org/ (accessed on 13 March 2017).
- Foody, G.M.; See, L.; Fritz, S.; Van der Velde, M.; Perger, C.; Schill, C.; Boyd, D.S. Assessing the accuracy of Volunteered Geographic Information arising from multiple contributors to an Internet based collaborative project: Accuracy of VGI. Trans. GIS 2013, 17, 847–860. [Google Scholar] [CrossRef]
- Foody, G.M.; See, L.; Fritz, S.; Van der Velde, M.; Perger, C.; Schill, C.; Boyd, D.S.; Comber, A. Accurate attribute mapping from Volunteered Geographic Information: Issues of volunteer quantity and quality. Cartogr. J. 2015, 52, 336–344. [Google Scholar] [CrossRef]
- Van Coillie, F.M.B.; Gardin, S.; Anseel, F.; Duyck, W.; Verbeke, L.P.C.; Wulf, R.R.D. Variability of operator performance in remote-sensing image interpretation: The importance of human and external factors. Int. J. Remote Sens. 2014, 35, 754–778. [Google Scholar] [CrossRef]
- Flanagin, A.; Metzger, M. The credibility of volunteered geographic information. GeoJournal 2008, 72, 137–148. [Google Scholar] [CrossRef]
- Antoniou, V.; Skopeliti, A. Measures and indicators of VGI quality: An overview. In ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences; ISPRS Annals: La Grande Motte, France, 2015; Volume II-3/W5, pp. 345–351. [Google Scholar]
- Allahbakhsh, M.; Benatallah, B.; Ignjatovic, A.; Motahari-Nezhad, H.R.; Bertino, E.; Dustdar, S. Quality control in crowdsourcing systems: Issues and directions. IEEE Internet Comput. 2013, 17, 76–81. [Google Scholar] [CrossRef]
- Fonte, C.C.; Bastin, L.; See, L.; Foody, G.; Lupia, F. Usability of VGI for validation of land cover maps. Int. J. Geogr. Inf. Sci. 2015, 29, 1269–1291. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Congalton, R.G. A review of assessing the accuracy of classifications of remotely sensed data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Stewart, I.; Global Cities Institute, University of Toronto, Toronto, Canada, LCZ metric. Personal communication, 2016.
- Surowiecki, J. The Wisdom of Crowds; Anchor Books: New York, NY, USA, 2005. [Google Scholar]
- Haklay, M.; Basiouka, S.; Antoniou, V.; Ather, A. How many volunteers does it take to map an area well? The validity of Linus’ Law to volunteered geographic information. Cartogr. J. 2010, 47, 315–322. [Google Scholar] [CrossRef]
- See, L.; Comber, A.; Salk, C.; Fritz, S.; Van der Velde, M.; Perger, C.; Schill, C.; McCallum, I.; Kraxner, F.; Obersteiner, M. Comparing the quality of crowdsourced data contributed by expert and non-experts. PLoS ONE 2013, 8, e69958. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Metadata Collected |
|---|---|
| General | ID; City name |
| Operator | Number of operators per training area set; highest degree (B.Sc./M.Sc./Ph.D.); total years of study (Number of years); University course; Experience with Image Classification (Self-Estimation 1); Age; Gender; City of origin |
| LCZ knowledge | Introduction in seminar/course (Yes/No); WUDAPT website visit (Yes/No); study of Stewart & Oke 2012 paper (Yes/No); study of LCZ fact sheets (Yes/No); completion of LCZ Driving test (Yes/No); Numbers of cities classified before (Number of cities); LCZ knowledge self-estimation (0–100%) |
| City knowledge | How long have you lived in the city of interest (Number of years); how long have you lived in similar (climate, morphology) cities (Number of years); Familiarity with city of interest self-estimation (0–100%) |
| Classification | Time invested for training area collection (Number of hours); Number of iterations (Number of iterations); Used online manuals? (Yes/No); Which LCZ did you find difficult to distinguish? (LCZ type) |
| Overall | Self-Rating (0–100%) of final classification [map] quality |
| Personality 2 | I like to follow a schedule; I know how to captivate people; I am relaxed most of the time; I don’t mind being the centre of attention; I see myself as sympathetic/warm, I see myself as dependable, self-disciplined; I see myself as open to new experiences; I see myself as calm, emotionally stable; I like to collaborate. |
| Institute ID | Name | Number of Students | Cities Classified (Number of Students) | Maximum Time for Completion | Number of TA Sets Used in Evaluation |
|---|---|---|---|---|---|
| ASU | Arizona State University | 7 | Phoenix (7) | 2 weeks (homework) | 7 |
| AUG | University of Augsburg | 12 | Augsburg (12), Vancouver (12) | homework | 14 |
| KUL | University of Leuven | 31 | Leuven (31) | 9 h | 28 |
| NOA | National Observatory of Athens & University of Peloponnese (Joint course) | 8 | Athens (8) | homework | 8 |
| TUB | Technical University of Berlin | 14 | Berlin (14) | 2 days (16 h) | 9 |
| GU | Ghent University | 28 | Antwerp (4), Berlin (5), Brussels (5), Dublin (4), Ghent (6), Vancouver (4) | 12 h | 28 |
| CITY | Antwerp | Athens | Augsburg | Berlin | Brussels | Dublin | Ghent | Leuven | Phoenix | Vancouver |
|---|---|---|---|---|---|---|---|---|---|---|
| N | 4 | 8 | 7 | 14 | 5 | 4 | 6 | 28 | 7 | 11 |
| 1. µ single runs | ||||||||||
| OA | 0.71 | 0.56 | 0.66 | 0.76 | 0.71 | 0.71 | 0.61 | 0.72 | 0.18 | 0.78 |
| ĸ | 0.67 | 0.52 | 0.58 | 0.72 | 0.67 | 0.65 | 0.55 | 0.64 | 0.12 | 0.73 |
| OAurb | 0.70 | 0.54 | 0.60 | 0.61 | 0.59 | 0.55 | 0.55 | 0.60 | 0.30 | 0.57 |
| OAbuiltup | 0.93 | 0.92 | 0.85 | 0.96 | 0.94 | 0.93 | 0.96 | 0.89 | 0.66 | 0.91 |
| WA | 0.93 | 0.91 | 0.90 | 0.95 | 0.93 | 0.91 | 0.91 | 0.92 | 0.64 | 0.93 |
| 2. best single run | ||||||||||
| OA | 0.75 | 0.74 | 0.71 | 0.93 | 0.85 | 0.74 | 0.72 | 0.83 | 0.28 | 0.87 |
| ĸ | 0.72 | 0.71 | 0.63 | 0.92 | 0.82 | 0.68 | 0.68 | 0.78 | 0.20 | 0.83 |
| OAurb | 0.72 | 0.74 | 0.81 | 0.89 | 0.74 | 0.65 | 0.75 | 0.80 | 0.44 | 0.82 |
| OAbuiltup | 0.93 | 0.97 | 0.90 | 0.99 | 0.98 | 0.95 | 0.99 | 0.97 | 0.79 | 0.96 |
| WA | 0.95 | 0.95 | 0.92 | 0.98 | 0.97 | 0.91 | 0.95 | 0.95 | 0.72 | 0.97 |
| 3. mode all TA | ||||||||||
| OA | 0.79 | 0.73 | 0.79 | 0.95 | 0.81 | 0.75 | 0.66 | 0.85 | 0.23 | 0.87 |
| ĸ | 0.76 | 0.70 | 0.72 | 0.93 | 0.78 | 0.69 | 0.61 | 0.80 | 0.17 | 0.83 |
| OAurb | 0.76 | 0.75 | 0.66 | 0.89 | 0.70 | 0.69 | 0.76 | 0.77 | 0.41 | 0.74 |
| OAbuiltup | 0.94 | 0.97 | 0.91 | 0.99 | 0.98 | 0.93 | 0.95 | 0.94 | 0.75 | 0.93 |
| WA | 0.95 | 0.95 | 0.94 | 0.99 | 0.97 | 0.92 | 0.93 | 0.95 | 0.68 | 0.96 |
| 4. all TA in | ||||||||||
| OA | 0.79 | 0.75 | 0.85 | 0.94 | 0.86 | 0.79 | 0.80 | 0.92 | 0.23 | 0.93 |
| ĸ | 0.77 | 0.72 | 0.80 | 0.93 | 0.84 | 0.74 | 0.76 | 0.90 | 0.17 | 0.91 |
| OAurb | 0.72 | 0.77 | 0.85 | 0.87 | 0.79 | 0.66 | 0.72 | 0.89 | 0.36 | 0.84 |
| OAbuiltup | 0.94 | 0.99 | 0.92 | 1.00 | 0.97 | 0.95 | 0.99 | 0.98 | 0.82 | 0.97 |
| WA | 0.96 | 0.96 | 0.96 | 0.99 | 0.98 | 0.93 | 0.97 | 0.98 | 0.72 | 0.98 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bechtel, B.; Demuzere, M.; Sismanidis, P.; Fenner, D.; Brousse, O.; Beck, C.; Van Coillie, F.; Conrad, O.; Keramitsoglou, I.; Middel, A.; et al. Quality of Crowdsourced Data on Urban Morphology—The Human Influence Experiment (HUMINEX). Urban Sci. 2017, 1, 15. https://doi.org/10.3390/urbansci1020015
Bechtel B, Demuzere M, Sismanidis P, Fenner D, Brousse O, Beck C, Van Coillie F, Conrad O, Keramitsoglou I, Middel A, et al. Quality of Crowdsourced Data on Urban Morphology—The Human Influence Experiment (HUMINEX). Urban Science. 2017; 1(2):15. https://doi.org/10.3390/urbansci1020015
Chicago/Turabian StyleBechtel, Benjamin, Matthias Demuzere, Panagiotis Sismanidis, Daniel Fenner, Oscar Brousse, Christoph Beck, Frieke Van Coillie, Olaf Conrad, Iphigenia Keramitsoglou, Ariane Middel, and et al. 2017. "Quality of Crowdsourced Data on Urban Morphology—The Human Influence Experiment (HUMINEX)" Urban Science 1, no. 2: 15. https://doi.org/10.3390/urbansci1020015
APA StyleBechtel, B., Demuzere, M., Sismanidis, P., Fenner, D., Brousse, O., Beck, C., Van Coillie, F., Conrad, O., Keramitsoglou, I., Middel, A., Mills, G., Niyogi, D., Otto, M., See, L., & Verdonck, M.-L. (2017). Quality of Crowdsourced Data on Urban Morphology—The Human Influence Experiment (HUMINEX). Urban Science, 1(2), 15. https://doi.org/10.3390/urbansci1020015