1. Introduction
This paper deals with applications of statistics and machine learning to poetry. This is an interdisciplinary field of research situated at the intersection of information theory, statistics, machine learning and literature, whose growth is due to recent developments in data science and technology. The importance of the paper consists of a quantitative approach to an area that until recently belonged more to the field of arts rather than to the field of exact sciences. We shall provide in the following some remarks that will place the subject of this paper in a proper historical perspective.
The entropy of a language has been introduced by Shannon [
1] in 1948. He defined the entropy of a language as a statistical parameter that measures how much information is produced on the average for each letter of a text in a language. During a text compression the letters have to be translated into binary digits 0 or 1. Then the entropy represents the average number of binary digits required per letter to encode each letter in the most efficient way. Shannon’s 1951 paper [
2] is based on an experiment by which he randomly chooses 100 passages, each of 15 characters, from the book
Jefferson the Virginian and uses for his calculation a human prediction approach, ignoring punctuation, lower case and upper case letters. Under these conditions, Shannon obtained that the entropy of English language is bounded between 0.6 and 1.3 bits per letter over 100-letter long sequences of English text. Since Shannon’s paper publication, many experiments have been carried out to improve the accuracy of the entropy of English texts.
However, finding a precise value of the language entropy is a difficult problem due to its statistical nature and the length of the text that needs to be involved in the computation. Even if the entropy of English has been researched for more than 6 decades by a variety of approaches, including both direct and indirect methods, an agreement on the final exact entropy value of English has not yet been reached as different authors reporting slightly distinct values. Among the trials of finding a better estimation we recall the work of Cover and King [
3], which used gambling estimates and reported a value between 1.25 and 1.35 bits per character. Using a method based on data compression, Teahan and Cleary [
4] reported an entropy of 1.46 bits per character, while Kontoyiannis [
5] found a value of 1.77 bits per character employing a method using string matching. More recently, Guerrero [
6] provided an approach for estimating entropy using direct computer calculations based on 21 literary works. According to Moradi et al. [
7], the measurements of the entropy of English texts depend on the subject of the experiment, the type of English text, and the methodology used to estimate the entropy.
Several other papers provide important theoretical material relating to Shannon’s paper. For instance, Maixner [
8] helps with the clarification of the details behind the derivation of Shannon’s lower bound to the Nth-order entropy approximations. On the other side, Savchuk [
9] provides necessary and sufficient conditions on the source distribution for Shannon’s bound to hold with equality. Limitations of entropy estimations can be found in papers of Nemetz [
10], Basharin [
11], Blyth [
12] and Pfaffelhuber [
13].
Some other papers deal with Shannon’s empirical results on English texts. Thus, Grignetti [
14] recalculates Shannon’s estimate of the average entropy of words in English text. Comments on contextual constraints in language can be found in Treisman [
15], while White [
16] uses a dictionary encoding technique to achieve compression for printed English. The effects of meaningful patterns in English texts on the entropy calculations is treated in Miller [
17].
Entropy of other languages are discussed in Jamison [
18] and Wanas [
19]. The entropy of written Spanish is treated in Guerrero [
20]. Statistical calculation of word entropies for four western languages can be found in Barnard [
21]. A simple and accessible reference on information theory is the book of Cover [
22].
The first part of this paper continues the previous ideas, presenting some familiar statistical tools based on the usage of letter frequency analysis. The underlying idea is that each language has its own letter distribution frequency, which can be characterized by certain statistical measures. For instance, in English, from the most frequent to least frequent, letters are ordered as
etaoin shrdlu cmfwyp vbgkjq xz, while in French they are ordered as
elaoin sdrétu cmfhyp vbgwqj xz. Even within the same language, writers write slightly differently, adapting the language to their own style. The statistical tools used in this paper and calculated for specific authors are inspired from Shannon’s work: entropy, informational energy, bigram, trigram,
N-gram, and cross-entropy. These statistics have been used to prove or disprove authorship of certain texts or to validate the language of a text. These tools can also be used in the construction of a plagiarism detection software. We apply these tools to several Romanian and English poetry. We note that Shakespeare and other English Renaissance authors as characterized by information theory are treated in Rosso [
23].
These tools have been useful, as each statistic measures a specific informational feature of the text. However, when it comes to the problem of generating a new text that shares the statistic similarities of a given author, we need to employ recent developments of machine learning techniques. This task can be accomplish by the most recent state-of-the-art advances in character-level language modeling and is presented in the second part of the paper.
However, this idea is not new. There have been several trials in the direction of word prediction. Traditionally, prediction systems have used word frequency lists to complete words already started by the user. Statistical relations between word sequences have been exploited to improve predictive accuracy; see Lesher [
24].
Building on Shannon’s experiment using an AI system has been approached for the first time by Moradi et al. [
7]. The authors explored and experimented using a LERS learning system, which was explained in detail by Grzymala-Busse [
25]. This system uses the rough set theory that is explained in Pawlak [
26,
27]. The LERS system can be trained by the use of some examples, to make educated guesses on the next letter in a given sequence of letters.
Continuing the idea, in this paper we use recurrent neural networks (RNNs) to generate Byron-type poetry and then to asses their informational deviation from a genuine Byron text. When this difference of similarity becomes small enough, the network training stops and we obtain a generator for Byron poetry. It is worth noting that a similar neural architecture can be employed to generate poetry similar to other authors. All our data and code files are shared using the author’s GitHub at
https://github.com/ocalin911/SCI_paper.
The main AI architecture used—RNN—has been successfully used to generate sequences in domains as music (Boulanger-Lewandowski et al. [
28] and Eck [
29]), or text and motion capture data (Sutskever [
30,
31]). RNNs can be trained for sequence generation by iteratively sampling from the network’s output distribution and then feeding back the sample as input at the next step.
This paper brings a few novel ideas to the field.
Section 2.6 provides a theoretical formula for the language entropy, while
Section 2.7 discusses the conveyed information of a group of consecutive letters about the next letter.
Section 2.8 introduces the concept of
N-gram informational energy and
Section 2.9 provides a way of measuring the distance between two texts. Generating Byron-type poetry is also novel in the sense that RNNs have not been used to generate poetry in the style of Byron.
2. Material and Methods
2.1. Letter Frequency
Letter frequency analysis was the first statistical approach to languages. The relative frequency of letters in a text can be transformed into a probability distribution dividing each frequency by the length of the text. When the text is long enough, the Law of Large Numbers assures the convergence of empirical probabilities to theoretical probabilities of each letter.
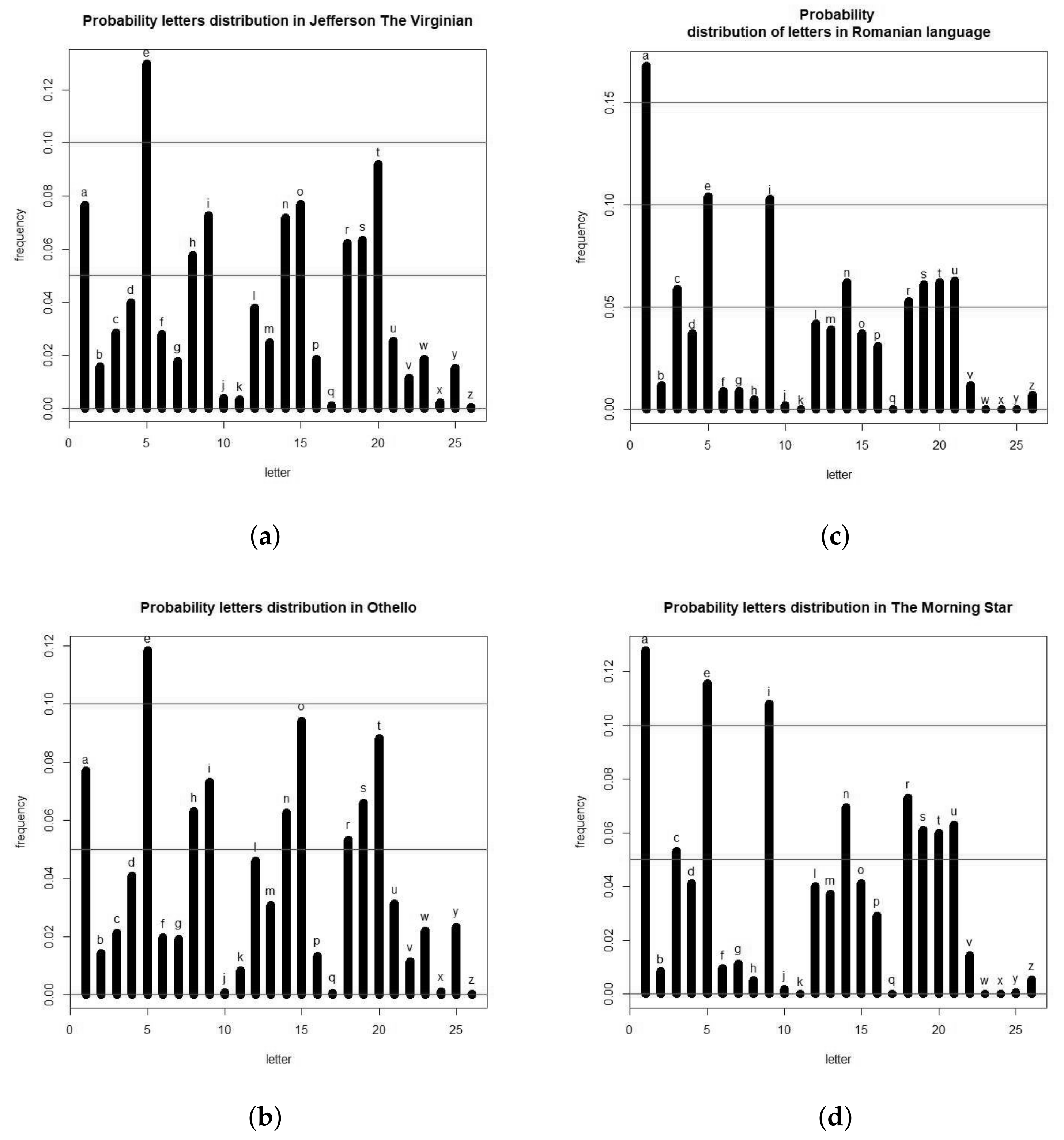
A few letter probability distributions are represented in
Figure 1. Parts a and b correspond to English texts,
Jefferson the Virginian by Dumas Malone and
Othello by Shakespeare, respectively. We notice a high frequency of letter “e” followed by “t”, “a” and “o”. In old English (
Othello) we notice a higher frequency of “o” over “t”.
Figure 1c,d correspond to Romanian texts,
Memories of Childhood by Ion Creang
and
The Morning Star, by Mihai Eminescu, respectively. We notice a high frequency of letter “a” followed by “e”, “i”, “n” or “r”. A bare eye-view inspection of letter probability histograms like the ones in
Figure 1 is not very efficient, since besides magnitudes of letter frequency, we cannot infer too much. This is why we need to employ some statistics which characterize these distributions from different perspectives. We shall present a few of these statistics in the next sections. The interested reader can find the ‘R’ code for the frequency plots online at the author’s Github:
https://github.com/ocalin911/SCI_paper/blob/master/Frequency.R.
2.2. Informational Entropy
The first interesting applications of statistics to poetry had been mainly based on concepts of information theory, such as entropy and informational energy. This way, poetry was treated from the point of view of statistical mechanics. From this point of view, each letter of the alphabet present in a given text was assimilated with a random variable having a certain probability of occurrence.
These probabilities can be approximated empirically by the associated frequencies measured from the text; see
Figure 1. According to the Law of Large Numbers, the quotient between the number of occurrences of a letter and the text length tends to the theoretical probability of the letter. Thus, the poem can be modeled by a finite random variable
X, which takes letter values
and is described by the probability distribution in
Table 1.
This distribution probability table provides the letter frequency structure of the text. Now, each letter is supposed to contribute the text with some “information”, which is given by the negative log-likelihood function; for instance, the letter “a” contains an information equal to
. The minus sign was considered for positivity reasons, while the logarithm function was chosen for its properties (the information contained by two letters is the sum of their individual information, namely,
). A weighted average of these letter information is given by the expression of
informational entropyThe statistical measure
H represents the amount of information produced, on average, for each letter of a text. It is measured in bits. We recall that one bit is the measure describing the information contained in a choice between two equally likely choices. Consequently, the information contained in
equally likely choices is equal to
N bits. It is worth noting that the previous entropy expression mimics the formula introduced in information theory by Shannon in his 1948 paper. It is worth noting that there is another notion of entropy that comes from Thermodynamics, which was established by Boltzmann( see p. 57 of [
32]) but we do not consider any applications of it in this paper.
Another interpretation of entropy is the following. Assume that during a text compression each letter is binary encoded as a sequence that consists of 0 s and 1 s. Then, the entropy is the average number of binary digits needed to represent each letter in the most efficient way. Given that the entropy of English is about 4 bits per letter and the ASCII code (Abbreviation from American Standard Code for Information Interchange, which is a character encoding standard for electronic communication) translates each letter into eight binary digits, it follows that this representation is not very efficient.
The value of the entropy H was related in poetry with the state of organization of the poem, such as rhythm or poem structure. For instance, a poem with a short verse has a smaller entropy, while a poem written in white verse (no rhythm) tends to have a larger entropy. Consequently, a poem has a smaller entropy than a regular plain text, due to its structure. The amount of constraint imposed on a text due to its structure regularity is called redundancy. Consequently, poetry has more redundancy than plain text. Entropy and redundancy depend also on the language used, being complimentary to each other, in the sense that the more redundant a text is, the smaller its entropy. For instance, a laconic text has reduced redundancy, since the omission of any word can cause non-recoverable loss of information.
The maximum of entropy is reached in the case when the random variable X is equally distributed, i.e., in the case when the text contains each letter an equal number of times, namely when each letter frequency is . The maximum entropy value is given in this case by bits per letter.
However, this maximum is far to be reached by any language, due to its own peculiarities such as preference towards using certain words more often, or bias towards using certain language structures. For instance, in English, there is a high frequency of letter “e” and a strong tendency of letter “t” to be followed by letter “h”. Further, “q” is always followed by a letter “u”, and so on.
It has been noticed that each poet has their own specific entropy range due to the usage of favorite words or a specific poem structure preferred by the poet. It has also been conjectured that it should be able to recognize the author of a text just from the text entropy alone. After the examination of several examples we are now certain that it is easier to recognize the poetry language rather than the poet itself.
Our experiments have shown that the entropy range for the English language is between 4.1 and 4.2 bits per letter. Other languages have a different range. For instance, the Romanian language has a range between 3.7 and 3.9 bits per letter. The fact that English has more entropy is due to the fact that the probability distribution of letters in English is more evenly distributed than in Romanian, fact that can be also seen from
Figure 1 after a careful look.
In the following, an entropy table is provided containing a few characteristic English writings; see
Table 2.
It is worth noting that Byron’s first poetry volume and Byron’s second volume (containing letters and journals) have the same entropy, 4.184 bits, which shows consistency across the works of this writer. We also note that Shakespeare’s works (Macbeth, Romeo and Juliet, Othello, King Richard III) contain a larger variation of entropy than Byron’s, taking values in the range 4.1–4.2 bits. The entire text of Jefferson the Virginian has an entropy of 4.158 bits (quite close to the entropy of 4.14 bits found by Shannon considering just a part of this work). The English translation of the works of the German philosopher Nietzsche (1844–1900) has an entropy of 4.147 bits. The lowest entropy occurs for the Bible chapter on Genesis, 4.105 bits, a fact explained by a strong tendency in repetition of certain specific biblical words.
For the sake of comparison, we shall provide next an entropy table containing a few Romanian authors; see
Table 3.
We have considered Eminescu’s famous poem, The Morning Star (Luceafarul), Ispirescu’s fairy tales and Crang’s Memories of Childhood (Amintiri din Copilrie). It is worth noting that all these writings have entropies that agree up to two decimals −3.87 bits. We infer that the entropy of Romanian language is definitely smaller than the entropy of English. One plausible explanation is the rare frequency of some letters in Romanian language, such as “q”, “w”, “x”, and “y”, comparative to English.
However, there are also some major limitations of entropy as an assessing information tool. First of all, the entropy does not take into account the order of letters. This means that if we scramble the letters of a nice poem into some rubbish text, we still have the same entropy value. Other questions have raised, such as whether the random variable X should include in its values blank spaces and punctation signs, fact that would definitely increase the information entropy value.
Even if entropy is a robust tool of assessing poems from the point of view of the information content, it does not suffice for all purposes, and hence it was necessary to consider more statistical measures for assessing the information of a text.
It is worth to mention that the entropy depends on the number of letters in the alphabet. If N denotes the number of letters in the alphabet, the maximum entropy of any text cannot exceed . Consequently, languages like Chinese or Japanese will have texts with a very high entropy. In this paper our concern is about texts in English (with 26 letters) and Romanian (with 31 letters, consisting of 26 letters of the Latin alphabet, plus 5 special characters obtained by applying diacritics).
2.3. Informational Energy
If information entropy was inspired from thermodynamics, then
informational energy is a concept inspired from the kinetic energy of gases. This concept was also used to asses poetry features related to poetic uncertainty as introduced and used for the first time by Onicescu in a series of works [
33,
34,
35] in the mid-1960s. Its definition resembles the definition of the kinetic energy as in the following
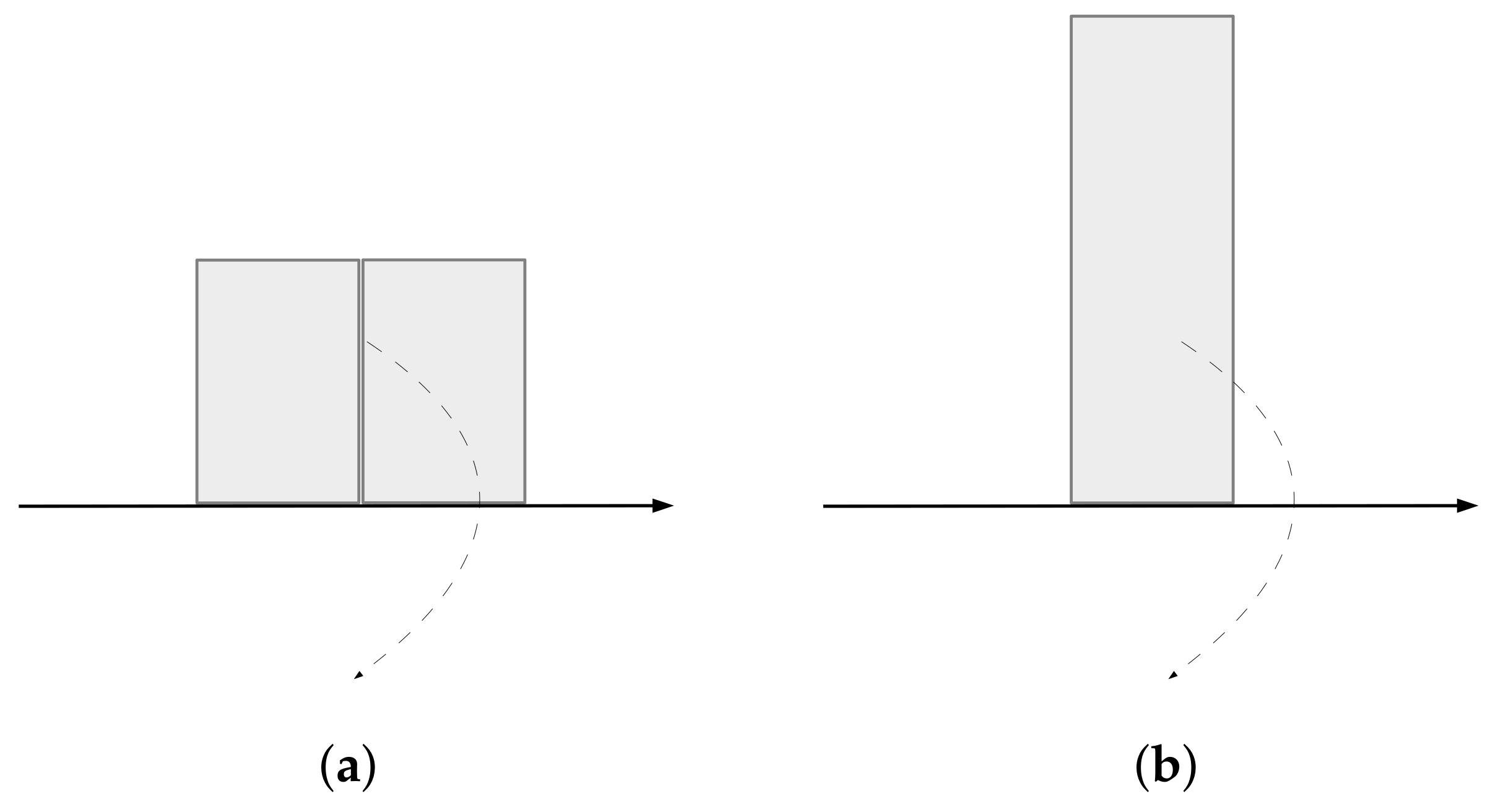
This statistical measure is also an analog of the moment of inertia from solid mechanics. For the definition and properties of the moment of inertia, the reader is referred to the book [
36]. This measures the capacity of rotation of the letters probability distribution
about the
x-axis. Heuristically, the uniform distribution will have the lowest informational energy, as it has the lowest easiness of rotation about the
x-axis; see
Figure 2.
This fact can be shown using Lagrange multipliers as follows. Let
denote the probability of each letter. We look for the letter distribution that minimizes
subject to constraints
and
. The associated Lagrangian is
Solving the Lagrange equations , we obtain , which is a uniform distribution. Since , is a positive definite matrix, this solution corresponds to a global minimum.
Therefore, a short verse and a regular rhythm in poetry tend to increase the informational energy. On the other side, using a free verse tends to decrease the value of
I. In addition to this, it has been noticed that entropy and informational energy have inverse variations, in the sense that any poem with a large informational energy tends to have a smaller entropy; see Marcus [
37]. We note that the entropy attains its maximum for the uniform distribution, while the informational energy reaches its minimum for the same distribution.
To get an idea about the magnitude and variation of the informational energy for the English language we provide
Table 4.
For the sake of comparison with Romanian language we include
Table 5:
We note that English language has a smaller informational energy than Romanian, the range for the former being 0.031–0.032, while for the latter, 0.036–0.042.
It is worth noting that most entropy limitations encountered before carry also over to the informational energy.
The fact that a fine poem and a rubbish text can exist with the same entropy and informational energy (we can transform one into the other by just making some permutations of the letters in the poem) shows the drastic limitation of the usage of these two information tools. The main limitation consists of using probability of individual letters, which completely neglects the meaning casted in the words of the poem. In order to fix this problem, one should consider the random variable X to take values in a dictionary rather than in an alphabet. This way, the variable X, which is still finite, has thousands of outcomes rather that just 26. For instance, if in a poem, the word “luck” is used five times and the poem has 200 words, then we compute the probability . Doing this for all words, we can compute an informational entropy and informational energy at the words level, which makes more sense than at the letters level. It has been noticed that the words with the highest frequency in English are “the”, “of”, “end”, “I”, “or”, “say”, etc. Their empirical probabilities are , , etc.
Consider two poems, denoted by A and B. Consequently, if poem A uses each word equally often (which confers that the poem uses a specific joyful structure) and poem B uses each word only once (which means the that poem uses a richer vocabulary), then poem A will have the largest possible entropy and poem B will have the lowest. This fact is based on the fact that the equiprobable distribution reaches the highest entropy.
Unfortunately, even this approach of defining a hierarchical entropy at the level of words is flawed. If we consider two poems, the original one and then the same poem obtained by writing the words in reversed order, then both poems would have the same entropy and informational energy, even if the poetic sense is completely lost in the latter poem. This is because the order of words matters in conferring a specific meaning. The poetical sense is destroyed by changing the words order. This can be explained by considering each word as a cohesive group of letters with strong statistical inferences with nearby groups of letters. We present in the following a fix using stochastic processes.
The applications of informational energy in social sciences and other systems can be found in [
38,
39,
40]. Applications of informational energy in physics and chemistry are contained in [
41,
42,
43], while applications to statistics and probability can be found in [
44,
45].
2.4. Marcov Processes
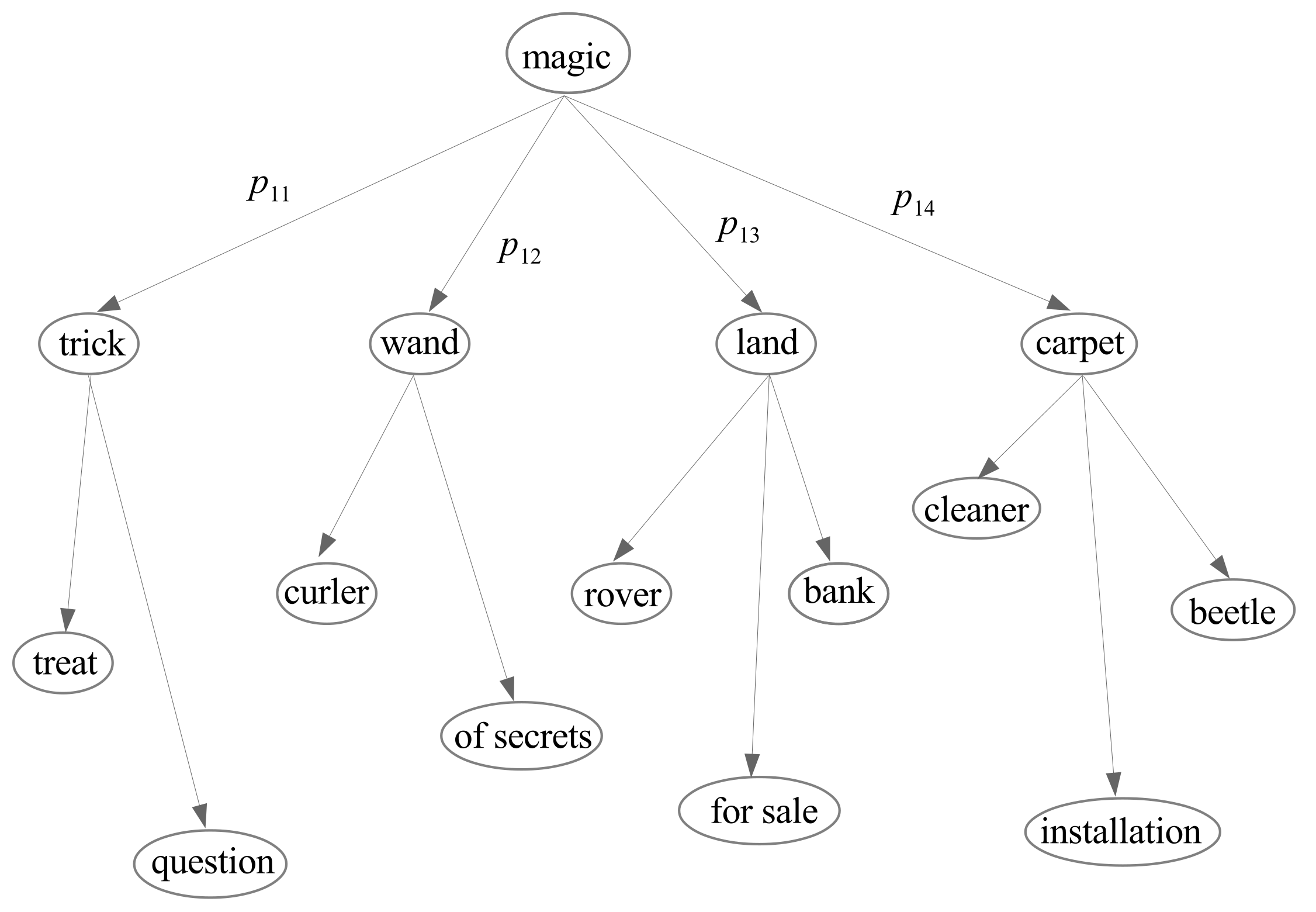
A mathematical model implementing the temporal structure of the poem is needed. The order of words can be modeled by a Markov process, by which each word is related with other words in the dictionary using a directional tree. Each node in this tree is associated with a word and each edge is assigned a transition probability describing the chance of going from one word to another.
The “Markovian” feature refers to the fact that the process does not have any memory; it just triggers the next word, given one word, with a certain probability. For example, the word “magic” can be followed by any of the words “trick”, “wand”, “land”, or “carpet”. In a poem, using the phrase “magic trick” might not be very poetical, but using “magic wand” or “magic land” seems to be better.
From this point of view, writing a poem means to navigate through a directional tree whose nodes are words in a given vocabulary of a certain language; see
Figure 3. Taking products of transition probabilities of edges joining consecutive words in the poem we obtain the total probability of the poem as a sequence of random variables (words) extracted from the dictionary. This approach involves a temporal structure between words, which marks its superiority from the aforementioned approaches. If one would have access to this directional tree and its probabilities then they would be able to generate new poems, statistically similar with the ones used to construct the tree.
This method in its current form is also limited. One reason is because the process does not have any memory. For instance, if a poem talks about “Odysseus” from the Greek mythology, then words such as ”legendary”, “hero”, and “ingenious” will have a larger probability to appear later in the poem, even if they are not directly following the word “Odysseus”.
It is worth noting that these Markov processes are based on words, not letters. So the size of the transition matrix is a lot larger than
. The size is actually
, where N is the number of words in the dictionary. This section is included just to make a theoretical transition to the RNN section. No simulations have been done by the author using this model, as it is quite large and hard to manage. The interested reader can find details about the definition, properties and applications of Markov processes in [
46] or [
47].
A superior method, which is not Markovian, will be described in the second part of the paper and regards the use of neural networks in poetry.
2.5. N-Gram Entropy
In his 1951 paper, Shannon studied the predictability of the English language introducing the concept of the
N-gram entropy. This is a sequence of conditional entropies,
, given by
where
is a block of
letters,
j is an actual letter,
is the probability of occurrence of the
N-letter block
,
is the probability of the block
and
is the conditional probability of letter
j to follow the block
, which is given by
.
can be considered as the conditional entropy of the next letter j when the preceding letters are given. Therefore, measures the entropy due to statistics extending over N adjacent letters of the text. This approach is useful when one tries to answer the following question: Given letters of a text, which letter is most likely to appear next in the text?
The
N-gram entropies,
, are considered as an approximating sequence of another object, a long-range statistic, called the
language entropy, defined by
and measured in bits (per letter). Computing the language entropy of a given poetry author is a complex computational problem. However, the first few
N-gram entropies can be computed relative easily and were found by Shannon.
First, regardless of the author,
(bits per letter), given that the language is English (with an alphabet of 26 letters). The 1-gram involves the entropy associated with letter frequency
for English language. For any poetry author, their
entropy should be smaller than 4.14 (bits per letter) due to the style structure constraints. It is worth noting that
, where
H is the aforementioned informational entropy. The interpretation of
is the number of random guesses one would take on average to rich the correct next letter in a text, without having any knowledge about previous letters.
The digram
measures the entropy over pairs of two consecutive letters as
can be interpreted as the number of random guesses one would take on average to enrich the correct next letter in a text, knowing the previous letter.
The trigram
can be also be computed as
Similarly, can be interpreted as the number of random guesses one would take on average to rich the correct next letter in a text, knowing the previous two letters.
2.6. Language Entropy
In the following, we shall provide an approximative formula for computing the language entropy given by Equation (
6). If
B is a letter block of length
N we shall use notation
to denote the length of the block
B. We define the entropies sequence
This sum is taken over
terms, most of which being equal to zero (when the block
B does not appear in the text, the term
is 0). For instance,
and
. Now,
can be written recursively in terms of
and
as
Iterating, we obtain
,
,
, ⋯,
. Then adding and performing all cancellations, yields
If the sequence
is convergent to the language entropy
, as
, then a well known property states that the sequence of arithmetic averages also converges to the same limit,
This leads to the following formula for the language entropy
In other words, tends to increase linearly with respect to N, and the long run proportionality factor is the language entropy.
We note that Equation (
6) is the definition formula for the language entropy
H, while the formula (
17) is obtained by direct computation in terms of
.
2.7. Conveyed Information
Shannon’s work is mainly concerned with the predictability of the English language. One way to continue this idea is to ask the following question:
How much information is conveyed by a block of letters about the next letter in the text? This is related to the previous question of finding the conditional probability of the next letter given a previous letter block. For this we recall the following notion of information theory, which can be found in more detail in [
48].
Let X and Y be two random variables. The information conveyed about X by Y is defined by , where is the entropy of random variable X and is the conditional entropy of X given Y. In our case X represents the random variable taking values in the alphabet , while Y is the random variable taking -letter blocks values; each of these blocks can be considered as a function .
The information conveyed by an
-letter group about the next letter in the text will be denoted by
and is given by
Similarly, we can define the information conveyed by a
-letter group about the next 2-letter group in the text by
This leads inductively to the formula of the information conveyed by an
M-letter group about the next
k-letter group in a text as
We have the following information inequalities:
Proposition 1. For any integers we have: Proof. (i) Since the conveyed information is non-negative, , then , fact that implies the first inequality.
(ii) The previous inequality can be written telescopically as
which after cancelling similar terms leads to the desired inequality. □
It is worth noting that for
, the second inequality becomes
, for any
, which implies
, for all
. This shows that the entropy associated with letter frequency,
, is the largest among all
N-gram entropies. This fact can be also noticed from the numerical values presented in
Section 2.5.
Another remark is that inequalities of Proposition 1 are strict as long as the text bears some meaningful information. This follows from the fact that if and only if X and Y are independent random variables.
2.8. N-Gram Informational Energy
Inspired by the work of Shannon and Onicescu [
33], we introduce next the concept of
N-gram informational energy, which is a statistic defined by
where
is a letter block of length
N and
is the probability that the block
B appears in the text. We note that
is the letter informational energy introduced before. Inspired by formula (
17), we define the
language informational energy by
The existence of this limit constitutes a future direction of research and will not be approached in this paper.
2.9. Comparison of Two Texts
In this section, we shall introduce a method of comparing two texts, by evaluating the information proximity of one text with respect to the other. We shall first consider a benchmark text in plain English with letter distribution p. This text will provide the distribution of letters in English.
The second text can be a poetry text, also in English, with letter distribution
q. We shall compare the texts by computing the Kullback–Leibler relative entropy,
. This measures a certain proximity between distributions
p and
q as in the following sense. If the benchmark text is considered efficient in expressing some idea, using poetry to express the same idea can be less efficient; thus, the expression
measures the inefficiency of expressing an idea using poetry rather than using plain English. From the technical point of view, the Kullback–Leibler relative entropy is given by the formula
The text with letter distribution
q will be called the
test text, while the one with distribution
p, the
benchmark text. We shall consider the benchmark text to be the entire text of the book
Jefferson the Virginian by Dumas Malone, as Shannon himself considered it initially, while investigating the prediction of English language in 1951. The first test text is the first volume of Byron poetry. A simulation in ’R’ provides the relative entropy value
The next test text is taken to be
Othello by Shakespeare, in which case
This shows a larger measure of inefficiency when trying to express Dumas’s ideas using Shakespearian language rather than using Byron-type language. This can be explained by the fact that Byron used a variant of English closer to Dumas’ language rather than Shakespeare. Consequently, the language used in Othello is farther from English than the one used in Byron’s poetry.
Considering further the test text as the
Genesis chapter, we obtain
This value, larger than the previous two, can be explained by the even older version of English used by the Bible.
These comparisons are based solely on the single letter distribution. It is interesting to consider a future direction of research, which compares two texts using a more complex relative entropy defined by
which is a Kullback–Leibler relative entropy considering
N-letter blocks rather than single letters. We obviously have
.
One question is whether the quotient approaches a certain value for N large. In this case, the value of the limit would be the languages relative entropy.
Another variant of comparing two texts is to compute the cross-entropy of one with respect to the other. The cross-entropy formula is given by
Since an algebraic computation provides
then the cross-entropy between two texts is obtained by adding the entropy of the benchmark text to the Kullback–Leibler relative entropy of the texts. Since
, then
. Given the distribution
p, the minimum of the cross-entropy
is realized for
, and in this case
.
The idea of comparing two texts using the relative or cross-entropy will be used to measure the information deviation of RNN-generated poems from genuine Byron poetry.
2.10. Neural Networks in Poetry
The comprehension of hidden probabilistic structures built among the words of a poem and their relation with the poetical meaning is a complex problem for the human mind and cannot be caught into a simple statistic or mathematical model. This difficulty comes from the fact that each poet has their own specific style features, while using an enormous knowledge and control over the statistics of the language they write in. Therefore, we need a system that could be able to learn abstract hierarchical representations of the poetical connotations represented by words and phrases.
Given the complexity of this task, one approach is to employ machine learning. This means to look for computer implemented techniques that are able to capture statistical regularities in a written text. After learning the author’s specific writing patterns, the machine should be able to adapt to the author’s style and generate new texts, which are statistically equivalent with the ones the machine was trained on.
2.10.1. RNNs
It turned out recently that one way to successfully approach this complex problem is to employ a specific type of machine learning, called Recurrent Neural Network (RNN), which dates back to 1986 and is based on David Rumelhart’s work [
49]. This belongs to a class of artificial neural networks where connections between nodes form a directed graph along a temporal sequence, similar to the directional tree previously mentioned in
Section 2.4.
The main feature of these networks is allowing the network to exhibit temporal dynamic behavior. The network input and output vectors at time
t are denoted respectively by
and
, while
represents the hidden state at time
t. In its simplest case, the transition equations of an RNN take the following form
See
Figure 4. Thus, the hidden states take values between
and 1, while the output is an affine function of the current hidden state. Matrices
W and
U represent the hidden-to-hidden state transition and input-to-hidden state transition, respectively.
b and
c denote bias vectors. During training the network parameters
adjust such that the output sequence
gets as close as possible to the sequence of target vectors,
. This tuning process, by which a cost function, such as
is minimized, is called
learning. This idea is the basis of many revolutionizing technologies, such as: machine translation, text-to-speech synthesis, speech recognition, automatic image captioning, etc. For instance, in machine translation from English to French,
represent a sentence in English, and
represent the French translation sentence. The statistical relationships between English and French languages is stored in the hidden states and parameters of the network, which are tuned in such a way that the translation is as good as possible.
Each network bares a certain capacity, which can be interpreted as the network ability to fit a large variety of target functions. This depends on the number of its parameters. If the network contains just a few units, the number of parameters is small and its capacity is low. Consequently, the network will underfit the data; for instance, considering the case of the previous example, the network cannot translate complex sentences. For this reason, the capacity has to be enhanced. There are two ways to do that: (i) by increasing the number of hidden units (horizontal expansion) and (ii) considering several layers of hidden states (deep neural network).
When increasing the network capacity two difficulties can occur: the vanishing gradient problem and the exploding gradient problem. The first problem can be addressed by considering special hidden units such as LSTM cells, which were introduced in 1997 by Hochreiter and Schmidhuber [
50]. We will not get into the details here, but the reader is referred to consult [
48].
In the rest of the paper we shall use an RNN consisting of a single-layer of LSTM cells to learn statistical features of Byron’s poems and then use these parameters to generate new Byron-type poems. The way we shall generate new poems is to input a certain “seed” phrase and use the trained network to generate the prediction of the next 400 characters which would follow the provided seed. We shall obtain a sequence of “poems”, as training progresses, of increasing quality. We shall then asses their informational deviation from a genuine Byron text, using the statistical measures introduced in the first part of the paper. When this difference of the similarity is small enough we shall stop training.
The next sections take the reader through all the steps necessary for the aforementioned goal. These include data collection, data processing and cleaning, choosing the neural model, training, and conclusions.
2.10.2. Data Collection
Any machine learning model is based on learning from data. Therefore, the first step is to collect data, as much and as qualitative as possible. Regarding our project, I found Byron’s works online under Project Gutenberg at
www.gutenberg.org. Since the website states “this eBook is for the use of anyone anywhere at no cost and with almost no restrictions whatsoever”, it is clear we are allowed to use it. Lord Byron’s work counts seven volumes. All contain poetry, but the second volume, which deals with letters and journals. Among all these files, we shall use for training only volume I of poetry, which can be found at
http://www.gutenberg.org/ebooks/8861.
The reason for which we had restricted our study to only one volume is the limited processing power available, as the training was done on a regular PC-laptop.
2.10.3. Data Processing and Clean-up
The quality of data is an important ingredient in the data preparation step, since if data are not well cleaned, regardless of the neural architecture complexity used, the results will not be qualitatively good.
In our case, almost all poems contain lots of footnotes and other explanatory notes, which are written in plain English by the publisher. Therefore, our next task was to remove these notes, including all forewords or comments from the publisher, keeping only the pure Byron’s work. This might take a while, as it is done semi-manually. The reader can find the cleaned-up text file at
https://github.com/ocalin911/SCI_paper/blob/master/book1.txt.
2.10.4. Choosing the Model
The neural network model employed in the analysis of Byron’s poetry is presented in
Figure 5. It consists of an RNN with 70 LSTM cells (with hidden states
,
), on the top of which is added a dense layer with 50 cells. We chose only one layer in the RNN because if considering a multiple layer RNN the number of network parameters increases, which might lead eventually to an overfit of data, which is restricted at this time to only one volume of poetry. The output of the network uses a softmax activation function, which provides a distribution of probability of the next predicted character. The input is done through 70 input variables,
. If the poetry text is written as a sequence of characters (not necessary only letters) as
then the text was parsed into chunks of 70 characters and fed into the network as follows. The first input values are the first 70 characters in the text as
The next input sequence is obtained by shifting to the right by a step of 3 characters as
The third input sequence is obtained after a new shift as
Since the text length is
characters, then the number of input sequences is 124,765. It also turns out that the number of characters in Byron’s poems is 63. This includes, besides 26 letters and 10 usual digits, other characters such as coma, period, colon, semicolon, quotation marks, question marks, accents, etc.; see
Figure 6. Therefore, the network output will be 63-dimensional.
The activation function in the dense layer is a ReLU function (which is preferable to sigmoid activation function as it usually provides better accuracy). The learning is using the Adam minimization algorithm—an adaptive momentum algorithm, which is a variation of the gradient descent method, with adjustable learning rate. Training occurs using batches of size 80 at a time and it trains for 150 epochs. Training takes roughly 3 min per epoch, taking about 7 h for all 150 epochs.
Since this is a multi-class classification problem (with 63 classes), the loss function is taken to be the categorical cross-entropy. Each class corresponds to a character given in
Figure 6.
If
q denotes the probability density of the next character forecasted by the network and
p is the probability density of the true character in the text, then during training the network minimizes the cross-entropy
Therefore, learning tries to minimize the average number of bits needed to identify a character correctly using the probability distribution q, rather than the true distribution p. Since the text contains poetry from only the first volume, in order to avoid overfitting, a dropout of has been introduced after both the LSTM and the dense layers.
3. Results and Discussion
During training, we had monitored the loss function expressed by the cross-entropy, which decreases steadily from 3.5 to 1.37 over 150 epochs; see
Figure 7. This decrease in loss is a sign of good learning. We have tried different hyperparameters (batch size, learning rate, number of epochs, step, parsing length, number of LSTM cells) and arrived to the ones used in this paper as being pretty close to optimal. The generated text seems to resemble more and more the genuine Byron poetry as the training process progresses and the loss decreases. Theoretically, if the cross-entropy loss is zero,
, then
, namely the generated text has the same letter distribution as the genuine Byron text.
In the beginning, after the first epoch, the generated text looks more like a random sequence of groups of letters. There are neither English words nor poetry structure present after the beginning seed phrase:
- what! not a word!–and am i the the cisseth pantses susthe the the lof lelen ban depilers in the shele whe whas the as hof bathe the with lens on bo sint the wor thire ched the the the ghordes ang the aned fors and rore dis the the the sors,
The loss after the first epoch is 2.605. The entropy of the generated text is .
After the second epoch the loss decreased to 2.187 and the text entropy increased to . The network already learnt some verse structure, even if most words are still not in English:
- Wake a wildly thrilling measure.
- There will my gentle girl and i,
- The bare pus the soun mare shes and the stist,
- And the and will sost an fing sote no on ass som yian,
- A whis for atile and or souns and pey a porin dave sis bund and are.
- Tha thaigh cill list the the beraich be for withe hond,
- Far om dill and butting of wole,
- O sould af mare hor wore sour;
- To will the ast dore he ares ereis s soar?
After epoch 26 the cross-entropy loss had a substantial decrease to 1.62, while the entropy is . In this case the generated text looks a lot more like English:
- No just applause her honoured name
- Of idiots that infest her age;
- No just applause her honoured name of strain,
- And still the last his breathed lings his press,
- Thou not his art of heart to loves of may,
- The spare that mays the ding the rain,
- Which cares the shep her loves of prose;
- Then heart the such the gleam the live decear;
- This still the gard, our thee in parter’s fiest
- The love through may the word,
- When bay and mights of some the song the new
- The sits again, and sing…
After 30 epochs, the loss is 1.59, while the entropy is (getting closer to Byron’s genuine poetry entropy of 4.184); the outcome has an improved English:
- Outhful eclogues of our pope?
- Yet his and philips’ faults, of differs still;
- To hours, where still the promenty glow.
- The dearts and the tome to dark,
- And to the child and fears of the and the farre;
- Though her decerance more thy poes’s to dark,
- And path of a still howard of day!
- Your conful in so later her stord,
- And praise of the dear the day,
- In proded the former frem this such,
- In the soul in sumery vain,
- And so and the Lamble…
In the following, we shall provide the epoch number, loss value and entropy and the generated texts for a few more samples. We note the decrease in loss and increase in entropy values:
Epoch 43, loss 1.54, entropy :
- The hall of my fathers, art gone to decay;
- In thy once smiling garms and stranger striating and and his die;
- The bounding poud the spreise of fall the live,
- The classic poed to the dear of dray–
- To must the dear a strong the combon the forth
- The great by the dear with this the breathing, well,
- In all the percid the thanding showe;
- When prate the that a some his will the say;
- Thou the eyes of the bard, and thought the sungod a fill;
Epoch 56, loss 1.4691, entropy :
- A transport of young indignation,
- With fervent contempt evermore to disdain you:
- I seembrate to the sought for the faint shill
- The gark her sweets thou greated of the sain,
- A dele the praise the seem and merben meet,
- I change eye may of thy spirit lead,
- No verse thy fain as gale the sight.
- 5.
- Then, the more the durming fort confine!
- The pallage in once the piling fain,
- And not stranger the saint despise me to fair,
- The lovering deep and the prines of critic…
Epoch 75, loss 1.4370, :
- Few short years will shower
- The gift of riches, and the pride of power;
- E’en now a name the seems who the prophears to fear,
- And stripling band the heart they discounts all the trays!
- One back with must a seem shill the pands,
- The love and the forger disgreand ford;
- And fur the versance the lead at lade;
- Who bard my path, and bounce love alone;
- The daughter land admartuner sweet the speak, while,
- May speak and the some fain the gold my pease,…
Epoch 90, loss 1.4187, entropy :
- And so perhaps you’ll say of me,
- In which your readers may agree.
- Still I write on, and so mine thee;
- Yet with the heart of earmoness of and cartale.
- 1.
- What and a seem the only soul its me,
- Who balling all of the shall fordst these page bare:
- And the shall helf the partless deep for the cheep;
- What shine! though all some can must here the seif.
- The tells the palling, while the charms the plies;
- And for the sight! when they the heart the prine,
Epoch 113, loss 1.3955, entropy :
- Hope’s endeavour,
- Or friendship’s tears, pride rush’d between,
- And blotted out the mander great.
- Who fate, though for the right the still grew,
- To siek’st envesing in stream and tome,
- In parth will be my faster and dear,
- To gromend the dare, which lead the glord,
- The pence with the steel to the foem
- And the tarth, i change the rofty cound,
- This cale the ang repire the view,
- For the the saight we fore before,
- And the fall to the deastex flow,…
Epoch 138, loss 1.3847, entropy :
- Live me again a faithful few,
- In years and feelings still the same,
- And I will fly the hoother shine,
- And child the dast the tarth with
- The tone the fall thy stain’d or sweet,
- And then long the pang the nommer reat,
- When lut the well the sames like the stand,
- When wit the changuid our foight with still thee,
- What mingtred her song each senate,
- And brand the senty art steps record,
- The spring the first by poesion the faint,
- Some light the blest the rest to sig…
Epoch 146, loss 1.377, entropy :
- Would have woman from paradise driven;
- Instead of his houris, a flimsy pretence,
- While voice is and the buld they consuce,
- Which menting parragues, chilfoued the resure
- And to might with from the gold a boy,
- The seems my son to cartan’s plaintus for the
- The ear in the still be the praces,
- And life the disonge to shere a chance;
- The mowting pours, the sonite of the fore
- The pures of sain, and all her all,
- And the presert, conal all, or the steems,…
Epoch 148, loss 1.37, entropy :
- Lengthened line majestic swim,
- The last display the free unfettered limb!
- Those for him as here a gay and speet,
- Revile to prayial though thy soul and the such
- Roprowans his view where the happling hall:
- He feelin sense with the gloolish fair to the daw;
- The scane the pands unpressar of all the shakenome from.
As it can be inferred from all presented samples, even if the generated Byron poetry is satisfactory, it is not perfect. There are words made up by the network, such as “happling hall” or “unpressar”, which cannot be found in any English dictionary. However, for one who does not know the language well, they look quite English. The way the network invents this words is using the statistical relation between letters, without understanding their meaning. Therefore, a human is using words by their meaning, while a machine is using words by their statistical inference from letters distribution.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}