6.1. Effects of Clustering Algorithm Improvement on Case Bridge Components
6.1.1. Comparison of Clustering Distributions of All Components among UM, MC, and 3*DP Method
Figure 10 presents a comparative analysis of clustering distribution results obtained using the UM and MC methods as well as the dimensionless data derived from tripling the original monitoring data, referred to as three times the original dimensional data (3*DP).
The clustering results from both the UM and MC methods are categorized into three groups, numbered 1 to 3. In contrast, the 3*DP data, which represent the original monitoring data scaled by a factor of three, exhibit a broader range of categories, specifically from 0 to 3.
Among the ten measurement points on the arch rib section, points A1, A2, A4, A5, A6, A7, A8, and A9 show similar distribution patterns across the three clustering groups in their bar charts.
For the four measurement points on the truss girder section, the distribution patterns of the MC and 3*DP methods in the bar charts of the clustering results are consistently similar across all categories.
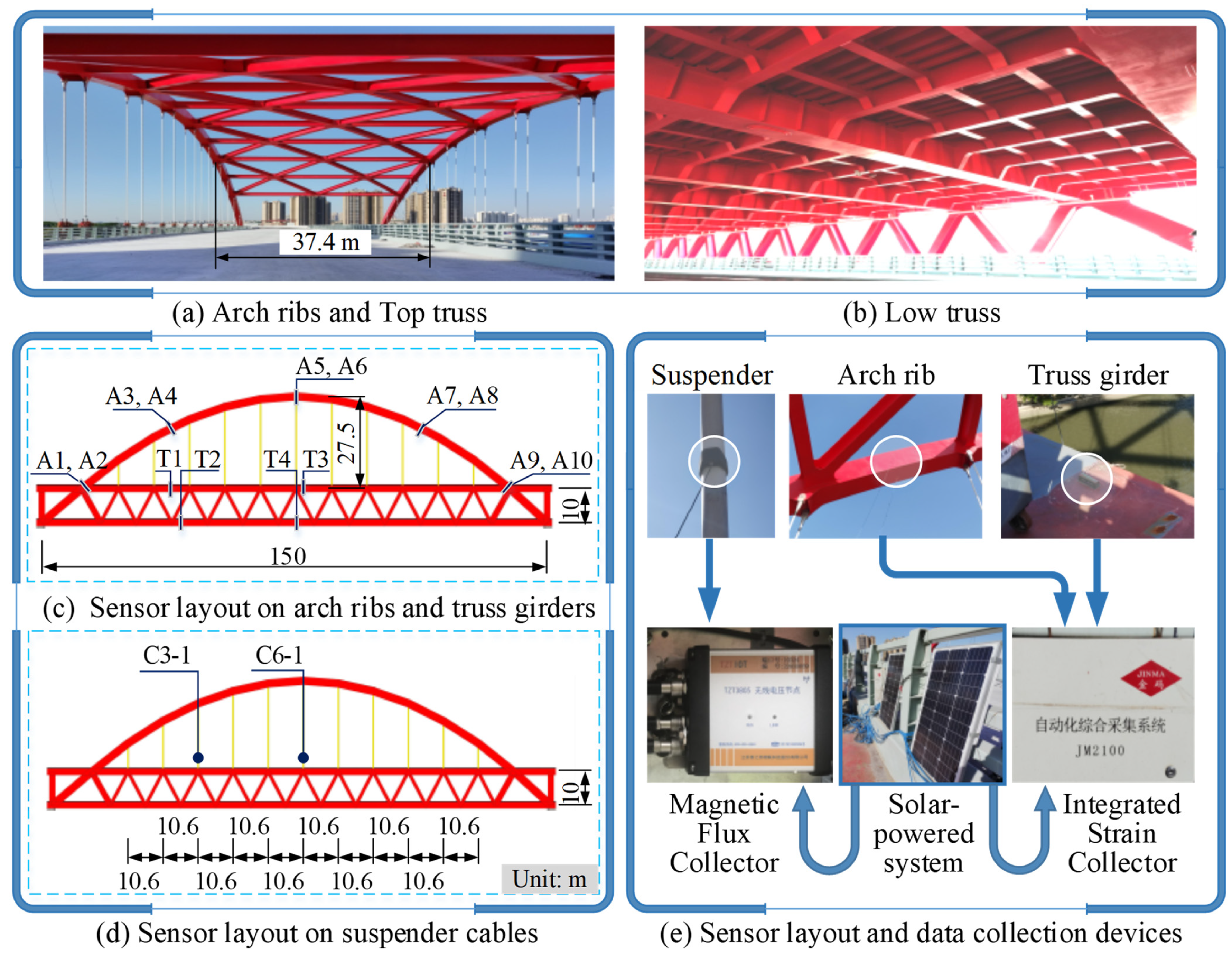
Regarding the two measurement points on the cable section, for the C3-1 cable, the distribution patterns of the MC and 3DP methods in the bar charts of the clustering results are alike, while there is a noticeable difference when compared to the UM method. For the C6-1 cable, the clustering results from the UM, MC, and 3DP methods all exhibit certain differences, indicating a more complex response to the clustering analysis.
After the cluster analysis, the cluster centers for the stress of suspender cable C3-1 are identified as 247.57 MPa, 957.73 MPa, and 1011.68 MPa. Correspondingly, the cluster centers for the stress of suspender cable C6-1 are 949.20 MPa, 222.67 MPa, and 986.04 MPa. The largest cluster center is located in the third category for both, indicating that this category corresponds to the most unfavorable stress on the cable structural system. Therefore, it is necessary to analyze separately the stress of the suspender cables with the largest cluster in the third category to assess the performance changes of the cable structural system. Of course, analyzing the cluster analysis results of the three types of cable stresses on the one hand can reflect the relative distances between the three cluster centers and on the other hand reflect the average change in the performance of the cables during the test period. Thus, it is essential to combine both situations to evaluate the performance of the cables.
6.1.2. Comparison of Key Components’ Cluster between UM and MC Method
The cloud rain diagram in
Figure 11 offers critical insights into the clustering outcomes of measurement points, delineating the differences between the UM and MC approaches.
An analysis of the semi-violin plot reveals a key distinction. While measurement point A7 maintains similar clustering patterns in both UM and MC states, the other points show notable variability. This suggests that the MC adjustments have influenced different measurement points in unique ways, indicating a need for a tailored strategy for each point.
Examining the box plots for the four key parameter measurement points, we observe a consistent alignment of the interquartile range and lower quartile with clustering points 2 and 1, irrespective of the clustering state. The uniformity of the whisker ranges, with minimums at 1 and maximums at 3, underscores a stable distribution pattern, indicative of reliable clustering across the board.
The jitter scatter plot provides further detail. Points A1 and C6-1 exhibit a balanced distribution across all three clustering points, suggesting a strong clustering characteristic. In contrast, A7 and T4 display an uneven distribution, hinting at sensitivity to fluctuations or a deviation from the overall trend, particularly in light of the MC adjustments.
Looking at the distribution of mean points, we see that for A1, T4, and C6-1, the MC state has shifted to higher values compared to the UM state. This shift indicates a more pronounced allocation of results to the three clusters following the improvements. However, for A7, the mean point in the MC state is lower than in the UM state, suggesting a potential decrease in its representativeness post-enhancement.
These observations highlight the varying effectiveness of the MC measures against the UM state and underscore the need for a nuanced strategy to ensure consistent clustering efficacy. It also points to a dual requirement: reinforcing robust points to maintain stability in the MC state and calibrating more sensitive points to ensure ongoing precision and reliability in the monitoring system.
6.2. Impact of Algorithm on Cluster Quality and Performance Metrics
Table 6 presents a comparative analysis of the clustering evaluation metrics for C3-1 and C6-1 hangers corresponding to the targeted stress thresholds, with the relative error
RMC-UM = (MC-UM)/UM×100%, including the average silhouette coefficient (ASC), Davies–Bouldin index (DBI), average deviation (AD), and
p-value by the Sign-Rank test from target values. A lower DBI indicates a better clustering performance, with higher separation between clusters and tighter cohesion within clusters [
39].
(1) Comparison of Cluster Centroids
For Cluster 1, both C3-1 and C6-1 showed no difference in centroids calculated by the UM and MC methods. In Cluster 2, MC resulted in a slightly lower centroid for C3-1 by 1.719% and a slightly higher centroid for C6-1 by 0.133% compared to UM. In Cluster 3, MC lowered the centroid for C3-1 by 3.408% and for C6-1 by 0.165%. Overall, the difference in centroids calculated by UM and MC for C3-1 and C6-1 ranged from 0% to 3.5%.
(2) Average Silhouette Coefficient
For C3-1, MC showed a lower silhouette coefficient than UM, with a difference of −10.049%, suggesting better separation with UM. For C6-1, the silhouette coefficient remained stable at 0.905 with both methods.
Across all conditions, C6-1 had a higher ASC with MC (0.905) than C3-1 (0.816 and 0.734), indicating better clustering quality with higher coefficients. However, for C3-1, the silhouette coefficient was lower with MC (0.734) than UM (0.816), suggesting slightly better separation with MC.
(3) Davies–Bouldin Index
C3-1′s DBI was 125.339% higher with MC than UM, indicating a potential decrease in clustering separation. C6-1′s index was only 2.564% higher with MC, showing minimal change. Generally, a lower index indicates better clustering. C3-1 had a lower index with UM (0.221) than MC (0.498), while C6-1′s index was slightly lower with UM (0.273) than MC (0.266), suggesting better separation with UM for C3-1.
(4) Average Deviation from Target Threshold
Using the same material limit stress target threshold of 1770 MPa for Cluster 3, the average deviation for C3-1 and C6-1 with UM was 40.826% and 42.843%, respectively, compared to 44.364% and 44.291% with MC. The difference in deviation for C3-1 between MC and UM was two percentage points, with a difference rate of 4.94%. For C6-1, the deviation was almost identical between the two methods, with a difference rate of 0.13%, indicating stable clustering results.
(5) Sign-Rank Test p-value Analysis
In Cluster 3, the p-values for C3-1 and C6-1 showed significant differences between UM and MC. For C3-1, MC’s p-value was significantly lower than UM’s, with a difference rate of −99.541%, indicating superior statistical significance with MC. For C6-1, MC’s p-value was double that of UM, suggesting a potential decrease in statistical significance with MC.
The Sign-Rank test results indicate that MC provided enhanced statistical significance for C3-1 in Cluster 3, while for C6-1, the significance was reduced. Since a lower p-value typically indicates higher statistical significance, MC may be more advantageous for C3-1.
In summary, the distribution, characteristics, and noise level of the data significantly impact the choice of algorithm and clustering results. The modified K-means (MC) algorithm showed different clustering effects compared to the unmodified K-means (UM) when processing data for C3-1 and C6-1. Statistical significance was higher for MC in Cluster 3 for C3-1, as evidenced by a lower p-value. In terms of centroid values, MC significantly affected the centroids for C3-1 in Cluster 2 and 3, usually yielding lower values than UM. In terms of clustering quality metrics, UM generally performed better in deviation and the Davies–Bouldin index, suggesting higher separation. For silhouette coefficient stability, C6-1 showed stable clustering effects with both methods, with a high silhouette coefficient. The choice of algorithm should be based on specific clustering objectives and data characteristics, considering multiple indicators, including statistical significance, centroid values, deviation, Davies–Bouldin index, and silhouette coefficient.
6.3. Influence of Single-Parameter Cloud Model Parameters on Clustering Quality
Figure 12 illustrates the predictive reliability and clustering quality of the clustering results for the hanger components C3-1 and C6-1 based on their single-parameter
EX,
EN, and
HE values.
(a) When analyzing the 96% confidence interval [CIlower, EX, CIupper, EX] corresponding to the structural system’s expectation value, the width of the confidence interval, CIHE = CIupper, EN − CIlower, EN, exhibits a trend of decreasing initially and then increasing with the increase in the single-parameter EX value. At an optimal EX value, the predictive reliability of the structural system is at its peak. However, as the EX value continues to rise or fall, the confidence interval widens, indicating increased uncertainty and decreased predictive reliability, reflecting a decline in the model’s predictive capability under extreme conditions.
(b) As the single-parameter EN value increases, both the single-parameter cloud model and the system cloud model’s entropy values also increase, while the HE value remains constant. Under the 96% confidence interval, the width of the confidence interval, CIHE, gradually widens, signifying that the uncertainty in clustering quality rises with an increase in EN. Specifically, as the EN value doubles from 0.5 to 1.3 times, the CIHE value increases from 0.224 to 0.59, indicating that predictions are more certain at lower entropy values, and uncertainty grows as the entropy value increases.
(c) The clustering quality of the single-parameter indicator cloud shows an increasing trend with the increase in HE. The hyper-entropy of the system cloud model increases with the hyper-entropy of the single-parameter cloud model, indicating an increase in system complexity or uncertainty. Nonetheless, the system’s EXC and ENC values remain stable, suggesting that the system’s predictive ability and uncertainty are maintained at a relatively constant state during changes in hyper-entropy. The evaluation of the confidence interval shows that CIlower, HE and CIupper,EN are relatively stable across the entire range of hyper-entropy values, indicating consistency and reliability in the measurement results. The width of the confidence interval, CIHE, varies within a narrow range, emphasizing the precision of the clustering results. The analysis of the confidence interval width, CIHE, reveals that it remains essentially unchanged with the increase in the single-parameter hyper-entropy value, indicating that the uncertainty of the predictive results is maintained at a relatively stable level across the entire range of hyper-entropy values.
In summary, the research findings underscore the significant impact of expectation, entropy, and hyper-entropy values on the accuracy and uncertainty of predictions within structural system forecasting and the clustering analysis. By meticulously adjusting these parameters, it is possible to enhance predictive reliability while gaining a better understanding and management of the uncertainties inherent in the forecasting process.



 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}