

Transport Infrastructure Management Based on LiDAR Synthetic Data: A Deep Learning Approach with a ROADSENSE Simulator



Abstract
1. Introduction
2. Implementation of ROADSENSE
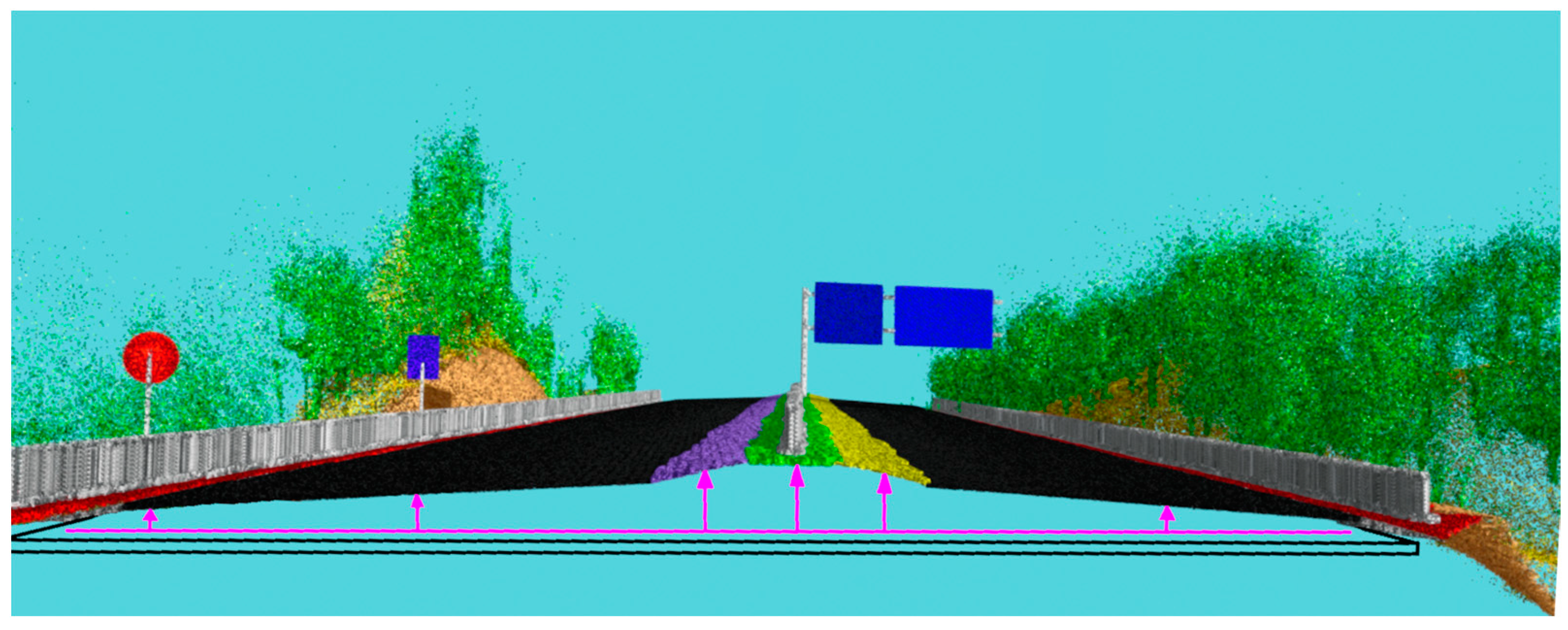
2.1. Geometric Design
2.2. Architecture and Modules
- seed (index 0): This is a random seed used in intermediate randomizers. Options: “None” or “integer number”. If the None option is selected, the simulator will consider the time.time() value. Specifying an int number will make all clouds and their features equal.
- road (index 1): This indicates whether the resulting point clouds will have a road or not. Options: “True” or “False”.
- spectral_mode (index 2): This parameter is used in the case of performing a spectral simulation on the resulting point clouds. Options: “True” or “False”. If True is set, the simulator will take longer to generate each point cloud since there are several intermediate calculations, like the normals estimation or the virtual trajectory simulation.
- road_type (index 3): This indicates the type of road to simulate. Options: “highway”, “national”, “local”, or “mixed”. If the “mixed” option is selected, the resulting point cloud dataset will consist of a mix of different types of roads.
- tree_path (index 4): This represents the absolute path to the directory where all of the tree segments are stored.
- number_of_clouds (index 5): This represents the total number of point clouds that will be simulated. It must be an integer number greater than zero.
- scale (index 6): This is a geometric scale of the resulting point cloud. Bigger scales will result in bigger sized point clouds but with less point densities. It must be an integer number greater than 0.
- number_of_trees (index 7): This represents the total number of trees per cloud. It must be an integer number greater than 0.
- number_of_transformations (index 8): This is the number of Euclidean transformations that will suffer each tree segment. It must be an int number. If the total number of tree segments specified in the “tree_path” is less than the “number_of_trees”, then the simulator will randomly repeat all segments until completion.
- X_buffer (indexes 9–11): This represents the width of the “X” element in meters. “X” can be “road”, “shoulder”, or “berm”. It must be a float number greater than 0.
- slope_buffer (index 12): This represents the width of the slope in meters. Options: “float number greater than 0” or “random”. If “random” is set, then there will be slopes with different widths in the final point clouds.
- noise_X (indexes 13–18): This represents the noise threshold in each XYZ direction per point of the “X” element. “X” can be “DTM”, “road”, “shoulder”, “slope”, “berm”, or “refugee_island”. It must be in the “(x,y,z)” bracket notation, where x, y, and z must be float numbers.
- number_of_trees_refugee_island (index 19): This represents the number of trees in the median strip. It must be an integer number.
- number_points_DTM (index 20): This represents the number of points in the edge of the DTM grid. It should be ~10 times the scale. It must be an integer number greater than 0.
- vertical_pumping (index 21): This indicates whether the simulated road will have vertical pumping or not, i.e., if the points closer to the axis road will have different heights than the ones that are further. Options: “True” or “False”.
- DTM_road_wizard.DTM_road_generator: This function generates all road-related geometries from scratch.
- cross_section.X_vertical_pumping: This function generates some sort of ground elevation in the road-related parts of the “X” road type, i.e., the points closer to the axis road will have a different height than the ones that are further. “X” can be highway, national, or mixed roads.
- reading_trees.read_segments: This function reads and stores external tree segments.
- road_generator.Road_Generator: This function generates all ground components of the road (except traffic signals and barriers).
- signal_generator.create_X_signal: This function generates signals regarding its “X” type. “X” can be “elevated” for elevated big traffic signals in highway and mixed roads or “triangular”, “circle”, or “square” for shaped vertical signals.
- tree_wizard.tree_generator: This function performs data augmentation with the previously read tree data and generates new tree segments.
- trajectory_simulation.compute_spectral_intensity: This function draws a trajectory over the generated 3D scene and performs a spectral simulation.
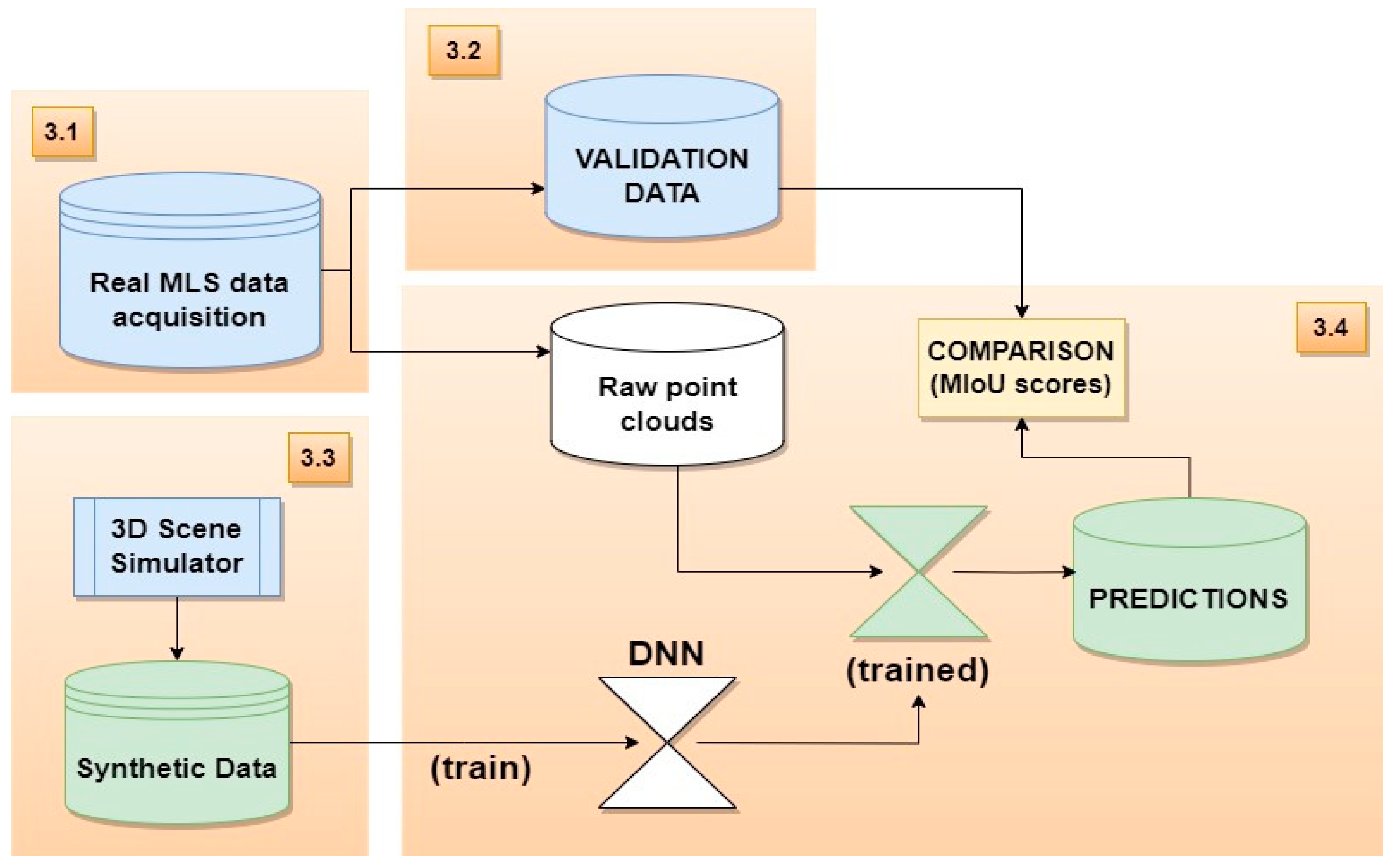
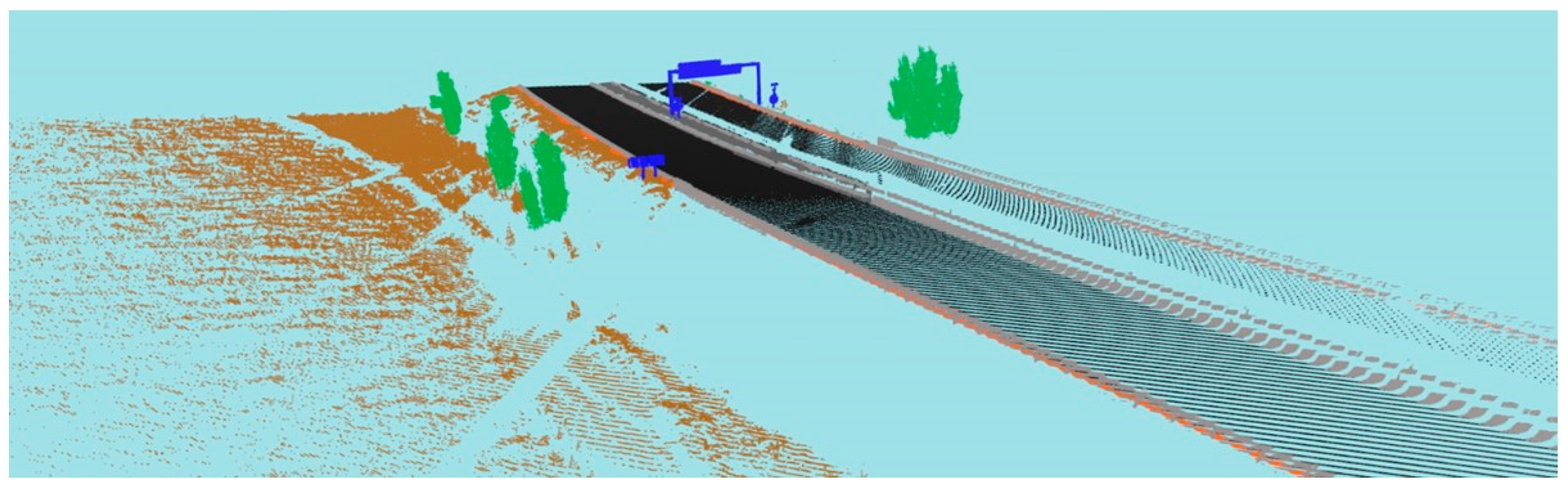
3. Case Study
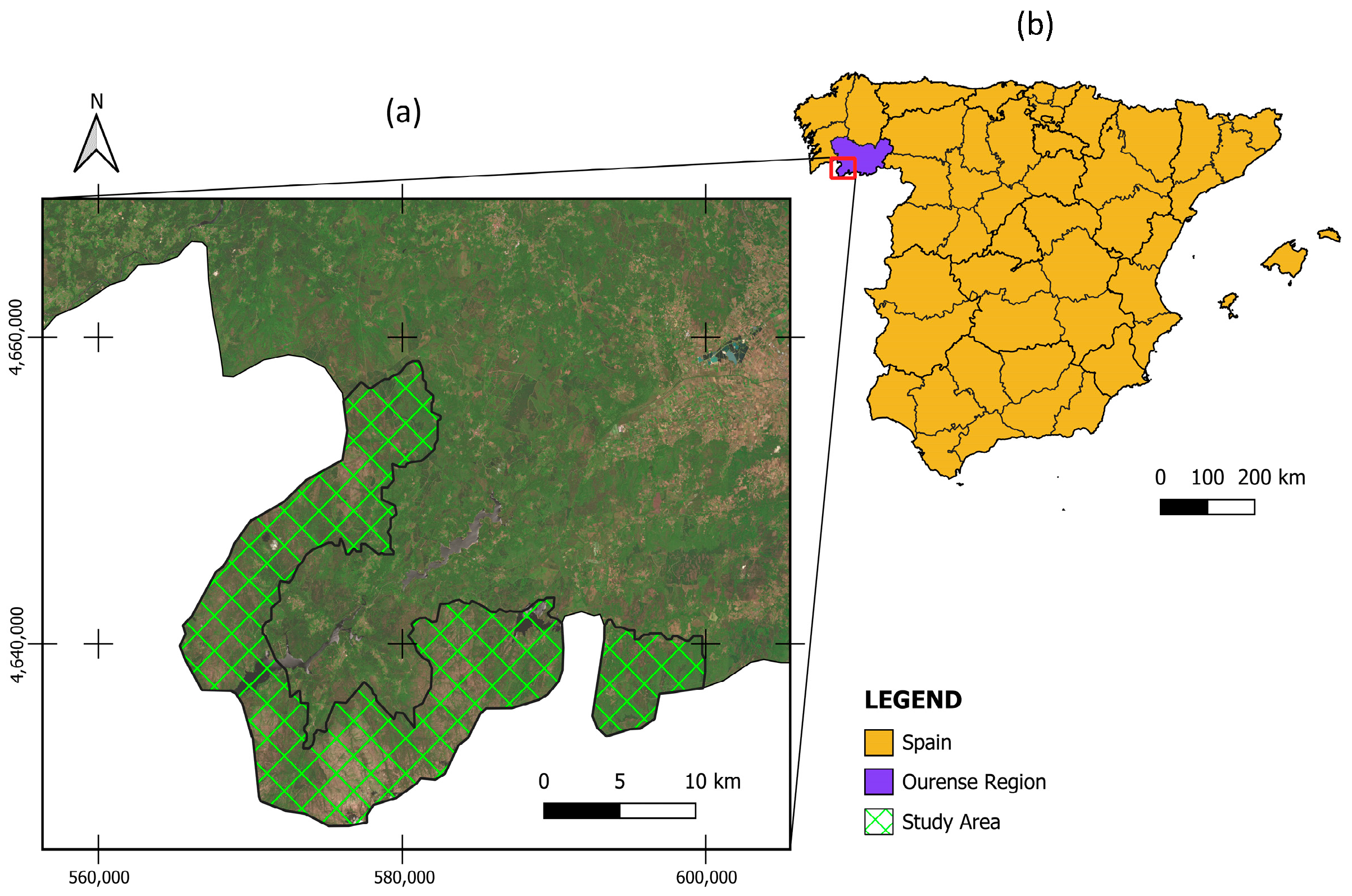
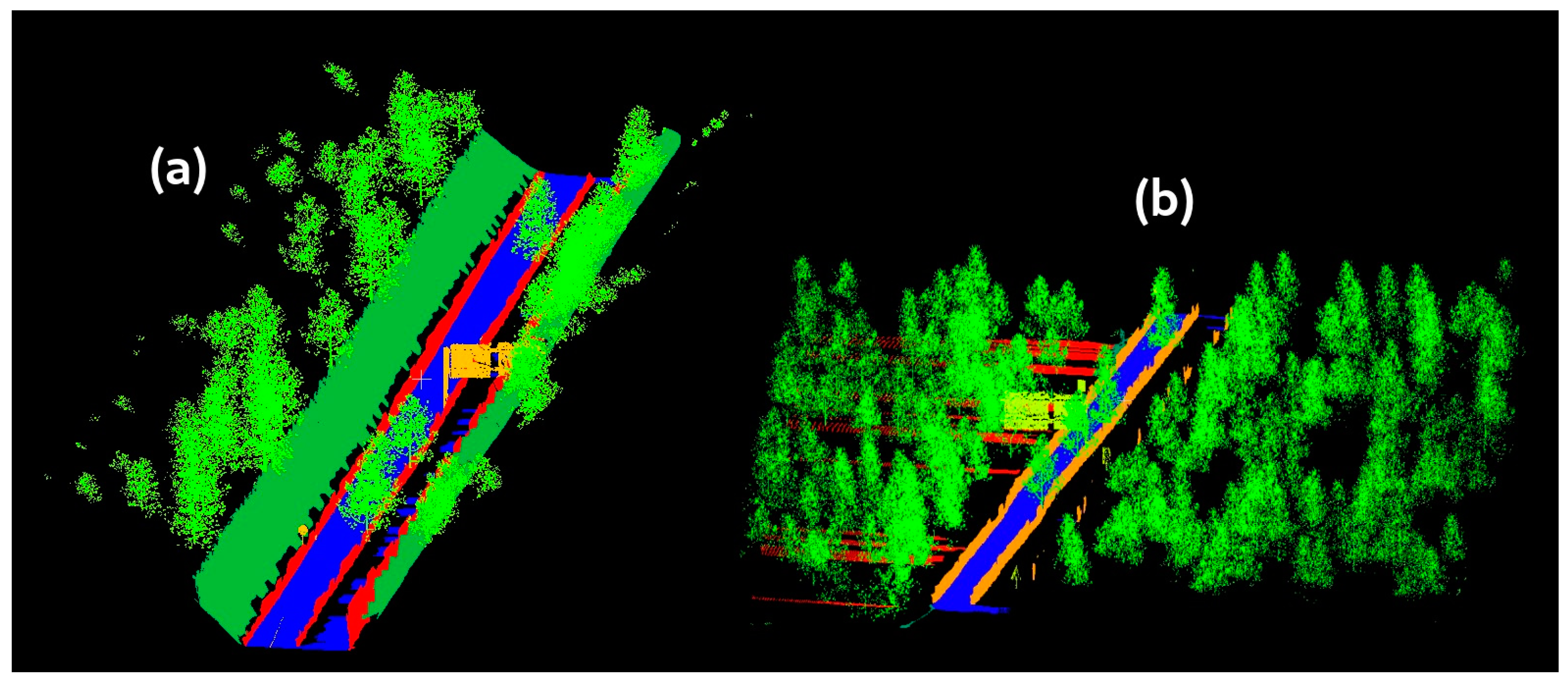
3.1. Real MLS Point Cloud Acquisition
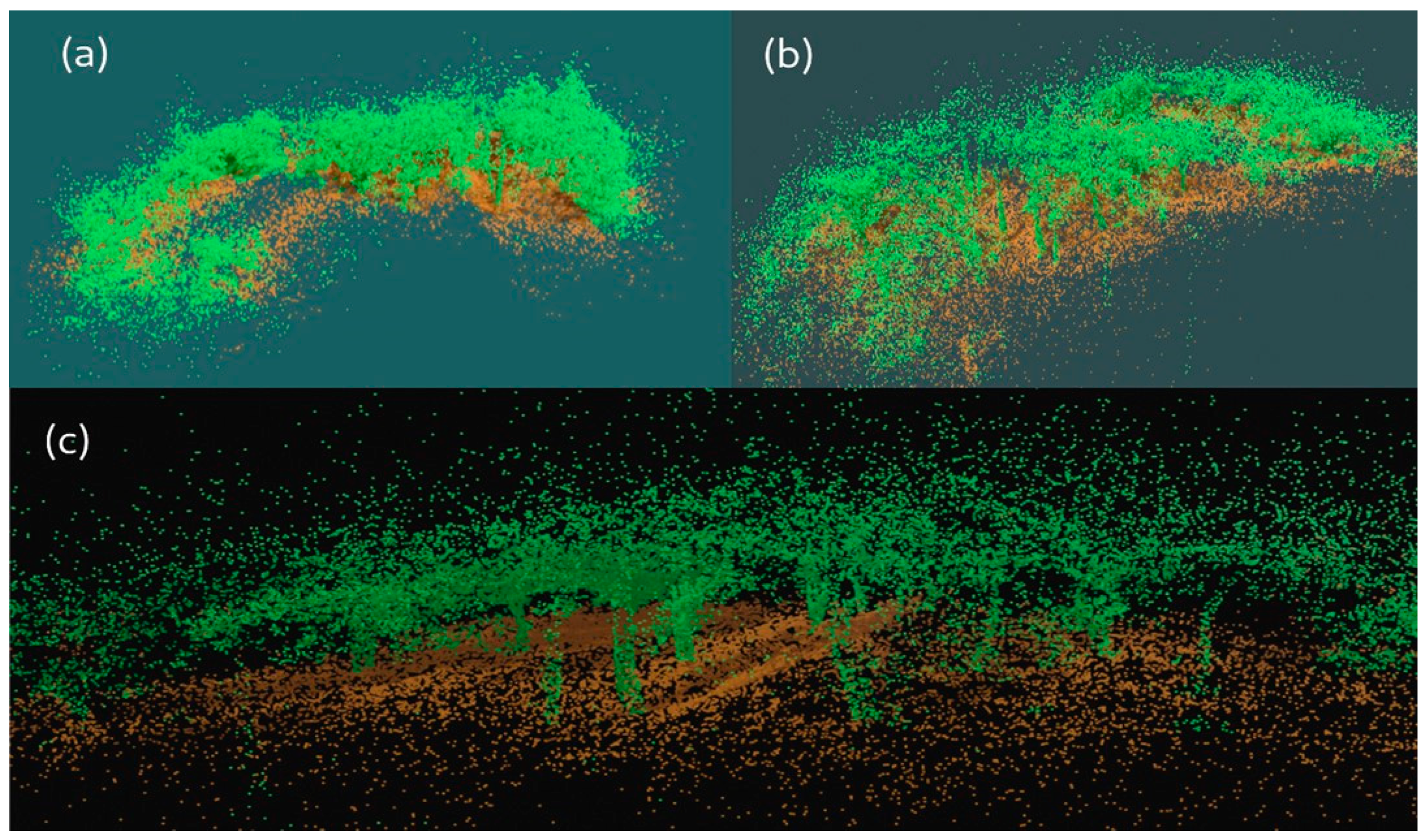
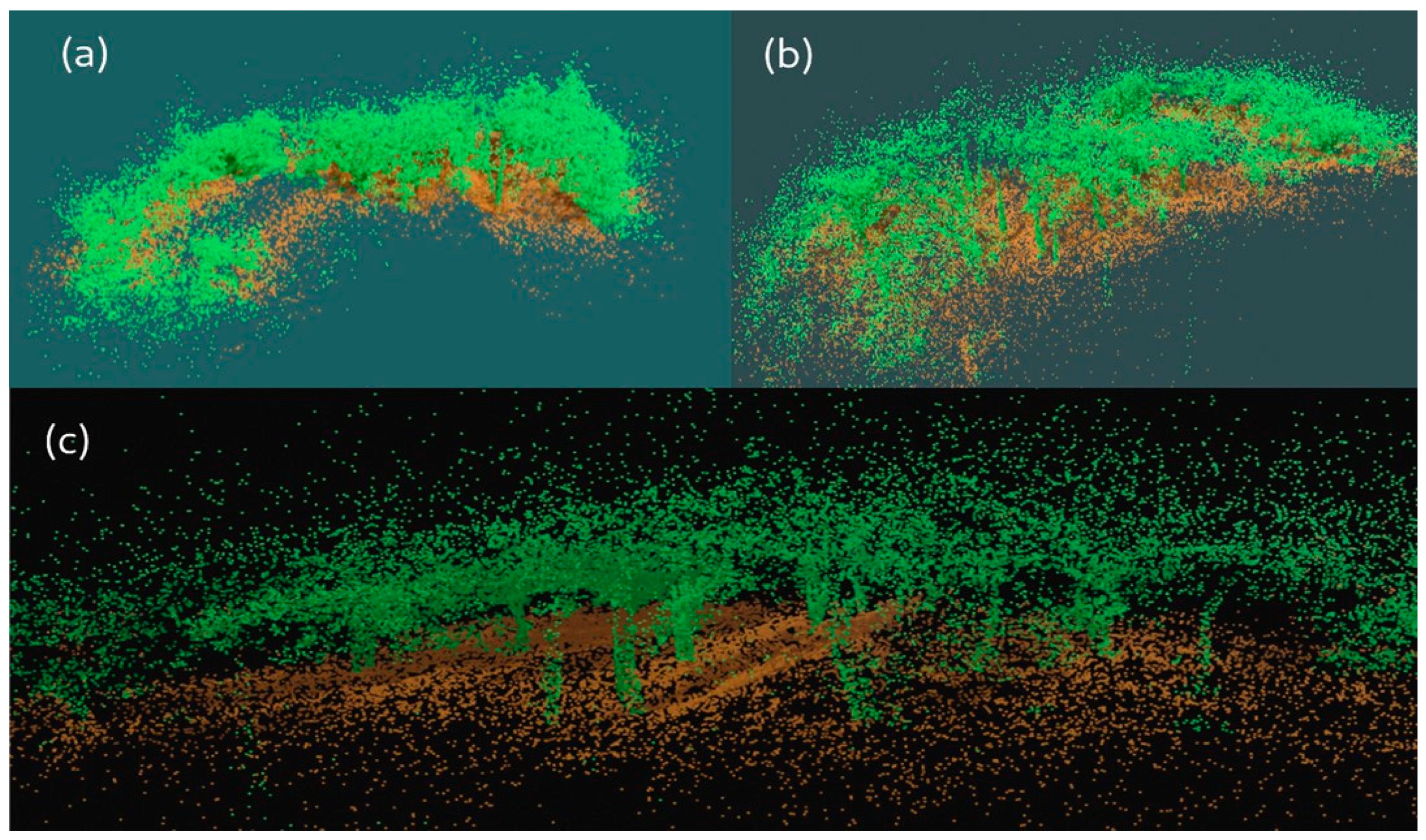
3.2. Validation Data of Forest Scenarios
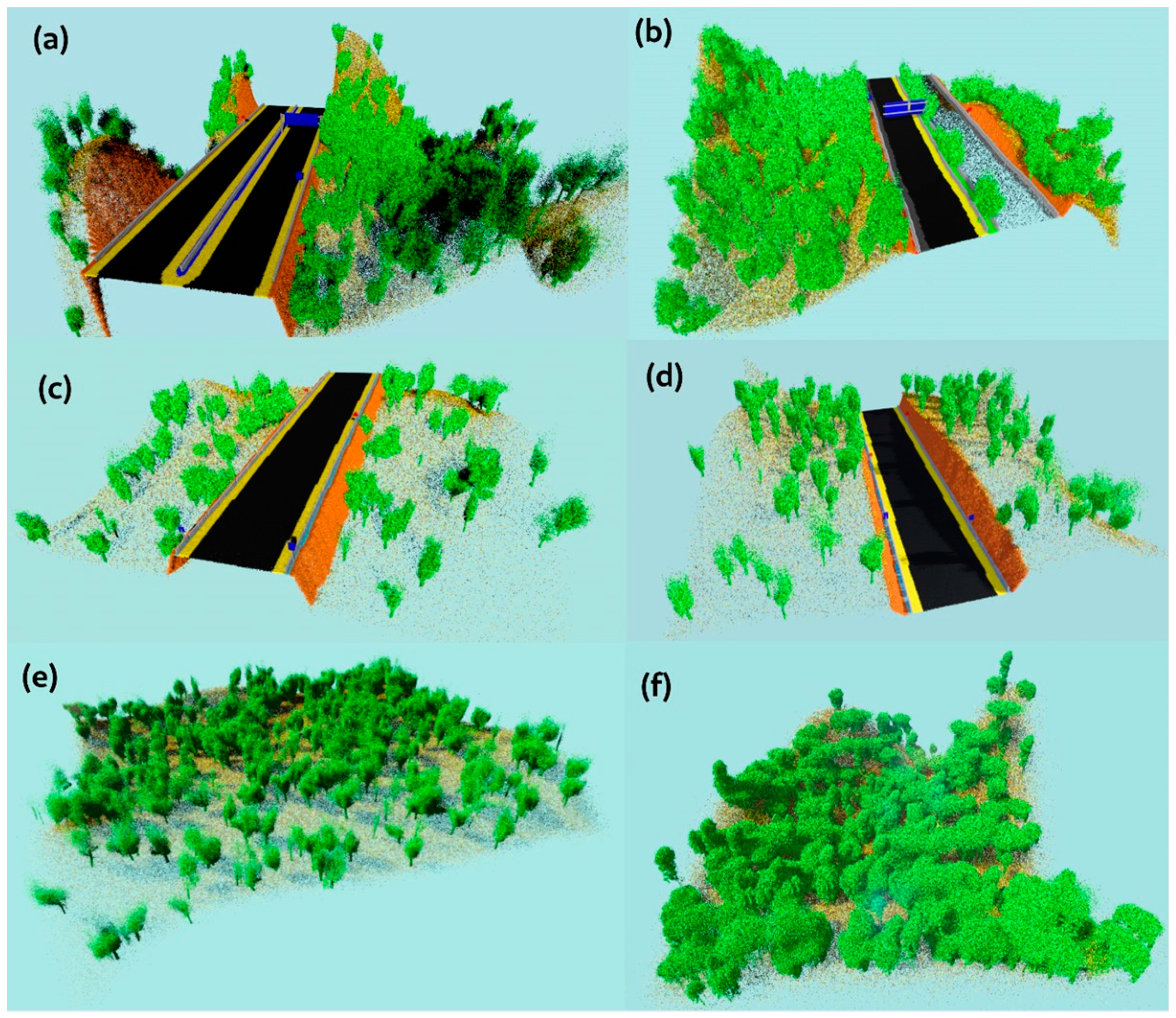
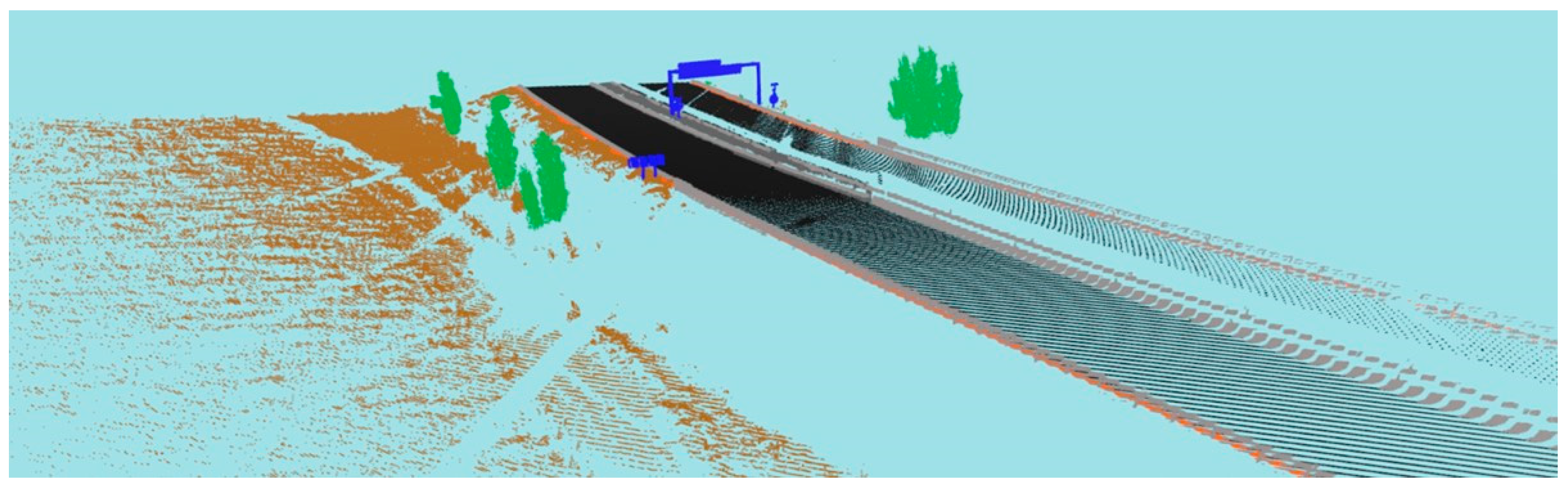
3.3. Generation of Synthetic Datasets
3.4. Semantic Segmentation with DNN Model
4. Results and Discussion
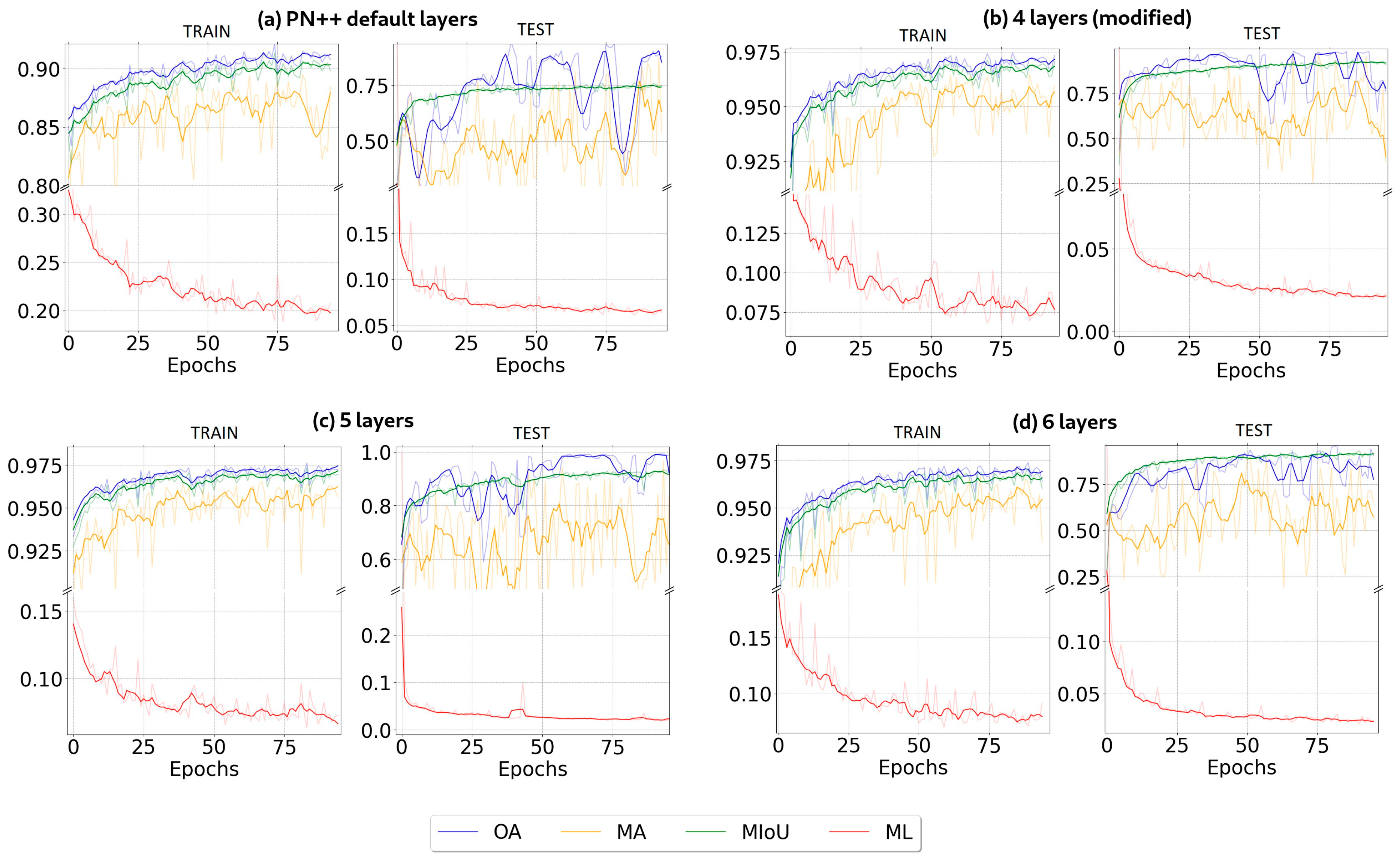
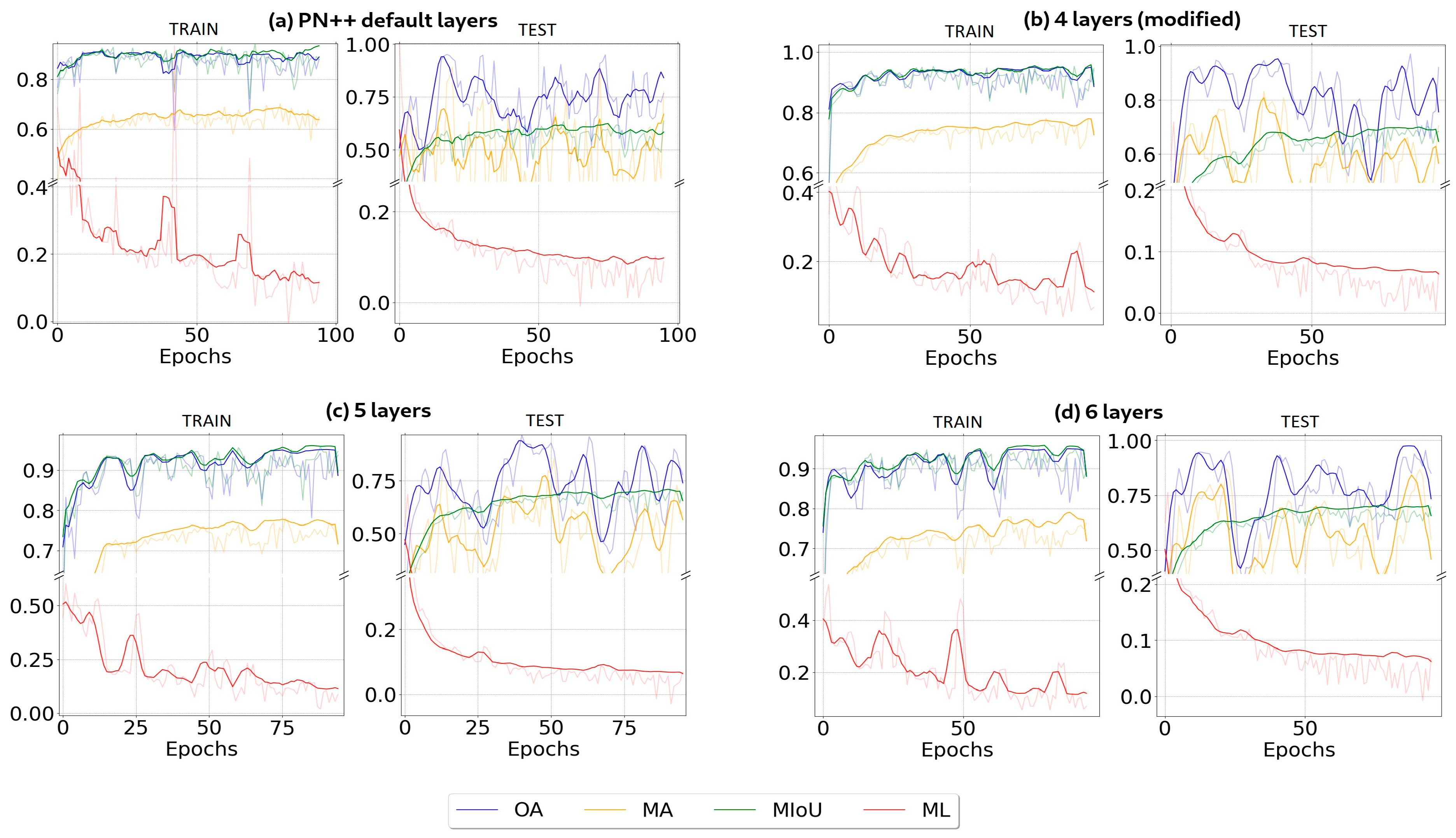
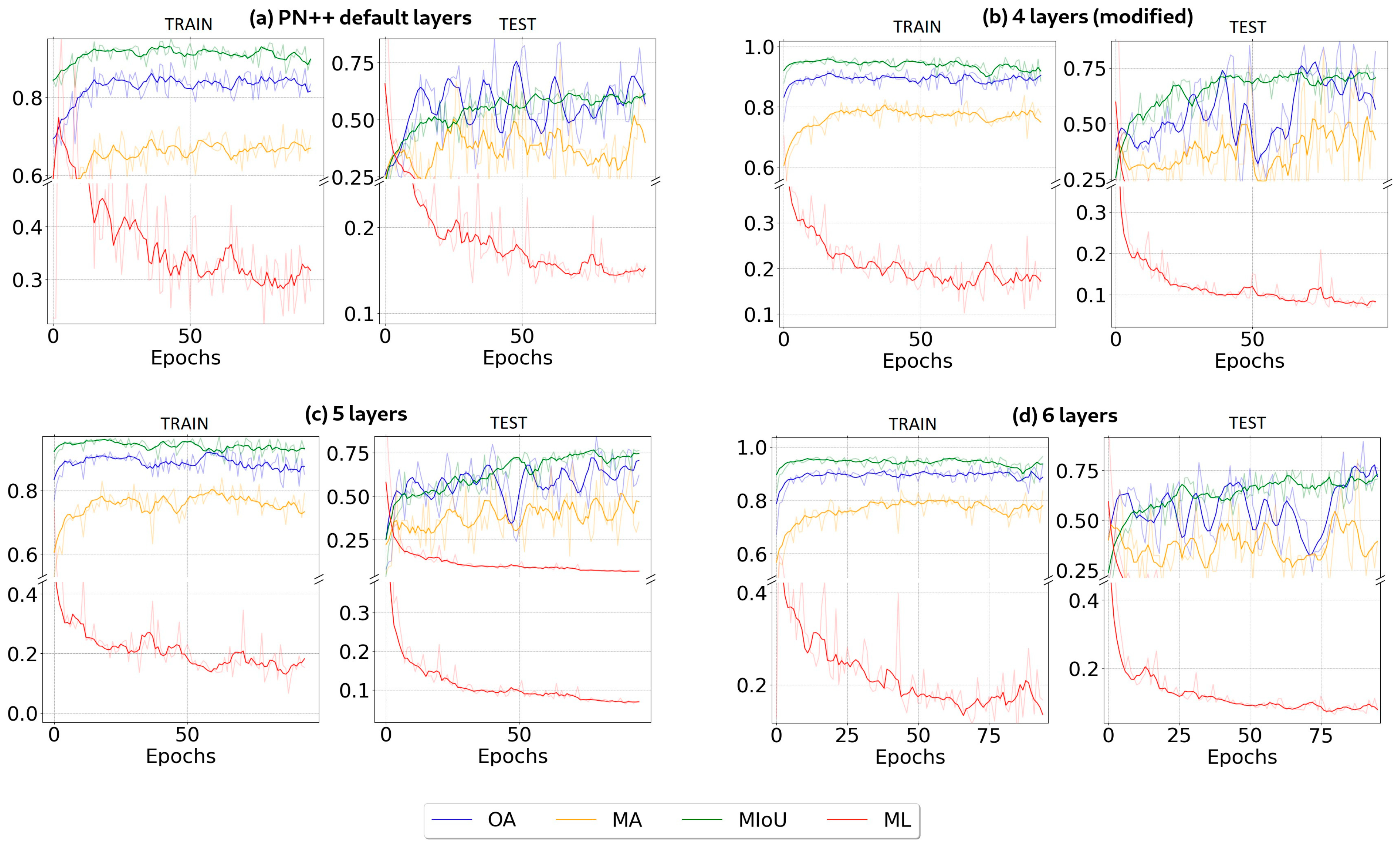
4.1. Segmentation Metrics
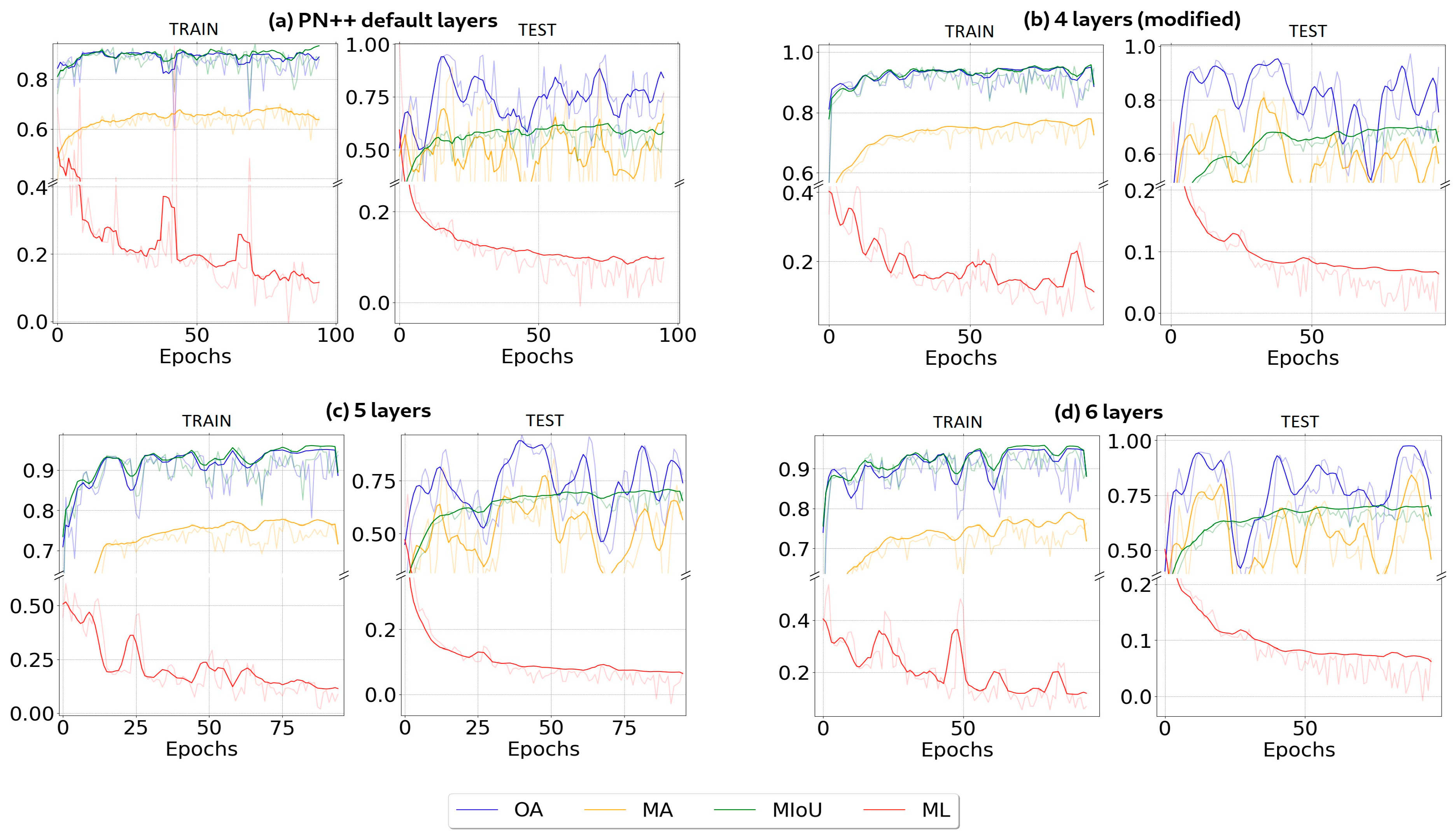
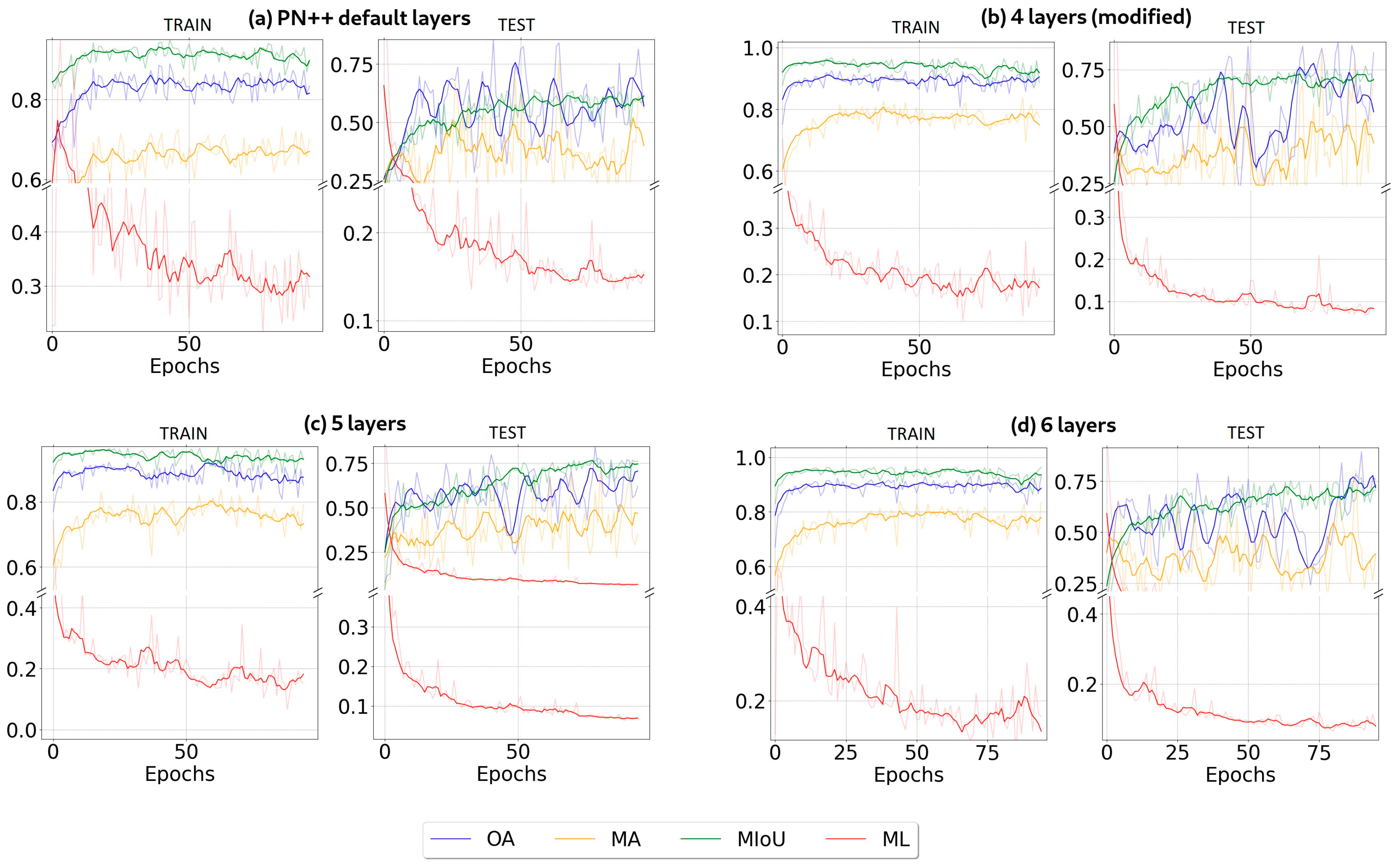
4.2. Architectures Training
4.3. DNN Performance: Inferences on Real LiDAR Point Clouds
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zimmer, W.; Ercelik, E.; Zhou, X.; Ortiz, X.J.D.; Knoll, A. A Survey of Robust 3D Object Detection Methods in Point Clouds. arXiv 2022, arXiv:2204.00106. [Google Scholar] [CrossRef]
- Velizhev, A.; Shapovalov, R.; Schindler, K. Implicit Shape Models for Object Detection in 3D Point Clouds. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2012, I–3, 179–184. [Google Scholar] [CrossRef]
- Kaartinen, E.; Dunphy, K.; Sadhu, A. LiDAR-Based Structural Health Monitoring: Applications in Civil Infrastructure Systems. Sensors 2022, 22, 4610. [Google Scholar] [CrossRef] [PubMed]
- Buján, S.; Guerra-Hernández, J.; González-Ferreiro, E.; Miranda, D. Forest Road Detection Using LiDAR Data and Hybrid Classification. Remote Sens. 2021, 13, 393. [Google Scholar] [CrossRef]
- Ma, H.; Ma, H.; Zhang, L.; Liu, K.; Luo, W. Extracting Urban Road Footprints from Airborne LiDAR Point Clouds with PointNet++ and Two-Step Post-Processing. Remote Sens. 2022, 14, 789. [Google Scholar] [CrossRef]
- Xu, D.; Wang, H.; Xu, W.; Luan, Z.; Xu, X. LiDAR Applications to Estimate Forest Biomass at Individual Tree Scale: Opportunities, Challenges and Future Perspectives. Forests 2021, 12, 550. [Google Scholar] [CrossRef]
- Iglesias, L.; De Santos-Berbel, C.; Pascual, V.; Castro, M. Using Small Unmanned Aerial Vehicle in 3D Modeling of Highways with Tree-Covered Roadsides to Estimate Sight Distance. Remote Sens. 2019, 11, 2625. [Google Scholar] [CrossRef]
- Chen, J.; Su, Q.; Niu, Y.; Zhang, Z.; Liu, J. A Handheld LiDAR-Based Semantic Automatic Segmentation Method for Complex Railroad Line Model Reconstruction. Remote Sens. 2023, 15, 4504. [Google Scholar] [CrossRef]
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep Learning for 3D Point Clouds: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 4338–4364. [Google Scholar] [CrossRef]
- Lawin, F.J.; Danelljan, M.; Tosteberg, P.; Bhat, G.; Khan, F.S.; Felsberg, M. Deep Projective 3D Semantic Segmentation; Springer: Cham, Switzerland, 2017; pp. 95–107. [Google Scholar]
- Lu, H.; Wang, H.; Zhang, Q.; Yoon, S.W.; Won, D. A 3D Convolutional Neural Network for Volumetric Image Semantic Segmentation. Procedia Manuf. 2019, 39, 422–428. [Google Scholar] [CrossRef]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. arXiv 2017, arXiv:1706.02413. [Google Scholar]
- Zhang, Y.; Chen, X.; Guo, D.; Song, M.; Teng, Y.; Wang, X. PCCN: Parallel Cross Convolutional Neural Network for Abnormal Network Traffic Flows Detection in Multi-Class Imbalanced Network Traffic Flows. IEEE Access 2019, 7, 119904–119916. [Google Scholar] [CrossRef]
- Thomas, H.; Qi, C.R.; Deschaud, J.-E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. KPConv: Flexible and Deformable Convolution for Point Clouds. arXiv 2019, arXiv:1904.08889. [Google Scholar]
- Fan, H.; Yang, Y. PointRNN: Point Recurrent Neural Network for Moving Point Cloud Processing. arXiv 2019, arXiv:1910.08287. [Google Scholar]
- Shi, W.; Ragunathan, R. Point-GNN: Graph Neural Network for 3D Object Detection in a Point Cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Wu, B.; Zhou, X.; Zhao, S.; Yue, X.; Keutzer, K. SqueezeSegV2: Improved Model Structure and Unsupervised Domain Adaptation for Road-Object Segmentation from a LiDAR Point Cloud. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 4376–4382. [Google Scholar]
- Yao, L.; Qin, C.; Chen, Q.; Wu, H. Automatic Road Marking Extraction and Vectorization from Vehicle-Borne Laser Scanning Data. Remote Sens. 2021, 13, 2612. [Google Scholar] [CrossRef]
- Jing, Z.; Guan, H.; Zhao, P.; Li, D.; Yu, Y.; Zang, Y.; Wang, H.; Li, J. Multispectral LiDAR Point Cloud Classification Using SE-PointNet++. Remote Sens. 2021, 13, 2516. [Google Scholar] [CrossRef]
- Zou, Y.; Weinacker, H.; Koch, B. Towards Urban Scene Semantic Segmentation with Deep Learning from LiDAR Point Clouds: A Case Study in Baden-Württemberg, Germany. Remote Sens. 2021, 13, 3220. [Google Scholar] [CrossRef]
- Tchapmi, L.P.; Choy, C.B.; Armeni, I.; Gwak, J.; Savarese, S. SEGCloud: Semantic Segmentation of 3D Point Clouds. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017. [Google Scholar]
- Wang, F.; Zhuang, Y.; Gu, H.; Hu, H. Automatic Generation of Synthetic LiDAR Point Clouds for 3-D Data Analysis. IEEE Trans. Instrum. Meas. 2019, 68, 2671–2673. [Google Scholar] [CrossRef]
- Lohani, B.; Mishra, R.K. Generating LiDAR Data in Laboratory: LiDAR Simulator. In Proceedings of the ISPRS Workshop on Laser Scanning 2007 and SilviLaser 2007, Espoo, Finland, 12–14 September 2007; pp. 264–269. [Google Scholar]
- Lovell, J.L.; Jupp, D.L.B.; Newnham, G.J.; Coops, N.C.; Culvenor, D.S. Simulation Study for Finding Optimal Lidar Acquisition Parameters for Forest Height Retrieval. For. Ecol. Manag. 2005, 214, 398–412. [Google Scholar] [CrossRef]
- Sun, G.; Ranson, K.J. Modeling Lidar Returns from Forest Canopies. IEEE Trans. Geosci. Remote Sens. 2000, 38, 2617–2626. [Google Scholar] [CrossRef]
- Morsdorf, F.; Frey, O.; Koetz, B.; Meier, E. Ray Tracing for Modeling of Small Footprint Airborne Laser Scanning Returns. In Proceedings of the ISPRS Workshop ‘Laser Scanning 2007 and SilviLaser 2007’, Espoo, Finland, 12–14 September 2007; ISPRS: Espoo, Finland, 2007; pp. 294–299. [Google Scholar]
- Kukko, A.; Hyyppä, J. Small-Footprint Laser Scanning Simulator for System Validation, Error Assessment, and Algorithm Development. Photogramm. Eng. Remote Sens. 2009, 75, 1177–1189. [Google Scholar] [CrossRef]
- Kim, S.; Min, S.; Kim, G.; Lee, I.; Jun, C. Data Simulation of an Airborne Lidar System; Turner, M.D., Kamerman, G.W., Eds.; SPIE: Bellingham, WA, USA, 2009; p. 73230C. [Google Scholar]
- Wang, Y.; Xie, D.; Yan, G.; Zhang, W.; Mu, X. Analysis on the Inversion Accuracy of LAI Based on Simulated Point Clouds of Terrestrial LiDAR of Tree by Ray Tracing Algorithm. In Proceedings of the 2013 IEEE International Geoscience and Remote Sensing Symposium—IGARSS, Melbourne, Australia, 21–26 July 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 532–535. [Google Scholar]
- Hodge, R.A. Using Simulated Terrestrial Laser Scanning to Analyse Errors in High-Resolution Scan Data of Irregular Surfaces. ISPRS J. Photogramm. Remote Sens. 2010, 65, 227–240. [Google Scholar] [CrossRef]
- Dayal, S.; Goel, S.; Lohani, B.; Mittal, N.; Mishra, R.K. Comprehensive Airborne Laser Scanning (ALS) Simulation. J. Indian. Soc. Remote Sens. 2021, 49, 1603–1622. [Google Scholar] [CrossRef]
- Bechtold, S.; Höfle, B. Helios: A Multi-Purpose Lidar Simulation Framework for Research, Planning and Training of Laser Scanning Operations with Airborne, Ground-Based Mobile and Stationary Platforms. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, III–3, 161–168. [Google Scholar] [CrossRef]
- Winiwarter, L.; Esmorís Pena, A.M.; Weiser, H.; Anders, K.; Martínez Sánchez, J.; Searle, M.; Höfle, B. Virtual Laser Scanning with HELIOS++: A Novel Take on Ray Tracing-Based Simulation of Topographic Full-Waveform 3D Laser Scanning. Remote Sens. Env. 2022, 269, 112772. [Google Scholar] [CrossRef]
- Comesaña Cebral, L.J.; Martínez Sánchez, J.; Rúa Fernández, E.; Arias Sánchez, P. Heuristic Generation of Multispectral Labeled Point Cloud Datasets for Deep Learning Models. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2022, XLIII-B2-2022, 571–576. [Google Scholar] [CrossRef]
- RIEGL MiniVUX-1DL Data Sheet. Available online: https://www.gtbi.net/wp-content/uploads/2021/06/riegl-minivux-1dl_folleto(EN).pdf (accessed on 17 July 2023).
- RIEGL VUX-1UAV Data Sheet. Available online: http://www.riegl.com/products/unmanned-scanning/riegl-vux-1uav22/ (accessed on 4 January 2024).
- Teledyne Optech Co. Teledyne Optech. 2024. Available online: https://www.teledyneoptech.com/en/home/ (accessed on 4 January 2024).
- Applanix Corp. Homepage. Available online: https://www.applanix.com/ (accessed on 4 January 2024).
- Carlotto, M.J. Effect of Errors in Ground Truth on Classification Accuracy. Int. J. Remote Sens. 2009, 30, 4831–4849. [Google Scholar] [CrossRef]
- Comesaña-Cebral, L.; Martínez-Sánchez, J.; Lorenzo, H.; Arias, P. Individual Tree Segmentation Method Based on Mobile Backpack LiDAR Point Clouds. Sensors 2021, 21, 6007. [Google Scholar] [CrossRef]
- Applied Geotechnologies Research Group ROADSENSE Dataset. Available online: https://universidadevigo-my.sharepoint.com/personal/geotech_uvigo_gal/_layouts/15/onedrive.aspx?id=%2Fpersonal%2Fgeotech%5Fuvigo%5Fgal%2FDocuments%2FPUBLIC%20DATA%2FDataSets%2Fsynthetic&ga=1 (accessed on 31 January 2024).
- OSM2World Home Page. 2024. Available online: https://osm2world.org/ (accessed on 4 January 2024).
- OpenStreetMap Official Webpage. 2024. Available online: https://www.openstreetmap.org/ (accessed on 4 January 2024).
- Kumar, A.; Anders, K.; Winiwarter, L.; Höfle, B. Feature Relevance Analysis for 3D Point Cloud Classification Using Deep Learning. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, IV-2/W5, 373–380. [Google Scholar] [CrossRef]
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Nießner, M. ScanNet: Richly-Annotated 3D Reconstructions of Indoor Scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Everingham, M.; Eslami, S.M.A.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Smith, L.N. A Disciplined Approach to Neural Network Hyper-Parameters: Part 1—Learning Rate, Batch Size, Momentum, and Weight Decay. arXiv 2018, arXiv:1803.09820. [Google Scholar]
- Fawaz, H.I.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.-A. Deep Learning for Time Series Classification: A Review. Data Min. Knowl. Discov. 2018, 33, 917–963. [Google Scholar] [CrossRef]
- Castillo, R.C.J.; Mendoza, R. On Smoothing of Data Using Sobolev Polynomials. AIMS Math. 2022, 7, 19202–19220. [Google Scholar] [CrossRef]
- Qian, G.; Li, Y.; Peng, H.; Mai, J.; Hammoud, H.A.A.K.; Elhoseiny, M.; Ghanem, B. PointNeXt: Revisiting PointNet++ with Improved Training and Scaling Strategies. Adv. Neural Inf. Process. Syst. 2022, 35, 23192–23204. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| miniVUX-1DL | VUX-1UAV | |
|---|---|---|
| Field of view | off-nadir | |
| Scanning pattern | Circular | Linear |
| Pulse repetition frequency | 100 kHz | 550 kHz |
| Wavelength | 905 nm (NIR) | 1550 nm |
| Beam divergence | mrad | 0.5 mrad |
| Footprint size at 100 m | mm | 50 mm |
| Accuracy | 15 mm at 50 m | 10 mm at 150 m |
| Precision | 10 mm at 50 m | 5 mm at 150 m |
| Features | HELIOS++ | ROADSENSE |
|---|---|---|
| Trajectory independent | No | Yes |
| Performs full-wave simulation | Yes | No |
| Scene creation flexibility | No | Yes |
| Performs multispectral simulation | Yes | Yes |
| Not dependent on laser scanner parameter setup | No | Yes |
| Provides semantic information | Yes | Yes |
| Not dependent on prior labeling procedures | No | Yes |
| Downsampling | Layer ID | Point Features | N_Points | Radius |
| 0 | [7,32,32,64] | 1024 | 0.1 | |
| 1 | [67,64,64,128] | 256 | 0.2 | |
| 2 | [131,128,128,256] | 64 | 0.4 | |
| 3 | [259,256,256,512] | 16 | 0.8 | |
| Upsampling | 4 | [1024,512,512,256] | 16 | 0.1 |
| 5 | [256,256,256,256] | 64 | 0.2 | |
| 6 | [64,128,256,128] | 256 | 0.4 | |
| 7 | [16,128,128,128] | 1024 | 0.8 |
| 4-Layer Version | 5-Layer Version | 6-Layer Version | Layer ID | Point Features | N_Points | Radius |
|---|---|---|---|---|---|---|
| ✓ | ✓ | ✓ | 0 | [7,32,32,64] | 65,536 | 0.1 |
| ✓ | ✓ | ✓ | 1 | [67,64,64,128] | 8192 | 0.2 |
| ✓ | ✓ | ✓ | 2 | [131,128,128,256] | 2048 | 0.4 |
| ✓ | ✓ | ✓ | 3 | [259,256,256,512] | 1024 | 0.5 |
| ✓ | ✓ | 4 | [512,512,512,1024] | 512 | 0.7 | |
| ✓ | 5 | [1024,1024,1024,2048] | 256 | 0.8 | ||
| ✓ | ✓ | ✓ | 6 | [256,4,128,128] | 256 | 0.1 |
| ✓ | ✓ | ✓ | 7 | [1024,64,128,128] | 512 | 0.2 |
| ✓ | ✓ | ✓ | 8 | [2048,64,128,128] | 1024 | 0.4 |
| ✓ | ✓ | ✓ | 9 | [4096,128,256,128] | 2048 | 0.5 |
| ✓ | ✓ | 10 | [8192,256,256,256] | 8192 | 0.7 | |
| ✓ | 11 | [65536,512,512,256] | 65,536 | 0.8 |
| Default | 4 Layers | 5 Layers | 6 Layers | ||
|---|---|---|---|---|---|
| OA (%) MA (%) | 98.113 | 97.768 | 97.440 | 98.051 | |
| 92.463 | 96.417 | 93.832 | 96.925 | ||
| IoU per class (%) | 0 | 10.074 | 75.910 | 76.022 | 10.074 |
| 1 | 2.075 | 96.290 | 95.014 | 2.075 | |
| 2 | 98.072 | 97.932 | 96.420 | 98.072 | |
| 3 | 1.002 | 95.010 | 95.227 | 1.002 | |
| 4 | 64.213 | 80.009 | 98.092 | 64.213 | |
| 5 | 30.026 | 22.069 | 31.440 | 30.026 | |
| 6 | 0.000 | 0.000 | 0.000 | 0.000 | |
| 7 | 75.363 | 72.073 | 68.962 | 75.363 | |
| MIoU (%) | 35.103 | 67.412 | 70.147 | 65.547 | |
| Default | 4 Layers | 5 Layers | 6 Layers | ||
|---|---|---|---|---|---|
| OA (%) MA (%) | 87.019 | 88.581 | 97.533 | 96.870 | |
| 80.839 | 82.336 | 94.892 | 96.347 | ||
| IoU per class (%) | 0 | 21.031 | 65.915 | 85.072 | 82.007 |
| 1 | 0.000 | 0.000 | 0.000 | 0.000 | |
| 2 | 92.762 | 91.057 | 93.996 | 95.044 | |
| 3 | 71.091 | 75.002 | 70.671 | 69.200 | |
| 4 | 31.059 | 66.931 | 82.552 | 91.404 | |
| 6 | 11.12 | 62.448 | 83.683 | 83.726 | |
| 7 | 23.331 | 78.798 | 79.385 | 77.481 | |
| MIoU (%) | 35.771 | 62.879 | 70.766 | 71.266 | |
| Default | 4 Layers | 5 Layers | 6 Layers | ||
|---|---|---|---|---|---|
| OA (%) MA (%) | 94.385 | 98.662 | 99.283 | 95.979 | |
| 87.976 | 96.370 | 96.594 | 89.102 | ||
| IoU per class (%) | 0 | 75.092 | 95.281 | 92.001 | 91.085 |
| 1 | 80.270 | 90.310 | 92.312 | 89.271 | |
| MIoU (%) | 77.681 | 92.796 | 92.157 | 90.178 | |
| Default | 4 Layers | 5 Layers | 6 Layers | ||
|---|---|---|---|---|---|
| OA (%) MA (%) | 90.841 | 86.804 | 79.798 | 95.119 | |
| 61.948 | 63.124 | 65.798 | 82.106 | ||
| IoU per class (%) | 0 | 30.527 | 75.842 | 75.432 | 76.028 |
| 1 | 91.280 | 96.016 | 94.942 | 95.796 | |
| 2 | 97.248 | 97.019 | 96.022 | 97.751 | |
| 3 | 55.161 | 94.043 | 94.498 | 93.742 | |
| 4 | 64.142 | 79.554 | 98.059 | 64.119 | |
| 5 | 59.247 | 21.800 | 20.796 | 29.129 | |
| 6 | 0.000 | 0.000 | 0.000 | 0.000 | |
| 7 | 88.014 | 71.180 | 68.030 | 75.067 | |
| MIoU (%) | 65.183 | 69.959 | 70.911 | 71.289 | |
| Default | 4 Layers | 5 Layers | 6 Layers | ||
|---|---|---|---|---|---|
| OA (%) MA (%) | 66.383 | 74.731 | 73.503 | 71.715 | |
| 51.205 | 53.563 | 50.655 | 52.865 | ||
| IoU per class (%) | 0 | 50.889 | 65.035 | 64.734 | 71.432 |
| 1 | 0.000 | 0.000 | 0.000 | 0.000 | |
| 2 | 92.742 | 91.031 | 93.826 | 84.510 | |
| 3 | 90.898 | 74.449 | 70.571 | 68.253 | |
| 4 | 50.607 | 66.465 | 82.194 | 85.830 | |
| 6 | 30.522 | 62.012 | 75.475 | 73.352 | |
| 7 | 52.992 | 78.766 | 78.880 | 70.679 | |
| MIoU (%) | 57.224 | 72.321 | 77.081 | 75.372 | |
| Default | 4 Layers | 5 Layers | 6 Layers | ||
|---|---|---|---|---|---|
| OA (%) MA (%) | 94.956 | 91.418 | 95.169 | 88.608 | |
| 68.160 | 74.094 | 77.870 | 65.868 | ||
| IoU per classes (%) | 0 | 70.210 | 85.550 | 86.605 | 85.145 |
| 1 | 79.909 | 90.519 | 91.824 | 89.471 | |
| MIoU (%) | 74.903 | 87.999 | 89.176 | 87.281 | |
| Work | Technology | Source | Task | Model | Max. MIoU (%) |
|---|---|---|---|---|---|
| [23] | MLS | Real | Urban and transport scene segmentation | SEGCloud | 61.30 |
| [20] | MLS | Real | Road marking segmentation | PointNet++ | 63.35 |
| [22] | MLS | Real | Urban and transport scene segmentation | ARandLA-Net | 54.40 |
| [21] | ALS | Real | Urban scene segmentation | PointNet++ | 44.28 |
| [19] | MLS | Synthetic | Urban scene segmentation | SqueezeSegV2 | 44.90 |
| [24] | Synthetic | Urban scene segmentation | SEGCloud based | 39.97 | |
| (Ours) | MLS | HELIOS++ | Transport scene segmentation | PointNet++ based | 77.08 |
| Forest scene segmentation | 89.18 | ||||
| Synthetic | ROADSENSE | Transport scene segmentation | 71.27 | ||
| Forest scene segmentation | 92.80 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Comesaña-Cebral, L.; Martínez-Sánchez, J.; Seoane, A.N.; Arias, P. Transport Infrastructure Management Based on LiDAR Synthetic Data: A Deep Learning Approach with a ROADSENSE Simulator. Infrastructures 2024, 9, 58. https://doi.org/10.3390/infrastructures9030058
Comesaña-Cebral L, Martínez-Sánchez J, Seoane AN, Arias P. Transport Infrastructure Management Based on LiDAR Synthetic Data: A Deep Learning Approach with a ROADSENSE Simulator. Infrastructures. 2024; 9(3):58. https://doi.org/10.3390/infrastructures9030058
Chicago/Turabian StyleComesaña-Cebral, Lino, Joaquín Martínez-Sánchez, Antón Nuñez Seoane, and Pedro Arias. 2024. "Transport Infrastructure Management Based on LiDAR Synthetic Data: A Deep Learning Approach with a ROADSENSE Simulator" Infrastructures 9, no. 3: 58. https://doi.org/10.3390/infrastructures9030058
APA StyleComesaña-Cebral, L., Martínez-Sánchez, J., Seoane, A. N., & Arias, P. (2024). Transport Infrastructure Management Based on LiDAR Synthetic Data: A Deep Learning Approach with a ROADSENSE Simulator. Infrastructures, 9(3), 58. https://doi.org/10.3390/infrastructures9030058