The Influence of Competing Social and Symbolic Cues on Observers’ Gaze Behaviour


Abstract
1. Introduction
2. Experiment 1
2.1. Methods
2.1.1. Participants
2.1.2. Apparatus
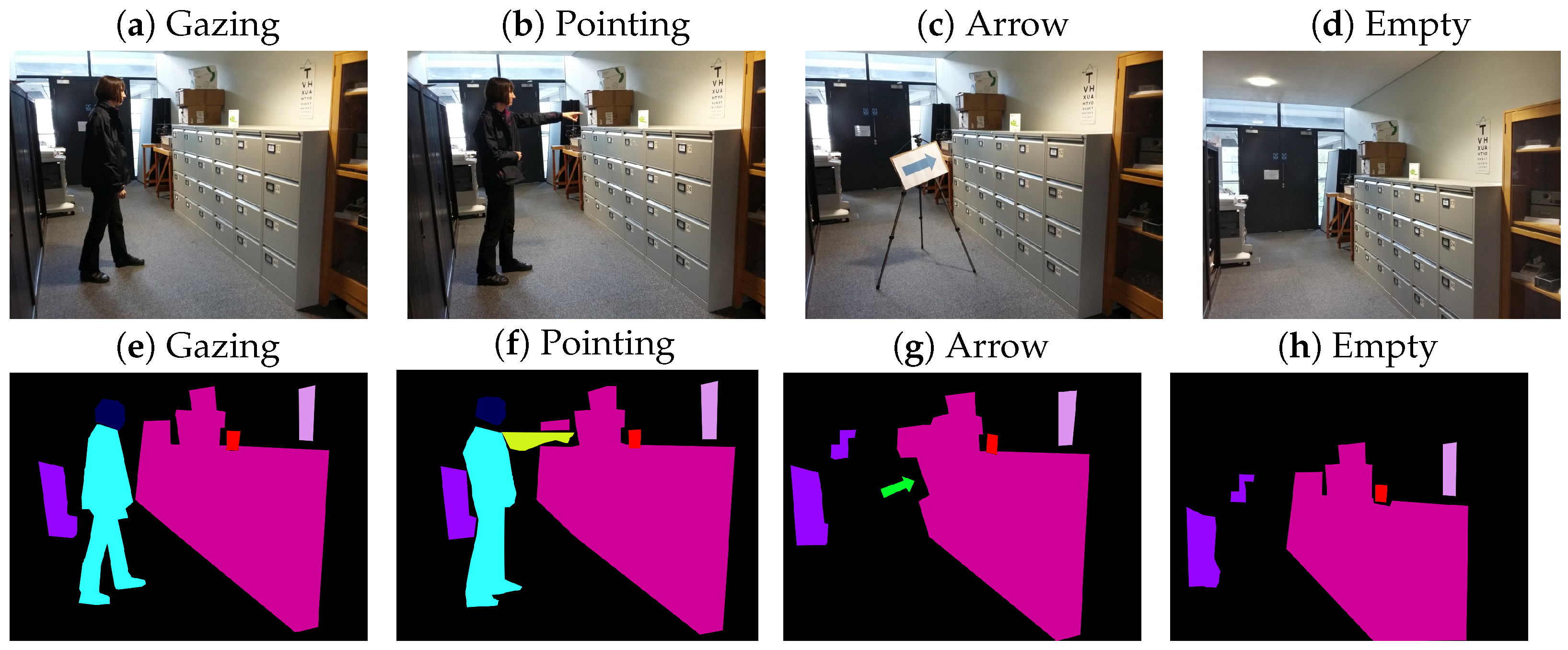
2.1.3. Stimuli
2.1.4. Design
2.1.5. Procedure
2.1.6. Data Analysis
2.2. Results
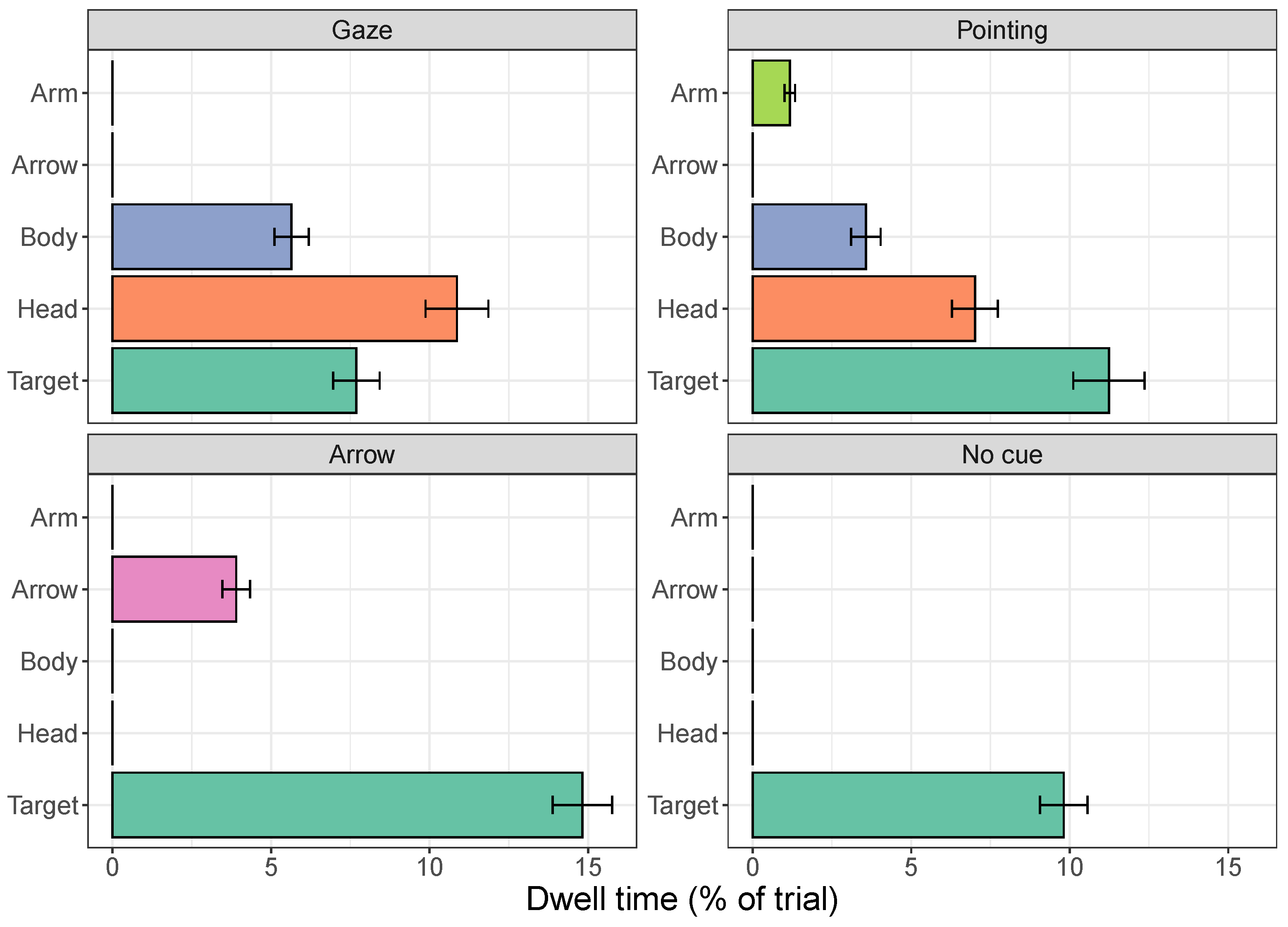
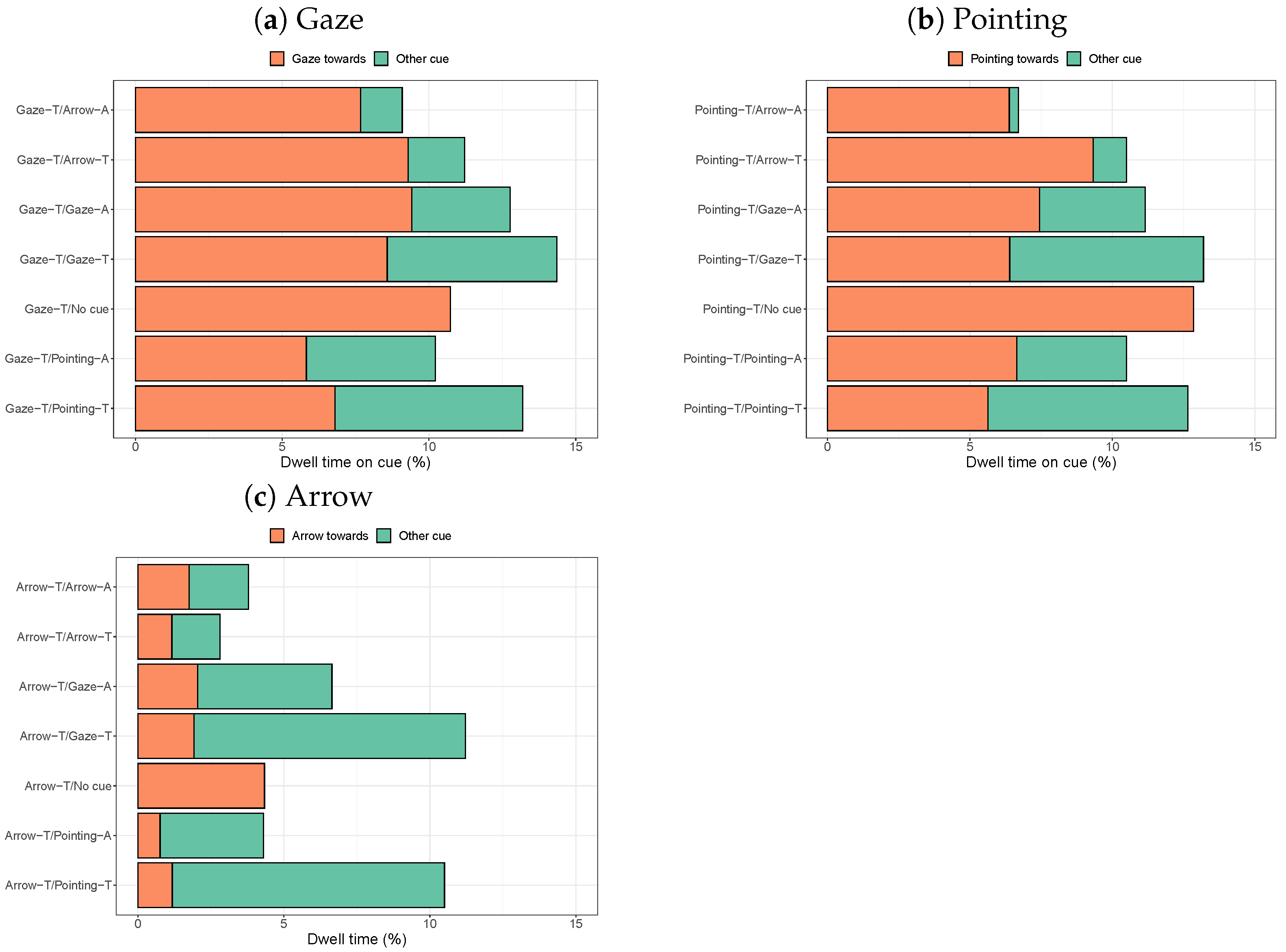
2.2.1. Dwell Times
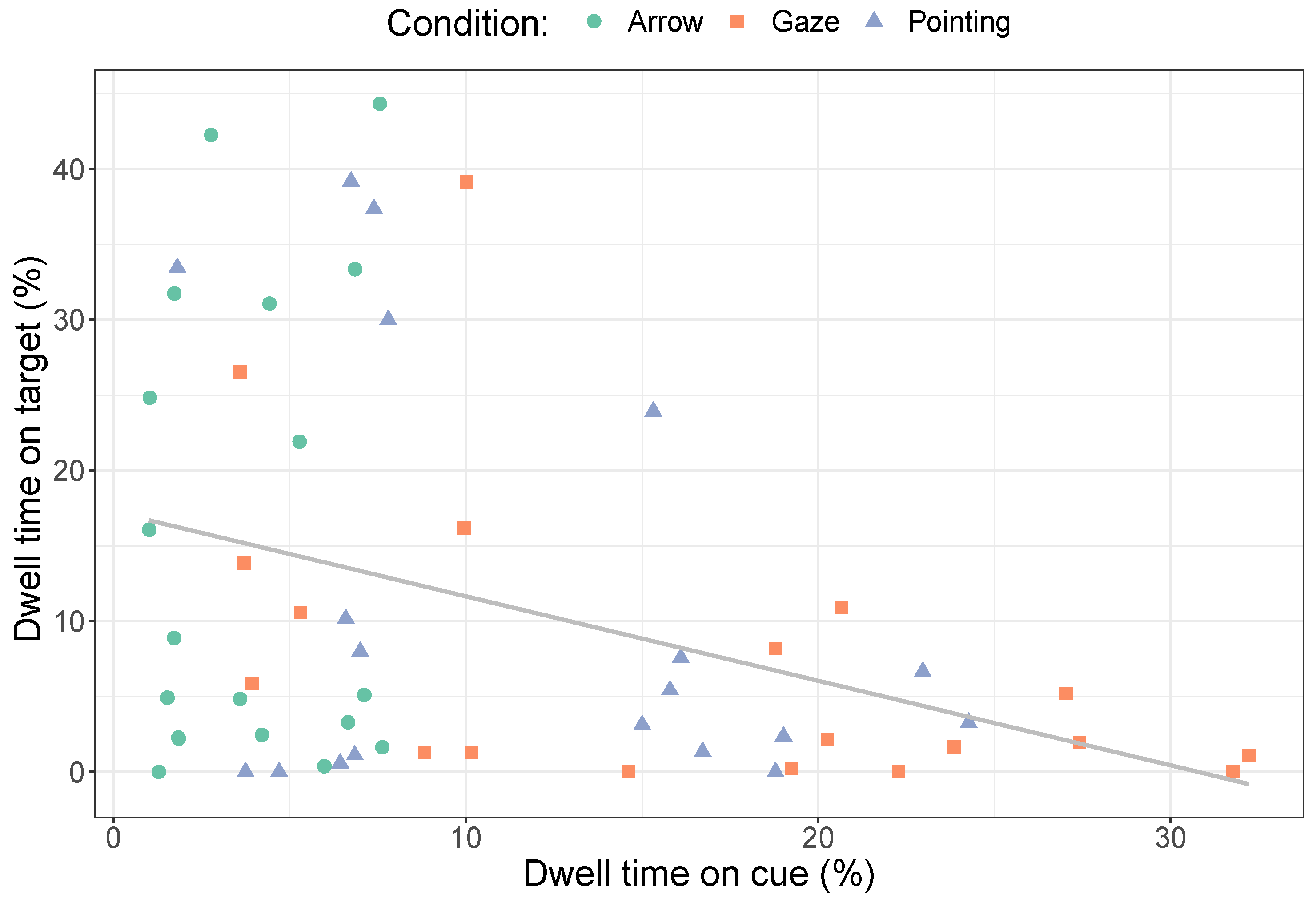
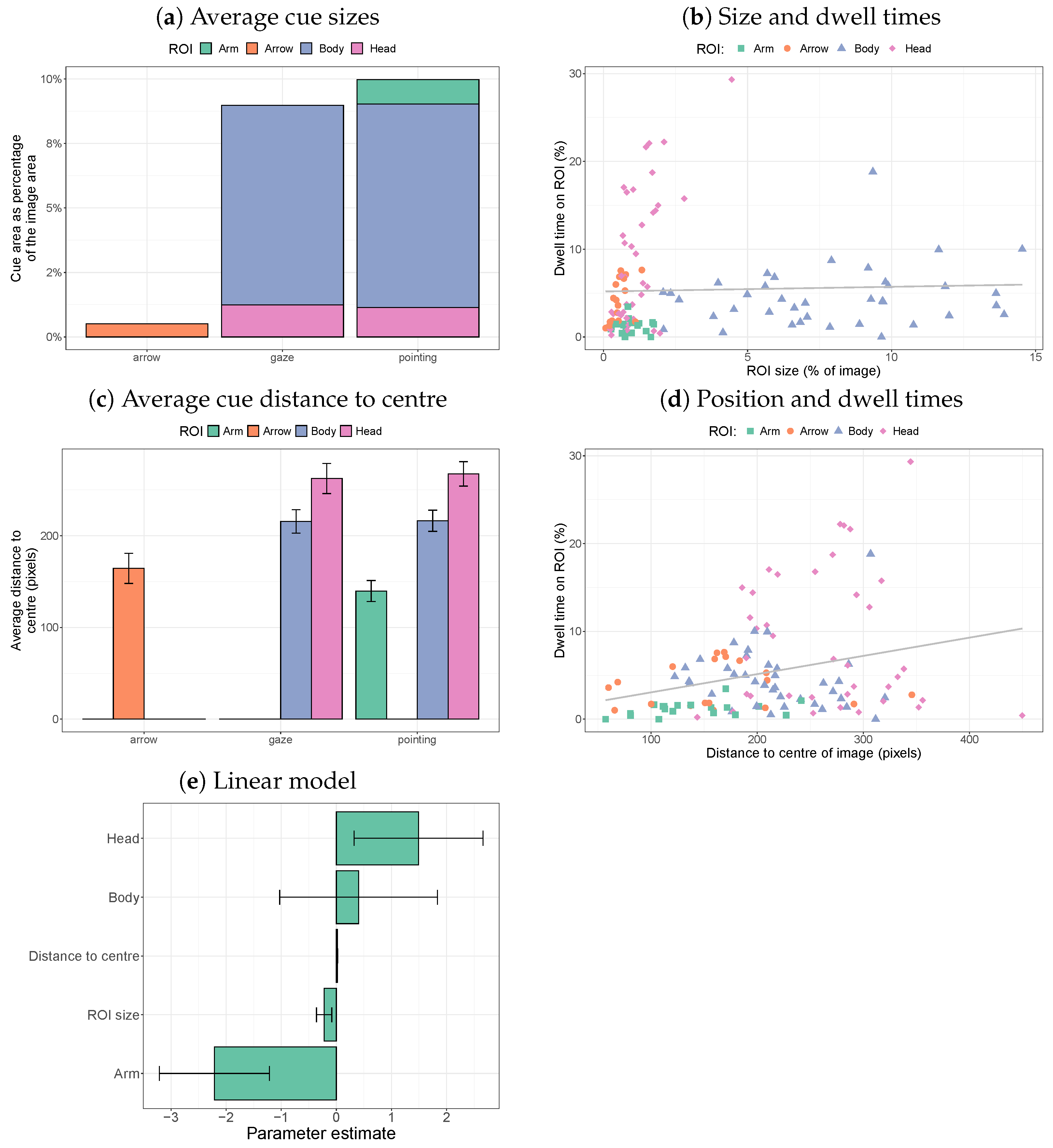
2.2.2. ROI Size and Position
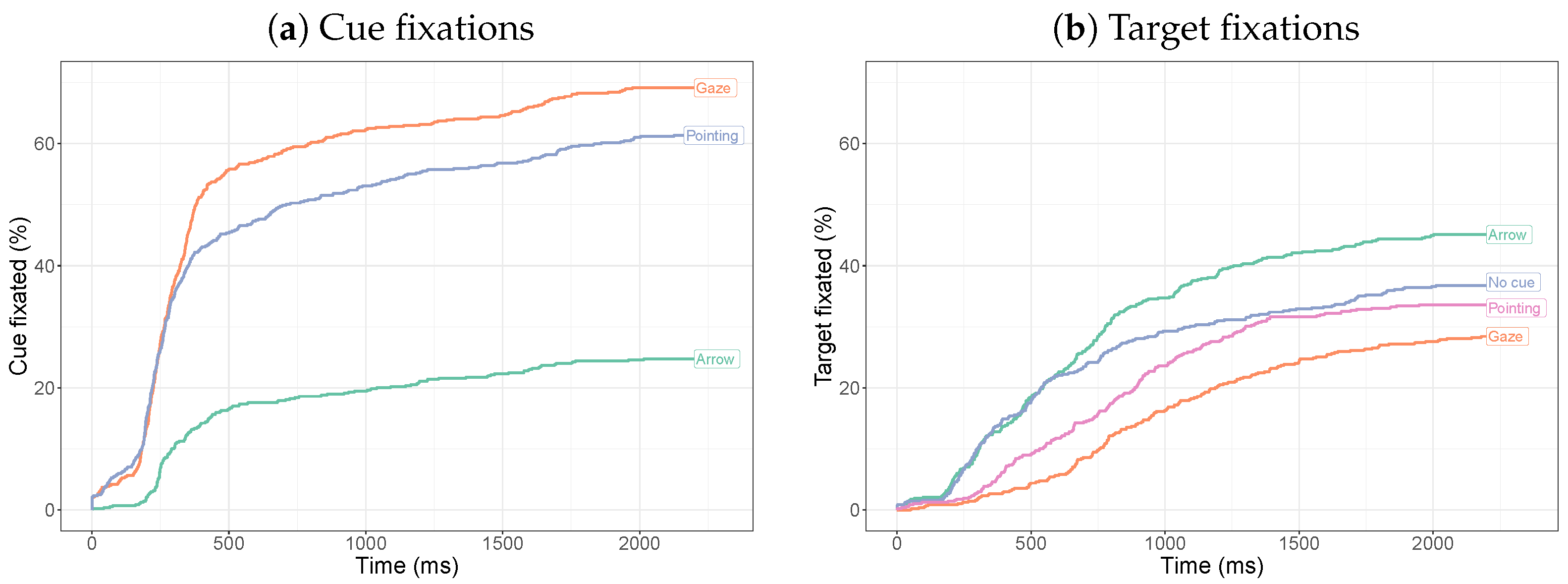
2.2.3. Time to First Fixation
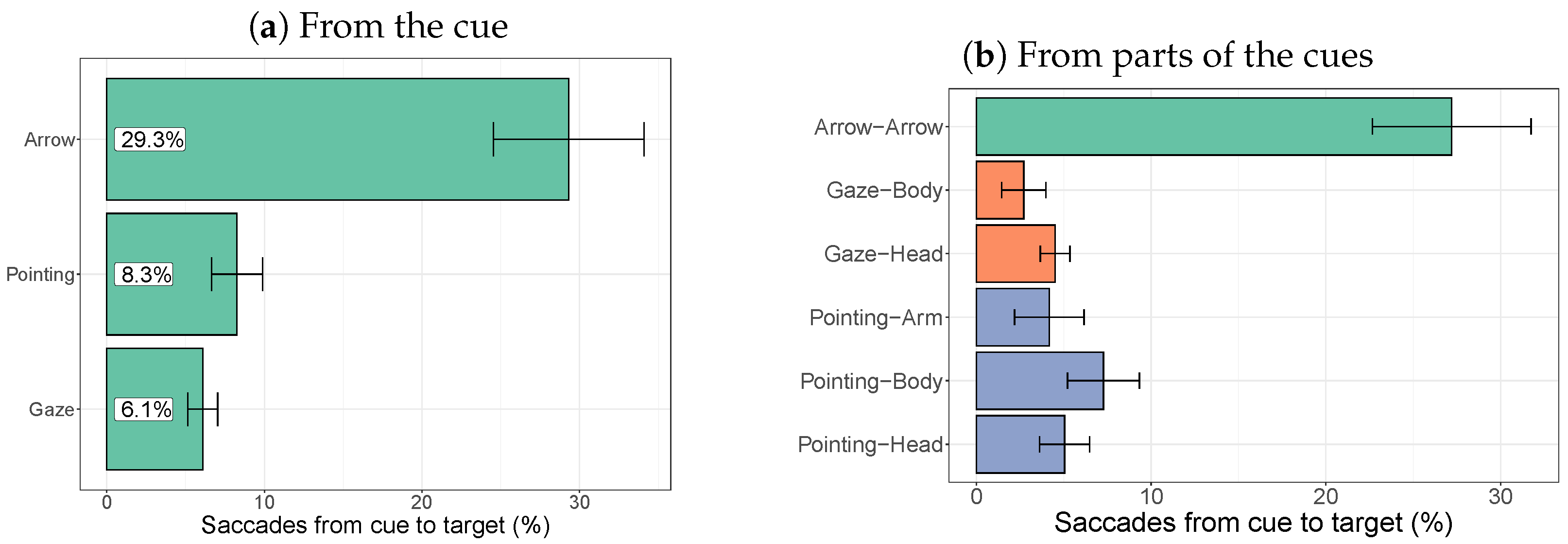
2.2.4. Target-Directed Saccades
2.3. Discussion
3. Experiment 2
3.1. Methods
3.2. Results
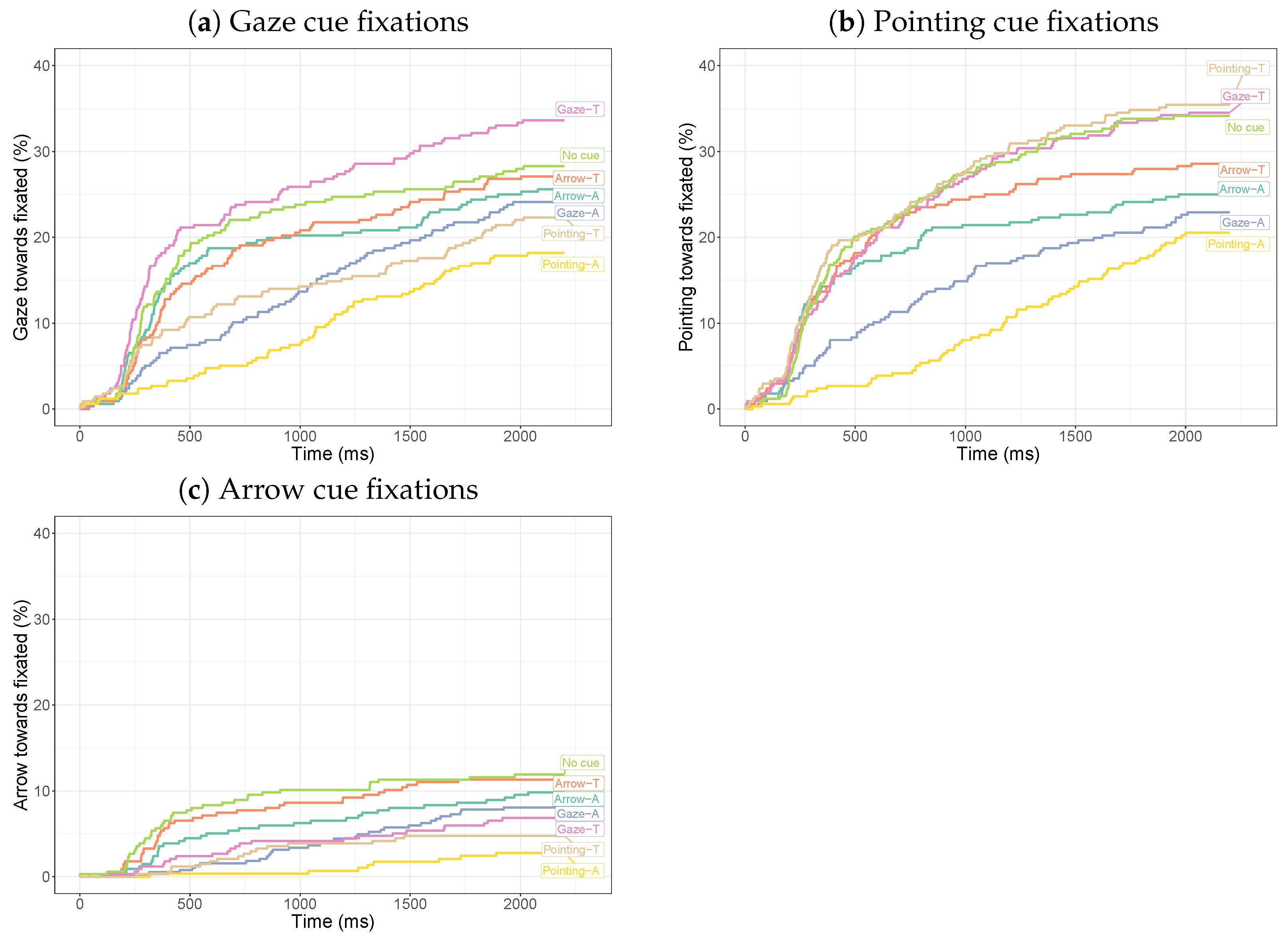
3.2.1. Dwell Times on Cues
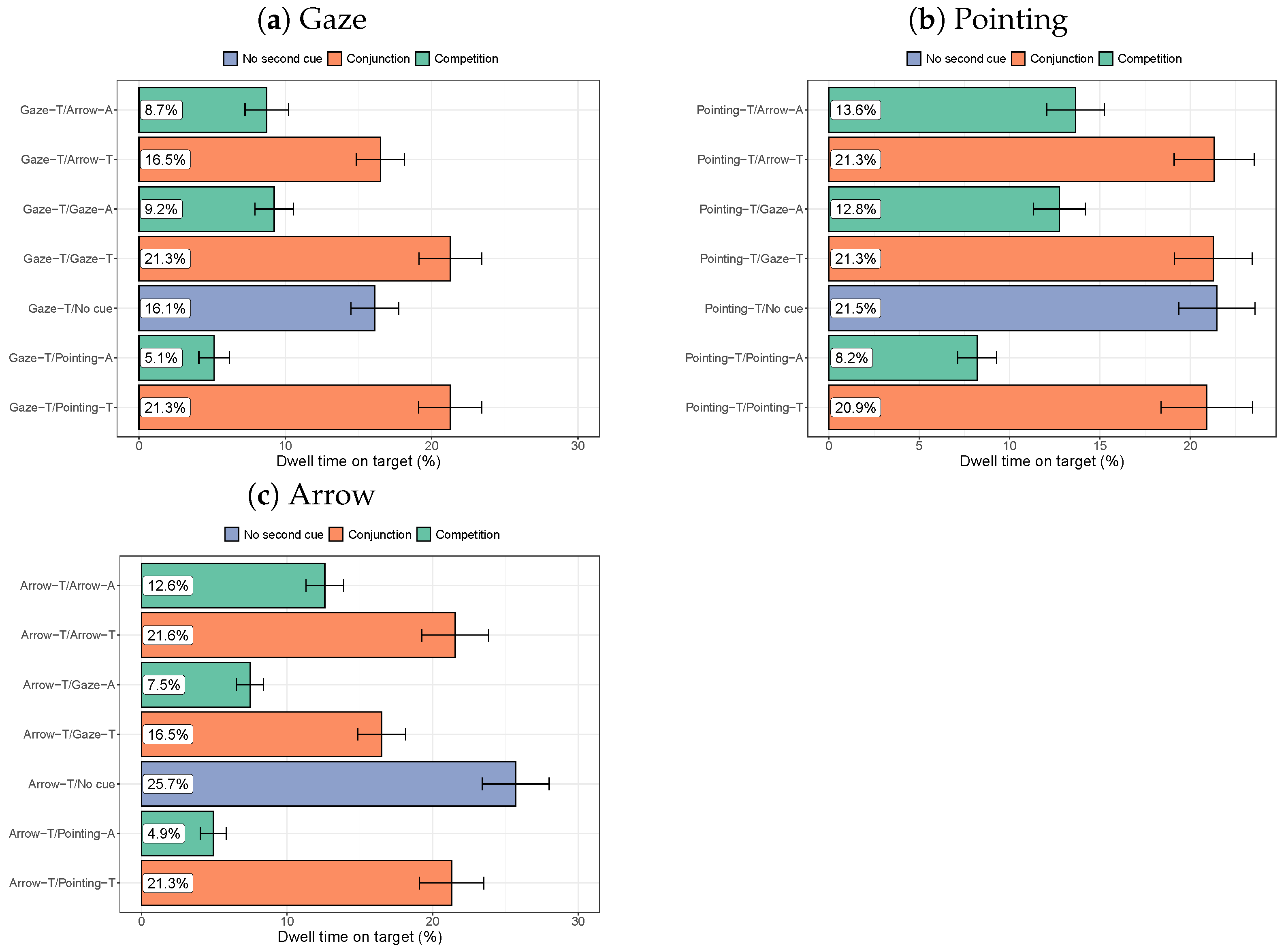
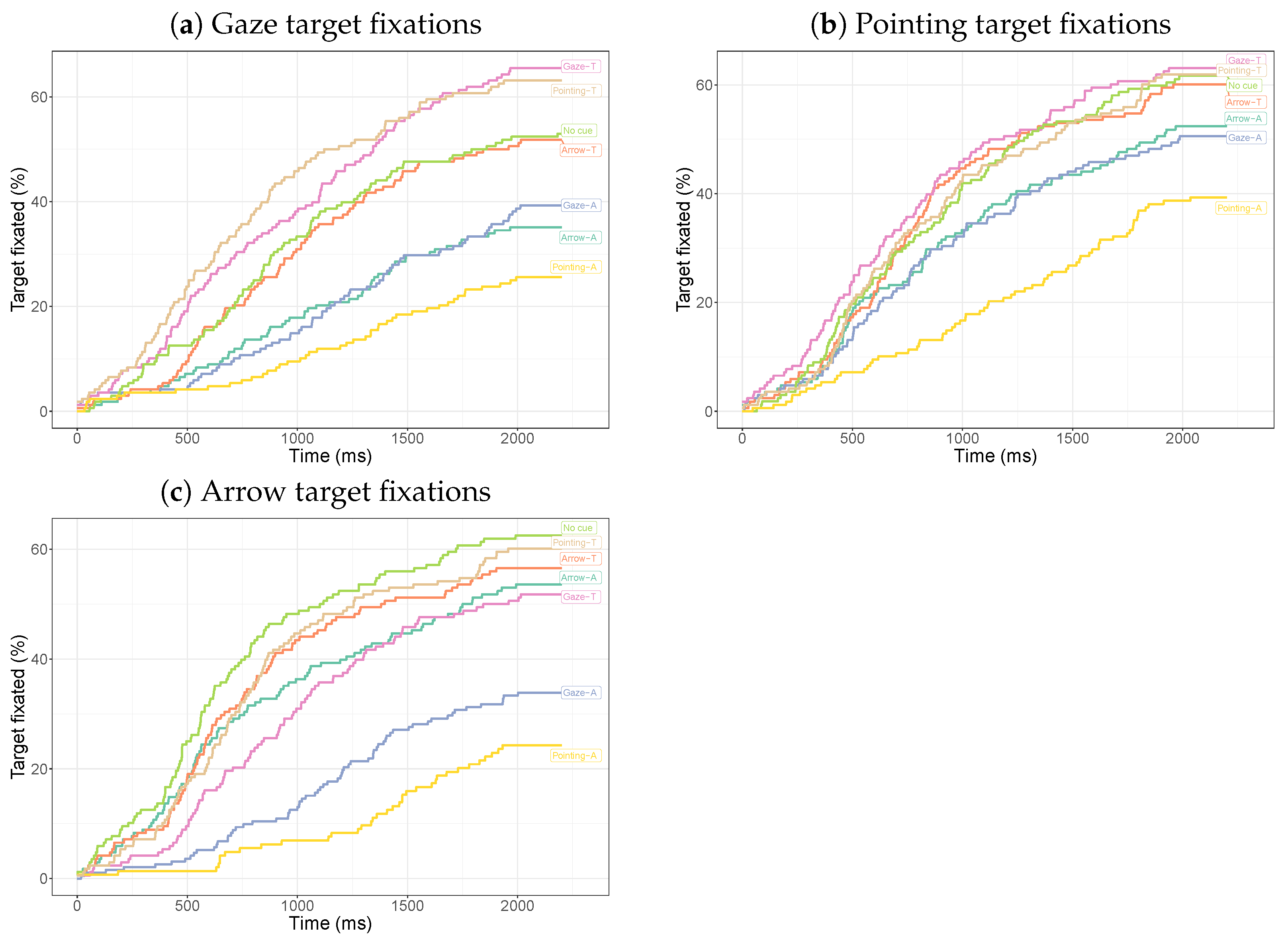
3.2.2. Dwell Times on the Target
3.2.3. Time to First Fixation
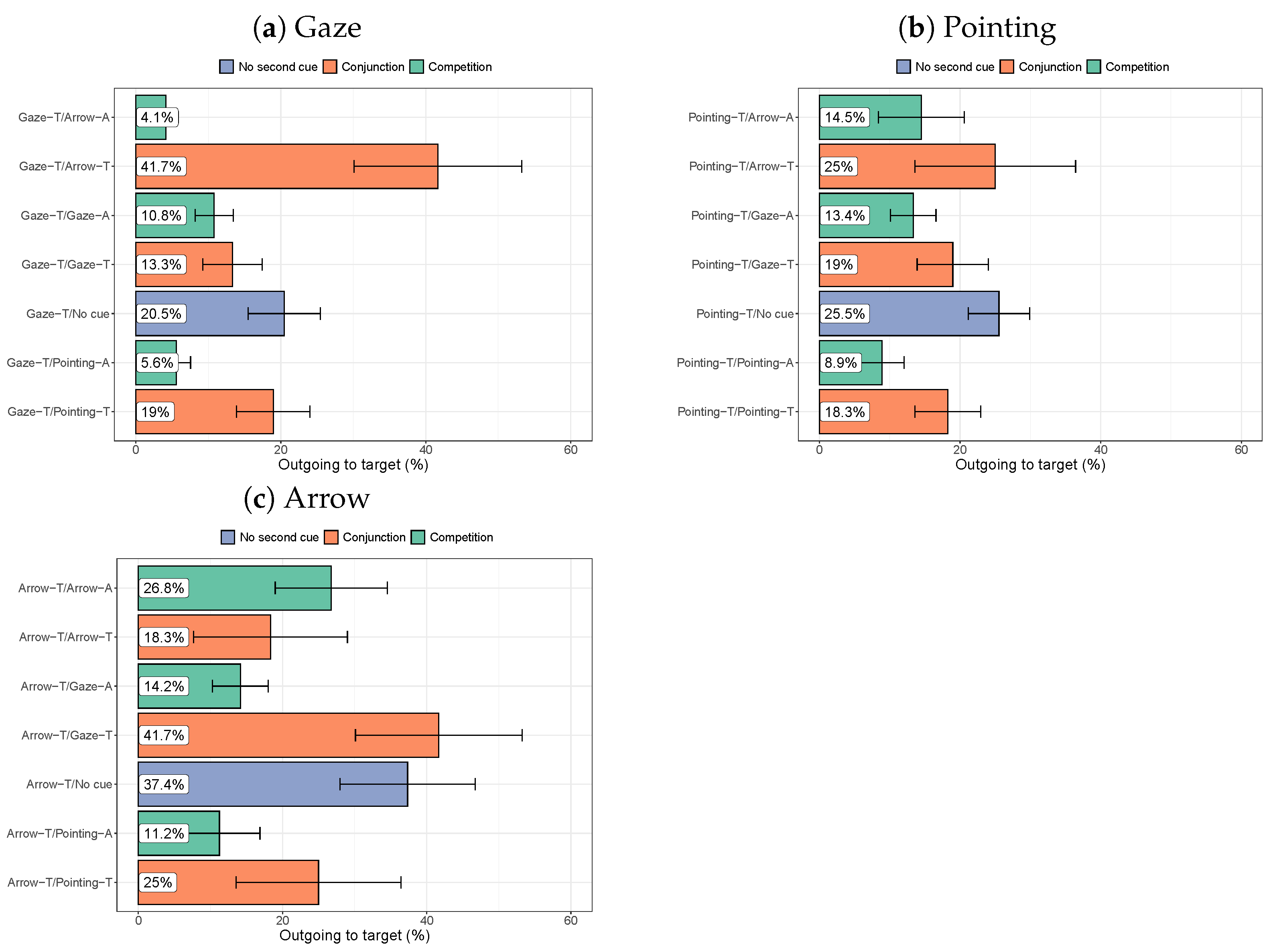
3.2.4. Target-Directed Saccades
3.3. Discussion
4. General Discussion
Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Posner, M.I. Orienting of attention. Q. J. Exp. Psychol. 1980, 32, 3–25. [Google Scholar] [CrossRef] [PubMed]
- Posner, M.I.; Cohen, Y. Components of visual orienting. Atten. Perform. X Control Lang. Process. 1984, 32, 531–556. [Google Scholar]
- Jonides, J. Voluntary versus automatic control over the mind’s eye’s movement. Atten. Perform. 1981, 87–203. [Google Scholar]
- Müller, H.J.; Rabbitt, P.M. Reflexive and voluntary orienting of visual attention: Time course of activation and resistance to interruption. J. Exp. Psychol. Hum. Percept. Perform. 1989, 15, 315. [Google Scholar] [CrossRef] [PubMed]
- Yantis, S.; Jonides, J. Abrupt visual onsets and selective attention: Evidence from visual search. J. Exp. Psychol. Hum. Percept. Perform. 1984, 10, 601. [Google Scholar] [CrossRef] [PubMed]
- Theeuwes, J.; Kramer, A.F.; Hahn, S.; Irwin, D.E. Our eyes do not always go where we want them to go: Capture of the eyes by new objects. Psychol. Sci. 1998, 9, 379–385. [Google Scholar] [CrossRef]
- Klein, R.M. Inhibition of return. Trends Cogn. Sci. 2000, 4, 138–147. [Google Scholar] [CrossRef] [PubMed]
- Driver, J.; Davis, G.; Ricciardelli, P.; Kidd, P.; Maxwell, E.; Baron-Cohen, S. Gaze Perception Triggers Reflexive Visuospatial Orienting. Vis. Cogn. 1999, 6, 509–540. [Google Scholar] [CrossRef]
- Friesen, C.K.; Kingstone, A. The eyes have it! Reflexive orienting is triggered by nonpredictive gaze. Psychon. Bull. Rev. 1998, 5, 490–495. [Google Scholar] [CrossRef]
- Friesen, C.K.; Ristic, J.; Kingstone, A. Attentional effects of counterpredictive gaze and arrow cues. J. Exp. Psychol. Hum. Percept. Perform. 2004, 30, 319. [Google Scholar] [CrossRef]
- Frischen, A.; Smilek, D.; Eastwood, J.D.; Tipper, S.P. Inhibition of return in response to gaze cues: The roles of time course and fixation cue. Vis. Cogn. 2007, 15, 881–895. [Google Scholar] [CrossRef]
- Baron-Cohen, S. The eye direction detector (EDD) and the shared attention mechanism (SAM): Two cases for evolutionary psychology. In Joint Attention: Its Origins and Role in Development; Moore, C., Dunham, P.J.E., Eds.; Lawrence Erlbaum Associates, Inc.: Mahwah, NJ, USA, 1995; pp. 71–79. [Google Scholar]
- Batki, A.; Baron-Cohen, S.; Wheelwright, S.; Connellan, J.; Ahluwalia, J. Is there an innate gaze module? Evidence from human neonates. Infant Behav. Dev. 2000, 23, 223–229. [Google Scholar] [CrossRef]
- Kuhn, G.; Tatler, B.W.; Cole, G.G. You look where I look! Effect of gaze cues on overt and covert attention in misdirection. Vis. Cogn. 2009, 17, 925–944. [Google Scholar] [CrossRef]
- Tipples, J. Eye gaze is not unique: Automatic orienting in response to uninformative arrows. Psychon. Bull. Rev. 2002, 9, 314–318. [Google Scholar] [CrossRef] [PubMed]
- Ristic, J.; Friesen, C.K.; Kingstone, A. Are eyes special? It depends on how you look at it. Psychon. Bull. Rev. 2002, 9, 507–513. [Google Scholar] [CrossRef]
- Ristic, J.; Wright, A.; Kingstone, A. Attentional control and reflexive orienting to gaze and arrow cues. Psychon. Bull. Rev. 2007, 14, 964–969. [Google Scholar] [CrossRef] [PubMed]
- Gibson, B.S.; Kingstone, A. Visual attention and the semantics of space: Beyond central and peripheral cues. Psychol. Sci. 2006, 17, 622–627. [Google Scholar] [CrossRef]
- Gibson, B.S.; Bryant, T.A. Variation in cue duration reveals top-down modulation of involuntary orienting to uninformative symbolic cues. Percept. Psychophys. 2005, 67, 749–758. [Google Scholar] [CrossRef]
- Tipples, J. Orienting to counterpredictive gaze and arrow cues. Percept. Psychophys. 2008, 70, 77–87. [Google Scholar] [CrossRef]
- Guzzon, D.; Brignani, D.; Miniussi, C.; Marzi, C. Orienting of attention with eye and arrow cues and the effect of overtraining. Acta Psychol. 2010, 134, 353–362. [Google Scholar] [CrossRef]
- Hommel, B.; Pratt, J.; Colzato, L.; Godijn, R. Symbolic control of visual attention. Psychol. Sci. 2001, 12, 360–365. [Google Scholar] [CrossRef]
- Vecera, S.P.; Rizzo, M. What are you looking at? Impaired ‘social attention’ following frontal-lobe damage. Neuropsychologia 2004, 42, 1657–1665. [Google Scholar] [CrossRef] [PubMed]
- Burton, A.M.; Bindemann, M.; Langton, S.R.; Schweinberger, S.R.; Jenkins, R. Gaze perception requires focused attention: Evidence from an interference task. J. Exp. Psychol. Hum. Percept. Perform. 2009, 35, 108–118. [Google Scholar] [CrossRef]
- Hermens, F. The effects of social and symbolic cues on visual search: Cue shape trumps biological relevance. Psihologija 2017, 50, 117–140. [Google Scholar] [CrossRef]
- Kingstone, A. Taking a real look at social attention. Curr. Opin. Neurobiol. 2009, 19, 52–56. [Google Scholar] [CrossRef] [PubMed]
- Birmingham, E.; Bischof, W.F.; Kingstone, A. Get real! Resolving the debate about equivalent social stimuli. Vis. Cogn. 2009, 17, 904–924. [Google Scholar] [CrossRef]
- Yarbus, A.L. Eye Movements and Vision; Springer: Greer, SC, USA, 1967. [Google Scholar] [CrossRef]
- Buswell, G.T. How People Look at Pictures: A Study of the Psychology and Perception in Art; University of Chicago Press: Chicago, IL, USA, 1935. [Google Scholar]
- Fletcher-Watson, S.; Findlay, J.M.; Leekam, S.R.; Benson, V. Rapid Detection of Person Information in a Naturalistic Scene. Perception 2008, 37, 571–583. [Google Scholar] [CrossRef]
- Hermens, F.; Walker, R. The influence of social and symbolic cues on observers’ gaze behaviour. Br. J. Psychol. 2015, 107, 484–502. [Google Scholar] [CrossRef]
- Fernandes, E.G.; Phillips, L.H.; Slessor, G.; Tatler, B.W. The interplay between gaze and consistency in scene viewing: Evidence from visual search by young and older adults. Attention Percept. Psychophys. 2021, 83, 1954–1970. [Google Scholar] [CrossRef]
- Zwickel, J.; Võ, M.L.H. How the presence of persons biases eye movements. Psychon. Bull. Rev. 2010, 17, 257–262. [Google Scholar] [CrossRef][Green Version]
- Bindemann, M.; Scheepers, C.; Ferguson, H.J.; Burton, A.M. Face, body, and center of gravity mediate person detection in natural scenes. J. Exp. Psychol. Hum. Percept. Perform. 2010, 36, 1477. [Google Scholar] [CrossRef] [PubMed]
- Tatler, B.W. The central fixation bias in scene viewing: Selecting an optimal viewing position independently of motor biases and image feature distributions. J. Vis. 2007, 7, 4. [Google Scholar] [CrossRef] [PubMed]
- Bates, D.; Mächler, M.; Bolker, B.; Walker, S. Fitting linear mixed-effects models using lme4. arXiv 2014, arXiv:1406.5823. [Google Scholar]
- Brysbaert, M. The Language-as-Fixed-Effect-Fallacy: Some Simple SPSS Solutions to a Complex Problem; Royal Holloway, University of London: London, UK, 2007. [Google Scholar]
- Birmingham, E.; Bischof, W.F.; Kingstone, A. Social Attention and Real-World Scenes: The Roles of Action, Competition and Social Content. Q. J. Exp. Psychol. 2008, 61, 986–998. [Google Scholar] [CrossRef] [PubMed]
- Birmingham, E.; Bischof, W.F.; Kingstone, A. Why do we look at people’s eyes? J. Eye Mov. Res. 2008, 1, 1–6. [Google Scholar] [CrossRef]
- Fletcher-Watson, S.; Leekam, S.; Benson, V.; Frank, M.; Findlay, J. Eye-movements reveal attention to social information in autism spectrum disorder. Neuropsychologia 2009, 47, 248–257. [Google Scholar] [CrossRef] [PubMed]
- Friesen, C.K.; Kingstone, A. Abrupt onsets and gaze direction cues trigger independent reflexive attentional effects. Cognition 2003, 87, B1–B10. [Google Scholar] [CrossRef] [PubMed]
- Tipper, C.M.; Handy, T.C.; Giesbrecht, B.; Kingstone, A. Brain Responses to Biological Relevance. J. Cogn. Neurosci. 2008, 20, 879–891. [Google Scholar] [CrossRef] [PubMed]
- Russell, B.C.; Torralba, A.; Murphy, K.P.; Freeman, W.T. LabelMe: A database and web-based tool for image annotation. Int. J. Comput. Vis. 2008, 77, 157–173. [Google Scholar] [CrossRef]
- Chen, X.; Mottaghi, R.; Liu, X.; Fidler, S.; Urtasun, R.; Yuille, A. Detect what you can: Detecting and representing objects using holistic models and body parts. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1971–1978. [Google Scholar]
- Park, S.; Aggarwal, J. Segmentation and tracking of interacting human body parts under occlusion and shadowing. In Proceedings of the Workshop on Motion and Video Computing, Orlando, FL, USA, 5–6 December 2002; IEEE: Piscataway, NJ, USA, 2002; pp. 105–111. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment Anything. arXiv 2023, arXiv:2304.02643. [Google Scholar]
- Engbert, R.; Kliegl, R. Microsaccades uncover the orientation of covert attention. Vis. Res. 2003, 43, 1035–1045. [Google Scholar] [CrossRef] [PubMed]
- Laubrock, J.; Kliegl, R.; Rolfs, M.; Engbert, R. When do microsaccades follow spatial attention? Atten. Percept. Psychophys. 2010, 72, 683–694. [Google Scholar] [CrossRef] [PubMed]
- Di Stasi, L.L.; Marchitto, M.; Antolí, A.; Cañas, J.J. Saccadic peak velocity as an alternative index of operator attention: A short review. Eur. Rev. Appl. Psychol. 2013, 63, 335–343. [Google Scholar] [CrossRef]
- Dalmaso, M.; Castelli, L.; Galfano, G. Attention holding elicited by direct-gaze faces is reflected in saccadic peak velocity. Exp. Brain Res. 2017, 235, 3319–3332. [Google Scholar] [CrossRef] [PubMed]
- Foulsham, T.; Kingstone, A. Are fixations in static natural scenes a useful predictor of attention in the real world? Can. J. Exp. Psychol. Can. Psychol. Expr. 2017, 71, 172. [Google Scholar] [CrossRef] [PubMed]
- Laidlaw, K.; Foulsham, T.; Kuhn, G.; Kingstone, A. Social attention to a live person is critically different than looking at a videotaped person. Proc. Natl. Acad. Sci. USA 2011, 108, 5548–5553. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Hermens, F. Fixation instruction influences gaze cueing. Vis. Cogn. 2015, 23, 432–449. [Google Scholar] [CrossRef][Green Version]
- Liu, L.; van Liere, R.; Nieuwenhuizen, C.; Martens, J.B. Comparing aimed movements in the real world and in virtual reality. In Proceedings of the 2009 IEEE Virtual Reality Conference, Atlanta, GA, USA, 14–18 March 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 219–222. [Google Scholar]
- Dong, W.; Qin, T.; Yang, T.; Liao, H.; Liu, B.; Meng, L.; Liu, Y. Wayfinding Behavior and Spatial Knowledge Acquisition: Are They the Same in Virtual Reality and in Real-World Environments? Ann. Am. Assoc. Geogr. 2022, 112, 226–246. [Google Scholar] [CrossRef]
- Gregory, N.J.; Antolin, J.V. Does social presence or the potential for interaction reduce social gaze in online social scenarios? Introducing the “live lab” paradigm. Q. J. Exp. Psychol. 2019, 72, 779–791. [Google Scholar] [CrossRef]
- Hermens, F.; Bindemann, M.; Burton, A.M. Responding to social and symbolic extrafoveal cues: Cue shape trumps biological relevance. Psychol. Res. 2015, 81, 24–42. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Combination | Cue 1 | Cue 2 | Number of Scenes |
|---|---|---|---|
| No cue | - | - | 7 |
| One cue | Arrow towards | - | 7 |
| Gaze towards | - | 7 | |
| Pointing towards | - | 7 | |
| Congruent | Arrow towards | Pointing towards | 7 |
| Arrow towards | Gaze towards | 7 | |
| Arrow towards | Arrow towards | 7 | |
| Gaze towards | Gaze towards | 7 | |
| Gaze towards | Pointing towards | 7 | |
| Pointing towards | Pointing towards | 7 | |
| Competition | Arrow towards | Pointing away | 7 |
| Arrow towards | Gaze away | 7 | |
| Arrow towards | Arrow away | 7 | |
| Arrow away | Pointing towards | 7 | |
| Arrow away | Gaze towards | 7 | |
| Gaze towards | Gaze away | 7 | |
| Pointing towards | Gaze away | 7 | |
| Pointing towards | Pointing away | 7 | |
| Pointing away | Gaze towards | 7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ioannidou, F.; Hermens, F. The Influence of Competing Social and Symbolic Cues on Observers’ Gaze Behaviour. Vision 2024, 8, 23. https://doi.org/10.3390/vision8020023
Ioannidou F, Hermens F. The Influence of Competing Social and Symbolic Cues on Observers’ Gaze Behaviour. Vision. 2024; 8(2):23. https://doi.org/10.3390/vision8020023
Chicago/Turabian StyleIoannidou, Flora, and Frouke Hermens. 2024. "The Influence of Competing Social and Symbolic Cues on Observers’ Gaze Behaviour" Vision 8, no. 2: 23. https://doi.org/10.3390/vision8020023
APA StyleIoannidou, F., & Hermens, F. (2024). The Influence of Competing Social and Symbolic Cues on Observers’ Gaze Behaviour. Vision, 8(2), 23. https://doi.org/10.3390/vision8020023