Satisfaction of Search Can Be Ameliorated by Perceptual Learning: A Proof-of-Principle Study


Abstract
1. Introduction
2. Experiment 1: Characterization of the Relationship between Perceptual Learning and SOS
2.1. Methods
2.1.1. Subjects
2.1.2. Stimuli
2.1.3. Task Paradigms
2.1.4. Camouflage Training Blocks
2.1.5. SOS Testing Blocks
2.2. Data Analysis
A Priori and Post Hoc Power Analyses
2.3. Results
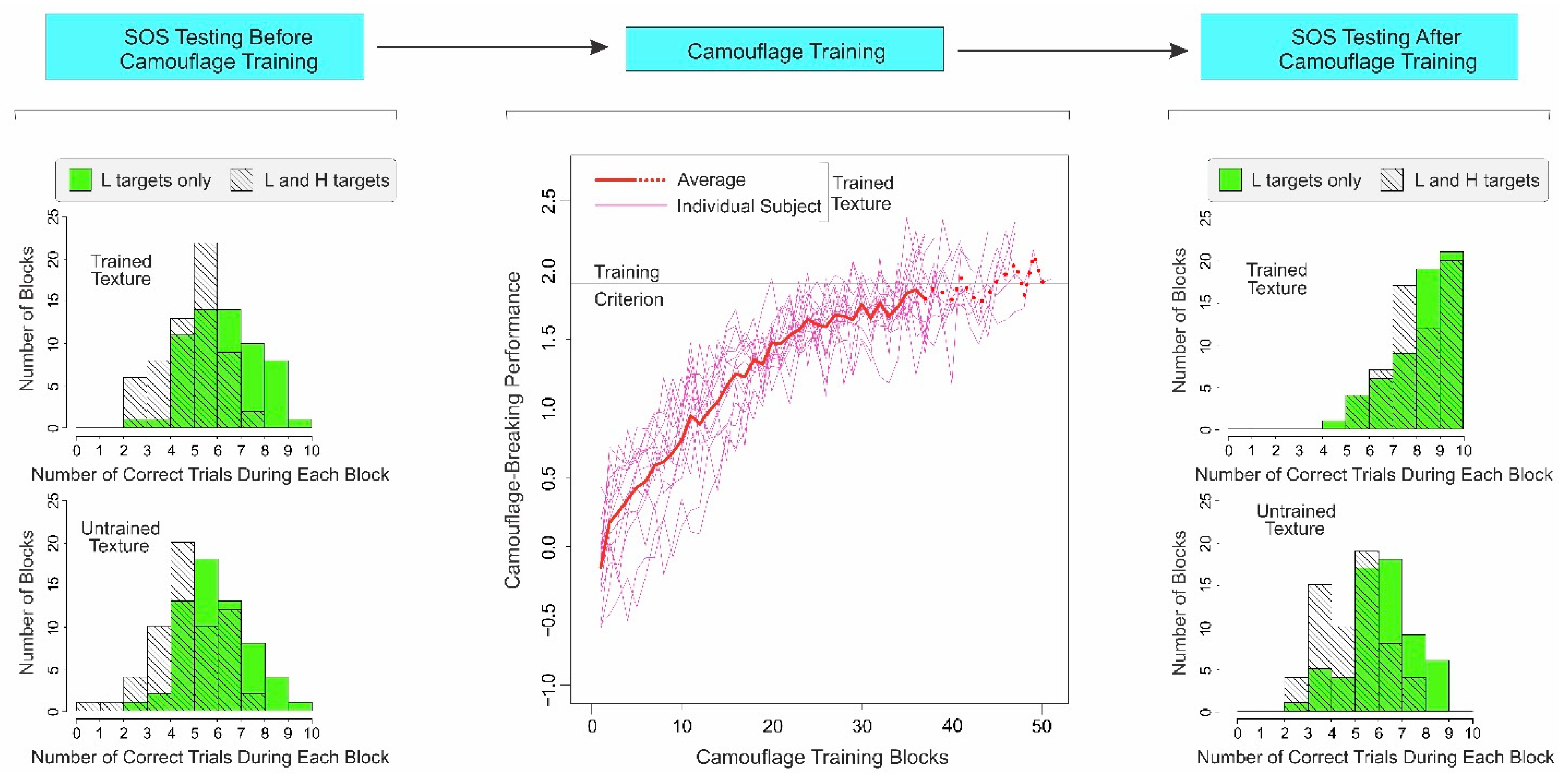
2.3.1. Subjects Show Substantial SOS before Camouflage Training
2.3.2. Camouflage-Breaking Performance Systematically Improves during Camouflage Training
2.3.3. After Camouflage Training, SOS Is Reduced for Trained Texture, and Not for Untrained Texture
2.4. Discussion
3. Experiment 2: Reduction in SOS Is Not Attributable to Non-Specific Learning and Other Exposure Effects
3.1. Methods
3.1.1. Subjects
3.1.2. Stimuli
3.1.3. SOS Testing Blocks
3.1.4. Camouflage Training Blocks
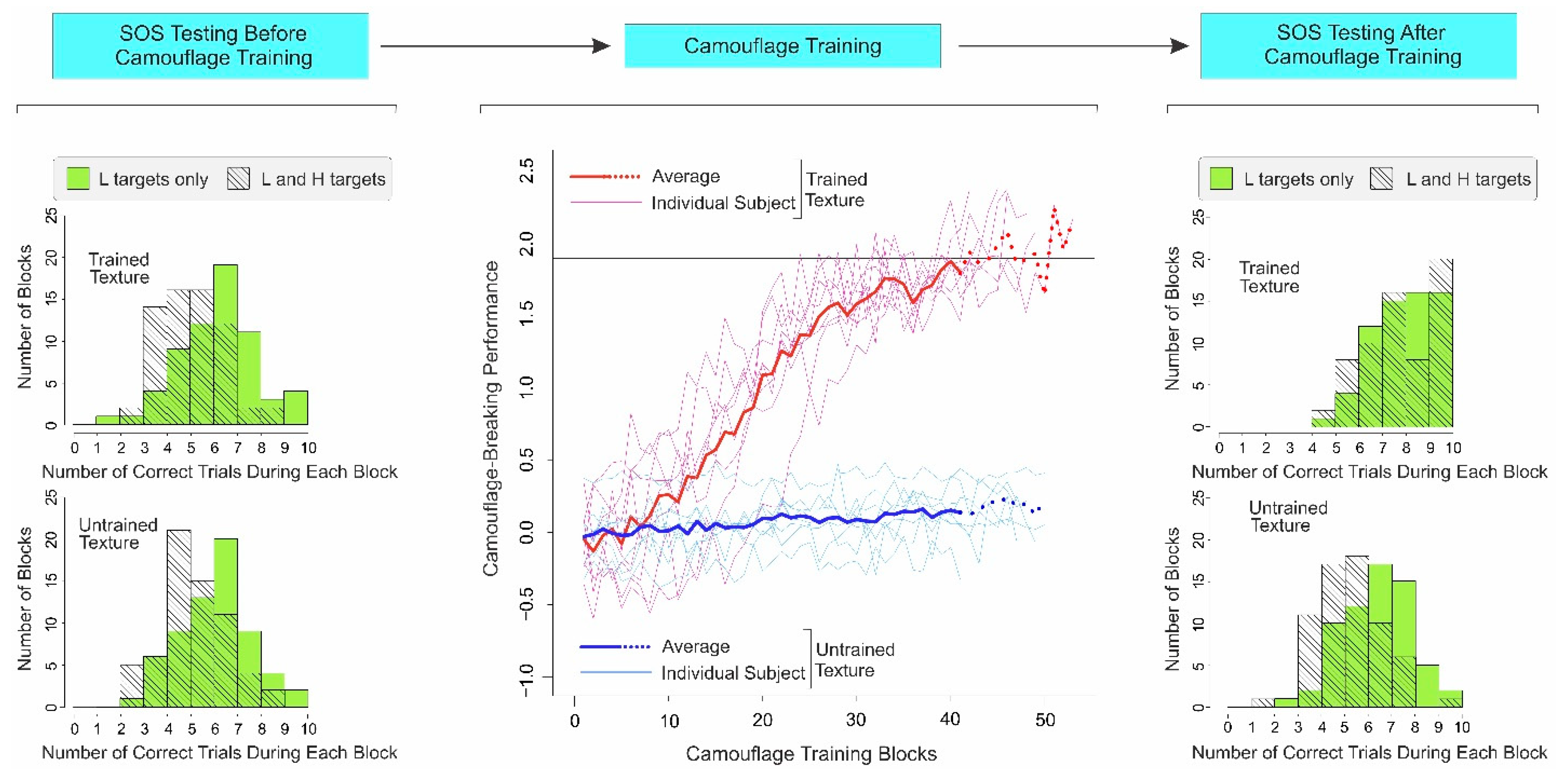
3.2. Results
Controlling for Exposure Effects of Camouflage Training
3.3. Discussion
4. General Discussion
4.1. Perceptual Learning Reduces SOS
4.2. How Generalizable Is Learning-Dependent SOS Reduction?
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Berbaum, K.S.; Franken, E.A., Jr.; Dorfman, D.D.; Rooholamini, S.A.; Kathol, M.H.; Barloon, T.J.; Behlke, F.M.; Sato, Y.; Lu, C.H.; el-Khoury, G.Y.; et al. Satisfaction of search in diagnostic radiology. Investig. Radiol. 1990, 25, 133–140. [Google Scholar] [CrossRef] [PubMed]
- Nodine, C.F.; Krupinski, E.A.; Kundel, H.L.; Toto, L.; Herman, G.T. Satisfaction of search (SOS). Investig. Radiol. 1992, 27, 571–573. [Google Scholar] [CrossRef]
- Rieskamp, J.; Hoffrage, U. Inferences under time pressure: How opportunity costs affect strategy selection. Acta Psychol. 2008, 127, 258–276. [Google Scholar] [CrossRef] [PubMed]
- Fleck, M.S.; Samei, E.; Mitroff, S.R. Generalized “satisfaction of search”: Adverse influences on dual-target search accuracy. J. Exp. Psychol. Appl. 2010, 16, 60–71. [Google Scholar] [CrossRef]
- Cain, M.S.; Adamo, S.H.; Mitroff, S.R. A taxonomy of errors in multiple-target visual search. Vis. Cogn. 2013, 21, 899–921. [Google Scholar] [CrossRef]
- Adamo, S.H.; Cox, P.H.; Kravitz, D.J.; Mitroff, S.R. How to correctly put the “subsequent” in subsequent search miss errors. Atten. Percept. Psychophys 2019, 81, 2648–2657. [Google Scholar] [CrossRef]
- Cain, M.S.; Vul, E.; Clark, K.; Mitroff, S.R. A bayesian optimal foraging model of human visual search. Psychol. Sci. 2012, 23, 1047–1054. [Google Scholar] [CrossRef]
- Connolly, K. Perceptual Learning. Stanf. Encycl. Philos. 2017. Available online: https://plato.stanford.edu/entries/perceptual-learning/ (accessed on 1 June 2022).
- Gibson, E.J. Perceptual learning. Annu. Rev. Psychol. 1963, 14, 29–56. [Google Scholar] [CrossRef]
- Goldstone, R.L. Perceptual learning. Annu. Rev. Psychol. 1998, 49, 585–612. [Google Scholar] [CrossRef]
- Fahle, M.; Poggio, T. Perceptual Learning; MIT Press: Cambridge, MA, USA, 2002; p. 455. [Google Scholar]
- Dosher, B.; Lu, Z.-L. Visual Perceptual Learning and Models. Annu. Rev. Vis. Sci. 2017, 3, 343–363. [Google Scholar] [CrossRef]
- Fahle, M.; Edelman, S.; Poggio, T. Fast perceptual learning in hyperacuity. Vis. Res. 1995, 35, 3003–3013. [Google Scholar] [CrossRef]
- Seitz, A.R. Perceptual learning. Curr. Biol. 2017, 27, R631–R636. [Google Scholar] [CrossRef] [PubMed]
- Gibson, J.J.; Gibson, E.J. Perceptual learning; differentiation or enrichment? Psychol. Rev. 1955, 62, 32–41. [Google Scholar] [CrossRef] [PubMed]
- Fahle, M.; Edelman, S. Long-term learning in vernier acuity: Effects of stimulus orientation, range and of feedback. Vis. Res. 1993, 33, 397–412. [Google Scholar] [CrossRef]
- Lobley, K.; Walsh, V. Perceptual learning in visual conjunction search. Perception 1998, 27, 1245–1255. [Google Scholar] [CrossRef]
- Sireteanu, R.; Rettenbach, R. Perceptual learning in visual search generalizes over tasks, locations, and eyes. Vis. Res. 2000, 40, 2925–2949. [Google Scholar] [CrossRef]
- Chun, M.M. Perceptual learning and memory in visual search. In From Perception to Consciousness: Searching with Anne Treisman; Wolfe, J., Robertson, L., Eds.; Oxford University Press: New York, NY, USA, 2012; pp. 227–236. [Google Scholar]
- Thayer, G.H. Camouflage in Nature and in War. Brooklyn Mus. Q. 1923, 10, 147–169. [Google Scholar]
- Cott, H.B. Camouflage. Adv. Sci. 1948, 4, 300–309. [Google Scholar]
- Brady, M.J.; Kersten, D. Bootstrapped learning of novel objects. J. Vis. 2003, 3, 413–422. [Google Scholar] [CrossRef]
- Cuthill, I.C.; Stevens, M.; Sheppard, J.; Maddocks, T.; Parraga, C.A.; Troscianko, T.S. Disruptive coloration and background pattern matching. Nature 2005, 434, 72–74. [Google Scholar] [CrossRef]
- Behrens, R.R. Revisiting Abbott Thayer: Non-scientific reflections about camouflage in art, war and zoology. Philos. Trans. R. Soc. B Biol. Sci. 2009, 364, 497–501. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Hegdé, J. Neural mechanisms of camouflage-breaking: A human fMRI study. J. Vis. 2012, 12, 582. [Google Scholar] [CrossRef]
- Branch, F.; Lewis, A.J.; Santana, I.N.; Hegde, J. Expert camouflage-breakers can accurately localize search targets. Cogn. Res. Princ. Implic. 2021, 6, 27. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Hegdé, J. Learning to break camouflage by learning the background. Psychol. Sci. 2012, 23, 1395–1403. [Google Scholar] [CrossRef]
- Sevilla, J.; Hegdé, J. “Deep” visual patterns are informative to practicing radiologists in mammograms in diagnostic tasks. J. Vis. 2017, 17, 90. [Google Scholar] [CrossRef]
- Streeb, N.; Chen, X.; Hegdé, J. Learning-dependent changes in brain responses while learning to break camouflage: A human fMRI study. J. Vis. 2012, 12, 1131. [Google Scholar] [CrossRef]
- Portilla, J.S.; Simoncelli, E.P. Texture modeling and synthesis using joint statistics of complex wavelet coefficients. In Proceedings of the IEEE Workshop on Statistical and Computational Theories of Vision, Fort Collins, CO, USA, 22 June 1999; pp. 1–32. [Google Scholar]
- Portilla, J.S.; Simoncelli, E.P. A Parametric Texture Model based on Joint Statistics of Complex Wavelet Coefficients. Int. J. Comput. Vis. 2000, 40, 49–71. [Google Scholar] [CrossRef]
- Hauffen, K.; Bart, E.; Brady, M.; Kersten, D.; Hegde, J. Creating objects and object categories for studying perception and perceptual learning. J. Vis. Exp. 2012, 69, e3358. [Google Scholar] [CrossRef]
- Green, D.M.; Swets, J.A. Signal Detection Theory and Psychophysics; Wiley: New York, NY, USA, 1966. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2019. [Google Scholar]
- Gallistel, C.R.; Fairhurst, S.; Balsam, P. The learning curve: Implications of a quantitative analysis. Proc. Natl. Acad. Sci. USA 2004, 101, 13124–13131. [Google Scholar] [CrossRef]
- Moriña, D.; Higueras, M.; Puig, P.; Oliveira Pérez, M. Generalized Hermite Distribution: Modelling with the R Package hermite. R. J. 2015, 7, 263–274. [Google Scholar] [CrossRef]
- Hegde, J. Deep learning can be used to train naïve, nonprofessional observers to detect diagnostic visual patterns of certain cancers in mammograms: A proof-of-principle study. J. Med. Imaging 2020, 7, 022410. [Google Scholar] [CrossRef]
- Rich, A.N.; Kunar, M.A.; Van Wert, M.J.; Hidalgo-Sotelo, B.; Horowitz, T.S.; Wolfe, J.M. Why do we miss rare targets? Exploring the boundaries of the low prevalence effect. J. Vis. 2008, 8, 11–17. [Google Scholar] [CrossRef] [PubMed]
- Park, E.; Branch, F.; Hegdé, J. Satisfaction of Search (Subsequent Search Miss) Can Be Ameliorated by Perceptual Learning. In Proceedings of the 31st Annual Convention of the Association for Psychological Science (APS), Washington, DC, USA, 25 May 2019. [Google Scholar]
- Wenger, M.J.; Copeland, A.M.; Bittner, J.L.; Thomas, R.D. Evidence for criterion shifts in visual perceptual learning: Data and implications. Percept. Psychophys 2008, 70, 1248–1273. [Google Scholar] [CrossRef]
- Schafer, R.; Vasilaki, E.; Senn, W. Perceptual learning via modification of cortical top-down signals. PLoS Comput. Biol. 2007, 3, e165. [Google Scholar] [CrossRef] [PubMed]
- Amitay, S.; Zhang, Y.X.; Jones, P.R.; Moore, D.R. Perceptual learning: Top to bottom. Vis. Res. 2014, 99, 69–77. [Google Scholar] [CrossRef]
- Aberg, K.C.; Herzog, M.H. Different types of feedback change decision criterion and sensitivity differently in perceptual learning. J. Vis. 2012, 12, 3. [Google Scholar] [CrossRef]
- Wolfe, J.M. When is it time to move to the next raspberry bush? Foraging rules in human visual search. J. Vis. 2013, 13, 10. [Google Scholar] [CrossRef] [PubMed]
- Bart, E.; Hegde, J. Deep Synthesis of Realistic Medical Images: A Novel Tool in Clinical Research and Training. Front. Neuroinform. 2018, 12, 82. [Google Scholar] [CrossRef]
- Hegdé, J.; Bart, E. Do different radiologists perceive medical images the same way? Some insights from Representational Similarity Analysis. Soc. Imaging Sci. Technol. 2019, 3, 1–6. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Condition Name | Description | Number of Trials per Block | Overall Prevalence |
|---|---|---|---|
| L target only (or ‘L-only’) | Image contained a single L target | 10 | ~16.7% |
| H target only | Image contained a single H target | 10 | ~16.7% |
| L and H targets (or ‘L-and-H’) | Image contained one L target and one H target (i.e., dual target image) | 10 | ~16.7% |
| No target | Image contained no target | 30 | 50% |
| Condition Name | Description | Number of Trials per Block | Overall Prevalence |
|---|---|---|---|
| L target only (or ‘L-only’) | Image contained a single L target | 10 | 25% |
| H target only | Image contained a single H target | 10 | 25% |
| L and H targets (or ‘L-and-H’) | Image contained one L target and one H target (i.e., dual target image) | 10 | 25% |
| No target | Image contained no target | 10 | 25% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, E.; Branch, F.; Hegdé, J. Satisfaction of Search Can Be Ameliorated by Perceptual Learning: A Proof-of-Principle Study. Vision 2022, 6, 49. https://doi.org/10.3390/vision6030049
Park E, Branch F, Hegdé J. Satisfaction of Search Can Be Ameliorated by Perceptual Learning: A Proof-of-Principle Study. Vision. 2022; 6(3):49. https://doi.org/10.3390/vision6030049
Chicago/Turabian StylePark, Erin, Fallon Branch, and Jay Hegdé. 2022. "Satisfaction of Search Can Be Ameliorated by Perceptual Learning: A Proof-of-Principle Study" Vision 6, no. 3: 49. https://doi.org/10.3390/vision6030049
APA StylePark, E., Branch, F., & Hegdé, J. (2022). Satisfaction of Search Can Be Ameliorated by Perceptual Learning: A Proof-of-Principle Study. Vision, 6(3), 49. https://doi.org/10.3390/vision6030049