Information Integration and Information Storage in Retinotopic and Non-Retinotopic Sensory Memory

Abstract
1. Introduction
2. Sequential Metacontrast and Feature Processing in Space and Time
2.1. Sequential Metacontrast
2.2. Visible Features of Invisible Targets
2.3. Non-Retinotopic Feature Integration and Stream Specificity
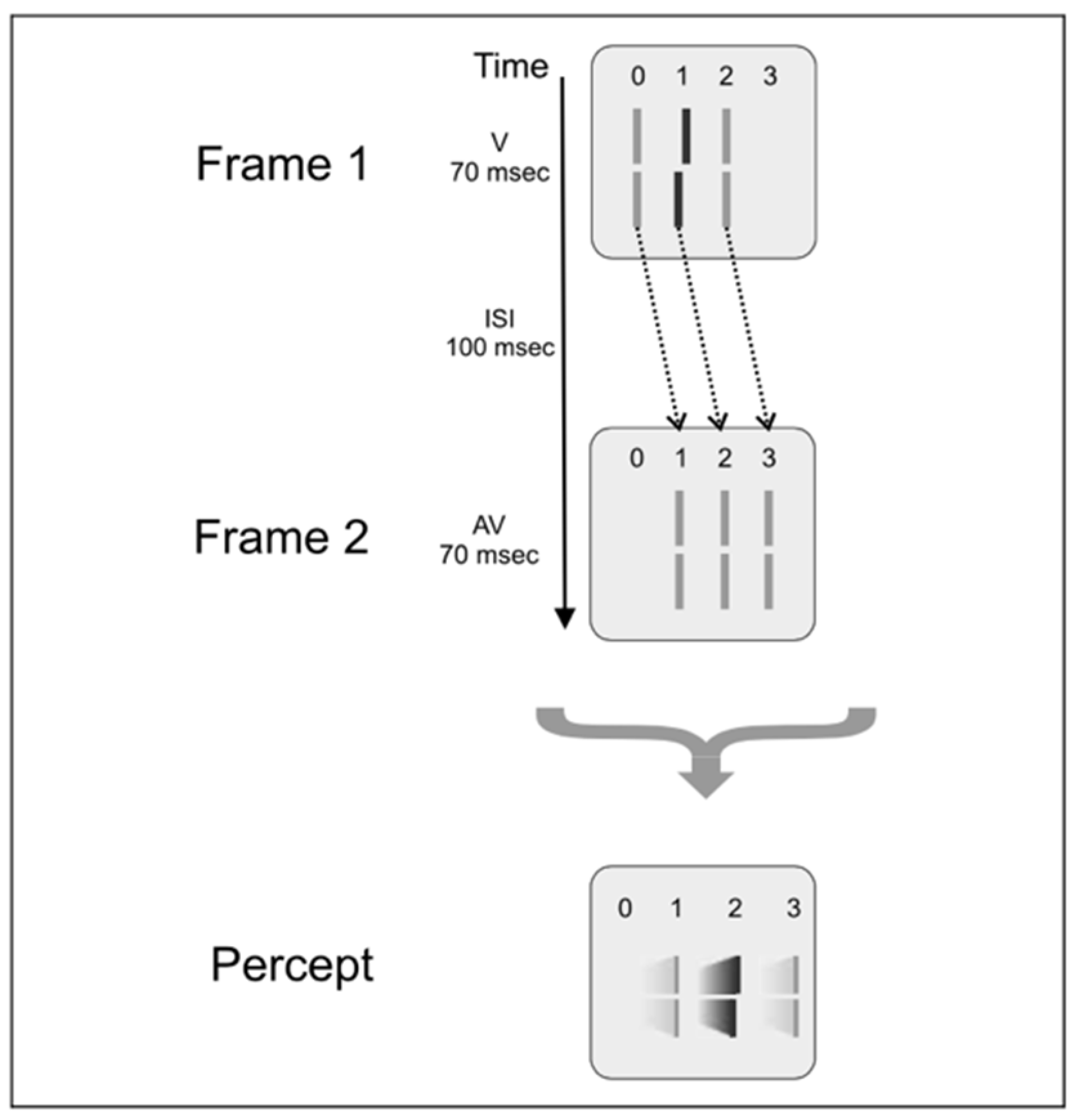
2.4. Feature Integration Is Approximately Linear
2.5. The Role of Attention and Mandatory Integration
2.6. “Object Identity” Established by Gestalt Grouping Controls Non-Retinotopic Feature Integration
2.7. Spatio-Temporal Extent of Feature Integration
3. Can rSM Be Dropped and Replaced Completely by nrSM?
4. A Quantitative Analysis of Memory Dynamics and Its Computational Implications
4.1. Ternus-Pikler Displays and Nonretinotopic Feature Integration
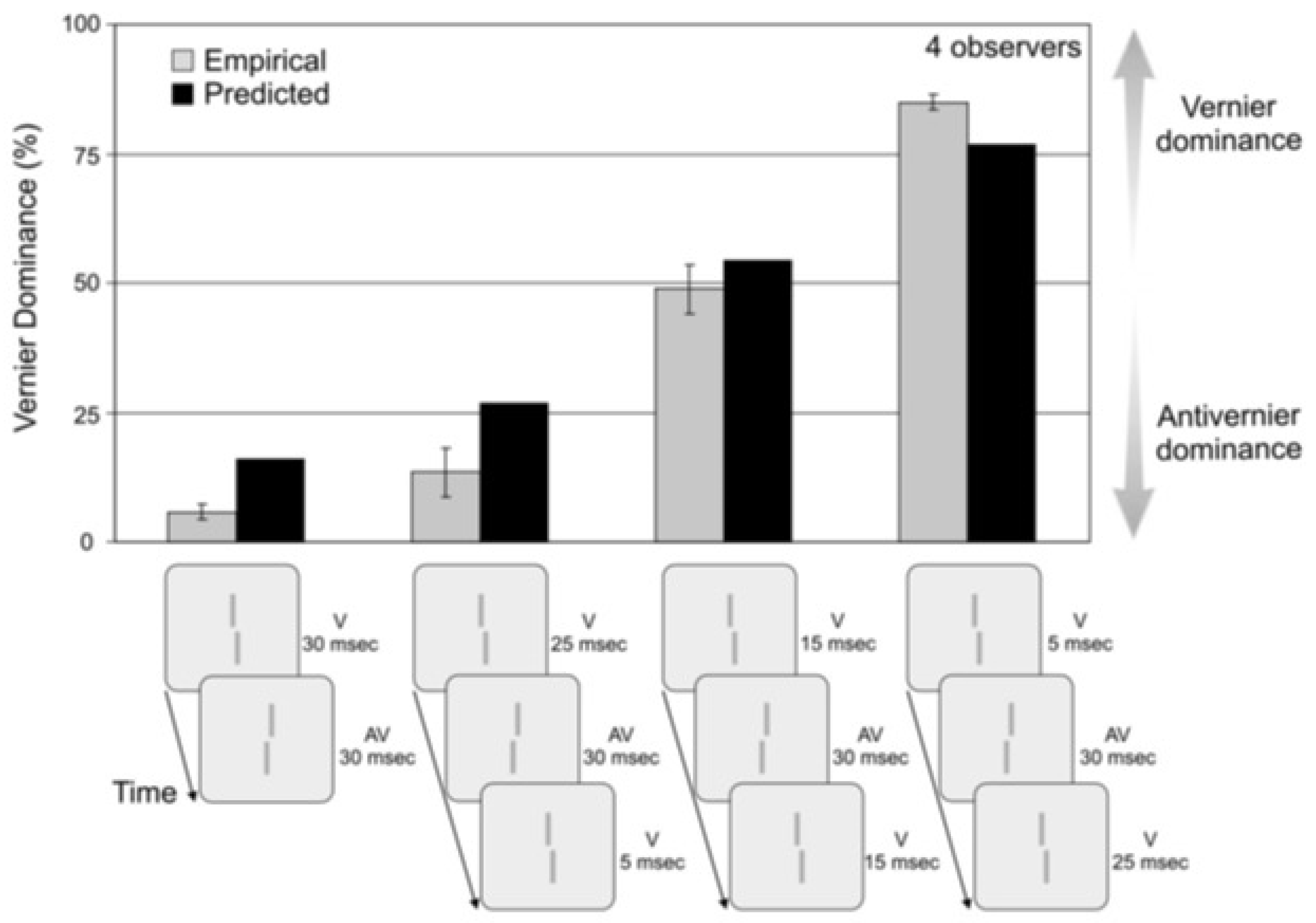
4.2. A Quantitative Analysis of Retinotopic and Non-Retinotopic Feature Integration
4.3. Retinotopic and Non-Retinotopic SM
5. Discussion and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Atkinson, R.C.; Shiffrin, R.M. Human memory: A proposed system and its control processes. In The psychology of Learning and Motivation; Spence, K.W., Spence, J.T., Eds.; Academic Press: New York, NY, USA, 1968; Volume 2, pp. 89–195. [Google Scholar]
- Haber, R.N. The impending demise of the icon: A critique of the concept of iconic storage in visual information processing. Behav. Brain Sci. 1983, 6, 1–11. [Google Scholar] [CrossRef]
- Ogmen, H.; Herzog, M.H. A new conceptualization of human sensory memory. Front. Psychol. 2016, 7, 830. [Google Scholar] [CrossRef]
- Noory, B.; Herzog, M.H.; Ogmen, H. Retinotopy of visual masking and non-retinotopic perception during masking. Atten. Percept. Psychophys. 2015, 77, 1263–1284. [Google Scholar] [CrossRef] [PubMed]
- Breitmeyer, B.G.; Ogmen, H. Visual Masking: Time Slices through Conscious and Unconscious Vision, 2nd ed.; Oxford University Press: Oxford, UK, 2006. [Google Scholar]
- Bachmann, T.; Francis, G. Visual Masking: Studying Perception, Attention, and Consciousness; Academic Press: Waltham, MA, USA, 2014. [Google Scholar]
- Piéron, H. Le processus du métacontraste. J. De Psychol. Norm. Et Pathol. 1935, 32, 5–24. [Google Scholar]
- Otto, T.U.; Ogmen, H.; Herzog, M.H. The flight path of the phoenix-the visible trace of invisible elements in human vision. J. Vis. 2006, 6, 1079–1086. [Google Scholar] [CrossRef]
- Efron, R. Conservation of temporal information by perceptual systems. Percept. Psychophys. 1973, 14, 518–530. [Google Scholar] [CrossRef]
- Bowen, R.W. Two pulses seen as three flashes: A superposition analysis. Vis. Res. 1989, 29, 409–417. [Google Scholar] [CrossRef]
- Purushothaman, G.; Ogmen, H.; Bedell, H.E. Suprathreshold intrinsic dynamics of the human visual system. Neural Comput. 2003, 15, 2883–2908. [Google Scholar] [CrossRef]
- Scharnowski, F.; Hermens, F.; Kammer, T.; Ogmen, H.; Herzog, M.H. Feature Fusion Reveals Slow and Fast Memories. J. Cogn. Neurosci. 2007, 19, 632–641. [Google Scholar] [CrossRef]
- Wutz, A.; Melcher, D. The temporal window of individuation limits visual capacity. Front. Psychol. 2014, 5, 952. [Google Scholar] [CrossRef]
- Otto, T.U.; Ogmen, H.; Herzog, M.H. Feature integration across space, time, and orientation. J. Exp. Psych. Hum. Percept. Perform. 2009, 6, 1670–1686. [Google Scholar] [CrossRef]
- Otto, T.U.; Ogmen, H.; Herzog, M.H. Attention and non-retinotopic feature integration. J. Vis. 2010, 10, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Treisman, A.; Gelade, G. A feature integration theory of attention. Cogn. Psychol. 1980, 12, 97–136. [Google Scholar] [CrossRef]
- Drissi-Daoudi, L.; Doerig, A.; Herzog, M.H. Feature integration within discrete time windows. Nat. Commun. 2019, 10, 1–8. [Google Scholar] [CrossRef]
- Drissi-Daoudi, L.; Ogmen, H.; Herzog, M.H. Features integrate along a motion trajectory when object integrity is preserved. J. Vis. 2021, 21, 4. [Google Scholar] [CrossRef]
- Herzog, M.H.; Drissi-Daoudi, L.; Doerig, A. All in Good Time: Long-Lasting Postdictive Effects Reveal Discrete Perception. TICS 2020, 24, 826–837. [Google Scholar] [CrossRef]
- Burr, D. Motion smear. Nature 1980, 284, 164–165. [Google Scholar] [CrossRef]
- McDougall, W. The sensations excited by a single momentary stimulation of the eye. Br. J. Psychol. 1904, 1, 78–113. [Google Scholar] [CrossRef]
- Dixon, N.F.; Hammond, E.J. The attenuation of visual persistence. Br. J. Psychol. 1972, 63, 243–254. [Google Scholar] [CrossRef] [PubMed]
- Di Lollo, V.; Hogben, J.H. Suppression of visible persistence. J. Exp. Psychol. Hum. Percept. Perform. 1985, 11, 304–316. [Google Scholar] [CrossRef] [PubMed]
- Farrell, J.E.; Pavel, M.; Sperling, G. The visible persistence of stimuli in stroboscopic motion. Vis. Res. 1990, 30, 921–936. [Google Scholar] [CrossRef]
- Castet, E. Effect of the ISI on the visible persistence of a stimulus in apparent motion. Vis. Res. 1994, 34, 2103–2114. [Google Scholar] [CrossRef]
- Chen, S.; Bedell, H.E.; Ogmen, H. A target in real motion appears blurred in the absence of other proximal moving targets. Vis. Res. 1995, 35, 2315–2328. [Google Scholar] [CrossRef]
- Ternus, J. Experimentelle Untersuchung über phänomenale Identität. Psychol. Forsch. 1926, 7, 81–136. [Google Scholar] [CrossRef]
- Pikler, J. Sinnesphysiologische Untersuchungen; Barth: Leipzig, Germany, 1917. [Google Scholar]
- Pantle, A.; Picciano, L. A multistable movement display: Evidence for two separate motion systems in human vision. Science 1976, 193, 500–502. [Google Scholar] [CrossRef]
- Grossberg, S. Nonlinear neural networks: Principles, mechanisms, and architectures. Neural Netw. 1988, 1, 17–61. [Google Scholar] [CrossRef]
- Coltheart, M. Iconic memory and visible persistence. Percep. Psychophys. 1980, 27, 183–228. [Google Scholar] [CrossRef]
- Korte, A. Kinematoskopische Untersuchungen [Cinematoscopic investigations]. Z. Für Psychol. 1915, 72, 193–296. (In German) [Google Scholar]
- Kolers, P.A. Aspects of Motion Perception; Pergamon Press: Oxford, UK, 1972. [Google Scholar]
- Neuhaus, W. Experimentelle Untersuchung der Scheinbewegung. Arch. Fur Diegesamte Psychol. 1930, 75, 315–458. [Google Scholar]
- Rüter, J.; Marcille, N.; Sprekeler, H.; Gerstner, W.; Herzog, M.H. Paradoxical evidence integration in rapid decision processes. PLoS Comput. Biol. 2012, 8, e1002382. [Google Scholar] [CrossRef]
- Rüter, J.; Sprekeler, H.; Gerstner, W.; Herzog, M.H. The silent period of evidence integration in fast decision making. PLoS ONE 2013, 8, e46525. [Google Scholar] [CrossRef] [PubMed]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensory Memory Type | Reference-Frame | Retention Period | Maskable? | Sensitive to Gestalt Grouping and Object Identity? | Robust Across Saccades? | Tuned For |
|---|---|---|---|---|---|---|
| rSM (traditional sensory/iconic memory) | Retinotopic | Varies with stimulus conditions such as background luminance but in general in the order of 100 ms | Yes | No | No | Static (or stabilized) stimuli during fixations and smooth pursuit |
| nrSM | Non-retinotopic | Longer than rSM and can extend to ca. 450 ms | No | Yes | Yes | Dynamic stimuli, in particular moving stimuli that preserve their spatiotemporal identity |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Öğmen, H.; Herzog, M.H. Information Integration and Information Storage in Retinotopic and Non-Retinotopic Sensory Memory. Vision 2021, 5, 61. https://doi.org/10.3390/vision5040061
Öğmen H, Herzog MH. Information Integration and Information Storage in Retinotopic and Non-Retinotopic Sensory Memory. Vision. 2021; 5(4):61. https://doi.org/10.3390/vision5040061
Chicago/Turabian StyleÖğmen, Haluk, and Michael H. Herzog. 2021. "Information Integration and Information Storage in Retinotopic and Non-Retinotopic Sensory Memory" Vision 5, no. 4: 61. https://doi.org/10.3390/vision5040061
APA StyleÖğmen, H., & Herzog, M. H. (2021). Information Integration and Information Storage in Retinotopic and Non-Retinotopic Sensory Memory. Vision, 5(4), 61. https://doi.org/10.3390/vision5040061