Salience Models: A Computational Cognitive Neuroscience Review


{kind=link}
{kind=link}
Abstract
1. Introduction
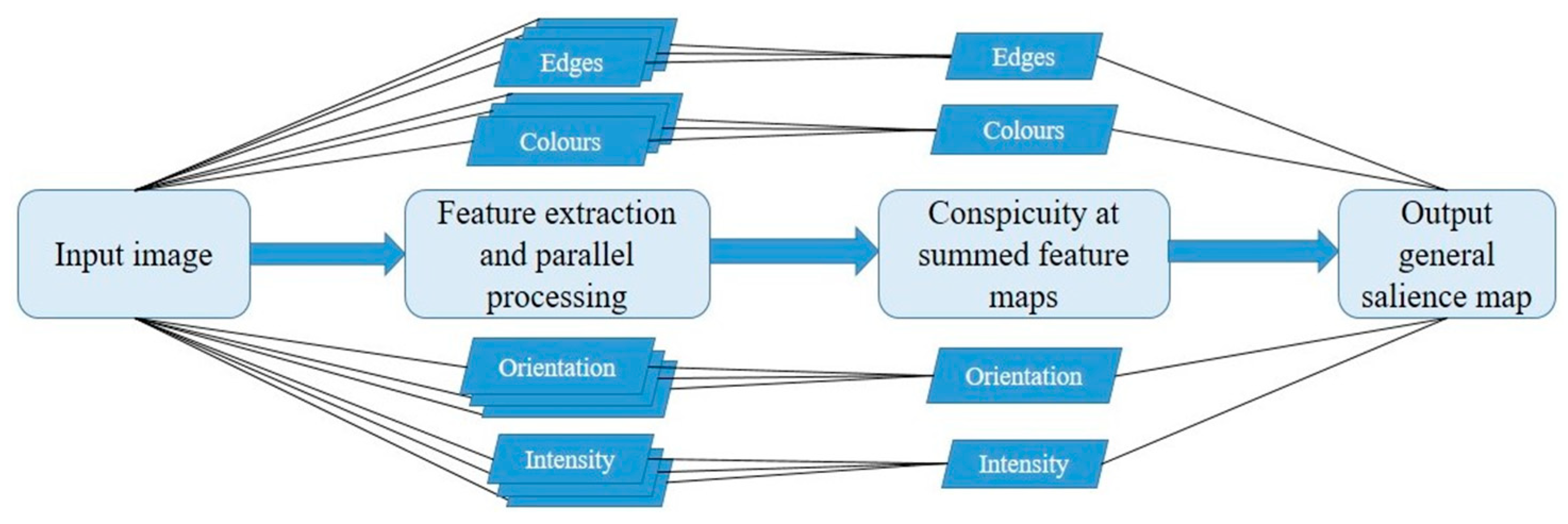
2. The Itti and Koch Model: Why Is It Seminal
3. What Is the Salience Problem?
4. Computational Salience Models
4.1. Direct Variations of the Itti and Koch Model
4.2. Biologically Driven Models
4.3. Top-Down Contributions
4.4. The ‘What’ and ‘Where’ Models
4.5. Object Models
4.6. Computationally-Driven Models
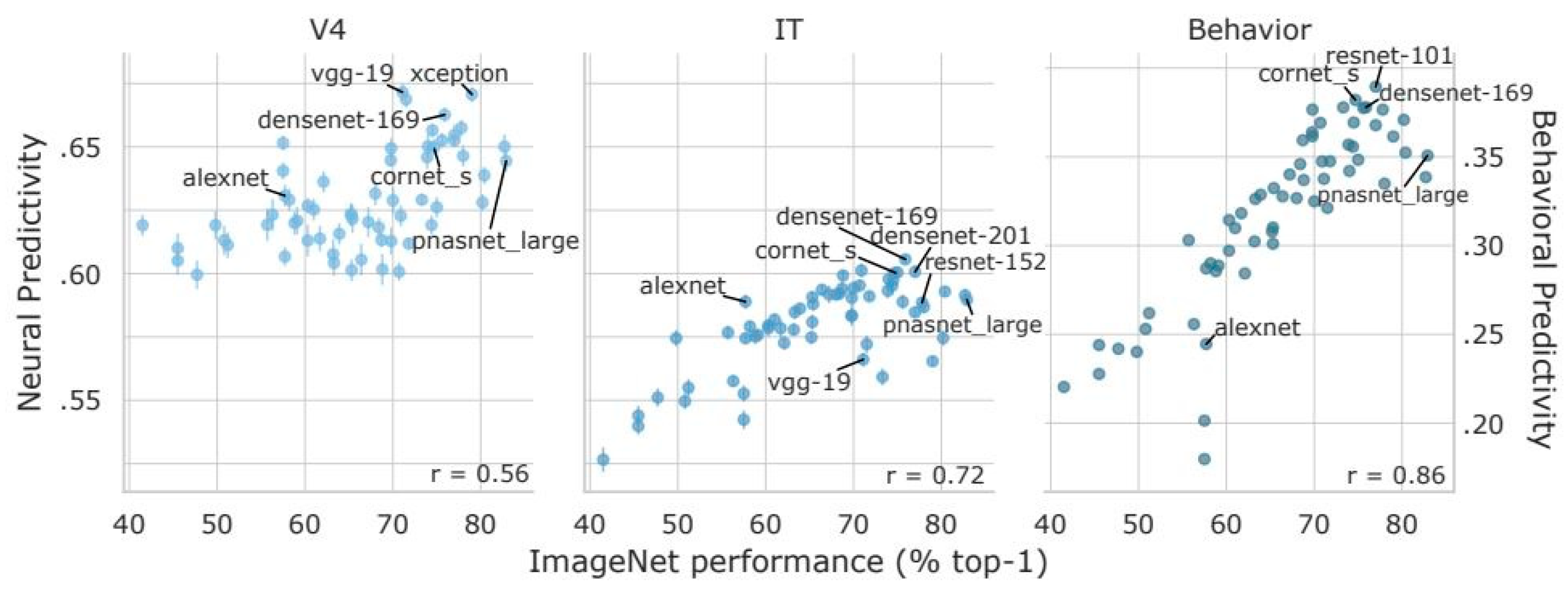
5. Deep Learning Classifiers
6. Metrics and Evaluation
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
Appendix B
References
- Itti, L.; Koch, C. Computational modelling of visual attention. Nat. Rev. Neurosci. 2001, 2, 194–203. [Google Scholar] [CrossRef] [PubMed]
- Koch, C.; Ullman, S. Shifts in selective visual attention: Towards the underlying neural circuitry. Hum. Neurobiol. 1985, 4, 219–227. [Google Scholar] [PubMed]
- Niebur, E.; Koch, C. Control of selective visual attention: Modeling the ‘‘where’’ pathway. In Advances in Neural Information Processing Systems; Touretzky, D.S., Mozer, M.C., Hasselmo, M.E., Eds.; MIT Press: Cambridge, MA, USA, 1996; Volume 8, pp. 802–808. [Google Scholar]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef]
- Itti, L.; Koch, C. A saliency-based search mechanism for overt and covert shifts of visual attention. Vis. Res. 2000, 40, 1489–1506. [Google Scholar] [CrossRef]
- Dacey, D.; Packer, O.S.; Diller, L.; Brainard, D.; Peterson, B.; Lee, B. Center surround receptive field structure of cone bipolar cells in primate retina. Vis. Res. 2000, 40, 1801–1811. [Google Scholar] [CrossRef]
- Burkitt, A.N. A Review of the Integrate-and-fire Neuron Model: I. Homogeneous Synaptic Input. Biol. Cybern. 2006, 95, 1–19. [Google Scholar] [CrossRef]
- Lee, D.K.; Itti, L.; Koch, C.; Braun, J. Attention activates winner-take-all competition among visual filters. Nat. Neurosci. 1999, 2, 375–381. [Google Scholar] [CrossRef]
- Posner, M.I.; Rafal, R.D.; Choate, L.S.; Vaughan, J. Inhibition of return: Neural basis and function. Cogn. Neuropsychol. 1985, 2, 211–228. [Google Scholar] [CrossRef]
- Klein, R.M.; MacInnes, W.J. Inhibition of Return is a Foraging Facilitator in Visual Search. Psychol. Sci. 1999, 10, 346–352. [Google Scholar] [CrossRef]
- Klein, R.M. Inhibition of return. Trends Cogn. Sci. 2000, 4, 138–147. [Google Scholar] [CrossRef]
- Kuffler, S.W. Discharge Patterns And Functional Organization Of Mammalian Retina. J. Neurophysiol. 1953, 16, 37–68. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Zhou, Y.; Yan, J.; Niu, Z.; Yang, J. Visual Saliency Based on Conditional Entropy. Lect. Notes Comput. Sci. 2010, 246–257. [Google Scholar] [CrossRef]
- Marques, O.; Mayron, L.M.; Borba, G.B.; Gamba, H.R. Using visual attention to extract regions of interest in the context of image retrieval. In Proceedings of the 44th Annual Southeast Regional Conference on-ACM-SE 44, Melbourne, FL, USA, 10–12 March 2006. [Google Scholar] [CrossRef]
- Treisman, A.M.; Gelade, G. A feature-integration theory of attention. Cogn. Psychol. 1980, 12, 97–136. [Google Scholar] [CrossRef]
- Klein, R. Inhibitory tagging system facilitates visual search. Nature 1988, 334, 430–431. [Google Scholar] [CrossRef]
- Bisley, J.W.; Mirpour, K. The neural instantiation of a priority map. Curr. Opin. Psychol. 2019, 29, 108–112. [Google Scholar] [CrossRef]
- Adeli, H.; Vitu, F.; Zelinsky, G.J. A Model of the Superior Colliculus Predicts Fixation Locations during Scene Viewing and Visual Search. J. Neurosci. 2016, 37, 1453–1467. [Google Scholar] [CrossRef]
- Sparks, D.L.; Hartwich-Young, R. The deep layers of the superior colliculus. Rev. Oculomot. Res. 1989, 3, 213–255. [Google Scholar]
- Henderson, J.M.; Shinkareva, S.V.; Wang, J.; Luke, S.G.; Olejarczyk, J. Predicting Cognitive State from Eye Movements. PLoS ONE 2013, 8, e64937. [Google Scholar] [CrossRef]
- Haji-Abolhassani, A.; Clark, J.J. An inverse Yarbus process: Predicting observers’ task from eye movement patterns. Vis. Res. 2014, 103, 127–142. [Google Scholar] [CrossRef]
- Mirpour, K.; Bolandnazar, Z.; Bisley, J.W. Neurons in FEF keep track of items that have been previously fixated in free viewing visual search. J. Neurosci. 2019, 39, 2114–2124. [Google Scholar] [CrossRef]
- Goodale, M.A.; Milner, A.D. Separate visual pathways for perception and action. Trends Neurosci. 1992, 15, 20–25. [Google Scholar] [CrossRef]
- Ungerleider, L.G.; Haxby, J.V. ‘What’ and ‘where’ in the human brain. Curr. Opin. Neurobiol. 1994, 4, 157–165. [Google Scholar] [CrossRef]
- Ungerleider, L.G.; Mishkin, M. Two cortical visual systems. In Analysis of Visual Behavior; Ingle, D.J., Goodale, M.A., Mansfield, R.J.W., Eds.; MIT Press: Cambridge, MA, USA, 1982; pp. 549–586. [Google Scholar]
- Subramanian, J.; Colby, C.L. Shape selectivity and remapping in dorsal stream visual area LIP. J. Neurophysiol. 2014, 111, 613–627. [Google Scholar] [CrossRef] [PubMed]
- Kravitz, D.J.; Saleem, K.S.; Baker, C.I.; Ungerleider, L.G.; Mishkin, M. The ventral visual pathway: An expanded neural framework for the processing of object quality. Trends Cogn. Sci. 2013, 17, 26–49. [Google Scholar] [CrossRef] [PubMed]
- Corbetta, M.; Shulman, G.L. Control of goal-directed and stimulus-driven attention in the brain. Nat. Rev. Neurosci. 2002, 3, 201–215. [Google Scholar] [CrossRef] [PubMed]
- Yarbus, A.L. Eye Movements and Vision; Plenum Press: New York, NY, USA, 1967. [Google Scholar]
- MacInnes, W.J.; Hunt, A.R.; Clarke, A.; Dodd, M.D. A Generative Model of Cognitive State from Task and Eye Movements. Cogn. Comput. 2018, 10, 703–717. [Google Scholar] [CrossRef] [PubMed]
- Borji, A.; Sihite, D.N.; Itti, L. Probabilistic learning of task-specific visual attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar] [CrossRef]
- Kanan, C.; Tong, M.H.; Zhang, L.; Cottrell, G.W. SUN: Top-down saliency using natural statistics. Vis. Cogn. 2009, 17, 979–1003. [Google Scholar] [CrossRef]
- Donner, T.; Kettermann, A.; Diesch, E.; Ostendorf, F.; Villringer, A.; Brandt, S.A. Involvement of the human frontal eye field and multiple parietal areas in covert visual selection during conjunction search. Eur. J. Neurosci. 2000, 12, 3407–3414. [Google Scholar] [CrossRef]
- Suzuki, M.; Gottlieb, J. Distinct neural mechanisms of distractor suppression in the frontal and parietal lobe. Nat. Neurosci. 2013, 16, 98–104. [Google Scholar] [CrossRef]
- Buschman, T.J.; Miller, E.K. Top-Down Versus Bottom-Up Control of Attention in the Prefrontal and Posterior Parietal Cortices. Science 2007, 315, 1860–1862. [Google Scholar] [CrossRef]
- Buschman, T.J.; Miller, E.K. Shifting the Spotlight of Attention: Evidence for Discrete Computations in Cognition. Front. Hum. Neurosci. 2010, 4, 194. [Google Scholar] [CrossRef] [PubMed]
- Corbetta, M.; Miezin, F.; Shulman, G.; Petersen, S. A PET study of visuospatial attention. J. Neurosci. 1993, 13, 1202–1226. [Google Scholar] [CrossRef] [PubMed]
- Corbetta, M.; Akbudak, E.; Conturo, T.E.; Snyder, A.Z.; Ollinger, J.M.; Linenweber, M.R.; Petersen, S.E.; Raichle, M.E.; Van Essen, D.C.; Drury, H.A.; et al. A common network of functional areas for attention and eye movements. Neuron 1998, 21, 761–773. [Google Scholar] [CrossRef]
- Liu, T.; Slotnick, S.D.; Serences, J.T.; Yantis, S. Cortical mechanisms of feature-based attentional control. Cereb. Cortex 2003, 13, 1334–1343. [Google Scholar] [CrossRef]
- Corbetta, M.; Shulman, G.L.; Miezin, F.M.; Petersen, S.E. Superior parietal cortex activation during spatial attention shifts and visual feature conjunction. Science 1995, 270, 802–805. [Google Scholar] [CrossRef]
- Donner, T.H.; Kettermann, A.; Diesch, E.; Ostendorf, F.; Villringer, A.; Brandt, S.A. Visual feature and conjunction searches of equal difficulty engage only partially overlapping frontoparietal networks. Neuroimage 2002, 15, 16–25. [Google Scholar] [CrossRef]
- Nobre, A.C.; Sebestyen, G.N.; Gitelman, D.R.; Frith, C.D.; Mesulam, M.M. Filtering of distractors during visual search studied by positron emission tomography. Neuroimage 2002, 16, 968–976. [Google Scholar] [CrossRef]
- Moore, T.; Fallah, M. Microstimulation of the frontal eye field and its effects on covert spatial attention. J. Neurophysiol. 2004, 91, 152–162. [Google Scholar] [CrossRef]
- Wardak, C.; Ibos, G.; Duhamel, J.R.; Olivier, E. Contribution of the monkey frontal eye field to covert visual attention. J. Neurosci. 2006, 26, 4228–4235. [Google Scholar] [CrossRef]
- Zhou, H.; Desimone, R. Feature-based attention in the frontal eye field and area V4 during visual search. Neuron 2011, 70, 1205–1217. [Google Scholar] [CrossRef]
- Miller, B.T.; D’Esposito, M. Searching for “the Top” in Top-Down Control. Neuron 2005, 48, 535–538. [Google Scholar] [CrossRef] [PubMed]
- Egeth, H.E.; Leonard, C.J.; Leber, A.B. Why salience is not enough: Reflections on top-down selection in vision. Acta Psychol. 2010, 135, 130–132. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Schall, J.D.; Cohen, J.Y. The neural basis of saccade target selection. In The Oxford Handbook of Eye Movements; Liversedge, S.P., Gilchrist, I.D., Everling, S., Eds.; Oxford University Press: Oxford, UK, 2012; pp. 357–374. [Google Scholar]
- Rodriguez-Sanchez, A.J.; Simine, E.; Tsotsos, J.K. Attention and visual search. Int. J. Neural Syst. 2007, 17, 275–288. [Google Scholar] [CrossRef]
- Wolfe, J.M.; Gancarz, G. Guided Search 3.0. In Basic and Clinical Applications of Vision Science; Springer: Dordrecht, The Netherlands, 1997; pp. 189–192. [Google Scholar]
- Fecteau, J.; Munoz, D. Salience, relevance, and firing: A priority map for target selection. Trends Cogn. Sci. 2006, 10, 382–390. [Google Scholar] [CrossRef] [PubMed]
- Desimone, R.; Duncan, J. Neural Mechanisms of Selective Visual Attention. Annu. Rev. Neurosci. 1995, 18, 193–222. [Google Scholar] [CrossRef]
- Wolfe, J.M.; Horowitz, T.S. Five factors that guide attention in visual search. Nat. Hum. Behav. 2017, 1, 0058. [Google Scholar] [CrossRef]
- Veale, R.; Hafed, Z.M.; Yoshida, M. How is visual salience computed in the brain? Insights from behaviour, neurobiology and modelling. Philos. Trans. R. Soc. B Biol. Sci. 2017, 372, 20160113. [Google Scholar] [CrossRef]
- Schiller, P.H.; Stryker, M. Single-unit recording and stimulation in superior colliculus of the alert rhesus monkey. J. Neurophysiol. 1972, 35, 915–924. [Google Scholar] [CrossRef]
- Schiller, P.H.; Chou, I.H. The effects of frontal eye field and dorsomedial frontal cortex lesions on visually guided eye movements. Nat. Neurosci. 1998, 1, 248. [Google Scholar] [CrossRef]
- Frintrop, S.; Rome, E.; Christensen, H.I. Computational visual attention systems and their cognitive foundations. ACM Trans. Appl. Percept. 2010, 7, 1–39. [Google Scholar] [CrossRef]
- Munoz, D.P.; Everling, S. Look away: The anti-saccade task and the voluntary control of eye movement. Nat. Rev. Neurosci. 2004, 5, 218–228. [Google Scholar] [CrossRef] [PubMed]
- Wolfe, J.M.; Horowitz, T.S. What attributes guide the deployment of visual attention and how do they do it? Nat. Rev. Neurosci. 2004, 5, 495–501. [Google Scholar] [CrossRef] [PubMed]
- Broadbent, D.E. Perception and Communication; Elsevier: Amsterdam, The Netherlands, 2013. [Google Scholar]
- Walther, D.; Itti, L.; Riesenhuber, M.; Poggio, T.; Koch, C. Attentional selection for object recognition—A gentle way. In International Workshop on Biologically Motivated Computer Vision; Springer: Berlin/Heidelberg, Germany, 2002; pp. 472–479. [Google Scholar]
- Riesenhuber, M.; Poggio, T. Neural mechanisms of object recognition. Curr. Opin. Neurobiol. 2002, 12, 162–168. [Google Scholar] [CrossRef]
- Tipper, S.P.; Weaver, B.; Jerreat, L.M.; Burak, A.L. Object-based and environment-based inhibition of return of visual attention. J. Exp. Psychol. Hum. Percept. Perform. 1994, 20, 478. [Google Scholar] [CrossRef]
- Draper, B.A.; Lionelle, A. Evaluation of selective attention under similarity transformations. Comput. Vis. Image Underst. 2005, 100, 152–171. [Google Scholar] [CrossRef]
- Eriksen, C.W.; James, J.D.S. Visual attention within and around the field of focal attention: A zoom lens model. Percept. Psychophys. 1986, 40, 225–240. [Google Scholar] [CrossRef]
- Posner, M.I. Orienting of attention. Q. J. Exp. Psychol. 1980, 32, 3–25. [Google Scholar] [CrossRef]
- Wolfe, J.M. Guided Search 2.0 A revised model of visual search. Psychon. Bull. Rev. 1994, 1, 202–238. [Google Scholar] [CrossRef]
- Navalpakkam, V.; Itti, L. Modeling the influence of task on attention. Vis. Res. 2005, 45, 205–231. [Google Scholar] [CrossRef]
- Awh, E.; Vogel, E.K.; Oh, S.-H. Interactions between attention and working memory. Neuroscience 2006, 139, 201–208. [Google Scholar] [CrossRef]
- Fougnie, D. The relationship between attention and working memory. In New Research on Short-Term Memory; Johansen, N.B., Ed.; Nova Science Publishers: New York, NY, USA, 2008; pp. 1–45. [Google Scholar]
- Rosen, M.L.; Stern, C.E.; Somers, D.C. Long-term memory guidance of visuospatial attention in a change-detection paradigm. Front. Psychol. 2014, 5, 266. [Google Scholar] [CrossRef] [PubMed]
- Harel, J.; Koch, C.; Perona, P. Graph-based visual saliency. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2007; pp. 545–552. [Google Scholar]
- Hopf, J.M. Attention to Features Precedes Attention to Locations in Visual Search: Evidence from Electromagnetic Brain Responses in Humans. J. Neurosci. 2004, 24, 1822–1832. [Google Scholar] [CrossRef] [PubMed]
- Li, Z. A saliency map in primary visual cortex. Trends Cogn. Sci. 2002, 6, 9–16. [Google Scholar] [CrossRef]
- Koene, A.R.; Li, Z. Feature-specific interactions in salience from combined feature contrasts: Evidence for a bottom–up saliency map in V1. J. Vis. 2007, 7, 6. [Google Scholar] [CrossRef] [PubMed]
- Horwitz, G.D.; Albright, T.D. Paucity of chromatic linear motion detectors in macaque V1. J. Vis. 2005, 5, 4. [Google Scholar] [CrossRef] [PubMed]
- Ts’o, D.Y.; Gilbert, C.D. The organization of chromatic and spatial interactions in the primate striate cortex. J. Neurosci. 1988, 8, 1712–1727. [Google Scholar] [CrossRef]
- Lennie, P.; Movshon, J.A. Coding of color and form in the geniculostriate visual pathway (invited review). J. Opt. Soc. Am. A 2005, 22, 2013. [Google Scholar] [CrossRef]
- Garg, A.K.; Li, P.; Rashid, S.M.; Callaway, M.E. Color and orientation are jointly coded and spatially organized in primate primary visual cortex. Science 2019, 364, 1275–1279. [Google Scholar] [CrossRef]
- Park, S.J.; Shin, J.K.; Lee, M. Biologically inspired saliency map model for bottom-up visual attention. In International Workshop on Biologically Motivated Computer Vision; Springer: Berlin/Heidelberg, Germany, 2002; pp. 418–426. [Google Scholar]
- Swindale, N.V. Neurophysiology: Parallel channels and redundant mechanisms in visual cortex. Nature 1986, 322, 775–776. [Google Scholar] [CrossRef]
- Aboudib, A.; Gripon, V.; Coppin, G. A biologically inspired framework for visual information processing and an application on modeling bottom-up visual attention. Cogn. Comput. 2016, 8, 1007–1026. [Google Scholar] [CrossRef]
- Hamker, F.H. Modeling feature-based attention as an active top-down inference process. BioSystems 2006, 86, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Duncan, J. An adaptive coding model of neural function in prefrontal cortex. Nat. Rev. Neurosci. 2001, 2, 820–829. [Google Scholar] [CrossRef] [PubMed]
- Wu, S.; Amari, S.I.; Nakahara, H. Population coding and decoding in a neural field: A computational study. Neural Comput. 2002, 14, 999–1026. [Google Scholar] [CrossRef] [PubMed]
- Wilder, J.D.; Kowler, E.; Schnitzer, B.S.; Gersch, T.M.; Dosher, B.A. Attention during active visual tasks: Counting, pointing, or simply looking. Vis. Res. 2009, 49, 1017–1031. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Wolfe, J.M.; Cave, K.R.; Franzel, S.L. Guided search: An alternative to the feature integration model for visual search. J. Exp. Psychol. Hum. Percept. Perform. 1989, 15, 419. [Google Scholar] [CrossRef]
- Julesz, B. A brief outline of the texton theory of human vision. Trends Neurosci. 1984, 7, 41–45. [Google Scholar] [CrossRef]
- Neisser, U. Visual search. Sci. Am. 1964, 210, 94–102. [Google Scholar] [CrossRef]
- Wolfe, J.M. Guided search 4.0. In Integrated Models of Cognitive Systems; Gray, W.D., Ed.; Oxford University Press: New York, NY, USA, 2007; pp. 99–119. [Google Scholar]
- Jiang, Y.V.; Swallow, K.M.; Rosenbaum, G.M. Guidance of spatial attention by incidental learning and endogenous cuing. Journal of experimental psychology. Hum. Percept. Perform. 2013, 39, 285–297. [Google Scholar] [CrossRef]
- Soto, D.; Humphreys, G.W.; Rotshstein, P. Dissociating the neural mechanisms of memory based guidance of visual selection. Proc. Natl. Acad. Sci. USA 2007, 104, 17186–17191. [Google Scholar] [CrossRef]
- Cave, K.R. The FeatureGate model of visual selection. Psychol. Res. 1999, 62, 182–194. [Google Scholar] [CrossRef]
- Cohen, R.A. Lateral Inhibition. Encycl. Clin. Neuropsychol. 2011, 1436–1437. [Google Scholar] [CrossRef]
- Rao, R.P.; Ballard, D.H. Probabilistic models of attention based on iconic representations and predictive coding. In Neurobiology of Attention; Academic Press: New York, NY, USA, 2005; pp. 553–561. [Google Scholar]
- Hinton, G.E.; Sejnowski, T.J. Learning and relearning in Boltzmann machines. Parallel Distrib. Process. Explor. Microstruct. Cogn. 1986, 1, 2. [Google Scholar]
- Nowlan, S.J. Maximum likelihood competitive learning. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 1990; pp. 574–582. [Google Scholar]
- Rao, R.P.; Ballard, D.H. Predictive coding in the visual cortex: A functional interpretation of some extra-classical receptive-field effects. Nat. Neurosci. 1999, 2, 79. [Google Scholar] [CrossRef] [PubMed]
- Mishkin, M.; Ungerleider, L.G.; Macko, K.A. Object vision and spatial vision: Two cortical pathways. Trends Neurosci. 1983, 6, 414–417. [Google Scholar] [CrossRef]
- Rybak, I.A.; Gusakova, V.I.; Golovan, A.V.; Podladchikova, L.N.; Shevtsova, N.A. Attention-Guided Recognition Based on “What” and “Where”: Representations: A Behavioral Model. In Neurobiology of Attention; Academic Press: New York, NY, USA, 2005; pp. 663–670. [Google Scholar]
- Deco, G.; Rolls, E.T. A neurodynamical cortical model of visual attention and invariant object recognition. Vis. Res. 2004, 44, 621–642. [Google Scholar] [CrossRef]
- Norman, J. Two visual systems and two theories of perception: An attempt to reconcile the constructivist and ecological approaches. Behav. Brain Sci. 2002, 25, 73–96. [Google Scholar] [CrossRef]
- Rolls, E.T.; Aggelopoulos, N.C.; Zheng, F. The Receptive Fields of Inferior Temporal Cortex Neurons in Natural Scenes. J. Neurosci. 2003, 23, 339–348. [Google Scholar] [CrossRef]
- Schenk, T.; McIntosh, R.D. Do we have independent visual streams for perception and action? Cogn. Neurosci. 2010, 1, 52–62. [Google Scholar] [CrossRef]
- Milner, A.D.; Goodale, M.A. Two visual systems re-viewed. Neuropsychologia 2008, 46, 774–785. [Google Scholar] [CrossRef]
- DiCarlo, J.J.; Zoccolan, D.; Rust, N.C. How Does the Brain Solve Visual Object Recognition? Neuron 2012, 73, 415–434. [Google Scholar] [CrossRef]
- Stein, T.; Peelen, M.V. Object detection in natural scenes: Independent effects of spatial and category-based attention. Atten. Percept. Psychophys. 2017, 79, 738–752. [Google Scholar] [CrossRef] [PubMed]
- Gauthier, I.; Tarr, M.J. Visual Object Recognition: Do We (Finally) Know More Now Than We Did? Annu. Rev. Vis. Sci. 2016, 2, 377–396. [Google Scholar] [CrossRef] [PubMed]
- Pylyshyn, Z.W.; Storm, R.W. Tracking multiple independent targets: Evidence for a parallel tracking mechanism. Spat. Vis. 1988, 3, 179–197. [Google Scholar] [CrossRef] [PubMed]
- Pylyshyn, Z.; Burkell, J.; Fisher, B.; Sears, C.; Schmidt, W.; Trick, L. Multiple parallel access in visual attention. Can. J. Exp. Psychol./Rev. Can. Psychol. Exp. 1994, 48, 260. [Google Scholar] [CrossRef]
- Backer, G.; Mertsching, B.; Bollmann, M. Data-and model-driven gaze control for an active-vision system. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 1415–1429. [Google Scholar] [CrossRef]
- Amari, S. Dynamics of pattern formation in lateral-inhibition type neural fields. Biol. Cybern. 1977, 27, 77–87. [Google Scholar] [CrossRef]
- Tipper, S.P.; Driver, J.; Weaver, B. Object-centred inhibition of return of visual attention. Q. J. Exp. Psychol. 1991, 43, 289–298. [Google Scholar] [CrossRef]
- Sun, Y.; Fisher, R. Object-based visual attention for computer vision. Artif. Intell. 2003, 146, 77–123. [Google Scholar] [CrossRef]
- Duncan, J.; Humphreys, G.; Ward, R. Competitive brain activity in visual attention. Curr. Opin. Neurobiol. 1997, 7, 255–261. [Google Scholar] [CrossRef]
- Pelli, D.G.; Tillman, K.A. The uncrowded window of object recognition. Nat. Neurosci. 2008, 11, 1129–1135. [Google Scholar] [CrossRef]
- Oliva, A.; Torralba, A.; Castelhano, M.; Henderson, J. Top-down control of visual attention in object detection. In Proceedings of the 2003 International Conference on Image Processing (Cat. No.03CH37429), Barcelona, Spain, 14–17 September 2003. [Google Scholar]
- Van der Voort van der Kleij, G.T.; van der Velde, F.; de Kamps, M. Learning Location Invariance for Object Recognition and Localization. Lect. Notes Comput. Sci. 2005, 235–244. [Google Scholar] [CrossRef]
- Tsotsos, J.K.; Culhane, S.M.; Wai, W.Y.K.; Lai, Y.; Davis, N.; Nuflo, F. Modeling visual attention via selective tuning. Artif. Intell. 1995, 78, 507–545. [Google Scholar] [CrossRef]
- Bruce, N.; Tsotsos, J. Saliency based on information maximization. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2006; pp. 155–162. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Olshausen, B.A.; Field, D.J. Emergence of simple-cell receptive field properties by learning a sparse code for natural images. Nature 1996, 381, 607–609. [Google Scholar] [CrossRef]
- Schill, K. A Model of Attention and Recognition by Information Maximization; Neurobiology of Attention Academic Press: New York, NY, USA, 2005; pp. 671–676. [Google Scholar]
- Shafer, G. Dempster-shafer theory. Encycl. Artif. Intell. 1992, 1, 330–331. [Google Scholar]
- Torralba, A.; Oliva, A.; Castelhano, M.S.; Henderson, J.M. Contextual guidance of eye movements and attention in real-world scenes: The role of global features in object search. Psychol. Rev. 2006, 113, 766. [Google Scholar] [CrossRef]
- Russell, B.C.; Torralba, A.; Murphy, K.P.; Freeman, W.T. LabelMe: A database and web-based tool for image annotation. Int. J. Comput. Vis. 2008, 77, 157–173. [Google Scholar] [CrossRef]
- Rubin, N. Figure and ground in the brain. Nat. Neurosci. 2001, 4, 857–858. [Google Scholar] [CrossRef]
- Zhang, J.; Sclaroff, S. Saliency detection: A boolean map approach. In Proceedings of the IEEE international conference on computer vision, Sydney, Australia, 1–8 December 2013; pp. 153–160. [Google Scholar]
- Huang, L.; Pashler, H. A Boolean map theory of visual attention. Psychol. Rev. 2007, 114, 599. [Google Scholar] [CrossRef]
- Judd, T.; Ehinger, K.; Durand, F.; Torralba, A. Learning to predict where humans look. In Proceedings of the 2009 IEEE 12th international conference on computer vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2106–2113. [Google Scholar]
- Najemnik, J.; Geisler, W.S. Optimal eye movement strategies in visual search. Nature 2005, 434, 387–391. [Google Scholar] [CrossRef]
- Bylinskii, Z.; Judd, T.; Oliva, A.; Torralba, A.; Durand, F. What do different evaluation metrics tell us about saliency models? IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 740–757. [Google Scholar] [CrossRef] [PubMed]
- Judd, T.; Durand, F.; Torralba, A. A Benchmark of Computational Models of Saliency to Predict Human Fixations; Technical rep. MIT-CSAIL-TR-2012-001; Massachusetts Institute of Technology: Cambridge, MA, USA, 2012. [Google Scholar]
- Bengio, Y. Learning deep architectures for AI. Found. Trends® Mach. Learn. 2009, 2, 1–127. [Google Scholar] [CrossRef]
- Huang, X.; Shen, C.; Boix, X.; Zhao, Q. Salicon: Reducing the semantic gap in saliency prediction by adapting deep neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 262–270. [Google Scholar]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Deng, L.; Yu, D. Deep learning: Methods and applications. Found. Trends® Signal Process. 2014, 7, 197–387. [Google Scholar] [CrossRef]
- Basheer, I.A.; Hajmeer, M. Artificial neural networks: Fundamentals, computing, design, and application. J. Microbiol. Methods 2000, 43, 3–31. [Google Scholar] [CrossRef]
- Bylinskii, Z.; Judd, T.; Borji, A.; Itti, L.; Durand, F.; Oliva, A.; Torralba, A. Mit Saliency Benchmark. 2015. Available online: http://saliency.mit.edu/ (accessed on 24 October 2019).
- Cadieu, C.F.; Hong, H.; Yamins, D.L.; Pinto, N.; Ardila, D.; Solomon, E.A.; Majaj, N.J.; DiCarlo, J.J. Deep neural networks rival the representation of primate IT cortex for core visual object recognition. PLoS Comput. Biol. 2014, 10, e1003963. [Google Scholar] [CrossRef]
- Kummerer, M.; Wallis, T.S.; Gatys, L.A.; Bethge, M. Understanding low-and high-level contributions to fixation prediction. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4789–4798. [Google Scholar]
- Jia, S. Eml-net: An expandable multi-layer network for saliency prediction. arXiv 2018, arXiv:1805.01047. [Google Scholar]
- Kruthiventi, S.S.; Ayush, K.; Babu, R.V. Deepfix: A fully convolutional neural network for predicting human eye fixations. IEEE Trans. Image Process. 2017, 26, 4446–4456. [Google Scholar] [CrossRef]
- Pan, J.; Sayrol, E.; Giro-i-Nieto, X.; McGuinness, K.; O’Connor, N.E. Shallow and deep convolutional networks for saliency prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 598–606. [Google Scholar]
- Dodge, S.F.; Karam, L.J. Visual saliency prediction using a mixture of deep neural networks. IEEE Trans. Image Process. 2018, 27, 4080–4090. [Google Scholar] [CrossRef]
- He, S.; Pugeault, N. Deep saliency: What is learnt by a deep network about saliency? arXiv 2018, arXiv:1801.04261. [Google Scholar]
- Zhang, J.; Zhang, T.; Dai, Y.; Harandi, M.; Hartley, R. Deep unsupervised saliency detection: A multiple noisy labeling perspective. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9029–9038. [Google Scholar]
- Li, G.; Yu, Y. Visual saliency based on multiscale deep features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5455–5463. [Google Scholar]
- Li, G.; Yu, Y. Deep contrast learning for salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 478–487. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2014; pp. 2672–2680. [Google Scholar]
- Pan, J.; Sayrol, E.; Nieto, X.G.I.; Ferrer, C.C.; Torres, J.; McGuinness, K.; OConnor, N.E. SalGAN: Visual saliency prediction with adversarial networks. In Proceedings of the CVPR Scene Understanding Workshop (SUNw), Honolulu, HI, USA, 26 July 2017. [Google Scholar]
- Fernando, T.; Denman, S.; Sridharan, S.; Fookes, C. Task specific visual saliency prediction with memory augmented conditional generative adversarial networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1539–1548. [Google Scholar]
- Elman, J. Finding structure in time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Adel Bargal, S.; Zunino, A.; Kim, D.; Zhang, J.; Murino, V.; Sclaroff, S. Excitation backprop for RNNs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1440–1449. [Google Scholar]
- Li, G.; Xie, Y.; Wei, T.; Wang, K.; Lin, L. Flow guided recurrent neural encoder for video salient object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, Munich, Germany, 8–14 September 2018; pp. 3243–3252. [Google Scholar]
- Tang, Y.; Wu, X.; Bu, W. Deeply-supervised recurrent convolutional neural network for saliency detection. In Proceedings of the 24th ACM international conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; ACM: New York, NY, USA, 2016; pp. 397–401. [Google Scholar]
- Kuen, J.; Wang, Z.; Wang, G. Recurrent attentional networks for saliency detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3668–3677. [Google Scholar]
- Liu, N.; Han, J. A deep spatial contextual long-term recurrent convolutional network for saliency detection. IEEE Trans. Image Process. 2018, 27, 3264–3274. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Wu, X. Constructing long short-term memory based deep recurrent neural networks for large vocabulary speech recognition. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, Australia, 19–24 April 2015; pp. 4520–4524. [Google Scholar]
- Sak, H.; Senior, A.; Beaufays, F. Long short-term memory recurrent neural network architectures for large scale acoustic modeling. In Proceedings of the Fifteenth Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014. [Google Scholar]
- Liu, Y.; Zhang, S.; Xu, M.; He, X. Predicting salient face in multiple-face videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4420–4428. [Google Scholar]
- Cornia, M.; Baraldi, L.; Serra, G.; Cucchiara, R. Predicting human eye fixations via an lstm-based saliency attentive model. IEEE Trans. Image Process. 2018, 27, 5142–5154. [Google Scholar]
- Wang, W.; Shen, J.; Dong, X.; Borji, A. Salient object detection driven by fixation prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1711–1720. [Google Scholar]
- Lee, H.; Ekanadham, C.; Ng, A.Y. Sparse deep belief net model for visual area V2. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2008; pp. 873–880. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference On Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar] [CrossRef]
- Schrimpf, M.; Kubilius, J.; Hong, H.; Majaj, N.J.; Rajalingham, R.; Issa, E.B.; Yamins, D.L. Brain-Score: Which artificial neural network for object recognition is most brain-like? BioRxiv 2018, 407007. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems (NIPS); The MIT Press: Cambridge, MA, USA, 2012; ISSN 10495258. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Liu, C.; Zoph, B.; Neumann, M.; Shlens, J.; Hua, W.; Li, L.-J.; Fei-Fei, L.; Yuille, A.; Huang, J.; Murphy, K. Progressive Neural Architecture Search. arXiv 2017, arXiv:1712.00559v3. [Google Scholar]
- Kubilius, J.; Schrimpf, M.; DiCarlo, J. CORnet: Modeling Core Object Recognition. arXiv 2018, arXiv:1808.01405. [Google Scholar]
- Ferri, C.; Hernández-Orallo, J.; Flach, P.A. A coherent interpretation of AUC as a measure of aggregated classification performance. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), Washington, DC, USA, 28 June–2 July 2011; pp. 657–664. [Google Scholar]
- Riche, N.; Duvinage, M.; Mancas, M.; Gosselin, B.; Dutoit, T. Saliency and human fixations: State-of-the-art and study of comparison metrics. In Proceedings of the IEEE International Conference On Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1153–1160. [Google Scholar]
- Kachurka, V.; Madani, K.; Sabourin, C.; Golovko, V. From human eye fixation to human-like autonomous artificial vision. In Proceedings of the International Work-Conference on Artificial Neural Networks, Palma de Mallorca, Spain, 10–12 June 2015; Springer: Champaign, IL, USA, 2015; pp. 171–184. [Google Scholar]
- Borji, A.; Sihite, D.N.; Itti, L. Quantitative analysis of human-model agreement in visual saliency modeling: A comparative study. IEEE Trans. Image Process. 2013, 22, 55–69. [Google Scholar] [CrossRef]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Merzon, L.; Zhulikov, G.; Malevich, T.; Krasovskaya, S.; MacInnes, J.W. Temporal Limitations of the Standard Leaky Integrate and Fire Model. High. Sch. Econ. Res. Pap. No. WP BRP 2018, 94, 1–16. [Google Scholar] [CrossRef]
- Nguyen, A.; Yosinski, J.; Clune, J. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 427–436. [Google Scholar]
- Harel, J. A Saliency Implementation in MATLAB. Available online:: http://www.vision.caltech.edu/~harel/share/gbvs.php (accessed on 19 February 2019).
- Itti, L. The iLab Neuromorphic Vision C++ Toolkit: Free tools for the next generation of vision algorithms. Neuromorphic Eng. 2004, 1, 10. [Google Scholar]
- Walther, D.; Koch, C. Modeling attention to salient proto-objects. Neural Netw. 2006, 19, 1395–1407. [Google Scholar] [CrossRef] [PubMed]
- Bruce, N.D.; Tsotsos, J.K. Saliency, attention, and visual search: An information theoretic approach. J. Vis. 2009, 9, 5. [Google Scholar] [CrossRef] [PubMed]
- Kootstra, G.; Nederveen, A.; De Boer, B. Paying attention to symmetry. In British Machine Vision Conference (BMVC2008); The British Machine Vision Association and Society for Pattern Recognition: Oxford, UK, 2008; pp. 1115–1125. [Google Scholar]
- Cerf, M.; Harel, J.; Einhäuser, W.; Koch, C. Predicting human gaze using low-level saliency combined with face detection. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2008; pp. 241–248. [Google Scholar]
- Li, J.; Levine, M.D.; An, X.; Xu, X.; He, H. Visual saliency based on scale-space analysis in the frequency domain. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 996–1010. [Google Scholar] [CrossRef] [PubMed]
- Borji, A.; Itti, L. CAT2000: A Large Scale Fixation Dataset for Boosting Saliency Research. arXiv 2015, arXiv:1505.03581. [Google Scholar]


© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Krasovskaya, S.; MacInnes, W.J. Salience Models: A Computational Cognitive Neuroscience Review. Vision 2019, 3, 56. https://doi.org/10.3390/vision3040056
Krasovskaya S, MacInnes WJ. Salience Models: A Computational Cognitive Neuroscience Review. Vision. 2019; 3(4):56. https://doi.org/10.3390/vision3040056
Chicago/Turabian StyleKrasovskaya, Sofia, and W. Joseph MacInnes. 2019. "Salience Models: A Computational Cognitive Neuroscience Review" Vision 3, no. 4: 56. https://doi.org/10.3390/vision3040056
APA StyleKrasovskaya, S., & MacInnes, W. J. (2019). Salience Models: A Computational Cognitive Neuroscience Review. Vision, 3(4), 56. https://doi.org/10.3390/vision3040056