


From Sparse to Dense Representations in Open Channel Flow Images with Convolutional Neural Networks

 ,
,  , , ,
, , ,  and
and
Abstract
1. Introduction
2. Materials and Methods
2.1. Super-Resolution Components
2.1.1. Convolutional Neural Networks
2.1.2. Generative Models VAEs-GANs
2.1.3. Physics-Informed Neural Networks (PINNs)
2.1.4. LSTM Networks
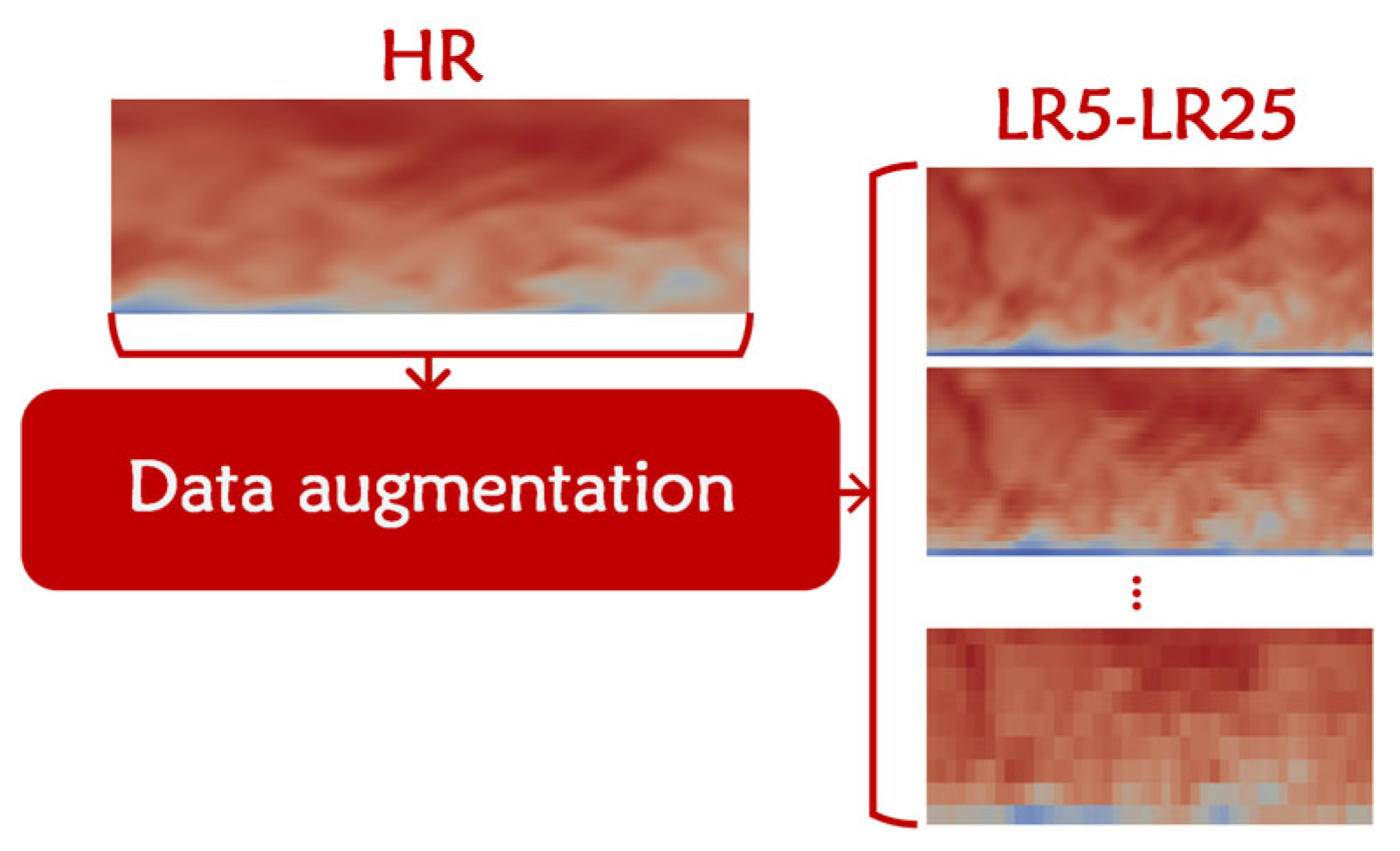
2.2. Simulation and Data Augmentation
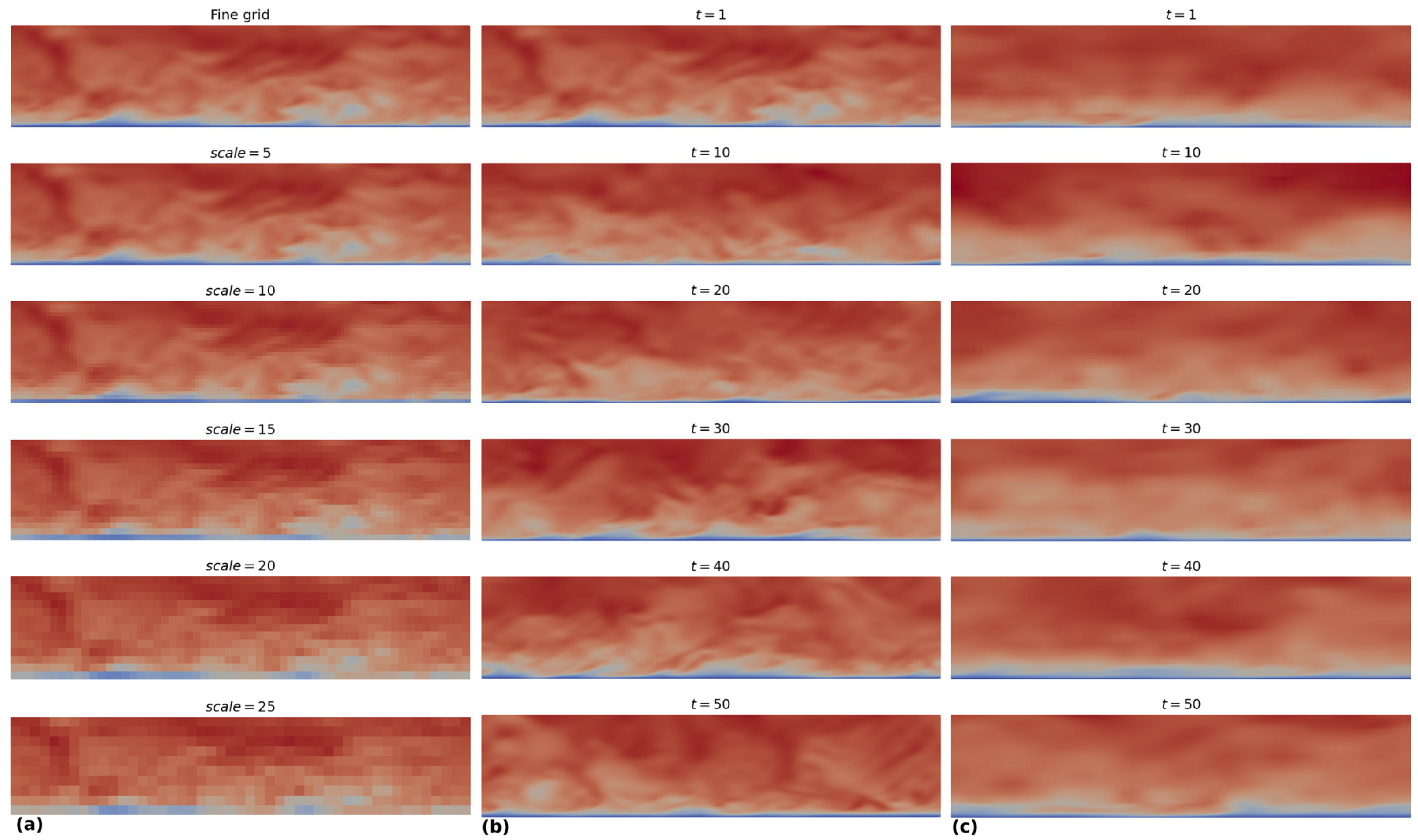
2.2.1. Open Channel Flow Data
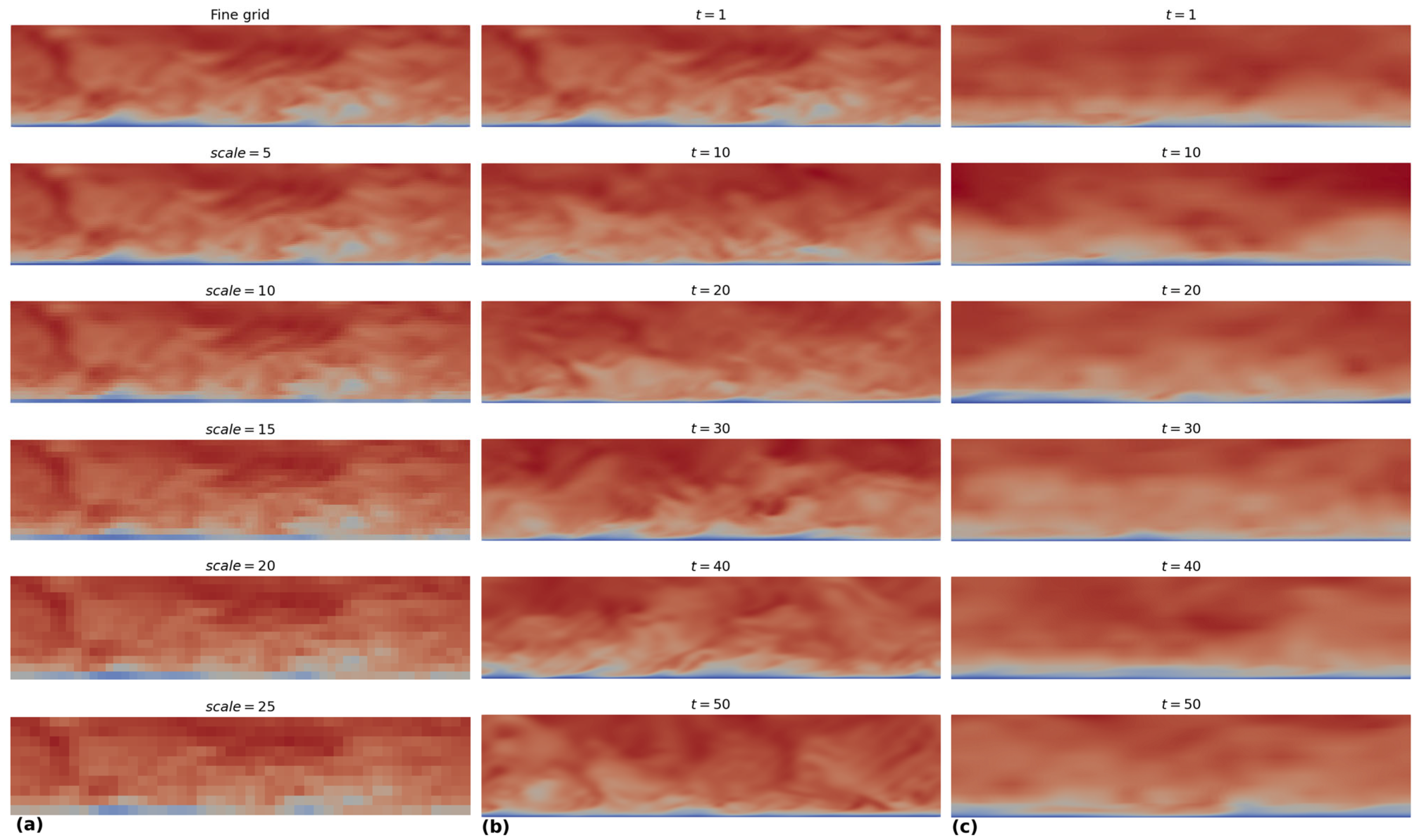
2.2.2. Data Curation
3. Results
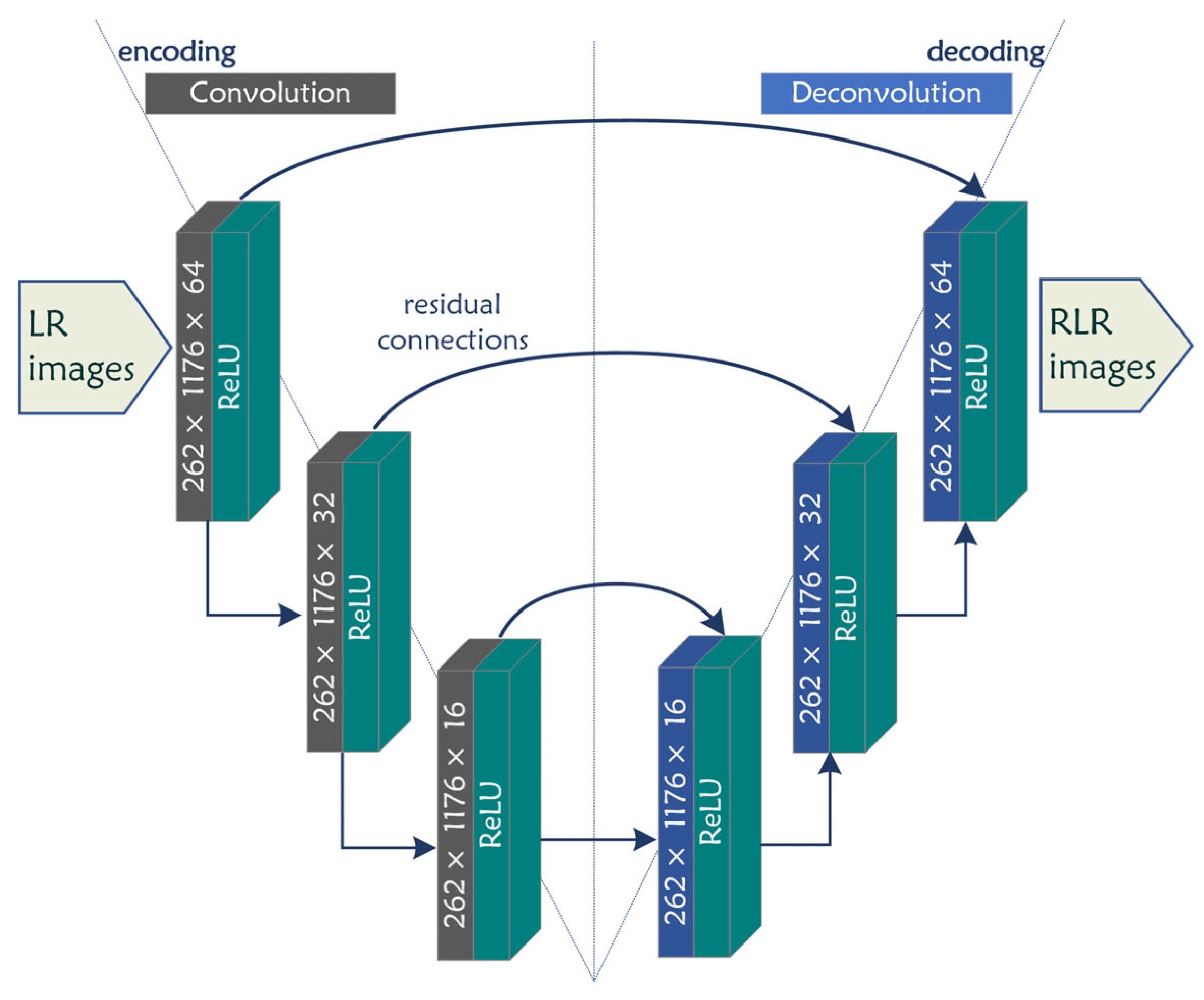
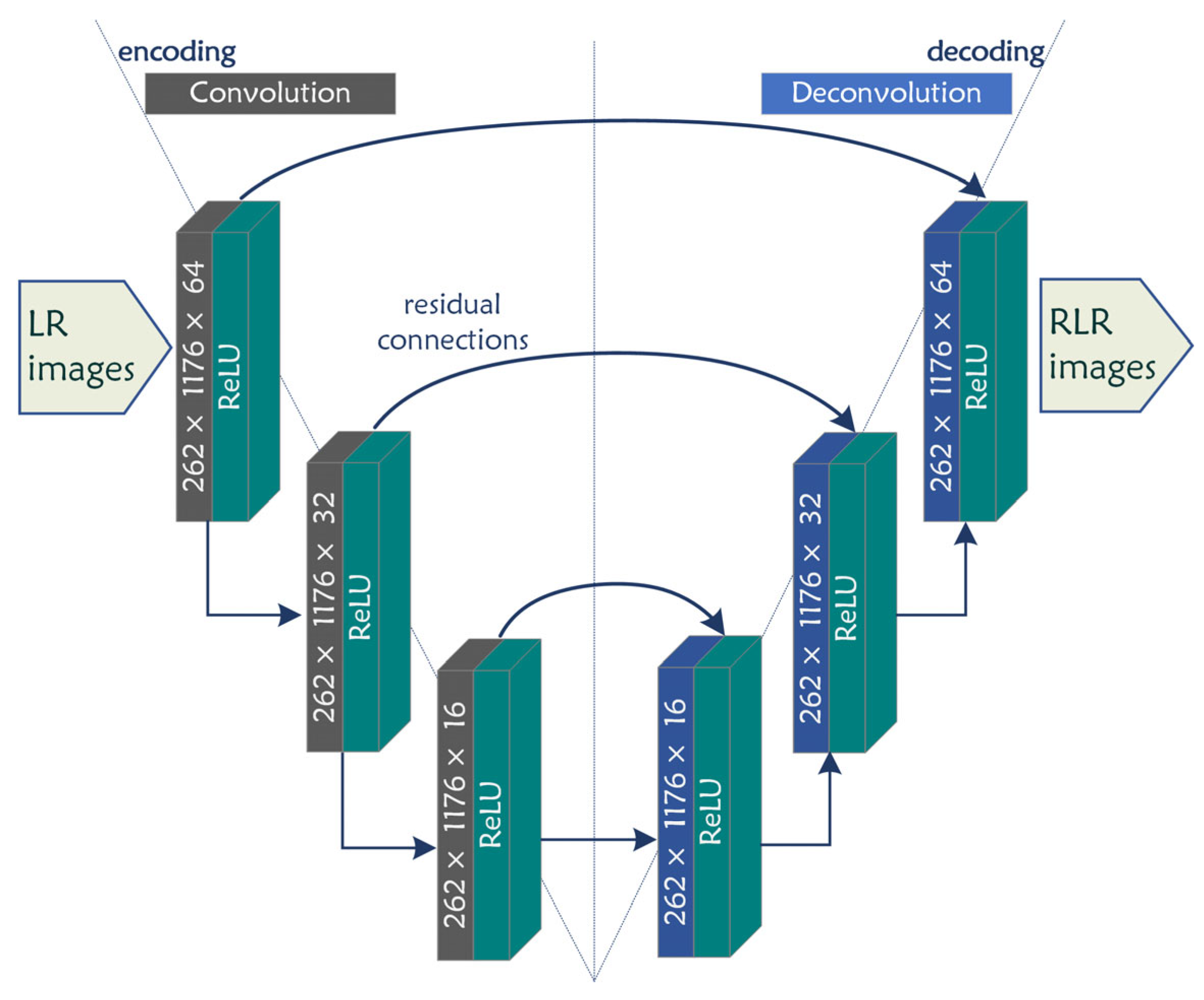
3.1. UpCNN Architecture
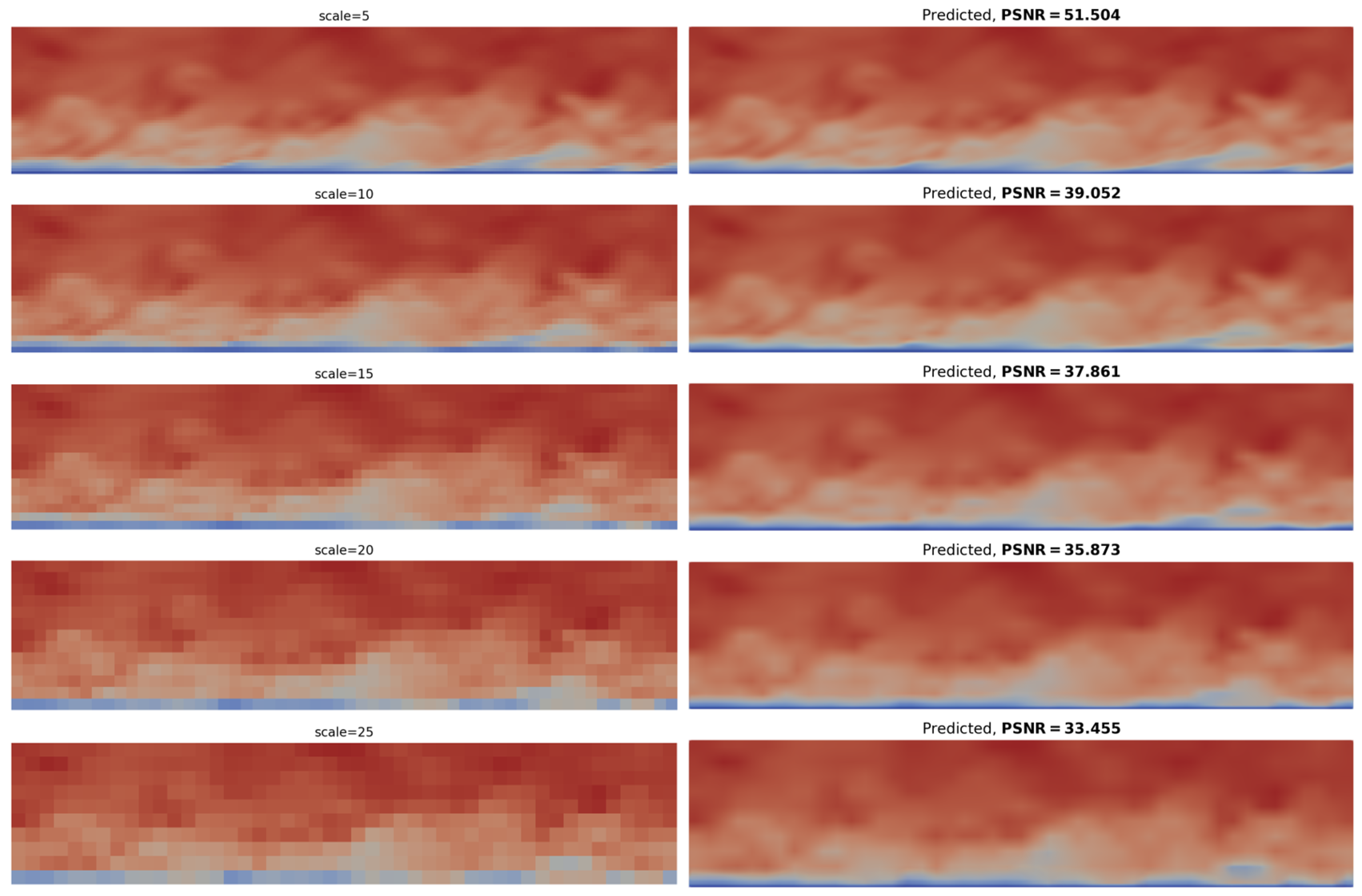
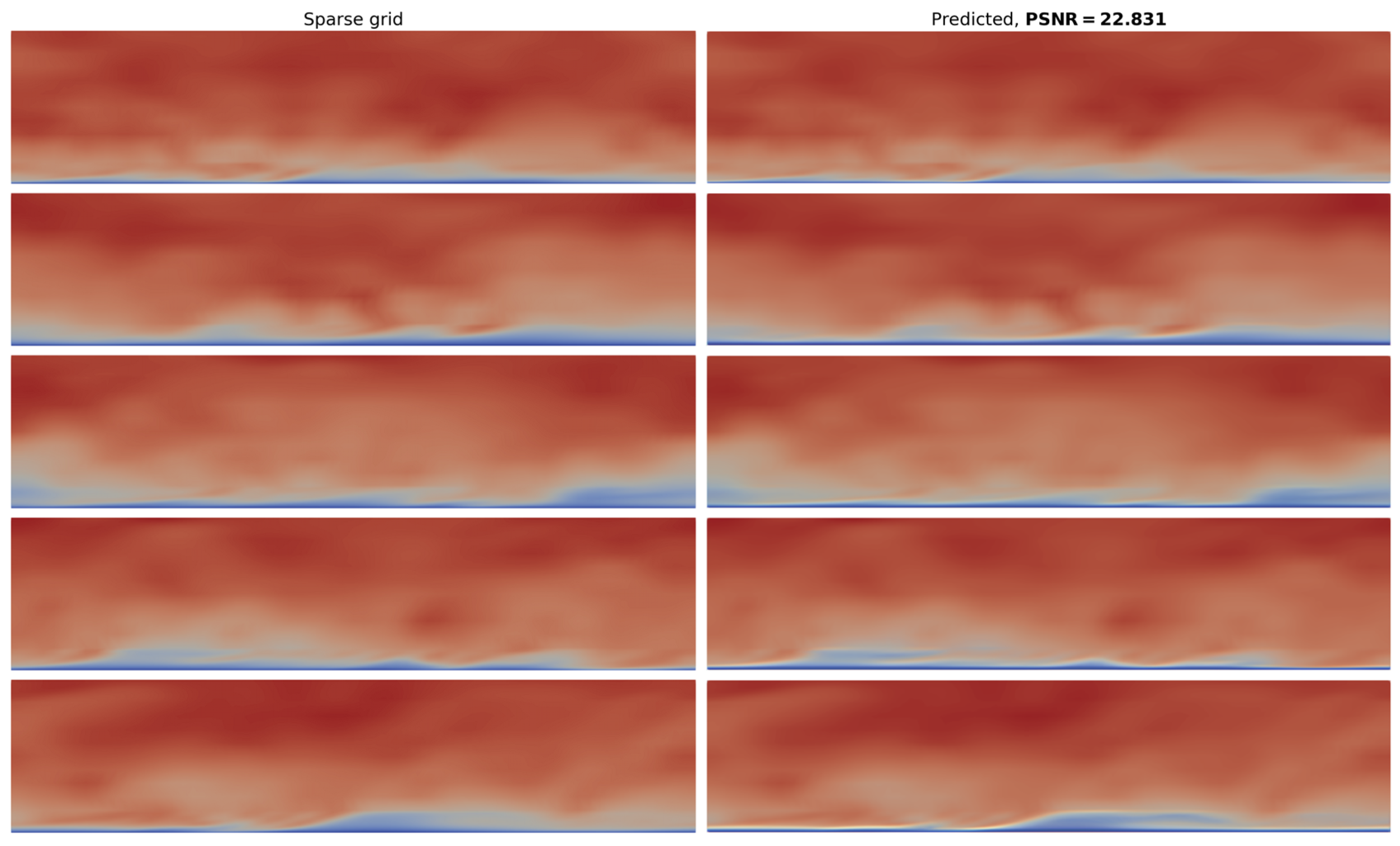
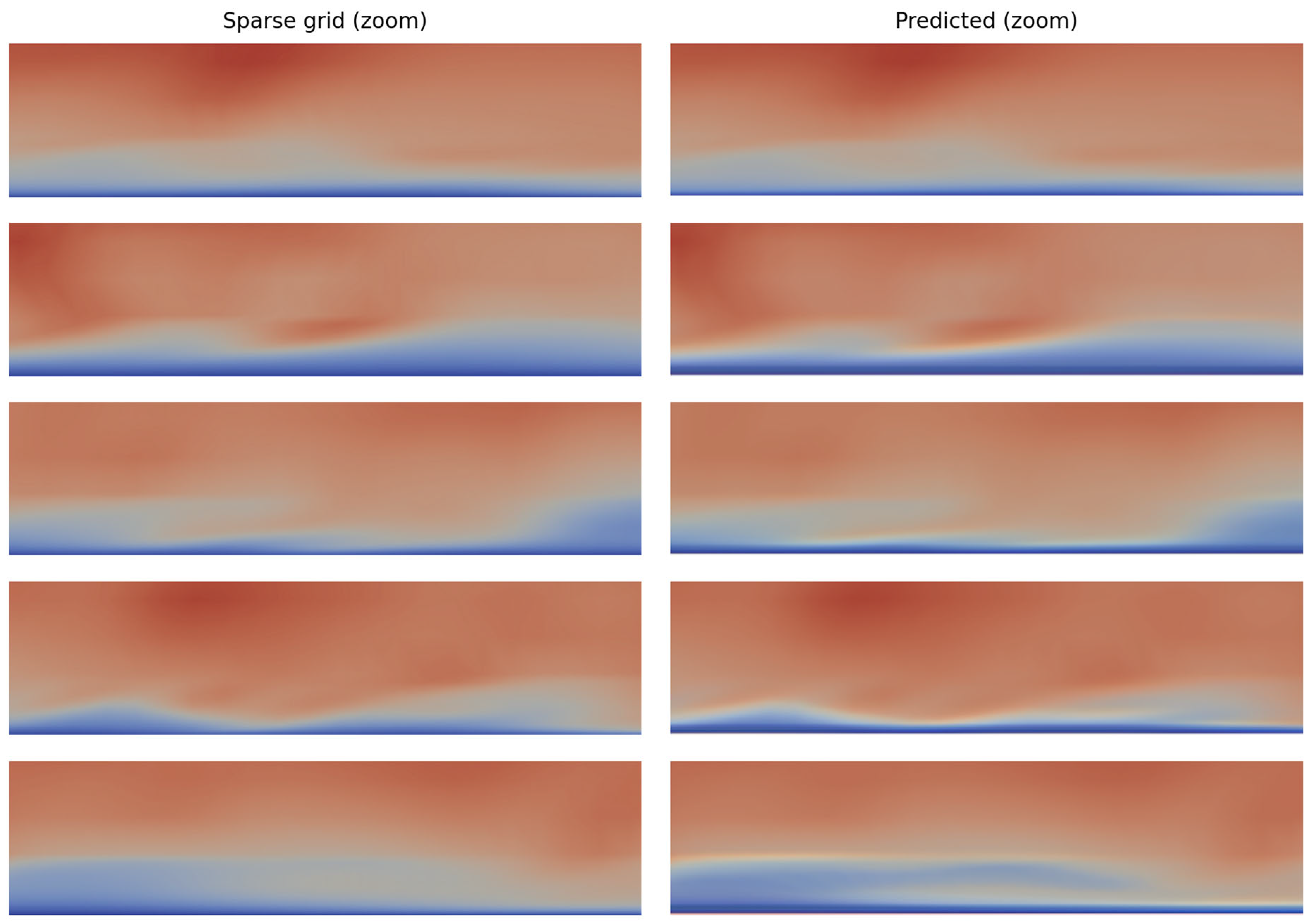
3.2. Reconstruction Metrics
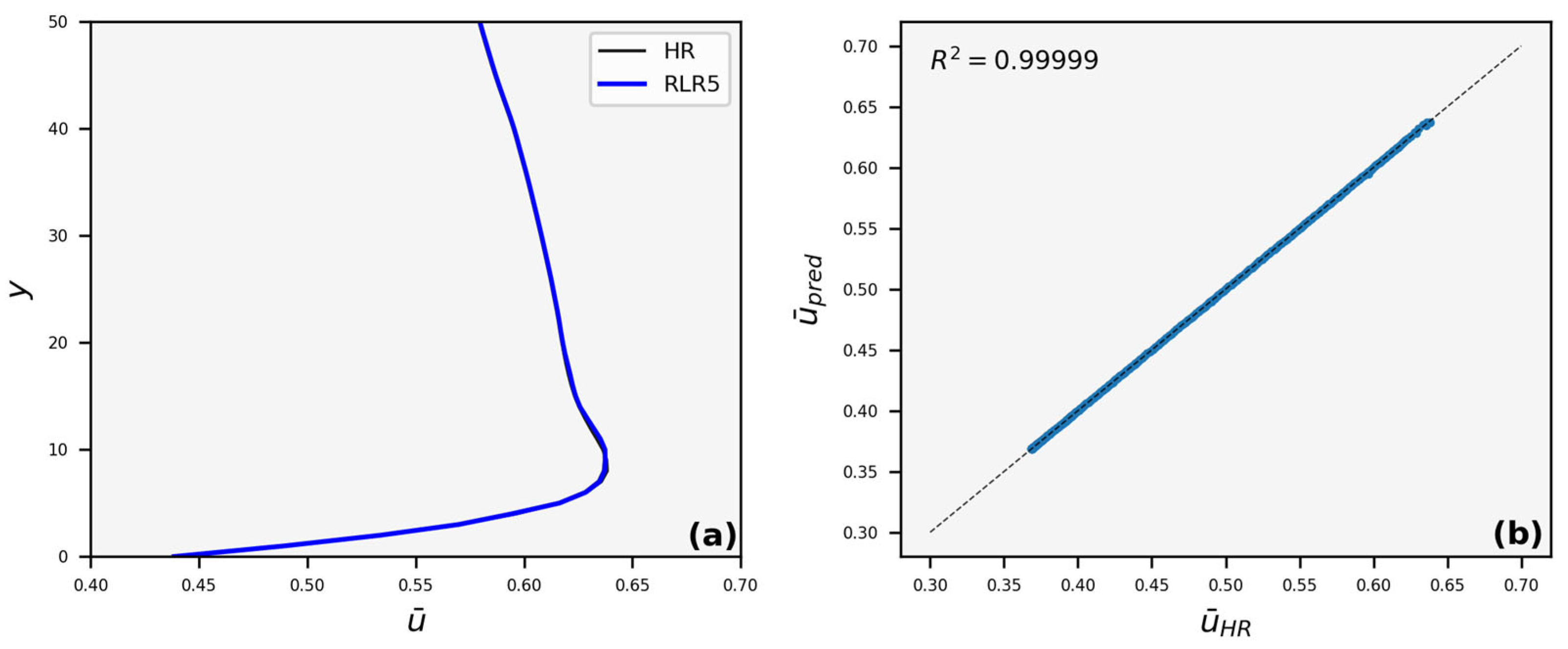
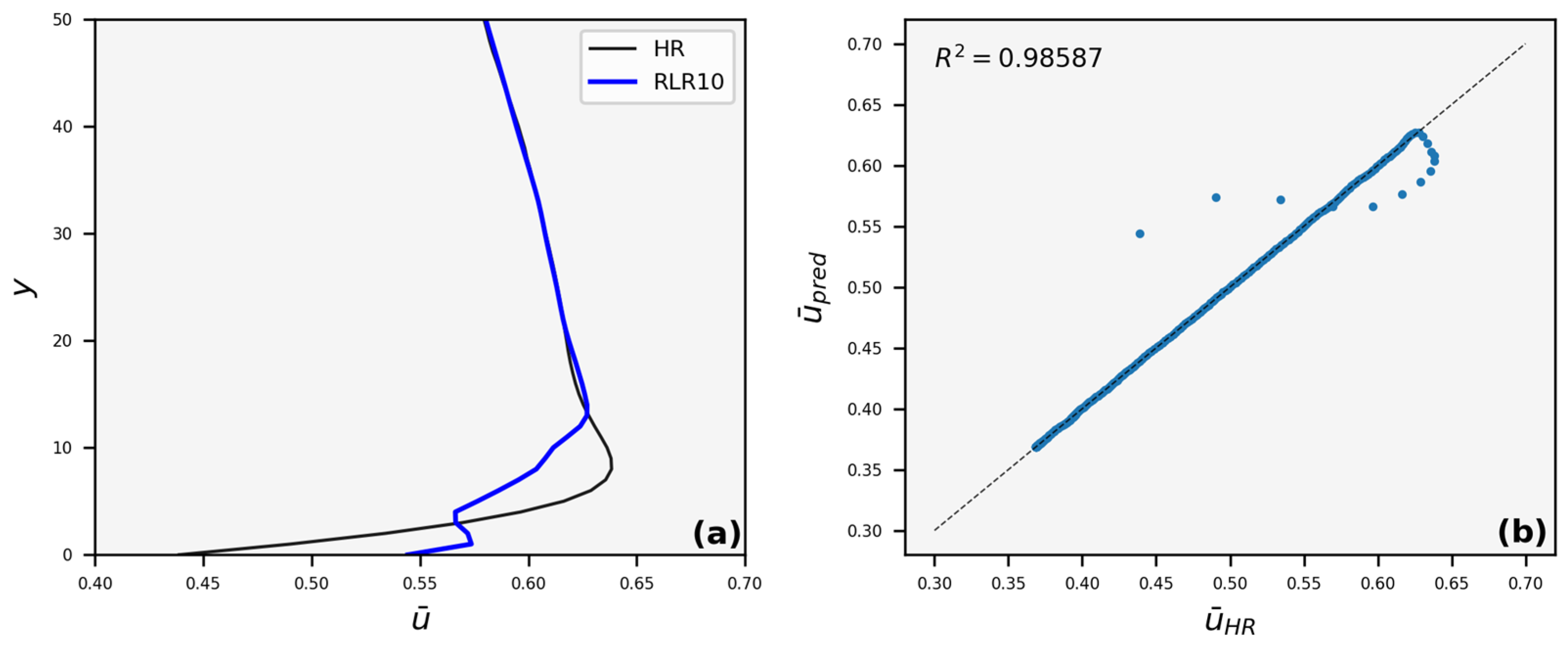
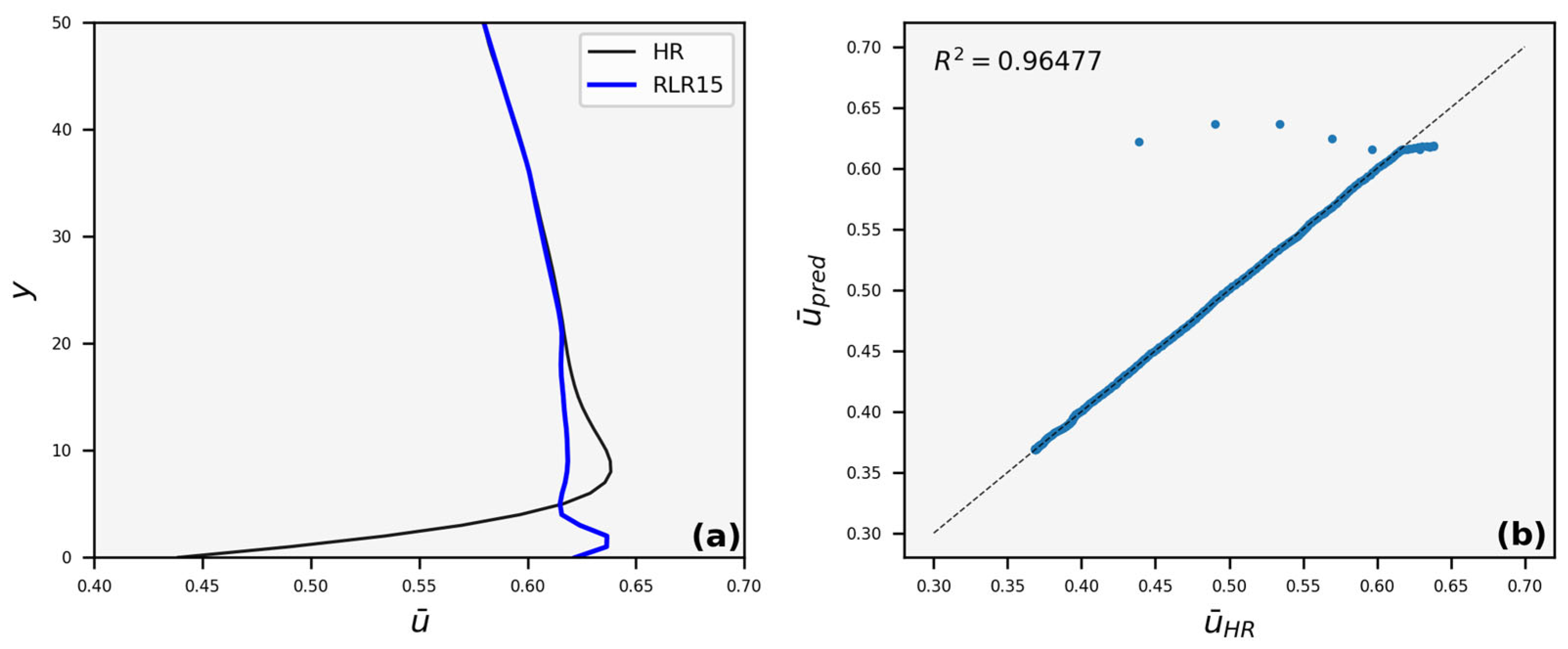
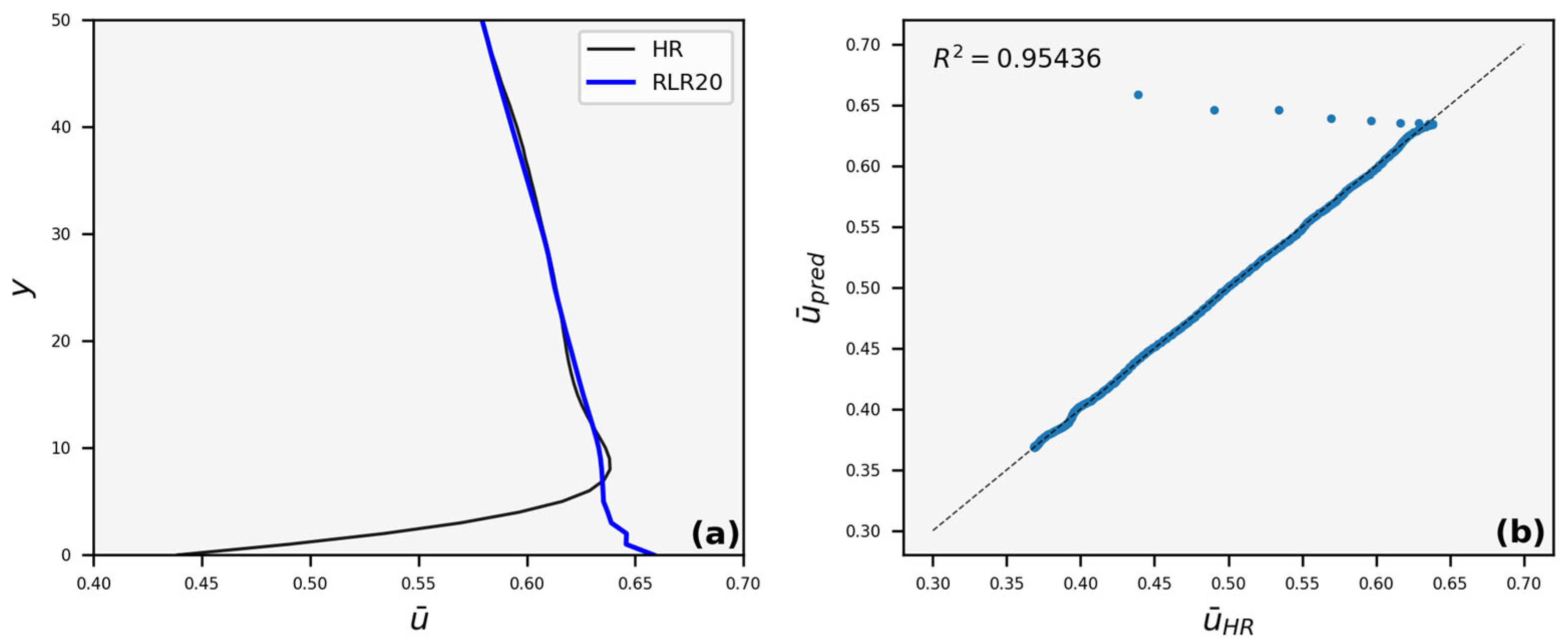
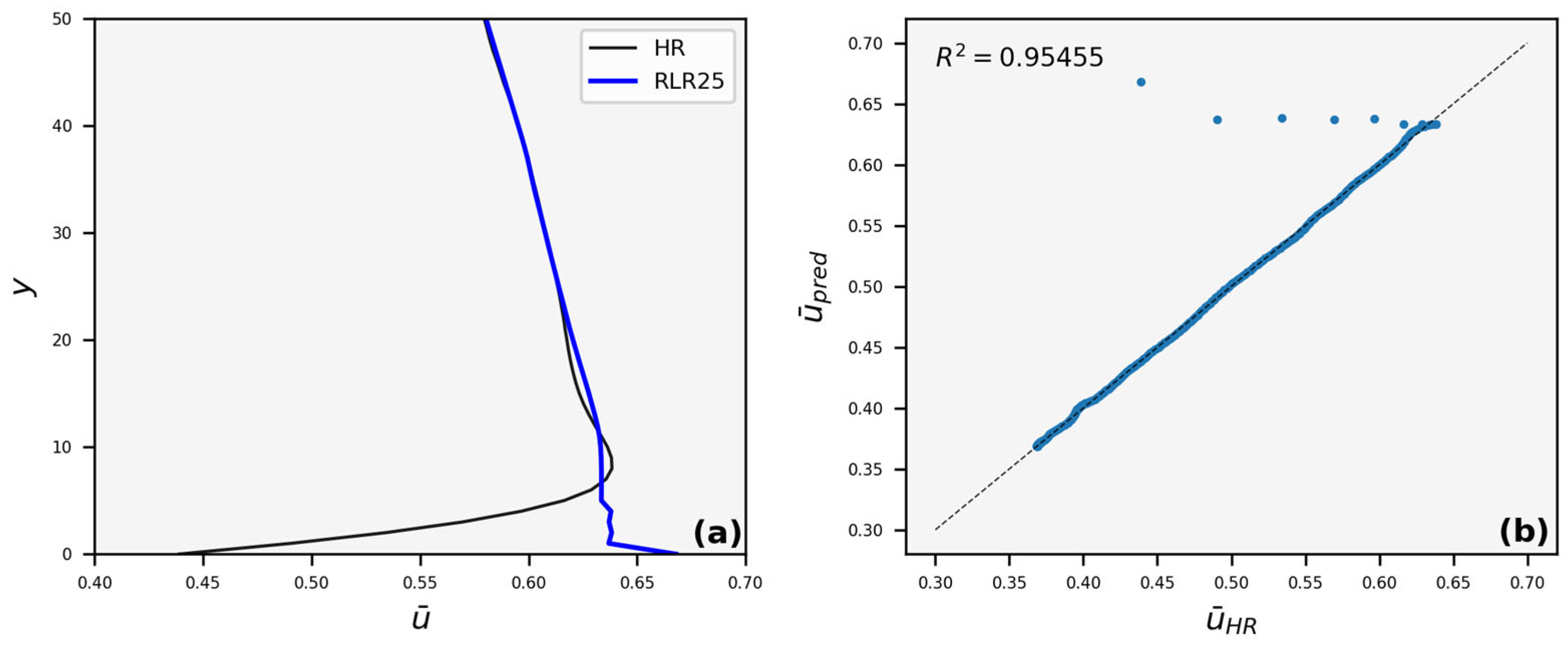
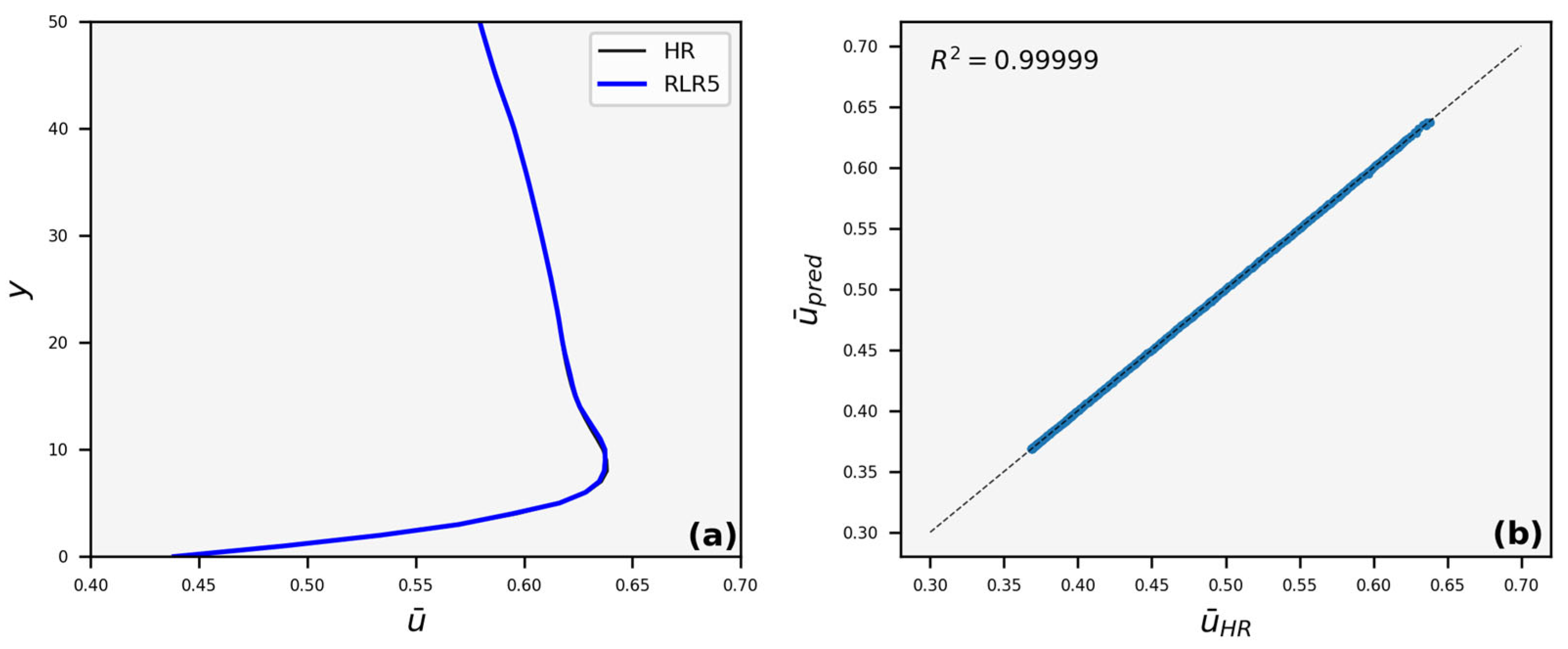
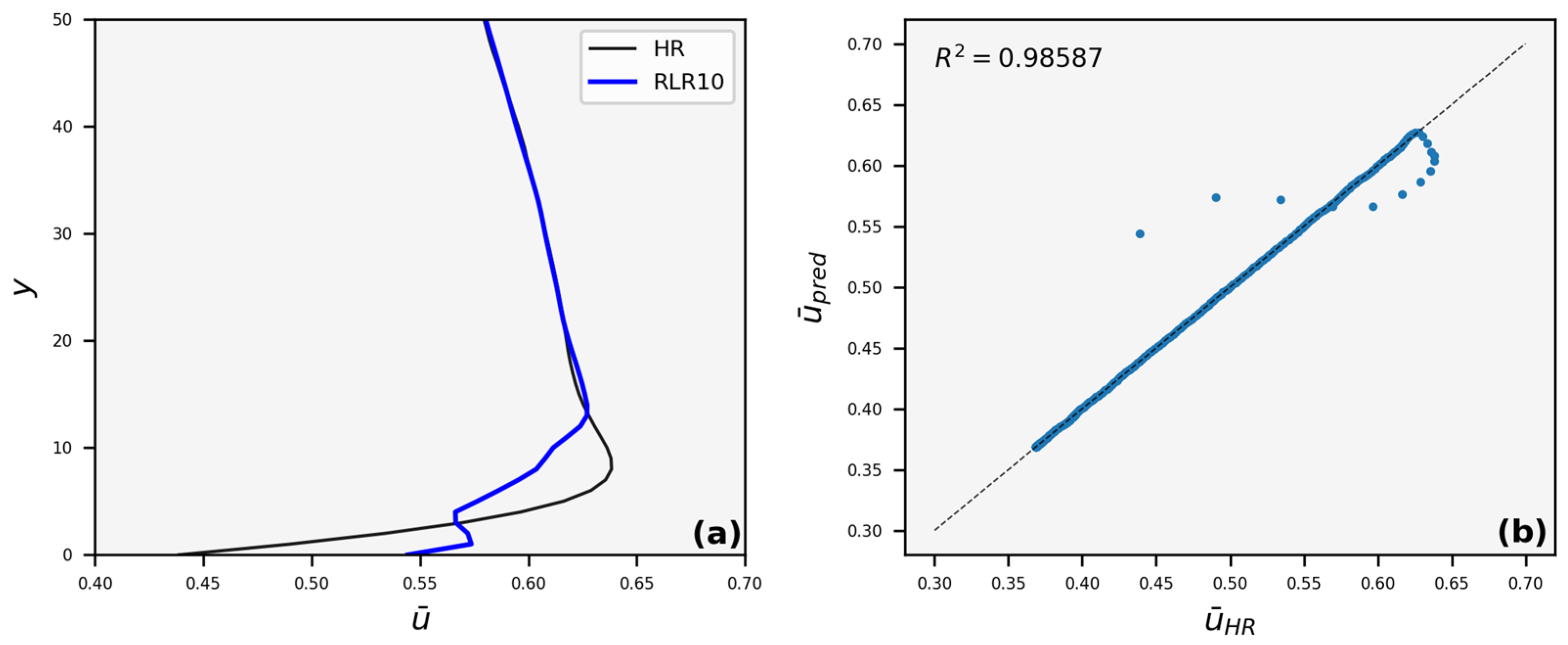
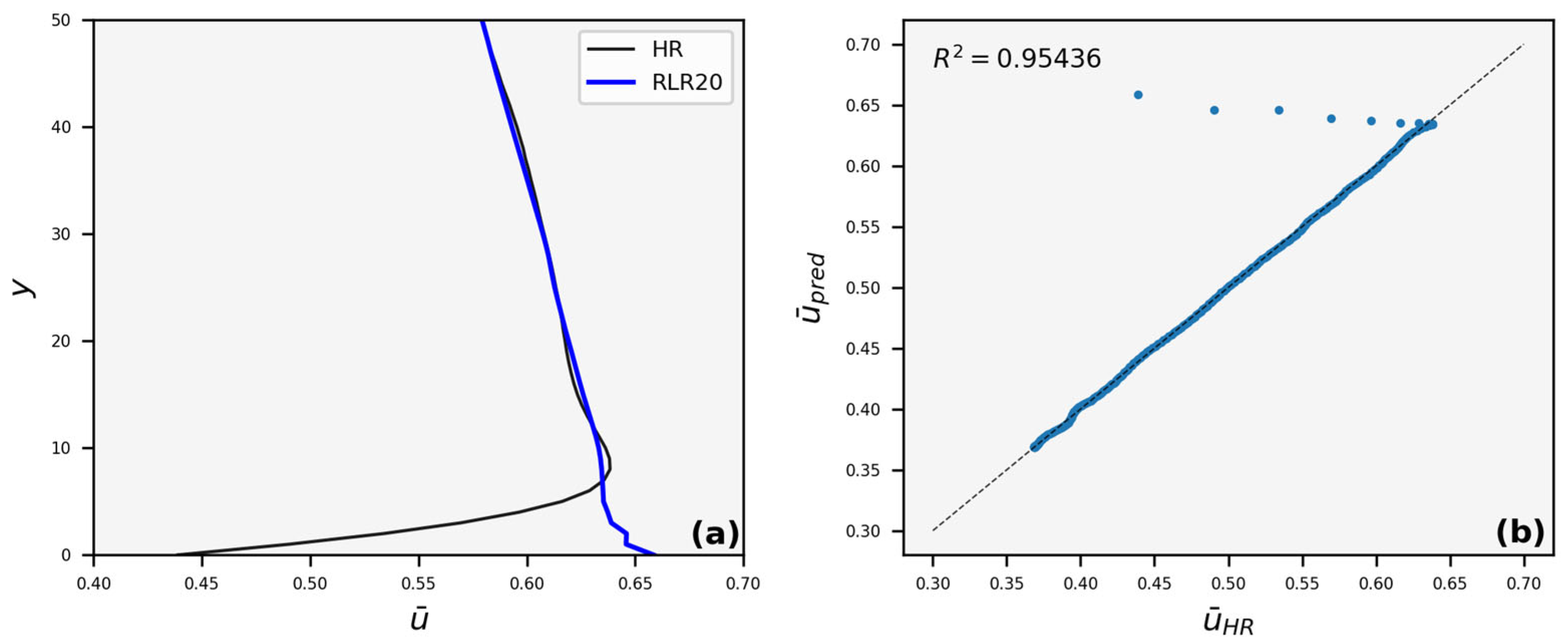
3.3. Velocity Profiles
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Moglen, G.E. Fundamentals of Open Channel Flow; CRC Press: Boca Raton, FL, USA, 2022. [Google Scholar]
- Nezu, I. Open-Channel Flow Turbulence and Its Research Prospect in the 21st Century. J. Hydraul. Eng. 2005, 131, 229–246. [Google Scholar] [CrossRef]
- Callaham, J.L.; Maeda, K.; Brunton, S.L. Robust Flow Reconstruction from Limited Measurements via Sparse Representation. Phys. Rev. Fluids 2019, 4, 103907. [Google Scholar] [CrossRef]
- Komori, S.; Ueda, H.; Ogino, F.; Mizushina, T. Turbulence Structure in Unstably-Stratified Open-Channel Flow. Phys. Fluids 1982, 25, 1539–1546. [Google Scholar] [CrossRef]
- Nezu, I.; Nakagawa, H. Numerical Calculation of Turbulent Open-Channel Flows in Consideration of Free-Surface Effect. Mem. Fac. Eng. Kyoto Univ. 1987, 49, 111–145. [Google Scholar]
- Rashidi, M.; Banerjee, S. Turbulence Structure in Free-Surface Channel Flows. Phys. Fluids 1988, 31, 2491–2503. [Google Scholar] [CrossRef]
- Komori, S.; Murakami, Y.; Ueda, H. Detection of Coherent Structures Associated with Bursting Events in an Open-Channel Flow by a Two-Point Measuring Technique Using Two Laser-Doppler Velocimeters. Phys. Fluids A Fluid Dyn. 1989, 1, 339–348. [Google Scholar] [CrossRef]
- Zhang, X.-L.; Xiao, H.; He, G.-W.; Wang, S.-Z. Assimilation of Disparate Data for Enhanced Reconstruction of Turbulent Mean Flows. Comput. Fluids 2021, 224, 104962. [Google Scholar] [CrossRef]
- Calzolari, G.; Liu, W. Deep Learning to Replace, Improve, or Aid CFD Analysis in Built Environment Applications: A Review. Build. Environ. 2021, 206, 108315. [Google Scholar] [CrossRef]
- Yousif, M.Z.; Yu, L.; Hoyas, S.; Vinuesa, R.; Lim, H. A Deep-Learning Approach for Reconstructing 3D Turbulent Flows from 2D Observation Data. Sci. Rep. 2023, 13, 2529. [Google Scholar] [CrossRef]
- Xiao, H.; Cinnella, P. Quantification of Model Uncertainty in RANS Simulations: A Review. Prog. Aerosp. Sci. 2019, 108, 1–31. [Google Scholar] [CrossRef]
- Moser, R.D.; Haering, S.W.; Yalla, G.R. Statistical Properties of Subgrid-Scale Turbulence Models. Annu. Rev. Fluid Mech. 2021, 53, 255–286. [Google Scholar] [CrossRef]
- Pope, S.B. Ten Questions Concerning the Large-Eddy Simulation of Turbulent Flows. New J. Phys. 2004, 6, 35. [Google Scholar] [CrossRef]
- Moin, P.; Mahesh, K. Direct Numerical Simulation: A Tool in Turbulence Research. Annu. Rev. Fluid Mech. 1998, 30, 539–578. [Google Scholar] [CrossRef]
- Argyropoulos, C.D.; Markatos, N. Recent Advances on the Numerical Modelling of Turbulent Flows. Appl. Math. Model. 2015, 39, 693–732. [Google Scholar] [CrossRef]
- Drikakis, D.; Sofos, F. Can Artificial Intelligence Accelerate Fluid Mechanics Research? Fluids 2023, 8, 212. [Google Scholar] [CrossRef]
- Chen, J.; Viquerat, J.; Heymes, F.; Hachem, E. A Twin-Decoder Structure for Incompressible Laminar Flow Reconstruction with Uncertainty Estimation around 2D Obstacles. Neural Comput. Appl. 2022, 34, 6289–6305. [Google Scholar] [CrossRef]
- Sahan, R.A.; Koc-Sahan, N.; Albin, D.C.; Liakopoulos, A. Artificial Neural Network-Based Modeling and Intelligent Control of Transitional Flows. In Proceedings of the 1997 IEEE International Conference on Control Applications, Hartford, CT, USA, 5–7 October 1997; pp. 359–364. [Google Scholar]
- Anwar, S.; Khan, S.; Barnes, N. A Deep Journey into Super-Resolution: A Survey. ACM Comput. Surv. 2020, 53, 1–34. [Google Scholar] [CrossRef]
- Fukami, K.; Fukagata, K.; Taira, K. Super-Resolution Analysis via Machine Learning: A Survey for Fluid Flows. Theor. Comput. Fluid Dyn. 2023, 37, 421–4444. [Google Scholar] [CrossRef]
- Gao, Q.; Pan, S.; Wang, H.; Wei, R.; Wang, J. Particle Reconstruction of Volumetric Particle Image Velocimetry with the Strategy of Machine Learning. Adv. Aerodyn. 2021, 3, 1–14. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, J.; Hoi, S.C. Deep Learning for Image Super-Resolution: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3365–3387. [Google Scholar] [CrossRef]
- Wang, Z.; Li, X.; Liu, L.; Wu, X.; Hao, P.; Zhang, X.; He, F. Deep-Learning-Based Super-Resolution Reconstruction of High-Speed Imaging in Fluids. Phys. Fluids 2022, 34, 037107. [Google Scholar] [CrossRef]
- Drygala, C.; di Mare, F.; Gottschalk, H. Generalization Capabilities of Conditional GAN for Turbulent Flow under Changes of Geometry. arXiv 2023, arXiv:2302.09945. [Google Scholar]
- Sofos, F.; Drikakis, D.; Kokkinakis, I.W.; Spottswood, S.M. Convolutional Neural Networks for Compressible Turbulent Flow Reconstruction. Phys. Fluids 2023, 35, 116120. [Google Scholar] [CrossRef]
- Bao, K.; Zhang, X.; Peng, W.; Yao, W. Deep Learning Method for Super-Resolution Reconstruction of the Spatio-Temporal Flow Field. Adv. Aerodyn. 2023, 5, 19. [Google Scholar] [CrossRef]
- Falk, T.; Mai, D.; Bensch, R.; Çiçek, Ö.; Abdulkadir, A.; Marrakchi, Y.; Böhm, A.; Deubner, J.; Jäckel, Z.; Seiwald, K.; et al. U-Net: Deep Learning for Cell Counting, Detection, and Morphometry. Nat. Methods 2019, 16, 67–70. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Obiols-Sales, O.; Vishnu, A.; Malaya, N.P.; Chandramowlishwaran, A. SURFNet: Super-Resolution of Turbulent Flows with Transfer Learning Using Small Datasets. In Proceedings of the 2021 30th International Conference on Parallel Architectures and Compilation Techniques (PACT), Atlanta, GA, USA, 26–29 September 2021; pp. 331–344. [Google Scholar]
- Kong, C.; Chang, J.-T.; Li, Y.-F.; Chen, R.-Y. Deep Learning Methods for Super-Resolution Reconstruction of Temperature Fields in a Supersonic Combustor. AIP Adv. 2020, 10, 115021. [Google Scholar] [CrossRef]
- Sofos, F.; Drikakis, D.; Kokkinakis, I.W.; Spottswood, S.M. A Deep Learning Super-Resolution Model for Turbulent Image Upscaling and Its Application to Shock Wave–Boundary Layer Interaction. Phys. Fluids 2024, 36, 025117. [Google Scholar] [CrossRef]
- Li, T.; Buzzicotti, M.; Biferale, L.; Bonaccorso, F. Generative Adversarial Networks to Infer Velocity Components in Rotating Turbulent Flows. Eur. Phys. J. E 2023, 46, 31. [Google Scholar] [CrossRef]
- Beck, A.; Kurz, M. A Perspective on Machine Learning Methods in Turbulence Modeling. GAMM-Mitteilungen 2021, 44, e202100002. [Google Scholar] [CrossRef]
- Buzzicotti, M. Data Reconstruction for Complex Flows Using AI: Recent Progress, Obstacles, and Perspectives. Europhys. Lett. 2023, 142, 23001. [Google Scholar] [CrossRef]
- Kamsu-Foguem, B.; Msouobu Gueuwou, S.L.; Kounta, C.A.K.A. Generative Adversarial Networks Based on Optimal Transport: A Survey. Artif. Intell. Rev. 2023, 56, 6723–6773. [Google Scholar] [CrossRef]
- Bode, M.; Gauding, M.; Lian, Z.; Denker, D.; Davidovic, M.; Kleinheinz, K.; Jitsev, J.; Pitsch, H. Using Physics-Informed Enhanced Super-Resolution Generative Adversarial Networks for Subfilter Modeling in Turbulent Reactive Flows. Proc. Combust. Inst. 2021, 38, 2617–2625. [Google Scholar] [CrossRef]
- Gundersen, K.; Oleynik, A.; Blaser, N.; Alendal, G. Semi-Conditional Variational Auto-Encoder for Flow Reconstruction and Uncertainty Quantification from Limited Observations. Phys. Fluids 2021, 33, 017119. [Google Scholar] [CrossRef]
- Cuomo, S.; Di Cola, V.S.; Giampaolo, F.; Rozza, G.; Raissi, M.; Piccialli, F. Scientific Machine Learning Through Physics–Informed Neural Networks: Where We Are and What’s Next. J. Sci. Comput. 2022, 92, 88. [Google Scholar] [CrossRef]
- Shu, D.; Li, Z.; Farimani, A.B. A Physics-Informed Diffusion Model for High-Fidelity Flow Field Reconstruction. J. Comput. Phys. 2023, 478, 111972. [Google Scholar] [CrossRef]
- Hu, Z.; Shukla, K.; Karniadakis, G.E.; Kawaguchi, K. Tackling the Curse of Dimensionality with Physics-Informed Neural Networks. arXiv 2023, arXiv:2307.12306. [Google Scholar]
- Cheng, C.; Zhang, G.-T. Deep Learning Method Based on Physics Informed Neural Network with Resnet Block for Solving Fluid Flow Problems. Water 2021, 13, 423. [Google Scholar] [CrossRef]
- Hasegawa, K.; Fukami, K.; Murata, T.; Fukagata, K. CNN-LSTM Based Reduced Order Modeling of Two-Dimensional Unsteady Flows around a Circular Cylinder at Different Reynolds Numbers. Fluid Dyn. Res. 2020, 52, 065501. [Google Scholar] [CrossRef]
- Yousif, M.Z.; Zhang, M.; Yu, L.; Vinuesa, R.; Lim, H. A Transformer-Based Synthetic-Inflow Generator for Spatially Developing Turbulent Boundary Layers. J. Fluid Mech. 2023, 957, A6. [Google Scholar] [CrossRef]
- Sofiadis, G.; Sarris, I. Microrotation Viscosity Effect on Turbulent Micropolar Fluid Channel Flow. Phys. Fluids 2021, 33, 095126. [Google Scholar] [CrossRef]
- Sofiadis, G.; Sarris, I. Reynolds Number Effect of the Turbulent Micropolar Channel Flow. Phys. Fluids 2022, 34, 075126. [Google Scholar] [CrossRef]
- Wanik, A.; Schnell, U. Some Remarks on the PISO and SIMPLE Algorithms for Steady Turbulent Flow Problems. Comput. Fluids 1989, 17, 555–570. [Google Scholar] [CrossRef]
- Barton, I.E. Comparison of SIMPLE-and PISO-Type Algorithms for Transient Flows. Int. J. Numer. Methods Fluids 1998, 26, 459–483. [Google Scholar] [CrossRef]
- Kim, J.; Moin, P.; Moser, R. Turbulence Statistics in Fully Developed Channel Flow at Low Reynolds Number. J. Fluid Mech. 1987, 177, 133–166. [Google Scholar] [CrossRef]
- Yoo, J.; Ahn, N.; Sohn, K.-A. Rethinking Data Augmentation for Image Super-Resolution: A Comprehensive Analysis and a New Strategy. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 8375–8384. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image Super-Resolution via Deep Recursive Residual Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2790–2798. [Google Scholar]
- Gu, J.; Sun, X.; Zhang, Y.; Fu, K.; Wang, L. Deep Residual Squeeze and Excitation Network for Remote Sensing Image Super-Resolution. Remote Sens. 2019, 11, 1817. [Google Scholar] [CrossRef]
- Tian, C.; Zhuge, R.; Wu, Z.; Xu, Y.; Zuo, W.; Chen, C.; Lin, C.-W. Lightweight Image Super-Resolution with Enhanced CNN. Knowl.-Based Syst. 2020, 205, 106235. [Google Scholar] [CrossRef]
- Wang, Y.; Su, T.; Li, Y.; Cao, J.; Wang, G.; Liu, X. DDistill-SR: Reparameterized Dynamic Distillation Network for Lightweight Image Super-Resolution. IEEE Trans. Multimed. 2023, 25, 7222–7234. [Google Scholar] [CrossRef]
- Duraisamy, K. Perspectives on Machine Learning-Augmented Reynolds-Averaged and Large Eddy Simulation Models of Turbulence. Phys. Rev. Fluids 2021, 6, 050504. [Google Scholar] [CrossRef]
- Bode, M.; Göbbert, J.H. Acceleration of Complex High-Performance Computing Ensemble Simulations with Super-Resolution-Based Subfilter Models. Comput. Fluids 2023, 271, 106150. [Google Scholar] [CrossRef]
- Nakamura, T.; Fukami, K.; Hasegawa, K.; Nabae, Y.; Fukagata, K. Convolutional Neural Network and Long Short-Term Memory Based Reduced Order Surrogate for Minimal Turbulent Channel Flow. Phys. Fluids 2021, 33, 025116. [Google Scholar] [CrossRef]
- Yu, L.; Yousif, M.Z.; Zhang, M.; Hoyas, S.; Vinuesa, R.; Lim, H.-C. Three-Dimensional ESRGAN for Super-Resolution Reconstruction of Turbulent Flows with Tricubic Interpolation-Based Transfer Learning. Phys. Fluids 2022, 34, 125126. [Google Scholar] [CrossRef]
- Ward, N.J. Physics-Informed Super-Resolution of Turbulent Channel Flows via Three-Dimensional Generative Adversarial Networks. Fluids 2023, 8, 195. [Google Scholar] [CrossRef]
- Liakopoulos, A. Explicit Representations of the Complete Velocity Profile in a Turbulent Boundary Layer. AIAA J. 1984, 22, 844–846. [Google Scholar] [CrossRef]
- Liakopoulos, A. Computation of High Speed Turbulent Boundary-Layer Flows Using the k–ϵ Turbulence Model. Int. J. Numer. Methods Fluids 1985, 5, 81–97. [Google Scholar] [CrossRef]
- Liakopoulos, A.; Palasis, A. On the Composite Velocity Profile in Zero Pressure Gradient Turbulent Boundary Layer: Comparison with DNS Datasets. Fluids 2023, 8, 260. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Nt | Nv | (H × W) | |
|---|---|---|---|
| HR | 40 | 10 | 262 × 1176 |
| LR5 | 40 | 10 | 52 × 235 |
| LR10 | 40 | 10 | 26 × 118 |
| LR15 | 40 | 10 | 17 × 78 |
| LR20 | 40 | 10 | 13 × 59 |
| LR25 | 40 | 10 | 10 × 47 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sofos, F.; Sofiadis, G.; Chatzoglou, E.; Palasis, A.; Karakasidis, T.E.; Liakopoulos, A. From Sparse to Dense Representations in Open Channel Flow Images with Convolutional Neural Networks. Inventions 2024, 9, 27. https://doi.org/10.3390/inventions9020027
Sofos F, Sofiadis G, Chatzoglou E, Palasis A, Karakasidis TE, Liakopoulos A. From Sparse to Dense Representations in Open Channel Flow Images with Convolutional Neural Networks. Inventions. 2024; 9(2):27. https://doi.org/10.3390/inventions9020027
Chicago/Turabian StyleSofos, Filippos, George Sofiadis, Efstathios Chatzoglou, Apostolos Palasis, Theodoros E. Karakasidis, and Antonios Liakopoulos. 2024. "From Sparse to Dense Representations in Open Channel Flow Images with Convolutional Neural Networks" Inventions 9, no. 2: 27. https://doi.org/10.3390/inventions9020027
APA StyleSofos, F., Sofiadis, G., Chatzoglou, E., Palasis, A., Karakasidis, T. E., & Liakopoulos, A. (2024). From Sparse to Dense Representations in Open Channel Flow Images with Convolutional Neural Networks. Inventions, 9(2), 27. https://doi.org/10.3390/inventions9020027