A Distance-Dependent Chinese Restaurant Process Based Method for Event Detection on Social Media

 ,
,  ,
,  ,
,
Abstract
:1. Introduction
2. Related Work
3. The Proposed Method
- The username of the author (metadata)
- The timestamp of the creation date (metadata)
- The actual textual content (of short length)
3.1. Message Similarity and Clustering
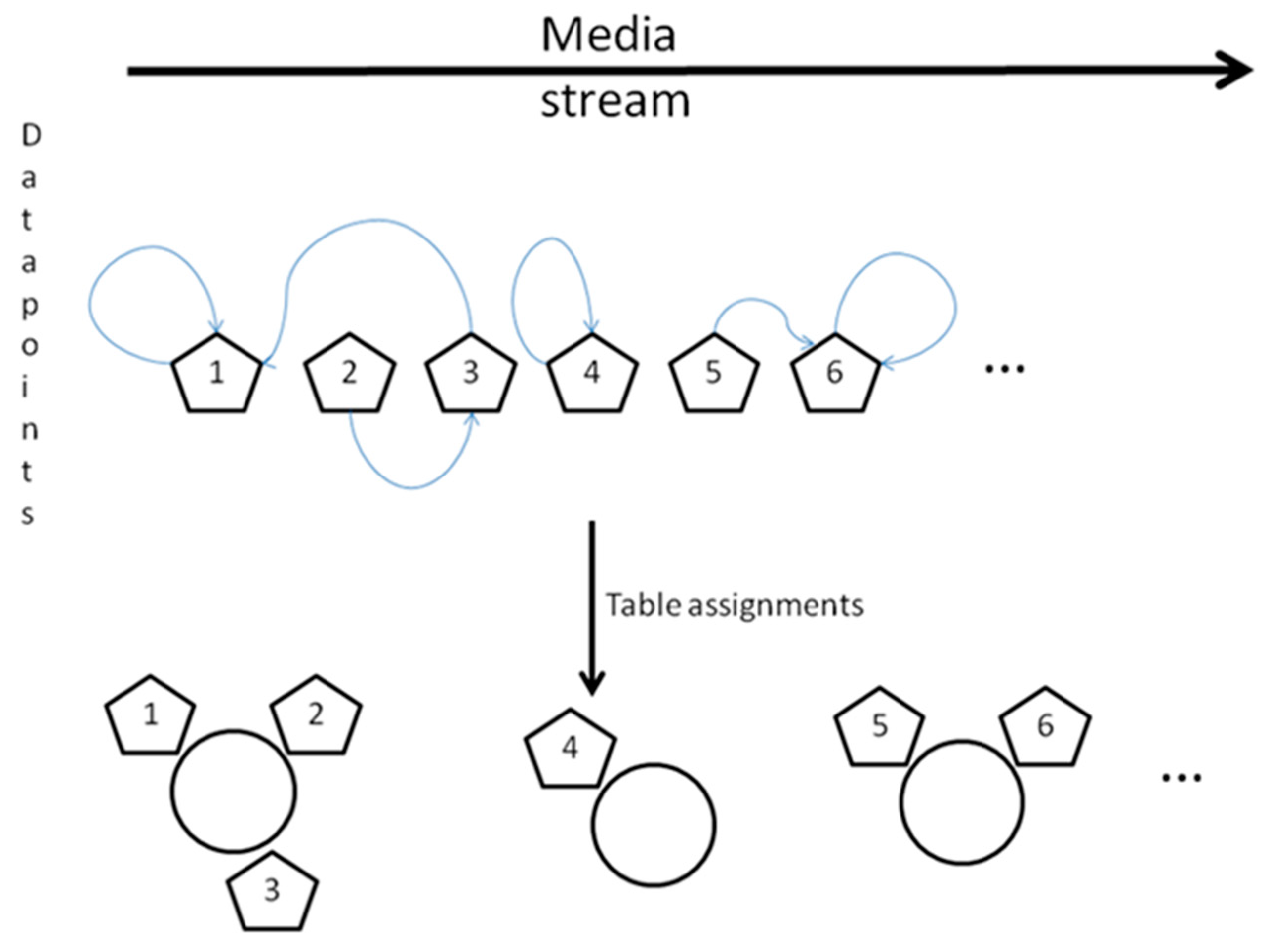
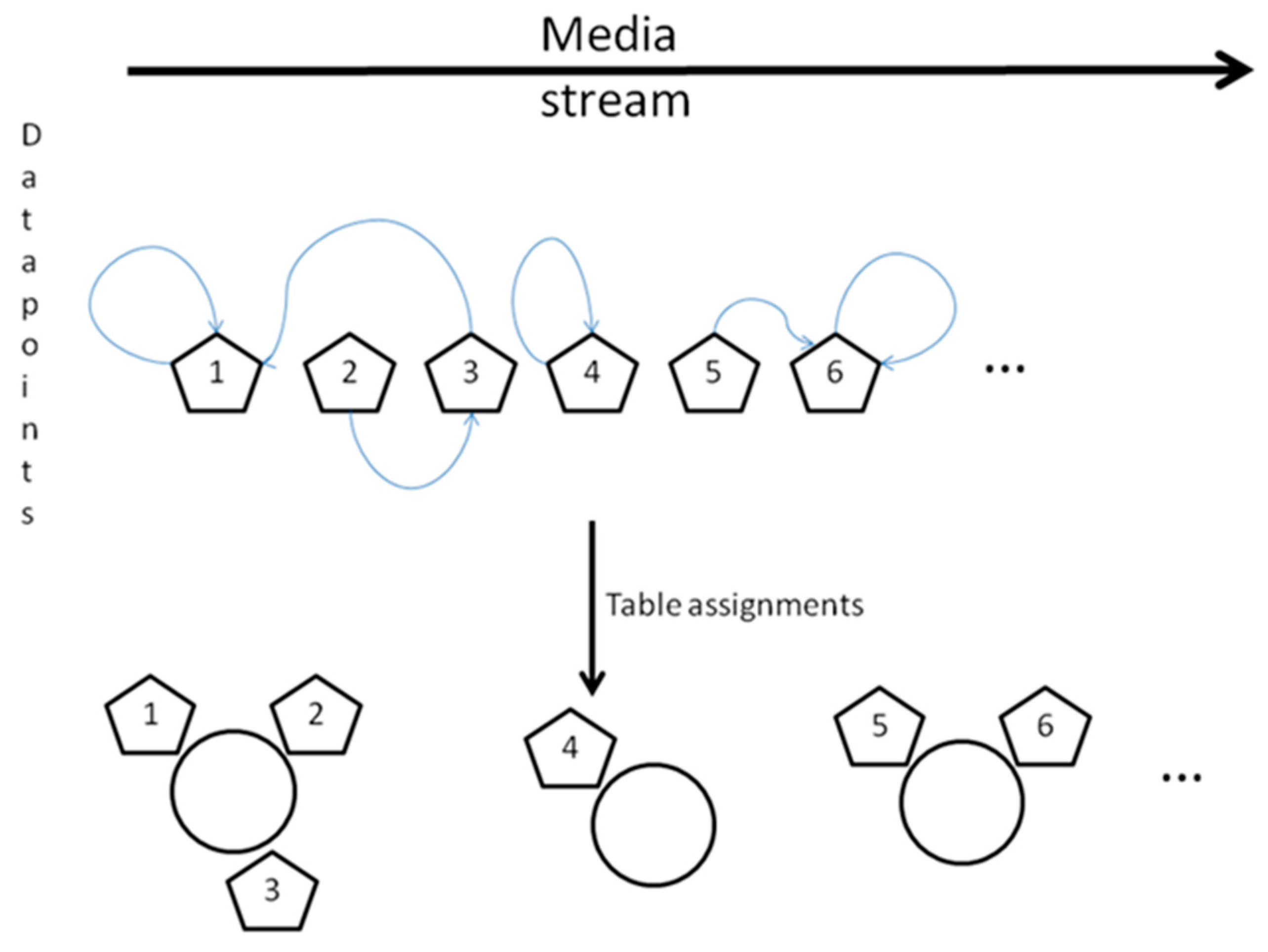
3.2. Methodology
- zi is the table assignment of the ith customer (id of the table that customer i chooses).
- K is the total number of occupied tables.
- nk is the number of customers sitting at table k, with k = 1, …, K.
- α is the concentration parameter.
- ci is the assignment of the ith customer (the identifier of the customer with whom the ith customer chooses to sit).
- dij is the “distance” between customers i and j, and D is the matrix of distances for all customer pairs.
- f is a decay function.
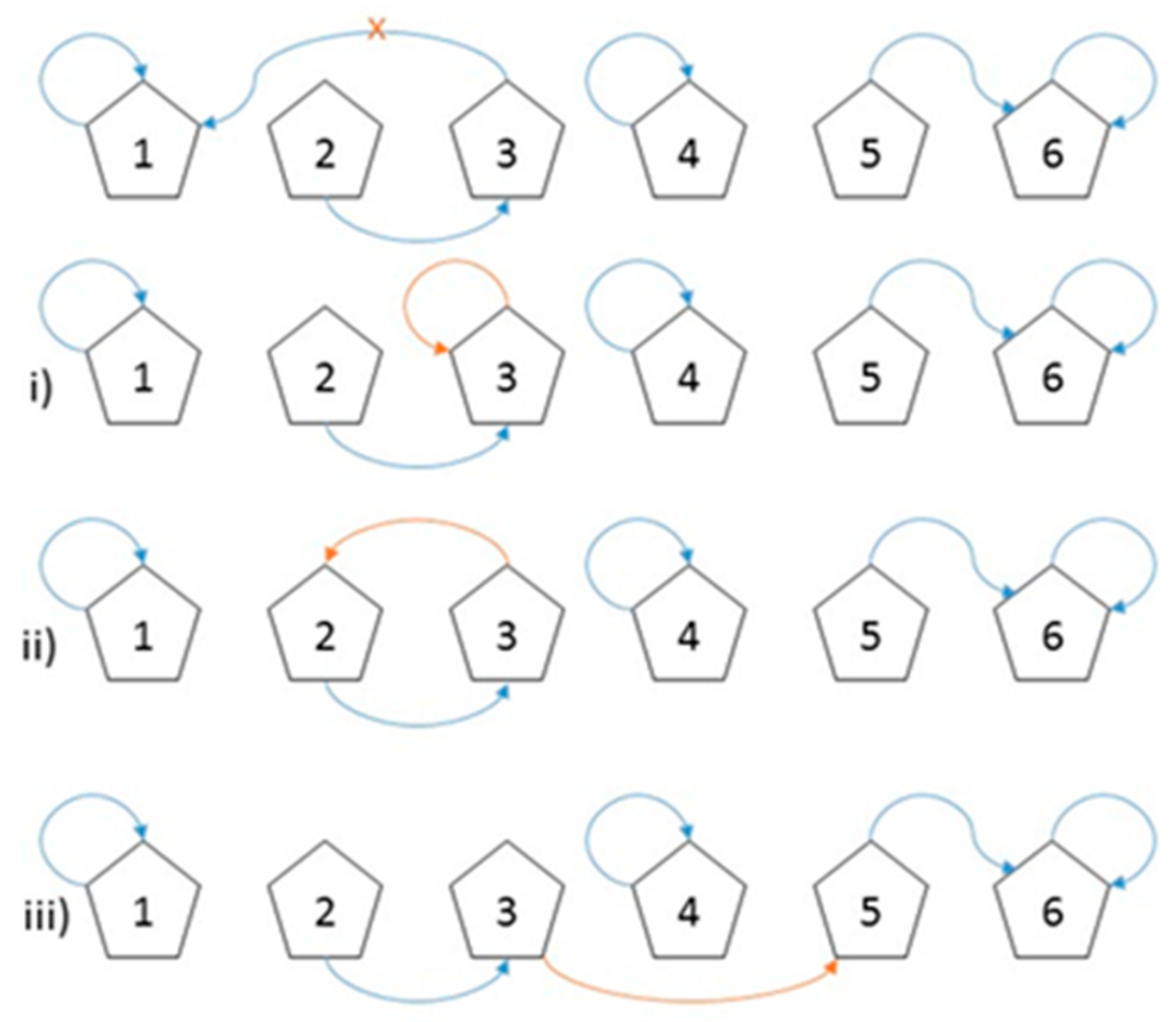
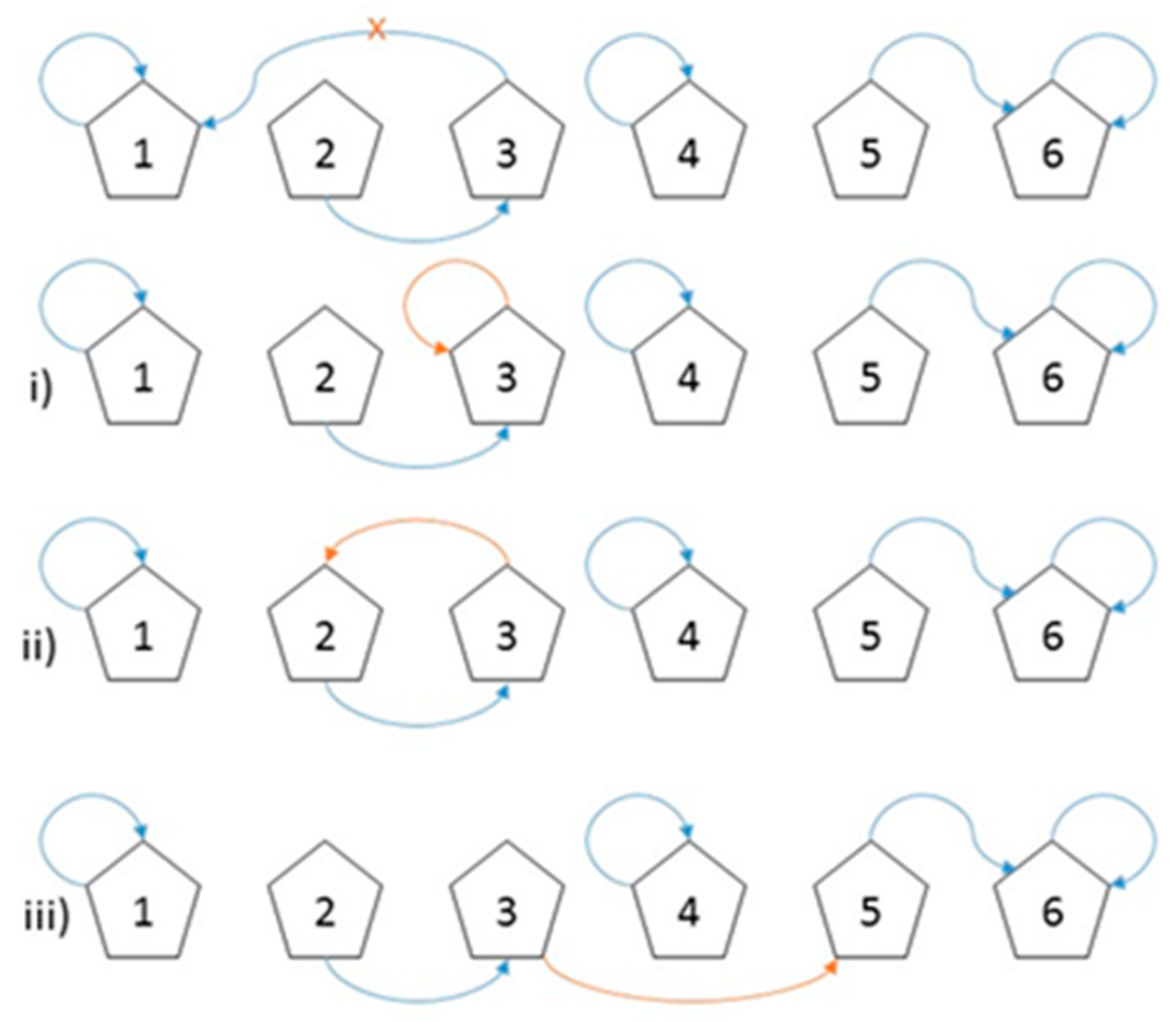
- The new customer assignment ci links to itself (self-loop), which does not change the likelihood since no tables are joined together.
- The new customer assignment ci links to another customer, who is already at its table under z(c−i). There is no change in the partition, since no tables are joined together.
- The new customer assignment ci links to another customer and tables k and l are joined
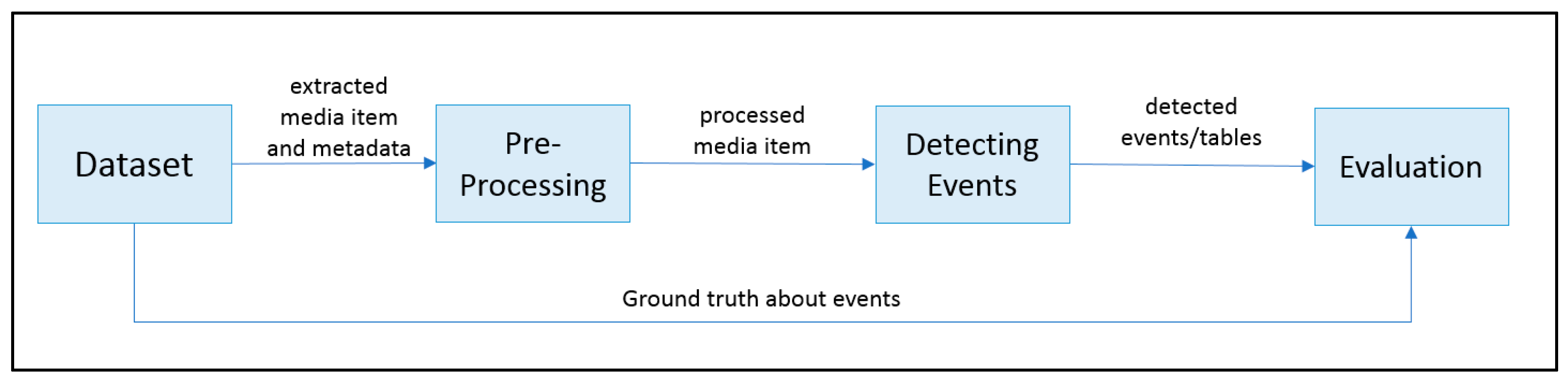
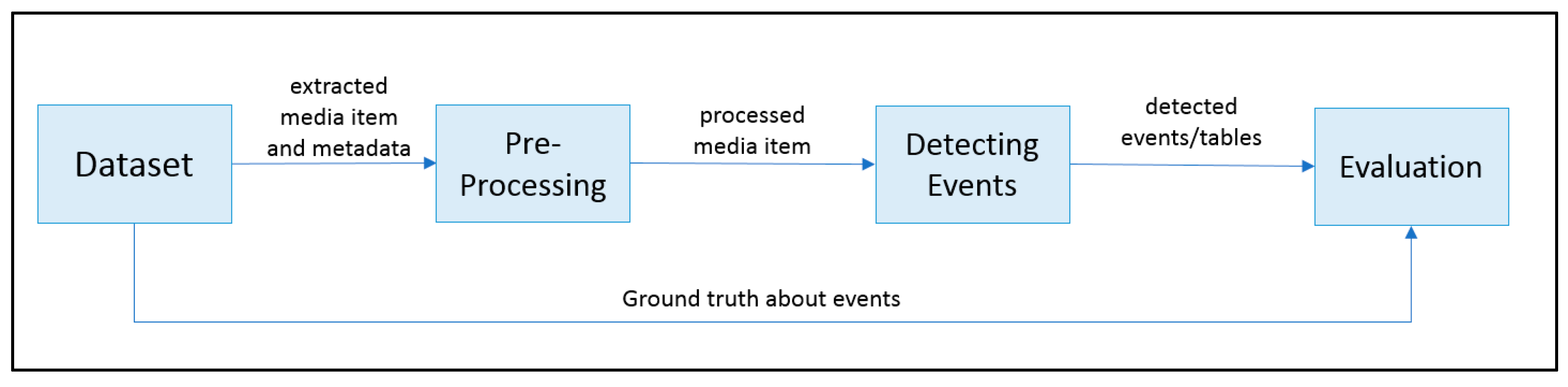
4. Implementation Details and Evaluation
4.1. Dataset
4.2. Implementation Details
4.3. Text Pre-Processing
- Hashtags: A type of metadata used by social media users. It typically consists of the character “#” followed by a string and is usually indicative of the topic the user refers to. We use them in the similarity function among different tweets (customers in our method based on ddCRP) and tested replacing them with “#” character or omitting them.
- RT (retweet): A re-post of an original tweet is called a retweet. It usually should be clustered together with the original one. Additionally, metadata fields indicate the number of times a specific post was retweeted.
- URL: We performed tests by keeping a link directing to an external source, replacing the whole link with the word “url” and removing it completely.
- Stemming and lemmatization: Our goal was to capture the “base form” of a word. For example house instead of houses, house’s etc.
- Stop-word removal: These are very common words such as “the”, “at”, etc.
4.4. Evaluation Metrics
- Normalized Mutual Information (NMI):where Ω = {ω1, ω2, …, ωk} is the set of clusters, C = {c1, c2, …, ck} is the set of classes, I(Ω, C) is mutual information between Ω and C, and H(Ω) and H(C) are the entropies of Ω and C, respectively.
- F1-score, calculated from Precision and Recall with the formulawhere Precision and Recall are defined as follows: A true positive (TP) decision assigns two similar items to the same cluster, a true negative (TN) decision assigns two dissimilar items to different clusters. There are two types of errors we can commit. A False Positive (FP) decision assigns two dissimilar item to the same cluster. A False negative (FN) decision assigns two similar items to different clusters.
4.5. Experimental Setup
- Chinese Restaurant Process (CRP): We used the training set to determine the optimal value of the concentration parameter a.
- Distance-dependent Chinese Restaurant Process based only on time (ddCRP only time): During this approach, in the similarity function, we used only the information about time among all the available metadata in each multimedia item. This way we could see the difference in the clustering results when we used more of the available metadata in the following algorithms.
- Distance-dependent Chinese Restaurant Process sequential (ddCRP sequential): We compared each customer only to customers previously assigned to tables instead of comparing to all customers in the dataset. This approach requires about half the time for training and evaluating.
- Distance-dependent Chinese Restaurant Process (ddCRP): We used the similarity function described in previous sections. The training set was used to reach the optimal values for the parameters of our algorithm such as the concentration parameter and the coefficients in the similarity function.
4.6. Results
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Event Ontology. Available online: http://motools.sourceforge.net/event/event.html (accessed on 30 November 2018).
- Atefeh, F.; Khreich, W. A survey of techniques for event detection in twitter. Comput Intell. 2015, 31, 132–164. [Google Scholar] [CrossRef]
- Hasan, M.; Orgun, M.A.; Schwitter, R. A survey on real-time event detection from the twitter data stream. J. Inf. Sci. 2017. [Google Scholar] [CrossRef]
- Benson, E.; Haghighi, A.; Barzilay, R. Event discovery in social media feeds. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies-Volume 1, Portland, Oregon, 19–24 June 2011; pp. 389–398. [Google Scholar]
- Doulamis, N.D.; Doulamis, A.D.; Kokkinos, P.; Varvarigos, E.M. Event detection in twitter microblogging. IEEE Trans. Cybern. 2016, 46, 2810–2824. [Google Scholar] [CrossRef] [PubMed]
- Petrović, S.; Osborne, M.; Lavrenko, V. Streaming first story detection with application to twitter. In Proceedings of the Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Los Angeles, CA, USA, 2–4 June 2010; pp. 181–189. [Google Scholar]
- Indyk, P.; Motwani, R. Approximate nearest neighbors: towards removing the curse of dimensionality. In Proceedings of the Thirtieth Annual ACM Symposium on Theory of Computing, Dallas, TX, USA, 24–26 May 1998; pp. 604–613. [Google Scholar]
- Petrović, S.; Osborne, M.; Lavrenko, V. Using paraphrases for improving first story detection in news and Twitter. In Proceedings of the 2012 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Montreal, QC, Canada, 3–8 June 2012; pp. 338–346. [Google Scholar]
- Moran, S.; McCreadie, R.; Macdonald, C.; Ounis, I. Enhancing first story detection using word embeddings. In Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, Pisa, Italy, 17–21 July 2016; pp. 821–824. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv, 2013; arXiv:1301.3781. [Google Scholar]
- Blei, D.M.; Frazier, P.I. Distance dependent Chinese restaurant processes. J. Mach. Learn. Res. 2011, 12, 2461–2488. [Google Scholar]
- Ghosh, S.; Ungureanu, A.B.; Sudderth, E.B.; Blei, D.M. Spatial distance dependent Chinese restaurant processes for image segmentation. In NIPS’11 Proceedings of the 24th International Conference on Neural Information Processing Systems; Curran Associates Inc.: Granada, Spain, 2011; pp. 1476–1484. [Google Scholar]
- Socher, R.; Maas, A.; Manning, C. Spectral chinese restaurant processes: Nonparametric clustering based on similarities. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 698–706. [Google Scholar]
- Li, C.; Phung, D.; Rana, S.; Venkatesh, S. Exploiting side information in distance dependent chinese restaurant processes for data clustering. In Proceedings of the 2013 IEEE International Conference on Multimedia and Expo (ICME), San Jose, CA, USA, 15–19 July 2013; pp. 1–6. [Google Scholar]
- Papaoikonomou, A.; Tserpes, K.; Kardara, M.; Varvarigou, T. A similarity-based chinese restaurant process for social event detection. In Proceedings of the MediaEval 2013 Workshop, Barcelona, Spain, 18–19 October 2013. [Google Scholar]
- Li, C.; Rana, S.; Phung, D.; Venkatesh, S. Data clustering using side information dependent Chinese restaurant processes. Knowl. Inf. Syst. 2016, 47, 463–488. [Google Scholar] [CrossRef]
- Lauri, M.; Frintrop, S. Object proposal generation applying the distance dependent Chinese restaurant process. In Proceedings of the Scandinavian Conference on Image Analysis, Tromsø, Norway, 12–14 June 2017; pp. 260–272. [Google Scholar]
- Pitman, J. Combinatorial Stochastic Processes: Ecole d’Eté de Probabilités de Saint-Flour XXXII-2002; Springer: Berlin, Germany, 2006. [Google Scholar]
- Reuter, T.; Papadopoulos, S.; Petkos, G.; Mezaris, V.; Kompatsiaris, Y.; Cimiano, P.; de Vries, C.; Geva, S. Social event detection at mediaeval 2013: Challenges, datasets, and evaluation. In Proceedings of the MediaEval 2013 Multimedia Benchmark Workshop, Barcelona, Spain, 18–19 October 2013. [Google Scholar]
- Social Event Detection. Available online: http://www.multimediaeval.org/mediaeval2013/sed2013/ (accessed on 1 November 2018).
- Petkos, G.; Papadopoulos, S.; Kompatsiaris, Y. Social event detection using multimodal clustering and integrating supervisory signals. In Proceedings of the 2nd ACM International Conference on Multimedia Retrieval, Hong Kong, China, 5–8 June 2012; p. 23. [Google Scholar]
- Reuter, T.; Cimiano, P. Event-based classification of social media streams. In Proceedings of the 2nd ACM International Conference on Multimedia Retrieval, Hong Kong, China, 5–8 June 2012; p. 22. [Google Scholar]
- Flickr Services. Available online: https://www.flickr.com/services/api/ (accessed on 14 November 2018).
- Reuter, T.; Papadopoulos, S.; Mezaris, V.; Cimiano, P. ReSEED: Social event dEtection dataset. In Proceedings of the 5th ACM Multimedia Systems Conference, Singapore, 19–21 March 2014; pp. 35–40. [Google Scholar]
- PostgreSQL: The World’s Most Advanced Open Source Database. Available online: https://www.postgresql.org/ (accessed on 14 November 2018).
- javax.xml.bind (Java Platform SE 7). Available online: https://docs.oracle.com/javase/7/docs/api/javax/xml/bind/package-summary.html (accessed on 29 November 2018).
- Opencsv. Available online: http://opencsv.sourceforge.net/ (accessed on 29 November 2018).
- Twitter API. Available online: https://developer.twitter.com/en/docs.html (accessed on 1 November 2018).
- Tweepy. Available online: http://www.tweepy.org/ (accessed on 29 November 2018).
- Evaluation of Clustering. Available online: https://nlp.stanford.edu/IR-book/html/htmledition/evaluation-of-clustering-1.html (accessed on 14 November 2018).
- Gupta, K.G.I.; Chandramouli, K. VIT@ MediaEval 2013 Social Event Detection Task: Semantic Structuring of Complementary Information for Clustering Events. In Proceedings of the MediaEval 2013 Workshop, Barcelona, Spain, 18–19 October 2013. [Google Scholar]
- Rafailidis, D.; Semertzidis, T.; Lazaridis, M.; Strintzis, M.G.; Daras, P. A Data-Driven Approach for Social Event Detection. In Proceedings of the MediaEval 2013 Workshop, Barcelona, Spain, 18–19 October 2013. [Google Scholar]
- CERTH @ MediaEval 2013 Social Event Detection Task | Request PDF. ResearchGate. Available online: https://www.researchgate.net/publication/283248185_CERTH_MediaEval_2013_social_event_detection_task (accessed on 30 November 2018).
- Zeppelzauer, M.; Zaharieva, M.; del Fabro, M. Unsupervised Clustering of Social Events. In Proceedings of the MediaEval 2013 Workshop, Barcelona, Spain, 18–19 October2013. [Google Scholar]
- Sutanto, T.; Nayak, R. Admrg@ MediaEval 2013 social event detection. In Proceedings of the MediaEval 2013 Multimedia Benchmark Workshop, Barcelona, Spain, 18–19 October 2013. [Google Scholar]
- Wistuba, M.; Schmidt-Thieme, L. Supervised Clustering of Social Media Streams. In Proceedings of the MediaEval 2013 Workshop, Barcelona, Spain, 18–19 October 2013. [Google Scholar]
- Vizuete, D.M.; Nieto, X.G. Upc at mediaeval 2013 social event detection task. In Proceedings of the MediaEval 2013 Multimedia Benchmark Workshop, Barcelona, Spain, 18–19 October 2013. [Google Scholar]
- Nguyen, T.-V.; Dao, M.-S.; Mattivi, R.; Sansone, E.; de Natale, F.G.; Boato, G. Event Clustering and Classification from Social Media: Watershed-based and Kernel Methods. In Proceedings of the MediaEval 2013 Workshop, Barcelona, Spain, 18–19 October 2013. [Google Scholar]
- Samangooei, S.; Hare, J.; Dupplaw, D.; Niranjan, M.; Gibbins, N.; Lewis, P.H.; Davies, J.; Jain, N.; Preston, J. Social event detection via sparse multi-modal feature selection and incremental density based clustering. In Proceedings of the MediaEval 2013 Workshop, Barcelona, Spain, 18–19 October 2013. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Lake Tahoe, Nevada, 2013; pp. 3111–3119. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| Feature | Description |
|---|---|
| flickr_picture_id | unique ID of the image |
| url | URL of image in Flickr |
| username | username of uploader |
| datetaken | timestamp of capturing the image |
| dateupload | timestamp of uploading the image |
| title | title of the image |
| description | text describing the image |
| latitude, longitude | image’s location |
| tags | keywords assigned to the image |
| event_id | ground truth event for this image |
| Algorithm 1 | NMI | F1-Measure |
|---|---|---|
| CRP | 0.56 | 0.1 |
| ddCRP (only time) | 0.890 | 0.594 |
| ddCRP sequential | 0.819 | 0.1412 |
| ddCRP | 0.907 | 0.655 |
| Approach | F1 | NMI |
|---|---|---|
| Semantic Structuring of Complementary Information [31] | 0.142 | |
| Similarity-based Chinese Restaurant Process [15] | 0.236 | 0.664 |
| Data-Driven approach [32] | 0.570 | 0.873 |
| Same Event Model—Based [33] | 0.704 | 0.910 |
| Unsupervised Clustering [34] | 0.780 | 0.940 |
| Clustering based on BM25, Sphinx and cosine similarity [35] | 0.81 | 0.954 |
| Quality Threshold clustering variant [36] | 0.878 | 0.965 |
| PhotoTOC [37] | 0.883 | 0.973 |
| Our proposed ddCRP based method | 0.907 | 0.6546 |
| Watershed-based and kernel methods [38] | 0.932 | 0.984 |
| Sparse multi-modal feature selection and incremental density-based clustering [39] | 0.946 | 0.985 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Palaiokrassas, G.; Voulodimos, A.; Litke, A.; Papaoikonomou, A.; Varvarigou, T. A Distance-Dependent Chinese Restaurant Process Based Method for Event Detection on Social Media. Inventions 2018, 3, 80. https://doi.org/10.3390/inventions3040080
Palaiokrassas G, Voulodimos A, Litke A, Papaoikonomou A, Varvarigou T. A Distance-Dependent Chinese Restaurant Process Based Method for Event Detection on Social Media. Inventions. 2018; 3(4):80. https://doi.org/10.3390/inventions3040080
Chicago/Turabian StylePalaiokrassas, Georgios, Athanasios Voulodimos, Antonios Litke, Athanasios Papaoikonomou, and Theodora Varvarigou. 2018. "A Distance-Dependent Chinese Restaurant Process Based Method for Event Detection on Social Media" Inventions 3, no. 4: 80. https://doi.org/10.3390/inventions3040080
APA StylePalaiokrassas, G., Voulodimos, A., Litke, A., Papaoikonomou, A., & Varvarigou, T. (2018). A Distance-Dependent Chinese Restaurant Process Based Method for Event Detection on Social Media. Inventions, 3(4), 80. https://doi.org/10.3390/inventions3040080