
Machine Learning Applications for Diagnosing Parkinson’s Disease via Speech, Language, and Voice Changes: A Systematic Review



Abstract
1. Introduction
2. Methods
2.1. Information Sources
2.2. Search Strategy
2.3. Inclusion and Exclusion Criteria
- a.
- Studies that focused on the classification, diagnosis, detection, or identification of PD.
- b.
- Studies that Applied ML/DL techniques for data processing and modeling.
- c.
- Studies that used datasets involving voice, speech, and/or language processing.
- d.
- Studies published in peer-reviewed journals, available as full-text papers in English, and open-access.
- Research was not conducted on human participants.
- Studies do not include voice biomarkers.
- Studies provided a limited or insufficient description of data modalities, study subjects, and ML methods used.
- Reviews, meta-analyses, conference abstracts, and editorial papers were excluded.
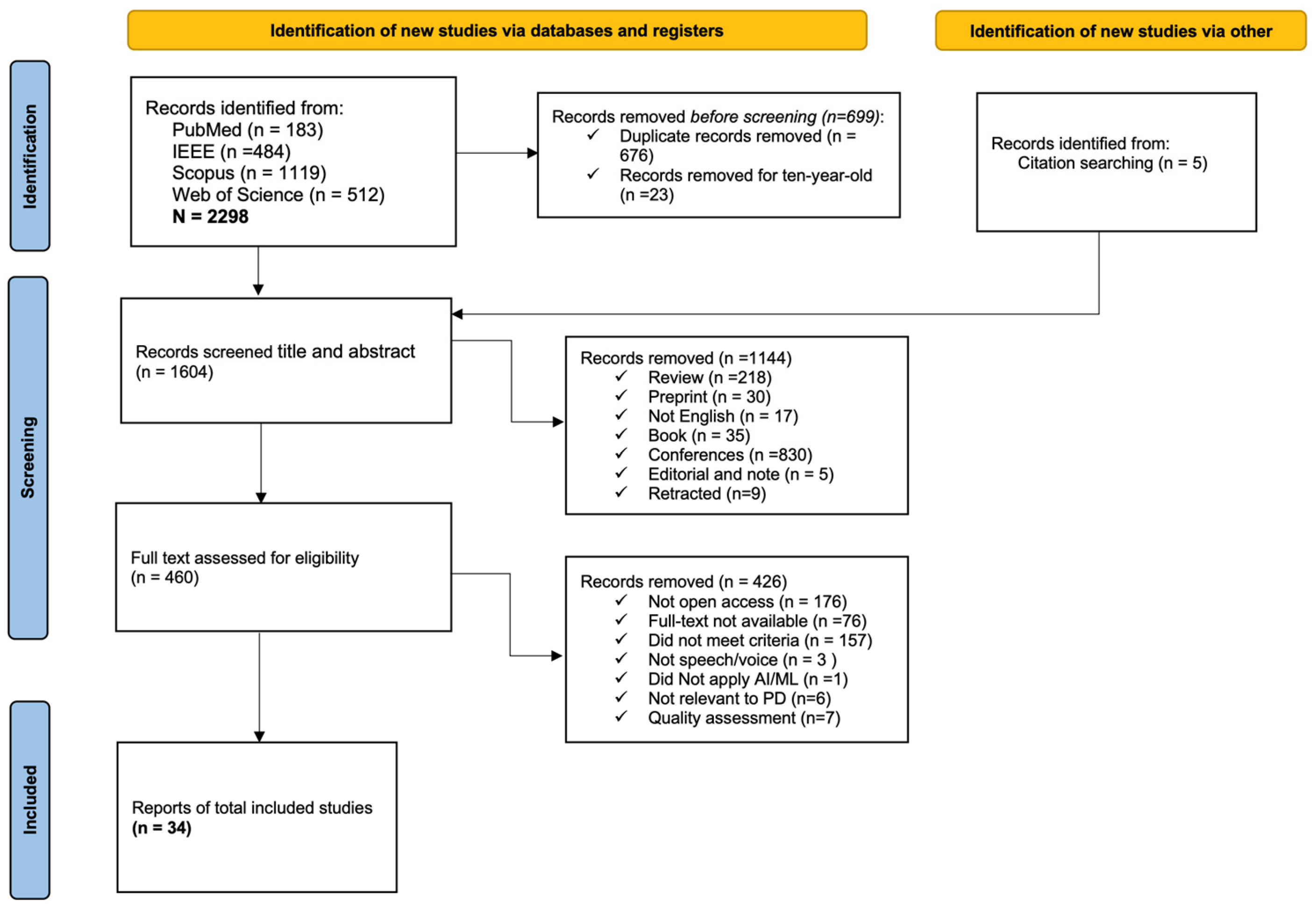
2.4. Study Selection
2.5. Data Extraction
2.6. Data Collection
2.7. Risk of Bias Assessment
2.8. Data Synthesis
2.9. Effect Measures
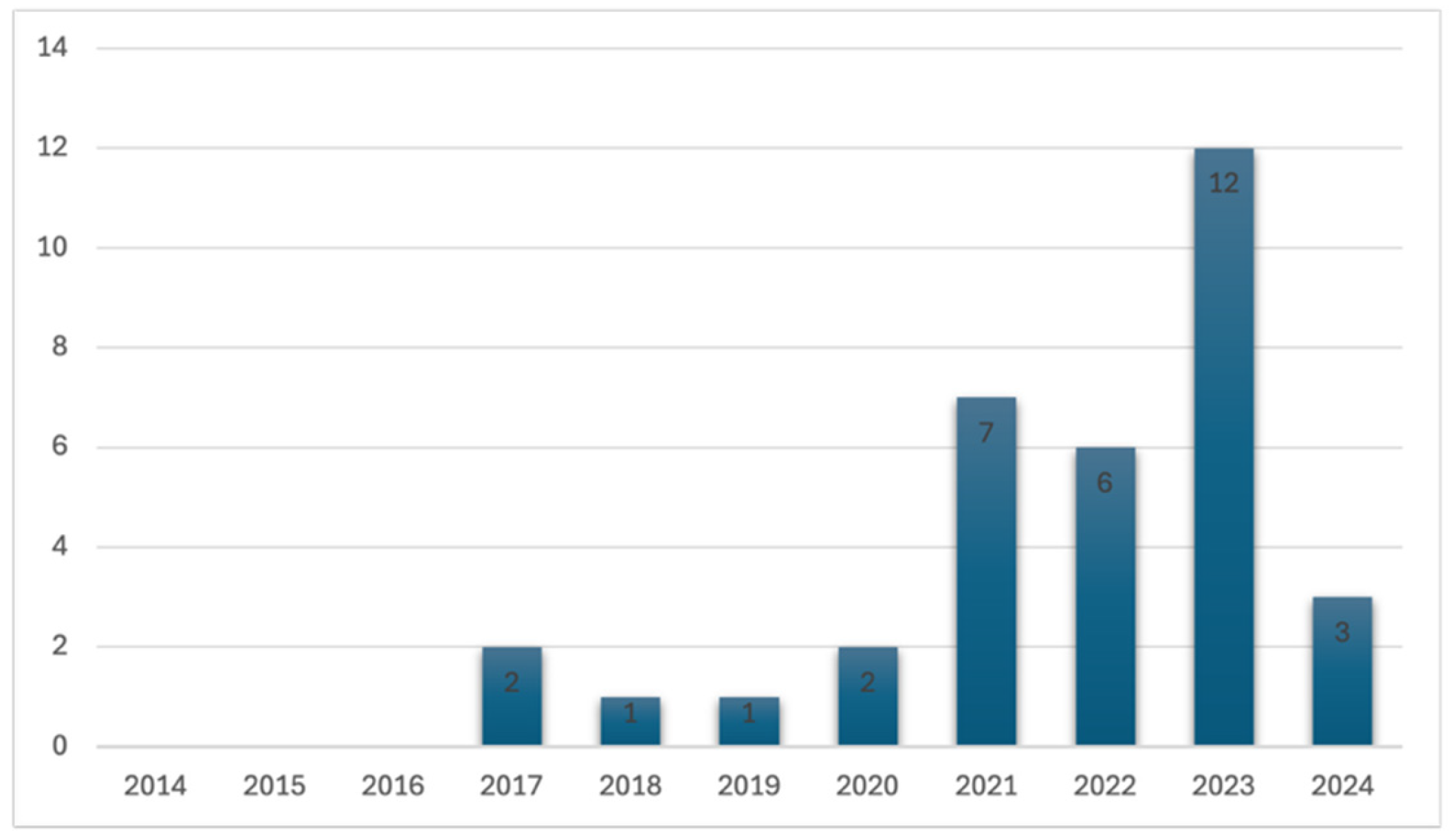
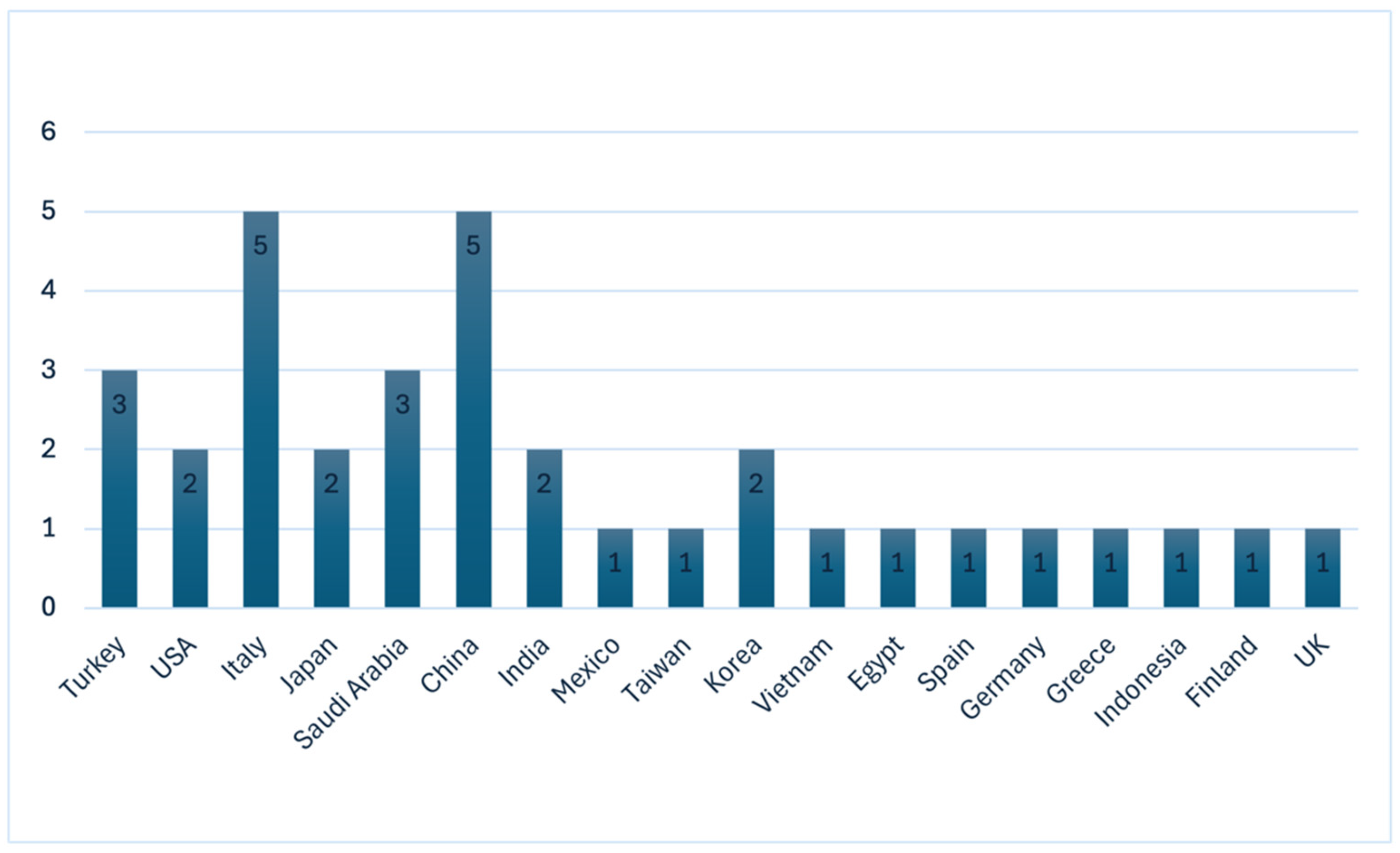
3. Results
3.1. Voice and Language Resources (Supplementary Table S6)
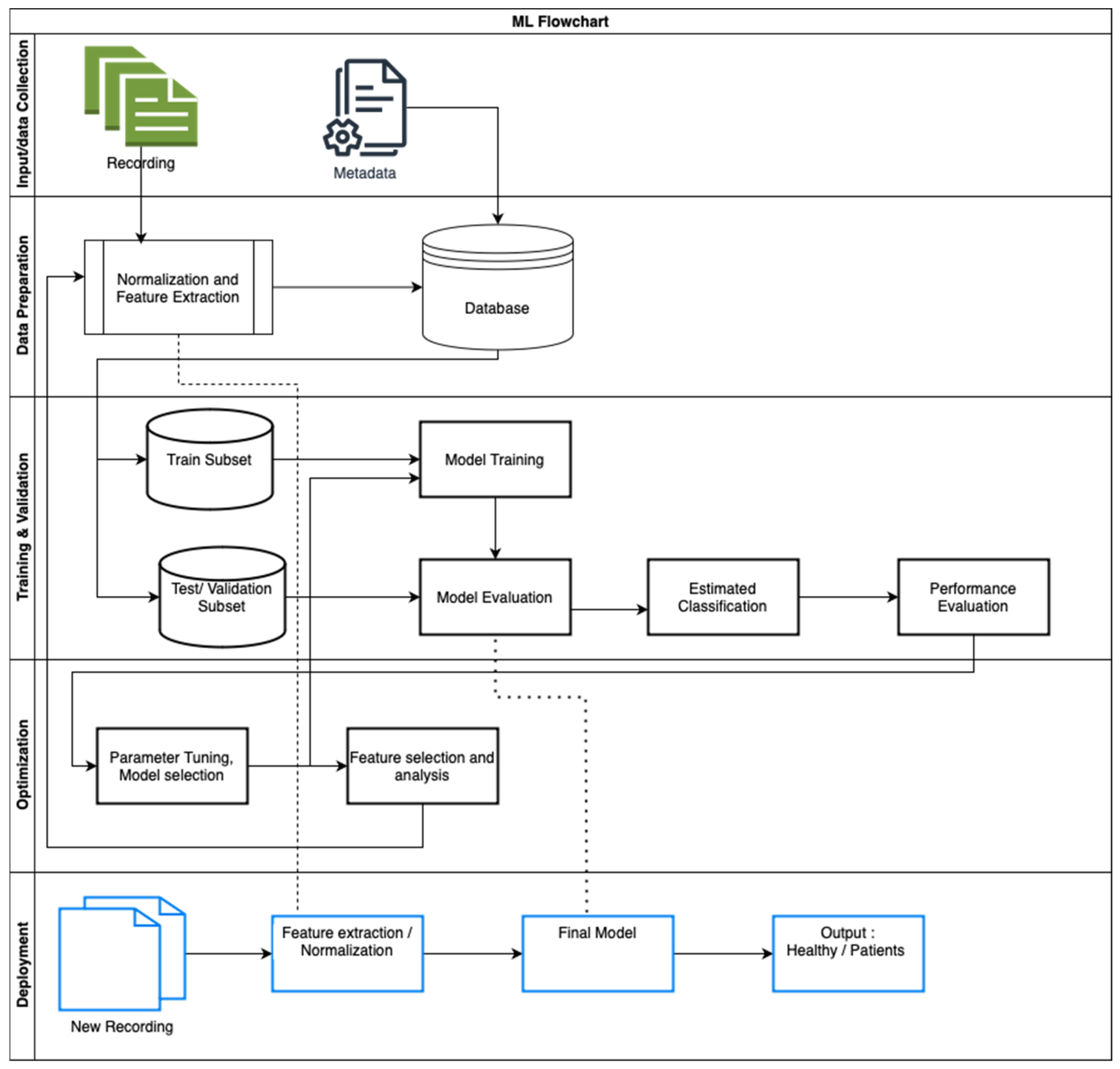
3.2. Machine Learning
3.3. Machine Learning/Deep Learning Models (Supplementary Table S7: Methods and Results)
3.4. Diagnostic Performance and Evaluation (Supplementary Table S7: Methods and Results)
3.4.1. Model Validation
3.4.2. Evaluation
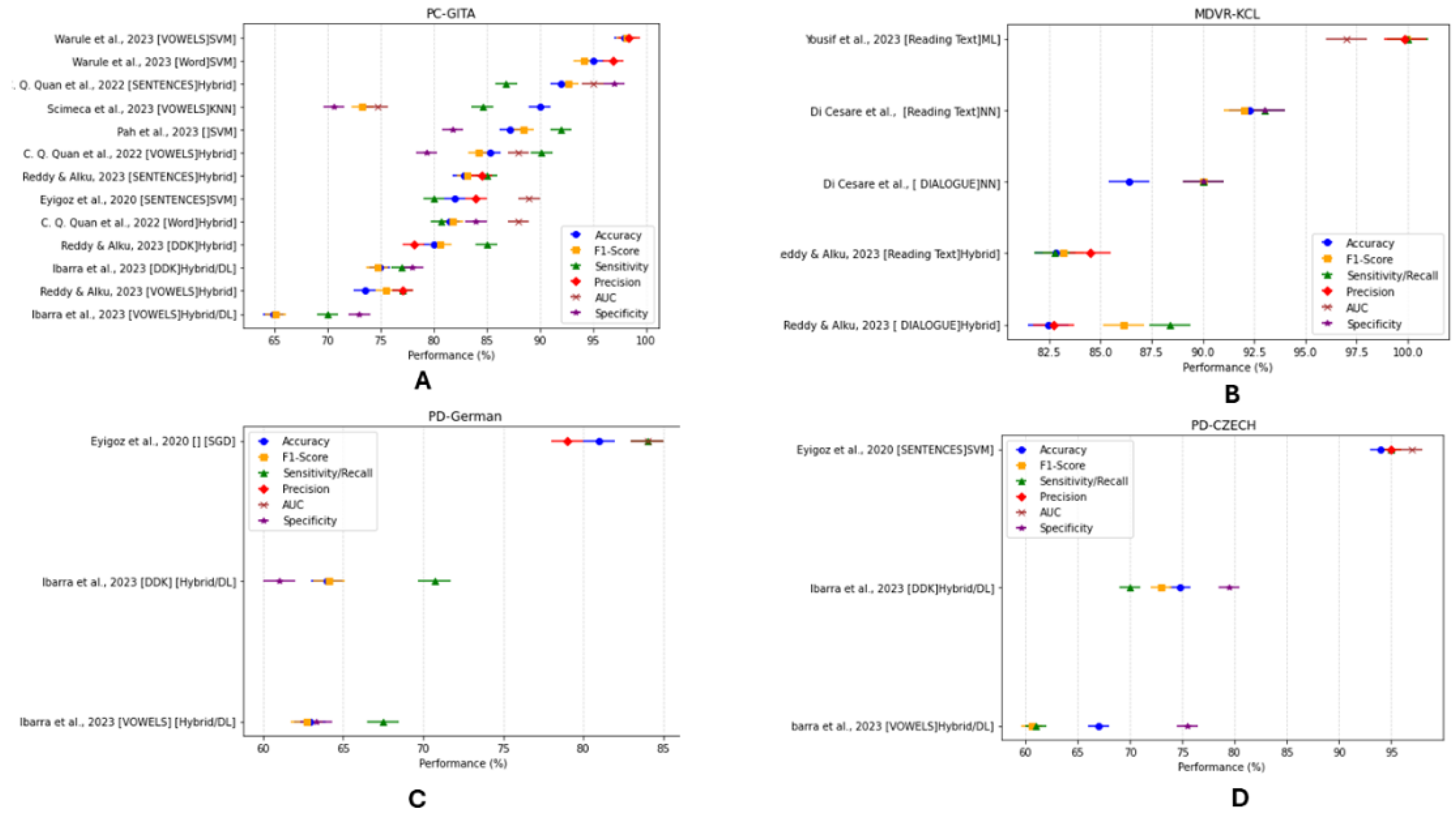
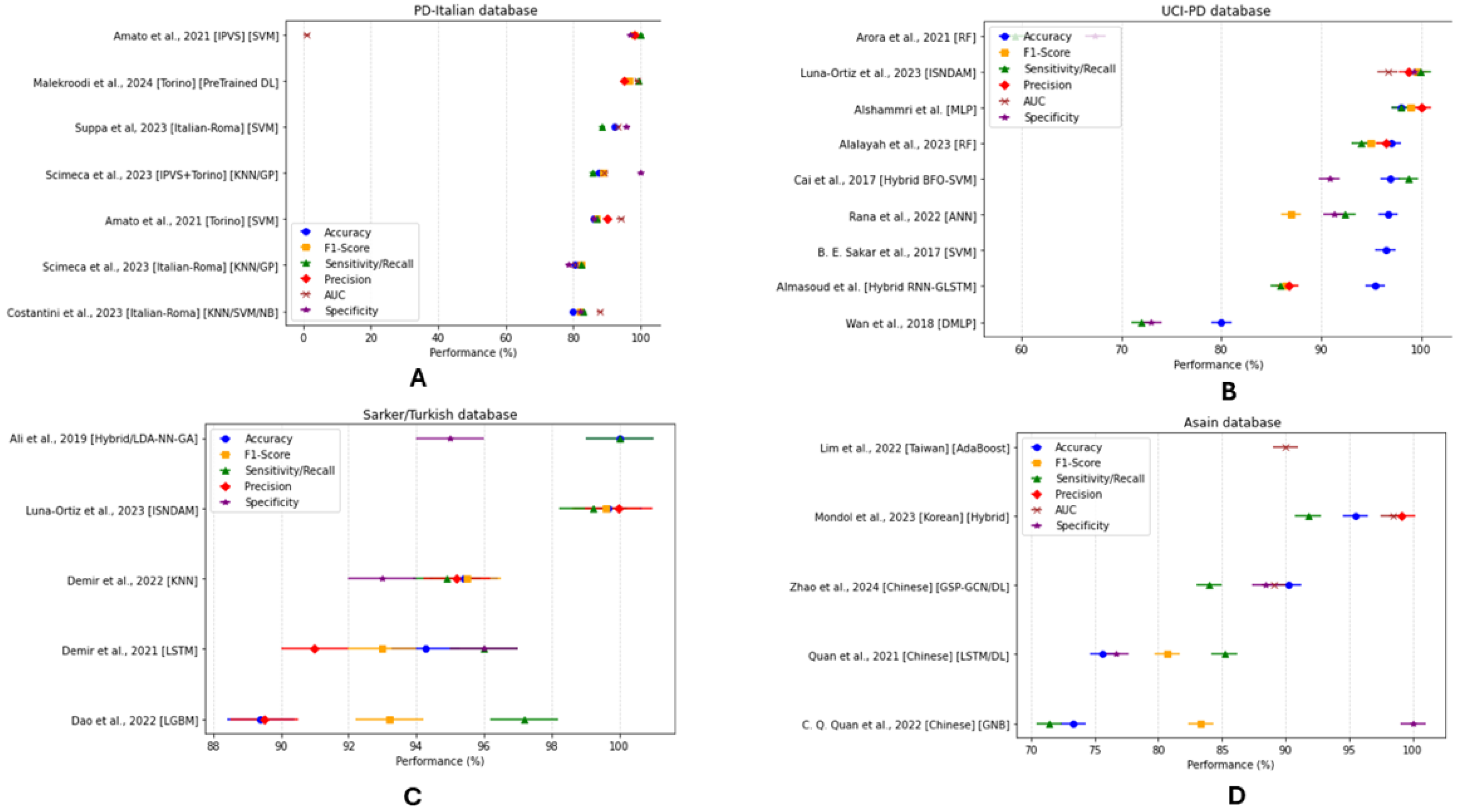
3.4.3. Classification Model Performance
4. Discussion
4.1. Voice and Speech Features
4.1.1. Voice and Speech Tasks
4.1.2. Cognitive and Clinical Features
4.1.3. Multilingual Classification Systems
4.2. Data Collection (Supplementary Table S6: Voice and Language Resources)
4.3. ML and DL Technique
4.4. Risk of Bias
4.5. Research Challenges and Recommendations
4.5.1. Methodological and Technical Challenges
4.5.2. Translational Challenges
4.6. Study Limitations
5. Conclusions
- Exploring novel approaches to construct automated, end-to-end systems.
- Reporting per-class metrics for better performance evaluation and system reliability.
- Investigating innovative techniques for the early detection of PD.
- Establish standardized datasets to set benchmarks for classification and regression tasks.
- Strengthening collaboration between researchers and clinical practitioners to facilitate the development of clinically relevant applications.
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Alshammri, R.; Alharbi, G.; Alharbi, E.; Almubark, I. Machine Learning Approaches to Identify Parkinson’s Disease Using Voice Signal Features. Front. Artif. Intell. 2023, 6, 1084001. [Google Scholar] [CrossRef] [PubMed]
- Poewe, W.; Seppi, K.; Tanner, C.M.; Halliday, G.M.; Brundin, P.; Volkmann, J.; Schrag, A.-E.; Lang, A.E. Parkinson Disease. Nat. Rev. Dis. Primers 2017, 3, 17013. [Google Scholar] [CrossRef] [PubMed]
- DeMaagd, G.; Philip, A. Parkinson’s Disease and Its Management: Part 1: Disease Entity, Risk Factors, Pathophysiology, Clinical Presentation, and Diagnosis. Pharm. Ther. 2015, 40, 504–532. [Google Scholar]
- Moya-Galé, G.; Levy, E.S. Parkinson’s Disease-Associated Dysarthria: Prevalence, Impact and Management Strategies. Res. Rev. Park. 2019, 9, 9–16. [Google Scholar] [CrossRef]
- Auclair-Ouellet, N.; Lieberman, P.; Monchi, O. Contribution of Language Studies to the Understanding of Cognitive Impairment and Its Progression over Time in Parkinson’s Disease. Neurosci. Biobehav. Rev. 2017, 80, 657–672. [Google Scholar] [CrossRef]
- Harel, B.; Cannizzaro, M.; Snyder, P.J. Variability in Fundamental Frequency during Speech in Prodromal and Incipient Parkinson’s Disease: A Longitudinal Case Study. Brain Cogn. 2004, 56, 24–29. [Google Scholar] [CrossRef]
- Suppa, A.; Asci, F.; Costantini, G.; Bove, F.; Piano, C.; Pistoia, F.; Cerroni, R.; Brusa, L.; Cesarini, V.; Pietracupa, S.; et al. Effects of Deep Brain Stimulation of the Subthalamic Nucleus on Patients with Parkinson’s Disease: A Machine-Learning Voice Analysis. Front. Neurol. 2023, 14, 1267360. [Google Scholar] [CrossRef]
- Luna-Ortiz, I.; Aldape-Pérez, M.; Uriarte-Arcia, A.V.; Rodríguez-Molina, A.; Alarcón-Paredes, A.; Ventura-Molina, E. Parkinson’s Disease Detection from Voice Recordings Using Associative Memories. Healthcare 2023, 11, 1601. [Google Scholar] [CrossRef]
- Iyer, A.; Kemp, A.; Rahmatallah, Y.; Pillai, L.; Glover, A.; Prior, F.; Larson-Prior, L.; Virmani, T. A Machine Learning Method to Process Voice Samples for Identification of Parkinson’s Disease. Sci. Rep. 2023, 13, 20615. [Google Scholar] [CrossRef]
- Al Kuwaiti, A.; Nazer, K.; Al-Reedy, A.; Al-Shehri, S.; Al-Muhanna, A.; Subbarayalu, A.V.; Al Muhanna, D.; Al-Muhanna, F.A. A Review of the Role of Artificial Intelligence in Healthcare. J. Pers. Med. 2023, 13, 951. [Google Scholar] [CrossRef]
- Ucuzal, H.; Arslan, A.K.; Çolak, C. Deep Learning Based-Classification of Dementia in Magnetic Resonance Imaging Scans. In Proceedings of the 2019 International Artificial Intelligence and Data Processing Symposium (IDAP), Malatya, Turkey, 21–22 September 2019; pp. 1–6. [Google Scholar]
- Koh, D.-M.; Papanikolaou, N.; Bick, U.; Illing, R.; Kahn, C.E.; Kalpathi-Cramer, J.; Matos, C.; Martí-Bonmatí, L.; Miles, A.; Mun, S.K.; et al. Artificial Intelligence and Machine Learning in Cancer Imaging. Commun. Med. 2022, 2, 133. [Google Scholar] [CrossRef]
- Goni, M.; Eickhoff, S.B.; Far, M.S.; Patil, K.R.; Dukart, J. Smartphone-Based Digital Biomarkers for Parkinson’s Disease in a Remotely-Administered Setting. IEEE Access 2022, 10, 28361–28384. [Google Scholar] [CrossRef]
- Costantini, G.; Cesarini, V.; Di Leo, P.; Amato, F.; Suppa, A.; Asci, F.; Pisani, A.; Calculli, A.; Saggio, G. Artificial Intelligence-Based Voice Assessment of Patients with Parkinson’s Disease Off and On Treatment: Machine vs. Deep-Learning Comparison. Sensors 2023, 23, 2293. [Google Scholar] [CrossRef] [PubMed]
- Demir, F.; Siddique, K.; Alswaitti, M.; Demir, K.; Sengur, A. A Simple and Effective Approach Based on a Multi-Level Feature Selection for Automated Parkinson’s Disease Detection. J. Pers. Med. 2022, 12, 55. [Google Scholar] [CrossRef] [PubMed]
- Amato, F.; Borzi, L.; Olmo, G.; Artusi, C.A.; Imbalzano, G.; Lopiano, L. Speech Impairment in Parkinson’s Disease: Acoustic Analysis of Unvoiced Consonants in Italian Native Speakers. IEEE Access 2021, 9, 166370–166381. [Google Scholar] [CrossRef]
- Pu, T.; Huang, M.; Kong, X.; Wang, M.; Chen, X.; Feng, X.; Wei, C.; Weng, X.; Xu, F. Lee Silverman Voice Treatment to Improve Speech in Parkinson’s Disease: A Systemic Review and Meta-Analysis. Park. Dis. 2021, 2021, 3366870. [Google Scholar] [CrossRef]
- Altham, C.; Zhang, H.; Pereira, E. Machine Learning for the Detection and Diagnosis of Cognitive Impairment in Parkinson’s Disease: A Systematic Review. PLoS ONE 2024, 19, e0303644. [Google Scholar] [CrossRef]
- Hecker, P.; Steckhan, N.; Eyben, F.; Schuller, B.W.; Arnrich, B. Voice Analysis for Neurological Disorder Recognition–A Systematic Review and Perspective on Emerging Trends. Front. Digit. Health 2022, 4, 842301. [Google Scholar] [CrossRef]
- Idrisoglu, A.; Dallora, A.L.; Anderberg, P.; Berglund, J.S. Applied Machine Learning Techniques to Diagnose Voice-Affecting Conditions and Disorders: Systematic Literature Review. J. Med. Int. Res. 2023, 25, e46105. [Google Scholar] [CrossRef]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 Statement: An Updated Guideline for Reporting Systematic Reviews. BMJ 2021, 372, n71. [Google Scholar] [CrossRef]
- Kitchenham, B.; Charters, S. Guidelines for Performing Systematic Literature Reviews in Software Engineering; Keele University: Keele, UK, 2007; Volume 2. [Google Scholar]
- De La Fuente Garcia, S.; Ritchie, C.W.; Luz, S. Artificial Intelligence, Speech, and Language Processing Approaches to Monitoring Alzheimer’s Disease: A Systematic Review. J. Alzheimer’s Dis. 2020, 78, 1547–1574. [Google Scholar] [CrossRef] [PubMed]
- Orozco-Arroyave, J.R.; Arias-Londoño, J.D.; Vargas-Bonilla, J.F.; González-Rátiva, M.C.; Nöth, E. New Spanish Speech Corpus Database for the Analysis of People Suffering from Parkinson’s Disease. In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC’14), Reykjavik, Iceland, 26–31 May 2014; Calzolari, N., Choukri, K., Declerck, T., Loftsson, H., Maegaard, B., Mariani, J., Moreno, A., Odijk, J., Piperidis, S., Eds.; European Language Resources Association (ELRA): Reykjavik, Iceland, 2014; pp. 342–347. [Google Scholar]
- Reddy, M.K.; Alku, P. Exemplar-Based Sparse Representations for Detection of Parkinson’s Disease from Speech. IEEE/ACM Trans. Audio Speech Lang. Process. 2023, 31, 1386–1396. [Google Scholar] [CrossRef]
- Pah, N.D.; Indrawati, V.; Kumar, D.K. Voice-Based SVM Model Reliability for Identifying Parkinson’s Disease. IEEE Access 2023, 11, 144296–144305. [Google Scholar] [CrossRef]
- Ibarra, E.J.; Arias-Londoño, J.D.; Zañartu, M.; Godino-Llorente, J.I. Towards a Corpus (and Language)-Independent Screening of Parkinson’s Disease from Voice and Speech through Domain Adaptation. Bioengineering 2023, 10, 1316. [Google Scholar] [CrossRef]
- Scimeca, S.; Amato, F.; Olmo, G.; Asci, F.; Suppa, A.; Costantini, G.; Saggio, G. Robust and Language-Independent Acoustic Features in Parkinson’s Disease. Front. Neurol. 2023, 14, 1198058. [Google Scholar] [CrossRef]
- Warule, P.; Mishra, S.P.; Deb, S. Time-Frequency Analysis of Speech Signal Using Chirplet Transform for Automatic Diagnosis of Parkinson’s Disease. Biomed. Eng. Lett. 2023, 13, 613–623. [Google Scholar] [CrossRef]
- Eyigoz, E.; Courson, M.; Sedeño, L.; Rogg, K.; Orozco-Arroyave, J.R.; Nöth, E.; Skodda, S.; Trujillo, N.; Rodríguez, M.; Rusz, J.; et al. From Discourse to Pathology: Automatic Identification of Parkinson’s Disease Patients via Morphological Measures across Three Languages. Cortex 2020, 132, 191–205. [Google Scholar] [CrossRef]
- Quan, C.; Ren, K.; Luo, Z.; Chen, Z.; Ling, Y. End-to-End Deep Learning Approach for Parkinson’s Disease Detection from Speech Signals. Biocybern. Biomed. Eng. 2022, 42, 556–574. [Google Scholar] [CrossRef]
- Little, M.A.; McSharry, P.E.; Hunter, E.J.; Spielman, J.; Ramig, L.O. Suitability of Dysphonia Measurements for Telemonitoring of Parkinson’s Disease. IEEE Trans. Biomed. Eng. 2009, 56, 1015–1022. [Google Scholar] [CrossRef]
- Rana, A.; Dumka, A.; Singh, R.; Rashid, M.; Ahmad, N.; Panda, M.K. An Efficient Machine Learning Approach for Diagnosing Parkinson’s Disease by Utilizing Voice Features. Electronics 2022, 11, 3782. [Google Scholar] [CrossRef]
- Almasoud, A.S.; Eisa, T.A.E.; Al-Wesabi, F.N.; Elsafi, A.; Al Duhayyim, M.; Yaseen, I.; Hamza, M.A.; Motwakel, A. Parkinson’s Detection Using RNN-Graph-LSTM with Optimization Based on Speech Signals. Comput. Mater. Contin. 2022, 72, 871–886. [Google Scholar] [CrossRef]
- Sakar, B.E.; Serbes, G.; Sakar, C.O. Analyzing the Effectiveness of Vocal Features in Early Telediagnosis of Parkinson’s Disease. PLoS ONE 2017, 12, e0182428. [Google Scholar] [CrossRef]
- Alalayah, K.M.; Senan, E.M.; Atlam, H.F.; Ahmed, I.A.; Shatnawi, H.S.A. Automatic and Early Detection of Parkinson’s Disease by Analyzing Acoustic Signals Using Classification Algorithms Based on Recursive Feature Elimination Method. Diagnostics 2023, 13, 1924. [Google Scholar] [CrossRef]
- Cai, Z.; Gu, J.; Chen, H.L. A New Hybrid Intelligent Framework for Predicting Parkinson’s Disease. IEEE Access 2017, 5, 17188–17200. [Google Scholar] [CrossRef]
- Sakar, C.; Serbes, G.; Gunduz, A.; Nizam, H.; Sakar, B. Parkinson’s Disease Classification. UCI Mach. Learn. Repos. 2018, 10, C5MS4X. [Google Scholar]
- Ali, L.; Zhu, C.; Zhang, Z.; Liu, Y. Automated Detection of Parkinson’s Disease Based on Multiple Types of Sustained Phonations Using Linear Discriminant Analysis and Genetically Optimized Neural Network. IEEE J. Transl. Eng. Health Med. 2019, 7, 2000410. [Google Scholar] [CrossRef]
- Demir, F.; Sengur, A.; Ari, A.; Siddique, K.; Alswaitti, M. Feature Mapping and Deep Long Short Term Memory Network-Based Efficient Approach for Parkinson’s Disease Diagnosis. IEEE Access 2021, 9, 149456–149464. [Google Scholar] [CrossRef]
- Dao, S.V.T.; Yu, Z.; Tran, L.V.; Phan, P.N.K.; Huynh, T.T.M.; Le, T.M. An Analysis of Vocal Features for Parkinson’s Disease Classification Using Evolutionary Algorithms. Diagnostics 2022, 12, 1980. [Google Scholar] [CrossRef]
- Jaeger, H.; Trivedi, D.; Stadtschnitzer, M. Mobile Device Voice Recordings at King’s College London (MDVR-KCL) from Both Early and Advanced’s Disease Patients and Healthy Controls; King’s College London (KCL) Hospital: London, UK, 2019. [Google Scholar]
- Yousif, N.R.; Balaha, H.M.; Haikal, A.Y.; El-Gendy, E.M. A Generic Optimization and Learning Framework for Parkinson Disease via Speech and Handwritten Records. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 10673–10693. [Google Scholar] [CrossRef]
- Di Cesare, M.G.; Perpetuini, D.; Cardone, D.; Merla, A. Machine Learning-Assisted Speech Analysis for Early Detection of Parkinson’s Disease: A Study on Speaker Diarization and Classification Techniques. Sensors 2024, 24, 1499. [Google Scholar] [CrossRef]
- Tsanas, A.; Little, M.A.; McSharry, P.E.; Ramig, L.O. Accurate Telemonitoring of Parkinson’s Disease Progression by Noninvasive Speech Tests. IEEE Trans. Biomed. Eng. 2009, 57, 884–893. [Google Scholar] [CrossRef] [PubMed]
- Wan, S.; Liang, Y.; Zhang, Y.; Guizani, M. Deep Multi-Layer Perceptron Classifier for Behavior Analysis to Estimate Parkinson’s Disease Severity Using Smartphones. IEEE Access 2018, 6, 36825–36833. [Google Scholar] [CrossRef]
- Bot, B.M.; Suver, C.; Neto, E.C.; Kellen, M.; Klein, A.; Bare, C.; Doerr, M.; Pratap, A.; Wilbanks, J.; Dorsey, E.R.; et al. The MPower Study, Parkinson Disease Mobile Data Collected Using ResearchKit. Sci. Data 2016, 3, 160011. [Google Scholar] [CrossRef]
- Koreman, J.C. A German Database of Patterns of Pathological Vocal Fold Vibration; Institut für Sexualwissenschaft: Berlin, Germany, 1997. [Google Scholar]
- Mondol, S.I.M.M.R.; Kim, R.; Lee, S. Hybrid Machine Learning Framework for Multistage Parkinson’s Disease Classification Using Acoustic Features of Sustained Korean Vowels. Bioengineering 2023, 10, 984. [Google Scholar] [CrossRef]
- Moro-Velazquez, L.; Gomez-Garcia, J.A.; Godino-Llorente, J.I.; Villalba, J.; Rusz, J.; Shattuck-Hufnagel, S.; Dehak, N. A Forced Gaussians Based Methodology for the Differential Evaluation of Parkinson’s Disease by Means of Speech Processing. Biomed. Signal Process. Control 2019, 48, 205–220. [Google Scholar] [CrossRef]
- Rusz, J.; Cmejla, R.; Tykalova, T.; Ruzickova, H.; Klempir, J.; Majerova, V.; Picmausova, J.; Roth, J.; Ruzicka, E. Imprecise Vowel Articulation as a Potential Early Marker of Parkinson’s Disease: Effect of Speaking Task. J. Acoust. Soc. Am. 2013, 134, 2171–2181. [Google Scholar] [CrossRef]
- Skodda, S.; Grönheit, W.; Schlegel, U. Intonation and Speech Rate in Parkinson’s Disease: General and Dynamic Aspects and Responsiveness to Levodopa Admission. J. Voice 2011, 25, e199–e205. [Google Scholar] [CrossRef]
- Dimauro, G.; Di Nicola, V.; Bevilacqua, V.; Caivano, D.; Girardi, F. Assessment of Speech Intelligibility in Parkinson’s Disease Using a Speech-To-Text System. IEEE Access 2017, 5, 22199–22208. [Google Scholar] [CrossRef]
- Arora, S.; Lo, C.; Hu, M.; Tsanas, A. Smartphone Speech Testing for Symptom Assessment in Rapid Eye Movement Sleep Behavior Disorder and Parkinson’s Disease. IEEE Access 2021, 9, 44813–44824. [Google Scholar] [CrossRef]
- Malekroodi, H.S.; Madusanka, N.; Lee, B.-I.; Yi, M. Leveraging Deep Learning for Fine-Grained Categorization of Parkinson’s Disease Progression Levels through Analysis of Vocal Acoustic Patterns. Bioengineering 2024, 11, 295. [Google Scholar] [CrossRef]
- Zhao, S.; Dai, G.; Li, J.; Zhu, X.; Huang, X.; Li, Y.; Tan, M.; Wang, L.; Fang, P.; Chen, X.; et al. An Interpretable Model Based on Graph Learning for Diagnosis of Parkinson’s Disease with Voice-Related EEG. NPJ Digit. Med. 2024, 7, 3. [Google Scholar] [CrossRef] [PubMed]
- Quan, C.; Ren, K.; Luo, Z. A Deep Learning Based Method for Parkinson’s Disease Detection Using Dynamic Features of Speech. IEEE Access 2021, 9, 10239–10252. [Google Scholar] [CrossRef]
- Wang, Q.; Fu, Y.; Shao, B.; Chang, L.; Ren, K.; Chen, Z.; Ling, Y. Early Detection of Parkinson’s Disease from Multiple Signal Speech: Based on Mandarin Language Dataset. Front. Aging Neurosci. 2022, 14, 1036588. [Google Scholar] [CrossRef] [PubMed]
- Laganas, C.; Iakovakis, D.; Hadjidimitriou, S.; Charisis, V.; Dias, S.B.; Bostantzopoulou, S.; Katsarou, Z.; Klingelhoefer, L.; Reichmann, H.; Trivedi, D.; et al. Parkinson’s Disease Detection Based on Running Speech Data from Phone Calls. IEEE Trans. Biomed. Eng. 2022, 69, 1573–1584. [Google Scholar] [CrossRef]
- Lim, W.S.; Chiu, S.I.; Wu, M.C.; Tsai, S.F.; Wang, P.H.; Lin, K.P.; Chen, Y.M.; Peng, P.L.; Chen, Y.Y.; Jang, J.S.R.; et al. An Integrated Biometric Voice and Facial Features for Early Detection of Parkinson’s Disease. NPJ Park. Dis. 2022, 8, 145. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Validation Method | Number of Studies and References |
|---|---|
| 5-fold CV | [25,56] |
| 10-fold CV | [7,13,14,15,16,27,28,29,34,43,49,57,58] |
| LOSOCV | [30,36,39,46,54,59] |
| K-fold CV | [37,46] |
| Nested CV | [44] |
| 3-fold CV | [55] |
| Grid Search CV | [1] |
| SoftMax | [40,43] |
| 5 × 2 CV | [8] |
| Random Sampling | [16] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hossain, M.A.; Traini, E.; Amenta, F. Machine Learning Applications for Diagnosing Parkinson’s Disease via Speech, Language, and Voice Changes: A Systematic Review. Inventions 2025, 10, 48. https://doi.org/10.3390/inventions10040048
Hossain MA, Traini E, Amenta F. Machine Learning Applications for Diagnosing Parkinson’s Disease via Speech, Language, and Voice Changes: A Systematic Review. Inventions. 2025; 10(4):48. https://doi.org/10.3390/inventions10040048
Chicago/Turabian StyleHossain, Mohammad Amran, Enea Traini, and Francesco Amenta. 2025. "Machine Learning Applications for Diagnosing Parkinson’s Disease via Speech, Language, and Voice Changes: A Systematic Review" Inventions 10, no. 4: 48. https://doi.org/10.3390/inventions10040048
APA StyleHossain, M. A., Traini, E., & Amenta, F. (2025). Machine Learning Applications for Diagnosing Parkinson’s Disease via Speech, Language, and Voice Changes: A Systematic Review. Inventions, 10(4), 48. https://doi.org/10.3390/inventions10040048