
Fish Face Identification Based on Rotated Object Detection: Dataset and Exploration


Abstract
:1. Introduction
2. Data Collection and Production
2.1. Data Collection
- (1)
- New Placement Period: At this stage, the water body and golden carp were newly added to the tank, along with the DEBAO water quality care agent, HANYANG nitrification bacteria and adsorbed substances of net hydroponic bacteria, and a water pump and oxygen changing machine were added. However, due to the failure to achieve a good balance state, the water quality was turbid. The water as a whole was green due to the growth of green algae.
- (2)
- Approaching Equilibrium Period: In this stage, due to the action of nitrification bacteria, the water reached a good equilibrium state, and the overall water was relatively clear. However, because the nitrification bacteria decomposed the excreta of the golden carp into ammonia nitrogen, without adding sea salt and adsorbed substances, and with the action of some algae, the water quality was clear, and the overall water was yellowish green.
- (3)
- Period of New Equilibrium: In this stage, due to the appropriate addition of sea salt, EFFICIENT, IMMUNE, BACTERCIDE and other water quality care adsorbents, ammonia nitrogen was neutralized, and the water was clear. However, due to the color interference of the water quality care agents, the water body was pale blue and green.
- (4)
- Stable Equilibrium Period: In this stage, the water body was in equilibrium, nitrification bacteria effectively treated the excreta of the golden crucian carp, ammonia nitrogen was neutralized by sea salt, the effect of the water quality care agent disappeared, the water quality was clear and the water body was almost colorless and transparent.
2.2. Data Processing
- (1)
- Downsize: Zoom the image down to an 8 by 8 size for a total of 64 pixels. The function of this step is to remove the details of the image, retaining only the basic information such as structure/light and shade, and to abandon the image differences caused by different sizes/proportions.
- (2)
- Simplify the colors: Convert the reduced image into 64 grayscale levels, i.e., all the pixel points only have 64 colors in total.
- (3)
- Calculate the mean: Calculate the grayscale average of all 64 pixels.
- (4)
- Compare the grayscale of the pixels: The gray level of each pixel is compared with the average value. If the gray level is greater than or equal to the average value, it is denoted as 1, and if the gray level is less than the average value, it is denoted as 0.
- (5)
- Calculate the hash value: The results of the previous comparison, combined together, form a 64-bit integer, which is the fingerprint of the image.
- (6)
- The order of the combination: As long as all the images are in the same order, once the fingerprint is obtained, the different images can be compared to see how many of the 64-bit bits are different. In theory, this is equivalent to the “Hamming distance” (in information theory, the Hamming distance between two strings of equal length is the number of different characters in the corresponding position of the two strings). If no more than 5 bits of data are different, the two images are similar; if more than 10 bits of data are different, this means that the two images are different.
3. Materials and Methods
3.1. Detection of Golden Crucian Carp
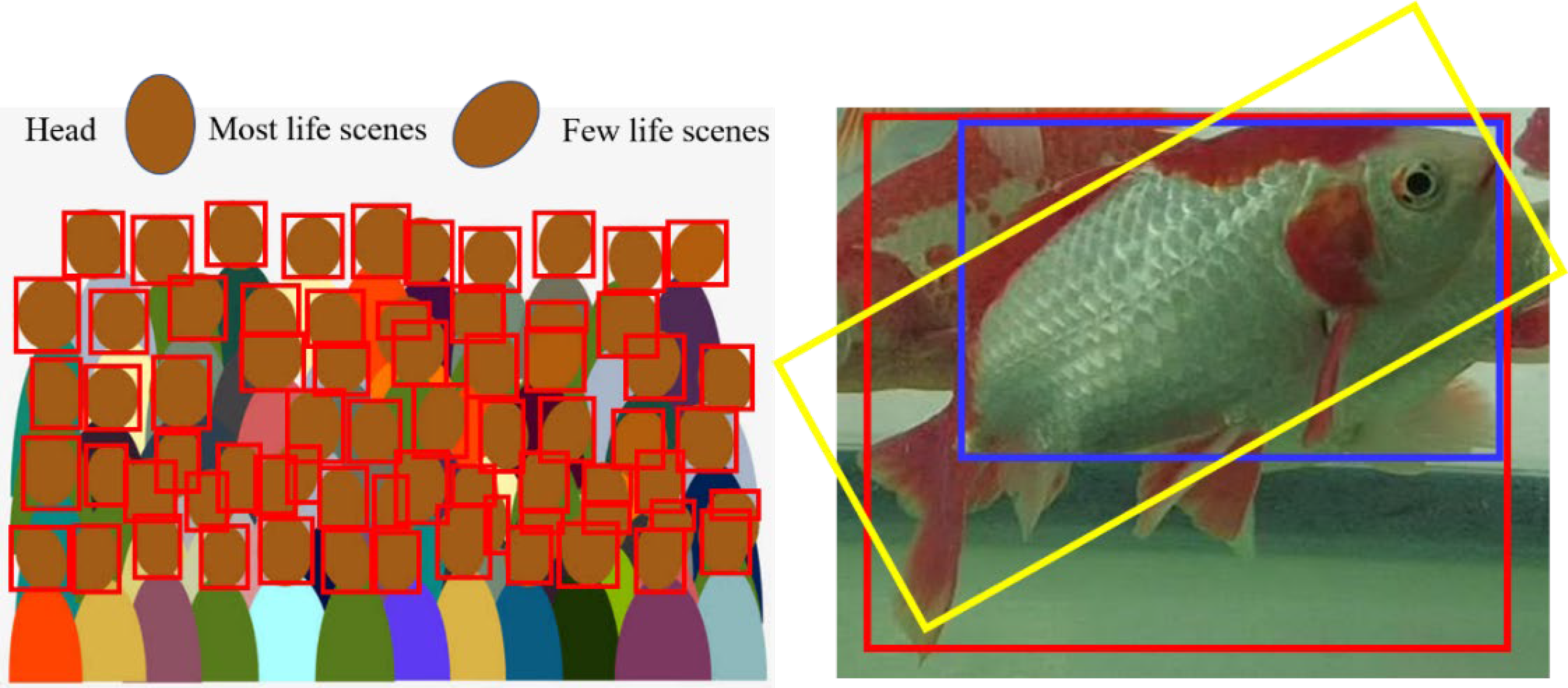
3.1.1. Rotating Box Representation
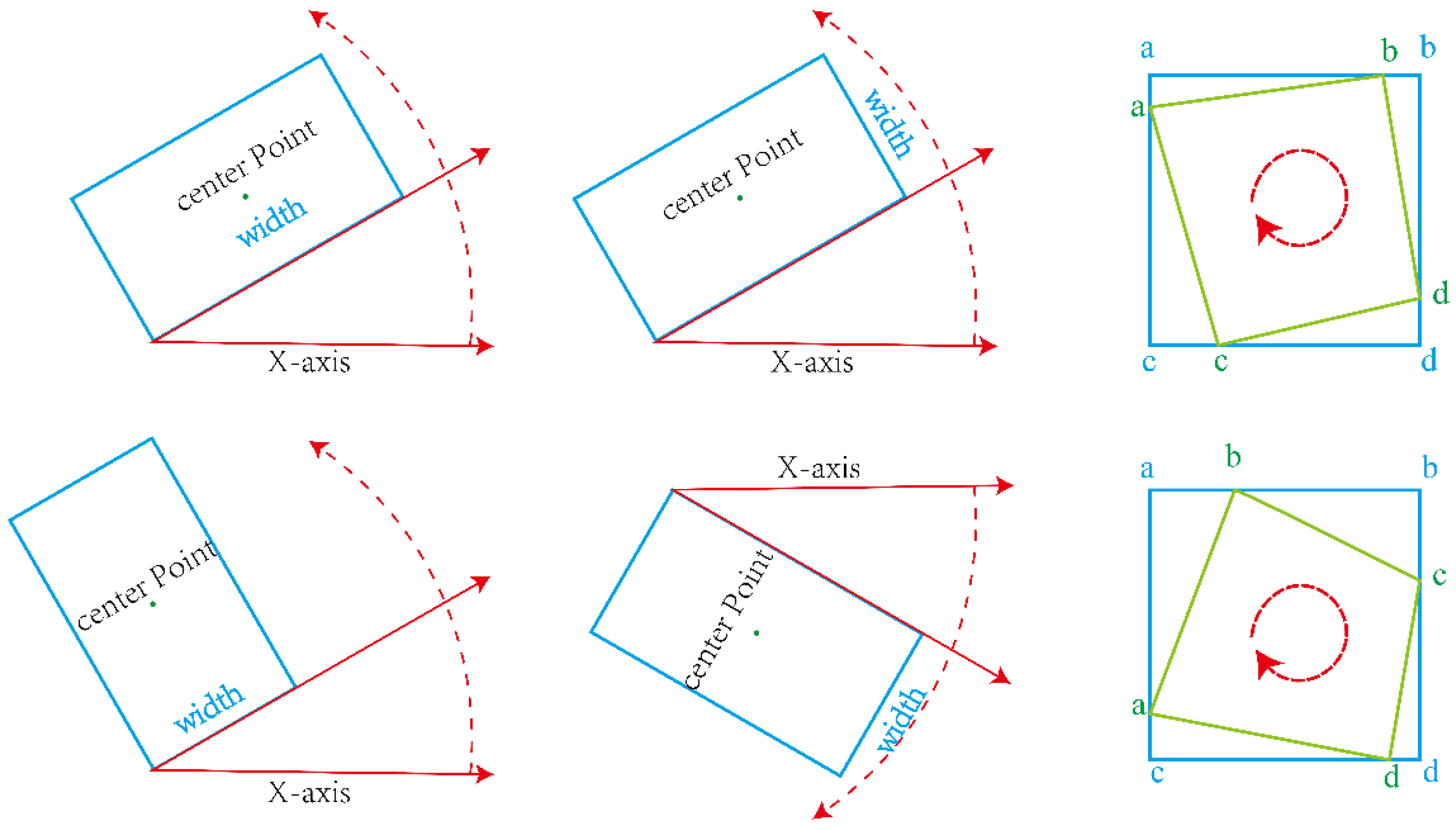
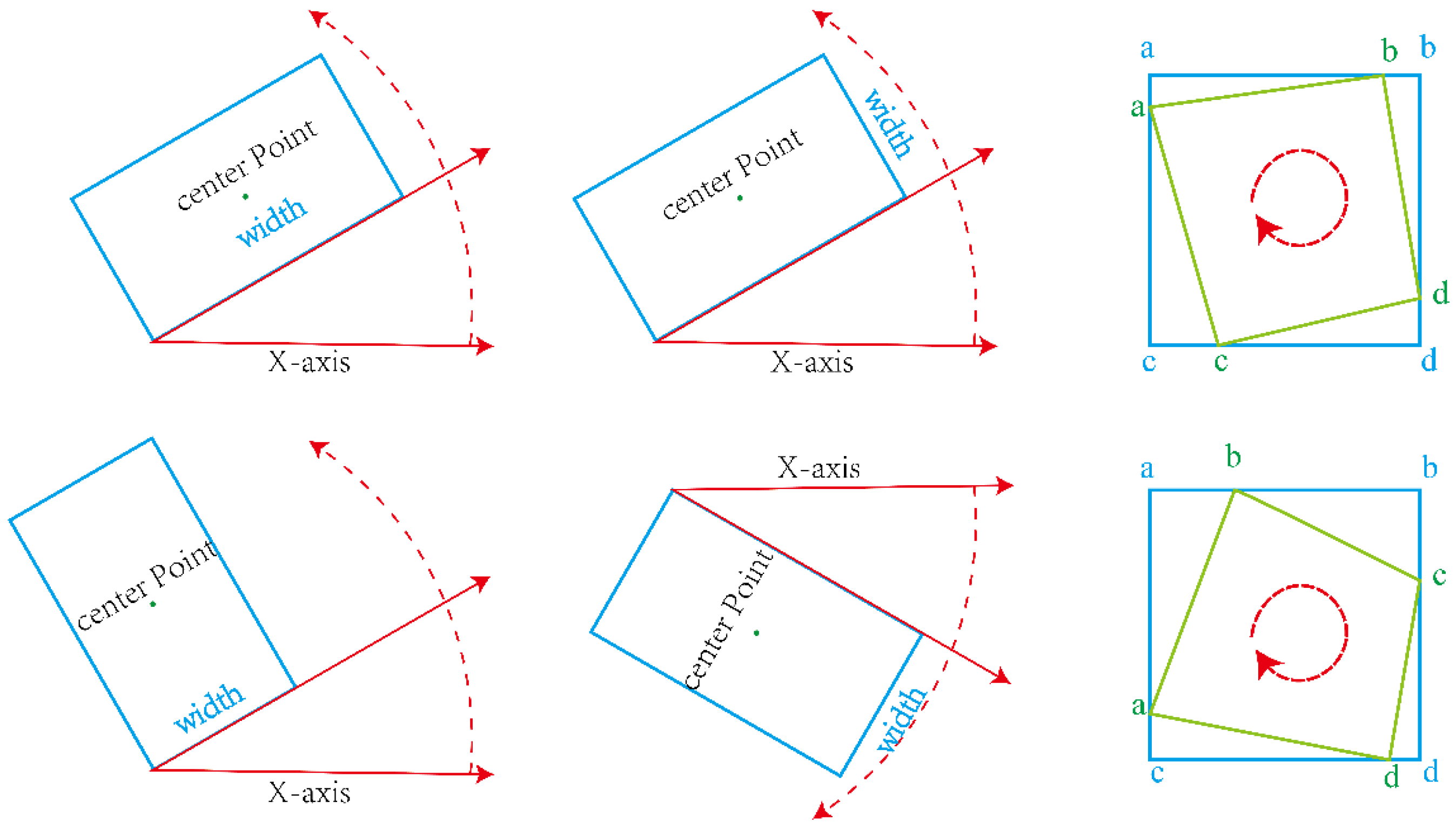
- (1)
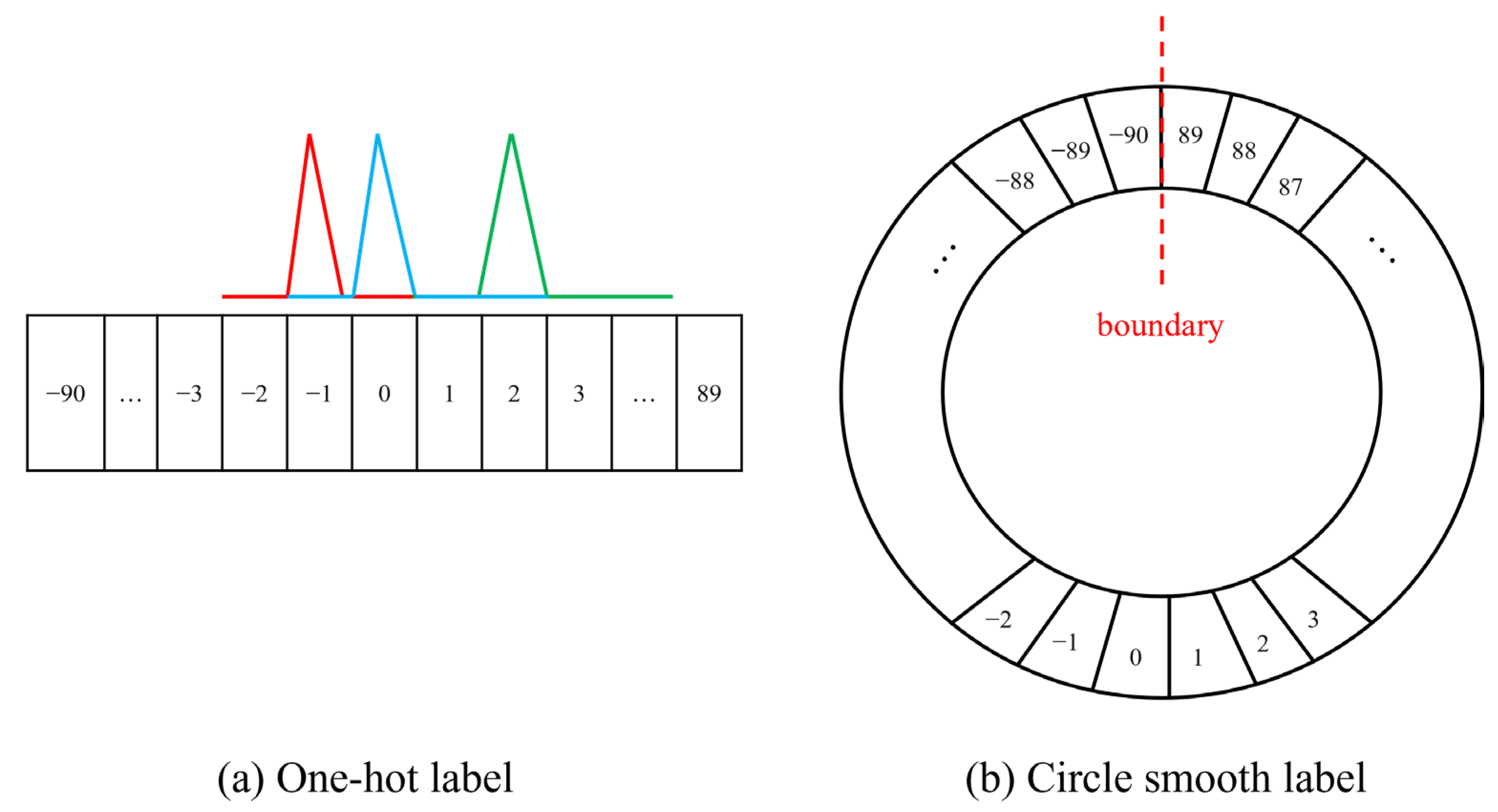
- Open CV notation: The parameters are [x, y, w, h, θ], where x and y are the coordinate axes. Angle θ refers to the acute angle formed when the x-axis rotates counterclockwise and first coincides with a certain side, which is denoted as w and the other side as h. The range of θ is [−90,0).
- (2)
- Long side representation: The parameters are [x, y, w, h, θ], where x and y are the coordinate axes, w is the long side of the box and h is the short side of the box. Angle θ refers to the angle between the long side of the box h and the x-axis, and the range of θ is [−90,90).
- (3)
- Four-point notation: The parameters are [x1, y1, x2, y2, x3, y3, x4, y4]. The four-point representation does not select the coordinate axis for definition, but rather, it selects the four vertices of the quadrilateral to record the changes, starting at the leftmost point (or above if it is a standard horizontal rectangle) and sorting counterclockwise.
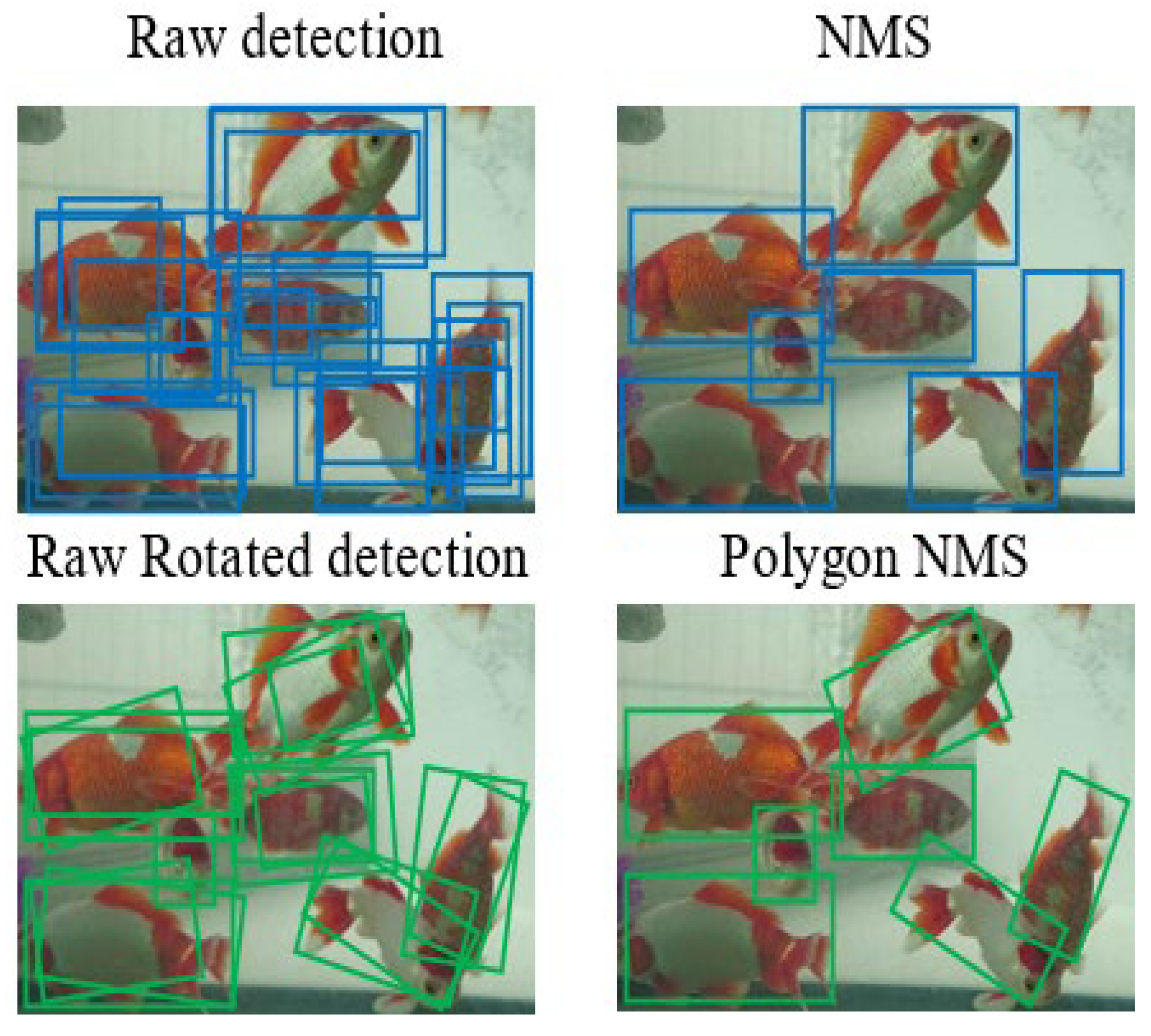
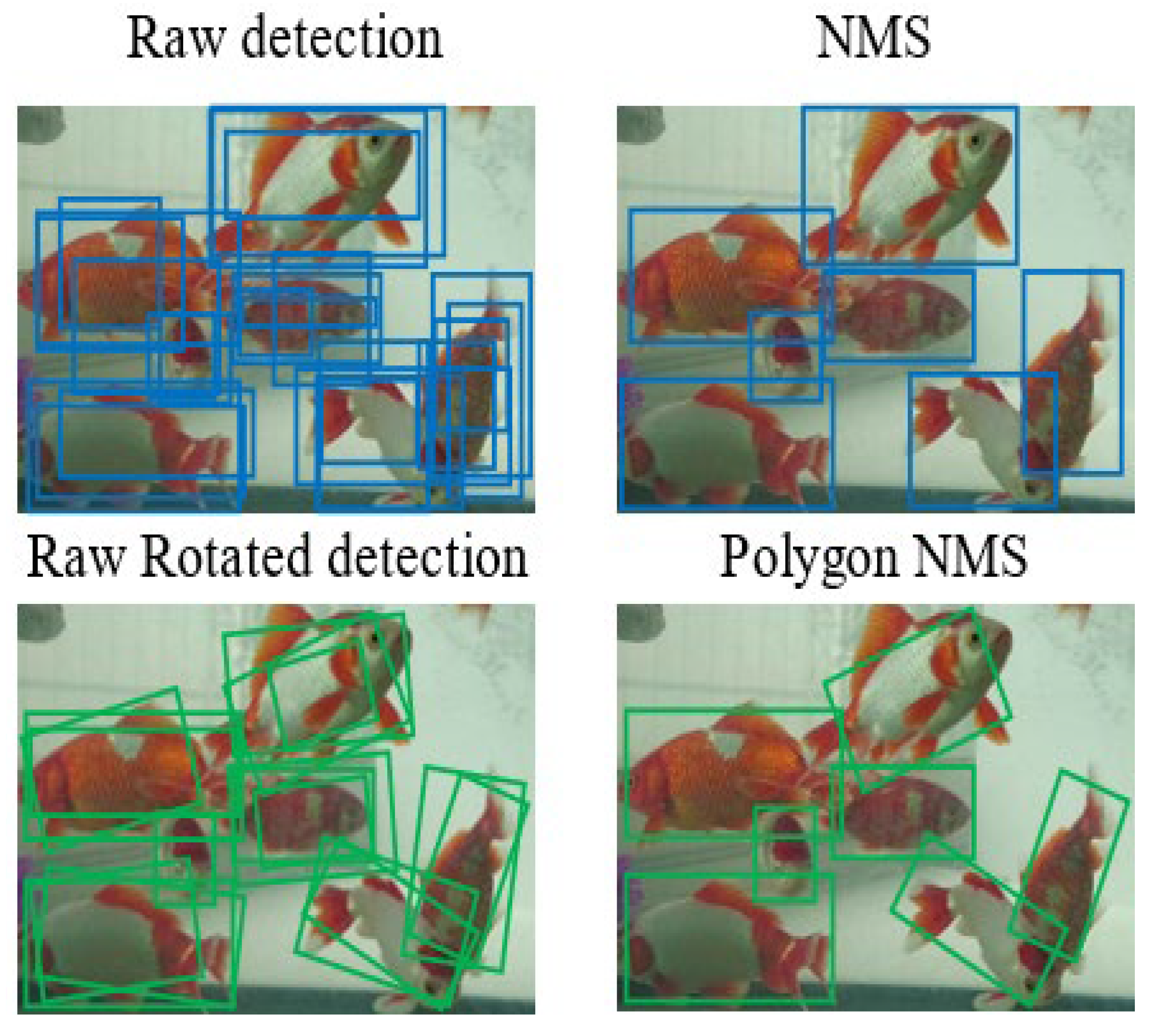
3.1.2. Polygon NMS
- (1)
- Sort the confidence of all predicted bboxes and obtain the one with the highest scores (add it to the list).
- (2)
- Solve the IoU (Polygon_IoU) in pairs with the bbox selected in the previous step, removing those boxes with an IoU greater than the threshold in the remaining bboxes.
- (3)
- Repeat the first two steps for all remaining boxes until the last bbox is left.
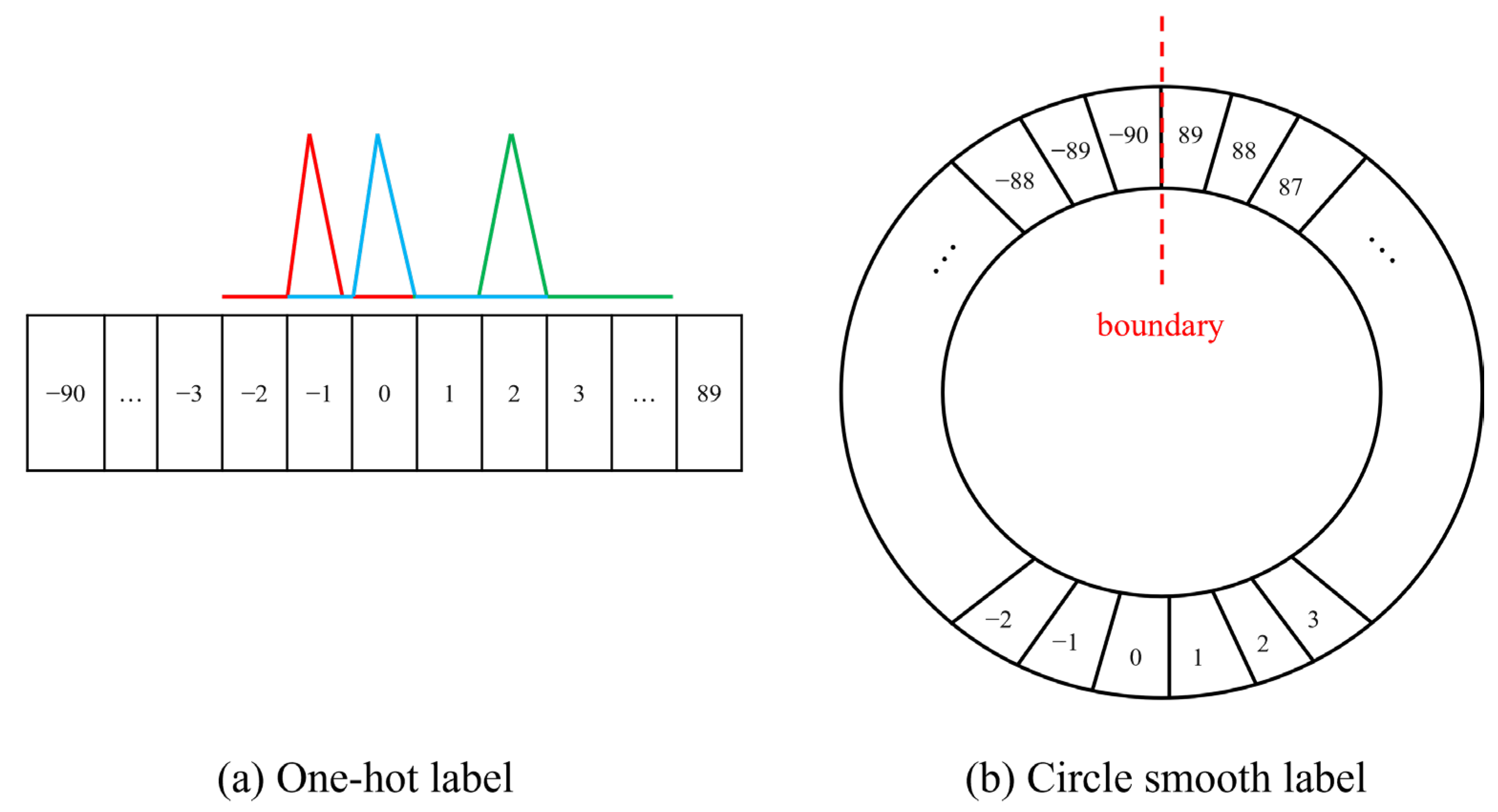
3.1.3. Handling Class Imbalance with Mosaic
- (1)
- There are many targets in the fish tank, densely or sparsely arranged.
- (2)
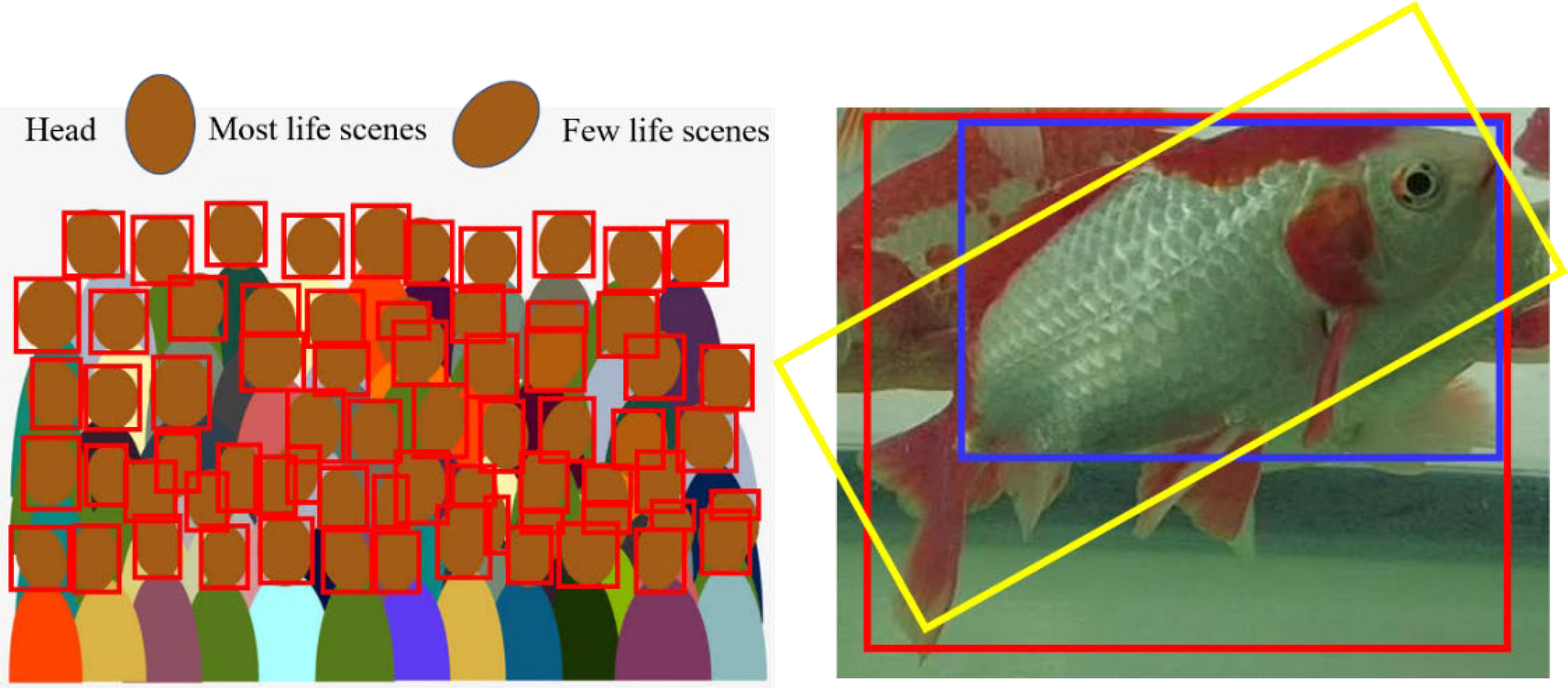
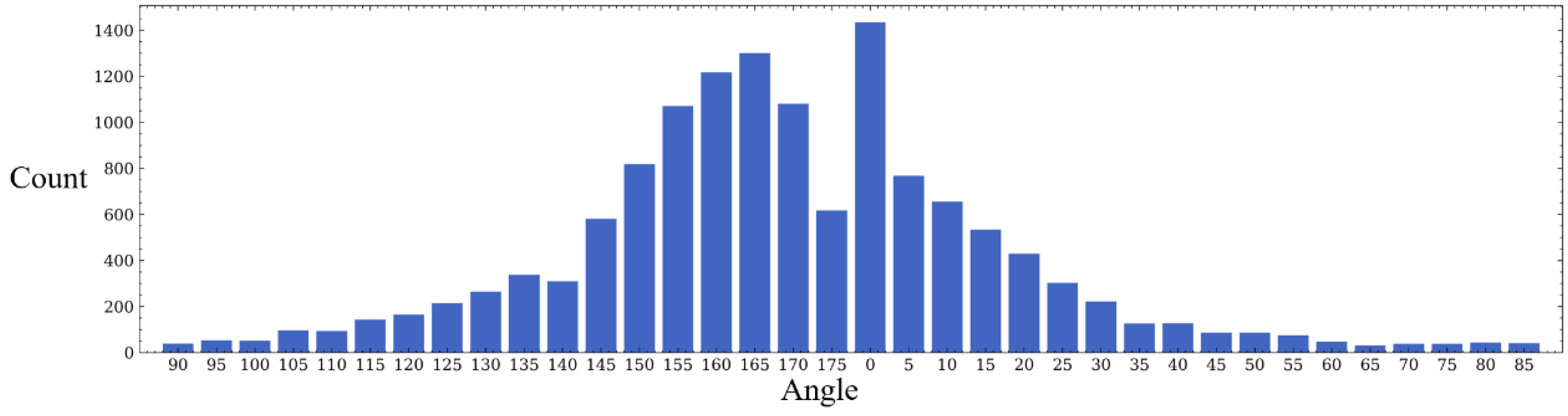
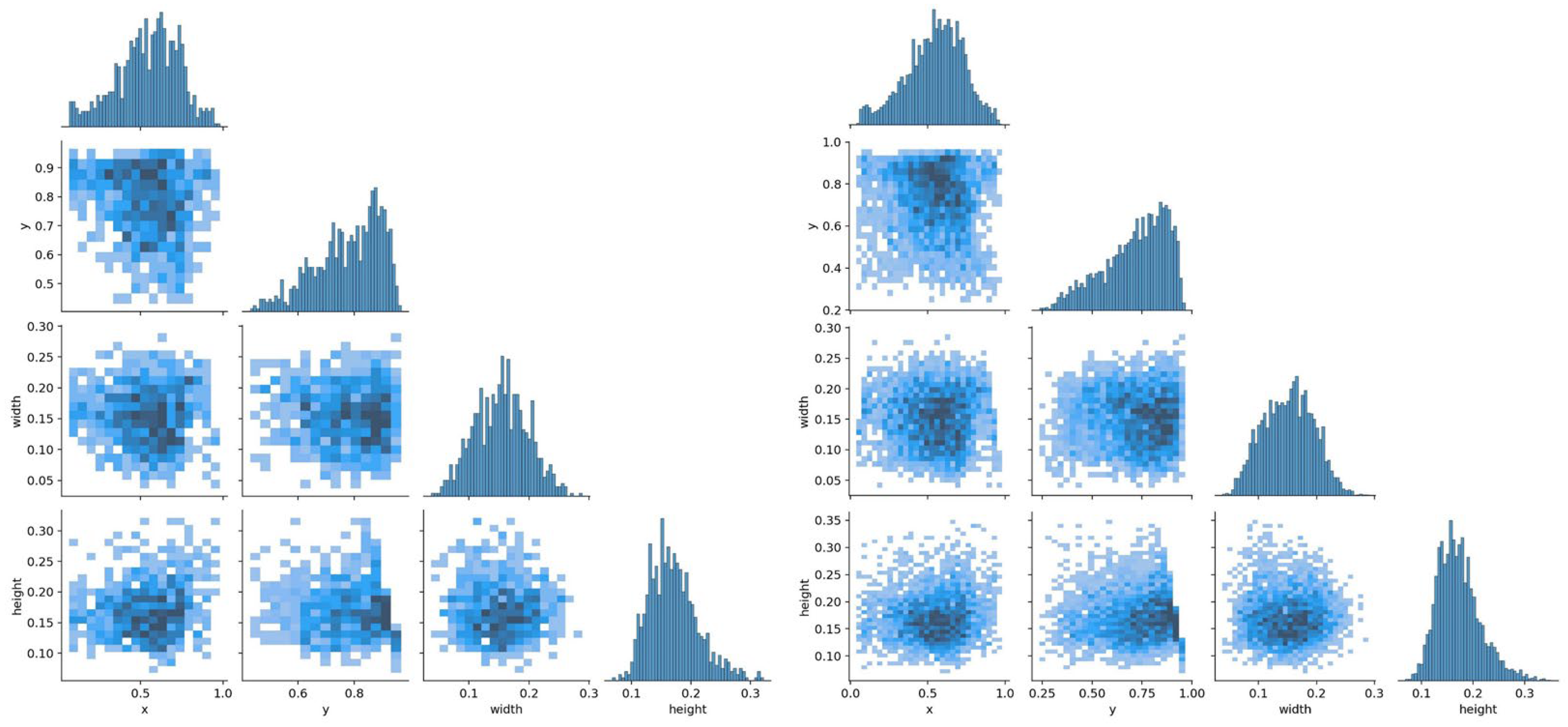
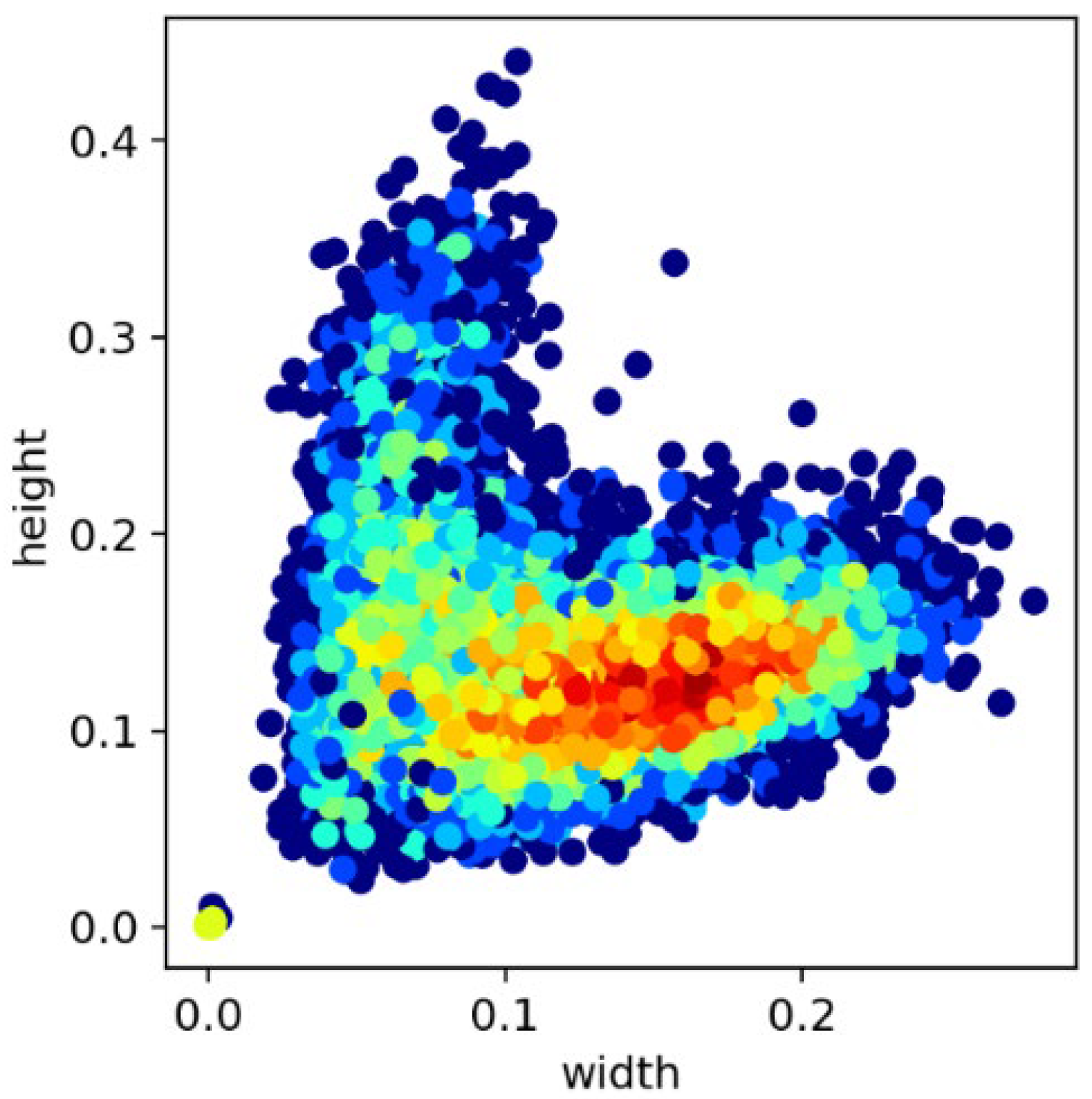
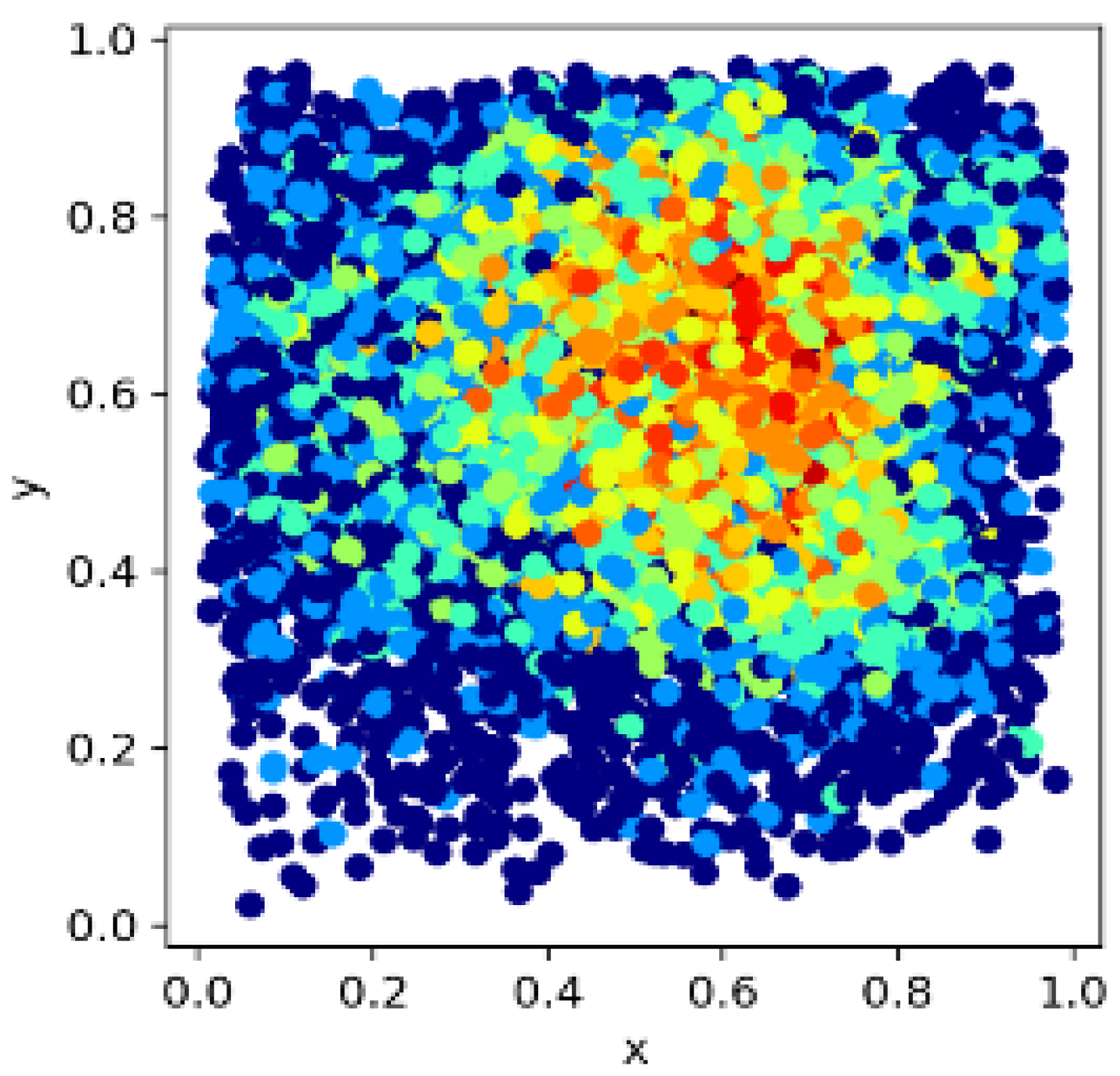
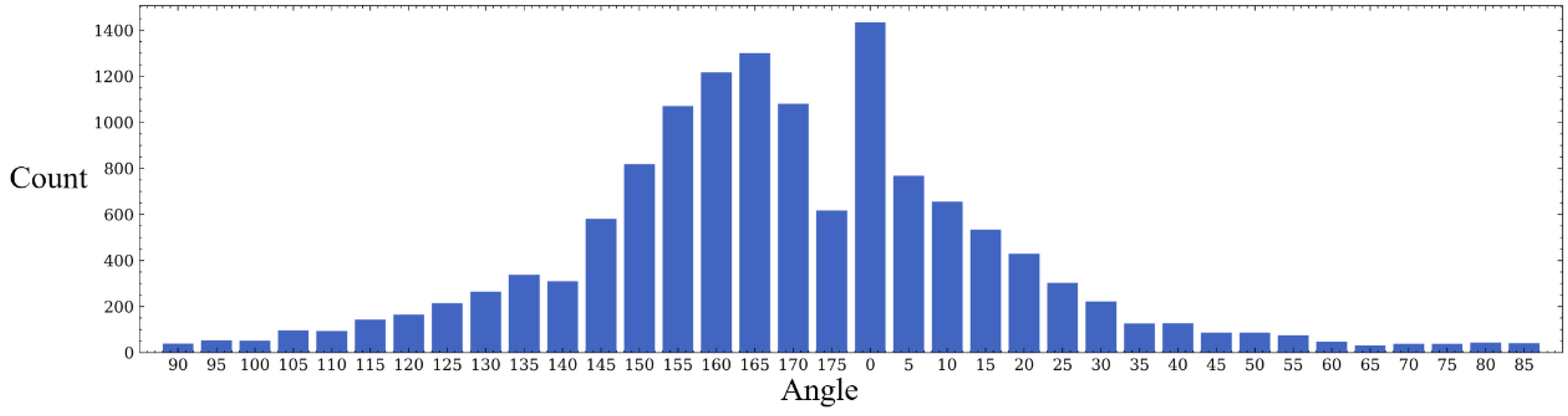
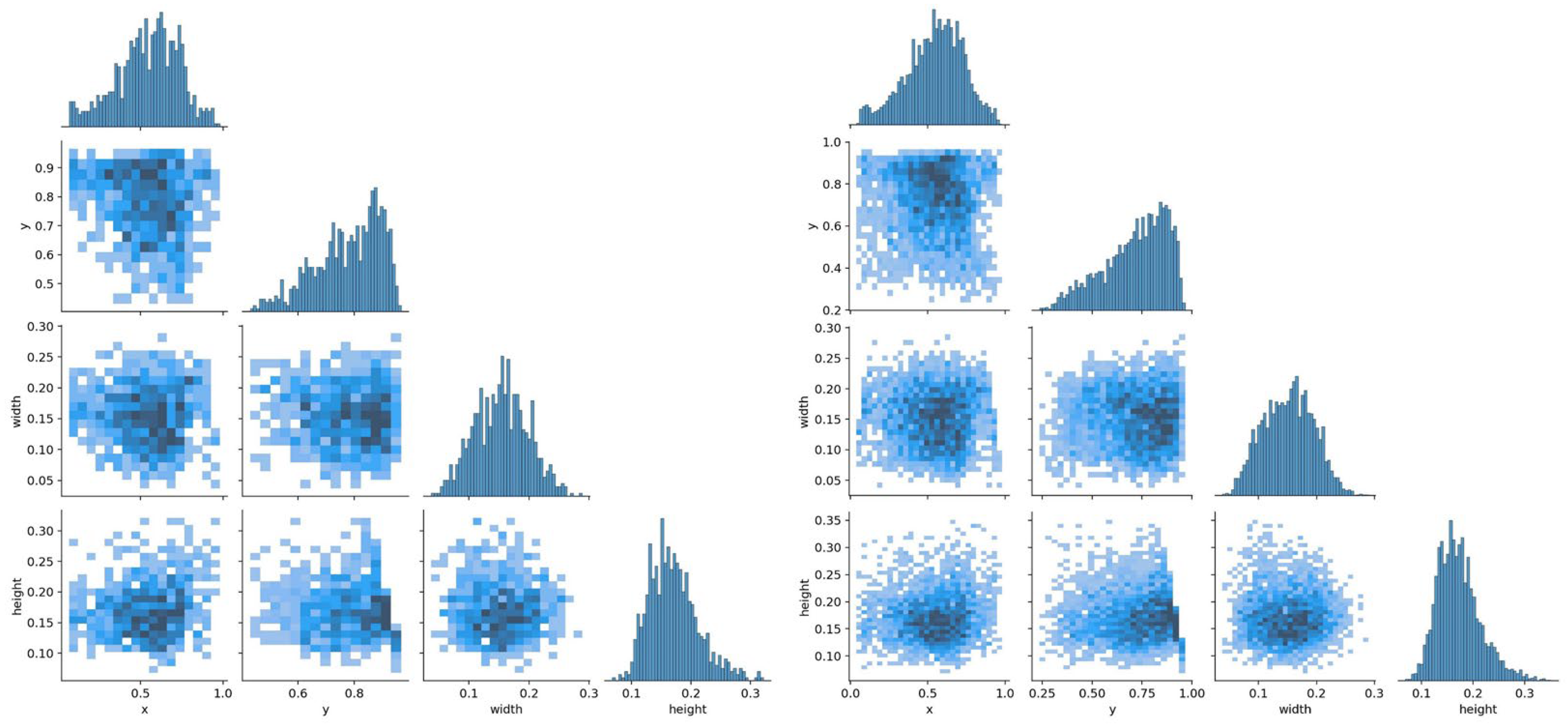
- As shown in Figure 10, the position of the target object is roughly uniformly distributed. However, it can be seen in Figure 11 that, most of the time (over 90%), the fish are not swimming in the water in a completely vertical or horizontal posture, most of which have non-uniform rotation angles that are between 0 and 40 degrees and 140 and 180 degrees.
- (3)
- Since the image needs to be scaled, it aggravates the uneven distribution of the target object.
3.2. Identification of Golden Crucian Carp
3.2.1. Identity Recognition
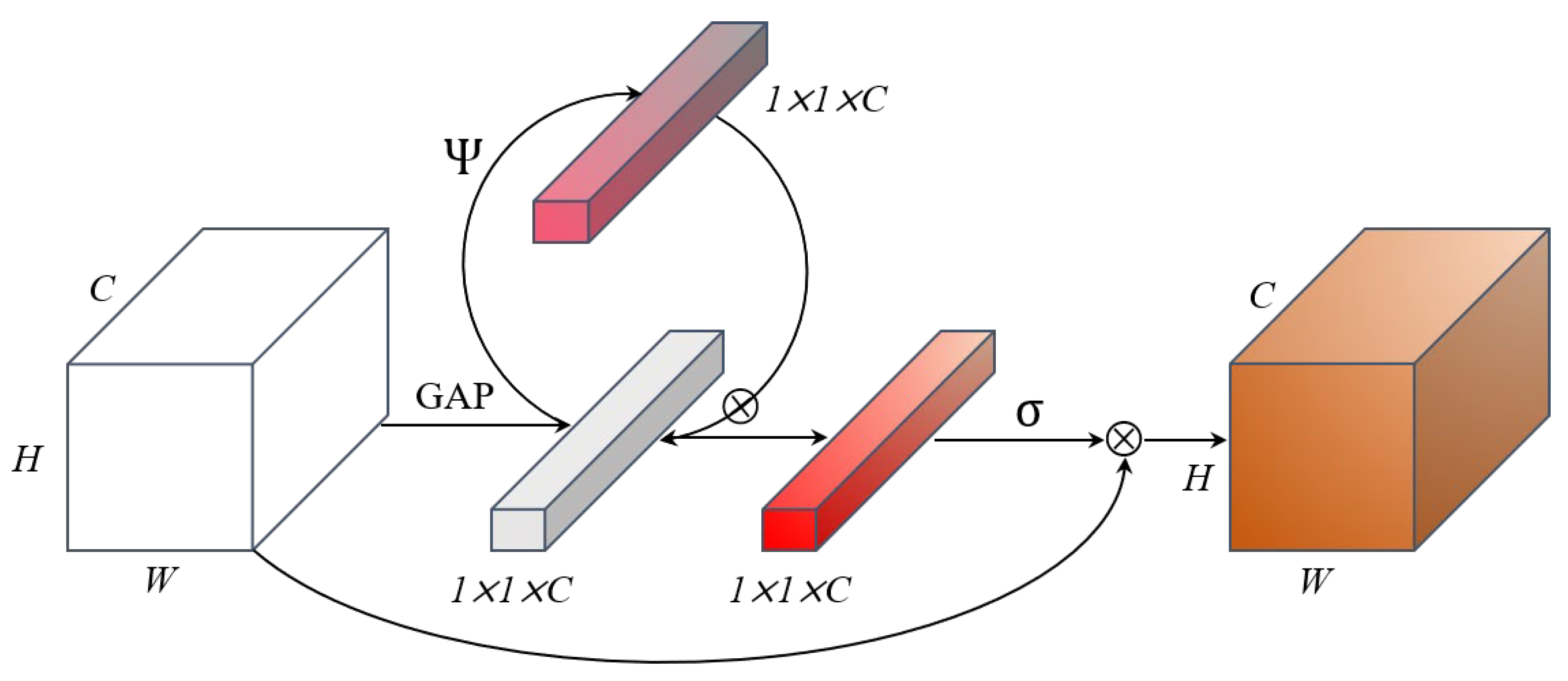
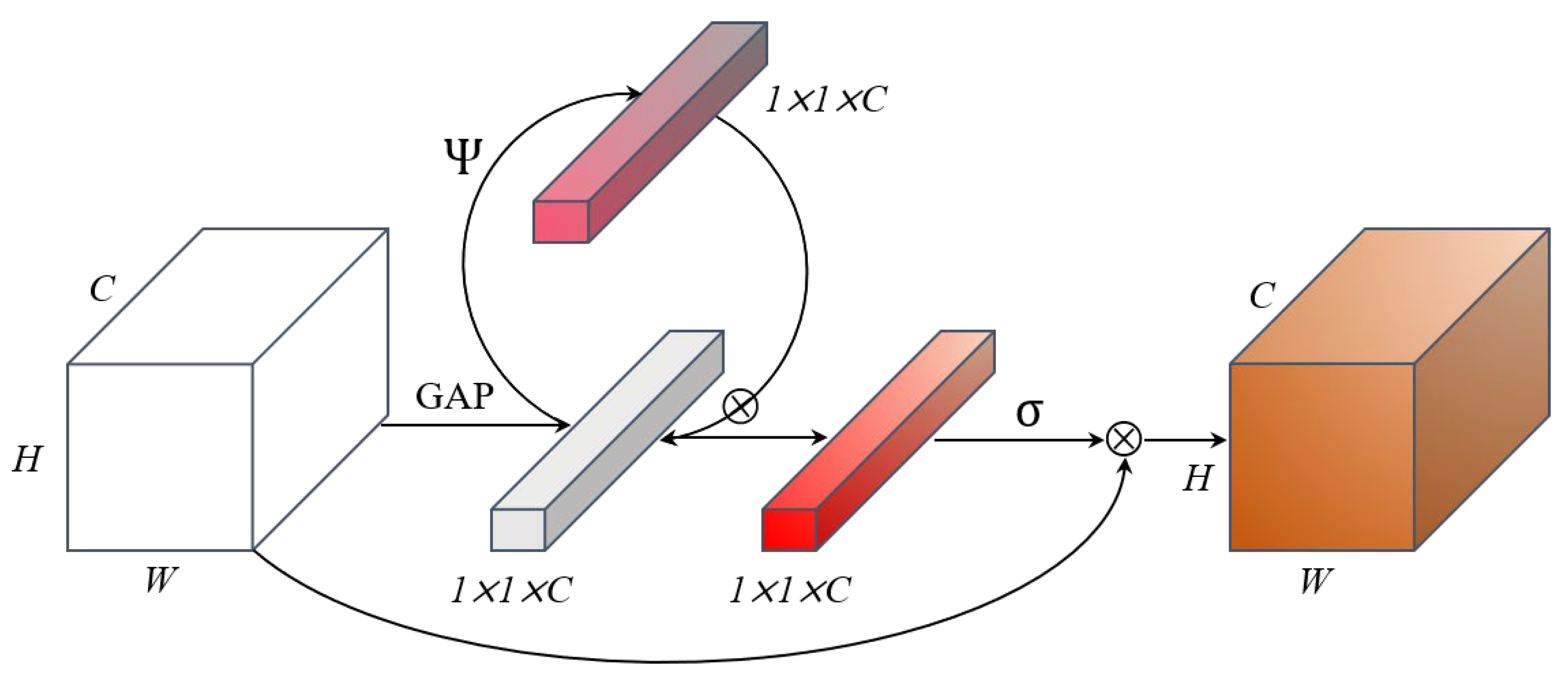
3.2.2. Self-SE Module of FFRNet
4. Results
4.1. Object Detection Experiment
4.2. Verification of the Rotated Bounding Box
4.3. FFRNet
5. Discussion
5.1. Contribution to Fish Facial Recognition
5.2. Robustness of the Process
5.3. Comparison of This Method with Other Methods
5.3.1. Standard and Rotating Boxes
5.3.2. Feature Extractor
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, H.F.; Feng, L.; Jiang, W.D.; Liu, Y.; Jiang, J.; Wu, P.; Zhao, J.; Kuang, S.Y.; Tang, L.; Tang, W.N.; et al. Flesh Shear Force, Cooking Loss, Muscle Antioxidant Status and Relative Expression of Signaling Molecules (Nrf2, Keap1, TOR, and CK2) and Their Target Genes in Young Grass Carp (Ctenopharyngodon idella) Muscle Fed with Graded Levels of Choline. PLoS ONE 2015, 10, e0142915. [Google Scholar] [CrossRef] [PubMed]
- Obasohan, E.E.; Agbonlahor, D.E.; Obano, E.E. Water pollution: A review of microbial quality and health concerns of water, sediment and fish in the aquatic ecosystem. Afr. J. Biotechnol. 2010, 9, 423–427. [Google Scholar]
- Zhang, G.; Tao, S.; Lina, Y.U.; Chu, Q.; Jia, J.; Gao, W. Pig Body Temperature and Drinking Water Monitoring System Based on Implantable RFID Temperature Chip. Trans. Chin. Soc. Agric. Mach. 2019, 50, 297–304. [Google Scholar]
- Blemel, H.; Bennett, A.; Hughes, S.; Wienhold, K.; Flanigan, T.; Lutcavage, M.; Lam, C.H.; Tam, C. Improved Fish Tagging Technology: Field Test Results and Analysis. In Proceedings of the OCEANS 2019—Marseille, IEEE, Marseille, France, 17–20 June 2019. [Google Scholar]
- Sun, Z.J.; Xue, L.; Yang-Ming, X.U.; Wang, Z. Overview of deep learning. Appl. Res. Comput. 2012, 29, 2806–2810. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 640–651. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.J.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Howard, A.; Sandler, M.; Chen, B.; Wang, W.J.; Chen, L.C.; Tan, M.X.; Chu, G.; Vasudevan, V.; Zhu, Y.K.; Pang, R.; et al. Searching for MobileNetV3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2020. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.Y.; Xu, C.J.; Xu, C. GhostNet: More Features from Cheap Operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Le, Q. MnasNet: Platform-Aware Neural Architecture Search for Mobile. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2018. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Honolulu, HI, USA, 21–27 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhou, X.; Wang, D.; Krhenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Jiang, Y.; Zhu, X.; Wang, X.; Yang, S.; Li, W.; Wang, H.; Fu, P.; Luo, Z. R2CNN: Rotational region CNN for orientation robust scene text detection. arXiv 2017, arXiv:1706.09579. [Google Scholar]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.S.; Lu, Q. Learning RoI Transformer for Oriented Object Detection in Aerial Images. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Chen, P.; Swarup, P.; Matkowski, W.M.; Kong, A.W.K.; Han, S.; Zhang, Z.; Rong, H. A study on giant panda recognition based on images of a large proportion of captive pandas. Ecol. Evol. 2020, 10, 3561–3573. [Google Scholar] [CrossRef]
- Hansen, M.F.; Smith, M.L.; Smith, L.N.; Salter, M.G.; Baxter, E.M.; Farish, M.; Grieve, B. Towards on-farm pig face recognition using convolutional neural networks. Comput. Ind. 2018, 98, 145–152. [Google Scholar] [CrossRef]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep face recognition. In Proceedings of the British Machine Vision Conference (BMVC), Swansea, UK, 7–10 September 2015; Volume 1, pp. 41.1–41.12. [Google Scholar]
- Freytag, A.; Rodner, E.; Simon, M.; Loos, A.; Kühl, H.S.; Denzler, J. Chimpanzee Faces in the Wild: Log-Euclidean CNNs for Predicting Identities and Attributes of Primates. In German Conference on Pattern Recognition; Springer International Publishing: Cham, Switzerland, 2016. [Google Scholar]
- Crouse, D.; Jacobs, R.L.; Richardson, Z.; Klum, S.; Jain, A.; Baden, A.L.; Tecot, S.R. LemurFaceID: A face recognition system to facilitate individual identification of lemurs. BMC Zool. 2017, 2, 2. [Google Scholar] [CrossRef]
- Salman, A.; Jalal, A.; Shafait, F.; Mian, A.; Shortis, M.; Seager, J.; Harvey, E. Fish species classification in unconstrained underwater environments based on deep learning. Limnol. Oceanogr. Methods 2016, 14, 570–585. [Google Scholar] [CrossRef]
- Chen, G.; Peng, S.; Yi, S. Automatic Fish Classification System Using Deep Learning. In Proceedings of the 2017 IEEE 29th International Conference on Tools with Artificial Intelligence (ICTAI), Boston, MA, USA, 6–8 November 2017. [Google Scholar]
- Funkuralshdaifat, N.F.; Talib, A.Z.; Osman, M.A. Improved deep learning framework for fish segmentation in underwater videos. Ecol. Inform. 2020, 59, 101121. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A Unified Embedding for Face Recognition and Clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- GitHub Repository. Available online: https://github.com/dlunion/DBFace (accessed on 21 March 2020).
- Lauer, J.; Zhou, M.; Ye, S.; Menegas, W.; Schneider, S.; Nath, T.; Rahman, M.M.; Santo, V.D.; Soberanes, D.; Feng, G.; et al. Multi-animal pose estimation, identification and tracking with DeepLabCut. Nat. Methods 2022, 19, 496–504. [Google Scholar] [CrossRef]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-oriented scene text detection via rotation proposals. IEEE Trans. Multimed. 2018, 20, 3111–3122. [Google Scholar] [CrossRef]
- Pan, S.; Fan, S.; Wong, S.W.; Zidek, J.V.; Rhodin, H. Ellipse detection and localization with applications to knots in sawn lumber images. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 3892–3901. [Google Scholar]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. Scrdet: Towards more robust detection for small, cluttered and rotated objects. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8232–8241. [Google Scholar]
- Deng, J.; Guo, J.; Zafeiriou, S. ArcFace: Additive Angular Margin Loss for Deep Face Recognition. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Liu, W.; Wen, Y.; Yu, Z.; Li, M.; Raj, B.; Song, L. SphereFace: Deep Hypersphere Embedding for Face Recognition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wang, H.; Wang, Y.; Zhou, Z.; Ji, X.; Gong, D.; Zhou, J.; Li, Z.; Liu, W. CosFace: Large Margin Cosine Loss for Deep Face Recognition. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]
- Chattopadhyay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-CAM++: Improved Visual Explanations for Deep Convolutional Networks. In Proceedings of the IEEE Winter Conf. on Applications of Computer Vision (WACV2018), Lake Tahoe, NV, USA, 12–15 March 2018. [Google Scholar]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for Simplicity: The All Convolutional Net. arXiv 2014, arXiv:1412.6806. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE Transactions on Pattern Analysis & Machine Intelligence, Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Radosavovic, I.; Kosaraju, R.P.; Girshick, R.; He, K.; Dollár, P. Designing Network Design Spaces. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–39 June 2016; pp. 2818–2826. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Houlsby, N. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Lin, B.; Su, H.; Li, D.; Feng, A.; Li, H.X.; Li, J.; Jiang, K.; Jiang, H.; Gong, X.; Liu, T. PlaneNet: An efficient local feature extraction network. PeerJ Comput. Sci. 2021, 7, e783. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Annotation Type | Dataset Size |
|---|---|
| Standard box | 1160 |
| Rotating box | 1160 |
| Dataset | Dataset Size |
|---|---|
| Standard detection datasets | 500 |
| Rotation detection datasets | 2912 |
| Model | P | R | F1 | mAP@0.5 | mAP@0.5:0.95 | Inference @Batch_Size 1 (ms) |
|---|---|---|---|---|---|---|
| CenterNet | 95.21% | 92.48% | 0.94 | 94.96% | 56.38% | 32 |
| YOLOv4s | 84.24% | 94.42% | 0.89 | 95.28% | 52.75% | 10 |
| YOLOv5s | 92.39% | 95.38% | 0.94 | 95.38% | 58.31% | 8 |
| EfficientDet | 88.14% | 91.91% | 0.90 | 95.19% | 53.43% | 128 |
| RatinaNet | 88.16% | 93.21% | 0.91 | 96.16% | 57.29% | 48 |
| Model | P | R | F1 | mIOU | mAngle | Inference @Batch_Size 1 (ms) |
|---|---|---|---|---|---|---|
| R-CenterNet | 88.72% | 87.43% | 0.88 | 70.68% | 8.80 | 76 |
| R-YOLOv5s | 90.61% | 89.45% | 0.90 | 75.15% | 8.26 | 43 |
| HSV_Aug | FocalLoss | Mosaic | MixUp | Fliplrud | Other Tricks | mAP@0.5 |
|---|---|---|---|---|---|---|
| 77.32% | ||||||
| √ | 77.98% | |||||
| √ | √ | 77.42% | ||||
| √ | √ | √ | 79.05% | |||
| √ | √ | √ | √ | 81.12% | ||
| √ | √ | 81.64% | ||||
| √ | √ | √ | √ | 80.68% | ||
| √ | √ | √ | Fliplrud | 81.37% | ||
| √ | √ | √ | √ | Fliplrud | 82.46% | |
| √ | √ | Fliplrud RandomScale | 79.99% | |||
| √ | √ | √ | √ | √ | Fliplrud RandomScale | 82.88% |
| Model_Head | Backbone | Rotated Detection 500 | Standard Detection 500 | ||
|---|---|---|---|---|---|
| Acc@Top1 | Acc@Top5 | Acc@Top1 | Acc@Top5 | ||
| Softmax | ResNet50 | 84.17 | 96.46 | 83.83 | 96.11 |
| FaceNet | ResNet50 | 86.32 | 98.13 | 80.01 | 94.87 |
| ResNet101 | 86.18 | 98.43 | 82.36 | 96.08 | |
| ResNet152 | 81.81 | 95.04 | 80.76 | 95.01 | |
| ArcFace | ResNet50 | 64.69 | 94.69 | 62.19 | 90.31 |
| ResNet101 | 69.06 | 92.81 | 65.94 | 92.5 | |
| ResNet152 | 64.38 | 93.44 | 64.69 | 92.5 | |
| CosFace | ResNet50 | 64.06 | 92.81 | 62.19 | 87.81 |
| ResNet101 | 63.75 | 90.94 | 65.94 | 87.81 | |
| ResNet152 | 65.31 | 86.56 | 59.38 | 85.62 | |
| SphereFace | ResNet50 | 62.19 | 89.06 | 50.31 | 85.31 |
| ResNet101 | 62.19 | 90.0 | 59.69 | 87.81 | |
| ResNet152 | 59.69 | 85.62 | 57.81 | 82.19 | |
| Model_Head | Backbone | Rotated Detection 2912 | |
|---|---|---|---|
| Acc@Top1 | Acc@Top5 | ||
| Softmax | ResNet50 | 85.78 | 96.45 |
| FaceNet | ResNet101 | 86.19 | 96.78 |
| ResNet50 | 85.02 | 96.34 | |
| ResNet101 | 87.89 | 97.08 | |
| ArcFace | ResNet152 | 89.13 | 99.13 |
| ResNet50 | 80.86 | 91.88 | |
| ResNet101 | 81.02 | 94.8 | |
| CosFace | ResNet152 | 82.22 | 94.53 |
| ResNet50 | 81.68 | 91.33 | |
| ResNet101 | 79.26 | 91.95 | |
| SphereFace | ResNet152 | 80.47 | 92.88 |
| ResNet50 | 81.68 | 91.33 | |
| ResNet101 | 79.96 | 90.7 | |
| ResNet152 | 80.94 | 91.31 | |
| Backbone | Image_Shape = (112,112,3) BatchSize = 64 | ||||
|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1 | Inference Time (ms) | |
| MobileNetv1 | 85.2 | 85.22 | 86.17 | 85.69 | 2.916 |
| MobileNetv2 | 87.51 | 87.68 | 87.53 | 87.54 | 5.237 |
| MobileNetv3_Small | 86.22 | 86.17 | 86.15 | 86.1 | 4.870 |
| MobileNetv3_Large | 88.15 | 88.22 | 88.14 | 88.1 | 6.242 |
| ShuffleNetv2 | 87.45 | 87.48 | 87.5 | 87.38 | 7.243 |
| RegNet_400 MF | 87.68 | 87.68 | 87.79 | 87.67 | 14.876 |
| inception_resnetv1 | 86.48 | 86.7 | 86.64 | 86.54 | 21.512 |
| ResNet50 | 87.3 | 87.5 | 87.35 | 87.24 | 12.72 |
| FFRNet | 90.13 | 89.98 | 89.76 | 89.87 | 4.782 |
| Backbone | Image_Shape = (224,224,3) | ||||
|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1 | Inference Time (ms) | |
| MobileNetv1 | 85.92 | 86.05 | 85.99 | 86.01 | 5.306 |
| MobileNetv2 | 88.2 | 88.32 | 88.26 | 88.18 | 10.332 |
| MobileNetv3_Small | 87.92 | 88.06 | 87.91 | 87.86 | 6.656 |
| MobileNetv3_Large | 88.84 | 88.82 | 88.77 | 88.73 | 11.962 |
| ShuffleNetv2 | 89.0 | 89.05 | 89.01 | 88.92 | 8.224 |
| RegNet_400 MF | 89.5 | 89.51 | 89.52 | 89.45 | 22.302 |
| EfficientNetv1_B0 | 89.85 | 89.94 | 89.92 | 89.82 | 16.906 |
| inception_resnetv1 | 87.03 | 87.14 | 87.09 | 87.01 | 34.905 |
| ResNet50 | 89.75 | 89.71 | 89.68 | 89.63 | 11.081 |
| vision_transformer | 84.63 | 84.85 | 84.69 | 84.67 | 26.768 |
| FFRNet | 92.01 | 91.87 | 91.66 | 91.76 | 5.720 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, D.; Su, H.; Jiang, K.; Liu, D.; Duan, X. Fish Face Identification Based on Rotated Object Detection: Dataset and Exploration. Fishes 2022, 7, 219. https://doi.org/10.3390/fishes7050219
Li D, Su H, Jiang K, Liu D, Duan X. Fish Face Identification Based on Rotated Object Detection: Dataset and Exploration. Fishes. 2022; 7(5):219. https://doi.org/10.3390/fishes7050219
Chicago/Turabian StyleLi, Danyang, Houcheng Su, Kailin Jiang, Dan Liu, and Xuliang Duan. 2022. "Fish Face Identification Based on Rotated Object Detection: Dataset and Exploration" Fishes 7, no. 5: 219. https://doi.org/10.3390/fishes7050219
APA StyleLi, D., Su, H., Jiang, K., Liu, D., & Duan, X. (2022). Fish Face Identification Based on Rotated Object Detection: Dataset and Exploration. Fishes, 7(5), 219. https://doi.org/10.3390/fishes7050219