1. Introduction
In aquaculture, low bait utilization has led to rising farming costs and water pollution, posing serious challenges for the industry [
1]. Statistics show that bait costs account for 40–60% of the total aquaculture expenses [
2]. Therefore, improving bait utilization efficiency has become a pressing issue. In practice, dynamically adjusting feeding strategies based on the amount of residual bait is key to improving bait utilization and reducing water pollution risks [
3]. However, there are still many challenges in accurately identifying and counting bait residues in aquaculture ponds. In complex underwater environments, bait detection is hindered by challenges such as bait aggregation, overlapping targets, missed detections of small or distant objects, and background noise caused by fish movement. These factors significantly affect detection accuracy and pose major obstacles to reliable bait residue recognition. In previous research work, many scholars have attempted to use acoustic methods to detect residual bait underwater. Llorens et al. utilized ultrasonic echo methods to enable the quantification of residual bait [
4]. However, these acoustic systems rely on particle-specific acoustic signatures [
5], and sonar-based methods often produce monochromatic, low-resolution images that limit detection performance [
6]. In addition, acoustic equipment is usually expensive, which further limits its widespread use in practical production.
With the rapid advancement of machine vision, many researchers have applied it to bait detection. Foster et al. [
7] proposed an image analysis algorithm to achieve automatic target identification and tracking. Parsonage et al. [
8] developed a computer vision system to provide real-time feedback on bait particle consumption. Atoum et al. [
9] achieved continuous detection of bait particles in video frames by applying a correlation filter to identify residual bait within local regions. An SVM classifier was used to suppress detection errors, providing a foundation for intelligent bait-feeding control. Li et al. [
10] proposed an adaptive threshold segmentation method for detecting residual bait particles in underwater images. However, traditional machine vision methods struggle with complex backgrounds and small targets, limiting their effectiveness in practical applications.
Deep learning can automatically extract high-dimensional features from large datasets, resulting in significantly higher accuracy compared to traditional machine learning methods [
11]. Currently, deep learning techniques have been widely used in aquaculture [
12]: Rauf et al. [
13] used deep convolutional neural networks to automatically identify fish based on visual features. Fernandes et al. [
14] applied image segmentation techniques to predict weight and carcass traits of Nile tilapia. Labao and Naval [
15] proposed a fish detection system based on deep network architecture for robust detection and counting of fish targets in a variety of biological backgrounds and lighting conditions. Zhao et al. [
16] applied a particle advection method to extract motion features from the entire fish population, eliminating the need for tracking and foreground segmentation. They also used augmented motion-captured images and recurrent neural networks to accurately identify, localize, and classify abnormal fish behavior in intensive aquaculture environments. Xu et al. [
17] proposed a fish species identification model based on SE-ResNet152 with class-balanced focal loss, addressing the overfitting caused by sample imbalance. However, these algorithms still fall short of meeting real-time detection requirements in practical aquaculture settings [
18].
The YOLO family of algorithms offers a promising solution for real-time object detection. As representative single-stage detectors, they are known for their high accuracy and fast inference speed and have been widely applied in aquaculture tasks. Cai et al. [
19] proposed an enhanced fish detection and counting method by using the YOLOv3 and MobileNet architectures. The method improves detection accuracy by incorporating a fixed selection strategy into the original YOLOv3 framework. Hu et al. [
20] improved average model accuracy by 27.21% and reduced computational cost by approximately 30% by applying dense concatenation and de-redundancy techniques to the feature extraction module of the YOLOv4 backbone. These enhancements make the algorithm more suitable for practical aquaculture environments. In addition, the YOLO algorithm also shows strong advantages in small target detection tasks in underwater environments [
21]. Even in low light environments and turty water environments, the YOLO algorithm can show excellent algorithm adaptability and complete the detection task well [
22].
The complexity of underwater imaging and the small size of bait particles [
23] make the YOLO algorithm prone to positional prediction errors. Moreover, bait particles often appear in clusters or overlap due to occlusion, while distant targets occupy only a few pixels in the image, making them especially prone to missed detection. Background noise from swimming fish and other dynamic elements further complicates the detection process [
24].
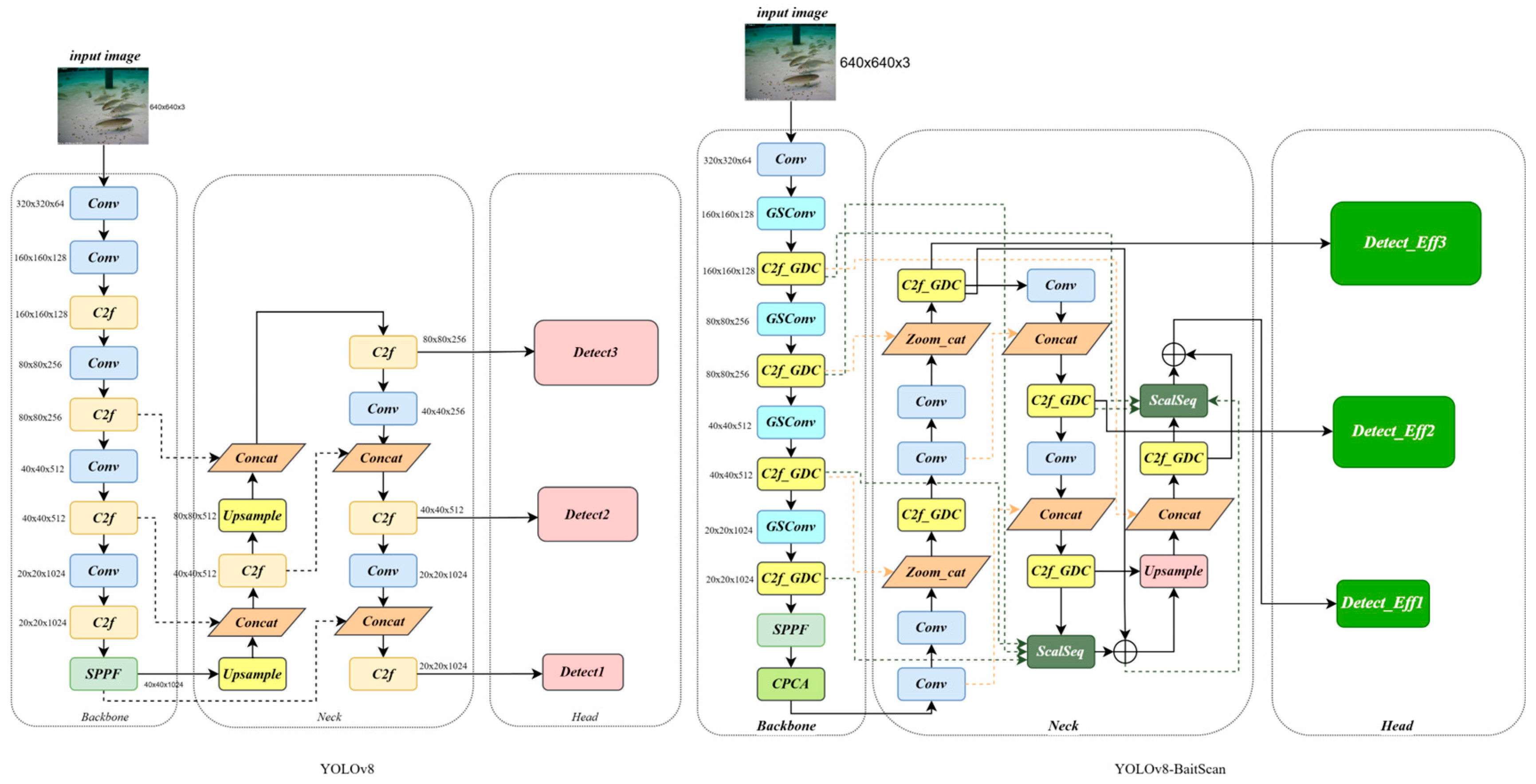
Therefore, this paper proposes an improved YOLOv8n-based method for more efficient and accurate detection and counting of bait residues. The approach is designed to address key challenges such as target aggregation, occlusion, missed detections of small distant baits, and interference from complex underwater backgrounds. By removing redundant operations, the model is streamlined for higher efficiency and better suitability in real-world aquaculture environments.
The remainder of this paper is organized as follows:
Section 2 presents the dataset and algorithmic improvements;
Section 3 analyzes the results of ablation experiments;
Section 4 discusses the experimental findings in depth; and
Section 5 concludes this study.
3. Results
3.1. Assessment of Indicators
Precision, recall, and F1-score are commonly used metrics to evaluate the correctness of object detection, with their calculation formulas shown in Equations (5)–(7). Precision is used to indicate the percentage of correctly predicted baits in the prediction results, recall indicates the percentage of correctly predicted baits to the total number of all baits, and the F1-score value, as a composite metric, is the reconciled average of precision and recall. Param and GFLOPS are model parametric and computational metrics, respectively, typically used to assess the computational complexity of the model. These metrics will be employed to evaluate the model’s performance before and after optimization in the subsequent sections of this study.
In this context, TP (True Positive) denotes correctly detected bait samples, FN (False Negative) denotes samples incorrectly identified as background, TN (True Negative) denotes samples correctly identified as background, and FP (False Positive) denotes samples incorrectly identified as bait. AP represents the area under the precision–recall (PR) curve and is used to measure the average accuracy of the model for a single category, with its value ranging from 0 to 1, as shown in Equation (8), where Pn is the precision value of the NTH point, Rn is the recall value of the NTH point, and N is the number of samples on the P-R curve. mAP denotes the average accuracy of multiple categories (single-category detection in this study) and is calculated as shown in Equation (9). mAP@50 and mAP@50:95 are the two metrics commonly used in mAP. mAP@50 indicates the average accuracy of the model at an IoU threshold of 0.5, while mAP@50:95 represents the average of mAP values calculated at IoU thresholds ranging from 0.5 to 0.95 (i.e., mAP@50, mAP@55, …, mAP@90, and mAP@95).
3.2. Experimental Parameter Setting
The experimental platform is shown in
Table 1. The experimental hyperparameter settings are shown in
Table 2. The experimental hyperparameters refer to the optimal hyperparameter settings given by the official authorities and are adjusted appropriately according to the specific experimental requirements.
3.3. Ablation Experiment
In order to verify that the improved algorithm has superior detection accuracy as well as speed for the bait counting task, the baseline model YOLOv8n is compared with the seven improved models based on YOLOv8n, and the results are shown in
Table 3. The experimental environment and parameter settings were kept consistent during this experiment to ensure the credibility of the experimental results. In addition, pre-trained weights were loaded in the training process to ensure the reliability of the experimental results.
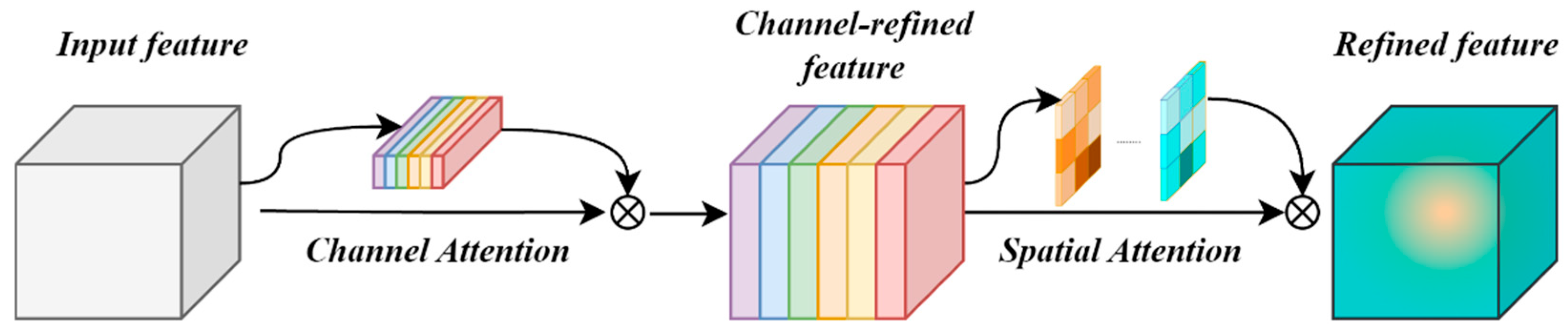
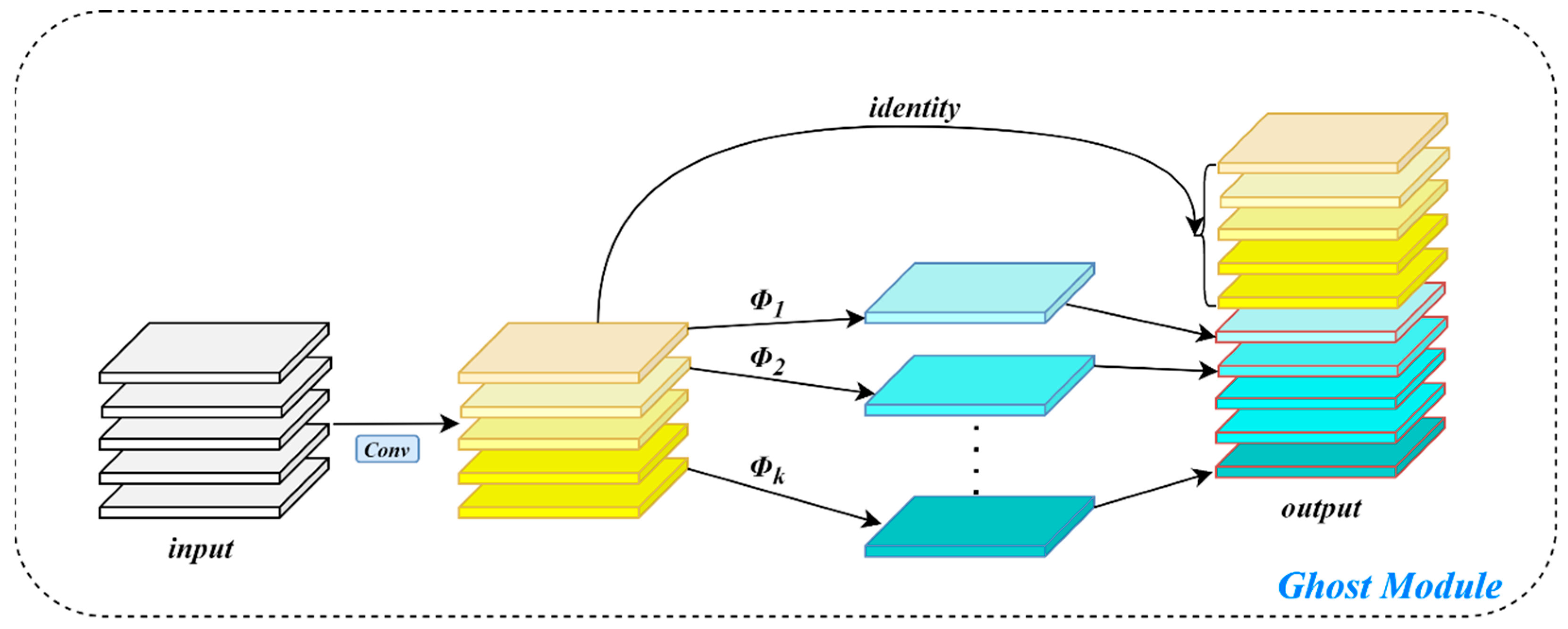
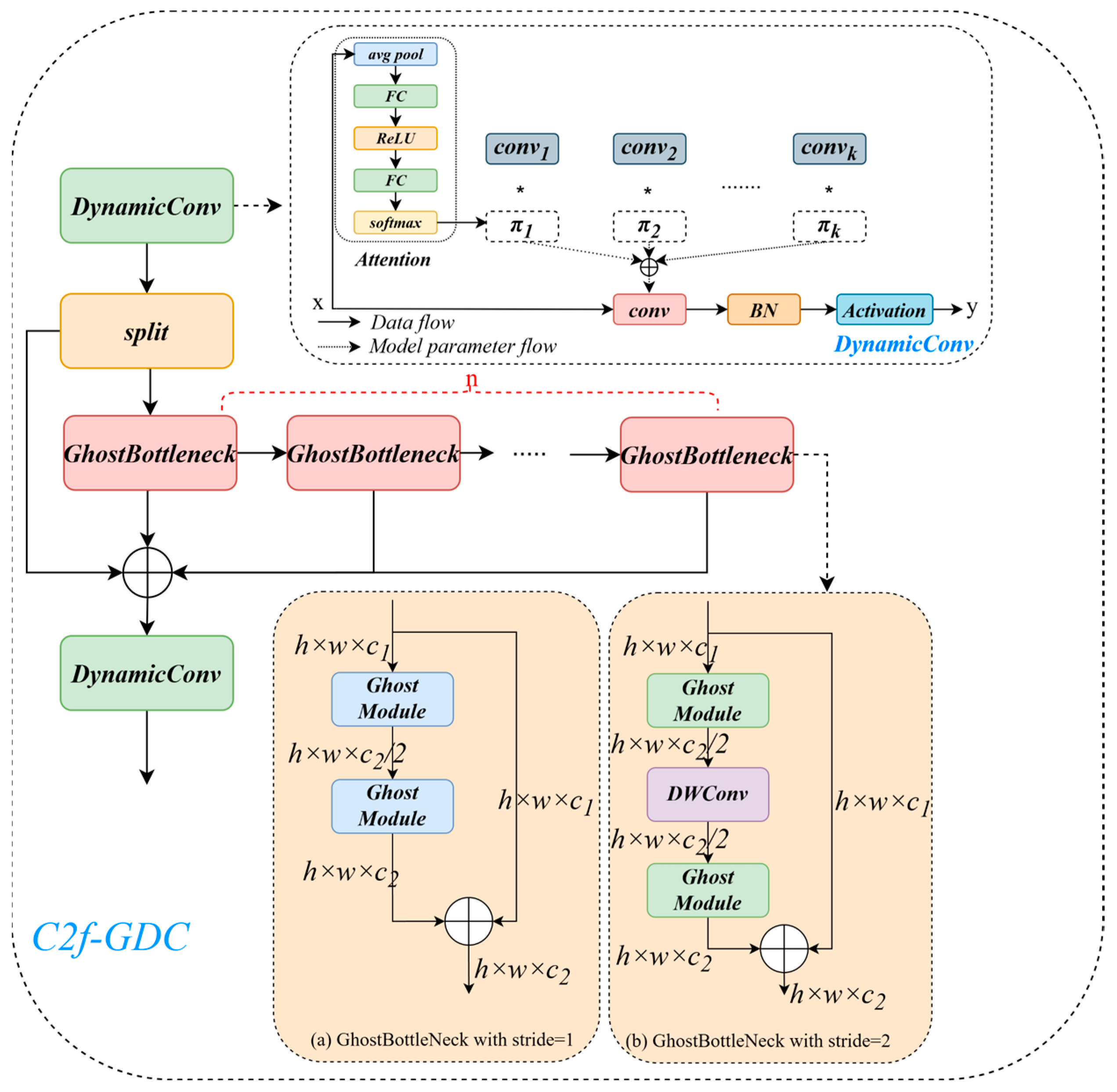
Applying the CPCA attention mechanism to the Backbone enhances the network’s focus on small bait regions, thereby improving detection precision. The MPDIoU loss further boosts detection performance by increasing localization accuracy and addressing bounding box duplication caused by overlapping bait particles. The improved Neck network and newly designed detection head significantly increase the recall of small, long-distance bait targets by effectively fusing multi-scale feature sequences. GhostConv and C2f-GDC reduce the model’s parameter count and computational cost with only a minimal impact on overall accuracy. Detect-Efficient, the proposed lightweight detection head, further reduces complexity by introducing PConv and enabling feature sharing across convolution layers. Additionally, with PConv, the convolutional kernel dynamically adjusts its range by ignoring missing or invalid data points, which leads to a notable improvement in detection accuracy.
Ultimately, the YOLOv8-BaitScan proposed in this study achieves significant performance improvements compared to the baseline YOLOv8n. Specifically, it improves recall by 33.6%, mAP@50 by 17%, mAP@50:95 by 10.6%, and F1-score by 18%. At the same time, the number of parameters and GFLOPS are reduced by 55.7% and 54.3%, respectively.
3.3.1. Analysis of the Effect of Introducing the CPCA Attention Mechanism
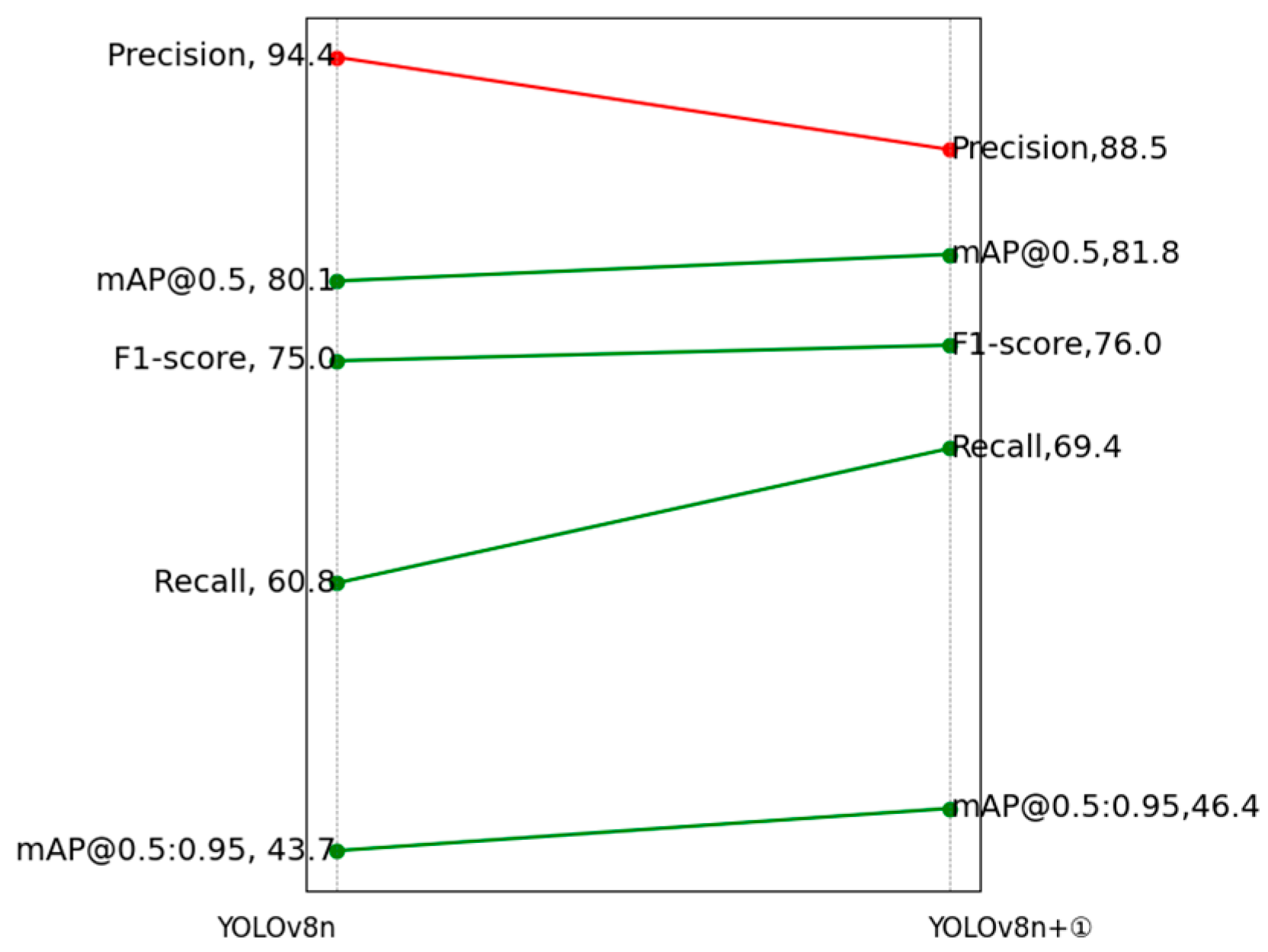
After integrating the CPCA module, all evaluation metrics improved except for precision(see
Figure 10). Specifically, recall increased by 8.6%, reaching 69.4%; mAP@50 increased by 1.7% to 81.8%; mAP@50:95 improved by 0.4%; and the F1-score rose by 1%. These results demonstrate that the CPCA attention mechanism effectively enhances the overall detection performance of the model.
3.3.2. Analysis of the Effect of Replacing the MPDIoU Loss Function
The introduction of the
MPDIoU loss function improves the model’s localization accuracy for bait targets, thereby enhancing overall detection performance. As shown in
Figure 11, comparing the effect of using the original loss function and
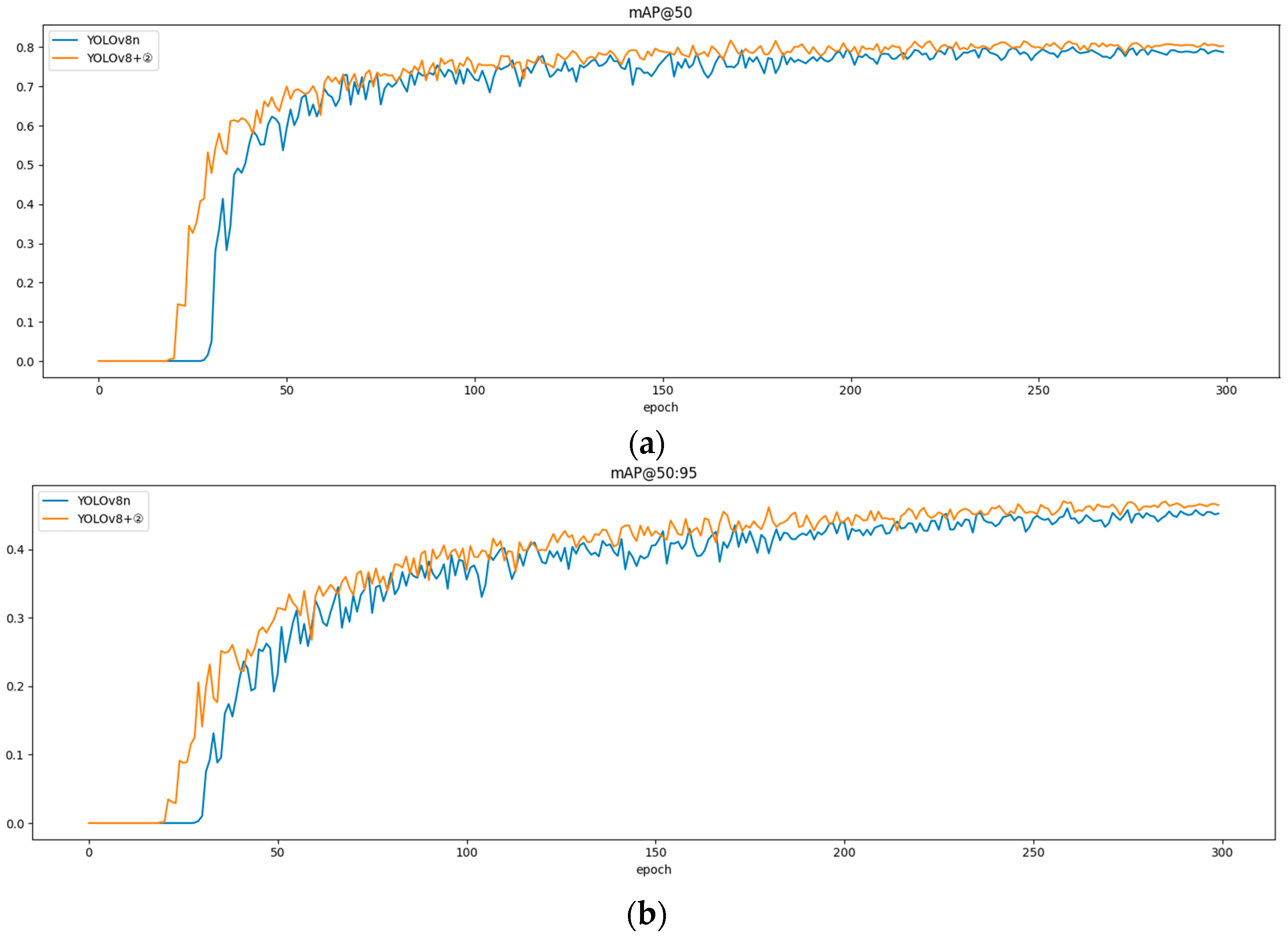
MPDIoU loss, it can be seen from the results that the
MPDIoU loss function is more suitable for the current bait residue detection task, and its effect is better than that of the original loss function in both the mAP@50 and mAP@50:95 metrics, which enhances the detection performance of the model. In addition to performance gains,
MPDIoU has a more concise mathematical formulation, which accelerates the training process and allows the model to converge faster. As illustrated in
Figure 11, the model using
MPDIoU shows a noticeable increase in mAP starting from epoch 20, whereas the model using the original loss function does not show a similar rise until epoch 35.
3.3.3. Analysis of the Effect of Neck Network Optimization and Replacement of Small Target Detection Layers
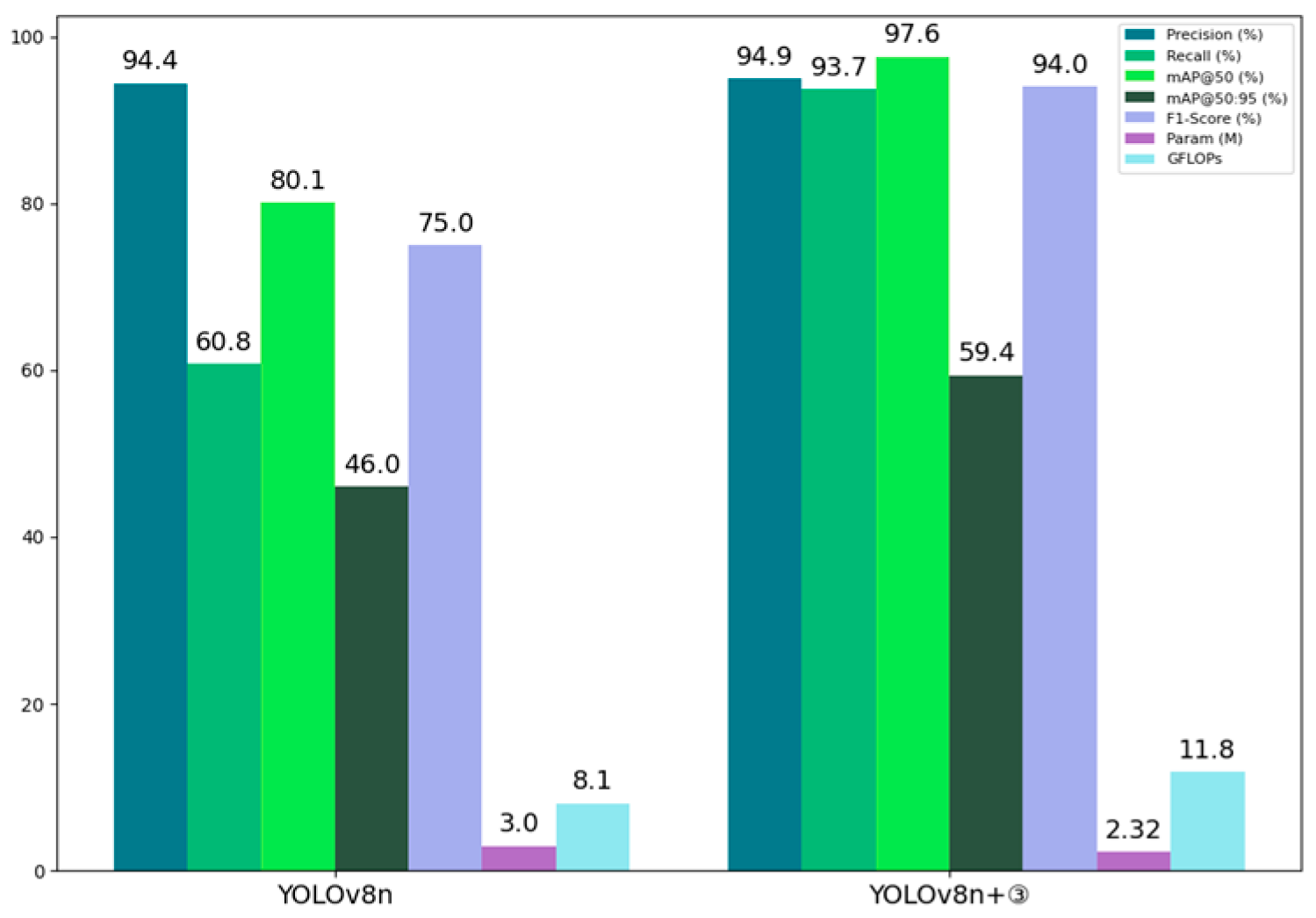
By redesigning the Neck part of the network, we enable the network to capture more feature information and reduce information loss during feature fusion. The bait detection accuracy is further improved by combining high-level information from deep feature maps with detailed information from shallow feature maps through the ScalSeq module, resulting in a multi-scale feature representation. In addition, by eliminating the redundant P5 large-target detection layer and adding the P2 small-target detection layer, the recall of long-range small baits is significantly improved, and thus the detection accuracy is significantly improved, with the recall increased to 93.7% and the mAP@50 increased to 97.6%.
Figure 12 shows the comparison of the indexes between the original model and the Neck partially improved and replaced one detection layer. As can be seen from the results, all the indexes are significantly improved after the introduction of the Neck partially improved and the replacement of the P2 detection layer, but then it also brings a substantial increase in the amount of computation, and the GFLOPS increases from 8.1 to 11.8, which is a 31% increase in computation, and increases the burden of the model inference.
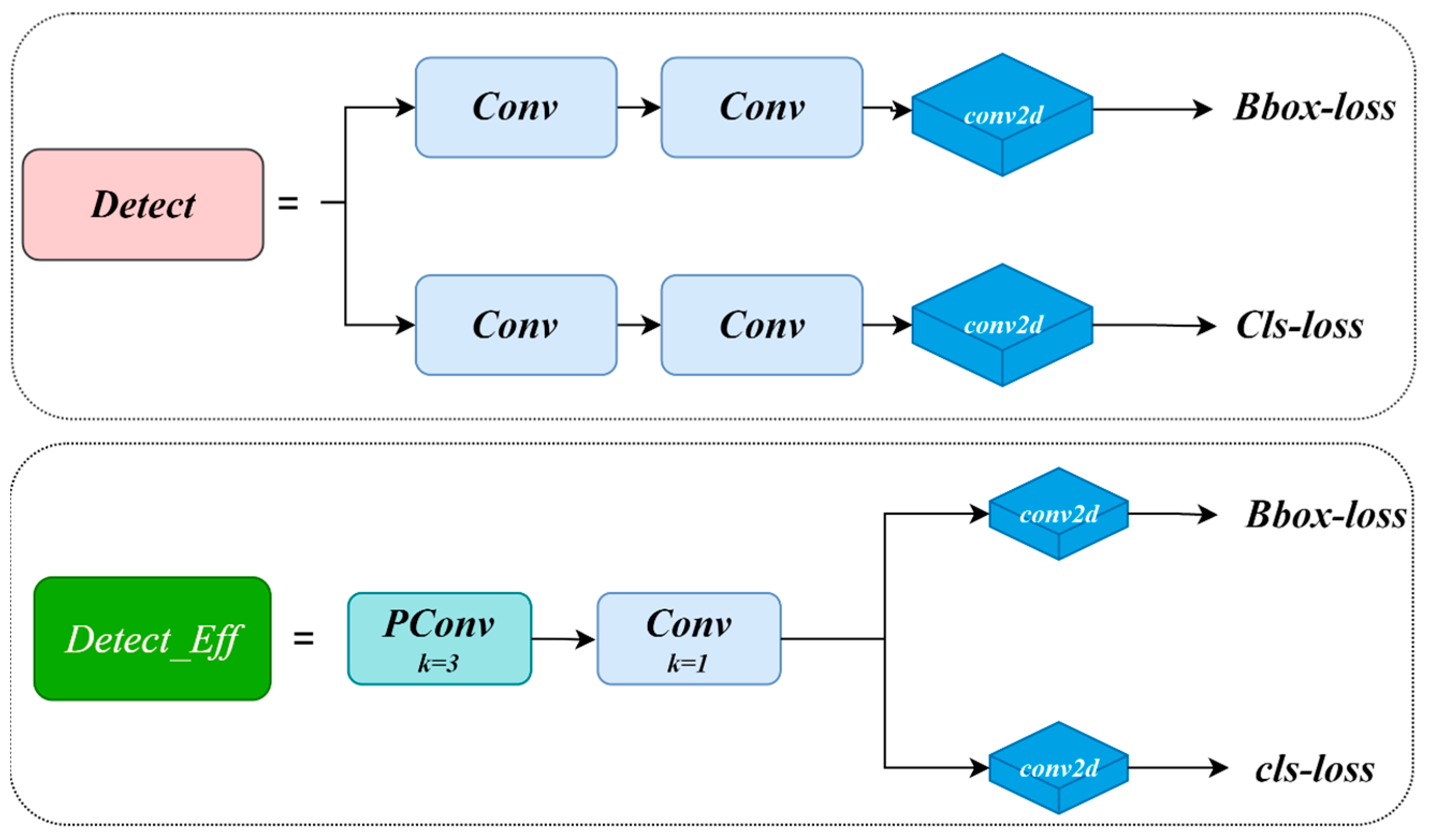
3.3.4. Analysis of the Effect of Introducing GhostConv, C2f-GDC Module, and Lightweight Detector Heads
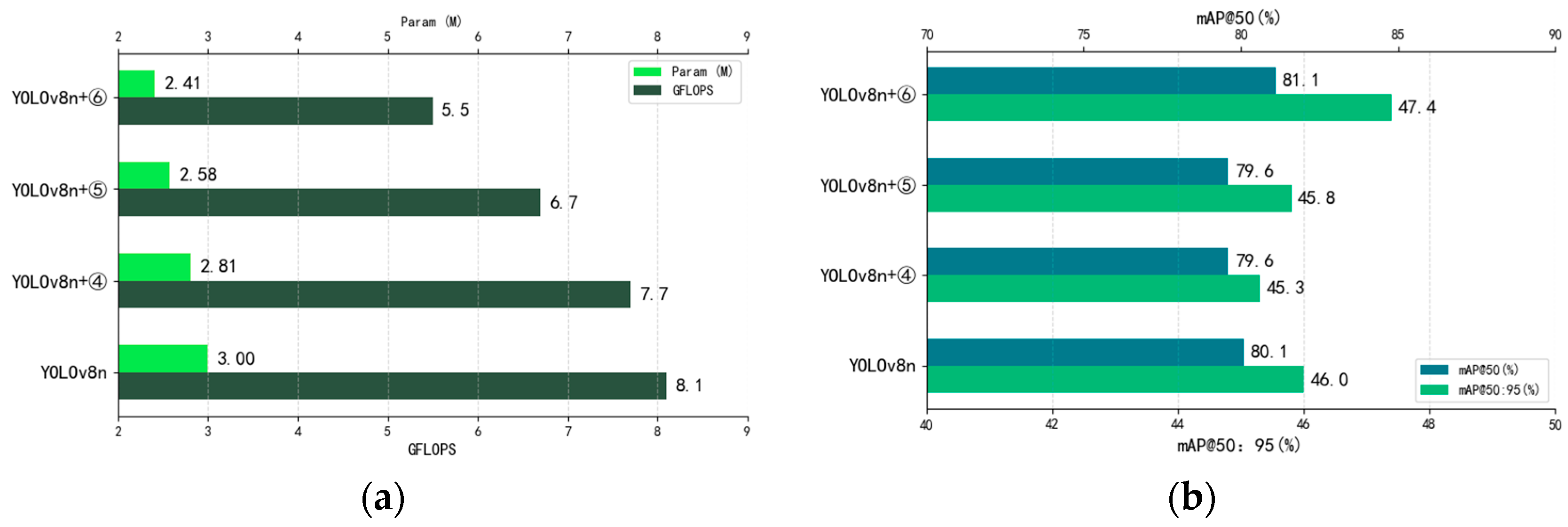
Figure 13a shows the comparison between the number of model parameters and computation amount and the original model after the introduction of GhostConv, C2f-GDC, and Detect-Efficient, and
Figure 13b shows the comparison between the model detection accuracy and the original model after the introduction of GhostConv, C2f-GDC, and Detect-Efficient. It can be seen that all the above methods can reduce the overall computation and number of parameters of the model to different degrees. Meanwhile, GhostConv and C2f-GDC reduce the computation while keeping the mAP@50 down by only 0.5%, whereas Detect-Efficient significantly reduces the computation and number of parameters while increasing the mAP@50 by 1.0%, which proves that Detect-Efficient detection head is more suitable for bait residue detection tasks.
3.4. Comparison of Different Attention Mechanisms
In order to verify the efficiency of the CPCA attention mechanism in the bait detection task, this paper compares the common attention mechanisms: MLCA, DA, CAFM, and MPCA.
Table 4 shows a comparison of the experimental results of different attention mechanisms.
Among the evaluated attention mechanisms, the integration of MLCA and DA resulted in a decrease in mAP@50, indicating that these mechanisms are not well-suited for bait detection tasks. In contrast, the incorporation of CAFM and MPCA led to modest improvements in mAP@50, with increases of only 0.3% and 0.7%, respectively. Notably, the CPCA attention mechanism demonstrated a more substantial enhancement, achieving a 1.7% increase in mAP@50. Based on these experimental results, this study adopts the CPCA attention mechanism within the backbone network of YOLOv8n to improve the detection performance for bait targets.
3.5. Comparison of Different Loss Functions
To investigate the impact of different loss functions on the performance of the YOLOv8-BaitScan model and to identify the most suitable loss function, the original CIoU loss was individually replaced with GIoU, SIoU, DIoU, and
MPDIoU. The performance differences in bait target detection were then systematically evaluated. The experimental results are summarized in
Table 5.
As presented in
Table 5, the
MPDIoU loss function demonstrates notable advantages. Compared to the original CIoU loss function,
MPDIoU yields a 6.3% increase in recall and a 1.6% improvement in mAP@50. In contrast, the use of GIoU not only fails to enhance detection performance but also results in a 0.2% decrease in mAP@50. Although SIoU contributes a 0.5% increase in mAP@50, its impact remains relatively limited when compared to
MPDIoU. DIoU achieves a 1.1% improvement in mAP@50; however, its performance gain is still inferior to that of
MPDIoU.
3.6. Comparison of Different Models
To highlight the advantages of the proposed YOLOv8-BaitScan model, we conducted a comparative evaluation against Faster R-CNN, YOLOv7-tiny, YOLOv8n, and YOLOv10n. The experimental results are summarized in
Table 6.
As shown in
Table 6, YOLOv8-BaitScan achieves a mAP@50 of 97.1%, significantly outperforming the other detection models. Furthermore, it requires the least computational resources, with only 1.33 million parameters and a computational cost of 3.7 GFLOPS. Although YOLOv10n is also a lightweight model, its detection accuracy is substantially lower, reaching only 71.7% mAP@50. In terms of the F1-score, YOLOv8-BaitScan attains an outstanding 93.0%, which is 15%, 21%, 18%, and 20% higher than Faster R-CNN, YOLOv7-tiny, YOLOv8n, and YOLOv10n, respectively.
3.7. Visualization
To further validate the superiority of the YOLOv8-BaitScan model, we conducted a visual comparison of the detection results against ground truth annotations, aiming to comprehensively highlight the improvements introduced by the proposed algorithm.
Figure 14 shows the detection performance of YOLOv8-BaitScan in different difficult recognition scenarios. (a) shows the detection results in the case of overlapping baits. The results show that YOLOv8-BaitScan can better identify overlapping baits, and (b) shows the detection results of long-distance bait. The optimized model greatly reduces the probability of missed detection of long-distance bait, and (c) shows the detection results under a large number of bait aggregation scenes. The results show that the optimized model has a better recognition effect for bait in aggregation scenes, and (d) shows the detection results in the case of background interference. The results show that YOLOv8-BaitScan can better complete the bait detection task in the case of background interference caused by fish swimming. The enhanced YOLOv8-BaitScan exhibits a marked improvement in prediction performance compared to the original YOLOv8n. It notably enhances the recall of long-range bait targets and achieves greater accuracy in bounding box localization. These advantages are particularly evident in challenging scenarios involving dense clustering, overlapping targets, and complex background interference. The results confirm the effectiveness and robustness of the proposed method.
Bait overlap, small targets at long-range bait, and background noise interference are great challenges in the bait residue counting task.
Figure 15 shows the heat map of the YOLOv8n algorithm and the YOLOv8-BaitScan proposed in this paper in the bait prediction results in different cases, which can more intuitively show the degree of attention of the algorithm to different regions in the picture before and after the improvement. Compared with the original YOLOv8n model, YOLOv8-BaitScan reduces the probability of bait target miss detection by applying more attention weights to the long-distance small-target bait and adding a new tiny-target detection layer, which makes the model more sensitive to the long-distance small-target bait, and thus reduces the probability of bait target miss detection to a great extent. In addition, the use of the
MPDIoU loss function enhances the localization precision of the predicted bounding boxes, particularly in cases involving dense aggregation and overlap. These improvements collectively contribute to the superior performance and robustness of YOLOv8-BaitScan in practical bait residue counting tasks.
4. Discussion
This study proposed YOLOv8-BaitScan to optimize the structure of the YOLOv8 network for bait detection tasks, aiming to achieve accurate and efficient detection of the number of bait in intensive aquaculture ponds and provide technical support for precision breeding. This model introduces the CPCA attention mechanism in the backbone part of the network, replaces the MPDIoU loss function, and optimizes the configuration of the detection layer. Finally, the computational load required by the model is reduced by the lightweight structure. Experimental results show that YOLOv8-BaitScan performs well in actual intensive aquaculture scenarios, and all indicators are significantly improved compared with the original benchmark model.
However, although the proposed YOLOv8-BaitScan performs well in the bait detection task, there are still some limitations of this model that need to be further solved to obtain better adaptability. Firstly, the required computational load will be limited on marginal computing power devices. Based on the current findings, there are several avenues for improving YOLOv8-BaitScan. One key area for future work is addressing the model’s computational load on resource-constrained devices. While the lightweight structure of YOLOv8-BaitScan offers some reduction in computational demands, further optimization techniques, such as pruning or quantization, could be explored to enable the model to run more efficiently on edge devices with limited computational power. Additionally, exploring hardware acceleration methods, such as the use of GPUs or specialized AI chips, may enhance real-time performance in practical deployment scenarios. Secondly, the baits fed in the process of intensive culture are diverse, so the performance of the model on different types of baits has not been further tested and verified, and the data set needs to be further expanded. Furthermore, the incorporation of domain-specific knowledge related to bait behavior and interaction with the surrounding environment could enhance the model’s performance. For instance, integrating temporal information, such as bait movement patterns or feeding frequency, could provide a more dynamic and accurate detection system. The combination of visual and temporal data might lead to more reliable predictions, especially in dynamic aquaculture settings. In addition, how to make the model automatically recognize other background interference such as algae as background is our further work. The interference such as algae was used as the background to make the model ignore its characteristics so as to realize the anti-interference of the model to the complex background.
In summary, while YOLOv8-BaitScan demonstrates promising results in bait detection for intensive aquaculture, there is still room for improvement in terms of computational efficiency, bait diversity handling, and model adaptability to real-world conditions. Future research should focus on these aspects to further enhance the model’s practical utility in precision aquaculture.
5. Conclusions
In this study, we introduce YOLOv8-BaitScan, an enhanced method for bait residue counting based on an improved version of YOLOv8n. This method addresses the challenges of detecting bait residues in complex aquaculture environments, where issues such as bait aggregation, target occlusion, long-distance detection of small targets, and background interference are common.
To assess the performance of the proposed algorithm, we conducted a series of ablation experiments. The results demonstrate that YOLOv8-BaitScan outperforms the YOLOv8n algorithm in several key metrics. Specifically, mAP@50 increased from 80.1% to 97.1%, and the F1-score improved from 75% to 93.0%. Additionally, to meet the real-time requirements of practical applications, YOLOv8-BaitScan is designed to be lightweight, reducing the model size to 1.33M parameters (a 55.7% reduction) and the computational complexity to 3.7 GFLOPS (a 54.3% reduction). These optimizations lead to significant improvements in the model’s efficiency and inference speed.
In conclusion, YOLOv8-BaitScan achieves a balance between high detection accuracy and computational efficiency, making it a promising solution for bait residue counting in aquaculture. It offers strong technical support for the development of scientific and effective feeding strategies, with potential applications in real-time monitoring systems for aquaculture.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}