1. Introduction
Public-key cryptographic algorithms are important for today’s cyber security. They are used for key exchange protocols or digital signatures, e.g., in communication standards like transport layer security (TLS), S/MIME, and PGP. Public-key encryption is based on a trapdoor-function which also defines the systems security. The most common public-key cryptosystems nowadays are the Rivest–Shamir–Adleman algorithm (RSA) and the elliptic curve cryptography (ECC). Those are based on the intractability of integer factorization and the elliptic curve discrete logarithm problem, respectively. Both problems can be solved using quantum algorithms [
1,
2]. Hence, large scale quantum computers threaten the security of today’s RSA and ECC cryptosystems.
To cope with this issue, many post-quantum encryption methods were proposed [
3], e.g., code-based cryptography. Code-based cryptography is based on the problem of decoding random linear codes, which is known to be NP-hard [
4]. The best-known code-based cryptosystems are the McEliece system [
5] and the Niederreiter system [
6].
For the McEliece system, the public key is a permuted and scrambled version of the generator matrix of an error correcting code. The message is encrypted by encoding the information with the scrambled generator matrix and adding intentional errors. The private key is the original generator matrix and the matrices used for scrambling and permutation. Using the private key, the received vector can be decoded into the original message. Due to the scrambling of the generator matrix, it is not possible to obtain its structure without the knowledge of the private key. Hence, an attacker needs to decode the received vector for a random-looking linear code. The best-known decoding attacks for code-based cryptosystems are based on information-set decoding (ISD) [
7], which is therefore the most interesting attack scenario [
8,
9,
10,
11]. For information-set decoding, the attacker tries to find an error-free information set, which is then used to re-encode the codeword.
The Niederreiter system is comparable to the McEliece system. However, secure digital signature schemes are only known for the Niederreiter system [
12]. Instead of the generator matrix, the scrambled parity check matrix is used as public key. For encryption, the message is encoded as an error vector, and the cypher text is the syndrome calculated with the public parity check matrix. The private key consists of the original parity check matrix, as well as the matrices used for scrambling. For decryption, a syndrome decoding algorithm is required, which recovers the error vector from the syndrome. As for the McEliece scheme, the most relevant attacks are based on ISD.
Different code families were proposed for those systems, e.g., Reed–Solomon (RS) codes [
13,
14], BCH codes [
15], LDPC codes [
16,
17,
18,
19], or polar codes [
20]. For some code families, there exist structural attacks, which make use of the structure of the codes, e.g., the attacks in [
21,
22].
In [
23], product codes of outer RS codes and inner one-Mannheim error correcting (OMEC) codes were proposed for the McEliece system. Those codes are defined over Gaussian integers, which are complex numbers with integers as real and imaginary parts [
24,
25]. They are able to correct more errors than maximum distance separable (MDS) codes. MDS codes are linear block codes which are optimal codes for the minimum Hamming distance, i.e., they achieve equality in the Singleton bound. The codes over Gaussian integers achieve a higher error correction capability due to restriction of the error values. The used channel model allows only errors of Mannheim weight (magnitude) one. The work factor of ISD only depends on the number of errors, but not on their values. A higher error correction capability leads to a higher work factor for comparable parameters. On the other hand, the concatenated codes presented in [
23] can be attacked with a combination of the structural attacks from [
21,
22].
In this work, we propose a new code construction based on generalized concatenated (GC) codes. This construction is motivated by the results in [
26], which show that GC codes are more robust against structural attacks than ordinary concatenated codes. Furthermore, we adapt the code construction to Eisenstein integers. Eisenstein integers are complex numbers of the form
, where
a and
b are integers and
is a third root of unity [
27]. Eisenstein integers form a hexagonal lattice in the complex plain [
28]. While the one-Mannheim error channel has four different error values, a similar channel model for Eisenstein integers has six different error values. In the Niederreiter cryptosystem, the message is encoded as an error vector. Hence, the representation with Eisenstein integers allows for longer messages compared with codes over Gaussian integers. In this work, we additionally derive and discuss the channel capacity of the considered weight-one channel over Eisenstein integers. Moreover, we extend the GC code construction to Eisenstein integers.
This publication is structured as follows. In
Section 2, we review the McEliece and the Niederreiter system, as well as the attacks based on information-set decoding. In
Section 3, we briefly explain Gaussian and Eisenstein integers, as well as the one-Mannheim error channel. We investigate the weight-one error channel for Eisenstein integers in
Section 4. In
Section 5, we adapt the product codes from [
23] to Eisenstein integers. The new code construction based on generalized concatenated codes is discussed in
Section 6. Finally, we conclude our work in
Section 7.
2. Code-Based Cryptosystems
In this section, we review the basics of the McEliece and Niederreiter systems, as well as information-set decoding.
2.1. The McEliece System
The McEliece cryptosystem utilizes the problem of decoding random linear codes as trapdoor function. In the following, we will shortly explain the basic concept of this system.
Consider a q-ary code of length n, dimension k, and error correction capability t. The code can be represented by its generator matrix , and should enable an efficient decoding algorithm for up to t errors. The public key is the pair . The matrix is a scrambled generator matrix , with the random non-singular scrambling matrix , and the permutation matrix . The private key consists of the three matrices .
For encrypting a message of length k, the message is encoded using the public generator matrix and a random error vector , containing at most t non-zero error values added, i.e., . Using the private key, the message can be decrypted by first computing . Note that is a permuted error vector and the permutation does not change the number of errors. We decode as . Finally, the message can be calculated using the inverse scrambling matrix.
2.2. The Niederreiter System
The Niederreiter system is based on the parity check matrix. Consider a code with parity check matrix and an efficient syndrome decoding algorithm . The public key is . The scrambled parity check matrix is calculated as , where is a random non-singular scrambling matrix, and is a random permutation matrix. The private key consists of the three matrices .
For encryption, a message is first encoded as an error vector of length n and at most t non-zero symbols. The cyphertext is the syndrome calculated using the public parity check matrix, i.e., . The legitimate recipient receives and computes . Applying the syndrome decoding algorithm results in the permuted error vector . Finally, the message is obtained using the inverse permutation . As for the McEliece system, this decoding is only feasible with the knowledge of the scrambling and permutation matrices and .
2.3. Information-Set Decoding
The best known attacks on the McEliece system as well as the Niederreiter system are based on information-set decoding (ISD). Those attacks do not rely on any code structure except linearity, i.e., the attacks try to decode a random-looking linear code. Such attacks were proposed in [
8,
9], and more recently, some improvements were proposed in [
10,
11]. We only review the basic concept of attacks based on ISD.
For the McEliece system, the attacker tries to recover the information vector from the cyphertext . To achieve this, the attacker tries to guess k error-free positions , such that the corresponding columns of the public generator matrix form a non-singular matrix . If such positions are found, the attacker can use Gaussian elimination on the guessed positions of and re-encode a codeword agreeing with in the guessed positions. If differs in at most t positions from , there are no errors in , and the attacker obtains .
For the Niederreiter system, the attacker tries to find an error vector of weight t, such that . To achieve this, an attacker tries random permutations on the public key and computes the systematic form as , where is the matrix that produces the systematic form and is the identity matrix. The attacker searches for a permutation such that the permuted message vector has all non-zeros in the rightmost positions. Such a permutation can be detected by the Hamming weight of the scrambled syndrome . Due to the systematic form of , the permuted message vector is .
The complexity of information-set decoding attacks is determined by the expected number of trials required to find a permutation fulfilling those criteria. The probability for such a permutation is
and the expected number of trials is
We use to measure the work factor for ISD attacks.
3. Codes over Gaussian and Eisenstein Integers
Next, we review some properties of Gaussian and Eisenstein integers, as well as some known code constructions for these number fields.
3.1. Gaussian and Eisenstein Integers
Gaussian integers are a subset of complex numbers with integers as real and imaginary parts, i.e., of the form
, where
a and
b are integers. We denote the set of Gaussian integers by
. The modulo operation in the complex plain is defined as
where
denotes rounding to the closest Gaussian integer, which is equivalent to rounding the real and imaginary parts individually. The set of Gaussian integers modulo
with
elements is denoted by
. For
, such that
, the set
is a finite field which is isomorph to the prime field
[
24].
We measure the weight
of a Gaussian integer
z as Mannheim weight which is the sum of the absolute values of its real and imaginary parts, i.e.,
where
is the set of Gaussian integers
, such that
. The Mannheim distance between two Gaussian integers is the weight of the difference
The Mannheim weight of a vector is the sum of Mannheim weights of all elements of the vector. The same holds for the Mannheim distance between two vectors.
Eisenstein integers are similar to Gaussian integers, but of the form
, where
a and
b are integers, and
is a third root of unity. Eisenstein integers form a hexagonal structure in the complex plain and are denoted as
. As for Gaussian integers, a finite field can be defined as the set
, where
and
. In contrast to Gaussian integers, the prime
p has to fulfill
due to the hexagonal structure. For such
, the field
is isomorph to the prime field
[
27].
We measure the weight of an Eisenstein integer as a hexagonal weight, which is defined by the minimum number of unit steps in directions which are a multiples of
. An Eisenstein integer
z can be written as
, with
. Note, that
is a sixth root of unity and
is a third root of unity. Hence,
can take the six powers of the sixth root of unity. The weight is defined as
As for Gaussian integers, the weight of a vector is the sum of weights of the elements, and the distance between two Eisenstein integers is the weight of the difference.
3.2. One Error Correcting (OEC) Codes
One error correcting (OEC) codes over Gaussian as well as over Eisenstein integers fields were proposed in [
24,
27], respectively. The parity check matrix
is defined as
where
is a primitive element of the field. A vector
is a codeword if, and only if,
. For codes over Eisenstein integers, we have
, and the length of an OEC code satisfies
. For OEC codes over Gaussian integers, we have
and
.
The dimension of an OEC code is , and the minimum Hamming distance is . The minimum hexagonal distance is for OEC codes over Eisenstein integers, and the minimum Mannheim distance is for OEC codes over Gaussian integers. Hence, such codes can detect any single error of arbitrary weight and correct a single error of Mannheim weight one or hexagonal weight one, respectively.
3.3. Product Codes over Gaussian Integers
In [
23] a product code construction from outer Reed–Solomon (RS) and inner one, error correcting (OEC) codes over Gaussian integers was proposed. In the following, we review this code construction. Later on, this construction is extended to codes over Eisenstein integers.
We consider an outer RS code
over
and an inner OEC code
over
, where
. Note that
denotes the minimum Hamming distance of the RS code, while
denotes the minimum Mannheim distance of the OEC code. The codeword of a product code can be represented as
-matrix. For encoding, first,
codewords of the outer RS code are encoded and written to the first
rows of the codeword matrix. Next, the symbols are mapped from
to the isomorphic
, and each column of the codeword matrix is encoded in the inner OEC code. The product code has length
, dimension
, and minimum Mannheim distance
, as shown in [
23].
For instance, consider the special case of the inner OEC codes of length
and minimum Mannheim distance
[
23]. These codes are generated by a field element
a of weight at least three. The parity check matrix is
and the generator matrix is
. Depending on the choice of
a, this can result in a code of minimum Mannheim distance
. Note, that this does not change the Hamming weight, hence, only one error of arbitrary weight can be detected. Like the original OEC codes proposed in [
24], this code can only correct one error of Mannheim weight one, but it can detect any error vector of weight two. The product code has length
and minimum Mannheim distance
.
In order to develop a low-complexity decoding algorithm that can decode up to half the minimum distance, a new channel model was considered in [
23]. This one-Mannheim error channel is a discrete memoryless channel restricting the error values to Mannheim weight one [
29]. Given an error probability
, each error symbol is zero with probability
. Error values are from the set
, which occur with probability
. Due to this restriction, the error vector in each inner codeword with
can have a Mannheim weight of at most two, and therefore can be detected by the inner OEC codes. While the inner decoder corrects any error vector of Mannheim weight one, it declares an erasure for each error vector of Mannheim weight two. Hence, all error positions are known for the outer RS decoder, and an erasure-only decoding method can be applied. Using the Forney algorithm, this erasure-only decoding can correct up to
erasures.
The restriction of the error values allows for a guaranteed error correction capability of errors, because erasures can be corrected, and each erasure requires at least two errors. One additional error can be corrected in any inner codeword. For code rates , this error correction capability is higher than the error correction capability of MDS codes, i.e., .
4. The Weight-One Error Channel
In this section, we extend the concept of the one Mannheim error channel from [
23] to Eisenstein integers. Furthermore, we derive the capacity for this weight-one error channel and discuss its relation to code-based cryptosystems. These results demonstrate that codes over Eisenstein integers are attainable, where the expected number of errors exceeds the number of redundancy symbols
, which prevents error free information sets.
While the minimum Hamming distance of codes over Eisenstein integer fields is comparable with other code constructions, they may have a significantly higher minimum hexagonal distance. This leads to an increased error correction capability in terms of hexagonal-weight errors. Hence, a channel model, which restricts the error weight, is advantageous for such codes.
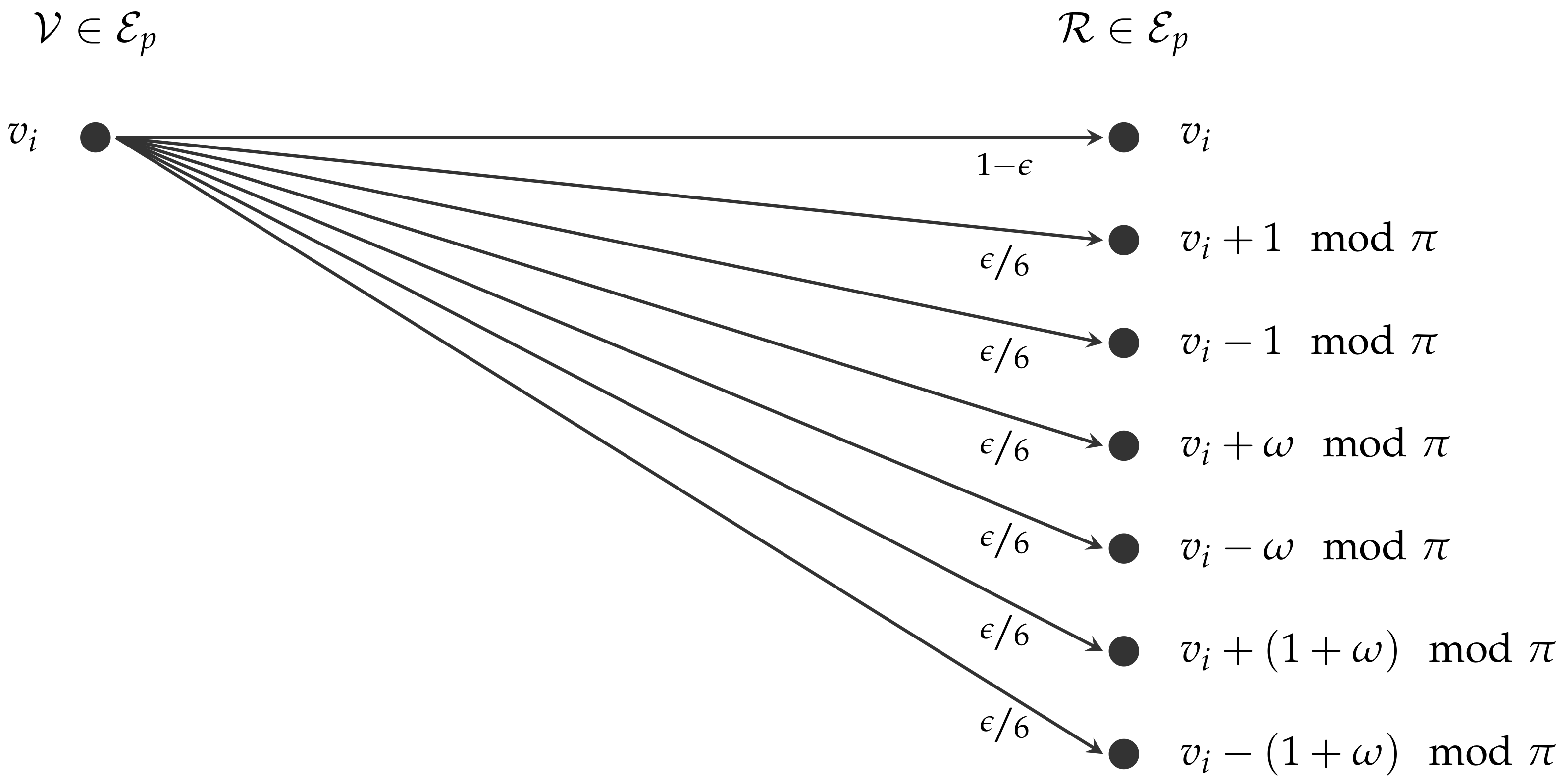
The weight-one error channel is a discrete memoryless channel, which restricts the error values to hexagonal weight one. Hence, only error values are possible. Note that is a third root of unity and is a sixth root of unity. Hence, these six possible values form a hexagon in the complex plain.
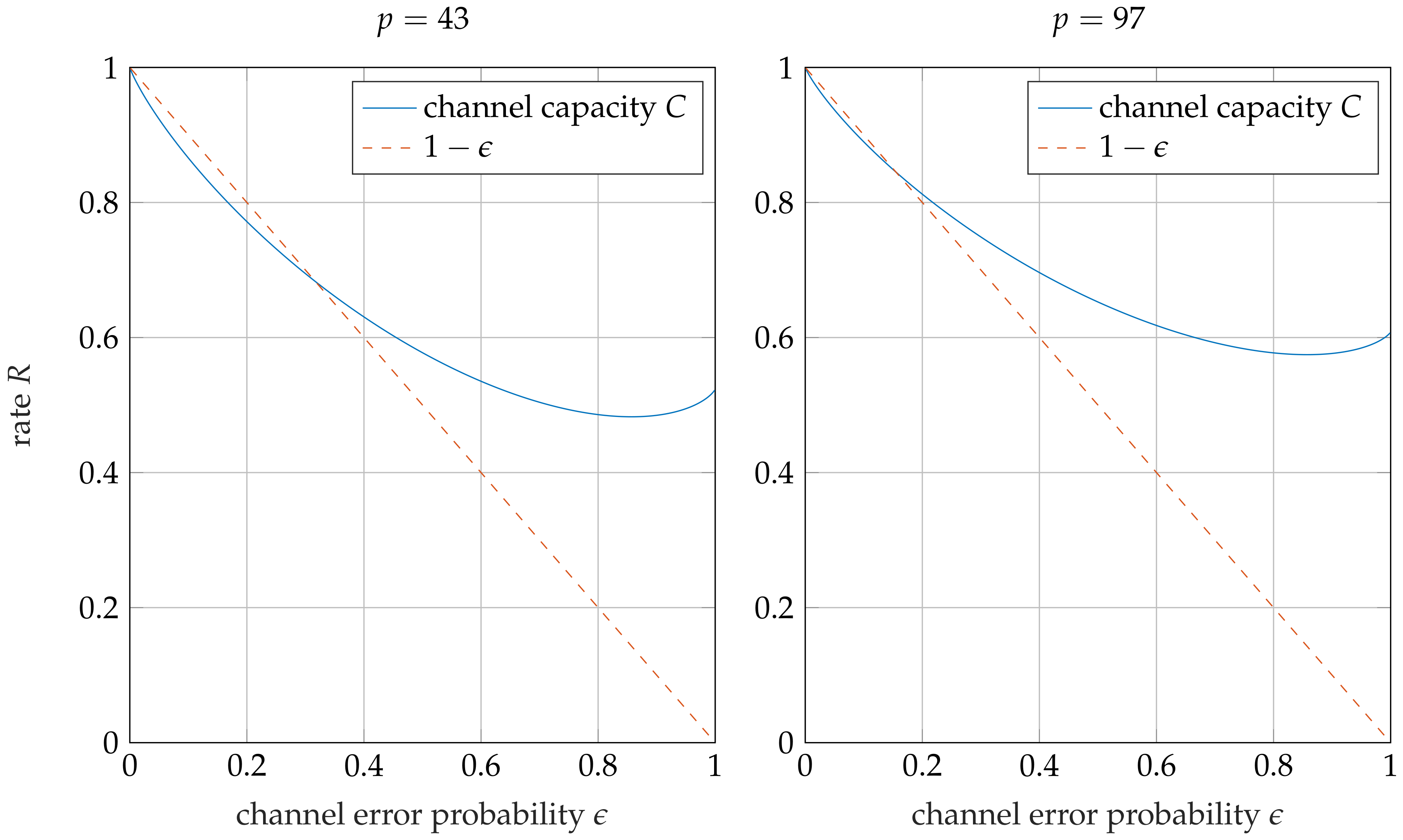
Figure 1 illustrates the channel model of the weight-one error channel. For a given channel error probability
, error-free transmission (
) occurs with probability
, while each of the six errors has the same probability of
.
Proposition 1. The channel capacity of the weight-one error channel with transmitted symbols is Proof. The channel capacity of a symmetric discrete memory-less channel is [
30]
where
is the cardinality of the output alphabet
and
the entropy of a row
of the transition matrix. The cardinality of the output alphabet
is
p. Each row of the transition matrix has seven non-zero elements, one element
for the case that no error happened, and six elements
for the six equally probable error values. Hence, the entropy is
and thus follows (
8). □
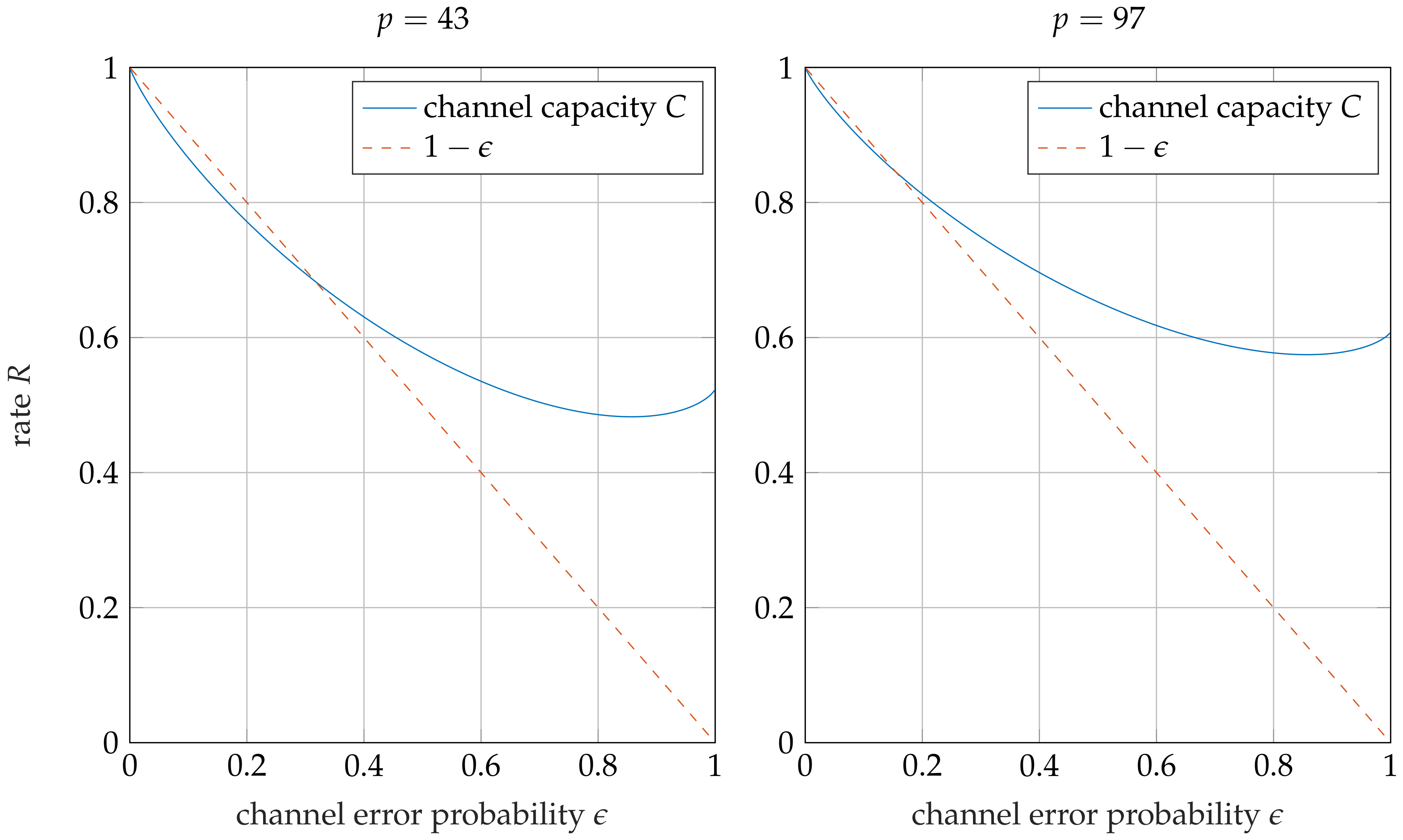
Example 1. Figure 2 shows the relative channel capacity of the weight-one error channel. This relative capacity is the supremum of all achievable code rates R. Moreover, the line is shown, on which the expected relative number of errors is equal to the relative amount of redundancy . For the achievable rate region above this line, the expected number of errors surpasses , and therefore no error-free information sets exist. As shown in Figure 2, codes which are able to correct more than errors are possible for code rates above or for and , respectively. 5. Product Codes over Eisenstein Integers
In this section, we adapt the product code construction from [
23] to Eisenstein integers for the Niederreiter system. The adaptation of the product code construction is trivial, i.e., we simply replace the inner codes over Gaussian integers by codes over Eisenstein integers. The restriction of applicable primes is different for Gaussian and Eisenstein integers. However, there are primes that fulfill both restrictions leading to the same code parameters. Nevertheless, Eisenstein integers have advantages for the Niederreiter cryptosystem, where the message is encoded as error vector of weight at most
t. The information mapping consists of two parts. One part defines the error positions, and can take
bits of information. The other part defines the error values and can take
bits of information, where
m is the number of possible error values. Codes over Eisenstein integers increase the message length compared to codes over Gaussian integers, because the number of possible error values
m for Eisenstein integers is higher than for Gaussian integers.
The Niederreiter cryptosystem requires an adaptation of decoding method, because only the syndrome is available, and the decoding method needs to find the corresponding error vector. In the following, we devise such a syndrome decoding procedure.
5.1. Syndrome Decoding
For the syndrome decoding, we use look-up tables for the inner OEC codes and erasure decoding for the outer RS codes. We consider the private parity check matrix of the form
where
is the parity check matrix of the outer RS code, and the lower part
is the Kronecker-product of the parity check matrix of the OEC codes and an
identity-matrix. With this definition, the first
syndrome values correspond to the RS code, and the last
syndrome values belong to the inner OEC codes. The public key is a scrambled version of the parity check matrix, i.e.,
, where
is a random invertible scrambling matrix, and
is a random permutation matrix.
To decode the scrambled syndrome , one first unscrambles the syndrome as , and then decodes the inner OEC codes using a look-up in a precomputed syndrome table. Since the inner codewords have a length of two, and the OEC codes have minimum hexagonal distance , any single error resulting from the weight-one error channel can be corrected, while any error vector of up to two errors can be detected. The precomputed syndrome table provides the error location and value for each correctable error pattern, i.e., each error pattern with only one error. For each error pattern with two errors, an erasure is declared. These erasures are resolved in the outer decoder. Since , the inner decoder produces parts of the permuted error vector, which is denoted as .
After the inner decoding, we update the residual syndrome for the outer decoder. The residual syndrome is the syndrome corresponding to an error vector
of lower weight. The syndrome to the partial error vector
can be computed using the private matrices
and
. This syndrome can be subtracted from the received syndrome
The outer RS code is now decoded using the residual syndrome
, as well as the erasure positions declared by the inner decoders. Since the inner decoders detected all error vectors, there are no unknown error positions, and erasure only decoding can be applied to the RS code. This is done using the Forney algorithm [
31]. Using the positions
corresponding to the
erasures, the error location polynomial can be calculated as
This polynomial has roots at
, with
. Similarly, we represent the residual syndrome as polynomial, i.e.,
and calculate the error-evaluator polynomial
using the key equation
The error values are determined as
where
is the derivative of
.
The RS decoder is able to find all error values in the information digits of the OEC codewords if the number of erasures
does not exceed
. Now, the step in (
12) can be used again, with an updated error vector
. Hence, the syndrome decoding of the OEC codewords can be repeated to find all remaining errors. The inner codewords have a length of two. Consequently, after correcting one position using the outer code, only a single weight-one error can remain, which is corrected using the syndrome table for the inner code.
Next, we estimate the error correcting capability of this decoding procedure. A minimum of channel errors is required to cause a decoding failure in the outer decoder, because erasures can be corrected by the outer decoder, and an erasure requires two errors in an inner codeword. Additionally, the OEC code corrects all single errors in the inner codewords. Therefore, at least errors can be corrected. Depending on the error positions, this decoding procedure can correct some patterns with up to errors. In comparison with MDS codes, which have an error correction capability of , the proposed construction is advantageous for code rates .
5.2. Code Examples
Table 1 shows a comparison of the proposed code construction with MDS codes. The table provides the field size
p, code length
n, dimension
k, and error correction capability
t, as well as the work factor
for information-set decoding. The left-hand side of the table considers the proposed code construction, while the right-hand side illustrates comparable MDS codes. In all examples, the work factor for information-set decoding of the proposed construction is significantly higher than for MDS codes.
Table 2 shows a comparison of the proposed code construction over Eisenstein integers, with the same construction over Gaussian integers from [
23], where we compare the message lengths for a Niederreiter system. Note that the restrictions of the field sizes are different. For
, we can construct only codes over Gaussian integers, whereas for
, we can construct only codes over Eisenstein integers. However, the corresponding codes are comparable. For
and
, Eisenstein and Gaussian integer fields exist. The message size with Eisenstein integers is notably increased. This results from the different channel models. Eisenstein integers allow for six different error values, instead of four with Gaussian integers. Due to the same code parameters, the work factor for information-set decoding is the same. Therefore, the codes over Eisenstein integers are only advantageous for Niederreiter systems.
6. Generalized Concatenated (GC) Codes over Gaussian and Eisenstein Integers
While the product code construction shows a significantly increased work factor for information-set decoding, the construction may not be secure against structural attacks. The attack proposed in [
22] may allow one to produce the concatenated structure of the code construction. Afterwards, the attack proposed in [
21] can produce the structure of the outer Reed–Solomon code.
In [
26], it was shown that generalized concatenated codes may withstand the aforementioned structural attacks. Furthermore, those codes enable higher code rates. In the following, we will discuss a generalize concatenated code construction, which may withstand the structural attacks, and has a higher work factor for information-set decoding than MDS codes, as well as the proposed product codes.
In this section, we propose a generalized concatenated code construction. First, we consider codes over Gaussian integers, which, in combination with the one-Mannheim error channel, is advantageous for use in code-based cryptosystems. We investigate a decoding procedure for those codes. Finally, we demonstrate that the GC construction can be extended to codes over Eisenstein integers.
6.1. Code Construction
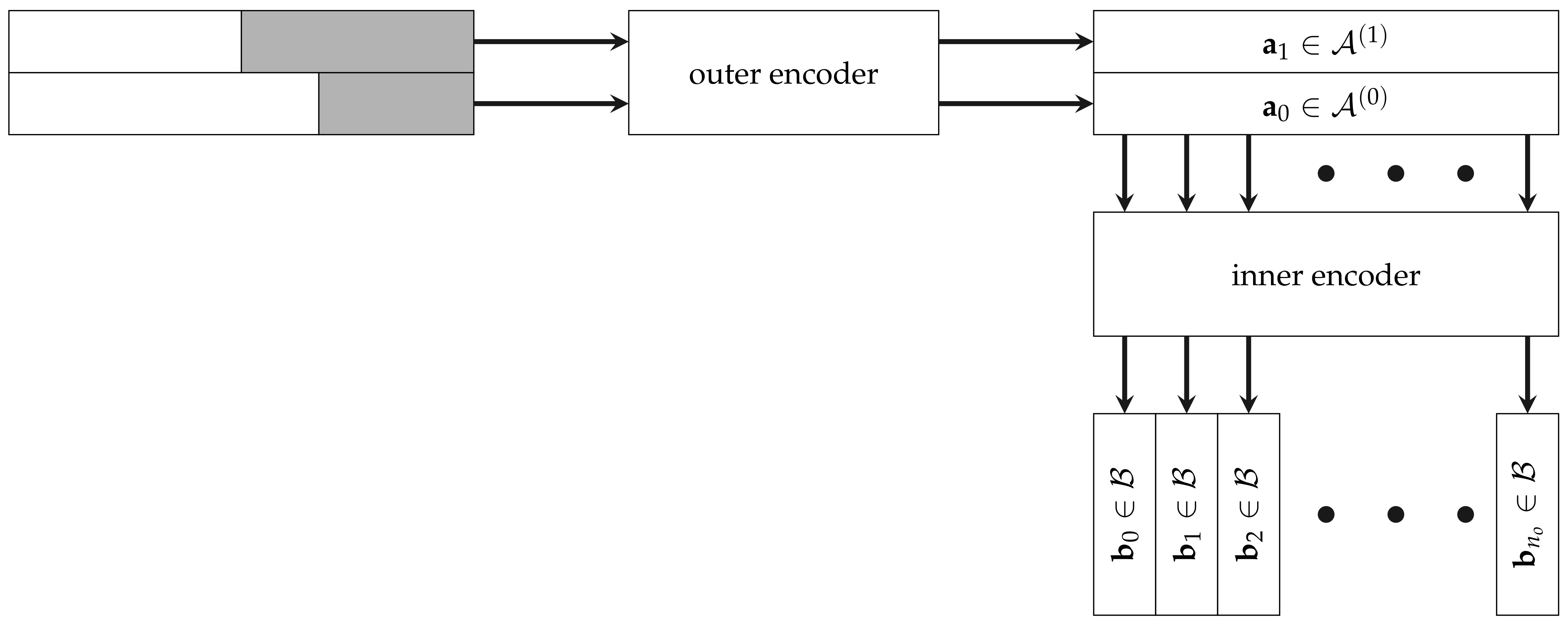
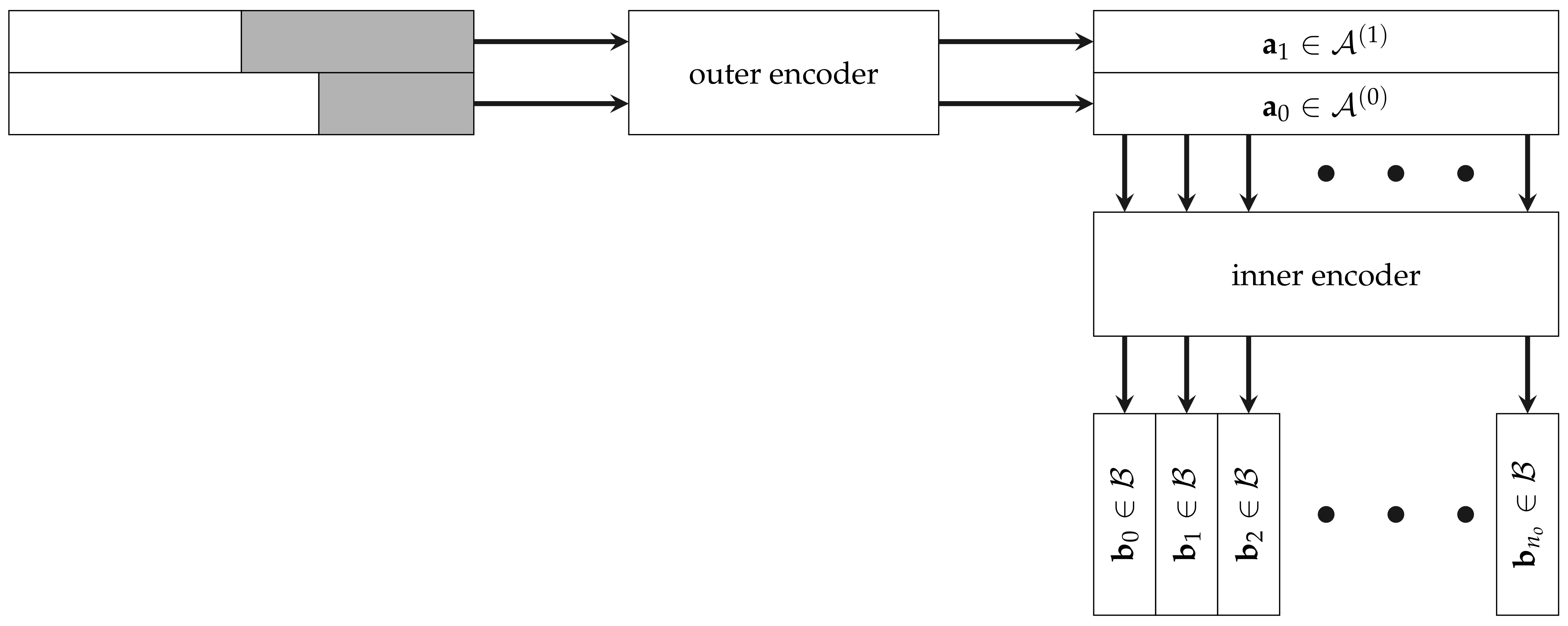
Generalized concatenated (GC) codes are multilevel codes with one inner code and multiple outer codes with different dimensions. The basic idea of GC codes is to partition the inner code into multiple levels of subcodes, which are then protected by different outer codes. For the sake of clarity, we only consider GC codes with two outer codes and of same length , but different dimensions. Again, we represent a codeword as a matrix, where each column is a codeword of the inner code .
Figure 3 shows the encoding of GC codewords, where first the outer encoder encodes the two codewords
and
. Then, each column is encoded by the inner encoder to a codeword
. The length of the GC code is
, as can be seen from the construction. The dimension is the sum of the outer dimensions.
For the inner codes, we consider codes over Gaussian integers which achieve a high error correction capability over the one-Mannheim error channel, and enable a partitioning into subcodes with increased minimum distance.
Table 3 shows some examples for such inner codes, with their field size
p, their modulus
, their generator matrix, as well as the minimum Mannheim distance
d of the code and
for the subcode. These codes are not constructed from one-Mannheim error correcting codes, but found by computed search. The generator matrix of the code
is chosen in the form
where
a,
b, and
c are elements of
. In this case, the first row is the generator matrix of a subcode
with minimum Mannheim distance
at least 7. This distance allows one to correct any possible error pattern introduced by the one-Mannheim error channel. Note that no codes with
were found for field sizes
.
For the GC construction, we consider inner codes of length
and dimension
, i.e.,
, where
is the minimum Mannheim distance. Those codes can correct up to two errors of Mannheim weight one. For the first level outer code
, we apply a Reed–Solomon code of length
and dimension
. Since the subcodes in
Table 3 are able to correct at least three errors of Mannheim weight one, the information digits of the second level need no further protection if the one-Mannheim error channel model is used.
The resulting GC code has length
and dimension
, because the second outer level is uncoded.
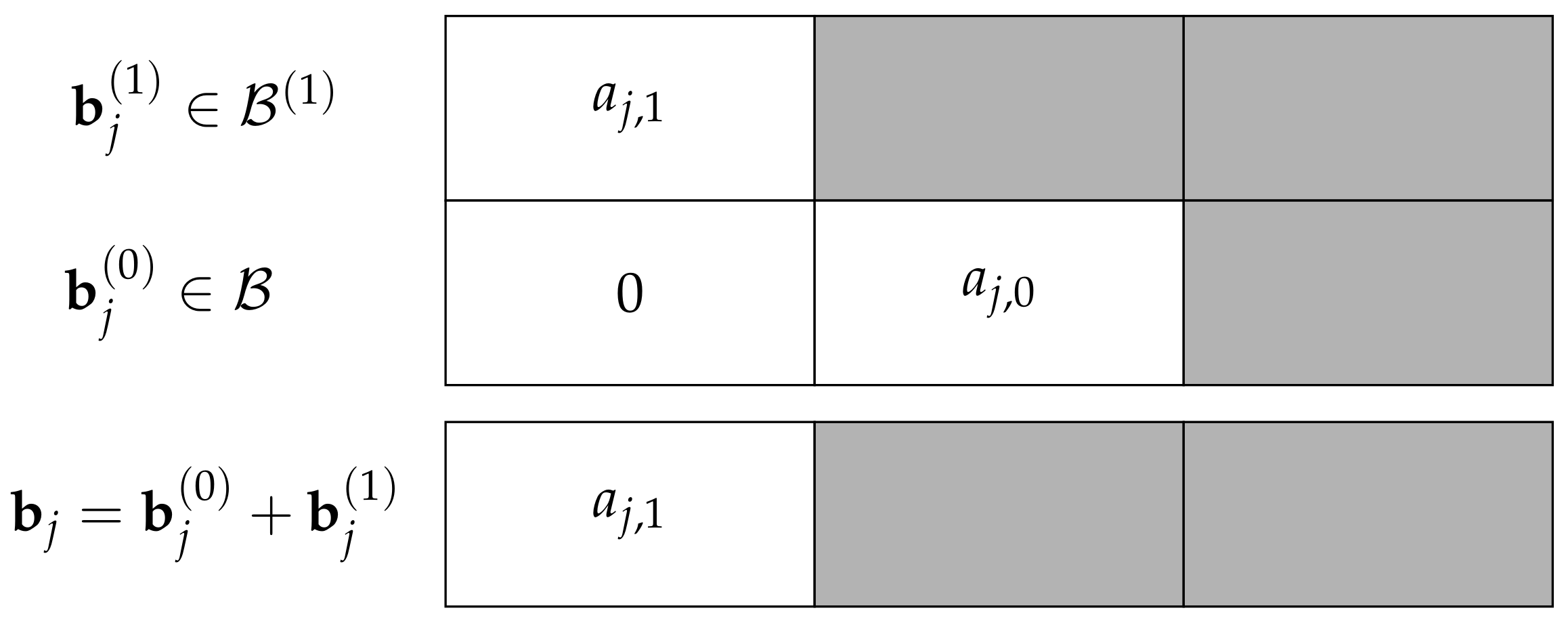
Figure 4 represents the encoding of a single column of the codeword. The outer code symbol
is encoded with the second row of the generator matrix
of the inner code, which results in a codeword
. The outer code symbol
is encoded with the first row of
, which is the generator matrix of the subcode, and results in
. The codeword in the
j-th column is the sum of two codewords, i.e.,
. Note, that the upper part of
Figure 4 has the same form as the generator matrix (
16), where the gray blocks represent the parity symbols.
6.2. Decoding
For decoding the GC code, we first decode the inner codes . While those codes are able to correct two errors of Mannheim weight one, we only correct one error, and therefore can detect any possible error pattern generated by the one-Mannheim error channel. A look-up table with precomputed syndromes is used for decoding all error patterns with a single error. In cases where more errors occur, we declare an erasure, and store the erasure location. Note that all error patterns are detected. Hence, an erasure only decoding can be applied for the outer RS code.
Decoding the outer code
requires the code symbols
for all positions where no erasure was declared. Note that the inner codeword in the
j-th column is the sum of two codewords of the subcodes, i.e.,
. The first digit of
is the outer code symbol
(cf.
Figure 4), as the second row of
has a zero in the first position. Hence, this symbol can be used to determine the codeword
of the subcode
. Subtracting
from
results in
.
Now, we can decode the row consisting of the symbols
, which we obtained by re-encoding. We apply an erasure decoding to the Reed–Solomon code [
31,
32], which is based on the Forney algorithm, as explained for the outer RS code in
Section 5.1. This method can correct up to
erasures.
The outer decoding determines all symbols in the codeword of the outer code . With these symbols, we can calculate the inner codewords for all columns with erasures. Furthermore, we can determine the inner codewords in the subcode. Finally, we can decode the resulting codewords in the subcode , which has a minimum distance , and can correct all remaining errors.
We summarize the GC code parameters and the properties of the proposed decoding algorithm in the next proposition.
Example 2.
Consider the code over with , as given in the first row of Table 3. In this example, we focus on the decoding of the j-th inner codeword. Let us assume and as information symbols of the inner codeword. The codewords encoded with the two individual rows of the generator matrix are and . The inner codeword is now .
We distinguish two cases for the decoding. First, consider the case where at most one error was introduced in the inner codeword. In this case, the inner codeword can be corrected and no errors remain for outer decoding. The first symbol of is equal to the information symbol . This symbol can be used to re-encode the codeword . Subtracting from gives , which has as its second symbol. This symbol is used by the outer RS decoder to correct the symbols corresponding to the erasures.
In the second case, more than one error was introduced in the inner codeword. In this case, the inner decoder results in an erasure. Note that the RS decoder does not need any symbol value for the erasure positions. Hence, no re-encoding is required to obtain . The value of is determined by the outer RS decoder. If the RS decoder is successful, we obtain the correct information digit . This value can be used to re-encode the codeword , which is subtracted from the received vector , resulting in the vector . The error vector is still the error introduced by the channel with restricted values. The error vector of Mannheim weight of at most three can be corrected in this code, because the inner subcode has minimum Mannheim distance .
Proposition 2. The generalized concatenated code with outer Reed-Solomon code and inner code over with subcode can correcterrors of Mannheim weight one. Proof. Let
be a transmitted codeword of the inner code and
a length three error vector with up to three errors of Mannheim weight one. For any codeword
, the Mannheim distance to the received sequence is lower bounded by
Hence, any error pattern of a Mannheim weight one can be corrected, and any error pattern of Mannheim weight two or three can be detected. For error patterns of weight greater than one, an erasure is declared. The outer Reed–Solomon code can correct up to
erasures [
32], and each erasure requires at least two errors. Hence,
errors can be corrected in the erasure positions, and at least one additional error in any position. This results in (
17) for the first level. If the first level decoding is successful, the second level is decoded in the inner subcode
with
. Note that this subcode is able to correct any possible error pattern with up to three errors, thus no outer decoding is required in the second level. The decoding procedure only fails if the first level fails, i.e., if more than
erasures happen, which requires more than
errors. □
The maximum number of errors, which can be corrected by this decoding procedure, is
. For this we assume, that each erasure results from three errors and each of the
inner codewords, which does not result in an erasure with exactly one error. On the other hand, this requires a very specific distribution of the errors. Nevertheless, the decoder is able to decode many error patterns with more than
errors. This is demonstrated in
Section 6.4.
6.3. GC Code Examples
The guaranteed error correction capability of the proposed code construction is
, which for code rates
, is higher than the error correction capability
of MDS codes. We compare the proposed code construction with the product code construction from [
23], as well as MDS codes with respect to the work factor for information-set decoding, created according to (
2).
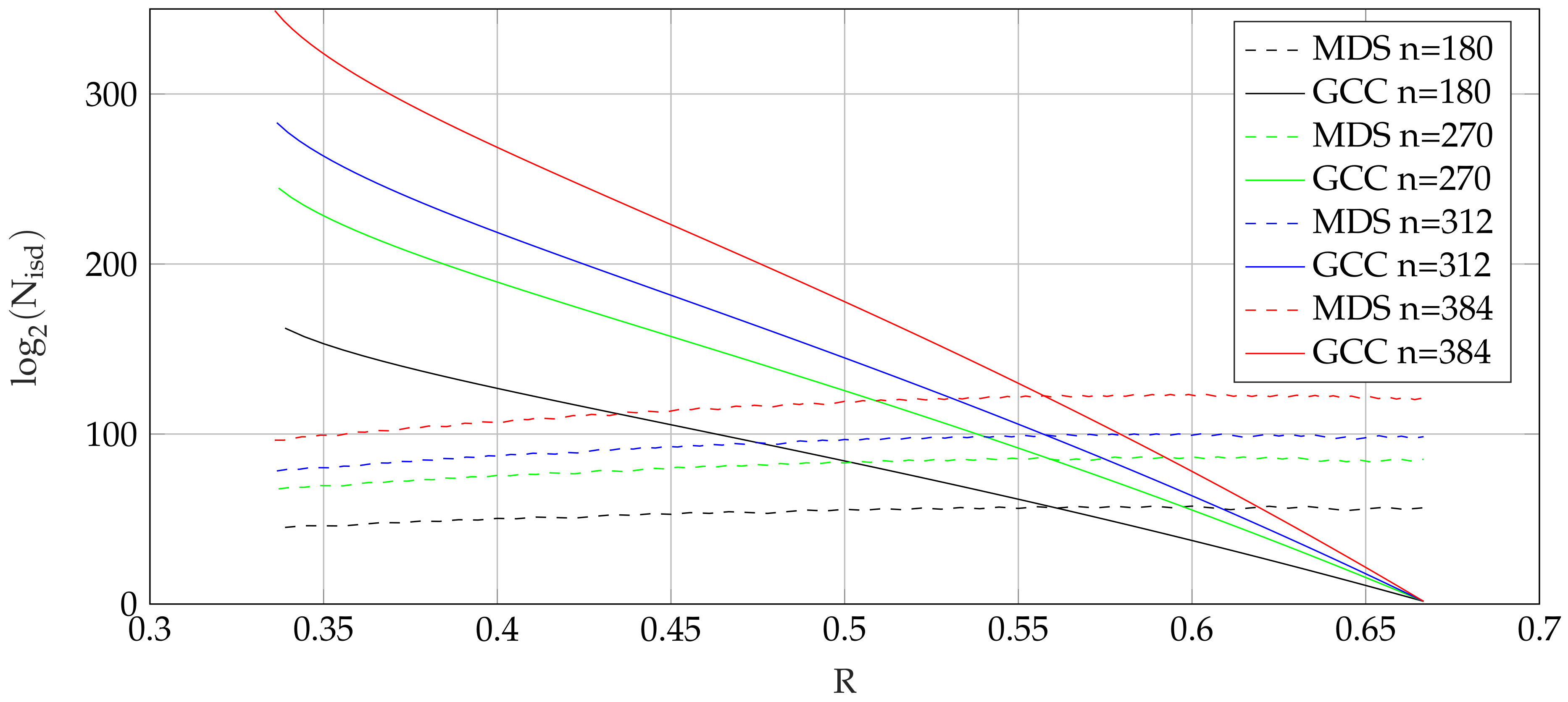
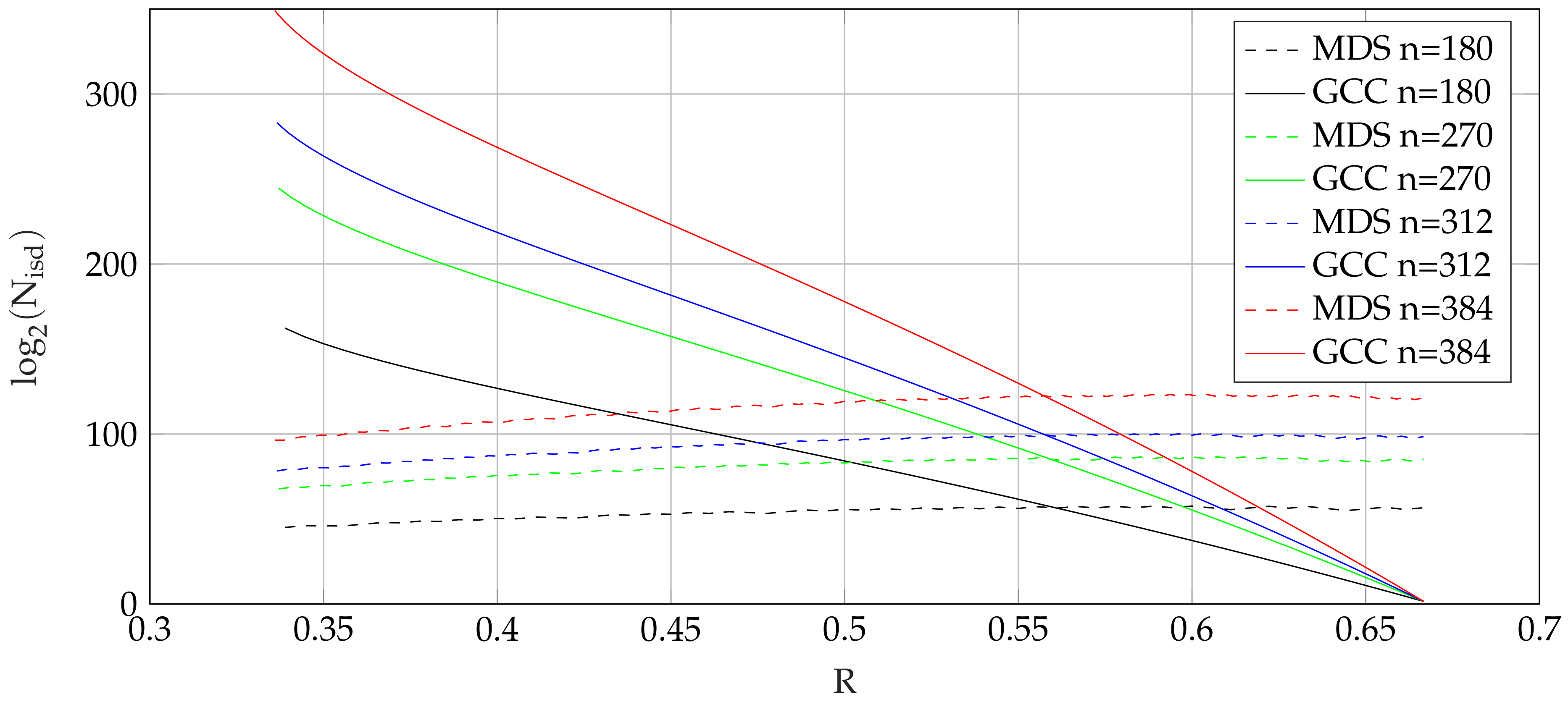
Table 4 shows a comparison of the proposed GC codes with comparable MDS codes. We compare the codes with varying code rate
R for constant code length
. For low code rates, a significant gain is achieved, which decreases for higher code rates. This effect is also shown in
Figure 5, where the work factors for ISD of GC codes and MDS codes are plotted over the code rate
R for different code length
n.
In
Table 5, we compare the proposed code construction with product codes over Gaussian integers proposed in [
23], since those codes are constructed for the same channel model. Note that those product codes are only applicable for low code rates, and have a higher work factor than MDS codes only for code rates
. Hence, we compare rate
product codes with rate
GC codes with comparable lengths. While the error correction capability is significantly higher for the product codes, due to the lower code rate, the work factor is much lower.
6.4. Decoding beyond the Guaranteed Error Correction Capability
The guaranteed error correction capability of the proposed generalized concatenated codes is given in (
17). Up to this bound, all possible error patterns can be corrected, but also, some error patterns with more errors are correctable. In this section, we discuss the error correction capability for decoding beyond the guaranteed error correction capability.
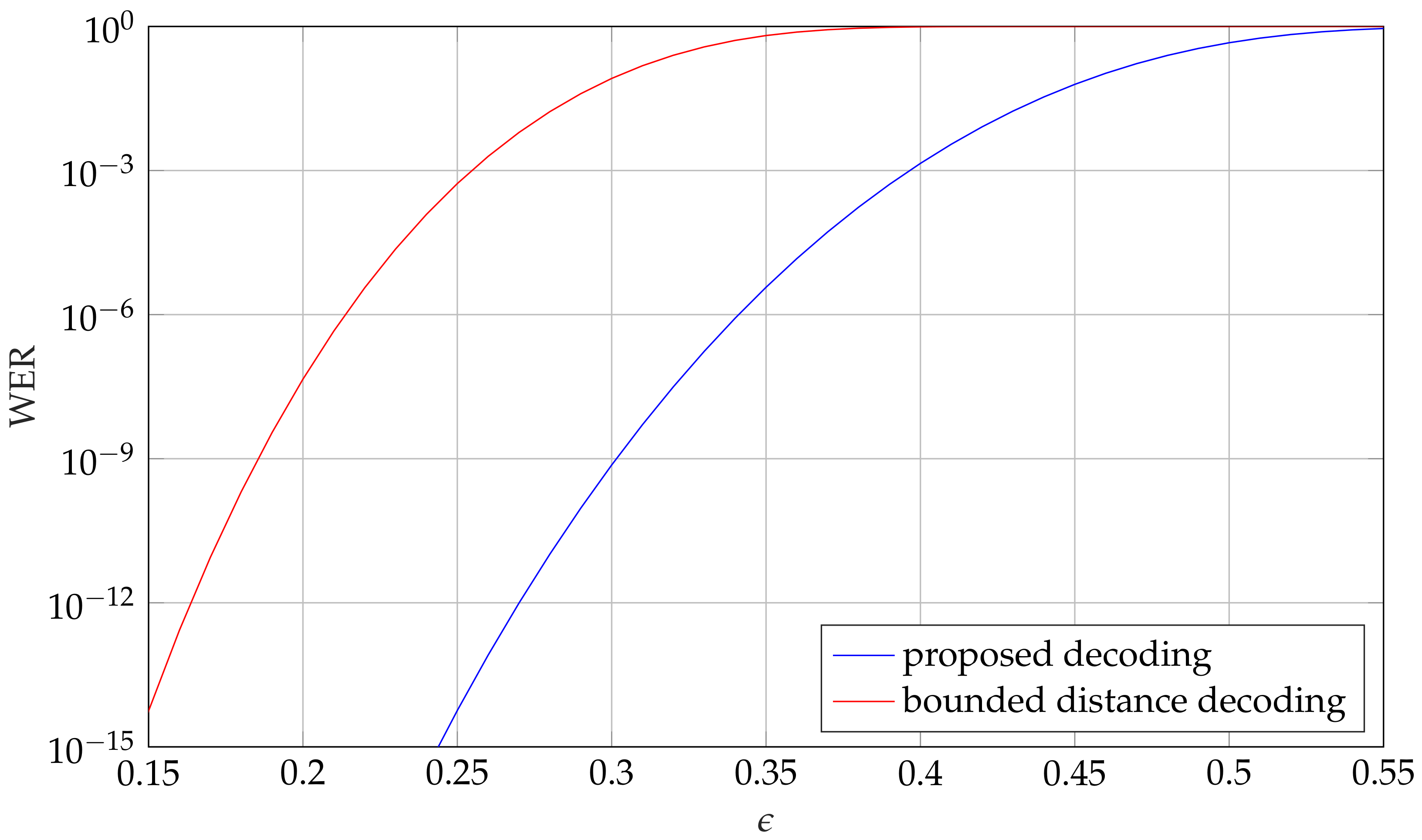
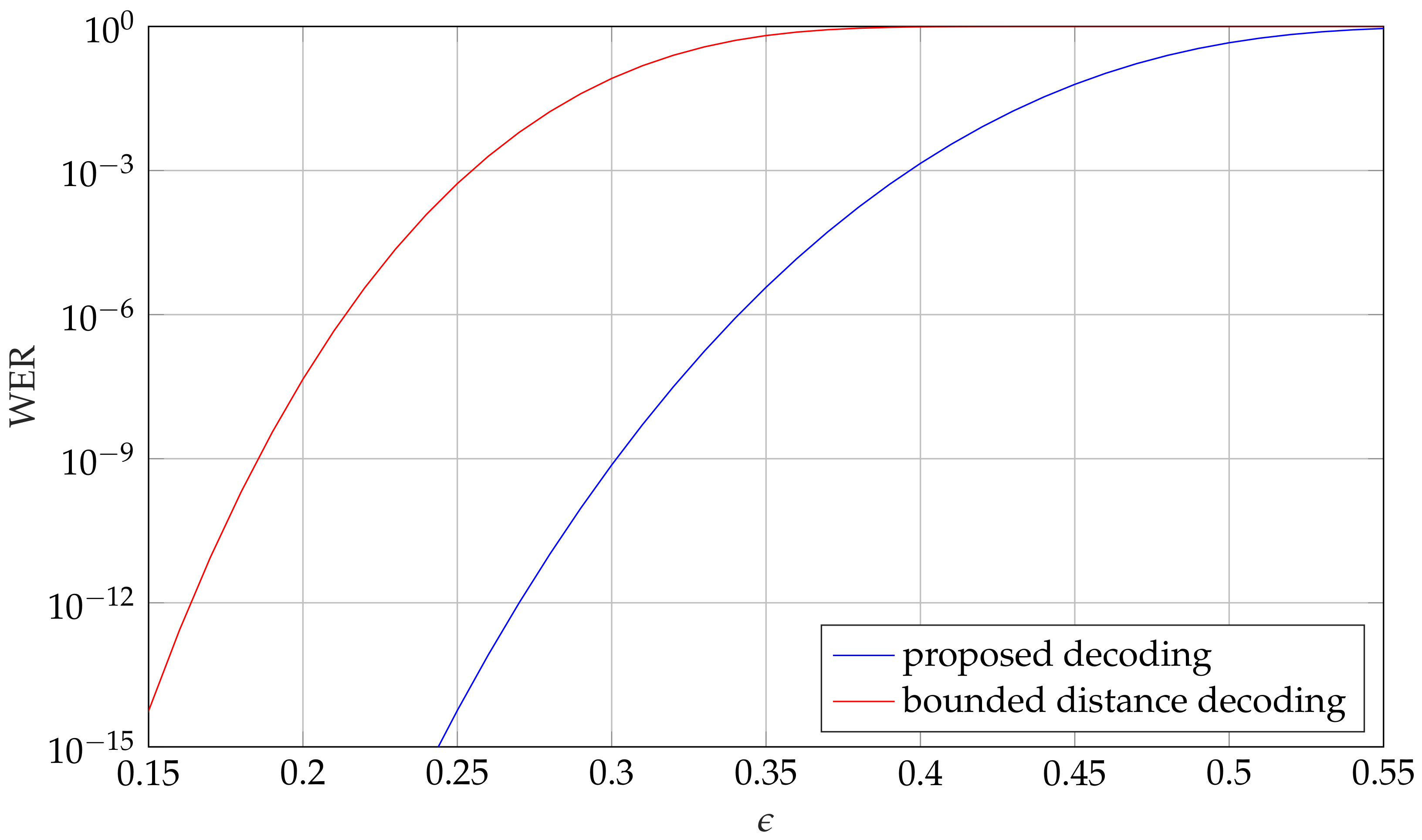
Example 3. Figure 6 shows the residual word error rate (WER) versus the channel error probability ϵ, with decoding beyond the guaranteed error correction capability. We compare the proposed decoding method with bounded distance decoding up to the guaranteed error correction capability for the GC code of length and rate . As can be seen, the proposed decoding method achieves a significant gain. On the other hand, decoding beyond the guaranteed error correction capability leads to a residual error rate. Note that this is the case for many decoders, which were proposed for McEliece systems [
16,
17,
18,
19]. While in some cases this may be undesirable, this allows for an increased number of errors, and therefore an increased work factor for information-set decoding.
Example 4. As an example, we compare the work factor for information-set decoding with the guaranteed error correction capability, with an expected number of errors such that the residual error rate is at most . Consider the code for length from Example 3. The proposed decoding allows for of errors, which corresponds to about 95 errors. According to (2), this results in a work factor of . The work factor for the guaranteed error correction capability is only , as shown in Table 5. Note that the work factor increases if a higher residual error rate is allowed. For instance, the work factor is increased to about for a residual error rate of . 6.5. Adaptation to Eisenstein Integers
As for the product code construction over Eisenstein integers, which was adapted from the product code construction over Gaussian integers proposed in [
23], the generalized concatenated code construction can also be applied to codes over Eisenstein integers. While the restrictions for the primes are different, using the same field size leads to the same code parameters, and therefore the same error correction capability. Hence, for the McEliece systems, this would result in the same work factor for information-set decoding-based attacks. However, for the Niederreiter system, the increased number of different error values leads to an increased message length. The adaption of the GC code construction to Eisenstein integers is straightforward given the partitioning of the inner codes.
Table 6 shows some possible inner codes over Eisenstein integer fields, which were found by computed search. For primes less than 223, no codes with
were found.
Example 5. For a comparison of the message length, we consider codes over fields of size , because this field size allows for inner codes over Gaussian as well as Eisenstein integers. Using the outer RS code of rate leads to GC codes of length and rate . Those codes can correct at least errors of Mannheim weight one or hexagonal weight one, respectively. The number of bits that can be mapped to the error vector for the Gaussian integer code is These bits are mapped to the error positions and to the error values. For the code over Eisenstein integers, the error values can take bits of information. Hence, the overall number of bits that can be mapped to the error vector is 628, which is about higher than for Gaussian integers. To use the increased message length, the error values cannot be mapped independently, but as a vector of length t, where each component can take six different values.
7. Conclusions
In this work, we have proposed a code construction based on generalized concatenated codes over Gaussian and Eisenstein integers for their use in code-based cryptosystems. These GC codes can be decoded with a simple decoding method that requires only table look-ups for the inner codes and erasure decoding of the outer Reed–Solomon codes. The proposed construction is a generalization of the ordinary concatenated codes proposed in [
23]. The GC codes enable higher code rates. While the number of correctable errors is lower than with the concatenated codes, the work factor for information-set decoding (ISD) is increased with GC codes. For rates
, the generalized concatenated codes can correct more errors than MDS codes. Very high work factors are achievable with short codes.
Codes over Eisenstein integers are advantageous for the Niederreiter system due to the increased message length. An investigation of the channel capacity of the weight-one error channel was performed. Capacity achieving codes over Eisenstein integers can correct more than errors, leading to increased security against information-set decoding attacks.
While we have adapted the GC code construction to Eisenstein integers, the syndrome decoding for the corresponding Niederreiter system, is still an open issue. An investigation of suitable decoding methods would be an interesting topic for further research.
The value of the proposed GC code construction can be seen when compared to the classic McEliece key encapsulation mechanism (KEM), which is among the finalists of the NIST standardization [
3]. For example, the security against ISD attacks for the parameter set
McEliece 348864 is
(according to (
2)) and the public-key size is about 261 kByte. A GC code over
, of length
and dimension
, results in the same work factor for ISD attacks, but its public-key size is only
kByte, which is about
of the key size for the classic McEliece system. For the longer code
McEliece 6688128, the work factor is about
, and the public-key size approximately 1045 kByte. A comparable GC code over
has length
, dimension
, work factor
, and public-key size of only
kByte. However, the classic McEliece KEM uses Goppa codes, as originally proposed by McEliece in 1984. Goppa codes are still considered to be secure, as no structural attacks on these codes were found. On the other hand, the proposed GC code construction has no complete security analysis against structural attacks, such as the attacks proposed in [
21,
26,
33]. This security analysis is subject to future work.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}